Accurate Traffic Flow Prediction in Heterogeneous Vehicular Networks in an Intelligent Transport System Using a Supervised Non-Parametric Classifier

 ,
, 
 , ,
, , 
Abstract
1. Introduction
2. Related Work
3. Theoretical Background
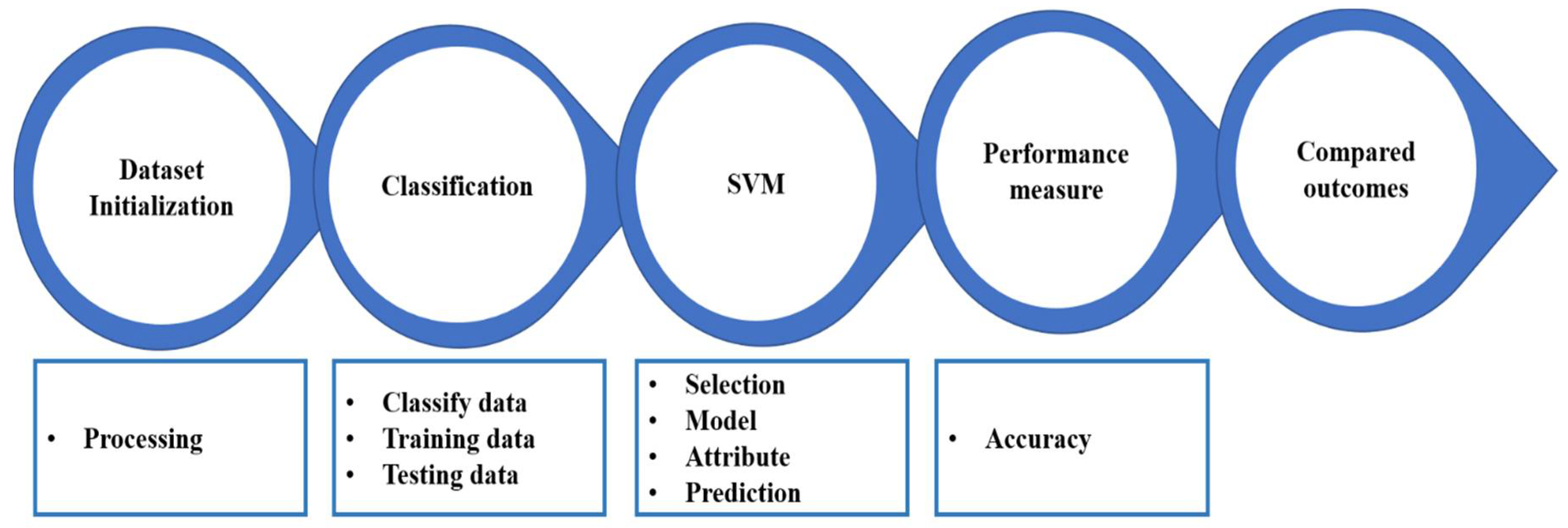
4. Proposed Model: RBF-Refined SVM Model
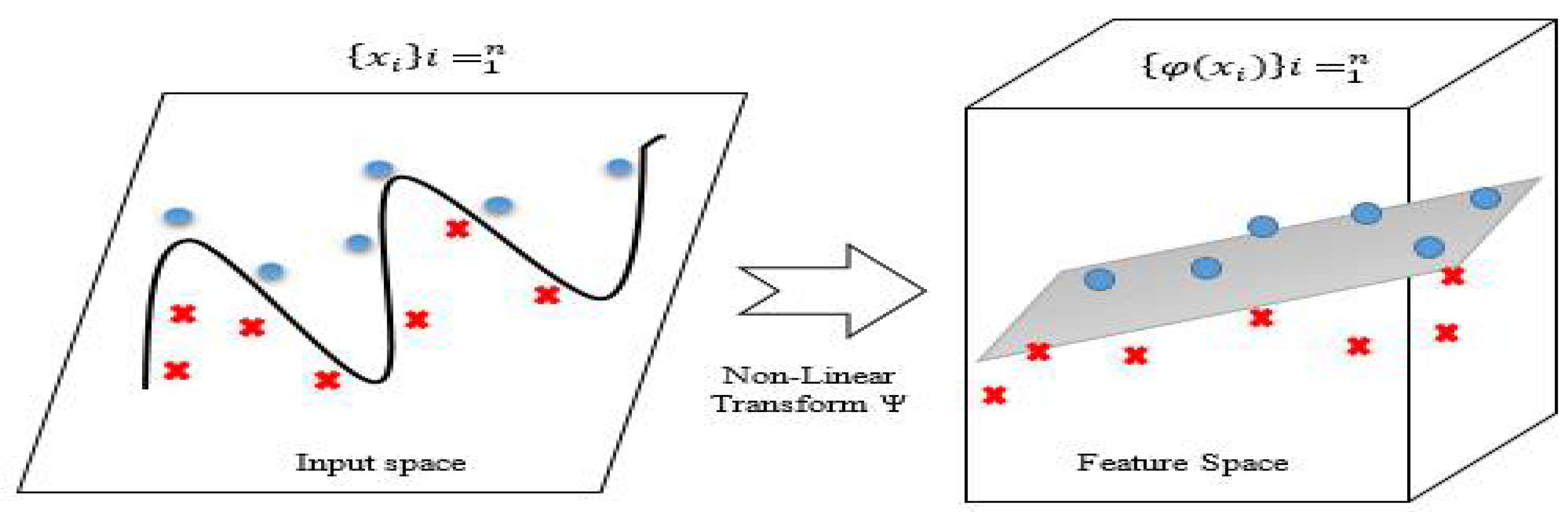
4.1. Overview: SVM
4.2. Pre-Processing: Data Initialization
4.3. Classification: Training and Testing Data
4.4. SVM-Based Selection: Model—RBF Kernel
4.5. Selection: Attribute
4.6. Performance Measure
5. Experimental Results
5.1. Overview of Dataset
5.2. Training and Testing of Dataset
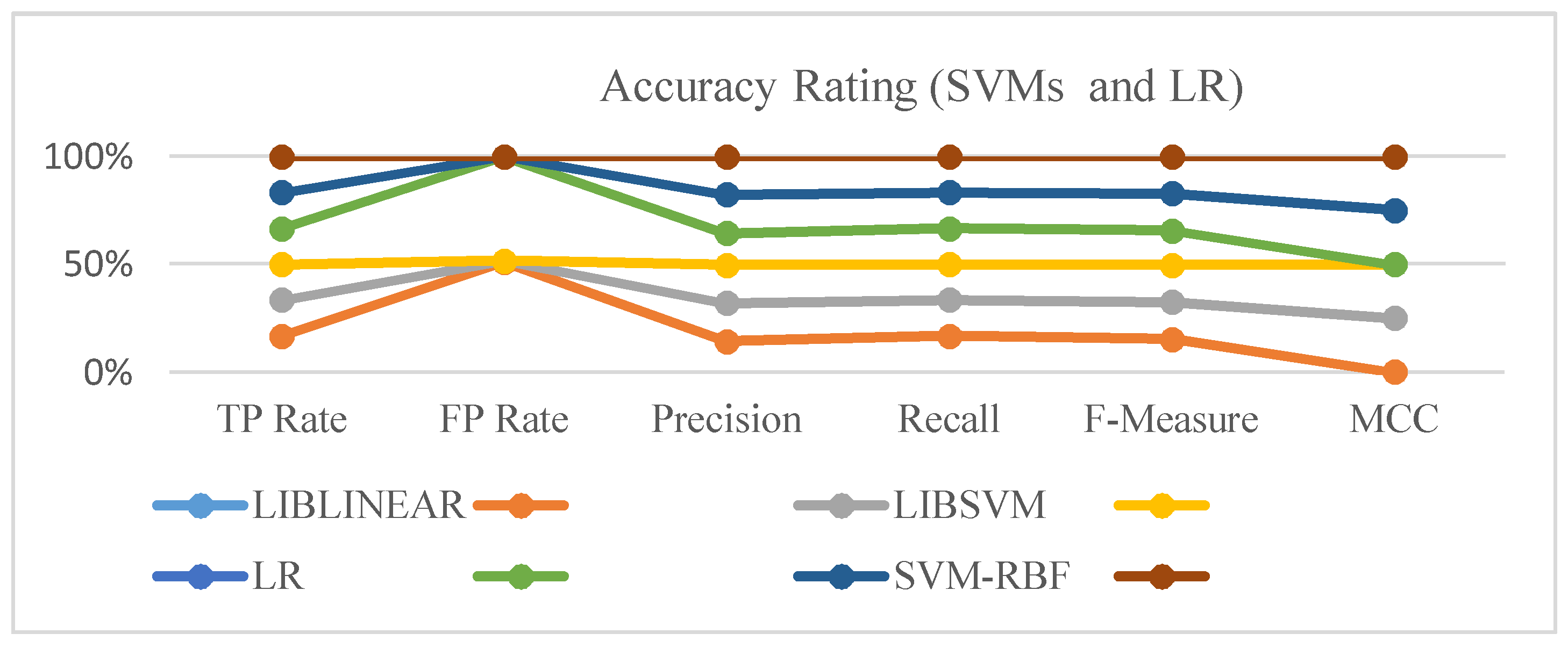
5.3. Comparison of Outcomes
6. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Atallah, R.F.; Khabbaz, M.J.; Assi, C.M. Vehicular networking: A survey on spectrum access technologies and persisting challenges. Veh. Commun. 2015, 2, 125–149. [Google Scholar] [CrossRef]
- Lloret, J.; Canovas, A.; Catalá, A.; Garcia, M. Group-based protocol and mobility model for VANETs to offer internet access. J. Netw. Comput. Appl. 2013, 36, 1027–1038. [Google Scholar] [CrossRef]
- Daraghmi, Y.A.; Stojmenovic, I.; Yi, C.W. Forwarding Methods in Data Dissemination and Routing Protocols for Vehicular Ad Hoc Networks. IEEE Netw. 2013, 27, 74–79. [Google Scholar] [CrossRef]
- Amadeo, M.; Campolo, C.; Molinaro, A. Named Data Networking for Priority-based Content Dissemination in VANETs. In Proceedings of the Vehicular Networking and Intelligent Transportation Systems (IEEE PIMRC WKSHPS), Valencia, Spain, 4–7 September 2016; pp. 4–7. [Google Scholar]
