1. Introduction
Feature-based matching is highly robust to image identity changes and distortions, which makes it provide high confident correspondences [
1]. Therefore, in remote sensing (RS), feature-based matching is widely used in applications with complex image changes such as wide-baseline stereo matching [
2,
3,
4] and bundle adjustment [
5,
6]. Furthermore, the dense and redundancy matched features in satellite imagery can be used for reconstructing high-resolution Digital Terrain Models (DTM) [
3,
7,
8], constructing a constraint initializer for the next step of dense matching [
9] and estimating Exterior Orientation/georeferencing Parameters (EOP) [
10] which may be not provided for commercially available [
11].
However, due to that the feature-matching algorithms usually require costly computations, they could be barely used for matching all features extracted from high-resolution pushbroom satellite imagery. For instance, a graph based method Graph Transformation Matching (GTM) [
12] was introduced to enforce the spatial constraint by constructing a median K-NN graph and its time computational complexity is
. Based on the basic idea of GTM, some algorithms were proposed for improving the robustness and accuracy of it: instead of using a fixed average distance for each image, the Weight Graph Transformation Matching (WGTM) algorithm [
13] used the angular distance between edges, which connect a feature-point to its K-NN graph, as the weight; the Spatial Order Constraints Bilateral-Neighbor Vote (SOCBV) [
14] algorithm replaced the undirected K-NN graph with a directed one and formulates the feature-matching problem as a binary discrimination problem; the Spatial Order Constraints (RSOC) [
15] formulated the feature-matching as an optimization problem for considering both local structure and global information; the Neighborhood Spatial Consistent Matching (NSCM) [
16] algorithm was proposed to remove outliers whose offsets between matched features have sudden mutations. The computational complexities of WGTM, SOCBV, RSOC and NSCM are
,
,
and
