1. Introduction
Power system state estimation (PSSE) has become an essential tool of energy and distribution management systems (EMS, DMS) aimed at controlling and planning of electric power grids [
1,
2]. With the advent of renewable energy along with the penetration of distributed energy resources (DERs), state estimation is assuming an expanded and prominent role. Determining factors, such as reliability and security, which have an influence upon service continuity, and economics, in terms of operating costs in power grids, greatly depend on the accuracy of the system state estimation, which in turn relies on the availability of reliable measurement data taken throughout the power system.
The power system state estimation is implemented by the control center (CC) which receives the measurement sets obtained from all the substations located throughout the network. These measurements range from bus voltages to bus real and reactive power injections, and branch reactive power flows in the power grid. Each substation is equipped with electronic instrumental transducers (EITs) which collect the analogue signals, process them and send the data to the CC.
The control center assumes, therefore, a crucial role in checking that the system satisfies the operational goals and ensures the power system reliability and security through the analysis of meter measurement data and power system models. However, the measurement data is not always accurate, on account of electromagnetic interferences, defective meters, noise in instruments and communications channels, errors in modeling pseudo measurements and false data injection attacks [
1,
3]. Such inaccurate measurements are commonly referred to as “bad data” (BD).
Many contributions to state estimation (SE) algorithms have been made in the past few decades [
2,
4,
5,
6,
7,
8]. Among them, weighted least squares (WLS) or least absolute value (LAV) estimators are commonly used in SE [
4,
5,
8] Furthermore, the availability of historical databases allows the extraction of information necessary to produce measurement forecasts, which can be integrated into the SE process. This scheme is known as forecasting-aided state estimation (FASE) [
6,
9]. These methods are, however, significantly affected by bad measurements resulting in poor state estimates [
2,
6]. Consequently, a pre-estimation BD detection in measurements is an important part of the SE problem. Unfortunately, not all BD can be detected and eliminated by a pre-estimation process. Therefore, virtually all WLS-based estimators systematically implement post-estimation detection and identification methods with more advanced features [
4].
In general, SE methods along with BD detection suffer from a main drawback, which questions the feasibility of their implementation in a real-time framework: the computational complexity, which is approximately proportional to the number of measurements used by the state estimator in the presence of BD. For instance, the computation of the residual covariance matrix in WLS algorithms, which requires the calculation of a subset of the elements in the inverse of the sparse gain matrix, is computationally intensive [
8]. Furthermore, the processes of SE and BD detection need multiple state estimations, i.e., it is an iterative process, which further increases the computational time since a re-estimation of the system is needed after every BD elimination.
To overcome this drawback, the amount of BD provided to the state estimator should be reduced by implementing a BD pre-filtering stage at a decentralized level in the substations. The proposed approach has all the advantages of decentralized methods: (1) scalability which is increased by reducing the communication overhead; (2) robustness to changes in the network configuration; (3) and computation and bandwidth overhead reduction at the control center level. More importantly, this decentralized approach eases the computational burden in the control center. Whereas BD post-estimation has received a lot of attention in literature in the past few years, BD pre-filtering lacks systematic procedures or new techniques at a decentralized level. The approach presented in this paper takes advantage of the computational resources, which are being installed in Secondary Substations in order to extend the real-time monitoring to Low Voltage (LV) grids. This is one of the main contributions of this paper.
This paper presents a strategy to filter the quantity of BD provided to the SE algorithms thereby significantly reducing the number of iterations required for the SE and BD detection and elimination. In particular, the strategy developed is aimed at detecting and identifying permanent meter failure, namely offset and gain errors, and meter malfunction in the measurement equipment (EITs), installed in secondary substations. The technique is based on short-term load forecasting (STLF), which in turn relies on a hybrid singular spectrum analysis—artificial neural network (SSA-ANN) approach for improved forecasting accuracy. Generally, in secondary substations, STLF has not been commonly used as an effective tool for error detection. It should be noted that at SS level, erroneous data is prevalent (up to 25% inaccurate measurements) which seriously jeopardizes the SE accuracy and forecasting [
10].
In the literature, there are many examples of using hybrid approaches based on SSA for forecasting in many different fields. In [
11] SSA is used for eliminating the noisy component of the time series and a local linear neuro-fuzzy model (LLNF) to forecast several well-known time series with different structures and characteristics. An integrated model based on ANN and SSA is presented in [
12] and is applied to forecast short-term wind speed. Recently, this model has also been used in [
13,
14] for precipitation forecasting. In [
15] authors study the importance of hybrid models for forecasting of hydrological data. The hybrid SSA-ANN model used in this paper differs from previous works in several ways: firstly, the grouping stage is automatized; secondly, it considers the residual as an important piece of information for the forecasting process; finally forecasting results are used for BD detection.
The remainder of this paper is organized as follows. In
Section 2 a global description of the system and the strategies developed for the BD detection are described.
Section 3 analyzes the STLF framework, and the results achieved are shown in
Section 4. Finally, some conclusions are drawn in
Section 5.
2. System Description
Secondary substations (SSs) are being provided with more intelligence in order to get a more accurate and realistic view on LV grids and to filter and analyze data before it is sent to the control center [
16]. Consequently, SSs can play an important role in this decentralized architecture, allowing the data flow to be optimized, thereby reducing the data that reaches the control center for analysis and decision-making.
