Optimal Camera Pose and Placement Configuration for Maximum Field-of-View Video Stitching


Abstract
1. Introduction
2. Related Works
3. Methods
3.1. Problem Formulation
3.2. Scene Space Model
3.3. Ensuring Continuity
- Let each camera be a node in the graph.
- Let the weight of an edge of the graph be the area of the intersection of the two connected nodes of the graph.
- Apply a simple threshold to remove any edges of the graph which do not satisfy the requirements for stitching.
3.4. Blind Spots
3.5. Greedy Heuristic
- Compute the footprint of all possible poses for the camera.
- If cameras have been placed already, identify the region of overlap with all previously placed cameras and discard all poses which do not overlap with the previously placed cameras.
- Identify the region of overlap between each pose and the region of interest.
- Choose the pose for which this region has maximum area.
- If two or more poses are tied, choose the pose whose footprint has the maximum area.
- Remove the chosen footprint from the region of interest.
- Repeat steps 1–6 for each other camera in your array.
3.6. Unified FIX Optimization
4. Camera Spaces
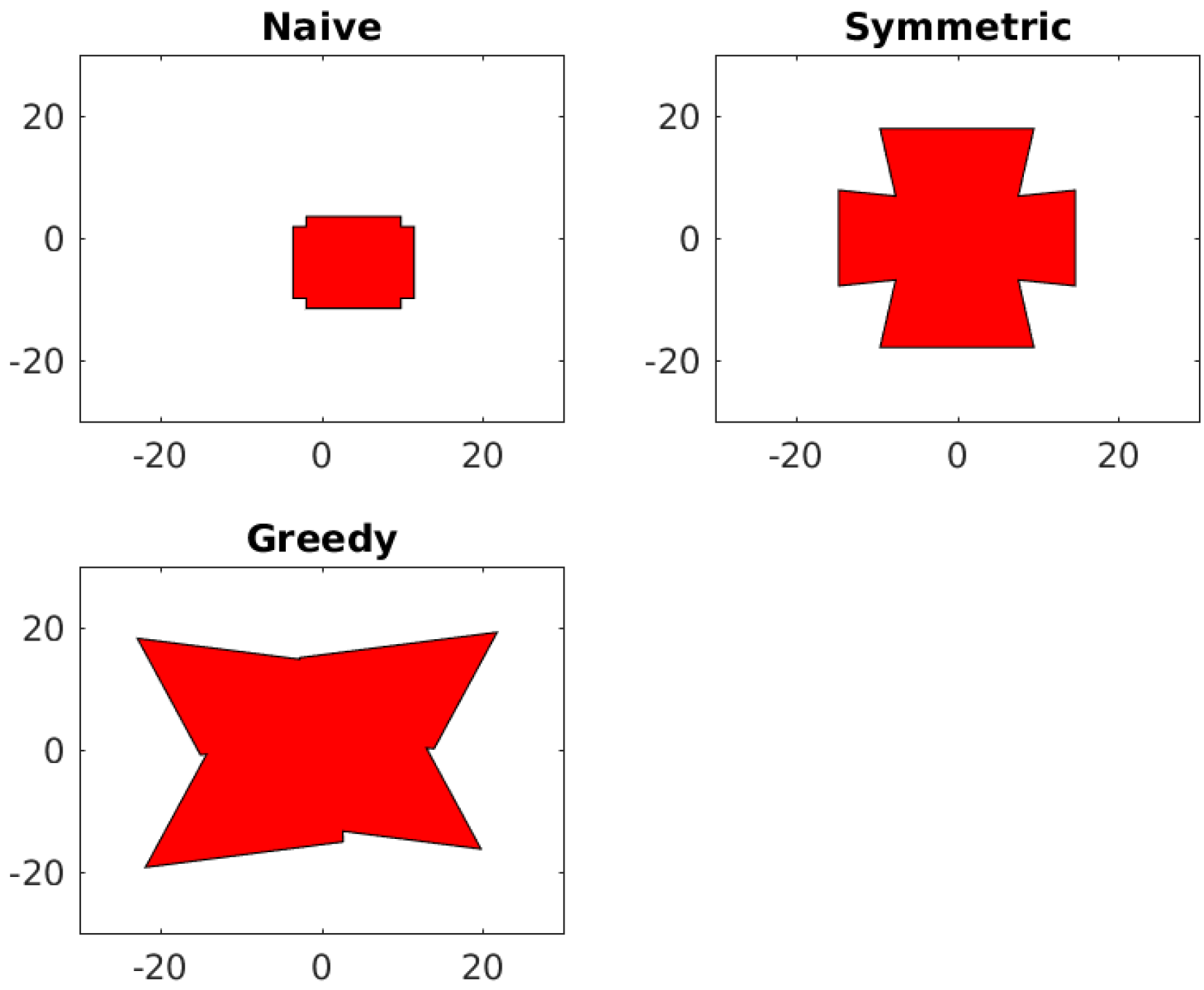
4.1. Asymmetric Camera Space
4.2. Symmetric Camera Space
4.3. Naive Camera Space
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hengstler, S.; Prashanth, D.; Fong, S.; Aghajan, H. MeshEye: A Hybrid-Resolution Smart Camera Mote for Applications in Distributed Intelligent Surveillance. In Proceedings of the 6th International Conference on Information Processing in Sensor Networks, Cambridge, MA, USA, 25–27 April 2007. [Google Scholar]
- Carrera, G.; Angeli, A.; Davison, A.J. SLAM-based automatic extrinsic calibration of a multi-camera rig. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Cabral, B.K. Introducing Facebook Surround 360: An Open, High-Quality 3D-360 Video Capture System. 2016. Available online: https://code.facebook.com/posts/1755691291326688 (accessed on 5 November 2017).
- Anderson, R.; Gallup, D.; Barron, J.T.; Kontkanen, J.; Snavely, N.; Hernández, C.; Agarwal, S.; Seitz, S.M. Jump: Virtual reality video. ACM Trans. Graph. 2016, 35, 198. [Google Scholar] [CrossRef]
- Gopro-Omni All Inclusive Synchronized 6-Camera Array. Available online: https://shop.gopro.com/virtualreality/omni-all-inclusive/MHDHX-006.html (accessed on 5 November 2017).
- Kanhere, A.; Van Grinsven, K.L.; Huang, C.C.; Lu, Y.S.; Greenberg, J.A.; Heise, C.P.; Hu, Y.H.; Jiang, H. Multicamera laparoscopic imaging with tunable focusing capability. J. Microelectromech. Syst. 2014, 23, 1290–1299. [Google Scholar] [CrossRef]
