Driver’s Facial Expression Recognition in Real-Time for Safe Driving



Abstract
:1. Introduction
2. Related Work
- To generate the optimal split function of a tree, we propose using data similarity for information gain instead of entropy.
- We improve the classification performance by changing the hierarchical structure of the classifier and improve the WRF instead of using a general RF.
- In experiments in which the results of our study were compared with those of state-of-the-art studies using various benchmark databases, the proposed method shows good performance with a fast speed.
- The proposed method is successfully applied to the database consisting of images captured in an actual driving environment, and we confirm that its FE accuracy is high despite changes in various external environments.
- Through the proposed FER method, we show the possibility to apply the proposed method to the embedded systems such as intelligent vehicles entertainment, education, virtual reality, and games without sacrificing accuracy.
3. Facial Expression Recognition Approach
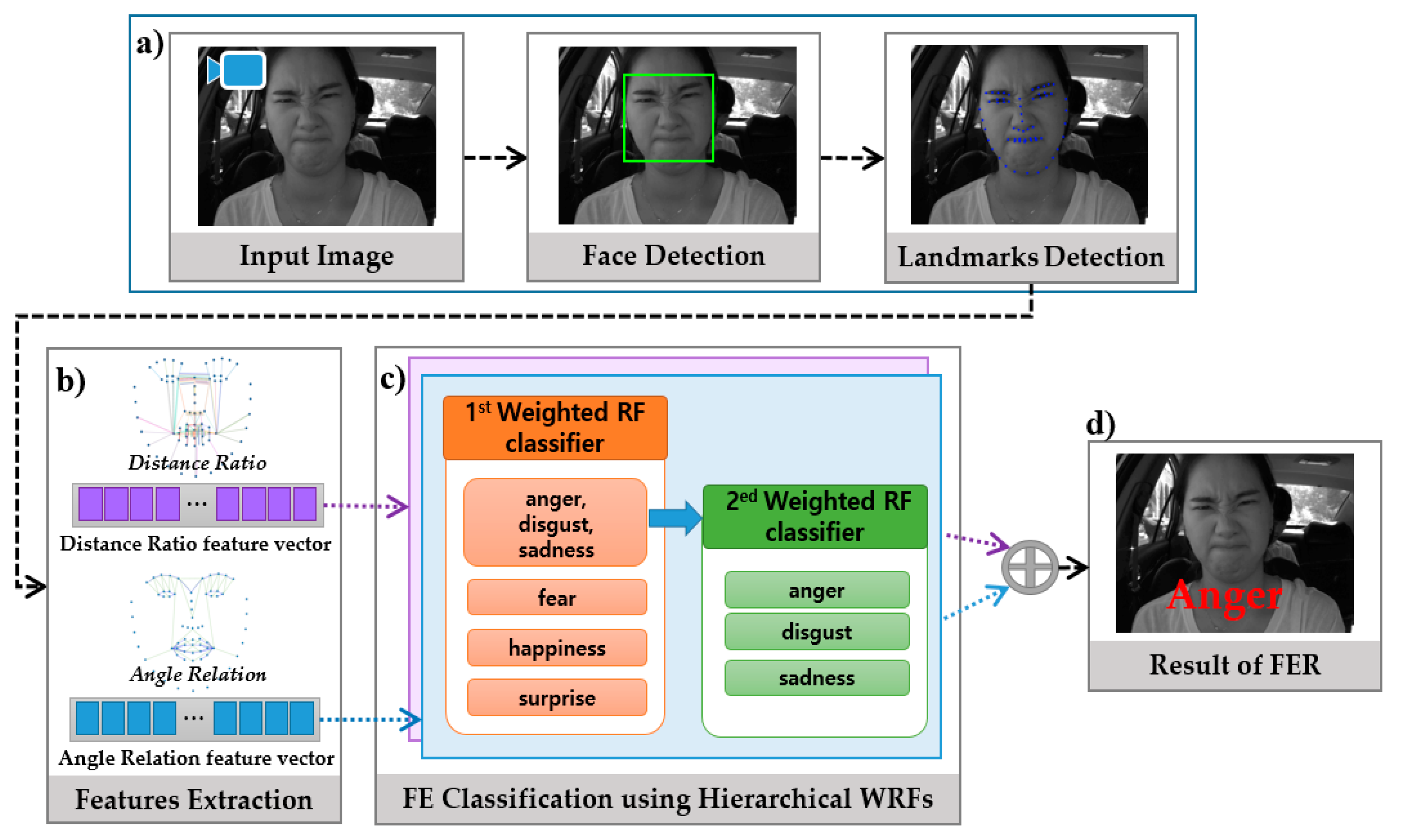
3.1 System Overview
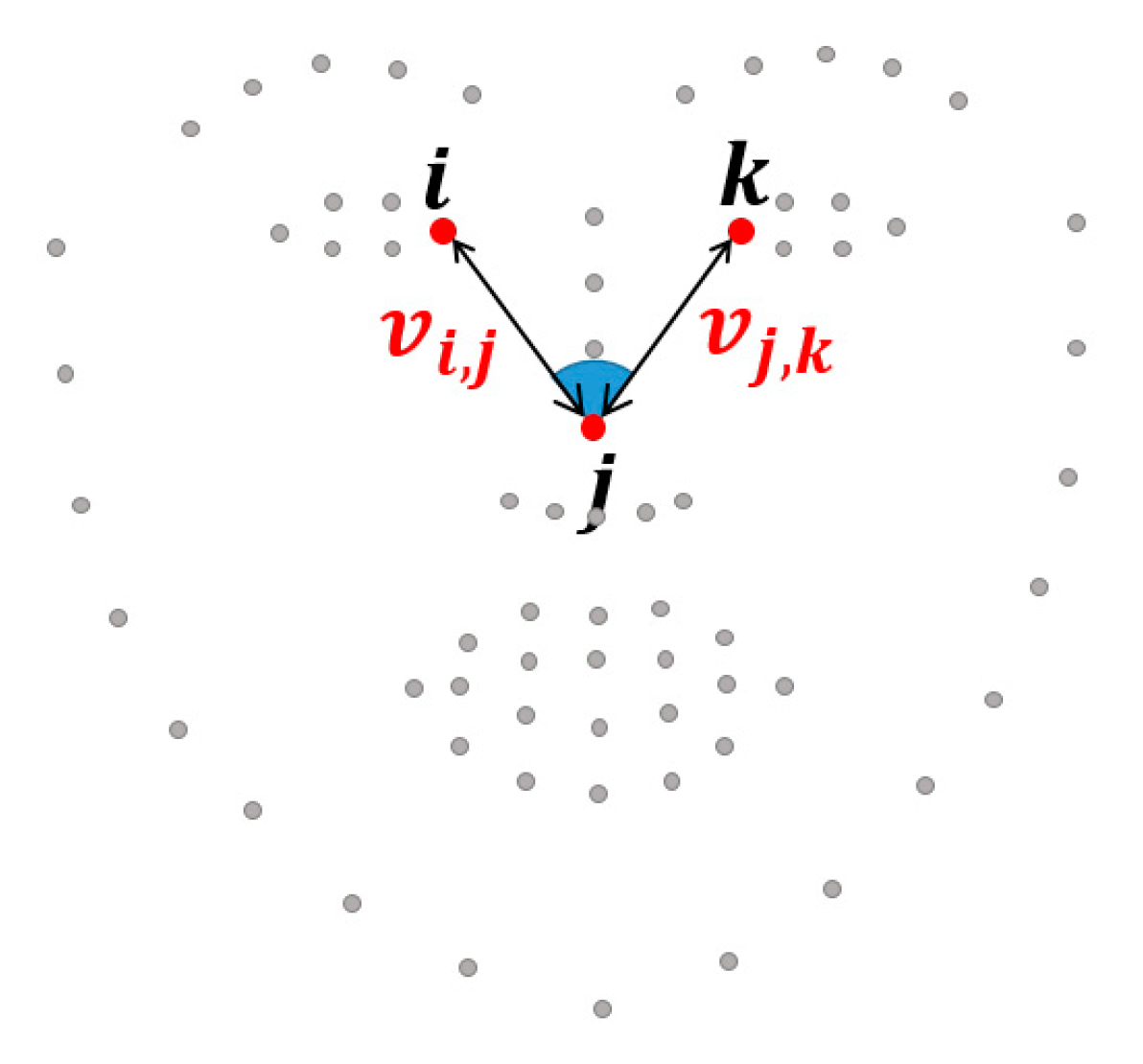
3.2. Geometric Features
3.3. Facial Expression Classification
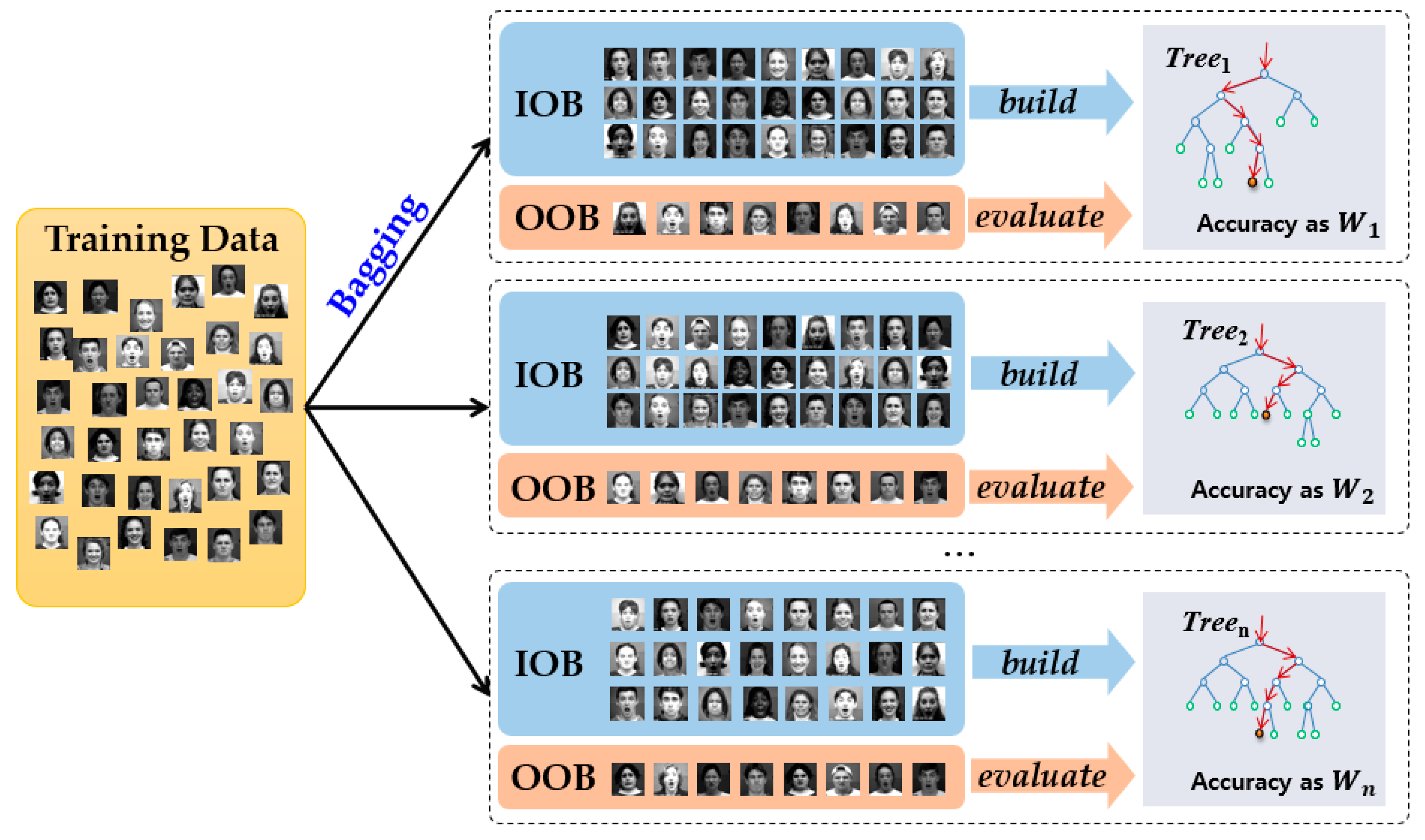
3.3.1. Random Forest Classifier
3.3.2. Data Similarity for Information Gain
3.3.3. Hierarchical Weighted Random Forest Classifier
4. Experimental Results
4.1. Databases
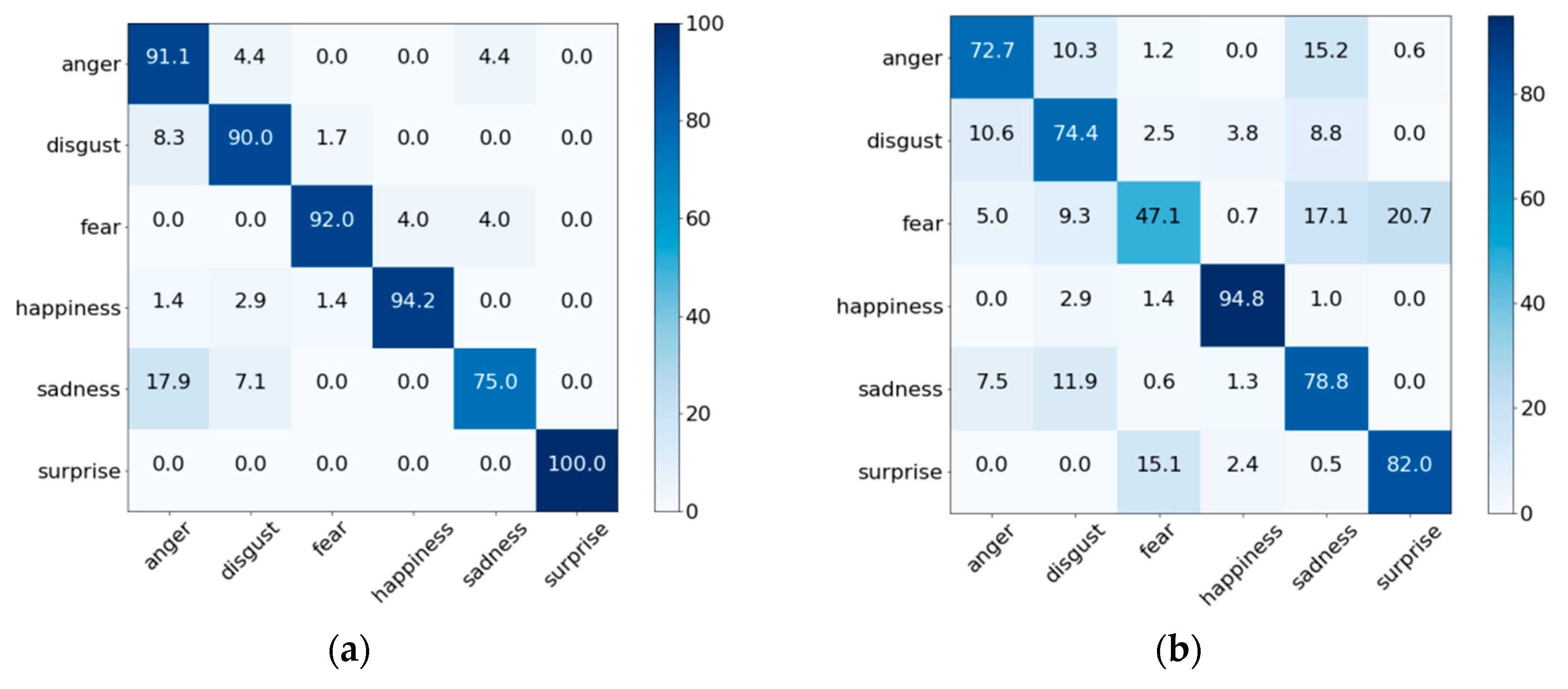
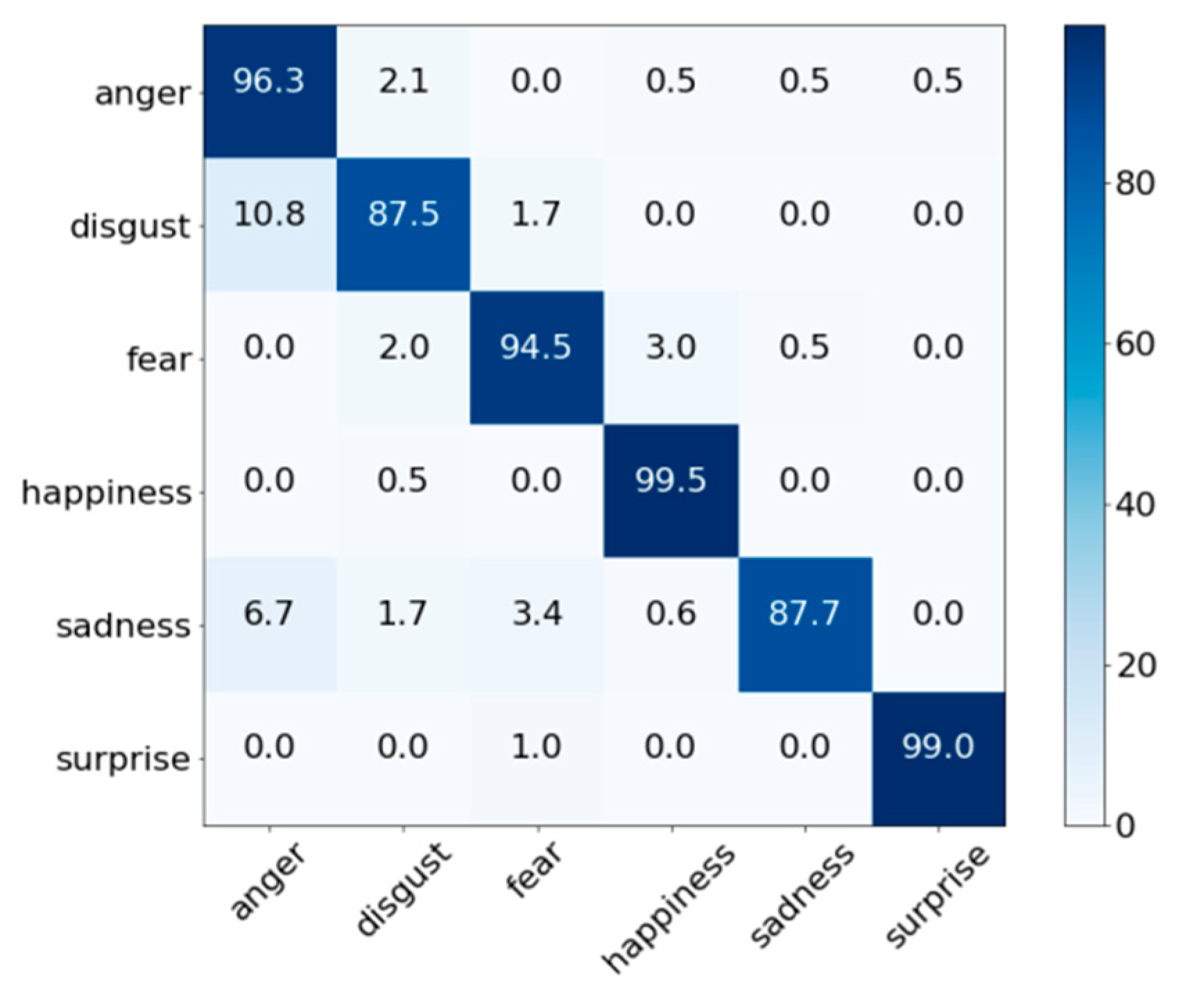
