1. Introduction
Traffic accidents are mainly caused by a diminished driver vigilance level and gaze distraction from the road [
1,
2]. Driver distraction is the main source of attention divergence from the roadway and can pose serious dangers to the lives of drivers, passengers, and pedestrians. According to the United States Department of Transportation, 3179 people were killed and 431,000 injured in 2014 due to distracted drivers [
3]. Any activity that can divert driver attention from the primary task of driving can lead to distracted driving. It can happen for many reasons, but the most common are using a smart phone, controlling the radio, eating and drinking, and operating a global positing system (GPS). According to the National Highway Traffic Safety Administration (NHTSA) the risk factor for auto wrecks increases three times when drivers are using their smart phones during driving [
4]. Using a smart phone causes the longest period of drivers taking their eyes off the road (EOR). In short, it can be a reason for driver distraction, and the technology of driver gaze detection can play a pivotal role in helping to avoid auto accidents. The classification of driver gaze attention is an area of increasing relevance in the pursuit of accident reduction.
Current road safety measures are approaching a level of maturity with the passage of time. One of the major contributions to this is the development of advanced driver assistance systems (ADAS) that can monitor driver attention and send alerts to improve road safety and avoid unsafe driving. Real-time estimation of driver gaze could be coupled with an alerting system to enhance the effectiveness of the ADAS [