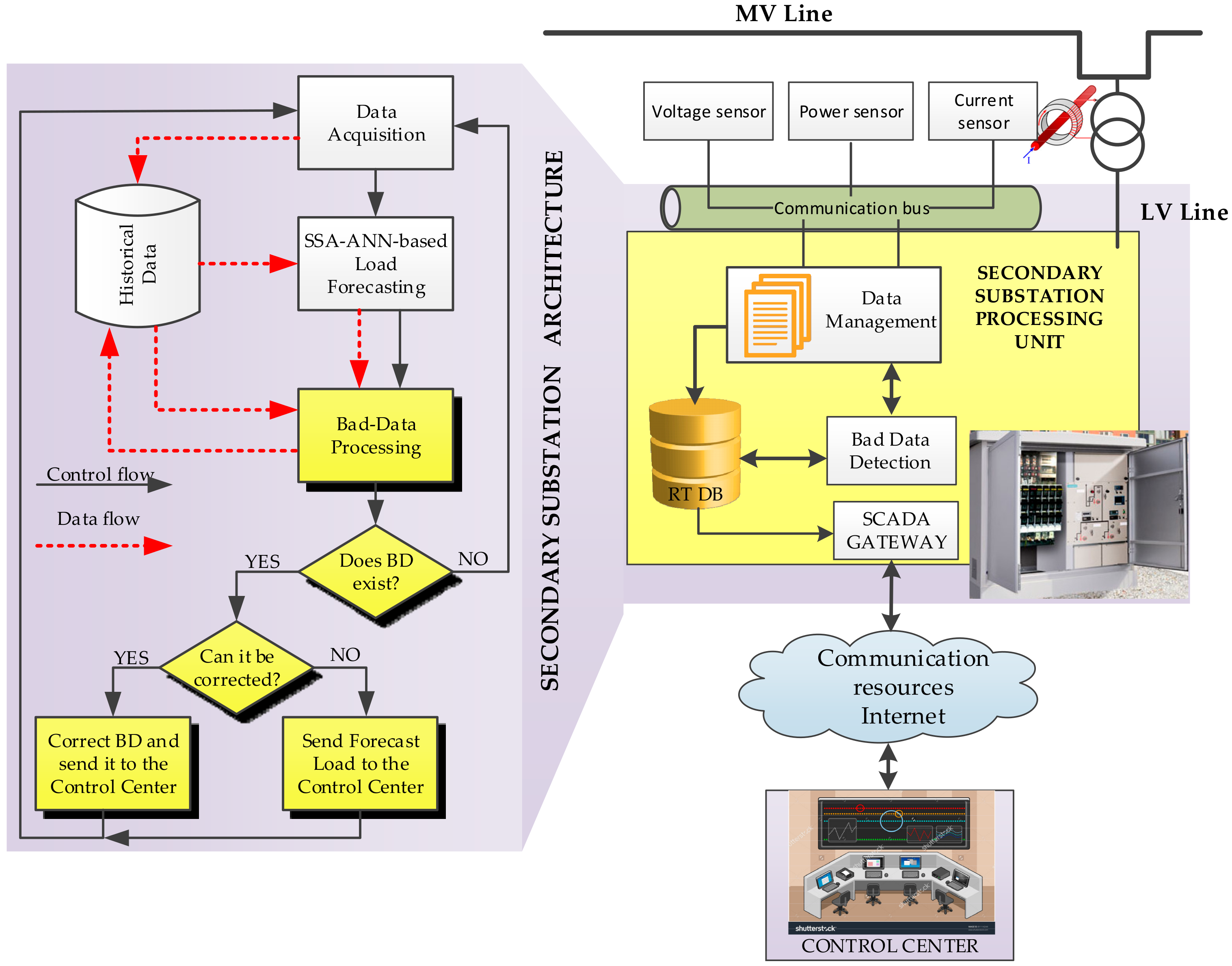
With this in mind,
Figure 1 shows a general view of the system presented in this paper and a flowchart of the algorithm implemented based on an iterative process. The main software components are represented in the substation processing unit. The data management module collects substation measurement data and stores it in the real time data base (RT DB). This data management module is, therefore, connected to the LV side by current transformers (CTs) and voltage transformers (VTs), which measure currents and voltages respectively. Furthermore, measurement units provide active and reactive power every ten minutes. For the case study, hourly average active power is considered. All the measurements are stored in the local data base, although they can be read and stored remotely in the control center database.
The bad data detection module implements the hybrid SSA-ANN-based algorithm for the detection, identification, and correction of the BD. This algorithm is depicted in the flowchart in
Figure 1. By using the proposed algorithm, BD is both detected and identified in the following step (bad data processing). Gain and offset errors in the measurement equipment are detected, quantified and used to correct, if possible, the erroneous measurements before they are sent to the control center. In the event of erroneous measurements, which do not fall into the patterns for the gain and the offset errors, forecast measurements are sent instead.
3. Short Term Load Forecasting Framework
In this section, the hybrid approach for STLF based on singular spectrum analysis (SSA) and artificial neural networks (ANN) is explained. In
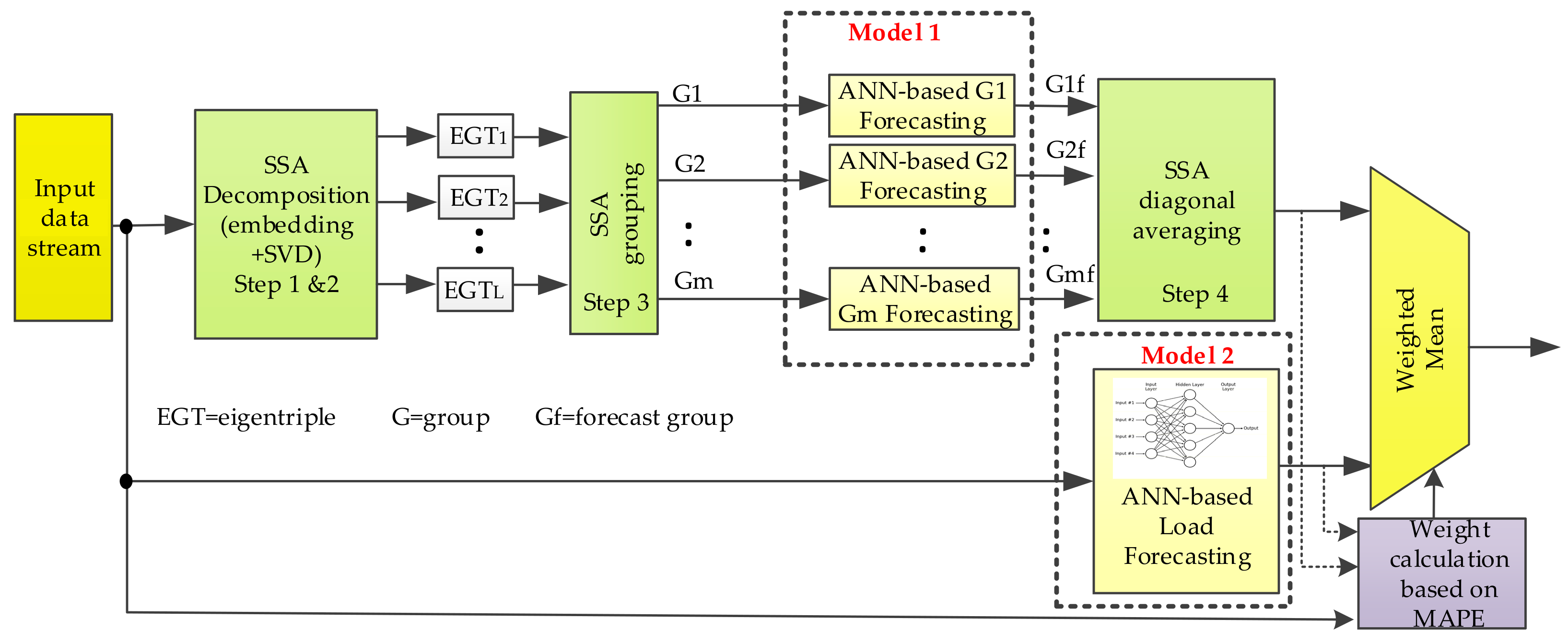
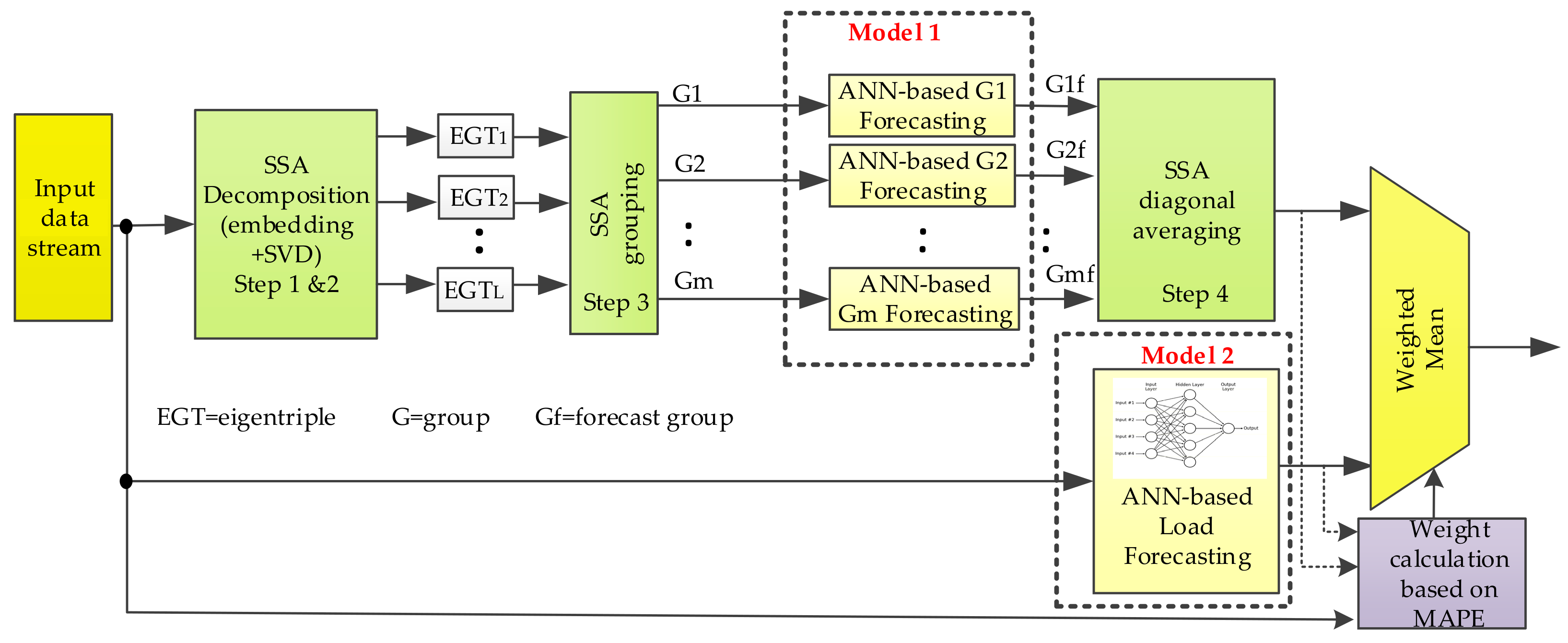
Figure 2 a block diagram of the prediction is shown in outline. The algorithm proposed in this paper consists of three different steps: (1) data preprocessing based on a SSA decomposition and a grouping stage to obtain the independent components of the time series (Model 1), namely trend, periodicities and residual. These components are then individually forecasted before the reconstruction step. By using SSA the forecasting process is boosted, since the extracted components show less complexity than the original time series, thereby facilitating the ANN learning process; (2) ANN-based STLF step in which the whole time series is predicted based on ANNs (Model 2); and (3) finally, by using mean absolute percentage error (MAPE), the weighted arithmetic mean of both forecasting datasets is calculated.