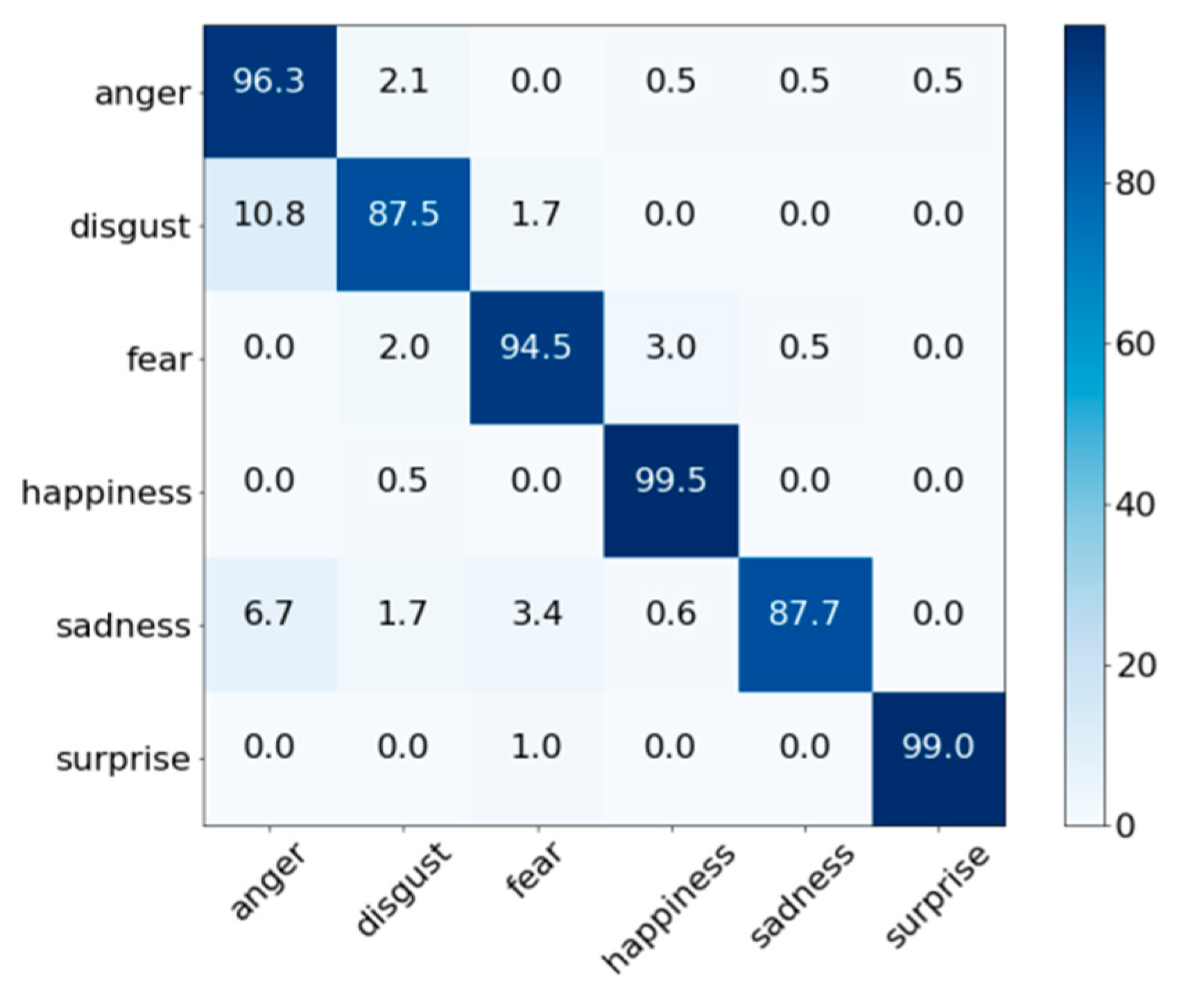
4.2. Facial Expression Recognition Performance Evaluation
4.3. Comparison of Parameter Numbers and Operations
4.4. Expression Recognition Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, H.; Ciftci, U.; Yin, L. Facial Expression Recognition by De-expression residue Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2168–2177. [Google Scholar]
- Bartneck, C.; Lyons, M.J. HCI and the face: Towards an art of the soluble. In Proceedings of the International Conference on Human-Computer Interaction: Interaction Design and Usability, Beijing, China, 22–27 July 2007; pp. 20–29. [Google Scholar]
- Hickson, S.; Dufour, N.; Sud, A.; Kwatra, V.; Essa, I.A. Eyemotion: Classifying facial expressions in VR using eye-tracking cameras. arXiv, 2017; arXiv:1707.07204. [Google Scholar]
- Chen, C.H.; Lee, I.J.; Lin, L.Y. Augmented reality-based self-facial modeling to promote the emotional expression and social skills of adolescents with autism spectrum disorders. Res. Dev. Disabil. 2015, 36, 396–403. [Google Scholar] [CrossRef] [PubMed]
- Zhan, C.; Li, W.; Ogunbona, P.; Safaei, F. A real-time facial expression recognition system for online games. Int. J. Comput. Games Technol. 2008, 2008, 542918. [Google Scholar] [CrossRef]
- Mourão, A.; Magalhães, J. Competitive affective gaming: Winning with a smile. In Proceedings of the ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 83–92. [Google Scholar]
