Visual Semantic Landmark-Based Robust Mapping and Localization for Autonomous Indoor Parking

 , ,
, ,
Abstract
1. Introduction
- We design and implement a low-cost and robust visual-based SLAM system using a typical visual landmark of parking slots with aid from a limited number of visual fiducial tags, which is immune to monotonous texture, varying illumination and dynamic conditions;
- We propose a robust SLAM back-end approach to associate parking slots considering the confidence level of the landmarks;
- We analyse the effectiveness and arrangement strategy of visual fiducial tags in a typical indoor parking lot.
2. Related Work
2.1. Visual SLAM
2.2. Semantic Landmark-Based SLAM
2.3. Robust SLAM
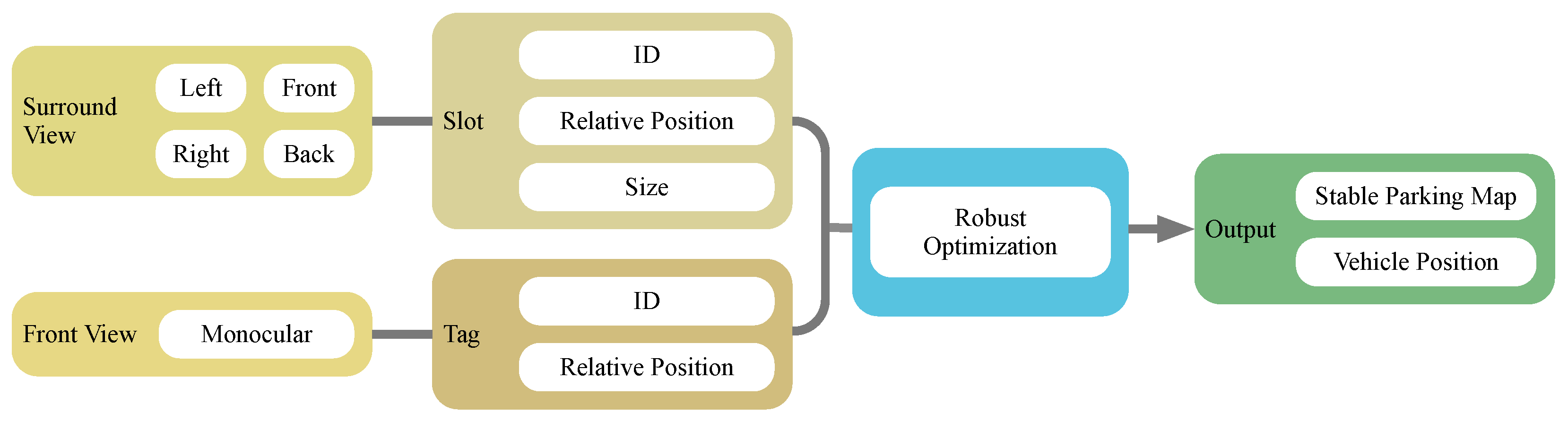
3. Approach
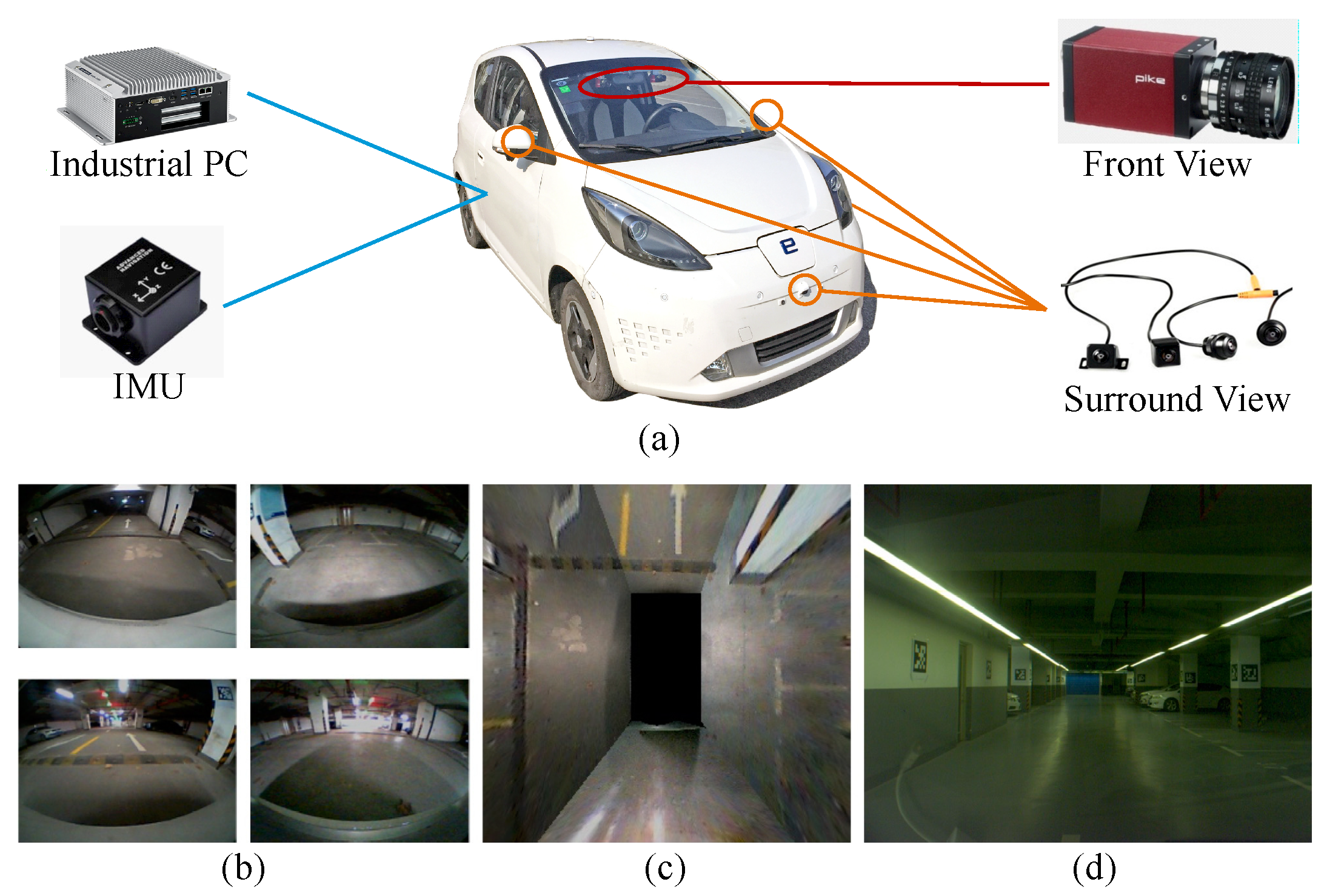
3.1. Semantic Landmark Recognition
3.1.1. Learning-Based Parking Slot Detection
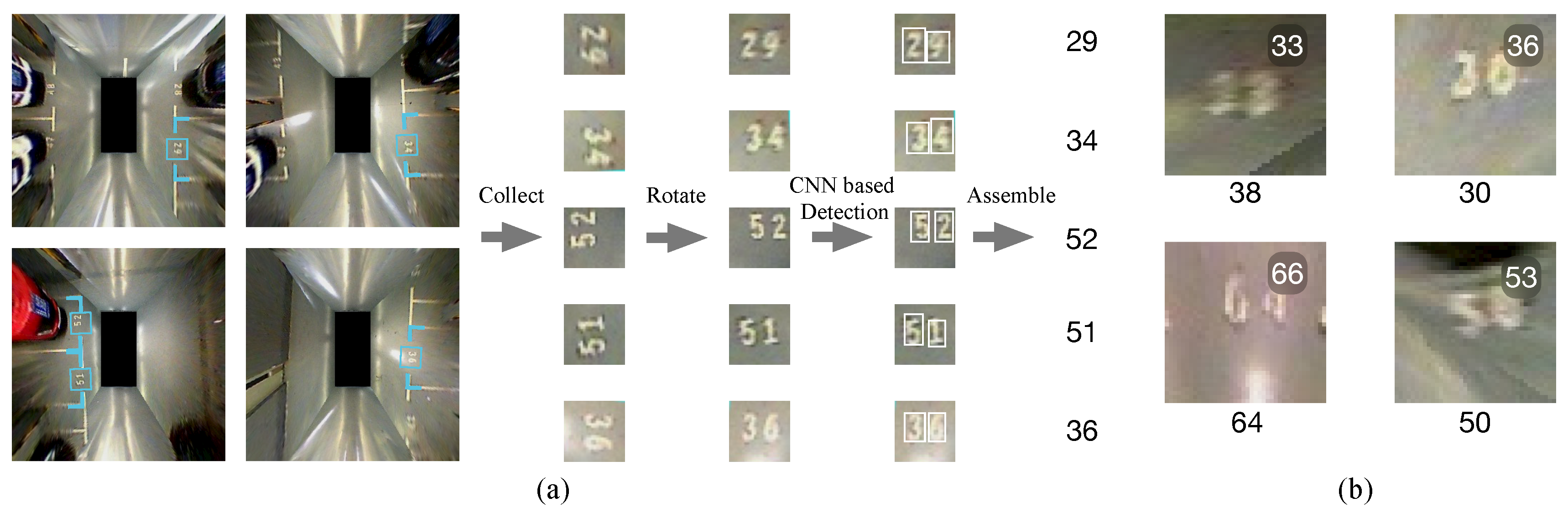
3.1.2. CNN-Based Slot ID Recognition
3.1.3. Visual Fiducial Tags
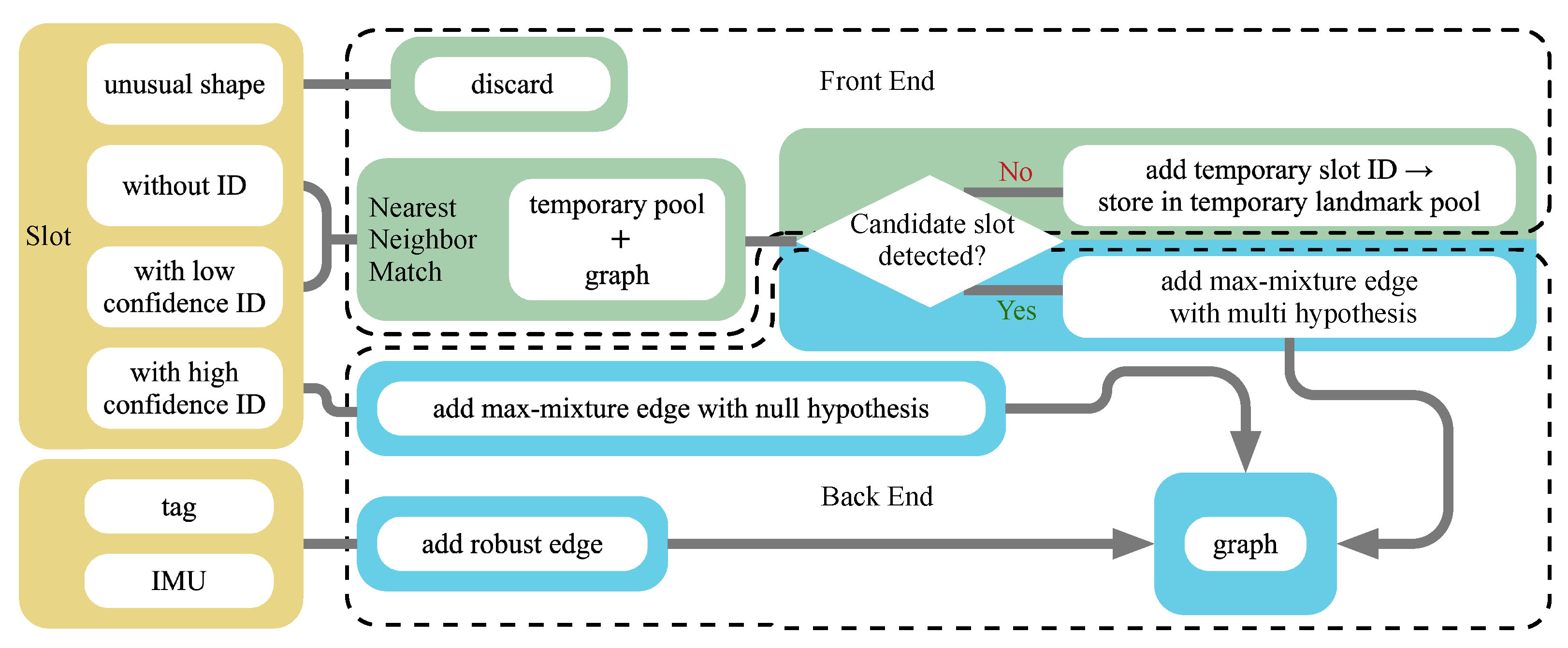
3.2. Semantic-Based Robust SLAM
3.2.1. Front-End
3.2.2. Back-End
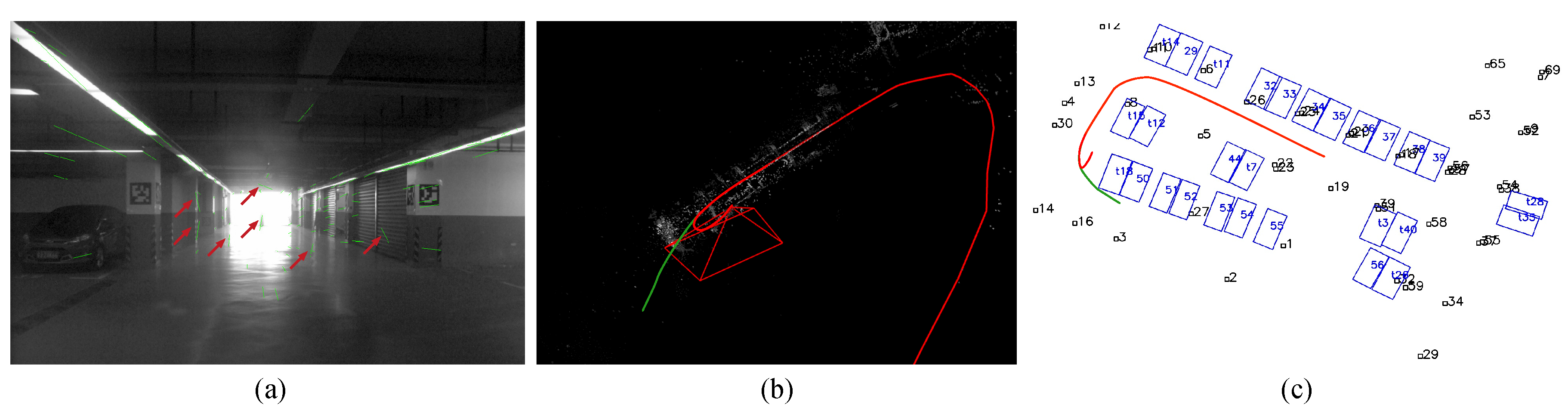
4. Experimental Analysis
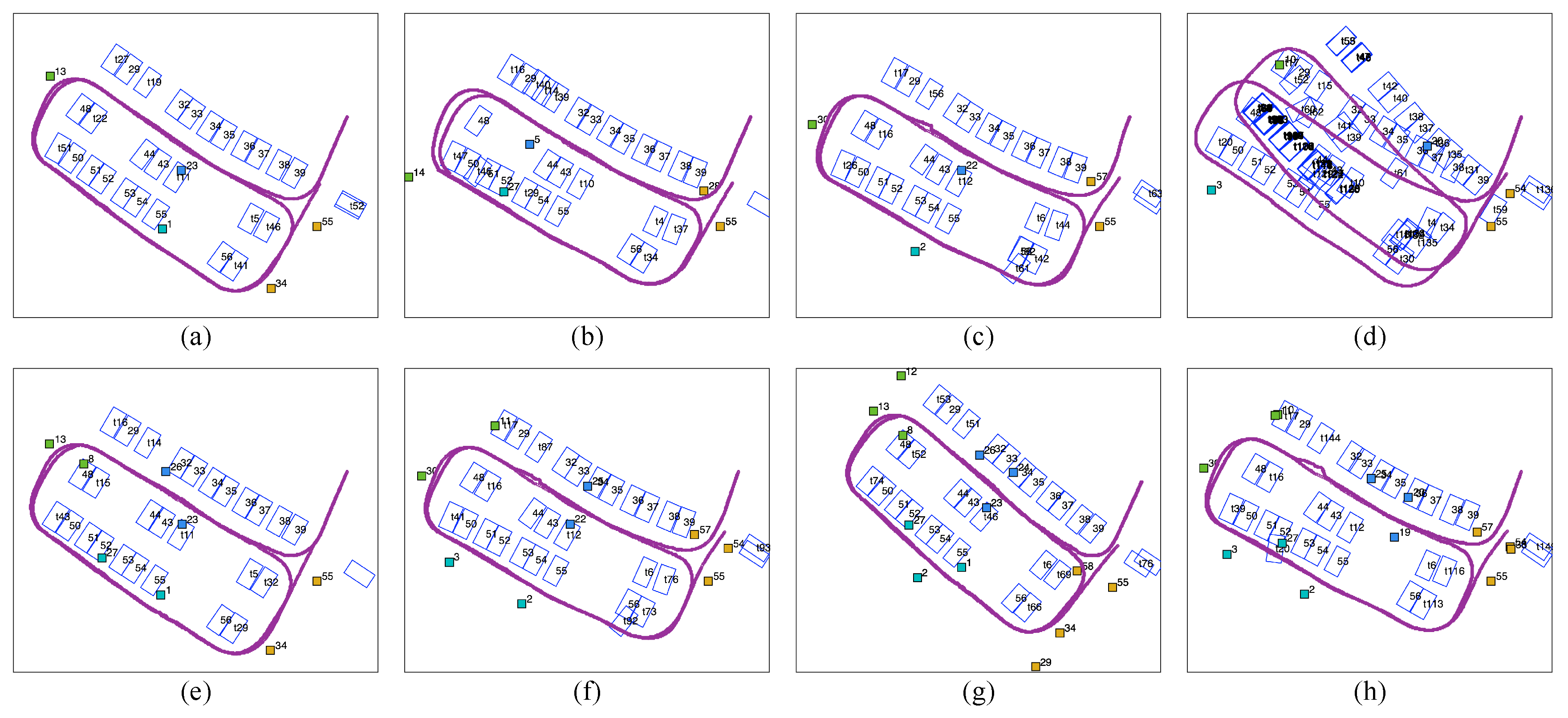
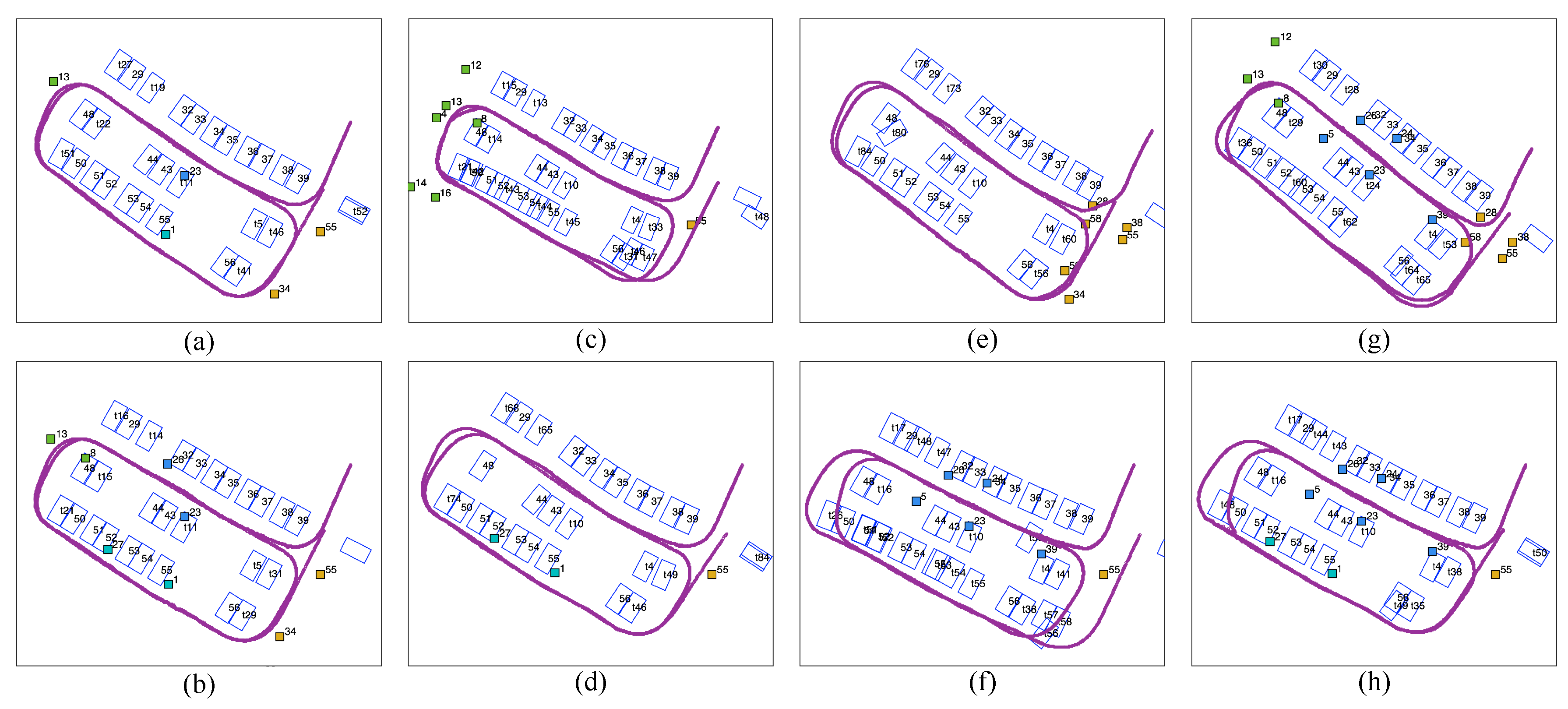
4.1. Mapping with Semantic Landmarks