From a practical point of view, the process of forecasting works as follows. The input data stream (
Figure 2) is provided by the data acquisition module (
Figure 1) and the database on which the historical data is stored. This dataset is simultaneously fed to the SSA-ANN-based forecasting model (Model 1) and ANN-based forecasting model (Model 2). Regarding Model 1, by using SSA the dataset is decomposed in several additive components in the shape of groups of eigentriples which are individually forecasted. Then a 24-h prediction of the load is obtained through a SSA-based reconstruction stage. As far as Model 2 is concerned, the 24-h forecast is carried out by using an ANN-based strategy. Finally, the accuracy of both forecasts is assessed by using MAPE and their weighted mean constitutes the final prediction. It is, therefore, a combined strategy which chooses the more accurate prediction of the two models mentioned before, by giving more priority to that prediction with less MAPE. The weights are updated on a daily basis so as to compensate for any time-dependent variation.
In principle, ANNs should be able to approximate and generalize any nonlinear function to any degree of accuracy. The load dataset is a time series which displays trend and different levels of seasonality (daily, weekly and annual), which makes it nonstationary. The nonstationary aspect of many time series is a significant factor which hinders the ANN prediction performance. Therefore, it seems reasonable to remove from the load series the somewhat deterministic information, enhancing the ANN learning ability for modelling the important features. However, in STLF, seasonal patterns can interact with exogenous variables, mainly meteorological variables, and clearly influence the load. Therefore, short-term load forecasting strategies should take seasonal patterns into consideration to capture this correlation, with the exception of the annual seasonality, since STLF timeframes are substantially shorter in length than the annual cycle.