respectively. Hence, unfortunately, the aforementioned algorithms could not be applied on matching dense features extracted from high-resolution satellite imagery, since the numbers of dense features are usually over
and the aforementioned algorithms will cost days or even run out of memory for matching the dense features [
17].
Moreover, the existing feature-matching algorithms are mostly based on the conventional feature-matching model—i.e., before they removing false-matches, the putative matches have to be generated by a global one-to-one matching whose computational complexity is
. Therefore, even some feature-matching algorithms (the locally linear transforming (LLT) [
18] and a probabilistic method [
19]) can reduce the computational complexity of removing false-matches to linearithmic, their computational complexities of generating putative matches are still
.
For replacing the conventional feature-matching model, this paper presents a fast dense (FD) feature-matching model which splits the global one-to-one matching into numerous dynamic local matchings so that the complexity of generating putative matches is reduced to linear. Moreover, based on the FD model, feature-matching algorithms with high computational complexity could also be used for matching dense features extracted from high-resolution satellite imagery since the numbers of features in each local matching are much less than the original number of features in the global matching. Note that, the definition of dense feature-matching in this paper is given as—matching images with features as dense as possible. Hence, the goal of dense feature-matching is to match the high-resolution images with all the extracted dense features.
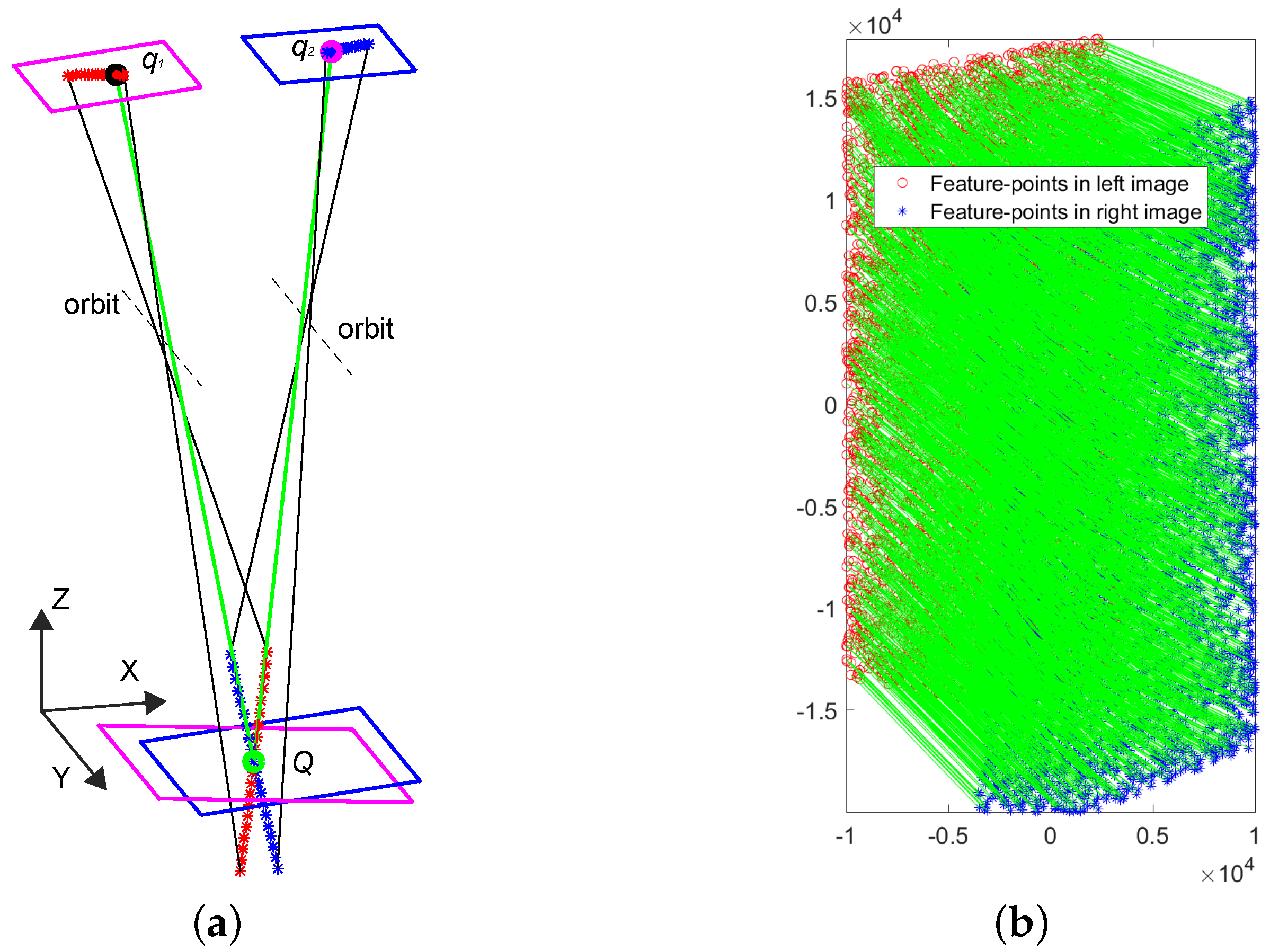
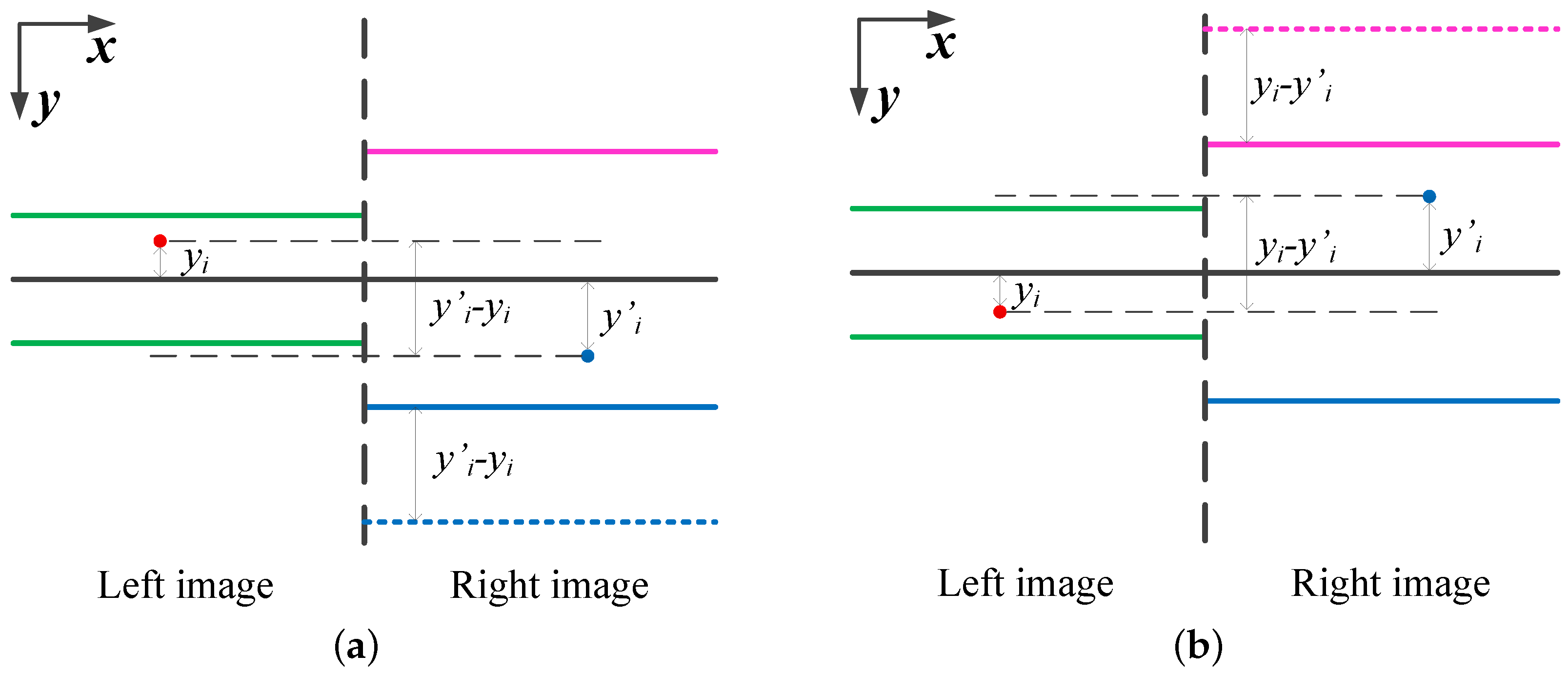
In particular, the FD model is designed to match features from cross-track pushbroom satellite imagery. Unlike frame cameras that have well-known epipolar geometry, the physical structures of linear pushbroom cameras are more diverse and complex; the resulting epipolar curves of linear pushbroom cameras are hyperbola-shaped not straight [
20,
21]. As a result, it is almost impossible to define the epipolar geometry of linear pushbroom cameras rigorously [
22].
