Personalized Physical Activity Coaching: A Machine Learning Approach

 ,
,
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Study Design
3.2. Data Set
3.3. Data Processing, Transformation, and Performance
3.4. Evaluation of the Performance of Algorithms and Models
3.5. Computing the Personalized Predictive Model
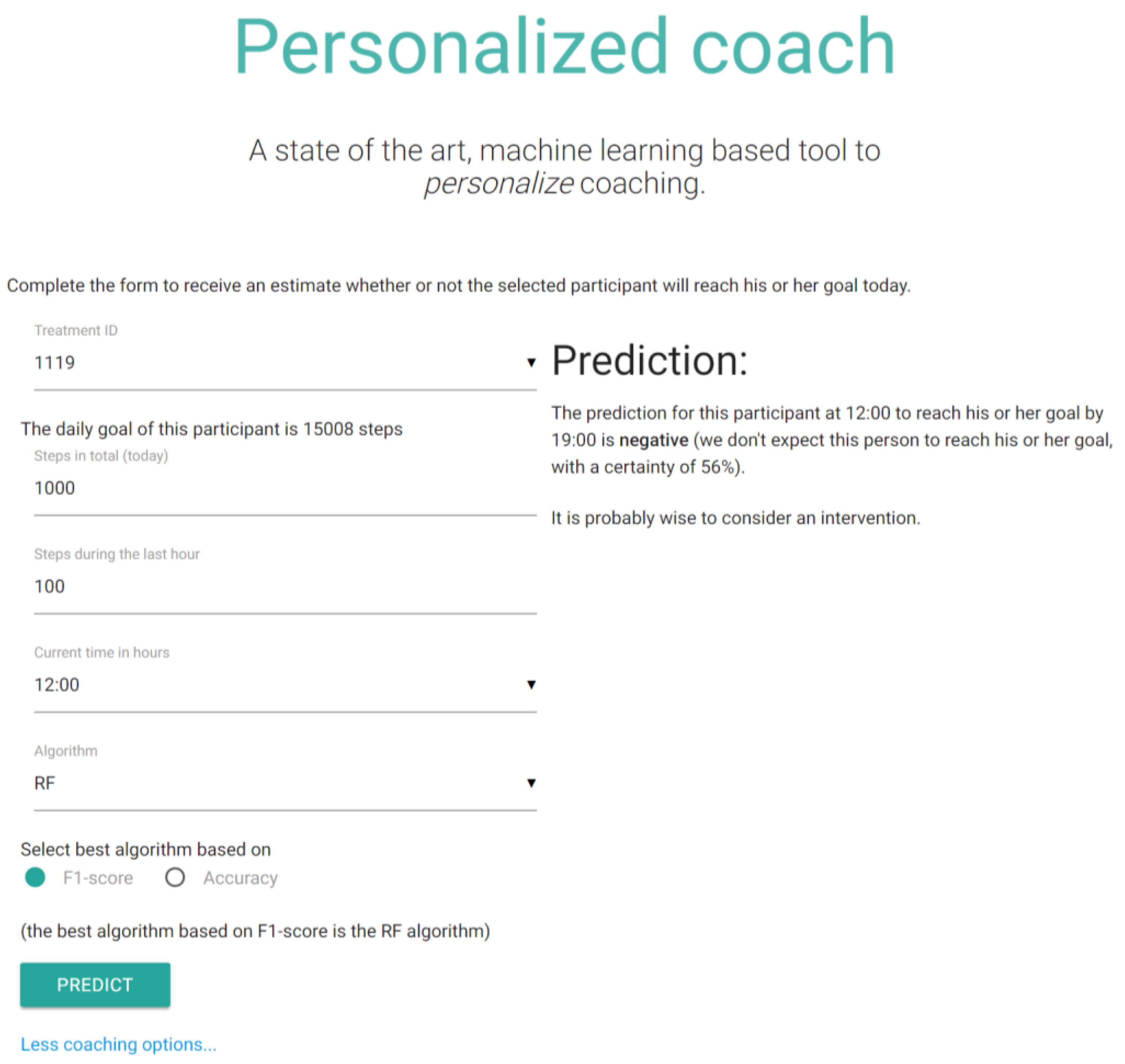
3.6. Proof of Concept
3.7. Implementation Details
4. Results
4.1. Accuracy and F1-Score on Group Level
4.2. Individual Algorithms
4.3. The Web Application
5. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- WHO. Global Action Plan for the Prevention and Control of Noncommunicable Diseases 2013–2020; World Health Organization: Genève, Switzerland, 2013; p. 102. [Google Scholar]
- Min-Lee, I.; Shiroma, E.J.; Lobelo, F.; Puska, P.; Blair, S.N.; Katzmarzyk, P.T.; Alkandari, J.R.; Andersen, L.B.; Bauman, A.E.; Brownson, R.C.; et al. Effect of physical inactivity on major non-communicable diseases worldwide: An analysis of burden of disease and life expectancy. Lancet 2012, 380, 219–229. [Google Scholar]
- Ekelund, U.; Steene-Johannessen, J.; Brown, W.J.; Fagerland, M.W.; Owen, N.; Powell, K.E.; Bauman, A.; Lee, I.M. Does physical activity attenuate, or even eliminate, the detrimental association of sitting time with mortality? A harmonised meta-analysis of data from more than 1 million men and women. Lancet 2016, 388, 1302–1310. [Google Scholar] [PubMed]
- Losina, E.; Yang, H.Y.; Deshpande, B.R.; Katz, J.N.; Collins, J.E. Physical activity and unplanned illness-related work absenteeism: Data from an employee wellness program. PLoS ONE 2017, 12, e0176872. [Google Scholar] [CrossRef] [PubMed]
- Matthews, C.E.; Hebert, J.R.; Freedson, P.S.; Iii, E.J.S.; Merriam, P.A.; Cara, B.; Ockene, I.S. Sources of Variance in Daily Physical Activity Levels in the Seasonal Variation of Blood Cholesterol Study. Am. J. Epidemiol. 2001, 153, 987–995. [Google Scholar] [CrossRef] [PubMed]
- Tudor-Locke, C.; Burkett, L.; Reis, J.P.; Ainsworth, B.E.; Macera, C.A.; Wilson, D.K. How many days of pedometer monitoring predict weekly physical activity in adults. Prev. Med. (Baltim.) 2005, 40, 293–298. [Google Scholar] [CrossRef] [PubMed]
- Gardner, B.; Smith, L.; Lorencatto, F.; Hamer, M.; Biddle, S.J. How to reduce sitting time? A review of behaviour change strategies used in sedentary behaviour reduction interventions among adults. Health Psychol. Rev. 2016, 10, 89–112. [Google Scholar] [PubMed]
- Baker, P.R.A.; Francis, D.P.; Soares, J.; Weightman, A.L.; Foster, C. Community wide interventions for increasing physical activity. Sao Paulo Med. J. 2011, 129, 436–437. [Google Scholar] [CrossRef]
- Conroy, D.E.; Hedeker, D.; McFadden, H.G.; Pellegrini, C.A.; Pfammatter, A.F.; Phillips, S.M.; Siddique, J.; Spring, B. Lifestyle intervention effects on the frequency and duration of daily moderate-vigorous physical activity and leisure screen time. Heal. Psychol. 2017, 36, 299–308. [Google Scholar] [CrossRef] [PubMed]
