1. Introduction
The Industrial Internet of Things (IIoT) is a new industrial concept that combines intelligent and autonomous machines, advanced predictive analytics, and machine–human collaboration to improve productivity, efficiency, and reliability. IIoT provides a world where smart, connected, embedded systems and products operate as part of larger systems [
1,
2,
3,
4]. This way, there is expected cost reduction and increased productivity in industry. A foundational technology for IIoT is the radio-frequency identification (RFID), which allows microchips to transmit identification data to a reader via wireless communication [
5].
In recent years, RFID technology has been identified as leading a new generation of identification systems due to its reliability, rapid identification, and low cost. RFID aims to boost efficiency in the automation process. Industrial environments have experienced a real advance, due to the use of innovations such as accurate control systems, intelligent sensors, cloud software and information transmission [
6]. In this sense, RFID systems minimize errors and improve productivity. All these components are part of the Internet implementation of things in industry.
However, despite RFID systems advantages, when there is a larger number of labels to identify, the greater is the probability of delays and errors in the identification process, compromising the system performance due to collisions. Thus, an efficient protocol is needed to assist in the identification process, especially when there is a huge number of labels.
Dynamic frame slotted ALOHA (DFSA) has been widely used for RFID [
7]. In this protocol, the reader organizes the time into one or more frames, and each frame is subdivided into time slots. Labels must be transmitted into only one slot per frame until fully identified by the reader. The length of subsequent frame to the initial frame is dynamically adjusted according to the estimation of the group of labels that competed for slots in the previous frame [
8]. This way, both the accuracy of estimating tag population and the adjustment of new frame length may affect the DFSA performance.
In general, the proposed estimators in the literature seek to improve the performance of DFSA. In [
9] it is highlighted an efficient estimator compared to its counterparts: Schoute [
10], Vogt [
11], Eom-Lee [
9] and Chen [
12]. However, when considering the identification process of 10,000 labels, some estimators require a considerable amount of computational resources (such as CPU and memory). Thus, both complexity and performance should be taken into consideration when implementing the algorithm in an RFID tag, especially those with single-chip microprocessor.
All information is stored on an electronic RFID microchip. The data stored on the tag’s chip will depend on the application. The purpose of a tag is to identify a particular object based on a unique identifier, called an ID or unique item identifier (UII) or even an electronic product code (EPC) code [
13]. According to standardized tags, the IDs with the EPC standard provide an improvement in the RFID system, facilitating integration with global networks. To meet the requirements to deploy multiple labels in industry, RFID increasingly requires labels with larger IDs [
14]. Once an ID is written to the label’s microchip, it can be read or even changed (if needed). The main precondition for the EPC standard is that all tags have a unique ID in the reader’s interrogation area, since IDs are not always evenly distributed.
The main problem for some tag anti-collision protocols is how the distribution and the size of IDs are performed [
15]. This way, tag anti-collision protocols in which IDs are randomly organized suffer from performance loss, increased latency and power consumption, and other issues. These issues occur in tree-based protocols since the tag response is contingent on the requests made by the reader. In an industrial environment that acts heterogeneously, many protocols do not know how to skip unnecessary queries, increasing the number of tags collision. Based on this problem, in this paper we decided to work with ALOHA-based protocols, since the problem of distributing IDs to tags in a heterogeneous manner does not affect the protocol performance.
This paper presents an extension for an estimator for ALOHA-based anti-collision protocols to identify a large number of labels. The proposal presents an ageing factor with an empirical value that acts as a factor rewarding or penalizing the successful slots according to the performance in the previous identification process. When considering industrial environments, there is a relevant problem related to the tags identification in medium access control (MAC) layer, especially when there is a huge number of labels to identify.
To evaluate the performance of the proposed estimator, a discrete event simulator was developed in C/C++ language. This simulator uses as reference the EPCglobal UHF Class-1 Gen-2 parameters adopted for DFSA passive label anti-collision protocols. The simulator implements an error-free channel, where a tag reader performs queries towards several tags.
The proposal addresses several contributions to solve the problem of tag collisions, being efficient and suitable for multiple scenarios. When compared to other approaches presented in the literature, it is possible to highlight some advantages of our estimator:
It can identify a large number of tags, presenting a low computational cost and good performance;
It presents an improved throughput, since it can reduce the number of colliding slots;
It uses an ageing factor that acts as a factor rewarding or penalizing the successful slots according to the performance in the previous identification process;
It is standard-compliant to EPCglobal UHF Class-1 Gen-2.
The remainder of the paper is organized as follows:
Section 2 presents the basics of RFID systems, by discussing its functionalities, type of tags, collisions occurrence, MAC and common applications.
Section 3 presents the ALOHA-based anti-collision protocol (DFSA) and reviews some other estimators proposed in the literature.
Section 4 describes our proposed DFSA estimator, which is an extension to Chen’s estimator.
Section 5 evaluates the performance of our estimator in different scenarios. Finally,
Section 6 concludes the paper and presents avenues for future research.
2. Radio-Frequency Identification (RFID)
Currently, there is a demand for manage multiple objects with higher speed and increased accuracy. Based on this demand, RFID technology appears to be appropriate to perform tasks such as identification, tracking, and automation of objects. An advantage of RFID over other identification systems is related to reading range, since it is not necessary the approximation of the object for its proper identification [
7].
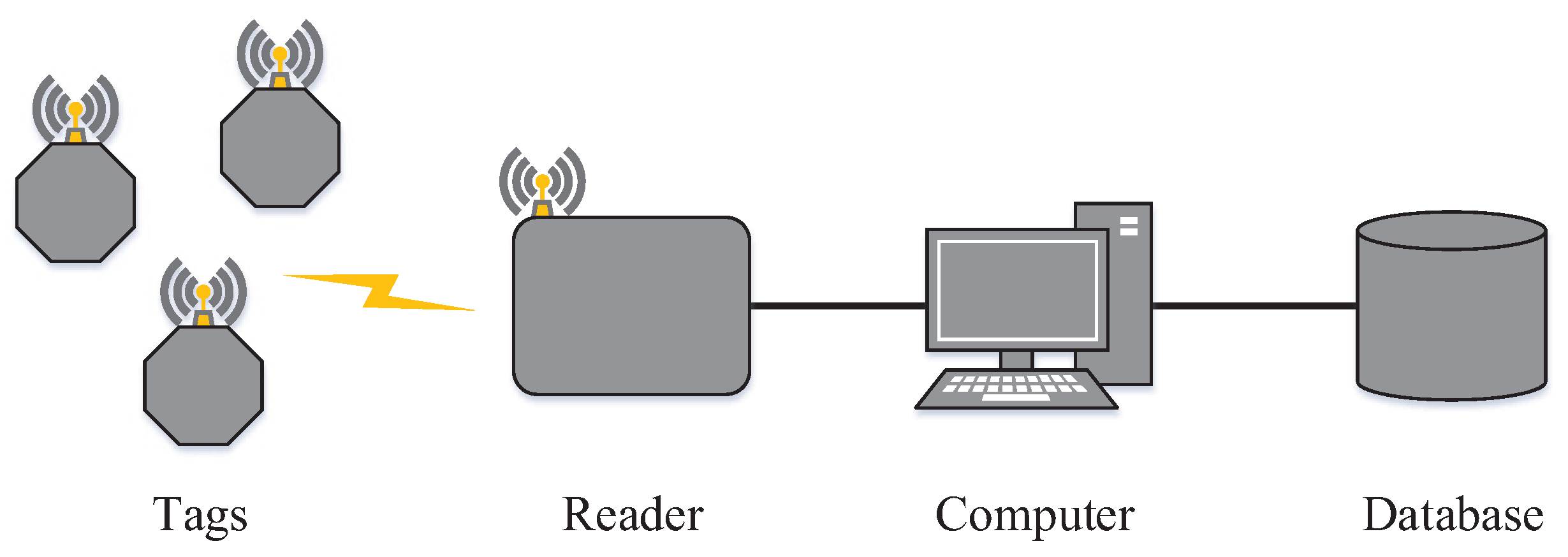
A basic RFID system consists of three main elements: readers, labels (or tags) and a database [
16].
