Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System

Abstract
:1. Introduction
2. Related Work
3. Methods
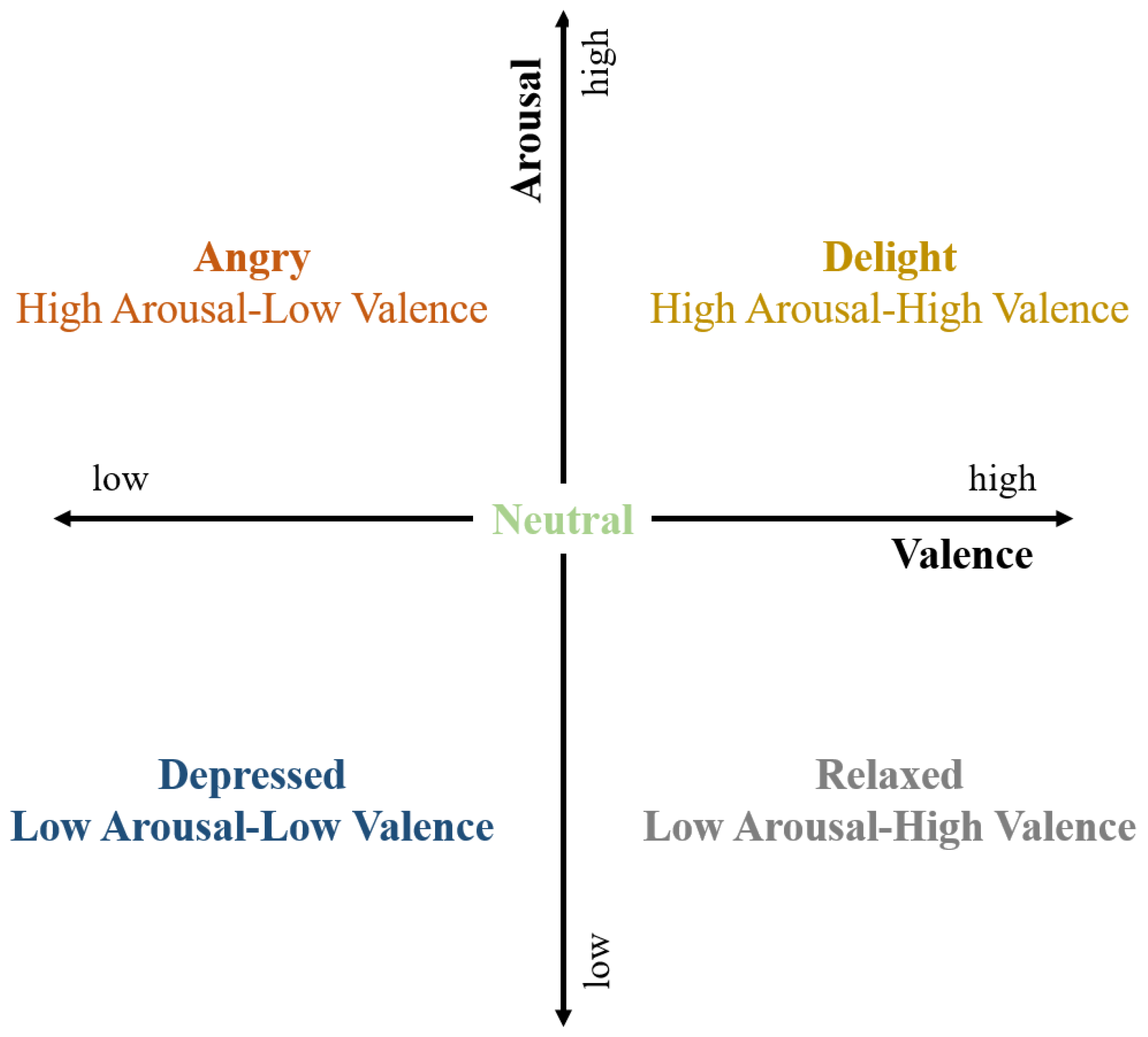
3.1. Multiple Label Classification
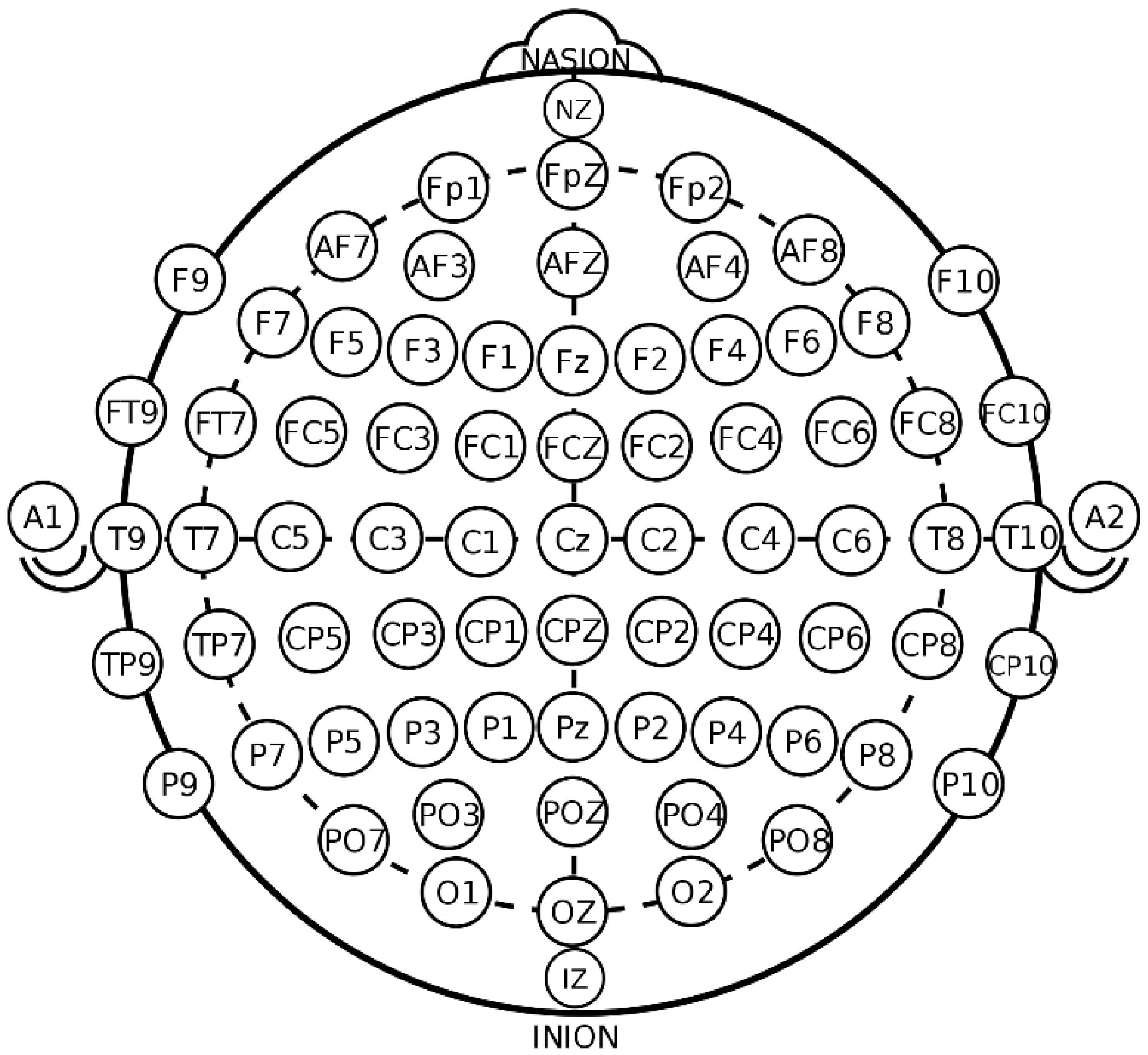
3.2. EEG Signal Transformation to Time to Frequency Axes
3.3. GSR Preprocessing Using Short Time Zero Crossing Rate
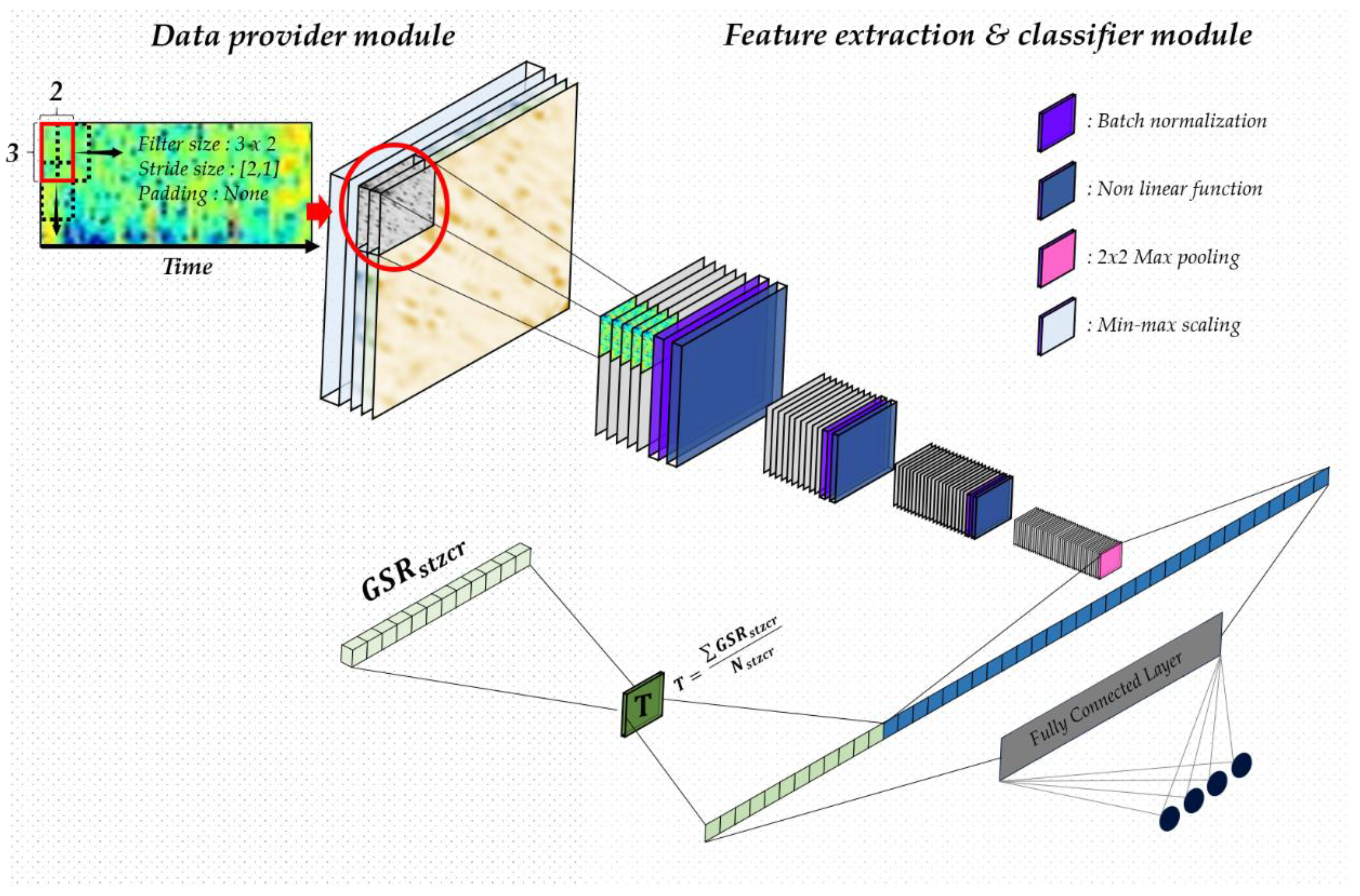
3.4. Fusion Convolution Neural Network Model for EEG Spectrograms and GSR Features
- (1)
- Normalize the batch data using the batch mean, , and variance, ,
- (2)
- Use the r and d values for scale and shift operations,
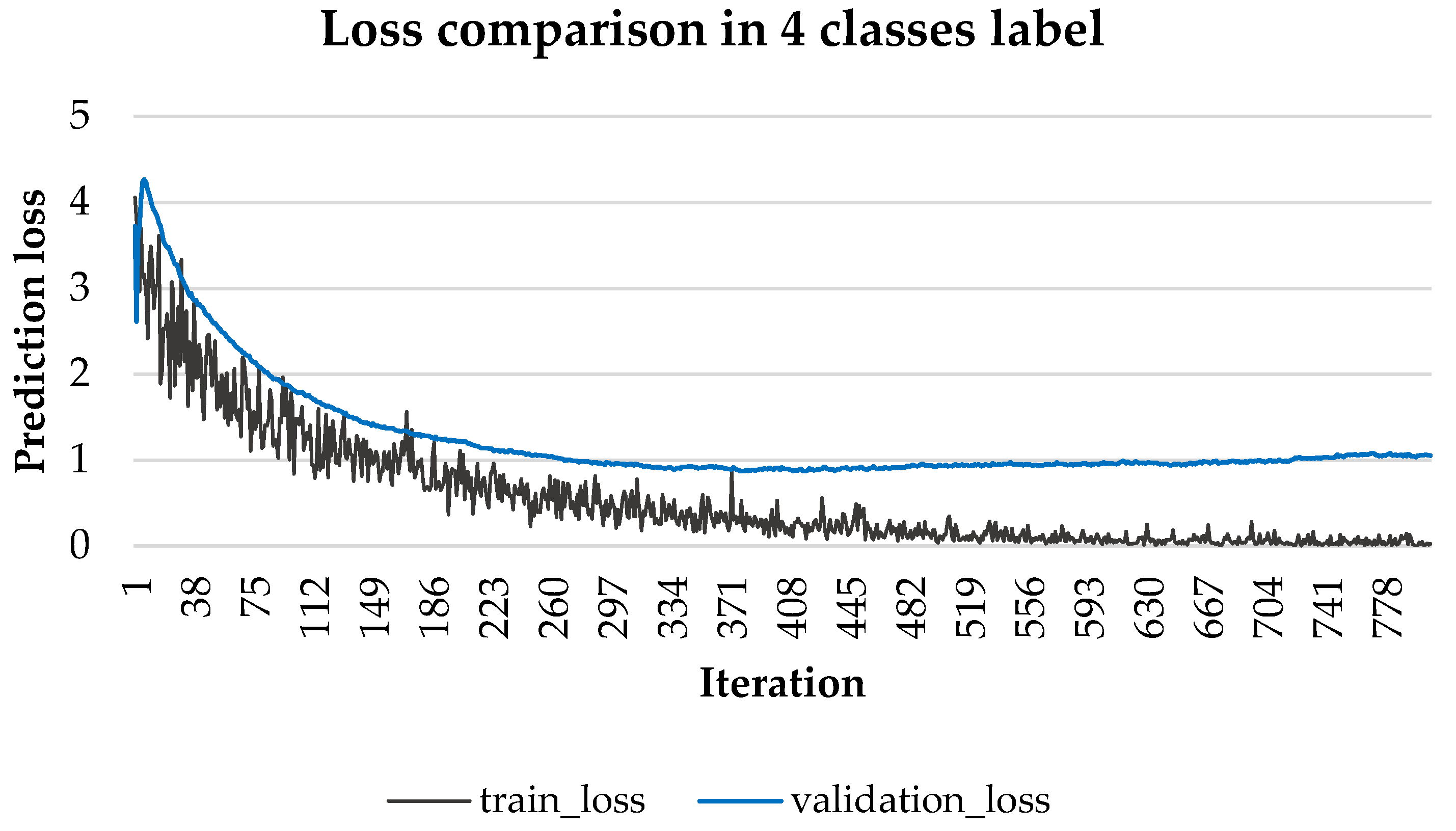
3.5. Training Strategy
4. Results and Discussions
4.1. Experiment Environment
4.2. Dataset
4.3. Performance Analysis
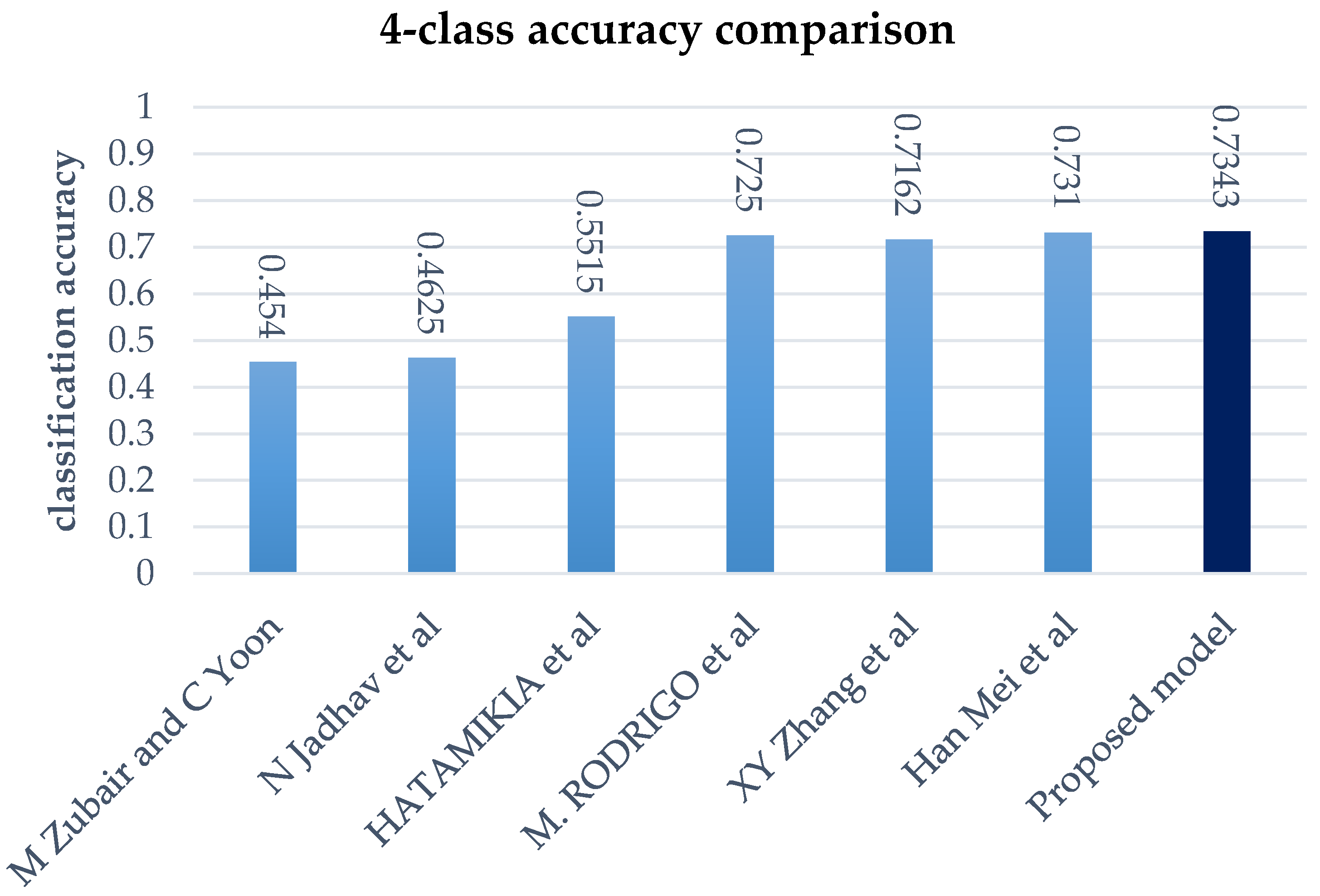
4.4. Comparison with Existing Models
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gunadi, I.G.A.; Harjoko, A.; Wardoyo, R.; Ramdhani, N. Fake smile detection using linear support vector machine. In Proceedings of the IEEE International Conference on Data and Software Engineering (ICoDSE), Yogyakarta, Indonesia, 25–26 November 2015; pp. 103–107. [Google Scholar]
- Wu, G.; Liu, G.; Hao, M. The analysis of emotion recognition from GSR based on PSO. In Proceedings of the IEEE International Symposium on Intelligence Information Processing and Trusted Computing (IPTC), Huanggang, China, 28–29 October 2010; pp. 360–363. [Google Scholar]
