Talk, Text, Tag? Understanding Self-Annotation of Smart Home Data from a User’s Perspective

 , , ,
, , ,  , and
, and 
Abstract
1. Introduction
2. Related Work
2.1. The Role of Annotations in Lifelong Machine Learning
2.2. Other Forms of Annotation in Everyday Life
2.3. Considerations about Self-Annotating Activity Data
2.4. Choosing Labels
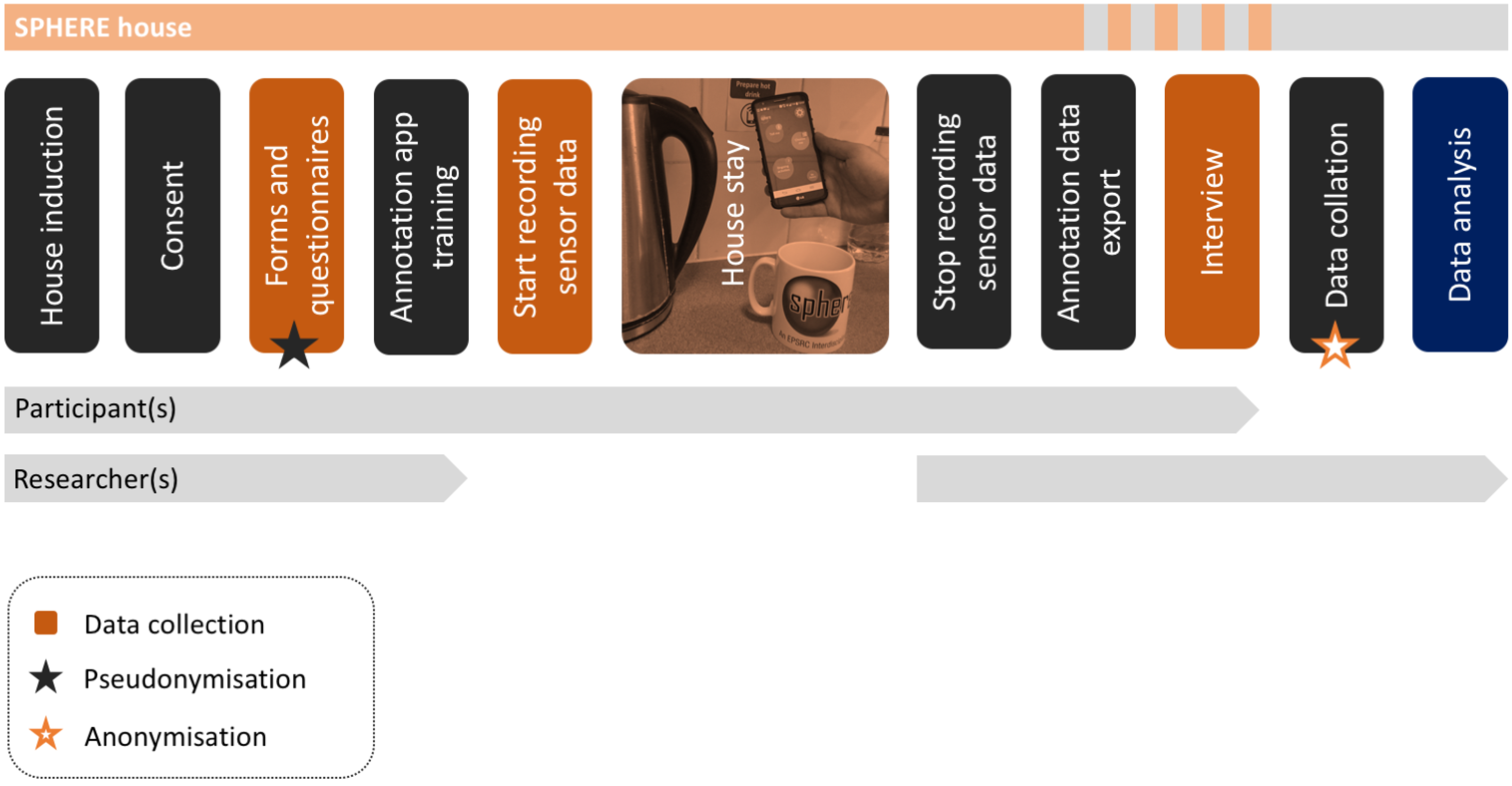
3. Materials and Methods
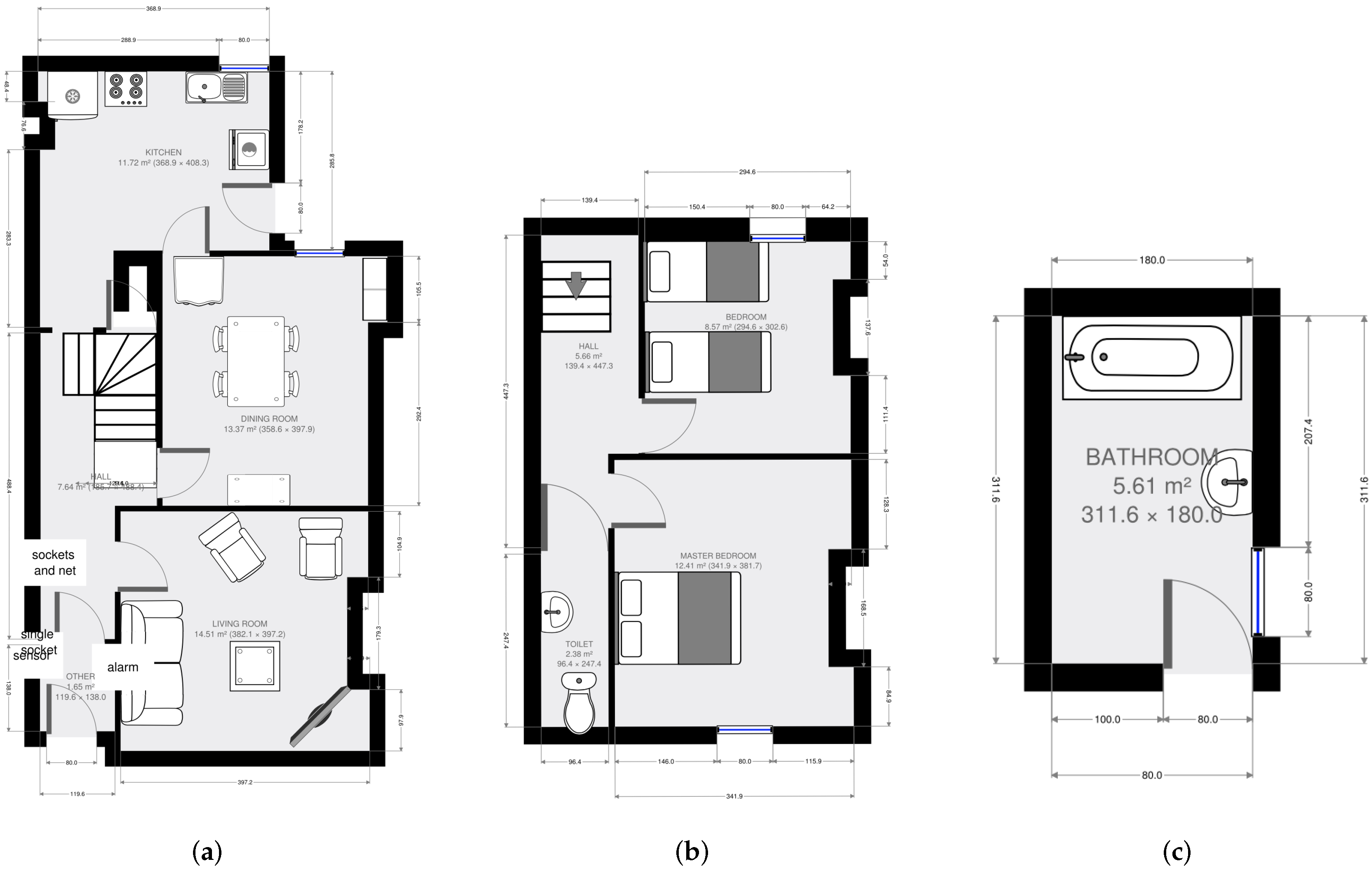
3.1. Setting and Sample
3.2. Data Collection
3.3. Data Analysis
4. Results
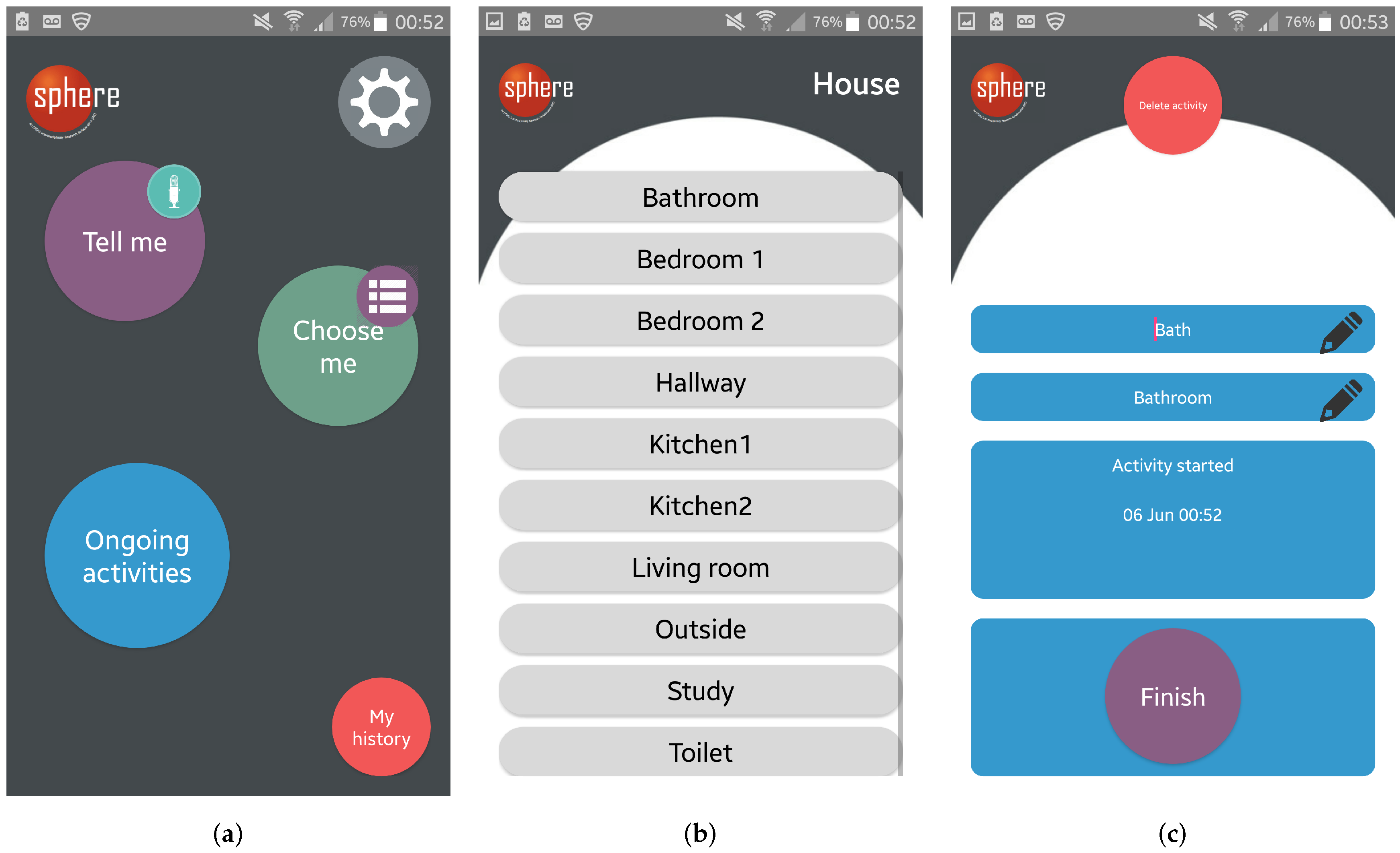
4.1. Mode of Logging
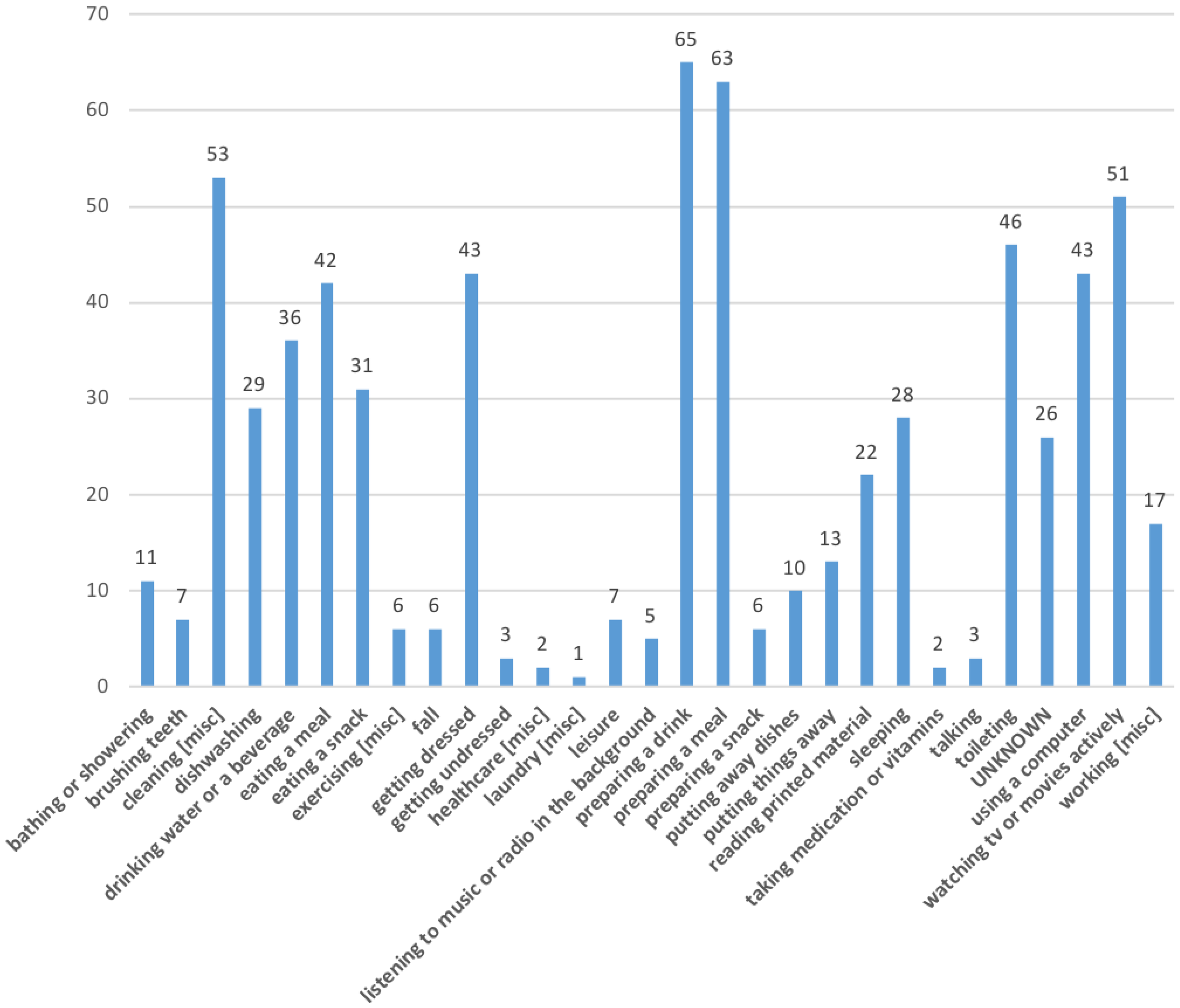
4.2. Logging Activities
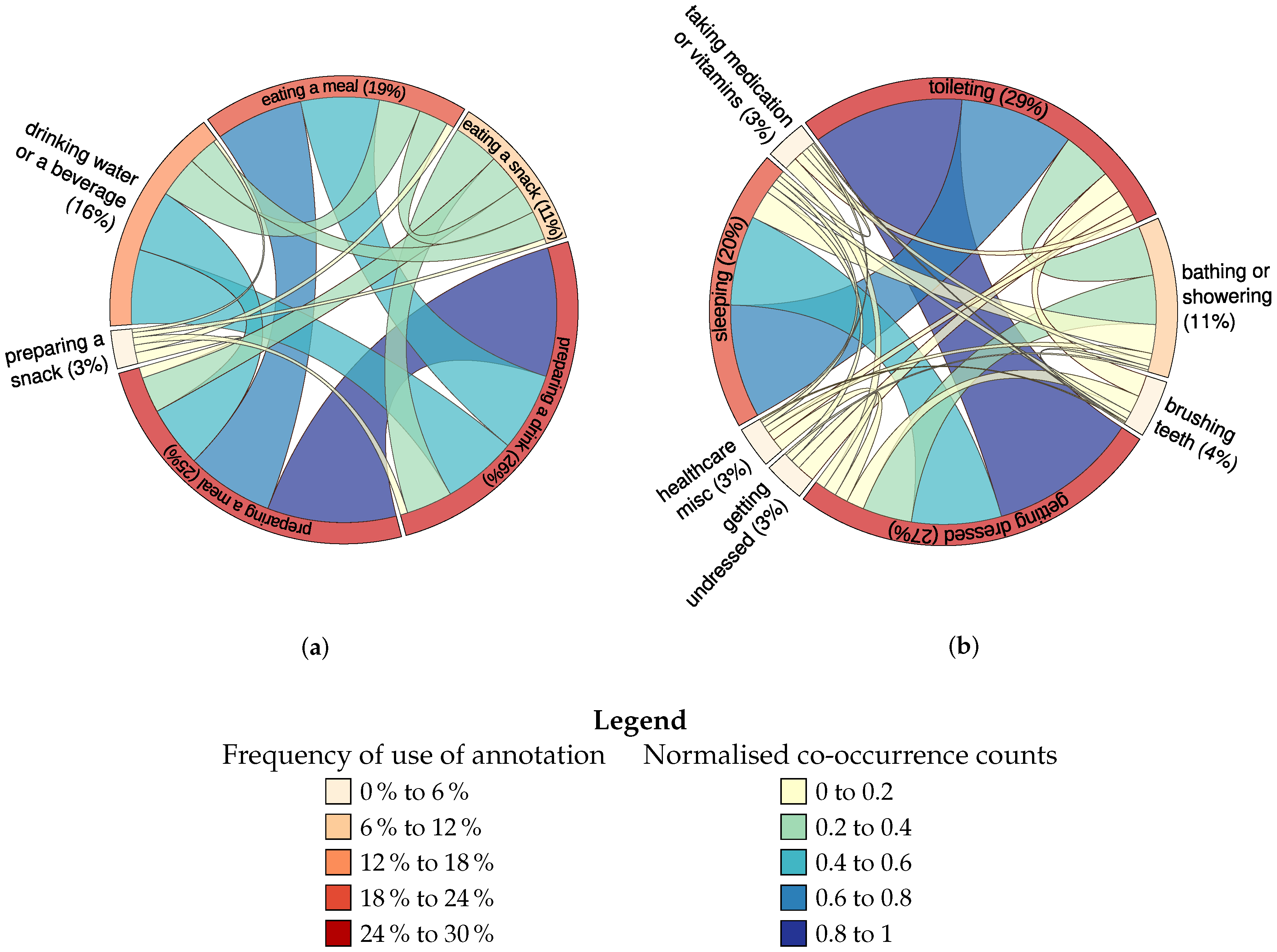
4.2.1. Distribution of Logged Terms
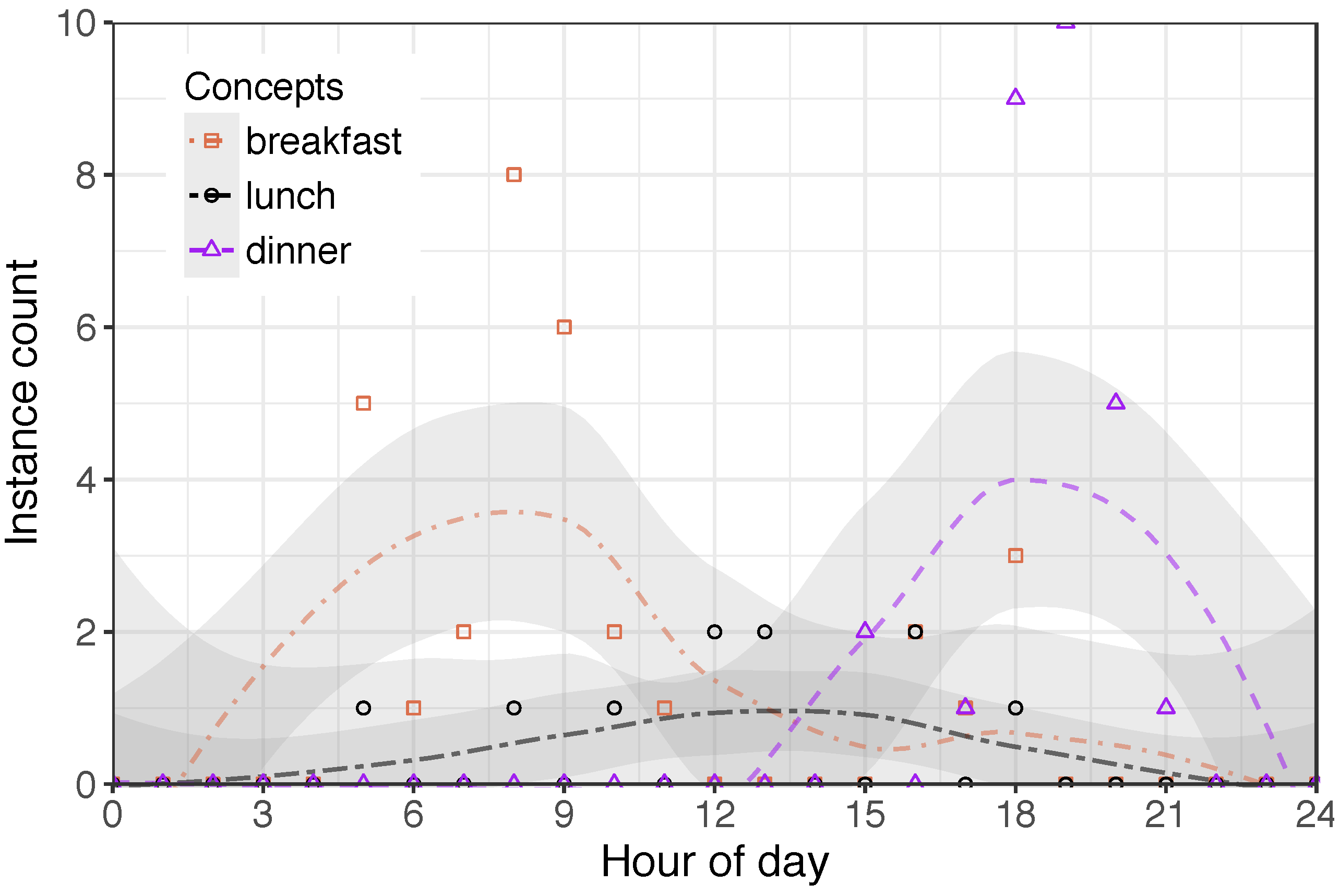
4.2.2. Note on Daily Routines
4.3. The Language of Labelling
Performative Usage
4.4. Duration of Activities
4.5. Location
5. Discussion
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AR | Activity Recognition |
| ADL | Activities of Daily Living |
| ATM | Automated Teller Machine |
| ARDUOUS | International Workshop on Annotation of useR Data for UbiquitoUs Systems |
| BLE | Bluetooth Low Energy |
| CSV | Comma Separated Values |
| JSON | JavaScript Object Notation |
| HCI | Human-Computer Interaction |
| MAC (address) | Media Access Control address |
| NFC | Near Field Communication |
| PIM | Personal Information Management |
| RSSI | relative Received Signal Strength Indicator |
| SPHERE | Sensor Platform for HEalthcare in a Residential Environment |
| UI | User Interface |
References
- Wait, S.; Harding, E. The State of Ageing and Health in Europe; Technical Report; International Longevity Centre-UK: London, UK; The Merck Company Foundation: New York, NY, USA, 2006. [Google Scholar]
- Papageorgiou, X.S.; Chalvatzaki, G.; Dometios, A.C.; Tzafestas, C.S.; Maragos, P. Intelligent Assistive Robotic Systems for the Elderly: Two Real-life Use Cases. In Proceedings of the 10th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA ’17), Island of Rhodes, Greece, 21–23 June 2017; ACM: New York, NY, USA, 2017; pp. 360–365. [Google Scholar] [CrossRef]
- Yordanova, K.; Koldrack, P.; Heine, C.; Henkel, R.; Martin, M.; Teipel, S.; Kirste, T. Situation Model for Situation-aware Assistance of Dementia Patients in Outdoor Mobility. J. Alzheimer’s Dis. 2017, 60, 1461–1478. [Google Scholar] [CrossRef] [PubMed]