Nevertheless, the FD model only aims to segment the global matching not eliminating the vertical-parallax of stereo images. Consequently, there is no need to apply the rigorous resampling method on the FD model. In this paper, the process of minimizing the vertical-parallaxes of the rectified correspondences is solved by a classic frame-based rectification method [
23] which is well-established and easily-implemented. To investigate the possibility of applying the classic frame based method on cross-track pushbroom satellite imagery, a comprehensive feasibility study is given in this paper. Based on this study, the larger difference of emission angles the satellite cameras have, the more complicated epipolar geometry they will get. As a result, the frame-based method may not work in pushbroom images which have large difference of emission angles. For increasing the success rate of the frame-based method on cross-track satellite imagery, a Correspondence-Direction-Constraint (CDC) algorithm is proposed in the FD model for obtaining the most favourable seed-matches.
To evaluate the FD method, a cross-track pushbroom based automatic feature-matching evaluation platform [
17] is introduced for providing comprehensive experiments end evaluating the matching results automatically. Meanwhile, 22 pairs of real cross-track pushbroom satellite images were also prepared for both training (2 pairs) the FD model and testing (20 pairs) the FD and the conventional models.
The primary research contributions of the FD model can be summarized as follows:
Based on the FD model, the computational complexity of generating putative feature-correspondences is reduced from to linear.
Features in a certain local matching are independent to the features in other local matchings. Hence, feature-matching can be operated in parallel by applying the FD model.
A comprehensive feasibility study of applying the classic frame-based rectification method on cross-track pushbroom satellite imagery is given in this paper.
Based on the CDC algorithm, the success rate of minimizing vertical-parallaxes of the pushbroom stereo images by the frame-based method is improved significantly.
The rest of this paper is organized as follows: the feasibility study of applying the classic frame-based method [
23] on cross-track pushbroom satellite imagery is introduced in
Section 2. The implementation detail of the FD model is described in
Section 3. Parameters setting and the performance evaluation of the FD model are discussed in
Section 4. Finally, the paper is concluded in
Section 5.
4. Experimental Results
As mentioned before, the main purpose of this paper is to reduce the computational complexity of feature-matching by replacing the conventional feature-matching model with the proposed FD model. Therefore, the performances of the FD model and the conventional feature-matching model were evaluated by performing three state-of-art feature-matching algorithms (LLT [
18], SOCBV [
14] and WGTM [
13]) on both an automatic feature-matching evaluation platform [
17] and 22 pairs of real HiRISE stereo images based on these two models (in
Section 4.4 and
Section 4.5). The computational complexity of the proposed FD model, the datasets and the parameters mentioned previously are discussed in
Section 4.1,
Section 4.2 and
Section 4.3 respectively.
In addition, all the experiments are performed on two personal computers, each with an Intel i5 CPU (3.3 GHz and 4 cores) and 16-GB RAM. The program of the proposed FD model is wrote in MATLAB code, where the source codes are available at
https://github.com/WenliangDu/FastDenseFeatureMatchingModel.
4.1. Computational Complexity
If the FD model is not operated in parallel, its time complexity is which can be simplified as , where N denotes the total number of feature-correspondences, a denotes the average number of feature-correspondences in each local matchings ().
The worst case of the FD model is that there is only one local matching in the FD model, which means and the worst complexity of the FD model is . The best case is that each correspondences are exactly arranged in each independent local matchings so that and the best complexity of the FD model is . To bring in the best performances of the existing feature-matching algorithms, in the experiments of real HiRISE images, the value of a was kept just larger than 300 which is also greatly less than N (usually more than 10,000).
4.2. Datasets
The datasets provided by the automatic feature-matching evaluation platform [
17] can evaluate the performances of the two models automatically. The platform was simulated as the HiRISE camera which is on board NASA’s Mars Reconnaissance Orbiter (MRO). Therefore, the specification of the simulated remote sensor was set as [
29]—focal length: 12 m, camera distance: 300 km, field of view (FOV):
, the number of pixels in the linear CCD array: 20,048 (10 RED CCDs), the number of along-track lines: 40,000. The source codes of the platform are available at
https://github.com/WenliangDu/RS-FeatureMatchingEvaluatingPlatform.
20 pairs of real HiRISE stereo images were used for testing the two models and the results were evaluated manually. 2 pairs of real HiRISE stereo images were used for training the value of
(in Equation (
7)) used in the FD model. The HiRISE stereo images could be downloaded from
https://hirise.lpl.arizona.edu.
4.3. Parameters Discussion
In
Section 3.2,
N features need to be sampled from
U and to match all the
for generating the initial seed-matches. In this paper, the value of
N is set as 1000.
