Evolutionary Design of Convolutional Neural Networks for Human Activity Recognition in Sensor-Rich Environments



Abstract
:1. Introduction
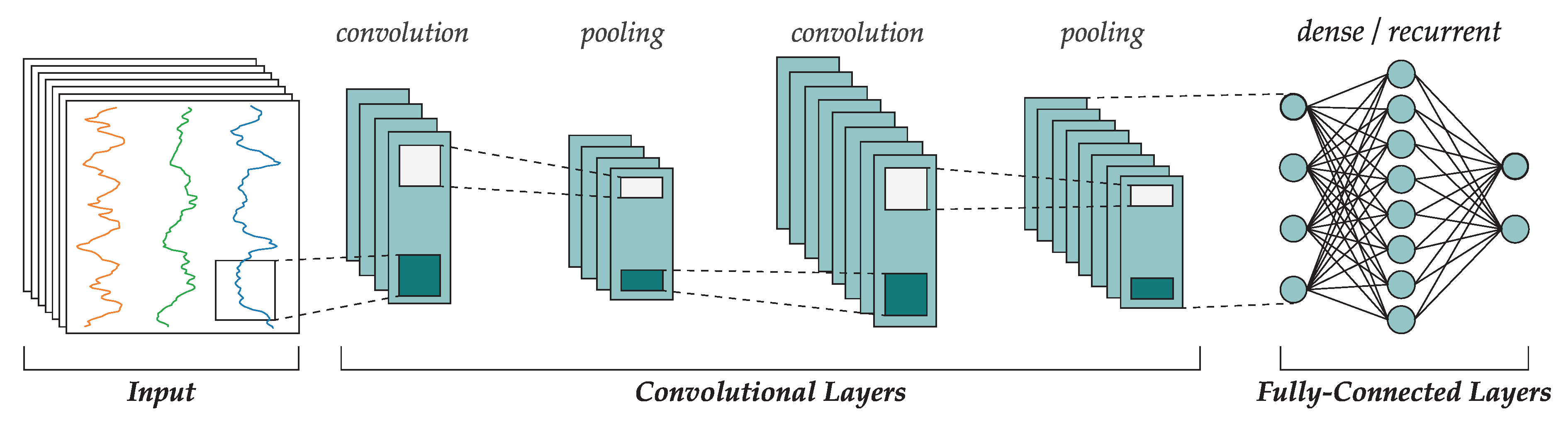
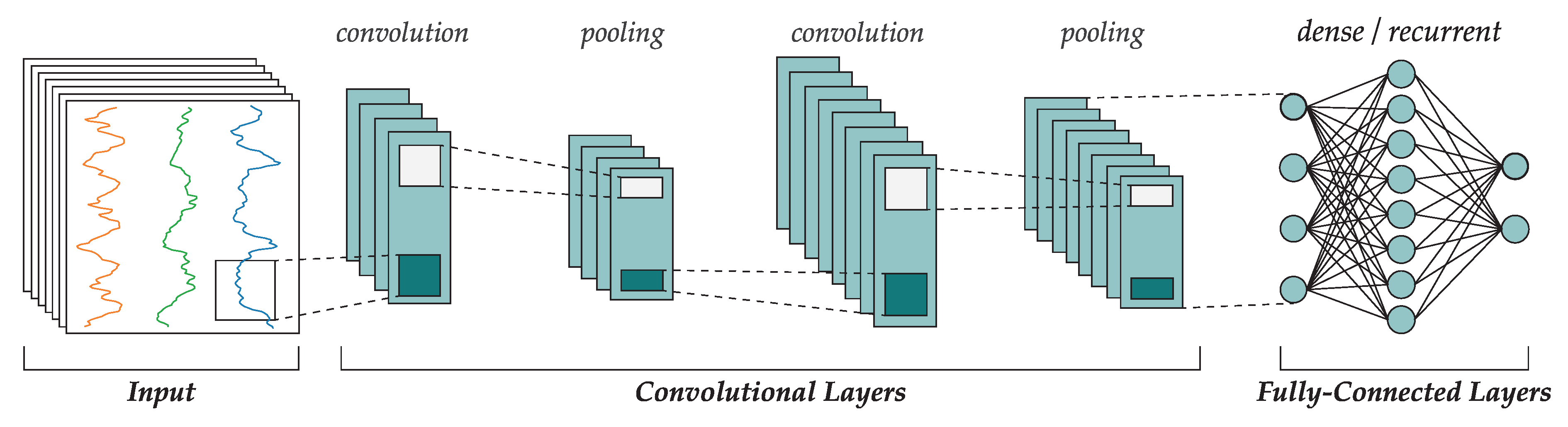
2. Convolutional Neural Networks
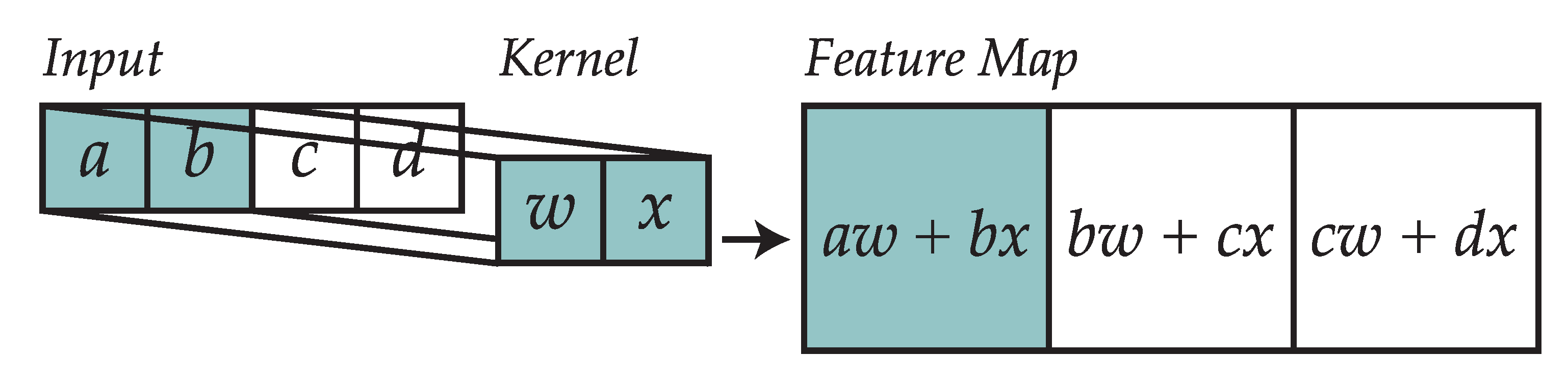
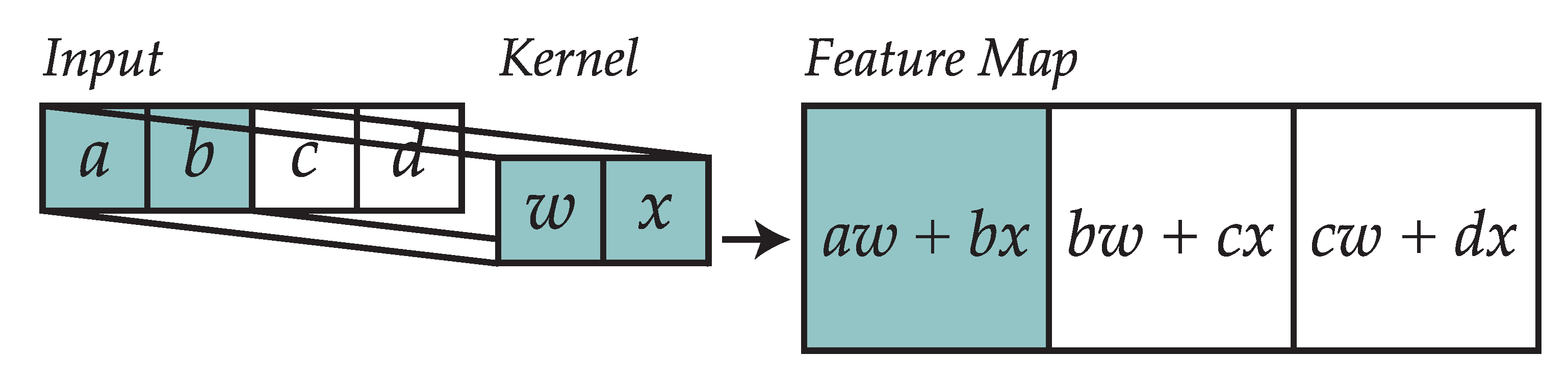
2.1. Convolutional Layers
2.2. Pooling
2.3. Dense and Recurrent Layers
2.4. Learning Rules
3. Related Work in Neuroevolution
- Var. Ly.: whether the proposal supports a variable number of layers (either convolutional, fully-connected, recurrent, etc.).