- Majumder, S.; Mondal, T.; Deen, M. Wearable Sensors for Remote Health Monitoring. Sensors 2017, 17, 130. [Google Scholar] [CrossRef] [PubMed]
- Zhu, N.; Diethe, T.; Camplani, M.; Tao, L.; Burrows, A.; Twomey, N.; Kaleshi, D.; Mirmehdi, M.; Flach, P.; Craddock, I. Bridging e-health and the internet of things: The sphere project. IEEE Intell. Syst. 2015, 30, 39–46. [Google Scholar] [CrossRef]
- Woznowski, P.; Burrows, A.; Diethe, T.; Fafoutis, X.; Hall, J.; Hannuna, S.; Camplani, M.; Twomey, N.; Kozlowski, M.; Tan, B.; et al. SPHERE: A sensor platform for healthcare in a residential environment. In Designing, Developing, and Facilitating Smart Cities; Springer: New York, NY, USA, 2017; pp. 315–333. [Google Scholar]
- Dawadi, P.N.; Cook, D.J.; Schmitter-Edgecombe, M.; Parsey, C. Automated assessment of cognitive health using smart home technologies. Technol. Health Care 2013, 21, 323–343. [Google Scholar] [PubMed]
- Intille, S.S.; Larson, K.; Tapia, E.M.; Beaudin, J.S.; Kaushik, P.; Nawyn, J.; Rockinson, R. Using a live-in laboratory for ubiquitous computing research. In Proceedings of the International Conference on Pervasive Computing, Dublin, Ireland, 7–10 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 349–365. [Google Scholar]
- Rashidi, P.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Discovering Activities to Recognize and Track in a Smart Environment. IEEE Trans. Knowl. Data Eng. 2011, 23, 527–539. [Google Scholar] [CrossRef] [PubMed]
- Yordanova, K.; Paiement, A.; Schröder, M.; Tonkin, E.; Woznowski, P.; Olsson, C.M.; Rafferty, J.; Sztyler, T. Challenges in Annotation of useR Data for UbiquitOUs Systems: Results from the 1st ARDUOUS Workshop. arXiv, 2018; arXiv:1803.05843. [Google Scholar]
- Schröder, M.; Yordanova, K.; Bader, S.; Kirste, T. Tool support for the online annotation of sensor data. In Proceedings of the 3rd International Workshop on Sensor-based Activity Recognition and Interaction, Rostock, Germany, 23–24 June 2016; ACM: New York, NY, USA, 2016; p. 9. [Google Scholar]
- Yordanova, K.; Krüger, F.; Kirste, T. Providing semantic annotation for the cmu grand challenge dataset. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athes, Greece, 19–23 March 2018. [Google Scholar]
- Twomey, N.; Diethe, T.; Kull, M.; Song, H.; Camplani, M.; Hannuna, S.; Fafoutis, X.; Zhu, N.; Woznowski, P.; Flach, P.; et al. The SPHERE challenge: Activity recognition with multimodal sensor data. arXiv, 2016; arXiv:1603.00797. [Google Scholar]
