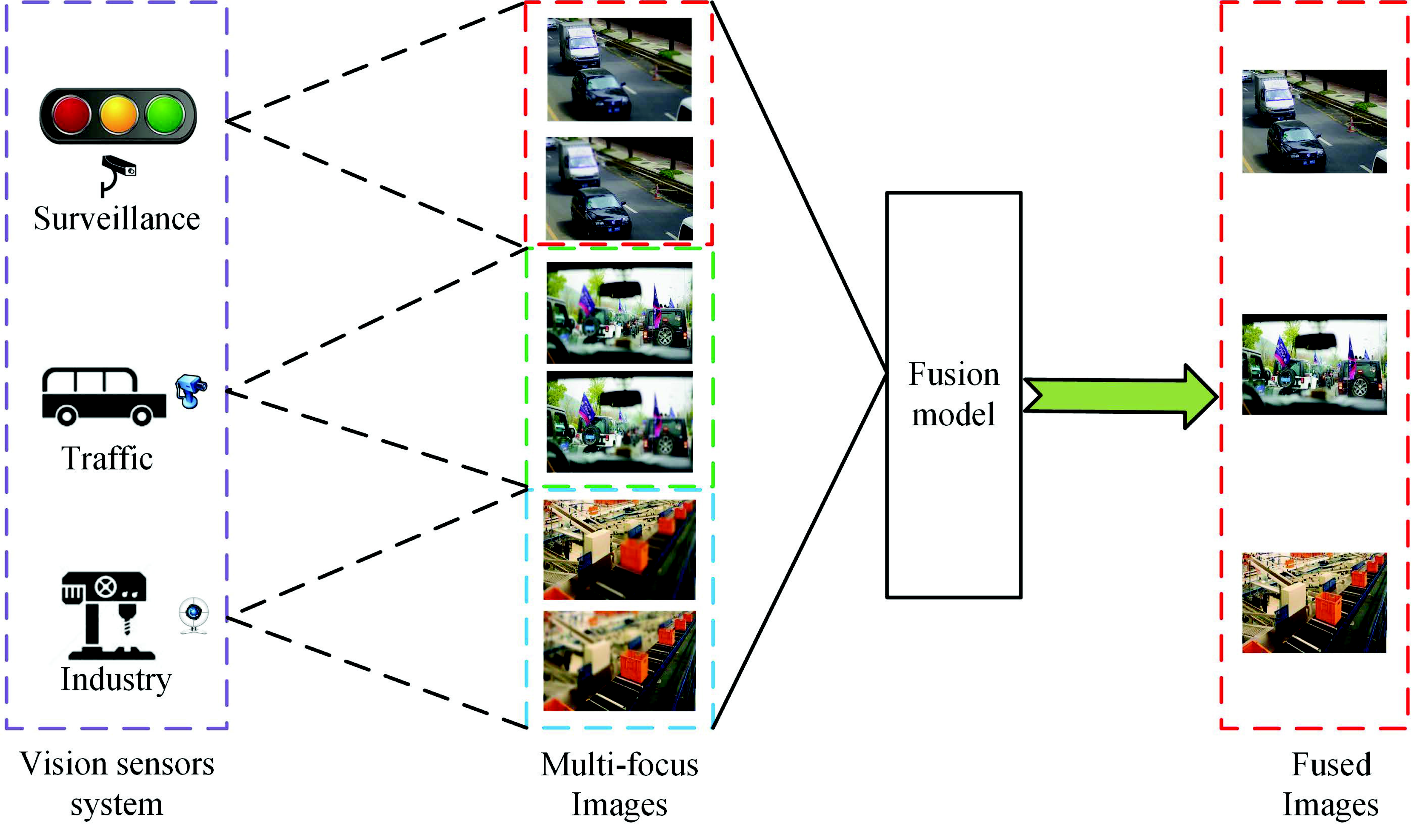
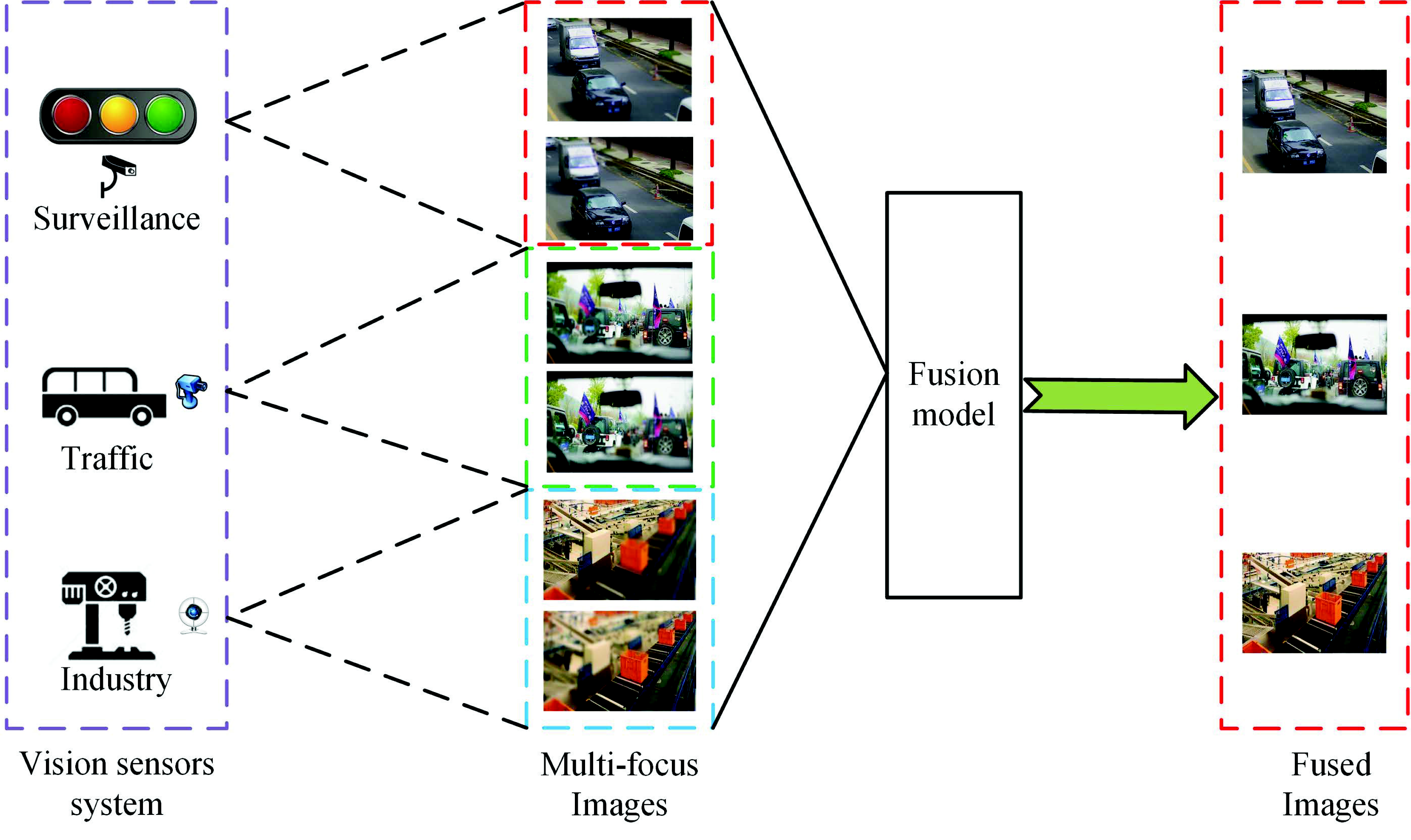
Multi-Focus Image Fusion Method for Vision Sensor Systems via Dictionary Learning with Guided Filter



Abstract
:1. Introduction
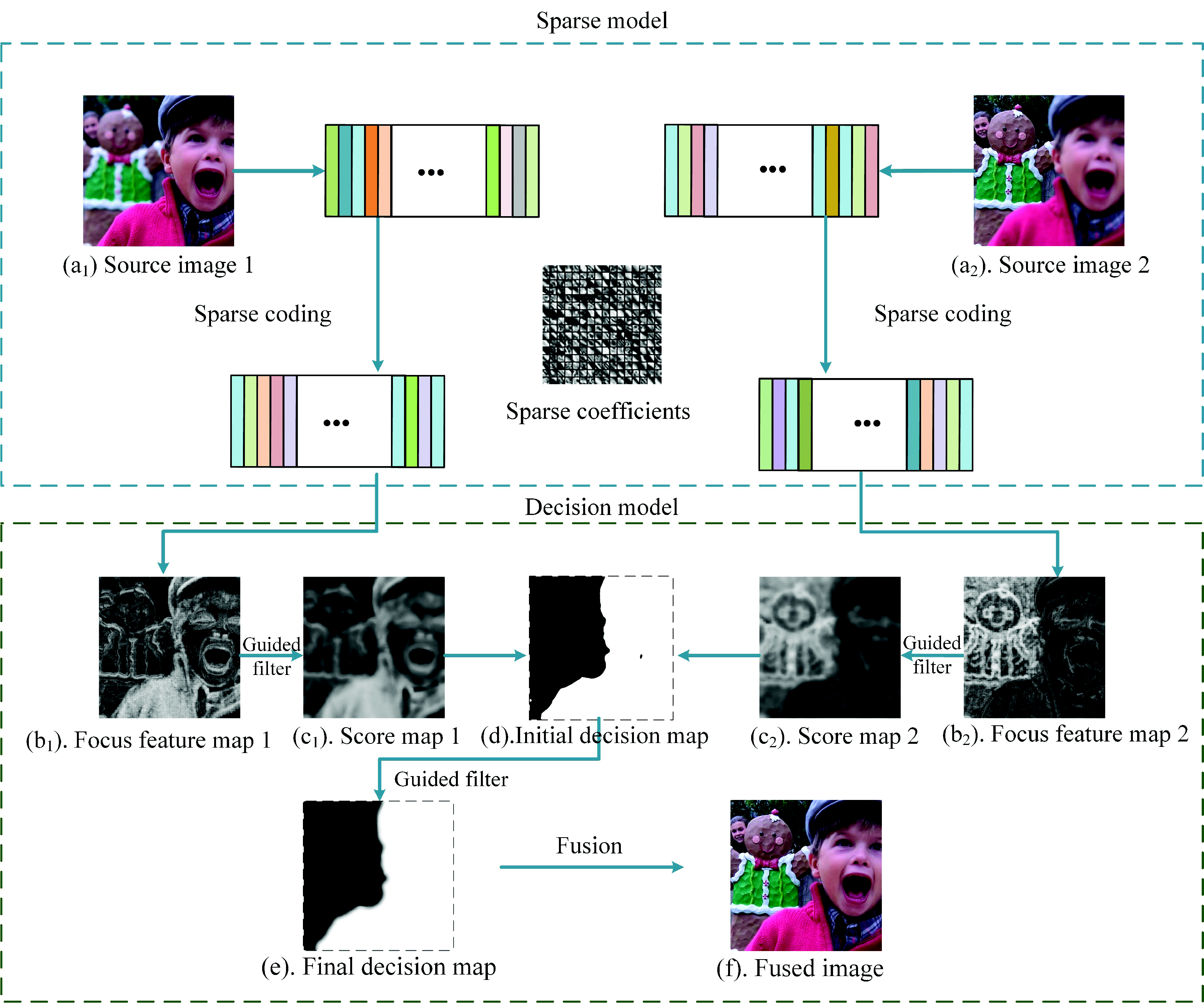
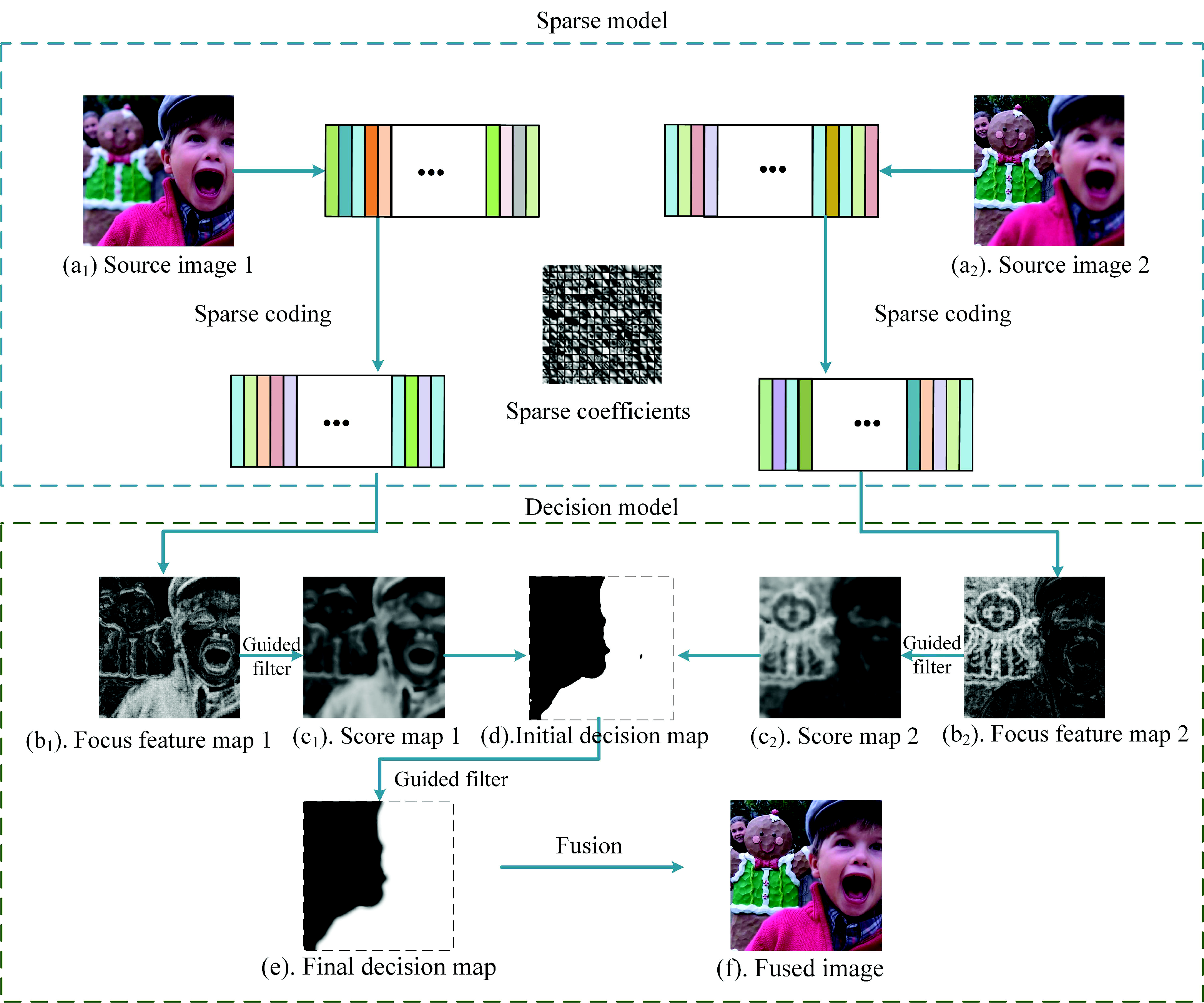
- For some ambiguous areas in the multi-focus image, the sparse coefficients cannot determine if they are focused or not. This often causes spatial inconsistency problems. For example, the initial map obtained by Mansour’s method [35] suffered from spatial inconsistency. The following process to refine the decision map requires much computational cost.
- The boundary between the focused area and the unfocused area is smooth, while the final decision map obtained by Mansour’s method [35] was sharp on the boundary. This may lead to halo effects on the boundary between the focused area and the unfocused area.
- We use sparse coefficients to classify the focused regions and the unfocused regions to build an initial decision map, as shown in Figure 2d, rather than directly fusing the sparse coefficients. The initial decision map would be optimized in the latter steps. In this way, we avoid the artifacts caused by improper selection of the sparse coefficients.
- To address the spatial inconsistency problem, we use the guided filter to smooth the focus feature maps, as shown in Figure 2b, fully considering the connection with the adjacent pixels. In this way, we effectively preserve the structure of images and avoid the spatial inconsistency problem.
- To generate a decision map, which concerns the the boundary information, a guided filter is used to refine the initial decision map. By doing so, the boundary of the final decision map, as shown in Figure 2e, is smoothed, and it has a slow transition. Thus, the halo artifact of the fused image is efficiently reduced.