- Conv.: whether the proposal evolves the convolutional layers or some of their parameters.
- FC: whether the proposal evolves fully-connected layers or some of their parameters.
- Rec.: whether the proposal observes the inclusion of recurrent layers or LSTM cells.
- Act. Fn.: whether the proposal evolves the activation function instead of hardcoding it.
- Opt. HP: whether the proposal supports the evolution of optimization hyperparameters (learning rate, momentum, batch size, etc.).
- Ens.: whether the proposal supports the construction of an ensemble of neural networks.
- W: whether the proposal evolves the weights of the network.
4. Human Activity Recognition
4.1. OPPORTUNITY Dataset
- Start: lie in the deckchair and then get up.
- Groom: move across the room, checking that objects are in the right drawers and shelves.
- Relax: go outside and walk around the building.
- Prepare coffee: use the coffeemaker to prepare coffee with milk (in the fridge) and sugar.
- Drink coffee: take coffee sips naturally.
- Prepare sandwich: made of bread, cheese and salami and using the bread cutter along with various knifes and plates.
- Eat the sandwich.
- Cleanup: clean the table, store objects back in their place or in the dish washer.
- Break: lie on the deckchair.
- Open and close the fridge.
- Open and close the dishwasher.
- Open and close 3 drawers at different heights.
- Open and close door 1.
- Open and close door 2.
- Turn on and off the lights.
- Clean table.
- Drink while standing.
- Drink while sitting.
4.2. OPPORTUNITY Challenge and State-of-the-Art Results
- Training set: comprises all ADL and drill sessions for subject 1 and ADL1, ADL2, and drill sessions for subjects 2 and 3.
