Unifying Terrain Awareness for the Visually Impaired through Real-Time Semantic Segmentation


 , ,
, ,
Abstract
:
1. Introduction
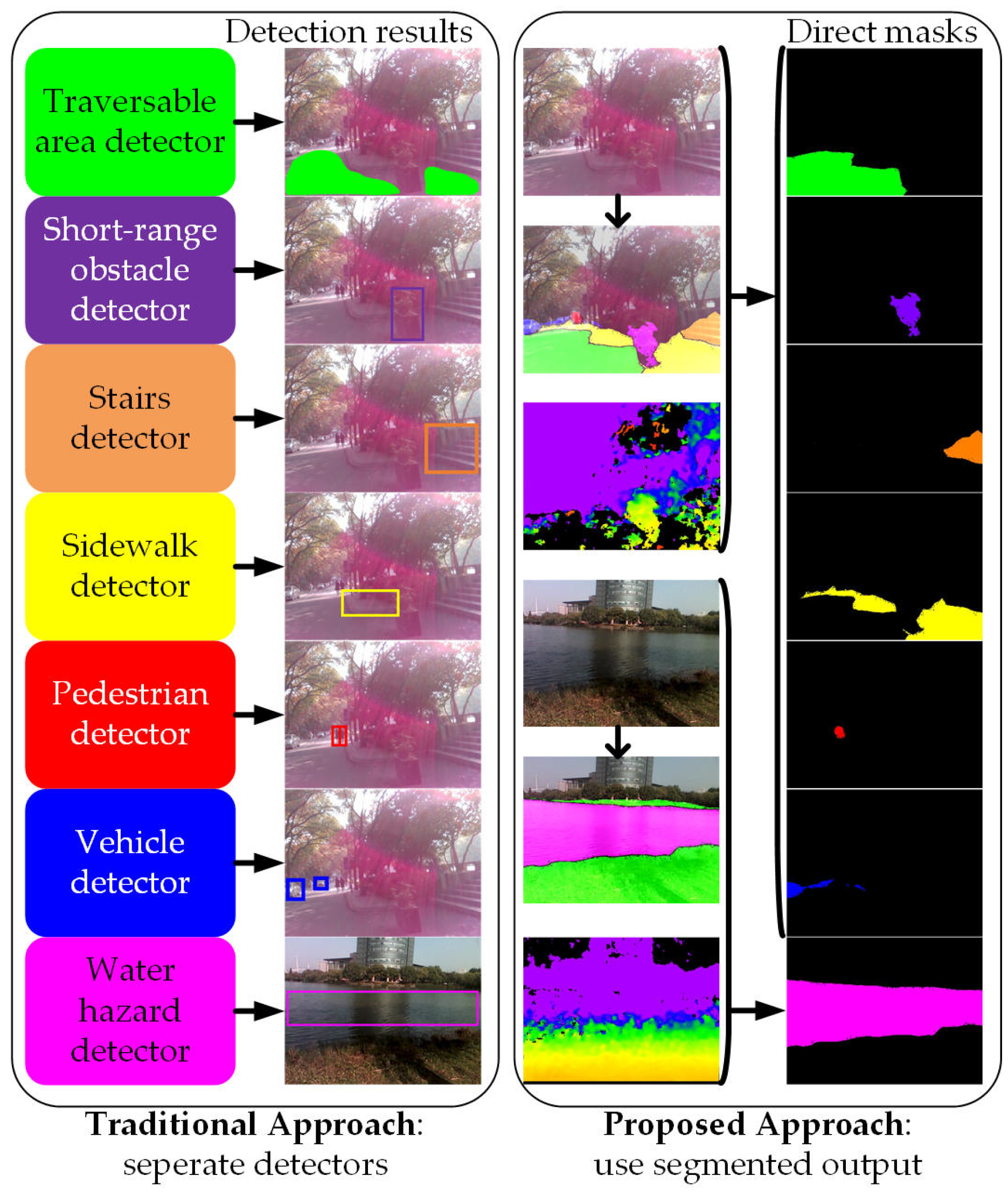
- A unification of terrain awareness regarding traversable areas, obstacles, sidewalks, stairs, water hazards, pedestrians and vehicles.
- A real-time semantic segmentation network to learn both global scene contexts and local textures without imposing any assumptions, while reaching higher performance than traditional approaches.
- A real-world navigational assistance framework on a wearable prototype for visually-impaired individuals.
- A comprehensive set of experiments on a large-scale public dataset, as well as an egocentric dataset captured with the assistive prototype. The real-world egocentric dataset can be accessed at [71].
- A closed-loop field test involving real visually-impaired users, which validates the effectivity and the versatility of our solution, as well as giving insightful hints about how to reach higher level safety and offer more independence to the users.
