Adaptive Correlation Model for Visual Tracking Using Keypoints Matching and Deep Convolutional Feature


Abstract
1. Introduction
- We propose a novel model updating method. Firstly, we establish a keypoints library to restore the reliable historical data, and then we obtain the pixel-level correspondence between the current frame and the previous frame using dense matching. Finally, the similarity score is calculated by comparing matched pairs of keypoints and is used to adjust the learning rate in model updating.
- We propose a method to fully exploit the hierarchical features generated of the DCNN, which can make full use of spatial detail information and semantic information.
- Based on the observation of different layers’ output, we propose a scale estimation method using deep convolutional features.
2. Related Work
2.1. Trackers with Convolutional Neural Network
2.2. Trackers with Correlation Filters
2.3. Trackers with Keypoints and Matching
3. Proposed Approach
3.1. Deep Convolutional Features
- CNN feature maps are high-dimensional features and contain information highly related to the target state.
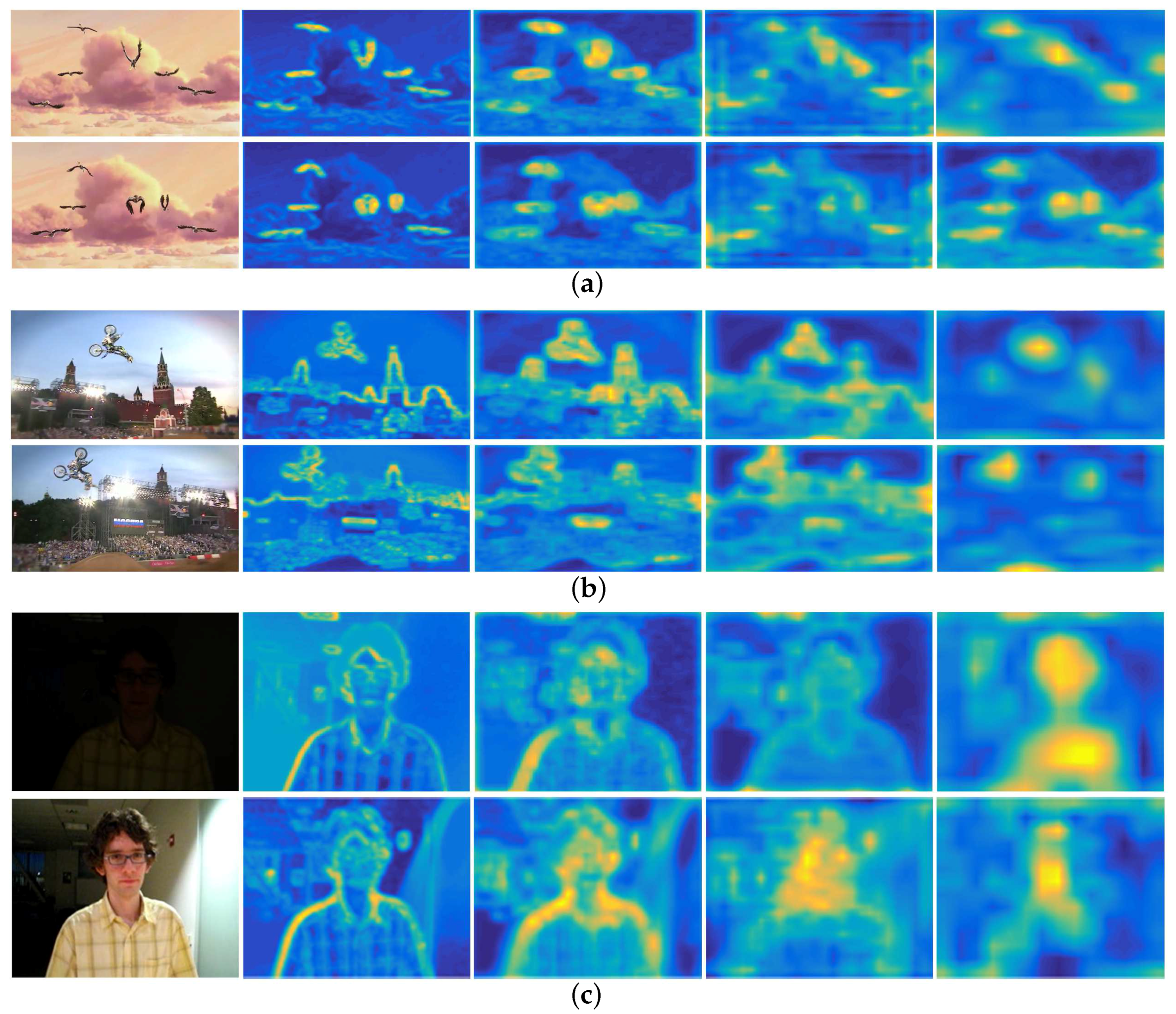
- Different layers of CNN encode different types of information. Feature maps of higher layers encode semantic information. As shown in Figure 2, although the appearance of the targets undergoes different variation (non-rigid deformation in Bird1, in-plane-rotation in MotorRolling, illumination variation in David), the region around the target is always bright yellow in feature maps of conv5-4 layer. This character is quite useful when the target undergoes severe appearance variation.