- Test set: comprises ADL4 and ADL5 for subjects 2 and 3.
5. Neuroevolution for Human Activity Recognition
5.1. Preprocessing
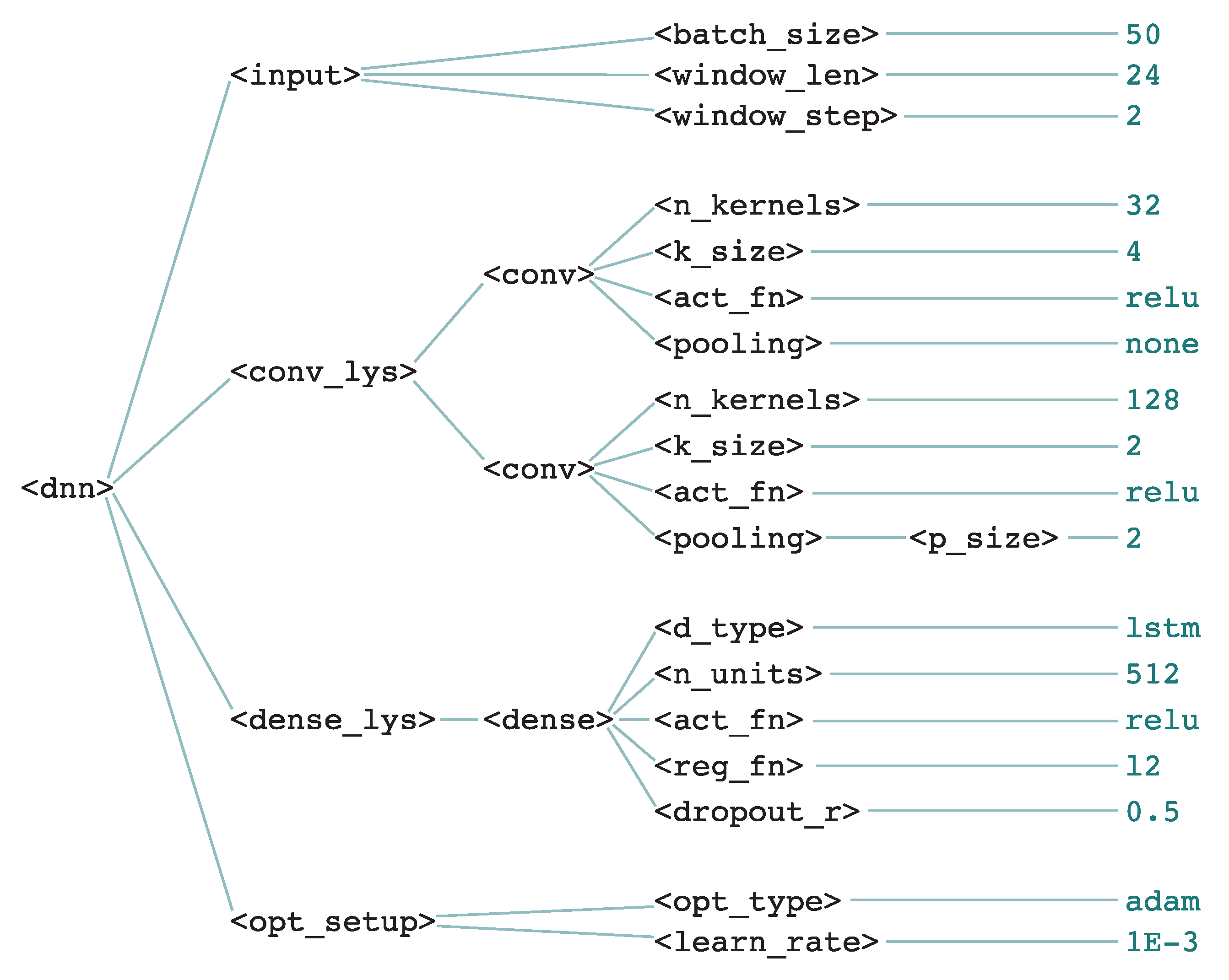
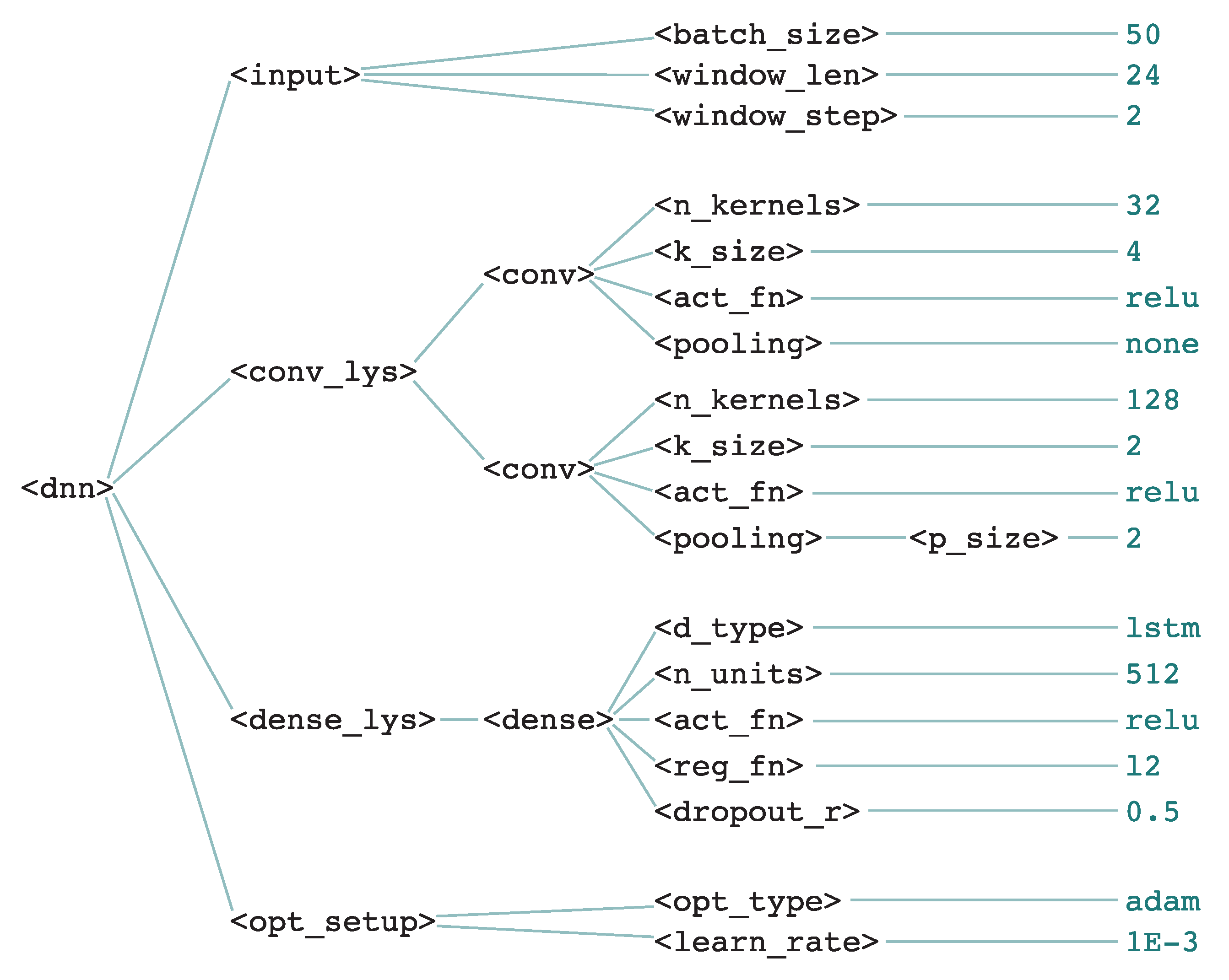
5.2. Grammatical Evolution of CNNs
- Tournament selection, with tournament size . The individual with the highest fitness wins the tournament.
- Single-point crossover: in GE, the reproduction will be performed using only one point for crossover, and will occur with a probability of . If crossover does not occur, then parents will be present in the following population. Crossover is forced to occur within the subsequences of the chromosomes that are actually used, thus guaranteeing that the crossover has an effective impact in the phenotype.
- Integer-flipping mutation, with a mutation rate of . The old integer will be replaced by a new random integer. All individuals are mutated, with the sole exception of elite individuals. Mutation also affects the parents that are not crossed and are passed to the next generation. None, one, or more than one positions can be mutated, depending on the value of .
- Elitism of size e. It must be noted that elite individuals are chosen based on the nominal fitness rather than the adjusted fitness.
6. Evaluation
6.1. Experimental Setup
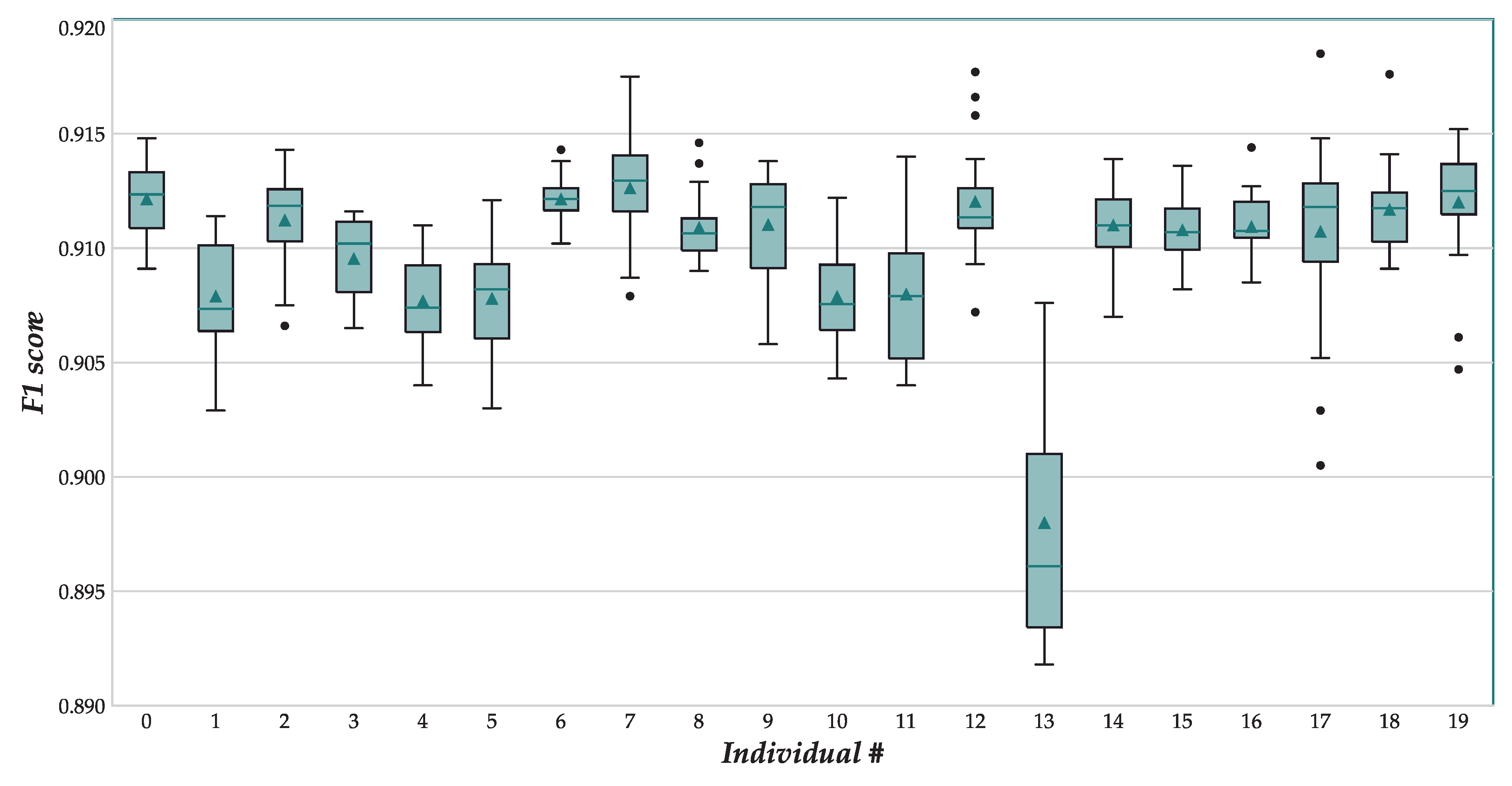
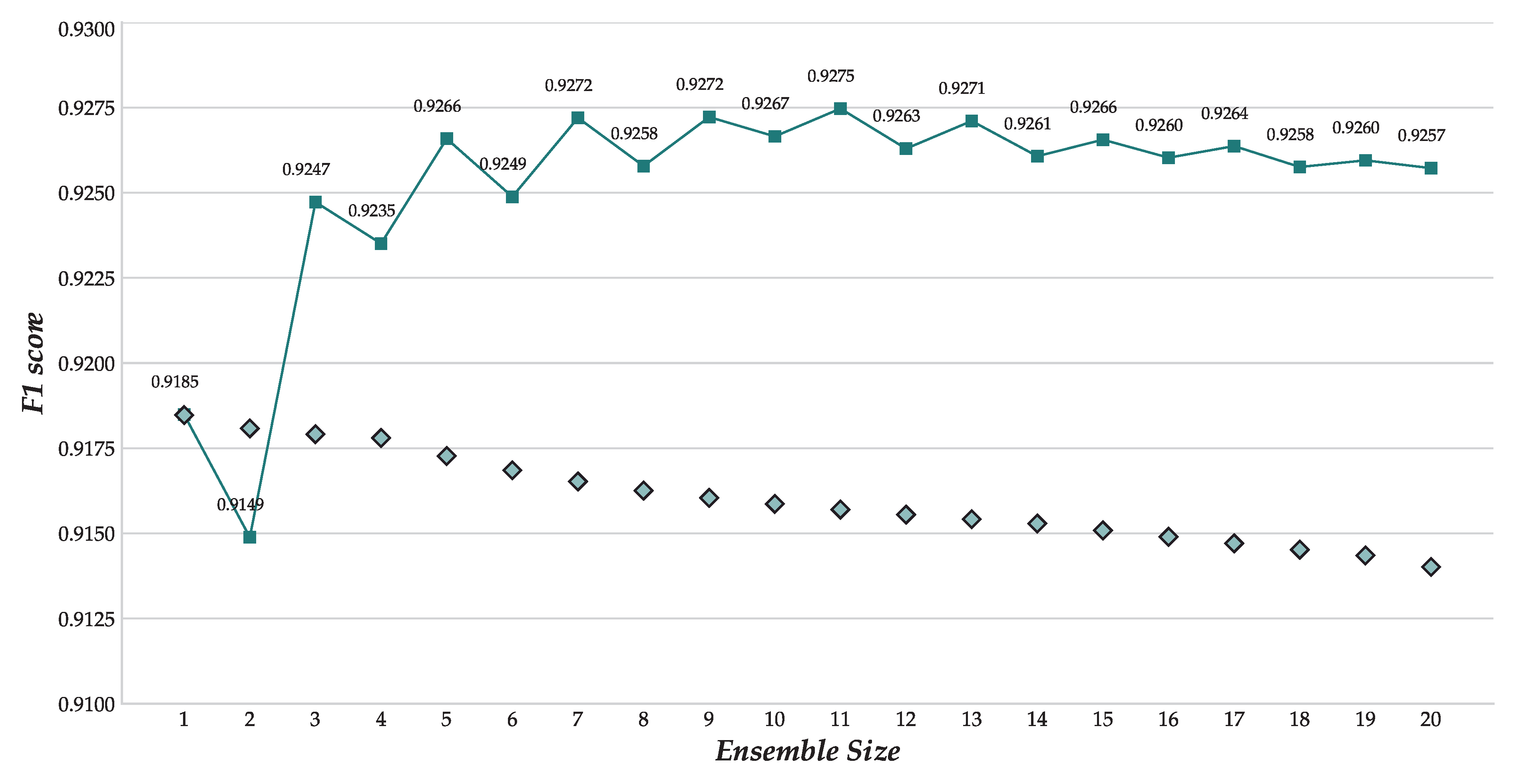
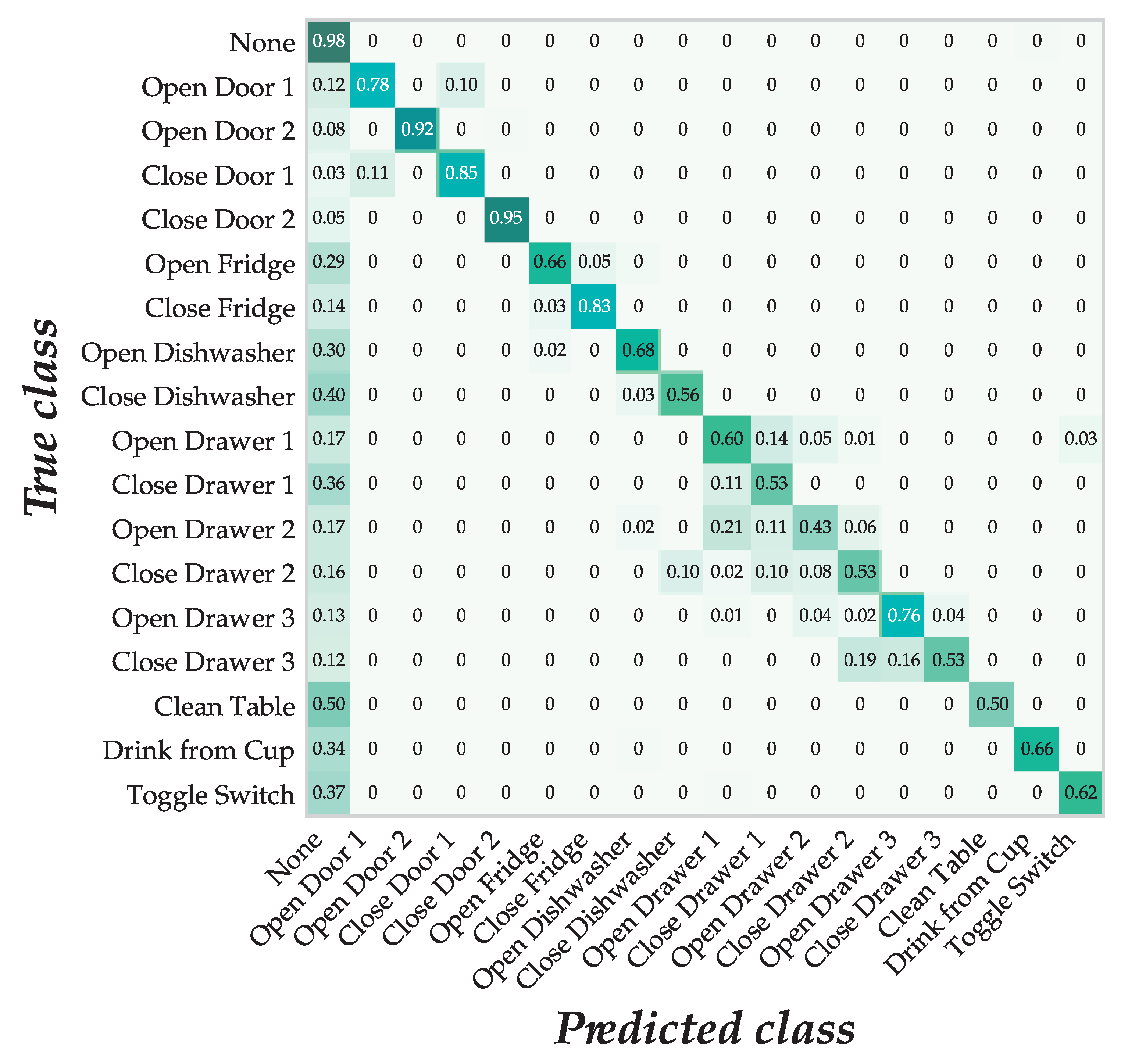
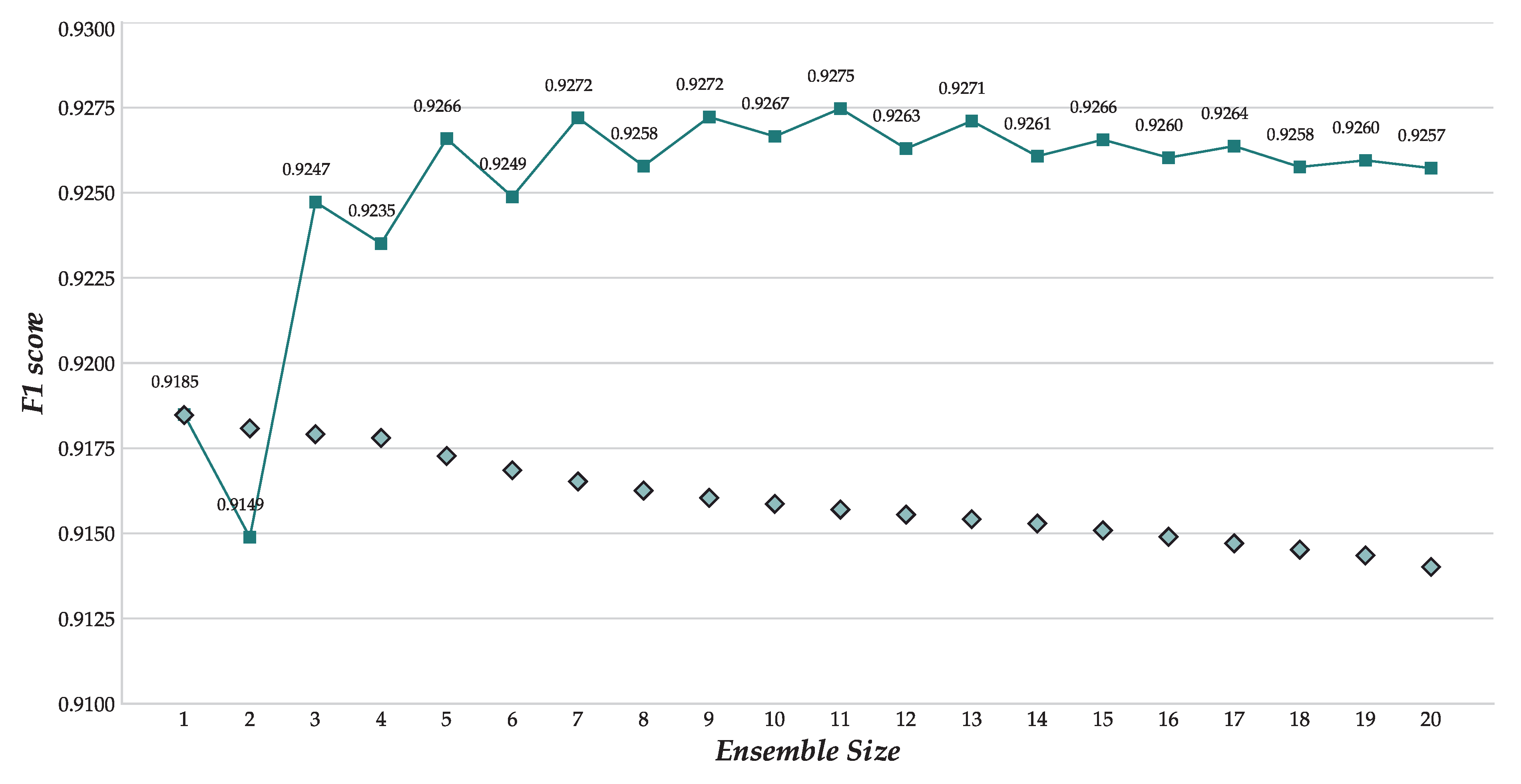
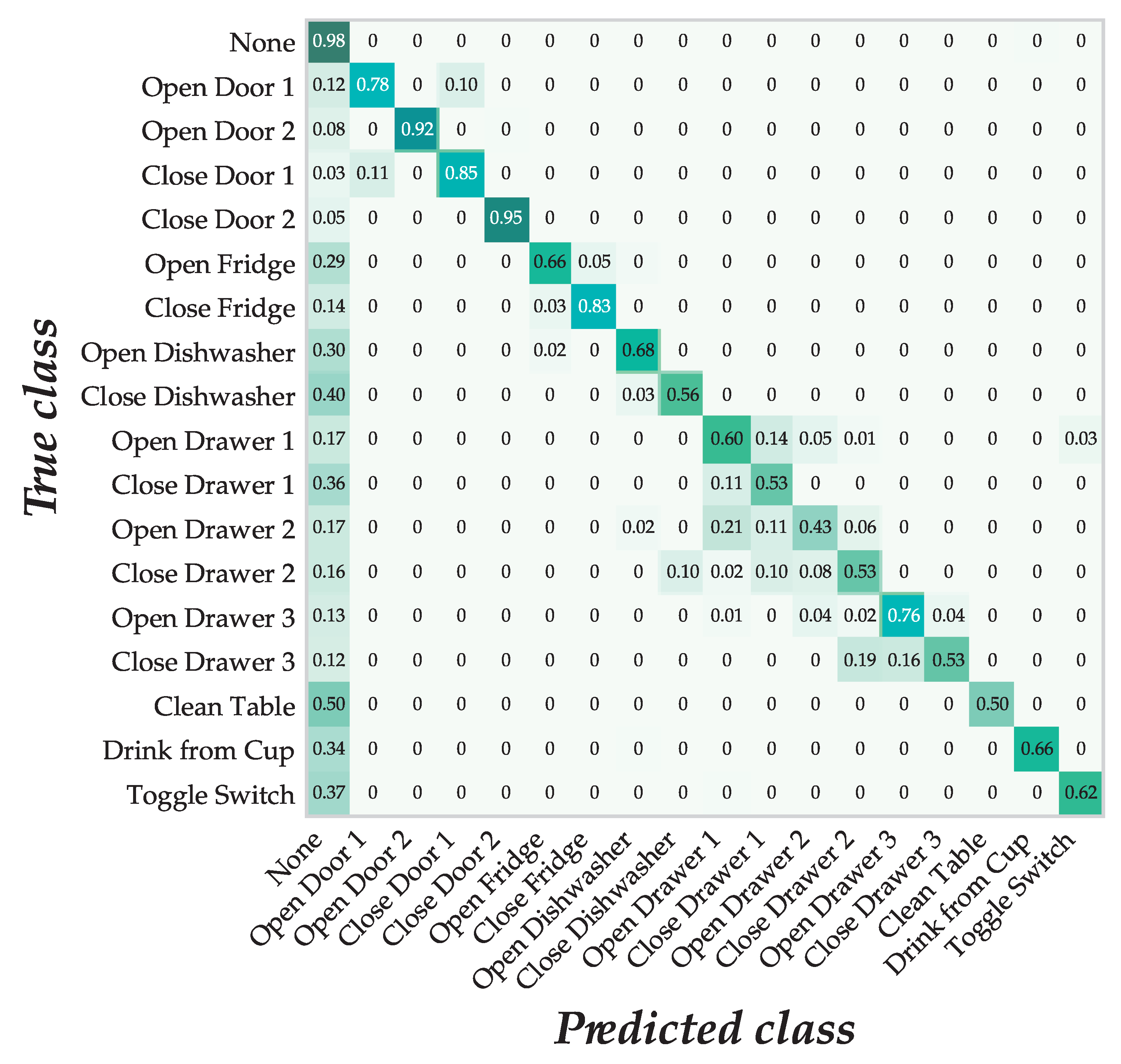
6.2. Results and Discussion
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| BNF | Backus-Naur Form |
| CNN | Convolutional Neural Network |
| GA | Genetic Algorithm |
| GE | Grammatical Evolution |
| GRU | Gated Recurrent Unit |
