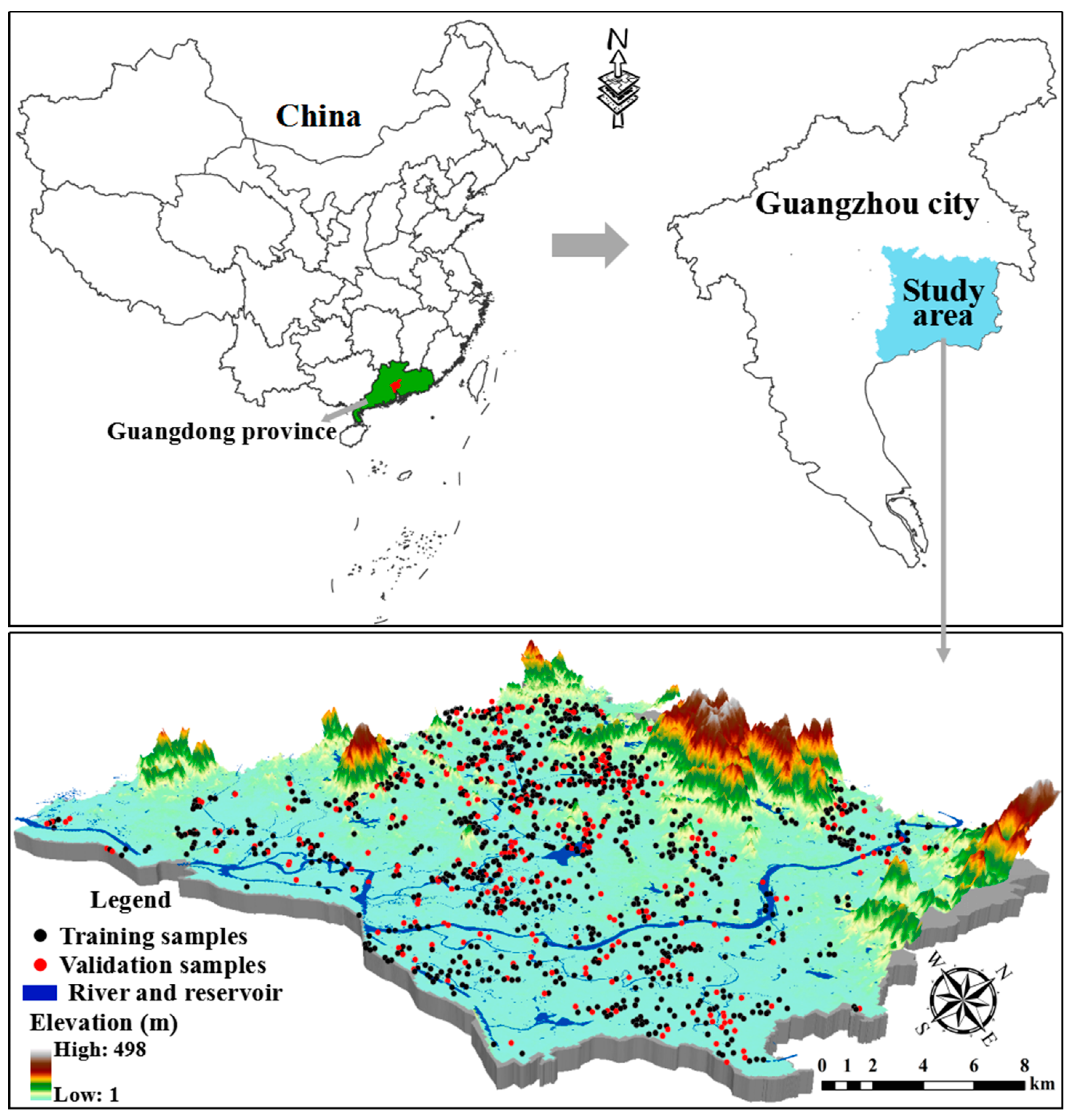
2.2. Field Sampling and Chemical Analysis
In order to reduce the interference of soil moisture, cloud cover and crops on the hyperspectral information obtained by the remote sensor, we chose to collect samples in the driest months (October–December 2008), to ensure bare soil in farmland after crops had been harvested. Using the basic grid partition method, five soil samples were randomly collected in five corners of an “X” shape. According to the actual size of fields, the area representing “X” shape is from 100 m
2 to 500 m
2 and mixed samples can avoid the content mutation of soil nutrients by single sample. The regularization problems which due to the average over the point spread function (PSF) in remote sensing images. The unit of regularization (i.e., resolution) in remote sensing image is very important for prediction results of soil properties. Regularization effects are capable of affecting the nonlinear structures embedded in high-dimensional space, with the great potential for computational efficacy, unmixing accuracy and robustness to noise in hyperspectral images [
28,
29].