2. Related Work
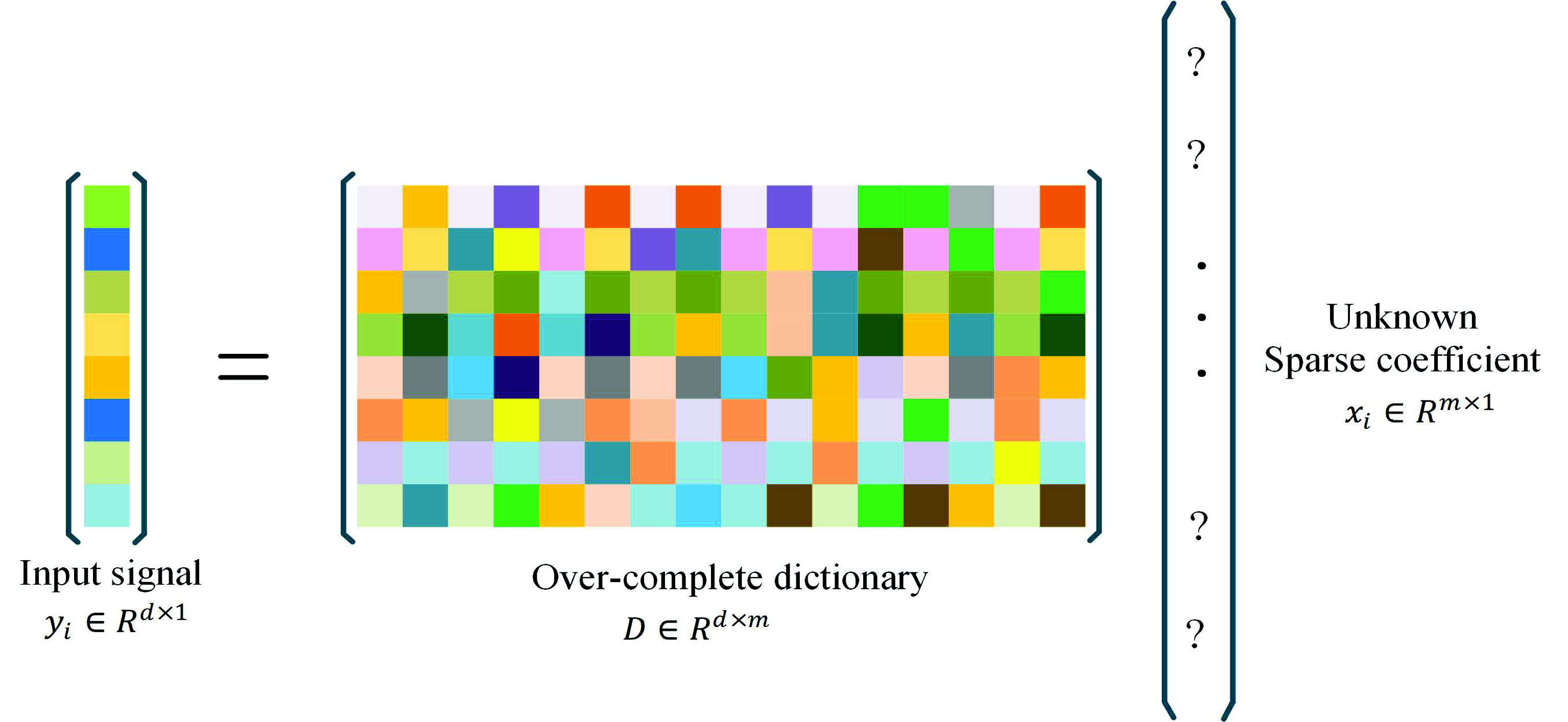
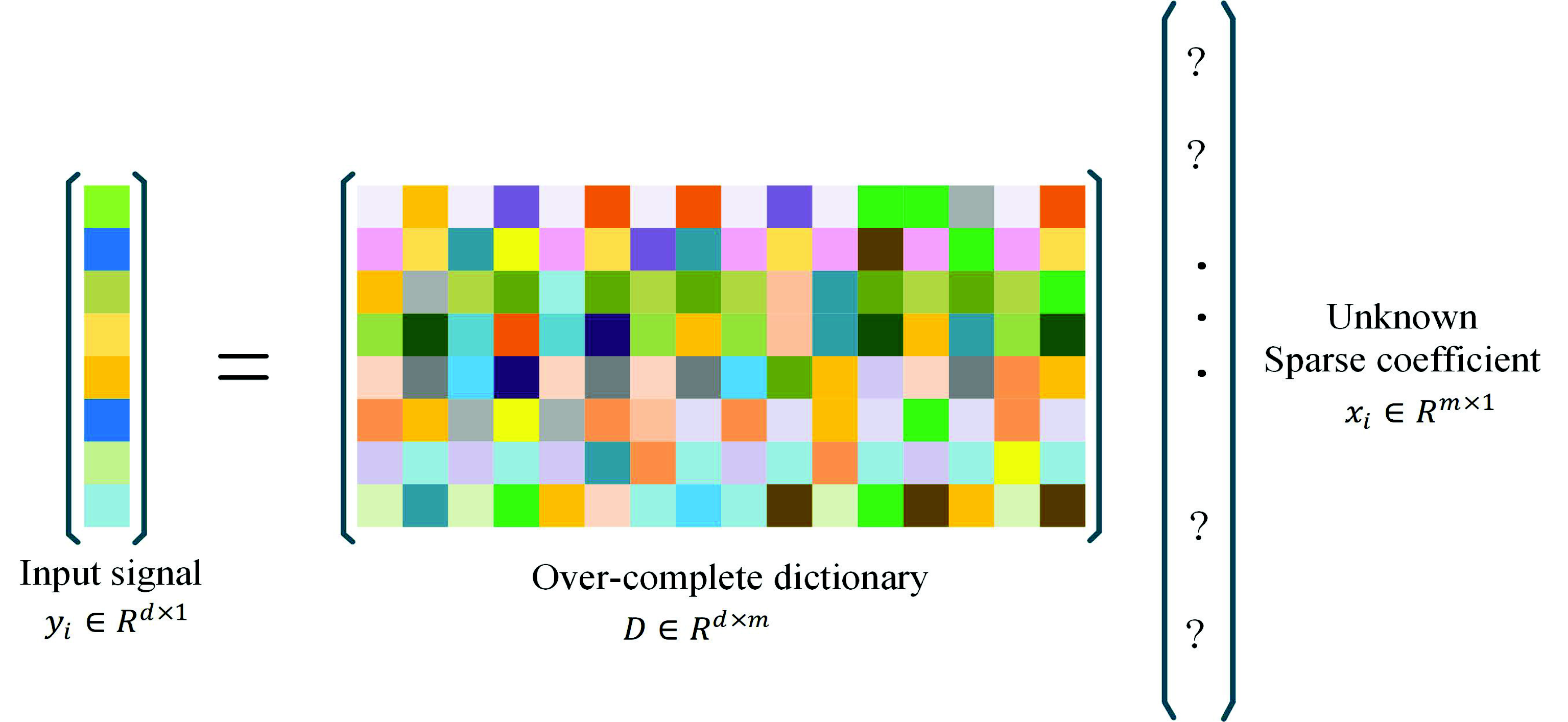
2.1. Sparse Coding
2.2. Guided Filter
3. Proposed Multi-Focus Image Fusion Method
- Learning dictionary
- Calculating the sparse coefficients and obtaining the initial decision map