| LSTM | Long Short-Term Memory |
| ReLU | Rectified Linear Unit |
References
- García, O.; Chamoso, P.; Prieto, J.; Rodríguez, S.; de la Prieta, F. A Serious Game to Reduce Consumption in Smart Buildings. In Highlights of Practical Applications of Cyber-Physical Multi-Agent Systems; Springer International Publishing: Cham, Switzerland, 2017; pp. 481–493. [Google Scholar]
- Canizes, B.; Pinto, T.; Soares, J.; Vale, Z.; Chamoso, P.; Santos, D. Smart City: A GECAD-BISITE Energy Management Case Study. In Proceedings of the Trends in Cyber-Physical Multi-Agent Systems. The PAAMS Collection—15th International Conference, PAAMS 2017; Springer International Publishing: Cham, Switzerland, 2018; pp. 92–100. [Google Scholar]
- Prieto, J.; Chamoso, P.; la Prieta, F.D.; Corchado, J.M. A generalized framework for wireless localization in gerontechnology. In Proceedings of the 2017 IEEE 17th International Conference on Ubiquitous Wireless Broadband (ICUWB), Salamanca, Spain, 12–15 September 2017; pp. 1–5. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and LSTM recurrent neural neworks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. arXiv, 2016; arXiv:1604.08880. [Google Scholar]
- Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary convolutional neural networks: An application to handwriting recognition. Neurocomputing 2018, 283, 38–52. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Network; MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv, 2014; arXiv:1409.1259. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. arXiv, 2012; arXiv:1212.5701. [Google Scholar]
