Escalator: An Autonomous Scheduling Scheme for Convergecast in TSCH

Abstract
1. Introduction
- We propose Escalator, a new autonomous timeslot and channel scheduling scheme for the convergecast in TSCH-based WSNs with RPL.
- We prove that Escalator generates a conflict-free schedule.
- We show through experiments that Escalator improves the packet delivery ratio, the end-to-end delay and the average energy efficiency for the convergecast compared to the existing autonomous schemes.
2. Background
2.1. TSCH Overview
2.2. RPL
3. Related Work
3.1. Scheduling of WSNs based on TDMA and Channel Hopping
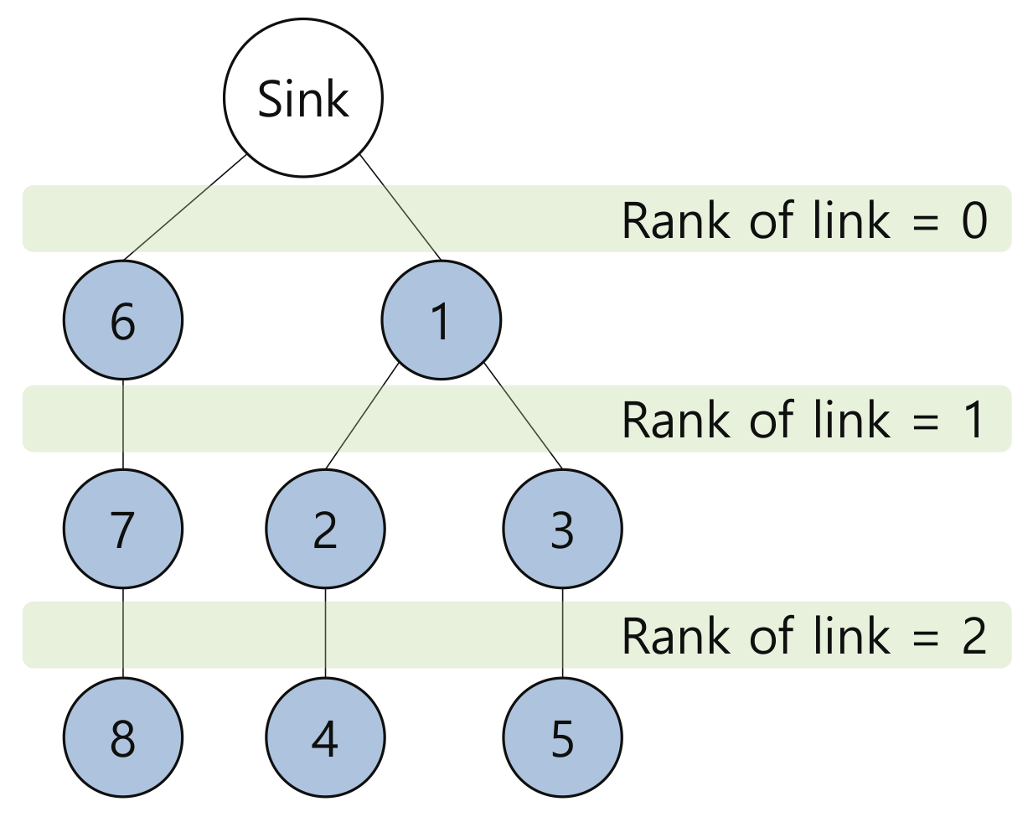
3.2. Timeslot Scheduling for Convergecast
4. Proposed Autonomous Scheduling Scheme for Convergecast
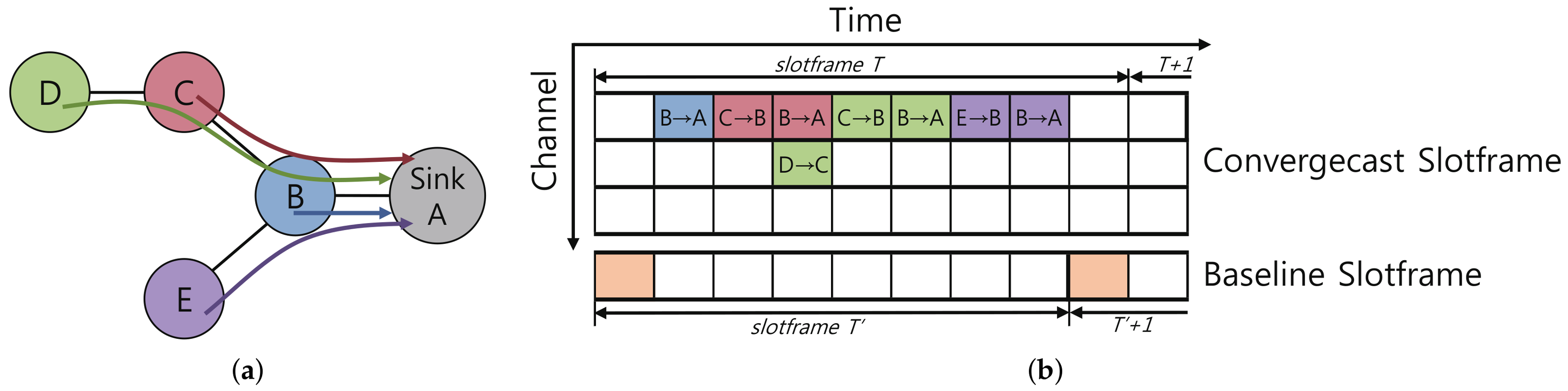
