Social Image Captioning: Exploring Visual Attention and User Attention

 ,
,
Abstract
:
1. Introduction
- Social image captioning is considered to generate diverse descriptions with corresponding user tags. User attention is proposed to address the different effects of generated visual descriptions and user tags, which lead to a personalized social image caption.
- A dual attention model is also proposed for social image captioning to combine the visual attention and user attention simultaneously. In this situation, generated descriptions maintain accuracy and diversity.
2. Related Work
3. Proposed Method
3.1. Preliminaries
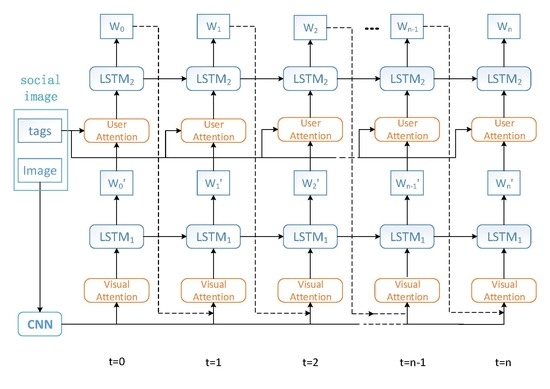
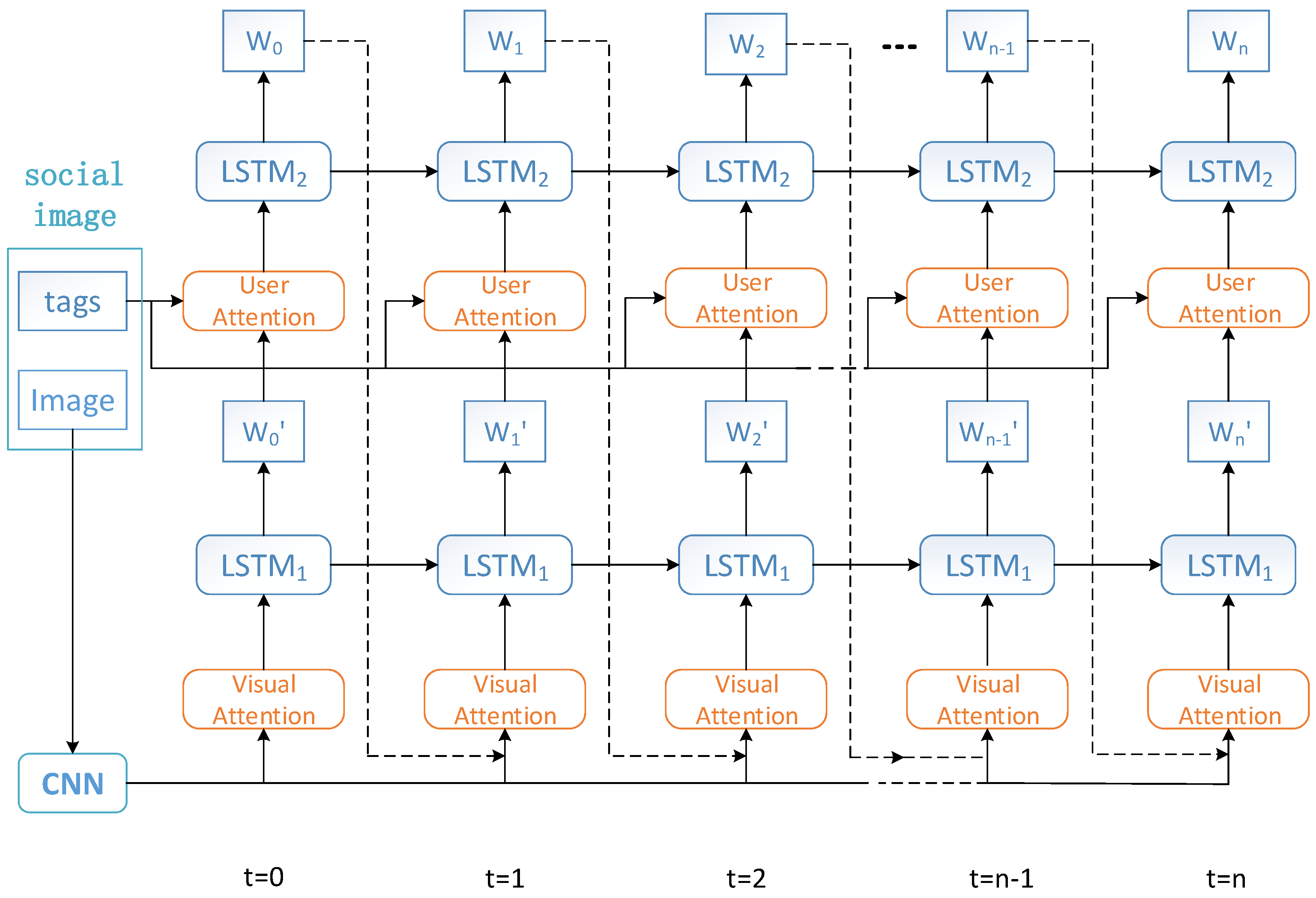
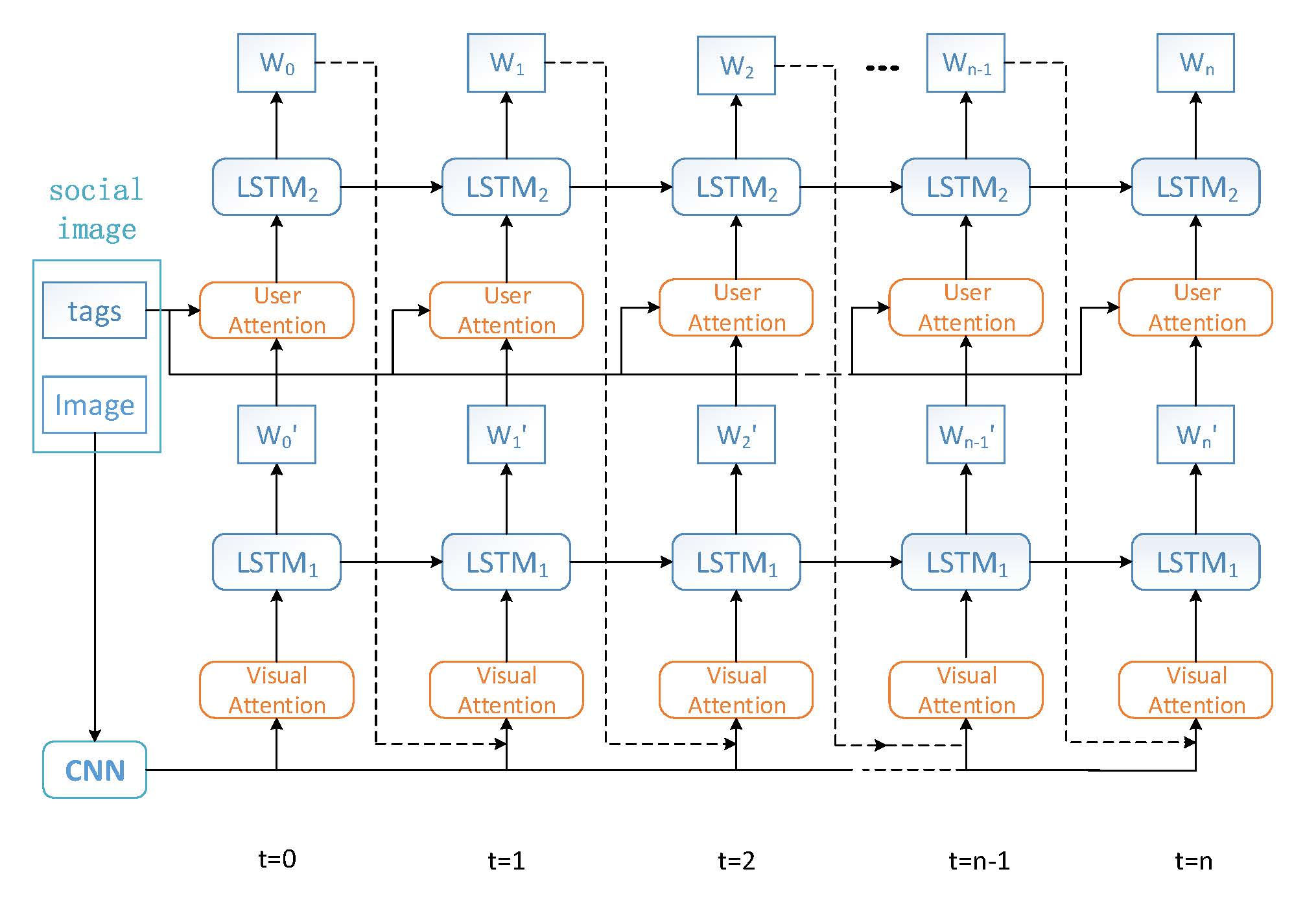
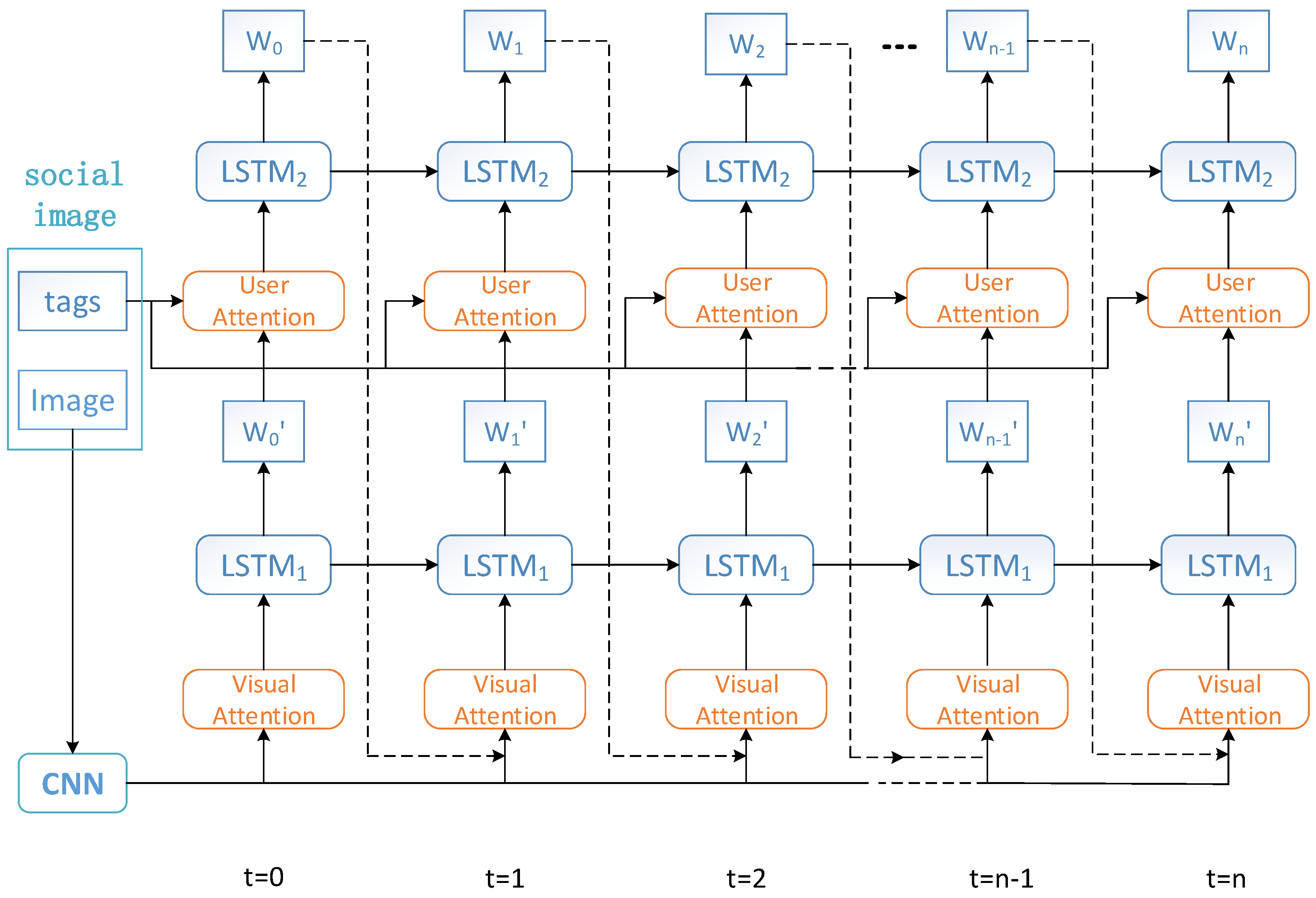
3.2. Dual Attention Model Architecture
3.3. Visual Attention
3.4. User Attention