The value of
in Equation (
7) is set as 1 for the datasets simulated by the automatic evaluation platform. In contrast, the value of
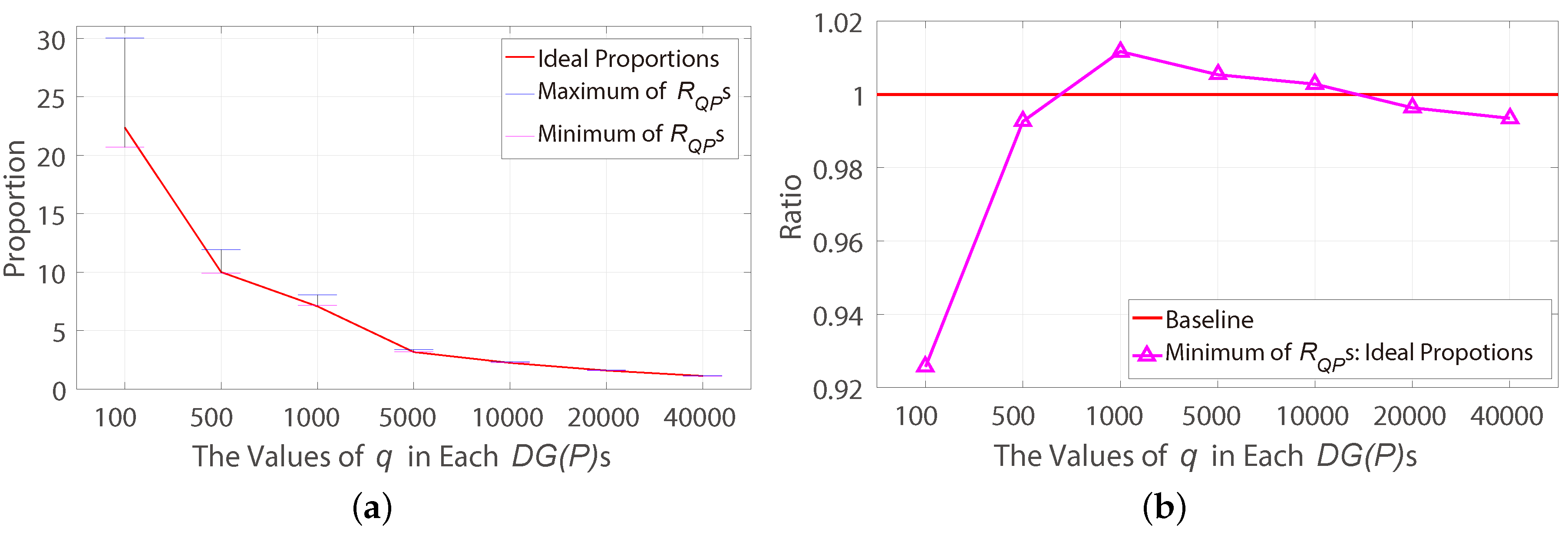
is trained by the 2 pairs of HiRISE images and set as
, which means the initial seed-matches/control-points generated by RANSAC may be not evenly-distributed, since the features in the flat area may be too similar to each other.
4.4. Automatic Performance Evaluation
Four groups of datasets were prepared by the automatic evaluation platform [
17] for evaluating the two models in various differences of slewing and emission angles (
to
), ratios of false-matches (
to
) and numbers of feature-correspondences (1000 to 5000). For each experiment in all the groups, 50 different datasets were prepared. Hence, the result of each experiment was gathered with the average values of 50 independent tests; totally, 850 datasets were simulated for automatically evaluating.
In the first two groups, the differences of slewing and emission angles were both varied from to . The ratio of false-matches, which can be also called as outliers’ ratio, was set as . Because the execution time of feature-matching algorithms based on the conventional model is usually to long, the number of feature-correspondences was selected as 2000. Note that, the slewing and emission angles of the platform were randomly sampled from to .
The performances of the three state-of-art feature-matching algorithms based on the two matching models were evaluated on four generic criteria [
13,
30]:
where
and
denote the number of resulting true-matches and false-matches respectively,
and