Figure 1 presents a basic RFID system. The reader is a device whose function is to identify the labels and, consequently, extract information from them. It uses radio-frequency waves for communication. Moreover, the reader controls the labels medium access, which is carried out by anti-collision protocols.
The database is the central entity of an RFID system. It has the role of processing and storing information according to the needs of each application. In general, it is a database in which information is stored and accessed by labels and readers.
Labels are the simplest elements of the system. They store information of objects which are associated with them. They have a unique identifier by which they can be identified. It is worth noting that passive tags are increasingly being used in RFID systems in industry. They are small, simple to manufacture, consequently, cheap. Moreover, passive tags are durable, since they do not have internal battery. Due to these characteristics, this paper is focused on passive tags only.
2.1. Collisions in RFID Systems
Since RFID systems use wireless medium for communication, there are some problems that arise from shared medium, such as collisions and signals interference [
17,
18,
19,
20]. In general, collisions may compromise the RFID systems communication, since errors in label identification may occur. Moreover, when collisions occur, a retransmission strategy is employed, which increase energy and bandwidth consumption [
21]. When considering passive tags, the collision problem can be exacerbated by its computational limitation. In most cases, the communication becomes impossible. This is a problem that might be address.
There are two types of collisions that need to be resolved: collisions among readers and collisions among tags. Collisions among readers occur when the signals of two or more readers overlap [
22], making it confusing for the tags to identify to which reader they should respond to. On the other hand, collisions among tags occur when two or more labels send information simultaneously to a single reader.
There are defined four MAC protocols: space division multiple access (SDMA), code division multiple access (CDMA), frequency division multiple access (FDMA) and time division multiple access (TDMA).
The SDMA protocol [
23] has the function of distributing different frequency bands to different neighboring regions. This method is widely used to perform signal coverage among adjacent cells, such as in the cellular telephone network. However, its use in RFID systems is unfeasible due to the use of several sectoral antennas and readers, thus increasing the complexity of the system [
7].
In the CDMA protocol [
6], uniformly distributed spectral propagation techniques are applied to the network elements with the same power and frequency. Each element has a different code to modulate the signal. However, when considering its use in RFID systems, this protocol presents some problems, since code division requires a high computational cost.
The FDMA protocol divides the available bandwidth into multiple frequency bands. Each user has a reserved frequency band, which can be used until the end of its transmission. However, the use of several frequency bands increases the tags and readers cost [
24].
In the TDMA protocol [
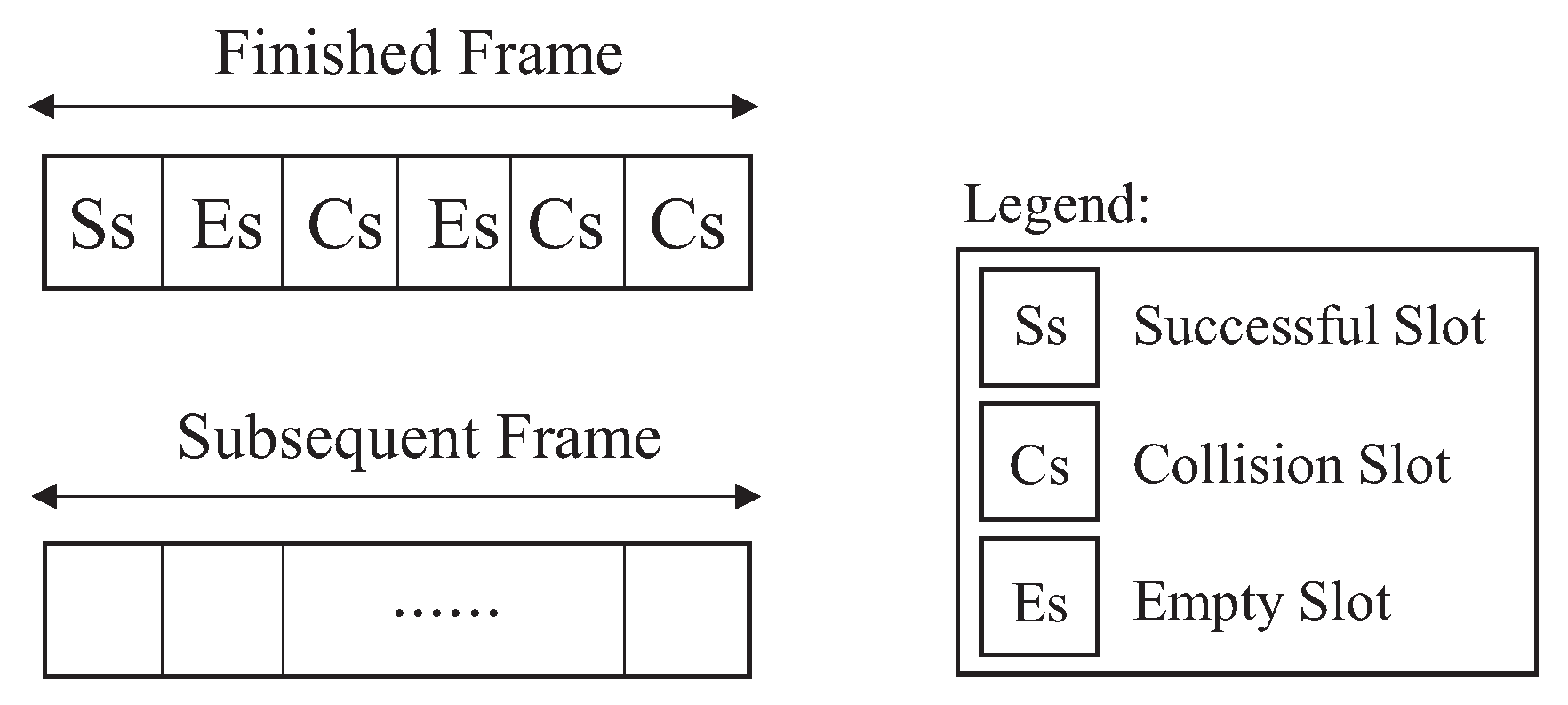
25], the channel is divided into several fixed-size time slots, where each element transmits in a given slot at a time, thus avoiding interference. Due to its simplicity and low computational cost, this protocol has become the most suitable option for RFID systems. By using TDMA, the available time intervals for labels transmission is classified in three ways: empty slots, when there are no transmissions; successful slots, when only one tag can transmit its identification; and colliding slots, when two or more tags attempt to transmit simultaneously within the same time slot.
To solve the issues caused by tags collision, several protocols have been identified in the literature [
22]. Given passive tags computational limitation and their potential use in the industrial market, its low cost renders it suitable to use TDMA as MAC in RFID systems. Moreover, TDMA can be divided into two categories of anti-collision protocols: tree-based protocols and ALOHA-based protocols. Being the latter, the most common for IIoT [
5].
2.2. Overview of DFSA in EPCglobal UHF Class-1 Gen-2
The DFSA anti-collision protocol was adopted by the
EPCglobal UHF Class-1 Gen-2 standard to solve passive tags collision problem for RFID systems [
26]. Its main strategy is to enable a dynamic adjustment of frame length for each reading cycle in label identification [
27,
28,
29]. This adjustment impacts on the DFSA performance, that is directly related to the frame length. As stated, the reader has the function of coordinating medium access, and thus it dynamically adjusts the frame length at each identification cycle. However, this also depends on the estimation of labels population that compete for time frames.