5]. However, these real-time systems are faced with many challenges for obtaining reliable EOR estimation and classification of the gaze zones. Some significant challenges include: varying illumination conditions; considerable variation in pupil and corneal reflection (CR) due to driver head position and eye movements; variations in physical features that may differ due to gender, skin color, ethnicity, and age; providing consistent accuracy for people wearing glasses or contact lenses; and designing a system for a calibration-free environment. Some of the previous studies have proven to be good under specific conditions, but they have limitations in actual car environments.
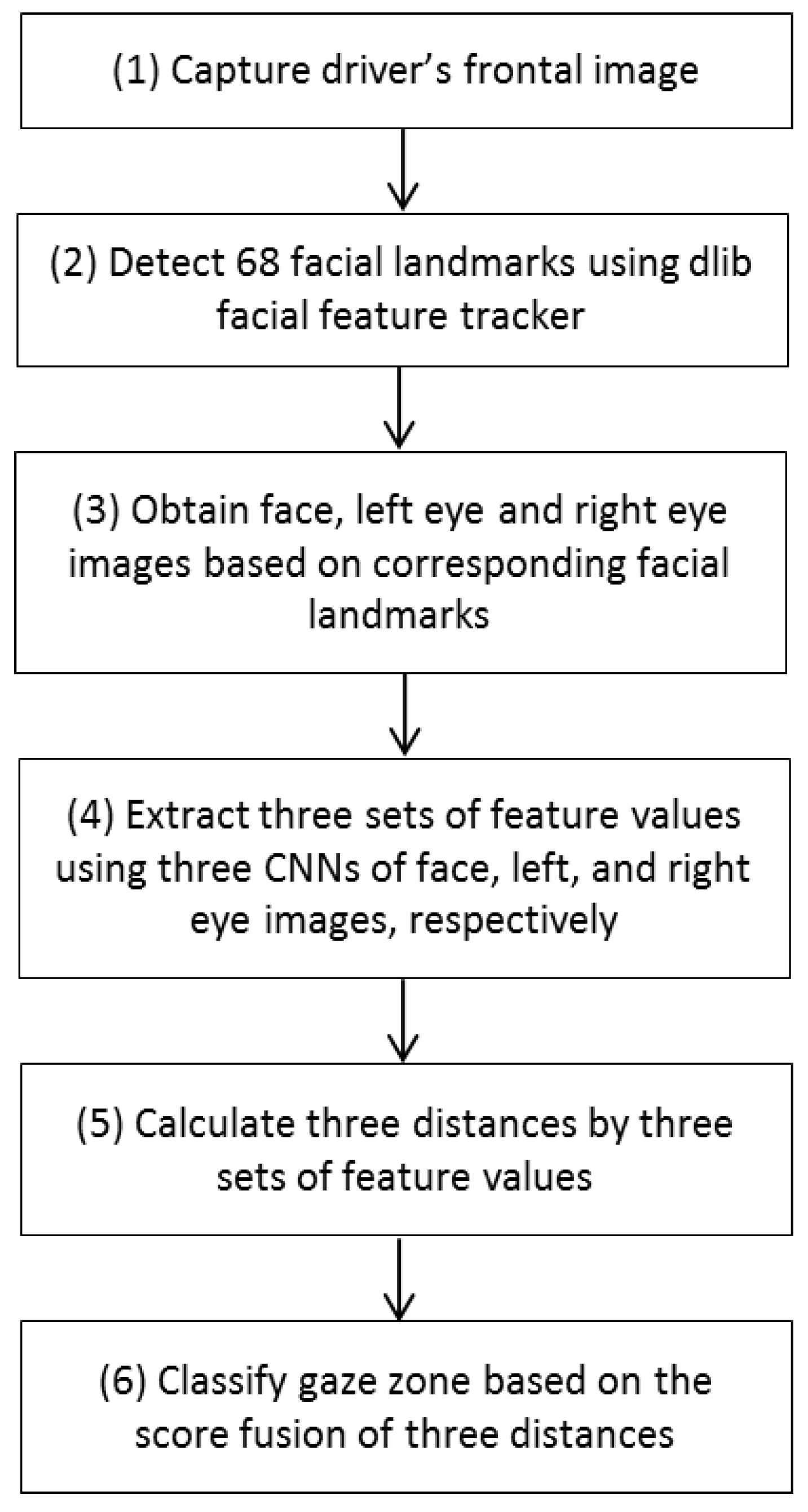
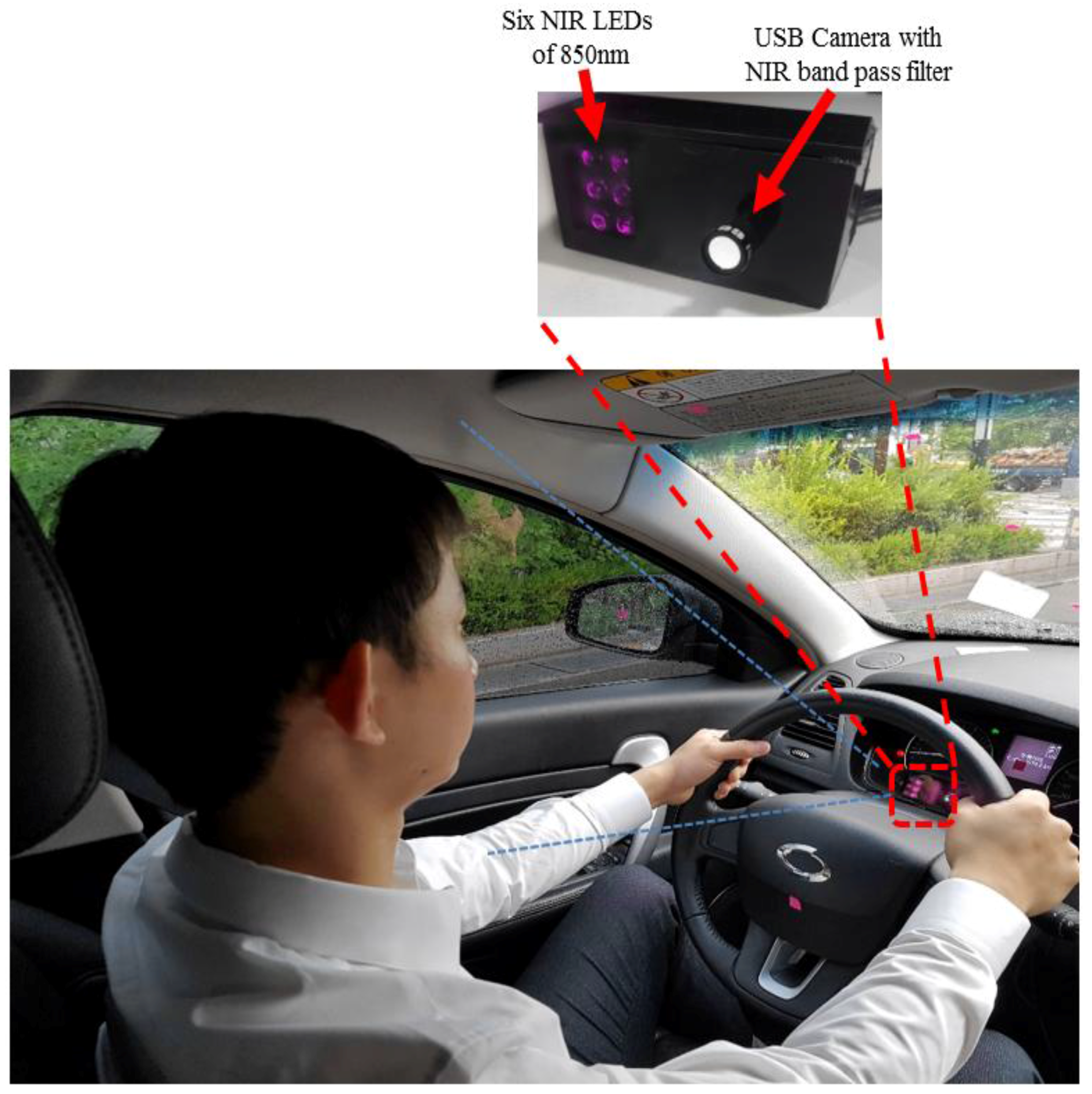
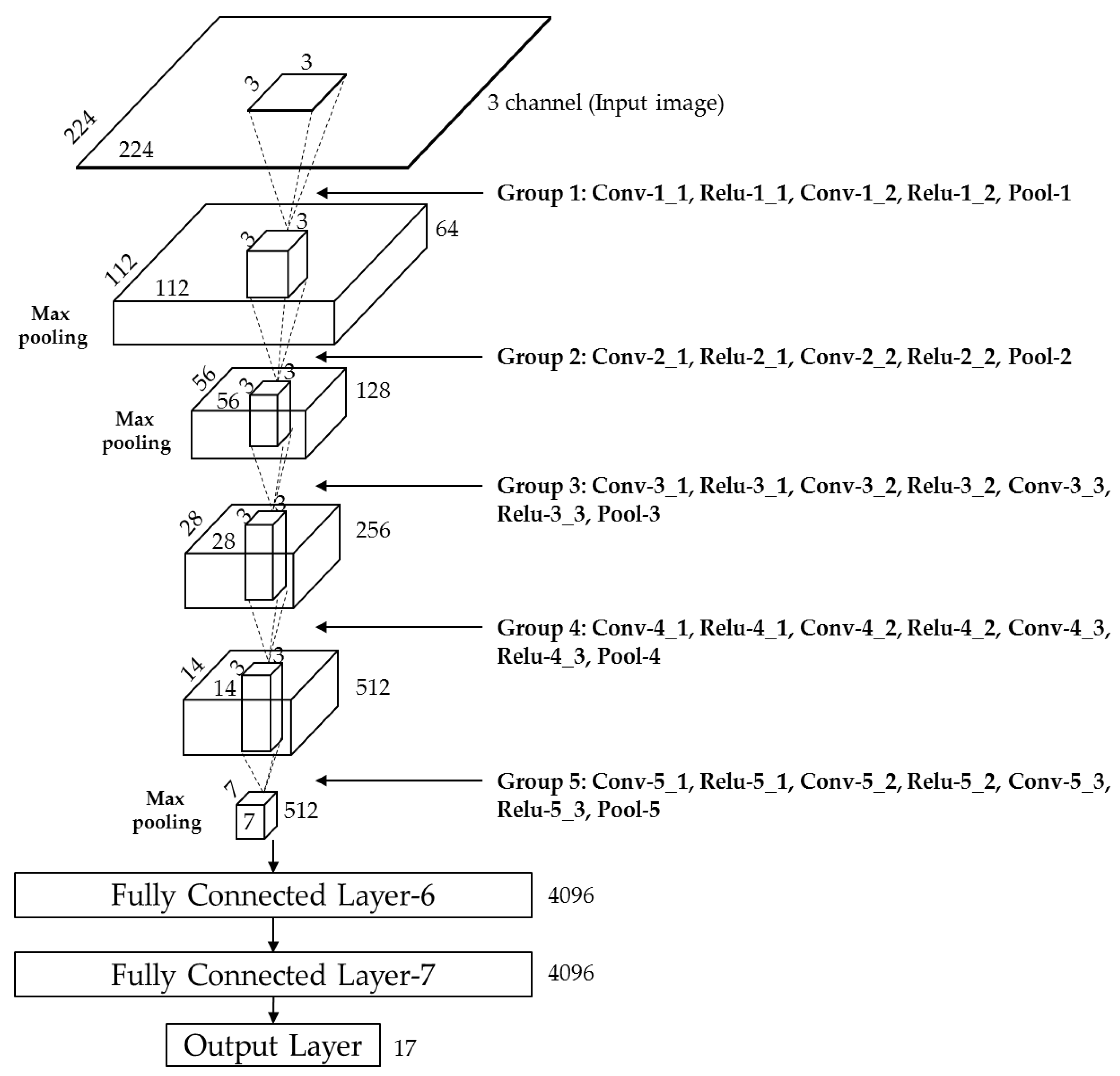
To overcome the limitations of previous systems and address the above-mentioned challenges, we propose a near-infrared (NIR) camera sensor-based gaze classification system for car environments using a convolutional neural network (CNN). It is an important issue as this research area has many applications. The proposed system can be used for reliable EOR estimation and ADAS. It uses state-of-the-art deep-learning techniques to solve gaze tracking in an unconstrained environment.
The remainder of this paper is organized as follows. In
Section 2, we discuss in detail the previous studies on gaze detection. In
Section 3, the contributions of our research are explained. Our proposed method and its working methodology overview are explained in
Section 4. The experimental setup is explained in
Section 5, and the results are presented.
Section 6 shows both our conclusions and discussions on some ideas for future work.