- Feature maps of lower layers retain more spatial details of the target, such as borders, corners, and curves. Taking David as an example, it is obvious that the texture of the face such as edges and contours are well preserved, including the corner of the ear, the boundary of the face, etc., which could be used to determine the boundary of the target and thus to make scale estimation.
3.2. Correlation Filter
3.2.1. Correlation Filters for Translation Estimation
3.2.2. Correlation Filters for Scale Estimation
3.3. Adaptive Model Updating
| Algorithm 1: Proposed tracking algorithm. |
| Input : Image I; initial target position and scale ; previous target position and scale . |
| Output : Estimated object position and scale . |
| Initialize correlation filters , and set , |
| Foreach |
| Extract multiple generated by VGG-Net; |
| Compute the translation correlation using Equation (5) and Equation (6) |
| Set to at the maximum of |
| Compute the translation correlation using Equation (9) |
| Set to at the maximum of |
| Compute discounting factor using Equation (12) to Equation (15) |
| Update , , , , K, D |
| End |
4. Experiments
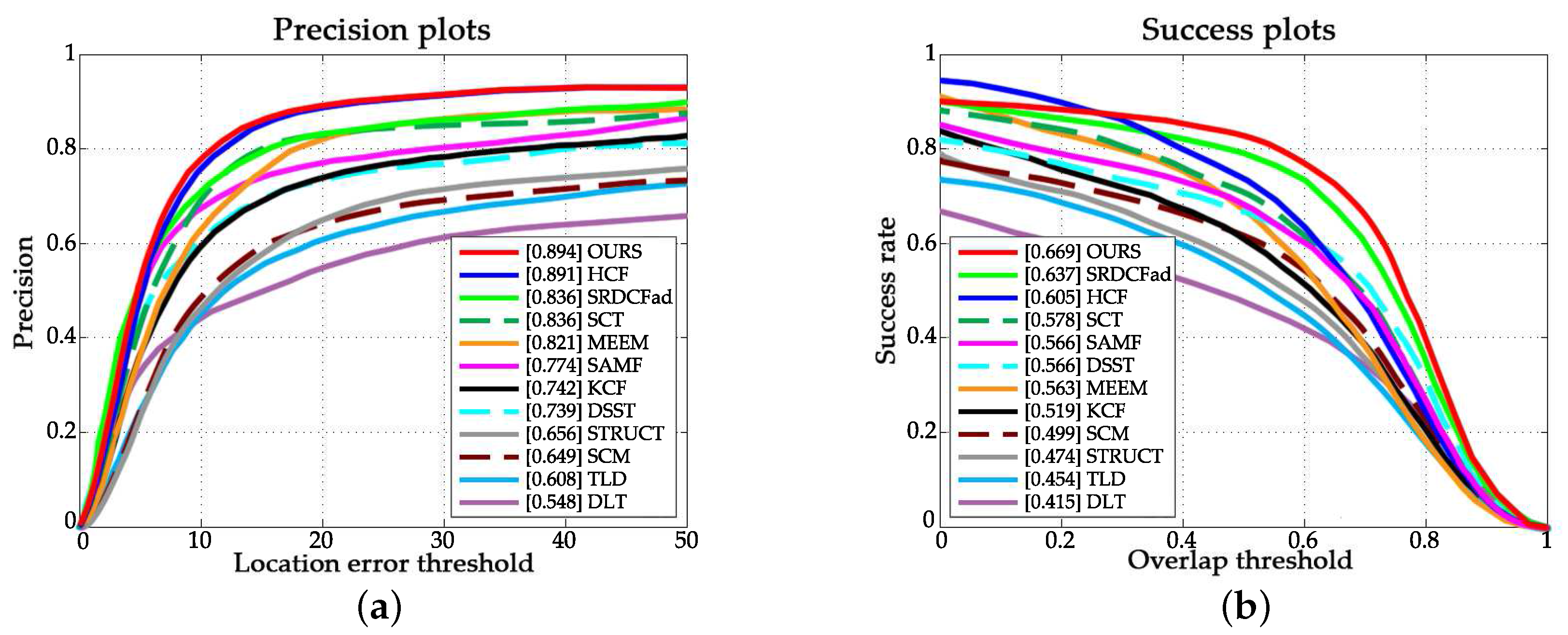
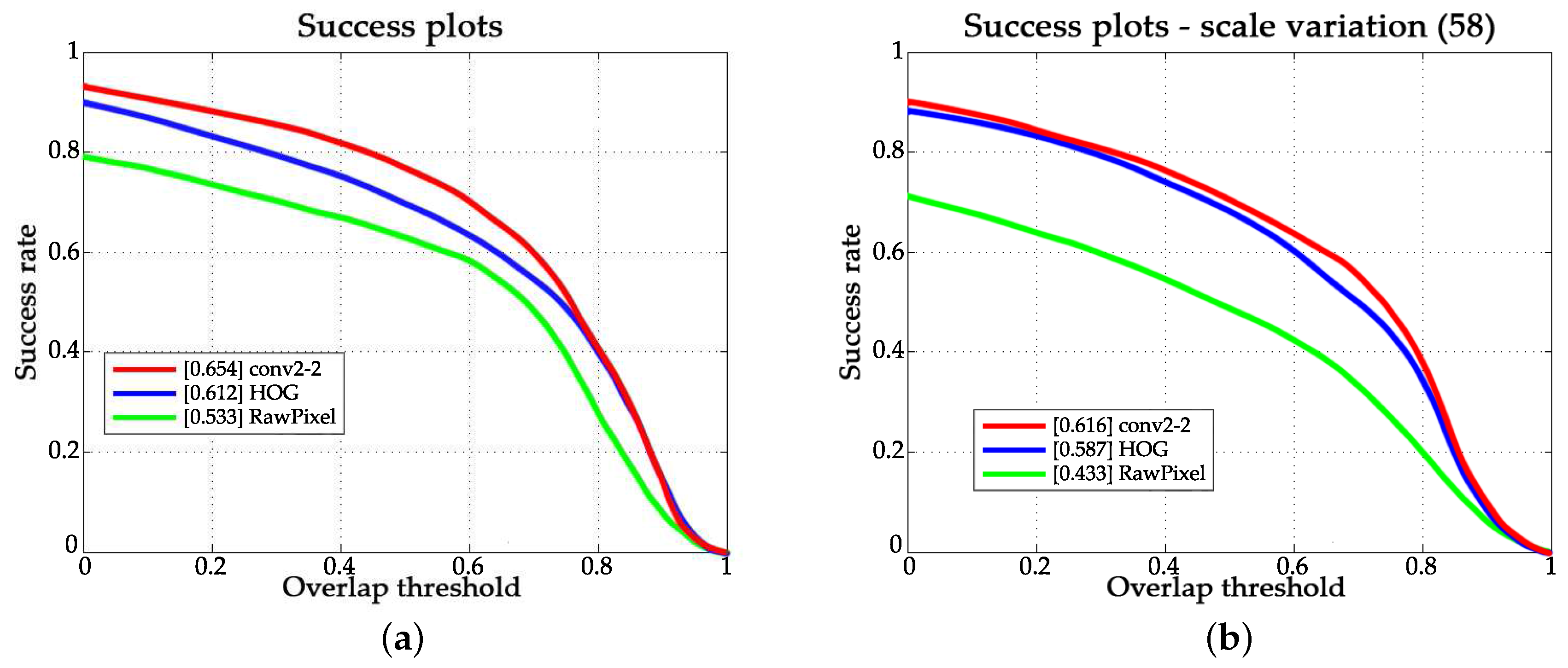
4.1. Quantitative Evaluation
