1. Introduction
In robots and unmanned aerial vehicle systems (UAVs), the ego-motion estimation is essential. To estimate the current pose of a robot, various sensors such as GPS, inertial measurement units (IMU), wheel odometers, and cameras have been used. In recent years, the visual-inertial odometry (VIO) algorithm, which fuses the information from a camera and an IMU, has been garnering increasing interest because it overcomes the shortcomings of other sensors and can operate robustly. For example, a GPS sensor can estimate the global position of the device, but it can only operate in outdoors and cannot get precise positions needed for autonomous UAV navigation. An IMU sensor measures acceleration and angular velocity at high frequency, but the pose estimated by integrating the sensor readings easily drifts due to the sensor noise and time-varying biases. Visual odometry (VO) is more precise than other methods for estimating the device poses because it utilizes the long-term observations of fine visual features. However, it is vulnerable to motion blur from fast motions, the lack of scene textures, and abrupt illumination changes. Furthermore, monocular VO systems cannot estimate the absolute scale of motion due to the theoretical limitation of the camera’s projective nature. By fusing IMU and visual information, VIO operates in extreme environments where the VO fails and achieves higher accuracy with metric scale.
Initially, VIO was approached by loosely-coupled fusion of visual and inertial sensors [
1,
2]. An extended Kalman filter (EKF) [
3,
4] is also used, as it can update the current state (e.g., the 3D pose and covariance) by solving a linearized optimization problem for all state variables in a tightly-coupled manner [
5,
6,
7]. The filtering-based approaches can estimate the current poses fast enough for real-time applications; however, they are less accurate than the optimization-based approach because of the approximation in the update step. Recently, optimization-based algorithms [
5,
6,
7,
8] have been developed for higher accuracy, but they require higher computational cost and suffer from divergence when the observation is poor or the initialization is not correct. Certainly, there is a trade-off between performance and speed, and it is difficult to optimize all the parameters in the initialization and update phase, especially when the information is insufficient.
In this work, we propose a VIO system that uses the tightly-coupled optimization framework of the visual and pre-integrated inertial observation, together with a robust initialization method for the scale and gravity. For real-time operation, the optimization cost for the trajectory estimation should not contain a large number of parameters. By using the pre-integrated IMU poses as the inertial costs, the number of pose parameters in the optimization window is drastically decreased, roughly from the number of frames to the number of keyframes. This reduction enables us to increase the size of the optimization window, which results in improved accuracy and robustness of the system. To account for the noise and error in the IMU biases, we introduce a local scale parameter in the device pose formulation.
Bootstrapping a VIO system requires careful treatment, as incorrect system parameters can easily break the system. The pose estimation problem for visual-inertial systems may not have a unique solution depending on the types of motion [
9], and it makes the initialization task more challenging. As the IMU readings contain time-varying biases, we do not use the initial IMU measurement for the motion scale estimation. Instead of assuming that the biases are given to the system, we start with an arbitrarily-scaled vision-only map and upgrade it to a fully-metric map when enough information on the bias is available. We propose an efficient method to compute the global scale and gravity direction in the bootstrapping stage, by combining the relative pose constraints in the optimization. Furthermore, the convergence criterion to determine when to upgrade to the metric map and finish the bootstrapping process is proposed. As it works without any assumption on the motion or biases, this greatly improves the applicability of the proposed algorithm in the real world.
The experiments with the EuRoC [
10] benchmark dataset confirm that our algorithm can estimate the reliable device poses with the correct real scale even in dynamic illumination changes and fast motions. On top of the robustness, we achieve better estimated pose accuracy compared to the state-of-the-art VIO algorithms. Our main contributions are summarized as follows:
We propose a novel visual-inertial odometry algorithm using non-linear optimization of tightly-coupled visual and pre-integrated IMU observations with a local scale variable. The old information and estimation results are marginalized and utilized in the optimization for better stability.
A robust online initialization algorithm for the metric scale and gravity directions is introduced. By enforcing the relative pose constraints between keyframes acquired from visual observations, the initial scale and gravity vectors can be estimated reliably, without assuming any bootstrapping motion patterns or that the bias parameters are given. To avoid failure due to the divergent scale variable in the optimization, we also propose a criterion that can determine the initialization window size adaptively and autonomously.
The experimental results show that the proposed method achieves higher accuracy than the state-of-the-art VIO algorithms on the well-known EuRoC benchmark dataset.
2. Related Work
The VIO algorithms focus on highly accurate pose estimation of a device by fusing visual and IMU information. Cameras provide the global and stationary information of the world, but the visual features are heavily affected by the external disturbances like fast motion, lighting, etc. IMU sensors generate instantaneous and metric motion cues, but integrating the motions for a long period of time results in a noisy and drifting trajectory. As these two sensors are complementary, there have been many attempts to combine the two observations.
Recent VIO algorithms can be classified into the filtering-based approach, which feeds the visual and inertial measurements to filters, and the optimization-based approach, using non-linear optimization for state estimation. The former approaches use an extended Kalman filter (EKF) [
11], which represents the state as a normal distribution with the mean and covariance. The EKF-based systems are faster than the optimization-based methods since they use linearized motion and observation models. In the multi-state constrained Kalman filter (MSCKF) [
3], the visual information and IMU data are combined into a filter and the body poses are updated by a 3D keypoint processing with high accuracy. Li and Mourikis [
4] proposed the new closed-form representation for the IMU error state transition matrix to improve the performance of MSCKF and the online model with extrinsic calibration. Hesch et al. [
12] developed an observability constraint, OC-VINS, that explicitly enforces the system’s unobservable direction, to prevent spurious information gain and reduce discrepancies. The optimization-based methods are more accurate than the filtering-based method; however, they suffer from a high computational cost. To overcome this limitation, optimizing only a small window of poses or running an incremental smoothing is proposed [
13,
14]. Leutenegger et al. [
5] proposed to calculate the position and velocity by integrating IMU measurements with VO’s keyframe interval while marginalizing out to old keyframe poses to mitigate complexity. However, these methods use the propagated poses of the IMU measurements for a certain interval, which has the disadvantage of re-integrating the linear acceleration value according to the device orientation changes for the local window. Forster et al. [
8] proposed extending the IMU pre-integration method [
15] to update the bias variables efficiently by calculating linear approximation IMU biases’ Jacobian for a very short interval using the IMU pre-integration method. Lupton and Sukkarieh [
16] proposed a sliding window optimization framework for the IMU pre-integration method and old keyframe marginalization in the local window, and Qin and Shen [
17] and Raul Mur-Artal and Tardos [
6] combined VIO with the SLAM system for more accurate pose estimation.
The optimization methods directly use IMU sensor measurements together with the visual features as the constraints of the pose variables, which results in a highly non-linear formulation. For accurate and stable pose estimation, the initialization of the metric scale and gravity direction is critical because the time-varying IMU biases need to be calculated from the device poses. If the biases are not estimated accurately, the following online pose optimization is likely to diverge. Martinelli [
9] demonstrated that there may exist multiple solutions in the visual-inertial structure from motion formulation. Mur-Artal and Tardos [
6] proposed a closed-form formulation for vision-based structure from motion with scale and IMU biases; however, one should wait for initialization until 15 s to make sure all values are observable. Weiss et al. [
18] proposed an initialization method that converges quickly using the extracted velocity and the dominant terrain plane based on the optical flow between two consecutive frames, but it requires aligning the initial pose and the gravity direction at the beginning. We discuss in
Section 5 how to calculate the metric scale and gravity using the pose graph optimization (PGO) [
19] and IMU pre-integration.