- Tieleman, T.; Hinton, G. Rmsprop: Divide the Gradient by a Running Average of Its Recent Magnitude, 2012. Coursera. Available online: https://es.coursera.org/learn/neural-networks/lecture/YQHki/rmsprop-divide-the-gradient-by-a-running-average-of-its-recent-magnitude (accessed on 20 April 2018).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Yao, X.; Liu, Y. A new evolutionary system for evolving artificial neural networks. IEEE Trans. Neural Netw. 1997, 8, 694–713. [Google Scholar] [CrossRef] [PubMed]
- Stanley, K.O.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Kassahun, Y.; Sommer, G. Efficient reinforcement learning through evolutionary acquisition of neural topologies. In Proceedings of the 13th European Symposium on Artificial Neural Networks, Bruges, Belgium, 29–29 April 2005; pp. 259–266. [Google Scholar]
- Koutník, J.; Schmidhuber, J.; Gomez, F. Evolving Deep Unsupervised Convolutional Networks for Vision-Based Reinforcement Learning. In Proceedings of the 2014 Genetic and Evolutionary Computation Conference, Vancouver, BC, Canada, 12–16 July 2014; pp. 541–548. [Google Scholar]
- Verbancsics, P.; Harguess, J. Image Classification using Generative NeuroEvolution for Deep Learning. In Proceedings of the 2015 IEEE Winter Conference on Applied Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 488–493. [Google Scholar]
- Stanley, K.O.; D’Ambrosio, D.B.; Gauci, J. A Hypercube-Based Encoding for Evolving Large-Scale Neural Networks. Artif. Life 2009, 15, 185–212. [Google Scholar] [CrossRef] [PubMed]
- Young, S.R.; Rose, D.C.; Karnowsky, T.P.; Lim, S.H.; Patton, R.M. Optimizing deep learning hyper-parameters through an evolutionary algorithm. In Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments, Austin, TX, USA, 15 November 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. CMA-ES for Hyperparameter Optimization of Deep Neural Networks. arXiv, 2016; arXiv:1604.07269. [Google Scholar]