- Krüger, F.; Heine, C.; Bader, S.; Hein, A.; Teipel, S.; Kirste, T. On the applicability of clinical observation tools for human activity annotation. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 129–134. [Google Scholar] [CrossRef]
- Woznowski, P.; Tonkin, E.; Laskowski, P.; Twomey, N.; Yordanova, K.; Burrows, A. Talk, text or tag? In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 123–128. [Google Scholar] [CrossRef]
- Diete, A.; Sztyler, T.; Stuckenschmidt, H. A smart data annotation tool for multi-sensor activity recognition. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 111–116. [Google Scholar] [CrossRef]
- Tolmie, P.; Crabtree, A.; Rodden, T.; Colley, J.; Luger, E. “This Has to Be the Cats”: Personal Data Legibility in Networked Sensing Systems. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing (CSCW ’16), San Francisco, CA, USA, 27 February–2 March 2016; ACM: New York, NY, USA, 2016; pp. 491–502. [Google Scholar] [CrossRef]
- Burrows, A.; Coyle, D.; Gooberman-Hill, R. Privacy, boundaries and smart homes for health: An ethnographic study. Health Place 2018, 50, 112–118. [Google Scholar] [CrossRef] [PubMed]
- Twomey, N.; Diethe, T.; Fafoutis, X.; Elsts, A.; McConville, R.; Flach, P.; Craddock, I. A Comprehensive Study of Activity Recognition Using Accelerometers. Informatics 2018, 5. [Google Scholar] [CrossRef]
- Parkka, J.; Ermes, M.; Korpipaa, P.; Mantyjarvi, J.; Peltola, J.; Korhonen, I. Activity classification using realistic data from wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 119–128. [Google Scholar] [CrossRef] [PubMed]
- Atallah, L.; Lo, B.; Ali, R.; King, R.; Yang, G.Z. Real-time activity classification using ambient and wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 1031–1039. [Google Scholar] [CrossRef] [PubMed]
- Tsipouras, M.G.; Tzallas, A.T.; Rigas, G.; Tsouli, S.; Fotiadis, D.I.; Konitsiotis, S. An automated methodology for levodopa-induced dyskinesia: Assessment based on gyroscope and accelerometer signals. Artif. Intell. Med. 2012, 55, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Maurer, U.; Smailagic, A.; Siewiorek, D.P.; Deisher, M. Activity recognition and monitoring using multiple sensors on different body positions. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks (BSN’06), Cambridge, MA, USA, 3–5 April 2006; pp. 4–116. [Google Scholar] [CrossRef]
