Abstract
In this paper, we compare six known linear distributed average consensus algorithms on a sensor network in terms of convergence time (and therefore, in terms of the number of transmissions required). The selected network topologies for the analysis (comparison) are the cycle and the path. Specifically, in the present paper, we compute closed-form expressions for the convergence time of four known deterministic algorithms and closed-form bounds for the convergence time of two known randomized algorithms on cycles and paths. Moreover, we also compute a closed-form expression for the convergence time of the fastest deterministic algorithm considered on grids.
1. Introduction
A distributed averaging (or average consensus) algorithm obtains in each sensor the average (arithmetic mean) of the values measured by all the sensors of a sensor network in a distributed way.
The most common distributed averaging algorithms are linear and iterative:
where:
is a real vector, n is the number of sensors of the network, which we label with , is the value measured by the sensor , is the value computed by the sensor in time and the weighting matrix is an real sparse matrix satisfying that if two sensors and are not connected (i.e., if and cannot interchange information), then . From the point of view of communication protocols, there exist efficient ways of implementing synchronous algorithms of the form of (1). (see, e.g., [1]). The linear distributed averaging algorithms can be classified as deterministic or randomized depending on the nature of the weighting matrices .
1.1. Deterministic Linear Distributed Averaging Algorithms
Several well-known deterministic linear distributed averaging algorithms can be found in [2] and [3]. Those algorithms are time-invariant and have symmetric weights, that is, the deterministic weighting matrix is symmetric and does not depend on t (and consequently, ).
In [2], the authors search among all the symmetric weighting matrices W the one that makes (1) the fastest possible and show that such a matrix can be obtained by numerically solving a convex optimization problem. This algorithm is called the fastest linear time-invariant (LTI) distributed averaging algorithm for symmetric weights. It should be mentioned that in [4], the authors proposed an in-network algorithm for finding such an optimal weighting matrix.
In [2], the authors also give a slower algorithm: the fastest constant edge weights algorithm. In this other algorithm, they consider a particular structure of symmetric weighting matrices that depends on a single parameter and find the value of that parameter that makes (1) the fastest possible.
In [3], another two algorithms can be found: the maximum-degree weights algorithm and the Metropolis–Hastings algorithm.
For other deterministic linear distributed averaging algorithms, we refer the reader to [5] and the references therein.
1.2. Randomized Linear Distributed Averaging Algorithms
For the randomized case, a well-known linear distributed averaging algorithm was given in [6]. That algorithm is called the pairwise gossip algorithm because only two randomly-selected sensors interchange information at each time instant t.
Another well-known randomized algorithm can be found in [7]. That algorithm is called the broadcast gossip algorithm because a single sensor is randomly selected at each time instant t and broadcasts its value to all its neighboring sensors. The broadcast gossip algorithm is a linear distributed consensus algorithm rather than a linear distributed averaging algorithm. However, the broadcast gossip algorithm converges to a random consensus value, which is, in expectation, the average of the values measured by all the sensors of the network. If one uses the directed version of the broadcast gossip algorithm [8] in a symmetric graph, one would converge to the true average.
For other randomized linear distributed averaging algorithms, we refer the reader to [9] and the references therein. The linear distributed averaging algorithms reviewed in Section 1.1 and Section 1.2 are the most cited algorithms in the literature on the topic.