- Daraghmi, Y.A.; Yi, C.W.; Chiang, T.C. Negative Binomial Additive Models for Short-Term Traffic Flow Forecasting in Urban Areas. IEEE Trans. Intell. Transp. Syst. 2014, 15, 784–793. [Google Scholar] [CrossRef]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; pp. 561–568. [Google Scholar]
- Vapnik, V.; Chapelle, O. Bounds on error expectation for support vector machines. Neural Comput. 2000, 12, 2013–2036. [Google Scholar] [CrossRef] [PubMed]
- Daraghmi, Y.A.; Stojmenovic, I.; Yi, C.W. A Taxonomy of Data Communication Protocols for Vehicular Ad Hoc Networks. In Mobile Ad Hoc Networking: Cutting Edge Directions, 2nd ed.; Wiley-IEEE Press: Hoboken, NJ, USA, 2013. [Google Scholar]
- Valenti, S.; Rossi, D.; Dainotti, A.; Pescapè, A.; Finamore, A.; Mellia, M. Reviewing traffic classification. In Data Traffic Monitoring and Analysis; Springer: Berlin/Heidelberg, Germany, 2013; pp. 123–147. [Google Scholar]
- Wang, Y.; Xiang, Y.; Zhang, J.; Yu, S. A novel semi-supervised approach for network traffic clustering. In Proceedings of the 5th IEEE International Conference on Network and System Security (NSS), Milan, Italy, 6–8 September 2011; pp. 169–175. [Google Scholar]
- Zhang, J.; Xiang, Y.; Wang, Y.; Zhou, W.; Xiang, Y.; Guan, Y. Network traffic classification using correlation information. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 104–117. [Google Scholar] [CrossRef]
- Sugiyama, M.; Kawanabe, M. Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Sahoo, G. Analysis of parametric & non parametric classifiers for classification technique using WEKA. Int. J. Inf. Technol. Comput. Sci. 2012, 4, 43. [Google Scholar]
- Chen, C.; Liu, Z.; Lin, W.-H.; Li, S.; Wang, K. Distributed modeling in a MapReduce framework for data-driven traffic flow forecasting. IEEE Trans. Intell. Transp. Syst. 2013, 14, 22–33. [Google Scholar] [CrossRef]