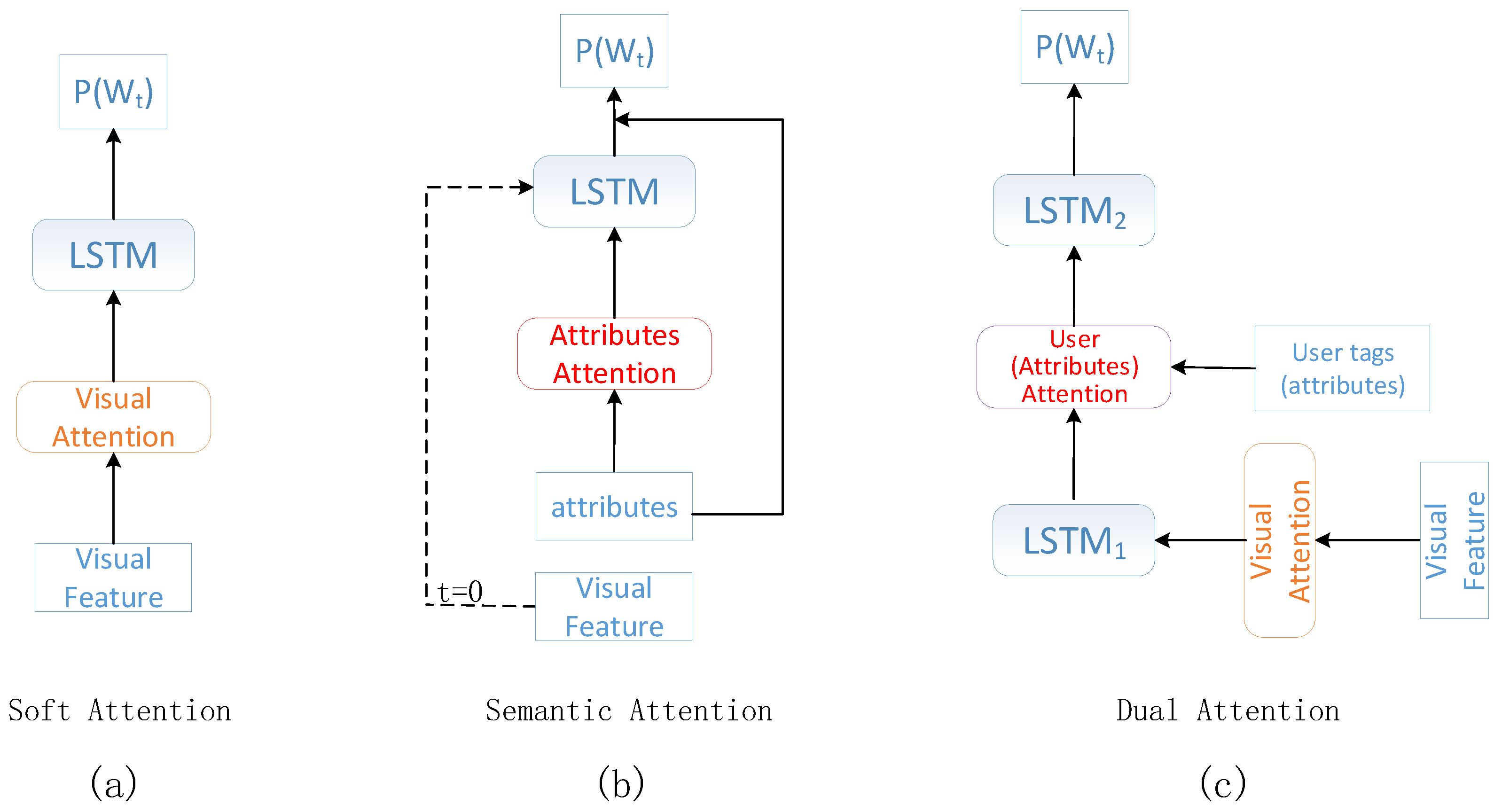
3.5. Combination of Visual and User Attentions
4. Experimental Results
4.1. Datasets and Evaluation Metrics
4.2. Overall Comparisons by Using Visual Attributes
- Guidance LSTM (gLSTM) [26] took the three different kinds of semantic information to guide the word generation in each time step. The guidance includes retrieval-based guidance (ret-gLSTM), semantic embedding guidance (emb-gLSTM) and image guidance (img-gLSTM).