- Intille, S.S.; Larson, K.; Beaudin, J.S.; Nawyn, J.; Tapia, E.M.; Kaushik, P. A Living Laboratory for the Design and Evaluation of Ubiquitous Computing Technologies. In Proceedings of the CHI ’05 Extended Abstracts on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; ACM: New York, NY, USA, 2005; pp. 1941–1944. [Google Scholar] [CrossRef]
- Jiang, J. A Literature Survey on Domain Adaptation of Statistical Classifiers. Technick Report. 2008. Available online: http://www.mysmu.edu/faculty/jingjiang/papers/dasurvey.pdf (accessed on 20 July 2018).
- Diethe, T.; Twomey, N.; Flach, P. Bayesian active transfer learning in smart homes. In Proceedings of the ICML Active Learning Workshop, Lille, France, 20 July 2015; Volume 2015. [Google Scholar]
- Diethe, T.; Twomey, N.; Flach, P. Active transfer learning for activity recognition. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Fafoutis, X.; Mellios, E.; Twomey, N.; Diethe, T.; Hilton, G.; Piechocki, R. An RSSI-based wall prediction model for residential floor map construction. In Proceedings of the 2015 IEEE 2nd World Forum on Internet of Things (WF-IoT), Milan, Italy, 14–16 December 2015; pp. 357–362. [Google Scholar]
- Twomey, N.; Diethe, T.; Craddock, I.; Flach, P. Unsupervised learning of sensor topologies for improving activity recognition in smart environments. Neurocomputing 2017, 234, 93–106. [Google Scholar] [CrossRef]
- Twomey, N.; Diethe, T.; Flach, P. On the need for structure modelling in sequence prediction. Mach. Learn. 2016, 104, 291–314. [Google Scholar] [CrossRef]
- Silver, D.L.; Yang, Q.; Li, L. Lifelong machine learning systems: beyond learning algorithms. In AAAI Spring Symposium: Lifelong Machine Learning; AAAI: Palo Alto, CA, USA, 2013; Volume 13, p. 5. [Google Scholar]
- Harvey, M.; Langheinrich, M.; Ward, G. Remembering Through Lifelogging: A survey of human memory augmentation. Pervasive Mob. Comput. 2016, 27, 14–26. [Google Scholar] [CrossRef]
- Jacquemard, T.; Novitzky, P.; O’Brolcháin, F.; Smeaton, A.F.; Gordijn, B. Challenges and Opportunities of Lifelog Technologies: A Literature Review and Critical Analysis. Sci. Eng. Ethics 2014, 20, 379–409. [Google Scholar] [CrossRef] [PubMed]
- Shah, M.; Mears, B.; Chakrabarti, C.; Spanias, A. Lifelogging: Archival and retrieval of continuously recorded audio using wearable devices. In Proceedings of the 2012 IEEE International Conference on Emerging Signal Processing Applications, Las Vegas, NV, USA, 12–14 January 2012; pp. 99–102. [Google Scholar] [CrossRef]
