1. Introduction
A spacecraft’s attitude information is necessary for most space missions, and is often derived from attitude estimation algorithms using onboard sensor data [
1,
2]. The applicable sensors include
star trackers, sun sensors, horizon sensors, magnetometers, global positioning systems and so on. Attitude estimation, in general, refers to some filtering-based approaches that take a dynamic model of the spacecraft’s motion into account [
2]. Generally, research into attitude estimation centers principally on two aspects: attitude parameterization and filtering algorithms. As for the aspect of attitude parameterization, researchers and engineers have been recognizing the utility of employing quaternion due to its computational efficiency and singularity avoidance. For attitude estimation filtering algorithms, Kalman type filters have received the most attention due in part to their ease of implementation and modest computational cost. However, the primary issue with the implementation of Kalman type filters in attitude estimation is maintaining the quaternion unit norm. A mathematically elegant solution to this problem is to use the quaternion for global attitude representation, taking singularity avoidance into consideration, while using unconstrained parameters for local attitude representation in the filtering process with reduced rank covariance [
3]. Within this framework, many general filtering algorithms have been applied to the attitude estimation problem, such as extended Kalman filter (EKF), unscented Kalman filter (UKF), cubature Kalman filter (CKF), divided difference filter (DDF), and so on [
3,
4,
5,
6,
7,
8]. For more details on these attitude estimation algorithms, one can refer to the survey paper [
9] and the most recent monograph [
2]. Among these filtering algorithms, the most representative are the EKF in its multiplicative form known as multiplicative EKF (MEKF) and UKF in its quaternion form known as unscented quaternion estimator (USQUE). Although the USQUE will be more accurate when a good priori estimate of the attitude is unavailable, its computational burden is cumbersome. Up to now, the MEKF is still the most prolific approach to on-board attitude estimation. Although considerable performance degradation may arise from the implicit linearization in MEKF when large initial condition errors are involved, some strategies within the MEKF framework can still be used to circumvent this drawback. This paper is dedicated to improving the performance of the MEKF taking both accuracy and computational efficiency into consideration.
Generally, spacecraft can obtain multiple or/and many noisy measurements in vector observations formed simultaneously from different attitude sensors, such as a three-axis magnetometer, star tracker, sun sensor, and so on. In this case, the Kalman gain necessitates an inversion of a
matrix with
denoting the number of vector observations. [
1] argues that this inversion is a cumbersome computational burden for real-time applications and a Murrell’s variation of the MEKF (MMEKF) was developed to avoid this expensive computation based on the linear update structure of the Kalman type filter (KTF). That is, the MMEKF was originally developed to alleviate the computational costs of the MEKF and cannot improve the accuracy performance of the MEKF. Murrell’s variation is virtually a sequential processing scheme of the measurements obtained simultaneously. In fact, the sequential strategy can also be used to improve the filtering performance in terms of accuracy. In [
10,
11,
12], the sequential processing scheme is applied to EKF-based radar target tracking problems, resulting in a filtering algorithm favorable to both estimation accuracy and computational efficiency. However, the sequential structure in [
10,
11,
12] cannot be transplanted to the MEKF superficially due to the special structure of the MEKF and the special characteristics of the attitude. These aforementioned facts represent the main motivation of this paper, which will focus on the investigation of a sequential processing scheme for the MEKF for attitude estimation. In the proposed sequential MEKF (SMEKF), the single vector observation model is re-linearized regarding the updated state estimate when the last single vector observation has been processed. This is the manner in which the proposed SMEKF can improve the accuracy performance, and is the main difference to the MMEKF. Meanwhile, in the sequential processing of these vector observations, the covariance is unchanged due to the special reset operation of the MEKF. This is the main difference to the traditional sequential EKF (SEKF).
The remainder of this paper is organized as follows. The MEKF and MMEKF for attitude estimation is first presented in
Section 2 to provide the necessary background information. In
Section 3, the SMEKF is developed in detail and compared to the MMEKF and the traditional SEKF. Finally, the numerical simulation results are reported alongside some traditional attitude estimation algorithms to illustrate the validity and superiority of the proposed SMEKF.
This paper can be viewed as a companion work to [
13], which makes use of iteration procedure to improve the performance of the MEKF. This paper and [
13] both seek to improve the filtering performance of some classical strategies within the MEKF framework. The main contribution of these works lies in their examination of the ways in which the classical strategies can be integrated into the special structure of MEKF.
2. MEKF and MMEKF
The attitude estimation problem with the quaternion kinematics model is given by
where the quaternion
must obey a normalization constraint
.
where
is a 3 × 3 identity matrix and
is the cross-product matrix.
The angular rate
is measured by a rate-integrating gyro, whose model is given by
where
is the measured observation and
is a bias vector.
and
are zero-mean Gaussian white noise processes with covariances usually given by
and
.
The discrete-time measurement function with n vector observations is given by
In (4), is the rotation matrix corresponding to the quaternion . is the measurement white noise for the i-th vector observation, whose covariance is . In this respect, the measurement noise is given by .
The explicit MEKF and MMEKF for attitude estimation are summarized in
Table 1.
Remark 1. It can be seen from Table 1 that the only difference between MEKF and MMEKF lies in the measurement update. In the MMEKF, the measurement update is performed for each vector observation individually. According to the gain calculation, Murrell’s approach reduces the taking of the inverse of amatrix to taking the inverse of amatrix. At first glance, this seems to significantly decrease the computational load. However, many other computational cost equations have also been added with Murrell’s variation. Therefore, the actual computational savings obtained by Murrell’s approach are not straightforward, which will be shown in the simulation study. Remark 2. It has been shown that during each processing of the vector observation, the measurement model is always linearized about the prior attitude estimate. This is the reason why Murrell’s approach cannot improve the accuracy performance.