1.3. Our Contribution
A key feature of a distributed averaging algorithm is its convergence time, because it allows one to establish the stopping criterion for the iterative algorithm. The convergence time is defined as the number of iterations t required in (1) until the effective value computed by the sensors, , has approached the steady state sufficiently close (to a threshold ). In the literature, we have not found closed-form expressions for the convergence time of the six linear distributed averaging algorithms mentioned in Section 1.1 and Section 1.2. A mathematical expression is said to be a closed-form expression if it is written in terms of a finite number of elementary functions (i.e., in terms of a finite number of constants, arithmetic operations, roots, exponentials, natural logarithms and trigonometric functions). In the present paper, we compute closed-form expressions for the convergence time of the deterministic algorithms and closed-form upper bounds for the convergence time of the randomized algorithms on two common network topologies: the cycle and the path. Observe that these closed-form formulas give us upper bounds for the convergence time of the considered algorithms (stopping criteria) on any network that contains as a subgraph a cycle or a path with the same number of sensors. Specifically, in this paper, we compute:
- a closed-form expression for the convergence time of the fastest LTI distributed averaging algorithm for symmetric weights on the considered topologies (see Section 2.1); moreover, we also compute a closed-form expression for the convergence time of this algorithm on a grid;
- a closed-form expression for the convergence time of the fastest constant edge weights algorithm on the considered topologies (see Section 2.2);
- a closed-form expression for the convergence time of the maximum-degree weights algorithm on the considered topologies (see Section 2.3);
- a closed-form expression for the convergence time of the Metropolis–Hastings algorithm on the considered topologies (see Section 2.3);
- closed-form lower and upper bounds for the convergence time of the pairwise gossip algorithm on the considered topologies (see Section 3.1);
- closed-form lower and upper bounds for the convergence time of the broadcast gossip algorithm on the considered topologies (see Section 3.2).
From these closed-form formulas, we study the asymptotic behavior of the convergence time of the considered algorithms as the number of sensors of the network grows. The obtained asymptotic and non-asymptotic results allow us to compare the considered algorithms in terms of convergence time and, consequently, in terms of the number of transmissions required, as well (see Section 4 and Section 5). The knowledge of the number of transmissions required lets us know the energy consumption of the distributed technique. The knowledge of the energy consumption is a key factor in the design of a new wireless sensor network (WSN), where one has to decide the number of nodes and the network topology. It should be mentioned that when designing new WSNs, cycles, paths and grids are topologies that are considered frequently.
2. Convergence Time of Deterministic Linear Distributed Averaging Algorithms
Different definitions of convergence time are used in the literature. We have found three different definitions for the convergence time of a deterministic linear distributed averaging algorithm (see [2,10,11]). In this paper, we consider the definition of -convergence time given in [11]:
where , is the spectral norm and , with being the matrix of ones and ⊤ denoting the transpose. If we replace the spectral norm by the infinity norm in that definition, we obtain the definition of -convergence time given in [10]. If the deterministic matrix in (1) does not depend on t, we denote the -convergence time by .
2.1. Convergence Time of the Fastest LTI Distributed Averaging Algorithm for Symmetric Weights
In this section, we give a closed-form expression for the -convergence time of the fastest LTI distributed averaging algorithm for symmetric weights, and we study its asymptotic behavior as the number of sensors of the network grows. We consider three common network topologies: the cycle, the grid and the path (see Figure 1).
Figure 1.
Considered network topologies with 16 sensors.
2.1.1. The Cycle
Let:
Using (4), Theorem 1 gives the expression of the weighting matrix of the fastest LTI distributed averaging algorithm for symmetric weights on a cycle with n sensors.
Theorem 1.
Let , with . Then, is the weighting matrix of the fastest LTI distributed averaging algorithm for symmetric weights on a cycle with n sensors, where:
with:
Proof.
See Appendix B. ☐
We now give a closed-form expression for the -convergence time of the fastest LTI distributed averaging algorithm for symmetric weights on a cycle. We also study the asymptotic behavior of this convergence time as the number of sensors of the cycle grows.
We first introduce some notation: Two sequences of numbers and are said to be asymptotically equal, and write , if and only if (see, e.g., [12] (p. 396)), and, consequently,
Let be two non-negative functions. We write (respectively, ) if there exist and such that (respectively, ) for all . If and , then we write .
Theorem 2.
Consider and , with . Let be as in Theorem 1. Then,
where log is the natural logarithm and denotes the smallest integer not less than x. Moreover,
Proof.
See Appendix C. ☐
Since the number of transmissions per iteration on a cycle with n sensors is n for the fastest LTI distributed averaging algorithm for symmetric weights, the total number of transmissions required for iterations is . From Theorem 2, we obtain:
and hence, .
2.1.2. The Grid
Let:
be the matrix for , and . We define:
where ⊗ is the Kronecker product. Using (12), Theorem 3 gives the expression of the weighting matrix of the fastest LTI distributed averaging algorithm for symmetric weights on a grid of r rows and c columns.
Theorem 3.
