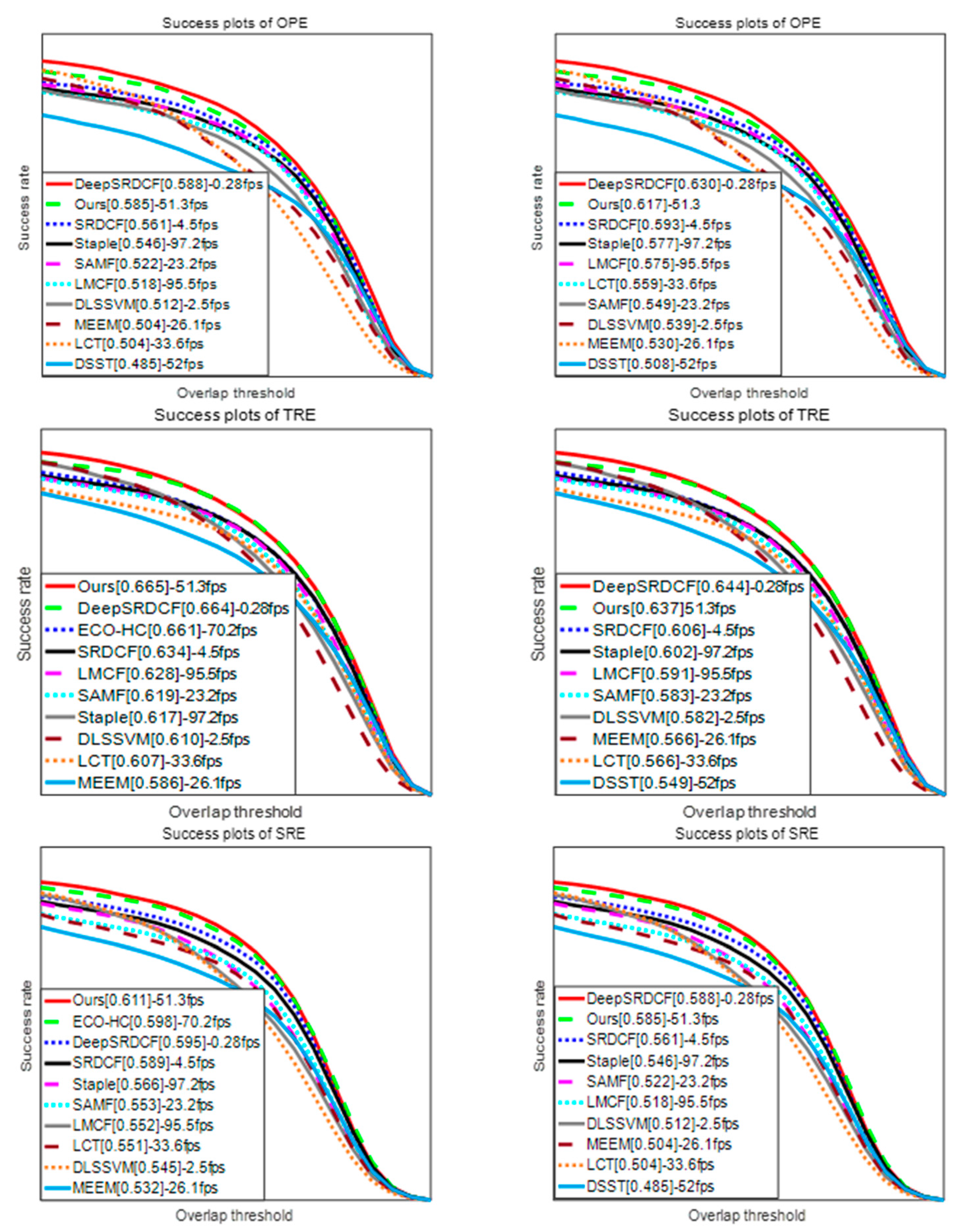
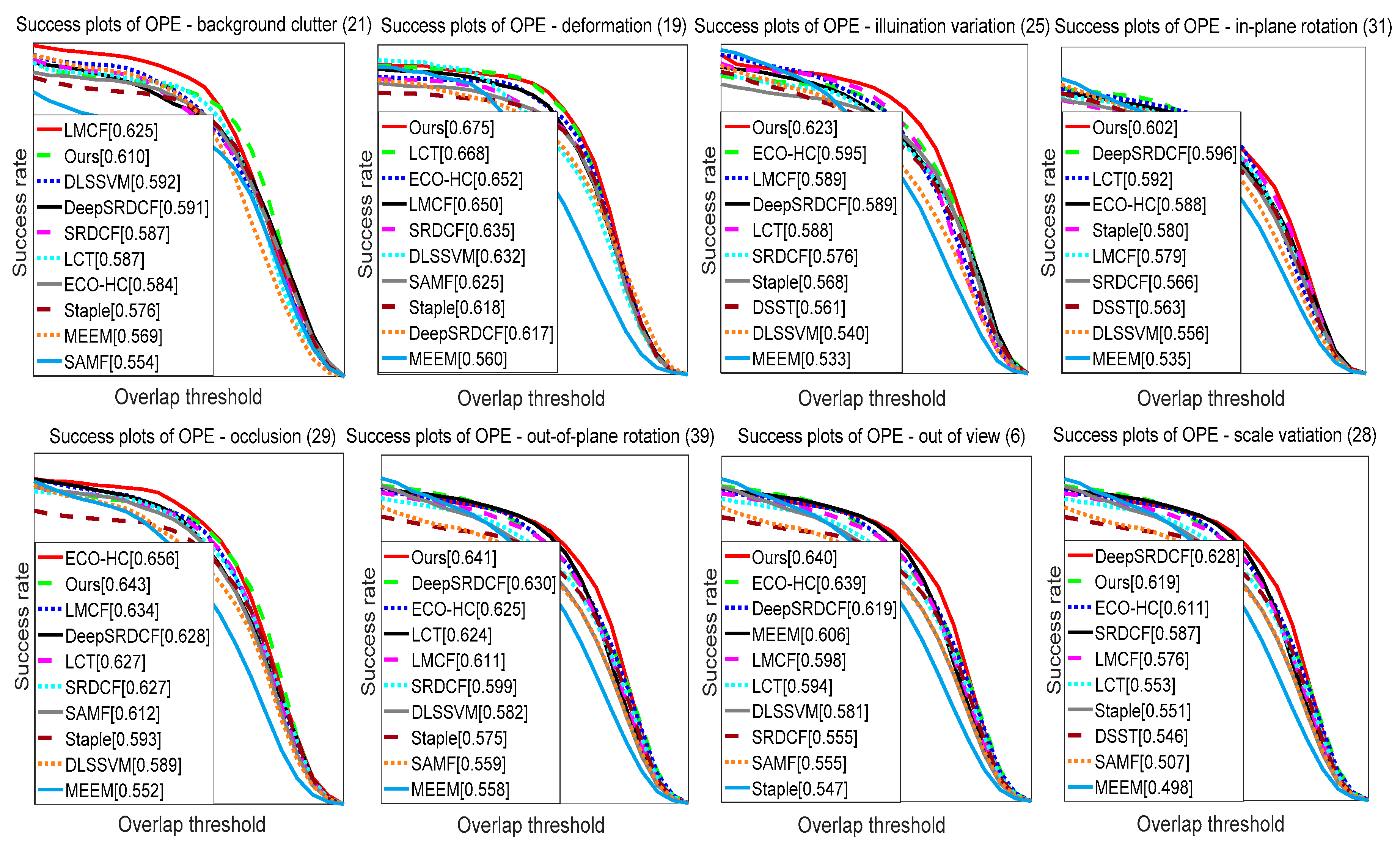
1. Introduction
Video tracking is an important part of computer vision and is widely used across a variety of fields including intelligent transportation, man-machine interaction, and military guidance [
1,
2]. This paper focuses on how to quickly and effectively address the tracking drift problem in object tracking processes when confronted with similarly colored backgrounds, object occlusions, low illumination color images, and sudden illumination changes.