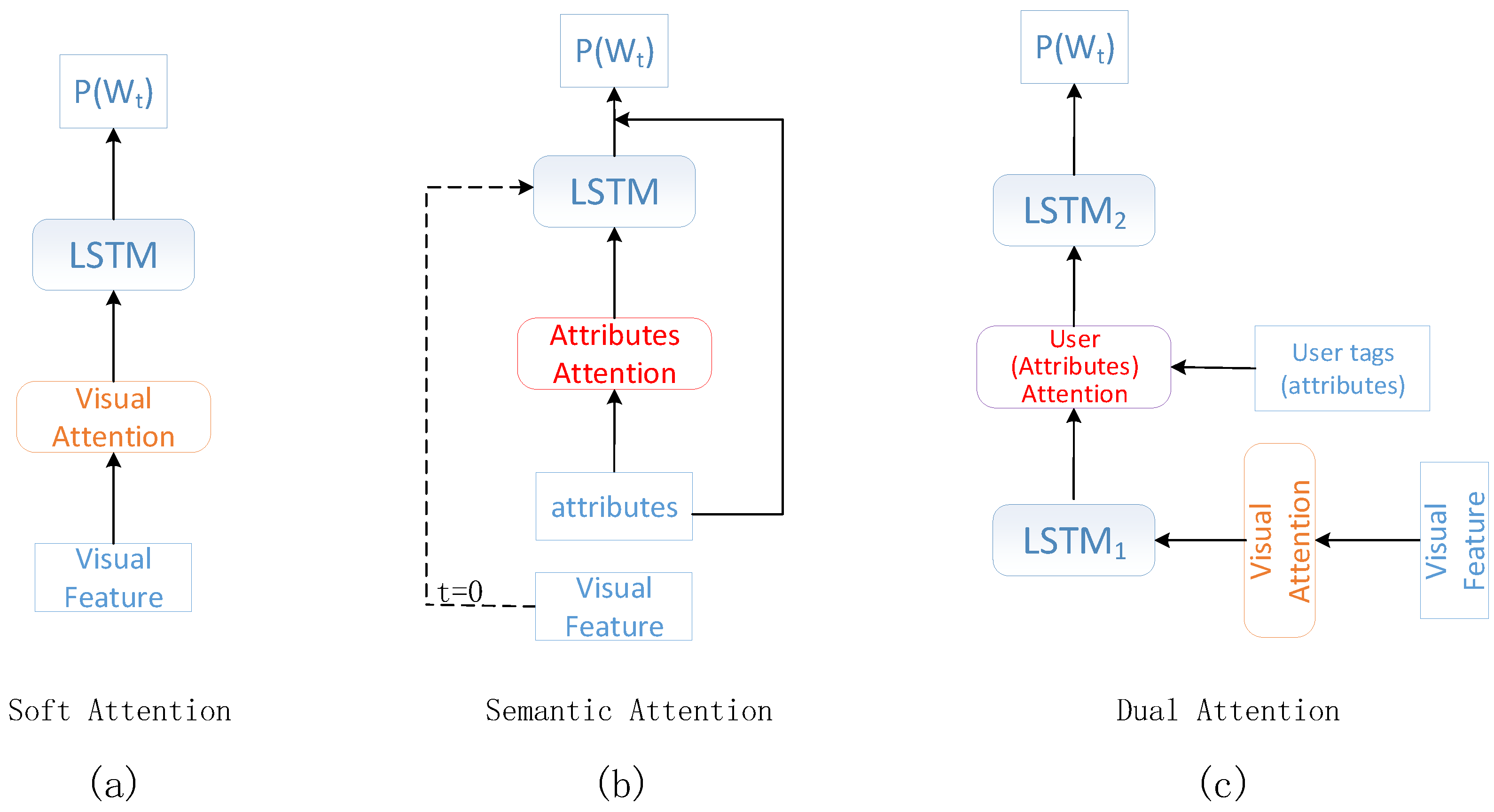
- Soft attention [4] put forward the spatial attention mechanism that performed on the visual features. Different weights were assigned to the corresponding regions of the feature map to represent context information. The context information was then input to the encoder-decoder framework.
- Semantic attention [5] injected the attribute attention and visual features () into the LSTM layer.
- Attribute-based image captioning with CNN and LSTM (Att-CNN + LSTM) [32] used the trained model to predict the multiple attributes as high-level semantic information of the image and incorporated them into the CNN-RNN approach.
- Boosting image captioning with attributes (BIC + Att) [33] constructed variants of architectures by feeding image representations and attributes into RNNs in different ways to explore the correlation between them.