- Bergman, O.; Beyth-Marom, R.; Nachmias, R. The User-subjective Approach to Personal Information Management Systems. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 872–878. [Google Scholar] [CrossRef]
- Coyle, L.; Ye, J.; McKeever, S.; Knox, S.; Staelber, M.; Dobson, S.; Nixon, P. Gathering Datasets for Activity Identification; CHI: Boston, MA, USA, 2009. [Google Scholar]
- Jones, W. Personal Information Management. Annu. Rev. Inf. Sci. Technol. 2007, 41, 453–504. [Google Scholar] [CrossRef]
- Bergman, O.; Beyth-Marom, R.; Nachmias, R. The project fragmentation problem in personal information management. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’06), Montréal, QC, Canada, 22–27 April 2006; ACM: New York, NY, USA, 2006; pp. 271–274. [Google Scholar] [CrossRef]
- Guy, M.; Tonkin, E.L. Tidying up tags. D-Lib Mag. 2006, 12, 1082–9873. [Google Scholar]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In Proceedings of the International Conference on Pervasive Computing, Linz/Vienna, Austria, 18–23 April 2004; Springer: New York, NY, USA, 2004; pp. 158–175. [Google Scholar]
- Lockton, D.; Harrison, D.; Stanton, N.A. The Design with Intent Method: A design tool for influencing user behaviour. Appl. Ergon. 2010, 41, 382–392. [Google Scholar] [CrossRef] [PubMed]
- Freed, M.; Remington, R. Human-machine system design: When does simulation pay? In Proceedings of the ICCM 2000: Third International Conference on Cognitive Modeling, Groningen, The Netherlands, 23–25 March 2000. [Google Scholar]
- Chung, P.H.; Byrne, M.D. Cue effectiveness in mitigating postcompletion errors in a routine procedural task. Int. J. Hum. Comput. Stud. 2008, 66, 217–232. [Google Scholar] [CrossRef]
- Byrne, M.D.; Bovair, S. A working memory model of a common procedural error. Cogn. Sci. 1997, 21, 31–61. [Google Scholar] [CrossRef]
- Jin, J.; Dabbish, L.A. Self-interruption on the Computer: A Typology of Discretionary Task Interleaving. In Proceedings of the CHI ’09 SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; ACM: New York, NY, USA, 2009; pp. 1799–1808. [Google Scholar] [CrossRef]
- Miyata, Y.; Norman, D.A. Psychological issues in support of multiple activities. In User Centered System Design: New Perspectives on Human-Computer Interaction; Semantic Scholar: Seattle, WA, USA, 1986; pp. 265–284. [Google Scholar]