Let , with . Then, the matrix is the weighting matrix of the fastest LTI distributed averaging algorithm for symmetric weights on a grid of r rows and c columns.
Proof.
See Appendix D. ☐
We now give a closed-form expression for the -convergence time of the fastest LTI distributed averaging algorithm for symmetric weights on a grid of r rows and c columns. We also study the asymptotic behavior of this convergence time as the number of rows of the grid grows.
Theorem 4.
Consider and , with . Without loss of generality, we assume . Then,
Moreover,
and consequently,
Proof.
Since the number of transmissions per iteration on a grid of r rows and c columns is for the fastest LTI distributed averaging algorithm for symmetric weights, the total number of transmissions required for iterations is:
If , from Theorem 4, we obtain:
and hence, . Observe that from (13), the optimal configuration for a grid with n sensors is obtained when .
2.1.3. The Path
Since the path with n sensors can be seen as a grid of n rows and one column, from Theorem 3, we conclude that is the weighting matrix of the fastest LTI distributed averaging algorithm for symmetric weights on a path of n sensors, and from Theorem 4, we conclude that:
Moreover,
and consequently,
Finally, from (16), we obtain:
and hence, .
2.2. Convergence Time of the Fastest Constant Edge Weights Algorithm
In [2], the authors consider the real symmetric weighting matrices given by:
where denotes the degree of the sensor (i.e., the number of sensors different from connected to ).
Observe that the weighting matrices of the fastest LTI distributed averaging algorithms for symmetric weights given in Section 2.1 for a cycle and a path, namely and , can be regarded as in (22) taking and , respectively. Therefore, the closed-form expression for the -convergence time of the fastest constant edge weights algorithm is given by Theorem 2 on a cycle and by Theorem 4 on a path. That is, the -convergence time of the fastest constant edge weights algorithm and the -convergence time of the fastest LTI distributed averaging algorithm for symmetric weights is the same on a cycle and on a path.
2.3. Convergence Time of the Maximum-Degree Weights Algorithm and of the Metropolis–Hastings Algorithm
For the maximum-degree weights algorithm [3], the weighting matrix considered is the real symmetric matrix in (22) with:
On the other hand, for the Metropolis–Hastings algorithm [3], the entries of the weighting matrix are given by:
where A is the adjacency matrix of the network, that is A is the real symmetric matrix given by:
2.3.1. The Cycle
Observe that the weighting matrices of the maximum-degree weights algorithm and the Metropolis–Hastings algorithm for a cycle with n sensors can be regarded as in (4) taking .
We now give a closed-form expression for the -convergence time of the maximum-degree weights algorithm and of the Metropolis–Hastings algorithm on a cycle. We also study the asymptotic behavior of this convergence time as the number of sensors of the cycle grows.
Theorem 5.
Consider and , with . Then:
Moreover,
and therefore,
Proof.
Since the number of transmissions per iteration on a cycle with n sensors is n for both algorithms, the total number of transmissions required for iterations is . From Theorem 5, we obtain:
and thus, .
2.3.2. The Path
Observe that the weighting matrices of the maximum-degree weights algorithm and of the Metropolis–Hastings algorithm for a path with n sensors can be regarded as in (11) taking .
We now give a closed-form expression for the -convergence time of the maximum-degree weights algorithm and of the Metropolis–Hastings algorithm on a path. We also study the asymptotic behavior of this convergence time as the number of sensors of the path grows.
Theorem 6.
Consider and , with . Then:
Moreover,
and therefore,
Proof.
Since the number of transmissions per iteration on a path with n sensors is n for both algorithms, the total number of transmissions required for iterations is . From Theorem 6, we obtain:
and thus, .
3. Convergence Time of Randomized Linear Distributed Averaging Algorithms
3.1. Lower and Upper Bounds for the Convergence Time of the Pairwise Gossip Algorithm
In the literature, we have found two different definitions for the convergence time of a randomized linear distributed averaging algorithm (see [6,7]). In this subsection, we consider the definition of -convergence time for a randomized linear distributed averaging algorithm given in [6]:
where and denotes probability.
