FaceLooks: A Smart Headband for Signaling Face-to-Face Behavior


Abstract
:1. Introduction
- Implementation of hardware and software of a headband device that quantitatively monitors and visually augments face-to-face behavior in real time, using IR communication.
- Evaluation of the performance of the device (e.g., detection range, response time, and comparison with a human coder and wearable gaze trackers) of the device in laboratory experiments.
- Conducting a field study in a special needs school to quantitatively monitor face-to-face behavior of children with intellectual disabilities and/or ASD during daily life activities, for example at mealtime.
- Conducting a field study in a class for demonstrating the effect of the visual representation for signaling the face-to-face behavior in children with intellectual disabilities.
2. Related Work
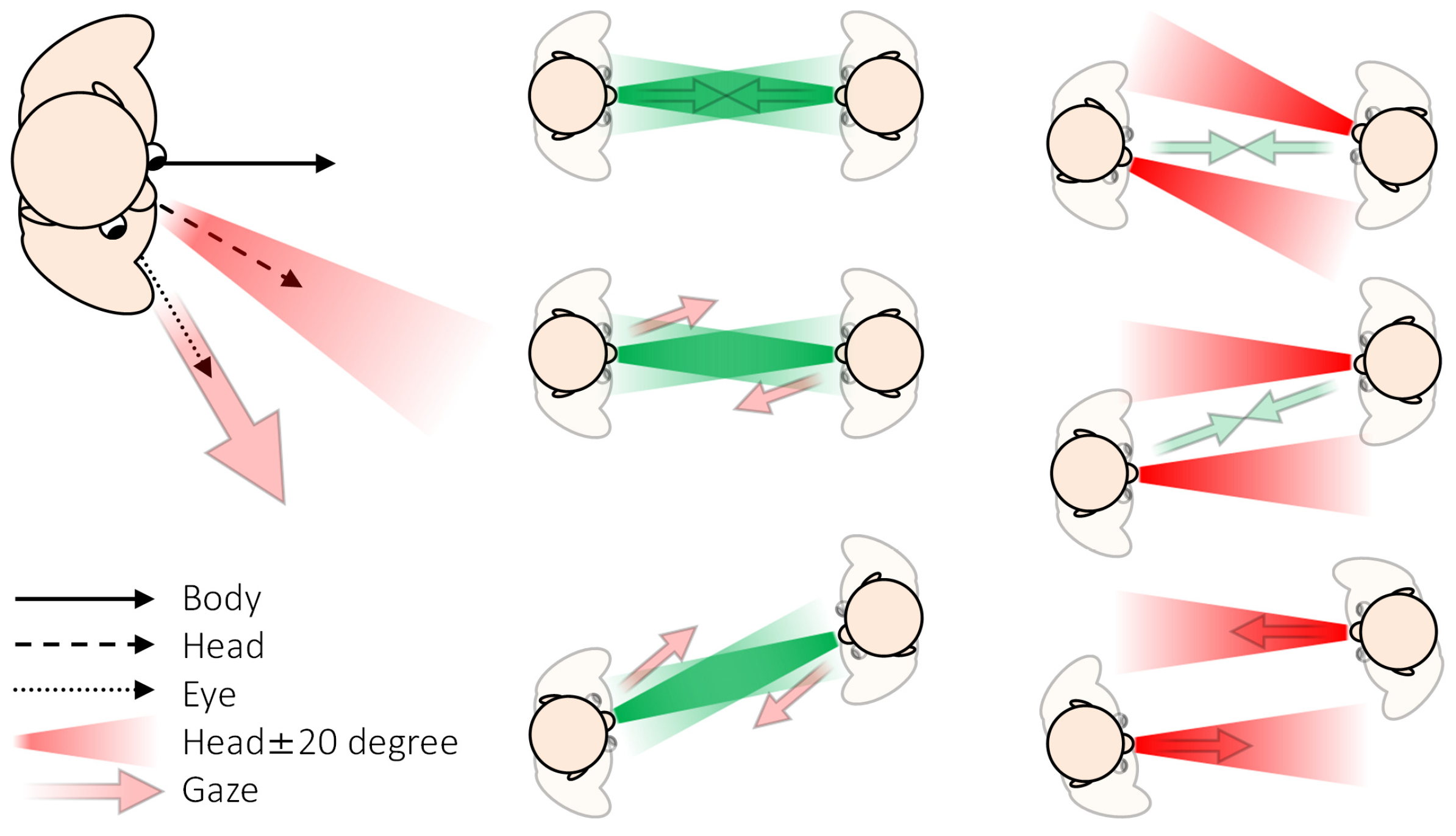
2.1. Face-to-Face Behavior and Social-Spatial Orientation
“An F-formation arises whenever two or more people sustain a spatial and orientational relationship in which the space between them is one to which they have equal, direct, and exclusive access [11]”.
2.2. Measurement of Social-Spatial Orientation
3. FaceLooks
3.1. Design Rationale and Concerns
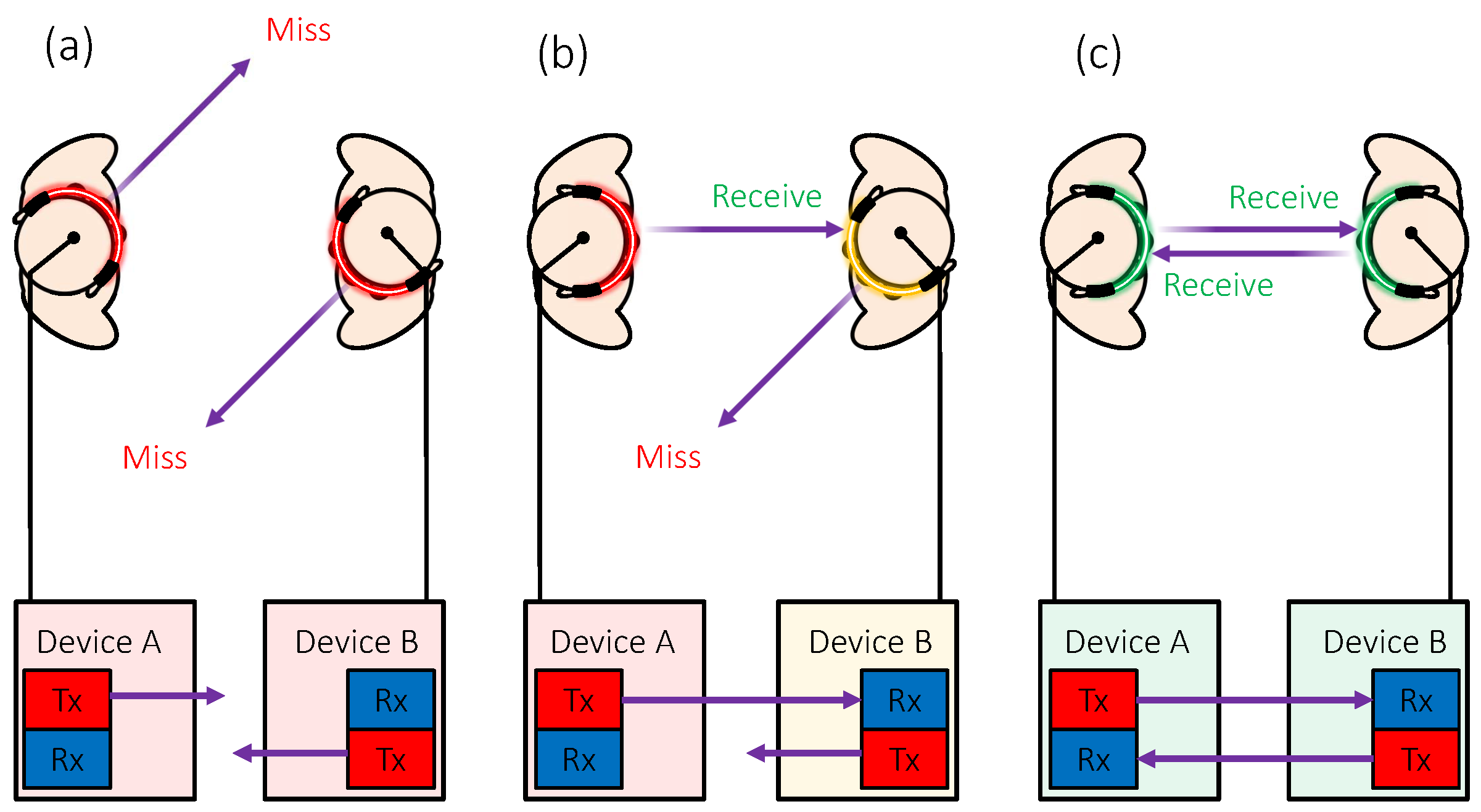
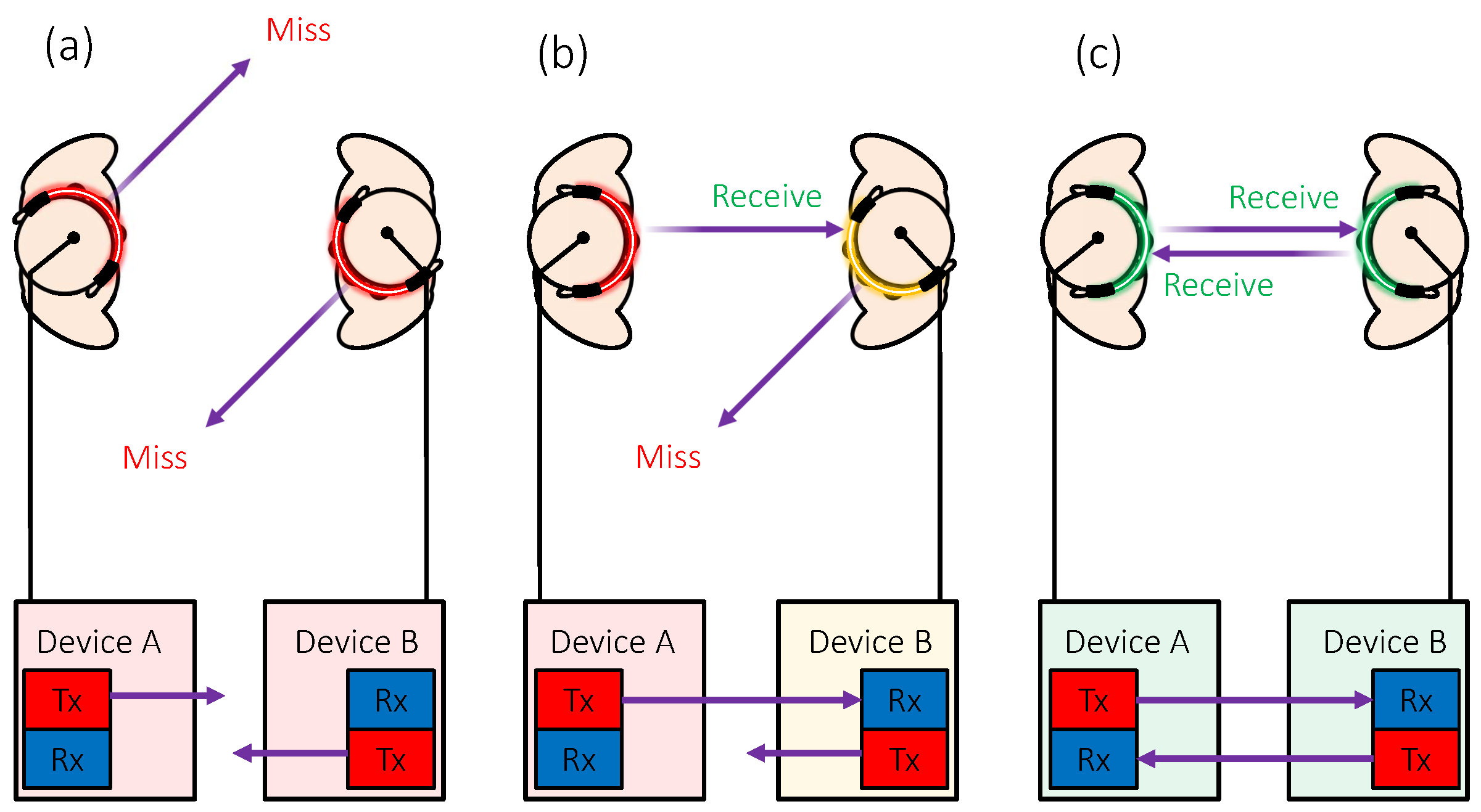
3.2. Working Principle
3.3. Implementation