- Ng, L.W.C.; Mackney, J.; Jenkins, S.; Hill, K. Does exercise training change physical activity in people with COPD? A systematic review and meta-analysis. Chron. Respir. Dis. 2012, 9, 17–26. [Google Scholar]
- Cleland, V.; Squibb, K.; Stephens, L.; Dalby, J.; Timperio, A.; Winzenberg, T.; Ball, K.; Dollman, J. Effectiveness of interventions to promote physical activity and/or decrease sedentary behaviour among rural adults: A systematic review and meta-analysis. Obes. Rev. 2017, 18, 727–741. [Google Scholar] [CrossRef] [PubMed]
- Prince, S.A.; Saunders, T.J.; Gresty, K.; Reid, R.D. A comparison of the effectiveness of physical activity and sedentary behaviour interventions in reducing sedentary time in adults: A systematic review and meta-analysis of controlled trials. Obes. Rev. 2014, 15, 905–919. [Google Scholar] [CrossRef] [PubMed]
- Höchsmann, C.; Schüpbach, M.; Schmidt-Trucksäss, A. Effects of Exergaming on Physical Activity in Overweight Individuals. Sports Med. 2016, 46, 845–860. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Sun, S.; He, Y.; Jiang, B. The effect of interventions targeting screen time reduction: A systematic review and meta-analysis. Medicine (Baltimore). 2016, 95, e4029. [Google Scholar] [CrossRef] [PubMed]
- Schoeppe, S.; Alley, S.; van Lippevelde, W.; Bray, N.A.; Williams, S.L.; Duncan, M.J.; Vandelanotte, C. Efficacy of interventions that use apps to improve diet, physical activity and sedentary behaviour: A systematic review. Int. J. Behav. Nutr. Phys. Act. 2016, 13, 127. [Google Scholar] [CrossRef] [PubMed]
- Beishuizen, C.R.L.; Stephan, B.C.M.; van Gool, W.A.; Brayne, C.; Peters, R.J.G.; Andrieu, S.; Kivipelto, M.; Soininen, H.; Busschers, W.B.; van Charante, E.P.M.; et al. Web-Based Interventions Targeting Cardiovascular Risk Factors in Middle-Aged and Older People: A Systematic Review and Meta-Analysis. J. Med. Internet Res. 2016, 18, e55. [Google Scholar]
- Shrestha, N.; Kt, K.; Jh, V.; Ijaz, S.; Hermans, V.; Bhaumik, S. Workplace interventions for reducing sitting at work (Review). Cochrane Database Syst. Rev. 2016, 14, 105. [Google Scholar]
- Commissaris, D.A.; Huysmans, M.A.; Mathiassen, S.E.; Srinivasan, D.; Koppes, L.L.; Hendriksen, I.J. Interventions to reduce sedentary behavior and increase physical activity during productive work: A systematic review. Scand. J. Work. Environ. Health 2016, 42, 181–191. [Google Scholar] [CrossRef] [PubMed]
- Mercer, K.; Li, M.; Giangregorio, L.; Burns, C.; Grindrod, K. Behavior Change Techniques Present in Wearable Activity Trackers: A Critical Analysis. JMIR mHealth uHealth 2016, 4, e40. [Google Scholar] [CrossRef] [PubMed]
- Duncan, M.; Murawski, B.; Short, C.E.; Rebar, A.L.; Schoeppe, S.; Alley, S.; Vandelanotte, C.; Kirwan, M. Activity Trackers Implement Different Behavior Change Techniques for Activity, Sleep, and Sedentary Behaviors. Interact. J. Med. Res. 2017, 6, e13. [Google Scholar] [CrossRef] [PubMed]