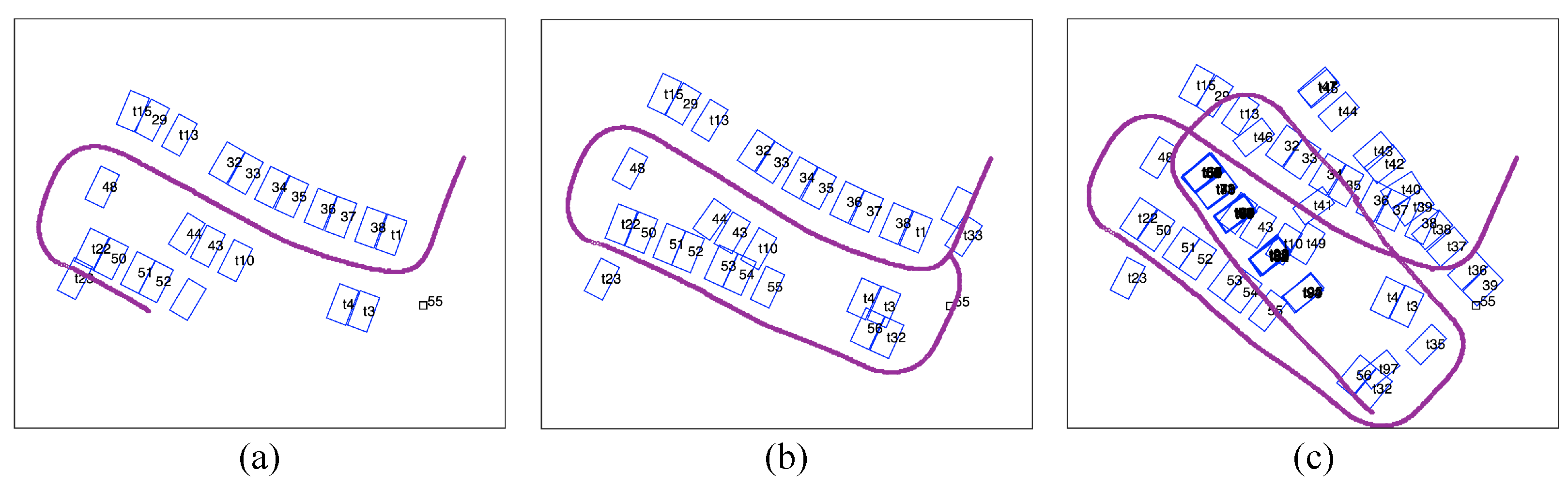
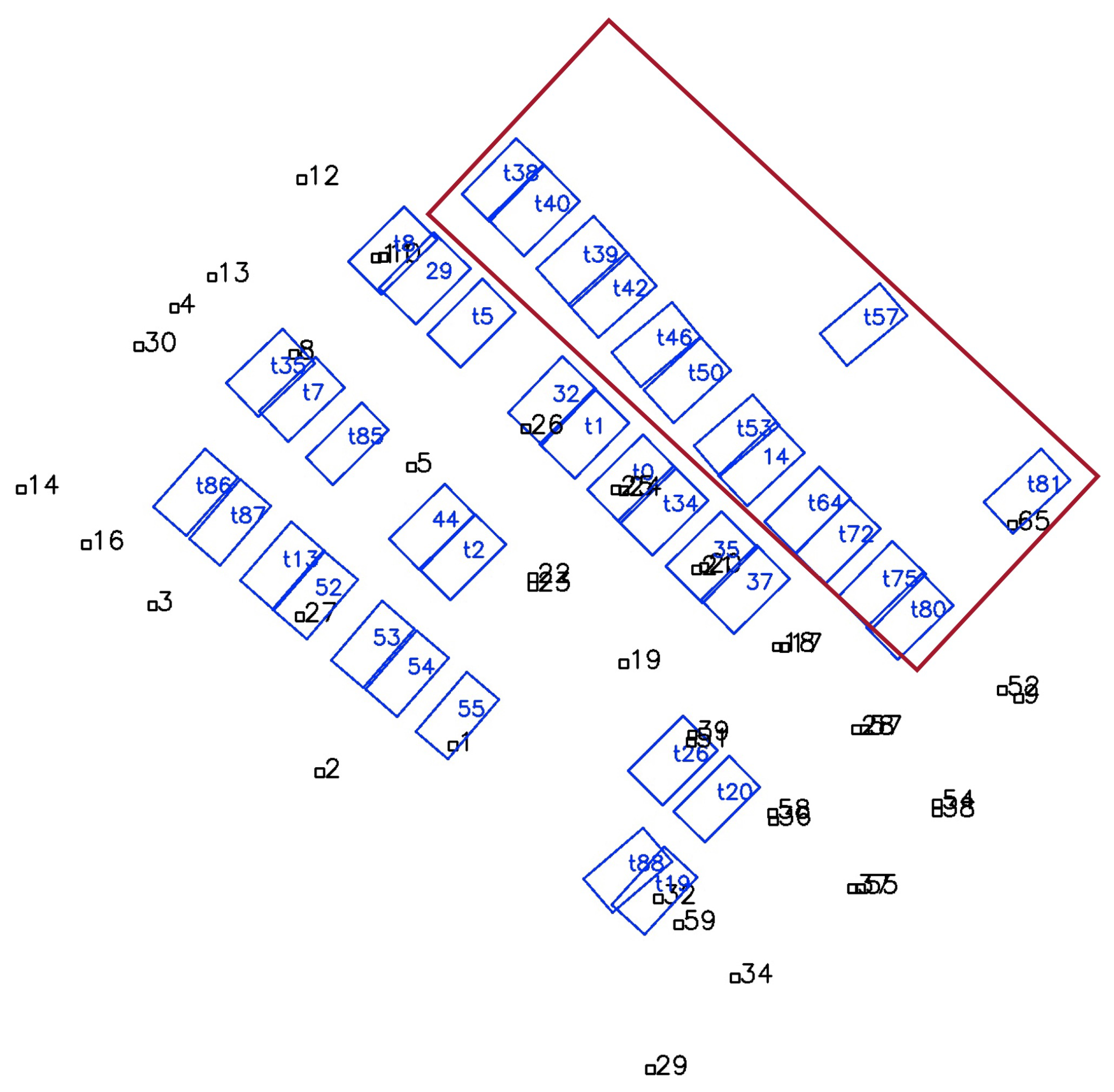
4.1.1. Parking Slot-Only Mapping
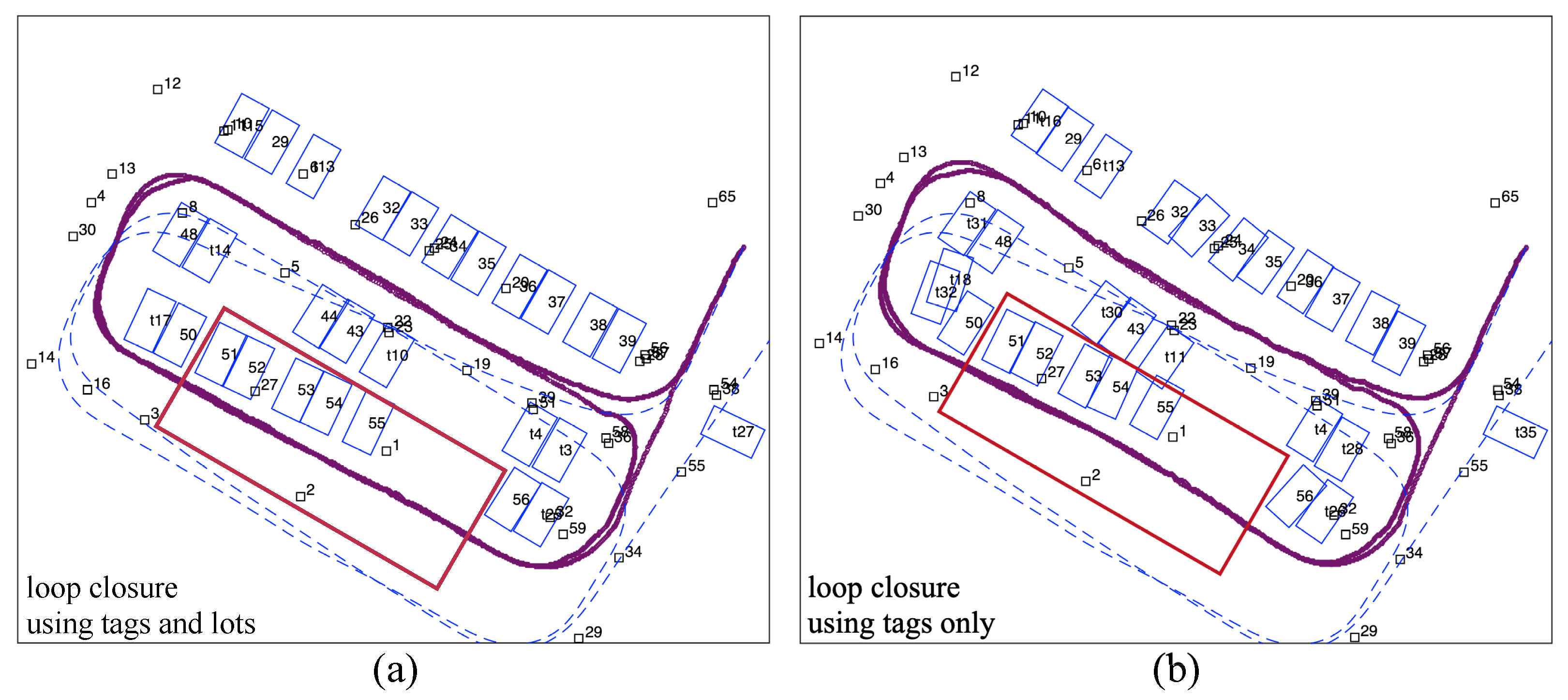
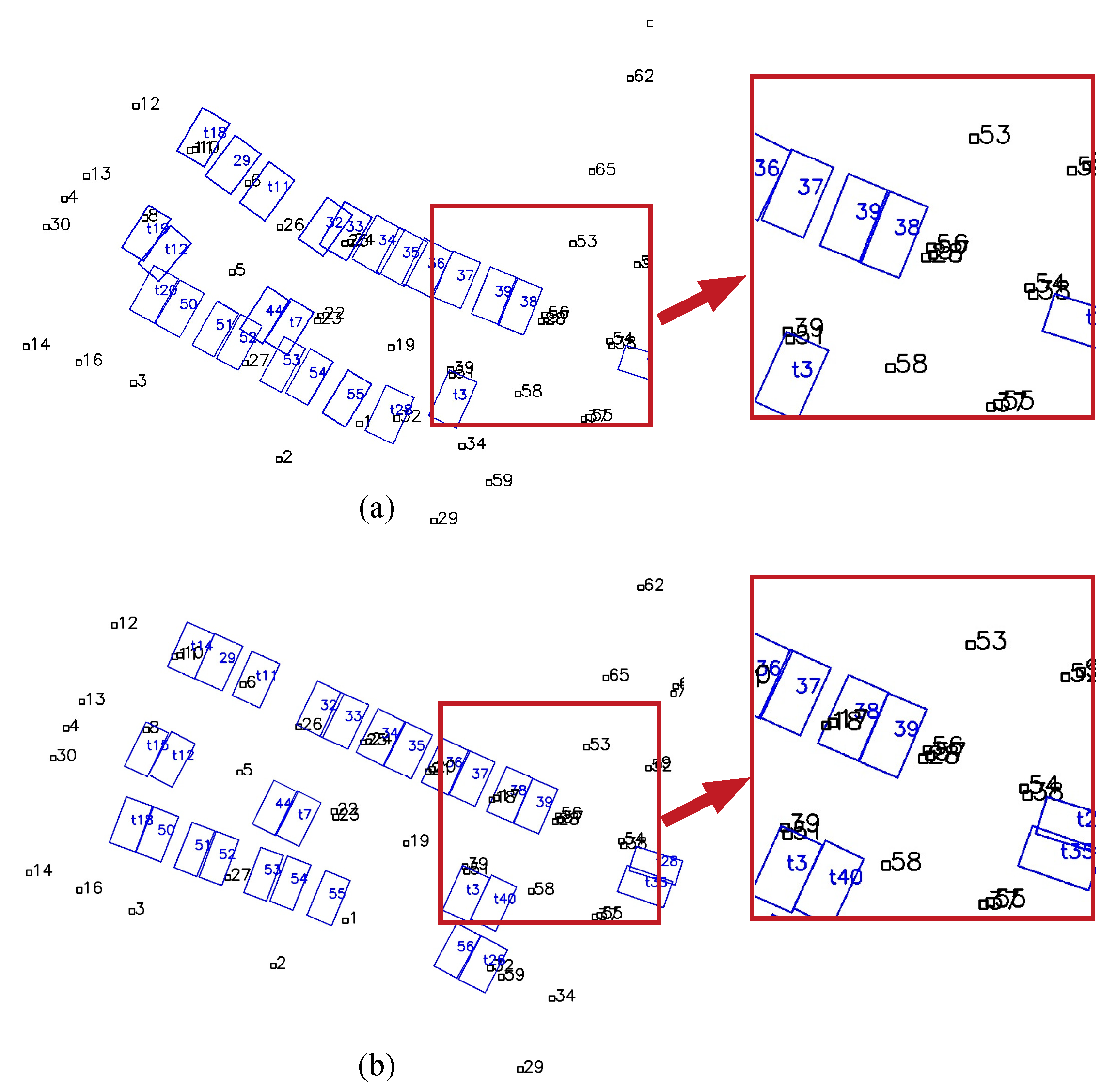
4.1.2. Tag-Aided Parking Slot Mapping
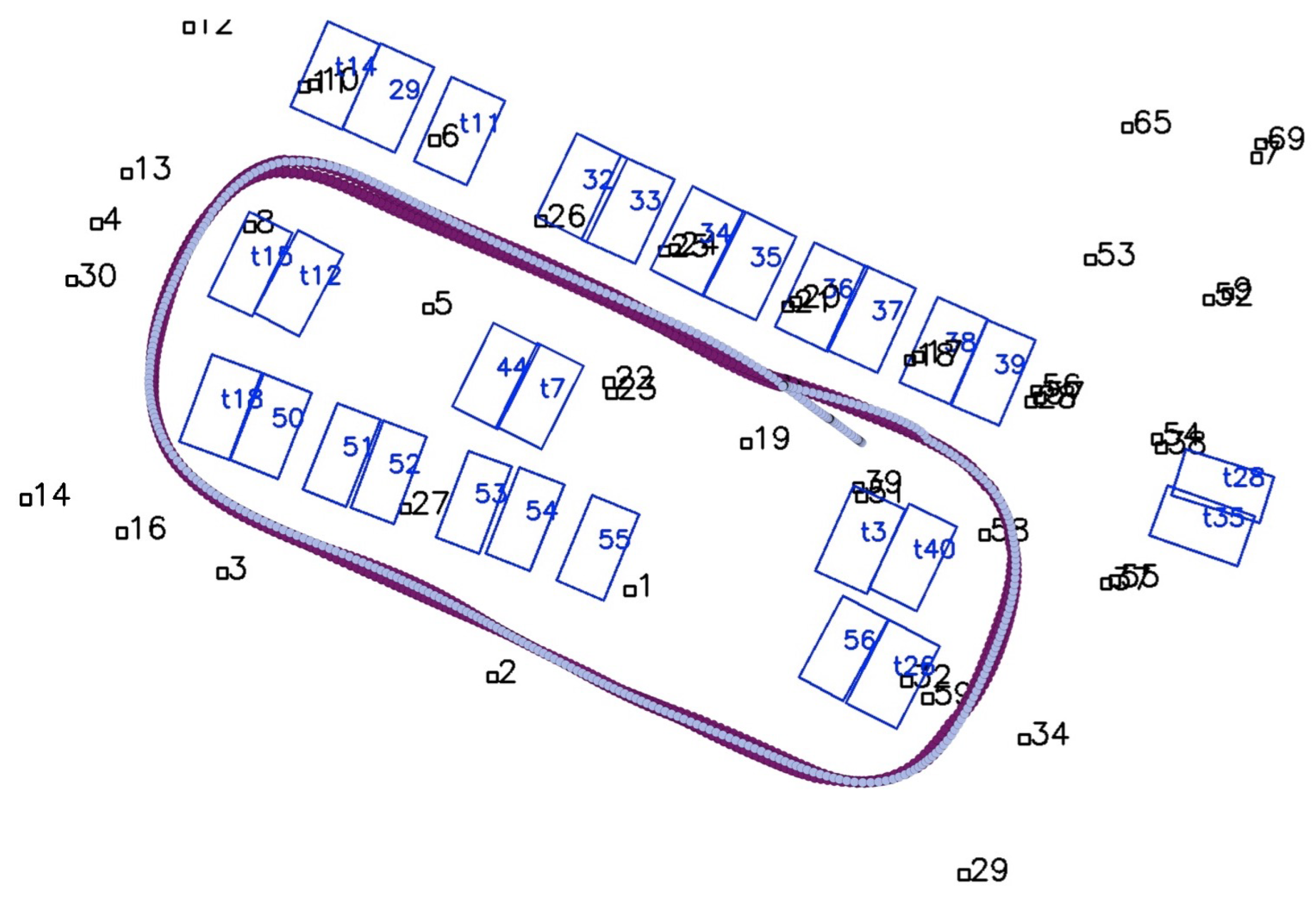
4.2. Online Localization Performance
Comparison with Traditional VSLAM Methods
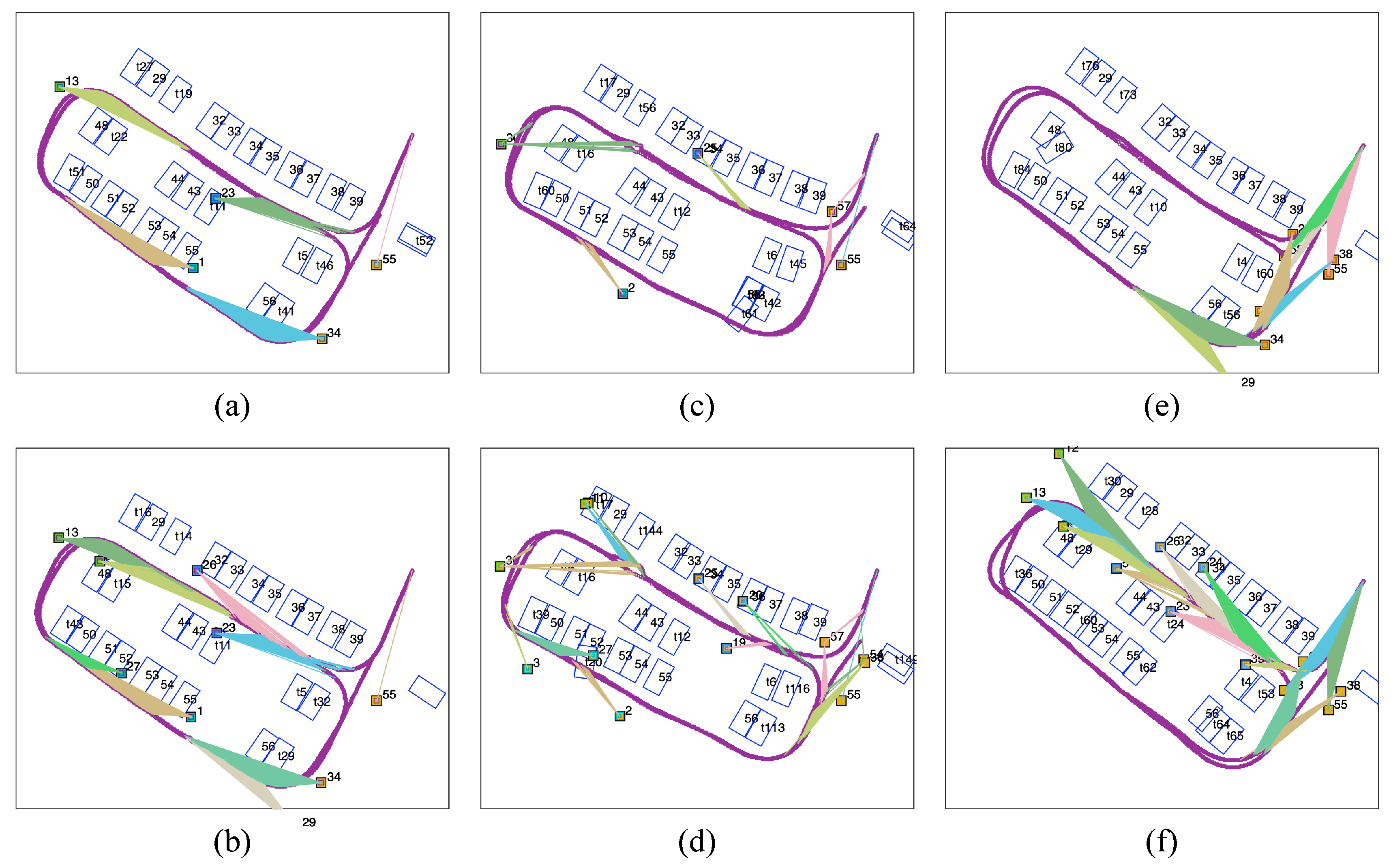
4.3. How Many Visual Fiducial Tags Are Needed?
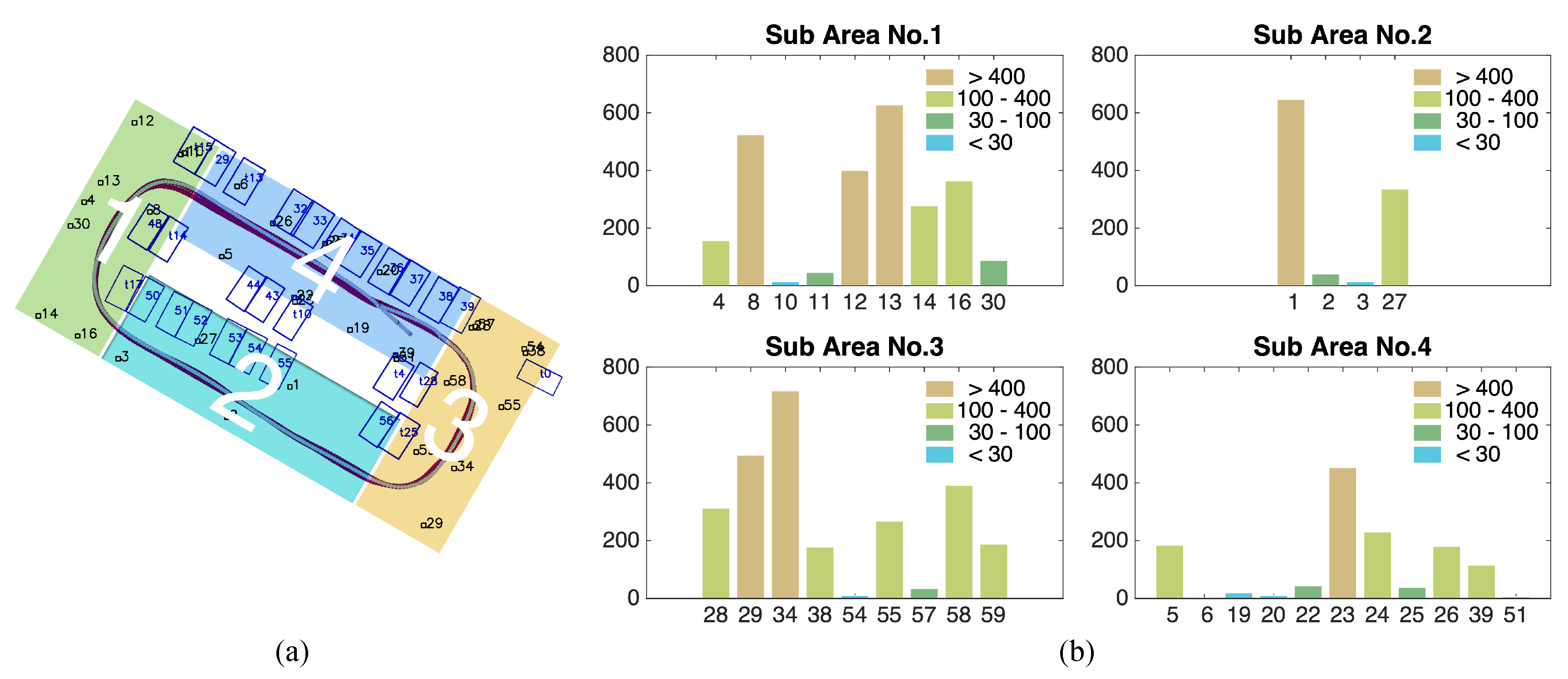
4.3.1. Observation Frequency-Based Analysis of Tags
4.3.2. Position-Based Analysis of Tags
4.3.3. Explanation Based on Graph Configuration
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Antoniou, C.; Gikas, V.; Papathanasopoulou, V.; Danezis, C.; Panagopoulos, A.D.; Markou, I.; Efthymiou, D.; Yannis, G.; Perakis, H. Localization And Driving Behavior Classification Using Smartphone Sensors in the Direct Absence Of GNSS. In Proceedings of the Transportation Research Board 94th Annual Meeting, Washington, DC, USA, 11–15 January 2015. [Google Scholar]
- Gikas, V.; Antoniou, C.; Retscher, G.; Panagopoulos, A.; Kealy, A.; Perakis, H.; Mpimis, T. A low-cost wireless sensors positioning solution for indoor parking facilities management. J. Locat. Based Serv. 2016, 10, 241–261. [Google Scholar] [CrossRef]