In recent years, correlation filters have attracted more attention for their advantages in efficiency and robustness. In [
3], a video tracking algorithm was proposed based on the sum of the mean square error of the minimum output of a correlation filter. Subsequently, Henriques et al. [
4] proposed a tracking algorithm based on the circulant structure of tracking-by-detection with kernels (CSK) that used cyclic structure coding to densely sample and train the Regularized Least Squares (RLS) of a nonlinear classifier. Later, CSK was improved with a Kernel Correlation Filter (KCF [
5]) that used a Histogram of Oriented Gradients (HOG [
6]) features tracking algorithm. Danelljan et al. [
7] introduced space regularization in the filter learning and penalized the filter coefficients according to their spatial position. Danelljan et al. [
8] used the multi-channel color features to extend CSK and obtained a good performance. Sui et al. [
9] greatly improved the filter tracking performance by introducing three sparse correlation-related loss functions into the training of the filter. Convolutional neural network (CNN) features have also demonstrated outstanding results in object classification, image identification, and so on [
10,
11,
12,
13,
14]. Ma et al. [
12] exploited the complementary nature of features extracted from three layers of CNN and used the coarse-to-fine translation estimation for object tracking. Danelljan et al. [
14] went beyond the conventional correlation filter framework and learned the correlation filter in the continuous spatial domain of various features, which achieved good tracking performance. However, their algorithm greatly reduced the tracking speed of the correlation filter. In terms of scale calculation, two consistent and relatively independent correlation filters were designed in [
15], which achieved object position tracking and scale conversion, respectively. Huang et al. [
16,
17] integrated the class-agnostic detection proposal method [
18] into the correlation filters tracking framework to solve the target scale and aspect ratio of the target deformation problem.
For different models of fusion and different fusion methods, however, tracking performance has not been so good. Kwon et al. [
19,
20] used complementary trackers to combine different observation and motion models, then integrated their estimation results into a sampling framework. Based on a historical frame and Multiple Experts using Entropy Minimization (MEEM) [
21], different Support Vector Machine (SVM) classifiers selected the classifier with the strongest object recognition capacity to decide the tracking result. Using global search, Smith et al. [
22] located potential candidate samples marked by contour features, having first obtained better positive and negative samples using weaker classifiers. Classifier tests and updates were then undertaken using stronger detectors. This helped to reduce the classifier search space and false object interference. Similar to the Correlation Filter Based Tracking Algorithm, the color-based tracking algorithm has achieved good performance in terms of speed and performance [
23,
24]. In the Sum of Template and Pixel-wise Leaners tracker (Staple [
25]), Bertinetto et al. took advantage of the complementary sample information by fusing the predictions of the filter model and the color model, therefore showing good performance in handling deformation and fast motion. However, it drifted when target objects underwent heavy illumination variation, occlusion, and background clutters. To further enhance the Staple tracker’s robustness, we not only studied a correlation filter model and a color model, but also integrated an object model based on contours features, which was proposed in Edge Boxes [
18], into tracker to generate a multi-complementary model for more robust tracking. Among them, the filter model relies on the spatial distribution of the target object and is relatively sensitive to the deformation. However, the color regression model and the contour-based detection model have good global characteristics and good adaptability to the target deformation. The color model is sensitive to the illumination transformation, but the filter regression and contour-based detection models are adaptable to the illumination changes of the target. The detection model relies only on the edge information of the image and the current size of the online learning ability is poor, but the good online learning ability of the color regression model and the filter regression model are a good supplement to the detection model, and less learning information also reduces the likelihood of elegant filter and color models. Since each model is responsible for the tracking of specific features, the three complementary models are then combined to form a more robust tracking algorithm. At the same time, using efficient data structures, the scores of tens of thousands of candidate boxes can be evaluated in a thousandth of a second [
18], and the object detection response scores can be efficiently calculated.
Currently, tracking detection frameworks are also very popular, playing a key role among numerous recent tracking methods [
26,
27,
28]. To mitigate the stability-plasticity dilemma of online model updating for visual tracking, Kalal et al. [
26] decomposed the tracking tasks into Tracking, Learning and Detecting (TLD), where tracking and detecting were mutually promoted. The tracking results provided training data to update the detector, and the detector re-initialized the tracker whenever it failed. This mechanism works well for long-term tracking [
26,
29,
30]. In [
31], a long-term filter was proposed that used stochastic sampling to solve the model drifting problem. Predicting objects in combination with multiple estimations can effectively complement each of the tracking methods to deliver a more robust performance. Long-term correlation tracking (LCT) [
30] is a classic long-time tracking algorithm, which solves the problems of target deformation, abrupt motion, and heavy occlusion that appear in long-time tracking. In the LCT algorithm, in addition to training the translation filter and the scale filter, a confidence detection filter is also trained from the reliable tracking results. The confidence detection filter can be a good measure of the confidence of the tracking results of the tracking module and the detection results in the detector module. Our algorithm is similar to the LCT algorithm, but we did not retrain an independent confidence filter same as the LCT algorithm. We improved the filter in the tracking module by high confidence updating to obtain our confidence detection filter. Furthermore, we also used the Average Peak-to Correlation Energy (APCE) [
32] to determine if the tracking results were reliable at the same time. To improve the robustness of the tracking, the LCT algorithm re-detected the target by training an online random fern classifier after the target tracking failed. In this paper, by combining the object detection model with the edges model and the color model-based histogram feature, we proposed a new detection method algorithm, which not only had good detection accuracy, but also had better detection efficiency than the traditional classifier-based detection method.
Based on the above issues, this paper proposed MMLT (Multi-Complementary model for Long-term Tracking), a long-term object tracker that combines a multiple complementary model. The main goal was to solve the difficulties in real scenes such as object occlusions, background clutters, motion blur, low illumination color images, and sudden illumination changes. The main contributions of our work are as follows.
By incorporating the object response model into the Staple algorithm, which combines a correlation filter and color model, the tracking robustness was greatly improved. Each model is responsible for the tracking of specific features and then combined three complementary models for robust visual tracking.
Unlike traditional classifier-based object detection, an efficient object detection model with contour features and color histogram features is proposed for the first time, which significantly improved detection efficiency and detection speed.
The redundancy aspect of the calculation of image features within each scale of the correlation filter module is optimized in this paper to improve the execution speed of the algorithm.
2. Multi-Complementary Model Tracking
Our baseline was the Staple (Sum of Template and Pixel-wise Leaners) algorithm. The Staple algorithm divides the tracking into the translational tracking phase and scale tracking phase. The translation tracking gives the position estimation and the scale tracking phase computes the target scale using a 1D correlation filter. During the translational tracking phase, Staple incorporates the response scores of the color model and correlation filter model (using HOG features) to achieve a good tracking performance. However, as the color information is easily disturbed by factors such as the environment and light, the performance of the tracker is limited. Thus, it is desirable that other additional features should be used as a complement to the color feature to improve the performance of the tracker. In this paper, the proposed MMT (Multi-Complementary Model Tracking), which incorporates the object model based on Edge Boxes [
18] in the translational tracking phase of Staple. Edge Boxes [
18] is based on the characteristics of the object contour edges information and has good adaptability to light and background changes. By fusing the multi-channel complementary feature response scores, the diversity of the sample information and discriminant can be utilized to a greater extent. This improves the generalizability of the tracker. In addition, we optimize the method of scales calculation, greatly reducing redundant operations and increasing the tracking speed.
Staple adopts the tracking-by-detection paradigm. As the location estimation and scale estimation are separate, they are responsible for their own work. In frame
t + 1, translation tracking obtains the new target position based on the fix size of target size
of the previous frame, then scale tracking updates the new scale with the new position computed by translation tracking. Therefore, in translation tracking of frame
t + 1, given a search patch
extracted around the previous target position, and the fix target size
, the Staple chooses the target bounding box
that gives the target location from a set
to maximize fusing scores:
where
is a valid inner region;
,
represents each bounding box
‘s location
in the region
; and
represents the size of the
is equal to the fix size
. The functions
and
are the image transformation such that
and
assign scores to the bounding box
according to the color model parameters and
filter model parameters
, respectively. In addition, color model parameters
and filter model parameters
are all trained from the previous target state and images, and parameters
and
represent the combination coefficients of the color model and filter model, respectively.
In this paper, by incorporating the object model to the Staple algorithm, we obtain the target bounding box
to maximize a new fusing score of the three complementary models. The scores function can be represented by:
where
, which is three in this paper, is the number of models; the function
is an image transformation such that
assigns a score to the bounding box
according to the models parameters
trained from the previous target state and images; and
,
and
are the combination coefficients of the color model, filter model, and object model scores, respectively. Moreover, they are renamed
,
, and
, respectively, in this paper.