As far as the trend is concerned, ANN-based forecasting of trend time series is not straightforward on account of the bounded feature of the activation function used for the neurons of the hidden layer. This fact can have undesired effects on the dataset normalization i.e., values that are out of the range used for normalization. It is important to note that in STLF a trend is a valuable indicator of a systematic drift in the data caused by, for instance, a sensor drift. Hence, removing the trends from the data may be detrimental, since trends are useful in detecting systematic errors in measurements. In order to deal with this issue, expected values of trend caused by systematic errors are considered when normalizing. In this work the inputs to the ANN have been normalized to [−1,1].
3.1. Introduction to Singular Spectrum Analysis
Basic SSA decomposes a time series
of length
into several components and reconstructs the series by eliminating the noise, i.e., the high frequency components of the noisy power load, provided that the signal can be separated from the noise. SSA consists of two main stages namely, decomposition and reconstruction, which, in turn, include two separate steps. The first step in the SSA decomposition is called embedding and consists in defining the trajectory matrix,
where
, the number of columns
and the window length
. The trajectory matrix
is based on
lagged copies of the time series and can be written as follows:
The value of the window length
depends upon the time series features. For instance, when the time series includes an integer-period component,
should be defined proportional to that period. The aim is to select a window length that produces separable and independent components to capture the trend and oscillations in the time series. Hence it is important that each
lagged copy of the time series incorporates an essential part of the behavior of the initial series [
17,
18]. The second step consists in computing the matrix
and determining the eigenvalues
being
taken in the decreasing order of magnitude
where
and the corresponding eigenvectors
of the matrix
by applying singular value decomposition (SVD). The trajectory matrix
can then be expressed as the sum of
rank one elementary matrices
where
is the number of non-zero eigenvalues of the matrix
as stated above. The elementary matrices can be expressed by the triples:
where
,
are the factor vectors,
are the eigenvalues,
are the singular values of
and the set
is called the spectrum of
. The collection (
) is called ith eigentriple of the matrix
. Therefore,
can be expressed as follows:
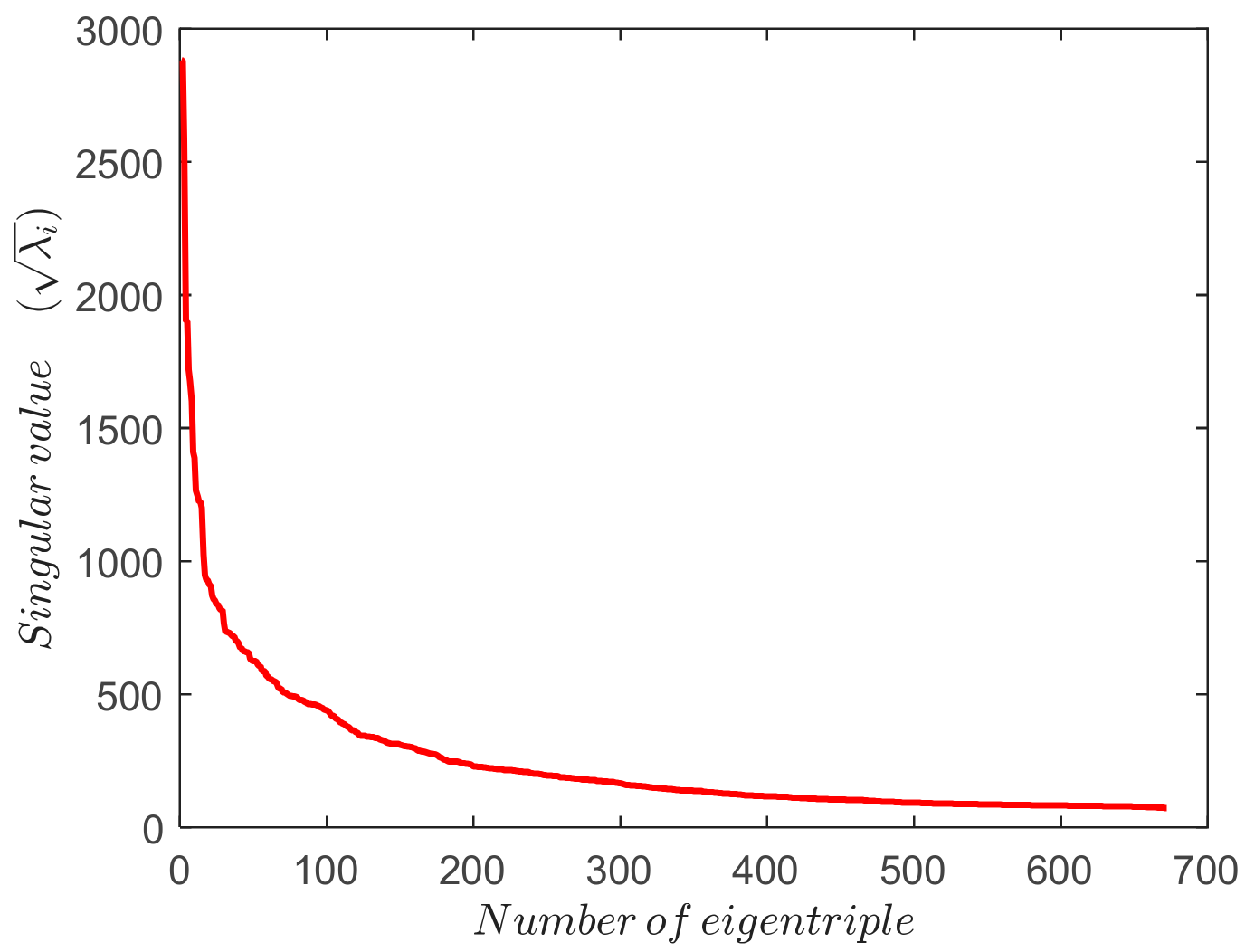
The plot of the singular values in decreasing order is called the singular spectrum and can be used to calculate the index
. Index r indicates the number of components corresponding to the largest eigenvalues of
that allows the signal from noise to be separated. In the simplest way, the grouping step consists in approximating
by the sum of the first
elementary matrices, and it can be expressed as:
Finally, the fourth step deals with the reconstruction of the one-dimensional series. By taking the average of the diagonals of each elementary matrix, elementary time series, which represent the different components of the behavior of the original time series, can be obtained.