- Ko, B. A Brief Review of Facial Emotion Recognition Based on Visual Information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Assari, M.A.; Rahmati, M. Driver drowsiness detection using face expression recognition. In Proceedings of the IEEE International Conference on Signal and Image Processing Applications, Kuala Lumpur, Malaysia, 16–18 November 2011; pp. 337–341. [Google Scholar]
- Zhao, K.; Chu, W.S.; Zhang, H. Deep Region and Multi-label Learning for Facial Action Unit Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3391–3399. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- Shan, C.; Gong, S.W.; McOwan, P. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Suk, M.H.; Prabhakaran, B. Real-time Mobile Facial Expression Recognition System—A Case Study. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 28 June 2014; pp. 132–137. [Google Scholar]
- Carcagnì, P.; Coco, M.D.; Leo, M.; Distante, C. Facial expression recognition and histograms of oriented gradients: A comprehensive study. Springer Plus 2015, 4, 645. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ai, H.; Wu, B.; Huang, C. Real time facial expression recognition with AdaBoost. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; pp. 1–4. [Google Scholar]
- Uddin, M.Z.; Lee, J.J.; Kim, T.S. An enhanced independent component-based human facial expression recognition from video. IEEE Trans. Consum. Electron. 2009, 55, 2216–2224. [Google Scholar] [CrossRef]
- Orrite, C.; Ganan, A.; Rogez, G. Hog-based decision tree for facial expression classification. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Póvoa de Varzim, Portugal, 10–12 June 2009; pp. 176–183. [Google Scholar]