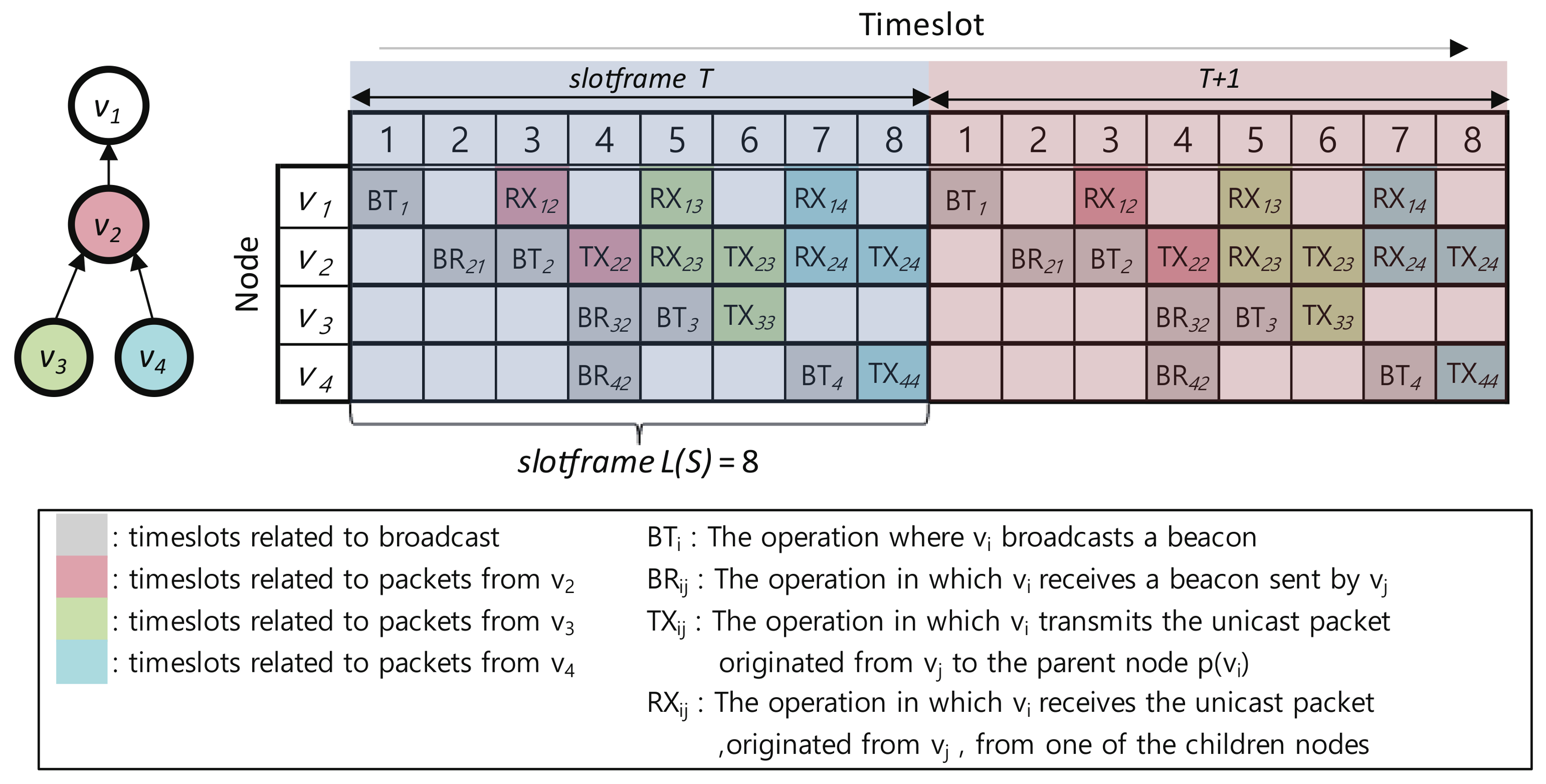
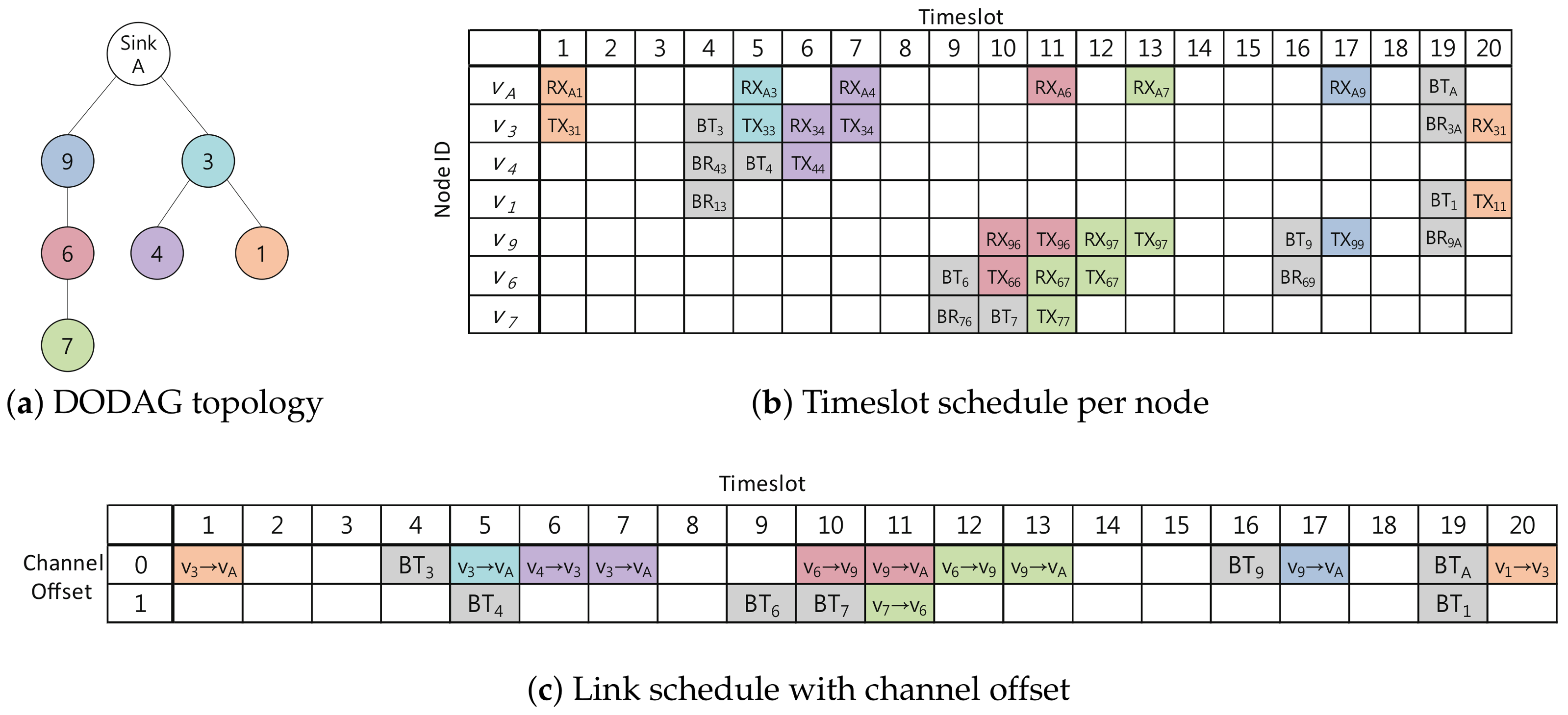
4.1. Timeslot Allocation Mechanism
- : The operation in which broadcasts a beacon
- : The operation in which receives a beacon sent by
- : The operation in which transmits a unicast packet originated from to the parent node
- : The operation in which receives a unicast packet, originated from , from one of the child nodes
- SET_BT(i): Node sets to timeslot (for example, = 1, = 3, = 5, = 7).
- SET_BR(i,j): Node , where , sets to timeslot to receive a broadcast beacon from (for example, = 2, = 4, = 4).
- SET_TX(i,i): Node , where ), sets to timeslot to send its unicast packet to ’s parent (for example, , , ).
- SET_RX(i,j): Node sets to the timeslot to receive the unicast packet generated by the node (for example, , , , , ).