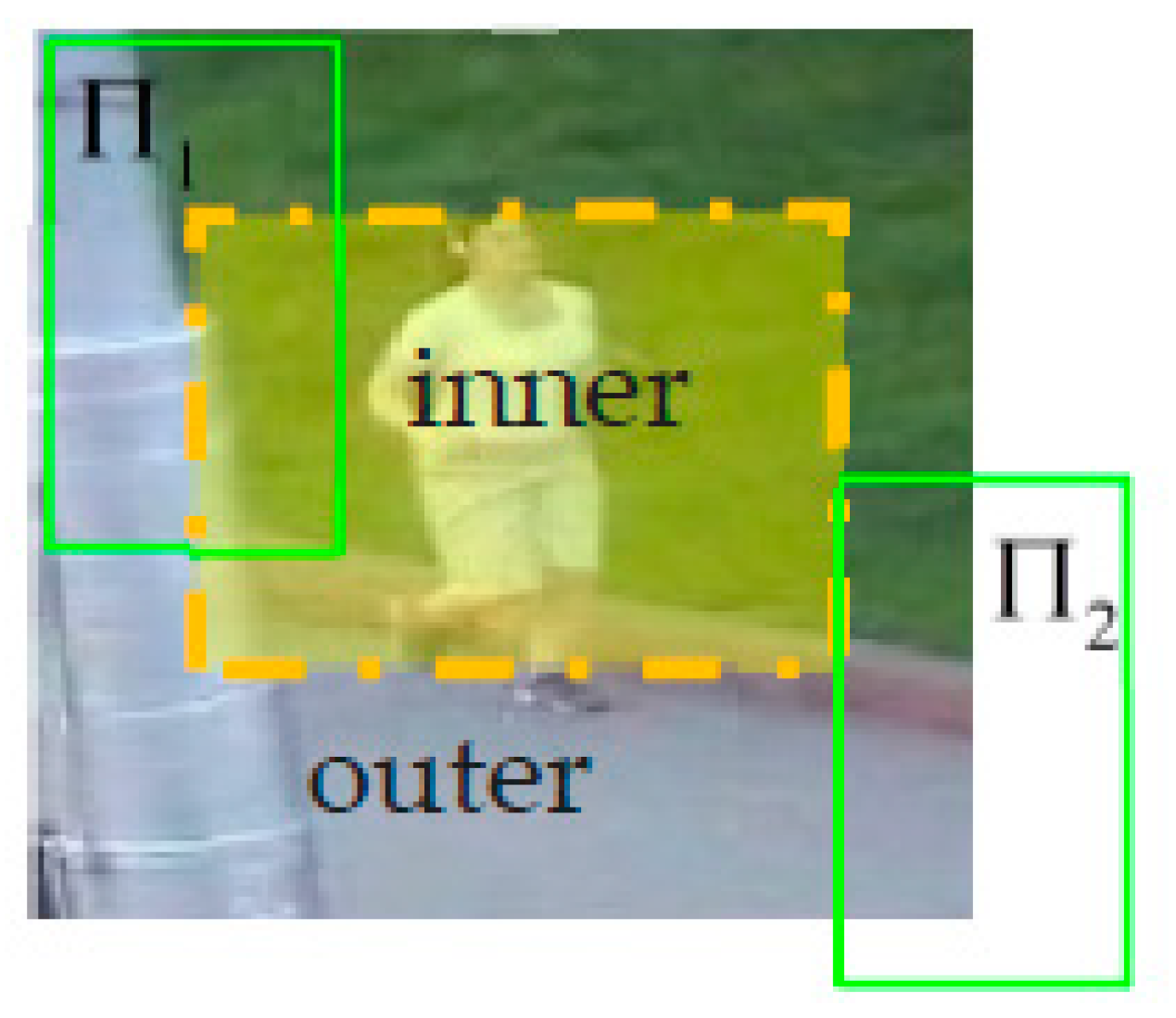
Before we introduce specific models, we first introduce the detailed concept of the inner region, which will be used in the three models based on a tracking-by-detection principle. Given a search area of
for tracking and a bounding box with a fixed size for the sliding window-based detection method, all the bounding boxes that center at different positions in a detection area of
cannot be used to detect. As shown in
Figure 1, the bounding box
centered the position so that it exceeded the yellow area, which has many pixels out of the overall detection area
, so the bounding boxes will not be detected. We named the position set consisting of all the center positions of these bounding box as the outer region, and the region at which the bounding box center can be detected was named as the inner region in this paper. This is labeled with yellow in
Figure 1. In addition, the set
was represented in all boxes (with the fix size of
) centered at different positions in the region
, which was all of the search sample space. Then, we use Multi-Complementary model to calculate the combination scores of all the bounding boxes in
and then estimate the target location at the max value of the combination scores.
Below, we introduce the filter model and color model used in Staple, as well as the object model that we have incorporated in Staple. In
Section 2.1 and
Section 2.2, we briefly introduce the filter model and color model used in Staple, and, in
Section 2.3, we introduce the object detection model based on Edge Boxes [
18] that we incorporated in Staple. In
Section 2.4, we describe the method of fusing the multiple model predictive response scores, which was used in Staple.
Section 2.5 presents how we optimized the scales calculation to significantly improve the speed of the algorithm.
2.1. Learning of Filter Model
In Staple, the filter model is a type of tracking-by-detection model. During the training process,
is a rectangular patch which is sampled from (
t)-th frame, and the corresponding
dimension Histogram of Oriented Gradients (HOG) feature map
,
is extracted from
. Then, by minimizing the objective function, a set of filters
for
dimensional features are trained. The loss function is then:
where * represents the circular correlation;
is the corresponding feature filter for each
dimension; and
is the desired correlation output, which generally selects the Gaussian function with a maximum value of 1. The second parameter
represents the coefficient of the regularization term. We then use Parseval’s Theorem for the frequency domain to obtain a fast solution, thus obtaining:
where
is the DFT conjugation of the Gaussian response
; and
and
are the dot-product operations of the frequency domain of the k-dimensional features map corresponding to the image patch
and the corresponding conjugate operation, respectively.
Based on the above model, we rename the filter used in the translation phase to the translation filter , with the corresponding numerator and denominator , respectively.
is updated with a learning factor
:
where
is the index of the frame.
Calculating the Filter Scores
Given a search patch
, which has a size of
and its inner region
in (
t+1)-th frame, the HOG feature map of
is extracted. When the
l-th dimension of the rectangular features map is marked as
, and its frequency domain is
, the correlation scores
of search area
is obtained by convolving features map
and correlation filter
, which is obtained in the previous frame with Equation (5). The specific formula is as follows:
where
and
are the numerator and denominator of the translation filter
obtained in the previous frame, respectively.
represents the inverse Discrete Fourier Transform (DFT) operator.
As the filter model is based on the tracking-by-detection principle, the scores value of a position in the response map can represent the score of the bounding box centered at different positions in search patch
to the object. Unlike the sliding-window-based detection of color and object model, the filter model uses the same properties as the circular convolution, forming the response shares the same size with the feature template (with the same size of
). In
Figure 1, we show that the inner region
is in the area of search patch
, therefore the filter response
of the inner region
can be obtained by cropping the filter response
of a search patch
, which corresponds to the scores of all the bounding box in set
.
2.2. Learning of Color Model
The color model is also based on the widely used tracking-by-detection principle, which selects the bounding box (gives the target position) with the highest score from the bounding box set as the final test result to localize the object of interest within a new frame. As with other classifier-based approaches, color models obtain parameters by learning both the positive and negative samples simultaneously.
We follow Staple, where the color features are based on RGB colors, and the bins color histograms are computed in a bins space. To have the sparse features to speed up the calculation, in the color model, the Staple algorithm maps each pixel represented by the RGB space into an index feature in a 32 × 32 × 32 bins space in the image.