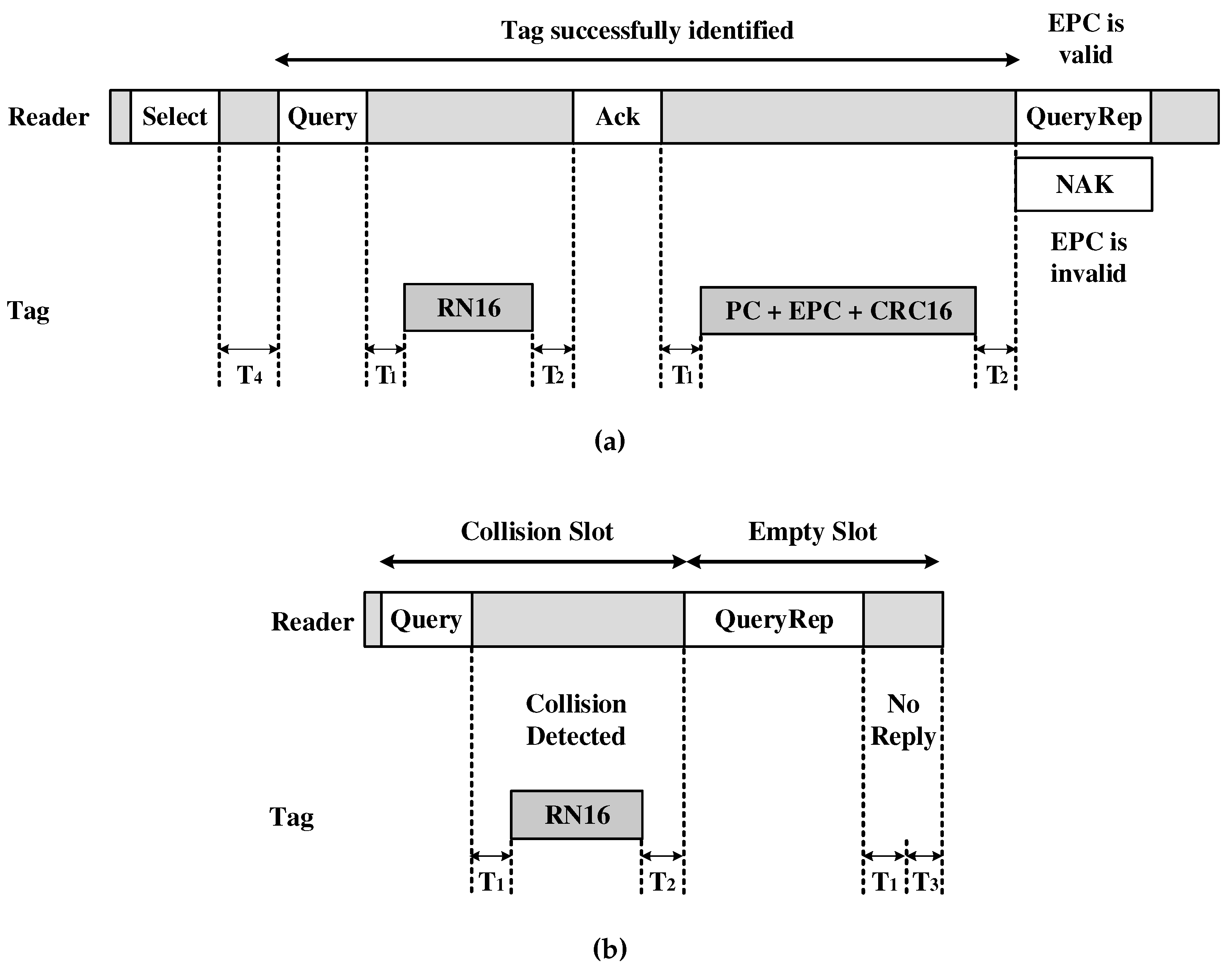
In the DFSA implementation, in addition to MAC, there are some commands to identify a group of labels: Select, to select a group of tags to be identified; Query, to identify the tag or a group of them; QueryAdjust, to adjust the frame length; QueryRep, to repeat the query; and Ack, to acknowledge frame transmission.
First, DFSA works with the reader triggering a transmission to identify a group of labels within its coverage radius, by sending Select command. Then, it sends a Query command to identify the selected tags, which specifies the minimum and maximum number of tags related to the initial frame length. The frame must be a power of 2. When a tag receives a Query command, it generates a 16-bit random number (RN16), and extracts part of a subset of Q-bit queries, generating a range interval counter. This counter is decremented by 1 as tags receive a QueryRep command. When this counter reaches zero, the tag sends its RN16. Actually, the real ID of a tag is 96-bit EPC. Thus, the RN16 can be considered as a temporary ID to reduce the collision interval. Having sent the Query command, the reader starts to check each record of each time interval for a possible RN16 communication reception.
For a given time slot, there are possibilities: successful slot, when the tag is successfully identified; slot in collision, when two or more tags competed for the same time interval; and empty slot, when there is no transmission (see
Figure 2a,b). When a slot or tag is successfully identified, the reader acknowledges the tag with an
. Then, the tag transmits its 96-bit EPC to the reader. If there is a collision of RN16, hence no tag identified, the reader finishes the transmission time interval, checks all time slots of frame
, and starts a new round of
Query transmissions with a new
Q updated.
2.3. Application Scenarios
RFID system applications include supply chain management, retail, aircraft maintenance, document fraud, baggage handling and healthcare [
30,
31,
32,
33]. Several organizations are exploring RFID in their core operations to leverage automation processes. For instance, Walmart reduced inventory shortfalls by an average of 30% following the launch of its RFID program [
34]; Throttleman solved problems with space constraints in storage [
35]; Metro Group achieved improved control in handling materials [
34]; and Cold Chain Logistics has been able to significantly reduce the damage caused by cold container failures due to poor internal temperature monitoring [
36]. The main results are displayed in
Table 1.
4. Proposed Extension for Estimator
The
EPCglobal UHF Class-1 Gen-2 standard adopts DFSA algorithm to address tags collision problem. However, it does not specify how to dynamically adjust the frame length [
35]. In this sense, this section presents a comprehensive and easy-to-implement approach to perform a frame length adjustment in DFSA protocol.
We consider that
n labels need to be identified, and their frame length is
L. We assume that the number of labels allocated in a given time slot can be modelled as a binomial distribution, where
represents the channel usage efficiency (also called normalized throughput):
Table 4 establishes a relationship between the frame length and tag population. For instance, when the amount of tags is in the interval of 90 to 177 (when
), the frame length must be 128 slots to increase system throughput. For a given number of labels, the appropriate frame length can be obtained from Equation (
16).
This constrained frame length will cause a reduction in channel efficiency when compared with the ideal case, in which the frame length is set according to the number of labels. Under this constraint, the average channel efficiency is given by
and
when they are the lower and upper limits, respectively, for a given frame length
. Based on the relationship between the frame length and tag population listed in
Table 4, the average channel efficiency can be obtained for each frame size used Equation (
15).
For instance, we consider that the number of labels is evenly distributed between 1 and 10,000. The maximum channel efficiency is 36.1%. This result means that the size of the constrained frame can lead to reductions of only 4.3% in performance. Since the frame size is a power of 2, the average channel efficiency is 36.1%. It can be considered as the optimal maximum performance of EPCglobal UHF Class-1 Gen-2 for collision avoidance.
This strategy provides a small performance improvement; however, it requires more computational resources. Therefore, we use the reader as the medium access coordinator, to adjust the subsequent frame length during the reading process, and to detect improper frame lengths before the end of each reading cycle. The latter can be treated as a rapid adaptation of the frame length. A simple, but efficient method is to reduce the computational complexity to be able to estimate the number of tags in collision. Based on the Schoute method, we propose an extension to estimate the number of tags in such a way that the tag accumulation is estimated according to the number of collision slots.