2. Related Works
Several studies have been conducted relating to the gaze classification systems [
6,
7,
8,
9]. Gaze classification can be broadly categorized into indoor desktop environments and outdoor vehicle environments. The former can be further divided into wearable device-based methods and non-wearable device-based methods. Wearable device-based methods include a camera and illuminator mounted on the subject’s head in the form of a helmet or a pair of glasses [
10,
11,
12,
13,
14,
15]. In [
13,
14], a mouse and a wheel chair are controlled by a head-mounted wearable eye-tracking system. Galante et al. proposed a gaze-based interaction system for patients with cerebral palsy to use communication boards on a 2D display. They proposed a system using a head-mounted device with two cameras for eye tracking and frontal viewing [
15]. In wearable systems, the problem of absolute head position can be easily avoided as wearable devices move along with head movements. However, the problem of user inconvenience arises when wearing the devices for long periods of time. To address this issue, the non-wearable device-based methods use non-wearable gaze-tracking devices such as cameras and illuminators to acquire face or eye images for gaze tracking [
16,
17,
18,
19,
20]. Su et al. proposed a gaze-tracking system that was based on a visible light web camera. In this system that detected a face on the basis of skin color, luminance, chrominance, and edges, eyes are tracked to control the mouse [
16]. A gaze-tracking system for controlling such applications as spelling programs or games was proposed by Magee et al. [
17] A remote gaze detection method was proposed by Lee et al. that uses wide- and narrow-view cameras as an interface for smart TVs [
18]. In addition, a typical example of the non-wearable eye-tracking method is the PCCR-based method [
19,
20]. One major advantage of PCCR-based methods is they require no complicated geometrical knowledge about lighting, monitors, cameras, or eyes. User convenience of non-wearable device-based methods is higher than that of the wearable gaze-tracking methods, but initial user calibration or camera calibration is required to map the camera, monitor, and user’s eye coordinates. In addition, these studies have focused only on indoor desktop environments considering small-sized monitors. In this study, we try to analyze the applicability of PCCR-based methods in a vehicle environment in which the head rotation of user is larger than that in desktop monitor environments and initial user calibration is difficult to perform.
The second category includes outdoor vehicle environments to classify the driver’s gaze position and their behavior while driving. Rough gaze position based on driver head orientation is usually acceptable in driver behavior analyzing systems. Gaze zone estimators are being used to generate the probability of driver attention position. Outdoor vehicle environments for gaze classification can be further divided into two categories: multiple camera-based methods and single camera-based methods.
In past research, multiple camera-based methods were mostly used for the outdoor vehicle environment [
21,
22,
23,
24]. When dealing with the challenges of more peripheral gaze directions or large gaze coverage, multiple cameras may be the most suitable solution. Ahlstrom et al. [
21] used multi-camera eye trackers in the car environment. They installed two hidden cameras, one at the A-pillar and one behind the center console of the car for covering forward-facing eye gazes. They tried to investigate the usefulness of a real-time distraction detection algorithm named AttenD. The performance, reliability, and accuracy of AttenD is directly dependent on eye-tracking quality. In addition, they defined the field relevant for driving (FRD) excluding the right-side mirror, but it is often the case that drivers gaze at the right-side mirror while driving.
Liang et al. observed driver distraction by using eye motion data in a support vector machine (SVM) model [
22]. They compared it with a logistic regression model and found the SVM model performed better in identifying distraction. However, wearing glasses or eye make-up can adversely affect the accuracy of this system. An initial calibration of 5 to 15 min is also required and can be time-consuming and annoying for drivers. The concept of a distributed camera framework for gaze estimation was given by Tawari et al. [
23]. They tracked facial landmarks and performed their correspondence matching in 3D face images. A random forest classifier in combination with proposed feature set was used for zone estimation. Since a visible light camera is used instead of a NIR light camera, it is greatly influenced by the external light conditions. Although the accuracy of the driver’s gaze was high, only eight frontal gaze regions were considered. Later they proposed [
24] that head pose for gaze classification can be estimated effectively by facial landmarks and their 3D correspondences. This is done by using a pose from an orthography and scaling (POS) algorithm [
25]. Later, they used a constrained local model (CLM) to extract and analyze the head pose and its dynamic in the multi-camera system [
26]. Although multiple camera-based methods show high accuracies of gaze estimation, the processing time is increased by the images of multiple cameras.
Considering this issue, single camera-based methods have been researched [
27,
28,
29,
30,
31]. SVM was used by Lee et al. to estimate driver gaze zones by using their pitch and yaw clues [
27]. The camera resolution of this system [
27] is low with low illuminator power, and the driver’s pupil center cannot be detected. Therefore, they estimated the driver’s gaze position only by measuring head rotation (not eye rotation), and obtained the experimental data by instructing drivers to rotate their heads intentionally and sufficiently. If a driver only moves the eyes to gaze at some position without head rotation (which is often the case while driving), their method cannot detect driver gaze position. Vicente et al. [
28] proposed a supervised descent method (SDM) using a scale invariant feature transform (SIFT) descriptor to express face shape by providing a clear representation against illumination. For eye pose estimation, facial feature landmarks use eye alignment to locate the eye region. There is an advantage that the camera position is not significantly affected by the change. However, the disadvantage is that the driver’s wide head rotation and the use of thick glasses can decrease its performance. In addition, accuracy of the gaze tracker system may be limited as pupil center position in the driver’s image can be mixed with the iris center position in daylight when not using the NIR light illuminator [
32]. In [
29,
30], they detected skin regions based on pre-trained skin color predicate by Kjeldsen et al.’s method [
33]. In the detected image, the eye region is classified as the non-skin region. If a non-skin region is detected above the lip corners, it becomes the most probable eye region. A small window is set and searched within the determined eye region to determine the pupil with the lowest pixel value, and the eye is traced using the optical flow algorithm of [
34]. Finally, assuming that the eyes are aligned, they estimated the driver’s gaze by modeling head movements using the position of both eyes, the back of the head just behind both eyes, and the center of the back of the head. In this study, it is not necessary to measure the distance from the driver’s head to the camera, but this is because it detects only the direction of the eyes. When the driver’s head and eyes rotate in opposite directions, or when the head does not rotate and only the eyes move, accuracy of tracking is decreased. In addition, since the iris center position is detected instead of the pupil center position, there is a limitation in improving the accuracy of eye tracking. Fridman et al. combined the histogram of oriented gradients (HOG) with a linear SVM classifier to find face region and classify feature vectors to gaze zones by random forest classifier [
31]. Previous studies use Purkinje images [
35] or detect facial feature points [
36] to estimate gaze. Purkinje images (PI) are the light reflections generated on the cornea and crystalline lens of the human eye [
37]. By analyzing the movements of these reflections (especially, the 1st and 4th PI), it is possible to identify the direction of eye rotation and determine gaze. However, this study did not evaluate the gaze detection accuracy in a vehicular environment [
35]. Fridman, et al. [
36] used facial feature points to find the iris and binarized it to estimate the area being gazed at. However, their accuracy was not high, because the iris could be detected in only 61.6% of the test images. There were limits to enhancing the accuracy of gaze detection because the center of the iris, and not the pupil, was detected. Choi et al. [
38] detected driver faces with a Haar feature face detector and used CNN to categorize gaze zones, but they considered only eight gaze regions. Vora et al. proposed the method of driver’s gaze estimation by CNN, but small numbers of gaze regions (six gaze regions) were considered in this research [
39]. Therefore, the detailed gaze position of the driver cannot be detected. Fu et al. proposed automatic calibration method for the driver’s head orientation by a single camera [
40]. However, their calibration method requires the driver to gaze at several positions such as the side mirrors, the rear-view mirror, the instrument board, and different zones in the windshield as calibration points, which causes inconvenience to the driver in the actual car environment. In addition, only 12 gaze zones were considered in their research.