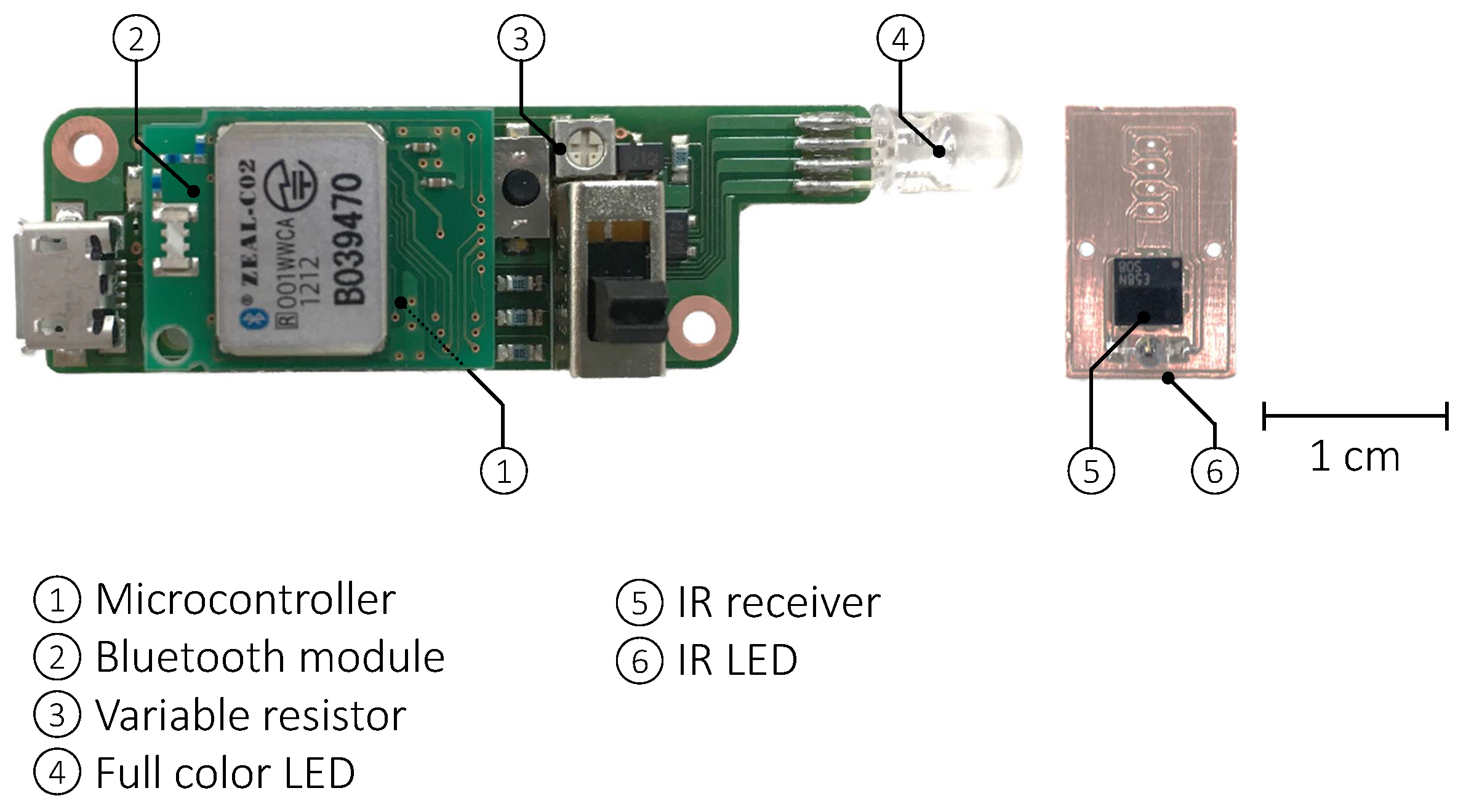
3.3.1. Hardware Components
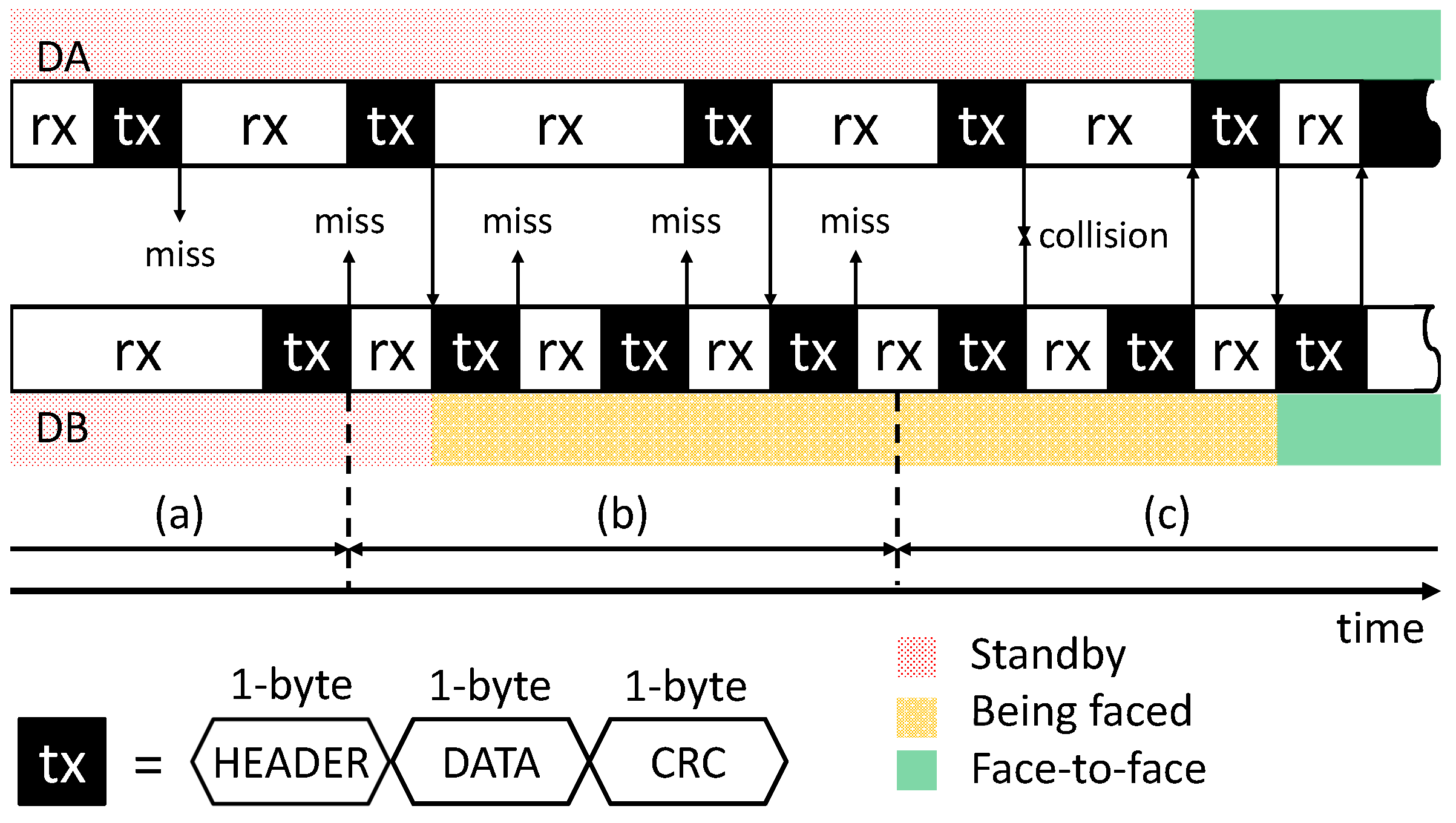
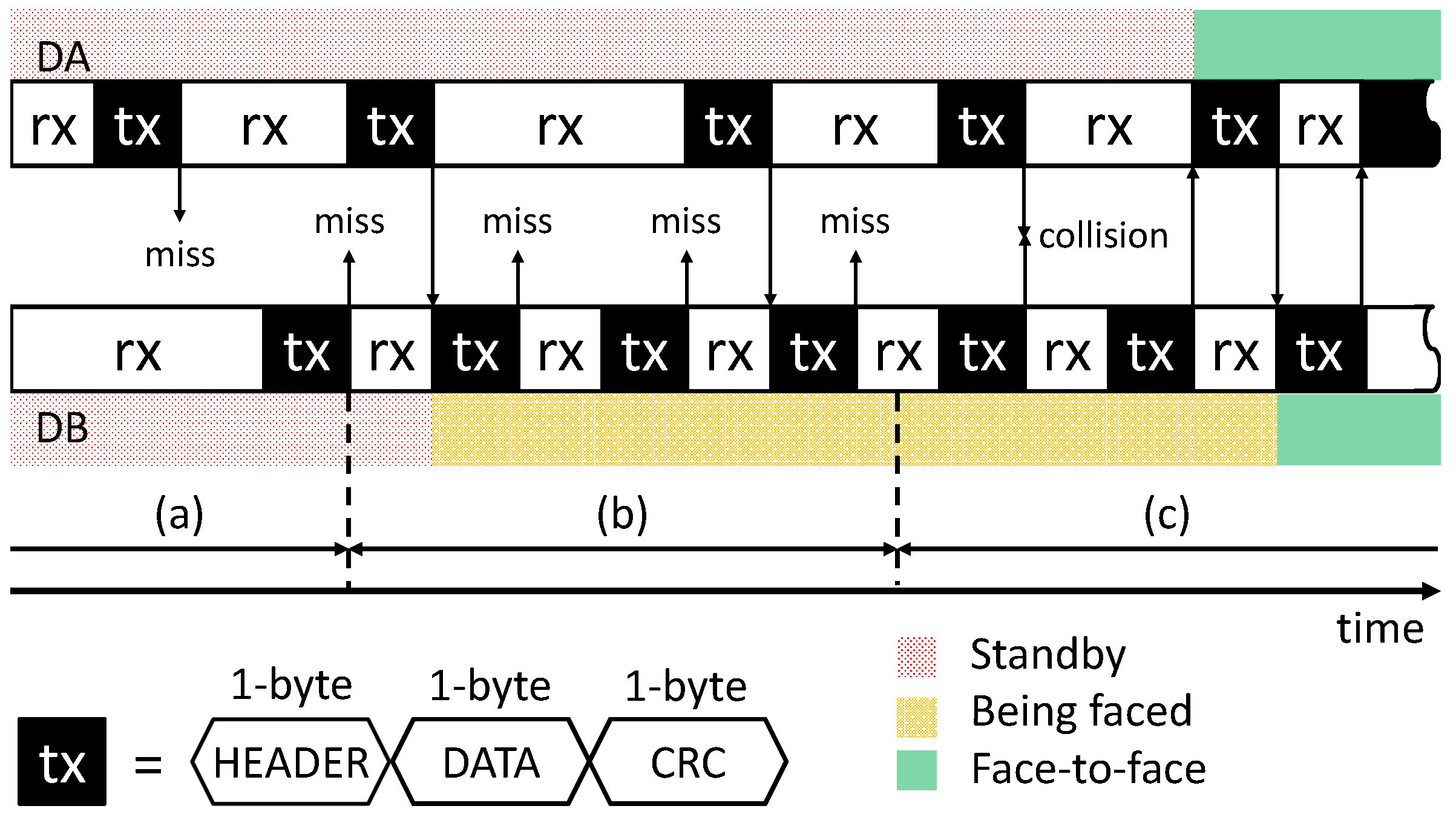
3.3.2. Communication Protocols
4. Device Performance Evaluation
4.1. Detection Range
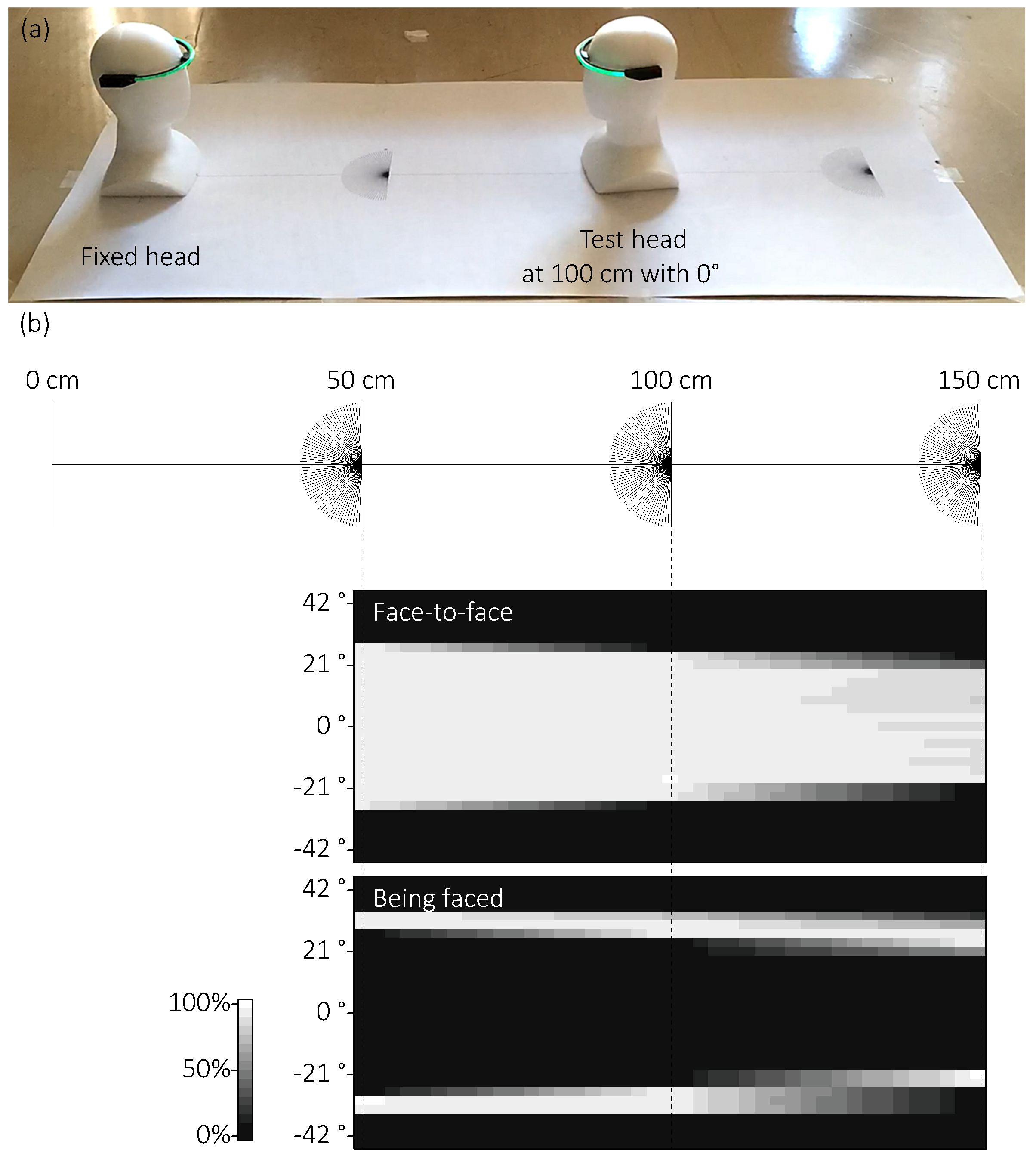
4.1.1. Setup
- Have the head fixed at the left end of the ruler to face the right end and have the other (test head) placed at the center of a protractors at {50, 100, or 150} cm to face the left end.
- Start IR communication of the devices with the device on the test head sending its state (i.e., SB, BF, or FtF) to the Android device for 60 s.
- If the Android device recorded a 60-s SB state for three trials in a row, go to the next procedure. If not, rotate the test head in a {clockwise (positive) or counter-clockwise (negative)} direction in 3° increments and go back to the Procedure 2.
- If there is still another condition, go back to Procedure 1 with a new condition. If not, end the experiment.
4.1.2. Results and Discussion
4.2. Response Time
4.2.1. Setup
- Quadruple the baud rate of the IR communication of the device on the test head, that is, from 2400 to 9600.
- Press the tact switch.
- Record the time interval displayed by the oscilloscope.
- If the measurements for each response time (TBF and TFtF) are repeated 50 times, end the experiment. If not, go back to Procedure 1.