3. System Overview
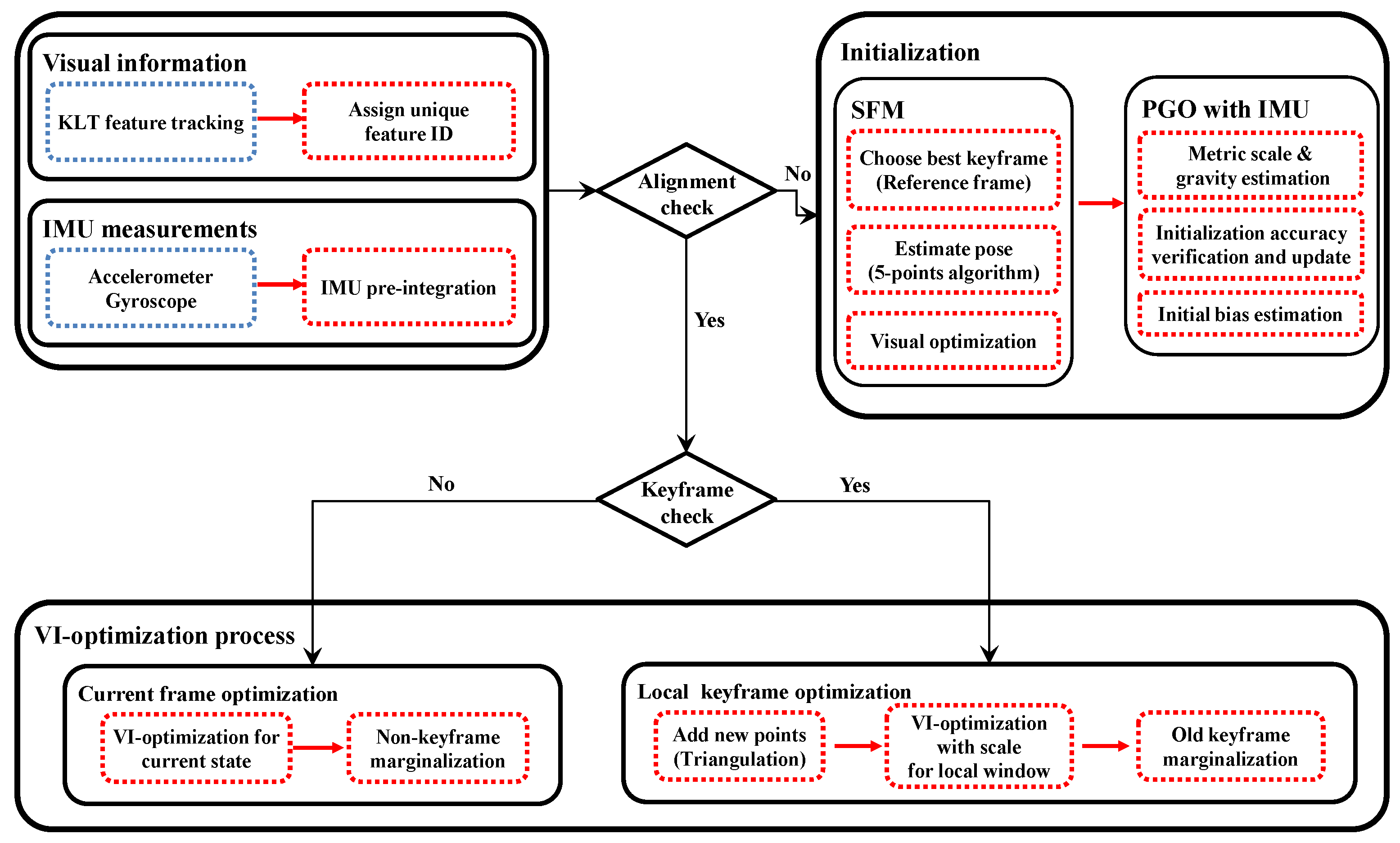
As shown in
Figure 1, the proposed visual-inertial odometry algorithm consists of visual feature tracking, IMU pre-integration, initialization, and optimization modules. We use the Kanade–Lucas–Tomasi (KLT) feature tracker [
20] to find the feature point correspondences for geometric modeling of camera poses and scene structure. Alternatively, one can use descriptor-matching algorithms [
21,
22,
23,
24] for this task, which also can be used for loop-closure finding in visual SLAM systems. We introduce a tightly-coupled visual-inertial odometry algorithm, which continuously estimates the motion state with a local scale parameter by minimizing the costs from visual information and IMU measurements (
Section 4). For successful operation, it is critical to measure the IMU biases from the reliable metric poses and gravity direction. In
Section 5, we present a robust initialization algorithm of the metric scale and gravity using pose graph optimization.
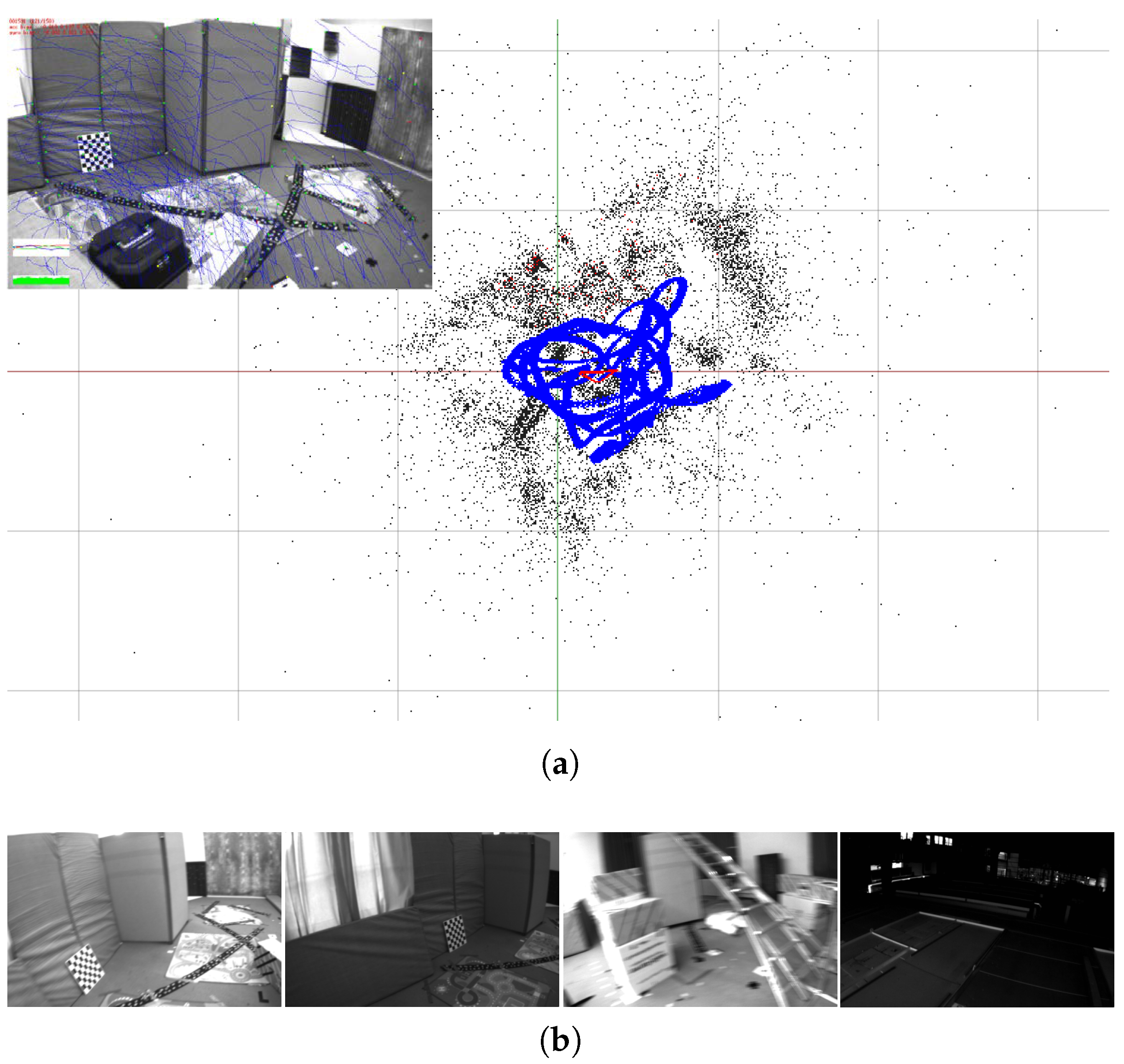
Figure 2 shows one example result of our VIO system and a few images of the challenging situations from the EuRoC dataset. More results and discussions are presented in
Section 6.
