A Strategy toward Collaborative Filter Recommended Location Service for Privacy Protection

Abstract
:1. Introduction
- This paper proposes a method to construct user position information profiles based on density measurements. The collaborative filtering recommendation method was used to recommend location services to reduce the frequency of server access, avoid privacy leaks and improve the service quality.
- According to the characteristics of the location service system, two different collaborative filtering recommendation methods based on position profile and position point were designed, respectively. Two different similarity measures were adopted. The Paillier cryptosystem was applied to the users’ position profiles.
- The feasibility and validity of the algorithm were verified on a real dataset. Some factors including data utility and communication cost were compared with the existing methods.
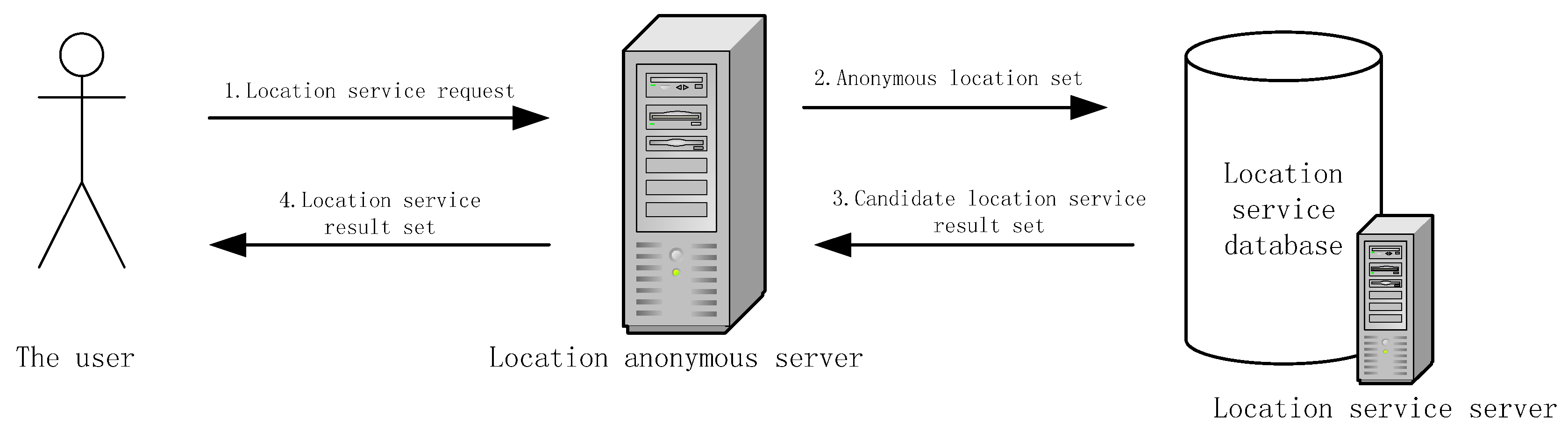
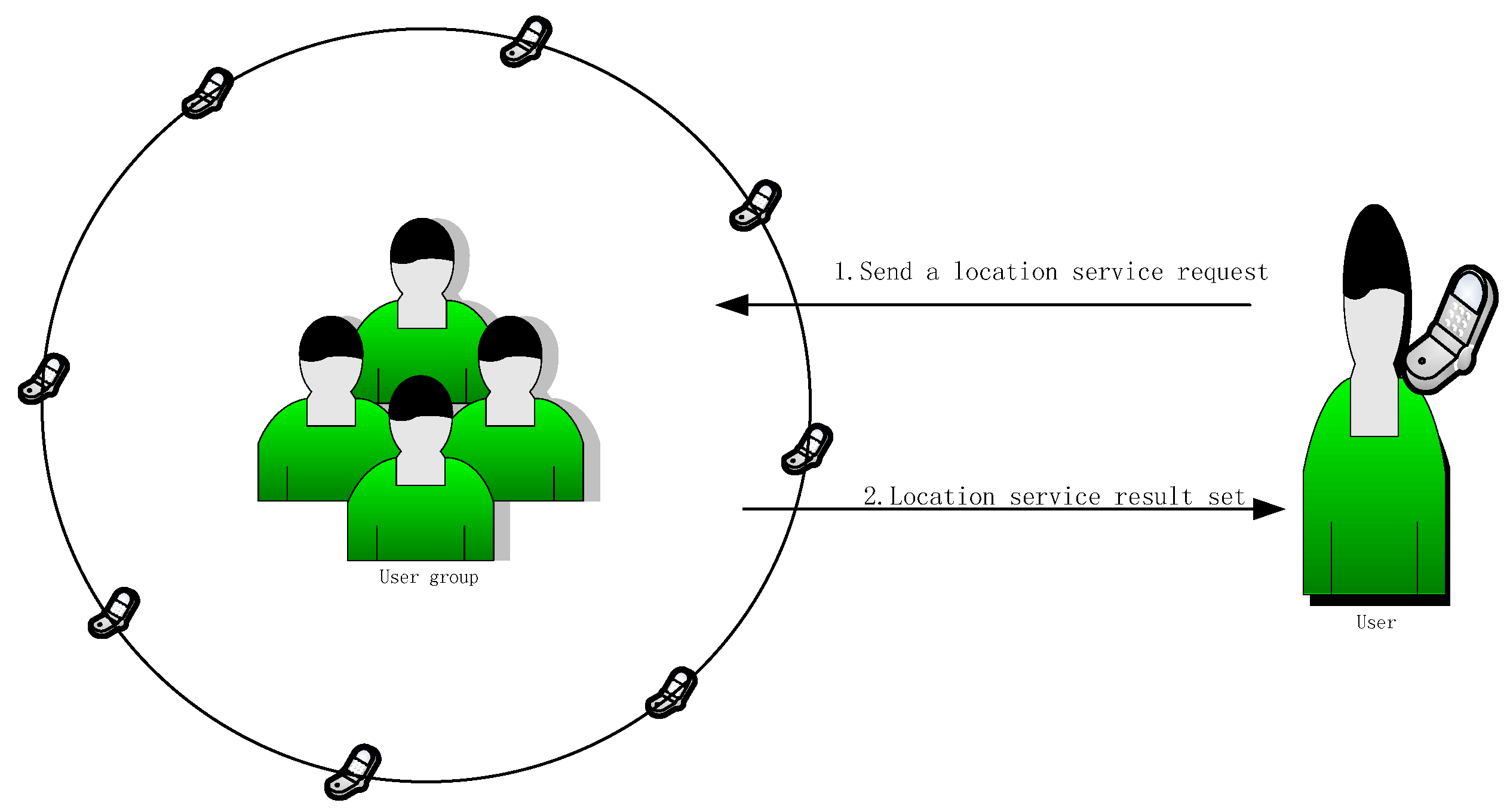
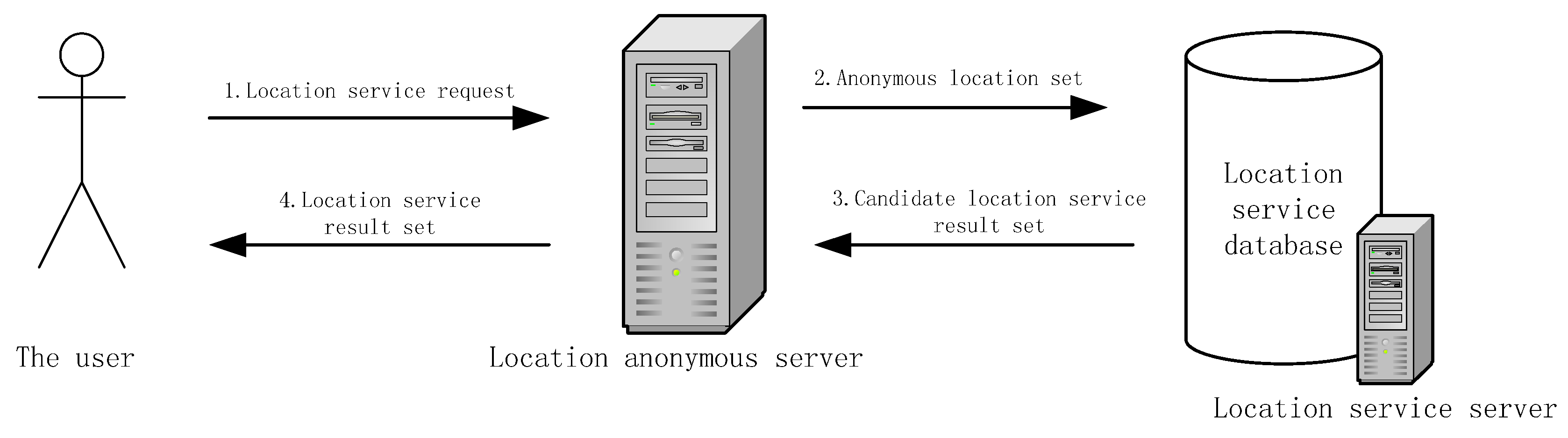
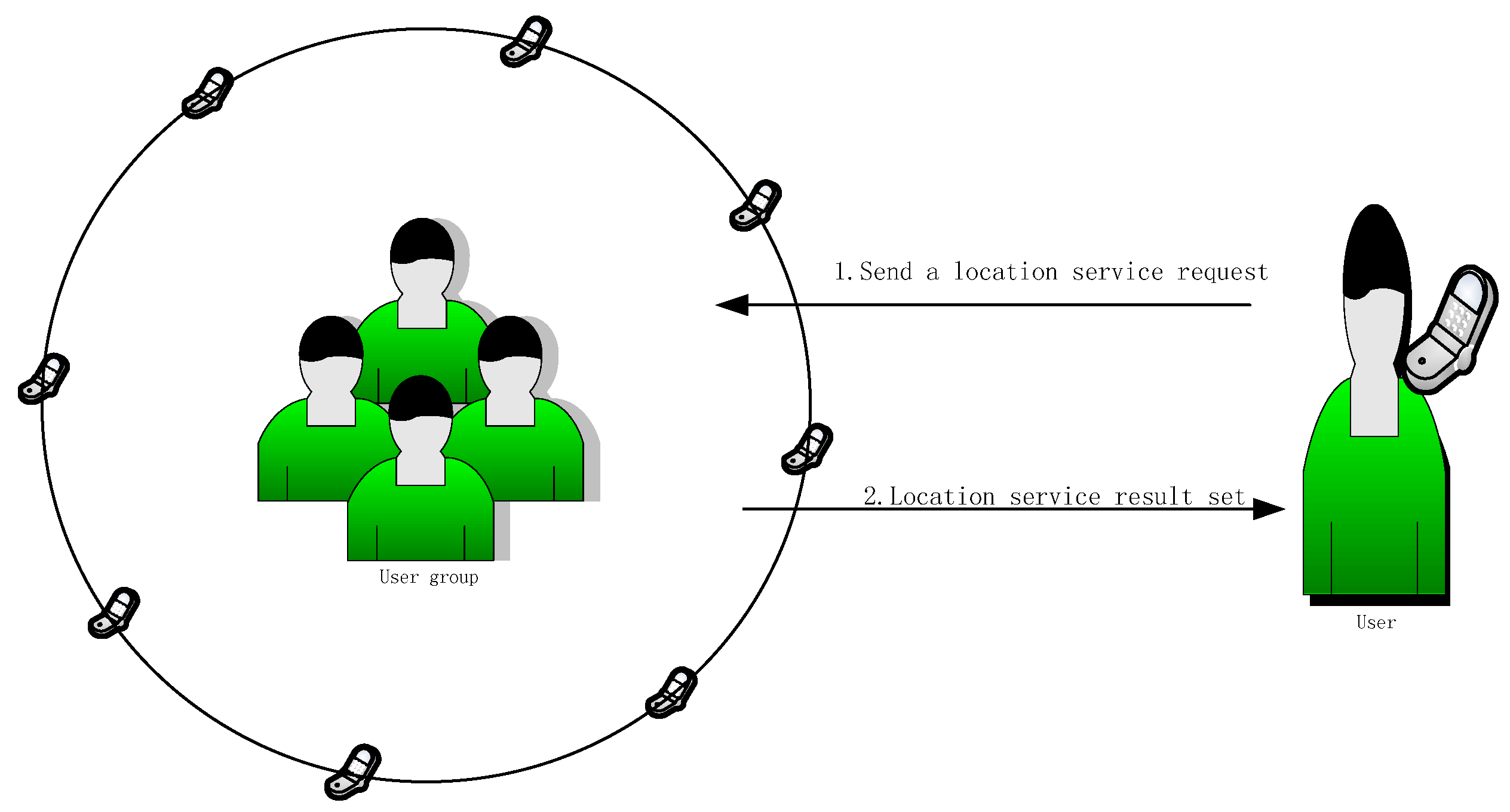