- Allen, J.J.B.; Coan, J.A.; Nazarian, M. Issues and assumptions on the road from raw signals to metrics of frontal EEG asymmetry in emotion. Biol. Psychol. 2004, 67, 183–218. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, L.A.; Trainor, L.J. Frontal brain electrical activity (EEG) distinguishes valence and intensity of musical emotions. Cognit. Emot. 2001, 15, 487–500. [Google Scholar] [CrossRef]
- Khalili, Z.; Moradi, M.H. Emotion detection using brain and peripheral signals. In Proceedings of the Biomedical Engineering Conference, Cairo, Egypt, 18–20 December 2008. [Google Scholar]
- Mu, L.; Lu, B.-L. Emotion classification based on gamma-band EEG. In Proceedings of the Annual International Conference of the IEEE, Minneapolis, MN, USA, 3–6 September 2009. [Google Scholar]
- Liu, Y.; Sourina, O. EEG based dominance level recognition for emotion-enabled interaction. In Proceedings of the IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012. [Google Scholar]
- Rozgic, V.; Vitaladevuni, S.N.; Prasad, R. Robust EEG emotion classification using segment level decision fusion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Yin, Z.; Wang, Y.; Liu, L.; Zhang, W.; Zhang, J. Cross-subject EEG feature selection for emotion recognition using transfer recursive feature elimination. Front. Neurorobot. 2017, 11, 19. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.J.; Yu, M.; Zhao, G.; Song, J.; Ge, Y.; Shi, Y. Real-time movie-induced discrete emotion recognition from EEG signals. IEEE Trans. Affect. Comput. 2017. [Google Scholar] [CrossRef]
