Accurate Initial State Estimation in a Monocular Visual–Inertial SLAM System



Abstract
1. Introduction
2. Related Work
3. Visual–Inertial Preliminaries
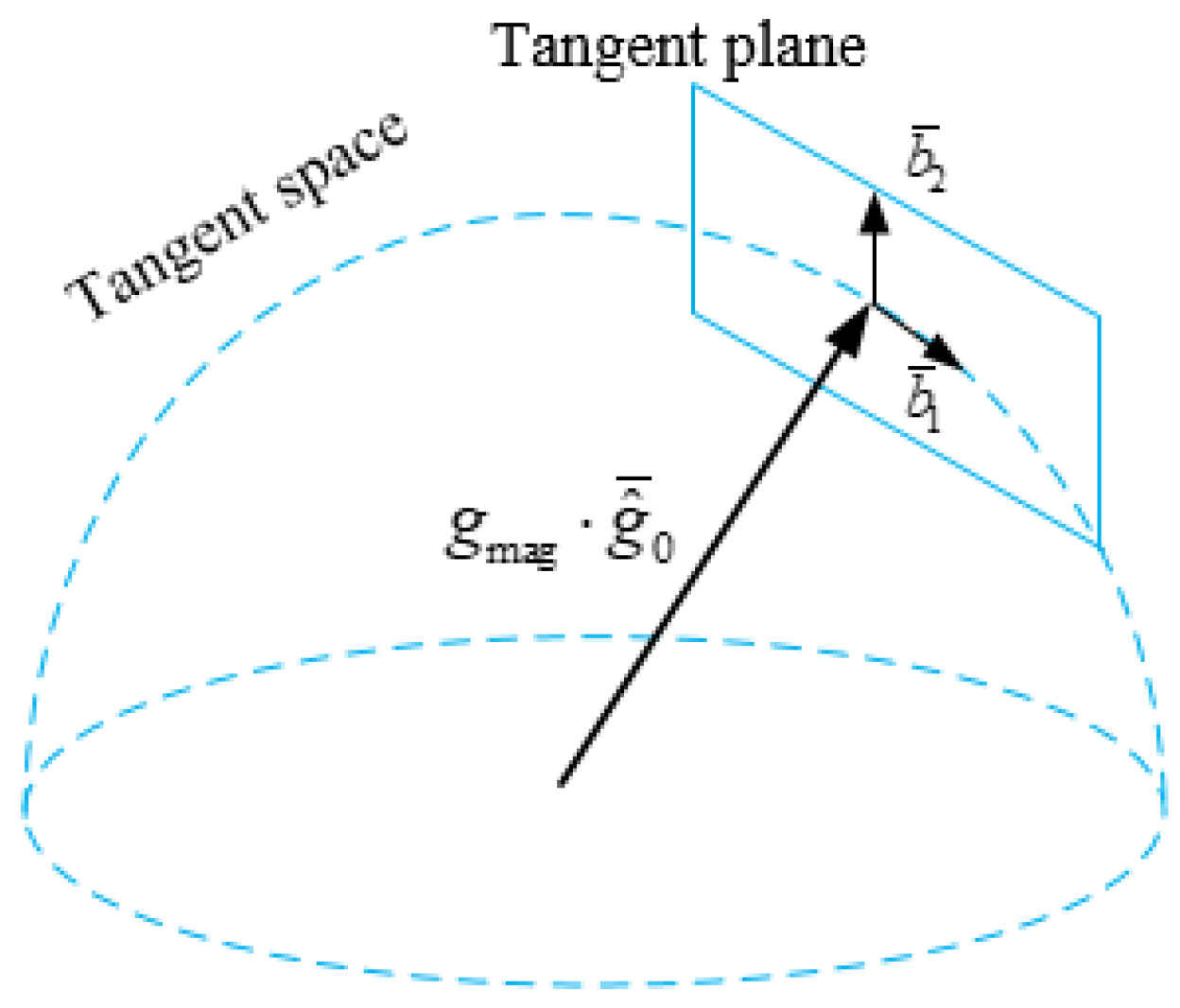
3.1. Visual Measurements
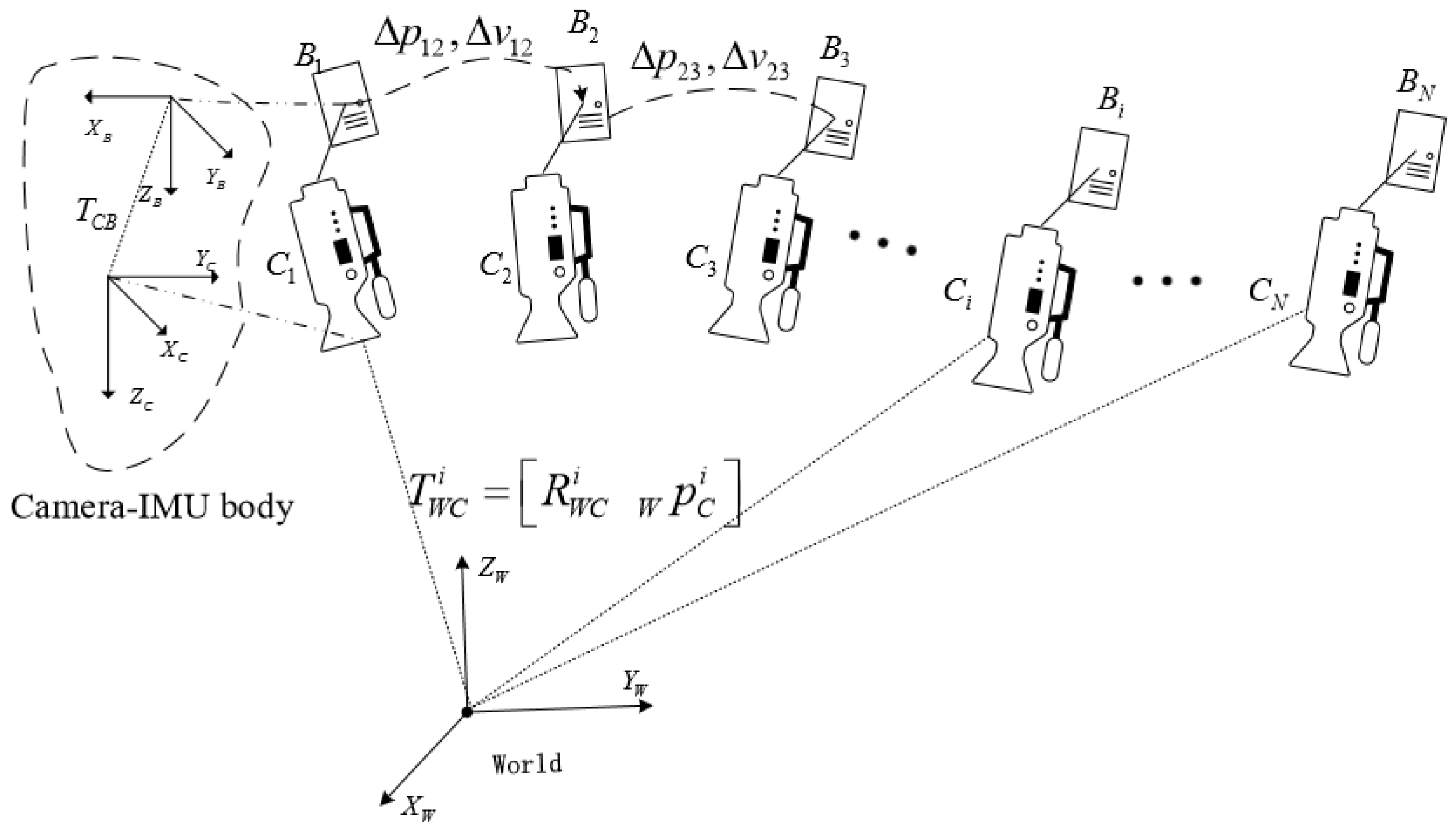
3.2. Inertial Measurements and Kinematics Model
3.3. IMU Pre-Integration
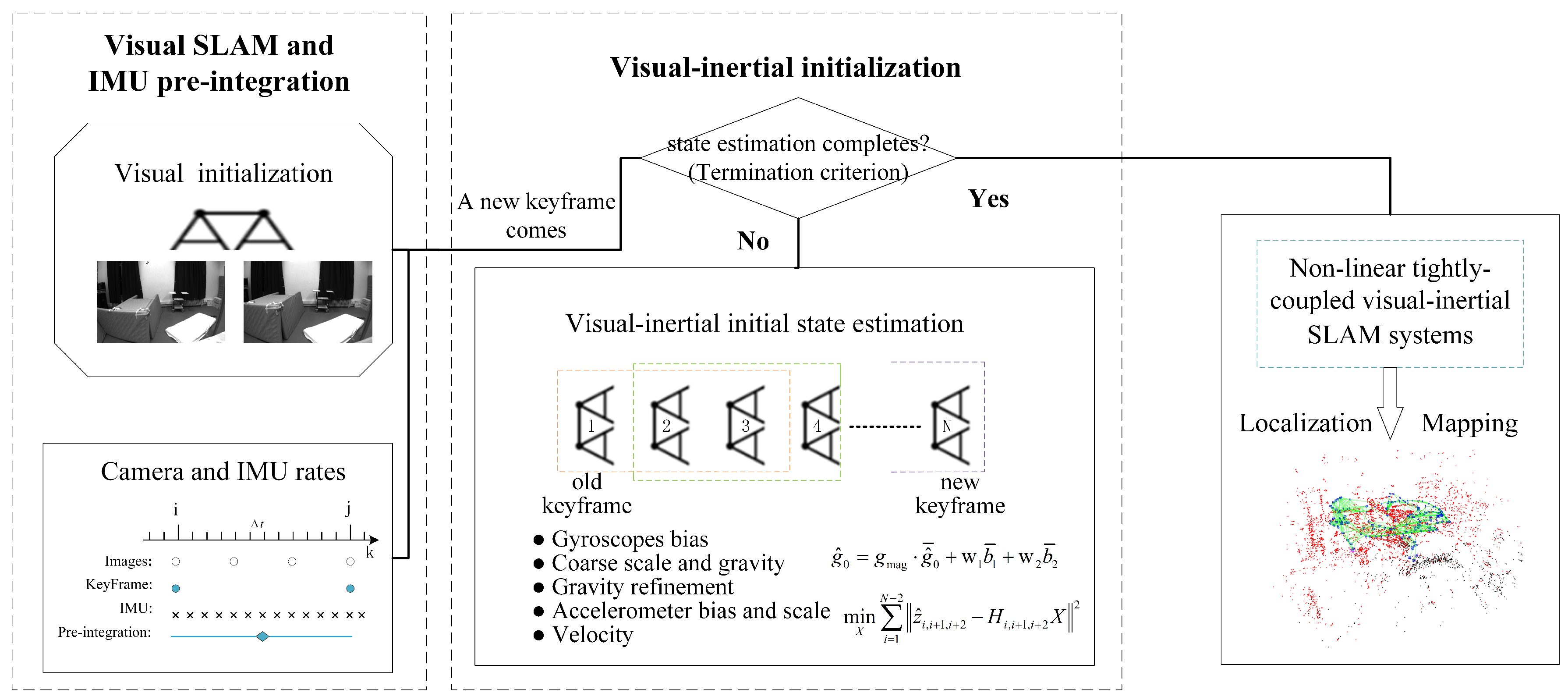
4. Visual–Inertial Initial State Estimation
4.1. Gyroscope Bias Estimation
4.2. Coarse Scale and Gravity Estimation
4.3. Gravity Refinement
4.4. Accelerometer Bias and Scale Estimation
4.5. Velocity Estimation
4.6. Termination Criterion
5. Experimental Results
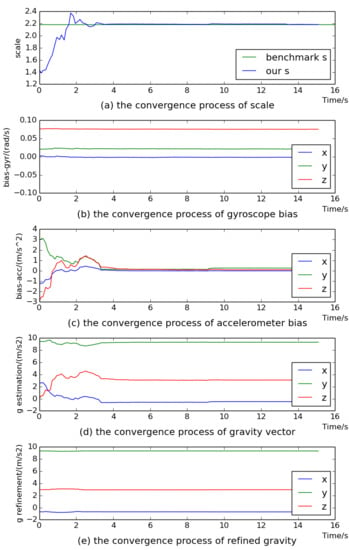
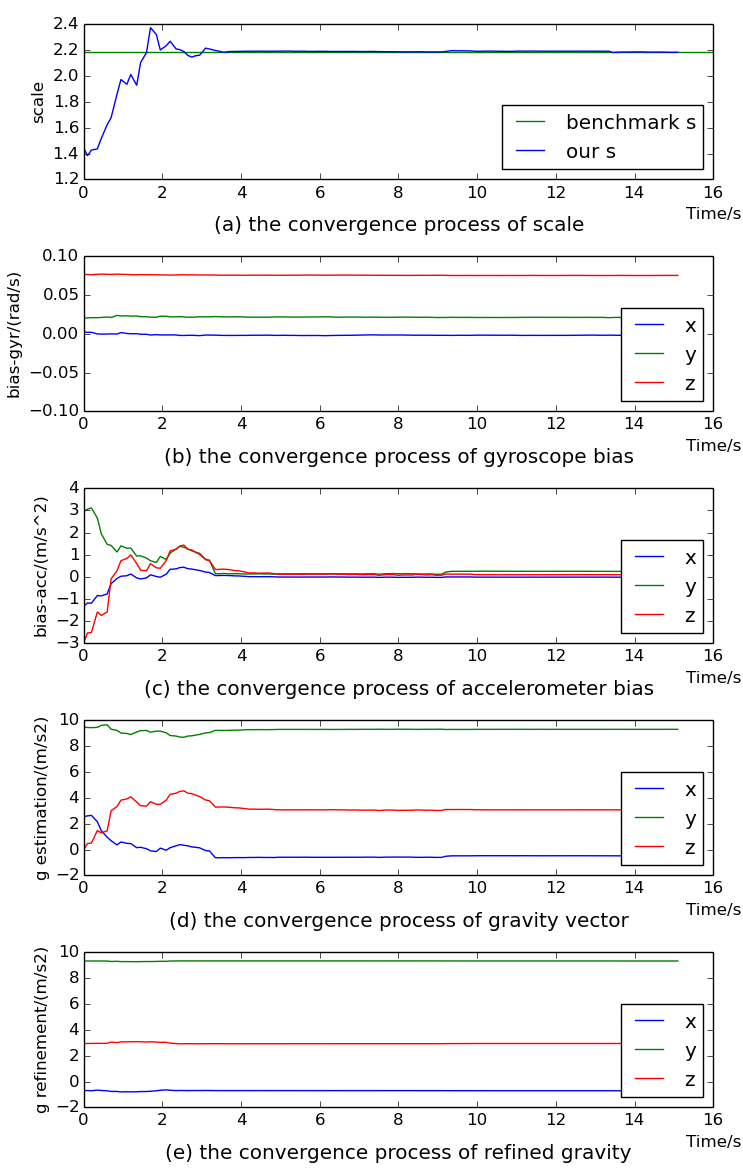
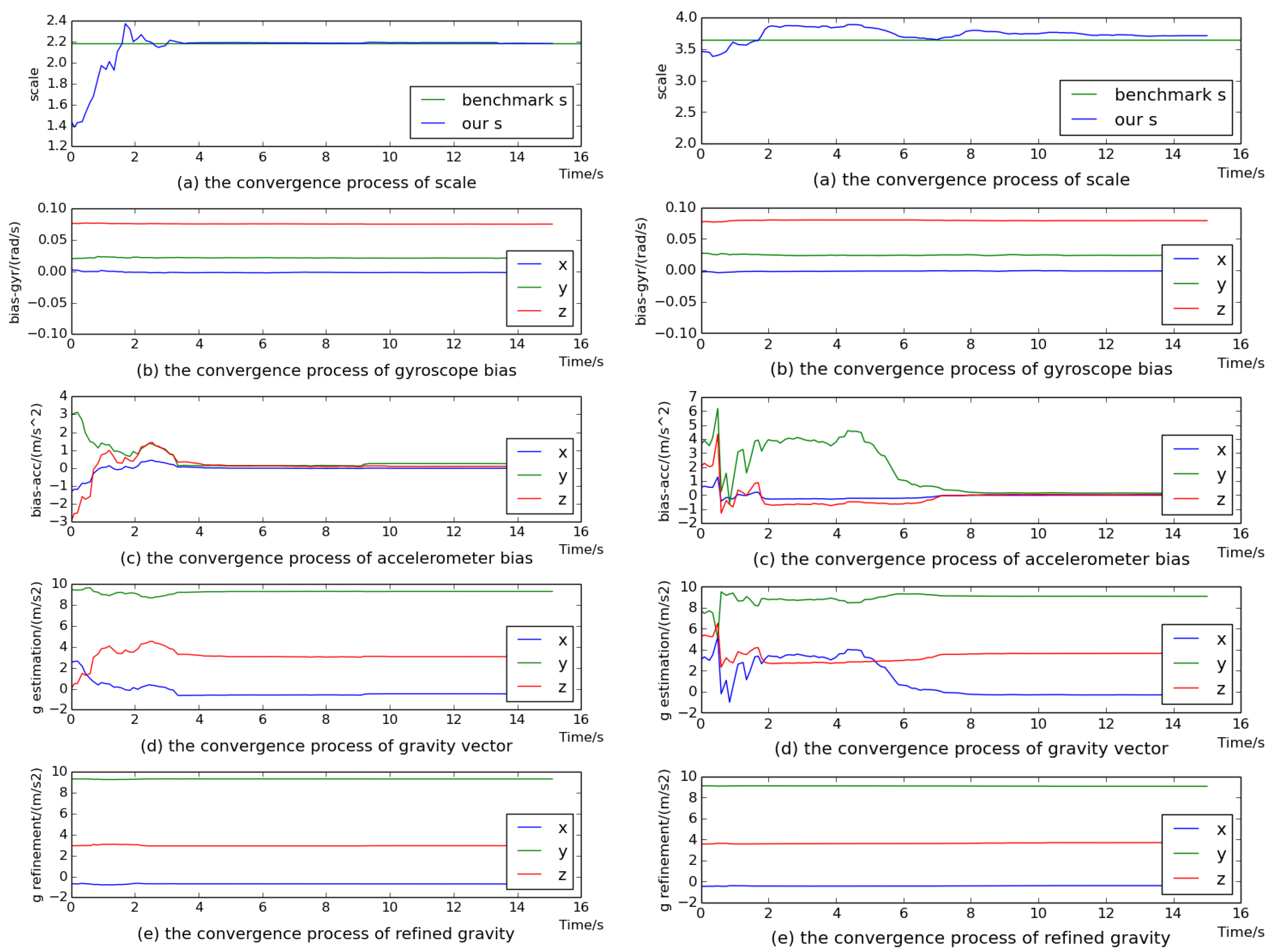
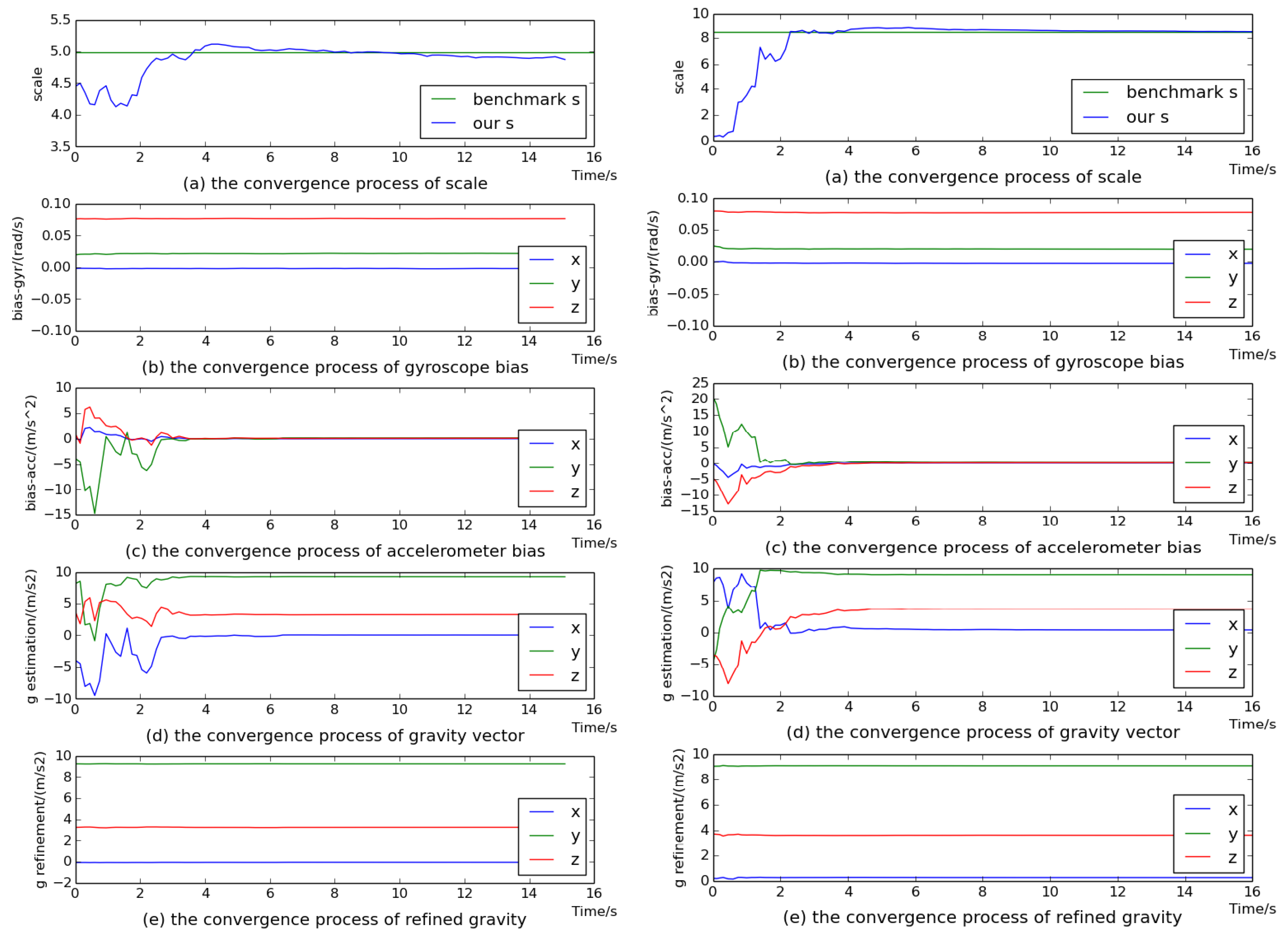
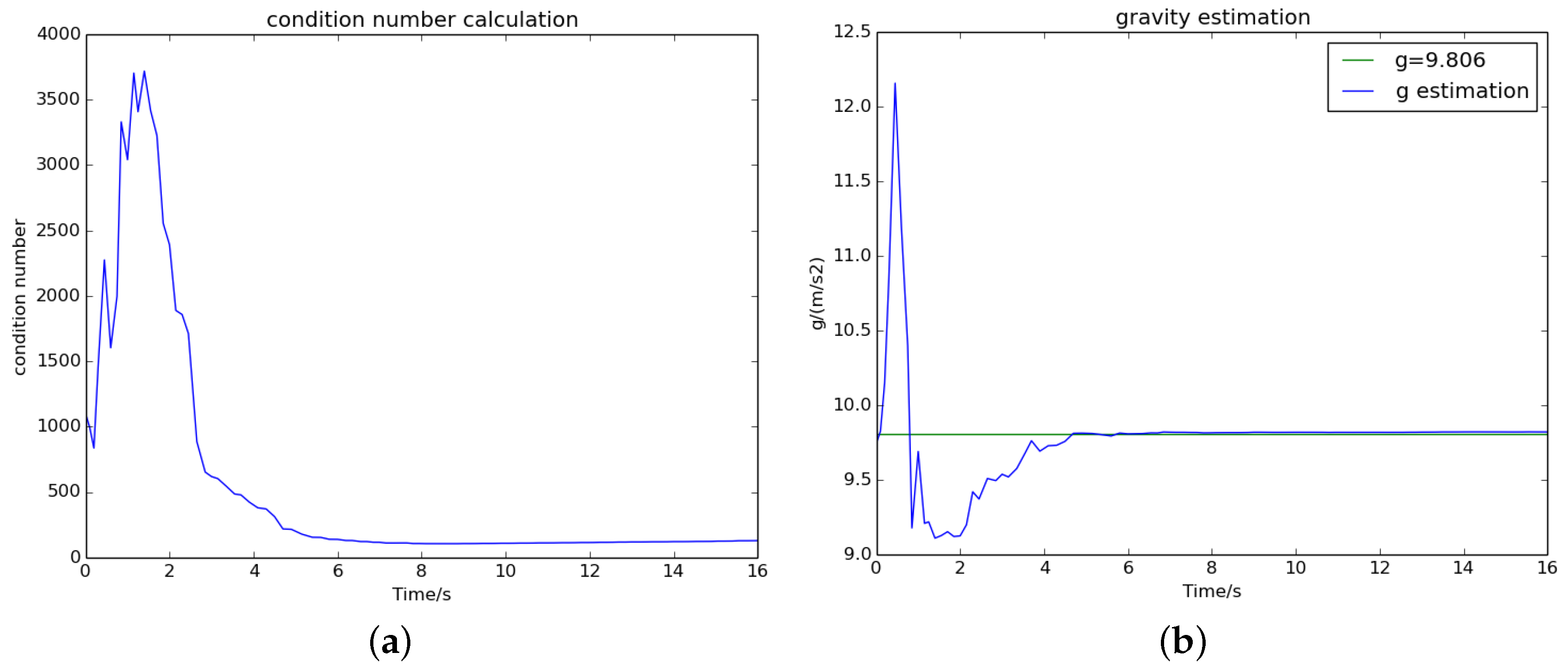
5.1. The Performance of Visual–Inertial Initial State Estimation
5.2. The Accuracy of Scale Estimation
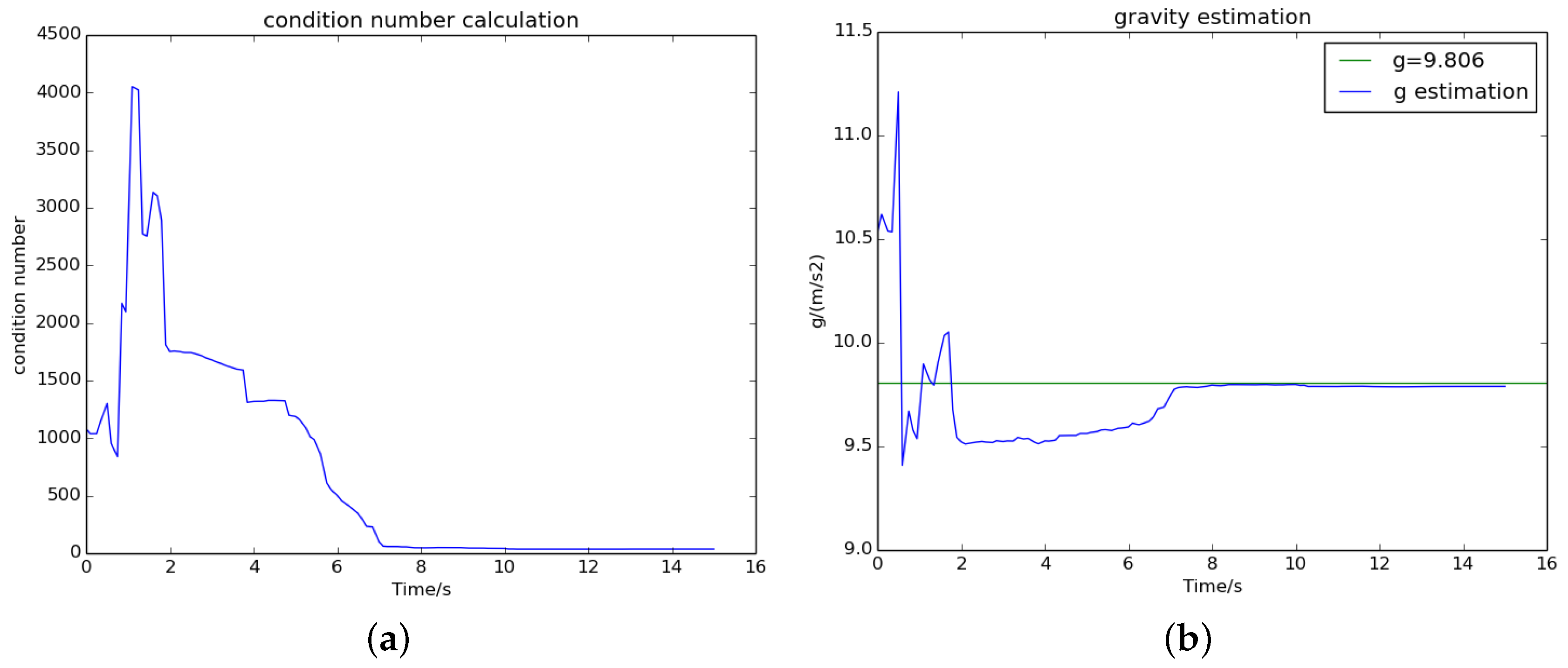
5.3. The Effect of Termination Criterion
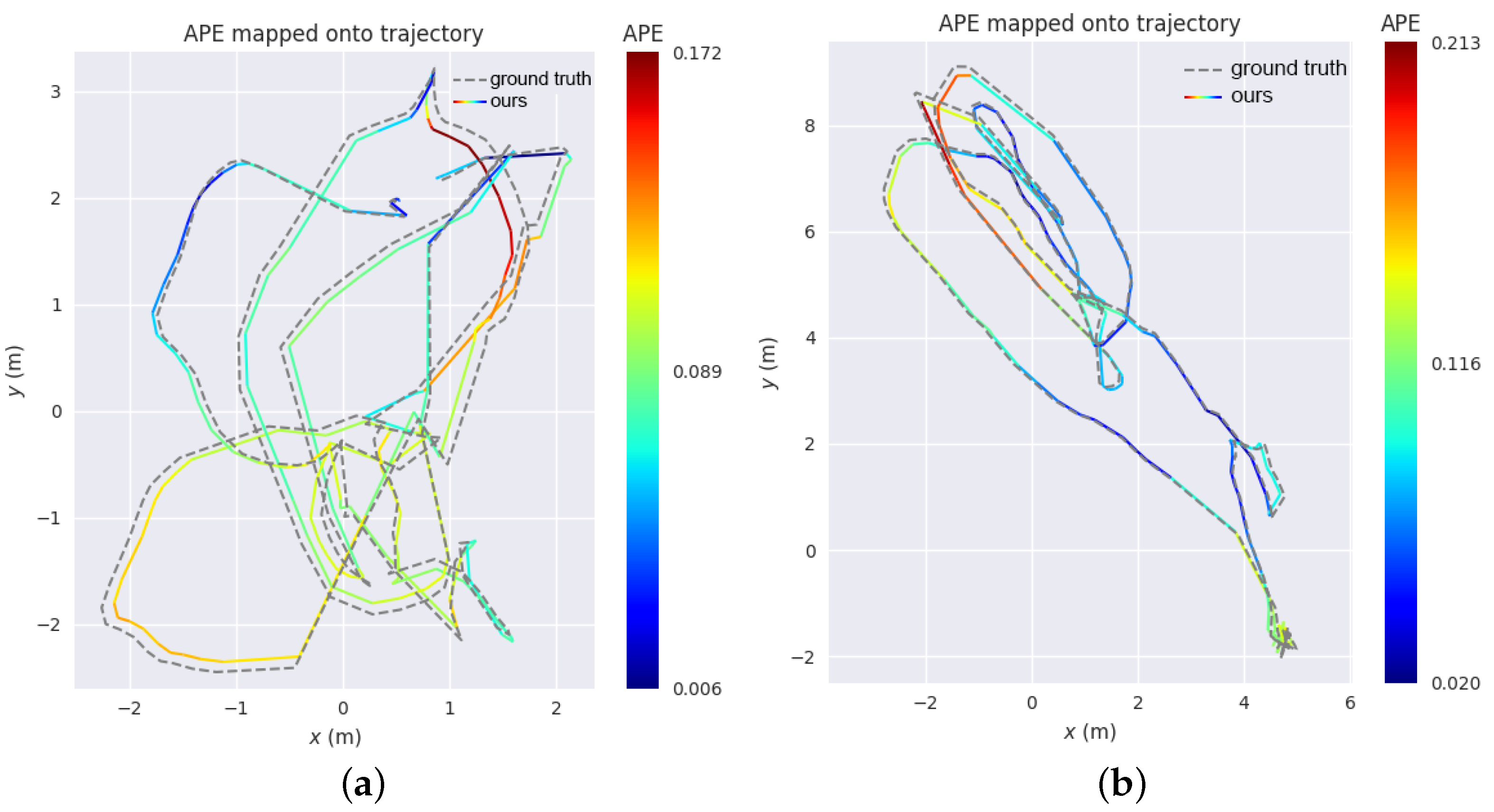
5.4. The Tracking Accuracy of Keyframes
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 225–234. [Google Scholar]
- Eade, E.; Drummond, T. Unified Loop Closing and Recovery for Real Time Monocular SLAM. In Proceedings of the 2008 19th British Machine Vision Conference, BMVC 2008, Leeds, UK, 1–4 September 2008; Volume 13, p. 136. [Google Scholar]