4.3. Overall Comparison by Using Man-Made User Tags
4.4. The Influence of Noise on the Dual Attention Model
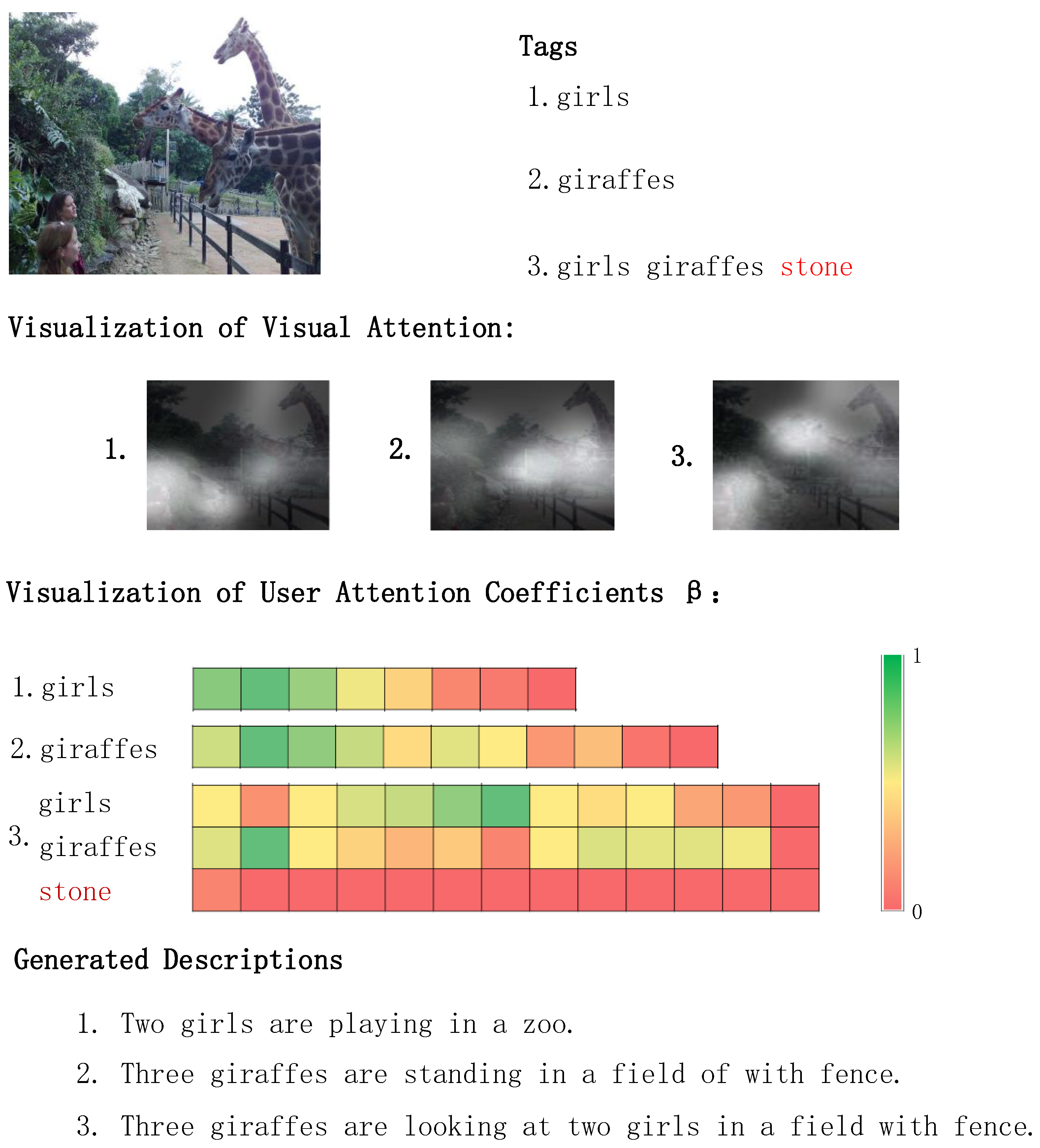
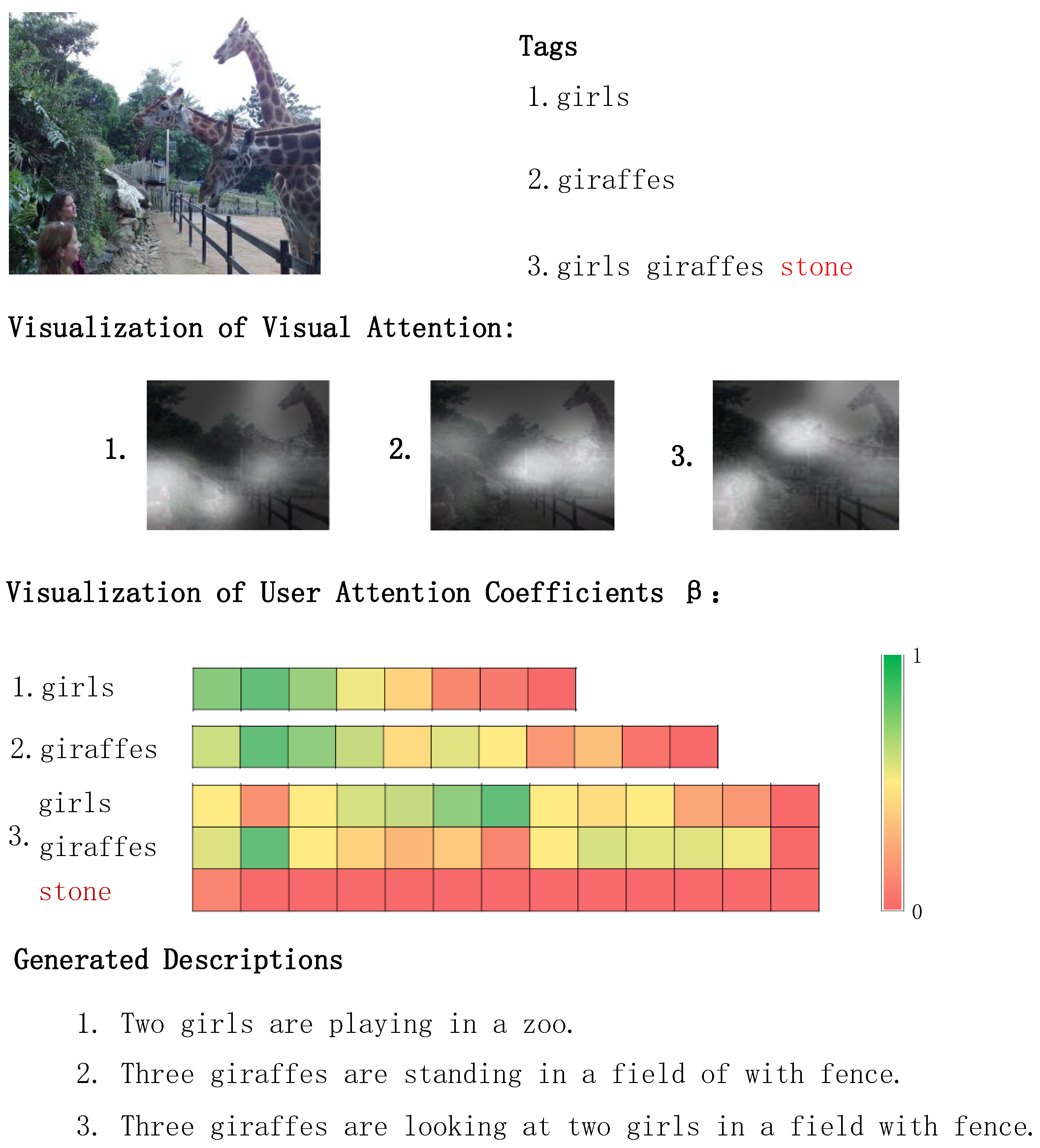
4.5. Qualitative Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shi, Y.; Larson, M.; Hanjalic, A. Tags as Bridges between Domains: Improving Recommendation with Tag-Induced Cross-Domain Collaborative Filtering. In Proceedings of the International Conference on User Modeling, Adaption and Personalization, Umap 2011, Girona, Spain, 11–15 July 2011; pp. 305–316. [Google Scholar]
- Liu, C.; Cao, Y.; Luo, Y.; Chen, G.; Vokkarane, V.; Ma, Y.; Chen, S.; Hou, P. A New Deep Learning-based Food Recognition System for Dietary Assessment on An Edge Computing Service Infrastructure. IEEE Trans. Serv. Comput. 1939. [Google Scholar] [CrossRef]
- Bian, J.; Barnes, L.E.; Chen, G.; Xiong, H. Early detection of diseases using electronic health records data and covariance-regularized linear discriminant analysis. In Proceedings of the IEEE Embs International Conference on Biomedical and Health Informatics, Orlando, FL, USA, 16–19 February 2017. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv, 2015; arXiv:1502.03044. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning with Semantic Attention. arXiv, 2016; arXiv:1603.03925. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. arXiv, 2016; arXiv:1606.00061. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 4, 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A.J. Stacked Attention Networks for Image Question Answering. arXiv, 2015; arXiv:1511.02274. [Google Scholar]
- Zhou, L.; Xu, C.; Koch, P.; Corso, J.J. Image Caption Generation with Text-Conditional Semantic Attention. arXiv, 2016; arXiv:1606.04621. [Google Scholar]