- Chanel, G.; Karim, A.-A.; Thierry, P. Valence-arousal evaluation using physiological signals in an emotion recall paradigm. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Montreal, QC, Canada, 7–10 October 2007. [Google Scholar]
- Zheng, W.L.; Dong, B.N.; Lu, B.-L. Multimodal emotion recognition using EEG and eye tracking data. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014. [Google Scholar]
- Nie, D.; Wang, X.-W.; Shi, L.-C.; Lu, B.-L. EEG based emotion recognition during watching movies. In Proceedings of the 5th International IEEE/EMBS Conference on Neural Engineering, Cancun, Mexico, 27 April–1 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 667–670. [Google Scholar]
- Inuso, G.; La Foresta, F.; Mammone, N.; Morabito, F.C. Brain activity investigation by EEG processing: Wavelet analysis, kurtosis and Renyi's entropy for artifact detection. In Proceedings of the International Conference on Information Acquisition, Seogwipo-si, Korea, 8–11 July 2007; pp. 195–200. [Google Scholar]
- Rossetti, F.; Rodrigues, M.C.A.; de Oliveira, J.A.C.; Garcia-Cairasco, N. EEG wavelet analyses of the striatum-substantia nigra pars reticulata-superior colliculus circuitry: Audiogenic seizures and anticonvulsant drug administration in Wistar audiogenic rats (WAR strain). Epilepsy Res. 2006, 72, 192–208. [Google Scholar] [CrossRef] [PubMed]
