Robust Single-Sample Face Recognition by Sparsity-Driven Sub-Dictionary Learning Using Deep Features †

 ,
,  , , and
, , and
Abstract

1. Introduction
- Face augmentation step: we enrich the character of the discriminative features by producing a very large collection of augmented images (considering several scales, crops, displacements and filtering). This way, besides facing the hurdle of availing of a SSPP for the gallery construction, we make the system robust to partial occlusions (collecting face sub-portions dual to the occlusions), multi-poses (parts of the faces are less sensitive to pose than the whole face), and low resolution (characterizing even very low-quality image versions).
- Sparse sub-dictionary learning step: given the huge quantity of data produced with the face augmentation step, it is essential to derive a space suitable for the classification, together with a succinct and effective model underlying the data. The feature space is obtained employing deep features coupled with the linear discriminant analysis, while the concise model is derived adopting the method of optimal directions (MOD) [13], which has proved to be very efficient for low-dimensional input data. The benefits of this approach is that, contrarily to generic learning algorithms [14], the label consistency between dictionary atoms and training data is maintained, allowing the direct application of the classification stage based on majority voting (a demo code is available on the website: https://github.com/phuselab/SSLD-face_recognition).
2. Related Works
(i) Learning Methods
(ii) Generative Methods
(iii) Local Methods
3. Method
3.1. Deep Features on Geometrical Transformations
3.2. Feature Projection into LDA Space
3.3. Sparse Sub-Dictionary Learning and Representation
3.3.1. Sparse Representation
3.3.2. Sparse Dictionary Learning
3.3.3. Computational Scheme
- Sparse coding: solve problem (3) for X only, fixing the dictionary ;
- Dictionary update: solve problem (3) for only, fixing X.
| Algorithm 1: SSLD: Learning Step |
 |
3.4. Identity Recovery via k-LiMapS Sparsity Promotion
- according to (1), for the whole pool D of features F build the LDA projected features , where q is the number of subjects in the gallery,
- for a test face image of identity , work out the LDA projections from the feature vectors for every (Equation (2)),
- for each feature, i.e., for all , solve the problem (Pa) consisting of finding the k-sparse solution satisfyingwhere results from the dictionary learning problem (3) applied to in the LDA space.
- Let be the function that maps the column-index t of to the subject in corresponding to the atom ,
- defineas the set of identity votes casted by the j-th feature, ,
- collect the votes together in the multi-set and, if the mode of V is unique, determine the subject identity consequently
- otherwise, apply the least squares residual criterion between the probe features of every winner and the linear combination of their respective dictionary atoms, so as to achieve a subject ranking.