- Qiu, S.; Cai, X.; Ju, C.; Sun, Z.; Yin, H.; Zügel, M.; Otto, S.; Steinacker, J.M.; Schumann, U. Step Counter Use and Sedentary Time in Adults: A Meta-Analysis. Medicine (Baltimore) 2015, 94, e1412. [Google Scholar] [CrossRef] [PubMed]
- Stephenson, A.; McDonough, S.M.; Murphy, M.H.; Nugent, C.D.; Mair, J.L. Using computer, mobile and wearable technology enhanced interventions to reduce sedentary behaviour: A systematic review and meta-analysis. Int. J. Behav. Nutr. Phys. Act. 2017, 14, 105. [Google Scholar] [CrossRef] [PubMed]
- de Vries, H.J.; Kooiman, T.J.M.; van Ittersum, M.W.; van Brussel, M.; de Groot, M. Do activity monitors increase physical activity in adults with overweight or obesity? A systematic review and meta-analysis. Obesity 2016, 24, 2078–2091. [Google Scholar] [PubMed]
- Li, L.C.; Sayre, E.C.; Xie, H.; Clayton, C.; Feehan, L.M. A Community-Based Physical Activity Counselling Program for People With Knee Osteoarthritis: Feasibility and Preliminary Efficacy of the Track-OA Study. JMIR mHealth uHealth 2017, 5, e86. [Google Scholar] [CrossRef] [PubMed]
- Miyauchi, M.; Toyoda, M.; Kaneyama, N.; Miyatake, H.; Tanaka, E.; Kimura, M.; Umezono, T.; Fukagawa, M. Exercise Therapy for Management of Type 2 Diabetes Mellitus: Superior Efficacy of Activity Monitors over Pedometers. J. Diabetes Res. 2016, 2016, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Cadmus-Bertram, L.A.; Marcus, B.H.; Patterson, R.E.; Parker, B.A.; Morey, B.L. Randomized Trial of a Fitbit-Based Physical Activity Intervention for Women. Am. J. Prev. Med. 2015, 49, 414–418. [Google Scholar] [CrossRef] [PubMed]
- Mansi, S.; Milosavljevic, S.; Tumilty, S.; Hendrick, P.; Higgs, C.; Baxter, D.G. Investigating the effect of a 3-month workplace-based pedometer-driven walking programme on health-related quality of life in meat processing workers: a feasibility study within a randomized controlled trial. BMC Public Health 2015, 15, 410. [Google Scholar] [CrossRef] [PubMed]
- Lewis, Z.H.; Lyons, E.J.; Jarvis, J.M.; Baillargeon, J. Using an electronic activity monitor system as an intervention modality: A systematic review. BMC Public Health 2015, 15, 585. [Google Scholar] [CrossRef] [PubMed]
- Freak-poli, R.; Cumpston, M.; Peeters, A.; Clemes, S. Workplace pedometer interventions for increasing physical activity (Review). Cochrane Database Syst. Rev. 2013, 4, CD009209. [Google Scholar]
- Compernolle, S.; Vandelanotte, C.; Cardon, G.; de Bourdeaudhuij, I.; de Cocker, K. Effectiveness of a web-based, computer-tailored, pedometer-based physical activity intervention for adults: a cluster randomized controlled trial. J. Med. Internet Res. 2015, 17, e38. [Google Scholar] [CrossRef] [PubMed]
- Slootmaker, S.M.; Chinapaw, M.J.M.; Schuit, A.J.; Seidell, J.C.; van Mechelen, W. Feasibility and Effectiveness of Online Physical Activity Advice Based on a Personal Activity Monitor: Randomized Controlled Trial. J. Med. Internet Res. 2009, 11, e27. [Google Scholar] [CrossRef] [PubMed]