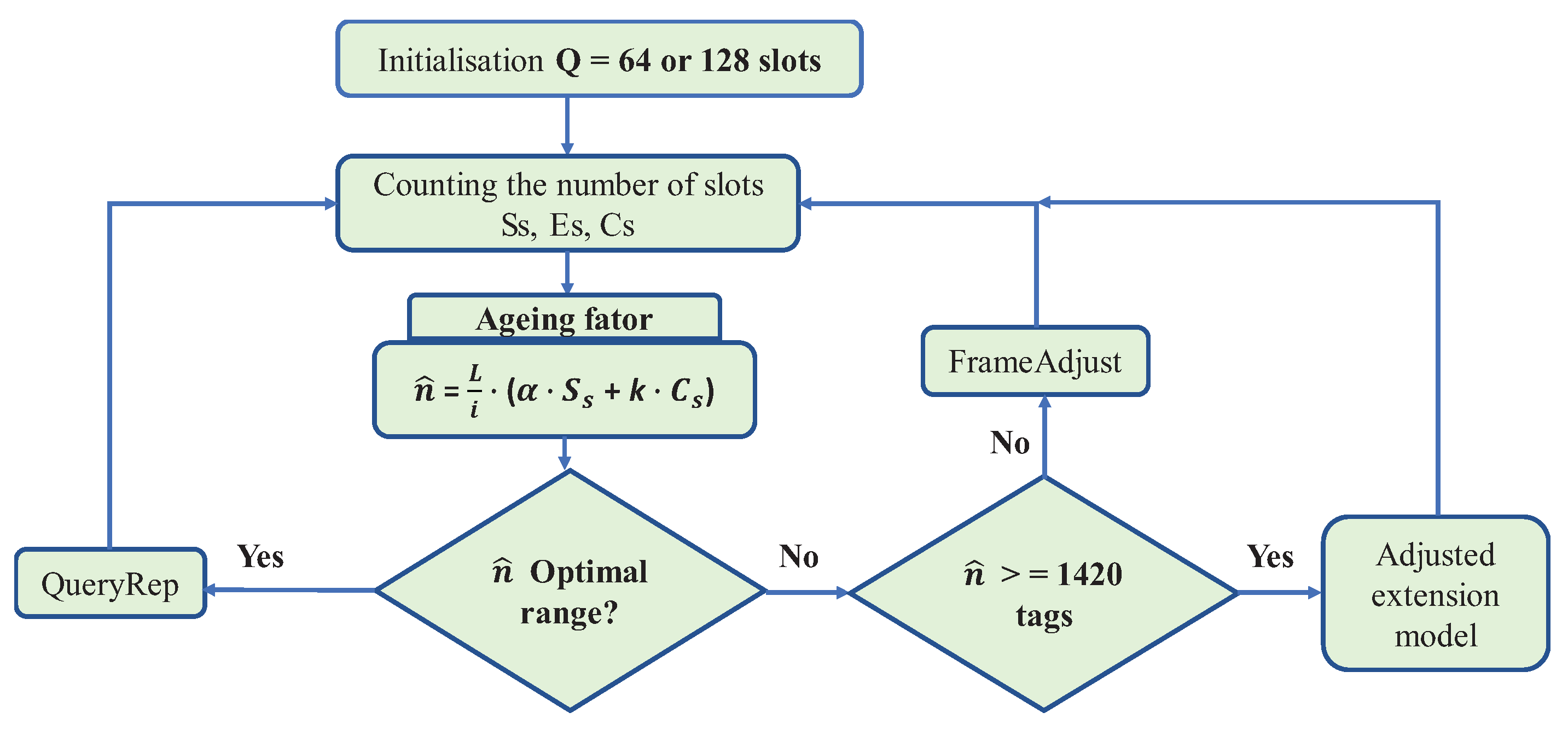
The proposed anti-collision protocol is shown in Figure 5. At first, the reader begins a reading cycle of tags, broadcasting a query command
Q for all tags within the its coverage area. This command corresponds to frame length
, meaning that there are
intervals in the current reading frame. Thus, in the last time slot, the reader starts recording the number of empty slots
, the number of slots successfully identified
, and the number of slots in collision
. An estimated number of labels is then generated to be read at the beginning of the reading cycle according to Equation (
17):
where
k represents a coefficient,
L the frame length, and
i the
ith time slot. Considering that there are at least two tags involved in a collision, the coefficient
k can be adjusted to be 2 as a minimum limit measure to perform tag estimation. To minimize complex implementations, we considered
, which is the same coefficient used in the Schoute method.
Moreover, the proposal presents an ageing factor (
) that acts rewarding or penalizing Equation (
17), according to the performance of the previous schedule. The factor
, is multiplied by the number of successful slots. This factor is the average representation of the number of successful slots in the previous frame, which means that the number of tags that had successful identification will directly impacts on the current frame. The average is the ratio between the number of successful slots over the total number of slots in a frame.
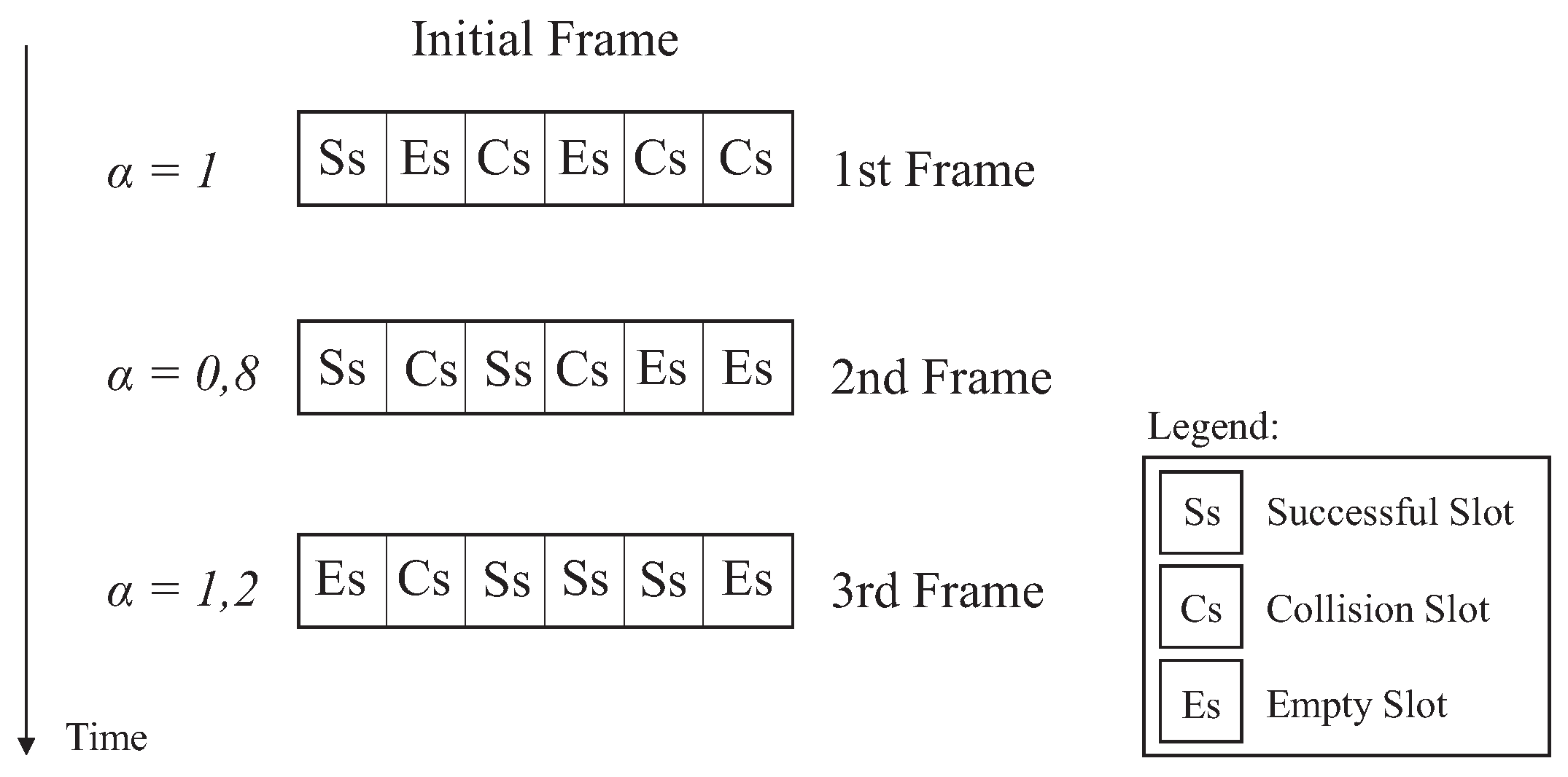
Initially, the ageing factor equals 1. There is no past, since the identification process is starting. In the following rounds the value of can be changed assuming values between the interval and . These values were empirically chosen, among others, since they presented a better performance for the ageing factor scheme. When is , it indicates that the number of successful slots in the previous frame is below the expected average, and then it will be penalized. On the other hand, if the next frame has a value greater than or equal to the average of successful slots, will be equal to , which means a reward for achieving several successful slots in the previous round. This technique makes it easy to estimate a successful slot according to the past schedule.