- Refining the initial decision map
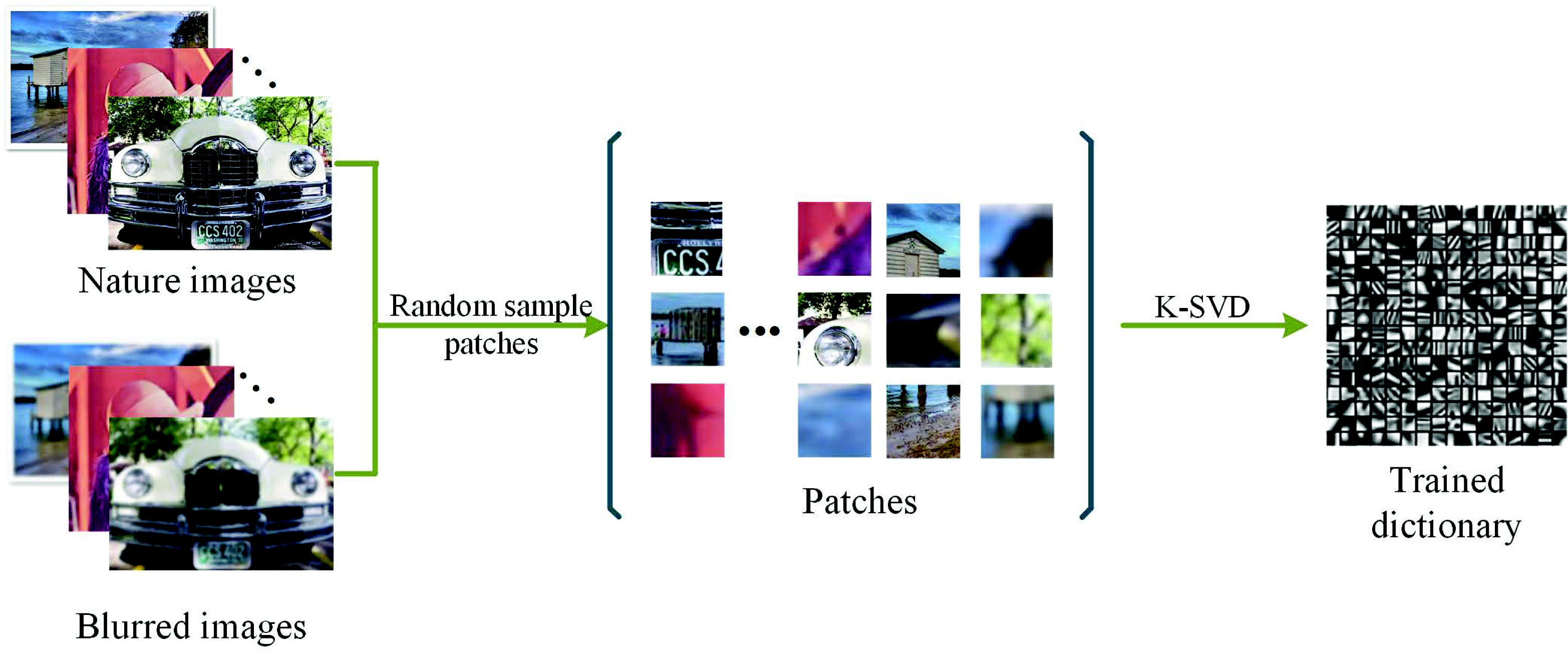
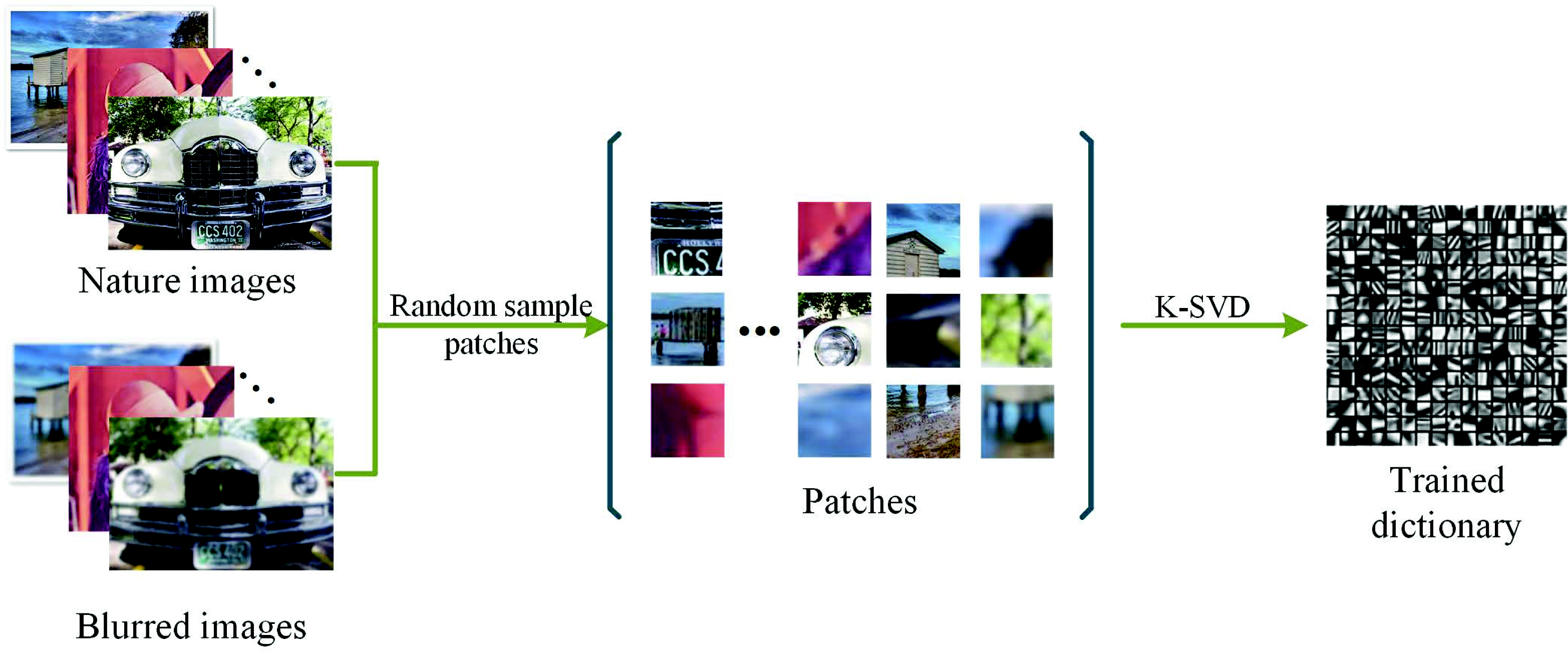
3.1. Learning Dictionary
3.2. Sparse Coding and Obtaining Initial Decision Map
3.3. Refining the Decision Map
3.4. Fusion
4. Experiments