- Ghosh, B.; Basu, B.; OMahony, M. Multivariate short-term traffic flow forecasting using time-series analysis. IEEE Trans. Intell. Transp. Syst. 2009, 10, 246–254. [Google Scholar] [CrossRef]
- Min, W.; Wynter, L. Real-time road traffic prediction with spatiotemporal correlations. Transp. Res. C 2011, 19, 606–616. [Google Scholar] [CrossRef]
- Żbikowski, K. Time series forecasting with volume weighted support vector machines. In International Conference: Beyond Databases, Architectures and Structures; Springer International Publishing: Basel, Switzerland, 2014; pp. 250–258. [Google Scholar]
- Cao, H.; Naito, T.; Ninomiya, Y. Approximate RBF Kernel SVM and Its Applications in Pedestrian Classification. In Proceedings of the 1st International Workshop on Machine Learning for Vision-based Motion Analysis—MLVMA’08, Marseille, France, 1–5 October 2008. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Harrell, F.E. Ordinal logistic regression. In Regression Modeling Strategies; Springer: New York, NY, USA, 2011; pp. 331–343. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVM Type | Kernel Function ) |
|---|---|
| Linear | |
| Polynomial | (d |
| Sigmoid | tanh( |
| Radial Basis Function (RBF) | exp (-‖‖2, |
| Kernel | Complexity | Optimality | Accuracy |
|---|---|---|---|
| Linear | High | High | Medium |
| Polynomial | High | Medium | Medium |
| RBF | Low | High | High |
| Sigmoidal | Medium | Low | Medium |
| Average-Merit | Average-Ranking Score | Attribute #/Name |
|---|---|---|
| 1 ± 0 | 1 ± 0 | 14 Bytes Received |
| 0.999 ± 0 | 2 ± 0 | 15 Signal Strength |
| 0.982 ± 0 | 3 ± 0 | 16 Noise Strength |
| 0.474 ± 0.003 | 4 ± 0 | 8 Sender Altitude (m) |
| 0.468 ± 0.002 | 5 ± 0 | 7 Sender Speed (km/h) |
| 0.415 ± 0.003 | 6 ± 0 | 12 Receiver Altitude (m) |
| 0.336 ± 0.001 | 7 ±0 | 1 Packet-Sequence-No # |