Figure 4 exemplifies the ageing factor process, where the initial frame starts with
. Since in the past there was any frame, so the second frame will receive penalizing factor of
. By calculating the average successful slots in the second frame, the third frame will be rewarded with
.
The reader should check whether the tags estimation is within the interval associated with frame length
L, as listed in
Table 4. If not, and if the tag number is ≥ 1420 the reader will adjust the frame length by sending a
FrameAdjust command to increase or decrease the number of slots in the next frame. Otherwise, if
is less than 1420 labels then an extension template will be applied according to
Table 4, by sending a
QueryRep command.
Figure 5 illustrates the proposed algorithm.
If a frame length adjustment is required, the reader needs to set a suitable length, based on the estimated
, and to estimate the number of tags according to the number of tags successfully identified (from Equation (
14)). Based on the
estimation, the reader adjusts the frame length using
QueryAdjust command or a
Q value based on
Table 4. However, if the frame length adjustment does not occur during the identification process, the reader adopts the Schoute estimator
to estimate the delay, where
is the number of collision slots at the end of the current frame.
According to the estimators presented in
Section 3, it was observed that the Chen estimator is the simplest. To increase the estimator precision, it is necessary a significant computational load to perform the mathematical calculations. Although a more accurate estimator improves the DFSA algorithm performance, it may lead to high costs, especially when the number of labels is huge, such as a population of 10,000 tags, for instance.
However, Chen estimator is only able to efficiently estimate if the maximum number of labels is up to 1420 tags. Above that, the estimator loses performance since it estimates a wrong length for next frame to accommodate such tag population.
Figure 6 illustrates Chen estimator performance, where it can be seen the throughput worsen as the number of tags increase. Thus, Chen estimator is not adequate to estimate a huge number of tags.
Seeking to improve Chen estimator performance, it is proposed an extension able to identify a tag population above 10,000, without compromising the computational performance. It is important to note that to implement the extension, some values have been added to the estimator through the proposed Equation (
18) and the size of the next frame remains
.
where
is the start of the new label interval, and
is the end of the new label interval. Thus,
and
correspond to the beginning and the end of the previous interval, respectively. Therefore, Equation (
18) demonstrates how better perform the proposed estimator. Its performance can be proved by Equation (
15).
This way, the estimator can identify a tag population above 10,000, maintaining a channel efficiency of 36.1%. Moreover, it does not require additional computational resources nor complex mathematical calculations, being a simple, fast, and efficient estimator. It can be implemented in a low-level hardware label and be used in conjunction with the DFSA anti-collision protocol without issue. Thus, the proposal is suitable for an industrial environment, where a large number of RFID tags is required.
5. Performance Evaluation
This section presents a performance evaluation of the proposed estimator, and it is compared with other estimators available in the literature (see
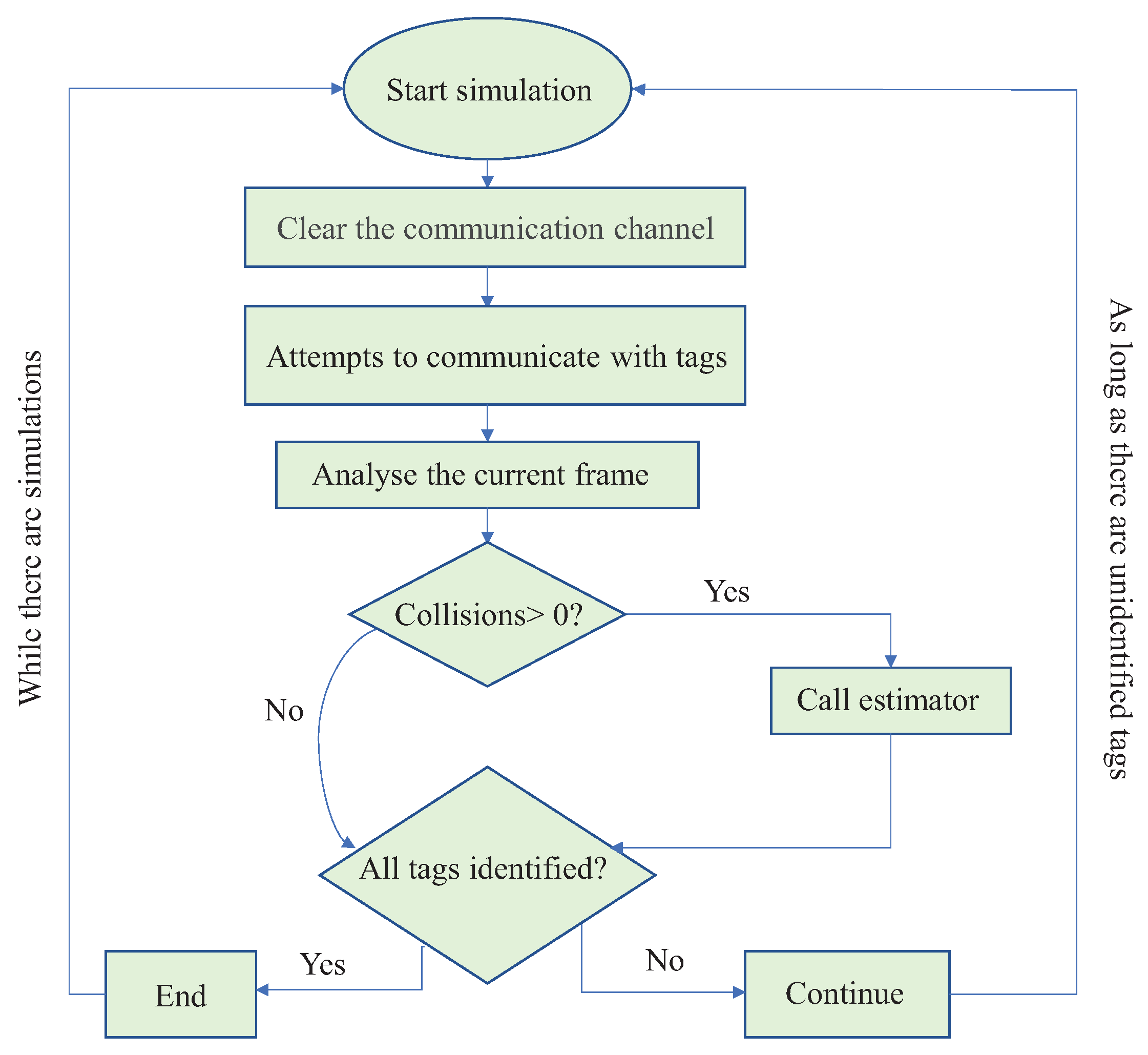
Section 3). To analyze the estimator performance, a discrete event simulator was developed in C/C++ language. This simulator models an RFID system scenario, where there are several tags and one reader, sharing an error-free channel. To ensure convergence, we performed 4000 simulations rounds.
Figure 7 illustrates a flowchart of how simulator was modelled. A simulation is initiated by clearing the communication channel, which is implemented as an array and each element is equivalent to a time slot. Then, the RFID tag reader sends a signal to each tag, and then waits for responses. We considered each array element as a counter, where its value is incremented by 1 when there is a tag response. Each tag is defined to respond only once. In the end, each slot in the array will contain the number of response attempts. Obviously, if there is a slot with 0 responses, it is considered an empty slot. A slot whose value equals 1 is considered a successful slot, and a slot whose value is greater than 1 is considered a colliding slot.