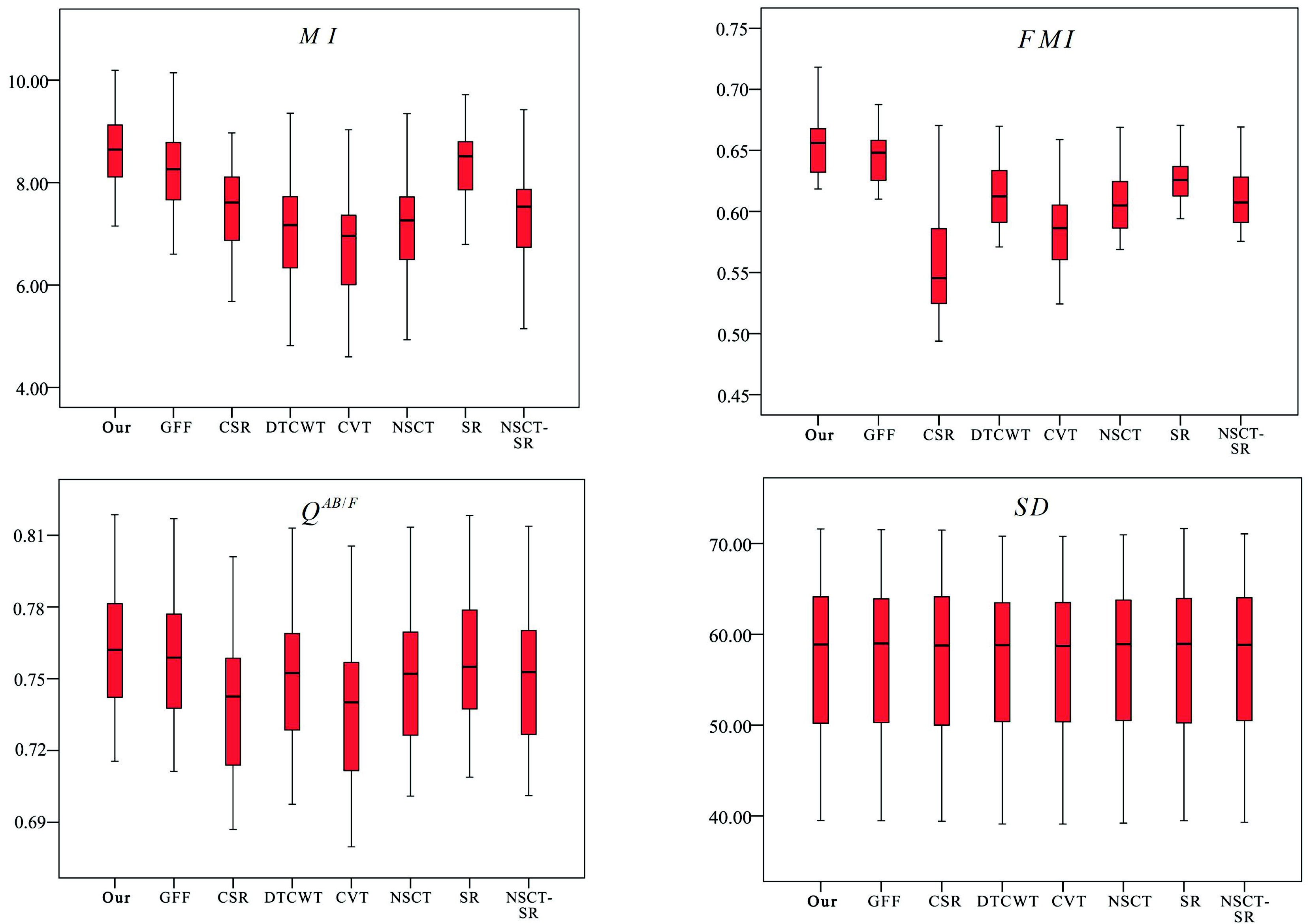
- Mutual information [40] measures how much information from the source images the fused image contains. When the value of is high, it indicates that the fused image contains more information from the source images.