As shown in
Figure 2, during the model training phase in frame t, given as a rectangular patch
which is sampled around the estimated location from frame t, Staple divided
into the foreground area
(shares the size with the estimated target of previous frame) and background area
. Additionally, they were used to calculate the proportion of each index feature (32 × 32 × 32 bins space) in the foreground area
and the background area
, respectively. Suppose
is a region,
, the proportion of each index feature
(32 × 32 × 32 bins space) in area
can be represented by
, where
represents the number of index feature
in area
and
represents the total number of pixels in area
. Therefore, for an online model,
and
can be followed by the following formula:
where
is the vector of
M is the dimension of the mapped space (32 × 32 × 32 bins), and
is a learning rate parameter.
When calculating the proportion of each index feature
in the foreground area
and background area
, respectively, the weight coefficient
for each index feature
is updated by the following equation:
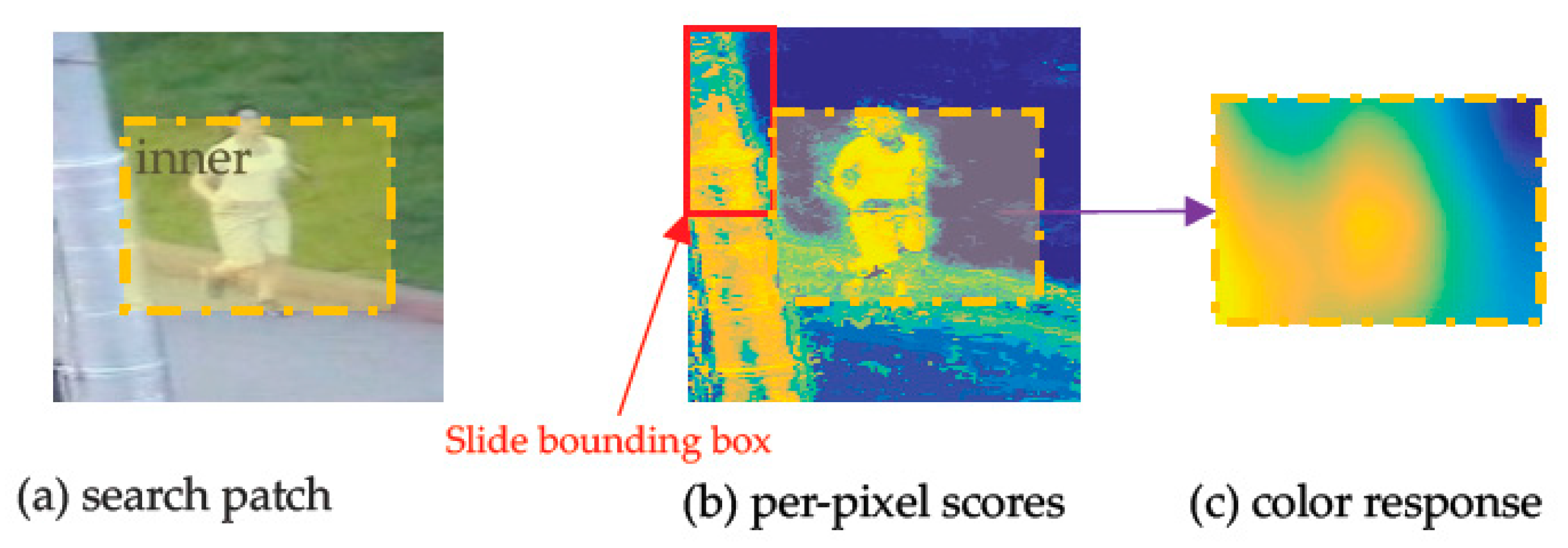
Given a RGB search patch
(shown in
Figure 3a) in frame
t + 1, first, per-pixel scores
(shown as heat map in
Figure 3b) of search patch
is obtained by looking up the table. Then, the score matrix
named color response (shown as heat map in
Figure 3c) of inner region
is obtained. The dotted yellow box region of search patch
represents the inner region
, and the red box used to generate all of the boxes center at inner region
of
in
Figure 3b is the slide bounding box
.
Given a search image = , which (with a magnification relative to target bounding box ) is extracted around and has a size of , as well as the target size , which is given for fixed-size target detection, we can obtain its inner region and a bounding box set corresponds to in frame t + 1. From Equation (2), we know that our goal is to calculate the response color scores of all bounding boxes in . However, first we need to calculate a score matrix which represents the score of different pixels in search image patch , and the score matrix is also named per-pixel scores in Staple. The calculation process is as follows.
From the above training process, we know that the score (weights
) of each index feature
has been obtained in the previous frame t, therefore the score
of each pixel
(RGB space) in
is obtained directly by looking it up in the table, therefore the score matrix
=
named per-pixel scores is formed. The example of a per-pixel score is shown as the heat map in
Figure 3b.
Then, we begin to calculate the color score of each bounding box
in set
. The color score of bounding box
is a pixel-based average score, that is, the color score (
) of each bounding box
is the average of the weight scores of all the pixels
in the bounding box
. The calculation formula is as follow:
Then, by sliding the bounding box with fix-size
on score matrix
, we can calculate all the color scores of bounding boxes in
with Equation (9). Therefore, the other score matrix
=
is obtained. Element
in
represents the color score of bounding box centered at position
in inner region
, which is computed in Equation (9).
shares the same size
with inner region
and is shown with the heat map in
Figure 3c. Additionally, supposing the size of
is
, we have
and
.
The fractional response of the sliding window can be accelerated by convolving the image in Staple. For more details, one can refer to the code of the Staple algorithm.
2.3. Learning of Object Model
Similar to the filter model and color model, the object model is also based on the tracking-by-detection principle to locate the target. In
Section 2.2, we find that, in the color model, the score of each bounding box is calculated based on the average of all pixel weight scores in the bounding box. In this section, we describe another approach, which is based on contour information to measure the probability score of the bounding box as a target.
In Edge Boxes [
18], the likelihood of the bounding box containing an object is based on the number of contours that are wholly contained in a bounding box. Using efficient data structures, millions of bounding boxes can be evaluated in a fraction of a second. Furthermore, this model does not require additional training process; given the location and size of bounding box and the image, the score of the target box can be calculated efficiently. Edge Boxes [
18] is introduced below.
Given a search area
, which (with a magnification relative to target bounding box
) is extracted around
and has size of
, as well as the target size
, which is given for a fixed-size target detection, similar to the color model, we can obtain its inner region
and a bounding box set
that corresponds to
in frame t+1. Again, similar to the color model, our goal is to calculate the response scores of all bounding boxes in
. However, before calculating the scores of the bounding boxes in
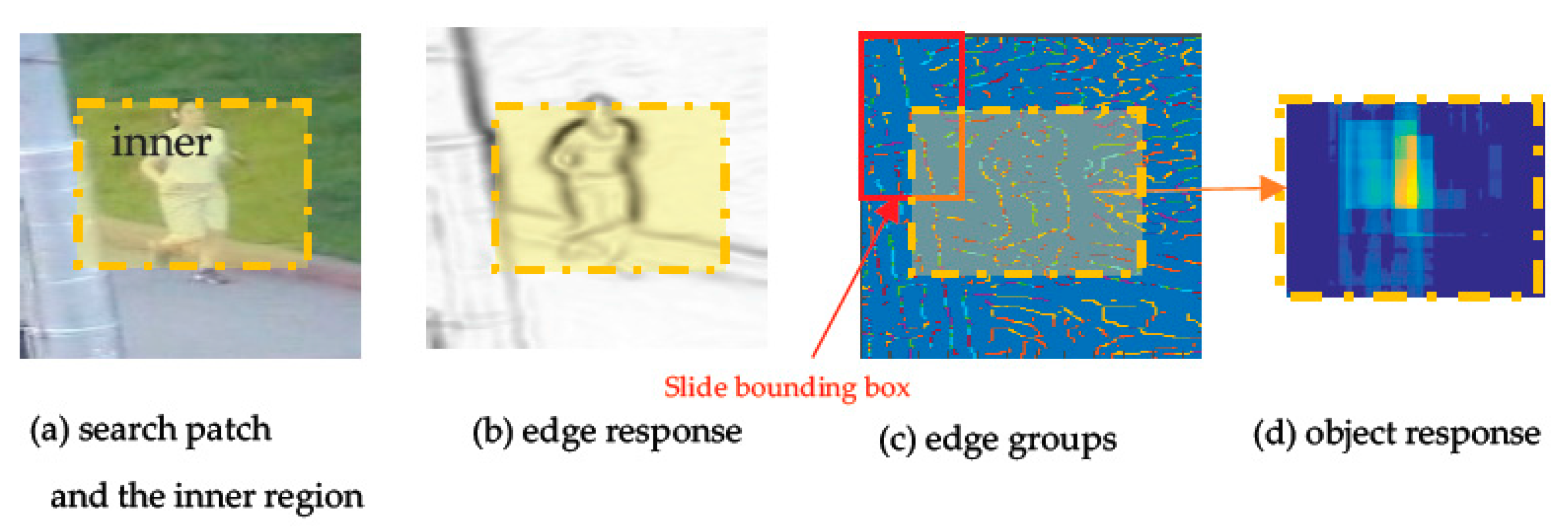
, we should obtain the edge response and edge groups of search area
in turn, with the method in Edge Boxes. Examples of edge response and edge groups are shown in
Figure 4b,c, respectively. Specific calculations can be found in Edge Boxes.