- Fernando, C.; Banarse, D.; Reynolds, M.; Besse, F.; Pfau, D.; Jaderberg, M.; Lanctot, M.; Wierstra, D. Convolution by Evolution: Differentiable Pattern Producing Networks. In Proceedings of the 2016 Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; pp. 109–116. [Google Scholar]
- Xie, L.; Yuille, A. Genetic CNN. arXiv, 2017; arXiv:1703.01513. [Google Scholar]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving Deep Neural Networks. arXiv, 2017; arXiv:1703.00548. [Google Scholar]
- Desell, T. Large Scale Evolution of Convolutional Neural Networks Using Volunteer Computing. In Proceedings of the 2017 Genetic and Evolutionary Computation Conference Companion, Berlin, Germany, 15–19 July 2017; pp. 127–128. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Leon-Suematsu, Y.; Tan, J.; Le, Q.V.; Kurakin, A. Large-Scale Evolution of Image Classifiers. arXiv, 2017; arXiv:1703.01041. [Google Scholar]
- Suganuma, M.; Shirakawa, S.; Nagao, T. A Genetic Programming Approach to Designing Convolutional Neural Network Architectures. In Proceedings of the 2017 Genetic and Evolutionary Computation Conference Companion, Berlin, Germany, 15–19 July 2017; pp. 497–504. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing Neural Network Architectures using Reinforcement Learning. arXiv, 2016; arXiv:1611.02167. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv, 2017; arXiv:1611.01578. [Google Scholar]
- Le, Q.V.; Zoph, B. Using Machine Learning to Explore Neural Network Architecture, 2017. Available online: https://research.googleblog.com/2017/05/using-machine-learning-to-explore.html (accessed on 20 April 2018).