| Algorithm 2: SSLD: Identity Recovery |
 |
4. Experimental Results
4.1. SSPP with Large Gallery Cardinality
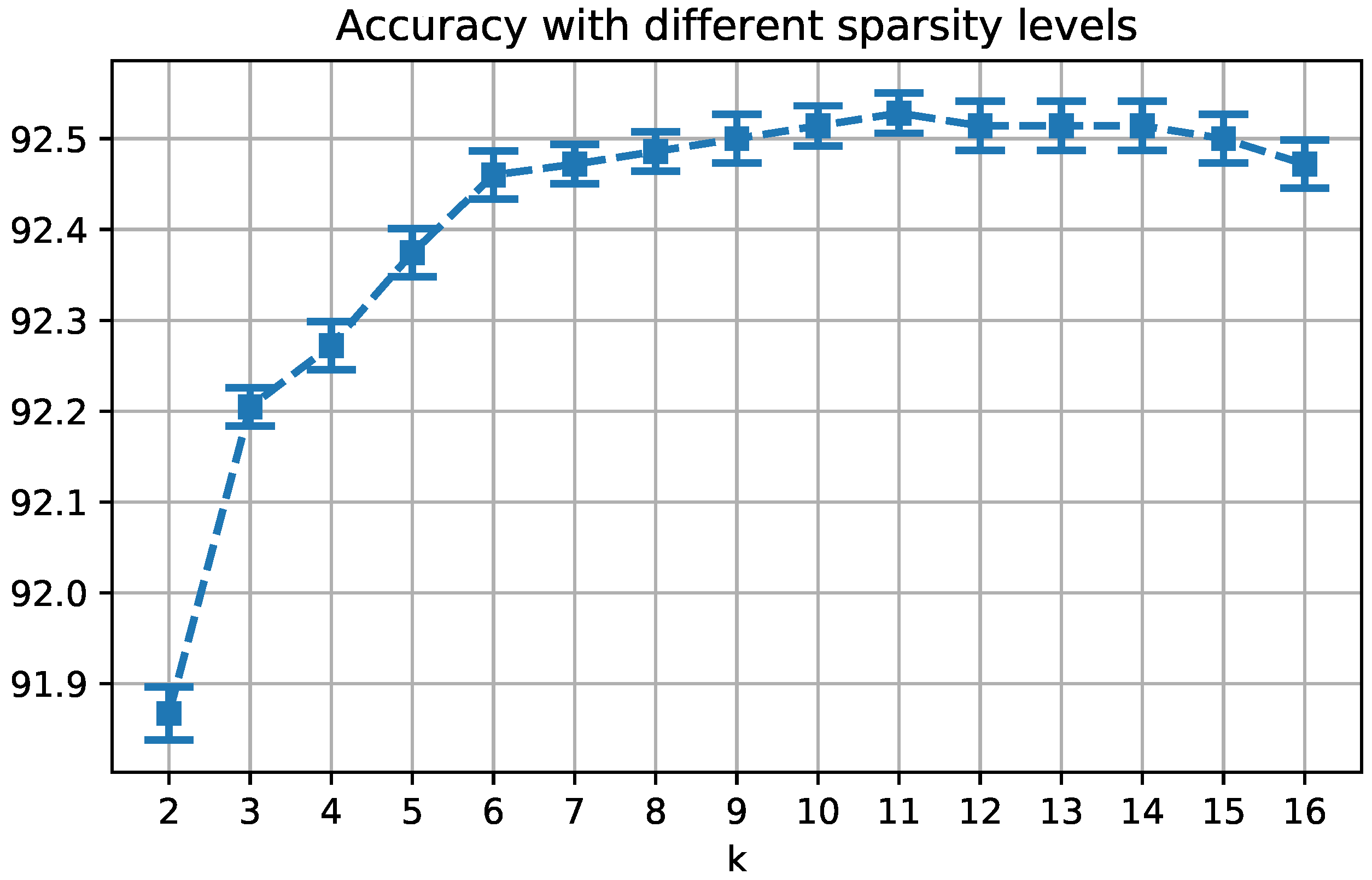
4.2. Low-Resolution Test Images
4.3. Disguised Test Images
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1701–1708. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Zhao, W.; Chellappa, R.; Phillips, J.; Rosenfeld, A. Face Recognition: A Literature Survey. ACM Comput. Sur. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Lahasan, B.; Lutfi, S.L.; San-Segundo, R. A survey on techniques to handle face recognition challenges: Occlusion, single sample per subject and expression. Artif. Intell. Rev. 2017, 2017, 1–31. [Google Scholar] [CrossRef]
- Ma, Z.; Ding, Y.; Li, B.; Yuan, X. Deep CNNs with Robust LBP Guiding Pooling for Face Recognition. Sensors 2018, 18, 3876. [Google Scholar] [CrossRef] [PubMed]
- Chu, Y.; Ahmad, T.; Bebis, G.; Zhao, L. Low-resolution Face Recognition with Single Sample Per Person. Signal Process. 2017, 141, 144–157. [Google Scholar] [CrossRef]
- Ortiz, E.G.; Becker, B.C. Face recognition for web-scale datasets. Comput. Vis. Image Understand. 2014, 118, 153–170. [Google Scholar] [CrossRef]
- Tan, X.; Chen, S.; Zhou, Z.H.; Zhang, F. Face recognition from a single image per person: A survey. Pattern Recognit. 2006, 39, 1725–1745. [Google Scholar] [CrossRef]
- Bodini, M.; D’Amelio, A.; Grossi, G.; Lanzarotti, R.; Lin, J. Single Sample Face Recognition by Sparse Recovery of Deep-Learned LDA Features. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 297–308. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. Proc. Br. Mach. Vis. 2015, 1, 1–12. [Google Scholar]
- Adamo, A.; Grossi, G. A fixed-point iterative schema for error minimization in k-sparse decomposition. In Proceedings of the 2011 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Bilbao, Spain, 14–17 December 2011; pp. 167–172. [Google Scholar] [CrossRef]
- Adamo, A.; Grossi, G.; Lanzarotti, R.; Lin, J. Sparse decomposition by iterating Lipschitzian-type mappings. Theor. Comput. Sci. 2017, 664, 12–28. [Google Scholar] [CrossRef]
- Engan, K.; Aase, S.O.; Husoy, J.H. Method of optimal directions for frame design. In Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal, Phoenix, AZ, USA, 15–19 March 1999. [Google Scholar] [CrossRef]
- Grossi, G.; Lanzarotti, R.; Lin, J. Orthogonal Procrustes Analysis for Dictionary Learning in Sparse Linear Representation. PLoS ONE 2017, 12, 1–16. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Zhou, X.; Guo, J. Equidistant prototypes embedding for single sample based face recognition with generic learning and incremental learning. Pattern Recognit. 2014, 47, 3738–3749. [Google Scholar] [CrossRef]
- Hu, J. Discriminative transfer learning with sparsity regularization for single-sample face recognition. Image Vis. Comput. 2017, 60, 48–57. [Google Scholar] [CrossRef]
