1. Introduction
Cameras are used to capture scalar phenomena in the form of images or videos, which provide more detailed and impressive data of the physical world [
1]. In recent years, the camera sensing system has tended to be more automatic and intelligent. Compared with traditional cameras, a camera sensing system contains a communication interface, memory, an operating system and a processor. Aiming at facilitating the follow-up image inspection and judgement, the current development trend is to integrate the image sensor and detection algorithm into the same system in order for it to become modular as a camera sensor [
2]. In most situations, imaging sensors are sensitive, accurate and well responding to objects. As a result, the detection of objects is important for the improvement of camera performance. This issue is most pronounced in the field of image processing and recognition. Due to the progress in machine learning methodologies, object detection models dramatically outperform manual detection, which exploit the best detection strategy by applying different algorithms. Neural network is one such principle with the potential to be beneficial for object detection optimizing.
The architecture of a convolutional neural network (CNN) was initially designed to take advantage of the 2D structure of an input signal [
3,
4]. Nevertheless, in line with the grand step in ImageNet Large Scale Visual Recognition Challenge (ILSVRC), the re-utilization of CNN is most pronounced due to its high precision in object detection and [
5]. Thereafter, studies on CNN models were conducted and the recognition accuracy kept updating simultaneously [
6,
7,
8,
9]. Concretely, the mean average precision (
) and detection speed as the target detection parameters for open source dataset like PASCAL VOC and COCO keep improving continually. Researchers prefer to give the first priority to the advance in selective search (SS) [
10] and region-based convolutional network (R-CNN) [
11]. Fast R-CNN, which is a state-of-the-art detection algorithm, is capable of providing real-time processing via very deep convolutional networks regardless of the region proposal [
12,
13]. Further, Region Proposal Network (RPN) is proposed where a multimodal convolutional network is applied to jointly predict objectness and localization on a fusion of image and temporal motion cues [
14]. Accordingly, for each Faster R-CNN, it is necessary to hold both a proposal network and a detection network, which is too sophisticated to optimize the model [
15]. Specifically, You Only Look Once (YOLOv2) is a current well-employed method, with recent publications exploring the promise of using a hierarchical view of object classification and combining distinct datasets together. The basic idea of YOLO is to divide the image into smaller grid cells with each grid cell predicting bounding boxes and confidence for those boxes and class probabilities [
16,
17]. Unlike YOLO, the SSD architecture combines predictions from multiple feature maps at different resolutions in the network, which naturally handles objects of different sizes and improves detection quality [
18].
The use of current-proposed detection model is, however, still limited, primarily because the single dataset, integrating difficulty, slow processing speed and low accuracy. For these reasons, the research is still ongoing to mitigate the deficiencies. In this research, we propose an object detection model EAO, statistic experience based adaptive one-shot detector, with the property of end-to-end detection. To enlarge the current detection dataset, a strategy for making a detection sample from a classification sample is proposed. Meanwhile, a detection dataset, namely ImageNet iLOC, for image processing models training and testing is constructed. The spectral clustering and ResNet methodology are integrated for image processing. The remaining part of this paper is organized as follows:
The background knowledge of spectral clustering, ResNet and stochastic gradient descent is depicted in
Section 2.
Section 3 describes the framework of EAO as well as the working principle in detail.
Section 4 shows the results achieved in object detection experiments and the analysis of the model. The research findings and future planning for camera sensing system are presented in
Section 5.
3. EAO Object Detection Methodology
In this section, we describe EAO for image capture and processing, which can effectively address the difficulties in object detection tasks. In the proposed algorithm, all the samples are taken from the open access image dataset ImageNet, PASCAL VOC and COCO.
3.1. From Classification Dataset to Detection Dataset
Current object detection samples only occupy a small part of the datasets for other purposes (e.g., classification and tagging) [
37,
38]. Previous works have been focused primarily on obtaining an even higher accuracy of classification samples [
6,
39]. In such work, images are presented for machine learning model training and further testing [
7,
8]. Alternatively, object detection datasets are used as a secondary source due to their finite applications. For this reason, the object classification dataset holds great promise for effective learning of given targets after the labeling and recognizing process. Consequently, a strategy for converting a classification sample into a detection sample is devised. Consequently, we made the detection dataset, namely ImageNet iLOC, for network training and put forward the strategy for converting classification samples into detection samples.