- BigML. Deepnets, 2017. Available online: https://bigml.com/whatsnew/deepnet (accessed on 20 April 2018).
- Davison, J. DEvol: Automated Deep Neural Network Design via Genetic Programming, 2017. Available online: https://github.com/joeddav/devol (accessed on 1 July 2017).
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the Seventh International Conference on Networked Sensing Systems, Kassel, Germany, 15–18 June 2010. [Google Scholar]
- Roggen, D.; Bächlin, M.; Schümm, J.; Holleczek, T.; Lombriser, C.; Tröster, G.; Widmer, L.; Majoe, D.; Gutknecht, J. An educational and research kit for activity and context recognition from on-body sensors. In Proceedings of the 2010 International Conference on Body Sensor Networks, Singapore, 7–9 June 2010; pp. 277–282. [Google Scholar]
- Stiefmeier, T.; Roggen, D.; Ogris, G.; Lukowicz, P.; Tröster, G. Wearable activity tracking in car manufacturing. IEEE Pervasive Comput. 2008, 7, 42–50. [Google Scholar] [CrossRef]
- Xsens. IMU Inertial Measurement Unit—Xsens 3D Motion Tracking, 2017. Available online: https://www.xsens.com/tags/imu/ (accessed on 5 April 2017).
- Pirkl, G.; Stockinger, K.; Kunze, K.; Lukowicz, P. Adapting magnetic resonant coupling based relative positioning technology for wearable activity recognition. In Proceedings of the 2008 International Symposium on Wearable Computers, Pittsburgh, PA, USA, 28 September–1 October 2008; pp. 47–54. [Google Scholar]
- Intersense. InterSense Wireless InertiaCube3, 2017. Available online: http://forums.ni.com/attachments/ni/280/4310/1/WirelessInertiaCube3.pdf (accessed on 5 April 2017).
- Zappi, P.; Lombriser, C.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, L.; Tröster, G. Activity recognition from on-body sensors: Accuracy-power trade-off by dynamic sensor selection. In Wireless Sensor Networks; Lecture Notes in Computer Science; Springer: New York, NY, USA, 2008; Volume 4913, pp. 17–33. [Google Scholar]
- Bannach, D.; Amft, O.; Lukowicz, P. Rapid prototyping of activity recognition applications. IEEE Pervasive Comput. 2008, 7, 22–31. [Google Scholar] [CrossRef]
- Roggen, D.; Tröster, G.; Lukowicz, P.; Ferscha, A.; del R. Millán, J. OPPORTUNITY Deliverable D5.1: Stage 1 Case Study Report and Stage 2 Specification; Technical Report; University of Passau: Passau, Germany, 2010. [Google Scholar]
- Project, O. Activity Recognition Challenge, 2011. Available online: http://opportunity-project.eu/challenge (accessed on 20 April 2018).
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.; Tröster, G.; del R. Millán, J.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Sagha, H.; Digumarti, S.T.; del R. Millán, J.; Chavarriaga, R.; Calatroni, A.; Roggen, D.; Tröster, G. Benchmarking classification techniques using the Opportunity human activity dataset. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; pp. 36–40. [Google Scholar]
- Cao, H.; Nguyen, M.N.; Phua, C.; Krishnaswamy, S.; Li, X.L. An Integrated Framework for Human Activity Classification. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 331–340. [Google Scholar]
- Webb, G.I. Decision tree grafting from the all-tests-but-one partition. In Proceedings of the 16th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999; Volume 2, pp. 702–707. [Google Scholar]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Vinyard, J. Efficient Overlapping Windows with Numpy, 2012. Available online: http://www.johnvinyard.com/blog/?p=268 (accessed on 23 February 2017).
- Ryan, C.; Collins, J.; O’Neill, M. Grammatical Evolution: Evolving Programs for an Arbitrary Language. In Proceedings of the 1st European Workshop on Genetic Programming; Lecture Notes in Computer Science; Springer: New York, NY, USA, 1998; Volume 1391, pp. 83–95. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Technique | Var. Ly. | Conv. | FC | Rec. | Act. Fn. | Opt. HP | Ens. | W |
|---|---|---|---|---|---|---|---|---|---|
| Koutník et al. [19] | CoSyNE | • | |||||||
| Verbancsics and Harguess [20] | GA (NEAT) | • | • | ||||||
| MENNDL [22] | GA | • | |||||||
| Loshchilov and Hutter [23] | CMA-ES | • | • | • | |||||
| GeNet [25] | GA | • | • | ||||||
| CoDeepNEAT [26] | GA (NEAT) | • | • | • | • | • | • | ||
| EXACT [27] | GA (NEAT) | • | • | ||||||
| Real et al. [28] | GA (NEAT) | • | • | • | |||||
| DEvol [34] | GP | • | • | • | • | ||||
| Suganuma et al. [29] | CGP | • | • | ||||||
| MetaQNN [30] † | RL | • | • | • | • | ||||
| Zoph and Le [31] † | RL | • | • | • | • | • | |||
| This work | GE | • | • | • | • | • | • | • |
| ID | Sensor System | Location and Observation |
|---|---|---|
| B1 | Commercial wireless microphones | Chest and dominant wrist |
| B2 | Custom Bluetooth acceleration sensors [36] | 12 on the body to sense limb movement |
| B3 | Custom motion jacket [37] | Includes 5 commercial RS485-networked XSens inertial measurement units [38] |
| B4 | Custom magnetic relative pos. sensor [39] | Senses distance of hand to body |
| B5 | InertiaCube3 [40] inertial sensor system | One per foot, on the shoe toe box, to sense modes of locomotion |
| B6 | Sun SPOT acceleration sensors | One per foot, right below the outer ankle, to sense modes of locomotion |
| O1 | Custom wireless Bluetooth acceleration and rate of turn sensors | 12 objects in the scenario to measure their use |