After all the edge groups have been calculated, from Edge Boxes, we know that the object score
of each bounding box
can be expressed as:
where
and
are the width and height of the bounding box
, respectively;
represents a central region of the
;
is an edge (corresponding to a pixel) which has an edge magnitude
, and
is the sum of the edge magnitude
for all edges
in
;
is a continuous value to indicate the probability that
belongs to a fixed bounding box
; and
is the penalty coefficient of the size of
. For more details, one can refer to the code of the Edge Boxes algorithm.
Therefore, we can calculate the object scores of each bounding box in
by sliding the bounding box. Then, the other score matrix
=
, named the object response of inner region
, is obtained, which shares the same size
with inner region
and is shown with the heat map in
Figure 4d, where
computed with Equation (10) is the object score of a bounding box in
, which has the position
in region
and the size of
.
2.4. Final Response Scores Calculation of MMT
Given a search area
, which has size of
, and the fixed target size
of the previous frame, similar to the color and object models, we can obtain its inner region
and a bounding box set
that corresponds to
in frame
t + 1. From the above, we know that we can obtain three scores including the color score
, filter score
, and object score
computed by the color model, filter model, and object model, respectively, and the three response scores all represent the possibility of all the bounding boxes (with the fixed size of
and contains our search space) centered at different positions in inner region
by different model parameters. Since the three response scores were all between 0 and 1 (1 to the object and 0 to other), the magnitude of the response scores was compatible. Therefore, we followed the Staple algorithm and fused the three response scores by linear weighting. For each
, we obtained three scores
,
, and
from three models, respectively. Finally, according to Equation (2), the final fusing score of bounding box
was calculated by weighting
,
and
as:
where
and
are the merge coefficients of the score of the color model and object detection, respectively, and the sizes set in the experiment were 0.2 and 0.25, respectively. Specific parameters of the experiment are presented below. When the fusing scores of all the bounding boxes centered in inner region
are computed, a fusing scores matrix
=
, named the final response, is obtained, where
, computed with Equation (11), is the fusing score of a bounding box in
, which has the position
in region
and the size of
. After selecting the target bounding box
with the largest corresponding score of the final response
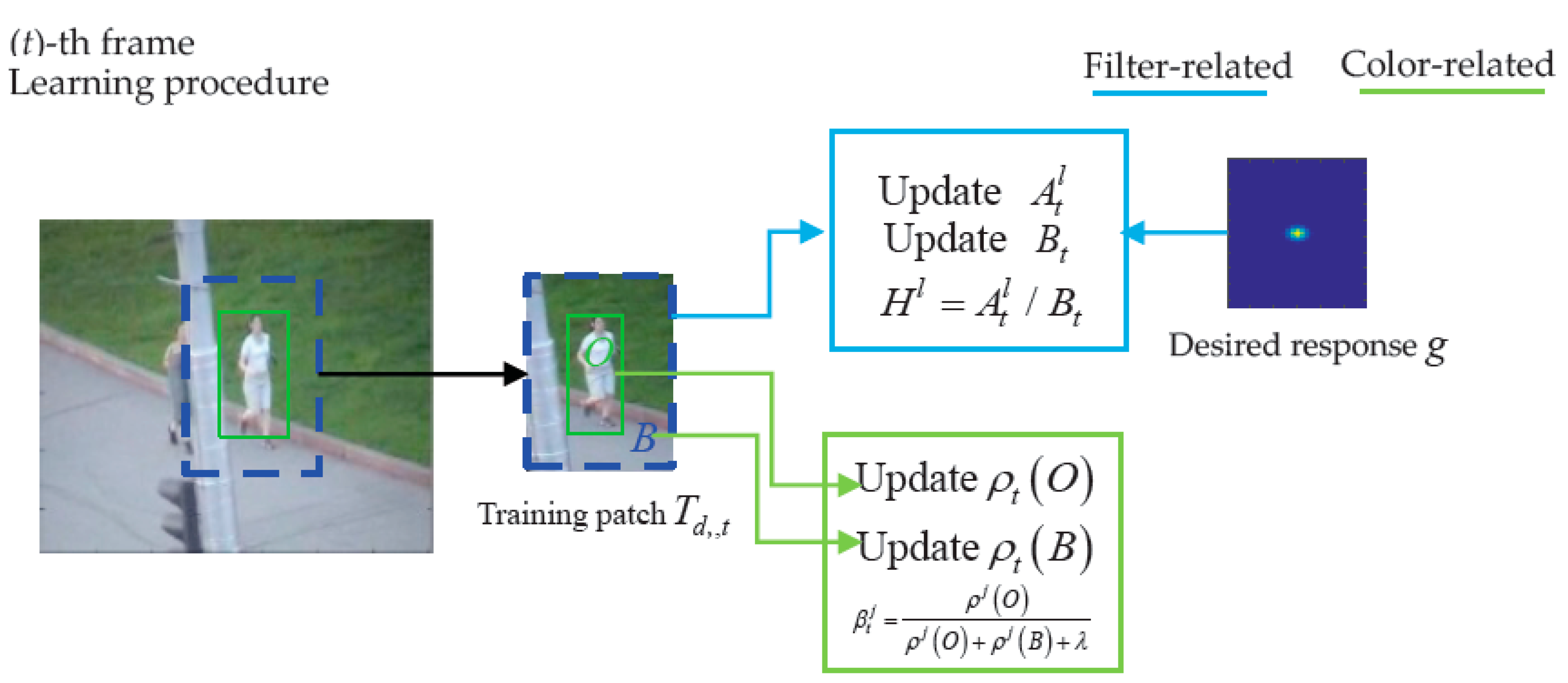
, the target scale is calculated by the scale filter. The transition tracking part of the MMT algorithm, which incorporates the object model to Staple, is shown in
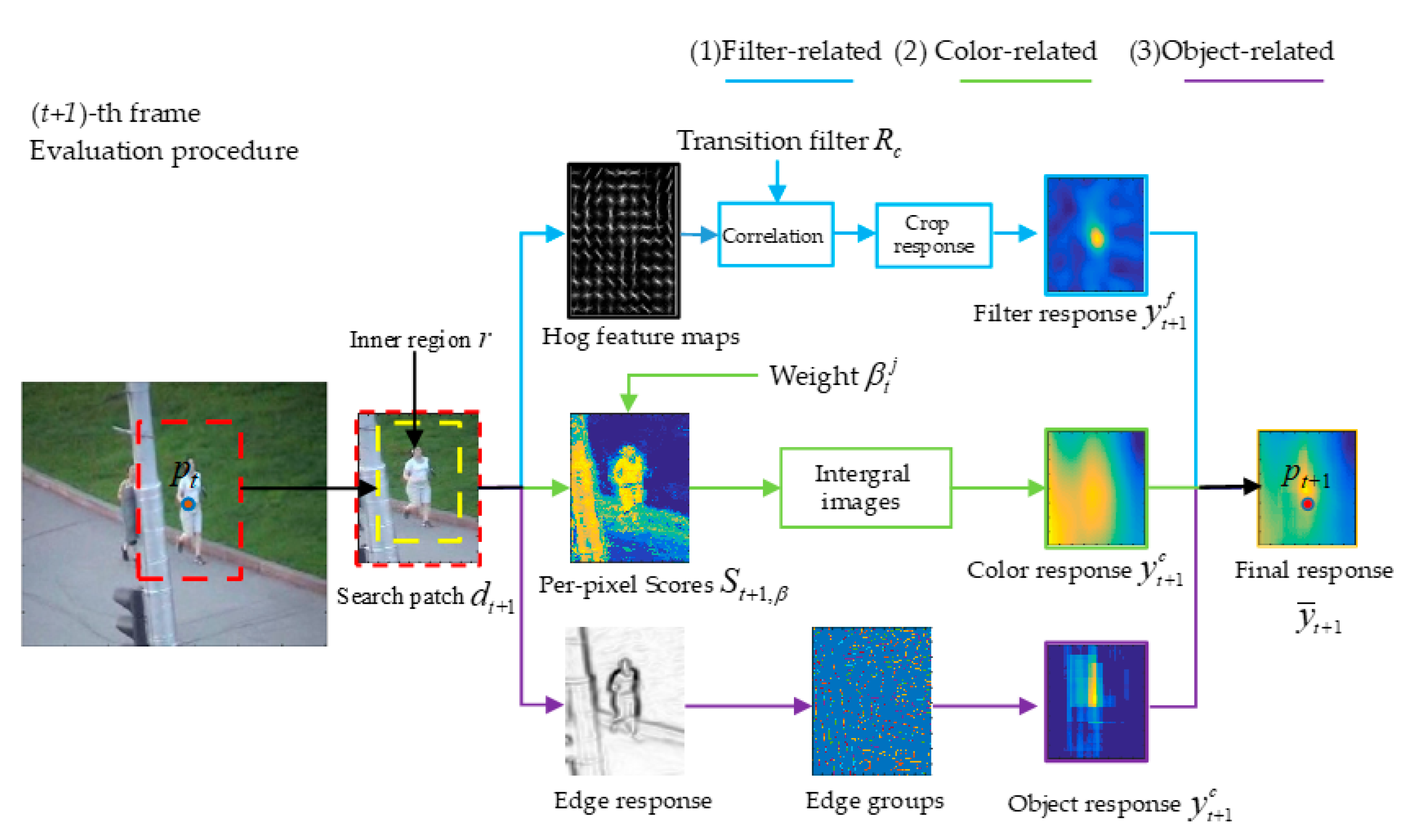
Figure 5 (learning procedure) and
Figure 6 (evaluation procedure).