We prove in Theorem A1 (Appendix A) that the definitions of -convergence time in (3) and (36) coincide when applied to deterministic LTI distributed averaging algorithms with symmetric weights (in particular, the four algorithms considered in Section 2). For those algorithms, we also obtain from Theorem A1 that:
where denotes the definition of convergence time given in [2].
We recall here that in the pairwise gossip algorithm [6], only two sensors interchange information at each time instant t. These two sensors and are randomly selected at each time instant t, and the weighting matrix , which we denote by , is the symmetric matrix given by:
for all .
In [6], a lower and an upper bound for the -convergence time of the pairwise gossip algorithm were introduced. We now give a closed-form expression for those bounds on a cycle and on a path, and we study their asymptotic behavior as the number of sensors of the network grows.
3.1.1. The Cycle
Theorem 7.
Consider and , with . Suppose that is the weighting matrix of the pairwise gossip algorithm given in (38) on a cycle with n sensors, where the edge is randomly selected at each time instant with probability . Then:
with:
Moreover,
and:
Proof.
Since the number of transmissions per iteration on a cycle with n sensors is two for the pairwise gossip algorithm, the total number of transmissions required for iterations is . From Theorem 7, we obtain and .
3.1.2. The Path
Theorem 8.
Consider and , with . Suppose that is the weighting matrix of the pairwise gossip algorithm given in (38) on a path with n sensors, where the edge is randomly selected at each time instant with probability . Then:
with:
Moreover,
and:
Proof.
Since the number of transmissions per iteration on a path with n sensors is two for the pairwise gossip algorithm, the total number of transmissions required for iterations is . From Theorem 8, we obtain and .
3.2. Lower and Upper Bounds for the Convergence Time of the Broadcast Gossip Algorithm
We begin this subsection with the definition of -convergence time for a randomized linear distributed averaging algorithm given in [7] (Equation (42)):
where .
It can be proven that the definitions of -convergence time in (36) and (49) coincide when applied to algorithms in which the matrix satisfies for all (in particular, the pairwise gossip algorithm and deterministic LTI distributed averaging algorithms with symmetric weights).
Observe that (49) is actually a definition for the convergence time of linear distributed consensus algorithms, not only of linear distributed averaging algorithms.
We recall here that in the broadcast gossip algorithm, a single sensor broadcasts at each time instant t. This sensor is randomly selected at each time instant t with probability , and the weighting matrix is given by:
for all , where and A is the adjacency matrix of the network. We denote by the weighting matrix in (50) when is the optimal parameter: (see [7] (Section V)).
In [7], a lower and an upper bound for the -convergence time of the broadcast gossip algorithm were introduced. We now give a closed-form expression for and for those bounds on a cycle and on a path. We also study the asymptotic behavior of the bounds as the number of sensors of the network grows.
3.2.1. The Cycle
Theorem 9.
Consider and , with . Suppose that is the weighting matrix in (50) when the network is a cycle with n sensors and φ is the optimal parameter: . Then:
and:
with:
Moreover,
and:
Proof.
See Appendix E. ☐
Since the number of transmissions per iteration on a cycle with n sensors is one for the broadcast gossip algorithm, the total number of transmissions required for iterations is . From Theorem 9, we obtain and .
3.2.2. The Path
Theorem 10.
Consider and , with . Suppose that is the weighting matrix in (50) when the network is a path with n sensors and φ is the optimal parameter: . Then:
and:
with:
Moreover,
and:
Proof.
See Appendix F. ☐
Since the number of transmissions per iteration on a path with n sensors is one for the broadcast gossip algorithm, the total number of transmissions required for iterations is . From Theorem 10, we obtain and .
4. Discussion
As in this paper we have used the same definition of converge time for both deterministic and randomized linear distributed averaging algorithms (namely, the one in (49)), the results given in Section 2 and Section 3 allow us to compare the considered algorithms on a cycle and on a path in terms of convergence time and, consequently, in terms of the number of transmissions required, as well. In particular, these results show the following:
- The behavior of the considered deterministic linear distributed averaging algorithms is as good as the behavior of the considered randomized ones in terms of the number of transmissions required on a cycle and on a path with n sensors: .