Other categories of gaze detection methods, such as regression-based methods, have been studied including appearance-based gaze estimation via uncalibrated gaze pattern recovery and adaptive linear regression for appearance-based gaze estimation [
41,
42].
Ghosh et al. [
43] proposed using eye detection and tracking to monitor driver vigilance. However, their method classified open or closed eyes instead of detecting the driver’s gaze position. In addition, the camera angle is small, and there is the limitation of movement of the driver’s head, which causes inconvenience to the driver. García et al. [
44] proposed a non-intrusive approach for drowsiness detection. Cyganek et al. proposed the hybrid visual system for monitoring the driver’s states of fatigue, sleepiness and inattention based on the driver’s eye recognition using the custom setup of visible light and NIR cameras and cascade of two classifiers [
45]. Chen et al. proposed the method of detection of alertness and drowsiness by fusing electroencephalogram (EEG) and eyelid movement by electrooculography (EOG) [
46]. However, as with the research in [
43], their method [
44,
45,
46] just recognized the alertness/drowsiness status of the driver by classifying open or closed eyes (or by physiological signals), not by detecting the driver’s gaze position. Kaddouhi et al. proposed the method of eye detection based on the Viola and Jones method, corner points, Shi-Tomasi detector, K-means, and eye template matching [
47]. This is just for the research of eye detection, and driver’s gaze position was not detected in this research.
In previous research [
48,
49,
50,
51], they investigated the drivers’ visual strategies, the distribution of fixation points, driving performance, and gaze behavior by on-road experiment or driving simulator. Their research was focused on the analyses of the driver’s visual characteristics while driving instead of proposing new gaze detection methods.