4. Visual Inertial Optimization
The goal of the visual-inertial odometer is to estimate the current motional state using visual information and inertial measurements at every time. The state
at time
t is defined as a quadruple:
where
special Euclidean group SE(3) is the rigid transformation parameter from the device to the world coordinate system,
is the velocity of the device, and
,
are the sensor biases. The IMU sensor bias is modeled as a random walk, whose derivation is zero-mean and Gaussian as
, where
. The coordinate systems are denoted as a prescript on the left side of the symbol, and there are the world (
), the device (
), and the camera (
) coordinate systems. The time or keyframe index is denoted as a subscript (
or
) of the symbol. Let us denote the rigid transformation corresponding to
as
, and ★ and
denote the composition/application and the inversion operators for SE(3) transformations, respectively. The world coordinate system is defined so that the gravity direction is aligned with the negative
z-axis. We follow the convention that the device coordinate system is aligned with the IMU coordinate system. The transformation from the camera to the device coordinate system is written as
, and it is pre-calculated in the device calibration process [
25,
26].
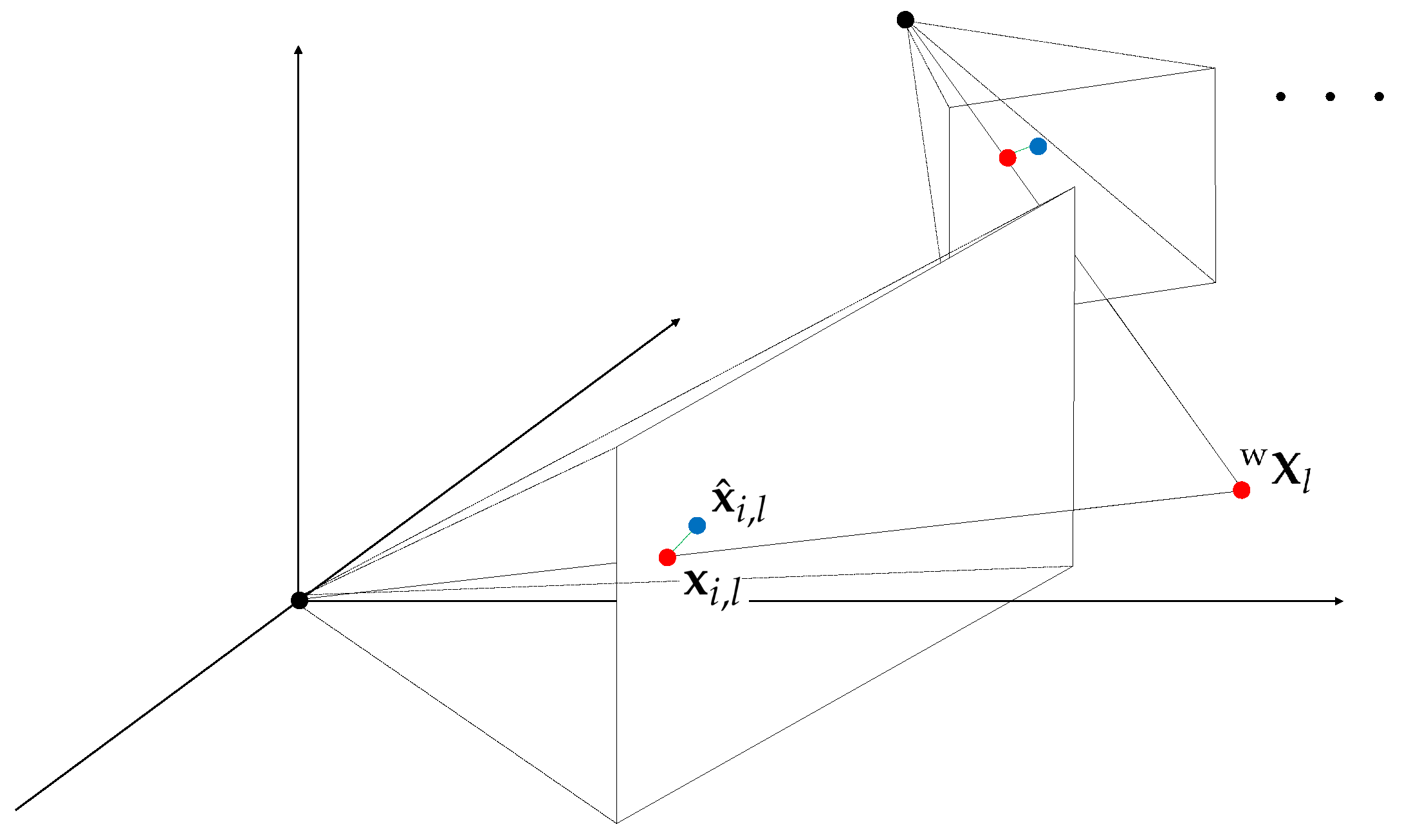
4.1. Visual Reprojection Error
The visual error term of our proposed method uses the re-projection error in the conventional local bundle adjustment. The error is the difference between the projected location
of a 3D landmark
and its tracked location
at the keyframe
i. As illustrated in
Figure 3, the visual cost
from the tracked features is defined as:
where
is the information matrix associated with the tracked feature point at the keyframe and
denotes the camera projection function.
is the Huber norm [
27], which is defined as:
4.2. IMU Pre-Integration
The IMU sensors measure the angular velocity and translational acceleration, and in theory, the 3D pose (orientation and position) of the device can be calculated by integrating the sensor readings over time. However, the raw IMU measurements contain significant noise and time-varying non-zero bias, and these make the integration-based pose estimation very challenging. The IMU angular velocity
and acceleration
measurements at time
t are modeled with the true acceleration
and angular velocity
as:
where
is the rotation from the world to the device coordinates (note the transpose),
is the constant gravity vector in the world,
,
are the acceleration and gyroscope biases, and
,
are the additive zero-mean noise. From the following relations,
for the image frames
k and
(at time
and
, respectively), the position, velocity, and orientation of the device can be propagated through the first and second integration used in [
28],
Assuming the acceleration
and the angular velocity
are constant between time interval
and
, we can simplify the above equations as follows:
The measurement rate of the IMU is much faster than that of the camera, as illustrated in
Figure 4, and it is computationally burdensome to re-integrate the values according to the changes of the state in the optimization framework. Thus, we adopt the pre-integration method, which represents IMU measurements in terms of the poses of the consecutive frames by adding IMU factors incrementally as in [
7,
29].
For two consecutive keyframes [
] where the time between two (
) can vary, the changes of position, velocity, and orientation that are not dependent to the biases can be written as follows from Equations (
11)–(
13):
where
represents the rotation from the frame
k to the time
i. We can calculate the right side of above equation directly from the IMU measurements and the biases between the two keyframes. However, these equations are functions of the biases,
and
. If the biases
and
between the keyframes are assumed to be fixed, we can obtain the values of
from the IMU measurements without re-integration.
However, in the case of bias, it changes slightly in the optimization window, and we use the recent IMU pre-integration described in [
7,
29] to reflect the bias changes in the optimization by updating delta measurements of bias using the Jacobians, which describe how the measurements change due to the estimation of the bias. The bias is updated from the delta measurements
and
using the first-order approximation as,
where
are the pre-integrated measurements from the fixed bias and Jacobians
are computed at integration time, describing how the measurements change from bias estimation [
29].
Finally, the local optimization cost of the IMU residual
for the interval of keyframes
i and
j using pre-integration is defined as follows:
where
is the information matrix associated with the IMU pre-integration covariance between the keyframes, reflecting the IMU factor noise. The computed measurement of IMU pre-integration factor is a function of the random noises
, which are assumed to be zero-mean and Gaussian. A covariance matrix of pre-integrated parameters
is propagated from the knowledge of the IMU sensor noise given in the sensor specifications. As the IMU biases follow the Brownian motion model, we penalize abrupt changes of the biases between consecutive keyframes with the bias costs at the bottom two entries in Equation (
25).
4.3. Online Optimization
Considering UAVs, the VIO system should estimate the current pose in real time using captured visual information and IMU measurement. We use the visual-inertial bundle adjustment framework and solve the optimization problem with the Gauss–Newton algorithm implemented in Ceres Solver [
30]. For the states
and the 3D landmarks
, the cost function is defined as follows for the optimization window:
where
is the prior information from marginalization, which is the factor for the states out of the local optimization window.