- SET_TX(i,j): Node , where , sets to timeslot to transmit the packet generated by to , the parent of (for example, , ).
| Algorithm 1 RPL callback handler for timeslot allocation. | |
| 1: procedure RPL callback handler(cm, j) | ▹j is a sender of the RPL control message cm |
| 2: ID of | ▹ set i to node’s own ID |
| 3: ID of | ▹ get parent ID of node |
| 4: ID of sink | ▹ get ID of sink |
| 5: if = DIO then | |
| 6: if route updated then | |
| 7: if first joining of DODAG then | |
| 8: if then | |
| 9: SET_TX(i, i) | |
| 10: SET_BR(i, j) | |
| 11: end if | |
| 12: SET_BT(i) | |
| 13: else if j≠k then | |
| 14: UNSET_BR(i, k) | |
| 15: SET_BR(i, j) | |
| 16: end if | |
| 17: end if | |
| 18: else if = DAO then | |
| 19: SET_RX(i, j) | |
| 20: if then | |
| 21: SET_TX(i, j) | |
| 22: end if | |
| 23: end if | |
| 24: end procedure | |
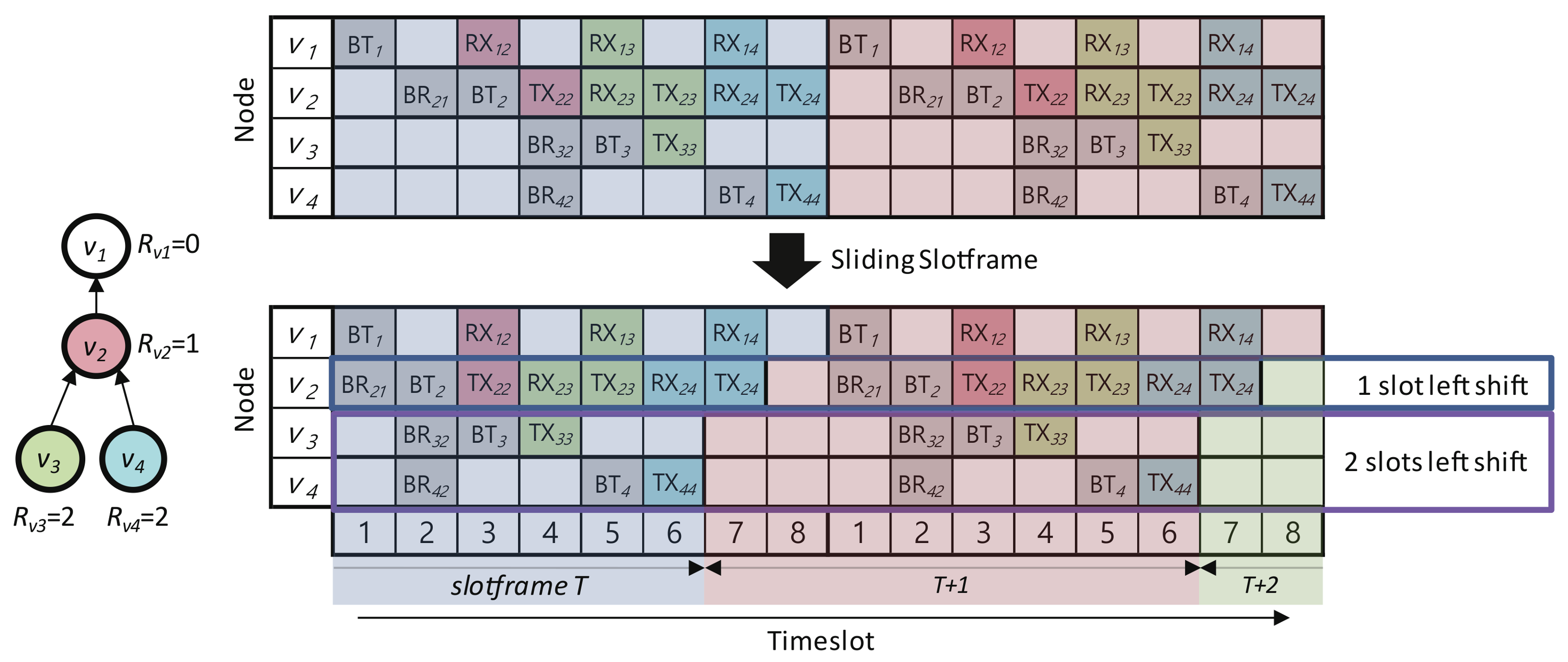
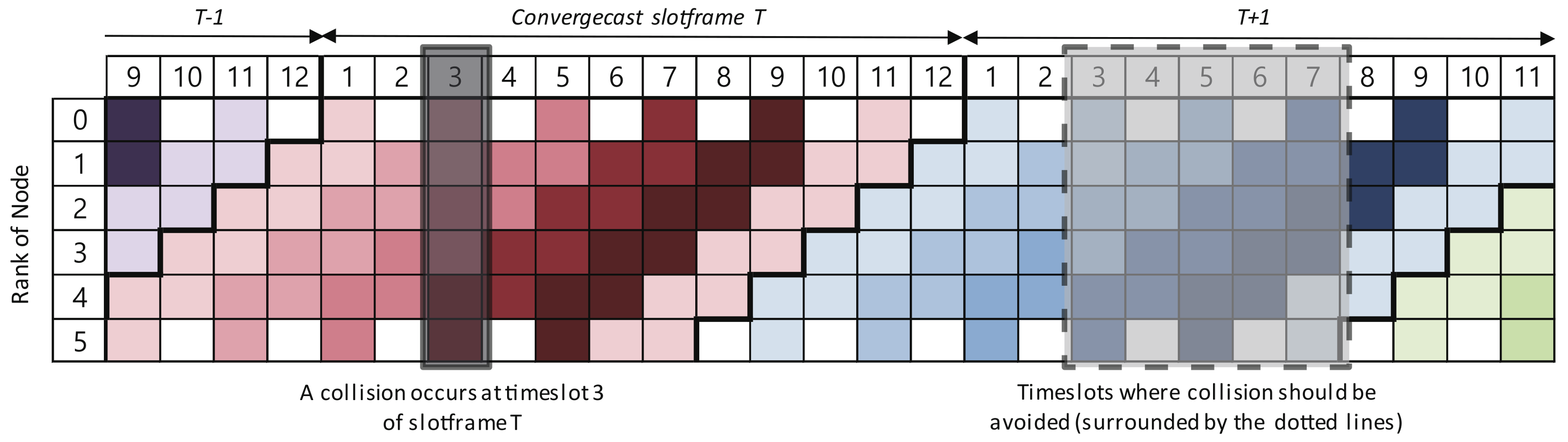
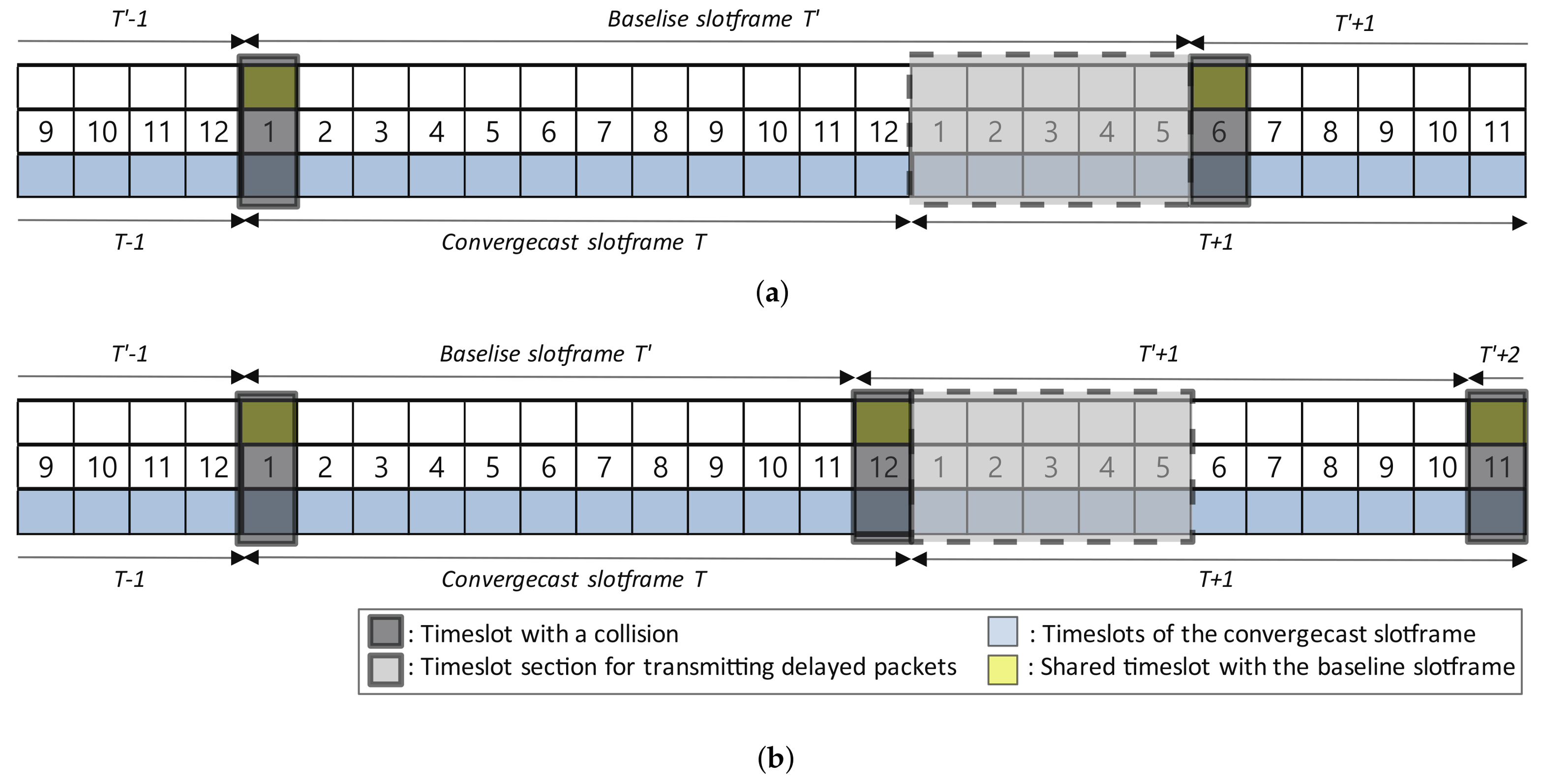
4.2. Sliding Slotframe Mechanism
4.3. Channel Offset Selection Mechanism
| Algorithm 2 Decide current timeslot operation and channel offset selection of the convergecast slotframe. | |
| 1: procedure Get current operation and channel offset(, i) | |
| 2: | ▹ relative timeslot number in current |
| 3: | ▹ get operation for from |
| 4: if then | |
| 5: if then | |
| 6: else if then | |
| 7: else if then | |
| 8: else if then | |
| 9: end if | |
| 10: end if | |
| 11: | ▹ relative timeslot number in current |
| 12: | ▹ get operation for from |
| 13: if then | ▹ if the operation of is not idle |
| 14: | ▹ the operation of is suppressed |