Remark 3. There is an explicit reset for the error state before the measurement update loop of the MMEKF, that is. The reset performed before the measurement update loop can also be viewed as being performed before the time update loop. This is because that the priori error state remains the zero vector in the time update. Actually, the reset operation has also been performed implicitly in the MEKF.This can be deduced from the state update equation. This reset operation is used to move the update information from the error state to the full state estimate [4]. 4. Simulation Example
In this section, Example 7.2 from [
1] (also Example 6.1 from [
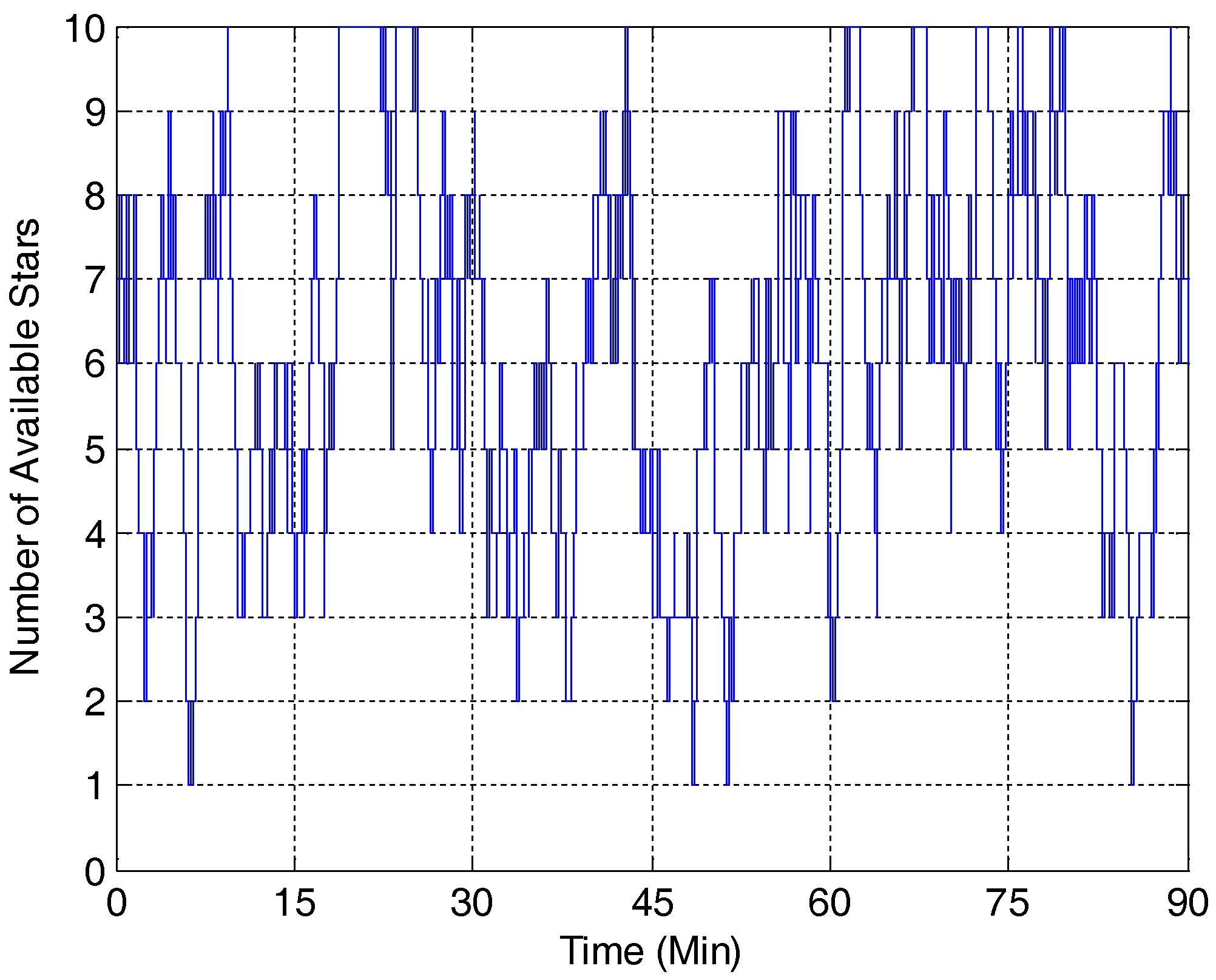
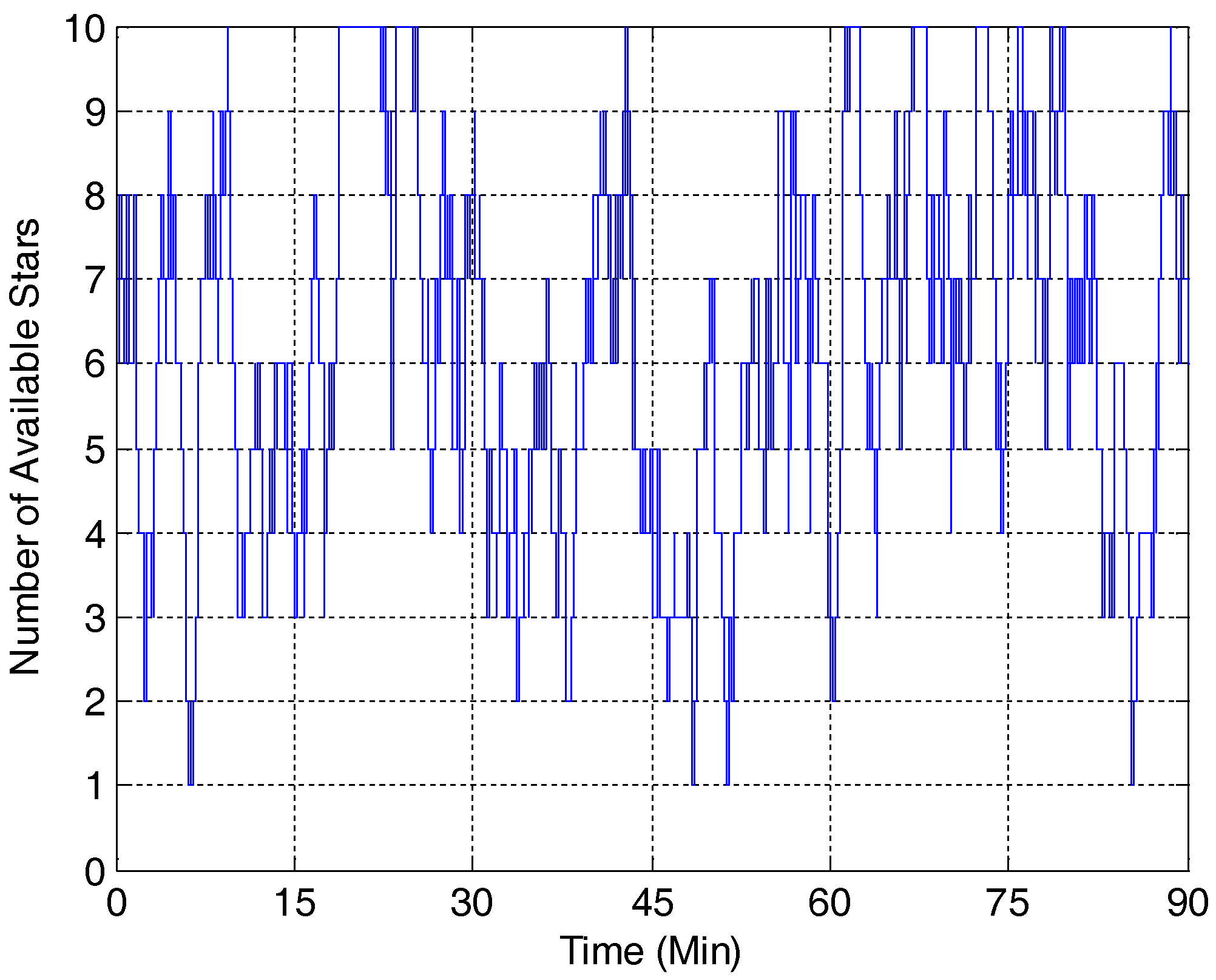
2]) is used to evaluate the performance of the developed SMEKF against some other attitude estimation methods, including MEKF, MMEKF, SEKF and USQUE. The number of available stars during the simulation is shown in
Figure 1. It shows that the star tracker can sense up to 10 stars at one time.
Specifically, several performance comparisons between these algorithms were made using the following four simulation cases:
- Case 1:
With initial attitude estimation error
- Case 2:
With initial attitude estimation error
- Case 3:
With initial attitude estimation error
- Case 4:
With initial attitude estimation error
The following simulation results are all averaged values from 100 Monte Carlo runs.