- Tarabanis, K.A.; Allen, P.K.; Tsai, R.Y. A survey of sensor planning in computer vision. IEEE Trans. Robot. Autom. 1995, 11, 86–104. [Google Scholar] [CrossRef]
- Mavrinac, A.; Chen, X. Modeling coverage in camera networks: A survey. Int. J. Comput. Vis. 2013, 101, 205–226. [Google Scholar] [CrossRef]
- Zhao, J.; Yoshida, R.; Cheung, S.C.; Haws, D. Approximate techniques in solving optimal camera placement problems. Int. J. Distrib. Sens. Netw. 2013, 9, 241913. [Google Scholar] [CrossRef]
- Szeliski, R. Image Alignment and Stitching: A Tutorial. Found. Trends Comput. Graph. Vis. 2016, 2, 1–104. [Google Scholar] [CrossRef]
- Fu, Y.; Zhou, J.; Deng, L. Surveillance of a 2D plane area with 3D deployed cameras. Sensors 2014, 14, 1988–2011. [Google Scholar] [CrossRef] [PubMed]
- Piciarelli, C.; Micheloni, C.C.; Foresti, G.L. PTZ camera network reconfiguration. In Proceedings of the Third ACM/IEEE International Conference on Distributed Smart Cameras, Como, Italy, 30 August–2 September 2009. [Google Scholar]
- Goodman, J.E. On the Largest Convex Polygon Contained in a Non-convex n-gon, or how to peel a potato. Geom. Dedicata 1981, 11, 99–106. [Google Scholar] [CrossRef]
- Woo, T.C. The Convex Skull Problem; Technical Report TR 86-31; Department of Industrial and Operations Engineering, University of Michigan: Ann Arbor, MI, USA, 1981. [Google Scholar]
- Chang, J.S.; Yap, C.K. A polynomial solution for the potato-peeling problem. Discret. Comput. Geom. 1986, 1, 155–182. [Google Scholar] [CrossRef]
- Horster, E.; Lienhart, R. On the Optimal Placement of Multiple Visual Sensors. In Proceedings of the 4th ACM International Workshop on Video Surveillance and Sensor Networks, Santa Barbara, CA, USA, 23–27 October 2006; pp. 111–120. [Google Scholar]
- Urrutia, J. Art Gallery and Illumination Problems. In Handbook of Computational Geometry; Elsevier Science: Amsterdam, The Netherlands, 2000; pp. 973–1027. [Google Scholar]
- Erdem, U.M.; Sclaroff, S. Optimal Placement of Cameras in Floorplans to Satisfy Task Requirements and Cost Constraints. Available online: https://www.researchgate.net/profile/Stan_Sclaroff/publication/228960034_Optimal_placement_of_cameras_in_floorplans_to_satisfy_task_requirements_and_cost_constraints/links/00b7d51dfdfbaf0412000000.pdf (accessed on 14 July 2018).
- Horster, E.; Lienhart, R. Optimal Placement of Visual Sensors. In Multi-Camera Networks: Concepts and Applications; Elsevier: Burlington, MA, USA, 2009. [Google Scholar]