2. Related Work
3. Methods
3.1. Description of the Scheme
3.2. Profile Construction
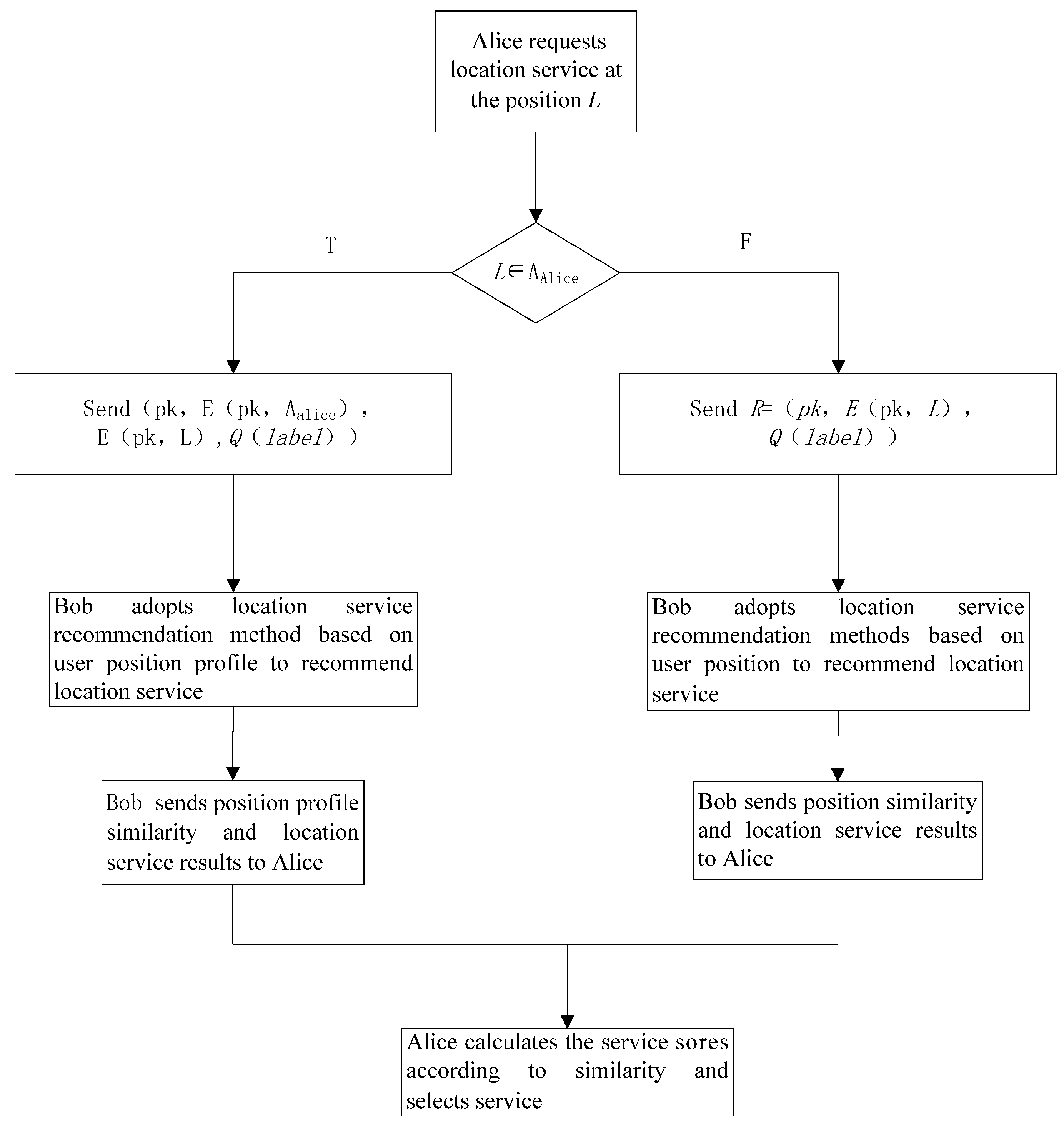
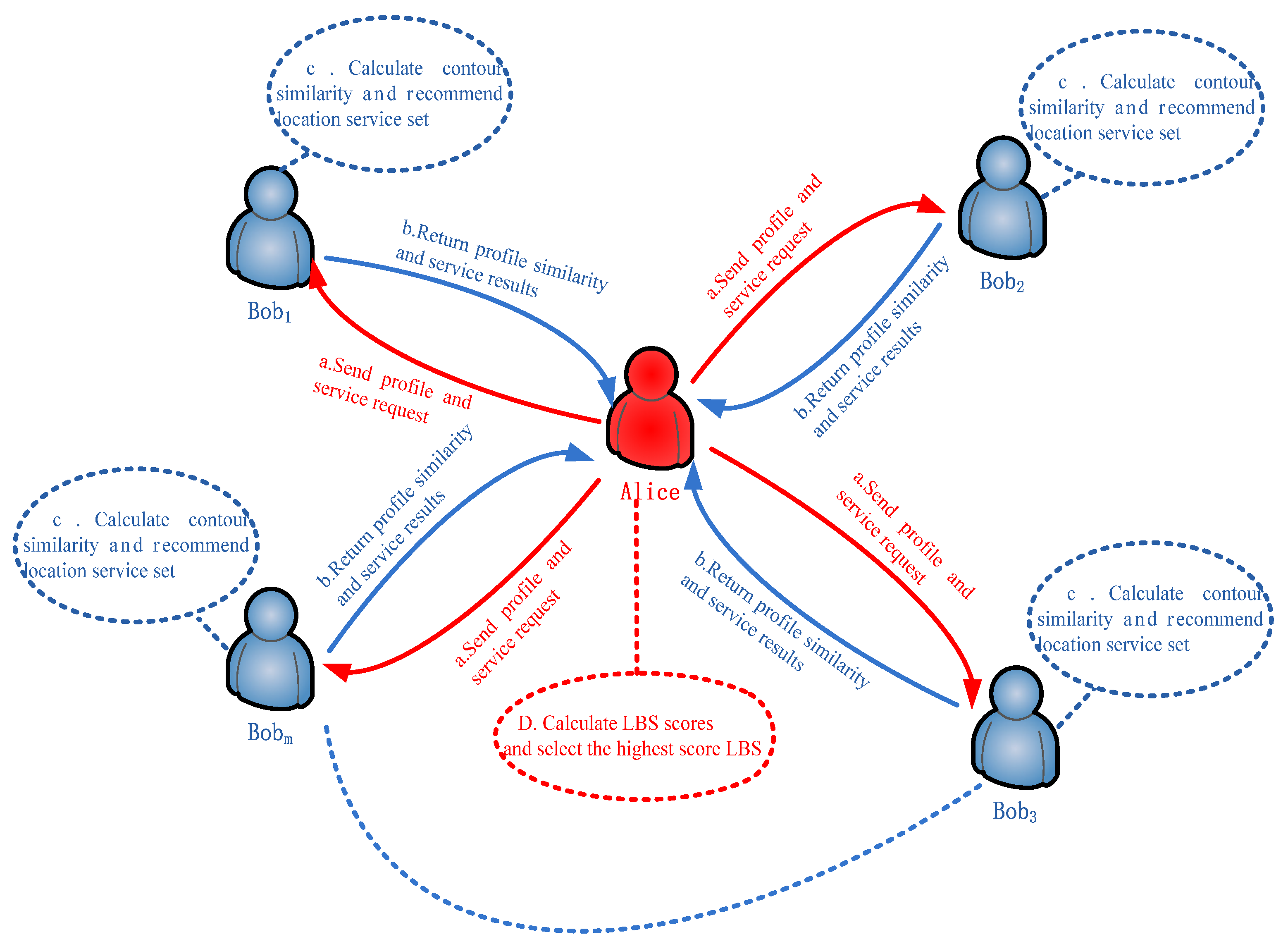
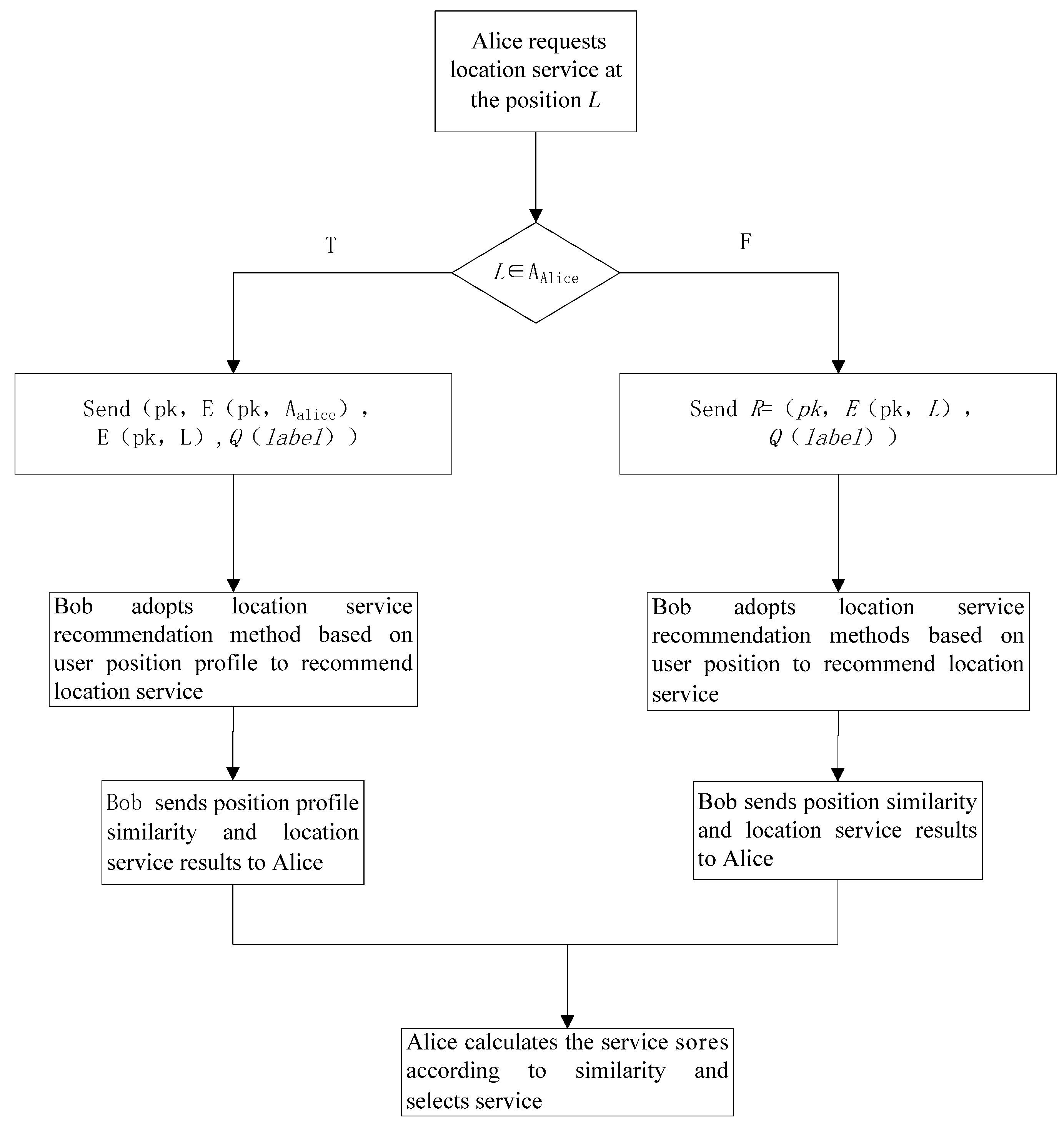
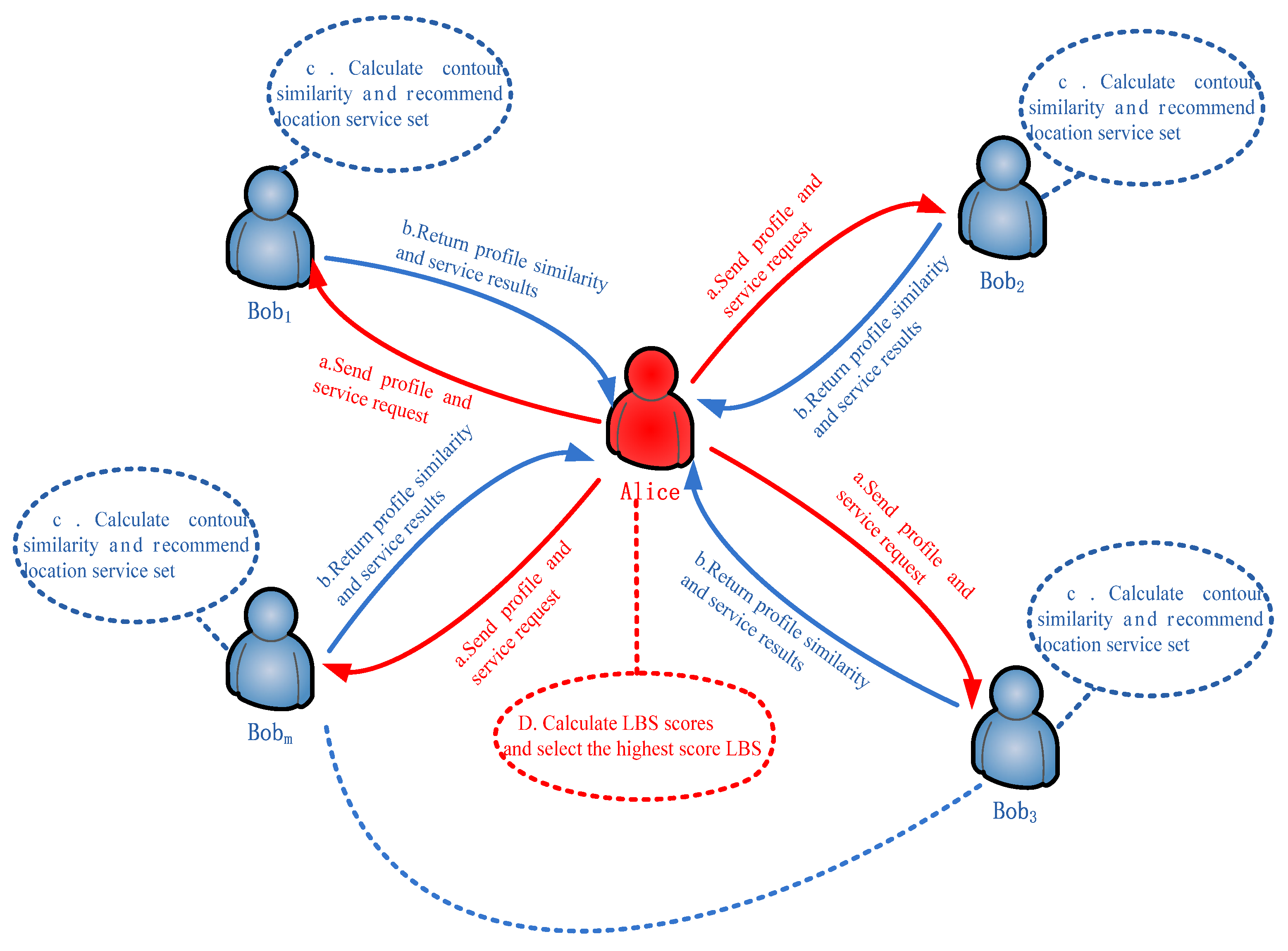
3.3. LBS Service Process
3.3.1. The Recommended Method Based on the Position Profile
3.3.2. The Recommendation Method Based on Requested Position Information
4. Security and Characterization
5. Results and Discussion
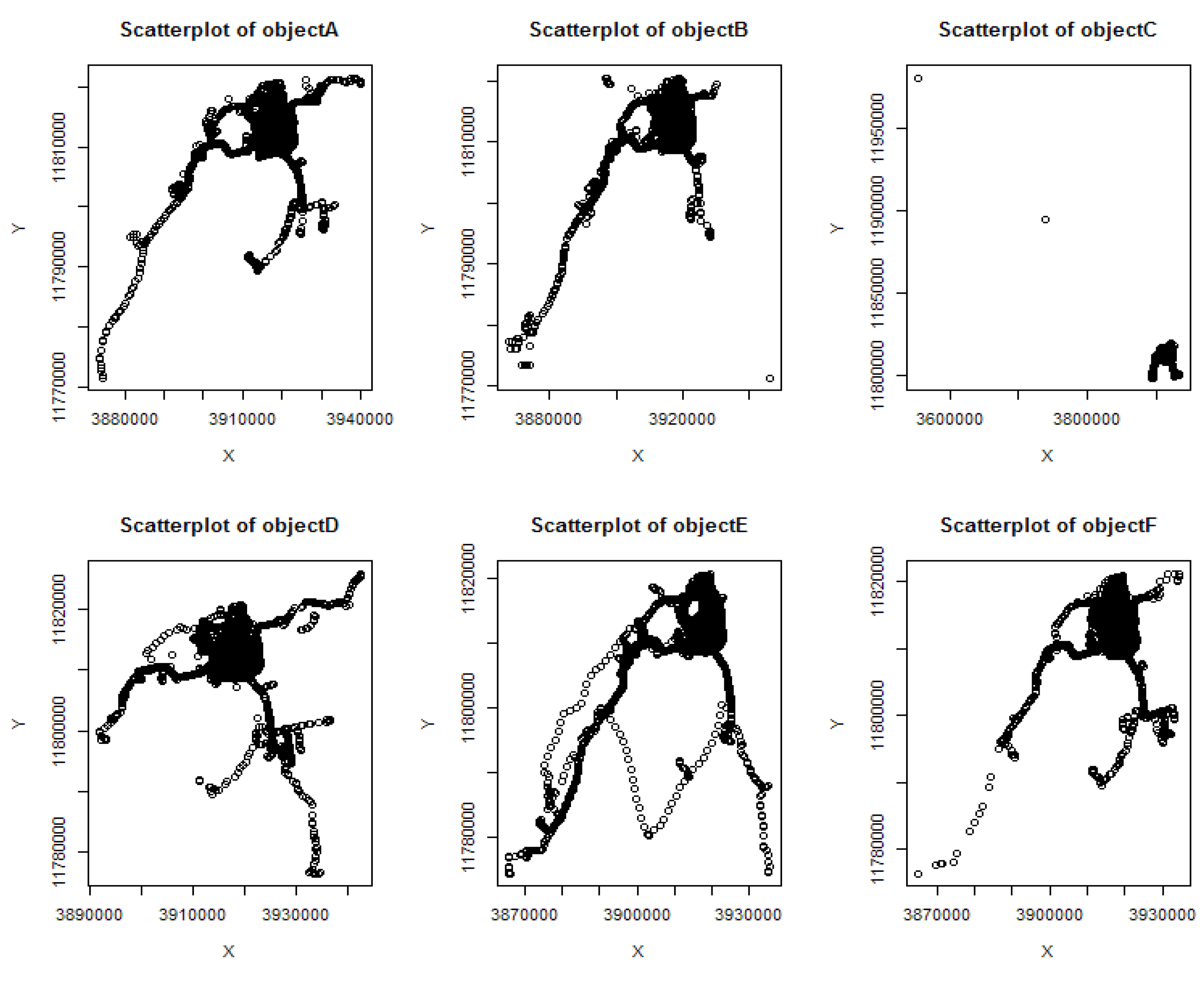
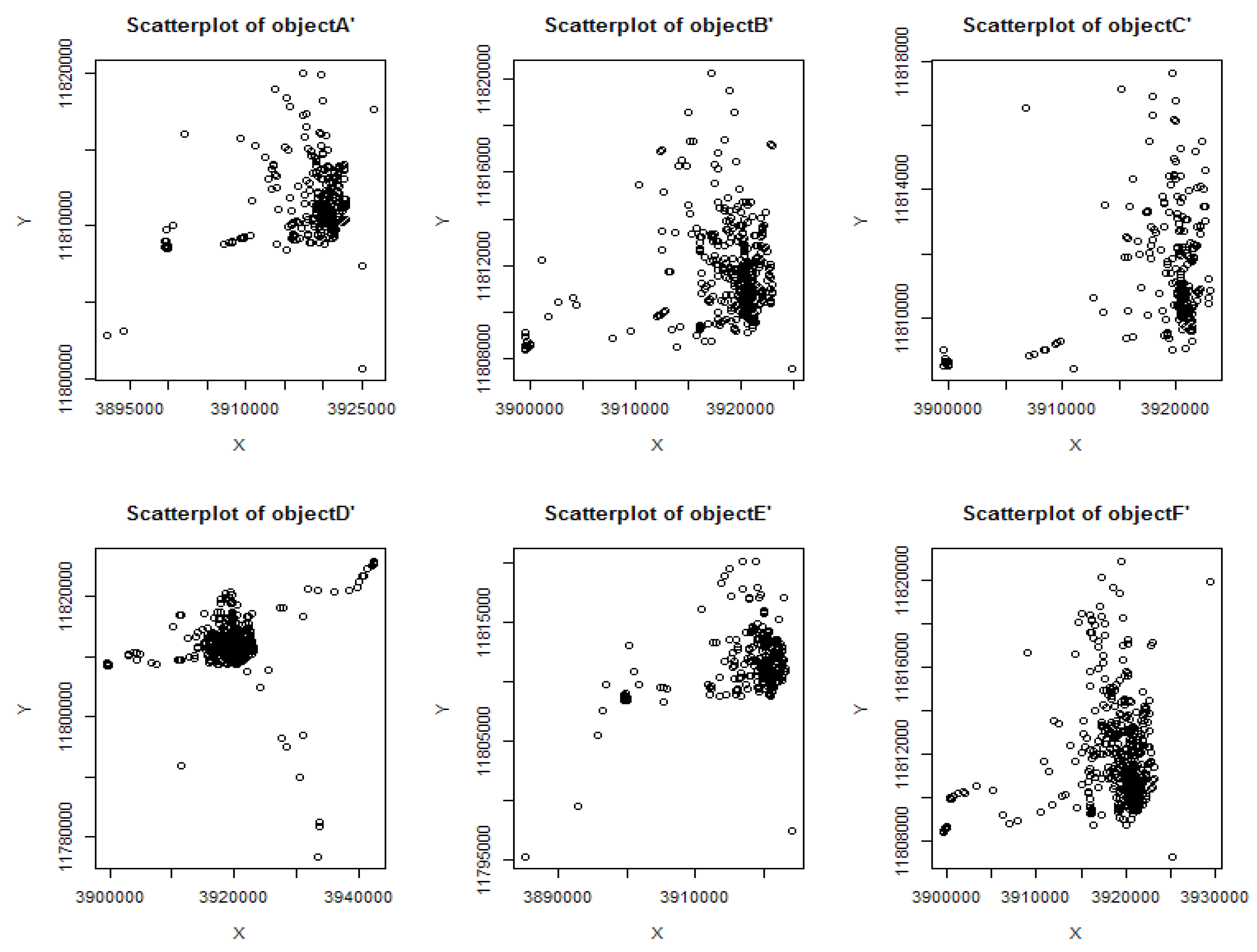
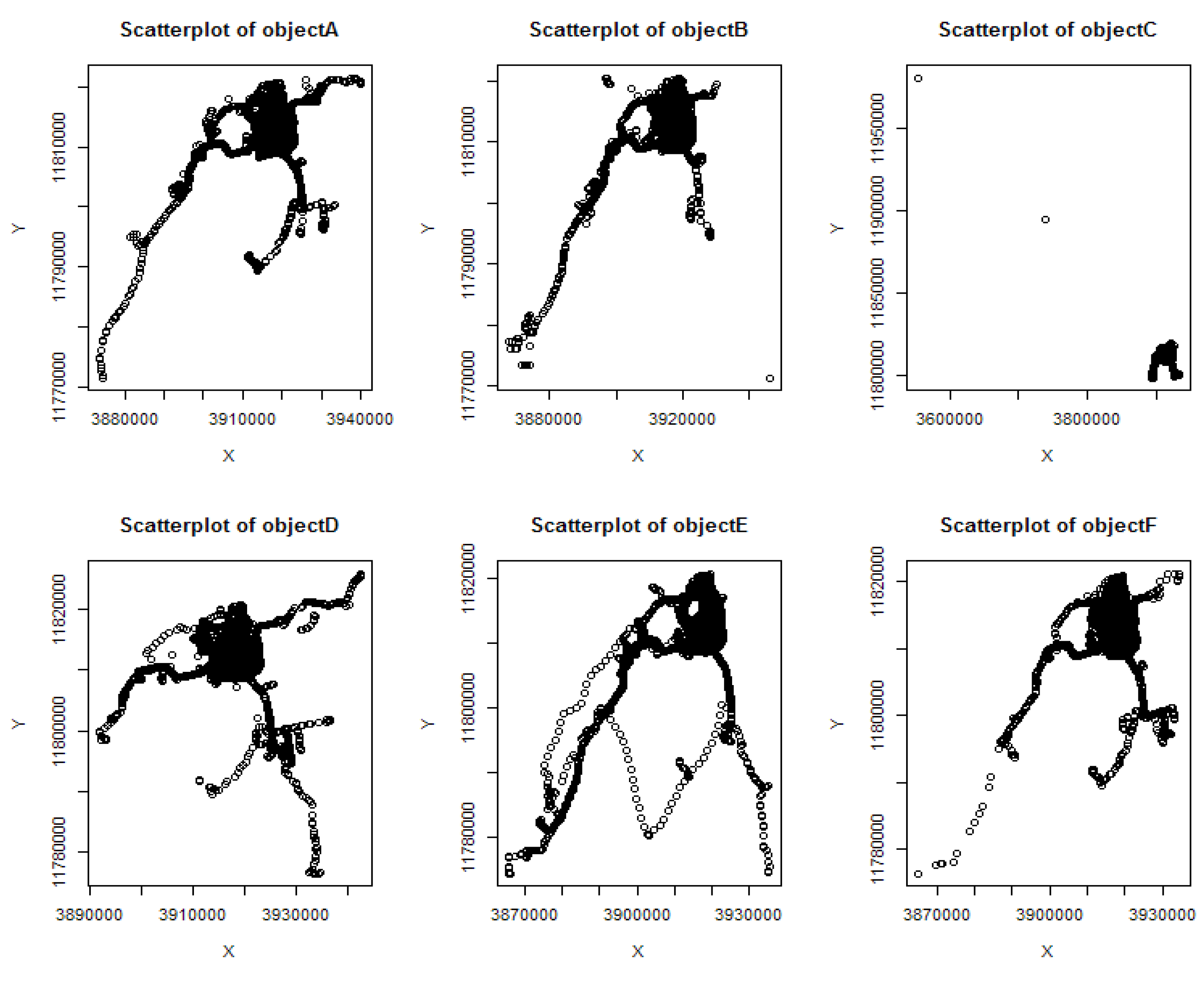
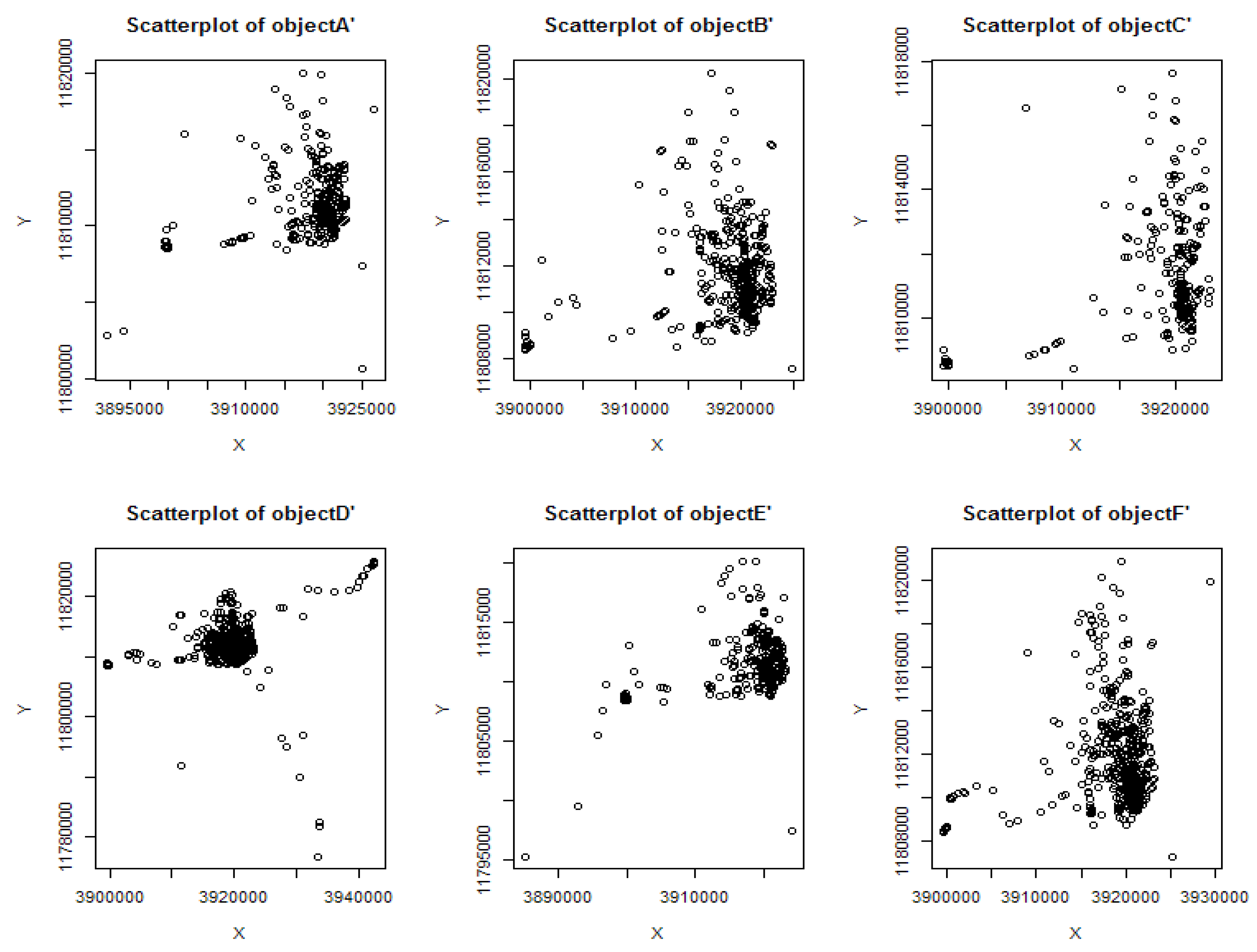
5.1. Analysis and Verification of Algorithm
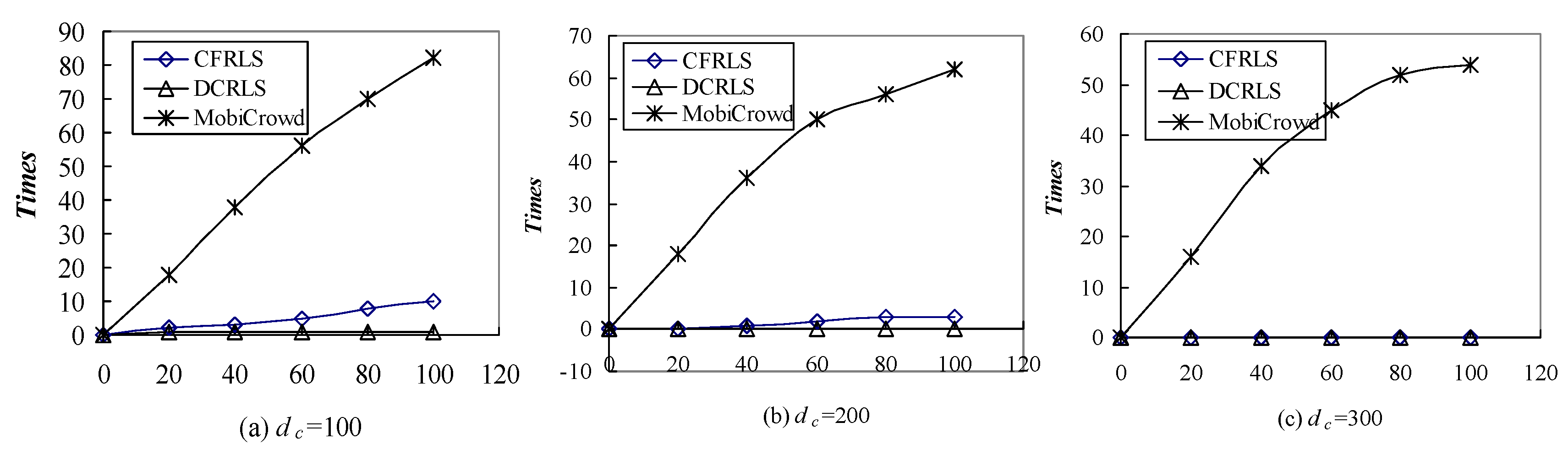
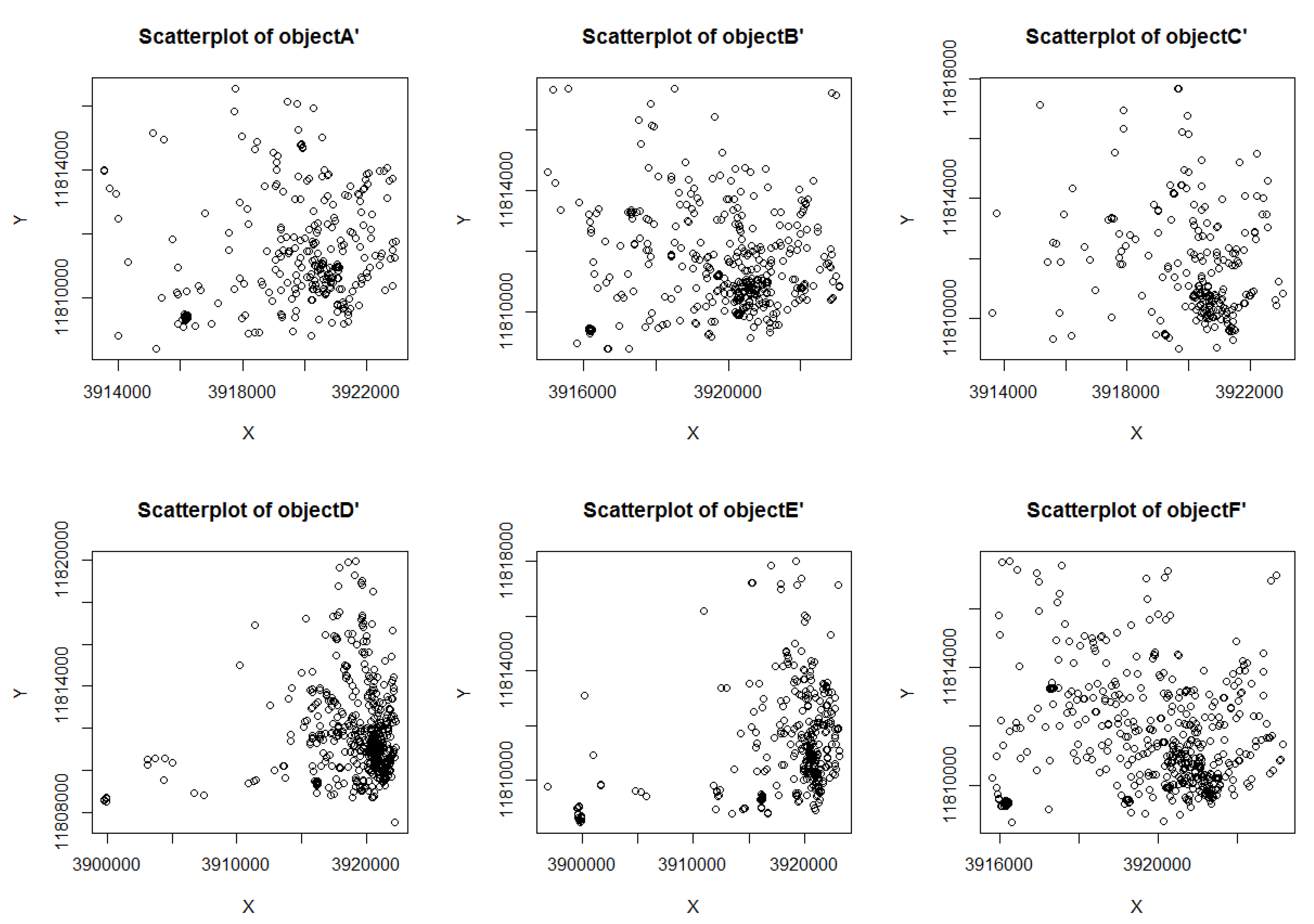
5.2. Algorithm Analysis and Verification of Service Request and Response Process
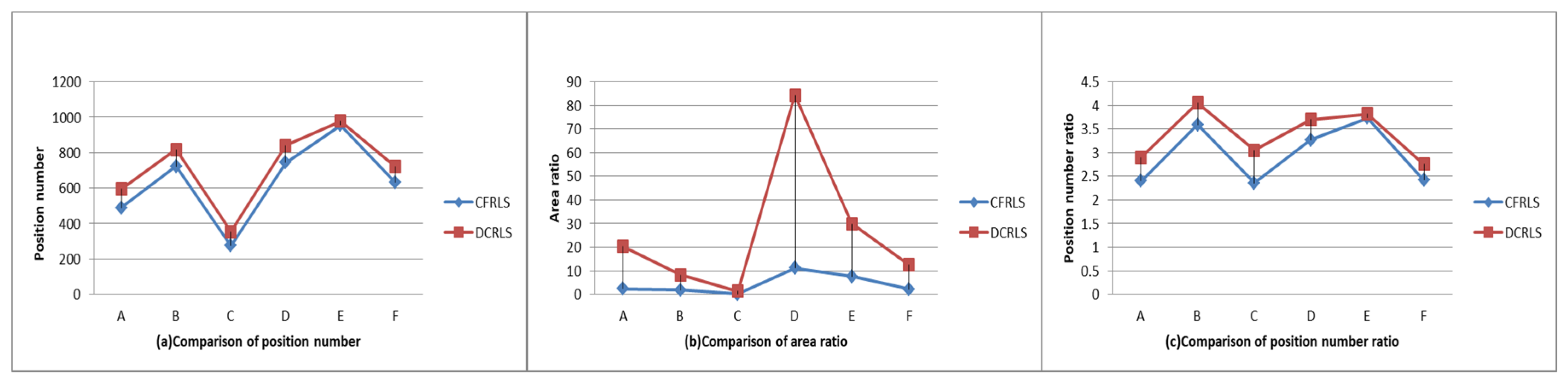
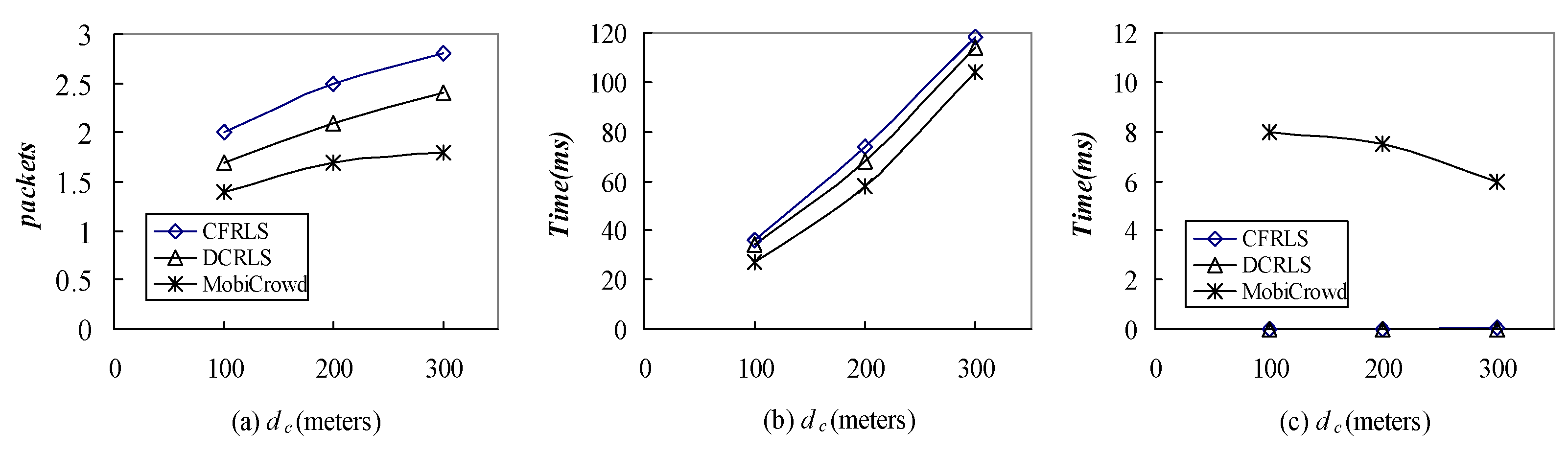
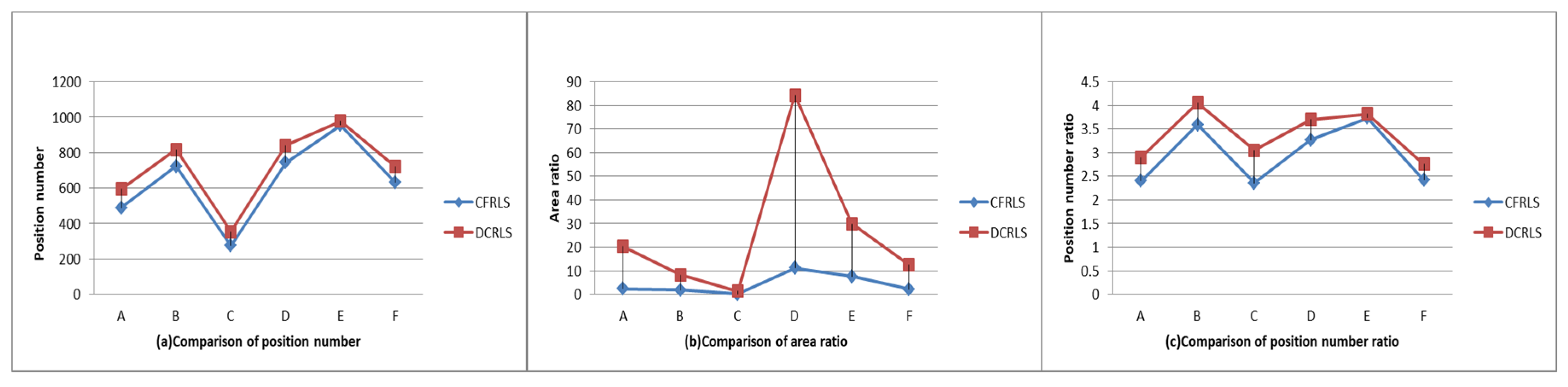
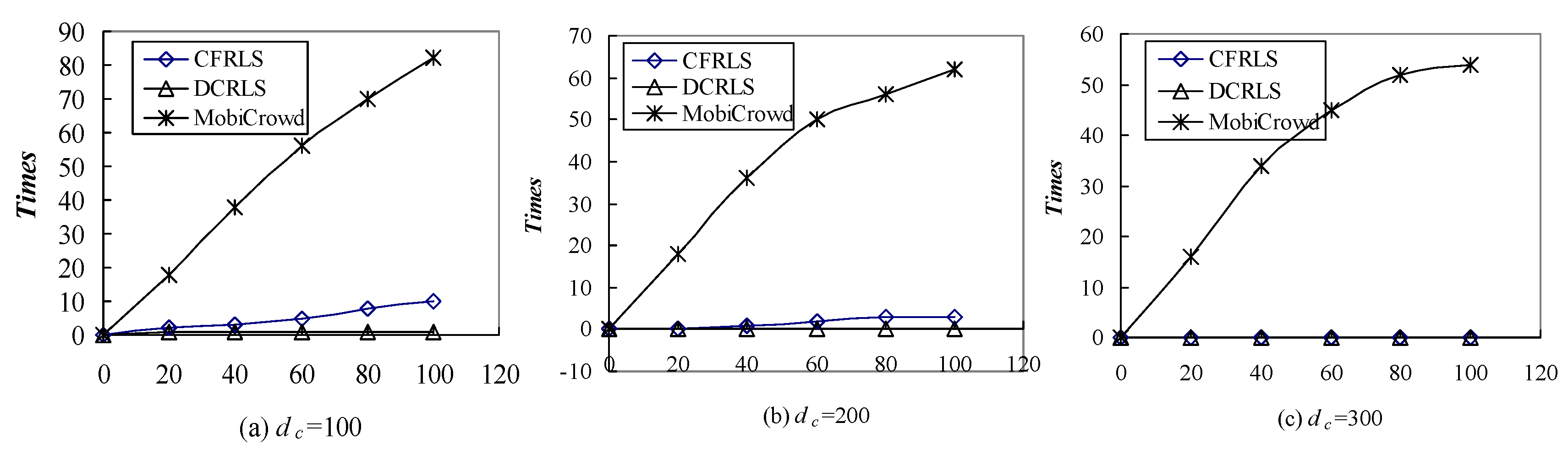
5.3. Comparison among CFRLS, DCRLS and MobiCrowd