2. Related Work
2.1. Traversability Awareness
2.2. Terrain Awareness
2.3. Semantic Segmentation for the Visually Impaired
2.4. Real-Time Pixel-Wise Semantic Segmentation
3. Approach
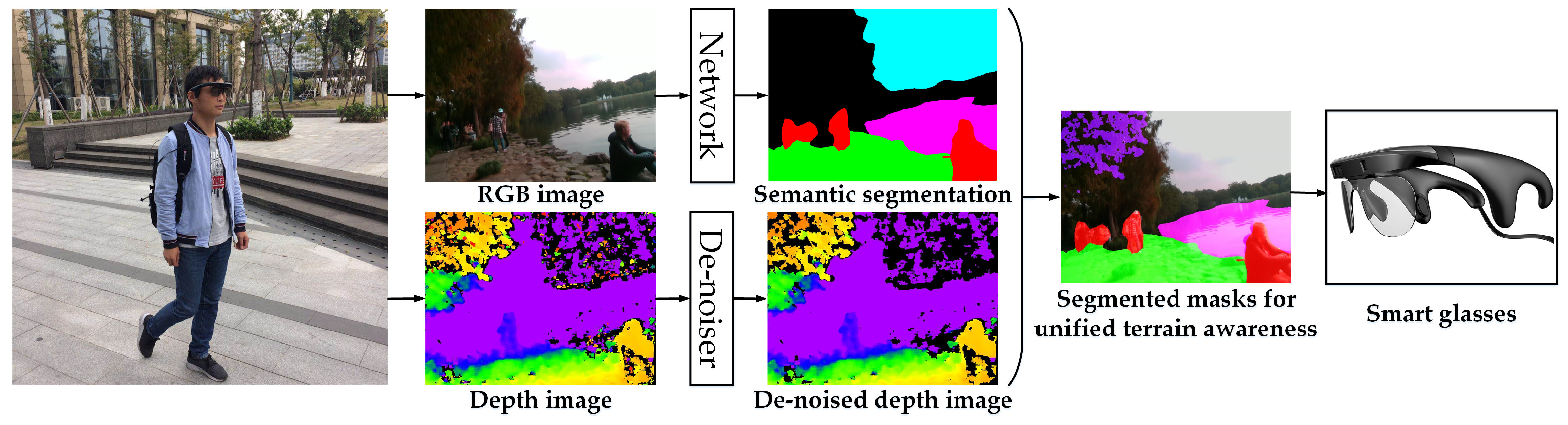
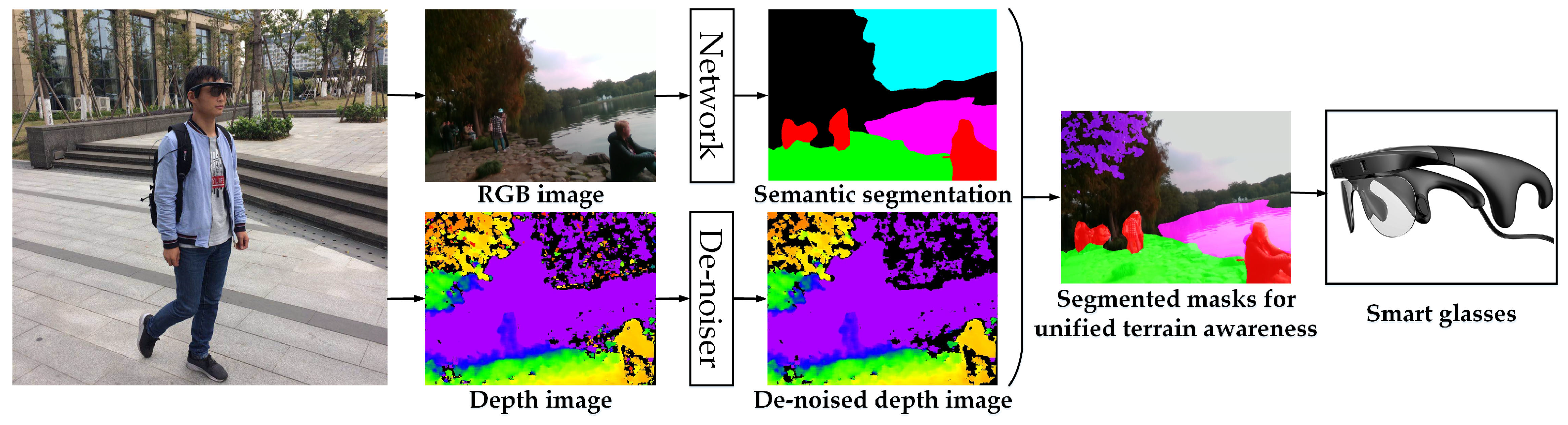
3.1. Wearable Navigation Assistance System
3.1.1. System Overview
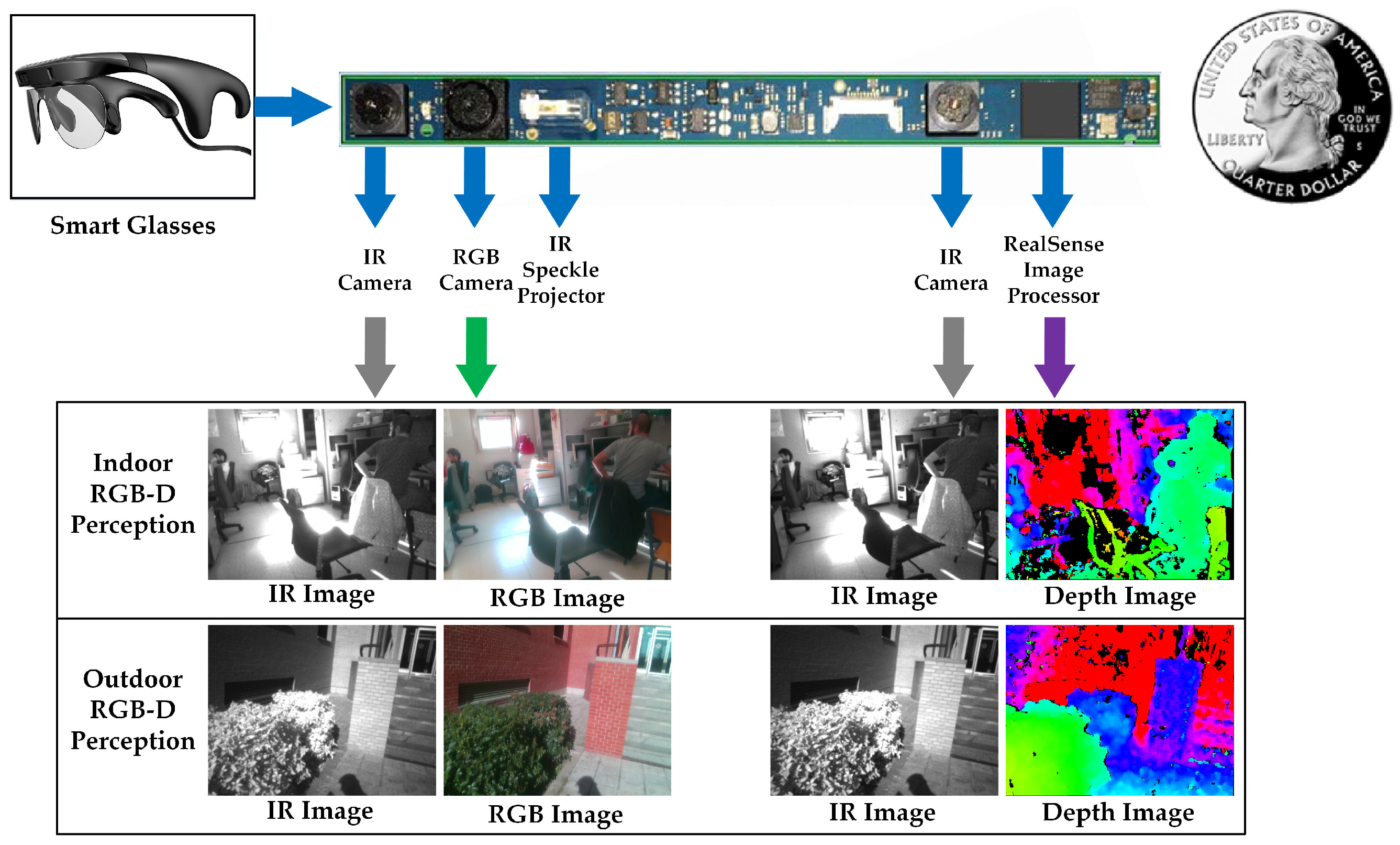
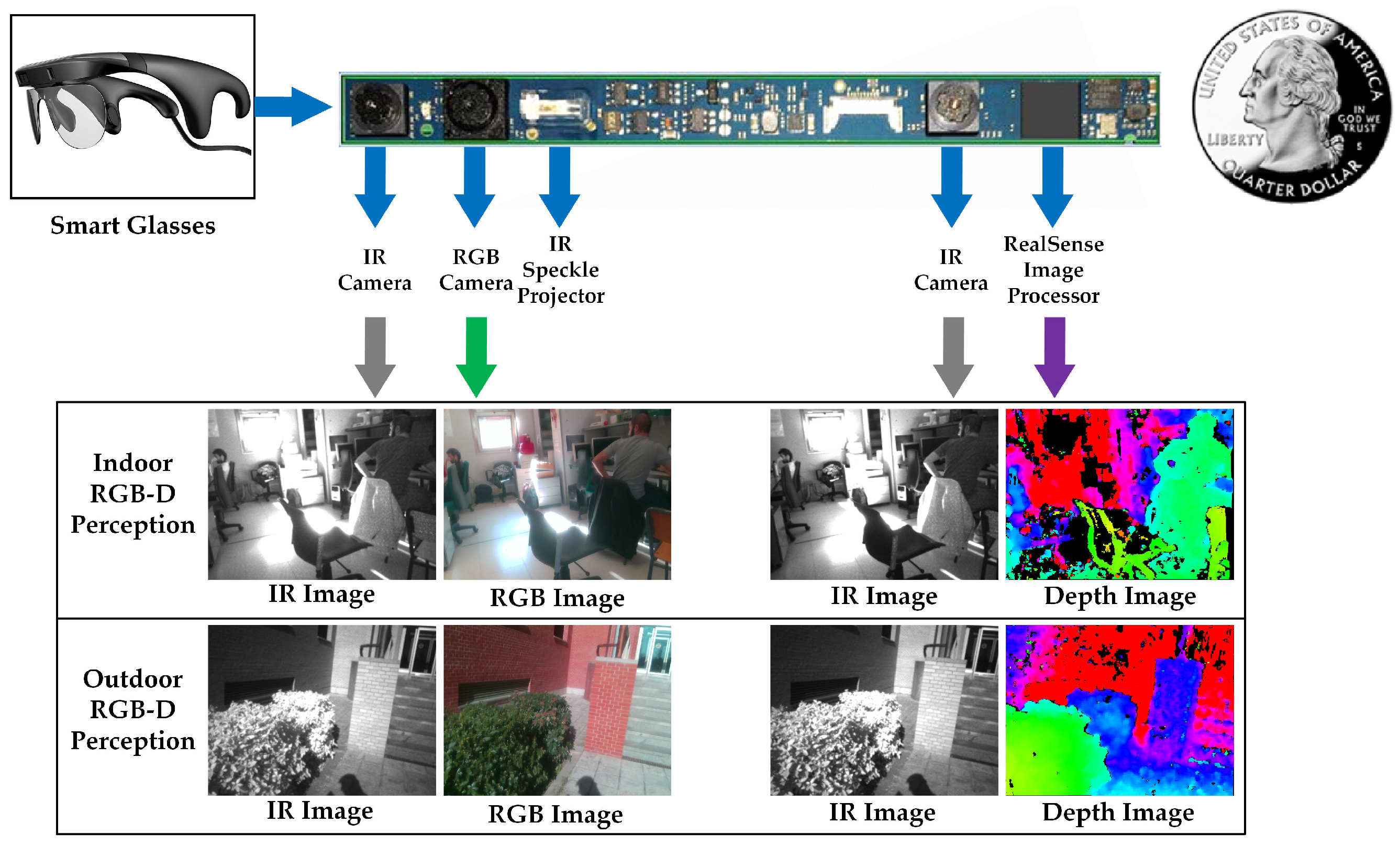
3.1.2. RGB-D Perception
- We enable a stream of a 640 × 480 RGB image, a stream of a 320 × 240 IR stereo pair with global shutter, which produces a high-speed stream of a 320 × 240 depth image. Depth information is projected to the RGB image so as to acquire a synchronized 640 × 480 depth stream.
- To achieve high environmental adaptability, the automatic exposure and gain control of the IR stereo pair are enabled, while the power of the IR projector is fixed.
- To enforce the embedded stereo matching algorithm to deliver dense maps, we use a different preset configuration with respect to the original depth image of RealSense (see