From Equation (2), we know that denotes the estimated position of the target in (t)-th frame and denotes the predicted position of the target in the (t + 1)-th frame. Given the search patch , which (with a magnification relative to target bounding box ) is extracted around the , and the size of the target in the previous frame, we can obtain inner region , , and a box set , which is our search sample space. The purpose of the transition tracking of the multi-complementary model is to choose the new target bounding box with max fusing score from the box set . Therefore, after the final response , which gives the fusing scores of all the boxes in calculated with Equation (11), is estimated at the peak of . When the new position is obtained, the scale of target is computed by the 1D correlation filter. Specific details about scale estimation can be found in the code of Staple. , , and are computed by the filter model, color model, and object model, respectively. These are used to obtain final response with Equation (11) and their calculation process will be explained below.
- (1)
Filter-related. In the (t + 1)-th frame, the search patch (with a magnification relative to target ) is extracted around the , and the search feature maps represented using HOG features are extracted from and then convolved with translation filter through Equation (6) to calculate the filter response of . Due to inner region , the filter response of inner region can be obtained by cropping the filter response (score matrix) of . is a matrix which takes the scores of all the bounding boxes (with the same size of , ) centered at different positions in inner region as elements.
- (2)
Color-related. In the (t + 1)-th frame, the per-pixel scores , which represent the scores of pixels at different positions of , are obtained by looking up the table of weight , then the color response , which represents the color scores of all the bounding boxes in set , is obtained with Equation (9).
- (3)
Object-related. In the (
t + 1)-th frame, we calculate the edge response and the boundary group for the search area
in turn with the method in Edge Boxes [
18]. Then, the object response
, which represents the object scores of all the bounding boxes in set
, is calculated with Equation (10).
2.5. Scale Calculation Optimization
When target bounding box
, which denotes the predicted position of the target in frame t+1, is obtained by translation tracking, the object scale can be calculated using the one-dimensional scale filter proposed in [
15]. The size range selection principle is as follows:
where
,
are the width and height of the object on the previous frame, respectively;
is the scale factor; and
is the scale number. We followed Staple and set
and
to 1.02 and 33, respectively.
Due to the classical scale calculation method in [
15] (which is also used in Staple), we needed to calculate the HOG feature maps of 33 scale image blocks during training and testing, which is very complicated. In frame t, the feature map of the scale testing and the scale training were all based on the same coordinates, which were obtained from the transition tracking of frame t. The scale testing needs to extract the 33-scale image patch features relative to the target scale of the (
t − 1)-th frame and scale training needs to extract the 33-scale image patch features relative to the target scale of the (
t)-th frame, respectively, as the two-frame scale change is usually small or even the same. In the case where the scale of the two frames before and after the change is
, the image features of the
sample blocks are repeatedly calculated, resulting in significant complexity. In this paper, we therefore reused the features of the scale image patch that were obtained in the process of doing the scale calculations during scale updating. This optimization method greatly improved the execution speed of the tracker.
3. Multi-Complementary Model for Long-Term Tracking
With the MMT tracker and the new proposed detection method, we constructed the MMLT (Multi-Complementary Model for Long-term Tracking) tracker. In the following, we introduce the online detection module in detail. In
Section 3.1, we describe the proposed online detector method used to get the candidate bounding boxes. In
Section 3.2, we present how we evaluated the confidence score of the candidate bounding box. In
Section 3.3, we present how we obtained the redetected target and how we decided whether to use it to reinitialize the tracker. In
Section 3.4, we introduce how the MMT tracker and online detection module worked together in MMLT comprehensively and introduce the detection module’s high confidence update mechanism in this paper.
3.1. The Online Detector
It is common sense that the detection module is necessary for a long-term tracking method to redetect the target in case of failed tracking when long-term occlusion or out-of-view arise. In addition, the detection method of learning a classifier online and using a classifier to search by sliding the window has high time complexity. Different from previous works [
26,
30] where the online classifier needs to be trained, in this paper, we combined an object detection method based on object contour [
18] and the color detection method [
25] to generate a fractional prediction response of the search area to redetect the target
. Due to the diversity of the sample, information and discriminant can be utilized to a greater extent. By integrating the dual prediction scores, we could form the fusing prediction response score for an object with greater confidence, resulting in better detection. This greatly improves the generalizability of the tracker.
Give a detection area = , which (with a magnification relative to target ) is extracted around , it has a size of and the fix target size obtained from the previous frame. Similar to the tracking module, we can also obtain its inner region and a bounding box set corresponding to . In addition, our goal is still to calculate the response scores of all bounding boxes in by the color and object parameters.
For the object detection model, according to the method in
Section 2.3, the edge response and edge groups of
are computed in turn. Then, we obtain object response
with Equation (10), which presents the object scores of all the bounding boxes centered in inner region
. At the same time, the per-pixel scores matrix
=
is obtained using
, and the color response
=
that represents the color scores of bounding boxes (with the same size of
) centered at different positions in inner region
is also computed efficiently through the integral images (Equation (9)).
After we obtain the predicted response scores of different models, the approach of fusing the predictions of the multi-complementary detection model is as follows.
Let us assume that the prediction results of different models are independent.
is chosen from a box set
, and
denotes a foreground-background label.
is the parameter corresponding with different models, which depends on the previous object state and previous frame. The likelihood of the candidate bounding box
belongs to the object under the model parameter
, which can be expressed as
, where
is the total number of models. Suppose the models are independent of each other, then we have the following decomposition:
Now, we have two independent model parameters: the color model parameter
and the object model parameter
. According to the color model parameter
, the probability that candidate bounding box
is the object can be calculated by
Likewise, according to the object detection model parameter
, the probability that the candidate bounding box
is the object can be calculated by
Therefore, according to Equation (13), we have the following formula to fuse the predictions of the different independent models for calculating the score of each bounding box
:
When we get the scores of all the bounding boxes in
, from Equation (16), we know the final response matrix
can be obtained by:
where
represents dot multiplication operations.
represents the final response scores of all the bounding boxes
(with the same size of
,
) centered at different positions in the inner region
.