- For a large enough number of sensors and regardless of the considered distributed averaging algorithm, the number of transmissions required on a path is four times larger than the number of transmissions required on a cycle.
5. Numerical Examples
For the numerical examples, we first consider a cycle and a path with five and 10 sensors. For each network topology, we present a figure: Figure 2 for the cycle and Figure 3 for the path. Figure 2 (resp. Figure 3) shows the number of transmissions of the fastest LTI distributed averaging algorithm for symmetric weights (resp. ) and of the Metropolis–Hastings algorithm (resp. ) with . The figure also shows the lower bound, , and upper bound, , given for the number of transmissions of the pairwise gossip algorithm, and the lower bound, , and upper bound, , given for the number of transmissions of the broadcast gossip algorithm (resp. , , and ). Furthermore, the figure shows the average number of transmissions of the pairwise gossip algorithm, , and of the broadcast gossip algorithm, , (resp. and ), that we have computed by using Monte Carlo simulations. In those simulations, we have performed 1000 repetitions of the corresponding algorithm for each , and we have considered that the values measured by the sensors, with , are independent identically distributed random variables with unit-variance, zero-mean and uniform distribution.
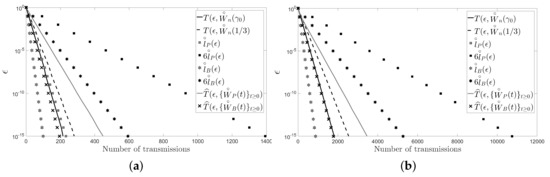
Figure 2.
(a) A cycle with five sensors; (b) a cycle with 10 sensors.
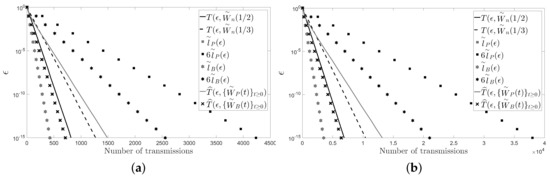
Figure 3.
(a) A path with five sensors; (b) a path with 10 sensors.
In this section, we present another two figures: Figure 4 and Figure 5. Unlike in Figure 2 and Figure 3, in Figure 4 and Figure 5, we have fixed instead of the number of sensors n of the network. Specifically, we have chosen and with .
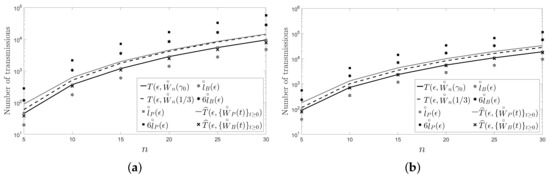
Figure 4.
A cycle: (a) ; (b) .
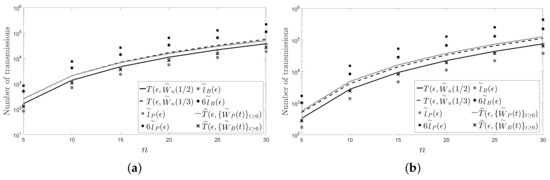
Figure 5.
A path: (a) ; (a) .
In the figures, it can be observed that the Metropolis–Hastings algorithm behaves on average better than the pairwise gossip algorithm in terms of the number of transmissions required on the considered networks. It can also be observed that the broadcast gossip algorithm behaves on average approximately equal to the fastest LTI distributed averaging algorithm for symmetric weights in terms of the number of transmissions required on those networks. However, we recall here that the broadcast gossip algorithm converges to a random consensus value instead of to the average consensus value, and it should be executed several times in order to get that average value in every sensor.
6. Conclusions
In this paper, we have studied the convergence time of six known linear distributed averaging algorithms. We have considered both deterministic (the fastest LTI distributed averaging algorithm for symmetric weights, the fastest constant edge weights algorithm, the maximum-degree weights algorithm and the Metropolis–Hastings algorithm) and randomized (the pairwise gossip algorithm and the broadcast gossip algorithm) linear distributed averaging algorithms. In the literature, we have not found closed-form expressions for the convergence time of the considered algorithms. We have computed closed-form expressions for the convergence time of the deterministic algorithms and closed-form upper bounds for the convergence time of the randomized algorithms on two common network topologies: the cycle and the path. Moreover, we have also computed a closed-form expression for the convergence time of the fastest LTI algorithm on a grid. From the computed closed-form formulas, we have studied the asymptotic behavior of the convergence time of the considered algorithms as the number of sensors of the considered networks grows.