- Akin, M.; Arserim, M.A.; Kiymik, M.K.; Turkoglu, I. A new approach for diagnosing epilepsy by using wavelet transform and neural networks. In Proceedings of the IEEE 23rd Annual International Conference on Engineering in Medicine and Biology, Istanbul, Turkey, 25–28 October 2001; pp. 1596–1599. [Google Scholar]
- Adeli, H.; Zhou, Z.; Dadmehr, N. Analysis of EEG records in an epileptic patient using wavelet transform. J. Neurosci. Methods 2003, 123, 69–87. [Google Scholar] [CrossRef]
- Adolphs, R.; Tranel, D.; Hamannb, S.; Youngc, A.W.; Calder, A.J.; Phelps, E.A.; Andersone, A.; Leef, G.P.; Damasio, A.R. Recognition of facial emotion in nine individuals with bilateral amygdala damage. Neuropsychologia 1999, 37, 1111–1117. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Pons, G.; Masip, D. Supervised Committee of Convolutional Neural networks in automated facial expression analysis. IEEE Trans. Affect. Comput. 2017. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, S.K.; Chellappa, R. Facenet2expnet: Regularizing a deep face recognition net for expression recognition. arXiv, 2016; arXiv:1609.06591. [Google Scholar]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Liu, Y.; Sourina, O. EEG based valence level recognition for real-time applications. In Proceedings of the IEEE international Conference on Cyberworlds, Darmstadt, Germany, 25–27 September 2012; pp. 53–60. [Google Scholar]