Figure 4b), by controlling how aggressive the algorithm is at discarding matched pixels. Precisely, most of the depth control thresholds are at the loosest setting, while only the left-right consistency constraint is adjusted to 30 from the range [0, 2047].
- As shown in Figure 2 and Figure 4d,e, the depth images are de-noised by eliminating small segments. Depth noises can be denoted as outliers in disparity images due to low texture, reflections, noise, etc. [88]. These outliers usually show up as small patches of disparity that is very different from the surrounding disparities. To identify these outliers, the disparity image is segmented by allowing neighboring disparities within one segment to vary by one pixel, considering a four-connected image grid. The disparities of all segments below a certain size are set to invalid. Following [77], we remove small segments with an area smaller than 200 pixels.
3.1.3. Feedback Device
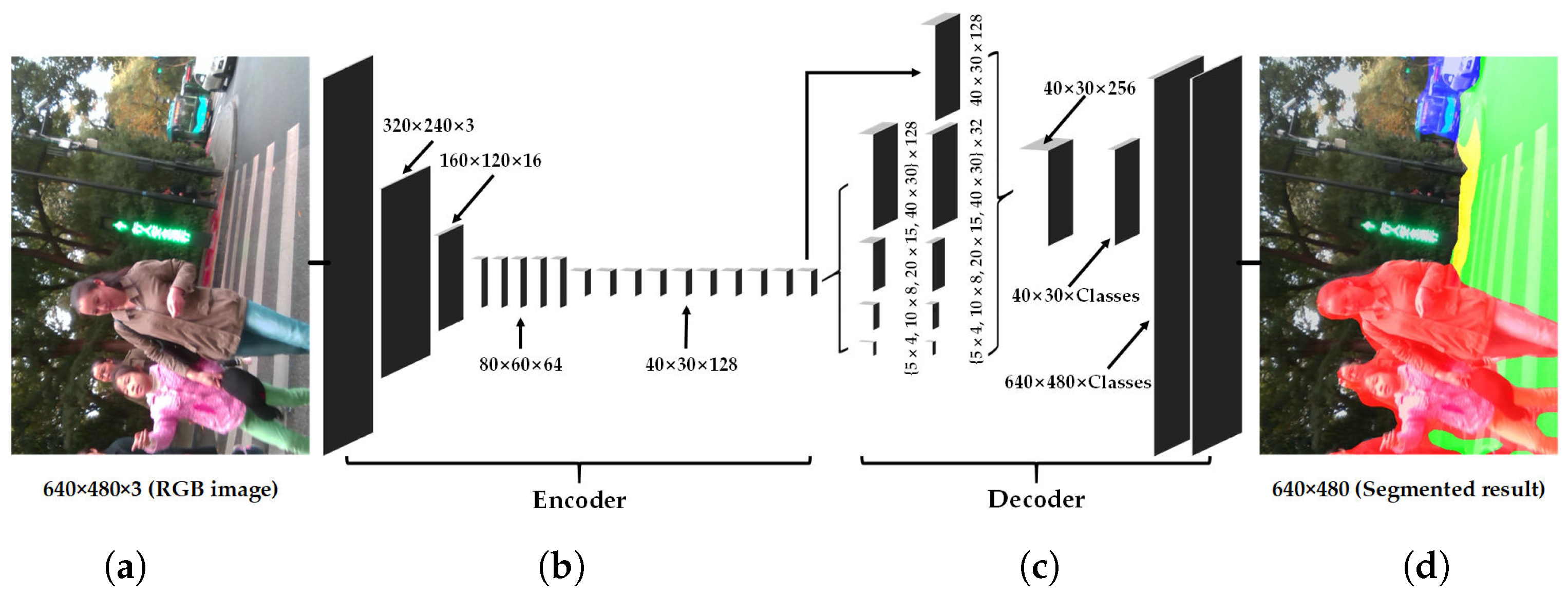
3.2. Real-Time Semantic Segmentation Architecture
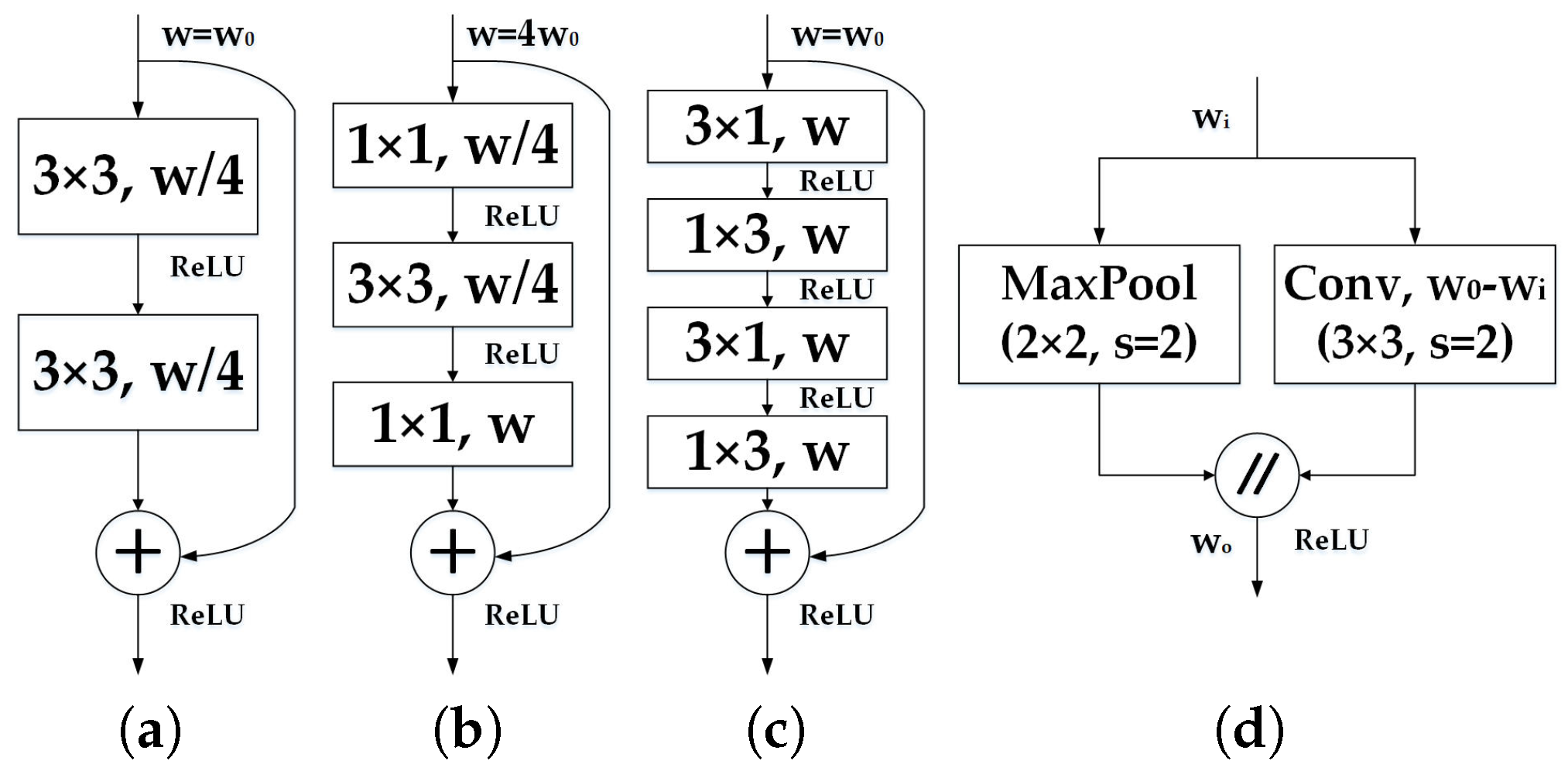