- Davison, A.J. Real-time simultaneous localisation and mapping with a single camera. In Proceedings of the 2003 Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; p. 1403. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 15–22. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Visual-Inertial Monocular SLAM With Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Li, P.; Qin, T.; Hu, B.; Zhu, F.; Shen, S. Monocular visual-inertial state estimation for mobile augmented reality. In Proceedings of the 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Nantes, France, 9–13 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 11–21. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual-inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Usenko, V.; Engel, J.; Stückler, J.; Cremers, D. Direct visual-inertial odometry with stereo cameras. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 1885–1892. [Google Scholar]
- Concha, A.; Loianno, G.; Kumar, V.; Civera, J. Visual-inertial direct SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 1331–1338. [Google Scholar]
- Jones, E.S.; Soatto, S. Visual-inertial navigation, mapping and localization: A scalable real-time causal approach. Int. J. Robot. Res. 2011, 30, 407–430. [Google Scholar] [CrossRef]
- Wu, K.; Ahmed, A.; Georgiou, G.; Roumeliotis, S. A Square Root Inverse Filter for Efficient Vision-aided Inertial Navigation on Mobile Devices. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 298–304. [Google Scholar]
- Strasdat, H.; Montiel, J.; Davison, A.J. Real-time monocular SLAM: Why filter? In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–7 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2657–2664. [Google Scholar]
- Yang, Z.; Shen, S. Monocular Visual–Inertial State Estimation With Online Initialization and Camera–IMU Extrinsic Calibration. IEEE Trans. Autom. Sci. Eng. 2017, 14, 39–51. [Google Scholar] [CrossRef]
- Shen, S.; Michael, N.; Kumar, V. Tightly-coupled monocular visual-inertial fusion for autonomous flight of rotorcraft MAVs. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; pp. 5303–5310. [Google Scholar]
- Hesch, J.A.; Kottas, D.G.; Bowman, S.L.; Roumeliotis, S.I. Consistency Analysis and Improvement of Vision-aided Inertial Navigation. IEEE Trans. Robot. 2014, 30, 158–176. [Google Scholar] [CrossRef]
- Martinelli, A. Closed-form solution of visual-inertial structure from motion. Int. J. Comput. Vis. 2014, 106, 138–152. [Google Scholar] [CrossRef]
- Engel, J.; Sturm, J.; Cremers, D. Scale-aware navigation of a low-cost quadrocopter with a monocular camera. Robot. Auton. Syst. 2014, 62, 1646–1656. [Google Scholar] [CrossRef]