- Haghighat, M.; Abdel-Mottaleb, M.; Alhalabi, W. Fully automatic face normalization and single sample face recognition in unconstrained environments. Expert Syst. Appl. 2016, 47, 23–34. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, Y.; Jia, K.; Lu, J.; Zhang, Y. Single Sample Face Recognition via Learning Deep Supervised Autoencoders. IEEE Trans. Inf. Forensics Sec. 2015, 10, 2108–2118. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Wu, Z.; Guo, J. From one to many: Pose-Aware Metric Learning for single-sample face recognition. Pattern Recognit. 2018, 77, 426–437. [Google Scholar] [CrossRef]
- Gao, Y.; Ma, J.; Yuille, A.L. Semi-Supervised Sparse Representation Based Classification for Face Recognition with Insufficient Labeled Samples. IEEE Trans. Image Process. 2017, 26, 2545–2560. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.F.; Dai, D.Q.; Ren, C.X.; Huang, K.K. Discriminative multi-scale sparse coding for single-sample face recognition with occlusion. Pattern Recognit. 2017, 66, 302–312. [Google Scholar] [CrossRef]
- Ji, H.K.; Sun, Q.S.; Ji, Z.X.; Yuan, Y.H.; Zhang, G.Q. Collaborative probabilistic labels for face recognition from single sample per person. Pattern Recognit. 2017, 62, 125–134. [Google Scholar] [CrossRef]
- Liu, F.; Tang, J.; Song, Y.; Bi, Y.; Yang, S. Local structure based multi-phase collaborative representation for face recognition with single sample per person. Inf. Sci. 2016, 346–347, 198–215. [Google Scholar] [CrossRef]
- Yang, M.; Wang, X.; Zeng, G.; Shen, L. Joint and collaborative representation with local adaptive convolution feature for face recognition with single sample per person. Pattern Recognit. 2017, 66, 117–128. [Google Scholar] [CrossRef]
- Ding, C.; Bao, T.; Karmoshi, S.; Zhu, M. Single sample per person face recognition with KPCANet and a weighted voting scheme. Signal Image Video Process. 2017, 11, 1213–1220. [Google Scholar] [CrossRef]
- Gu, J.; Hu, H.; Li, H. Local robust sparse representation for face recognition with single sample per person. IEEE/CAA J. Autom. Sin. 2018, 5, 547–554. [Google Scholar] [CrossRef]
- Pei, T.; Zhang, L.; Wang, B.; Li, F.; Zhang, Z. Decision Pyramid Classifier for Face Recognition Under Complex Variations Using Single Sample Per Person. Pattern Recognit. 2017, 64, 305–313. [Google Scholar] [CrossRef]
- Wiskott, L.; Fellous, J.; Kruger, N.; von der Malsburg, C. Face recognition by elastic bunch graph matching. In Intelligent Biometric Techniques in Fingerprints and Face Recognition; CRC Press: Boca Raton, FL, USA, 1999; pp. 355–396. [Google Scholar]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv, 2017; arXiv:1712.04621. [Google Scholar]
- Cuculo, V.; Lanzarotti, R.; Boccignone, G. Using sparse coding for landmark localization in facial expressions. In Proceedings of the 2014 5th European Workshop on Visual Information Processing (EUVIP), Paris, France, 10–12 December 2014; pp. 1–6. [Google Scholar]