After the samples were mixed thoroughly, we collected 1 kg of each sample; 1297 topsoil (0–20 cm) samples were collected in this study (
Figure 1). The GPS data of all samples were recorded before samples were air-dried naturally at room temperature. After removing plant residues and stones, all samples were passed through a 100-mesh nylon sieve (0.2 mm). The determination of soil total nitrogen (TN) was measured by the method described by Walkley and Black [
30]; the soil available phosphorus (AP) was extracted by 0.5 mol L
−1 NaHCO
3 and then measured via the Mo-Sb colorimetric method; and soil available potassium (AK) was extracted by 1 mol L
−1 NH
4-OAc with 1:5 weight-to-volume ratio and then measured by flame photometry [
31].
2.5. Non-Spatial Prediction Models
The stepwise linear regression (SLR) model is often used to assess the linear relationship between multiple independent variables and it can be used for variable screening and avoided collinearity for soil nutrient prediction [
16]. Stepwise regression can also be used for variable screening. SLR can remove the weakly significant variables while retaining those with high contribution rate. In this study, the SLR model was used to identify the optimal combination of input PCs with targets. The linear fitting relationships between hyperspectral auxiliary variables and soil nutrients were also extracted. The SLR model was performed in MATLAB 2013b software. The formula of SLR model (Equation (1)) is defined as follows [
32]:
where
is the estimation value of SLR for soil nutrients,
b is a regression constant,
are regression coefficients and
are the input PCs converted from hyperspectral variables.
The support vector machine (SVM) model is a supervised learning method that was used to solve the regression problem in this study. The SVM method can identify the separating optimal hyperplane in multi-dimensional spatial data and seeks to minimize the error of all training samples. The SVM model overcomes the limitation of neural networks, which tend to rely on local optimal solutions [
33]. Therefore, the SVM model is well suited to soil nutrient prediction with multi-dimensional variables.
Given a dataset with
N samples,
(where
is the input vector,
is a target output and
N is the number of data points), the standard form of SVM [
34] is as follows:
where
maps the input space to the feature space,
and
are optimized coefficients during the training phase,
is the insensitive loss function,
C is the regularized constant and
and
are two positive slack variables. The dual form is
where
and
are non-negative Lagrangian multipliers; therefore, the regression function can be given as
where
is the kernel function. In this study, the radial basis function (RBF) was used as the kernel function. The libsvm package [
35] was imported into the MATLAB 2013b software to construct the SVM model and a multi-dimensional fitting relationship between soil nutrients content and the input PCs was established [
36,
37,
38,
39]. The SVM model parameters set as follows: the type of SVM was epsilon support vector regression (SVR); the meshgrid function was used to find optimum parameters, which including the parameter C of epsilon-SVR and gamma in kernel function; the epsilon in loss function of epsilon-SVR was 0.01 [
35].