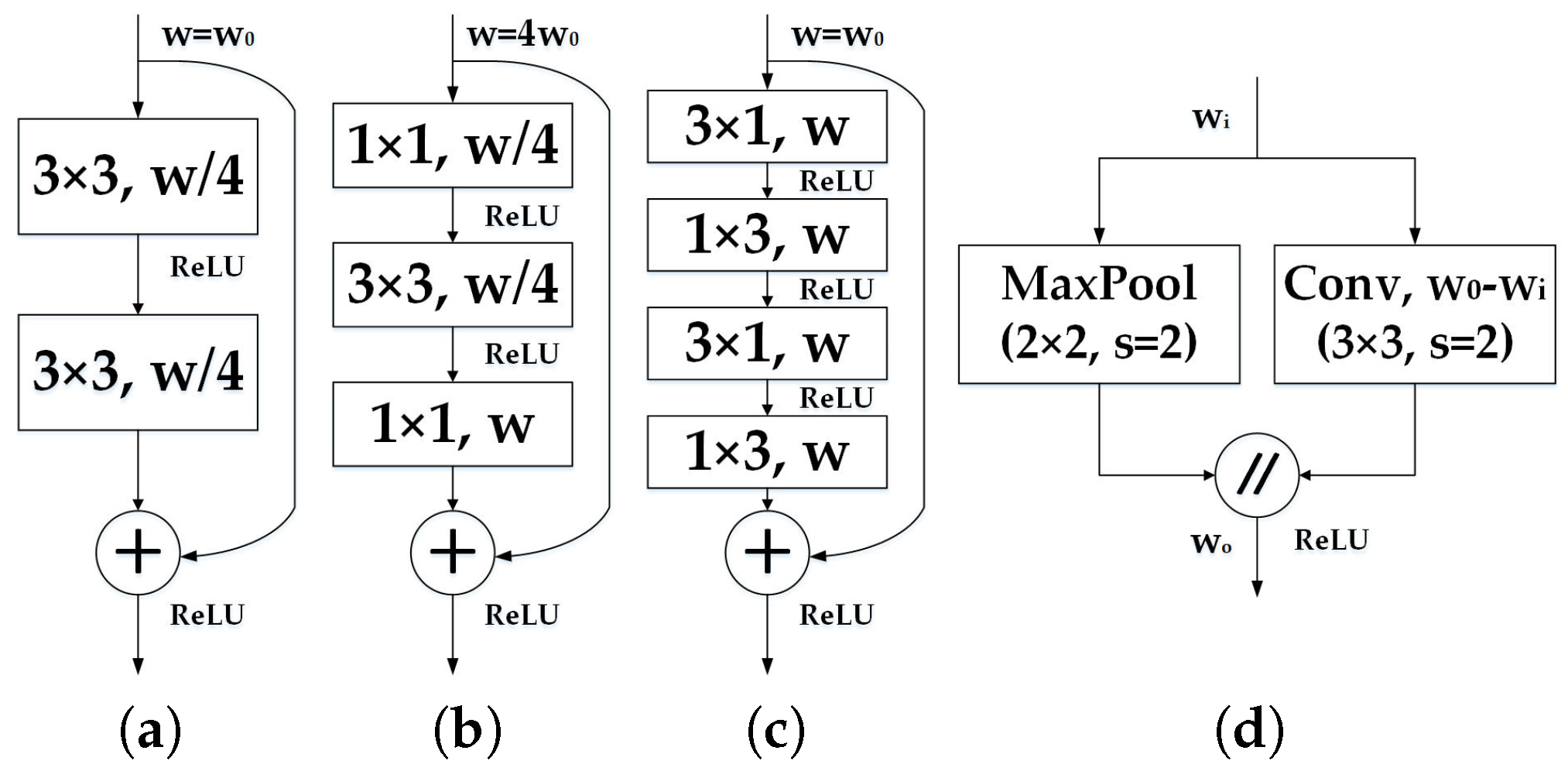
3.2.1. Encoder Architecture
3.2.2. Decoder Architecture
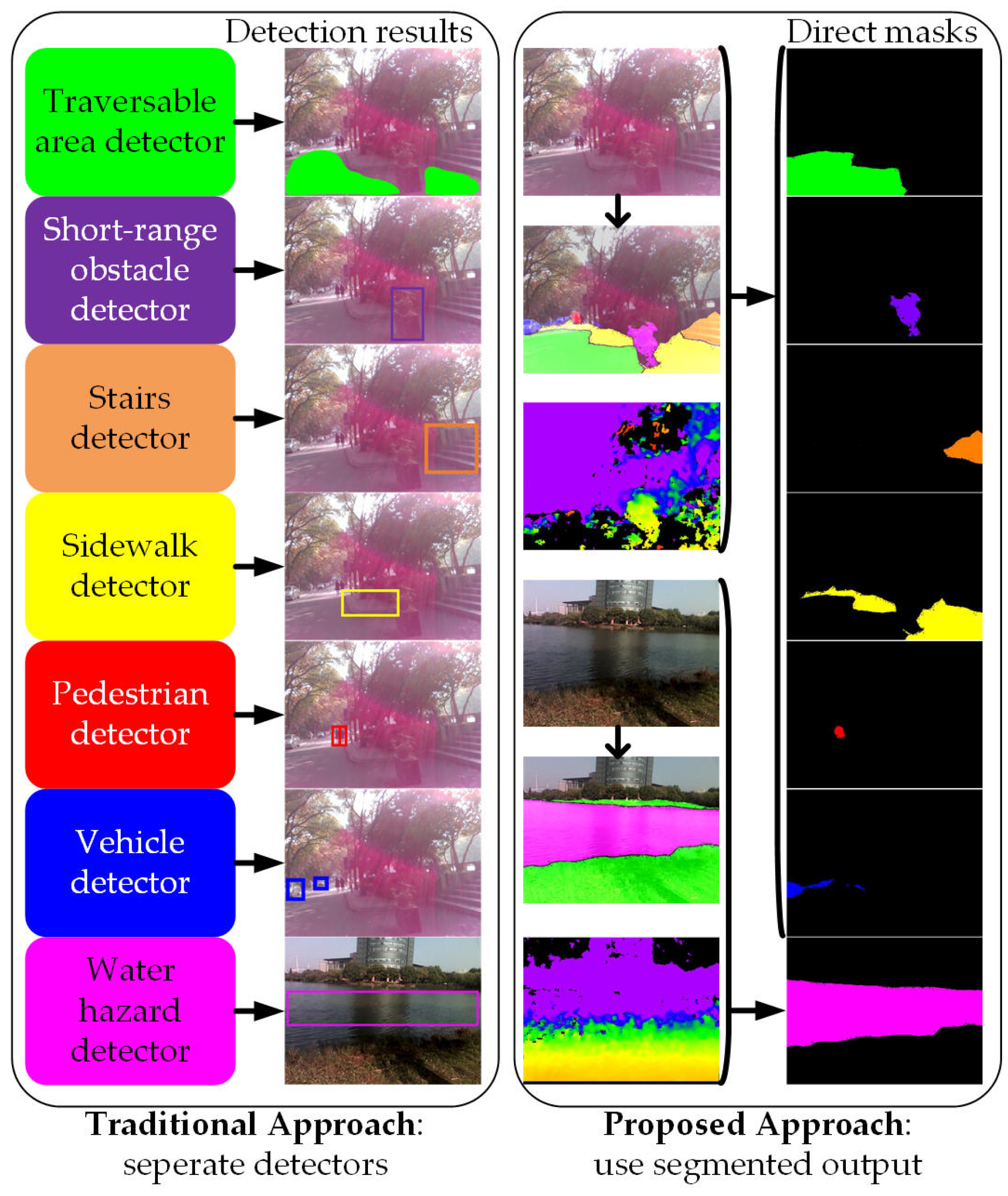
- The context relationship is universal and important especially for complex scene understanding. If the network mispredicts descending stairs in front of a lake, the visually impaired would be left vulnerable in dynamic environments. The common knowledge should be learned by the data-driven approach that stairs are seldom over a lake.
- There are many class label pairs that are texture-confusing in classification such as sidewalk/pavement versus roadways. For visually-impaired people, it is desired to identify the traversable areas that are sidewalks beyond the detection of “walkable” ground planes. Following this rationale, such distinctions should be made consistently.
- Scene targets such as pedestrians and vehicles have arbitrary sizes from the sensor perspective. For close-range obstacle avoidance and long-range warning of the fast-approaching objects, a navigation assistance system should pay much attention to different sub-regions that contain inconspicuous-category stuff.