| 15: | |
| 16: end if | |
| 17: return | |
| 18: end procedure | |
4.4. Baseline Slotframe Size Determination
5. Analysis of Escalator
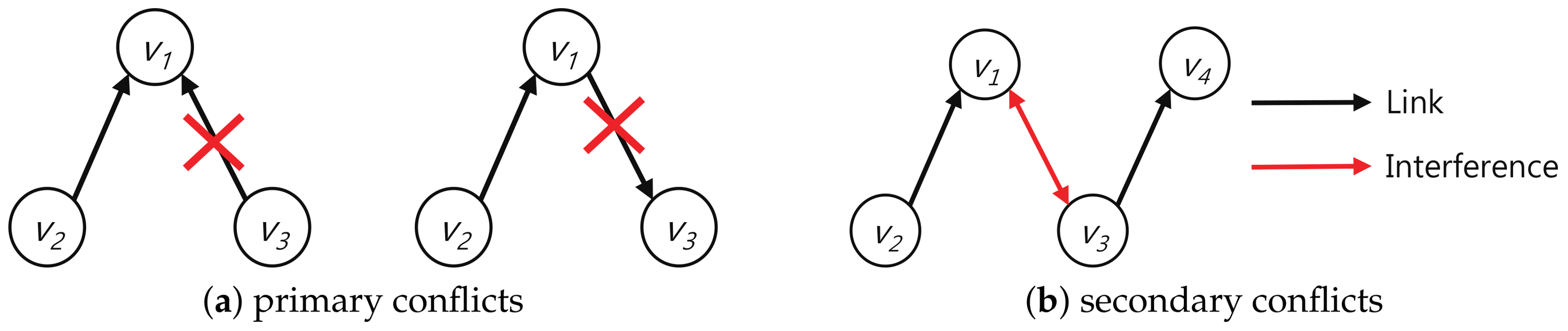
5.1. Conflict Definition
5.2. Proof of the Conflict-Freeness of Convergecast Schedule
5.3. Performance Analysis
5.3.1. End-to-End Delay Analysis by the Overlap of Convergecast and Baseline Slotframes
5.3.2. Bandwidth and Buffering Capability
6. Evaluation
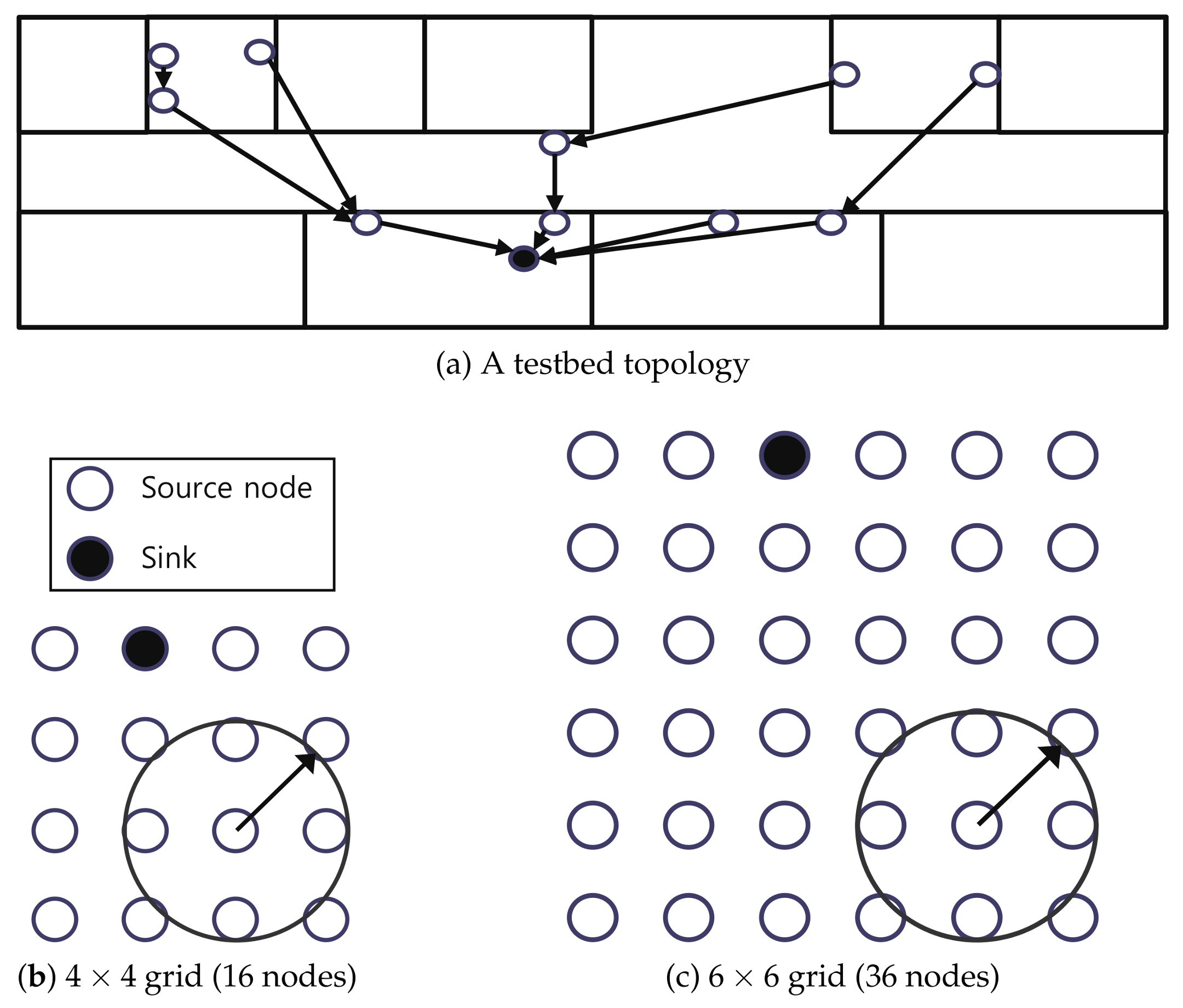
6.1. Experimental Setup
6.2. Performance Metric
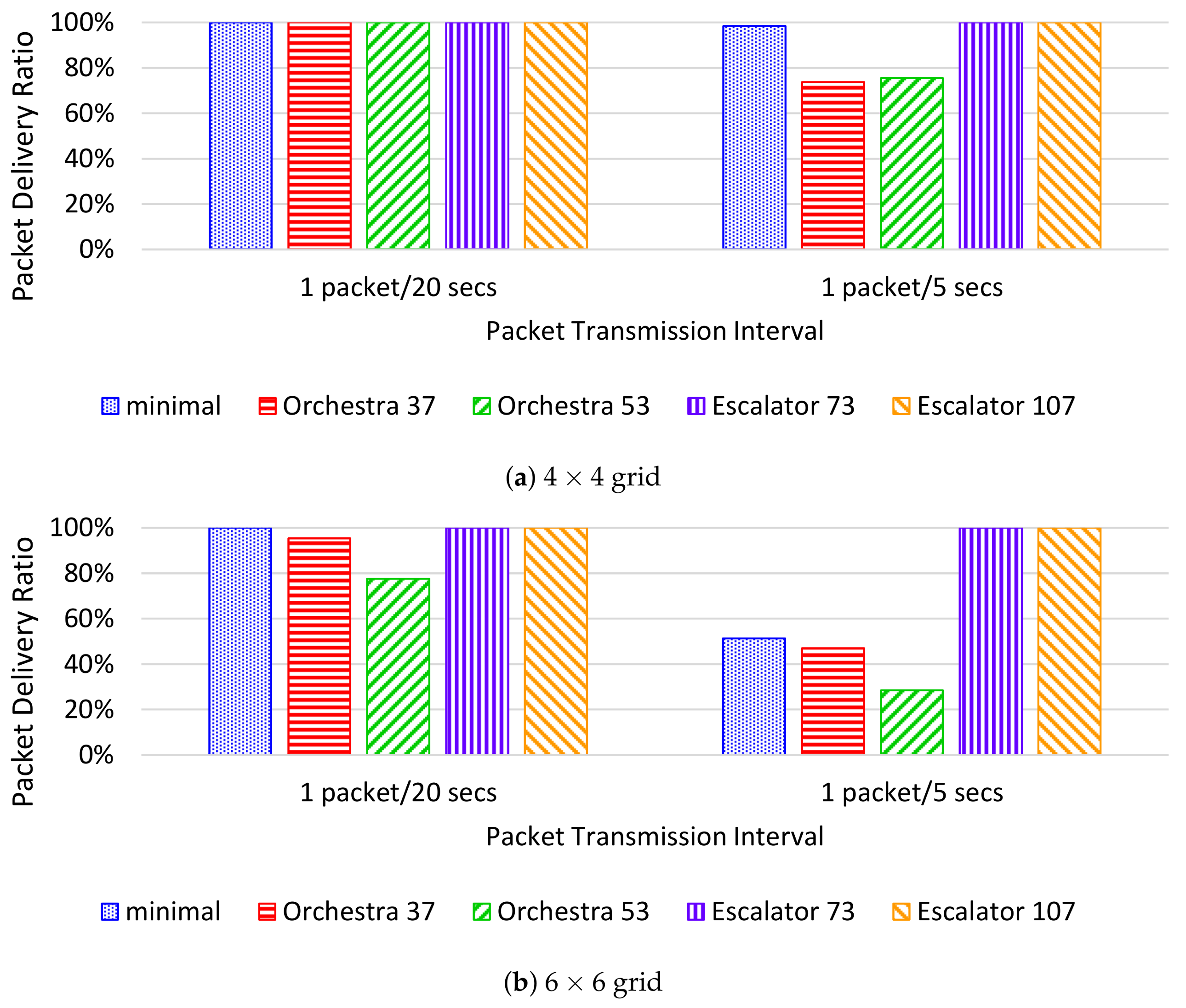
- The packet delivery ratio (PDR) is the percentage of packets successfully delivered to the sink. The PDR is measured as the ratio of the number of packets received by the sink to the total number of packets transmitted by nodes.