Once the communication is started, current frame is analyzed to verify the collisions occurrence. If there is no collision, there is no need to adjust frame length. However, if there is a collision, a call to the estimator is made and a new frame length is computed.
The identification time varies since there are different slot times duration, depending on whether they are successful, collision or empty.
Table 5 presents approximate values of each slot time. These values are based on the
EPCglobal UHF Class-1 Gen-2 standard for passive UHF systems.
To obtain the required time to communicate with all tags, we need to compute all time slots and commands used in the communication process. The parameters used in the simulation process for this computation are shown in
Table 6. These parameters are defined according to the
EPCglobal UHF Class-1 Gen-2 standard. It is worth noting that in our simulator the time to select tags (
) is not considered, since we consider all tags in the simulation scenario as selected.
The metrics considered for this performance evaluation comprises: the number of empty slots, the number of slots in collision, the number of slots needed to identify all labels, and channel throughput. Moreover, most evaluations presented in the literature considers only a tag population of up to 1000. In this performance evaluation we considered a tag population of up to 10,000 tags.
We chose to use initial frames with 64 and 128 slots since they present better behavior in relation to the metrics mentioned in the paper, when considering a scenario with large number of labels. These values are also widely adopted in literature.
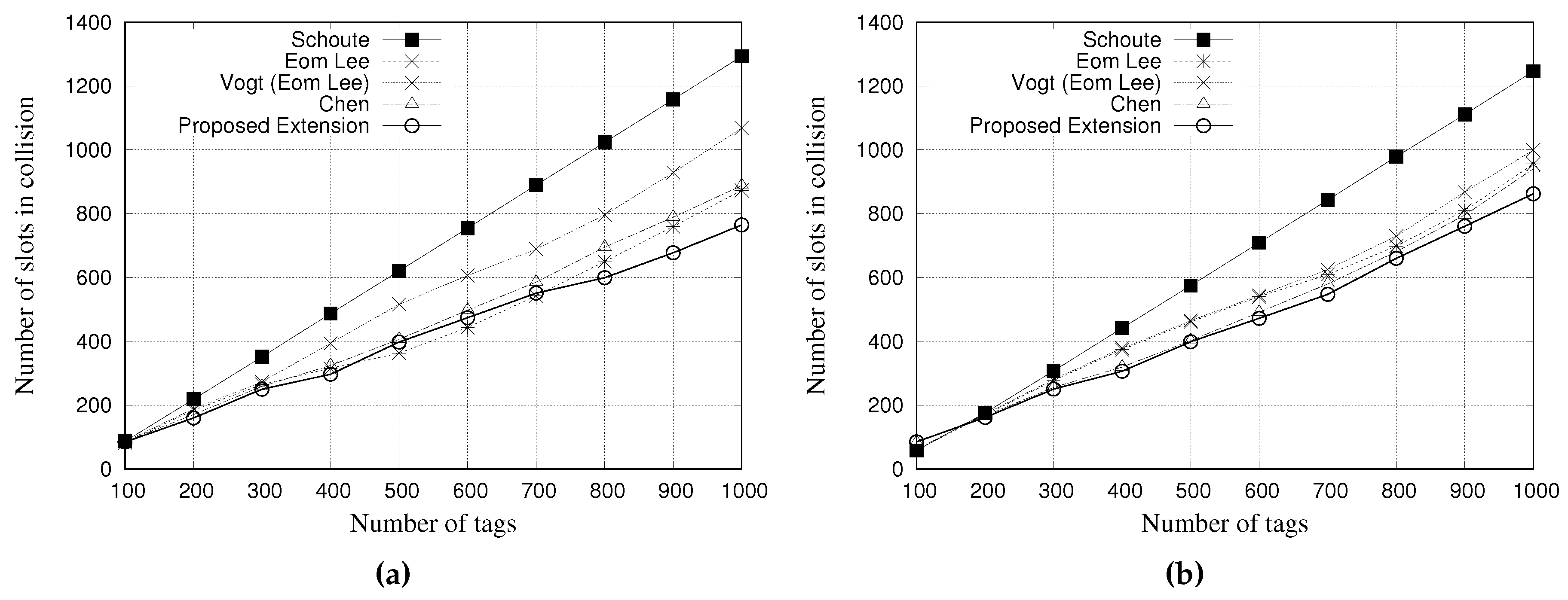
5.1. Simulation Results for Slots in Collision
A collision slot occurs when two or more tags contend simultaneously for the same slot.
Figure 8 and
Figure 9 present the performance evaluation of multiple estimators regarding the number of slots in collision.
Figure 8a,b show the results for a tag population of 1000 tags, with frame lengths of 64 and 128 slots, respectively.
Figure 9a,b show the results for a tag population of 10,000 tags, with frame lengths of 64 and 128 slots, respectively.
The results show that, regardless of the frame length of 64 or 128 slots, Schoute estimator presents a larger number of slots in collision when compared with other estimators. On the other hand, our proposed estimator can reduce the number of slots in collision. These results indicate that our proposed ageing factor can adjust the subsequent frame accordingly, to avoid collisions.
From the results of
Figure 9, regardless of the frame length, Chen estimator presents the worst performance, since it is not able to correctly estimate tag population above 3000. Consequently, the frame length is not adjusted to accommodate such number of labels. As it can be seen, other estimators were able to adjust the frame length to accommodate a tag population up to 10,000. However, there are some performance differences among estimators. Schoute estimator presented a slightly worst performance when compared with Eom-Lee, Vogt, and our proposed estimator. On the other hand, our proposed estimator presented the best performance. Regardless of the frame length of 64 or 128 slots, the proposed estimator is less prone to collisions, even considering a large tag population. The ageing factor seems to be more accurate in estimating subsequent frame length based on previous frame, thus leading to less collisions.