Both ResNet and Spectral cluster provide good performances in the field of image classification and image segmentation. On the other hand, cropping [
33,
40] and warping [
11,
41] will inevitably bring deviation as well. According to the basic theory of deep learning and the experimental outcomes, the improvement in working performance and normalization definitely outweighs the working error. Spectral clustering is a kind of unsupervised learning method. In the case of image processing, spectral clustering is used to outline the object and further determine its relative position. In addition, the ResNet approach is employed for object classifying and matching.
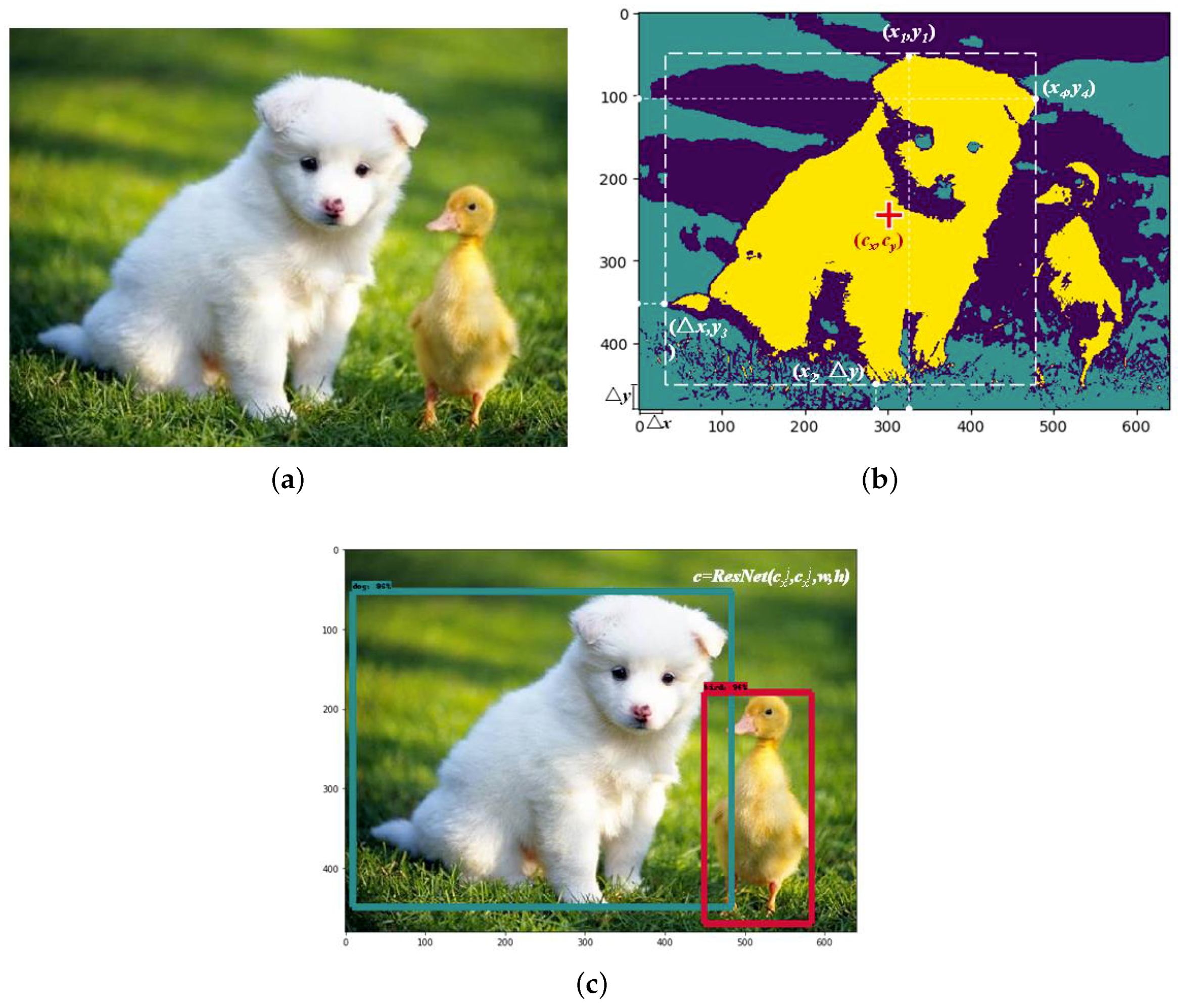
Generally, an object set is defined as
where
and
indicate the coordinate of the ground truth box center, the width
w and height
h characterize the size of ground truth box and
designate the object label. The ground truth box of the detection object is determined by spectral clustering. Specifically, we shall define the coordinate of left border
L and bottom border
D as the feature vectors for each sample. To start with, an input image sample is segmented into
pixels while the feature vectors can be expressed as
and
. The spectral clustering algorithm is deployed on the aforementioned pixels to acquire each cluster, which represents one detection object
and
where
O stand for the object set in the image. In line with each cluster, the coordinate vector of each pixel point of the object is defined as
. Therefore, each pixel point, with the maximum and minimum distance to the image boundary
can be calculated. Let
,
,
and
be the upper, bottom, left and right vertex of object contour respectively, we shall thus define
Moreover, the coordinates of the anchor box vertexes can be represented by
,
,
and
which are furthest to the image boundary on each side.