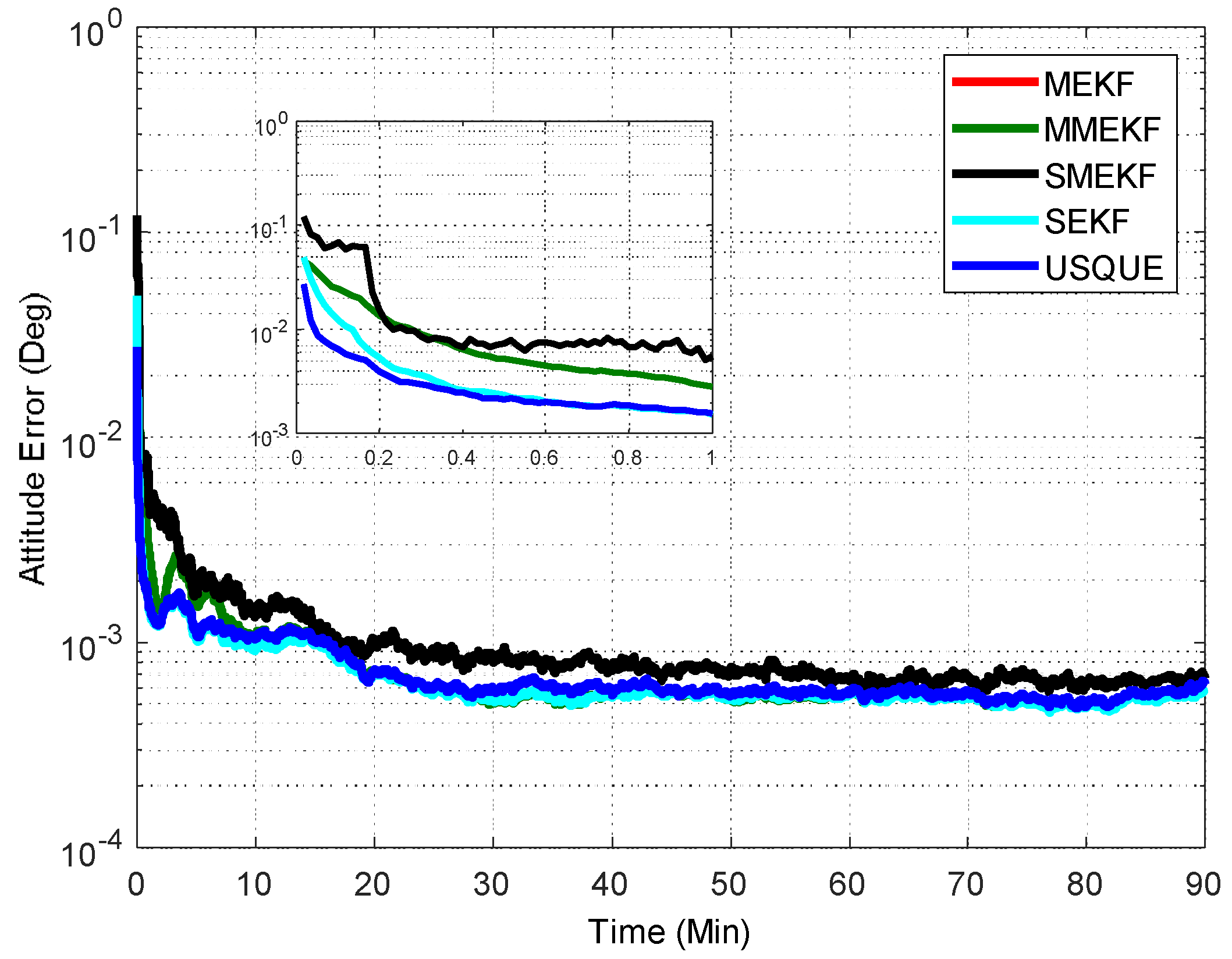
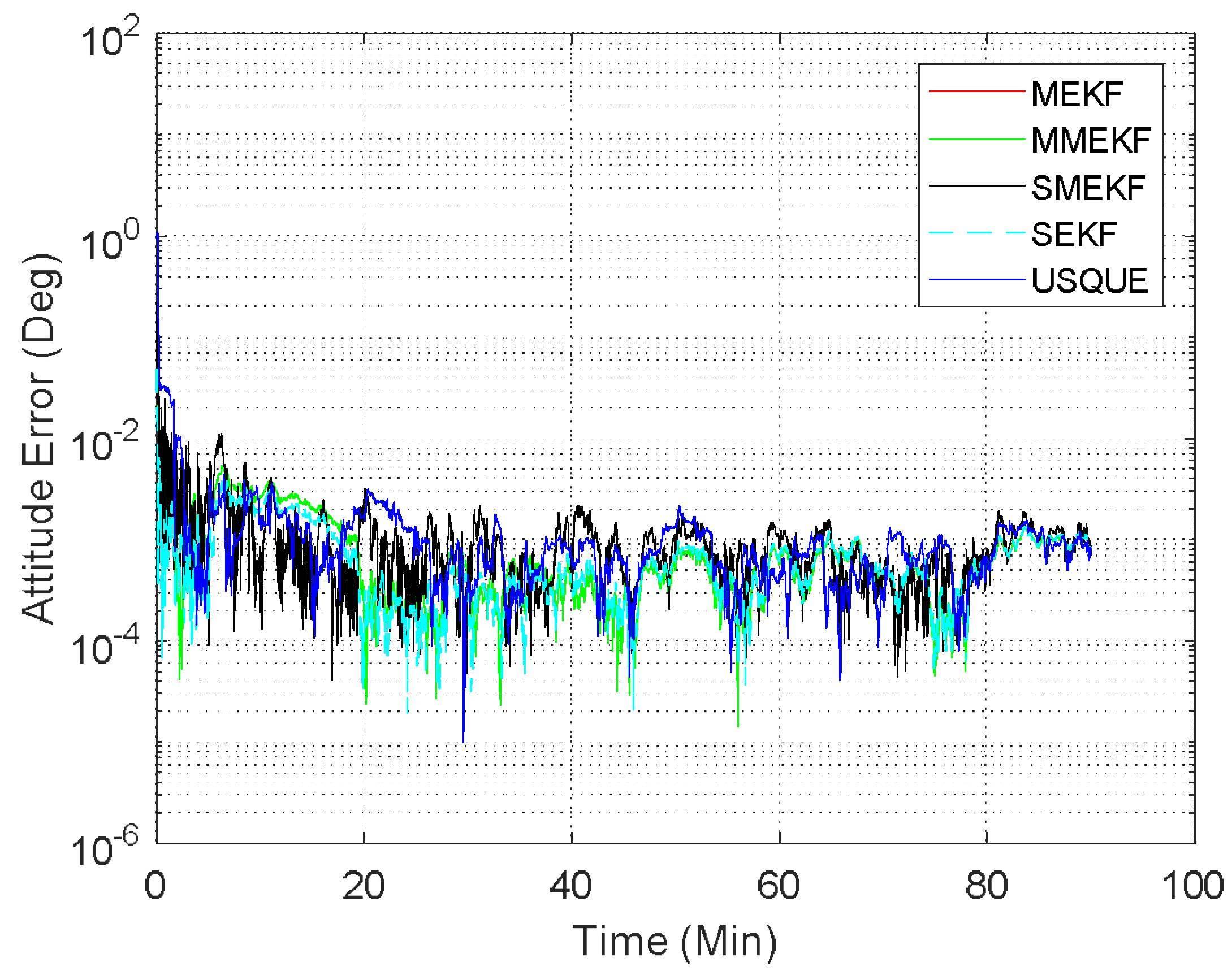
In the first case, the initial attitude covariance was set to
and the bias covariance was set to
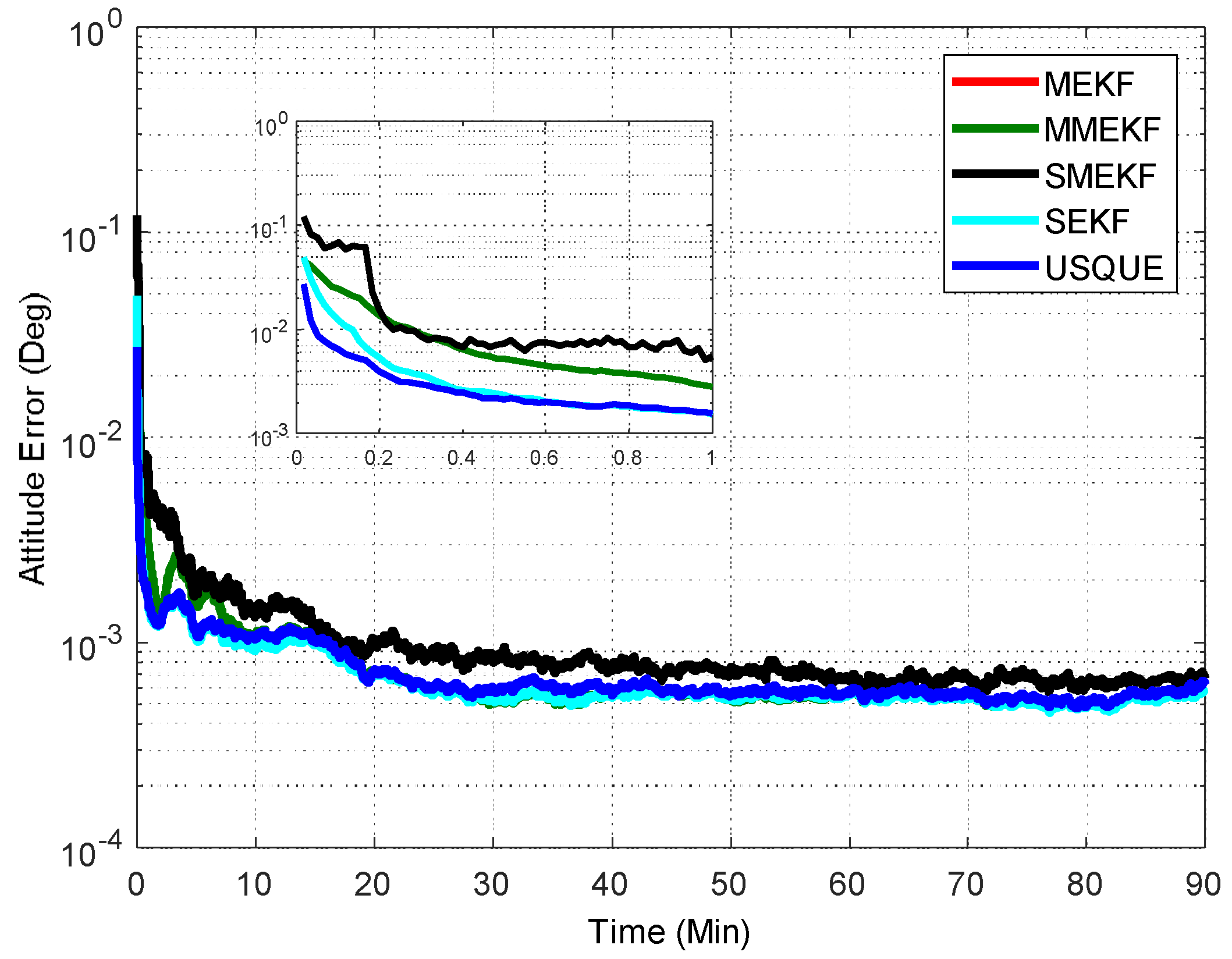
. The norm of the total attitude estimation error for this case is shown in
Figure 2. The performance details from the first minutes of each filter are illustrated in the sub-graph. It shows that all the attitude estimation filters exhibit very similar performance. In fact, the performance of MEKF and MMEKF are identical to each other and their curves cannot be distinguished in
Figure 2. The superiority of the SMEKF and USQUE over other filters in terms of accuracy is not so obvious for small initial error conditions. The seemingly underperformance of the proposed SMEKF in
Figure 2 may be caused by one contingency of the 100 Monte Carlo runs. We have carried out one time simulation under the initial condition in Case 1. The corresponding results are shown in
Figure 3. It is clearly shown that these attitude estimators perform quite similarly.
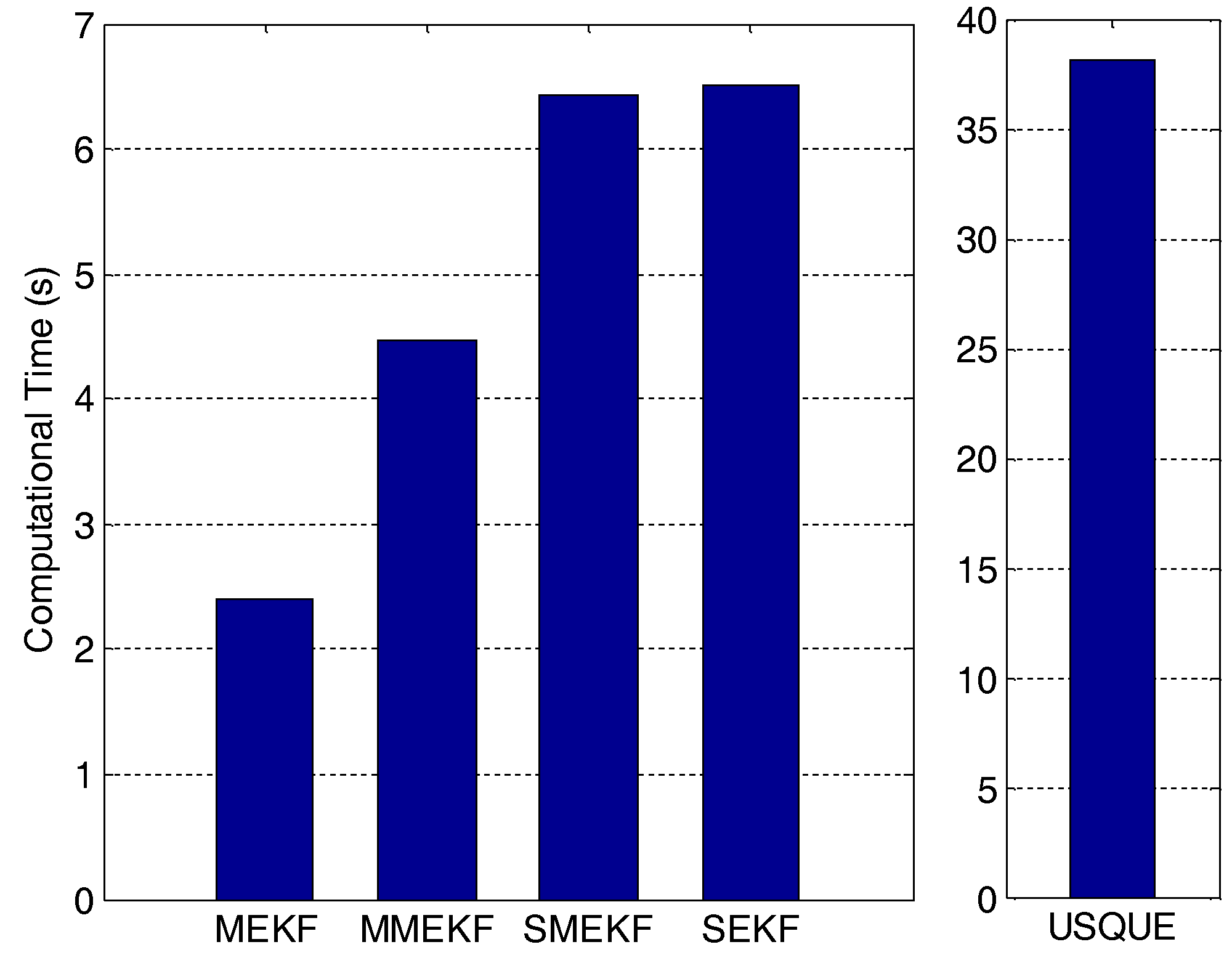
Both algorithms were implemented using Matlab on a computer with 2.66 G CPU, 2.0 G memory and the Windows 7 operating system. The averaged computation times of 100 Monte Carlo runs are shown in
Figure 4. Interestingly, the Murrell version does not save computational cost and in contrast, it increases the computational cost. This can be explained as follows: the computational savings from exchanging the inversion of the
matrix for the inversion of the
matrix is only obvious for cases with large numbers of vector observations at a time. For small matrices, lower order components of the computational cost equations can have a large influence on the actual computational cost [
14]. The developed SMEKF has an even larger computational burden than the MMEKF. This is because the measurement update and attitude update are both performed for every processing step of the vector observation. The computational cost of the SEKF is slightly greater than that of the SMEKF due to the fact that the covariance is updated in the processing loop of the SEKF. The computational cost of the USQUE is much larger than that of the other filters. In this respect, if other filters show appropriate performance, the USQUE will be not preferred due to its large computational cost.