- Edge retention [41] calculates how much edge information transferred from the input images to the fused image. When the value of is high, it indicates that the fused image contains more edge information from the source images. The ideal value is 1.
- Feature mutual information [42] is a non-reference objective image fusion metric that calculates the amount of feature information, like gradients and edges, existing in the fused image. When the value of is high, it indicates that the fused image contains more feature information from the source images. The ideal value is 1.
- The standard deviation is used to measure the contrast in the fused image. When the value of is high, it indicates that the contrast of the fused image is higher.
4.1. Fusion of Multi-Focus “Face” Images
4.2. Fusion of Multi-Focus “Golf” Images
4.3. Fusion of Multi-Focus “Puppy” Images
4.4. Statistical Analysis of Fusion Results
4.5. Comparison of Computational Cost
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pavlidis, I.; Morellas, V.; Tsiamyrtzis, P.; Harp, S. Urban surveillance systems: From the laboratory to the commercial world. Proc. IEEE 2001, 89, 1478–1497. [Google Scholar] [CrossRef]
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Stathaki, T. Image Fusion: Algorithms and Applications; Elsevier: New York, NY, USA, 2008. [Google Scholar]
- Tian, J.; Chen, L.; Ma, L.; Yu, W. Multi-focus image fusion using a bilateral gradient-based sharpness criterion. Optics Commun. 2011, 284, 80–87. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Li, S.; Kwok, J.T.; Wang, Y. Combination of images with diverse focuses using the spatial frequency. Inf. Fusion 2001, 2, 169–176. [Google Scholar] [CrossRef]
- Miao, Q.; Wang, B. A novel adaptive multi-focus image fusion algorithm based on PCNN and sharpness. In Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Security and Homeland Defense IV; SPIE: Bellingham, WA, USA, 2005; pp. 704–712. [Google Scholar]
- Song, Y.; Wu, W.; Liu, Z.; Yang, X.; Liu, K.; Lu, W. An adaptive pansharpening method by using weighted least squares filter. IEEE Geosci. Remote Sens. Lett. 2016, 13, 18–22. [Google Scholar] [CrossRef]
- Jian, L.; Yang, X.; Zhou, Z.; Zhou, K.; Liu, K. Multi-scale image fusion through rolling guidance filter. Futur. Gener. Comput. Syst. 2018, 83, 310–325. [Google Scholar] [CrossRef]
- Zuo, Y.; Liu, J.; Bai, G.; Wang, X.; Sun, M. Airborne infrared and visible image fusion combined with region segmentation. Sensors 2017, 17, 1127. [Google Scholar] [CrossRef] [PubMed]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. Read. Comput. Vis. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Toet, A. Image fusion by a ratio of low-pass pyramid. Pattern Recognit. Lett. 1989, 9, 245–253. [Google Scholar] [CrossRef]
- Petrovic, V.S.; Xydeas, C.S. Gradient-Based Multiresolution Image Fusion; IEEE Press: Piscataway, NJ, USA, 2004; pp. 228–237. [Google Scholar]
- Li, H.; Manjunath, B.S.; Mitra, S.K. Multisensor image fusion using the wavelet transform. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 6 August 2002; pp. 235–245. [Google Scholar]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel- and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Kumar, B.K.S. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform. Signal Image Video Process. 2013, 7, 1125–1143. [Google Scholar] [CrossRef]
- Tessens, L.; Ledda, A.; Pizurica, A.; Philips, W. Extending the depth of field in microscopy through curvelet-based frequency-adaptive image fusion. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. I-861–I-864. [Google Scholar]
- Zhang, Q.; Guo, B.L. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process. 2009, 89, 1334–1346. [Google Scholar] [CrossRef]
- Huang, Y.; Bi, D.; Wu, D. Infrared and visible image fusion based on different constraints in the non-subsampled shearlet transform domain. Sensors 2018, 18, 1169. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Yang, X.; Pang, Y.; Peng, J.; Jeon, G. A multifocus image fusion method by using hidden Markov model. Opt. Commun. 2013, 287, 63–72. [Google Scholar] [CrossRef]
- Gao, H. A simple multi-sensor data fusion algorithm based on principal component analysis. In Proceedings of the 2009 ISECS International Colloquium on Computing, Communication, Control, and Management, Sanya, China, 8–9 August 2009; pp. 423–426. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, pp–4311. [Google Scholar] [CrossRef]
- Yang, X.; Wu, W.; Liu, K.; Chen, W.; Zhang, P.; Zhou, Z. Multi-sensor image super-resolution with fuzzy cluster by using multi-scale and multi-view sparse coding for infrared image. Multimed. Tools Appl. 2017, 76, 24871–24902. [Google Scholar] [CrossRef]
- Li, H.; Liu, F. Image denoising via sparse and redundant representations over learned dictionaries in wavelet domain. In Proceedings of the 2009 Fifth International Conference on Image and Graphics, Xi’an, China, 20–23 September 2009; pp. 754–758. [Google Scholar]