In Equation (12), the function
stands for calculating the distance of the vertex. Accordingly, the basis parameters
w,
h and
are obtained, i.e.,
Hereafter, the image label is determined by the value of confidence via ResNet. In addition, following the results from Faster R-CNN, SSD, YOLO, etc., we conduct a considerable number of experiments on object detection. The confidence value is adjusted based on experimental outcomes. We find that 85% for the confidence threshold results in a best working capability. If and only if
the target ground truth outputs the label of
.
Figure 1 presents an example of two target objects recognition for a particular image. The object recognition process with ImageNet iLOC is described as Algorithm 1.
| Algorithm 1 Generating object detection dataset based on spectral clustering |
Input: Classification sample X and the size of the dataset is n.
Output: Detection object D
- 1:
functionClassificationToDetection(X) - 2:
Initialization - 3:
for to n do - 4:
Compute the left and bottom coordinates of sample - 5:
Update the coordinate set - 6:
Spectral clustering for detection object O based on sample - 7:
for to do - 8:
Compute the upper vertex , bottom vertex , left vertex and right vertex of object - 9:
Update the object coordinate base on Equation ( 12) - 10:
Compute the width w and height h of the anchor box base on Equation ( 13) - 11:
Compute the center coordinate of the anchor box base on Equation ( 13) - 12:
Update the positioning information of as - 13:
Compute the parameter of object as - 14:
if then - 15:
Compute the ground-truth box of object as - 16:
Update the detection dataset with - 17:
else - 18:
continue - 19:
end if - 20:
end for - 21:
end for - 22:
return the new detection dataset D - 23:
end function
|
3.2. Prior Box Generating
As a rule, objects are sought to be delineated before their identification [
10]. In order to get a unique partitioning of the object, most bounding boxes are defined manually based on experience. In most cases, the bounding boxes lack statistical analysis, which restrain the intersection over union (IOU) overlapping [
11,
13]. Previous work has paid less attention to both the anchor box (Faster) and the default boxes (SSD). Box shape and number are taken from subjective estimation. For this reason, the ground-true box cannot be approached and the object cannot be detected. In this research, K-means++ is employed for box shape clustering. The objects can be better outlined. Further, the efficiency of bounding boxes is improved by revising the parameter
k. Thereupon, we focus on the prior data from the novel datasets to accurately construct the bounding box. Providing the exploratory nature of the figure composition, the images contain different configurations regarding the color, shape, as well as texture of the objects. The goal of this stage is to take K-means++ clustering to detect the shape and size of the object prior box, and thus to improve the convergence speed and detection accuracy. Unlike K-means clustering employed in YOLO and DSSD, K-means++ gets an increasing number of cluster centers, which reduces the uncertainty of random selection and improves the clustering speed and accuracy [
18,
42,
43].
Considering the model complexity and high recall,
is adopted as a good tradeoff for further computing (
Figure 2). Normally, the Euclidean distance is used to denote the distance between an element and the cluster center in the clustering algorithm. Note that the objects are of different sizes; the Euclidean distance cannot exactly reflect the object location in the image. We shall thus use a more appropriate form to demonstrate the distance, which is shown in Equation (
14):
where
represents the samples and
the cluster center. Function
outputs the overlapping ratio of this object to the cluster.