- Rao, C.R. The Utilization of Multiple Measurements in Problems of Biological Classification. J. R. Stat. Soc. 1948, 10, 159–203. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugenics 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations, 3rd ed.; JHU Press: Baltimore, MD, USA, 2012. [Google Scholar]
- Natarajan, B.K. Sparse Approximate Solutions to Linear Systems. SIAM J. Comput. 1995, 24, 227–234. [Google Scholar] [CrossRef]
- Grossi, G.; Lanzarotti, R.; Lin, J. High-rate compression of ECG signals by an accuracy-driven sparsity model relying on natural basis. Digit. Signal Process. 2015, 45, 96–106. [Google Scholar] [CrossRef]
- Adamo, A.; Grossi, G.; Lanzarotti, R. Sparse representation based classification for face recognition by k-limaps algorithm. In Proceedings of the ICISP 2012—International Conference on Image and Signal Processing, Agadir, Morocco, 28–30 June 2012; pp. 245–252. [Google Scholar]
- Grossi, G.; Lanzarotti, R.; Lin, J. Robust Face Recognition Providing the Identity and Its Reliability Degree Combining Sparse Representation and Multiple Features. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1656007. [Google Scholar] [CrossRef]
- Adamo, A.; Grossi, G.; Lanzarotti, R. Local features and sparse representation for face recognition with partial occlusions. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 3008–3012. [Google Scholar]
- Engan, K.; Aase, S.O.; Husoy, J.H. Designing frames for matching pursuit algorithms. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 15 May 1998; pp. 1817–1820. [Google Scholar]
- Zhang, Z.; Xu, Y.; Yang, J.; Li, X.; Zhang, D. A Survey of Sparse Representation: Algorithms and Applications. IEEE Access 2015, 3, 490–530. [Google Scholar] [CrossRef]
- Elad, M. Sparse and Redundant Representations; Springer: New York, NY, USA, 2010. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Martinez, A.M. The AR Face Database; CVC Technical Report 24; Ohio State University: Columbus, OH, USA, 1998. [Google Scholar]
- Dong, X.; Wu, F.; Jing, X.Y. Generic Training Set based Multimanifold Discriminant Learning for Single Sample Face Recognition. KSII Trans. Internet Inf. Syst. 2018, 12, 1. [Google Scholar]
- Wang, X.; Yang, M.; Shen, L.; Chang, H. Robust local representation for face recognition with single sample per person. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 11–15. [Google Scholar]
- Zeng, J.; Zhao, X.; Gan, J.; Mai, C.; Zhai, Y.; Wang, F. Deep Convolutional Neural Network Used in Single Sample per Person Face Recognition. Comput. Intell. Neurosci. 2018, 2018, 3803627. [Google Scholar] [CrossRef] [PubMed]
- Karaaba, M.F.; Surinta, O.; Schomaker, L.R.B.; Wiering, M.A. Robust Face Identification with Small Sample Sizes using Bag of Words and Histogram of Oriented Gradients. In Proceedings of the 11th Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Rome, Italy, 27–29 February 2016; pp. 582–589. [Google Scholar]