- Stojanović, D.; Stojanović, N. Indoor localization and tracking: Methods, technologies and research challenges. Facta Univ. Ser. Autom. Control Robot. 2014, 13, 57–72. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2017, 31, 1147–1163. [Google Scholar] [CrossRef]
- Grimmett, H.; Buerki, M.; Paz, L.; Pinies, P. Integrating metric and semantic maps for vision-only automated parking. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; pp. 2159–2166. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Younes, G.; Asmar, D.C.; Shammas, E.A. A survey on non-filter-based monocular Visual SLAM systems. arXiv, 2016; arXiv:1607.00470. [Google Scholar]
- Houben, S.; Neuhausen, M.; Michael, M.; Kesten, R.; Mickler, F.; Schuller, F. Park marking-based vehicle self-localization with a fisheye topview system. J. Real-Time Image Process. 2015. [Google Scholar] [CrossRef]
- Himstedt, M.; Maehle, E. Online semantic mapping of logistic environments using RGB-D cameras. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417720781. [Google Scholar] [CrossRef]
- Li, L.; Zhang, L.; Li, X.; Liu, X.; Shen, Y.; Xiong, L. Vision-based parking-slot detection: A benchmark and a learning-based approach. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 649–654. [Google Scholar]
- Huang, Y.; Zhao, J.; He, X.; Zhang, S.; Feng, T. Vision-based Semantic Mapping and Localization for Autonomous Indoor Parking. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 636–641. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Bansal, A.; Badino, H.; Huber, D. Analysis of the CMU Localization Algorithm under Varied Conditions; Technical Report CMU-RI-TR-15-05; Robotics Institute: Pittsburgh, PA, USA, 2015. [Google Scholar]
- Davison, A.J. Real-Time Simultaneous Localisation and Mapping with a Single Camera. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; p. 1403. [Google Scholar]
- Strasdat, H.; Montiel, J.; Davison, A.J. Real-time monocular SLAM: Why filter? In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–7 May 2010; pp. 2657–2664. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.J.; Davison, A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the 2013 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar]
- Wang, S.; Fidler, S.; Urtasun, R. Lost Shopping! Monocular Localization in Large Indoor Spaces. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2695–2703. [Google Scholar]