denote the number of missing true-matches and false-matches. Therefore, the
describes the degree of true-matches to all matches, the
gives the degree of remaining true-matches to all remaining feature-correspondences, the
tells the degree of the number of remaining true-matches to the number of all true-matches, the
states the degree of the number of discriminated false-matches to the number of all false-matches.
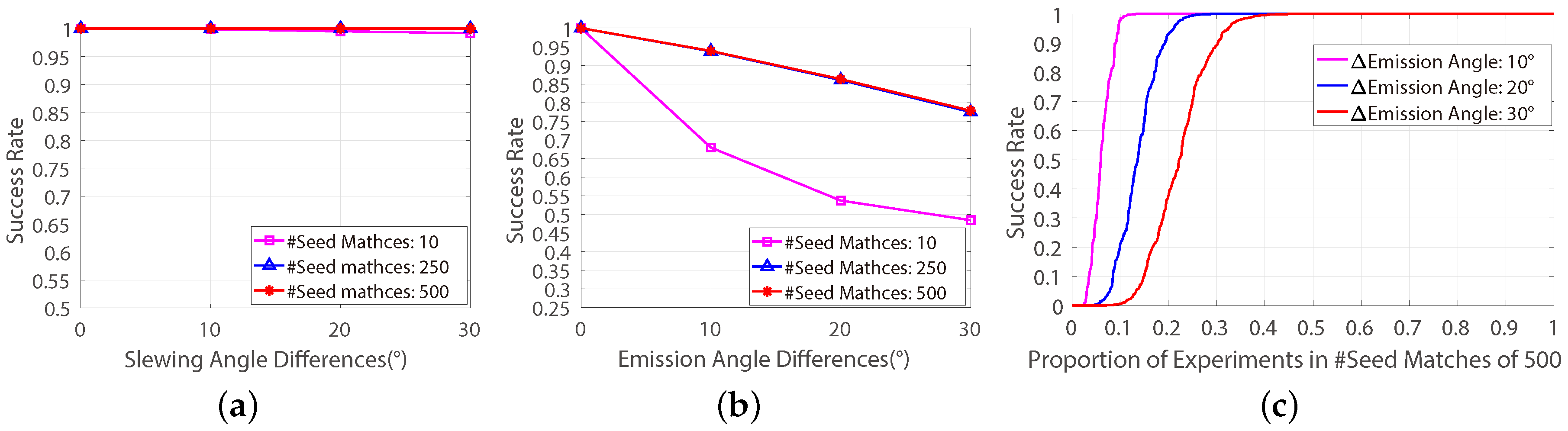
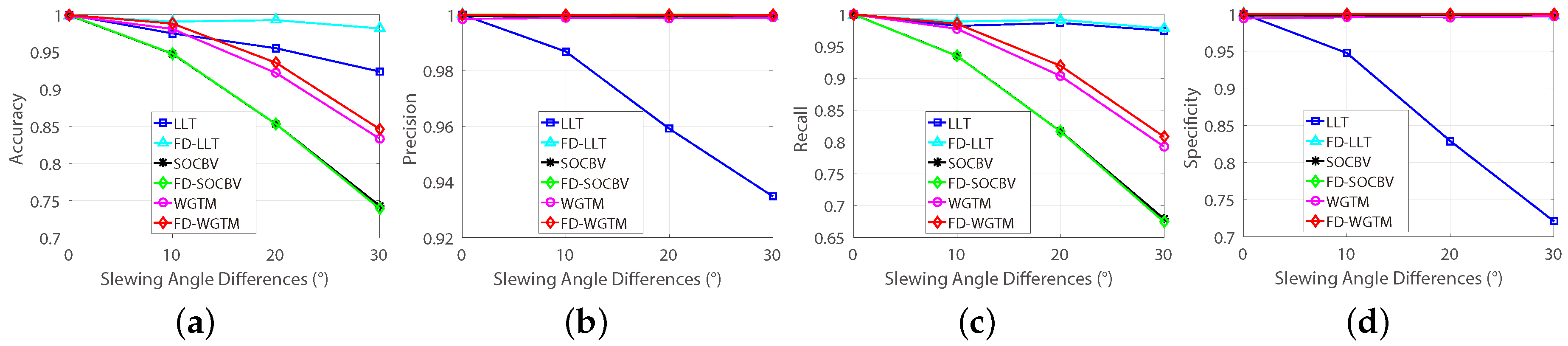
The automatic evaluation results of the first group datasets are shown in
Figure 10, where the “FD-” means that the corresponding algorithm was performed on the FD model, otherwise the algorithm was performed on the conventional model. Apparently, the abilities of preserving true-matches of SOCBV and WGTM algorithms based on both the two models are declined while increasing the differences of slewing angle (see
Figure 10a,c). In contrast, the ability of removing false-matches of the LLT is improved significantly when it is based on the FD method (see
Figure 10b,d).
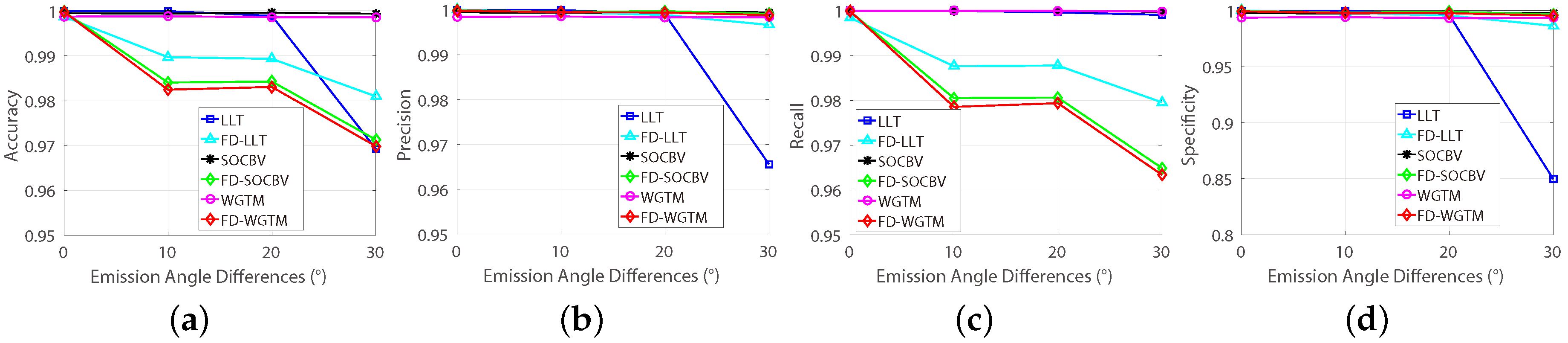
According to
Figure 11, in contrast to the three method based on the conventional model, the abilities of preserving true-matches of the three method based on the FD model are indeed decreased but not insignificant (1 to
, see
Figure 11c), which is reasonable, since the epipolar geometry is getting more complicated while increasing the differences of the emission angle. However, when the difference of emission angle goes to
, the ability of eliminating false-matches declines of the LLT based on the FD model is greater than it is based on the conventional model.