Although there exist different definitions of convergence time in the literature, in this paper, we have proven that one of them (namely, the one in (49)) encompasses all the others for the algorithms here considered. As we have used the definition of converge time in (49) for both deterministic and randomized linear distributed averaging algorithms, the obtained closed-form formulas and asymptotic results allow us to compare the considered algorithms on cycles and paths in terms of convergence time and, consequently, in terms of the number of transmissions required, as well.
We now summarize the most remarkable conclusions:
- The best algorithm among the considered deterministic distributed averaging algorithms is not worse than the best algorithm among the considered randomized distributed averaging algorithms for cycles and paths.
- The weighting matrix of the fastest LTI distributed averaging algorithm for symmetric weights and the weighting matrix of the fastest constant edge weights algorithm are the same on cycles and on paths.
- The number of transmissions required on a path with n sensors is asymptotically four-times larger than the number of transmissions required on a cycle with the same number of sensors.
- The number of transmissions required grows as on cycles and on paths for the six algorithms considered.
- For the fastest LTI algorithm, the number of transmissions required grows as on a square grid of n sensors (i.e., ).
A future research direction of this work would be to generalize the analysis presented in the paper to other network topologies. In particular, networks that can be decomposed into cycles and paths could be studied.
Acknowledgments
This work was supported in part by the Spanish Ministry of Economy and Competitiveness through the RACHELproject (TEC2013-47141-C4-2-R), the CARMENproject (TEC2016-75067-C4-3-R) and the COMONSENSnetwork (TEC2015-69648-REDC).
Author Contributions
Jesús Gutiérrez-Gutiérrez conceived the research question. Jesús Gutiérrez-Gutiérrez, Marta Zárraga-Rodríguez and Xabier Insausti proved the main results. Xabier Insausti performed the simulations. Jesús Gutiérrez-Gutiérrez, Marta Zárraga-Rodríguez and Xabier Insausti wrote the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Comparison of Several Definitions of Convergence Time
We begin by giving a property of the spectral norm. Its proof is implicit in the Appendix of [1].
Lemma A1.
Let B and P be two real symmetric matrices with (or equivalently, ). Suppose that P is idempotent. Then:
- for all .
- for all .
- for all .
We recall that an matrix A is idempotent if and only if . An example of idempotent matrix is with , since for all .
The following result gives an eigenvalue decomposition for the matrix for all .
Lemma A2.
If , then , where is the Fourier unitary matrix.
Proof.
From [13] (Lemma 2) or [14] (Lemma 3), we obtain that is a circulant matrix with:
for all . Therefore, . ☐
We finish this subsection with a result regarding the -convergence time.
Theorem A1.
Let B be an real symmetric matrix with and . If , then:
Proof.
Let . We first prove that the following statements are equivalent:
- for all .
- for all .
1⇒2 Fix . If , applying Lemma A2 yields:
where is the identity matrix. If , from Lemma A2 and [2] (Theorem 1), we obtain:
2⇒1 If , then:
Consequently,
To prove (A10). we have used the equivalence . To show (A12) and (A13), we have applied the definition of the spectral norm (see, e.g., [15] (pp. 603, 609)) and Assertion 3 of Lemma A1, respectively. To prove (A14), we have used [2] (Theorem 1) ().
As:
we only need to show that to finish the proof, where:
and:
with:
Since:
we have for all and, consequently, . If is a decreasing sequence for all , then:
and therefore,
and . Thus, if we prove that these sequences are decreasing, the proof is complete. Given , from Lemma A1 and [2] (Theorem 1), we conclude that:
for all . To prove the two equalities in (A26), we have used Assertion 2 of Lemma A1. To show the first inequality in (A26), we have applied a well-known inequality on the spectral norm (see, e.g., [15] (p. 611)), and to prove the second inequality in (A26), we have used [2] (Theorem 1) (). ☐
Appendix B. Proof of Theorem 1
Let be the real symmetric matrix given by:
Observe that the matrix in (A27) satisfies .