- OuYang, Y.; Sang, N. Robust automatic facial expression detection method. J. Softw. 2013, 8, 1759–1764. [Google Scholar] [CrossRef]
- Greche, L.; Es-Sbai, N. Automatic System for Facial Expression Recognition Based Histogram of Oriented Gradient and Normalized Cross Correlation. In Proceedings of the 2016 International Conference on Information Technology for Organizations Development (IT4OD), Fez, Morocco, 30 March–1 April 2016. [Google Scholar]
- Zavaschi, T.H.H.; Britto, A.S., Jr.; Oliveira, L.E.S.; Koerich, A.L. Fusion of feature sets and classifiers for facial expression recognition. Expert Syst. Appl. 2013, 40, 646–655. [Google Scholar] [CrossRef]
- Barroso, E.; Santos, G.; Proenca, H. Facial expressions: Discriminability of facial regions and relationship to biometrics recognition. In Proceedings of the 2013 IEEE Workshop on Computational Intelligence in Biometrics and Identity Management (CIBIM), Nanyang, Singapore, 16–19 April 2013; pp. 77–80. [Google Scholar]
- Luo, Y.; Wu, C.; Zhang, Y. Facial expression recognition based on fusion feature of PCA and LBP with SVM. Optik-Int. J. Light Electron Opt. 2013, 124, 2767–2770. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, T.; Mao, Q.; Xu, C. Joint pose and expression modeling for facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3359–3368. [Google Scholar]
- Hasani, B.; Mahoor, M.H. Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2278–2288. [Google Scholar]