- Weiss, S.; Achtelik, M.W.; Lynen, S.; Chli, M. Real-time onboard visual-inertial state estimation and self-calibration of MAVs in unknown environments. In Proceedings of the IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 957–964. [Google Scholar]
- Tanskanen, P.; Kolev, K.; Meier, L.; Camposeco, F.; Saurer, O.; Pollefeys, M. Live Metric 3D Reconstruction on Mobile Phones. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 Decmber 2014; pp. 65–72. [Google Scholar]
- Weiss, S.; Siegwart, R. Real-time metric state estimation for modular vision-inertial systems. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 4531–4537. [Google Scholar]
- Bryson, M.; Johnson-Roberson, M.; Sukkarieh, S. Airborne smoothing and mapping using vision and inertial sensors. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 2037–2042. [Google Scholar]
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. On-Manifold Preintegration for Real-Time Visual–Inertial Odometry. IEEE Trans. Robot. 2015, 33, 1–21. [Google Scholar] [CrossRef]
- Kneip, L.; Weiss, S.; Siegwart, R. Deterministic initialization of metric state estimation filters for loosely-coupled monocular vision-inertial systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 2235–2241. [Google Scholar]
- Faessler, M.; Fontana, F.; Forster, C.; Scaramuzza, D. Automatic re-initialization and failure recovery for aggressive flight with a monocular vision-based quadrotor. In Proceedings of the IEEE International Conference on Robotics and Automation, Washington, DC, USA, 26–30 May 2015; pp. 1722–1729. [Google Scholar]
- Weiss, S.; Brockers, R.; Albrektsen, S.; Matthies, L. Inertial Optical Flow for Throw-and-Go Micro Air Vehicles. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 262–269. [Google Scholar]
- Qin, T.; Shen, S. Robust Initialization of Monocular Visual-Inertial Estimation on Aerial Robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003; pp. 1865–1872. [Google Scholar]
- Farrell, J. Aided Navigation: GPS with High Rate Sensors; McGraw-Hill, Inc.: New York, NY, USA, 2008. [Google Scholar]
- Lupton, T.; Sukkarieh, S. Visual-Inertial-Aided Navigation for High-Dynamic Motion in Built Environments Without Initial Conditions. IEEE Trans. Robot. 2012, 28, 61–76. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| V1_01_Easy | V1_02_Medium | ||||||||
| No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error | No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error |
| 1 | 2.19802 | 2.22213 | 2.31443 | 3.98% | 1 | 2.28028 | 2.11539 | 2.22096 | 4.75% |
| 2 | 2.18622 | 2.21418 | 2.28095 | 2.93% | 2 | 2.21166 | 2.17452 | 2.18273 | 0.38% |