Figure 3 shows the clustering result based on dataset ImageNet and COCO while most bounding boxes are of slender shapes. This involves boxing the object with the clustering outcome, which compares the same image via different bounding approaches. The bounding boxes from K-means++ clustering outcomes show better working performance, evidenced by a higher IOU overlapping proportion.
3.3. Multi-Resolution Feature Mapping
Object capturing on real images is both laborious and time-consuming. The single-shot detector (SSD), which significantly outperforms other methods, combines the standard architecture and the auxiliary structure for high quality image classification. For each feature layer of size
, SSD assigns default boxes of different scales to every single cell. However, the bounding boxes cannot always accurately detect the object. The box in the red solid line is the specific ground truth. As depicted by an example in
Figure 4a, for objects of different sizes, default boxes of high-resolution from SSD fail to cover the targets, which in turn increase the computing amount. Meanwhile, in the layers of low resolution, objects are missed because the boxes are too large. To best fit a specific layer, the resolution largely affects the number of boxes: for a high-resolution cell the default boxes are redundant while for a low-resolution one, more boxes need to be stacked and revise the prior boxes into slender shapes handled carefully. Note that the prior boxes are assigned due to the clustering results; the total number of boxes decrease with the overlapping ratio increases in
Figure 4b.
In this research, we employ the feed-forward convolutional neural network to generate a fixed-size set of bounding boxes and a non-maximum suppression approach to determine the final detections, which optimizes the current SSD. According to
Section 3.2, computation with K-means++ clustering for object detection is facilitated by taking
. For every single image, the number of target objects is so limited that the cost can be significantly reduced by assigning bounding boxes more precisely. Within one layer, each cell maps to a specific region of the original image, the size of which varies based on different resolution of the convolutional layer. Considering the image segmentation principle, bounding boxes can be defined due to layer resolution and the cell property. For this reason, we come up with the strategy that more bounding boxes should be assigned to the convolutional layer of lower resolution, and vice versa.
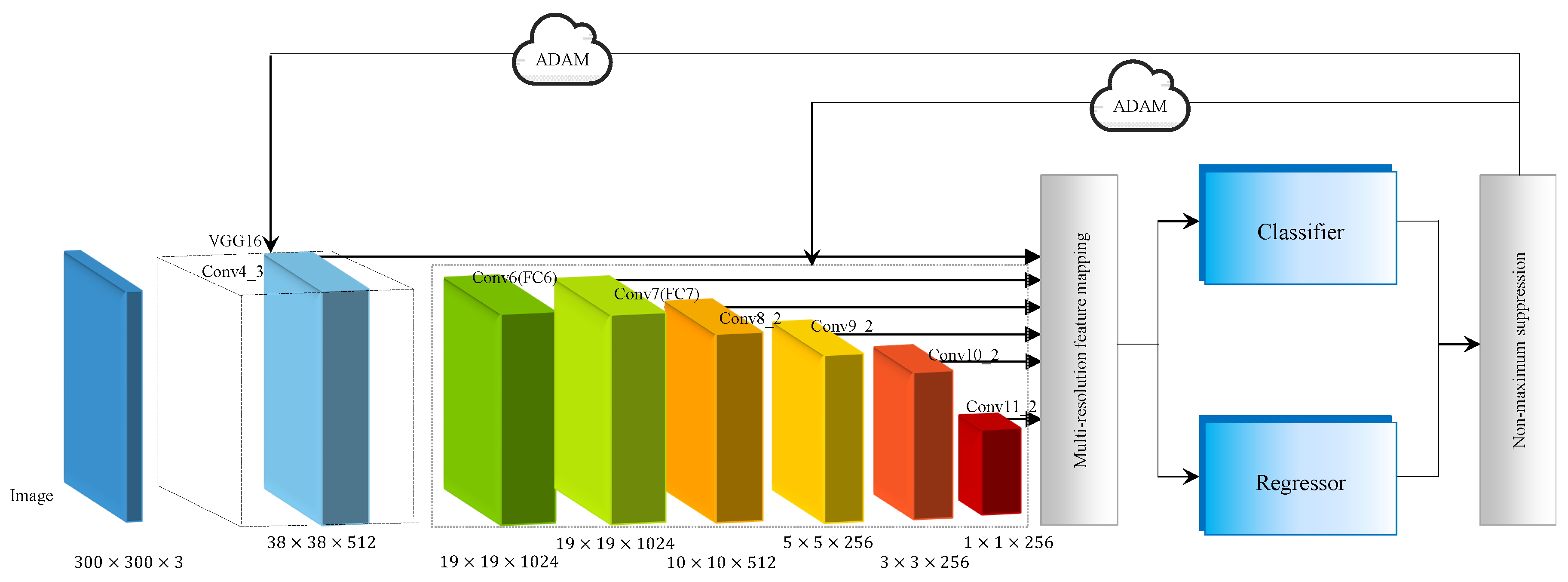
The model architecture is shown in
Figure 5. EAO is initiated with standard VGG 16 as base network, which is a classical network for feature mapping [
44]. Instead of using max-pooling, we employ the stochastic-pooling algorithm to address the issue of overfitting [
45]. The multi-resolution detection layers are then integrated to seed the detection algorithm. The feature mapping is on the foundation of activation function Rectified Linear Unit (ReLU) to prevent gradient disappearance and results in faster learning [
46]. By using the classical VGG 16 version, the basic layer conv4_3 is kept and the two fully connected layers, FC6 and FC7 are converted into typical
convolution layers [
47]. The latter is utilized as the detection layer. As a result, the network is deployed by multiple feature maps, whose sizes are
,
,
,
,
and
. The convolutional layers decrease in size progressively. In each detection layer, a