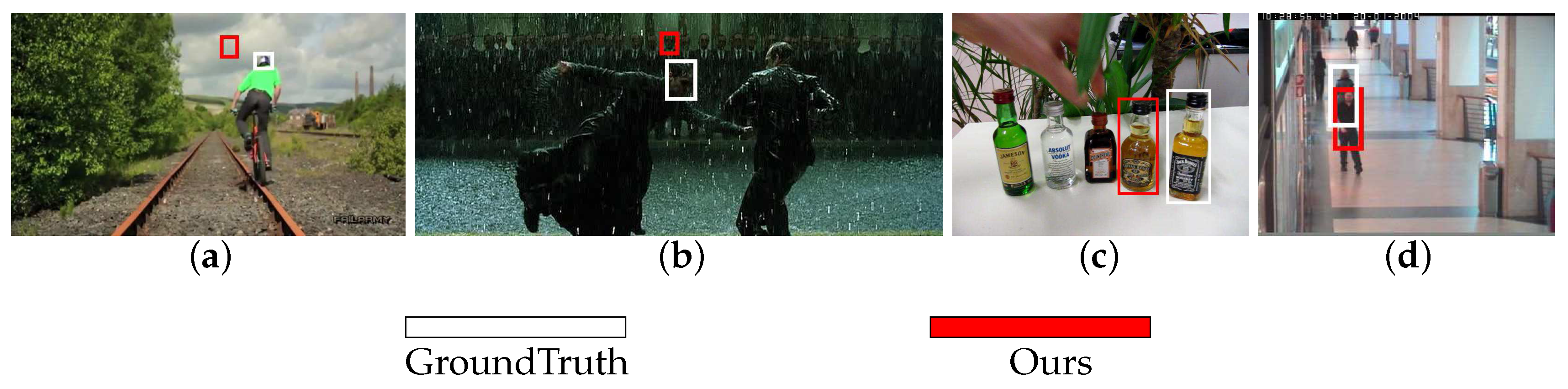
4.2. Qualitative Evaluation
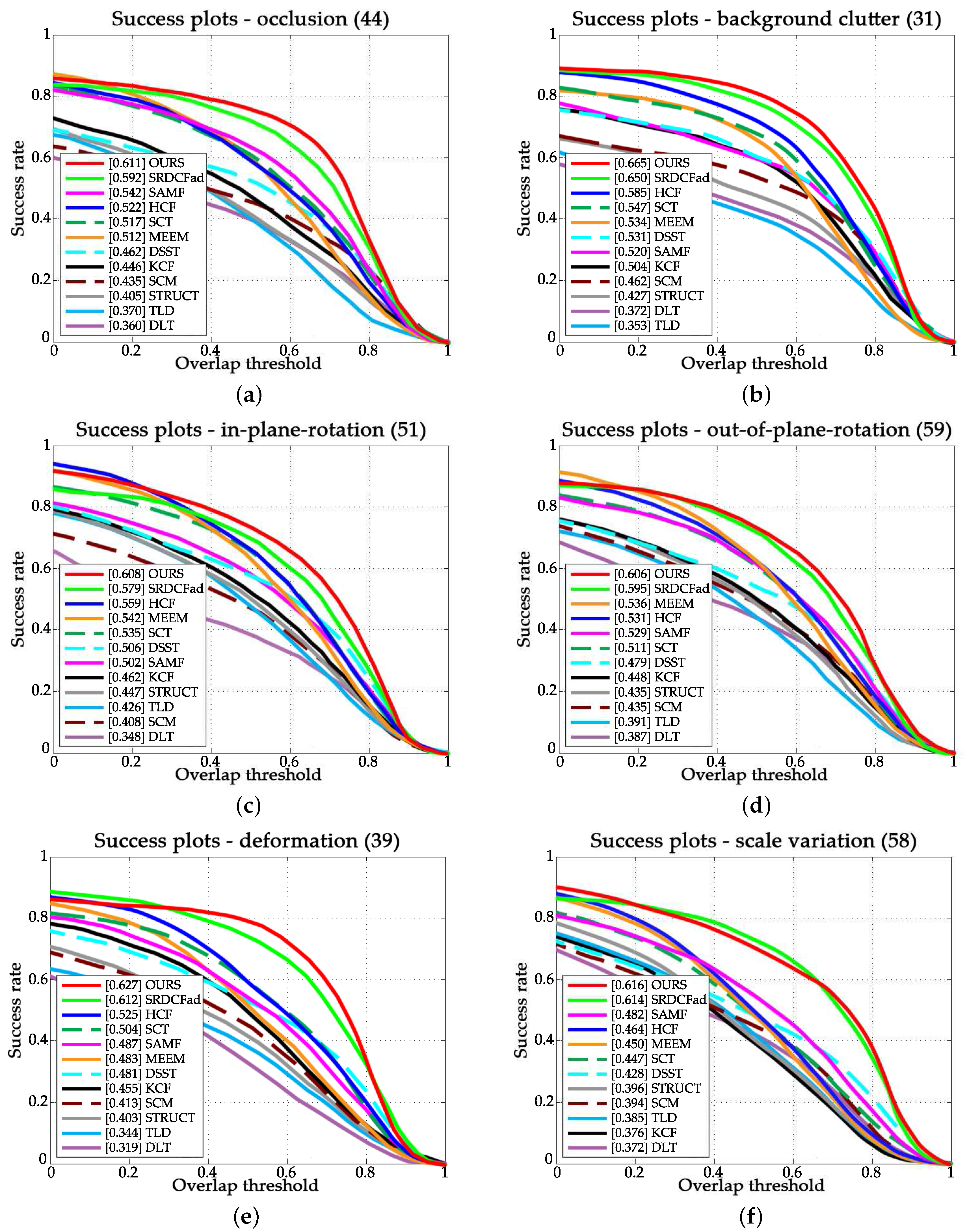
4.2.1. Performance against Background Information Variation
4.2.2. Performance against Target Appearance Variation
4.3. Demonstrations
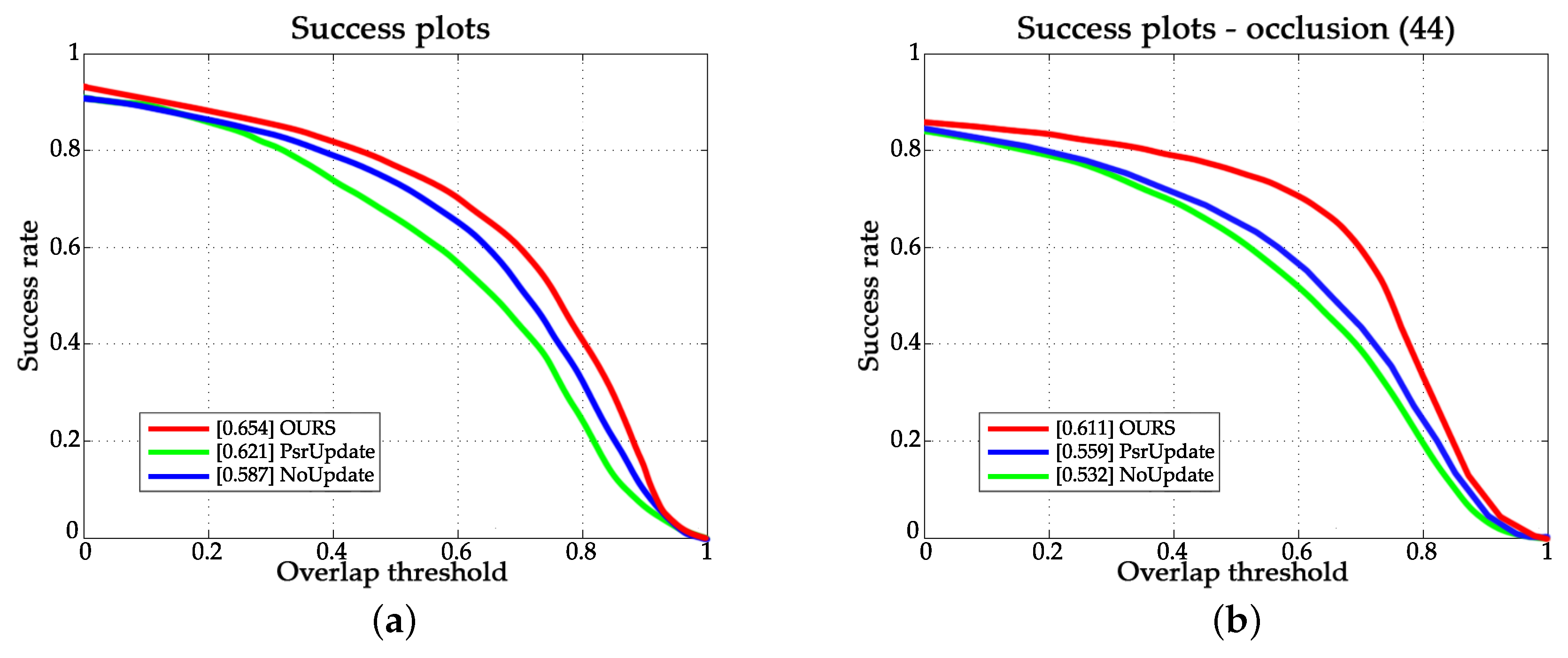
4.3.1. Evaluation of the Updating Method
4.3.2. Evaluation of Scale Estimation
4.4. Failure Cases
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Babenko, B.; Yang, M.H.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Khan, F.S.; Felsberg, M.; Weijer, J. Adaptive Color Attributes for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1090–1097. [Google Scholar]
- Nebehay, G.; Pflugfelder, R. Clustering of static-adaptive correspondences for deformable object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2784–2791. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Santiago, Chile, 7–13 December 2015; pp. 621–629. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Advances in Neural Information Processing Systems; NIPS: La Jolla, CA, USA, 2013; pp. 809–817. [Google Scholar]
- Wang, N.; Li, S.; Gupta, A.; Yeung, D. Transferring Rich Feature Hierarchies for Robust Visual Tracking. arXiv, 2015; arXiv:1501.04587. [Google Scholar]