We define the function as . We next prove that:
Observe that . As is circulant, its eigenvalues are (see, e.g., [16] (Equation (3.7)) or [17] (Equation (5.2))):
Let be the Fourier unitary matrix. It is well known (see, e.g., [16] (Equation (3.11)) or [17] (Lemma 5.1)) that is an unit eigenvector of associated with the eigenvalue for all . From Lemma A2:
Case 1: Assume that n is even. Then,
Therefore, and are unit eigenvectors of associated to . As:
for all , from [4] (Theorem 1), we obtain three subgradients of f at , namely , and , given by:
for all . If , we have that , where is the zero matrix. The result now follows from [18] (p. 12) and the fact that a convex combination of subgradients of f at is also a subgradient of f at .
Case 2: Assume that n is odd. Then,
Therefore, and are unit eigenvectors of associated with , and and are unit eigenvectors of associated with . As:
for all , from [4] (Theorem 1), we obtain four subgradients of f at , namely , , and given by:
for all . If , we have that . The result now follows from [18] (p. 12) and the fact that a convex combination of subgradients of f at is also a subgradient of f at .
Since , applying [2] (Theorem 1) and Theorem A1, Theorem 1 holds.
Appendix C. Proof of Theorem 2
We begin by proving (9). Applying Taylor’s theorem (see, e.g., [19] (p. 113)), there exist two bounded functions such that:
and:
for all . Therefore, from (A31) and (A38), we have:
where is the bounded sequence of real numbers given by:
Thus,
Finally, we prove (7). If , then there exists , with , such that:
Thus, if , then:
or equivalently,
Appendix D. Proof of Theorem 3
We denote with the set of all the real symmetric matrices such that:
where is the adjacency matrix of a grid of r rows and c columns. Consider the bijection defined in [4] (Equation (8)), where (i.e., q is the number of edges when the network is viewed as an undirected graph).
We define the function as . We next prove that:
Without loss of generality, we can assume that . We first show that :
and:
The eigenvalues of are (see, e.g., [20]):
and therefore, the eigenvalues of are given by with . Their associated orthonormal eigenvectors are given by and with , (see, e.g., [20]). Consequently, the eigenvalues of are and associated orthonormal eigenvectors are with and .
From [4] (Lemma 1),
Then, and are unit eigenvectors of associated with and , respectively, and their entries are given by:
for all and .
Let be the set of edges of the grid. An edge connects the sensors , and we enumerate the edges such that for all . We consider that the edges of the grid are sorted as follows: , , and are the set of horizontal, vertical, northwest-southeast diagonal and northeast-southwest diagonal edges, respectively. Moreover, if with and , then the edge precedes the edge in .
From [4] (Theorem 1) , we obtain two subgradients of f, and given by:
where ,
for all ,
for all , and:
for all , . If , we have that . The result now follows from [18] (p. 12) and the fact that a convex combination of subgradients of f at a certain point is also a subgradient of f at that point.
Since , applying [2] (Theorem 1) and Theorem A1, Theorem 3 holds.