- Chang, J.Y.; Chen, J.L. A facial expression recognition system using neural networks. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 10–16 July 1999; pp. 3511–3516. [Google Scholar]
- Jeong, M.; Heo, D.; Nam, J.Y.; Ko, B.C. A Real Time Facial Expression Recognition for Online Embedded Devices Requiring User’s Emotional Interaction. In Proceedings of the Multi Conference on Computer Science and Information Systems(MCCSIS), Madrid, Spain, 17–20 July 2018; pp. 214–220. [Google Scholar]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models-their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Sauer, P.; Cootes, T.; Taylor, C. Accurate regression procedures for active appearance models. In Proceedings of the British Machine Vision Conference (BMVC), Scotland, UK, 29 August–2 September 2011; pp. 1–11. [Google Scholar]
- Choi, H.C.; Oh, S.Y. Realtime Facial Expression Recognition using Active Appearance Model and Multilayer Perceptron. In Proceedings of the 2006 International Joint Conference, Busan, Korea, 18–21 October 2006; pp. 5924–5927. [Google Scholar]
- Tanchotsrinon, C.; Phimoltares, S.; Maneeroj, S. Facial expression recognition using graph-based features and artificial neural networks. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques (IST), Penang, Malaysia, 17–18 May 2011; pp. 331–334. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the IEEE computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2018; pp. 94–101. [Google Scholar]