- Poirier, J.; Bennett, W.L.; Jerome, G.J.; Shah, N.G.; Lazo, M.; Yeh, H.-C.; Clark, J.M.; Cobb, N.K. Effectiveness of an Activity Tracker- and Internet-Based Adaptive Walking Program for Adults: A Randomized Controlled Trial. J. Med. Internet Res. 2016, 18, e34. [Google Scholar]
- Finkelstein, E.A.; Haaland, B.A.; Bilger, M.; Sahasranaman, A.; Sloan, R.A.; Nang, E.E.K.; Evenson, K.R. Effectiveness of activity trackers with and without incentives to increase physical activity (TRIPPA): A randomised controlled trial. Lancet Diabetes Endocrinol. 2016, 4, 983–995. [Google Scholar] [CrossRef]
- Mamykina, L.; Lindtner, S.; Lin, J.J.; Mamykina, L.; Lindtner, S.; Delajoux, G.; Strub, H.B. Fish’n’Steps: Encouraging Physical Activity with an Interactive Computer Game. In Ubicomp 2006: Ubiquitous Computing; Springer-Verlag: Berlin/Heidelberg, Germany, 2006; Volume 4206. [Google Scholar]
- Toscos, T.; Faber, A.; Connelly, K.; Upoma, A.M. Encouraging physical activity in teens. Can technology help reduce barriers to physical activity in adolescent girls? In Pervasive Computing Technologies for Healthcare, 2008; IEEE: Tampere, Finland, 2008; Volume 3, pp. 218–221. [Google Scholar]
- Wang, J.; Chen, R.; Sun, X.; She, M.F.H.; Wu, Y. Recognizing human daily activities from accelerometer signal. Procedia Eng. 2011, 15, 1780–1786. [Google Scholar] [CrossRef]
- Li, X.; Dunn, J.; Salins, D.; Zhou, G.; Zhou, W.; Rose, S.M.S.; Perelman, D.; Colbert, E.; Runge, R.; Rego, S.; et al. Digital Health: Tracking Physiomes and Activity Using Wearable Biosensors Reveals Useful Health-Related Information. PLoS Biol. 2017, 15, e2001402. [Google Scholar] [CrossRef] [PubMed]
- Catal, C.; Tufekci, S.; Pirmit, E.; Kocabag, G. On the use of ensemble of classifiers for accelerometer-based activity recognition. Appl. Soft Comput. J. 2015, 37, 1018–1022. [Google Scholar] [CrossRef]
- Maman, Z.S.; Yazdi, M.A.A.; Cavuoto, L.A.; Megahed, F.M. A data-driven approach to modeling physical fatigue in the workplace using wearable sensors. Appl. Ergon. 2017, 65, 515–529. [Google Scholar] [CrossRef] [PubMed]
- Mollee, J.S.; Middelweerd, A.; te Velde, S.J.; Klein, M.C.A. Evaluation of a personalized coaching system for physical activity: User appreciation and adherence. Proceedings of ACM 11th EAI International Conference on Pervasive Computing Technologies for Healthcare, Barcelona, Spain, 23–26 May 2017. [Google Scholar]
- Gerdes, M.; Martinez, S.; Tjondronegoro, D. Conceptualization of a Personalized eCoach for Wellness Promotion. Proceedings of ACM 11th EAI International Conference on Pervasive Computing, Barcelona, Spain, 23–26 May 2017. [Google Scholar]
- den Akker, H.O.; Jones, V.M.; Hermens, H.J. Tailoring real-time physical activity coaching systems: A literature survey and model. User Model. User-Adapt. Interact. 2014, 24, 351–392. [Google Scholar] [CrossRef]
- van, M.W.; Ittersum, H.K.E.O.; de Groot, M. Self-Tracking-Supported Health Promotion: A Randomized Trial among Dutch Employees. Eur. J. Public Heal. 2017, in press. [Google Scholar]