- Naser, D.S.; Saha, G. Recognition of emotions induced by music videos using DT-CWPT. In Proceedings of the IEEE Indian Conference on Medical Informatics and Telemedicine (ICMIT), Kharagpur, India, 28–30 March 2013; pp. 53–57. [Google Scholar]
- Chen, J.; Hu, B.; Moore, P.; Zhang, X.; Ma, X. Electroencephalogram based emotion assessment system using ontology and data mining techniques. Appl. Soft Comput. 2015, 30, 663–674. [Google Scholar] [CrossRef]
- Yoon, H.J.; Chung, S.Y. EEG based emotion estimation using Bayesian weighted-log-posterior function and perceptron convergence algorithm. Comput. Biol. Med. 2013, 43, 2230–2237. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Shang, Y. Modeling physiological data with deep belief networks. Int. J. Inf. Education Technol. 2013, 3, 505. [Google Scholar]
- Li, X.; Zhang, P.; Song, D.; Yu, G.; Hou, Y.; Hu, B. EEG based emotion identification using unsupervised deep feature learning. In Proceedings of the SIGIR2015 Workshop on Neuro-Physiological Methods in IR Research, Santiago, Chile, 13 August 2015. [Google Scholar]
- Yin, Z.; Zhao, M.; Wang, Y.; Yang, J.; Zhang, J. Recognition of emotions using multimodal physiological signals and an ensemble deep learning model. Comput. Methods Programs Biomed. 2017, 140, 93–110. [Google Scholar] [CrossRef] [PubMed]