| 3 | 2.12814 | 2.14899 | 2.19818 | 2.24% | 3 | 2.32011 | 2.29834 | 2.24939 | 2.18% |
| 4 | 2.32220 | 2.32414 | 2.43320 | 4.48% | 4 | 2.46152 | 2.41389 | 2.43513 | 0.87% |
| 5 | 2.11896 | 2.14095 | 2.04617 | 4.63% | 5 | 2.29164 | 2.24925 | 2.24915 | 0.00% |
| V2_01_easy | V2_02_medium | ||||||||
| No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error | No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error |
| 1 | 3.15119 | 3.13984 | 3.09290 | 1.52% | 1 | 3.72664 | 3.66760 | 3.47209 | 5.63% |
| 2 | 3.15596 | 3.18330 | 3.04272 | 4.62% | 2 | 3.71125 | 3.64681 | 3.59466 | 1.45% |
| 3 | 2.97907 | 2.92119 | 2.96395 | 1.44% | 3 | 3.57335 | 3.53126 | 3.47022 | 1.76% |
| 4 | 3.11335 | 3.11445 | 3.06949 | 1.46% | 4 | 3.52077 | 3.41453 | 3.21689 | 6.14% |
| 5 | 2.91192 | 2.90283 | 2.95193 | 1.66% | 5 | 3.78522 | 3.67040 | 3.44327 | 6.60% |
| MH_01_easy | MH_02_easy | ||||||||
| No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error | No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error |
| 1 | 1.38302 | 1.36595 | 1.35822 | 0.57% | 1 | 3.9205 | 3.97242 | 4.23094 | 6.11% |
| 2 | 3.54077 | 3.51395 | 3.50519 | 0.25% | 2 | 4.09284 | 4.05315 | 4.30175 | 5.78% |
| 3 | 3.28325 | 3.25925 | 3.39144 | 3.90% | 3 | 3.26533 | 3.25786 | 3.49253 | 6.72% |
| 4 | 4.30154 | 4.27641 | 4.43791 | 3.64% | 4 | 1.37276 | 1.39001 | 1.47774 | 5.94% |