- Li, H.; Li, Y.; Porikli, F. DeepTrack: Learning Discriminative Feature Representations by Convolutional Neural Networks for Visual Tracking. In Proceedings of the IEEE British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; p. 3. [Google Scholar]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.H. Robust Visual Tracking via Convolutional Networks Without Training. IEEE Trans. Image Proc. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 472–488. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-detection with Kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; pp. 65.1–65.11. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I. Robust Fragments-based Tracking using the Integral Histogram. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–23 June 2006; pp. 798–805. [Google Scholar]
- Zhang, T.; Jia, K.; Xu, C.; Ma, Y.; Ahuja, N. Partial Occlusion Handling for Visual Tracking via Robust Part Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1258–1265. [Google Scholar]
- Lowe, D.G.; Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Grabner, M.; Grabner, H.; Bischof, H. Learning Features for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Hare, S.; Saffari, A.; Torr, P.H.S. Efficient Online Structured Output Learning for Keypoint-Based Object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1894–1901. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Liu, L.; Shen, C.; van den Hengel, A. The Treasure Beneath Convolutional Layers: Cross-Convolutional-Layer pooling for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 17–22 June 2015; pp. 4749–4757. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Adaptive Decontamination of the Training Set: A Unified Formulation for Discriminative Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 1430–1438. [Google Scholar]
- Choi, J.; Chang, H.J.; Jeong, J.; Demiris, Y.; Choi, J.Y. Visual Tracking Using Attention-Modulated Disintegration and Integration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 4321–4330. [Google Scholar]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust Tracking via Multiple Experts Using Entropy Minimization. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 188–203. [Google Scholar]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the European Conference on Computer Vision Workshop, Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H.S. Struck: Structured Output Tracking with Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed]