4.2.2. Results and Discussion
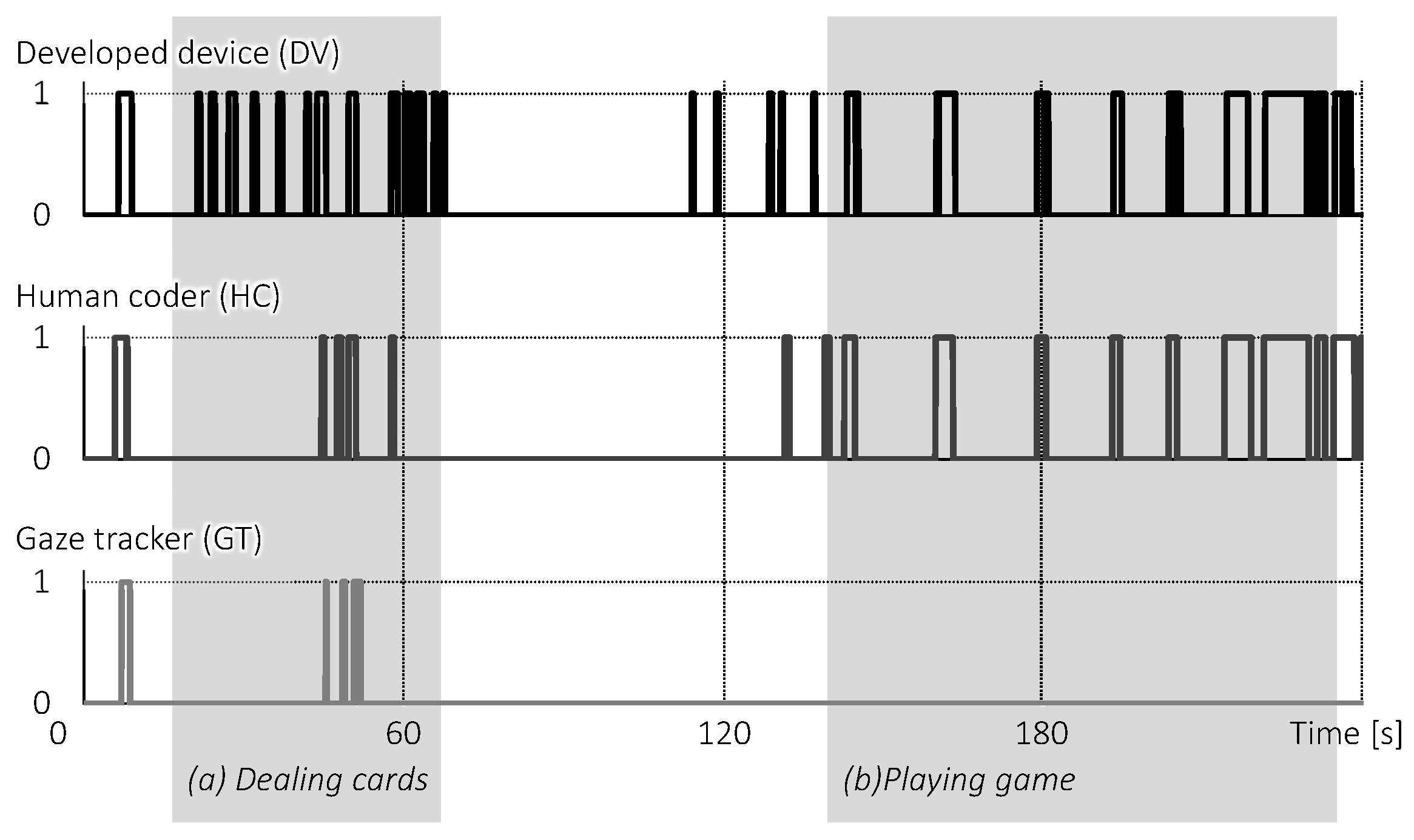
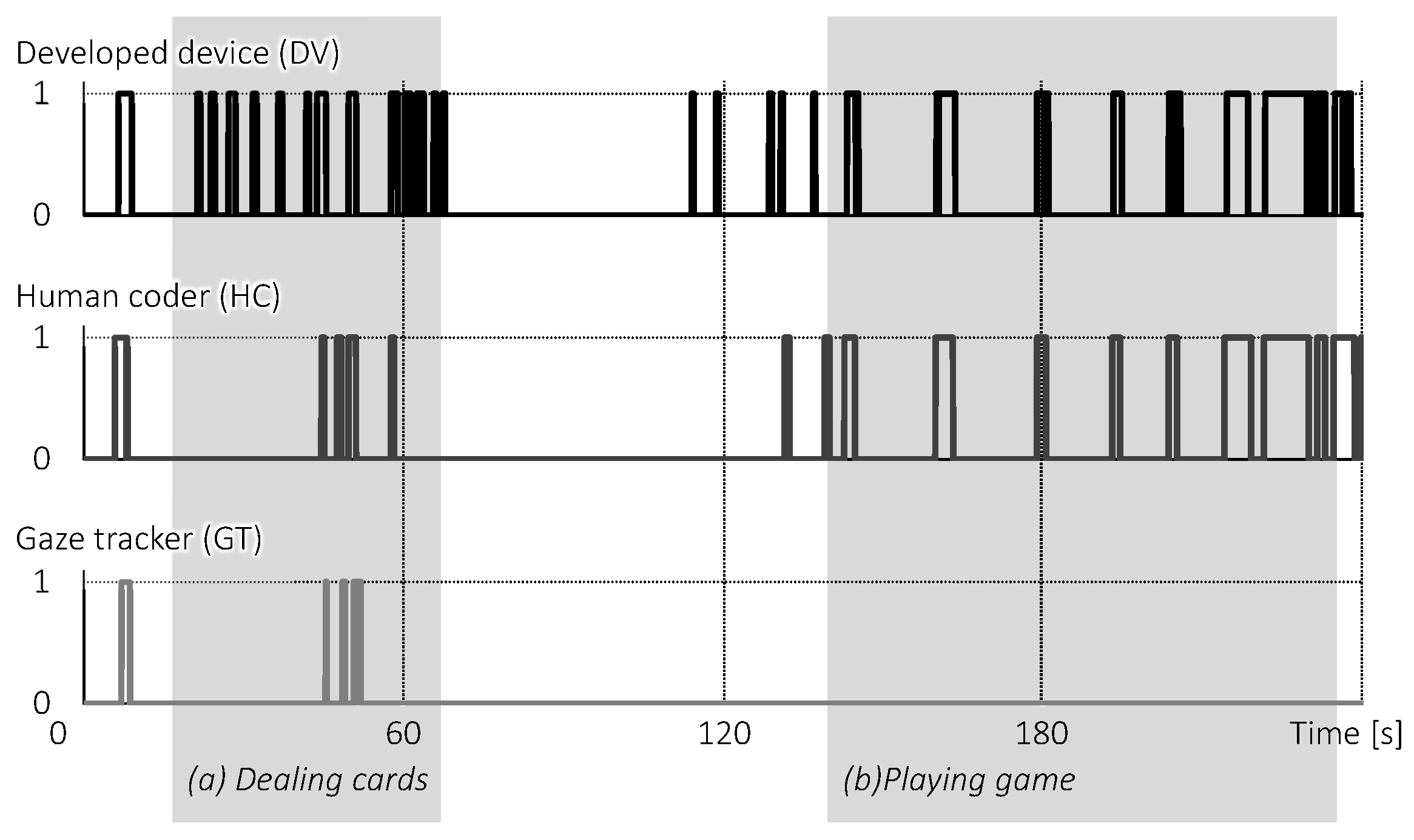
4.3. Comparison with Human Coder and Gaze Trackers
4.3.1. Setup
4.3.2. Results and Discussion
5. Field Study
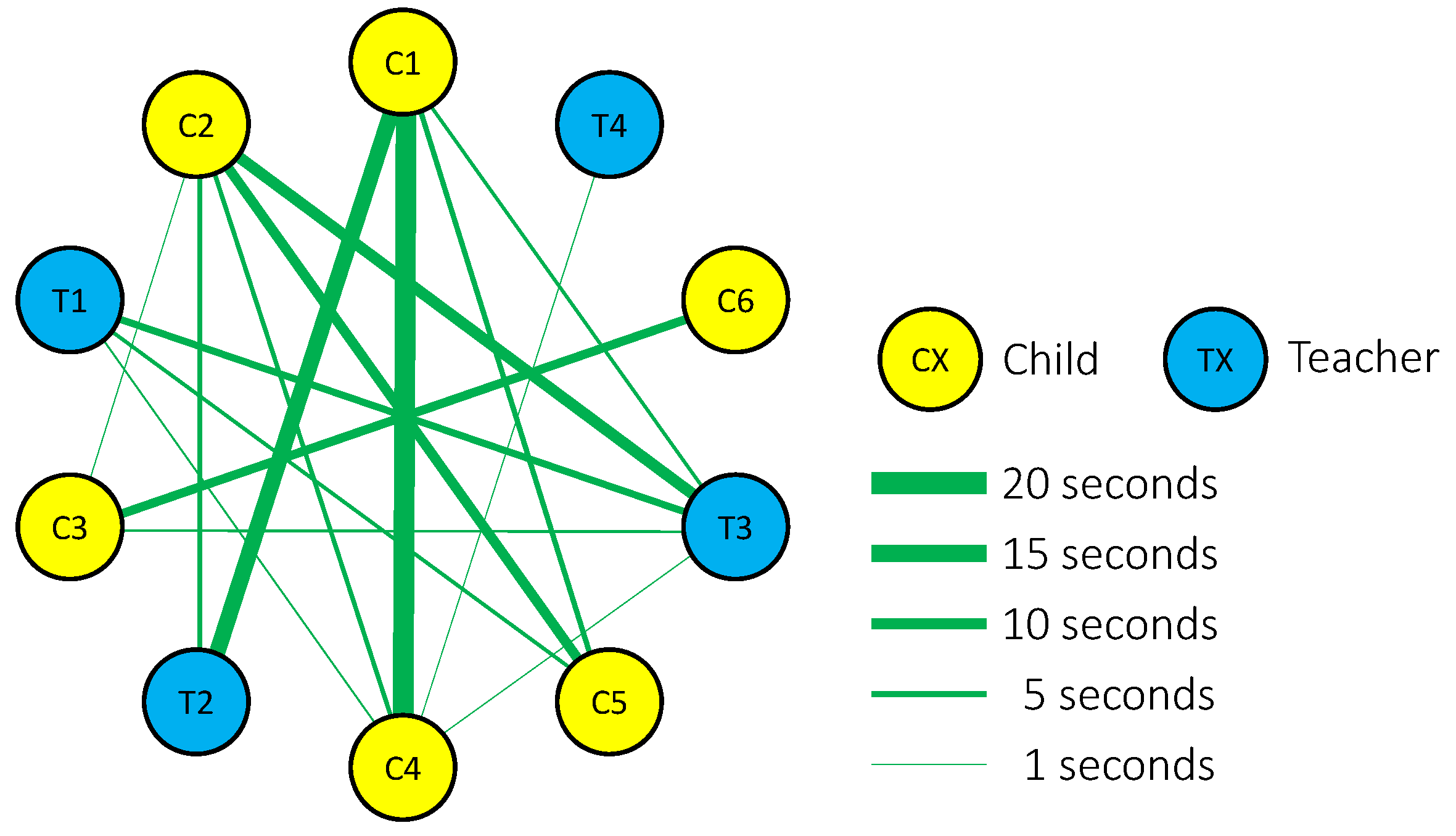
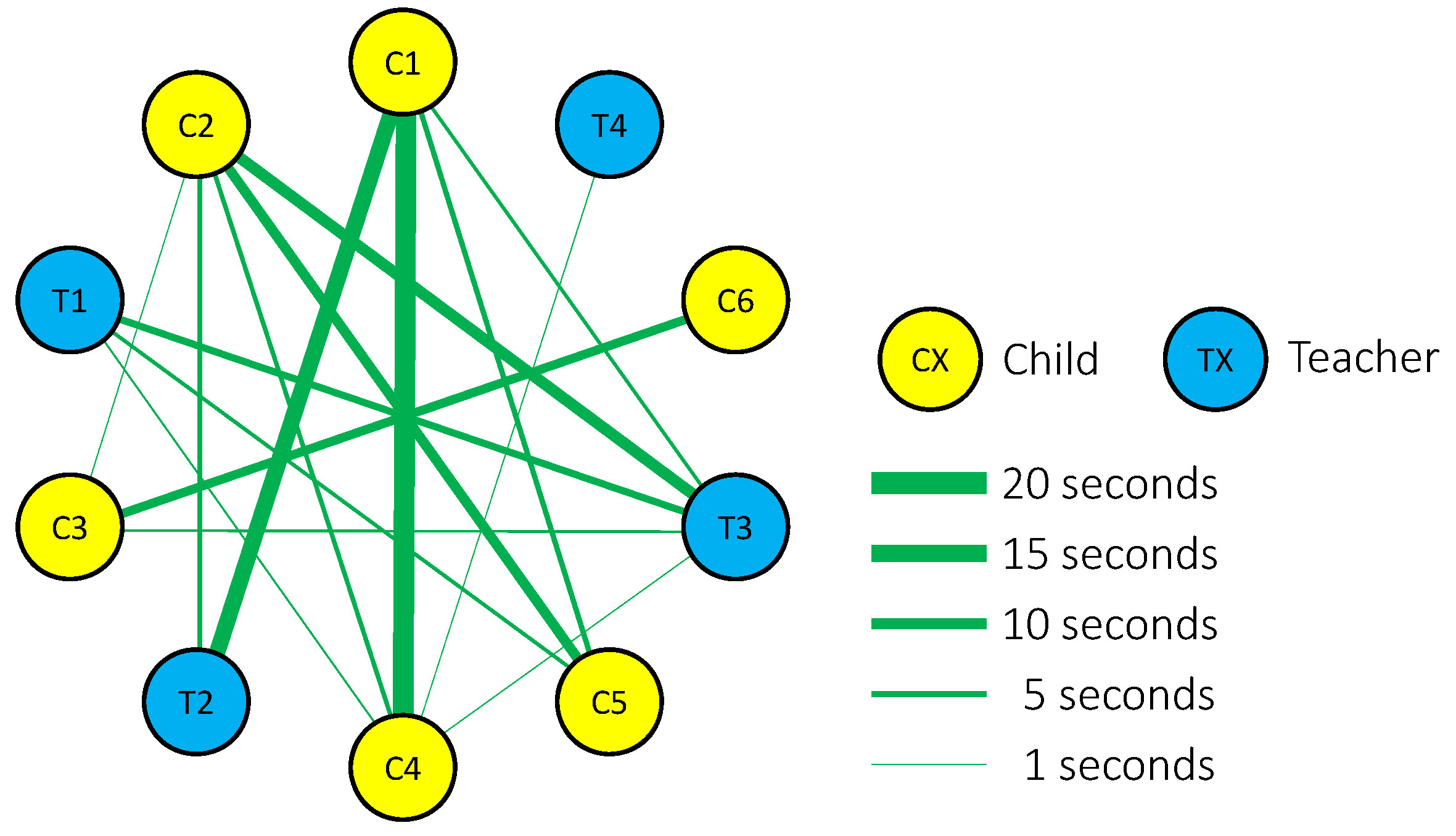
5.1. Quantitative Measurement of Face-to-Face Behavior among Children with Intellectual Disabilities and/or ASD during Activities of Daily Life
5.1.1. Participants
5.1.2. Study Protocol
5.1.3. Results and Discussion
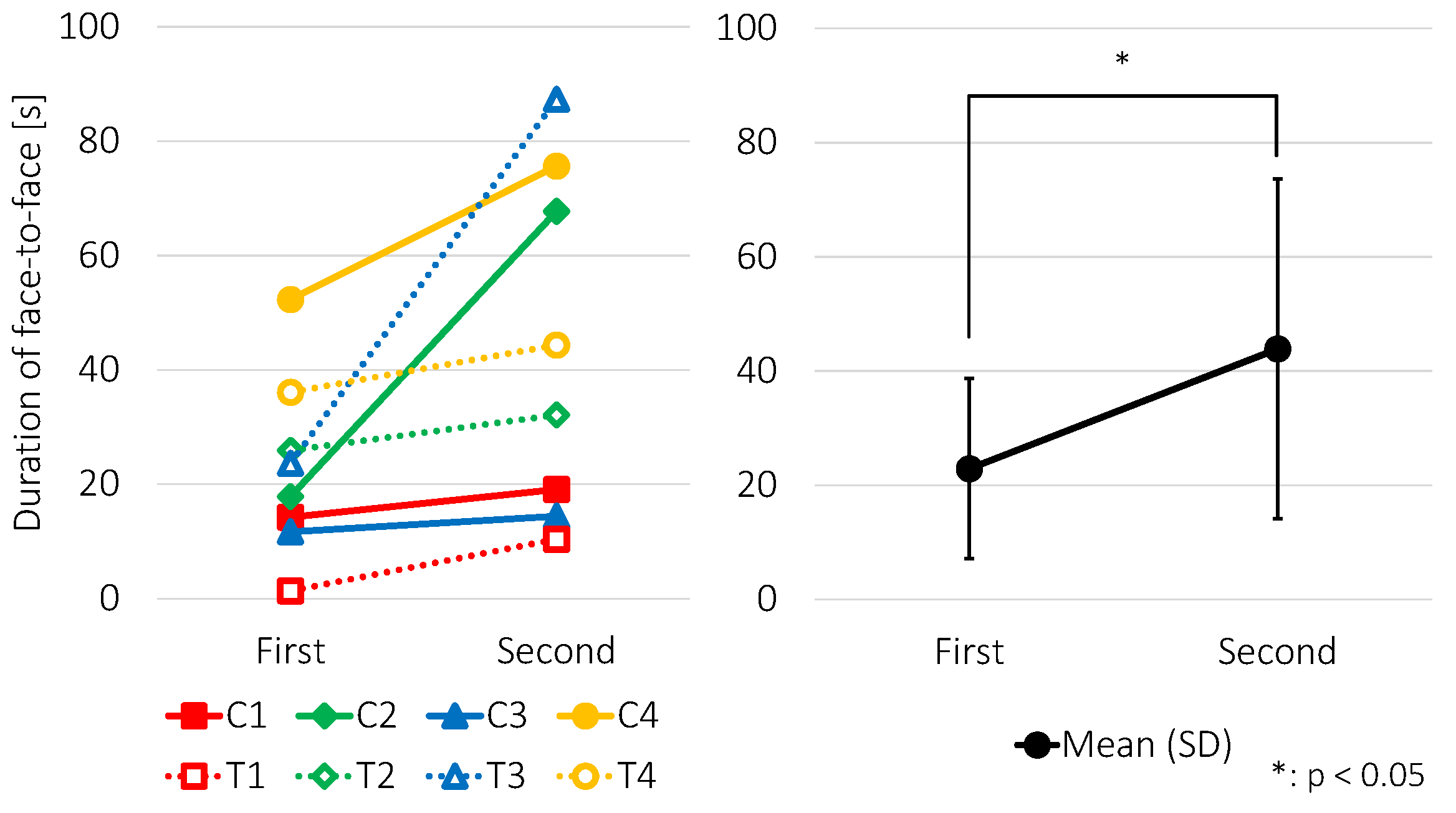
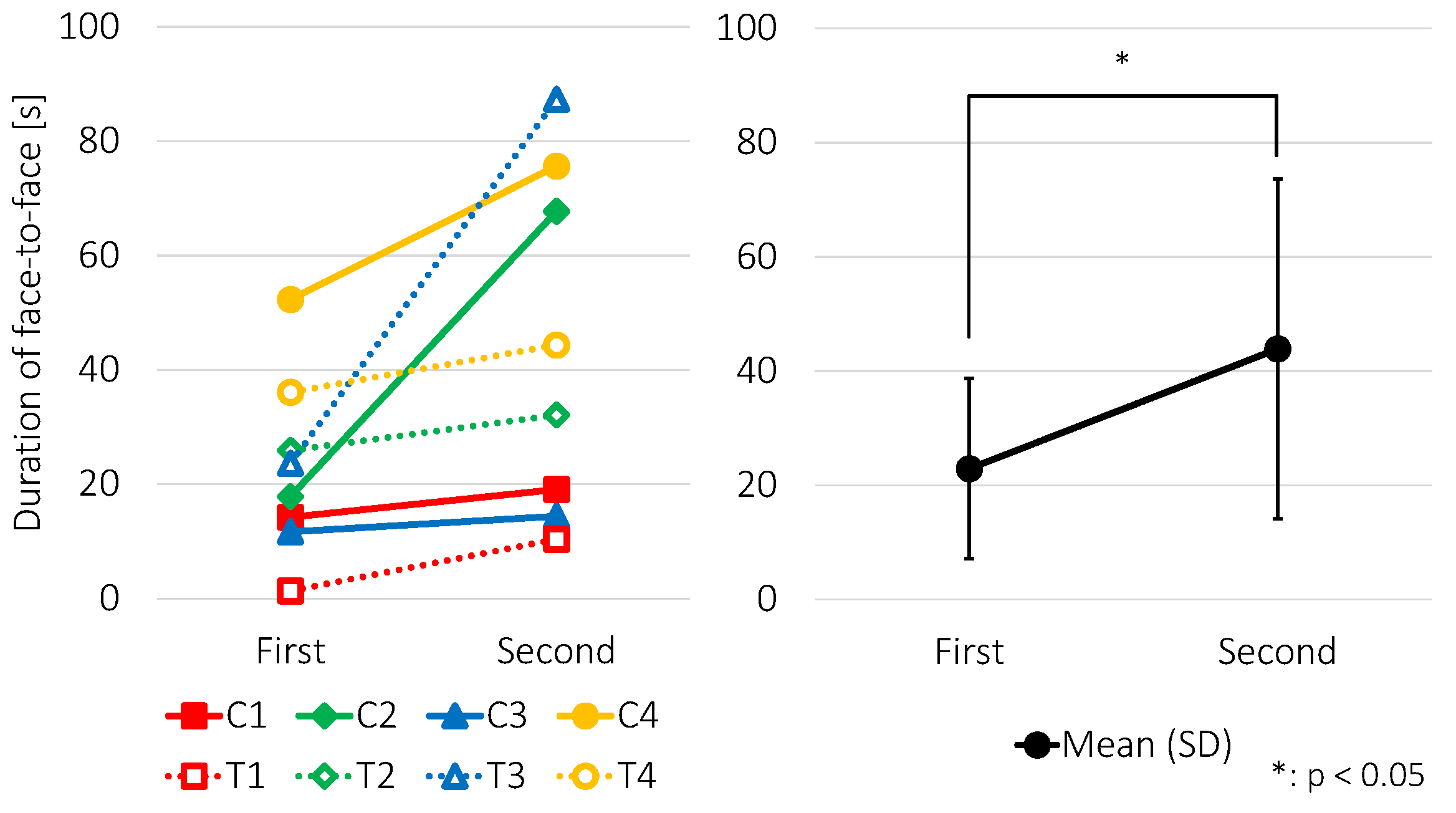
5.2. Facilitating Face-to-Face Behavior
5.2.1. Participants
5.2.2. Study Protocol
5.2.3. Results and Discussion
6. Discussion
6.1. Effectiveness of the FaceLooks Devices
6.2. Limitations and Possible Solutions
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Stiefelhagen, R.; Zhu, J. Head orientation and gaze direction in meetings. In Proceedings of the Extended Abstracts on Human Factors in Computing Systems, Minneapolis, MN, USA, 20–25 April 2002; pp. 858–859. [Google Scholar]
- Cohn, J.F.; Reed, L.I.; Moriyama, T.; Xiao, J.; Schmidt, K.; Ambadar, Z. Multimodal coordination of facial action, head rotation, and eye motion during spontaneous smiles. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 129–135. [Google Scholar]
- Ono, E.; Nozawa, T.; Ogata, T.; Motohashi, M.; Higo, N.; Kobayashi, T.; Ishikawa, K.; Ara, K.; Yano, K.; Miyake, Y. Fundamental deliberation on exploring mental health through social interaction pattern. In Proceedings of the 2012 ICME International Conference on Complex Medical Engineering (CME), Kobe, Japan, 1–4 July 2012; pp. 321–326. [Google Scholar]
- Speer, L.L.; Cook, A.E.; McMahon, W.M.; Clark, E. Face processing in children with autism: Effects of stimulus contents and type. Autism 2007, 11, 265–277. [Google Scholar] [CrossRef] [PubMed]
- Koegel, L.K.; Singh, A.K.; Koegel, R.L.; Hollingsworth, J.R.; Bradshaw, J. Assessing and improving early social engagement in infants. J. Posit. Behav. Interv. 2014, 16, 69–80. [Google Scholar] [CrossRef] [PubMed]
- Solish, A.; Perry, A.; Minnes, P. Participation of children with and without disabilities in social, recreational and leisure activities. J. Appl. Res. Intellect. Disabil. 2010, 23, 226–236. [Google Scholar] [CrossRef]