- Cutrell, E.B.; Czerwinski, M.; Horvitz, E. Effects of Instant Messaging Interruptions on Computing Tasks. In Proceedings of the CHI ’00 Extended Abstracts on Human Factors in Computing Systems, The Hague, The Netherlands, 1–6 April 2000; ACM: New York, NY, USA, 2000; pp. 99–100. [Google Scholar] [CrossRef]
- Nielsen, J. 10 Usability Heuristics for User Interface Design; Nielsen Norman Group: Fremont, CA, USA, 1995. [Google Scholar]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Cui, Z.; Jones, D.; O’Brien, P. Semantic B2B Integration: Issues in Ontology-based Approaches. Sigmod. Rec. 2002, 31, 43–48. [Google Scholar] [CrossRef]
- Keet, C.M. Enhancing Comprehension of Ontologies and Conceptual Models Through Abstractions. In Proceedings of the AI*IA 2007: Artificial Intelligence and Human-Oriented Computing, Rome, Italy, 10–13 September 2007; Basili, R., Pazienza, M.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 813–821. [Google Scholar]
- Falconer, S.M.; Noy, N.F.; Storey, M.A.D. Towards Understanding the Needs of Cognitive Support for Ontology Mapping. Ontol. Match. 2006, 225, 25–36. [Google Scholar]
- Harrison, B.L.; Baecker, R.M. Designing video annotation and analysis systems. Gr. Interface 1992, 92, 157–166. [Google Scholar]
- Rosch, E. Principles of categorization. In Concepts: Core Readings; MIT Press: Cambridge, MA, USA, 1999; pp. 189–206. [Google Scholar]
- Rodríguez González, F. The naming of meals. Engl. Today 1993, 9, 45–52. [Google Scholar] [CrossRef]
- Barlow, M. Individual usage: A corpus-based study of idiolects. Int. J. Corpus Linguist. 2013, 18, 4. [Google Scholar]
- Krishnan, N.; Cook, D.J.; Wemlinger, Z. Learning a taxonomy of predefined and discovered activity patterns. J. Ambient Intell. Smart Environ. 2013, 5, 621–637. [Google Scholar] [PubMed]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Nat. Sci. Rev. 2017, 5, 44–53. [Google Scholar] [CrossRef]
- Woznowski, P.; Fafoutis, X.; Song, T.; Hannuna, S.; Camplani, M.; Tao, L.; Paiement, A.; Mellios, E.; Haghighi, M.; Zhu, N.; et al. A multi-modal sensor infrastructure for healthcare in a residential environment. In Proceedings of the 2015 IEEE International Conference on IEEE Communication Workshop (ICCW), London, UK, 8–12 June 2015; pp. 271–277. [Google Scholar]
- Tonkin, E.; Woznowski, P. Activities of Daily Living Ontology for Ubiquitous Systems. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19 March 2018. [Google Scholar]