- Li, X.; Belaroussi, R. Semi-Dense 3D Semantic Mapping from Monocular SLAM. arXiv, 2016; arXiv:1611.04144. [Google Scholar]
- Gálvez-López, D.; Salas, M.; Tardós, J.D.; Montiel, J.M.M. Real-time monocular object SLAM. Robot. Auton. Syst. 2016, 75 Pt B, 435–449. [Google Scholar] [CrossRef]
- Mccormac, J.; Handa, A.; Davison, A.; Leutenegger, S.; Mccormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Sünderhauf, N.; Pham, T.T.; Latif, Y.; Milford, M.; Reid, I. Meaningful maps with object-oriented semantic mapping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5079–5085. [Google Scholar]
- Yang, S.; Scherer, S. CubeSLAM: Monocular 3D Object Detection and SLAM without Prior Models. arXiv, 2018; arXiv:1806.00557. [Google Scholar]
- Sünderhauf, N.; Protzel, P. Switchable constraints for robust pose graph SLAM. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 1879–1884. [Google Scholar]
- Olson, E.; Agarwal, P. Inference on networks of mixtures for robust robot mapping. Int. J. Robot. Res. 2013, 32, 826–840. [Google Scholar] [CrossRef]
- Latif, Y.; Cadena, C.; Neira, J. Robust loop closing over time for pose graph SLAM. Int. J. Robot. Res. 2013, 32, 1611–1626. [Google Scholar] [CrossRef]
- Xie, L.; Wang, S.; Markham, A.; Trigoni, N. GraphTinker: Outlier rejection and inlier injection for pose graph SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 6777–6784. [Google Scholar]