- Guha, T.; Ward, R.K. Learning Sparse Representations for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1576. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Bai, C.; Kpalma, K.; Ronsin, J. Multi-object tracking using sparse representation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 2312–2316. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Wu, W.; Liu, K.; Chen, W.; Zhou, Z. Multiple dictionary pairs learning and sparse representation-based infrared image super-resolution with improved fuzzy clustering. Soft Comput. 2018, 22, 1385–1398. [Google Scholar] [CrossRef]
- Li, H.; Yang, X.; Jian, L.; Liu, K.; Yuan, Y.; Wu, W. A sparse representation-based image resolution improvement method by processing multiple dictionary pairs with latent Dirichlet allocation model for street view images. Sustain. Cities Soc. 2018, 38, 55–69. [Google Scholar] [CrossRef]
- Wei, S.; Zhou, X.; Wu, W.; Pu, Q.; Wang, Q.; Yang, X. Medical image super-resolution by using multi-dictionary and random forest. Sustain. Cities Soc. 2018, 37, 358–370. [Google Scholar] [CrossRef]
- Yang, B.; Li, S. Multifocus image fusion and restoration with sparse representation. IEEE Trans. Instrum. Meas. 2010, 59, 884–892. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z. Multi-focus image fusion based on sparse representation with adaptive sparse domain selection. In Proceedings of the 2013 Seventh International Conference on Image and Graphics, Qingdao, China, 26–28 July 2013; pp. 591–596. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Yin, H.; Li, S.; Fang, L. Simultaneous image fusion and super-resolution using sparse representation. Inf. Fusion 2013, 14, 229–240. [Google Scholar] [CrossRef]
- Nejati, M.; Samavi, S.; Shirani, S. Multi-focus image fusion using dictionary-based sparse representation. Inf. Fusion 2015, 25, 72–84. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1397–1409. [Google Scholar]
- Meng, F.; Yang, X.; Zhou, C.; Li, Z. A sparse dictionary learning-based adaptive patch inpainting method for thick clouds removal from high-spatial resolution remote sensing imagery. Sensors 2017, 17, 2130. [Google Scholar] [CrossRef] [PubMed]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; Volume 1, pp. 40–44. [Google Scholar]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Haghighat, M.B.A.; Aghagolzadeh, A.; Seyedarabi, H. A Non-Reference Image Fusion Metric Based on Mutual Information of Image Features; Pergamon Press, Inc.: Oxford, UK, 2011; pp. 744–756. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | DTCWT | CVT | NSCT | GFF | SR | NSCT-SR | CSR | SRGF |
|---|---|---|---|---|---|---|---|---|
| 7.9033 | 7.5579 | 7.9802 | 8.9431 | 8.8896 | 8.1653 | 8.2092 | 9.3347 | |
| 0.7313 | 0.7141 | 0.7283 | 0.7419 | 0.7392 | 0.7294 | 0.7130 | 0.7450 | |
| 0.6190 | 0.5790 | 0.6092 | 0.6517 | 0.6263 | 0.6125 | 0.5278 | 0.6594 | |
| 59.3473 | 59.3677 | 59.4553 | 59.5281 | 59.4959 | 59.2802 | 59.3981 | 59.5499 |
| Methods | DTCWT | CVT | NSCT | GFF | SR | NSCT-SR | CSR | SRGF |
|---|---|---|---|---|---|---|---|---|
| 6.5533 | 6.2184 | 6.7132 | 7.3211 | 7.0351 | 6.9582 | 6.6367 | 7.5833 | |
| 0.7546 | 0.7396 | 0.7571 | 0.7613 | 0.7564 | 0.7583 | 0.7448 | 0.7658 | |
| 0.6397 | 0.6122 | 0.6365 | 0.6597 | 0.6328 | 0.6405 | 0.5836 | 0.6660 | |
| 39.1174 | 39.1125 | 39.2127 | 39.4650 | 39.4650 | 39.3129 | 39.4160 | 39.4795 |
| Methods | DTCWT | CVT | NSCT | GFF | SR | NSCT-SR | CSR | SRGF |
|---|---|---|---|---|---|---|---|---|
| 5.4492 | 5.3010 | 5.6032 | 6.8045 | 6.7931 | 5.9459 | 6.2977 | 7.5010 | |
| 0.7617 | 0.7555 | 0.7625 | 0.7735 | 0.7713 | 0.7643 | 0.7618 | 0.7771 | |
| 0.6229 | 0.6097 | 0.6220 | 0.6560 | 0.6387 | 0.6259 | 0.6013 | 0.6767 | |
| 46.6263 | 46.6002 | 46.7993 | 47.4477 | 47.2562 | 47.1882 | 47.3329 | 47.5366 |
| Methods | Sum of Squares | F-Value | p-Value |
|---|---|---|---|
| 198.053 | 9.869 | 0.000 | |
| 0.166 | 1.812 | 0.089 | |
| 0.324 | 17.777 | 0.000 | |
| 11,717.513 | 0.001 | 1.000 |
| Metrics | MI | FMI |
|---|---|---|
| Methods | p-value | p-value |
| GFF | 0.185 | 0.437 |
| CSR | 0.000 | 0.000 |
| DTCWT | 0.000 | 0.001 |
| CVT | 0.000 | 0.000 |
| NSCT | 0.000 | 0.000 |
| SR | 0.308 | 0.027 |
| NSCT-SR | 0.000 | 0.000 |
| Methods | DTCWT | CVT | NSCT | GFF | SR | NSCT-SR | CSR | SRGF | SRGF | SRGF |
|---|---|---|---|---|---|---|---|---|---|---|
| Running time (S) | 1.012 | 1.841 | 6.4687 | 1.181 | 60.226 | 42.739 | 105.692 | 120.300 | 67.671 | 43.023 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Yang, X.; Wu, W.; Liu, K.; Jeon, G. Multi-Focus Image Fusion Method for Vision Sensor Systems via Dictionary Learning with Guided Filter. Sensors 2018, 18, 2143. https://doi.org/10.3390/s18072143
Li Q, Yang X, Wu W, Liu K, Jeon G. Multi-Focus Image Fusion Method for Vision Sensor Systems via Dictionary Learning with Guided Filter. Sensors. 2018; 18(7):2143. https://doi.org/10.3390/s18072143
Chicago/Turabian StyleLi, Qilei, Xiaomin Yang, Wei Wu, Kai Liu, and Gwanggil Jeon. 2018. "Multi-Focus Image Fusion Method for Vision Sensor Systems via Dictionary Learning with Guided Filter" Sensors 18, no. 7: 2143. https://doi.org/10.3390/s18072143
APA StyleLi, Q., Yang, X., Wu, W., Liu, K., & Jeon, G. (2018). Multi-Focus Image Fusion Method for Vision Sensor Systems via Dictionary Learning with Guided Filter. Sensors, 18(7), 2143. https://doi.org/10.3390/s18072143