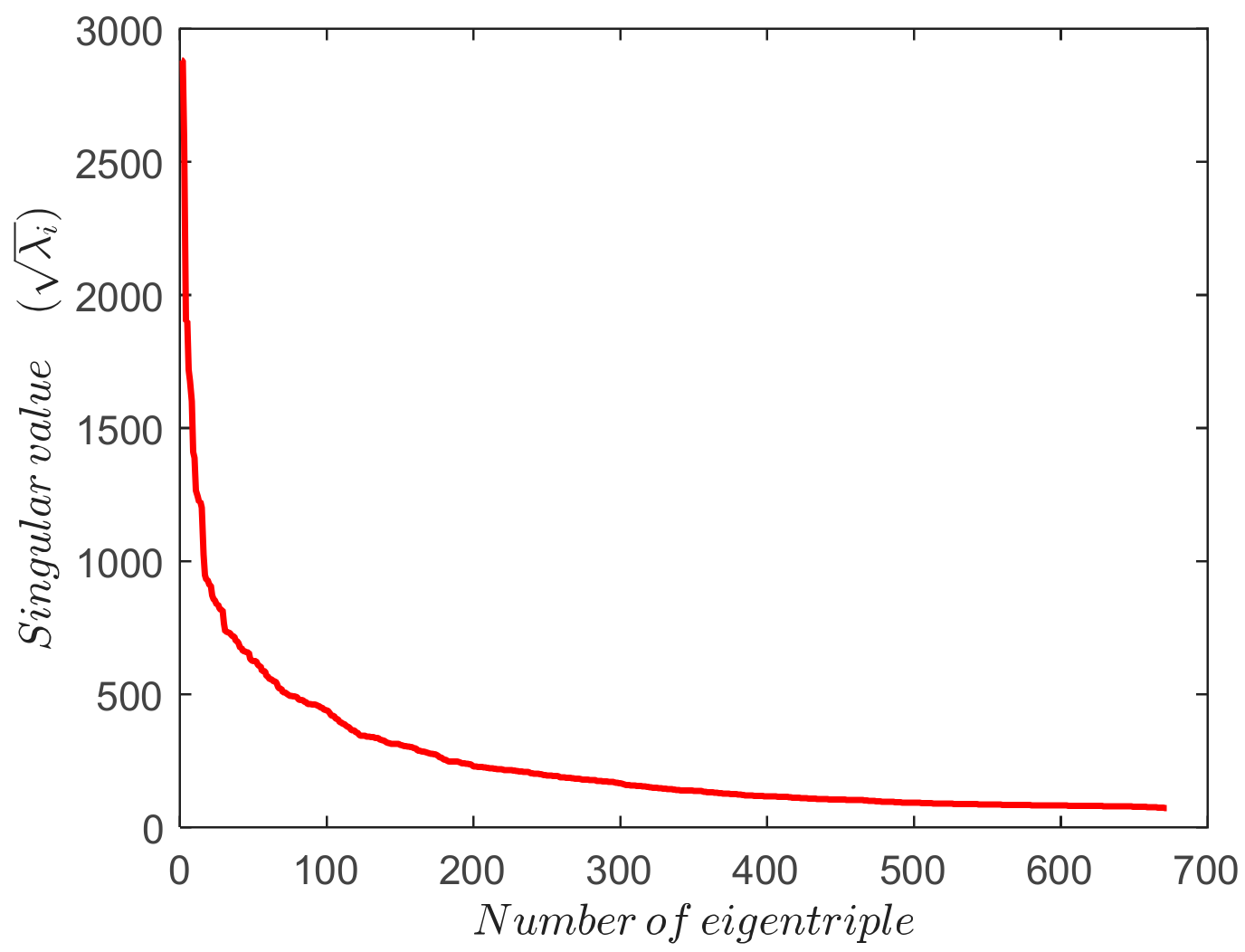
The work presented in this paper introduces some improvements in order to automatize the grouping step of the algorithm so it can be used independently of the data being considered. To achieve this purpose, the grouping phase, based on some quality features, automatically selects those eigentriples that represent the trend and oscillations in the signal. Firstly, an initial window length
suitable for extracting the trend and most periodicities is selected. A value of
(
weeks window length) works well as the main frequencies are dividers of this value or are close to it. In the second step, the number of eigentriples to represent has to be determined. The importance of each eigentriple is directly proportional to the amplitude of its eigenvalue, so it is possible from the singular spectrum (
Figure 3) to select those eigentriples that contain the most information in the signal, i.e., the most variance explained. The remaining eigentriples constitute the residual, which still contains signal information as strong separability is not always possible. The absence of strong separability is not a problem since a well-trained ANN can extract the signal pattern from the noise in the residual.
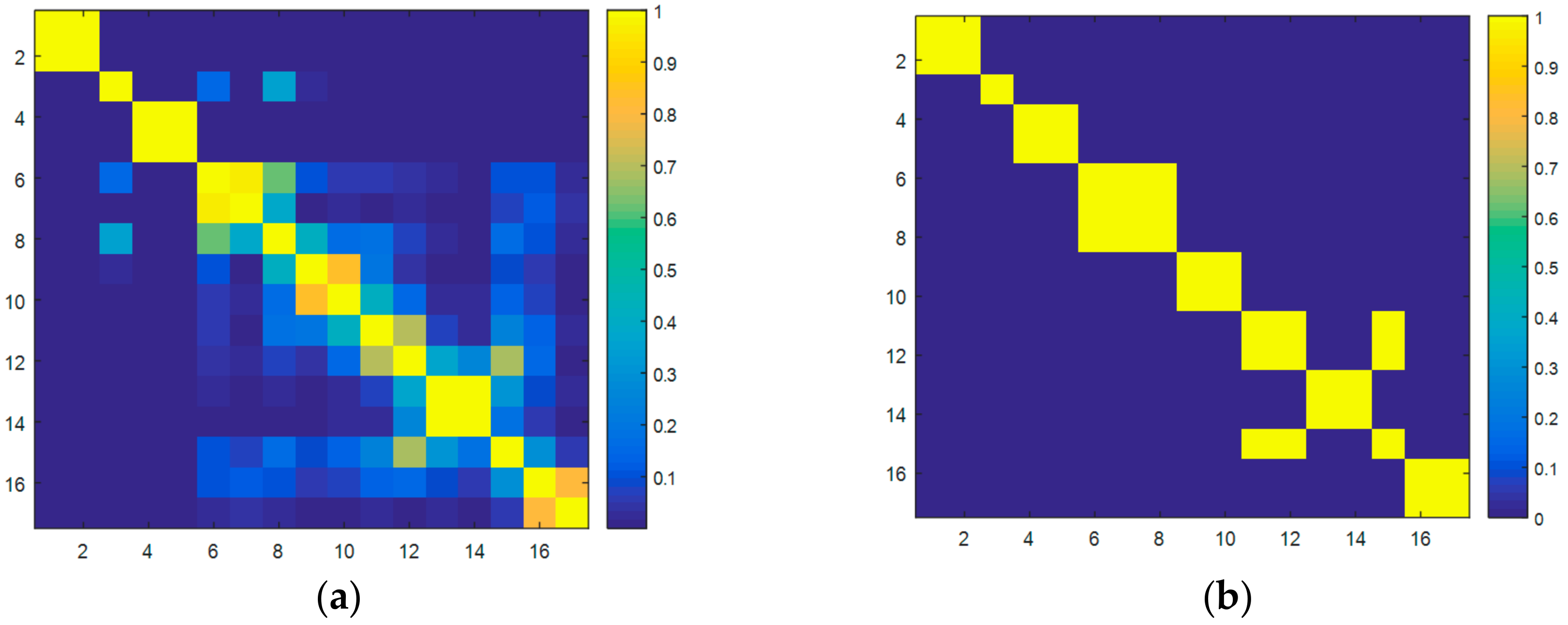
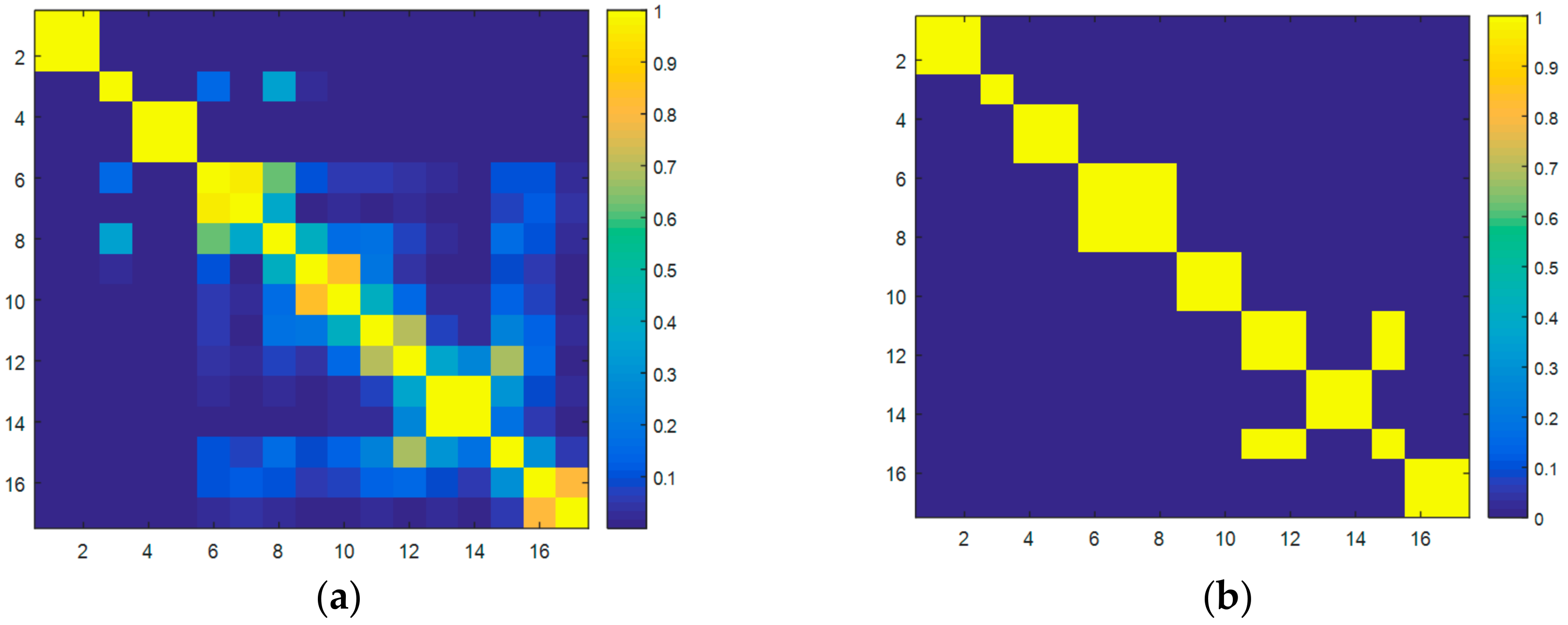
The eigentriples that carry the most variance explained are then grouped in the third phase of the SSA process. To do so, the weighted correlation of the eigentriples (
Figure 4a) is used to cluster them when a percentage of correlation is accomplished. After several simulations, a minimum correlation of
has been selected to group the eigentriples (
Figure 4b).
3.2. SSA-ANN-Based Load Forecasting Strategy
Both forecasting models (Model 1 and Model 2 in