- Zhu, P.; Yang, M.; Zhang, L.; Lee, I.Y. Local Generic Representation for Face Recognition with Single Sample per Person. In Computer Vision—ACCV 2014; Cremers, D., Reid, I., Saito, H., Yang, M.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 34–50. [Google Scholar]
- Shang, K.; Huang, Z.H.; Liu, W.; Li, Z.M. A single gallery-based face recognition using extended joint sparse representation. Appl. Math. Comput. 2018, 320, 99–115. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
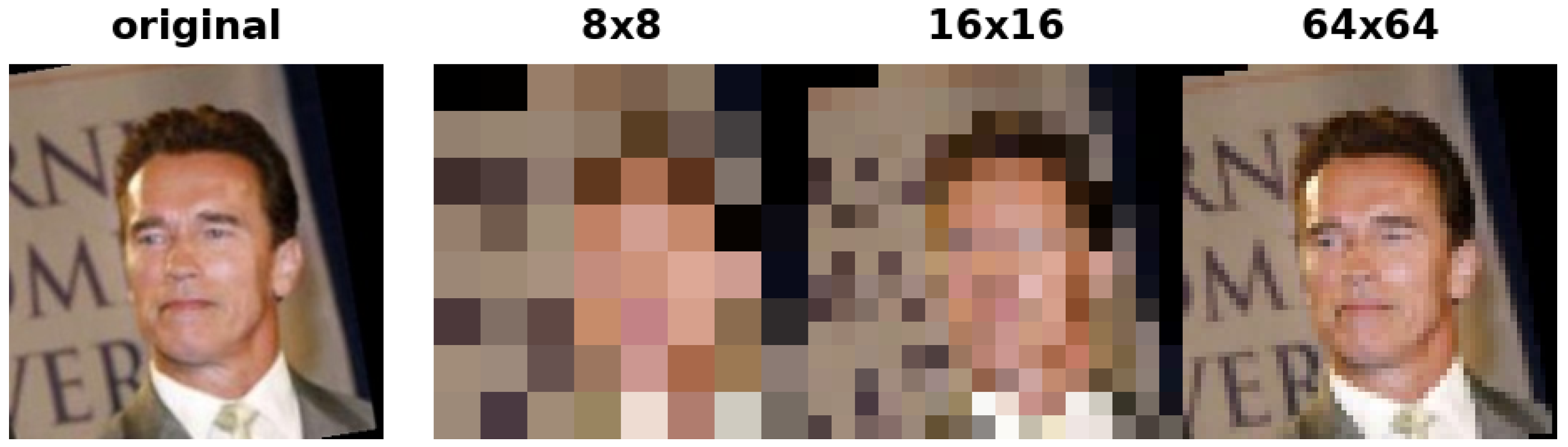{kind=link}
{kind=link}
| LFW ≤ 100 sbj | |||||||
| [44] | [45] | [46] | [24] | [26] | [18] | [20] | SSLD |
| 32 (50) | 37 (50) | 74 (50) | 86 (50) | 50 (80) | 31.39 ± 1.74 (80) | 92.57 (100) | 94.38 ± 0.81 (100) |
| LFW ≤ 158 sbj | |||||||
| [25] | [47] | [48] | [23] | [49] | SSLD | ||
| 46.3 (120) | 27.14 ± 1.0 (150) | 30 (158) | 37.9 (158) | 50 (158) | 92.78 ± 1.2 (158) | ||
| LFW 793 sbj | LFW 1680 sbj | ||||||
| [24] | SSLD | [16] | SSLD | ||||
| 65.3 | 86.43 ± 1.03 | 21.01 | 84.2 ± 0.5 | ||||
| Method | |||
|---|---|---|---|
| [6] | 12.28 | 15.06 | - |
| SSLD | 0.74 ± 0.18 | 12.18 ± 6.89 | 90.84 ± 1.13 |
| SSLD w/LR | 9.5 ± 0.69 | 45.57 ± 1.31 | 90.62 ± 0.99 |
| Method | Illumination | Expression | Sunglasses | Scarf | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | avg. | S1 | S2 | avg. | S1 | S2 | avg. | S1 | S2 | avg. | |
| SRC | 94.70 | 62.20 | 78.45 | 95.30 | 63.60 | 79.45 | 88.10 | 46.90 | 67.50 | 50.60 | 25.80 | 38.20 |
| GSRC | 96.40 | 61.10 | 78.75 | 94.20 | 64.20 | 79.20 | 84.70 | 41.40 | 63.05 | 46.90 | 20.60 | 33.75 |
| LS-MPCRC | 98.90 | 80.0 | 89.45 | 96.90 | 80.30 | 88.60 | 97.80 | 72.50 | 85.15 | 89.40 | 65.60 | 77.50 |
| SSLD | 99.66 | 98.33 | 98.99 | 95.0 | 94.13 | 94.56 | 87.0 | 83.56 | 85.28 | 97.0 | 90.41 | 93.70 |
| Method | Illumination | Expression | Occlusions | Occl + Ill | Overall |
|---|---|---|---|---|---|
| Pixel+LRA | 72.2 | 66.0 | 40.8 | 19.0 | 47.8 |
| Gabor+LRA | 79.2 | 93.5 | 70.3 | 52.5 | 72.4 |
| LBP+LRA | 92.3 | 94.7 | 92.5 | 83.9 | 90.1 |
| SSLD | 98.99 | 94.56 | 90.18 | 82.02 | 91.43 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cuculo, V.; D’Amelio, A.; Grossi, G.; Lanzarotti, R.; Lin, J. Robust Single-Sample Face Recognition by Sparsity-Driven Sub-Dictionary Learning Using Deep Features. Sensors 2019, 19, 146. https://doi.org/10.3390/s19010146
Cuculo V, D’Amelio A, Grossi G, Lanzarotti R, Lin J. Robust Single-Sample Face Recognition by Sparsity-Driven Sub-Dictionary Learning Using Deep Features. Sensors. 2019; 19(1):146. https://doi.org/10.3390/s19010146
Chicago/Turabian StyleCuculo, Vittorio, Alessandro D’Amelio, Giuliano Grossi, Raffaella Lanzarotti, and Jianyi Lin. 2019. "Robust Single-Sample Face Recognition by Sparsity-Driven Sub-Dictionary Learning Using Deep Features" Sensors 19, no. 1: 146. https://doi.org/10.3390/s19010146
APA StyleCuculo, V., D’Amelio, A., Grossi, G., Lanzarotti, R., & Lin, J. (2019). Robust Single-Sample Face Recognition by Sparsity-Driven Sub-Dictionary Learning Using Deep Features. Sensors, 19(1), 146. https://doi.org/10.3390/s19010146