- Wolpert, D.H. The Lack of A Priori Distinctions Between Learning Algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Raschka, S.; Mirjalili, V. Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Scikit Learn, Choosing the Right Estimator. Available online: http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html (accessed on 15 February 2018).
- Machine Learning Algorithm Cheat Sheet for Microsoft Azure Machine Learning Studio. Available online: https://docs.microsoft.com/en-us/azure/machine-learning/studio/algorithm-cheat-sheet (accessed on 15 February 2018).
- scikit-learn v0.18. Available online: http://scikit-learn.org/0.18/documentation.html (accessed on 15 February 2018).
- Anaconda. Available online: www.anaconda.com (accessed on 15 February 2018).
- Jupyter Notebooks. Available online: https://jupyter.org (accessed on 15 February 2018).
- Oracle Express Edition 11g2. Available online: http://www.oracle.com/technetwork/database/database-technologies/express-edition/overview/index.html (accessed on 15 February 2018).
- Flask. Available online: http://flask.pocoo.org/ (accessed on 15 February 2018).
- Chan, C.B.; Ryan, D.A.; Tudor-Locke, C. Relationship between objective measures of physical activity and weather: a longitudinal study. Int. J. Behav. Nutr. Phys. Act. 2006, 3, 21. [Google Scholar] [CrossRef] [PubMed]
- Fogg, B. A behavior model for persuasive design. In Proceedings of the 4th International Conference on Persuasive Technology (Persuasive ’09), Claremont, CA, USA, 26–29 April 2009; p. 1. [Google Scholar]
- Blok, J.; Dol, A.; Dijkhuis, T. Toward a Generic Personalized Virtual Coach for Self-management : A Proposal for an Architecture. Proceedings of eTELEMED 2017, the Ninth International Conference on eHealth, Telemedicine, and Social Medicine, Nice, France, 19–23 March 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True Class | |||
| Yes | No | ||
| Predicted class | Yes | True Positives (TP) | False Negatives (FN) |
| No | False Positives (FP) | True Negatives (TN) |
| Algorithm Name | Mean Accuracy (Standard Deviation) | Mean F1 (Standard Deviation) | Rank |
|---|---|---|---|
| AdaBoost (ADA) | 0.776623 (0.002080) | 0.854157 (0.001626) | 1 |
| Neural Networking (NN) | 0.777774 (0.001545) | 0.852797 (0.002938) | 2 |
| Support Vector Classifier (SVC) | 0.770728 (0.002505) | 0.856341 (0.002405) | 3 |
| Stochastic Gradient Descent (SGD) | 0.767623 (0.005490) | 0.853575 (0.004574) | 4 |
| KNeighborsClassifier (KNN) | 0.749171 (0.005683) | 0.829826 (0.005544) | 5 |
| Logistic Regression (LR) | 0.742125 (0.009821) | 0.825725 (0.008487) | 6 |
| Random Forest (RF) | 0.737451 (0.003210) | 0.819065 (0.003840) | 7 |
| Decision Tree (DT) | 0.720535 (0.004787) | 0.804220 (0.003006) | 8 |
| Algorithm name | Hyperparameters | Values |
|---|---|---|
| AdaBoost (ADA) | n_estimators: number of decision trees in the ensemble | [10,50] |
| learning rate: the shrink of the contribution of each successive decision tree in the ensemble | [0.1, 0.5, 1.0, 10.0] | |
| Decision Tree (DT) | criterion: the algorithm to use to decide on split | [‘gini’, ‘entropy’] |