Considering the limitations of existing studies, we investigated a method for driver gaze classification in the car environment using deep CNN. In
Table 1, we have summarized the comparison of the proposed method and existing methods on gaze classification in vehicle environment.
6. Conclusions
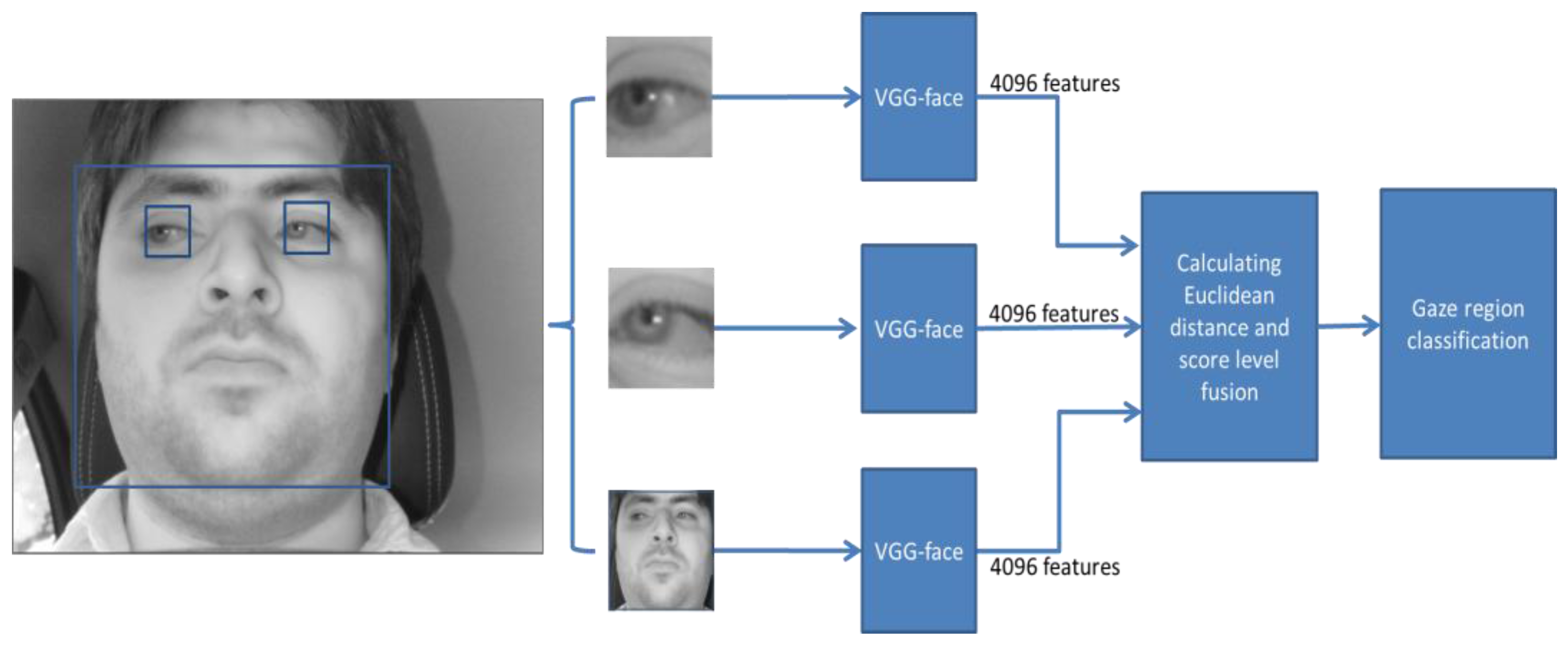
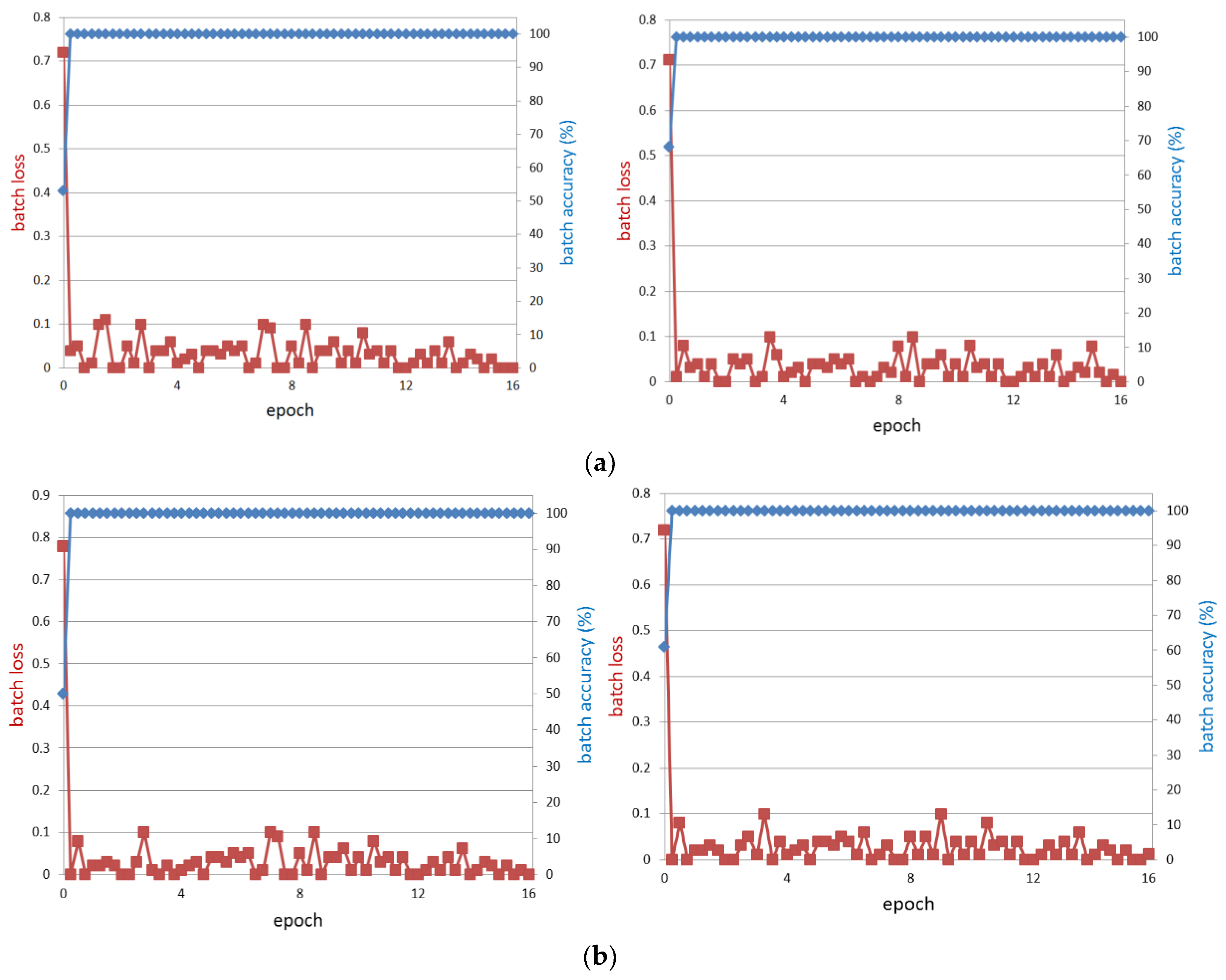
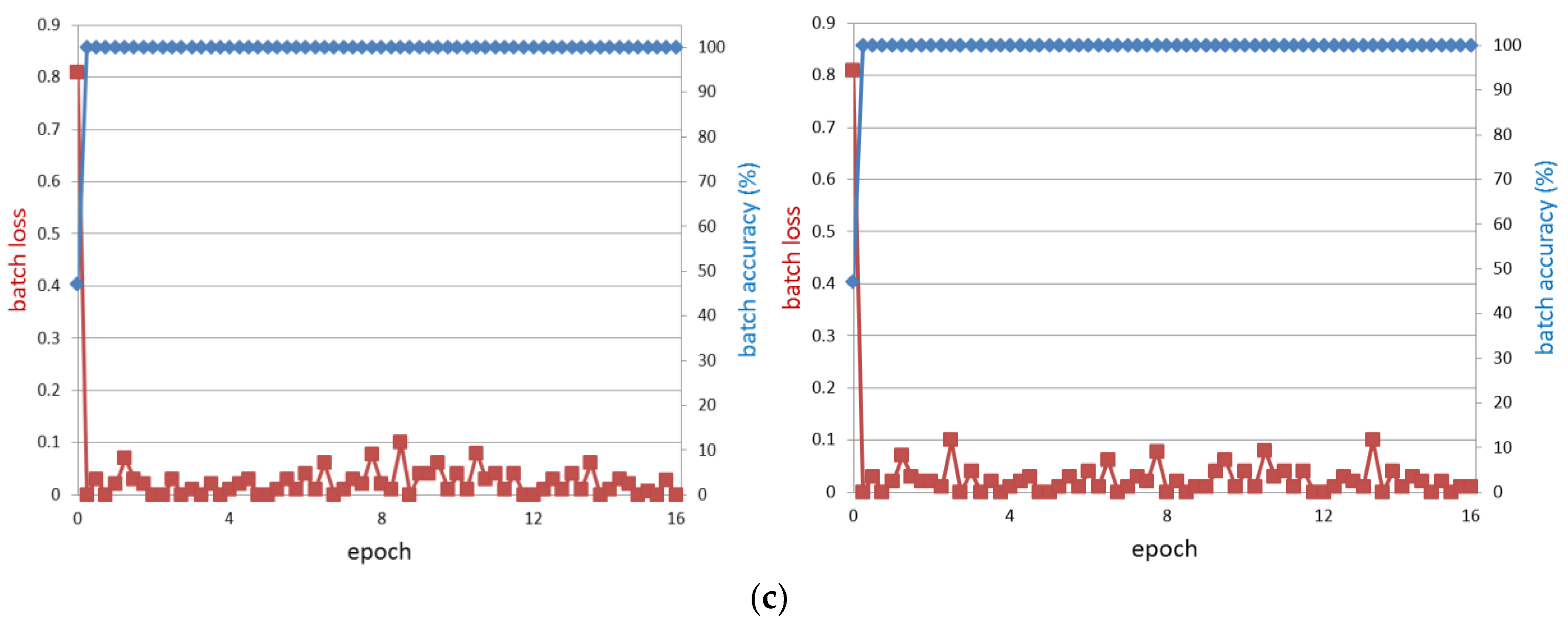
In this study, we proposed a method of driver gaze classification in the vehicular environment based on CNN. For driver gaze classification, face, left eye, and right eye images are obtained from input image based on the ROI defined by facial landmarks from the Dlib facial feature tracker. We performed fine tuning with a pre-trained CNN model separately for the extracted cropped images of face, left eye, and right eye using VGG-face network to obtain the required gaze features from the fully connected layer of the network. Three distances based on all the obtained features are combined to find the final result of classification. The impact of PCCR vector on gaze classification is also studied. We compared the performance of the proposed gaze classification method using CNN with PCCR vector and without PCCR vector. We verified from the results that the driver gaze classification without PCCR vector is suitable in terms of accuracy. We also compared the accuracies of our method with those of a previous method. Evaluations were also performed on open CAVE-DB, and we can confirm that our method outperformed the previous method. Based on the processing time, we can find that our system can be operated at a speed of 78.6~89.2 frames per second.