- Developmental Disabilities Monitoring Network Surveillance Year Principal Investigators. Prevalence of autism spectrum disorder among children aged 8 years—Autism and developmental disabilities monitoring network, 11 sites, United States, 2010. Surveill. Summ. 2014, 63, 1–21. [Google Scholar]
- Guitton, D.; Volle, M. Gaze control in humans: Eye-head coordination during orienting movements to targets within and beyond the oculomotor range. J. Neurophysiol. 1987, 58, 427–459. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Emoto, M.; Nakashima, R.; Matsumiya, K.; Kuriki, I.; Shioiri, S. Eye-position distribution depending on head orientation when observing movies on ultrahigh-definition television. ITE Trans. Media Technol. Appl. 2015, 3, 149–154. [Google Scholar] [CrossRef]
- Hall, E.T. The Hidden Dimension; Doubleday & Co.: New York, NY, USA, 1966. [Google Scholar]
- Kendon, A. Conducting Interaction: Patterns of Behavior in Focused Encounters; CUP Archive: Cambridge, UK, 1990. [Google Scholar]
- Vernon, T.W.; Koegel, R.L.; Dauterman, H.; Stolen, K. An early social engagement intervention for young children with autism and their parents. J. Autism Dev. Disord. 2012, 42, 2702–2717. [Google Scholar] [CrossRef] [PubMed]
- Ye, Z.; Li, Y.; Fathi, A.; Han, Y.; Rozga, A.; Abowd, G.D.; Rehg, J.M. Detecting eye contact using wearable eye-tracking glasses. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 699–704. [Google Scholar]
- Freedman, E.G.; Sparks, D.L. Eye-head coordination during head-unrestrained gaze shifts in rhesus monkeys. J. Neurophysiol. 1997, 77, 2328–2348. [Google Scholar] [CrossRef] [PubMed]
- Stahl, J.S. Amplitude of human head movements associated with horizontal saccades. Exp. Brain Res. 1999, 126, 41–54. [Google Scholar] [CrossRef] [PubMed]
- Setti, F.; Hung, H.; Cristani, M. Group detection in still images by F-formation modeling: A comparative study. In Proceedings of the 2013 14th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Paris, France, 3–5 July 2013; pp. 1–4. [Google Scholar]
- Setti, F.; Lanz, O.; Ferrario, R.; Murino, V.; Cristani, M. Multi-scale F-formation discovery for group detection. In Proceedings of the 2013 20th IEEE International Conference on Image Processing (ICIP), Melbourne, VIC, Australia, 15–18 September 2013; pp. 3547–3551. [Google Scholar]
- Setti, F.; Russell, C.; Bassetti, C.; Cristani, M. F-formation detection: Individuating free-standing conversational groups in images. PLoS ONE 2015, 10, e0123783. [Google Scholar]