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Singh, M.P.; Yu, B.; Venkatraman, M. Community-based service location. Commun. ACM 2001, 44, 49–54. [Google Scholar] [CrossRef]
- Grutester, M.; Grunwald, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications and Services (MobiSys ’03), San Francisco, CA, USA, 5–8 May 2003; pp. 31–42. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- To, H.; Ghinita, G.; Fan, L.; Shahabi, C. Differentially Private Location Protection for Worker Datasets in Spatial Crowdsourcing. IEEE Trans. Mob. Comput. 2017, 16, 934–949. [Google Scholar] [CrossRef]
- Chow, C.Y.; Mokbel, M.F. Privacy in location-based services: A system architecture perspective. SIGSPATIAL Spec. 2009, 1, 23–27. [Google Scholar] [CrossRef]
- Chow, C.Y.; Mokbel, M.F.; Liu, X. Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments. Geoinformatica 2011, 15, 351–380. [Google Scholar] [CrossRef]
- Shokri, R.; Theodorakopoulos, G.; Papadimitratos, P.; Kazemi, E.; Hubaux, J.-P. Hiding in mobile crowd: Location privacy through collaboration. IEEE Trans. Dependable Secur. Comput. 2014, 11, 266–279. [Google Scholar]
- Wang, P.; Yang, J.; Zhang, J.P. Protection of Location Privacy Based on Distributed Collaborative Recommendations. PLoS ONE 2016, 11, e0163053. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Cui, X.; Li, D.; Yuan, D.; Wang, M. The location privacy protection research in location-based service. In Proceedings of the IEEE International Conference on Geoinformatics, Beijing, China, 18–20 June 2010. [Google Scholar]
- Bayardo, R.J.; Agrawal, R. Data privacy through optimal k-anonymization. In Proceedings of the IEEE 21st International Conference on Data Engineering (ICDE 2005), Tokoyo, Japan, 5–8 April 2005; pp. 217–228. [Google Scholar]
- Kou, G.; Peng, Y.; Wang, G. Evaluation of clustering algorithms for financial risk analysis using MCDM methods. Inf. Sci. 2014, 275, 1–12. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Amini, S.; Janne, L.; Hong, J.; Lin, J.; Norman, S.; Toch, E. Cache: Caching location-enhanced content to improve user privacy. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services (MobiSys 2011), Bethesda, MD, USA, 28 June–1 July 2011; pp. 197–210. [Google Scholar]