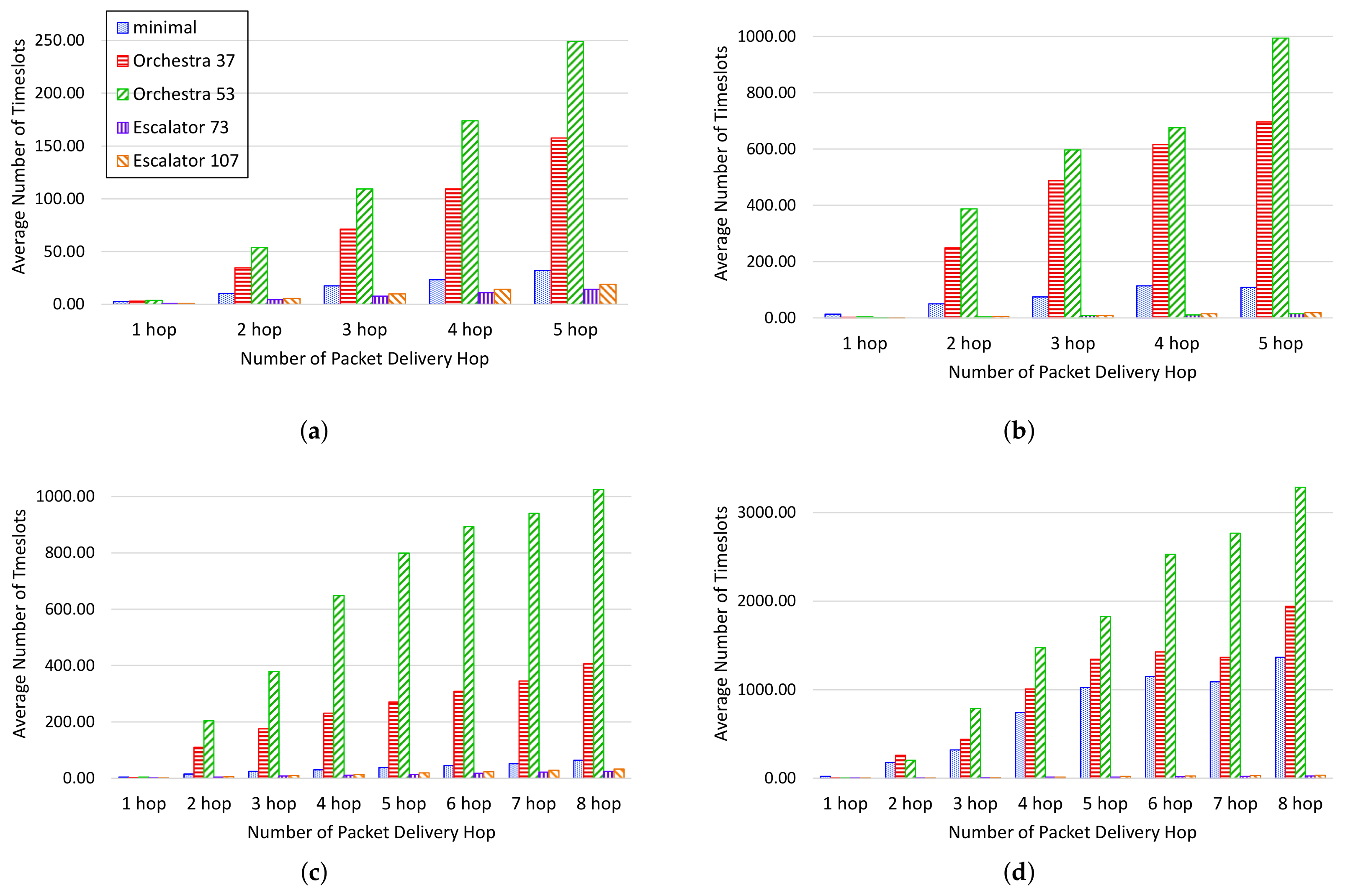
- The end-to-end delay means the number of timeslots that a packet takes to reach from a source node to the sink. We measure the ASN when the packet leaves from the source node and the ASN when the packet arrives at the sink. The difference between these two ASNs is used to calculate the end-to-end delay. We evaluated the performance by measuring the average of the end-to-end delay by the number of hops of the packet.
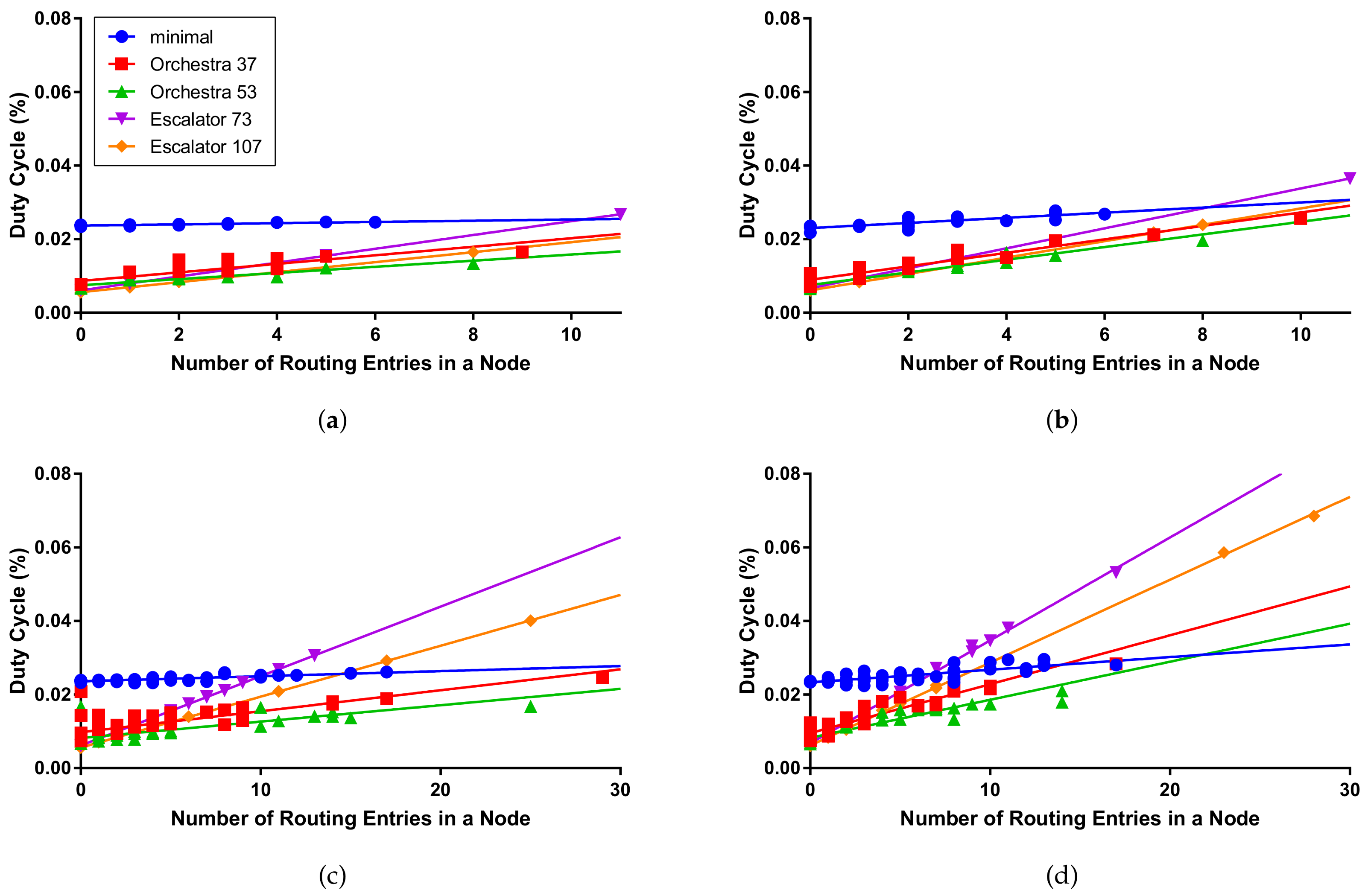
- The duty cycle means the ratio of the radio usage time to the total operation time of nodes. The duty cycle is measured only in the simulation, and CPU usage time and radio transmit and receive times are measured while transmitting 2000 packets for each node. We evaluated the performance by measuring the duty cycle by the number of routes in the node.