| 0.335 ± 0.004 | 8 ± 0 | 2 Time in Sec |
| 0.104 ± 0.001 | 9 ± 0 | 9 Receiver Latitude |
| 0.091 ± 0.002 | 10 ± 0 | 10 Receiver Longitude |
| 0.078 ± 0.001 | 11 ±0 | 6 Sender Longitude |
| 0.078 ± 0.001 | 12 ± 0 | 5 Sender Latitude |
| 0.017 ± 0.003 | 13 ± 0 | 3 Time in unit sec |
| 0 ± 0 | 14 ± 0 | 4 Bytes Sent |
| 0 ± 0 | 15 ± 0 | 11 Receiver Speed |
| Actual/Predicted | No | Yes |
|---|---|---|
| No | TN | FP |
| Yes | FN | TP |
| Traffic Dataset | Using Traditional Training Set | Using Cross-Validation Set | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy (SVM-RBF) % | Accuracy (LIBSVM) % | Accuracy (LIBLINEAR) % | Logistic Regression (LR) % | Accuracy (SVM-RBF) % | Accuracy (LIBSVM) % | Accuracy (LIBLINEAR) % | Logistic Regression (LR)% | |
| Lap5 N | 99.8 | 94.7 | 44.2 | 62.3 | 100 | 99.7 | 78.6 | 82.5 |
| Lap4 N | 98.7 | 93.5 | 63.1 | 66.5 | 99.7 | 97.3 | 84.3 | 86.6 |
| Lap3 N | 97.5 | 89.5 | 61.5 | 65.1 | 99.8 | 93.7 | 87.6 | 85.1 |
| Lap2 N | 99.1 | 92.7 | 57.8 | 59.5 | 99.9 | 98.7 | 89.7 | 79.3 |
| Lap1 N | 96.7 | 92.5 | 67.1 | 77.4 | 99.9 | 98.5 | 94.3 | 89.6 |
| Lap5 S | 96.5 | 90.5 | 65.5 | 64.5 | 99.8 | 97.7 | 88.6 | 85.4 |
| Lap4 S | 98.3 | 93.5 | 63.1 | 66.3 | 99.7 | 97.3 | 83.4 | 89.3 |
| Lap3 S | 95.5 | 85.5 | 61.5 | 63.5 | 99.8 | 94.7 | 86.5 | 83.6 |
| Lap2 S | 99.1 | 92.7 | 57.8 | 67.9 | 99.9 | 98.7 | 89.7 | 89.7 |
| Lap1 S | 96.7 | 92.5 | 67.1 | 66.3 | 99.9 | 98.5 | 94.3 | 88.4 |
| Classifier Type | TP Rate | FP Rate | Precision | Recall | F-Measure | MCC | ROC Area | PRC Area | Class |
|---|---|---|---|---|---|---|---|---|---|
| LIBLINEAR | 1.000 | 1.000 | 0.787 | 1.000 | 0.881 | 0.000 | 0.500 | 0.787 | Y |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.500 | 0.213 | N | |