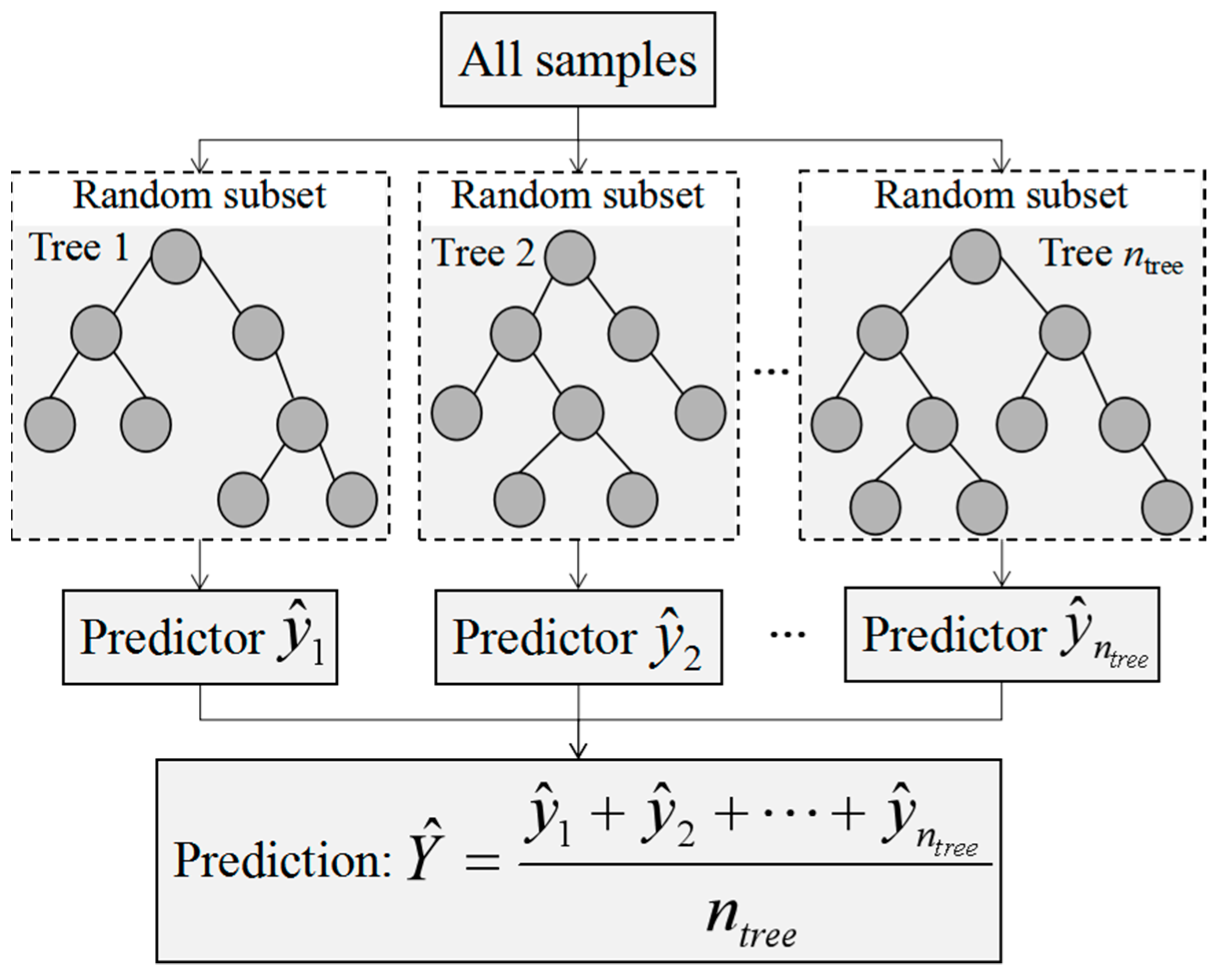
The random forest (RF) model was developed from the decision tree models using ensemble learning methods [
40]. The RF model is an algorithm as well as an idea of combination and integration. The main structure of the RF algorithm is depicted in
Figure 2. First, the bootstrap method was used to randomly form
ntree samples from the original training dataset from which multiple classification regression trees were constructed (
). Then, voting rules were used to divide the optimal tree nodes and the average values of decision trees (i.e.,
) with the most output were taken as the prediction results [
41,
42]. The RF model solves the overgrowth phenomenon of decision trees with non-equilibrium sample fitting and does not need to be pruned. In this study, the number of decision trees was 1000 and the number of variables split by each decision tree model was 2. The RF model was carried out in MATLAB 2013b.