6.3. Testbed Results
6.4. Simulation Results
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pister, K.; Doherty, L. TSMP: Time synchronized mesh protocol. In Proceedings of the Parallel and Distributed Computing and Systems, Orlando, FL, USA, 16–18 November 2008; pp. 391–398. [Google Scholar]
- IEC. IEC 62591: Industrial Networks—Wireless Communication Network and Communication Profiles—WirelessHART™; IEC: Geneva, Switzerland, 2010. [Google Scholar]
- International Society of Automation. ANSI/ISA-100.11a-2011 Wireless Systems for Industrial Automation: Process Control and Related Applications; ISA: Research Triangle Park, NC, USA, 2011. [Google Scholar]
- IEEE. 802.15.4e-2012-IEEE Standard for Local and Metropolitan Area Networks–Part 15.4: Low-Rate Wireless Personal Area Networks (LR-WPANs) Amendment 1: MAC Sublayer; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Watteyne, T.; Mehta, A.; Pister, K. Reliability Through Frequency Diversity: Why Channel Hopping Makes Sense. In Proceedings of the 6th ACM Symposium on Performance Evaluation ofWireless Ad Hoc, Sensor, and Ubiquitous Networks, Tenerife, Canary Islands, Spain, 28–29 October 2009; ACM: New York, NY, USA, 2009; pp. 116–123. [Google Scholar] [CrossRef]
- Lennvall, T.; Svensson, S.; Hekland, F. A comparison of WirelessHART and ZigBee for industrial applications. In Proceedings of the 2008 IEEE International Workshop on Factory Communication Systems, Dresden, Germany, 21–23 May 2008; pp. 85–88. [Google Scholar] [CrossRef]
- Sgora, A.; Vergados, D.J.; Vergados, D.D. A Survey of TDMA Scheduling Schemes in Wireless Multihop Networks. ACM Comput. Surv. 2015, 47, 53:1–53:39. [Google Scholar] [CrossRef]
- Duquennoy, S.; Nahas, B.A.; Landsiedel, O.; Watteyne, T. Orchestra: Robust Mesh Networks through Autonomously Scheduled TSCH. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; ACM: New York, NY, USA, 2015; pp. 337–350. [Google Scholar] [CrossRef]
- Zhang, H.; Arora, A.; Choi, Y.; Gouda, M.G. Reliable bursty convergecast in wireless sensor networks. Comput. Commun. 2007, 30, 2560–2576. [Google Scholar] [CrossRef]
- Brandt, A.; Vasseur, J.; Hui, J.; Pister, K.; Thubert, P.; Levis, P.; Struik, R.; Kelsey, R.; Clausen, T.H.; Winter, T. RPL: IPv6 Routing Protocol for Low-Power and Lossy Networks. 2015. Available online: https://www.rfc-editor.org/info/rfc6550 (accessed on 11 April 2018). [CrossRef]
- Watteyne, T.; Palattella, M.R.; Grieco, L.A. Using IEEE 802.15.4e Time-Slotted Channel Hopping (TSCH) in the Internet of Things (IoT): Problem Statement. 2015. Available online: https://www.rfc-editor.org/info/rfc7554 (accessed on 11 April 2018). [CrossRef]
- Vasseur, J.; Farrel, A.; Ash, G. A Path Computation Element (PCE)-Based Architecture. 2006. Available online: https://www.rfc-editor.org/info/rfc4655 (accessed on 11 April 2018). [CrossRef]
- Wang, Q.; Vilajosana, X.; Watteyne, T. 6top Protocol (6P). Technical Report, Internet Engineering Task Force; Internet Engineering Task Force; Internet-Draft; Work in Progress. 2017. Available online: https://datatracker.ietf.org/doc/draft-ietf-6tisch-6top-protocol/ (accessed on 11 April 2018).
- Ergen, S.C.; Varaiya, P. TDMA scheduling algorithms for wireless sensor networks. Wirel. Netw. 2010, 16, 985–997. [Google Scholar] [CrossRef]
- Han, S.; Zhu, X.; Mok, A.K.; Chen, D.; Nixon, M. Reliable and Real-Time Communication in Industrial Wireless Mesh Networks. In Proceedings of the 17th IEEE Real-Time and Embedded Technology and Applications Symposium, Chicago, IL, USA, 11–14 April 2011; pp. 3–12. [Google Scholar] [CrossRef]
- Palattella, M.R.; Accettura, N.; Dohler, M.; Grieco, L.A.; Boggia, G. Traffic Aware Scheduling Algorithm for reliable low-power multi-hop IEEE 802.15.4e networks. In Proceedings of the 2012 IEEE 23rd International Symposium on Personal, Indoor and Mobile Radio Communications-(PIMRC), Sydney, NSW, Australia, 9–12 September 2012; pp. 327–332. [Google Scholar] [CrossRef]
- Tinka, A.; Watteyne, T.; Pister, K.S.J.; Bayen, A.M. A decentralized scheduling algorithm for time synchronized channel hopping. EAI Endorsed Trans. Mob. Commun. Appl. 2011, 1, 1–13. [Google Scholar] [CrossRef]
- Accettura, N.; Palattella, M.R.; Boggia, G.; Grieco, L.A.; Dohler, M. Decentralized Traffic Aware Scheduling for multi-hop Low power Lossy Networks in the Internet of Things. In Proceedings of the 2013 IEEE 14th International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Madrid, Spain, 4–7 June 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Domingo-Prieto, M.; Chang, T.; Vilajosana, X.; Watteyne, T. Distributed PID-Based Scheduling for 6TiSCH Networks. IEEE Commun. Lett. 2016, 20, 1006–1009. [Google Scholar] [CrossRef]
- Aijaz, A.; Raza, U. DeAMON: A Decentralized Adaptive Multi-Hop Scheduling Protocol for 6TiSCH Wireless Networks. IEEE Sens. J. 2017, 17, 6825–6836. [Google Scholar] [CrossRef]
- Papadopoulos, G.Z.; Matsui, T.; Thubert, P.; Texier, G.; Watteyne, T.; Montavont, N. Leapfrog collaboration: Toward determinism and predictability in industrial-IoT applications. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Gomes, P.H.; Watteyne, T.; Krishnamachari, B. MABO-TSCH: Multihop and blacklist-based optimized time synchronized channel hopping. Trans. Emerg. Telecommun. Technol. 2017. [Google Scholar] [CrossRef]
- Hosni, I.; Théoleyre, F. Self-healing distributed scheduling for end-to-end delay optimization in multihop wireless networks with 6TiSCh. Comput. Commun. 2017, 110, 103–119. [Google Scholar] [CrossRef]