- Cattuto, C.; Van den Broeck, W.; Barrat, A.; Colizza, V.; Pinton, J.F.; Vespignani, A. Dynamics of person-to-person interactions from distributed RFID sensor networks. PLoS ONE 2010, 5, e11596. [Google Scholar] [CrossRef] [PubMed]
- Miura, A.; Isezaki, T.; Suzuki, K. Social playware with an enhanced reach for facilitating group interaction. In Proceedings of the Extended Abstracts on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 1155–1160. [Google Scholar]
- Choudhury, T.K. Sensing and Modeling Human Networks. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2004. [Google Scholar]
- Olguín, D.O.; Waber, B.N.; Kim, T.; Mohan, A.; Ara, K.; Pentland, A. Sensible organizations: Technology and methodology for automatically measuring organizational behavior. IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 43–55. [Google Scholar] [CrossRef] [PubMed]
- Otsuka, R.; Yano, K.; Sato, N. An organization topographic map for visualizing business hierarchical relationships. In Proceedings of the IEEE Pacific Visualization Symposium, Beijing, China, 20–23 April 2009; pp. 25–32. [Google Scholar]
- Kumano, S.; Otsuka, K.; Ishii, R.; Yamato, J. Automatic gaze analysis in multiparty conversations based on collective first-person vision. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–8. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar]
- Littlewort, G.; Whitehill, J.; Wu, T.; Fasel, I.; Frank, M.; Movellan, J.; Bartlett, M. The computer expression recognition toolbox (CERT). In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011), Santa Barbara, CA, USA, 21–25 March 2011; pp. 298–305. [Google Scholar]
- Fathi, A.; Hodgins, J.K.; Rehg, J.M. Social interactions: A first-person perspective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1226–1233. [Google Scholar]
- Watanabe, J.; Nii, H.; Hashimoto, Y.; Inami, M. Visual resonator: interface for interactive cocktail party phenomenon. In Proceedings of the CHI’06 Extended Abstracts on Human Factors in Computing Systems, Montréal, QC, Canada, 22–27 April 2006; pp. 1505–1510. [Google Scholar]
- Lambert, D. Body Language 101: The Ultimate Guide to Knowing When People Are Lying, How They Are Feeling, What They Are Thinking, and More; Skyhorse Publishing: New York City, NY, USA, 2008. [Google Scholar]
- Wing, L. The Autism Spectrum: A Guide for Parents and Professionals; Constable: London, UK, 1996. [Google Scholar]