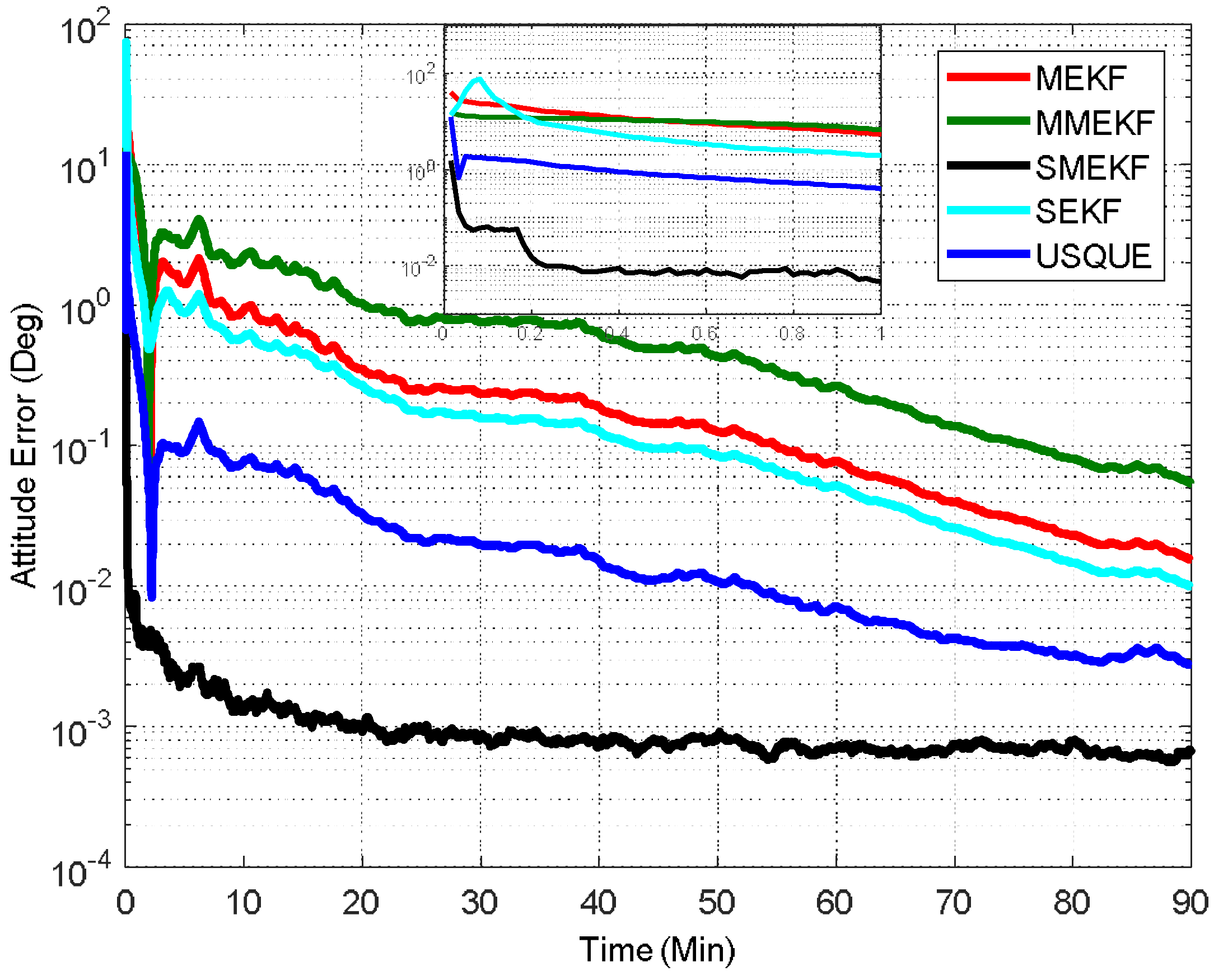
In the second case, the initial attitude covariance was set to
and the initial bias covariance was unchanged. The norm of the total attitude estimation error for this case is shown in
Figure 5. The performance details for the first minutes of each filter are illustrated in the sub-graph. It shows that the proposed SMEKF still has a fast convergent speed and an accurate steady state. In contrast, the performance of the other four filters was much degraded. In particular, the MMEKF performed even worse than the original MEKF. This indicates that there are no advantages to using MMEKF, as the actual computational savings are also not straightforward. The SEKF can indeed outperform the MEKF, as shown in
Figure 5. However, the performance improvement is compromised compared to the SMEKF. This validates that the covariance should not be updated in the sequential processing loop. The USQUE performs much better than the MEKF, which indicates that it is more robust to the large initial estimate error. However, the performance improvement is at the cost of large computational burden, as shown in
Figure 4. In this case, the SMEKF was the best, as it had the most accurate performance with appropriate computational cost.