- Vilajosana, X.; Pister, K.; Watteyne, T. Minimal IPv6 over the TSCH Mode of IEEE 802.15.4e (6TiSCH) Configuration. 2017. Available online: https://www.rfc-editor.org/info/rfc8180 (accessed on 11 April 2018). [CrossRef]
- Gandham, S.; Zhang, Y.; Huang, Q. Distributed time-optimal scheduling for convergecast in wireless sensor networks. Comput. Netw. 2008, 52, 610. [Google Scholar] [CrossRef]
- Incel, O.D.; Ghosh, A.; Krishnamachari, B.; Chintalapudi, K.K. Multi-Channel Scheduling for Fast Convergecast in Wireless Sensor Networks. In Technical Report CENG-2008-9; University of Southern California: Los Angeles, CA, USA, 2008. [Google Scholar]
- Zhang, H.; Soldati, P.; Johansson, M. Optimal link scheduling and channel assignment for convergecast in linear WirelessHART networks. In Proceedings of the 2009 7th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks, Seoul, Korea, 23–27 June 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Soua, R.; Minet, P.; Livolant, E. Wave: a distributed scheduling algorithm for convergecast in IEEE 802.15.4e TSCH networks. Trans. Emerg. Telecommun. Technol. 2016, 27, 557–575. [Google Scholar] [CrossRef]
- Djukic, P.; Valaee, S. Delay Aware Link Scheduling for Multi-Hop TDMA Wireless Networks. IEEE/ACM Trans. Netw. 2009, 17, 870–883. [Google Scholar] [CrossRef]
- Dunkels, A.; Gronvall, B.; Voigt, T. Contiki—A lightweight and flexible operating system for tiny networked sensors. In Proceedings of the 29th Annual IEEE International Conference on Local Computer Networks, Tampa, FL, USA, 16–18 November 2004; pp. 455–462. [Google Scholar] [CrossRef]
- Osterlind, F.; Dunkels, A.; Eriksson, J.; Finne, N.; Voigt, T. Cross-Level Sensor Network Simulation with COOJA. In Proceedings of the 2006 31st IEEE Conference on Local Computer Networks, Tampa, FL, USA, 14–16 November 2006; pp. 641–648. [Google Scholar] [CrossRef]
- Eriksson, J.; Dunkels, A.; Finne, N.; Osterlind, F.; Voigt, T. Mspsim—An extensible simulator for msp430-equipped sensor boards. In Proceedings of the European Conference on Wireless Sensor Networks (EWSN), Delft, The Netherlands, 29–31 January 2007; Volume 118. [Google Scholar]
- Huang, Y.F.; Hsu, C.H. Energy Efficiency of Dynamically Distributed Clustering Routing for Naturally Scattering Wireless Sensor Networks. J. Netw. Intell. 2018, 3, 50–57. [Google Scholar]
- Kong, L.; Pan, J.S.; Sung, T.W.; Tsai, P.W.; Snášel, V. An Energy Balancing Strategy Based on Hilbert Curve and Genetic Algorithm for Wireless Sensor Networks. Wirel. Commun. Mob. Comput. 2017, 2017, 13. [Google Scholar] [CrossRef]
- Ghosal, A.; Halder, S. Lifetime Optimizing Clustering Structure Using Archimedes’ Spiral-Based Deployment in WSNs. IEEE Syst. J. 2017, 11, 1039–1048. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| G | The network consisting of nodes V and links E |
| N | The number of nodes in the network |
| V | The set of nodes in the network |
| E | The set of links in the network |
| Duration of timeslot | |
| The number of available orthogonal channel | |
| The channel offset that is used for multiple channel usage at a single timeslot | |
| The channel offset used for | |
| The total number of timeslots that have elapsed since the start of the network | |
| The convergecast slotframe | |
| The baseline slotframe | |
| The size of slotframe S in timeslot unit | |
| A node with ID i | |
| The preferred parent of node | |
| The set of the direct child nodes of node | |
| The set of nodes in the sub-graph of node , excluding itself | |
| A link for which the sender is and the receiver is | |
| Hop count of node , the number of hops from the sink to node | |
| Operation at timeslot in slotframe S, which is one of the following four operations | |
| The operation in which broadcasts a beacon | |
| The operation in which receives a beacon sent by | |
| The operation in which transmits a unicast packet originated from | |
| to the parent node | |
| The operation in which receives a unicast packet, originated from , | |
| from one of the child nodes | |
| The timeslot section from to | |
| Least common multiple of a and b | |
| Maximum hop counts of the packet-forwarding path in network G | |
| Average end-to-end delay of node | |
| Average bandwidth of node in network G | |
| Average required buffer capability of nodes in network G |
| Duty Cycle (%) | ||||||||
|---|---|---|---|---|---|---|---|---|
| grid, 20 s | grid, 5 s | grid, 20 s | grid, 5 s | |||||
| Average | Max | Average | Max | Average | Max | Average | Max | |
| minimal | 2.40 | 2.47 | 2.44 | 2.77 | 2.41 | 2.61 | 2.48 | 2.96 |
| Orchestra 37 | 1.06 | 1.65 | 1.20 | 2.56 | 1.15 | 2.46 | 1.31 | 2.83 |
| Orchestra 53 | 0.89 | 1.34 | 1.02 | 1.96 | 0.96 | 1.68 | 1.08 | 2.10 |
| Escalator 73 | 0.92 | 2.67 | 1.12 | 3.65 | 1.20 | 3.05 | 1.54 | 5.31 |
| Escalator 107 | 0.78 | 1.64 | 0.98 | 2.39 | 0.99 | 4.01 | 1.32 | 6.85 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, S.; Hwang, D.; Kim, K.-H.; Kim, K. Escalator: An Autonomous Scheduling Scheme for Convergecast in TSCH. Sensors 2018, 18, 1209. https://doi.org/10.3390/s18041209
Oh S, Hwang D, Kim K-H, Kim K. Escalator: An Autonomous Scheduling Scheme for Convergecast in TSCH. Sensors. 2018; 18(4):1209. https://doi.org/10.3390/s18041209
Chicago/Turabian StyleOh, Sukho, DongYeop Hwang, Ki-Hyung Kim, and Kangseok Kim. 2018. "Escalator: An Autonomous Scheduling Scheme for Convergecast in TSCH" Sensors 18, no. 4: 1209. https://doi.org/10.3390/s18041209
APA StyleOh, S., Hwang, D., Kim, K.-H., & Kim, K. (2018). Escalator: An Autonomous Scheduling Scheme for Convergecast in TSCH. Sensors, 18(4), 1209. https://doi.org/10.3390/s18041209