Figure 2) are based on neural networks on account of their approximation ability for non-linear mapping and generalization. Depending on the model considered, the process of forecasting s individually applied to each group of eigentriples from the SSA decomposition step and the residual (Model 1), or to the whole time series (Model 2).
In this paper the ANN topology is based on a nonlinear autoregressive with exogenous inputs (NARX) model where the load is explained by the historical values of the load i.e., lagged observations, the temperature and the day of the week and month, which are crucial for the ANN to keep track of the seasonal components and weather fluctuations [
19]. The ANN has three layers: (1) an input layer, whose inputs depend on the data to be forecast; (2) a hidden layer with a number of neurons, which depends on the complexity of the function to be learned and the training set used; and (3) a
-neuron output layer since a static approach is implemented, which forecasts the
-h load simultaneously. The transfer functions for the neurons of the hidden and output layers are log-sigmoid and linear respectively.
Regarding the input layer, the input data depends on the model. Whereas in Model 1, the input data set consists of different samples from the corresponding group of eigentriples, in Model 2, the input data set is based on the whole time series. In both cases the data structure consists of: (1) hourly load of the previous day; (2) hourly load of the previous week same day; (3) hourly load taken the same day, two weeks before the day to be forecasted; (4) hourly dry-bulb temperature of the same day; and (5) the weekday and the month, expressed by cosine functions. As for the hidden layer, in Model 1, all the ANNs used for forecasting the groups of eigentriples have neurons in the hidden layer, which provide the best prediction results. As far as the residual is concerned, a -neuron hidden layer offers the best performance as they are more difficult to predict. In model 2, . neurons are used as well.