- Zhong, W.; Lu, H.; Yang, M.H. Robust Object Tracking via Sparse Collaborative Appearance Model. IEEE Trans. Image Proc. 2014, 23, 2356–2368. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ours | SRDCFad | HCF | SCT | MEEM | SAMF | DSST | KCF | STRUCT | TLD | SCM | DLT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Average FPS | 3 | 3 | 6 | 44 | 11 | 12 | 56 | 192 | 10 | 22 | 0.4 | 0.6 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Xu, T.; Deng, H.; Shi, G.; Guo, J. Adaptive Correlation Model for Visual Tracking Using Keypoints Matching and Deep Convolutional Feature. Sensors 2018, 18, 653. https://doi.org/10.3390/s18020653
Li Y, Xu T, Deng H, Shi G, Guo J. Adaptive Correlation Model for Visual Tracking Using Keypoints Matching and Deep Convolutional Feature. Sensors. 2018; 18(2):653. https://doi.org/10.3390/s18020653
Chicago/Turabian StyleLi, Yuankun, Tingfa Xu, Honggao Deng, Guokai Shi, and Jie Guo. 2018. "Adaptive Correlation Model for Visual Tracking Using Keypoints Matching and Deep Convolutional Feature" Sensors 18, no. 2: 653. https://doi.org/10.3390/s18020653
APA StyleLi, Y., Xu, T., Deng, H., Shi, G., & Guo, J. (2018). Adaptive Correlation Model for Visual Tracking Using Keypoints Matching and Deep Convolutional Feature. Sensors, 18(2), 653. https://doi.org/10.3390/s18020653