convolution is applied to extract the feature of prior boxes. At each feature map cell, the offsets relative to the ground-truth box in the cell, as well as the conditional probabilities of the object category are picked. For a given cell with
k prior boxes, we focus here on the four offsets involved with the ground-truth box. These layers are followed by a softmax classifier and a linear regressor, which predicts the category of the prior box and calculates the offset between the prior box and ground-truth box, respectively. Final detections are produced through non-maximum suppression step. Within the model, the random optimizer ADAM is taken for end-to-end training optimization.
Following the K-means++ clustering outcome, the shapes of bounding boxes for each layer are dedicatedly devised. The average IOU of a different detection model is presented (
Table 1). With different bounding boxes assigned, a better average IOU of EAO is observed.
3.4. Training
The training process is originated from minimizing the loss of multitask objective function [
48]. Supposing
x is the convolution result for matching the predicted box
p and the ground-truth box
g, we introduce the classification loss (
) and the regression loss (
). Considering the multiple object categories, the overall objective loss function is a weighted sum of the classification loss and the regression loss:
where
N is the number of matched boxes,
c is the multiple-class confidence and
is the weight term for controlling detection error. Typically, the regression loss is determined by
which characterizes the localization accuracy between the predicted box
p and the ground truth [
12].
One of the key processes gleaned from the Faster R-CNN is that the offset of the width (
w), the height (
h) and the central point (
) can be obtained as the solution of regression. This idea is developed in our strategy for model evolution. We thus define the width, height and center of the predicted box, prior box and the ground-truth box. The offset vector between the prior box and the predicted box is
while that of the predicted box is
p and the ground-truth box is
g. Thereby, we have
in line with
Note that the confidence loss is the softmax loss over multiple-class confidence
c, the classification loss is defined as
together with
After the prior boxes generated, each of the prior boxes with IOU overlap higher than 0.7 are selected as a positive proposal. On the other hand, negative training samples imply the overlap is lower than 0.3. The rest of the prior boxes are removed from inputs of the training model. Since most of the prior boxes are negative in practical use, the min-batch method is used to keep the ratio of matched to unmatched boxes to 1:1. For an image lacking positive samples, we employ the negative ones for supplementing. In this case, the ADAM algorithm is employed to improve the model accuracy based on offset revising.
4. Experiments
Experiments are conducted on three challenging datasets: PASCAL VOC 2007, PASCAL VOC 2012 and COCO to evaluate the working performance of EAO. All the state-of-the-art algorithms, i.e., SSD, YOLO and Faster R-CNN, are trained with image detection datasets. The dataset, namely Imagenet, is taken for model training. In this manuscript, we introduce the self-made dataset ImageNet iLOC for EAO training after training with traditional detection samples. The detection accuracy outperforms other methods. The performance evolution is presented in
Section 4.4.2. All the testing datasets in this research are the same.