In order to estimate the best metric scale, we add the local scale factor
into our cost function (Equation (
26)) and optimize it together with other variables. When a new keyframe is added, we assume that the device experiences the motion changes and perform joint optimization including the local scale
variable. To prevent the scale from becoming zero or negative, we use the exponential parameterization
instead of using
directly. The updated IMU residual is:
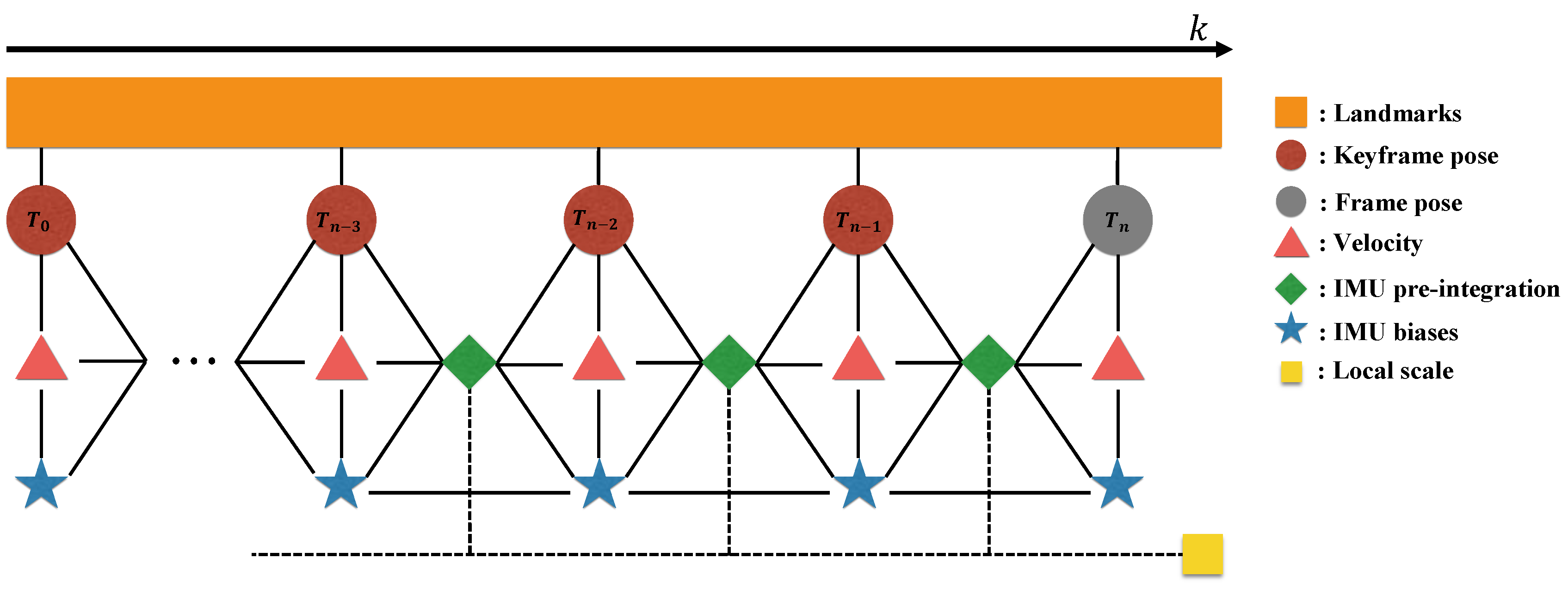
Figure 5 shows the graphical model of our visual inertial local bundle adjustment. We perform local optimization with the sufficiently accurate scale variable computed by bootstrapping in
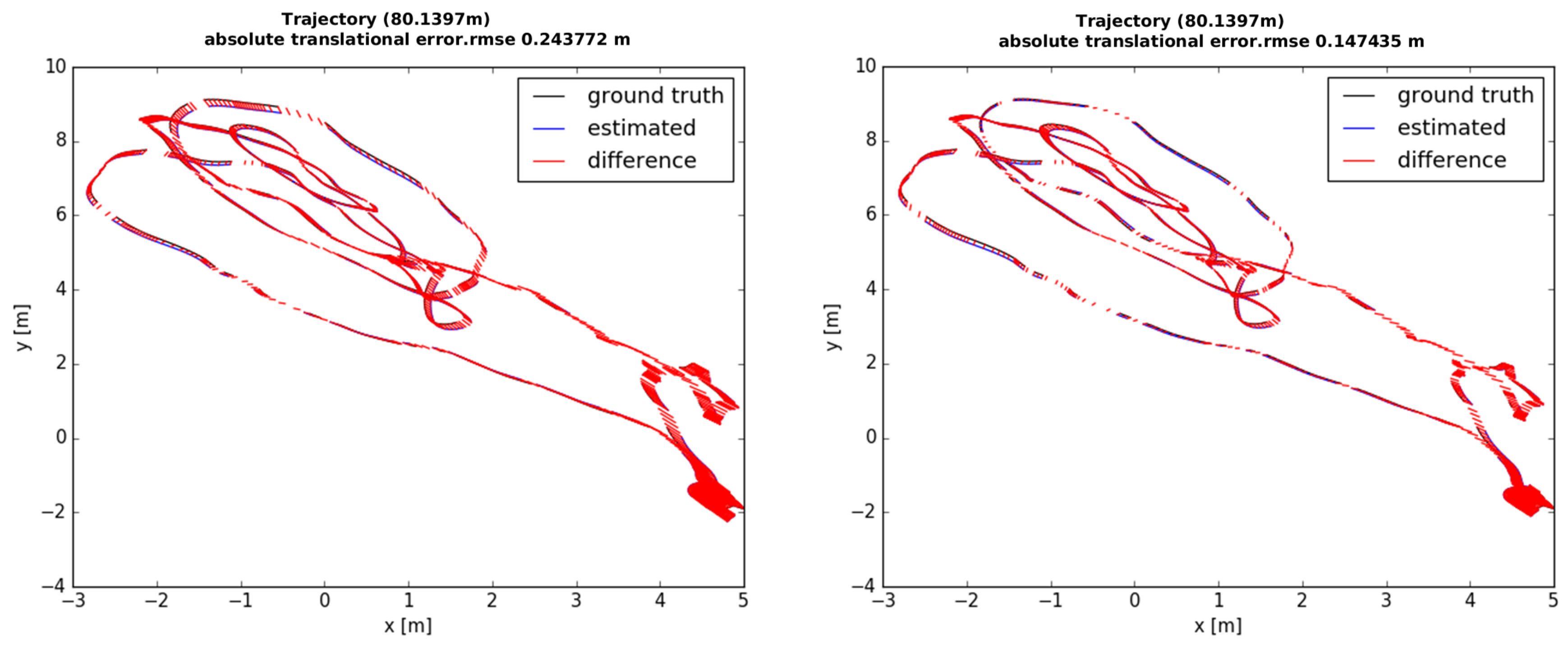
Section 5, and the optimized local scale is marginalized to prior information along with the poses of the old keyframes.
Figure 6 shows the comparison results with or without the local scale variable. Optimization involving local scale factor achieves accurate estimation of poses, since this approach is able to refine local scale information.