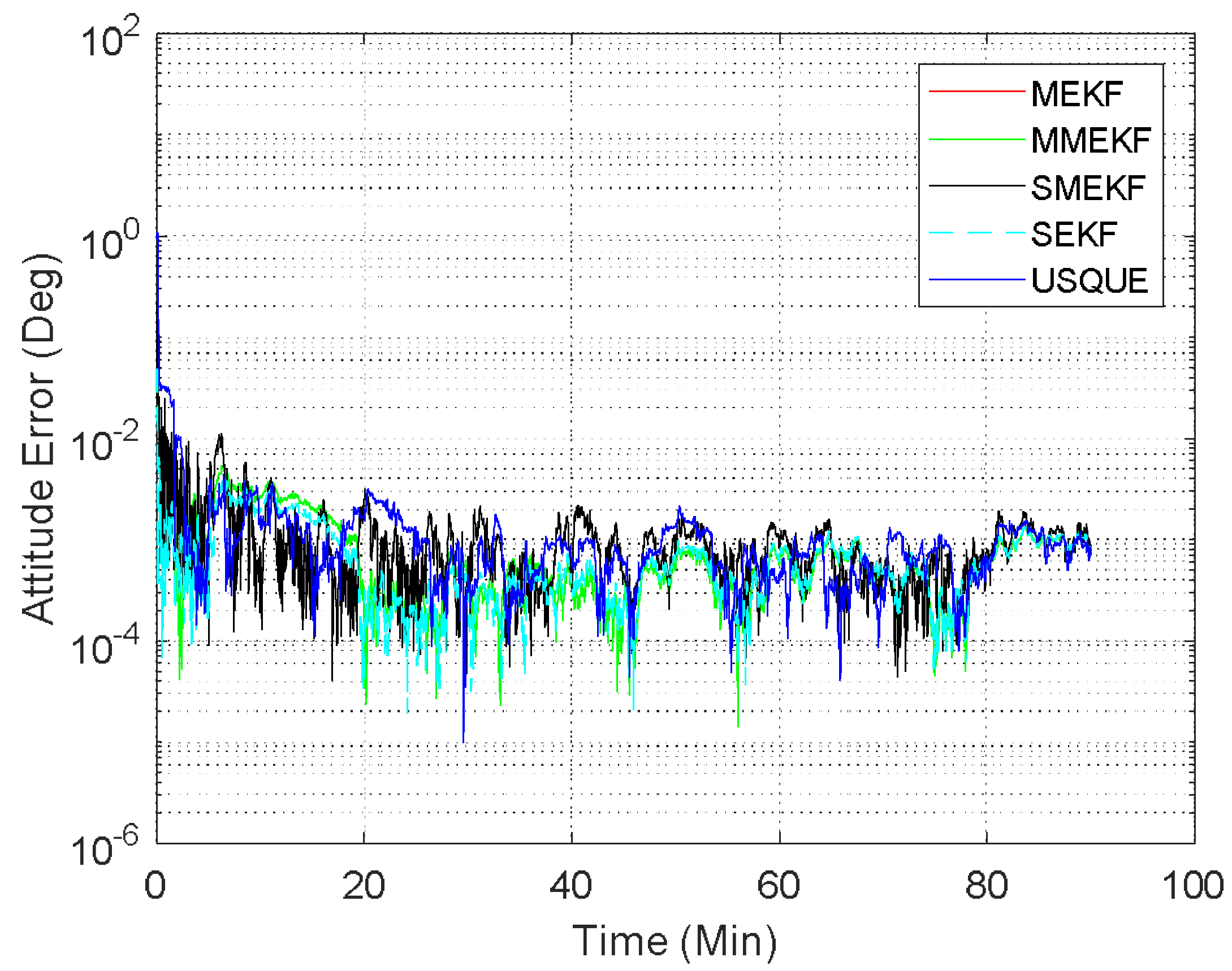
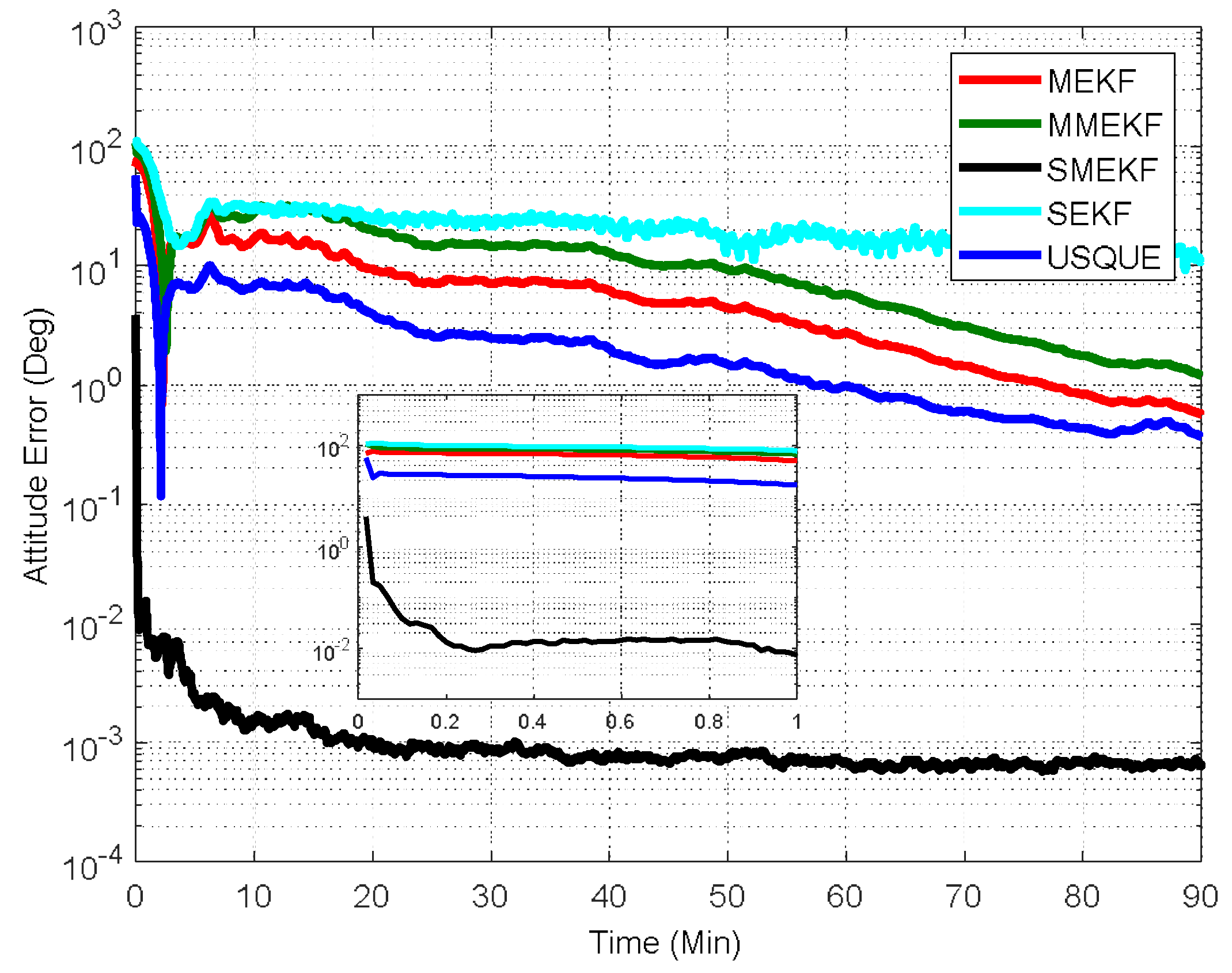
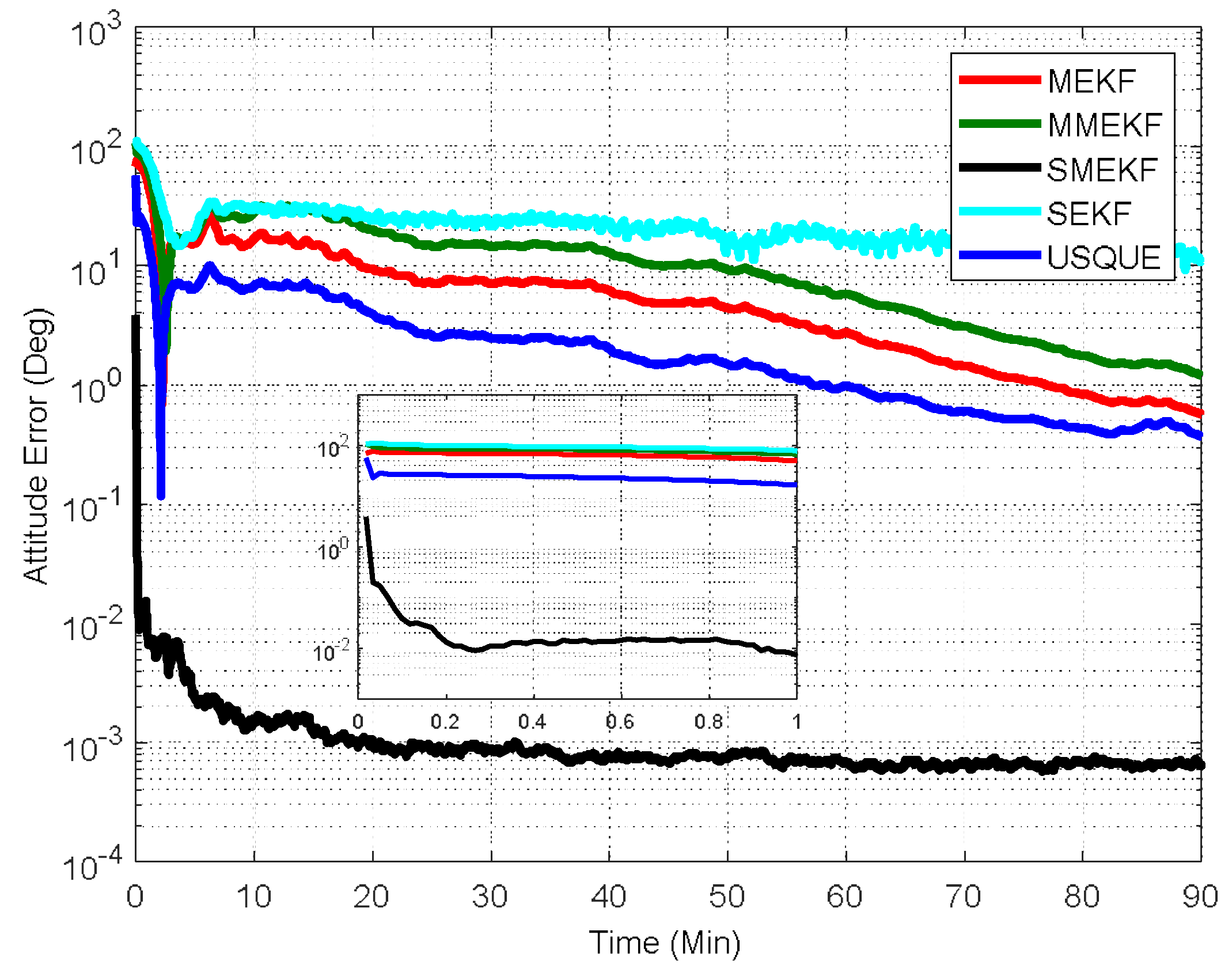
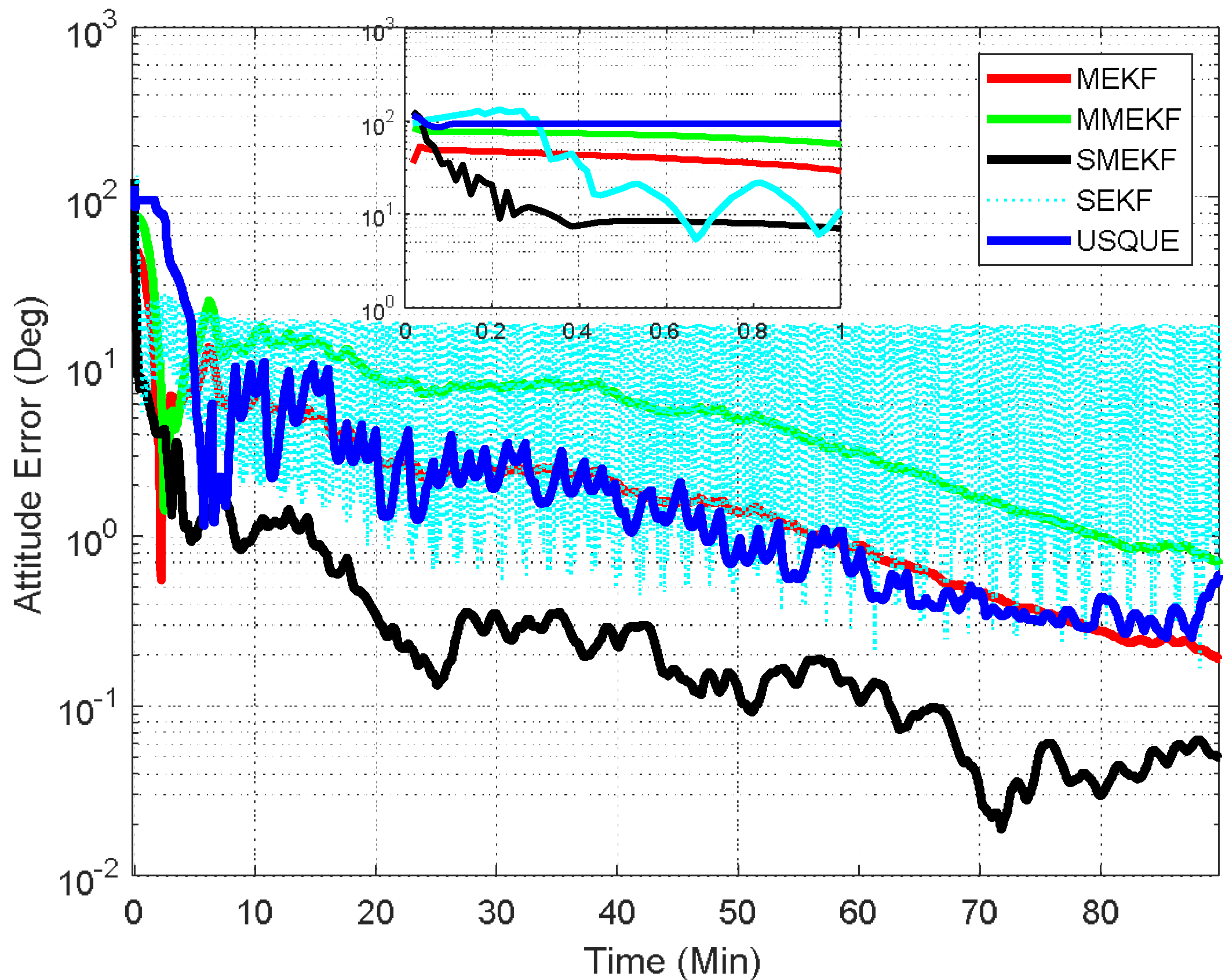
In the third case, the initial attitude covariance was set to
and the initial bias covariance is unchanged. This simulation illustrates a possible realistic scenario where the initial attitude estimate is totally unknown. The norm of the total attitude estimation error for this case is shown in
Figure 6. The performance details for the first minutes of each filter are illustrated in the sub-graph. In this case, the superiority of the SMEKF over other filters is more obvious. This indicates that the SMEKF can handle the large initial estimate error appropriately and is robust to a wide range of initial estimate error. Interestingly, the SEKF cannot even converge in this case, which indicates that applying the SEKF for the attitude estimate is superficially crude. The performance of the MEKF, MMEKF and USQUE is further degraded. From the three cases, it can be concluded that the robustness of the USQUE is compromised in this simulation example. In contrast, the SMEKF showed consistent performance even in these three cases.