- Sterle, C.; Sforza, A.; Amideo, A.E.; Piccolo, C. A unified solving approach for two and three dimensional coverage problems in sensor networks. Optim. Lett. 2016, 10, 1101–1123. [Google Scholar] [CrossRef]
- Chakrabarty, K.; Iyengar, S.S.; Qi, H.; Cho, E. Grid coverage for surveillance and target location in distributed sensor networks. IEEE Trans. Comput. 2002, 51, 1448–1453. [Google Scholar] [CrossRef]
- Wang, C.; Qi, F.; Shi, G.; Wang, X. A Sparse Representation-Based Deployment Method for Optimizing the Observation Quality of Camera Networks. Sensors 2013, 13, 11453–11475. [Google Scholar] [CrossRef] [PubMed]
- Angella, F.; Reithler, L.; Gallesio, F. Optimal deployment of cameras for video surveillance systems. In Proceedings of the 2007 IEEE Conference on Advanced Video and Signal Based Surveillance, London, UK, 5–7 September 2007. [Google Scholar]
- Malik, R.; Bajcsy, P. Automated placement of multiple stereo cameras. In Proceedings of the 8th ECCV Workshop on Omnidirectional Vision, Camera Networks and Non-Classical Cameras, Marseille, France, 17 October 2008. [Google Scholar]
- Zhao, J.; Cheung, S.C.; Nguyen, T. Optimal visual sensor network configuration. In Multi-Camera Networks: Principles and Applications; Aghajan, H., Cavallaro, A., Eds.; Academic Press: Burlington, NJ, USA, 2009; Chapter 6; pp. 139–162. [Google Scholar]
- Chabra, R.; Ilie, A.; Rewkowski, N.; Cha, Y.W.; Fuchs, H. Optimizing placement of commodity depth cameras for known 3D dynamic scene capture. In Proceedings of the 2017 IEEE Virtual Reality (VR), Los Angeles, CA, USA, 18–22 March 2017. [Google Scholar]
- Zhang, X.; Alarcon-Herrera, J.L.; Chen, X. Optimization for 3D model-based multi-camera deployment. IFAC Proc. Vol. 2014, 47, 10126–10131. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Alarcon-Herrera, J.L.; Fang, Y. 3-D model-based multi-camera deployment: A recursive convex optimization approach. IEEE/ASME Trans. Mechatron. 2015, 20, 3157–3169. [Google Scholar] [CrossRef]
- Altahir, A.A.; Asirvadam, V.S.; Hamid, N.H.; Sebastian, P.; Saad, N.; Ibrahim, R.; Dass, S.C. Modeling multicamera coverage for placement optimization. IEEE Sens. Lett. 2017, 1, 1–4. [Google Scholar] [CrossRef]
- Vatti, B.R. A generic solution to polygon clipping. Commun. ACM 1992, 35, 56–63. [Google Scholar] [CrossRef]
- Molano, R.; Rodríguez, P.G.; Caro, A.; Durán, M.L. Finding the largest area rectangle of arbitrary orientation in a closed contour. Appl. Math. Comput. 2012, 218, 9866–9874. [Google Scholar] [CrossRef]