- Liu, C.; Sun, F.; Wang, C.; Wang, F.; Yuille, A. MAT: A Multimodal Attentive Translator for Image Captioning. arXiv, 2017; arXiv:1702.05658. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Dhar, S.; Li, S. Baby talk: Understanding and generating simple image descriptions. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1601–1608. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. arXiv, 2016; arXiv:1612.01887. [Google Scholar]
- Park, C.C.; Kim, B.; Kim, G. Attend to You: Personalized Image Captioning with Context Sequence Memory Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii Convention Center, HI, USA, 21–26 July 2017; pp. 6432–6440. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. arXiv, 2016; arXiv:1611.05594. [Google Scholar]
- Mitchell, M.; Dodge, X.H.; Mensch, A.; Goyal, A.; Berg, A.; Yamaguchi, K.; Berg, T.; Stratos, K.; Daumé, H., III. Generating image descriptions from computer vision detections. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Multimodal neural language models. Proc. Mach. Learn. Res. 2014, 32, 595–603. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Okeyo, G.; Chen, L.; Wang, H. An Agent-mediated Ontology-based Approach for Composite Activity Recognition in Smart Homes. J. Univ. Comput. 2013, 19, 2577–2597. [Google Scholar]
- Okeyo, G.; Chen, L.; Wang, H.; Sterritt, R. Dynamic sensor data segmentation for real-time knowledge-driven activity recognition. Pervasive Mob. Comput. 2014, 10, 155–172. [Google Scholar] [CrossRef]
- Wang, Y.; Lin, Z.; Shen, X.; Cohen, S.; Cottrell, G.W. Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition. arXiv, 2017; arXiv:1704.06972. [Google Scholar]
- Ren, Z.; Wang, X.; Zhang, N.; Lv, X.; Li, L.J. Deep Reinforcement Learning-based Image Captioning with Embedding Reward. arXiv, 2017; arXiv:1704.03899. [Google Scholar]