The artificial neural networks (ANNs) comprise a classic nonlinear prediction model. ANNs can be used to model complex nonlinear relationships with limited discontinuous points between hyperspectral auxiliary variables and soil nutrients. Based on self-adjustment of internal control parameters in the human brain, the ANN model includes three layers (an input layer, hidden layer and output layer) [
43,
44]. A back-propagation neural network (BPNN), given its structural simplicity and robustness in simulation [
45], was applied to estimate soil nutrient contents in the study. The BPNN model can also incorporates the need to adjust activation functions (i.e., the sigmoid function) (Equation (7)), number of neurons (
n) and weights (i.e., input weights
and output weights
). The input of the hidden layer (Equation (5)) and that of the output layer (Equation (6)) are calculated as follows [
46]:
where
and
are the inputs of the hidden layer and the output layer, respectively;
is the variable of the
th input node; and
and
are the bias values of the hidden layer and the output layer, respectively. The sigmoid function
is applied as follows:
In order to fully exploit the nonlinear characteristics between hyperspectral variables and soil nutrients, a BPNN model with two hidden layers was constructed in this study which to ensure model stability. The BPNN model was performed in MATLAB 2013b.
2.6. Hybrid Kriging Method
The hybrid kriging method (i.e., artificial neural network–ordinary kriging (ANNOK)) integrated a non-spatial method (the BPNN model) and spatial interpolation approach of ordinary kriging. First, according to the established BPNN model between input PCs and targets, the residuals (Equation (8)) of BPNN were calculated by their estimated and measured values. Second, the semivariogram (Equation (10)) [
47] and ordinary kriging (Equation (9)) of BPNN residuals were calculated. Finally, the estimated values of the BPNN method and the ordinary kriging values of the BPNN residuals were summed (Equation (11)).
where
is the residual value of the BPNN model at sampling site
;
and
are the measured soil nutrient values and the BPNN model estimate, respectively;
denotes the estimated BPNN residuals at a site
with ordinary kriging;
is the number of soil samples;
is the optimal weight;
and
denote the experimental semivariogram and number of pairs of sampling sites separated by
(a lag distance between
and
); and
is the final estimated value of soil nutrient contents by back propagation neural network-ordinary kriging (BPNNOK). The ArcGIS 10.3 was used to implement spatial interpolation and geostatistical calculations.