| 5 | 3.87869 | 3.88449 | 4.03829 | 3.81% | 5 | 3.32629 | 3.35212 | 3.57335 | 6.19% |
| MH_03_medium | MH_04_difficult | ||||||||
| No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error | No. | VI ORB-SLAM2 | Ours | Benchmark Scale | Error |
| 1 | 3.51556 | 3.53472 | 3.67447 | 3.80% | 1 | 2.15634 | 2.16695 | 2.20023 | 1.51% |
| 2 | 4.12347 | 4.21518 | 4.35231 | 3.15% | 2 | 1.88379 | 1.92157 | 2.05139 | 6.32% |
| 3 | 4.87332 | 4.96042 | 4.983 | 0.45% | 3 | 1.14818 | 1.19114 | 1.22704 | 2.93% |
| 4 | 5.35339 | 5.34029 | 5.43041 | 1.66% | 4 | 8.52259 | 8.51992 | 8.47516 | 0.53% |
| 5 | 5.17706 | 5.18087 | 5.35175 | 3.19% | 5 | 2.2521 | 2.26677 | 2.13573 | 6.13% |
| Sequence | Ours | VI ORB-SLAM2 | ORB-SLAM2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ME (m) | RMSE (m) | SSE (m2) | ME (m) | RMSE (m) | SSE (m2) | ME (m) | RMSE (m) | SSE (m2) | |
| V1_01_easy | 0.3522 | 0.5214 | 43.0723 | 0.3574 | 0.5293 | 44.4517 | 0.3119 | 0.4549 | 31.5616 |
| V1_02_medium | 0.4407 | 0.6515 | 53.7404 | 0.4321 | 0.6069 | 58.1439 | 0.4022 | 0.5256 | 43.0167 |
| V1_03_difficult | × | × | × | × | × | × | × | × | × |
| V2_01_easy | 0.1868 | 0.2315 | 8.7623 | 0.1876 | 0.2293 | 8.5764 | 0.1711 | 0.2208 | 8.1043 |
| V2_02_medium | 0.3361 | 0.6166 | 39.4145 | 0.3538 | 0.6151 | 40.3685 | 0.4316 | 0.6523 | 94.1142 |
| V2_03_difficult | × | × | × | × | × | × | × | × | × |