3.3. Bad Data Processing. Error Correction/Elimination
The next step in the algorithm presented in this paper consists in processing the BD due to offset and gain errors and measurements which are very large or very small. Offset and gain errors can be identified and corrected and/or eliminated before they are sent to the control center. However, complete elimination of these errors requires properly calibrated and maintained measuring equipment. Measurements which are very large or very small are commonly known as outliers, which must be removed from the data base and replaced by the forecast data in order to avoid missing data. An outlier detection method based on principal component analysis (PCA) has been used in this work [
20,
21].
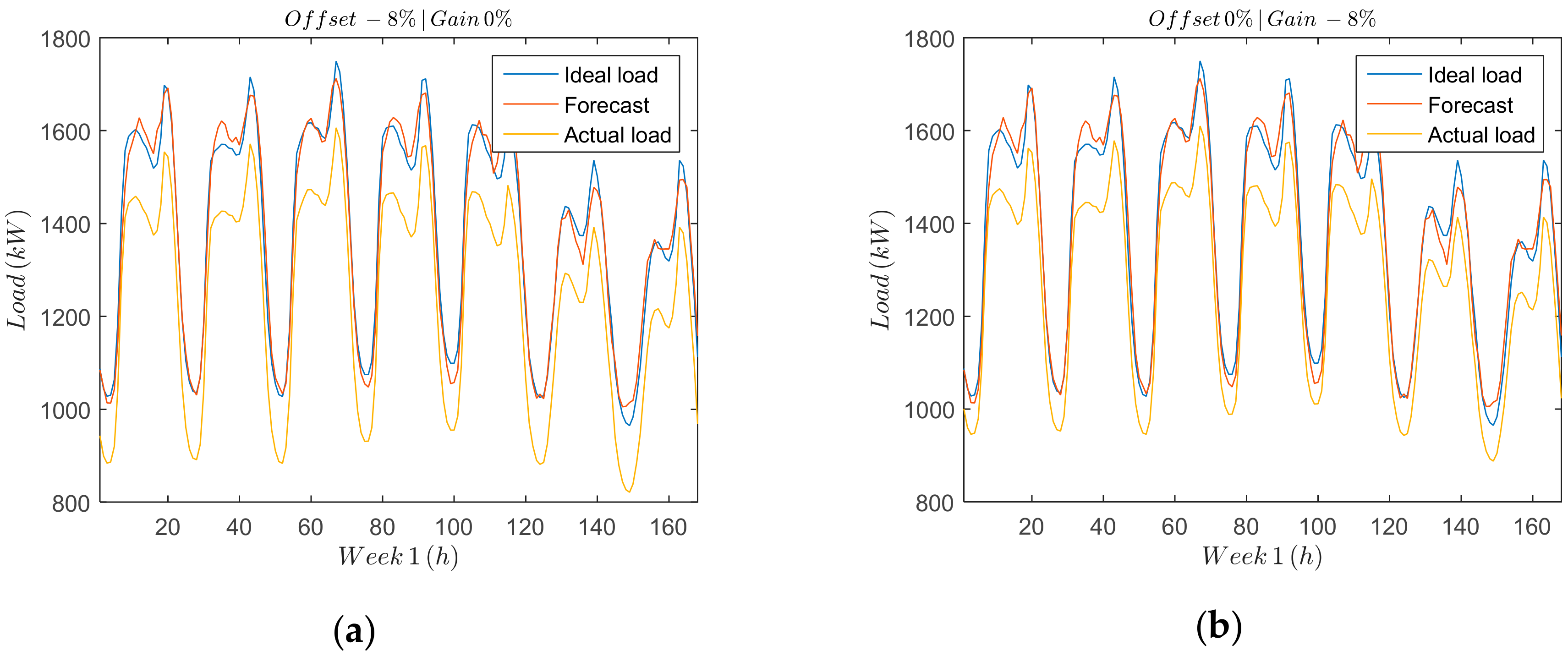
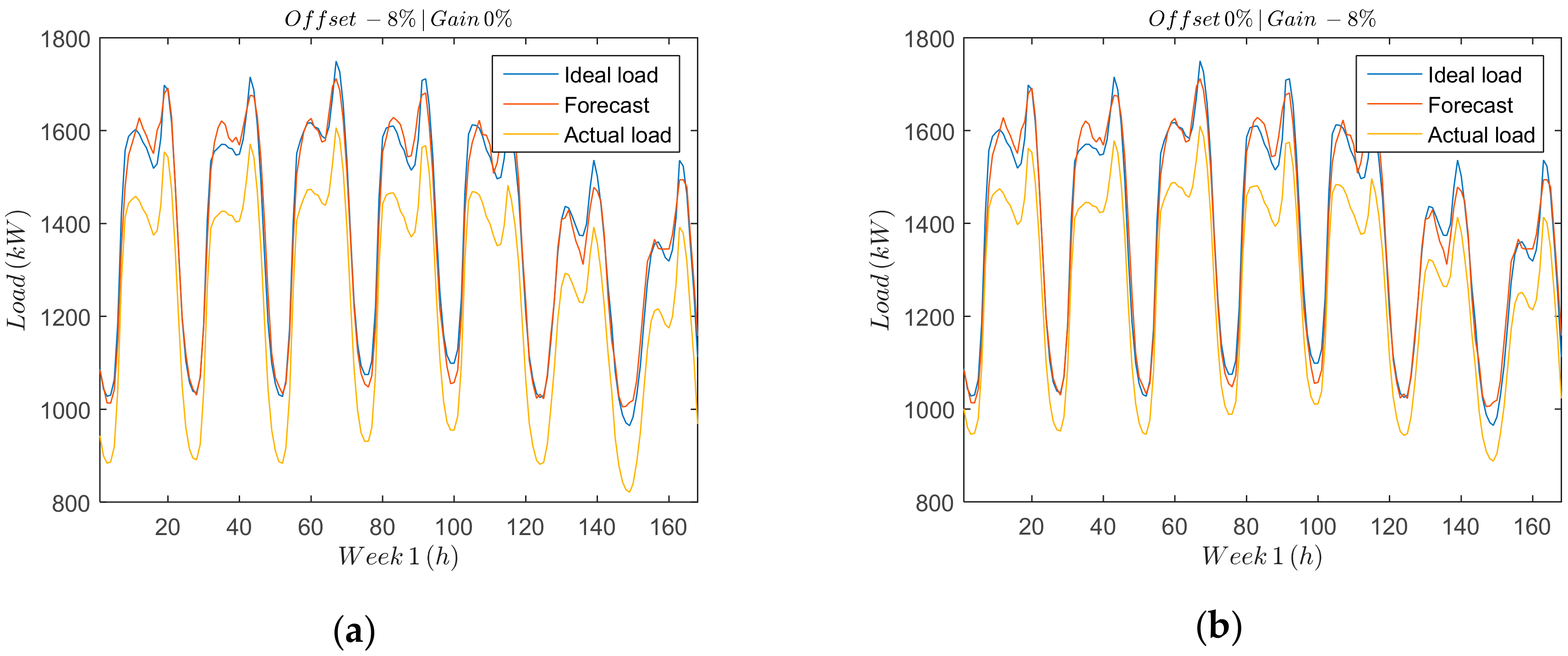
Offset and gain errors (
Figure 5a,b) can be easily detected and identified due to their systematic effects in the measurement data. It is important to characterize both errors so that the remaining sources of deviation of the measured data from the forecasting load can be attributed to random effects. Offset errors are additive and can be represented by a positive or negative term in the measured data.