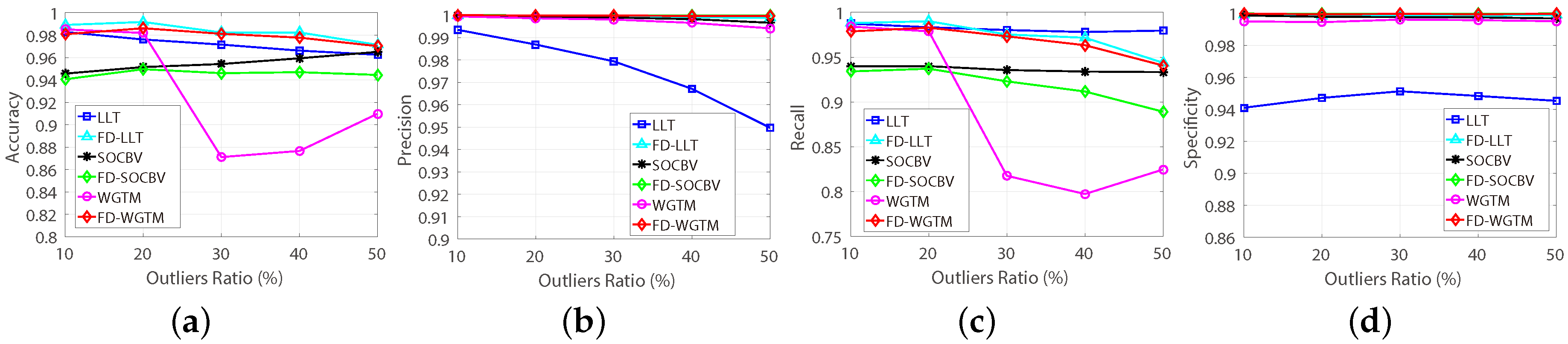
The performances of the three matching algorithms on various ratios of false-matches are shown in
Figure 12. As can be seen, for higher ratios of false-matches, the ability of WGTM algorithm for preserving true-matches and the ability of LLT algorithm for eliminating false-matches are improved when they are performed on the FD model (see
Figure 12c,d). As can be seen in
Figure 12d, the three algorithms can remove nearly all the false-matches based on the FD model.
The datasets with various numbers of feature-correspondences were used for evaluating the running time of the two models; the corresponding results are shown in
Table 1. Obviously, when SOCBV and WGTM algorithms were performed on the FD model, their operating time reduced substantially then they were performed on the conventional model. Therefore, by applying the FD model, SOCBV and WGTM algorithms could be performed on high-resolution pushbroom satellite images which contain very dense feature-correspondences, even the complexities of them are very high. On the other hand, for the LLT algorithm, its operating time increased slightly when it was performed on the FD model, while its operating time is still very low.
4.5. Performance Evaluation on HiRISE images
The three algorithms were only performed on the FD model for matching the 22 pairs of real HiRISE images, because the complexities of SOCBV and WGTM algorithms are so high that they may cost days or even weeks for matching one pair of HiRISE images when they are based on the conventional feature-matching model. Besides, the LLT algorithms runs out of memory for matching some of the 22 pairs of HiRISE images when it is based on the convention model obtained.
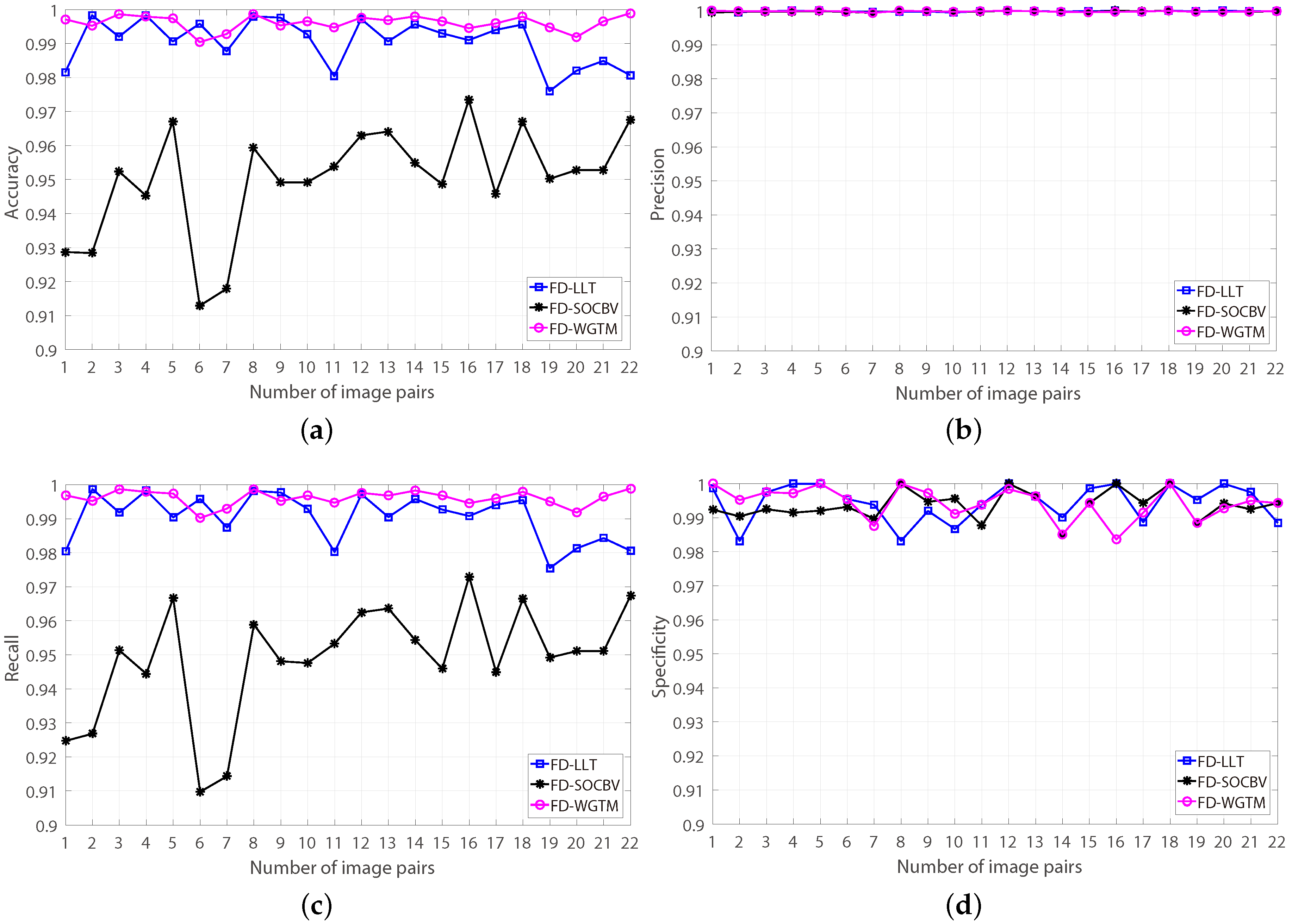
The results of the three algorithms of matching the 22 pairs of real HiRISE images based on the FD model were evaluated manually. A manual evaluation for a matching result of an algorithm performed on one pair of HiRISE images cost us at least five minutes of human operator time, since the numbers of the resulting correspondences of most matching results are more than
. The evaluating results are shown in
Figure 13. It is apparent that, for all the 22 pairs of HiRISE images, all the three algorithms achieved good matching results when they were based on the FD model (more than
false-matches can be eliminated).