- Yang, Z.; Yuan, Y.; Wu, Y.; Salakhutdinov, R.; Cohen, W.W. Encode, Review, and Decode: Reviewer Module for Caption Generation. arXiv, 2016; arXiv:1605.07912. [Google Scholar]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv, 2014; arXiv:1406.1078. [Google Scholar]
- Rafferty, J.; Nugent, C.; Liu, J.; Chen, L. A Mechanism for Nominating Video Clips to Provide Assistance for Instrumental Activities of Daily Living. In International Workshop on Ambient Assisted Living; Springer: Cham, Switzerland, 2015; pp. 65–76. [Google Scholar]
- Jia, X.; Gavves, E.; Fernando, B.; Tuytelaars, T. Guiding the Long-Short Term Memory Model for Image Caption Generation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2407–2415. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the Meeting on Association for Computational Linguistics, Philadephia, PA, USA, 6 July 2002; pp. 311–318. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor Universal: Language Specific Translation Evaluation for Any Target Language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.; Hengel, A.V.D. What Value Do Explicit High Level Concepts Have in Vision to Language Problems? In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 203–212. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting Image Captioning with Attributes. arXiv, 2016; arXiv:1611.01646. [Google Scholar]
- Fang, H.; Platt, J.C.; Zitnick, C.L.; Zweig, G.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollar, P.; Gao, J. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]

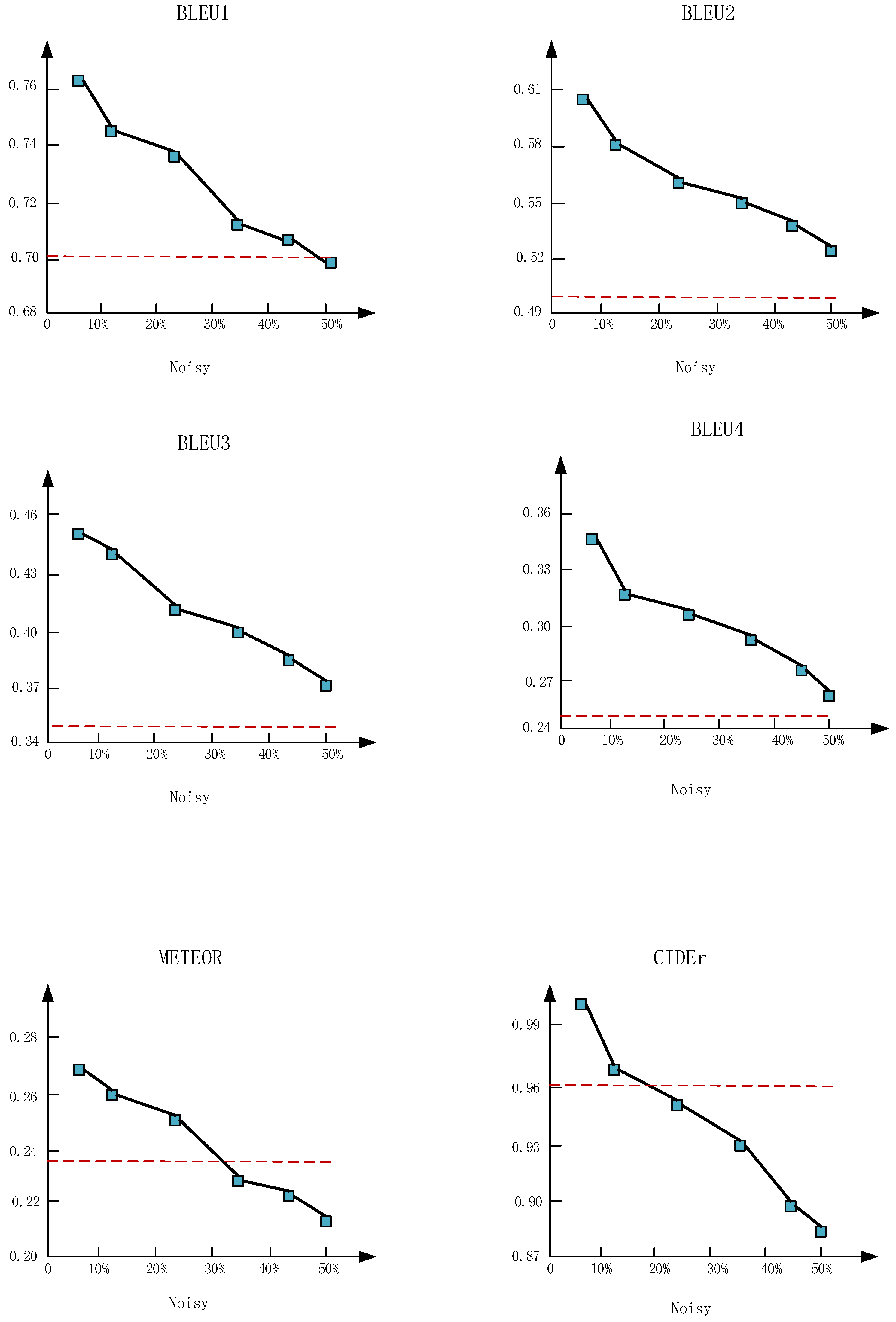

{kind=link}
{kind=link}
{kind=link}
{kind=link}
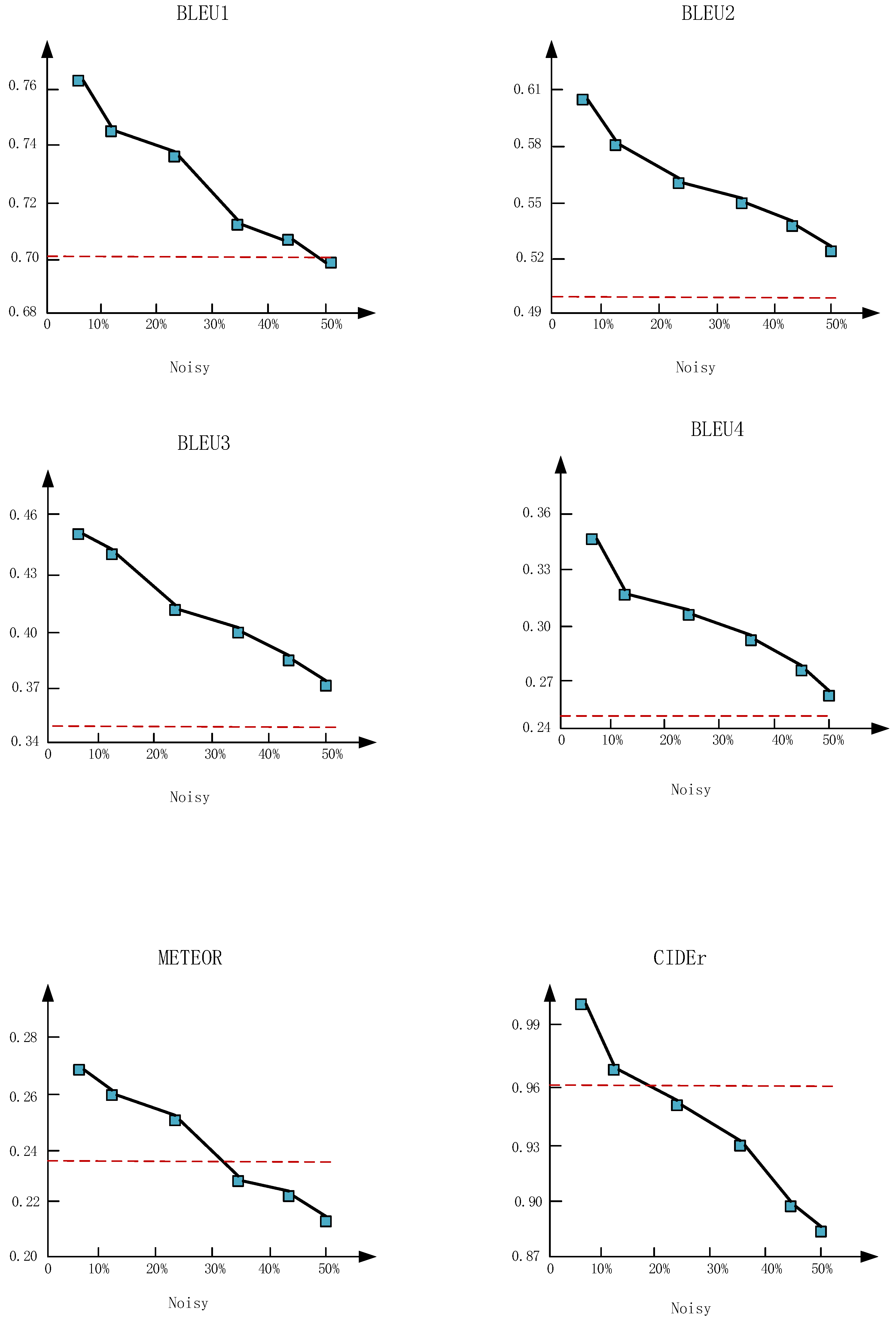{kind=link}
{kind=link}
| Method | MS-COCO | |||||
|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | METEOR | CIDEr | |
| gLSTM [26] | 0.67 | 0.491 | 0.358 | 0.264 | 0.227 | 0.812 |
| Soft Attention [4] | 0.707 | 0.492 | 0.344 | 0.243 | 0.239 | - |