- Christie, I.C.; Friedman, B.H. Autonomic specificity of discrete emotion and dimensions of affective space: A multivariate approach. Int. J. Psychophysiol. 2004, 51, 143–153. [Google Scholar] [CrossRef] [PubMed]
- Tabar, Y.R.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2016, 14, 016003. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Karyana, D.N.; Wisesty, U.N.; Nasri, J. Klasifikasi EEG menggunakan Deep Neural Network Dengan Stacked Denoising Autoencoder. Proc. Eng. 2016, 3, 5296–5303. [Google Scholar]
- Zubair, M.; Yoon, C. EEG Based Classification of Human Emotions Using Discrete Wavelet Transform. In Proceedings of the Conference on IT Convergence and Security 2017, Seoul, Korea, 25–28 September 2017; pp. 21–28. [Google Scholar]
- Jadhav, N.; Manthalkar, R.; Joshi, Y. Electroencephalography based emotion recognition using gray-level co-occurrence matrix features. In Proceedings of the International Conference on Computer Vision and Image Processing, Roorkee, India, 26–28 February 2016; pp. 335–343. [Google Scholar]
- Hatamikia, S.; Nasrabadi, A.M. Recognition of emotional states induced by music videos based on nonlinear feature extraction and som classification. In Proceedings of the IEEE 21st Iranian Conference on Biomedical Engineering (ICBME), Tehran, Iran, 26–28 November 2014; pp. 333–337. [Google Scholar]