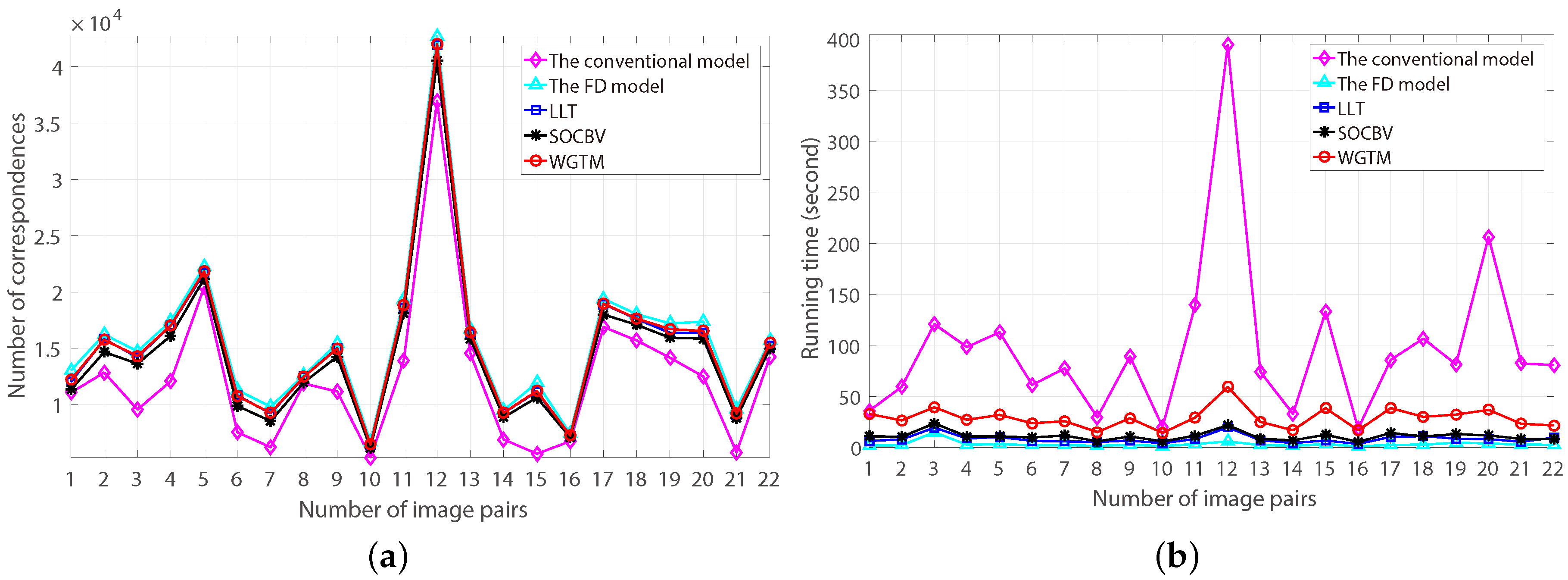
The number of resulting correspondences generated by the three algorithms based on the FD model and the number of putative correspondences generated by the conventional and the FD model are shown in
Figure 14a. As can be seen, all the three algorithms preserved more correspondences than the putative correspondences generated by the conventional model, since the FD model obtained much more putative correspondences than the conventional model.
The running time of eliminating false-matching by the three algorithms and generating putative-correspondences by the two models is shown in
Figure 14b. Obviously, the running time of the three algorithms and the FD model is all shorter than the running time of the conventional model. More specifically, based on the FD model, the running time of the SOCBV and WGTM algorithms for eliminating false-matches from the 22 pairs of high-resolution HiRISE images is always lower than 1 min, even the computational complexities of the two algorithms are both
.
5. Conclusions
To match dense features extracted from high-resolution cross-track pushbroom satellite imagery in efficiently, this paper proposed a fast dense (FD) feature-matching model. The FD model splits the global one-to-one matching into a large number of local matchings by minimizing the vertical-parallaxes with the help of a classic frame-based rectification method [
23]. By replacing the conventional feature-matching model with the FD model, the computational complexity of generating putative-correspondences is reduced from
to linear. Based on the FD model, the existing feature-matching algorithms could be applied on matching dense features extracted from high-resolution satellite imagery, even they have high computational complexities.