In general, the probability of to the object is large when both the color score and the object detection score of are high. If the gets a low score from any one model, it is considered as not likely to be the target. Therefore, in this paper, the color score and the object detection score are merged by multiplication to obtain more reliable detection results.
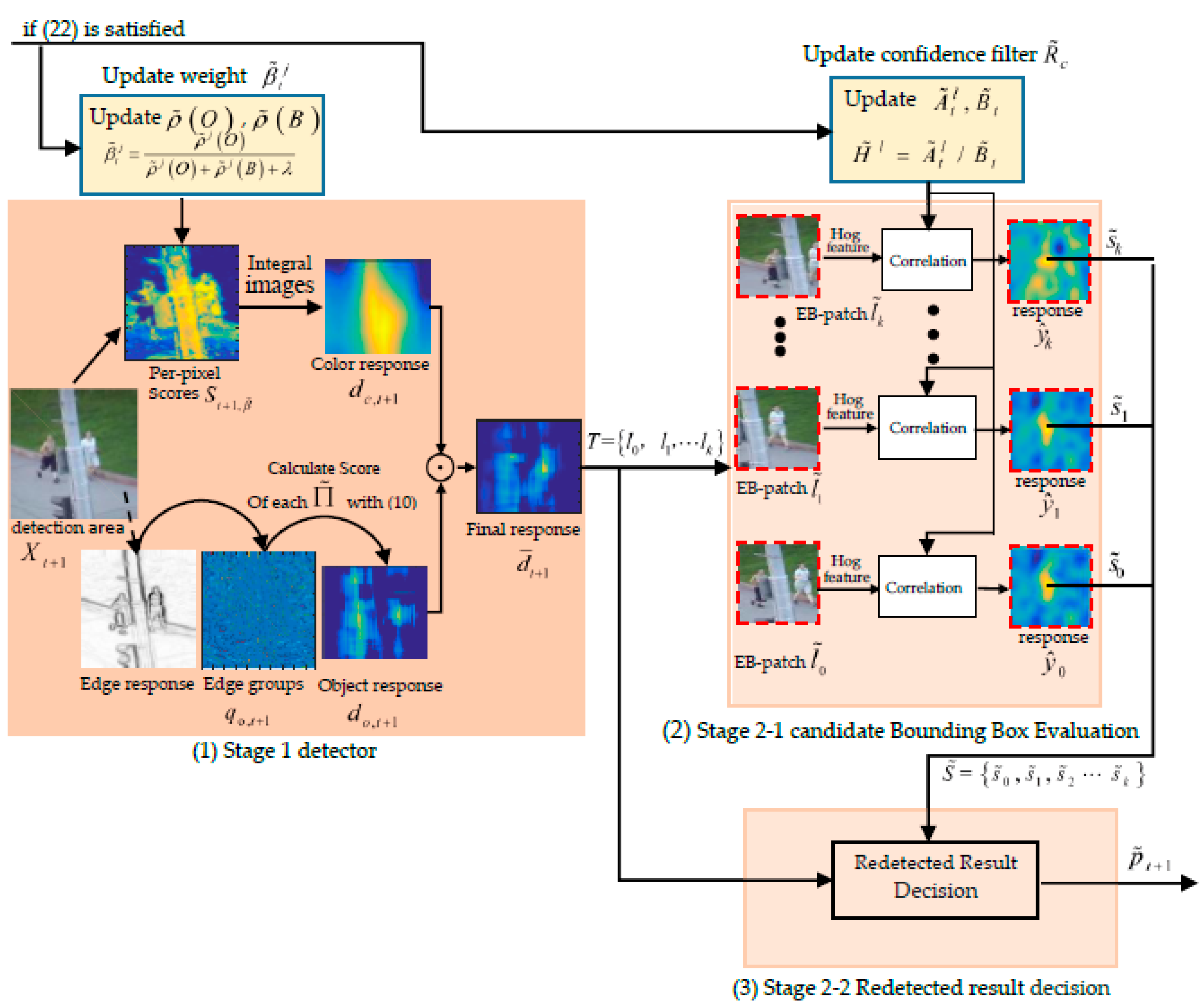
Having calculated the final response of inner region (in detection area ), the corresponding peaks of could be used to obtain the possible object location. Then, the purpose of the detector is to detect the top-w (w = 10) confident detection bounding boxes from (corresponding to inner region ). First, we select the bounding box centered at the peak (with the largest response score in the final response ) to the candidate bounding boxes set . When the ratio between the response score of the bounding box centered at other peaks to is greater than a threshold , the corresponding bounding box is also added to . Similar to CCT, the bounding box centered at the position in the previous frame is also added to as a candidate bounding box for evaluation. At the same time, we limited the total number of candidate bounding boxes so that it does not exceed w = 10. Finally, we obtain the candidate bounding box set .
3.2. Candidate Bounding Box Evaluation
After the detection module detects the candidate bounding box set
, a robust mechanism is needed to measure the confidence score of each candidate bounding box
. However, to effectively measure the confidence score of each bounding box, we follow the Collaborative Correlation Tracker (CCT) [
31] and consider not only the target area corresponding to the bounding box, but also the information of its background area. That is, for each candidate bounding box
, we extract the image region samples EB-patch
, which centers at the location of
and has the same magnification relative to the candidate bounding box as transition filter
. The EB-patch
is measured by a well-trained filter
(similar to
) to obtain the confidence score
of the corresponding candidate bounding box
.
First, we obtain the candidate EB-patch set
corresponding to
. For each EB-patch
, its HOG features map
is calculated, which convolved with confidence filter
in Equation (6), to obtain the confidence filter response
. In addition, we used the maximum score
of
as the confidence score of the candidate bounding box
. Finally, the candidate confidence scores
are also obtained. The calculation of
is given in
Section 3.3.
3.3. Redetected Result Decision
When the candidate confidence scores
is obtained, the final redetected target can be calculated as:
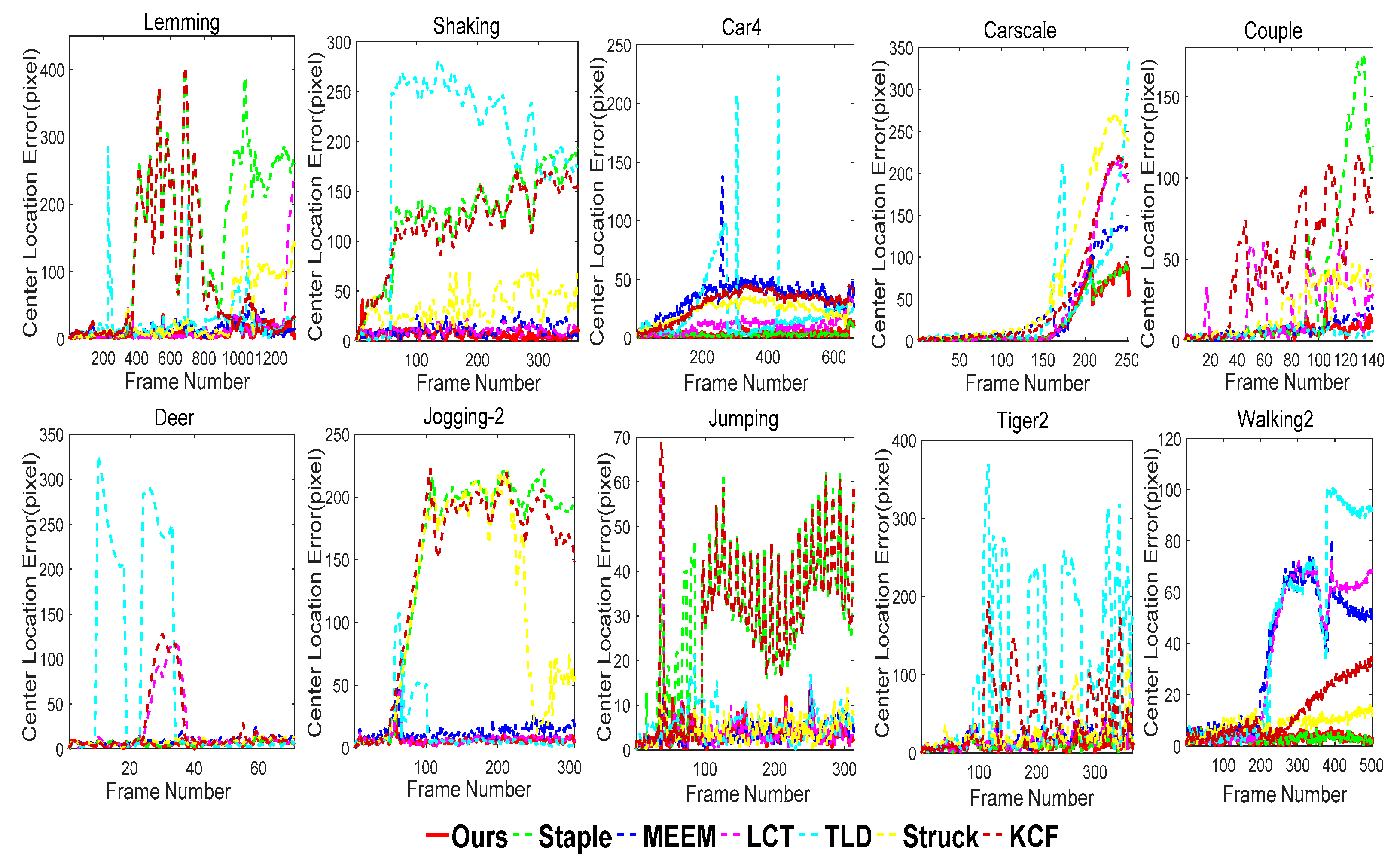
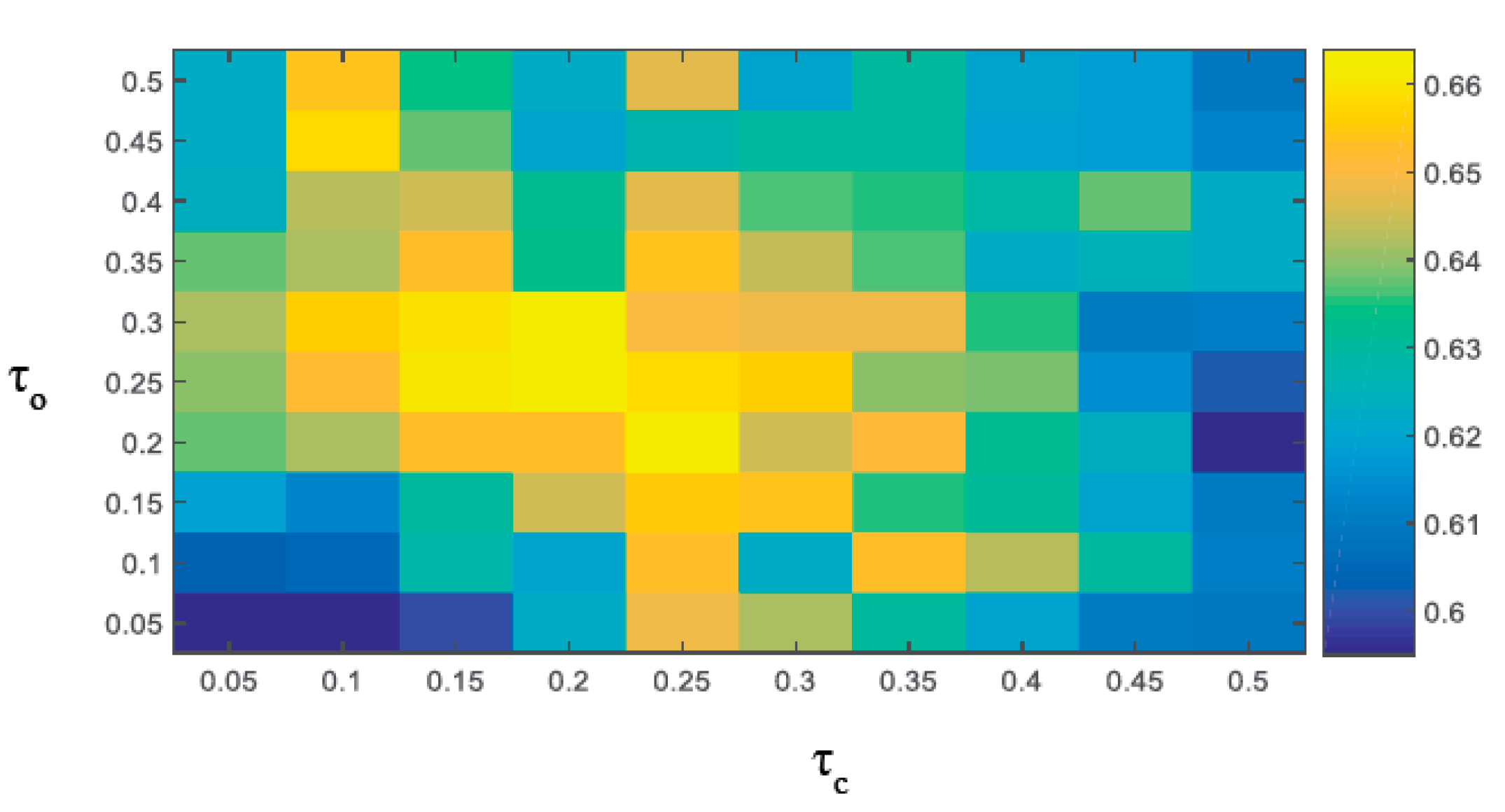
Then, the bounding box is the final redetected target . When and is higher than a certain threshold , is accepted, and is then used to initialize the tracker. When or is lower than , we consider is not correct, and it is not accepted.
3.4. Multi-Complementary Model for Long-Term Tracking
Clearly, a robust long-term tracking algorithm requires a re-detection module in case of tracking failure. Similar to LCT, we use the threshold
as the activation confidence to activate the detector. First, MMT performs the target tracking process in each frame. When the activation confidence