- Martínez-Rodrigo, A.; García-Martínez, B.; Alcaraz, R.; Fernández-Caballero, A.; González, P. Study of Electroencephalographic Signal Regularity for Automatic Emotion Recognition. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Philadelphia, PA, USA, 7–10 November 2017; pp. 766–777. [Google Scholar]
- Zhang, X.-Y.; Wand, W.-R.; Shen, C.Y.; Sun, Y.; Huang, L.-X. Extraction of EEG Components Based on Time-Frequency Blind Source Separation. In Proceedings of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Matsue, Japan, 12–15 August 2017; pp. 3–10. [Google Scholar]
- Mei, H.; Xu, X. EEG based emotion classification using convolutional neural network. In Proceedings of the IEEE International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Shenzhen, China, 15–17 December 2017; pp. 130–135. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label 1 | Data quantity |
|---|---|
| HAHV | 458 |
| HALV | 294 |
| LAHV | 255 |
| LALV | 273 |
| Total | 1280 |
| Label 1 | Data quantity | Label 2 | Data quantity |
|---|---|---|---|
| HA | 752 | HV | 713 |
| LA | 528 | LV | 567 |
| Total | 1280 | Total | 1280 |
| CPU | Intel Core i5-6600 |
| GPU | NVIDIA GeForce GTX 1070 8GBytes |
| RAM | DDR4 16GBytes |
| OS | Ubuntu 16.04. |
| Frameworks | Tensorflow1.3 MATLAB/ EEG toolbox |
| Results A 1 | Results B 2 | |||||
|---|---|---|---|---|---|---|
| Clssification Methods | Two Class Classification Accuracy 3 | Four Class Classification Accuracy 4 | Two Class Classification Accuracy 3 | Four Class Classification Accuracy 4 | ||