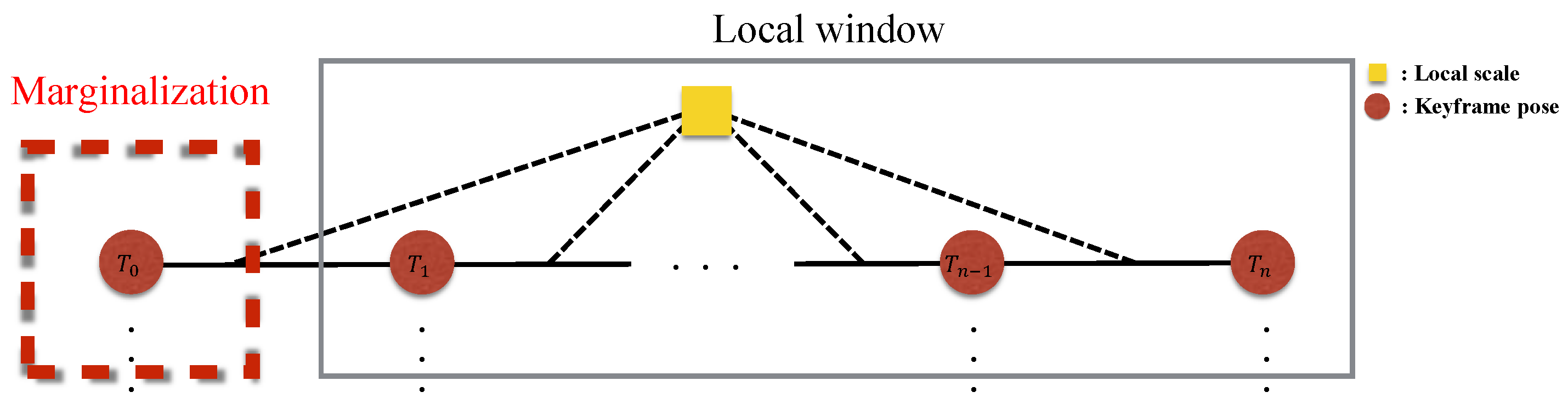
4.4. Marginalization
The optimization-based VIO algorithms need to marginalize out the old information so as not to slow down the processing speed [
5,
7]. The marginalization does not eliminate the old information outside of the local optimization window of keyframes, but converts it into a linearized approximate form to the remaining state variables using the Schur complement [
32]. When a new keyframe is added into the local optimization window and the window size exceeds the preset threshold, the state (the pose, velocity, and bias) of the oldest keyframe in the window is marginalized (
Figure 7 illustrates keyframe marginalization in a graphical model). On the other hand, if the current frame is not selected as a keyframe, only the visual information is dropped, while the IMU measurements are kept for IMU pre-integration. The marginalized factor is applied to be a prior of the next optimization, which helps to find a better solution than simply fixing the keyframe poses outside of the optimization window.
5. Bootstrapping
Unlike the monocular visual odometry where the absolute scale of the map is not recoverable, the visual-inertial odometry needs to find the important parameters such as the scale of the map and gravity direction to estimate the metric state robustly. Moreover, there are many motion patterns in which the multiple solutions of IMU bias parameters exist, such as constant velocity motions including no motion [
9]; thus, optimization involving all state variables without precise initialization may not converge to the true solution. For these reasons, some VIO systems require approximate manual initialization of the gravity vectors or IMU biases, or real scale distance information using different sensors [
33]. The map of visual features is constructed starting from the two keyframes with sufficient parallax, and it is continuously updated as more keyframes are observed. However, the IMU measurements for these keyframes may not observe any significant changes in acceleration, and this can cause failure in bootstrapping the VIO system.
In this work, we propose a bootstrapping method that computes the accurate scale and gravity through stepwise optimization using relative pose constraints. Our method consists of vision-only map building, pose graph optimization with IMU pre-integration, convergence check, and IMU bias update.
5.1. Vision-Only Map Building
The first step, vision-only map building, is identical to monocular visual odometry [
34,
35] and structure from motion algorithms (SFM) [
36]. The system finds the first two keyframes
and
with sufficient motion, by checking the numbers of inlier features by a homography and a fundamental by the five-point algorithm [
37], as only the fundamental matrix can explain the non-planar scene with enough parallax depth, and it is important for reliable 3D point reconstruction [
35]. If the absolute scale of motion is not available, the visual map is initialized with an arbitrary scale, and the inlier features are triangulated and their 3D positions registered. The gravity direction is roughly initialized with the average of the initial acceleration readings (we experimentally use the first 30 readings @200 Hz), and the world coordinate system is set by aligning the gravity to
y-down. Once the initial map with 3D points is built, the poses of later keyframes are computed by the Perspective-n-Point (PNP) algorithm [
38] Local bundle adjustment using Equation (
2) is performed initially and whenever a keyframe is added to improve the accuracy of pose and point positions. Until the scale and gravity are reliably measured in the next steps, purely vision-only map building is continued.
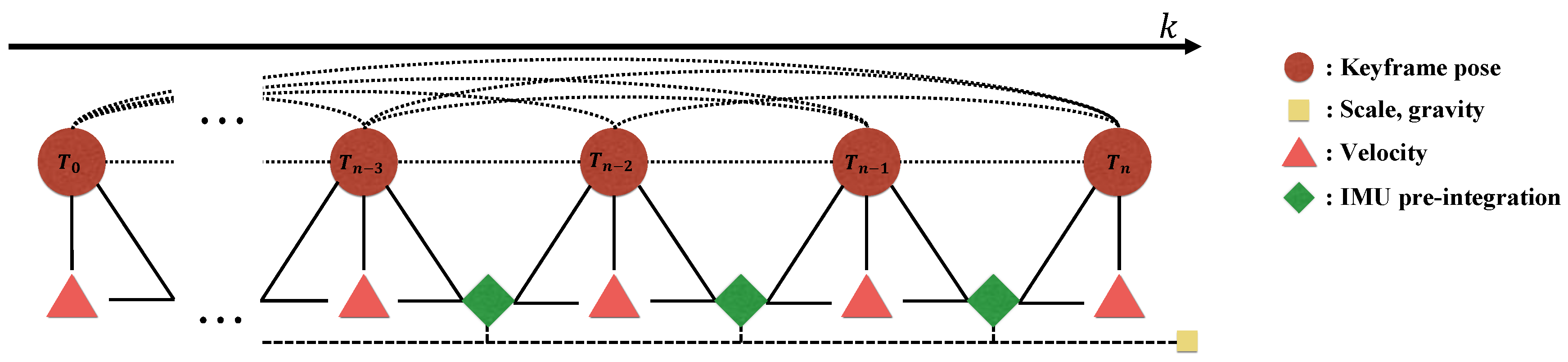
5.2. Pose Graph Optimization with IMU Pre-Integration
While the purely-visual mapping is running, we try to estimate the metric scale using the pre-integrated IMU factor. For easy formulation and efficient estimation, we adopt the pose graph optimization (PGO) framework [
19,
39,
40], which constructs a graph of keyframes where the edges represent the relative pose constraints between keyframes, and optimizes the keyframe poses so that the inconsistency of the relative poses and constraints are minimized (note that this is equivalent to marginalizing the landmarks in a standard bundle adjustment). PGO is commonly used in monocular SLAM systems to fix the scale drift in loop closures using
relative poses. In contrast, we use
relative poses with a global scale parameter
s for the entire map, as the scale drift for a short period of initialization time is not significant. Additional constraints from the pre-integrated IMU and the gravity vector are added to PGO, and the factors in our formulation are illustrated in
Figure 8. Furthermore, to expedite the convergence, the gravity vector
is also included in the active parameters. Because the magnitude of gravity
is always 9.8, we include the constraint
when performing the optimization.
Formally, we define the state for PGO with all keyframe poses, velocities, the gravity, and the global scale
s as:
In this section, we parameterize
an SE(3) transformation with a pair of a translation vector
and a Hamiltonian quaternion [
41]
, i.e.,
, where
is the function converting a quaternion to a
rotation matrix.
While performing visual pose estimation, we calculate IMU pre-integration for keyframes using Equations (
20)–(
22), in which bias and noise are initialized as zero. Using Equations (
20) and (
21) for consecutive keyframes
i and
j, we obtain the scale error cost
:
where
denotes the information matrix, and we use the sub-block of
.
For the relative pose between two keyframes
i and
j given as
and
, the relative pose costs in PGO are given as follows:
where (
) is the relative pose constraint between keyframe
i and
j in the current map,
returns the vector (imaginary) part of
, and
is the information matrix from the keyframe pose covariance. We define the optimization cost for a new state
by combining Equations (
28) and (
31) for whole keyframes
n as follows:
5.3. Convergence Check
While the proposed scale and gravity optimization can be calculated in real time at the moment of insertion of a new keyframe, we need to determine when to update the current map with the optimized parameters to initialize the VIO process. We use two ways to measure the convergence: the covariance of
and the variance of the global scale variable.
is the optimal solution for the states
for the maximum likelihood estimation. Then, the covariance of
is given by,
where
is the Jacobian of Equation (
32) at
. One way to measure the quality of the solution for the non-linear least squares problem is to analyze the covariance of the solution. For a non-linear cost function of the state
and the maximum likelihood estimate
,
can be computed as the Jacobian of Equation (
32) at the optimal state
. We apply the optimized scale and gravity to the system initialization when the largest eigenvalue of the optimized covariance
is less than the threshold
and the scale variance is less than the threshold
at the same time.