- Perikos, I.; Paraskevas, M.; Hatzilygeroudis, I. Facial expression recognition using adaptive neuro-fuzzy inference systems. In Proceedings of the 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 1–6. [Google Scholar]
- Lyons, M.J.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wave. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo (ICME), Amsterdam, The Netherlands, 6 July 2005; pp. 317–321. [Google Scholar]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd International Conference on Language Resources and Evaluation Workshop on EMOTION, Valletta, Malta, 17-23 May 2010; pp. 65–70. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply learning deformable facial action parts model for dynamic expression analysis. In Proceedings of the Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014; pp. 143–157. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-pie. In Proceedings of the Eighth IEEE International Conference on Automatic Face and Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–8. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Static facial expression analysis in tough conditions: Data, evaluation protocol and benchmark. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2106–2112. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Ko, B.C.; Jeong, M.; Nam, J.Y. Fast human detection for intelligent monitoring using surveillance visible sensors. Sensors 2014, 14, 21247–21257. [Google Scholar] [CrossRef] [PubMed]
- Ko, B.C.; Kim, D.T.; Jung, J.H.; Nam, J.Y. Three-level cascade of random forests for rapid human detection. Opt. Eng. 2013, 52, 1–11. [Google Scholar] [CrossRef]
- Ko, B.C.; Kim, H.H.; Nam, J.Y. Classification of potential water body using Landsat 8 OLI and combination of two boosted random forest classifiers. Sensors 2015, 15, 13763–13777. [Google Scholar] [CrossRef] [PubMed]
- Li, H.B.; Wang, W.; Ding, H.W.; Dong, J. Trees weighting random forest method for classifying high-dimensional noisy data. In Proceedings of the IEEE International Conference on E-Business Engineering, Shanghai, China, 10–12 November 2013; pp. 160–163. [Google Scholar]
- Ko, B.C.; Kwak, J.Y.; Nam, J.Y. Wildfire smoke detection using temporal-spatial features and random forest classifiers. Opt. Eng. 2012, 51, 017208. [Google Scholar] [CrossRef]
- Jeong, M.; Ko, B.C.; Kwak, S.; Nam, J.Y. Driver Facial Landmark Detection in Real Driving Situations. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2753–2767. [Google Scholar] [CrossRef]
- FER-2013. Available online: https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data (accessed on 21 November 2018).
- KDEF. Available online: http://www.emotionlab.se/resources/kdef (accessed on 27 November 2017).
- KMU-FED. Available online: http://cvpr.kmu.ac.kr/KMU-FED.htm (accessed on 4 December 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1, 1097–1105. [Google Scholar] [CrossRef]
- Liu, X.; Vijaya Kumar, B.V.K.; You, J.; Jia, P. Adaptive Deep Metric Learning for Identity-Aware Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 20–29. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; 1–9arXiv:1704.04861. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv, 2016; 1–13arXiv:1602.07360. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison Methods | Accuracy (%) | |