3.3. Implementation Details
3.3.1. Dataset
3.3.2. Data Augmentation
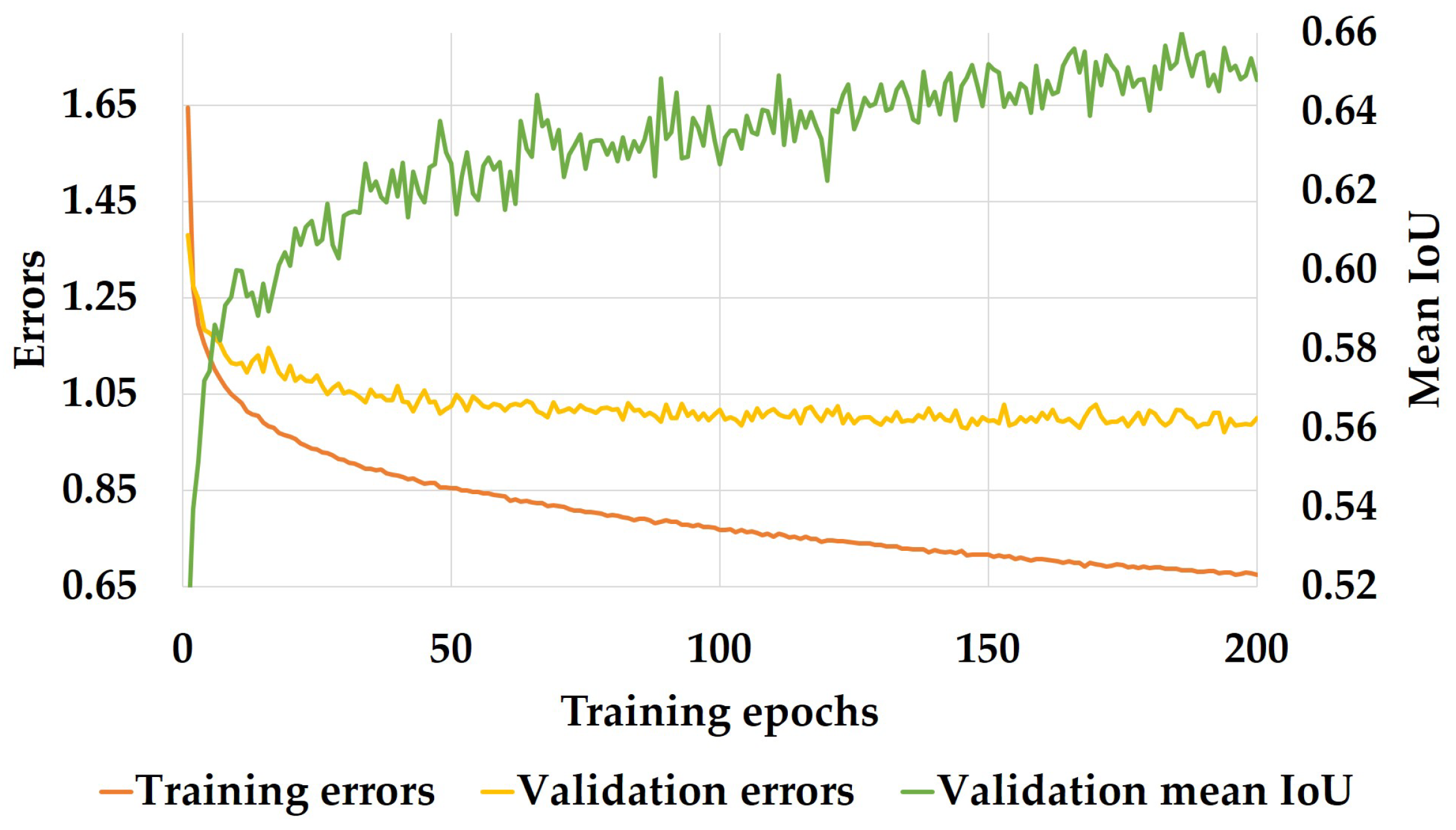
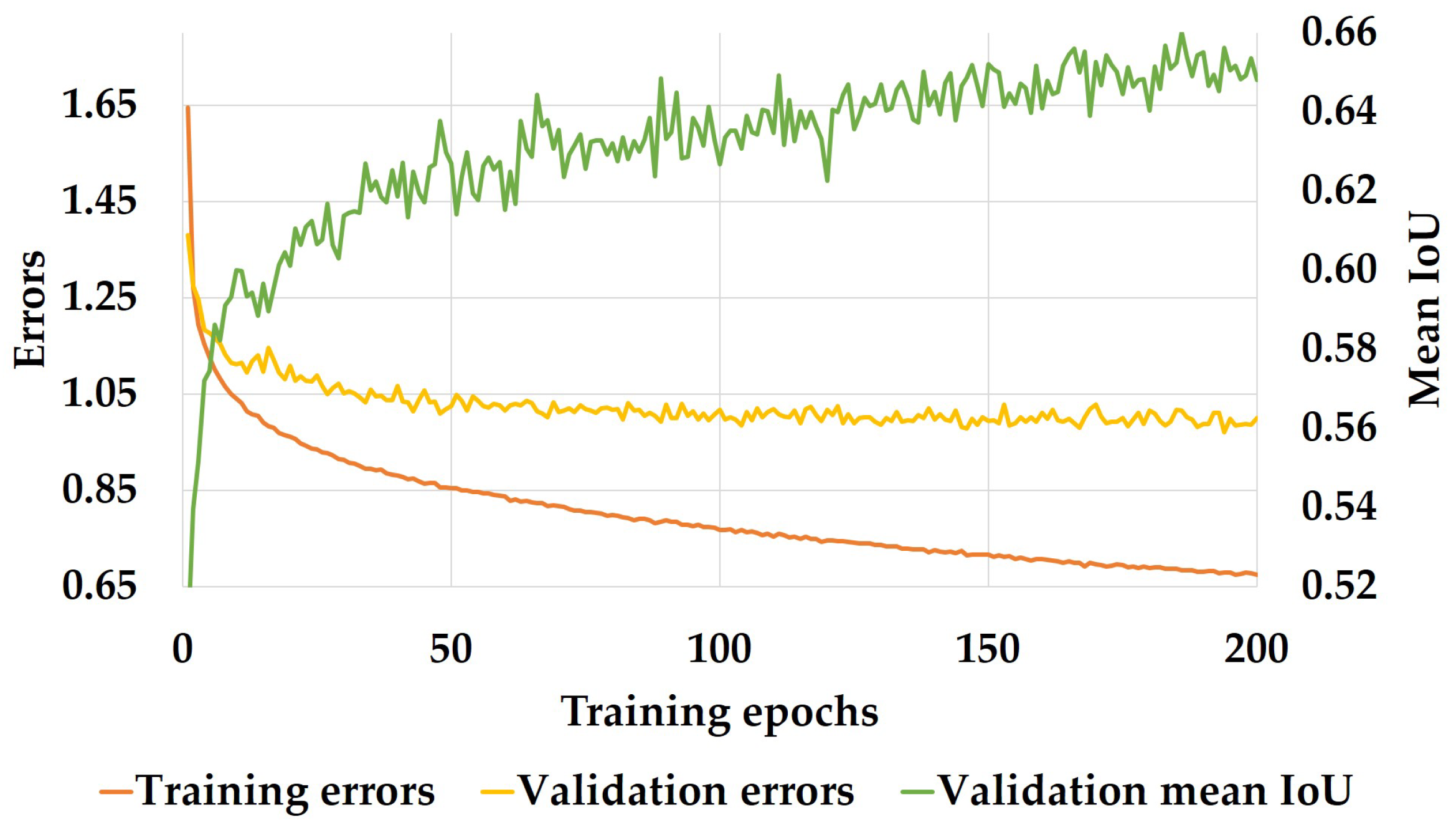
3.3.3. Training Setup
4. Experiments and Discussions
4.1. Experiment Setup
4.2. Real-Time Performance
4.3. Segmentation Accuracy
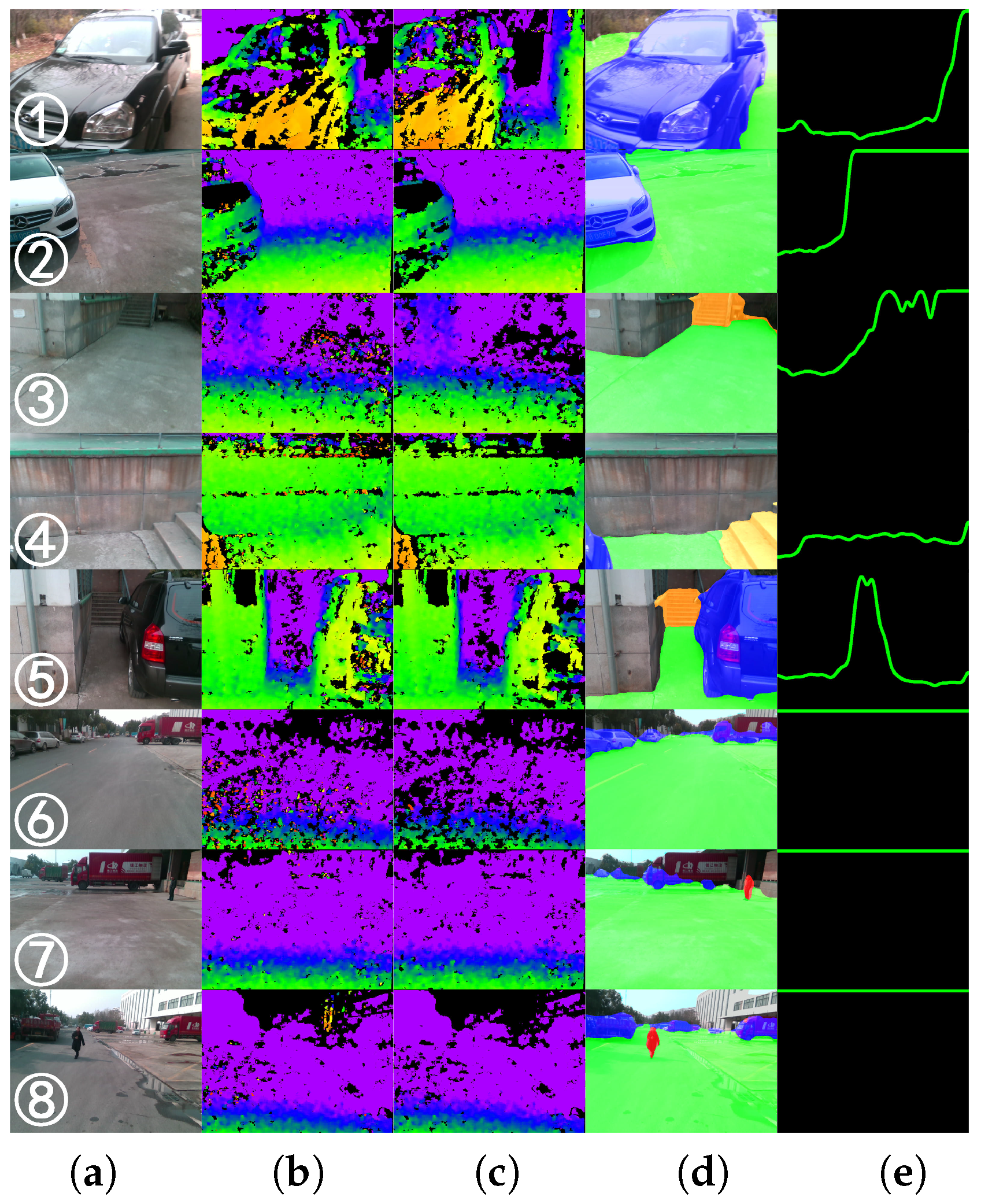
4.4. Real-World Performance
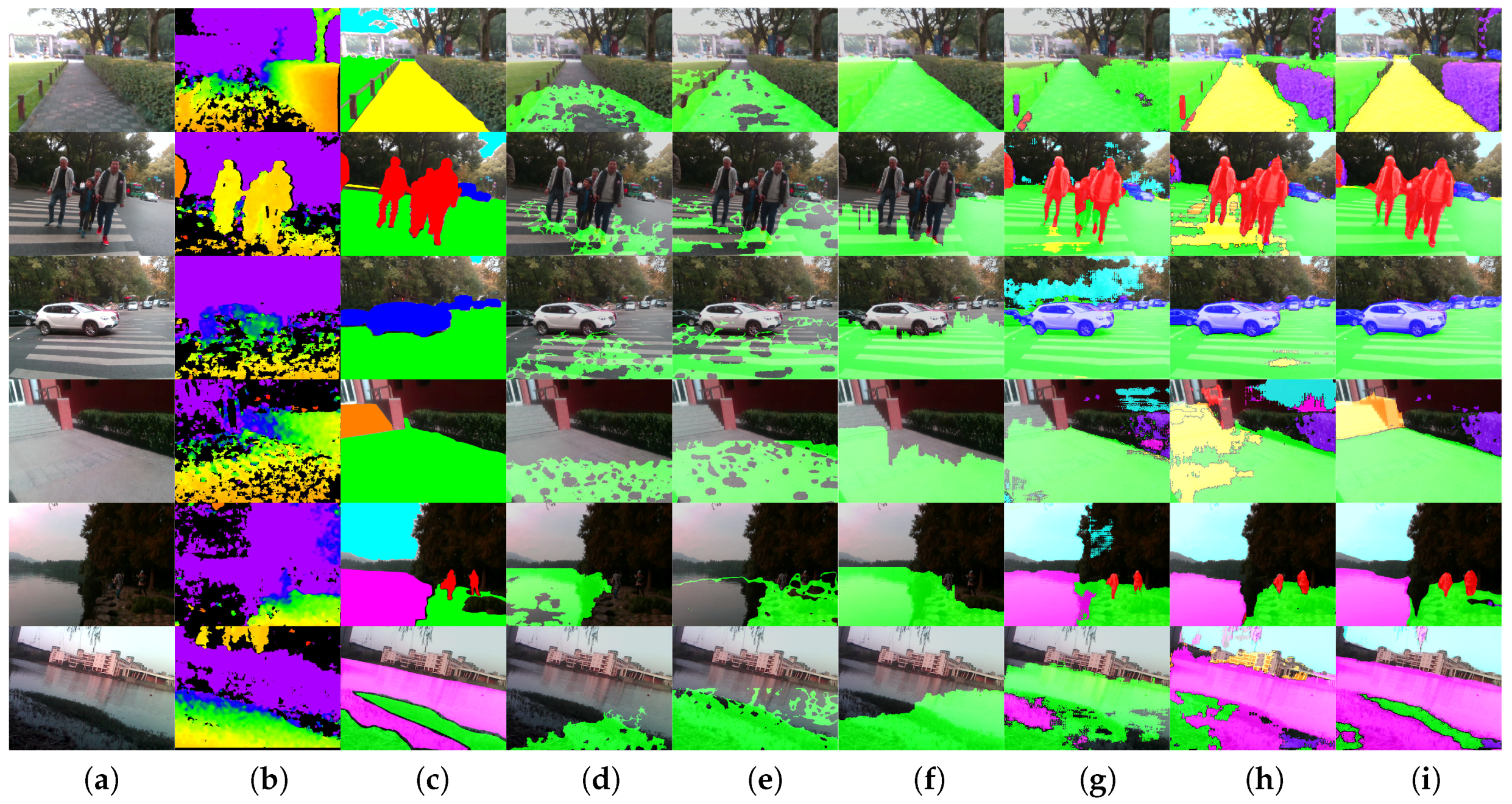
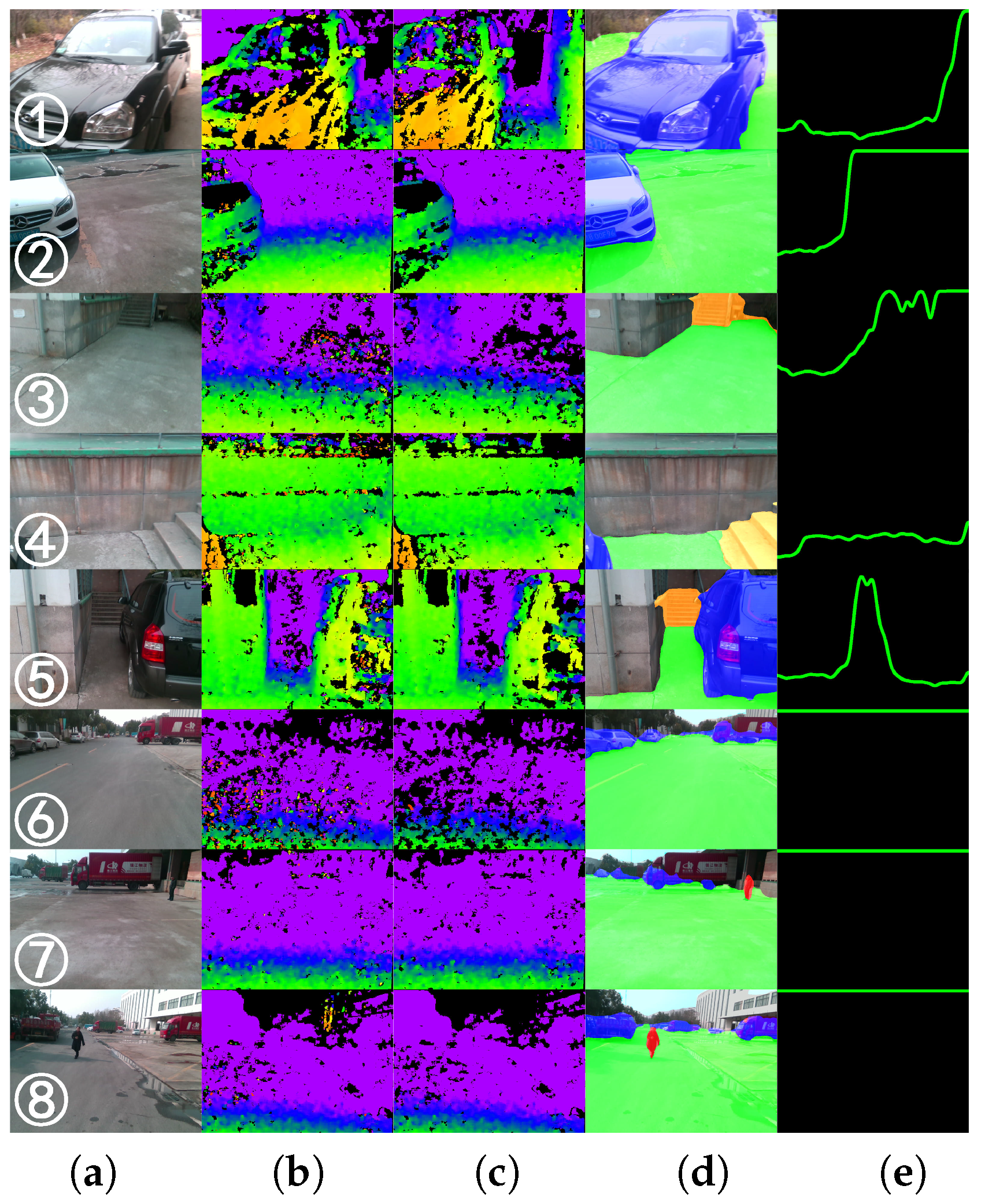
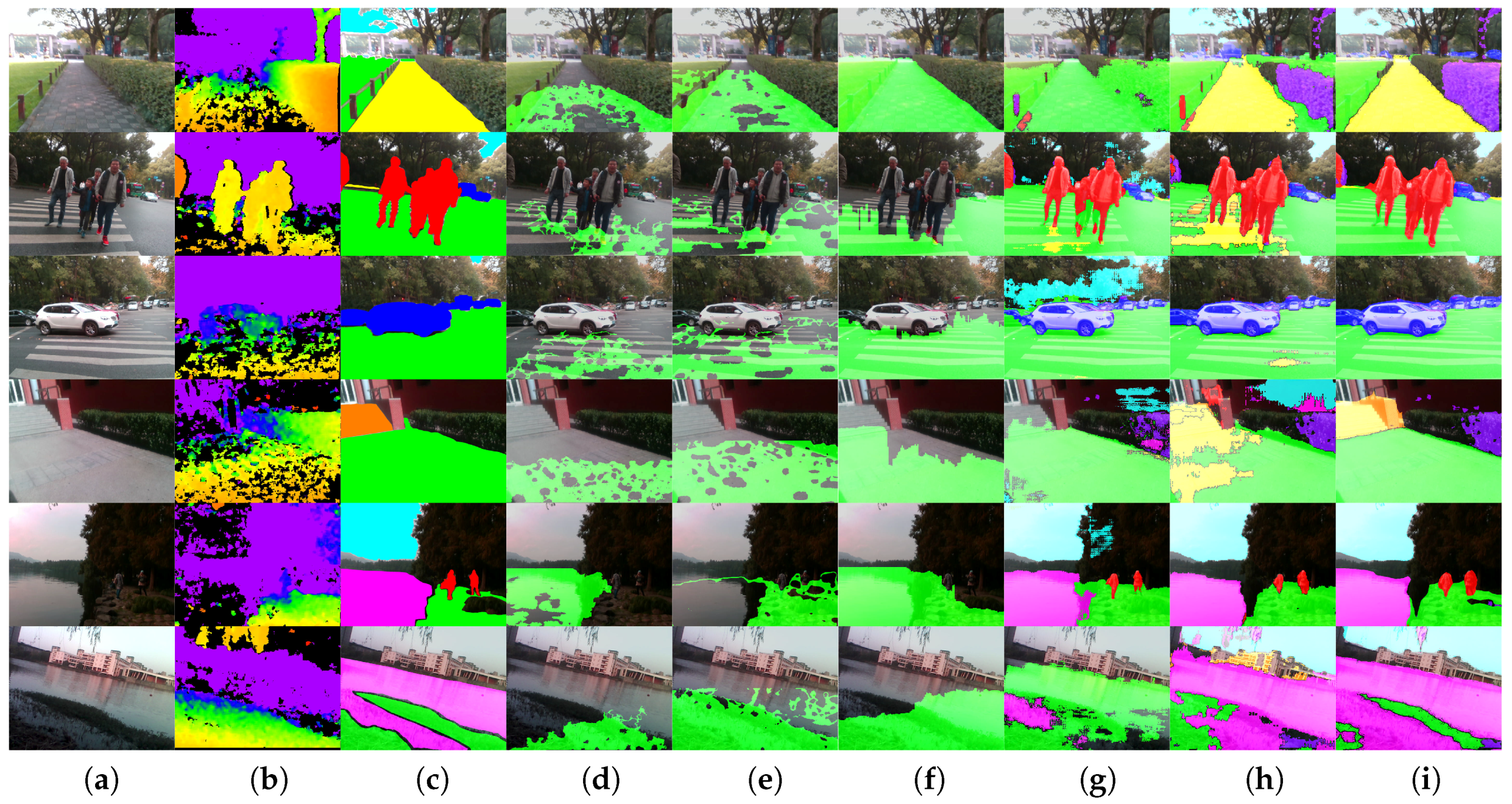
4.5. Qualitative Analysis
4.6. Indoor/Outdoor Detection Analysis
5. Field Test
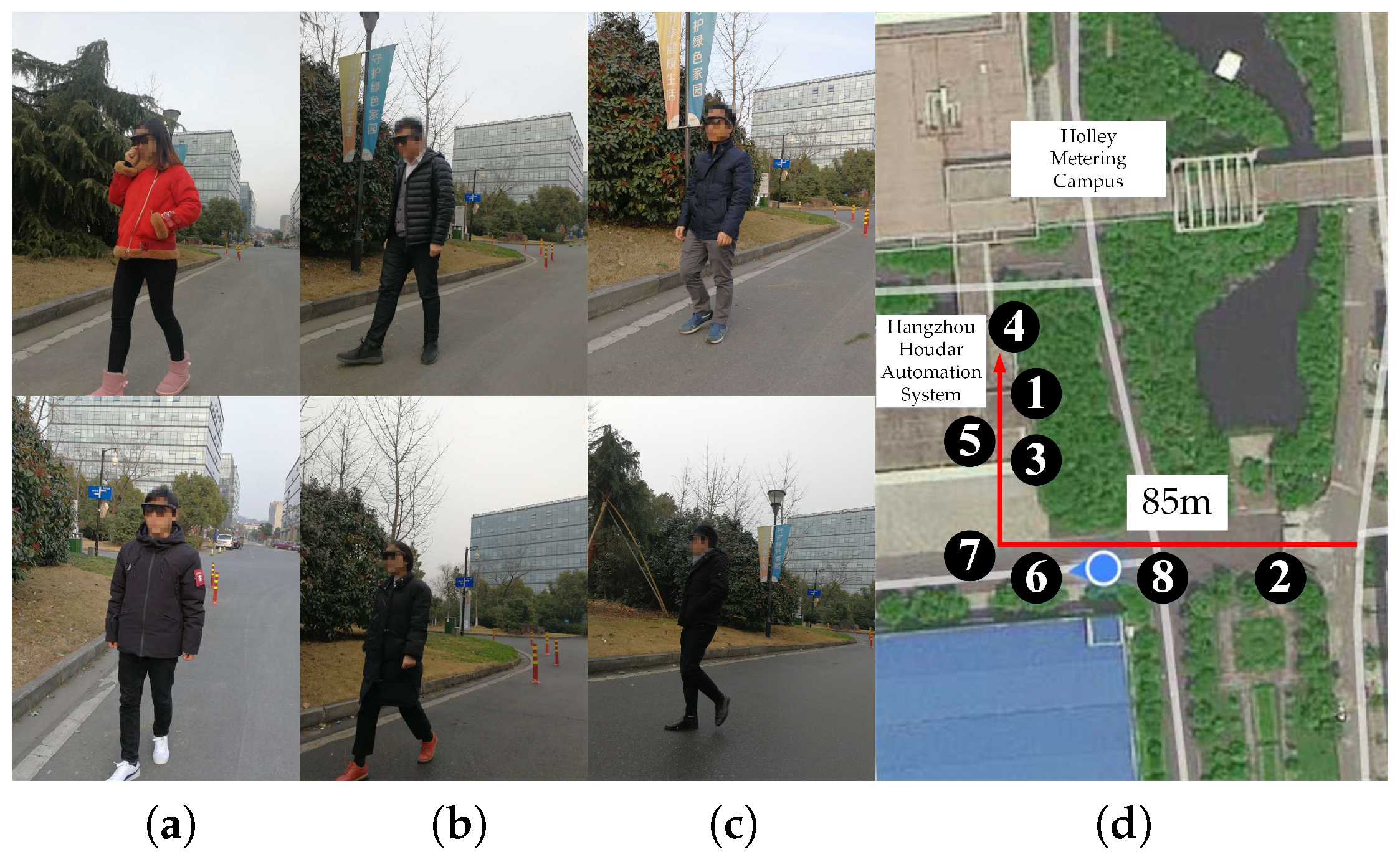
5.1. Field Test Setup
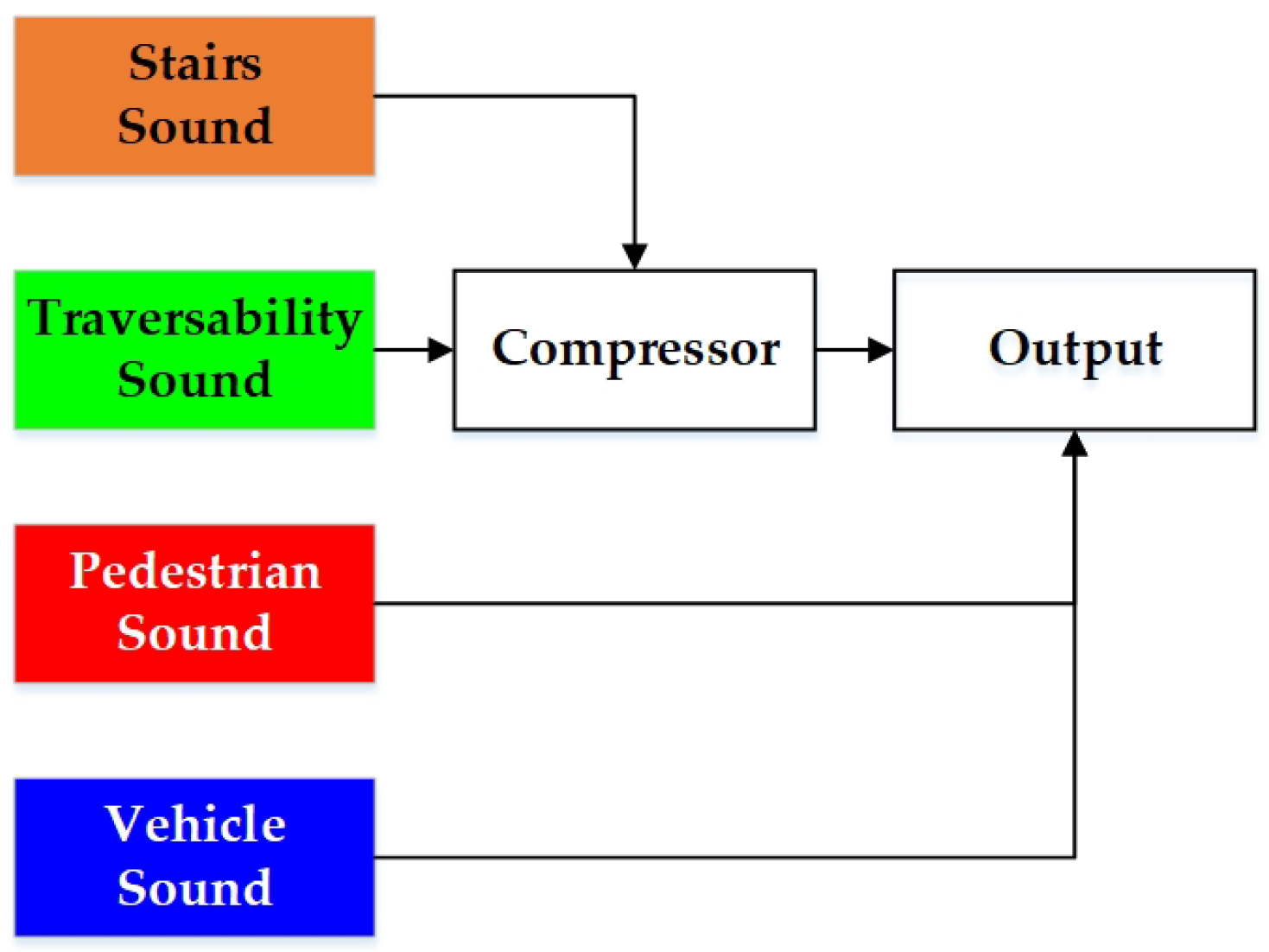
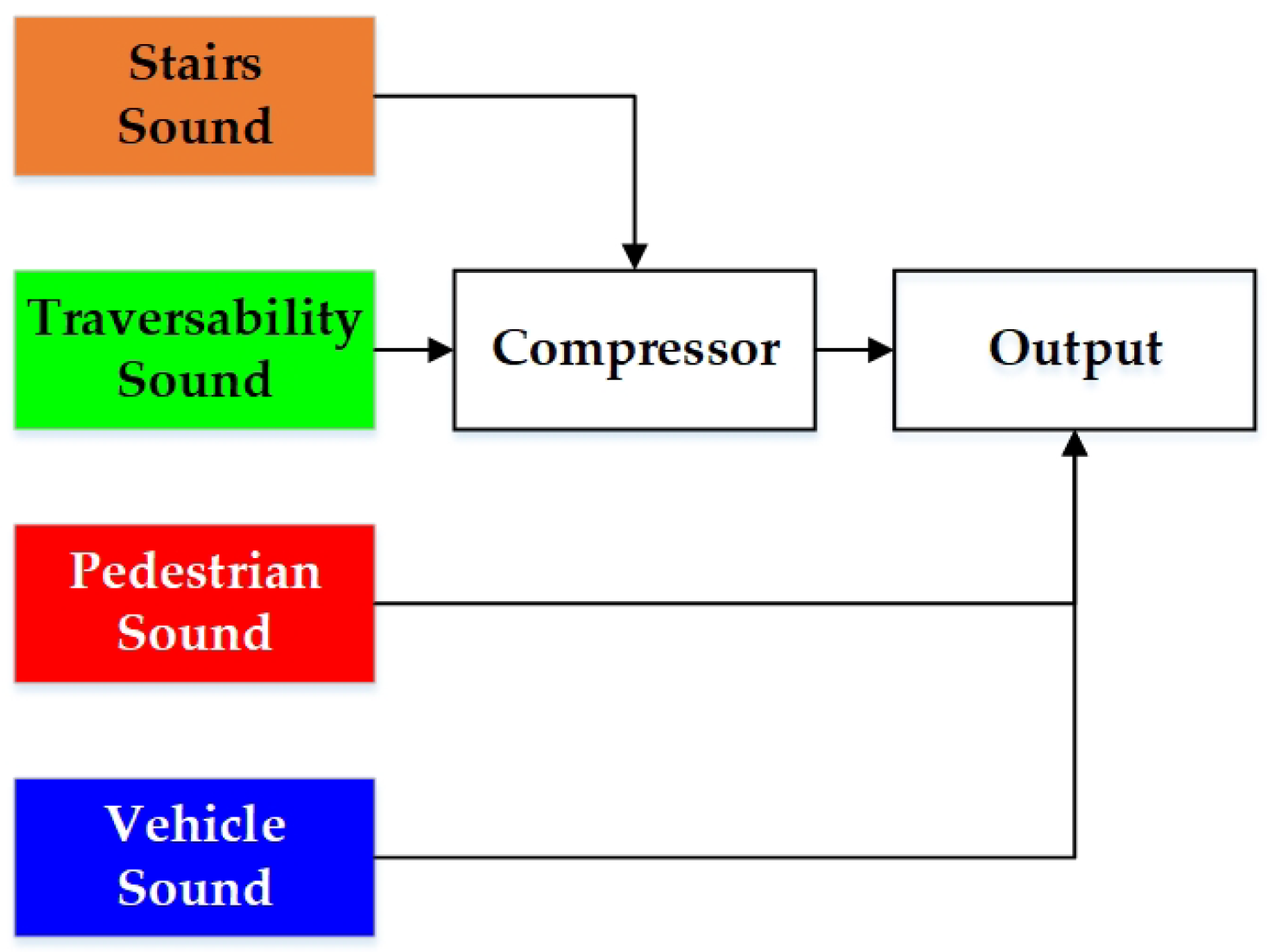
5.2. Stereo Sound Feedback
5.3. Field Test Results
5.4. Feedback Information from Participants
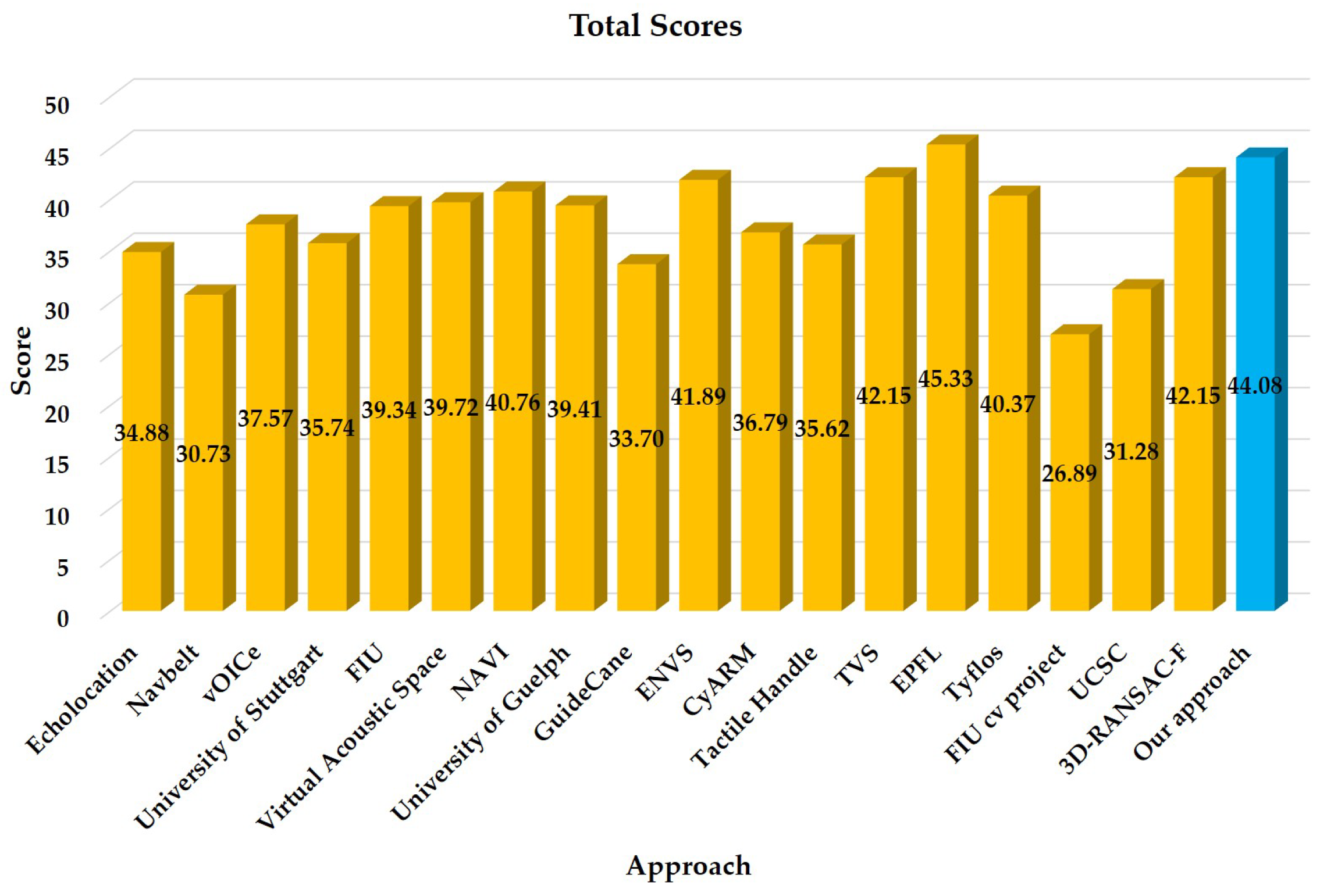
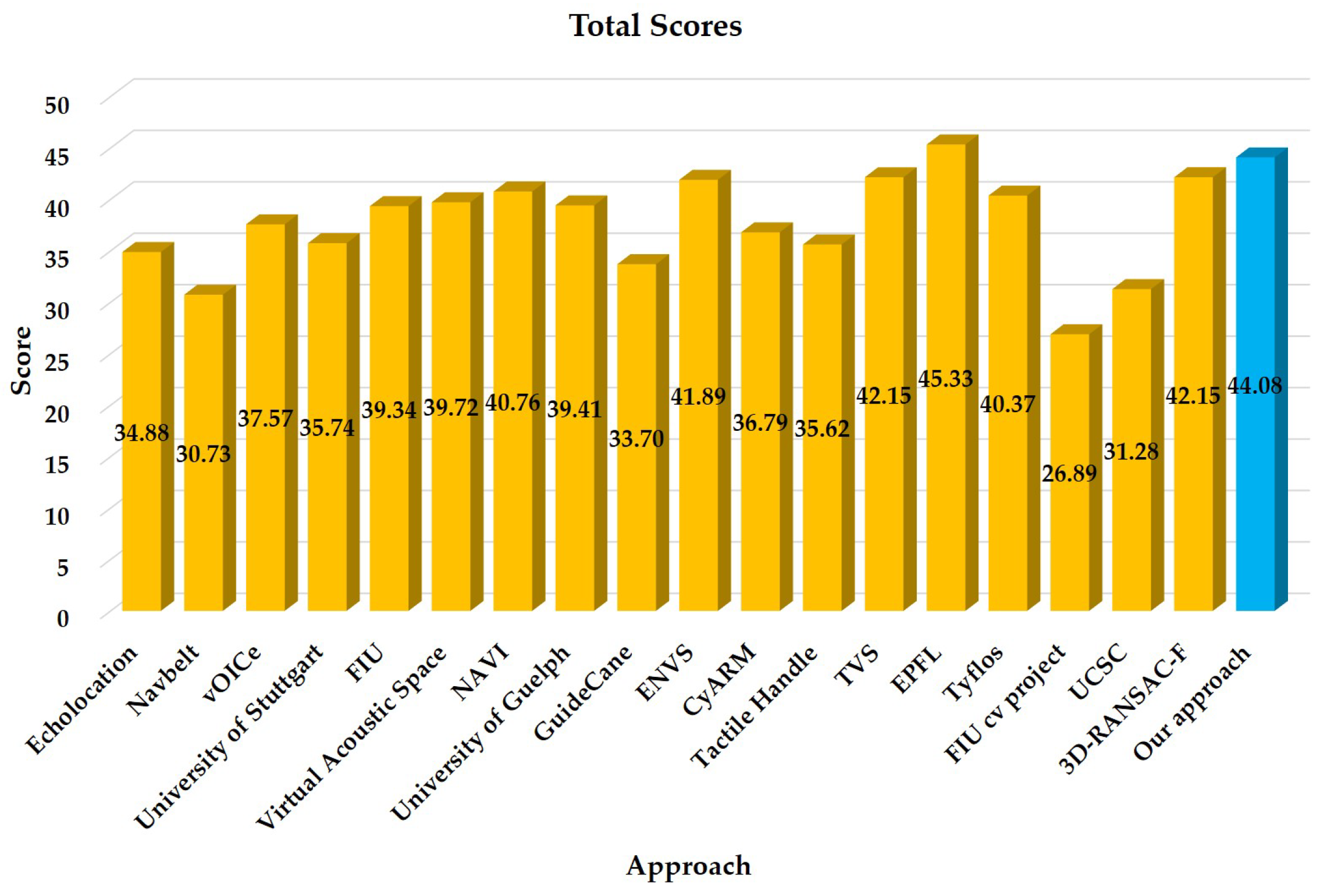
5.5. Maturity Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| TAWS | Terrain Awareness and Warning System |