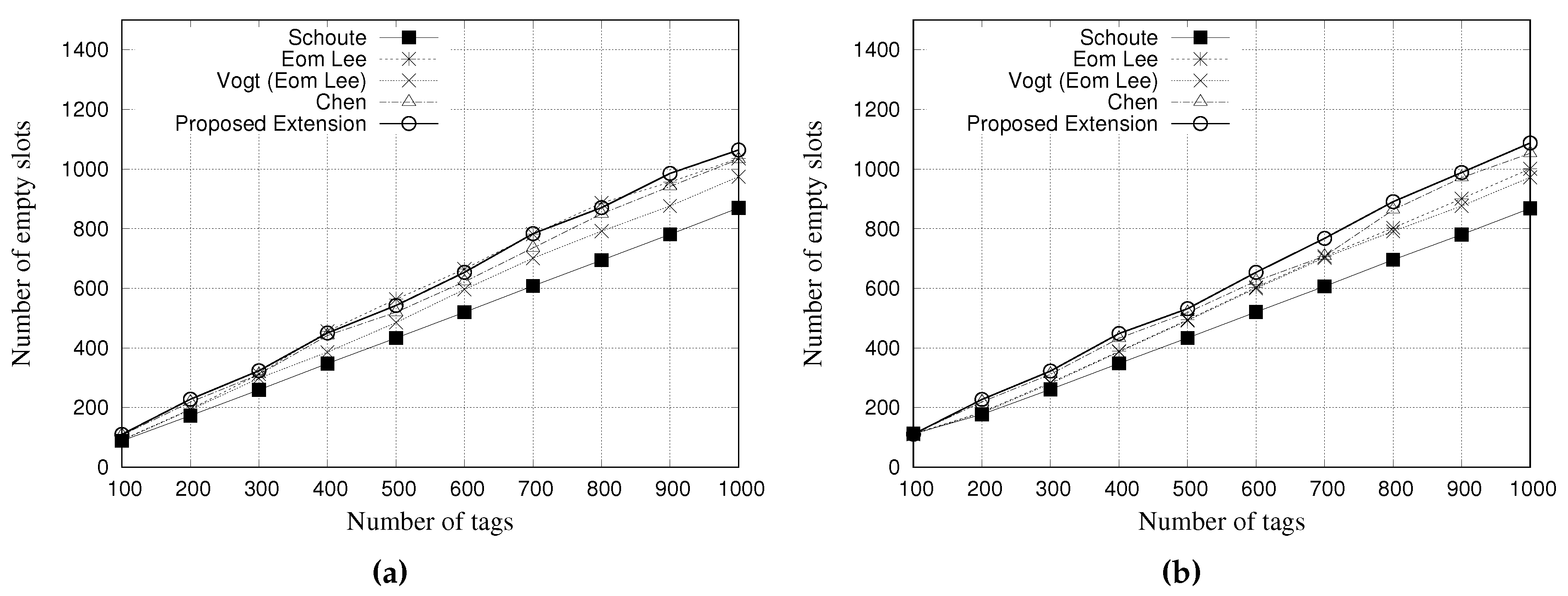
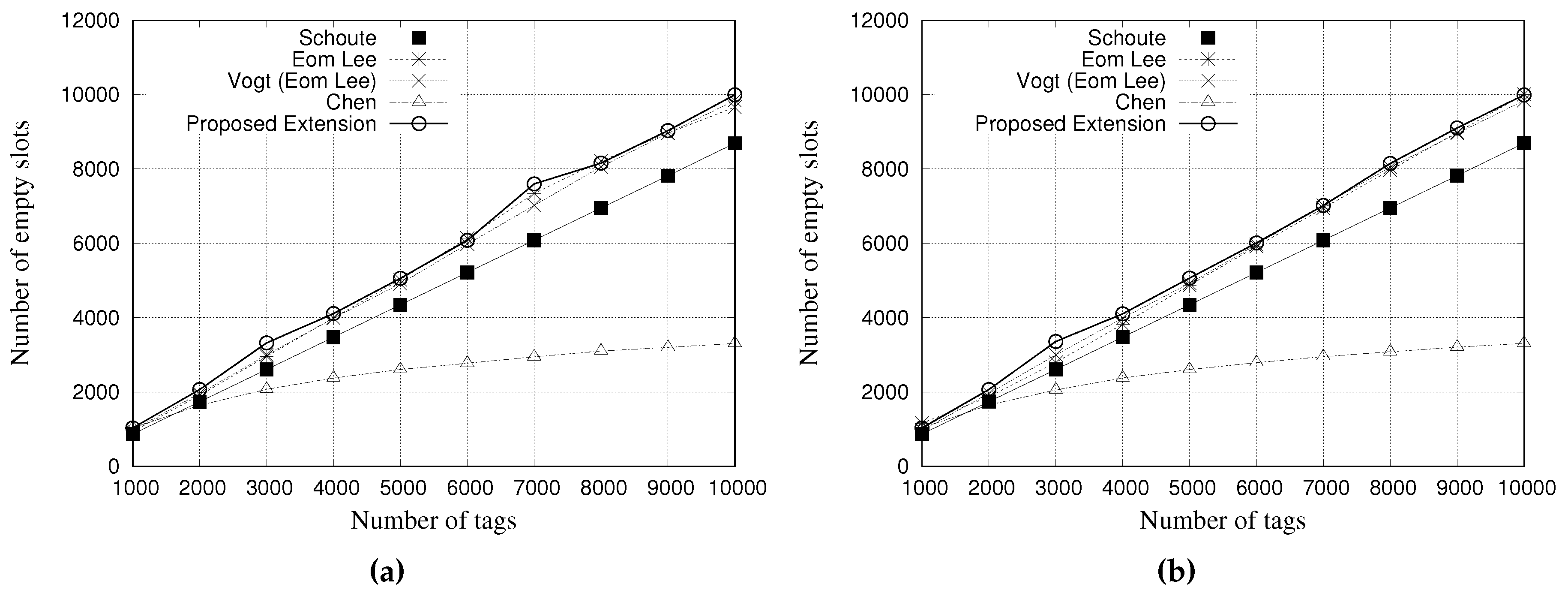
5.2. Simulation Results for Empty Slots
An empty slot occurs when none tag contended for that slot.
Figure 10 and
Figure 11 present the performance evaluation of multiple estimators regarding the number of empty slots.
Figure 10a,b show the results for a tag population of 1000 tags, with frame lengths of 64 and 128 slots, respectively.
Figure 11a,b show the results for a tag population of 10,000 tags, with frame lengths of 64 and 128 slots, respectively.
The results indicate that the Schoute estimator can reduce the number of empty slots in both scenarios. It is justified by the multiplication of the number of colliding slots by the constant of 2.39 to generate the subsequent frame. This reduces the number of empty slots but increases the number of slots in collision.
Despite Chen estimator as several slots in collision, here it presents fewer empty slots when compared with the other estimators. It is important to note that Chen estimator has a limitation or maximum size of its subsequent frame, which consequently impacts on this result.
Again, the results of other estimators are very similar, but our proposal presents a small reduction in the total number of slots when compared with other estimators.
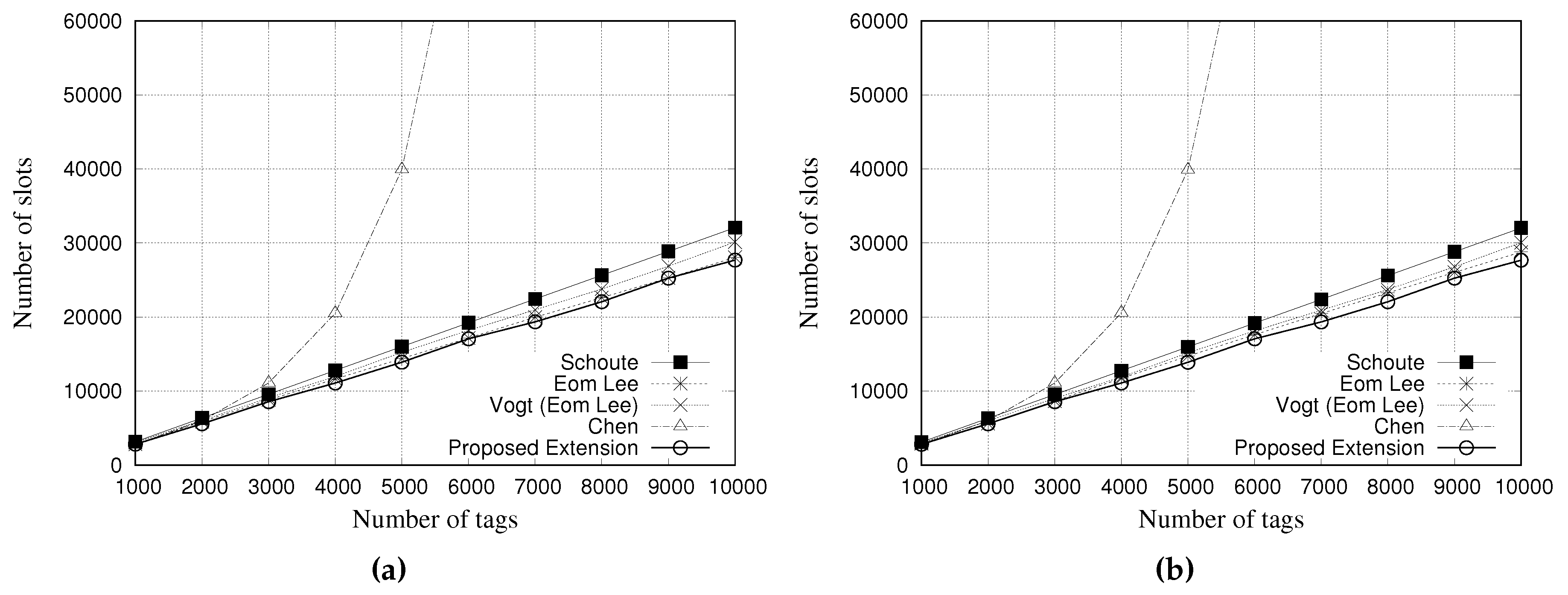
5.3. Simulation Results for Total Number of Slots
This performance evaluation considered the total amount of slots used by each estimator during the simulation process.