| MH_01_easy | 0.3727 | 0.5512 | 59.1512 | 0.3773 | 0.5605 | 61.0061 | 0.3399 | 0.4861 | 47.2790 |
| MH_02_easy | 0.2876 | 0.4018 | 30.7535 | 0.3276 | 0.4589 | 38.1945 | 0.3301 | 0.4727 | 40.7942 |
| MH_03_medium | 0.6190 | 0.9968 | 216.467 | 0.5960 | 1.0918 | 175.914 | 0.6939 | 1.0975 | 193.548 |
| MH_04_difficult | 0.5646 | 0.7044 | 89.1064 | 0.5745 | 0.8837 | 123.787 | 0.4581 | 0.5573 | 58.0247 |
| MH_05_difficult | 0.5477 | 0.6724 | 86.5826 | 0.5730 | 0.7036 | 90.0694 | 0.4589 | 0.5716 | 63.9264 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, X.; Chen, J.; Zhou, Z.; Leng, Z.; Fan, L. Accurate Initial State Estimation in a Monocular Visual–Inertial SLAM System. Sensors 2018, 18, 506. https://doi.org/10.3390/s18020506
Mu X, Chen J, Zhou Z, Leng Z, Fan L. Accurate Initial State Estimation in a Monocular Visual–Inertial SLAM System. Sensors. 2018; 18(2):506. https://doi.org/10.3390/s18020506
Chicago/Turabian StyleMu, Xufu, Jing Chen, Zixiang Zhou, Zhen Leng, and Lei Fan. 2018. "Accurate Initial State Estimation in a Monocular Visual–Inertial SLAM System" Sensors 18, no. 2: 506. https://doi.org/10.3390/s18020506
APA StyleMu, X., Chen, J., Zhou, Z., Leng, Z., & Fan, L. (2018). Accurate Initial State Estimation in a Monocular Visual–Inertial SLAM System. Sensors, 18(2), 506. https://doi.org/10.3390/s18020506