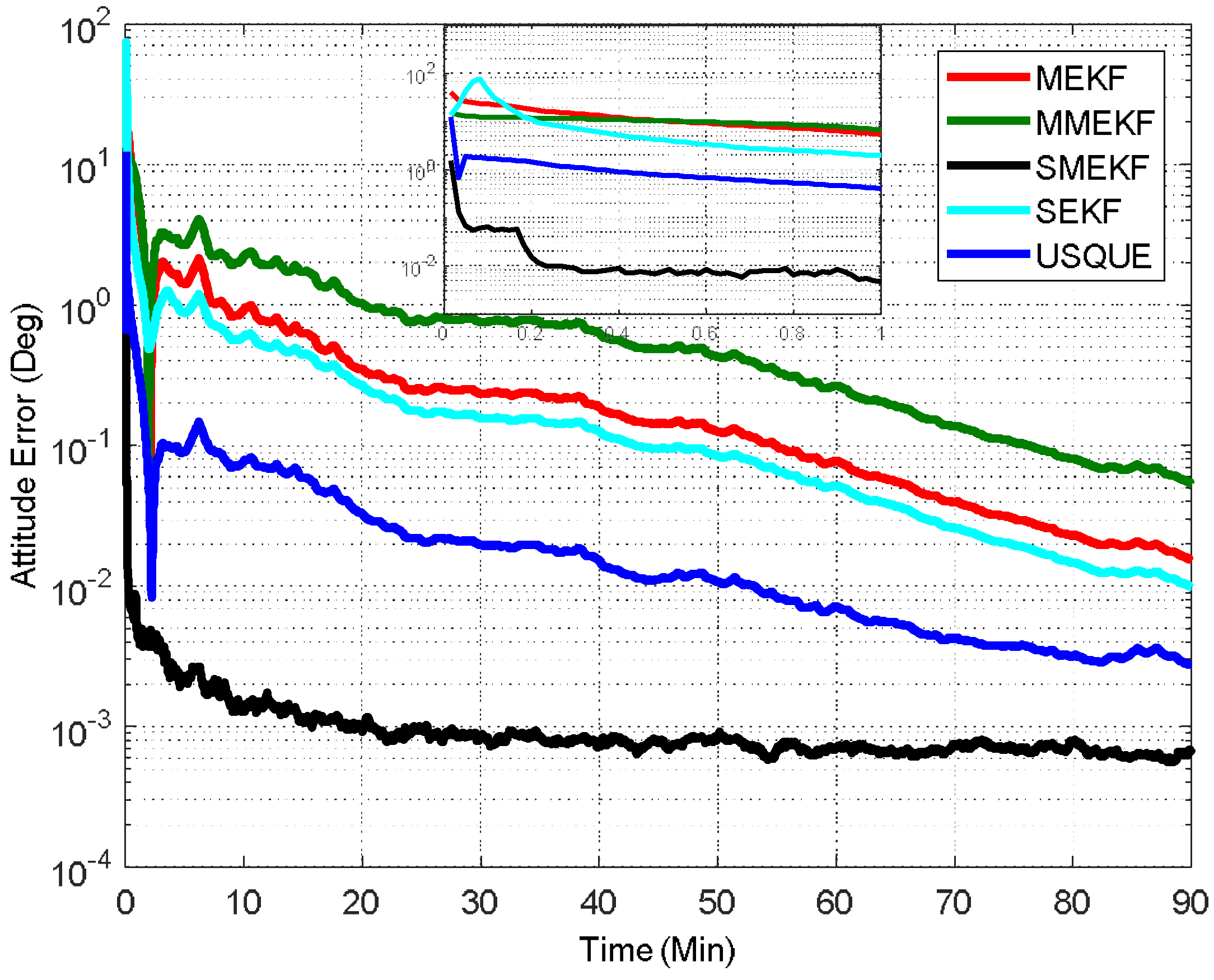
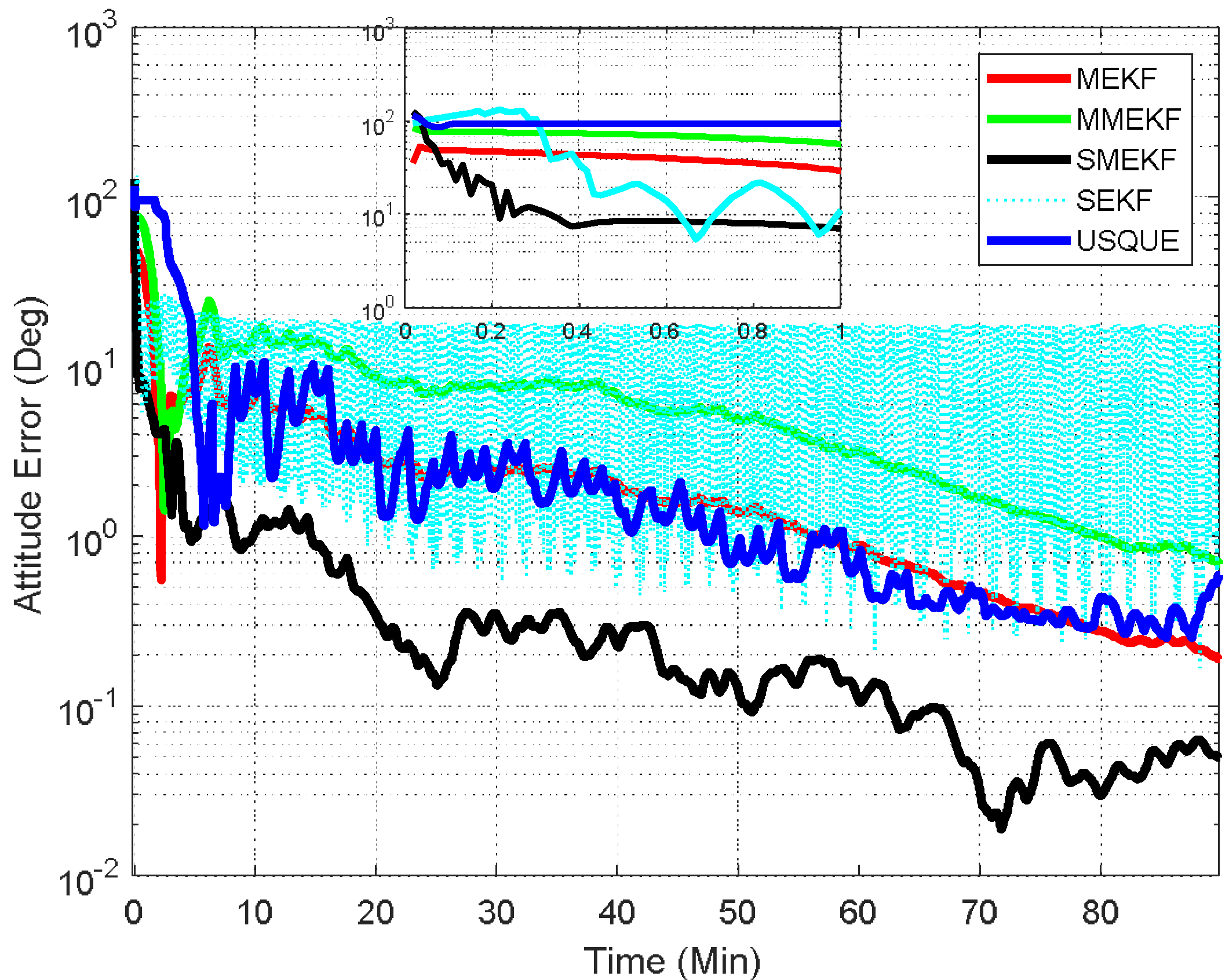
In the fourth case, the initial attitude covariance was set to
and the initial bias covariance was unchanged. This case is an extreme condition which may not occur in practice. This case is mainly used to evaluate these attitude estimators under such extreme conditions. The corresponding results are shown in
Figure 7. The performance details for the first minutes of each filter are illustrated in the sub-graph. It can be seen that in this case all these attitude estimators cannot converge to the steady-state as compared with the results in the last three cases. However, the superiority of the proposed SMEKF over other attitude estimators can still be observed in this case.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}