Figure 12 and
Figure 13 present the performance evaluation of multiple estimators regarding the total number of slots.
Figure 12a,b show the results for a tag population of 1000 tags, with frame lengths of 64 and 128 slots, respectively.
Figure 13a,b show the results for a tag population of 10,000 tags, with frame lengths of 64 and 128 slots, respectively.
Regarding the results with 1000 tags, all the estimators presented the same performance in relation to the total number of slots used, regardless of the frame length.
The results presented in
Figure 13a,b, indicate that Chen estimator needs to use more slots to identify all tags. Above 5000 tags, the number of slots is greater than 60,000, presenting a degradation in communication performance. This result, and the above presented, indicate that Chen estimator is not suitable for large a tag population.
Our proposed estimator presented a performance very similar to the other estimators, by using almost the same quantity of slots to read all tags. In this scenario, there are almost no difference among estimators, except Chen’s one.
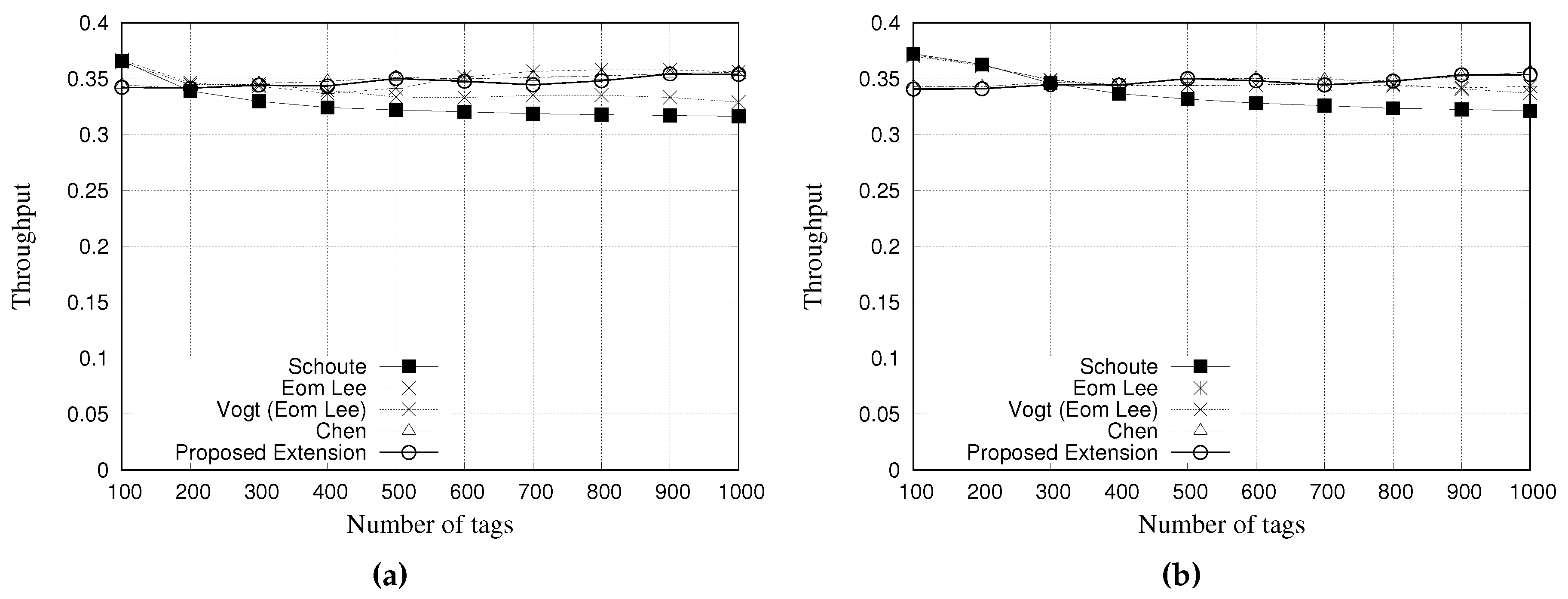
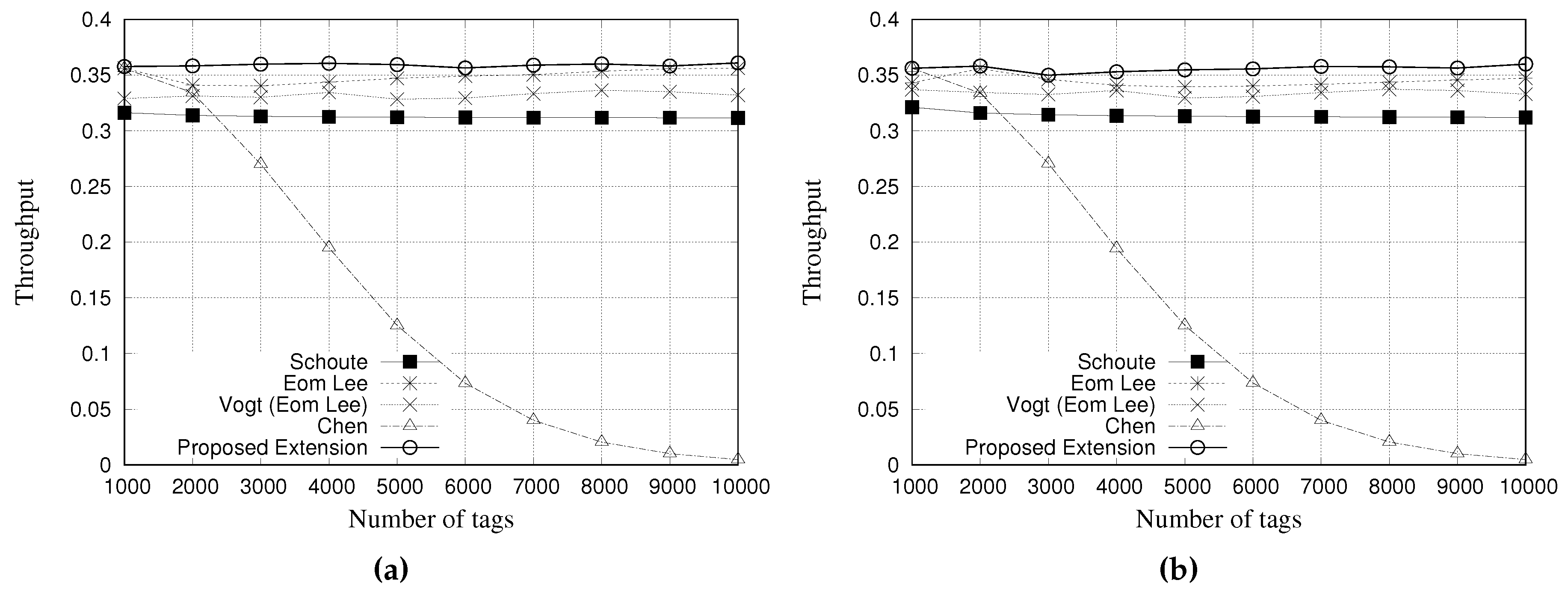
5.4. Simulation Results for Throughput
The throughput is calculated as Equation (
19):
where
,
and
are the average number of successful slots, colliding slots, and empty slots, respectively.
Figure 14 and
Figure 15 present the simulation results of multiple estimators regarding the throughput.
Figure 14a,b show the results for a tag population of 1000 tags, with frame lengths of 64 and 128 slots, respectively.
Figure 15a,b show the results for a tag population of 10,000 tags, with frame lengths of 64 and 128 slots, respectively.
From the results with 1000 tags, it is possible to note that all the estimators presented a similar throughput. Vogt and Eom-Lee presented a slightly lower throughput when compared with Chen and our proposed estimator, despite the results being very similar.
From the results with 10,000 tags, as it can be seen, the Chen estimator presents a low throughput performance when compared with other estimators. This behavior is justified by the large number of slots needed to identify all tags. Regarding our proposed estimator, it presents an improved performance when compared to others, despite being very similar.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}