4.1. Dataset
PASCAL VOC2007: The PASCAL VOC project provides standardized labelled images for object recognition. Meanwhile, the evaluation of recognition method on these datasets can be achieved through its evaluation server. There are images of 20 classes in PASCAL VOC2007. In order to detect objects from a number of visual object classes in realistic scenes, we take 16,551 images from the VOC2007 training collection and validation collection for training and 4952 pieces of test data for testing.
PASCAL VOC2012: Compared to PASCAL VOC2007, the size of image dataset increased substantially. In PASCAL VOC2012, each training image is associated to an annotation file providing object class label for each object. In this stage, all the 10,991 images from the dataset are used to evaluate the capability of EAO.
MS COCO: MS COCO consists of over 10,000 image samples of 91 object classes which aims at gathering images of complex daily scenes containing common objects in their natural context. However, objects in COCO tend to be smaller than those in PASCAL VOC, detection boxes assigning can therefore be adjusted for different layers.
4.2. Evaluation Protocol
Mean average precision(
): For a given task, a classical evaluation protocol is to compute the
curve. Recall stands for the proportion of all positive examples ranked above a given rank while precision for the proportion of all examples above that rank from the positive class [
49]. Formally, the
that indicates the shape of
outcome is proposed to evaluate the detection performance of PASCAL VOC. The
is specified by 11-points interpolated average precision, which is the average of the maximum precision for recall levels at a fixed set of uniformly-spaced recall values
[
50]. The precision at each recall level
r is interpolated by taking the maximum precision. The
is expressed as
together with
where is p(
) the measured precision at recall
.
IOU: IOU is taken as a standardized metric for characterizing the performance of an object detector on MS COCO. Considering that more small objects appear in images of MS COCO, we evaluate the model detection precision for IOU
[
11].
4.3. Implementation Details
We evaluate EAO in comparison to SSD, YOLO and Faster R-CNN. To start with, we fine-tune the model with ADAM optimizer and set
. The initial learning rate is 0.001. The exponential decay rates vary slightly for different datasets after the first-step iteration. Working parameters for distinguished datasets are given in
Table 2.
For each dataset, the EAO with two different types of input,
and
, is taken for training and testing. To further improve the recognition precision, we make and release the object classification dataset ImageNet iLOC with the proposed method in
Section 3.1 and pre-train EAO with it. Subsequently, the model is applied to PASCAL VOC2012. The iterations for the pre-training process is fixed at 150k. However, this number differs in the second training step which are conducted on each dataset’s own training images. The differences depend on the size of dataset.
4.4. Results
4.4.1. PASCAL VOC2007
The network is first evaluated on PASCAL VOC2007 dataset, which is a basic task for object detection. We use the initialization parameters for 40k iterations, then continue training for 20k iterations with revised parameters in
Table 2.
Table 3 summarises all the results comparing with some state-of-the-art approaches, in terms of
on all categories.
According to the testing outcome, our model trained with input
, which keeps the same aspect ratio with SSD300, is of a higher accuracy (
vs.
for SSD300). Our results denote EAO outperforms SSD when improving the original input size to
. A
is gained and the recall reaches 85–90%. In contrast with R-CNN, EAO is particularly effective due to the classifier and the regressor. To further assess the property of EAO from different resolution, we record the working process by employing analysis tool Tensorboard provided by Google tensorflow. With the multi-resolution network applied, a higher IOU can be obtained. Compared to SSD, EAO is highlighted with the convergence speed and the detection accuracy, which is expressed in
Figure 6.
Most object recognition methods are limited in object detection since the object information is prone to be filtered through multi-layer convolution. On the one hand,
Table 3 shows the detection precision for a small object is improved from a higher resolution network. On the other hand, prior boxes of various size are applied to different layers based on the pre-processing step in
Section 3.1. Consequently, EAO provides higher robustness and detection precision than SSD (
Figure 7). From prior boxes proposed to a high precision model, the oscillation processes stop after 60K and 80K times iteration for EAO512 and SSD512 separately. Crucially, EAO is amenable to efficiently stabilize the detection outcomes.