- Pfingsthorn, M.; Birk, A. Representing and solving local and global ambiguities as multimodal and hyperedge constraints in a generalized graph SLAM framework. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 4276–4283. [Google Scholar]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic slam. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1722–1729. [Google Scholar]
- Mu, B.; Liu, S.Y.; Paull, L.; Leonard, J.; How, J.P. SLAM with objects using a nonparametric pose graph. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4602–4609. [Google Scholar]
- Olson, E. AprilTag: A robust and flexible visual fiducial system. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3400–3407. [Google Scholar]
- Hong, S.; Roh, B.; Kim, K.; Cheon, Y.; Park, M. PVANet: Lightweight Deep Neural Networks for Real-time Object Detection. arXiv, 2016; arXiv:1611.08588. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003; pp. 1865–1872. [Google Scholar]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Point No. 1 | Reference | Mean | STD | |||||
| x | −8.404 | −8.324 | −8.631 | −8.368 | −8.172 | −8.257 | ||
| y | 7.477 | 7.973 | 7.171 | 7.563 | 7.761 | 7.909 | ||
| 0.147 | 0.068 | 0.374 | 0.111 | 0.084 | 0.157 | 0.125 | ||
| 0.432 | 0.063 | 0.739 | 0.346 | 0.148 | 0.346 | 0.265 | ||
| 0.456 | 0.093 | 0.828 | 0.364 | 0.171 | 0.382 | 0.289 | ||
| Test Point No. 2 | Reference | Mean | STD | |||||
| x | −1.947 | −2.021 | −2/023 | −1.709 | −1.695 | −1.942 | ||
| y | 9.838 | 9.706 | 9.816 | 9.371 | 9.538 | 9.756 | ||
| 0.005 | 0.079 | 0.081 | 0.233 | 0.247 | 0.129 | 0.106 | ||
| 0.082 | 0.050 | 0.059 | 0.385 | 0.219 | 0.159 | 0.144 | ||
| 0.082 | 0.093 | 0.100 | 0.450 | 0.330 | 0.211 | 0.169 | ||
| Test Point No. 3 | Reference | Mean | STD | |||||
| x | −4.896 | −5.178 | −5.269 | −5.183 | −4.924 | −5.184 | ||
| y | 5.995 | 6.533 | 5.941 | 6.249 | 6.138 | 6.167 | ||
| 0.289 | 0.006 | 0.085 | 0.001 | 0.261 | 0.128 | 0.138 | ||
| 0.172 | 0.367 | 0.236 | 0.082 | 0.029 | 0.177 | 0.133 | ||
| 0.336 | 0.367 | 0.251 | 0.082 | 0.263 | 0.26 | 0.110 | ||
| No. | No. | |||||||
|---|---|---|---|---|---|---|---|---|
| 14 | −48.898 | 7.298 | 16 | −44.462 | 5.201 | 4.90 | 4.84 | 0.06 |
| 4 | −44.169 | 20.138 | 30 | −45.621 | 17.461 | 3.04 | 2.97 | 0.07 |
| 54 | 5.620 | 5.202 | 57 | 0.146 | 7.650 | 5.99 | 5.83 | 0.16 |
| 19 | −14.118 | 6.760 | 39 | −8.928 | 4.102 | 5.83 | 5.87 | 0.04 |
| 8 | −36.820 | 19.263 | 10 | −33.176 | 25.916 | 7.58 | 7.42 | 0.16 |