Appendix E. Proof of Theorem 9
From [21] (Equation (3.4a)), the eigenvalues of are given by and, consequently, . From [7] (Corollary 1), we have:
and therefore, (51) holds. The entries of the expectation of are given by:
for all . Thus, . Therefore, combining (A29) and (A30) yields:
As:
we get:
and consequently,
Appendix F. Proof of Theorem 10
From [20], the eigenvalues of are given by and, consequently, . From [7] (Corollary 1), we have:
and therefore, (56) holds. The entries of the expectation of are given by:
for all . Thus, . Therefore, combining (A63) and [4] (Lemma 1) yields:
As:
we get:
and consequently,
References
- Insausti, X.; Camaró, F.; Crespo, P.M.; Beferull-Lozano, B.; Gutiérrez-Gutiérrez, J. Distributed pseudo-gossip algorithm and finite-length computational codes for efficient in-network subspace projection. IEEE J. Sel. Top. Signal Process. 2013, 7, 163–174. [Google Scholar] [CrossRef]
- Xiao, L.; Boyd, S. Fast linear iterations for distributed averaging. Syst. Control Lett. 2004, 53, 65–78. [Google Scholar] [CrossRef]
- Xiao, L.; Boyd, S.; Kimb, S.J. Distributed average consensus with least-mean-square deviation. J. Parallel Distrib. Comput. 2007, 67, 33–46. [Google Scholar] [CrossRef]
- Insausti, X.; Gutiérrez-Gutiérrez, J.; Zárraga-Rodríguez, M.; Crespo, P.M. In-network computation of the optimal weighting matrix for distributed consensus on wireless sensor networks. Sensors 2017, 17, 1702. [Google Scholar] [CrossRef] [PubMed]
- Olshevsky, A.; Tsitsiklis, J. Convergence speed in distributed consensus and averaging. SIAM Rev. 2011, 53, 747–772. [Google Scholar] [CrossRef]
- Boyd, S.; Ghosh, A.; Prabhakar, B.; Shah, D. Randomized gossip algorithms. IEEE Trans. Inf. Theory 2006, 52, 2508–2530. [Google Scholar] [CrossRef]
- Aysal, T.C.; Yildiz, M.E.; Sarwate, A.D.; Scaglione, A. Broadcast gossip algorithms for consensus. IEEE Trans. Signal Process. 2009, 57, 2748–2761. [Google Scholar] [CrossRef]
- Wu, S.; Rabbat, M.G. Broadcast Gossip Algorithms for Consensus on Strongly Connected Digraphs. IEEE Trans. Signal Process. 2013, 61, 3959–3971. [Google Scholar] [CrossRef]
- Dimakis, A.D.G.; Kar, S.; Moura, J.M.F.; Rabbat, M.G.; Scaglione, A. Gossip algorithms for distributed signal processing. Proceed. IEEE 2010, 98, 1847–1864. [Google Scholar] [CrossRef]
- Olshevsky, A.; Tsitsiklis, J. Convergence speed in distributed consensus and averaging. SIAM J. Control Optim. 2009, 48, 33–55. [Google Scholar] [CrossRef]
- Olshevsky, A.; Tsitsiklis, J. A lower bound for distributed averaging algorithms on the line graph. IEEE Trans. Autom. Control 2011, 56, 2694–2698. [Google Scholar] [CrossRef]
- Apostol, T.M. Calculus; John Wiley & Sons: Hoboken, NJ, USA, 1967; Volume 1. [Google Scholar]
- Gutiérrez-Gutiérrez, J.; Crespo, P.M. Asymptotically equivalent sequences of matrices and Hermitian block Toeplitz matrices with continuous symbols: Applications to MIMO systems. IEEE Trans. Inf. Theory 2008, 54, 5671–5680. [Google Scholar] [CrossRef]
- Gutiérrez-Gutiérrez, J.; Crespo, P.M. Asymptotically equivalent sequences of matrices and multivariate ARMA processes. IEEE Trans. Inf. Theory 2011, 57, 5444–5454. [Google Scholar] [CrossRef]
- Bernstein, D.S. Matrix Mathematics; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Gray, R.M. Toeplitz and circulant matrices: A review. Found. Trends Commun. Inf. Theory 2006, 2, 155–239. [Google Scholar] [CrossRef]
- Gutiérrez-Gutiérrez, J.; Crespo, P.M. Block Toeplitz matrices: Asymptotic results and applications. Found. Trends Commun. Inf. Theory 2011, 8, 179–257. [Google Scholar] [CrossRef]
- Shor, N.Z. Minimization Methods for Non-Differentiable Functions; Springer: Berlin, Germany, 1985. [Google Scholar]
- Apostol, T.M. Mathematical Analysis; Addison-Wesley: Boston, MA, USA, 1974. [Google Scholar]
- Yueh, W.C.; Cheng, S.S. Explicit Eigenvalues and inverses of tridiagonal Toeplitz matrices with four perturbed corners. ANZIAM J. 2008, 49, 361–387. [Google Scholar] [CrossRef]
- Gray, R.M. On the asymptotic eigenvalue distribution of Toeplitz matrices. IEEE Trans. Inf. Theory 1972, 18, 725–730. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).