| A1 | Commercial wired microphone array | Four in each room side to sense ambient sound |
| A2 | Commercial Ubisense localization system | Placed in the corners of the room to sense user location |
| A3 | Axis network cameras | Placed in three locations for localization, documentation, and visual annotation |
| A4 | XSens inertial sensor [37,38] | Placed on the table and the chair to sense vibration and use |
| A5 | USB networked acceleration sensors [41] | 8 placed on doors, drawers, shelves, and the lazy chair to sense usage |
| A6 | Reed switches | 13 placed on doors, drawers and shelves, to sense usage providing ground truth |
| A7 | Custom power sensors | Connected to coffee machine and bread cutter to sense usage |
| A8 | Custom pressure sensors | 3 placed on the table to sense usage after subjects placed plates and cups on them |
| Technique | Locomotion | Gestures | ||
|---|---|---|---|---|
| with null class | no null class | with null class | no null class | |
| CStar [45] | 0.63 | 0.87 | 0.88 | 0.77 |
| 1-NN [45] | 0.84 | 0.85 | 0.87 | 0.55 |
| SStar [45] | 0.64 | 0.86 | 0.86 | 0.70 |
| 3-NN [45] | 0.85 | 0.85 | 0.85 | 0.56 |
| NStar [45] | 0.61 | 0.86 | 0.84 | 0.65 |
| Integrated Framework [47] | – | 0.927 | 0.821 | – |
| SPO + 1NN + Smooth. [47] | – | 0.917 | 0.811 | – |
| SPO + SVM + Smooth. [47] | – | 0.897 | 0.804 | – |
| SPO + SVM [47] | – | 0.885 | 0.797 | – |
| SVM [47] | – | 0.883 | 0.762 | – |
| SPO + 1NN [47] | – | 0.890 | 0.777 | – |
| 1NN [47] | – | 0.890 | 0.705 | – |
| LDA [45] | 0.59 | 0.64 | 0.69 | 0.25 |
| UP [45] | 0.60 | 0.84 | 0.64 | 0.22 |
| QDA [45] | 0.68 | 0.77 | 0.53 | 0.24 |
| NCC [45] | 0.54 | 0.60 | 0.51 | 0.19 |
| MI [45] | 0.83 | 0.86 | – | – |
| MU [45] | 0.62 | 0.87 | – | – |
| NU [45] | 0.53 | 0.75 | – | – |
| UT [45] | 0.52 | 0.73 | – | – |
| b-LSTM-S [5] | – | – | 0.927 | – |
| DeepConvLSTM [4] | 0.895 | 0.930 | 0.915 | 0.866 |
| LSTM-S [5] | – | – | 0.912 | – |
| LSTM-F [5] | – | – | 0.908 | – |
| CNN [5] | – | – | 0.894 | – |
| DNN [5] | – | – | 0.888 | – |
| Baseline CNN [4] | 0.878 | 0.912 | 0.883 | 0.783 |
| CNN + Smooth. [49] | – | – | 0.822 | – |
| CNN [49] | – | – | 0.818 | – |
| MV + Smooth. [49] | – | – | 0.788 | – |
| MV [49] | – | – | 0.778 | – |
| DBN [49] | – | – | 0.701 | – |
| DBN + Smooth. [49] | – | – | 0.700 | – |
| Parameter | Symbol | Value |
|---|---|---|
| Population size | 50 | |
| Maximum number of generations | G | 100 |
| Number of generations without improvements (stop condition) | 30 | |
| Codon size | 256 | |
| Maximum chromosome length | 100 | |
| Tournament size | 3 | |
| Crossover rate | 0.7 | |
| Mutation rate | 0.015 | |
| Elite size | e | 1 |
| # | Fitness | Architecture | |||||
|---|---|---|---|---|---|---|---|
| 1 | 0.9094 | ||||||
| c | | |||||||
| d | | |||||||
| 2 | 0.9037 | ||||||
| c | | |||||||
| d | | |||||||
| 3 | 0.9031 | ||||||
| c | | |||||||
| d | | |||||||
| 4 | 0.9025 | ||||||
| c | | |||||||
| d | | |||||||
| 5 | 0.9013 | ||||||
| c | | |||||||
| d | | |||||||
| 6 | 0.9013 | ||||||
| c | | |||||||
| d | | |||||||
| 7 | 0.9010 | ||||||
| c | | |||||||
| d | | |||||||
| # | Mean | Std. Dev. | Median | Minimum | Maximum |
|---|---|---|---|---|---|
| 1 | 0.912150 | 0.001528 | 0.91235 | 0.9091 | 0.9148 |
| 2 | 0.907910 | 0.002371 | 0.90735 | 0.9029 | 0.9114 |
| 3 | 0.911230 | 0.002044 | 0.91185 | 0.9066 | 0.9143 |
| 4 | 0.909540 | 0.001801 | 0.91020 | 0.9065 | 0.9116 |
| 5 | 0.907695 | 0.002126 | 0.90740 | 0.9040 | 0.9110 |
| 6 | 0.907805 | 0.002299 | 0.90820 | 0.9030 | 0.9121 |
| 7 | 0.912155 | 0.001004 | 0.91215 | 0.9102 | 0.9143 |
| 8 | 0.912635 | 0.002196 | 0.91295 | 0.9079 | 0.9175 |
| 9 | 0.910900 | 0.001453 | 0.91065 | 0.9090 | 0.9146 |
| 10 | 0.911030 | 0.002295 | 0.91180 | 0.9058 | 0.9138 |
| 11 | 0.907885 | 0.002182 | 0.90755 | 0.9043 | 0.9122 |
| 12 | 0.907995 | 0.002917 | 0.90790 | 0.9040 | 0.9140 |
| 13 | 0.912040 | 0.002446 | 0.91135 | 0.9072 | 0.9177 |
| 14 | 0.898005 | 0.005668 | 0.89610 | 0.8918 | 0.9076 |
| 15 | 0.911005 | 0.001863 | 0.91100 | 0.9070 | 0.9139 |
| 16 | 0.910800 | 0.001365 | 0.91070 | 0.9082 | 0.9136 |
| 17 | 0.910945 | 0.001438 | 0.91075 | 0.9085 | 0.9144 |
| 18 | 0.910730 | 0.004045 | 0.91180 | 0.9005 | 0.9185 |
| 19 | 0.911695 | 0.001979 | 0.91175 | 0.9091 | 0.9176 |
| 20 | 0.912015 | 0.002713 | 0.91250 | 0.9047 | 0.9152 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary Design of Convolutional Neural Networks for Human Activity Recognition in Sensor-Rich Environments. Sensors 2018, 18, 1288. https://doi.org/10.3390/s18041288
Baldominos A, Saez Y, Isasi P. Evolutionary Design of Convolutional Neural Networks for Human Activity Recognition in Sensor-Rich Environments. Sensors. 2018; 18(4):1288. https://doi.org/10.3390/s18041288
Chicago/Turabian StyleBaldominos, Alejandro, Yago Saez, and Pedro Isasi. 2018. "Evolutionary Design of Convolutional Neural Networks for Human Activity Recognition in Sensor-Rich Environments" Sensors 18, no. 4: 1288. https://doi.org/10.3390/s18041288
APA StyleBaldominos, A., Saez, Y., & Isasi, P. (2018). Evolutionary Design of Convolutional Neural Networks for Human Activity Recognition in Sensor-Rich Environments. Sensors, 18(4), 1288. https://doi.org/10.3390/s18041288