| Arousal | Valence | Arousal | Valence | |||
| Proposed Fusion Model | 0.7812 | 0.8125 | 0.7500 | 0.7656 | 0.8046 | 0.7343 |
| Model | Accuracy | ||
|---|---|---|---|
| Arousal | Valence | ||
| CNS feature based single modality | [23] | 0.6200 | 0.5760 |
| PNS feature based single modality | [23] | 0.5700 | 0.6270 |
| Liu and Sourina | [24] | 0.7651 | 0.5080 |
| Naser and Saha | [25] | 0.6620 | 0.6430 |
| Chen et al. | [26] | 0.6909 | 0.6789 |
| Yoon and Chung | [27] | 0.7010 | 0.7090 |
| Li et al. | [29] | 0.6420 | 0.5840 |
| Wang and Shang | [28] | 0.5120 | 0.6090 |
| Proposed fusion CNN model | 0.7656 | 0.8046 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, Y.-H.; Shin, S.-B.; Kim, S.-D. Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System. Sensors 2018, 18, 1383. https://doi.org/10.3390/s18051383
Kwon Y-H, Shin S-B, Kim S-D. Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System. Sensors. 2018; 18(5):1383. https://doi.org/10.3390/s18051383
Chicago/Turabian StyleKwon, Yea-Hoon, Sae-Byuk Shin, and Shin-Dug Kim. 2018. "Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System" Sensors 18, no. 5: 1383. https://doi.org/10.3390/s18051383
APA StyleKwon, Y.-H., Shin, S.-B., & Kim, S.-D. (2018). Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System. Sensors, 18(5), 1383. https://doi.org/10.3390/s18051383