- Shokri, R.; Papadimitratos, P.; Theodorakopoulos, G.; Hubaux, J.P. Collaborative Location Privacy. In Proceedings of the IEEE 8th International Conference on Mobile Adhoc and Sensor Systems, Valencia, Spain, 17–22 October 2011. [Google Scholar]
- Chow, C.; Mokbel, M.F.; Liu, X. A peer-to-peer spatial cloaking algorithm for anonymous location-based services. In Proceedings of the ACM Symposium on Advances in Geographic Information Systems (ACM GIS ’06), Arlington, VA, USA, 10–11 November 2006; pp. 171–178. [Google Scholar]
- Boutet, A.; Frey, D.; Guerraoui, R.; Jégou, A.; Kermarrec, A.M. Privacy-preserving distributed collaborative filtering. Computing 2016, 98, 827–846. [Google Scholar] [CrossRef]
- Chen, K.; Liu, L. Privacy-Preserving Multiparty Collaborative Mining with Geometric Data Perturbation. IEEE Trans. Parallel Distrib. Syst. 2009, 20, 1764–1776. [Google Scholar] [CrossRef]
- Zhu, T.; Ren, Y.; Zhou, W.; Rong, J.; Xiong, P. An effective privacy preserving algorithm for neighborhood-based collaborative filtering. Future Gener. Comput. Syst. 2014, 36, 142–155. [Google Scholar] [CrossRef]
- Polatidis, N.; Georgiadis, C.K.; Pimenidis, E.; Mouratidis, H. Privacy-preserving collaborative recommendations based on random perturbations. Expert Syst. Appl. 2016, 71, 18–25. [Google Scholar] [CrossRef]
- Huang, Z.; Zeng, D.; Chen, H. A Comparison of Collaborative-Filtering Recommendation Algorithms for E-commerce. IEEE Intell. Syst. 2007, 22, 68–78. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Advances in Cryptology—EUROCRYPT ’99; Lecture Notes in Computer Science; Springer: Berlin, Germany, 1999; Volume 1592, pp. 223–238. [Google Scholar]
- Piorkowski, M.; Sarafijanovic-Djukic, N.; Grossglauser, M. A parsimonious model of mobile partitioned networks with clustering. In Proceedings of the First International Communication Systems and Networks and Workshops (COMSNETS 2009), Bangalore, India, 5–10 January 2009. [Google Scholar]