Figure 9 shows one example of global scale estimation in the bootstrapping process. In the experiments, the scale and gravity initialization in the bootstrapping stage are estimated to reliable values within 5 s on average for the EuRoC dataset.
5.4. IMU Biases Update
After the optimized scale and gravity are applied to the poses, we can calculate the initial IMU biases while fixing all pose variables
in the optimization using Equation (25). As the biases are updated, pre-integration for the local window keyframes is re-computed. At this point, the bootstrapping of the VIO is complete, and afterwards, the online optimization is performed using the framework presented in
Section 4.3. Algorithm 1 shows the overall procedure of our method. Our proposed system runs from the bootstrapping to online visual inertial optimization efficiently. In
Section 6, we discuss our results with the other comparison methods and how the estimated metric scale converges to the true values by the proposed bootstrapping.
| Algorithm 1: Proposed online VIO algorithm. |
|
6. Experiments
We use the EuRoC [
10] dataset, which contains various challenging motions, to evaluate the performance of the proposed algorithm quantitatively. The dataset is collected from the Firefly micro-aerial vehicle equipped with a stereo camera and an IMU at high flying speeds. We use only the left images with inertial sensor data. The sensor data in the EuRoC dataset are captured by a global shutter WVGA monochrome camera at 20 fps and the IMU at 200 Hz. This dataset consists of five “Machine Hall” sequences and six “Vicon Room” sequences, whose difficulties are labeled as easy, normal, and difficult, depending on the motion speed and environmental illumination changes. Both datasets contain the ground-truth positions measured by the Leica MS50 laser tracker and the Vicon motion capture systems, which are well calibrated to be used as the benchmark datasets in various VO/VIO/SLAM applications. The proposed system is implemented in C++ without GPU acceleration and is executed on a laptop with Intel Core i7 3.0 G CPU and 16 GB RAM in real time.
6.1. Comparison with the State-of-the-Art Algorithms
We compare the proposed algorithm with the recent state-of-the-art approaches using the same evaluation method by Delmerico and Scaramuzza [
33], where the evaluation results of the VIO systems were presented. All parameter settings are kept unchanged in all tests, and the metric is the RMSE position error over the alignment trajectory to the ground-truth pose via
[
44]. Note that, because our proposed method is not a SLAM system, we only compare ours with the systems that do not have loop closing. We directly compare the RMSE results with those of Open Keyframe-based Visual-Inertial SLAM (OKVIS) [
5], Robust Visual Inertial Odometry (ROVIO) [
45], Monocular Visual-Inertial Systems (VINS-Mono) [
17], Semi-direct Visual Odometry (SVO) + Multi Sensor Fusion (MSF) [
46,
47], and SVO + Georgia Tech Smoothing and Mapping (GTSAM) [
29] presented in [
33].
OKVIS is an open source VIO system that minimizes the visual re-projection errors for landmarks and IMU measurement with non-linear optimization. It uses a direct integration model without using the IMU pre-integration method. ROVIO is an EKF-based VIO system that updates the pose state using multi-level patches around feature points with propagated IMU motion and minimization of photometric errors. VINS-Mono is similar to OKVIS as it uses the non-linear optimization based on a sliding window, but it incorporates the IMU pre-integration for relative pose constraints between the keyframes. In addition, the authors propose a loop closure using 4DOF pose graph optimization, which is not included in our comparison. SVO + MSF is an algorithm that combines semi-direct visual odometry (SVO) [
47], which can quickly estimate the frame poses based on visual patches and IMU measurement, with the EKF framework. Note that it needs manual initialization using extra sensors. SVO + GTSM optimizes structureless visual reprojection error with IMU pre-integration, performing full-smoothing factor graph optimization by [
14]. These methods differ from usage of visual terms (re-projection and photometric error), IMU terms (IMU pre-integration and direct integration), and minimization methods. Unlike with SLAM systems, VIO does not use re-localization and loop closing. Momentary failures in pose estimation, e.g., due to fast motion or dramatic illumination changes in Vicon Room1-03 (V1-03) or V2-03, can result in large pose errors in a long trajectory, and this is useful in evaluating the robustness of the systems.
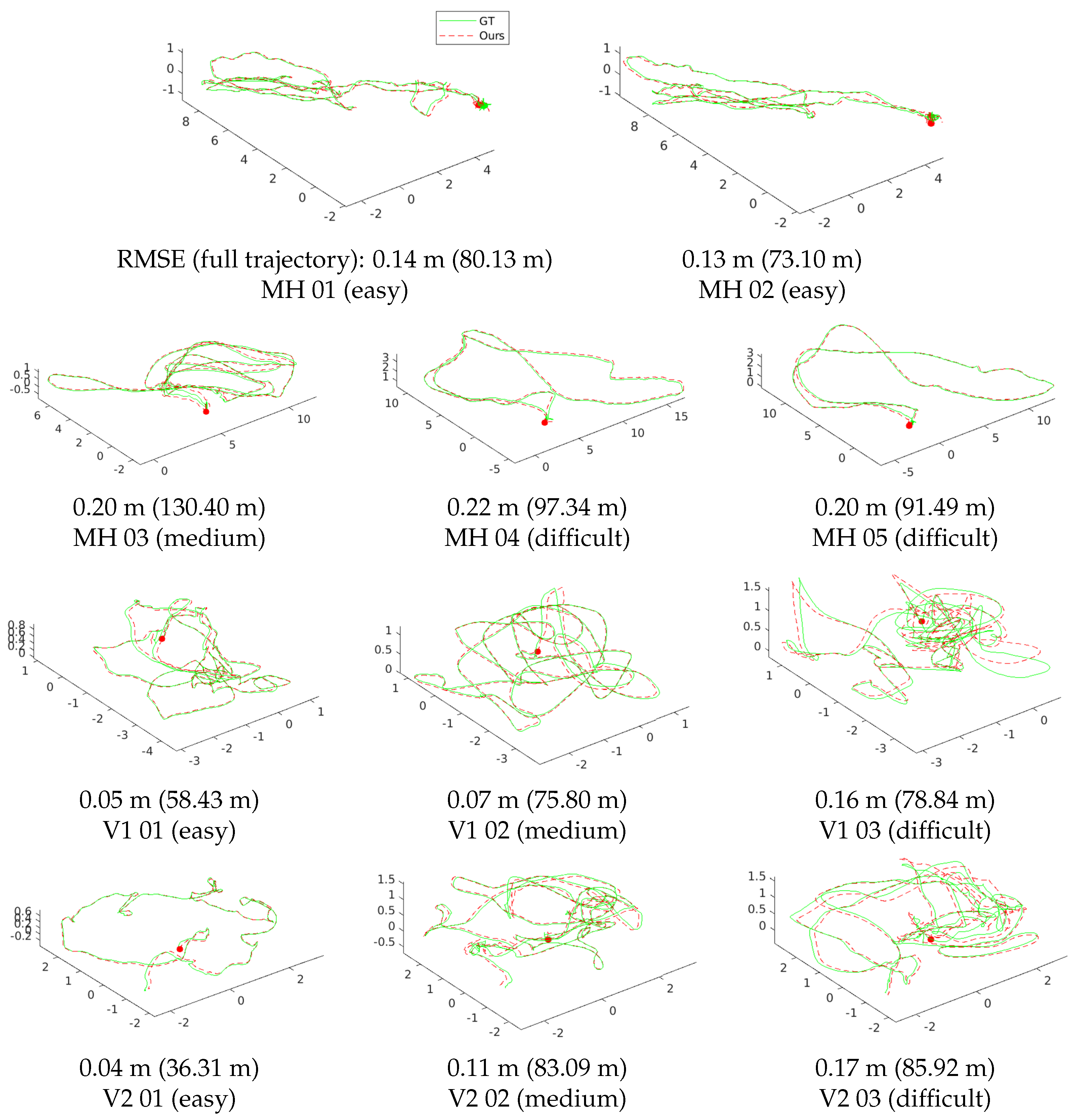
Table 1 shows the RMSE of the proposed algorithm and the state-of-the-art VIO systems in terms of the estimated full trajectories of EuRoC.