| max_features: the number of features to consider when to split | [‘auto’,‘sqrt’,‘log2’] | |
| KNeighborsClassifier (KNN) | metrics: the distance metric to use | [‘minkowski’,‘euclidean’,‘manhattan’] |
| weights: weight function used | [‘uniform’,‘distance’] | |
| n_neighbors: number of neighbors to use for queries | [5, 6, 7, 8, 9] | |
| Neural Networking (NN) | learning_rate_init: the control of the step-size in updating the weights | [‘constant’, ‘invscaling’, ‘adaptive’] |
| activation: the activation function for the hidden layer | [‘identity’, ‘logistic’, ‘tanh’, ‘relu’] | |
| learning_rate: the rate for the weight of the updates | [0.01, 0.05, 0.1, 0.5, 1.0] | |
| Logistic Regression (LR) | C: regularization strength | [0.001, 0.01, 0.1, 1, 10, 100, 1000] |
| penalty: whether to use Lasso (L1) or Ridge (L2) regularization | [‘l1’, ‘l2’] | |
| fit_intercept: whether or not to compute the intercept of the linear classifier | [True, False] | |
| Stochastic Gradient Descent (SGD) | fit_intercept: whether or not the intercept should be computed | [True, False] |
| l1_ratio: the penalty is set to L1 or L2 | [0,0.15,1] | |
| loss: quantification of the loss | [‘log’,‘modified_huber’] | |
| Support Vector Classifier (SVM) | kernel: the kernel type to be used in the algorithm | [‘linear’,‘rbf’] |
| Random Forest (RF) | n_estimators:number of decision trees | [10, 50, 100, 500] |
| max_features: the number of features to consider when to split | [0.1, 0.25, 0.5, 0.75, ‘sqrt’, ‘log2’, None] | |
| criterion: which algorithm should be used to decide on split | [‘gini’, ‘entropy’] |
| Participant | Parameters | Values |
|---|---|---|
| 1119 | criterion max_features n_estimators | gini sqrt 50 |
| 1121 | criterion max_features n_estimators | entropy log2 50 |
| Hyperparameter | Value | Number of Occurrences |
|---|---|---|
| criterion | entropy | 7 |
| gini | 37 | |
| max_features | 0.1 | 4 |
| 0.25 | 5 | |
| 0.5 | 7 | |
| 0.75 | 15 | |
| log2 | 2 | |
| sqrt | 2 | |
| null | 9 | |
| n_estimators | 10 | 3 |
| 100 | 17 | |
| 50 | 16 | |
| 500 | 6 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dijkhuis, T.B.; Blaauw, F.J.; Van Ittersum, M.W.; Velthuijsen, H.; Aiello, M. Personalized Physical Activity Coaching: A Machine Learning Approach. Sensors 2018, 18, 623. https://doi.org/10.3390/s18020623
Dijkhuis TB, Blaauw FJ, Van Ittersum MW, Velthuijsen H, Aiello M. Personalized Physical Activity Coaching: A Machine Learning Approach. Sensors. 2018; 18(2):623. https://doi.org/10.3390/s18020623
Chicago/Turabian StyleDijkhuis, Talko B., Frank J. Blaauw, Miriam W. Van Ittersum, Hugo Velthuijsen, and Marco Aiello. 2018. "Personalized Physical Activity Coaching: A Machine Learning Approach" Sensors 18, no. 2: 623. https://doi.org/10.3390/s18020623
APA StyleDijkhuis, T. B., Blaauw, F. J., Van Ittersum, M. W., Velthuijsen, H., & Aiello, M. (2018). Personalized Physical Activity Coaching: A Machine Learning Approach. Sensors, 18(2), 623. https://doi.org/10.3390/s18020623