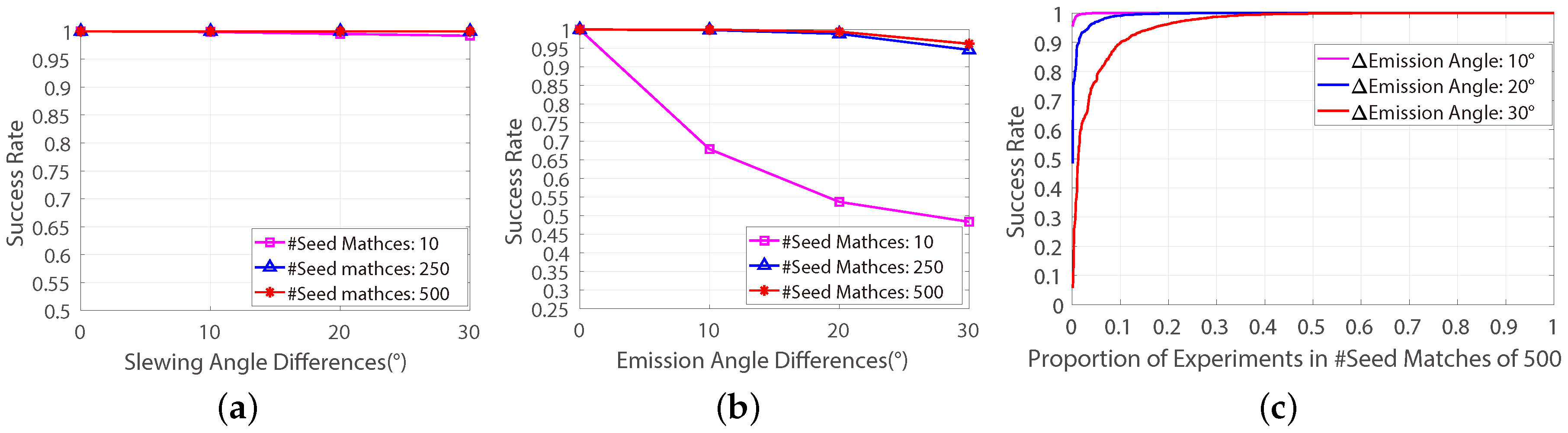
To ensure that the classic frame-based method is suitable for minimizing the vertical-parallaxes of cross-track pushbroom satellite imagery, a feasibility study was given in this paper by applying the frame-based method on 2.1 million independent experiments which were provided by a cross-track pushbroom based automatic feature-matching evaluating platform [
17]. This feasibility study shows that the success rate of the frame-based method for minimizing vertical-parallaxes of cross-track pushbroom images will decline when it is performed on images with large differences of emission angle of the satellite cameras (see
Figure 3). In order to increase the success rate, in the FD model, a correspondence-direction-constraint (CDC) algorithm was proposed to get the most favourable seed-matches for the frame-based method. Based on the FD model, the frame-based method could be used for getting reasonable splitting results in all the 2.1 million experiments (see
Figure 4).
The procedures of FD model include feature extraction, seed-matches initialization, minimizing vertical-parallaxes, dynamic searching range division and generating putative-correspondences. In the procedure of seed-matches initialization, a hypothesis was presented and verified by 7 million independent experiments for ensuring the initial seed-matches are evenly-distributed, since the evenly-distributed seed-matches can help dynamically adjust the searching ranges in the later procedure. In the procedure of minimizing vertical-parallaxes, the CDC algorithm was proposed for improving the stability of the frame-based method by identifying the most favourable combination of the initial seed-matches based on the k-means method. Eventually, the dynamic searching ranges are generated based on Equations (
14)–(
16). Because the features in a certain searching range are independent to features in other searching ranges, the matching process can be operated in parallel based on the FD model.
The performances of the FD model and the conventional feature-matching model were evaluated on both the cross-track pushbroom based automatic evaluating platform and real HiRISE images. Three state-of-art feature-matching algorithms (LLT [
18], SOCBV [
14] and WGTM [
13]) were used for evaluating the two models. According to the evaluation results based on the automatic evaluating platform, the running time of the SOCBV and WGTM algorithms reduced substantially when they were based on the FD model. Meanwhile, based on the FD model, all the three algorithms achieved the comparable matching results as they achieved based on the conventional model. On the other hand, the matching results of the two models on real HiRISE images were evaluated manually. The manual evaluating results shows that all the three algorithms achieved extremely good matching results for all the real HiRISE images prepared by this paper.
In the future, the dense and efficient matching results provided by the FD model may be used for automatic epipolar resampling of the cross-track pushbroom satellite imagery. Furthermore, the existing epipolar resampling methods are mostly based on the assumption that the trajectory of the remote sensor is straight [
20,
21,
22]. However, the remote sensors may be suffered high-frequency pointing variations (“jitter”) [
29]. Therefore, based on the dense matching results, the assumption of straight trajectory may be eliminated for the future epipolar resampling methods. Eventually, to bring in the best performances of the three feature-matching algorithms, in the experiments of real HiRISE images, the number of correspondences in each local matching was kept just larger than 300, which means the best performance of the FD model was not achieved. Therefore, a more suitable feature-matching algorithm for the FD model could be developed in the future.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}