Figure 10 shows the estimated trajectories of our method and the ground-truth poses. Our system works robustly and accurately in all sequences without any failures. ROVIO, VINS, and OKVIS operate robustly in all sequences, but show low accuracy at V2-03, which is difficult to initialize robustly due to fast motion, and MH-05, which contains a night-time outdoor scene. SVO + GTSAM achieves superior performance in the “Machine Hall” sequences with far features with illumination changes; however, it fails to estimate correct trajectories of some “Vicon Room” sequences with fast motion (V1-03, V2-02∼03). Our algorithm performs well in MH-04∼05 and V1∼2-03, which are the most difficult sequences with dramatic illumination changes, motion blur, and dark illumination. Accurate scale and gravity initialization helps with the reliable estimation of the bias, and it in turn enables estimating exact poses even when the feature tracking is unstable. We have the best performance for overall without any failure cases, due to our tightly-coupled optimization framework with the robust initialization method using relative pose constraints. The most important aspect of the UAV applications is to estimate the vehicle ego-motion stably for the entire running. The proposed method is suited for this purpose since it can yield accurate poses from the global metric scale and gravity estimation using visual and inertial information together.
6.2. Bootstrapping Experiments
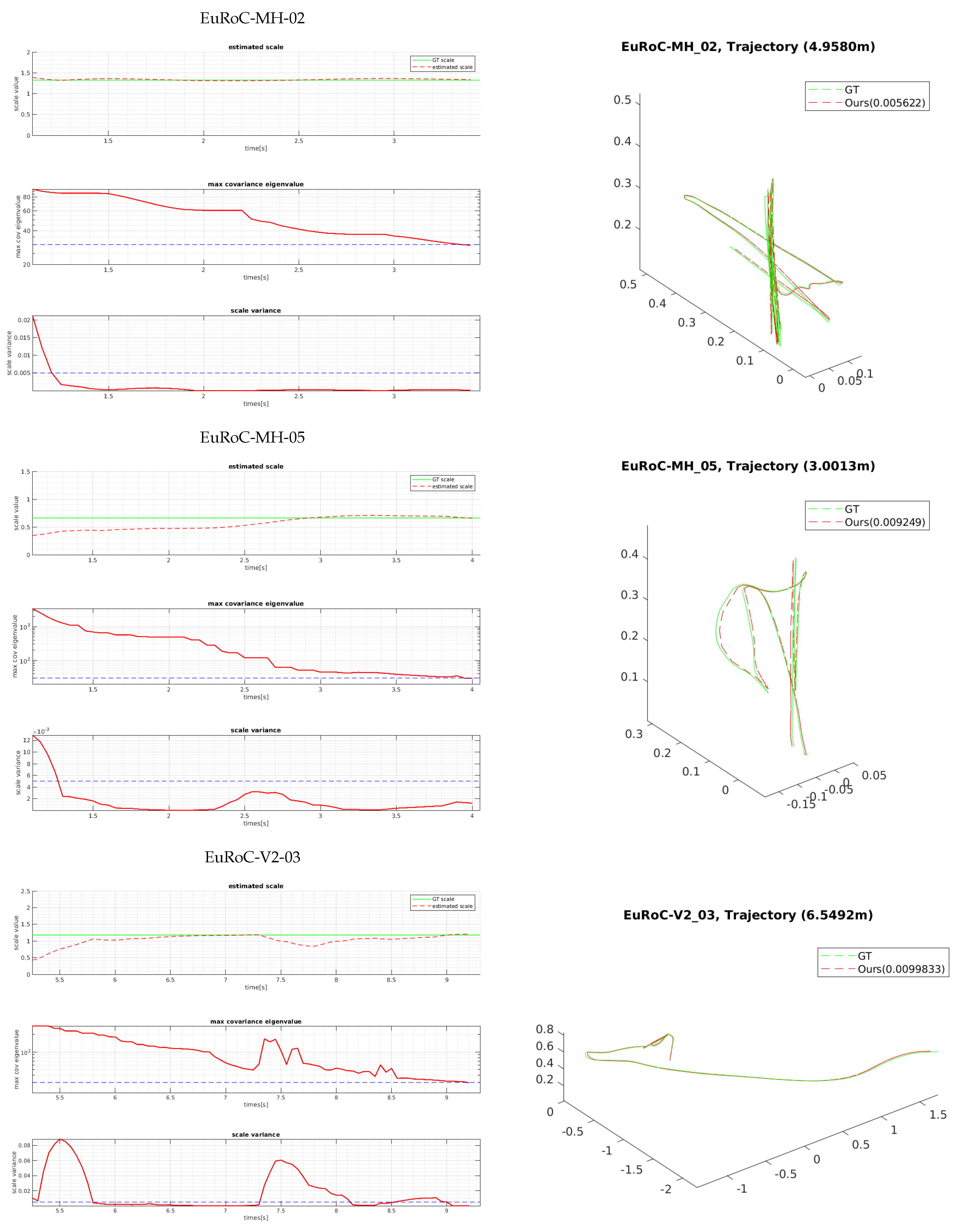
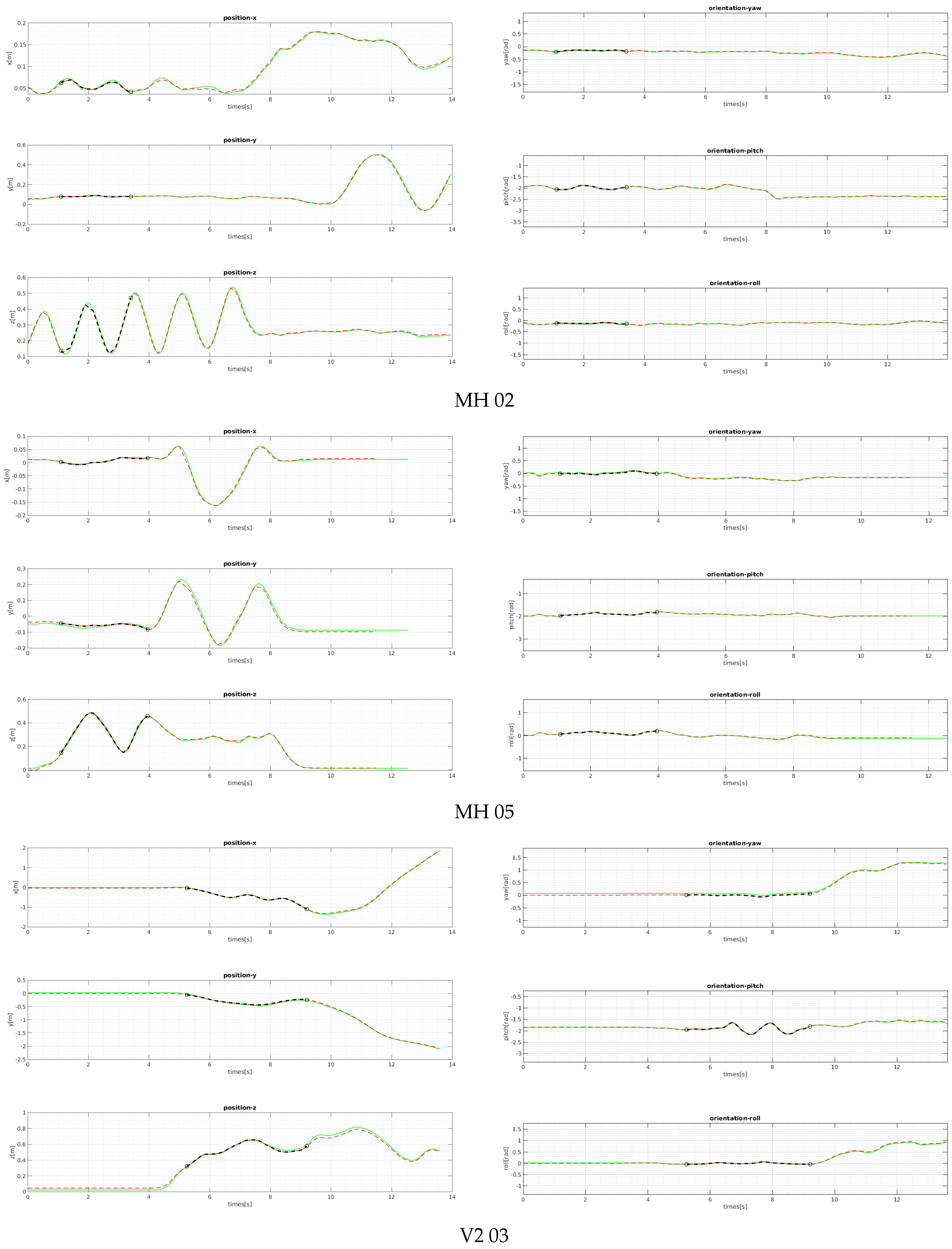
We evaluated the proposed bootstrapping using a few challenging datasets of MH 02 (easy), MH 05 (difficult), and V2 03 (difficult).