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef]
- Woznowski, P.; Kaleshi, D.; Oikonomou, G.; Craddock, I. Classification and suitability of sensing technologies for activity recognition. Comput. Commun. 2016, 89, 34–50. [Google Scholar] [CrossRef]
- McConville, R.; Byrne, D.; Craddock, I.; Piechocki, R.; Pope, J.; Santos-Rodríguez, R. Understanding the quality of calibrations for indoor localisation. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 676–681. [Google Scholar]
- Zollers, A. Emerging motivations for tagging: Expression, performance, and activism. In Proceedings of the 16th International World Wide Web Conference Workshop on Tagging and Metadata for Social Information Organization, Banff, AB, Canada, 8–12 May 2007. [Google Scholar]
- Lenci, A. Distributional semantics in linguistic and cognitive research. Ital. J. Linguist. 2008, 20, 1–31. [Google Scholar]
- Woznowski, P.R.; Tonkin, E.L.; Flach, P.A. Activities of Daily Living Ontology for Ubiquitous Systems. Sensors 2018, 18. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | Start Activity | Terminate Activity | Location Info | Room |
|---|---|---|---|---|
| Room-based list | ✓ | ✓ | ✓ | All |
| NFC | ✓ | ✓ | ✓ | Kitchen, bedroom(s) |
| Voice | ✓ | ✗ | Not explicitly | All |
| Ongoing list | ✗ | ✓ | ✗ | All |
| Finish all | ✗ | ✓ | ✗ | All |
| P. ID | START | END | DA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RB List | NFC | Voice | RB List | Ongoing List | Finish All | NFC | UT | ||
| P1 | 118 | — | 7 | 74 | 30 | 17 | — | 4 | 31 |
| P2 | 72 | — | — | 45 | 27 | — | — | — | 24 |
| P3 | 54 | 14 | 1 | 51 | 7 | 6 | 5 | — | 35 |
| P4 | 26 | 31 | 2 | 20 | 17 | — | 22 | — | 30 |
| P5 | 47 | 22 | — | 2 | 54 | — | 13 | — | 23 |
| P7 | 59 | — | — | 37 | 13 | 5 | — | 4 | 20 |
| P8 | 28 | 8 | — | 16 | 18 | — | — | 2 | 18 |
| P9 | 43 | — | — | 30 | 13 | — | — | — | 14 |
| P10 | 64 | — | — | 59 | 5 | — | — | — | 21 |
| P12 | 74 | — | 7 | 68 | 12 | — | — | 1 | 27 |
| Avg | 58.5 | 18.75 (7.5) | 4.25 (1.7) | 40.2 | 19.6 | 9.3 (2.8) | 13.3 (4) | 2.75 (1.1) | 24 |
| P. ID | <1 min | 1–3 min | 3–5 min | <10 min | <30 min | <1 h | 1–2 h | >2 h | Unk. |
|---|---|---|---|---|---|---|---|---|---|
| P1 | 46 | 14 | 13 | 8 | 19 | 9 | 3 | 9 | 4 |
| P2 | 10 | 5 | 9 | 15 | 10 | 7 | 7 | 9 | — |
| P3 | 22 | 8 | 7 | 8 | 14 | 3 | 3 | 4 | — |
| P4 | 29 | 5 | 3 | 4 | 10 | 2 | 2 | 4 | — |
| P5 | 3 | 6 | 10 | 14 | 13 | 4 | 6 | 13 | — |