- Knauer, C.; Schlipf, L.; Schmidt, J.M.; Tiwary, H.R. Largest inscribed rectangles in convex polygons. J. Discret. Algorithms 2012, 13, 78–85. [Google Scholar] [CrossRef]
- Hall-Holt, O.; Katz, M.J.; Kumar, P.; Mitchell, J.S.; Sityon, A. Finding large sticks and potatoes in polygons. In Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithm, Miami, FL, USA, 22–24 January 2006; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2006. [Google Scholar]
- Culberson, J.C.; Reckhow, R.A. Covering polygons is hard. In Proceedings of the 29th Annual Symposium on Foundations of Computer Science, White Plains, NY, USA, 24–26 October 1988; pp. 601–611. [Google Scholar]
- Orourke, J.; Supowit, K.J. Some NP-hard polygon decomposition problems. IEEE Trans. Inf. Theory 1983, 29, 181–190. [Google Scholar] [CrossRef]
- Wilburn, B. High-performance imaging with large camera arrays. In Proceedings of the ACM SIGGRAPH 2006 Courses (SIGGRAPH 06), Boston, MA, USA, 30 July–3 August 2006. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | FOV Area (cm2) | Evaluation Time (s) |
|---|---|---|
| Naive | 578 | 0.122 |
| Symmetric | 955 | 0.177 |
| Greedy | 11,220 | 0.519 |
| Exhaustive | 11,220 | 38,274 |
| Upper Bound | 18,214 | 0.073 |
| Approach | FOV Area (cm2) | Evaluation Time (s) |
|---|---|---|
| Naive | 215 | 1.423 |
| Symmetric | 795 | 0.700 |
| Greedy | 1153 | 15.862 |
| Upper Bound | 1514 | 0.203 |
| Approach | Max Area (cm2) | Max Conv. Reg. (cm2) |
|---|---|---|
| Naive | 577 | 577 |
| Symmetric | 795 | 795 |
| Greedy | 11,220 | 5069 |
| Exhaustive | 11,220 | 5104 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Watras, A.J.; Kim, J.-J.; Liu, H.; Hu, Y.H.; Jiang, H. Optimal Camera Pose and Placement Configuration for Maximum Field-of-View Video Stitching. Sensors 2018, 18, 2284. https://doi.org/10.3390/s18072284
Watras AJ, Kim J-J, Liu H, Hu YH, Jiang H. Optimal Camera Pose and Placement Configuration for Maximum Field-of-View Video Stitching. Sensors. 2018; 18(7):2284. https://doi.org/10.3390/s18072284
Chicago/Turabian StyleWatras, Alex J., Jae-Jun Kim, Hewei Liu, Yu Hen Hu, and Hongrui Jiang. 2018. "Optimal Camera Pose and Placement Configuration for Maximum Field-of-View Video Stitching" Sensors 18, no. 7: 2284. https://doi.org/10.3390/s18072284
APA StyleWatras, A. J., Kim, J.-J., Liu, H., Hu, Y. H., & Jiang, H. (2018). Optimal Camera Pose and Placement Configuration for Maximum Field-of-View Video Stitching. Sensors, 18(7), 2284. https://doi.org/10.3390/s18072284