| WHO | World Health Organization |
| CV | Computer Vision |
| VI | Visually Impaired |
| RGB-D | RGB-Depth |
| FPS | Frames Per Second |
| pRGB-D | polarized RGB-Depth |
| CNN | Convolutional Neural Network |
| RANSAC | RANdom SAmpling Consensus |
| IMU | Inertial Measurement Unit |
| IR | Infrared |
| RGB-IR-D | RGB-Infrared-Depth |
| ToF | Time-of-Flight |
| RGB-IR | RGB-Infrared |
| FCN | Fully-Convolutional Network |
| Non-bt-1D | Non-bottleneck-1D |
| HSV | Hue Saturation Value |
| BN | Batch-Normalization |
| IoU | Intersection-over-Union |
| TP | True Positives |
| FP | False Positives |
| FN | False Negatives |
| PA | Pixel-wise Accuracy |
| CCP | Correctly-Classified Pixels |
| LP | Labeled Pixels |
| dB | decibel |
| st | semi-tone |
| GPS | Global Positioning System |
| SLAM | Simultaneous Localization And Mapping |
| USB | Universal Serial Bus |
References
- Terrain Awareness and Warning System. Available online: https://en.wikipedia.org/wiki/Terrain_awareness_and_warning_system (accessed on 15 February 2018).