| Mean | 0.10 | RMSE | 0.05 | |||||
| Detection Time Per Frame | |||||
| AprilTag Detection | 0.055 | Slot Detection | 0.048 | ID Detection | 0.143 |
| Optimization Time Per Frame | |||||
| Frame 1000 | 0.011 | Frame 2000 | 0.074 | Frame 3000 | 0.137 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Huang, Y.; He, X.; Zhang, S.; Ye, C.; Feng, T.; Xiong, L. Visual Semantic Landmark-Based Robust Mapping and Localization for Autonomous Indoor Parking. Sensors 2019, 19, 161. https://doi.org/10.3390/s19010161
Zhao J, Huang Y, He X, Zhang S, Ye C, Feng T, Xiong L. Visual Semantic Landmark-Based Robust Mapping and Localization for Autonomous Indoor Parking. Sensors. 2019; 19(1):161. https://doi.org/10.3390/s19010161
Chicago/Turabian StyleZhao, Junqiao, Yewei Huang, Xudong He, Shaoming Zhang, Chen Ye, Tiantian Feng, and Lu Xiong. 2019. "Visual Semantic Landmark-Based Robust Mapping and Localization for Autonomous Indoor Parking" Sensors 19, no. 1: 161. https://doi.org/10.3390/s19010161
APA StyleZhao, J., Huang, Y., He, X., Zhang, S., Ye, C., Feng, T., & Xiong, L. (2019). Visual Semantic Landmark-Based Robust Mapping and Localization for Autonomous Indoor Parking. Sensors, 19(1), 161. https://doi.org/10.3390/s19010161