Figure 11 and
Figure 12 show the plots of the bootstrapping progress, as well as the trajectory and individual parameters of our estimation vs. the ground-truth for the first 15 s. With insufficient short-term initial poses, the estimated scale is very likely to be incorrect and unstable, but it is also not desirable for the bootstrapping to take too long. The proposed two variance-based metrics can effectively determine if the scale can be estimated reliably, and they can be computed easily from the PGO with IMU pre-integration. Even when the visual observation is noisy and insufficient in MH 05 and V2 03 due to fast motion, our proposed bootstrapping estimates the metric scale within 5 s. Furthermore, the estimated initial scale in short bootstrapping time is gradually refined by the local scale factor throughout in the online visual-inertial optimization framework for improved pose estimation.
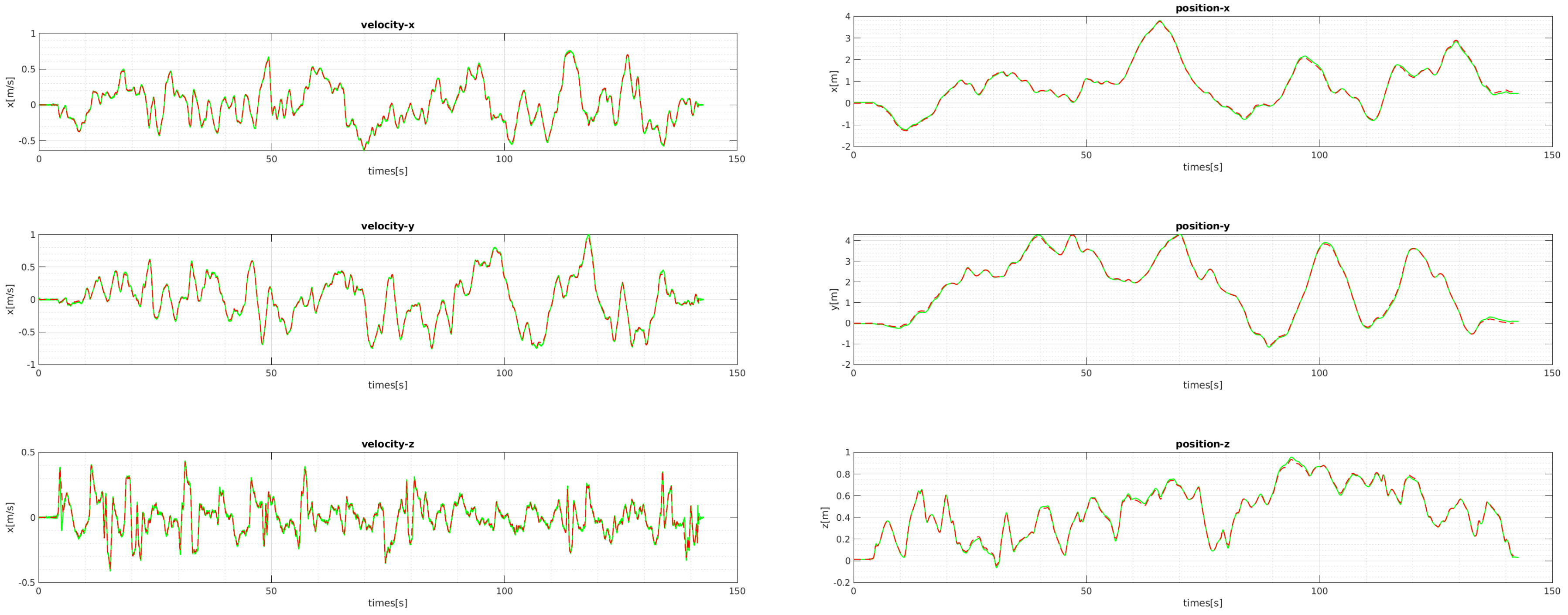
Figure 13 shows the plots of the comparison for the positions and velocities of V1-01. Our proposed initialization and online scale update method successfully estimates positions and velocities, which involve the metric scale.
The estimated scale graphs of
Figure 11 show that our estimated scale variable converged to the optimal scale in bootstrapping. The true scale value is computed by aligning the estimated visual trajectory with the ground-truth poses via similarity transformation [
42]. The two graphs below them show the convergence-check parameters in bootstrapping, which are described in
Section 5.3. Experimentally, we set the maximum eigenvalue of the covariance
to 30 and the scale variance
to 0.005. Note that the variances can be estimated when there exists meaningful motion. For example, in
Figure 11, the first 0.6 (MH 02)∼5.1 (V2 03) seconds are not used. When both metrics drop below the thresholds, bootstrapping is finished, and the estimated scale is applied to the entire trajectory. In contrast, ref. [
6] is designed to wait for 15 s to find the initial variables (scale, gravity, and biases) by the closed-form solution. Once the parameters are found at the beginning, they are not updated afterwards; thus, if the calculated scale variable is not accurate, the following pose estimation can fail completely. Compared to [
6], our method provides an adaptive and reliable bootstrapping.
Figure 12 shows our position and orientation estimates after bootstrapping compared with the ground-truth. The proposed method provides reliable scaled position and aligned orientation; thus, it is suited for various robotics systems in the real world.
7. Conclusions
In this paper, we propose a robust and accurate monocular visual inertial odometry system, which can be applied to UAVs in unknown environments. Even when the initial motion is not known and constrained, we optimize the relative motion with the IMU pre-integration factors to solve the highly non-linear problem effectively and estimate the reliable states with convergence criteria to bootstrap the system. We also estimate the local scale and update it with marginalization of old keyframes to overcome the limitation of the sliding window approach. We evaluate the robustness and accuracy of the proposed method with the EuRoC benchmark dataset, which contains various challenges, and show that ours outperform the state-of-the-art VIO systems.
The problem of state estimation of UAVs is a challenging research topic due to its dynamic motion and interaction with the unknown environment. Therefore, we are interested in further extending the algorithm with additional sensors for stable operation in the real world. In addition, we are planning the dense map reconstruction from the reliable device poses estimated from various sensors. The high-density reconstruction of the environment can be applied to various applications such as obstacle detection, re-localization, and 3D object tracking, which will help UAVs become more practical.
















{kind=link}
{kind=link}
{kind=link}
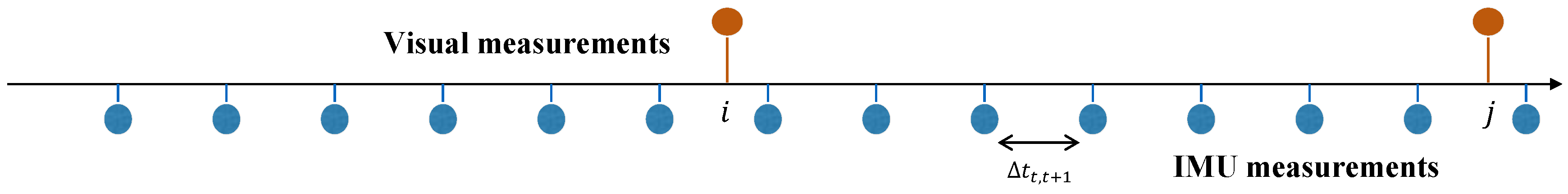{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}