- Wang, S.; Yu, J. Everyday information behavior of the visually impaired in China. Inf. Res. 2017, 22. paper 743. [Google Scholar]
- Bhowmick, A.; Hazarika, S.M. An insight into assistive technology for the visually impaired and blind people: State-of-the-art and future trends. J. Multimodal User Interfaces 2017, 11, 149–172. [Google Scholar] [CrossRef]
- Bourne, R.R.; Flaxman, S.R.; Braithwaite, T.; Cicinelli, M.V.; Das, A.; Jonas, J.B.; Keeffe, J.; Kempen, J.H.; Leasher, J.; Limburg, H.; et al. Magnitude, temporal trends, and projections of the global prevalence of blindness and distance and near vision impairment: A systematic review and meta-analysis. Lancet Glob. Health 2017, 5, e888–e897. [Google Scholar] [CrossRef]
- Tian, Y. RGB-D sensor-based computer vision assistive technology for visually impaired persons. In Computer Vision and Machine Learning with RGB-D Sensors; Shao, L., Han, J., Kohli, P., Zhang, Z., Eds.; Springer: Cham, Switzerland, 2014; pp. 173–194. [Google Scholar]
- Elmannai, W.; Elleithy, K. Sensor-based assistive devices for visually-impaired people: Current status, chanllenges, and future directions. Sensors 2017, 17, 565. [Google Scholar] [CrossRef] [PubMed]
- Pradeep, V.; Medioni, G.; Weiland, J. Robot vision for the visually impaired. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 July 2010; pp. 15–22. [Google Scholar]
- Dakopoulos, D.; Bourbakis, N.G. Wearable obstacle avoidance electronic travel aids for blind: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 40, 25–35. [Google Scholar] [CrossRef]
- Rodríguez, A.; Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Almazán, J.; Cela, A. Assisting the visually impaired: Obstacle detection and warning system by acoustic feedback. Sensors 2012, 12, 17476–17496. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez, A.; Bergasa, L.M.; Alcantarilla, P.F.; Yebes, J.; Cela, A. Obstacle avoidance system for assisting visually impaired people. In Proceedings of the IEEE Intelligent Vehicles Symposium Workshops, Madrid, Spain, 3–7 June 2012; p. 16. [Google Scholar]
- Ni, D.; Song, A.; Tian, L.; Xu, X.; Chen, D. A walking assistant robotic system for the visually impaired based on computer vision and tactile perception. Int. J. Soc. Robot. 2015, 7, 617–628. [Google Scholar] [CrossRef]
- Schwarze, T.; Lauer, M.; Schwaab, M.; Romanovas, M.; Bohm, S.; Jurgensohn, T. An intuitive mobility aid for visually impaired people based on stereo vision. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–18 December 2015; pp. 17–25. [Google Scholar]
- Yang, K.; Wang, K.; Zhao, X.; Cheng, R.; Bai, J.; Yang, Y.; Liu, D. IR stereo RealSense: Decreasing minimum range of navigational assistance for visualy impaired individuals. J. Ambient Intell. Smart Environ. 2017, 9, 743–755. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Chen, H.; Bai, J. Reducing the minimum range of a RGB-depth sensor to aid navigation in visually impaired individuals. Appl. Opt. 2018, 57, 2809–2819. [Google Scholar] [CrossRef] [PubMed]
- Martinez, M.; Roitberg, A.; Koester, D.; Stiefelhagen, R.; Schauerte, B. Using Technology Developed for Autonomous Cars to Help Navigate Blind People. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 1424–1432. [Google Scholar]
- Caraiman, S.; Morar, A.; Owczarek, M.; Burlacu, A.; Rzeszotarski, D.; Botezatu, N.; Herghelegiu, P.; Moldoveanu, F.; Strumillo, P.; Moldoveanu, A. Computer Vision for the Visually Impaired: The Sound of Vision System. In Proceedings of the IEEE Conference on Computer Vision Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1480–1489. [Google Scholar]
- Herghelegiu, P.; Burlacu, A.; Caraiman, S. Negative obstacle detection for wearable assistive devices for visually impaired. In Proceedings of the 2017 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 564–570. [Google Scholar]
- Koester, D.; Schauerte, B.; Stiefelhagen, R. Accessible section detection for visual guidance. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo Workshops, San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Schauerte, B.; Koester, D.; Martinez, M.; Stiefelhagen, R. Way to go! Detecting open areas ahead of a walking person. In Proceedings of the 2014 European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 349–360. [Google Scholar]
- Cheng, R.; Wang, K.; Yang, K.; Zhao, X. A ground and obstacle detection algorithm for the visually impaired. In Proceedings of the IET International Conference on Biomedical Image and Signal Processing, Beijing, China, 19 November 2015; pp. 1–6. [Google Scholar]
- Lin, Q.; Han, Y. A Dual-Field Sensing Scheme for a Guidance System for the Blind. Sensors 2016, 16, 667. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Wang, K.; Hu, W.; Bai, J. Expanding the detection of traversable area with RealSense for the visually impaired. Sensors 2016, 16, 1954. [Google Scholar] [CrossRef] [PubMed]
- Aladren, A.; López-Nicolás, G.; Puig, L.; Guerrero, J.J. Navigation assistance for the visually impaired using RGB-D sensor with range expansion. IEEE Syst. J. 2016, 10, 922–932. [Google Scholar] [CrossRef]
- Lee, Y.H.; Medioni, G. RGB-D camera based wearable navigation system for the visually impaired. Comput. Vis. Image Underst. 2016, 149, 3–20. [Google Scholar] [CrossRef]
- Wang, H.C.; Katzschmann, R.K.; Teng, S.; Araki, B.; Giarré, L.; Rus, D. Enabling independent navigation for visually impaired people through a wearable vision-based feedback system. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 6533–6540. [Google Scholar]
- Saleh, K.; Zeineldin, R.A.; Hossny, M.; Nahavandi, S.; El-Fishawy, N.A. Navigational Path Detection for the Visually Impaired using Fully Convolutional Networks. In Proceedings of the IEEE Conference on Systems, Man and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 1399–1404. [Google Scholar]
- Perez-Yus, A.; Bermudez-Cameo, J.; Lopez-Nicolas, G.; Guerrero, J.J. Depth and Motion Cues with Phosphene Patterns for Prosthetic Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1516–1525. [Google Scholar]
- Mehta, S.; Hajishirzi, H.; Shapiro, L. Identifying Most Walkable Direction for Navigation in an Outdoor Environment. arXiv, 2017; arXiv:1711.08040. [Google Scholar]
- Burlacu, A.; Baciu, A.; Manta, V.I.; Caraiman, S. Ground geometry assessment in complex stereo vision based applications. In Proceedings of the 2017 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 558–563. [Google Scholar]
- Ghilardi, M.C.; Macedo, R.C.; Manssour, I.H. A new approach for automatic detection of tactile paving surfaces in sidewalks. Procedia Comput. Sci. 2016, 80, 662–672. [Google Scholar] [CrossRef]
- Phung, S.L.; Le, M.C.; Bouzerdoum, A. Pedestrian lane detection in unstructured scenes for assistive navigation. Comput. Vis. Image Underst. 2016, 149, 186–196. [Google Scholar] [CrossRef]
- Ahmed, F.; Yeasin, M. Optimization and evaluation of deep architectures for ambient awareness on a sidewalk. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2692–2697. [Google Scholar]
- Li, Z.; Rahman, M.; Robucci, R.; Banerjee, N. PreSight: Enabling Real-Time Detection of Accessibility Problems on Sidewalks. In Proceedings of the 2017 14th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), San Diego, CA, USA, 12–14 June 2017; pp. 1–9. [Google Scholar]
- Lee, Y.H.; Leung, T.S.; Medioni, G. Real-time staircase detection from a wearable stereo system. In Proceedings of the 2012 21st International Conference On Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 3770–3773. [Google Scholar]
- Guerrero, J.J.; Pérez-Yus, A.; Gutiérrez-Gómez, D.; Rituerto, A.; López-Nicolaás, G. Human navigation assistance with a RGB-D sensor. In Proceedings of the VI Congreso Internacional de Diseno, Redes de Investigacion y Tecnologia para todos (DRT4ALL), Madrid, Spain, 23–25 September 2015; pp. 285–312. [Google Scholar]
- Schwarze, T.; Zhong, Z. Stair detection and tracking from egocentric stereo vision. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Québec City, QC, Canada, 27–30 September 2015; pp. 2690–2694. [Google Scholar]
- Munoz, R.; Rong, X.; Tian, Y. Depth-aware indoor staircase detection and recognition for the visually impaired. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Perez-Yus, A.; Gutiérrez-Gómez, D.; Lopez-Nicolas, G.; Guerrero, J.J. Stairs detection with odometry-aided traversal from a wearable RGB-D camera. Comput. Vis. Image Underst. 2017, 154, 192–205. [Google Scholar] [CrossRef]
- Stahlschmidt, C.; von Camen, S.; Gavriilidis, A.; Kummert, A. Descending step classification using time-of-flight sensor data. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 362–367. [Google Scholar]
- Cloix, S.; Bologna, G.; Weiss, V.; Pun, T.; Hasler, D. Low-power depth-based descending stair detection for smart assistive devices. EURASIP J. Image Video Process. 2016, 2016, 33. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Cheng, R.; Hu, W.; Huang, X.; Bai, J. Detecting traversable area and water hazards for the visually impaired with a pRGB-D sensor. Sensors 2017, 17, 1890. [Google Scholar] [CrossRef] [PubMed]
- KR-VISION Technology: To Tackle the Challenges for the Visually Impaired. Available online: http://krvision.cn/ (accessed on 15 February 2018).
- Yang, K.; Wang, K.; Cheng, R.; Zhu, X. A new approach of point cloud processing and scene segmentation for guiding the visually impaired. In Proceedings of the IET International Conference on Biomedical Image and Signal Processing, Beijing, China, 19 November 2015; pp. 1–6. [Google Scholar]
- Mocanu, B.; Tapu, R.; Zaharia, T. When ultrasonic sensors and computer vision join forces for efficient obstacle detection and recognition. Sensors 2016, 16, 1807. [Google Scholar] [CrossRef] [PubMed]
- Rizzo, J.R.; Pan, Y.; Hudson, T.; Wong, E.K.; Fang, Y. Sensor fusion for ecologically valid obstacle identification: Building a comprehensive assistive technology platform for the visually impaired. In Proceedings of the 2017 7th International Conference on Modeling, Simulation, and Applied Optimization (ICMSAO), Sharjah, UAE, 4–6 April 2017; pp. 1–5. [Google Scholar]
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Smart guiding glasses for visually impaired people in indoor environment. IEEE Trans. Consum. Electron. 2017, 63, 258–266. [Google Scholar] [CrossRef]
- Pisa, S.; Piuzzi, E.; Pittella, E.; Affronti, G. A FMCW radar as electronic travel aid for visually impaired subjects. In Proceedings of the XXI IMEKO World Congress “Measurement in Research and Industry”, Prague, Czech Republic, 30 August–4 September 2015. [Google Scholar]
- Di Mattia, V.; Petrini, V.; Pieralisi, M.; Manfredi, G.; De Leo, A.; Russo, P.; Cerri, G.; Scalise, L. A K-band miniaturized antenna for safe mobility of visually impaired people. In Proceedings of the 2015 IEEE 15th Mediterranean Microwave Symposium (MMS), Lecce, Italy, 30 November–2 December 2015; pp. 1–4. [Google Scholar]
- Di Mattia, V.; Manfredi, G.; De Leo, A.; Russo, P.; Scalise, L.; Cerri, G.; Scalise, L. A feasibility study of a compact radar system for autonomous walking of blind people. In Proceedings of the 2016 IEEE 2nd International Forum on Research and Technologies for Society and Industry Leveraging a Better Tomorrow (RTSI), Bologna, Italy, 7–9 September 2016; pp. 1–5. [Google Scholar]
- Kwiatkowski, P.; Jaeschke, T.; Starke, D.; Piotrowsky, L.; Deis, H.; Pohl, N. A concept study for a radar-based navigation device with sector scan antenna for visually impaired people. In Proceedings of the 2017 First IEEE MTT-S International Microwave Bio Conference (IMBIOC), Gothenburg, Sweden, 15–17 May 2017; pp. 1–4. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in neural information processing systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrel, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICVV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Romera, E.; Bergasa, L.M.; Arroyo, R. Can we unify monocular detectors for autonomous driving by using the pixel-wise semantic segmentation of CNNS? arXiv, 2016; arXiv:1607.00971. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ADE20K dataset. arXiv, 2016; arXiv:1608.05442. [Google Scholar]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.G.; Lee, S.W.; Fidler, S.; Urtasun, R.; Yuille, A. The role of context for object detection and semantic segmentation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 891–898. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. COCO-Stuff: Thing and stuff classes in context. arXiv, 2016; arXiv:1612.03716. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv, 2016; arXiv:1606.02147. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Treml, M.; Arjona-Medina, J.; Unterthiner, T.; Durgesh, R.; Friedmann, F.; Schuberth, P.; Mayr, A.; Heusel, M.; Hofmarcher, M.; Widrich, M.; et al. Speeding up semantic segmentation for autonomous driving. In Proceedings of the MLLITS, NIPS Workshop, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Efficient convnet for real-time semantic segmentation. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Redondo Beach, CV, USA, 11–14 June 2017; pp. 1789–1794. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M. Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. arXiv, 2017; arXiv:1704.08545. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. arXiv, 2017; arXiv:1707.03718. [Google Scholar]
- Oliveira, G.L.; Bollen, C.; Burgard, W.; Brox, T. Efficient and robust deep networks for semantic segmentation. Int. J. Robot. Res. 2017, 0278364917710542. [Google Scholar] [CrossRef]
- Horne, L.; Alvarez, J.M.; McCarthy, C.; Barnes, N. Semantic labelling to aid navigation in prosthetic vision. In Proceedings of the 2015 37th Annual Internal Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 3379–3382. [Google Scholar]
- Horne, L.; Alvarez, J.; McCarthy, C.; Salzmann, M.; Barnes, N. Semantic labeling for prosthetic vision. Comput. Vis. Image Underst. 2016, 149, 113–125. [Google Scholar] [CrossRef]
- Terrain Awareness Dataset. Available online: http://wangkaiwei.org/projecteg.html (accessed on 15 February 2018).