| LIBSVM | 1.000 | 0.011 | 0.997 | 1.000 | 0.999 | 0.993 | 0.995 | 0.997 | Y |
| 0.989 | 0.000 | 1.000 | 0.989 | 0.995 | 0.993 | 0.995 | 0.991 | N | |
| SVM-RBF | 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Y |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | N | |
| LR | 1.000 | 0.951 | 0.822 | 1.000 | 0.924 | 0.000 | 0.650 | 0.822 | Y |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.585 | 0.265 | N |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Sayed, H.; Sankar, S.; Daraghmi, Y.-A.; Tiwari, P.; Rattagan, E.; Mohanty, M.; Puthal, D.; Prasad, M. Accurate Traffic Flow Prediction in Heterogeneous Vehicular Networks in an Intelligent Transport System Using a Supervised Non-Parametric Classifier. Sensors 2018, 18, 1696. https://doi.org/10.3390/s18061696
El-Sayed H, Sankar S, Daraghmi Y-A, Tiwari P, Rattagan E, Mohanty M, Puthal D, Prasad M. Accurate Traffic Flow Prediction in Heterogeneous Vehicular Networks in an Intelligent Transport System Using a Supervised Non-Parametric Classifier. Sensors. 2018; 18(6):1696. https://doi.org/10.3390/s18061696
Chicago/Turabian StyleEl-Sayed, Hesham, Sharmi Sankar, Yousef-Awwad Daraghmi, Prayag Tiwari, Ekarat Rattagan, Manoranjan Mohanty, Deepak Puthal, and Mukesh Prasad. 2018. "Accurate Traffic Flow Prediction in Heterogeneous Vehicular Networks in an Intelligent Transport System Using a Supervised Non-Parametric Classifier" Sensors 18, no. 6: 1696. https://doi.org/10.3390/s18061696
APA StyleEl-Sayed, H., Sankar, S., Daraghmi, Y.-A., Tiwari, P., Rattagan, E., Mohanty, M., Puthal, D., & Prasad, M. (2018). Accurate Traffic Flow Prediction in Heterogeneous Vehicular Networks in an Intelligent Transport System Using a Supervised Non-Parametric Classifier. Sensors, 18(6), 1696. https://doi.org/10.3390/s18061696