|---|---|---|
| CK+ | MMI | |
| Real-time mobile FER [12] | 85.5 | - |
| AlexNets [49] | 92.2 | 56.0 |
| 3DCNN-DAP [36] | 92.4 | 63.4 |
| DNN [33] | 93.2 | 77.9 |
| Inception-ResNet and LSTM [23] | 93.2 | 77.6 |
| Adaptive Deep Metric Learning [50] | - | 78.5 |
| Single-WRF | 92.2 | 70.9 |
| Proposed hierarchical WRF+Info.Gain | 90.9 | 69.7 |
| Proposed hierarchical WRF+Data.Sim | 92.6 | 76.7 |
| Methods | Accuracy (%) | No. of Parameters (M) | No. of Operations (M) |
|---|---|---|---|
| AlexNets [49] | 85.5 | 61 | 720 |
| DNN [33] | 93.2 | 9 | 25 |
| MobileNet [51] | 92.1 | 1.32 | 76 |
| SqueezeNet [52] | 89.1 | 1.25 | 1700 |
| Proposed method | 92.6 | 0.25 | 0.0067 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, M.; Ko, B.C. Driver’s Facial Expression Recognition in Real-Time for Safe Driving. Sensors 2018, 18, 4270. https://doi.org/10.3390/s18124270
Jeong M, Ko BC. Driver’s Facial Expression Recognition in Real-Time for Safe Driving. Sensors. 2018; 18(12):4270. https://doi.org/10.3390/s18124270
Chicago/Turabian StyleJeong, Mira, and Byoung Chul Ko. 2018. "Driver’s Facial Expression Recognition in Real-Time for Safe Driving" Sensors 18, no. 12: 4270. https://doi.org/10.3390/s18124270
APA StyleJeong, M., & Ko, B. C. (2018). Driver’s Facial Expression Recognition in Real-Time for Safe Driving. Sensors, 18(12), 4270. https://doi.org/10.3390/s18124270