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. In Readings in Computer Vision; Elsevier: New York, NY, USA, 1987; pp. 726–740. [Google Scholar]
- Leong, K.Y.; Egerton, S.; Chan, C.K. A wearable technology to negotiate surface discontinuities for the blind and low vision. In Proceedings of the 2017 IEEE Life Sciences Conference (LSC), Sydney, Australia, 13–15 December 2017; pp. 115–120. [Google Scholar]
- Wedel, A.; Franke, U.; Badino, H.; Cremers, D. B-spline modeling of road surfaces for freespace estimation. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 808–833. [Google Scholar]
- Badino, H.; Franke, U.; Pfeiffer, D. The stixel world-a compact medium level representation of the 3D-world. In Proceedings of the Joint Pattern Recognition Symposium, Jena, Germany, 9–11 September 2009; pp. 51–60. [Google Scholar]
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Manhattan-world stereo. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1422–1429. [Google Scholar]
- Geiger, A.; Roser, M.; Urtasun, R. Efficient large-scale stereo matching. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; pp. 25–38. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 1–14. [Google Scholar]
- Poggi, M.; Nanni, L.; Mattoccia, S. Crosswalk recognition through point-cloud processing and deep-learning suited to a wearable mobility aid for the visually impaired. In Proceedings of the International Conference on Image Analysis and Processing, Genova, Italy, 7–11 September 2015; pp. 282–289. [Google Scholar]
- Cheng, R.; Wang, K.; Yang, K.; Long, N.; Hu, W.; Chen, H.; Bai, J.; Liu, D. Crosswalk navigation for people with visual impairments on a wearable device. J. Electron. Imaging 2017, 26, 053025. [Google Scholar] [CrossRef]
- Cheng, R.; Wang, K.; Yang, K.; Long, N.; Bai, J.; Liu, D. Real-time pedestrian crossing lights detection algorithm for the visually impaired. Multimedia Tools Appl. 2017, 1–21. [Google Scholar] [CrossRef]
- Miksik, O.; Vineet, V.; Lidegaard, M.; Prasaath, R.; Nießner, M.; Golodetz, S.; Hicks, S.L.; Perez, P.; Izadi, S.; Torr, P.H.S. The semantic paintbrush: Interactive 3D mapping and recognition in large outdoor spaces. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3317–3326. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel RealSense Stereoscopic Depth Cameras. arXiv, 2017; arXiv:1705.05548. [Google Scholar]
- AfterShokz: Bone Conduction Headphones. Available online: https://aftershokz.com/ (accessed on 15 February 2018).
- Konolige, K. Projected texture stereo. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010; pp. 148–155. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv, 2016; arXiv:1605.07146. [Google Scholar]
- Alvarez, L.; Petersson, L. Decomposeme: Simplifying convnets for end-to-end learning. arXiv, 2016; arXiv:1606.05426. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv, 2014; arXiv:1405.3866. [Google Scholar]
- Rigamonti, R.; Sironi, A.; Lepetit, V.; Fua, P. Learning separable filters. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2754–2761. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; Berg, A.C.; Li, F. Imagenet large scale visual recognition challenge. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International conference on machine learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv, 2012; arXiv:1207.0580. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of convnet features for place recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Kolarik, A.J.; Cirstea, S.; Pardhan, S. Evidence for enhanced discrimination of virtual auditory distance among blind listeners using level and direct-to-reverberant cues. Exp. Brain Res. 2013, 224, 623–633. [Google Scholar] [CrossRef] [PubMed]
- Dufour, A.; Després, O.; Candas, V. Enhanced sensitivity to echo cues in blind subjects. Exp. Brain Res. 2005, 165, 515–519. [Google Scholar] [CrossRef] [PubMed]
- Grond, F.; Berger, J. Parameter mapping sonification. In The Sonification Handbook; Logos Verlag Berlin GmbH: Berlin, Germany, 2011; pp. 363–397. [Google Scholar]
- Shepard Tone. Available online: https://en.wikipedia.org/wiki/Shepard_tone (accessed on 15 February 2018).
- FMOD. Available online: https://www.fmod.com (accessed on 15 February 2018).
- AMAP. Available online: http://www.autonavi.com/ (accessed on 15 February 2018).
- Li, W.H. Wearable computer vision systems for a cortical visual prosthesis. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops (ICCVW), Sydney, Australia, 1–8 December 2013; pp. 428–435. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Out-F | Out-Res |
|---|---|---|---|
| 0 | Scaling 640 × 480 | 3 | 320 × 240 |
| 1 | Down-sampler block | 16 | 160 × 120 |
| 2 | Down-sampler block | 64 | 80 × 60 |
| 3–7 | 5 × Non-bt-1D | 64 | 80 × 60 |
| 8 | Down-sampler block | 128 | 40 × 30 |
| 9 | Non-bt-1D (dilated 2) | 128 | 40 × 30 |
| 10 | Non-bt-1D (dilated 4) | 128 | 40 × 30 |
| 11 | Non-bt-1D (dilated 8) | 128 | 40 × 30 |
| 12 | Non-bt-1D (dilated 16) | 128 | 40 × 30 |
| 13 | Non-bt-1D (dilated 2) | 128 | 40 × 30 |
| 14 | Non-bt-1D (dilated 4) | 128 | 40 × 30 |
| 15 | Non-bt-1D (dilated 8) | 128 | 40 × 30 |
| 16 | Non-bt-1D (dilated 2) | 128 | 40 × 30 |
| 17a | Original feature map | 128 | 40 × 30 |
| 17b | Pooling and convolution | 32 | 40 × 30 |
| 17c | Pooling and convolution | 32 | 20 × 15 |
| 17d | Pooling and convolution | 32 | 10 × 8 |
| 17e | Pooling and convolution | 32 | 5 × 4 |
| 17 | Up-sampler and concatenation | 256 | 40 × 30 |
| 18 | Convolution | C | 40 × 30 |
| 19 | Up-sampler | C | 640 × 480 |
| Architectures | IoU on ADE20K [57] | Fwt at 320 × 240 | Fwt at 448 × 256 | Fwt at 640 × 480 |
|---|---|---|---|---|
| UNet [62] | 28.5% | 27 ms | 43 ms | 131 ms |
| SegNet [60] | 55.6% | N/A | 69 ms | 178 ms |
| ENet [61] | 58.4% | 15 ms | 17 ms | 24 ms |
| SQNet [63] | 55.5% | 33 ms | 44 ms | 89 ms |
| LinkNet [67] | 56.5% | N/A | 14 ms | 32 ms |
| ERFNet [65] | 63.1% | 15 ms | 20 ms | 44 ms |
| Our ERF-PSPNet | 66.0% | 13 ms | 16 ms | 34 ms |
| Networks | Sky | Floor | Road | Grass | Sidewalk | Ground | Person | Car | Water | Stairs | Mean IoU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| UNet [62] | 75.3% | 22.4% | 41.4% | 52.7% | 5.3% | 25.3% | 16.8% | 21.1% | 20.4% | 4.2% | 28.5% |
| SegNet [60] | 91.3% | 61.8% | 63.0% | 62.8% | 36.0% | 72.3% | 31.4% | 63.0% | 58.4% | 15.6% | 55.6% |
| ENet [61] | 89.7% | 72.4% | 69.4% | 56.5% | 38.2% | 75.0% | 26.7% | 64.8% | 67.3% | 23.7% | 58.4% |
| SQNet [63] | 92.2% | 59.1% | 66.7% | 65.1% | 37.0% | 68.8% | 31.2% | 54.2% | 63.0% | 17.1% | 55.5% |
| LinkNet [67] | 91.3% | 63.5% | 66.3% | 63.5% | 35.6% | 71.6% | 30.6% | 61.0% | 66.6% | 15.4% | 56.5% |
| ERFNet [65] | 93.2% | 77.3% | 71.1% | 64.5% | 46.1% | 76.3% | 39.7% | 70.1% | 67.9% | 24.1% | 63.1% |
| Our ERF-PSPNet | 93.0% | 78.7% | 73.8% | 68.7% | 51.6% | 76.8% | 39.4% | 70.4% | 77.0% | 30.8% | 66.0% |
| Approaches | IoU | Pixel-Wise Accuracy | With Depth | Within 2 m | 2–3 m | 3–5 m | 5–10 m |
|---|---|---|---|---|---|---|---|
| 3D-RANSAC-F [9] | 50.1% | 67.2% | 73.3% | 53.9% | 91.8% | 85.2% | 61.7% |
| UNet [62] | 52.1% | 59.6% | 57.1% | 56.9% | 48.1% | 54.0% | 56.5% |
| SegNet [60] | 73.1% | 90.1% | 89.5% | 86.1% | 84.0% | 87.7% | 89.3% |
| ENet [61] | 62.4% | 85.2% | 88.4% | 79.9% | 84.3% | 89.7% | 93.1% |
| LinkNet [67] | 74.1% | 89.2% | 93.8% | 93.4% | 92.8% | 93.5% | 93.5% |
| Our ERF-PSPNet | 82.1% | 93.1% | 95.9% | 96.0% | 96.3% | 96.2% | 96.0% |
| Accuracy Term | Sky | Traversability | Ground | Sidewalk | Stairs | Water | Person | Car |
|---|---|---|---|---|---|---|---|---|
| IoU | 88.0% | 82.1% | 72.7% | 55.5% | 67.0% | 69.1% | 66.8% | 67.4% |
| Pixel-wise Accuracy | 95.3% | 93.1% | 81.2% | 93.1% | 90.1% | 86.3% | 90.8% | 93.1% |
| With Depth | N/A | 95.9% | 84.9% | 93.1% | 90.8% | 89.8% | 90.4% | 92.7% |
| Within 2 m | N/A | 96.0% | 76.9% | 95.0% | 91.9% | 96.2% | 97.7% | 94.3% |
| 2–3 m | N/A | 96.3% | 81.7% | 96.5% | 91.9% | 82.3% | 93.7% | 95.2% |
| 3–5 m | N/A | 96.2% | 87.4% | 94.5% | 89.4% | 76.9% | 93.6% | 90.8% |
| 5–10 m | N/A | 96.0% | 86.6% | 93.6% | 93.1% | 84.3% | 87.4% | 91.4% |
| Users | Collisions | Times of Asking for Help | Traversing Time to Reach the Stairs |
|---|---|---|---|
| User 1 | 1 | 1 | 208 s |
| User 2 | 1 | 0 | 91 s |
| User 3 | 0 | 2 | 123 s |
| User 4 | 1 | 1 | 157 s |
| User 5 | 0 | 2 | 323 s |
| User 6 | 1 | 1 | 143 s |
| Users | Male or Female | Feedback in Time? | Comfortable to Wear? | Useful? | Advice for Improvement |
|---|---|---|---|---|---|
| User 1 | Female | Yes | No | Yes | Provide a detailed tutorial |
| User 2 | Male | Yes | Yes | Yes | Feedback about the curbs |
| User 3 | Male | Yes | Yes | Yes | |
| User 4 | Male | Yes | Yes | Yes | Design a wireless prototype |
| User 5 | Female | Yes | Yes | Yes | |
| User 6 | Male | Yes | No | Yes |
| Features | Aims | Weights | Scores |
|---|---|---|---|
| F1 | Real-Time | 9.3 | 7.83 |
| F2 | Wearable | 8.6 | 7.83 |
| F3 | Portable | 5.7 | 6.33 |
| F4 | Reliable | 7.1 | 7.33 |
| F5 | Low-Cost | 5.0 | - |
| F6 | Friendly | 4.3 | 8.17 |
| F7 | Functionalities | 2.7 | 9.33 |
| F8 | Simple | 2.9 | 4.83 |
| F9 | Robust | 2.1 | 5.67 |
| F10 | Wireless | 1.4 | - |
| F11 | Performance | 10.0 | 7.5 |
| F12 | Originality | 1.4 | 9.33 |
| F13 | Availability | 5.0 | 10.0 |
| F14 | Future | 6.4 | 8.83 |
| Total | Maturity | - | 44.08 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying Terrain Awareness for the Visually Impaired through Real-Time Semantic Segmentation. Sensors 2018, 18, 1506. https://doi.org/10.3390/s18051506
Yang K, Wang K, Bergasa LM, Romera E, Hu W, Sun D, Sun J, Cheng R, Chen T, López E. Unifying Terrain Awareness for the Visually Impaired through Real-Time Semantic Segmentation. Sensors. 2018; 18(5):1506. https://doi.org/10.3390/s18051506
Chicago/Turabian StyleYang, Kailun, Kaiwei Wang, Luis M. Bergasa, Eduardo Romera, Weijian Hu, Dongming Sun, Junwei Sun, Ruiqi Cheng, Tianxue Chen, and Elena López. 2018. "Unifying Terrain Awareness for the Visually Impaired through Real-Time Semantic Segmentation" Sensors 18, no. 5: 1506. https://doi.org/10.3390/s18051506
APA StyleYang, K., Wang, K., Bergasa, L. M., Romera, E., Hu, W., Sun, D., Sun, J., Cheng, R., Chen, T., & López, E. (2018). Unifying Terrain Awareness for the Visually Impaired through Real-Time Semantic Segmentation. Sensors, 18(5), 1506. https://doi.org/10.3390/s18051506