- Suzuki, K.; Hachisu, T.; Iida, K. EnhancedTouch: A Smart Bracelet for Enhancing Human-Human Physical Touch. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; ACM: New York, NY, USA, 2016; pp. 1282–1293. [Google Scholar]
- Boyd, L.E.; Rangel, A.; Tomimbang, H.; Conejo-Toledo, A.; Patel, K.; Tentori, M.; Hayes, G.R. SayWAT: Augmenting Face-to-Face Conversations for Adults with Autism. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 4872–4883. [Google Scholar]
- Gruebler, A.; Suzuki, K. Design of a wearable device for reading positive expressions from facial emg signals. IEEE Trans. Affect. Comput. 2014, 5, 227–237. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TBF | TFtF | |
|---|---|---|
| Mean (SD) (ms) | 351.75 (144.77) | 310.27 (97.54) |
| Size | Diameter: 15 cm |
| Height: 2 cm | |
| Weight | 75 g |
| Battery | Feedback on: 1–2 h. |
| Feedback off: 3–4 h | |
| Detection range | FtF: ±18.0–27.0° |
| BF: FtF + 10° | |
| Response time | 350 ms |
| HC | GT | ||
|---|---|---|---|
| Total | 0.634 | 0.067 | |
| FLAND | Period (a) | 0.233 | 0.013 |
| Period (b) | 0.817 | 0.001 | |
| Total | - | 0.050 | |
| HC | Period (a) | - | 0.126 |
| Period (b) | - | 0.097 |
| n | Chronological Age (Years) | ||
|---|---|---|---|
| Experiment 1 | Children (C1–C6) | Male = 3 | 13–14 |
| Female = 3 | |||
| Teachers (T1–T4) | Male = 2 | 20–50 | |
| Female = 2 | |||
| Experiment 2 | Children (C1–C4) | Male = 2 | 15–17 |
| Female = 2 | |||
| Teachers (T1–T4) | Male = 3 | 20–50 | |
| Female = 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hachisu, T.; Pan, Y.; Matsuda, S.; Bourreau, B.; Suzuki, K. FaceLooks: A Smart Headband for Signaling Face-to-Face Behavior. Sensors 2018, 18, 2066. https://doi.org/10.3390/s18072066
Hachisu T, Pan Y, Matsuda S, Bourreau B, Suzuki K. FaceLooks: A Smart Headband for Signaling Face-to-Face Behavior. Sensors. 2018; 18(7):2066. https://doi.org/10.3390/s18072066
Chicago/Turabian StyleHachisu, Taku, Yadong Pan, Soichiro Matsuda, Baptiste Bourreau, and Kenji Suzuki. 2018. "FaceLooks: A Smart Headband for Signaling Face-to-Face Behavior" Sensors 18, no. 7: 2066. https://doi.org/10.3390/s18072066
APA StyleHachisu, T., Pan, Y., Matsuda, S., Bourreau, B., & Suzuki, K. (2018). FaceLooks: A Smart Headband for Signaling Face-to-Face Behavior. Sensors, 18(7), 2066. https://doi.org/10.3390/s18072066