| Semantic Attention * [5] | 0.709 | 0.537 | 0.402 | 0.304 | 0.243 | - |
| Att-CNN + LSTM * [32] | 0.74 | 0.56 | 0.42 | 0.31 | 0.26 | 0.94 |
| BIC+ Att * [33] | 0.73 | 0.565 | 0.429 | 0.325 | 0.251 | 0.986 |
| DAM (Attributes) * | 0.738 | 0.570 | 0.432 | 0.327 | 0.258 | 0.991 |
| Method | MS-COCO | |||||
|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | METEOR | CIDEr | |
| Semantic Attention | 0.710 | 0.540 | 0.401 | 0.298 | 0.261 | - |
| Att-CNN + LSTM | 0.689 | 0.524 | 0.387 | 0.285 | 0.249 | 0.883 |
| BIC + Att | 0.696 | 0.526 | 0.386 | 0.285 | 0.248 | 0.871 |
| DAM (Tags) | 0.76 | 0.597 | 0.452 | 0.342 | 0.261 | 1.051 |
| Method | MS-COCO | |||||
|---|---|---|---|---|---|---|
| B-1 | B-2 | B-3 | B-4 | METEOR | CIDEr | |
| Semantic Attention | 0.512 | 0.364 | 0.264 | 0.192 | 0.236 | 1.967 |
| Att-CNN + LSTM | 0.490 | 0.344 | 0.249 | 0.183 | 0.220 | 1.884 |
| BIC + Att | 0.485 | 0.343 | 0.251 | 0.188 | 0.219 | 1.090 |
| DAM (Tags) | 0.544 | 0.400 | 0.296 | 0.221 | 0.258 | 2.293 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Chu, X.; Zhang, W.; Wei, Y.; Sun, W.; Wu, C. Social Image Captioning: Exploring Visual Attention and User Attention. Sensors 2018, 18, 646. https://doi.org/10.3390/s18020646
Wang L, Chu X, Zhang W, Wei Y, Sun W, Wu C. Social Image Captioning: Exploring Visual Attention and User Attention. Sensors. 2018; 18(2):646. https://doi.org/10.3390/s18020646
Chicago/Turabian StyleWang, Leiquan, Xiaoliang Chu, Weishan Zhang, Yiwei Wei, Weichen Sun, and Chunlei Wu. 2018. "Social Image Captioning: Exploring Visual Attention and User Attention" Sensors 18, no. 2: 646. https://doi.org/10.3390/s18020646
APA StyleWang, L., Chu, X., Zhang, W., Wei, Y., Sun, W., & Wu, C. (2018). Social Image Captioning: Exploring Visual Attention and User Attention. Sensors, 18(2), 646. https://doi.org/10.3390/s18020646