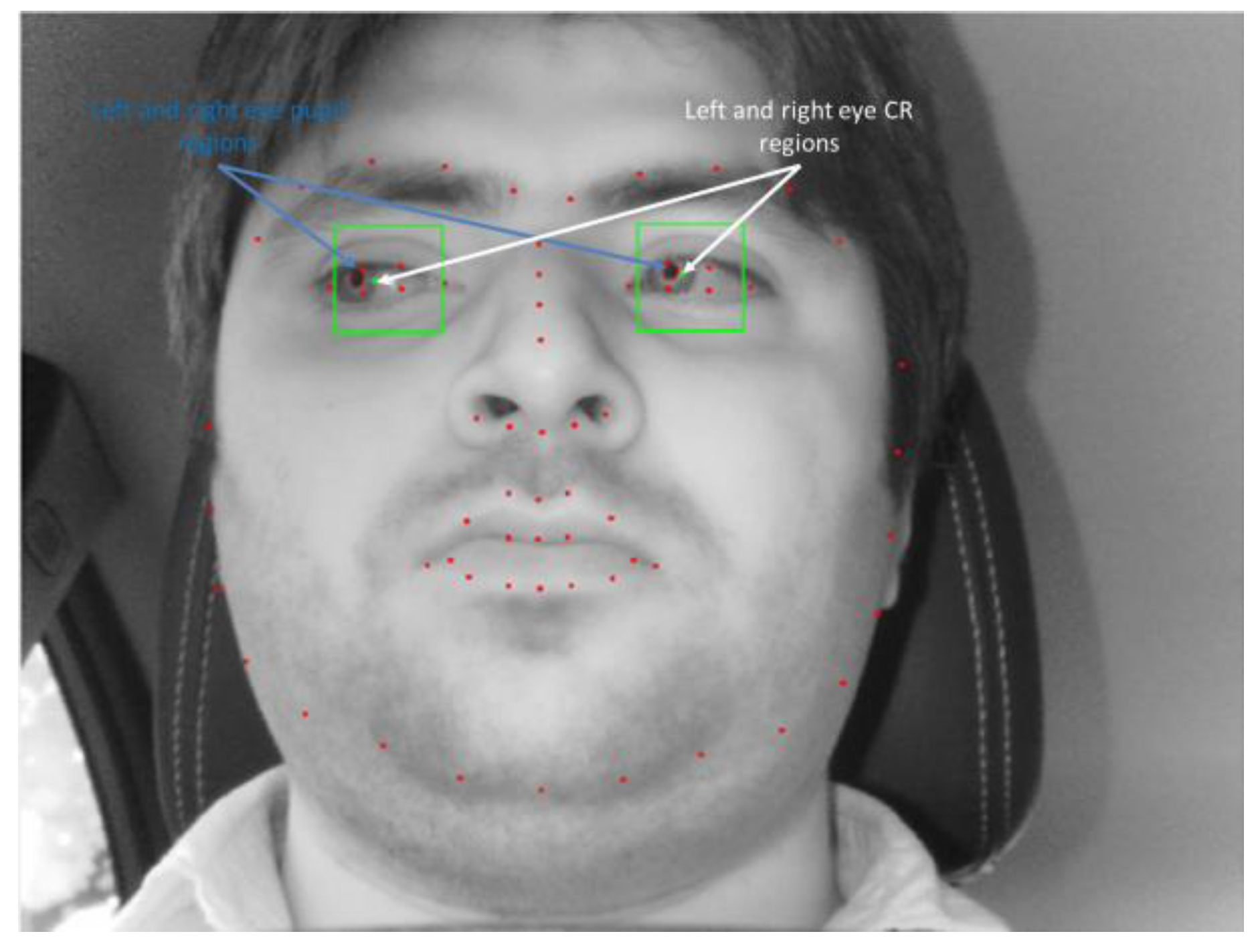
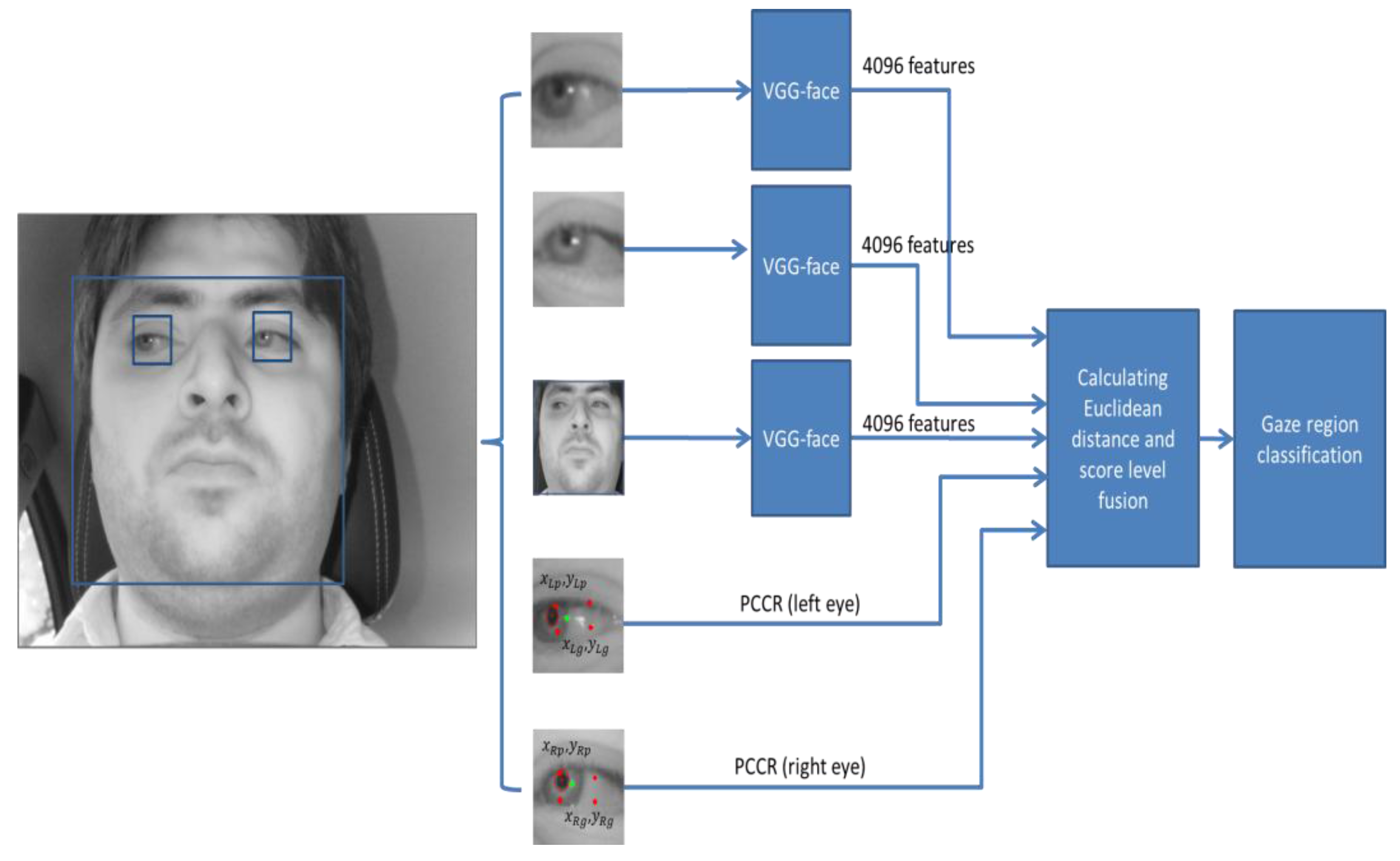
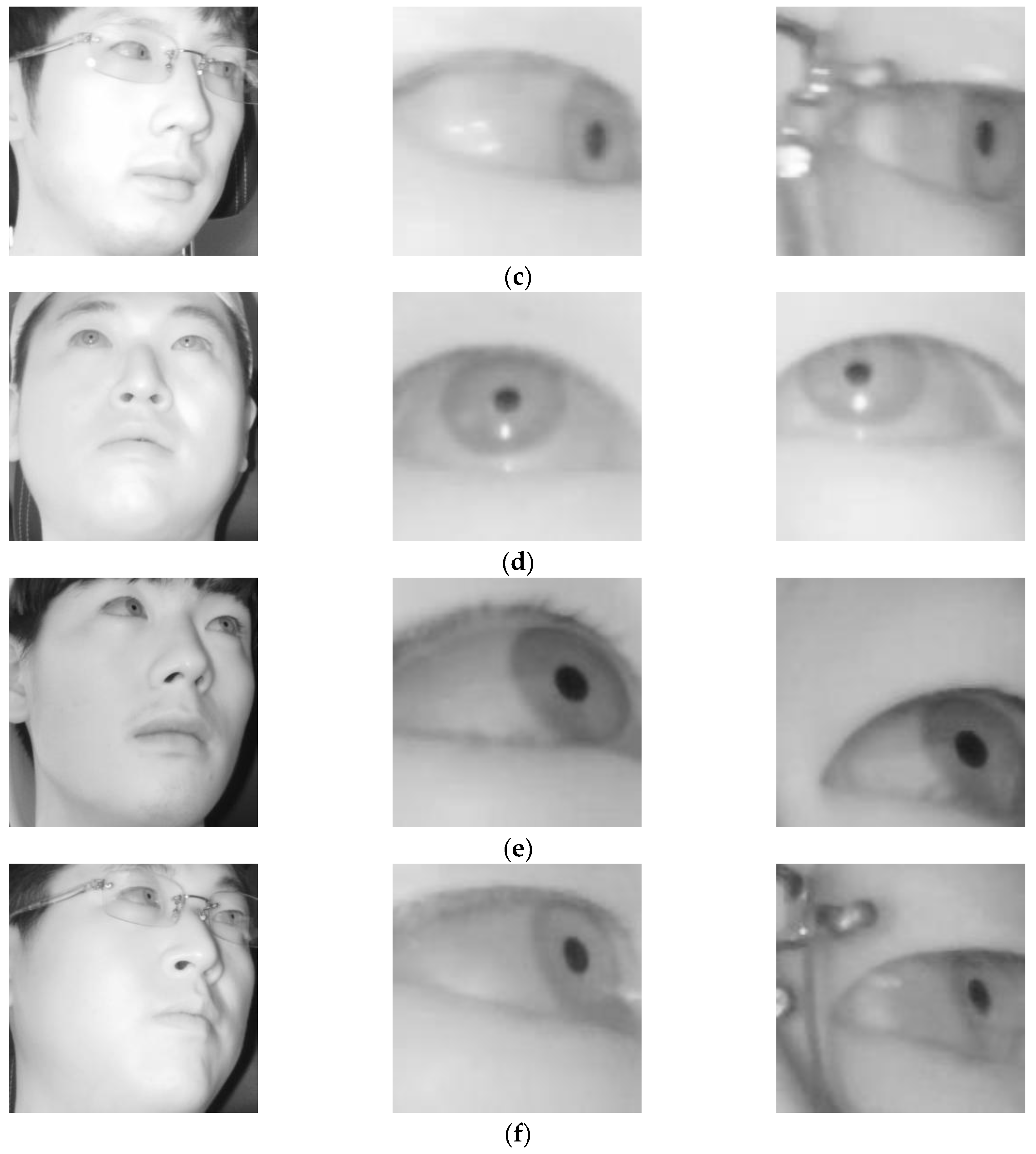
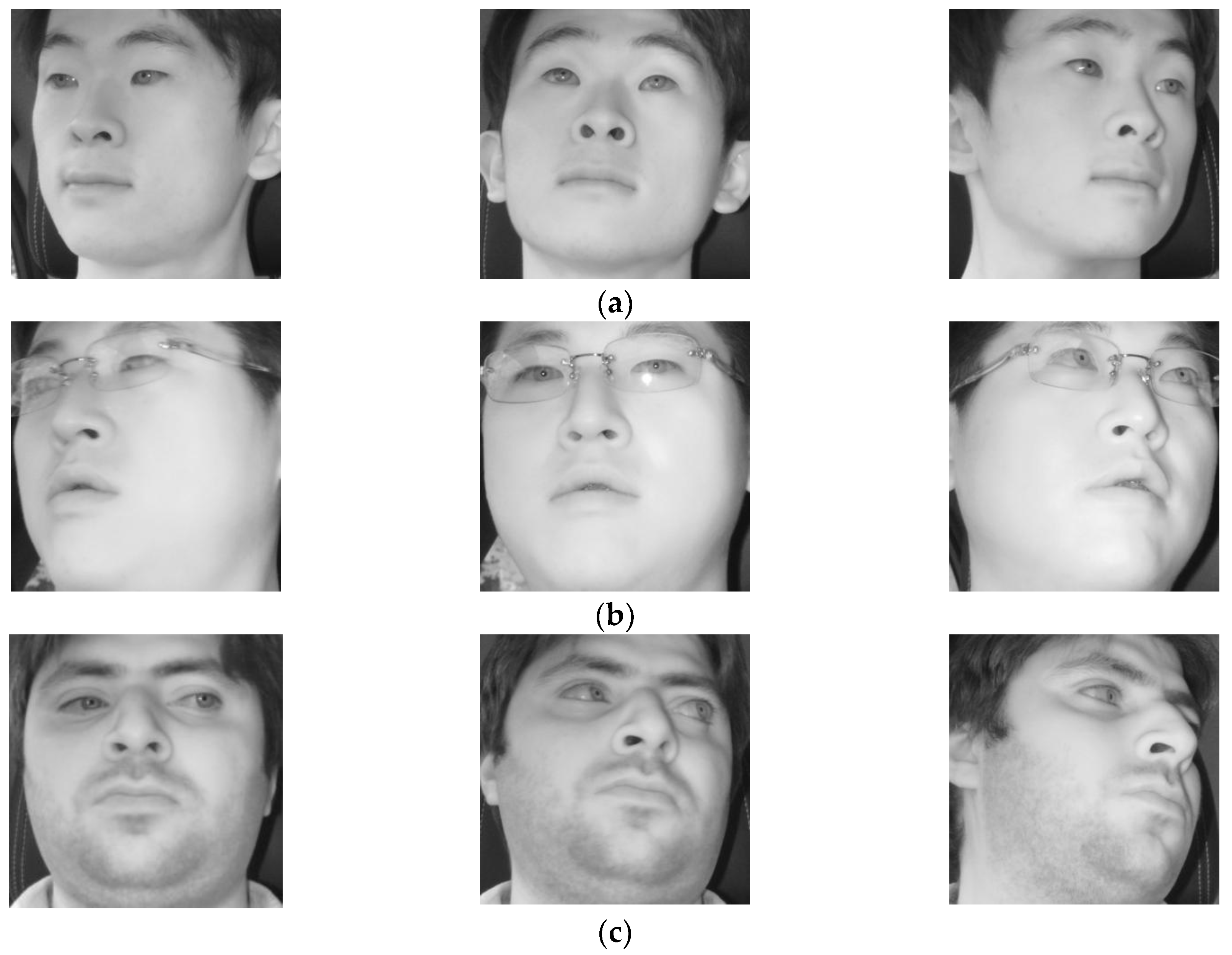
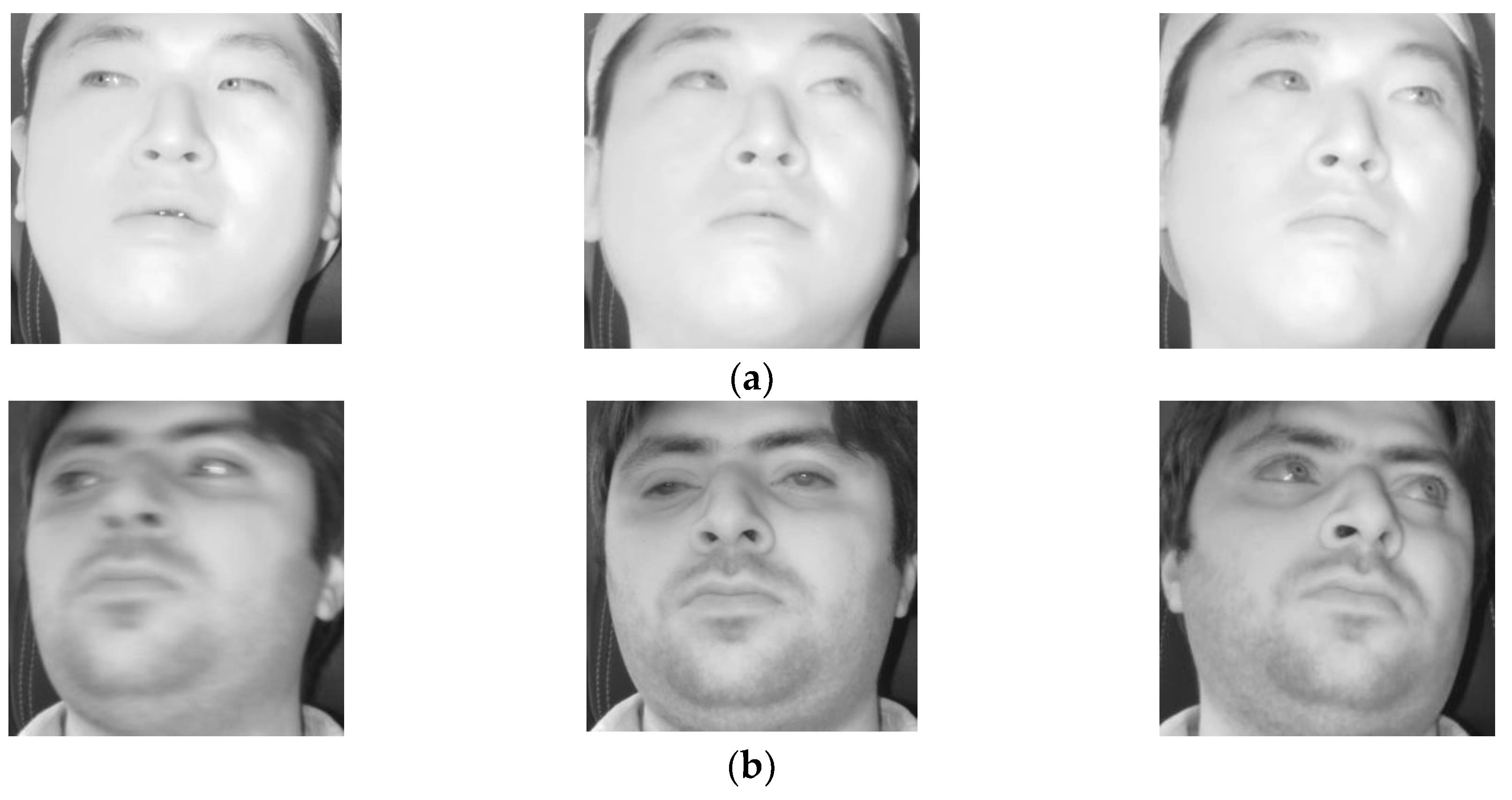
As shown in
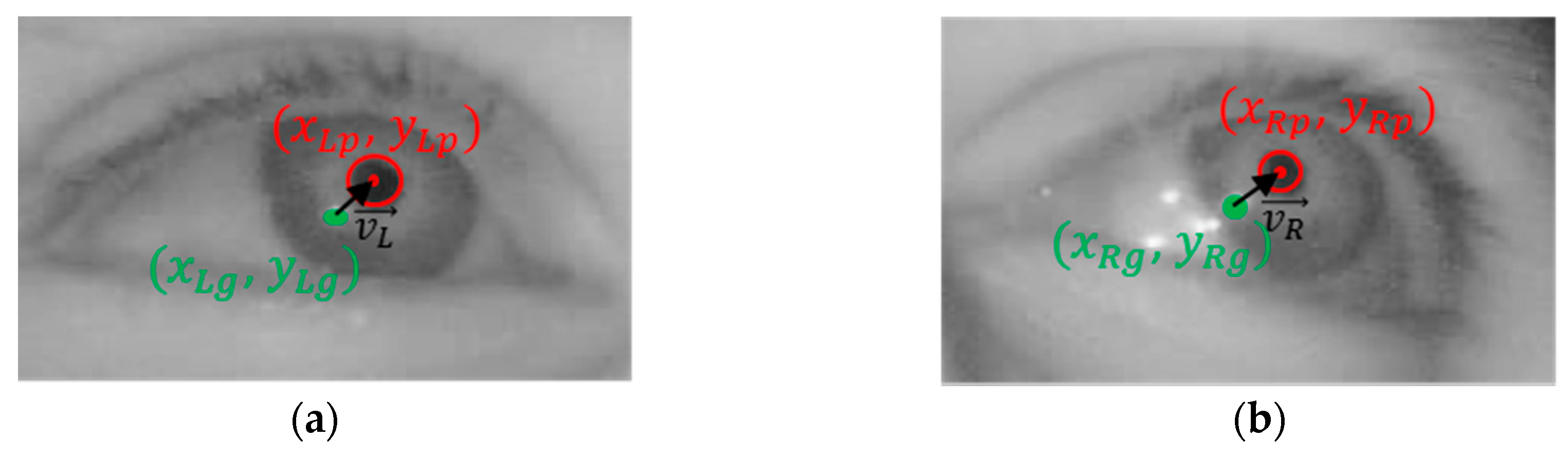
Figure 4, the Dlib facial feature tracker cannot detect the position of the pupil and iris. Therefore, in case the driver gazes at a position just by eye movement (not by head movement) when gazing at the position close to our gaze-tracking camera, the method using only facial landmarks by the Dlib facial feature tracker cannot detect accurate gaze position. To solve this problem, the pupil center and corneal reflection position are detected by the method outlined in
Section 4.3, and PCCR vector was used for scheme 2 of
Figure 8. However, the accuracy of scheme 2 is lower than that of scheme 1 not using PCCR vector as shown in
Table 7 and
Table 8.
The reason why we used a NIR camera and illuminator is to use the movement of the pupil within eye region (iris region) for gaze estimation for better accuracy. However, our method can also be applied to the images by visible light camera without an additional illuminator, which was proved by the experiments with open Columbia gaze dataset CAVE-DB [
77] as explained in
Section 5.3.4. In case of severe head and eye rotation, which causes disappearance of one of two eyes in the captured image, the error of gaze estimation can be increased, and this is the limitation of our research. This can be solved by using multiple cameras, but it can also increase the processing time. We would research a solution to this problem by using multiple cameras at fast processing speeds in future work. In addition, we would check the effect of image resolution, blurring level, or severe occlusion on the face image on the accuracy of the gaze estimator.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}