4.4.2. PASCAL VOC2012
Aiming at obtaining a comprehensive evaluation of the proposed model, we assign to each model the training set provided by PASCAL VOC2012. Distinctively, we enlarge the training set of EAO, which contains both ImageNet iLOC data sets (produced in
Section 3.1) and PASCAL VOC2012 trainval sets. Then all models are evaluated on PASCAL VOC2012 test set. The outcome similar to that from PASCAL VOC2007 is acquired (
Table 4). According to the test results, the detection precision of EAO512 attains a 75.8 percent, which outperforms that of Faster R-CNN, YOLO and SSD via training from basic dataset. Moreover, by adopting the training sets from ImageNet, iLOC yields a 3.4 percent and a 3.6 percent improvement for EAO300 and EAO512, respectively. We also note that the performance of EAO300, with the new expansion data augmentation, is better than that of original EAO512 trained by PASCAL VOC2012. This happens because, given more exact detection objects, the model will be trained to work in a more accurate and faster mode. Incorporating the spectral clustering on objects and the bounding box prediction, our proposed object detection dataset is shown to greatly boost the detection accuracy. Likewise, it is noteworthy that the working performance on objects that are difficult to recognize is improved, like the boat and the bird.
4.4.3. MS COCO
For the purpose of identifying our network on a more general, large-scale image dataset, we apply the models to MS COCO. Because objects in MS COCO tend to be smaller than those from PASCAL VOC, we train EAO with the initialization parameter for the first 140k iterations, followed by 40k iterations with the specifications in
Table 2. Considering the bounding box generating strategy in
Section 3.2, we use smaller prior boxes for all layers. The numbers and the sizes of the prior boxes for various layers are then determined based on the feature map principle.
We take the whole trainval set for model training and the whole test set for testing. The results can be visualized in
Table 5. The working performance of EAO300 is close to that of SSD512 while EAO512 exceeds the state-of-the-art methods on MS COCO dataset in all criteria. Specifically, both EAO300 and EAO512 significantly outperform other methods on
. The reason for this is most objects in MS COCO are relatively small while SSD and Faster R-CNN tend to fails to capture the delicate boundaries of small objects. The recognition results and the convergence process are presented in
Figure 8 and
Figure 9, respectively.
4.4.4. Inference Time
As long as a large number of prior boxes are generated from our method, it is advisable to perform non-maximum suppression during inference. We filter most boxes with a confidence threshold of 0.05. The top 150 detections of each image are maintained by integrated non-maximum suppression and jaccard overlap of 0.45 per class. Note that 20 object classes belong to the PASCAL VOC dataset; the best result on each image is 1.3 ms with a
input while the total runtime on all detection layers is 1.9 ms. A quantitative comparison with other competing approaches is depicted in
Table 6.
As long as a large number of prior boxes are generated from our method, it is advisable to perform non-maximum suppression during inference. We filter most boxes with a confidence threshold of 0.05. The top 150 detections of each image are maintained by integrated non-maximum suppression and jaccard overlap of 0.45 per class. Note that 20 object classes belong to PASCAL VOC dataset; the best result on each image is 1.3 ms. On
images, it takes all the six detection layers 1.9 ms on non-maximum suppression when running on a Xeon-E7-8800 v3 CPU with 2 GTX1080 Ti GPU and a Dell R740 server. A qualitative comparison with other competing approaches is depicted in
Table 6. For the same image dataset, the Fast YOLO shows a decent inference time of 155 FPS but a poor detection precision. With the additional feature mapping layer applied to the region proposal network, the Fast R-CNN is slowed down by feature downsampling. Besides, outcomes of EAO are slightly better than SSD on both running time and detection precision. In particular, EAO300 achieves a
of 76.6 while maintaining a real-time speed of 61 FPS.
5. Discussion and Conclusions
This paper introduces EAO as an end-to-end convolutional network for object recognition, which is efficient and reliable to detect objects with a high precision for camera sensing. Aiming at facilitating the image processing, we make the detection dataset, namely ImageNet iLOC, via the spectral clustering method. This paper also proposes a detailed study of the prior box generating principle. Comprehensively, a multi-resolution network model for object detection is constructed and trained. Experiments are carried out on classical image datasets. By using the pretraining dataset ImageNet iLOC, an improved working performance is obtained. All experimental results are carefully analyzed. Compared to some state-of-the-art methods, the results validate the effectiveness of EAO and demonstrate the high efficiency in both the runtime and recognition accuracy.
Future work will address more complex situations where objects are presented in the camera-video form. The current model can be extended to a recurrent neural network by integrating it with other algorithms.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}