- Domingo-Ferrer, J.; Trujillo-Rasua, R. Microaggregation- and permutation-based anonymization of movement data. Inf. Sci. 2012, 208, 55–80. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
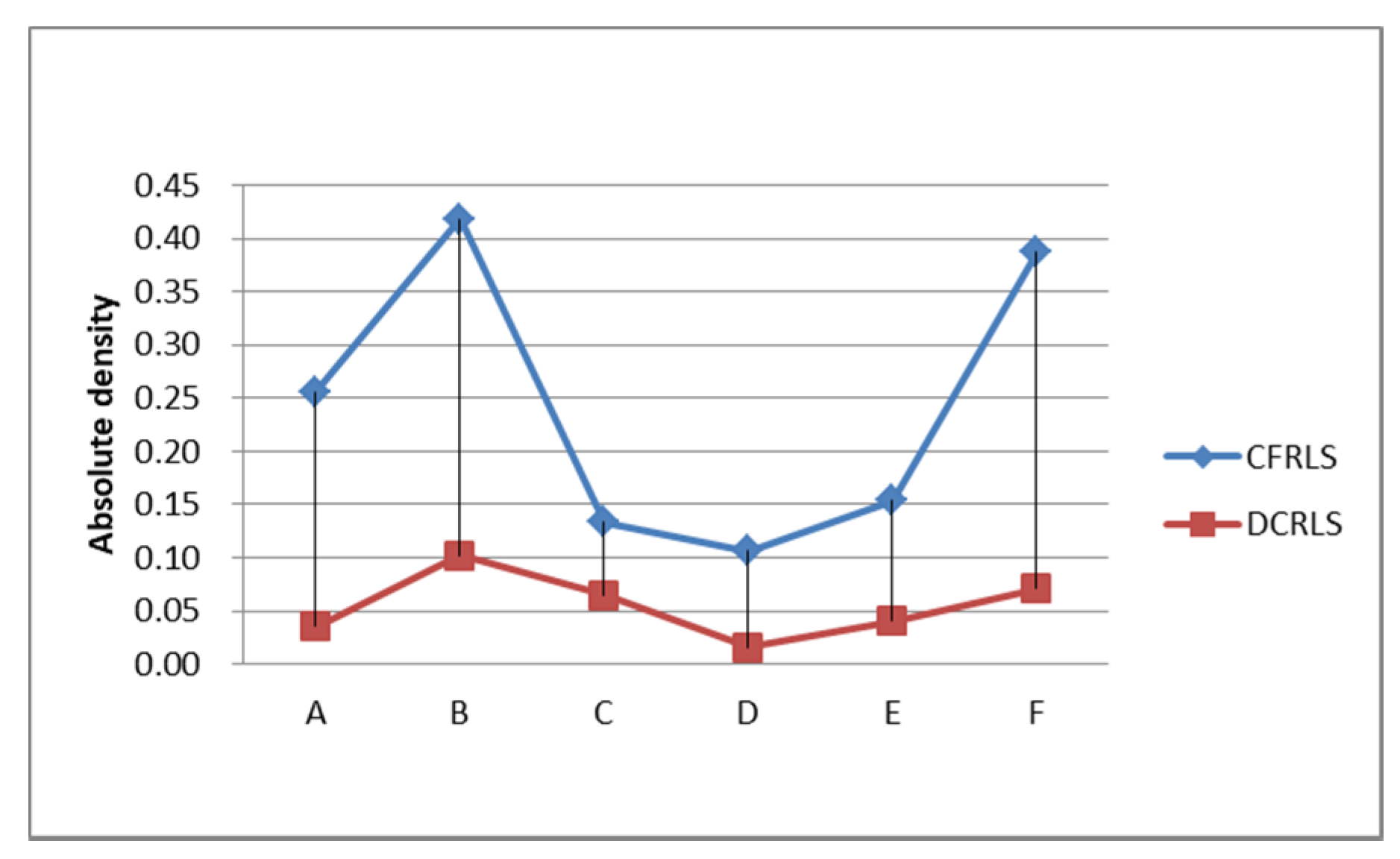
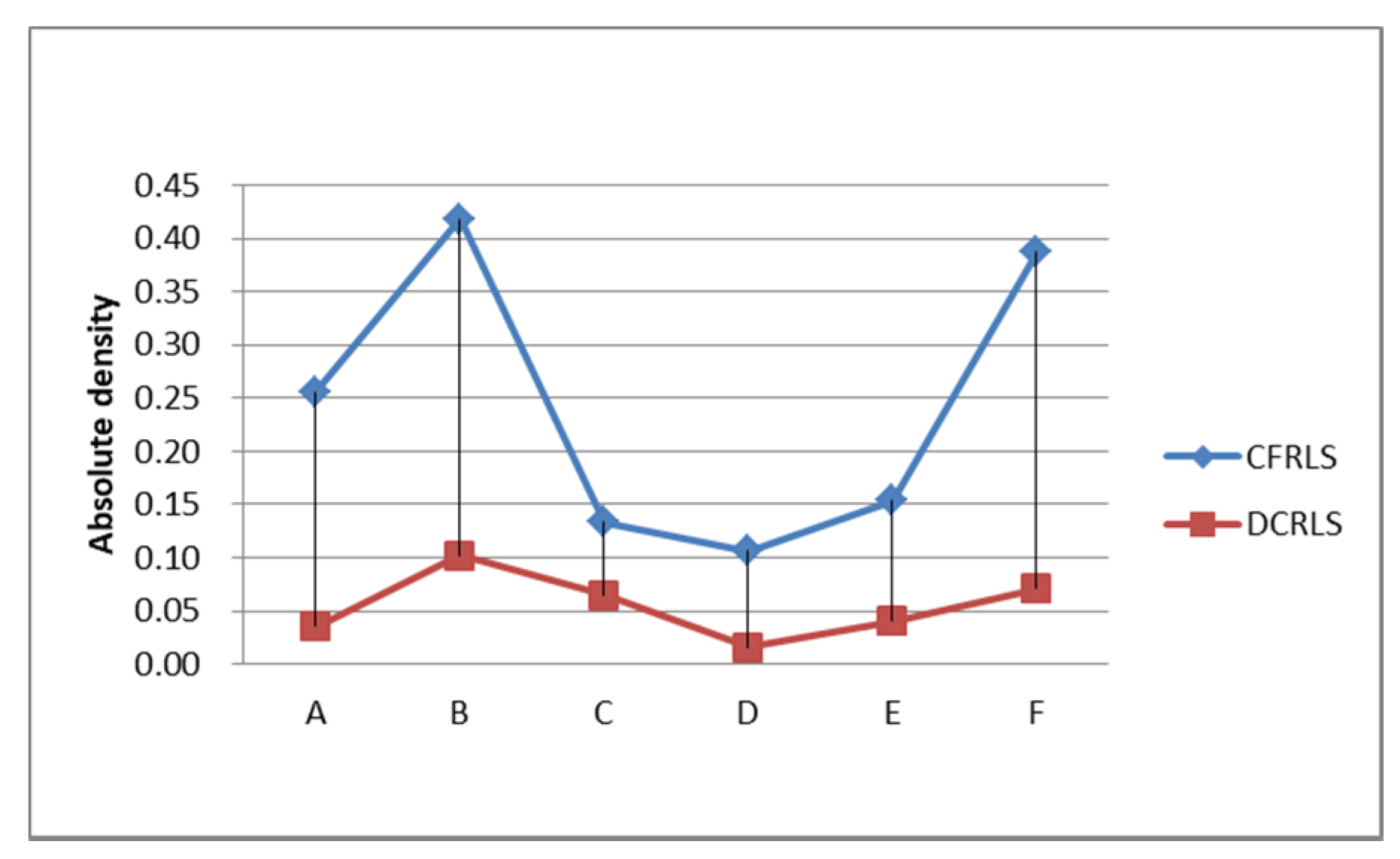
| Name | Number OP | Number P | Ratio RE | Ratio NP | Abdensity |
|---|---|---|---|---|---|
| object A | 20,543 | 489 | 2.3% | 2.4% | 0.26 |
| object B | 20,159 | 724 | 1.79% | 3.59% | 0.42 |
| object C | 11,616 | 274 | 0.12% | 2.36% | 0.13 |
| object D | 22,694 | 743 | 11.11% | 3.27% | 0.11 |
| object E | 25,611 | 957 | 7.64% | 3.74% | 0.15 |
| object F | 26,165 | 632 | 2.09% | 2.42% | 0.39 |
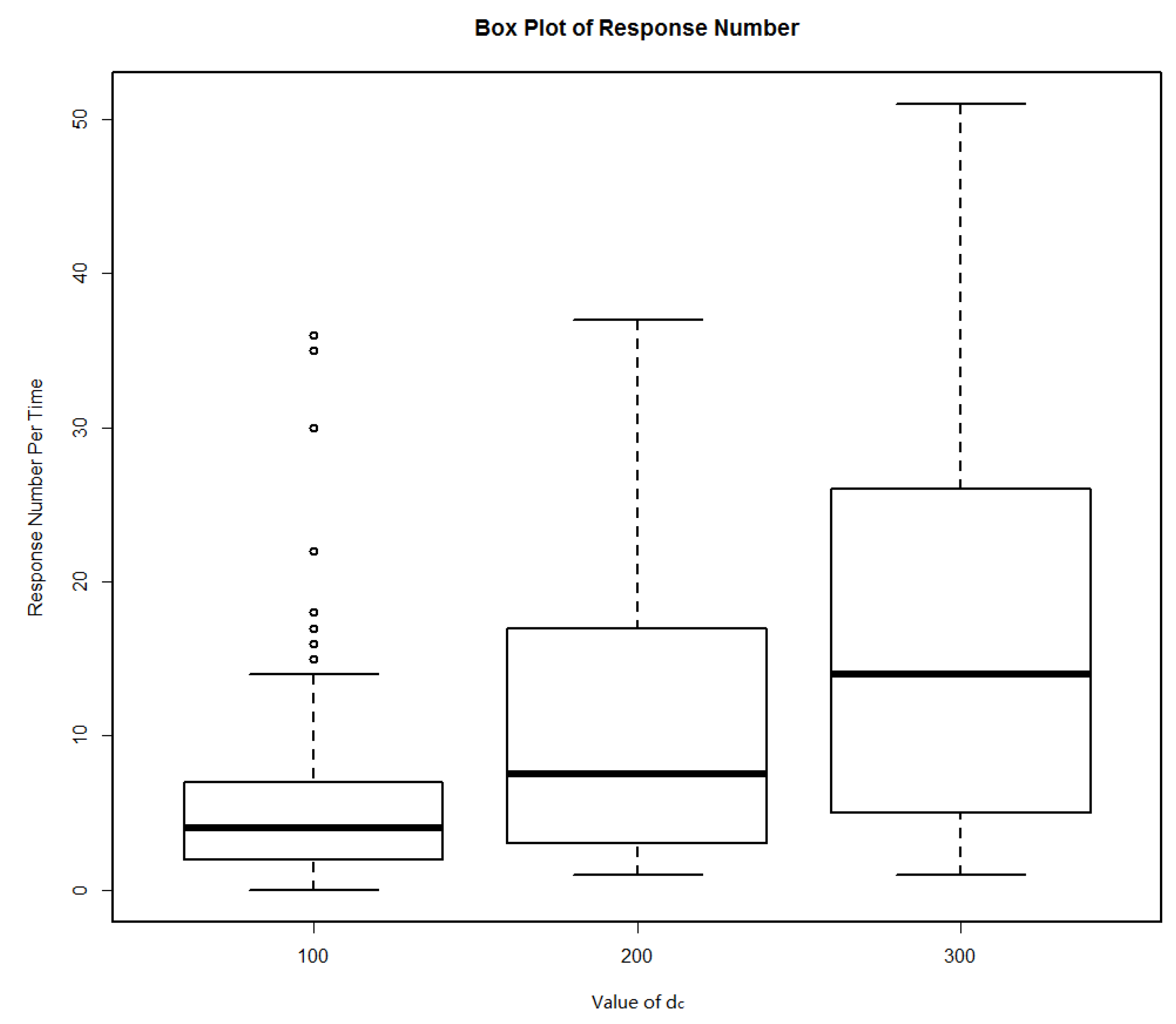
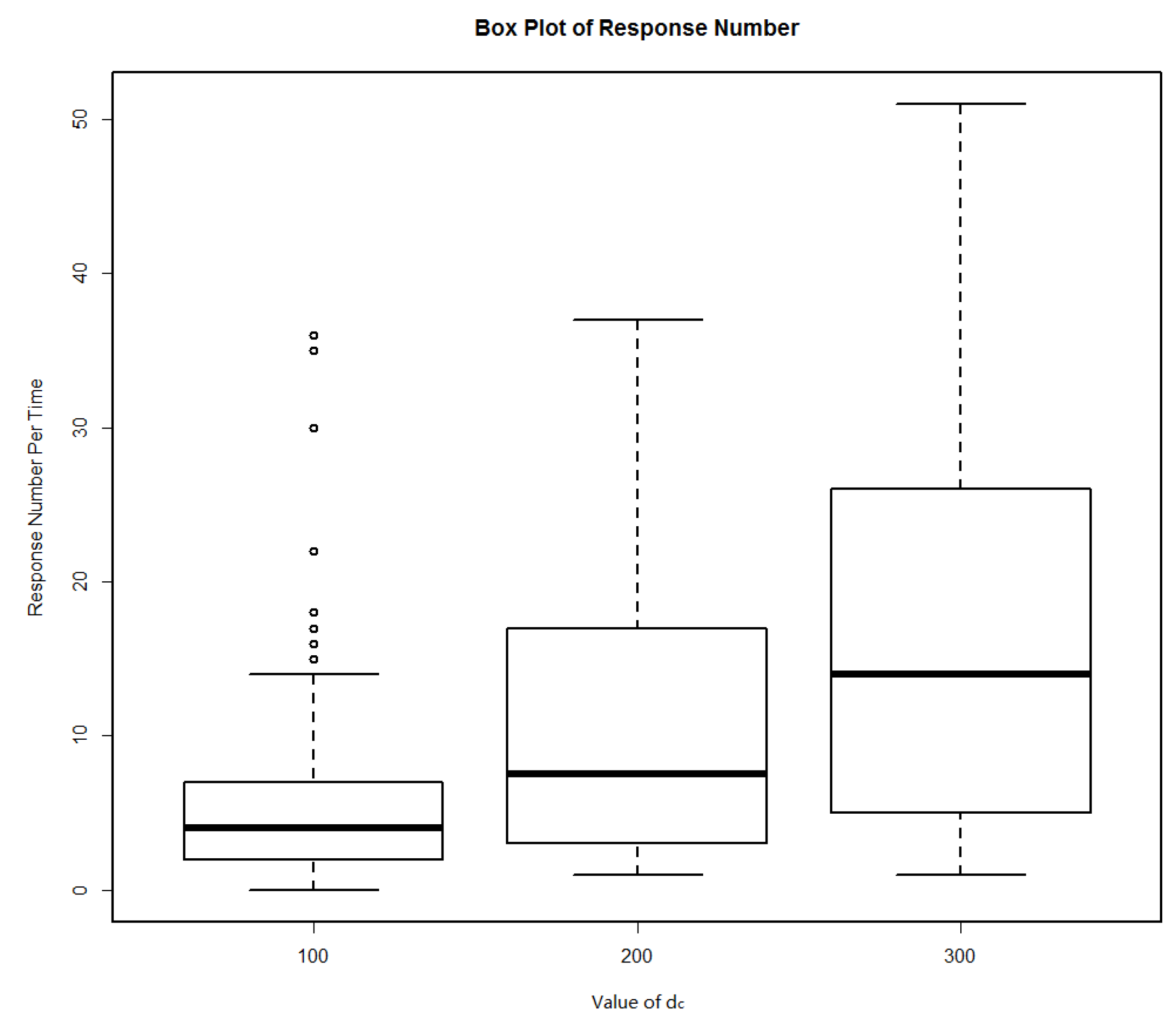
| dc (m) | Minimum | Maximum | Average | Failure Rate (%) |
|---|---|---|---|---|
| 100 | 0 | 36 | 5.88 | 0.01 |
| 200 | 1 | 37 | 11.22 | 0 |
| 300 | 1 | 51 | 17.26 | 0 |
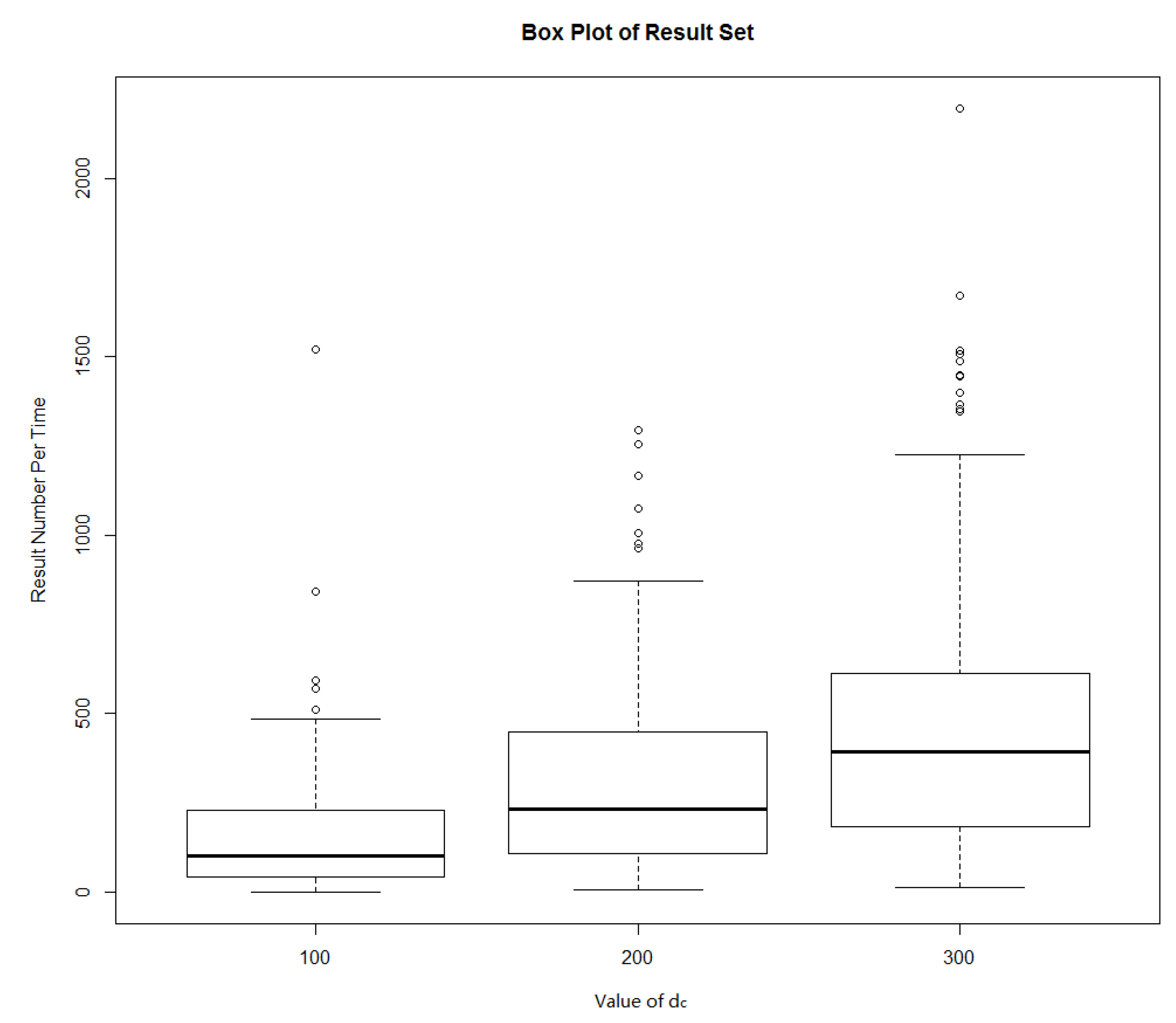
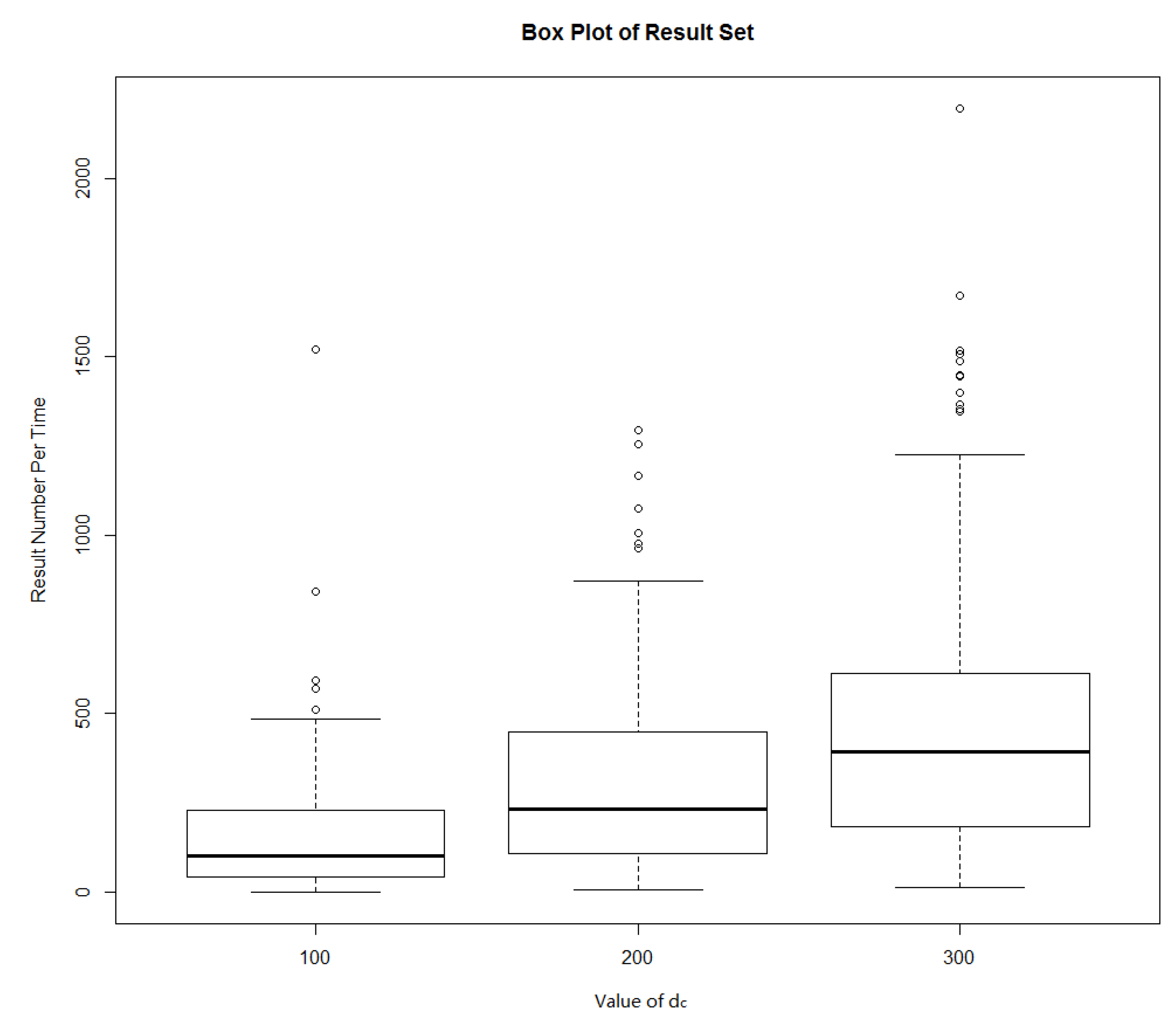
| dc (m) | Minimum | Maximum | Average | Failure Rate (%) |
|---|---|---|---|---|
| 100 | 0 | 1520 | 169.11 | 1% |
| 200 | 5 | 1294 | 340.56 | 0% |
| 300 | 13 | 2195 | 520.5 | 0% |
| Item | CFRLS | DCRLS | MobiCrowd |
|---|---|---|---|
| Architecture tiers | 2 tiers | 2 tiers | 3 tiers |
| Dependence on trusted third party | Low | heavy | medium |
| Privacy protect among peers | good | low | weak |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Yang, J.; Zhang, J. A Strategy toward Collaborative Filter Recommended Location Service for Privacy Protection. Sensors 2018, 18, 1522. https://doi.org/10.3390/s18051522
Wang P, Yang J, Zhang J. A Strategy toward Collaborative Filter Recommended Location Service for Privacy Protection. Sensors. 2018; 18(5):1522. https://doi.org/10.3390/s18051522
Chicago/Turabian StyleWang, Peng, Jing Yang, and Jianpei Zhang. 2018. "A Strategy toward Collaborative Filter Recommended Location Service for Privacy Protection" Sensors 18, no. 5: 1522. https://doi.org/10.3390/s18051522
APA StyleWang, P., Yang, J., & Zhang, J. (2018). A Strategy toward Collaborative Filter Recommended Location Service for Privacy Protection. Sensors, 18(5), 1522. https://doi.org/10.3390/s18051522