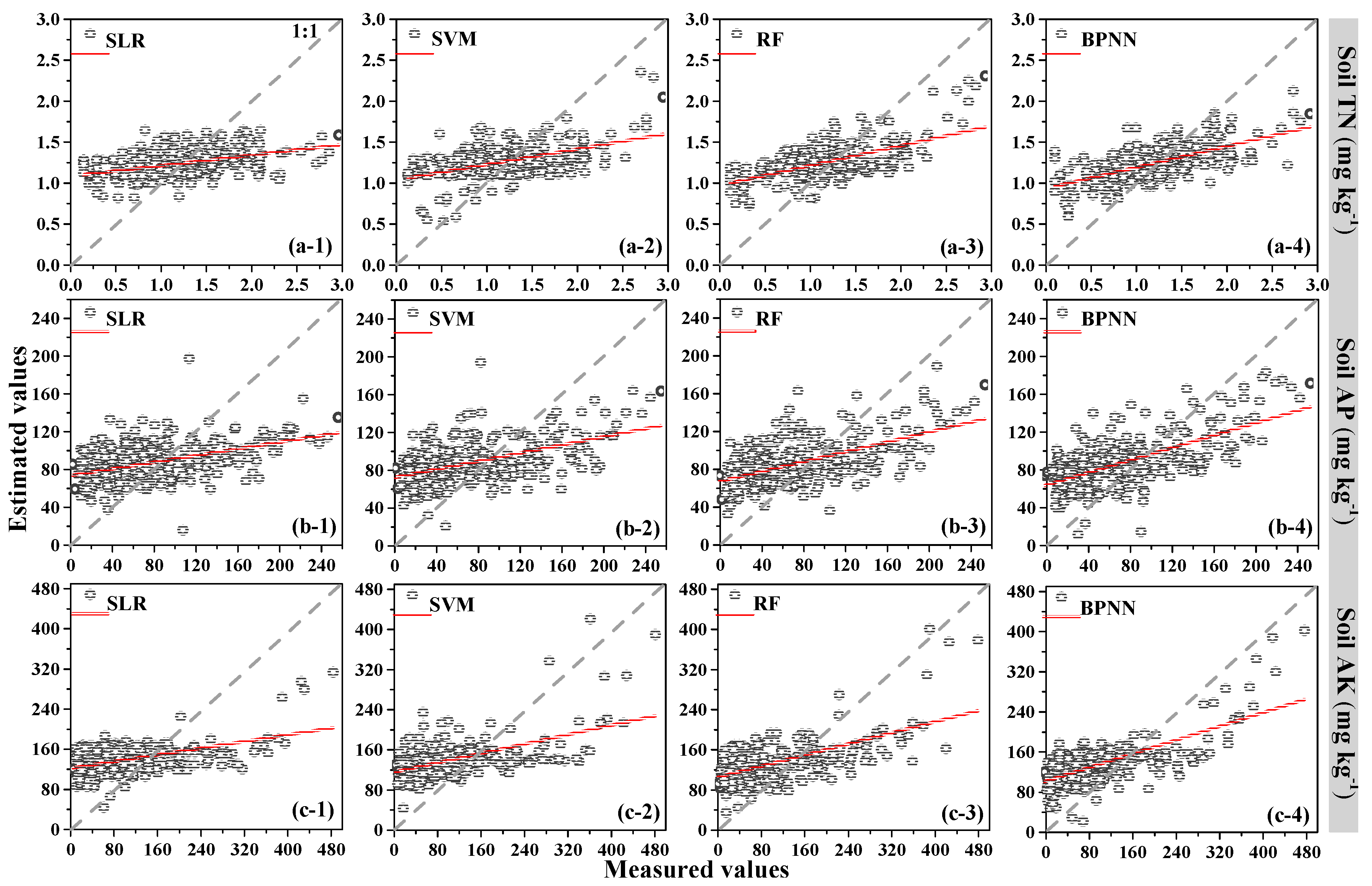
2.7. Validation of Predictive Performance
An independent validation dataset (324 samples, 25% percentage of the total dataset) was randomly extracted using the “create subset” function in ArcGIS 10.3. The validation set did not participate in the model training as independent verification. The mean absolute error (
MAE) (Equation (12)), root mean square error (
RMSE) (Equation (13)), coefficient of determination (
R2) (Equation (14)) and ratio of performance to deviation (
RPD) (Equation (15)) [
48] were calculated to assess the predictive accuracy of soil nutrients.
where
is the estimated value per the SLR, SVM, RF and BPNN models; and
is the stationary mean of
.
STD is the standard deviation of soil nutrient measurement (mg kg
−1), where a higher
RPD value indicates greater accuracy for the quality of prediction models across three classes: the lowest predictive performance (
RPD ≤ 1.4), fairly acceptable predictive performance (1.4 <
RPD < 2) and accurate predictive performance (
RPD ≥ 2) [
49,
50].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}