, the detector is activated to redetect the target, where
is the filter response of the transition tracking, which is computed in Equation (6). For the detection process, first, the detector has to compute the possible candidate bounding box set
, and then the candidate EB-patch set
corresponds to set
. Then, the confidence score set
is obtained by calculating the confidence score of each EB-patch in
S with the confidence filter
and Equation (6). Then, the redetected result decision module computes the redetected target
and decides whether to use it to reinitialize the tracker. The overall procedure of the online detection module is shown in
Figure 7.
Similar to LCT, our confidence filter model is only updated when the tracking results are reliable. LCT uses the response value of the confidence filter to measure the reliability of the tracking results. We follow LMCF (Large Margin Object Tracking with Circulant Feature Maps) [
32] and considered whether the object tracking results are reliable depending on both the maximum response value and the response map’s APCE (Average Peak-to Correlation Energy) [
32]. LCT trained an independent confidence filter to evaluate the confidence score of each candidate box in the detector. However, this adds extra time complexity to the algorithm. CCT uses the filter used in the tracking process to evaluate the confidence score of each candidate bounding box; thus, as the tracking model drifted, the detection model also drifted. Therefore, the reliability of the re-detection result obtained by the detection module could not be guaranteed. In this paper, we use a copy version
of translation filter
in the tracking process to measure each EB-patch to obtain the confidence score of each candidate bounding box; however, to prevent drift occurring in the detection model, as in the tracking model, different from
, which is updated each frame, the filter
is updated only when the tracking result is reliable. Therefore, we update the numerator
and denominator
of the confidence filter
(
) when Equation (22) is satisfied. The formula is as follows:
where
and
are polynomials that have been calculated in the updating of numerator
and denominator
of transition filter
in the transition tracking process with Equation (5).
Following the updating mechanism of filter , are also the copy versions of for detecting in the detector, which are updated with Equation (7) only when Equation (22) is satisfied. Similar to , the updating of is in Equation (8). The high confidence update mechanism that represents a reliable tracking in detection model is as follows.
In the (
t)-th frame, we follow LMCF [
32] and use the maximum filter response value
and the APCE (Average Peak-to Correlation Energy) [
32] of the filter response map
as a reference for updating the model, where
is the filter response of translational tracking phase, which is obtained by Equation (6) in the (
t)-th frame. The calculation method of APCE can refer to LMCF. Then, we consider the object tracking results reliable when both criterion
and the response map’s APCE
are greater than their respective
(
) frames historical average values
and
. Thus, whether the target tracking result in the current frame is reliable can be judged by whether the following conditions are satisfied:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}