| P7 | 4 | 11 | 4 | 9 | 10 | 8 | 6 | 3 | 4 |
| P8 | 8 | 6 | 4 | 6 | 5 | 1 | — | 4 | 2 |
| P9 | 4 | 1 | 6 | 5 | 12 | 9 | 3 | 3 | — |
| P10 | 4 | 3 | 5 | 12 | 24 | 10 | 3 | 3 | — |
| P12 | 14 | 10 | 10 | 20 | 14 | 6 | 3 | 3 | 1 |
| Total | 144 | 69 | 71 | 101 | 131 | 59 | 36 | 55 | 11 |
| P. ID | Bathroom | Bed 1 | Bed 2 | Hall | Kitchen | LR | Out | Study | Toilet | ? | UT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | 8:5 | 11:11 | 19:7 | 6:5 | 42:29 | 10:6 | 5:2 | 10:2 | 7:7 | 7:47 | 4 |
| P2 | 3:2 | 14:14 | 7:- | 1:1 | 16:8 | 15:9 | 2:1 | 1:1 | 13:9 | -:27 | - |
| P3 | 1:1 | 11:8 | -:- | 4:4 | 27:20 | 19:19 | -:- | 4:2 | 2:2 | 1:13 | - |
| P4 | -:- | 1:- | 12:5 | 4:4 | 25:22 | 15:11 | -:- | -:- | -:- | 2:17 | - |
| P5 | 5:- | 9:1 | 1:- | -:- | 22:13 | 27:1 | 5:- | -:- | -:- | -:54 | |
| P7 | 4:3 | -:- | 6:4 | -:- | 15:15 | 20:9 | 4:- | 4:- | 6:6 | -:18 | 4 |
| P8 | 2:1 | 4:3 | -:- | -:- | 14:5 | 13:5 | -:- | -:- | 3:2 | -:18 | 2 |
| P9 | 1:1 | 11:6 | -:- | -:- | 11:11 | 14:8 | -:- | -:- | 6:4 | -:13 | - |
| P10 | 1:- | 16:16 | -:- | -:- | 23:22 | 24:21 | -:- | -:- | -:- | -:5 | - |
| P12 | 1:1 | 27:23 | -:- | 5:5 | 24:24 | 8:6 | -:- | -:- | 9:9 | 7:12 | 1 |
| Total | 26:14 | 104:82 | 45:16 | 20:19 | 219:169 | 165:95 | 16:3 | 19:5 | 46:39 | 17:224 | 11 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tonkin, E.L.; Burrows, A.; Woznowski, P.R.; Laskowski, P.; Yordanova, K.Y.; Twomey, N.; Craddock, I.J. Talk, Text, Tag? Understanding Self-Annotation of Smart Home Data from a User’s Perspective. Sensors 2018, 18, 2365. https://doi.org/10.3390/s18072365
Tonkin EL, Burrows A, Woznowski PR, Laskowski P, Yordanova KY, Twomey N, Craddock IJ. Talk, Text, Tag? Understanding Self-Annotation of Smart Home Data from a User’s Perspective. Sensors. 2018; 18(7):2365. https://doi.org/10.3390/s18072365
Chicago/Turabian StyleTonkin, Emma L., Alison Burrows, Przemysław R. Woznowski, Pawel Laskowski, Kristina Y. Yordanova, Niall Twomey, and Ian J. Craddock. 2018. "Talk, Text, Tag? Understanding Self-Annotation of Smart Home Data from a User’s Perspective" Sensors 18, no. 7: 2365. https://doi.org/10.3390/s18072365
APA StyleTonkin, E. L., Burrows, A., Woznowski, P. R., Laskowski, P., Yordanova, K. Y., Twomey, N., & Craddock, I. J. (2018). Talk, Text, Tag? Understanding Self-Annotation of Smart Home Data from a User’s Perspective. Sensors, 18(7), 2365. https://doi.org/10.3390/s18072365