Figure 5a shows the load measured deviation due to the offset error, which is compared against the full scale. Gain errors, on the other hand, are multiplicative and affect all the measurements proportionally.
Figure 5b shows a comparison between the measured, the forecast and the ideal load, over a period of seven days for an offset error
Figure 5a and a gain error
Figure 5b of
.
The worst-case scenario is that both errors can occur together and with different signs. Considering that gain and offset errors are uncorrelated, they can be described as follows:
where
represents the measured load profile,
. is the ideal measurement load profile, i.e., when no errors occur, and
and
represent the gain and offset errors, respectively.
By using the strategy presented previously, the forecast load profile
can be determined. Since the process of forecasting introduces a random error
, Equation (5) can be rewritten as:
Needless to say, the better the load prediction, the smaller the error introduced. However, this error can be negligible as it is a random error with mean
. Therefore, by using different averaging processes, Equation (6) can be reformulated as:
Differentiating both terms in Equation (7) leads to:
then, the following equation can be obtained by solving for α:
Finally, substituting the gain error into Equation (7), and solving for β leads to:
The proposed system is able to estimate the value of gain and offset errors independently. Erroneous measurements can be corrected if they follow the offset and gain pattern, i.e., if the deviation between the and can be expressed in terms of α and/or β and, therefore, a correction can be applied to compensate for the effect. Outliers, on the other hand, are replaced by forecasted values. The same applies for missing data.
3.4. Load Forecasting Accuracy Assessment: Weight Calculation
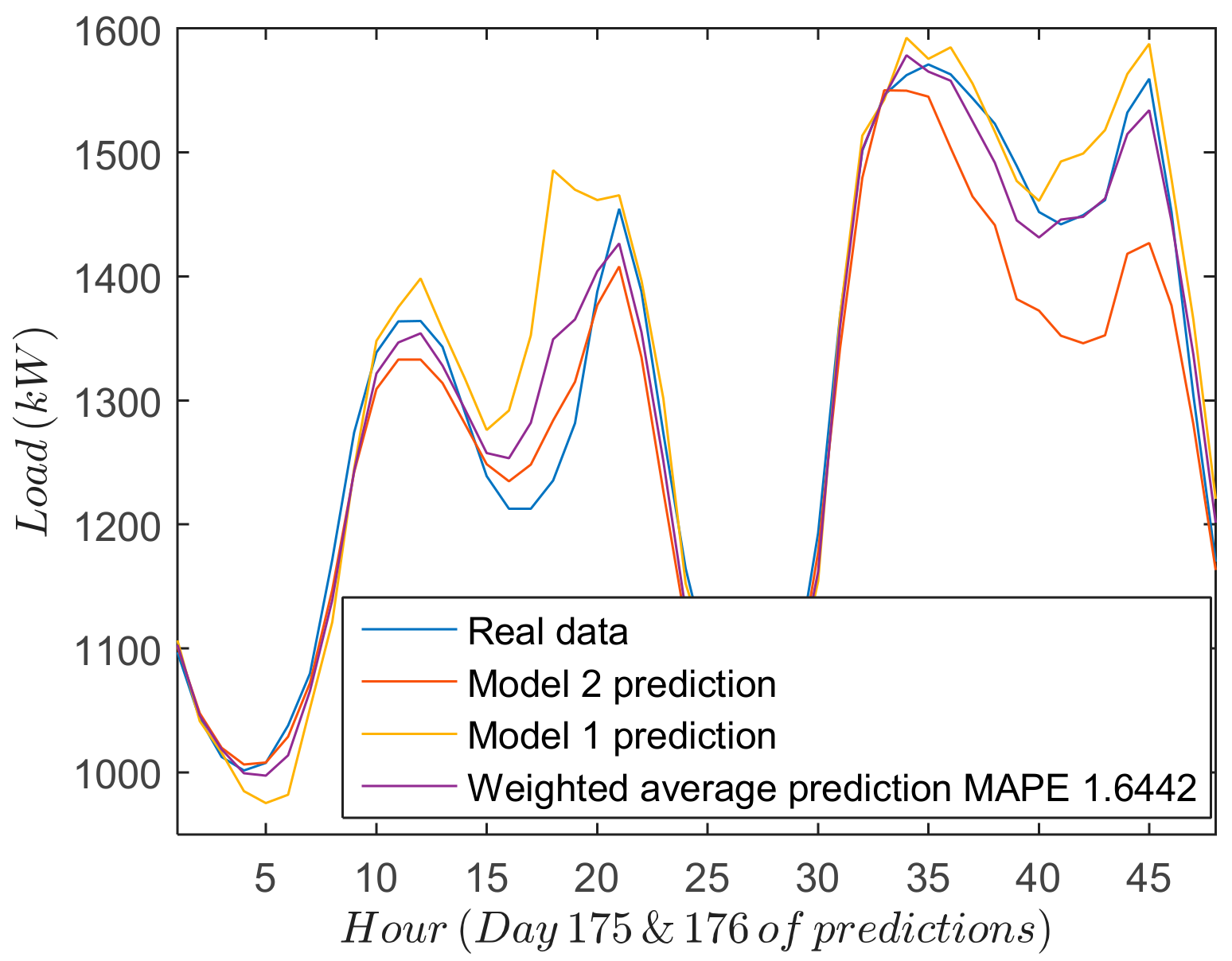
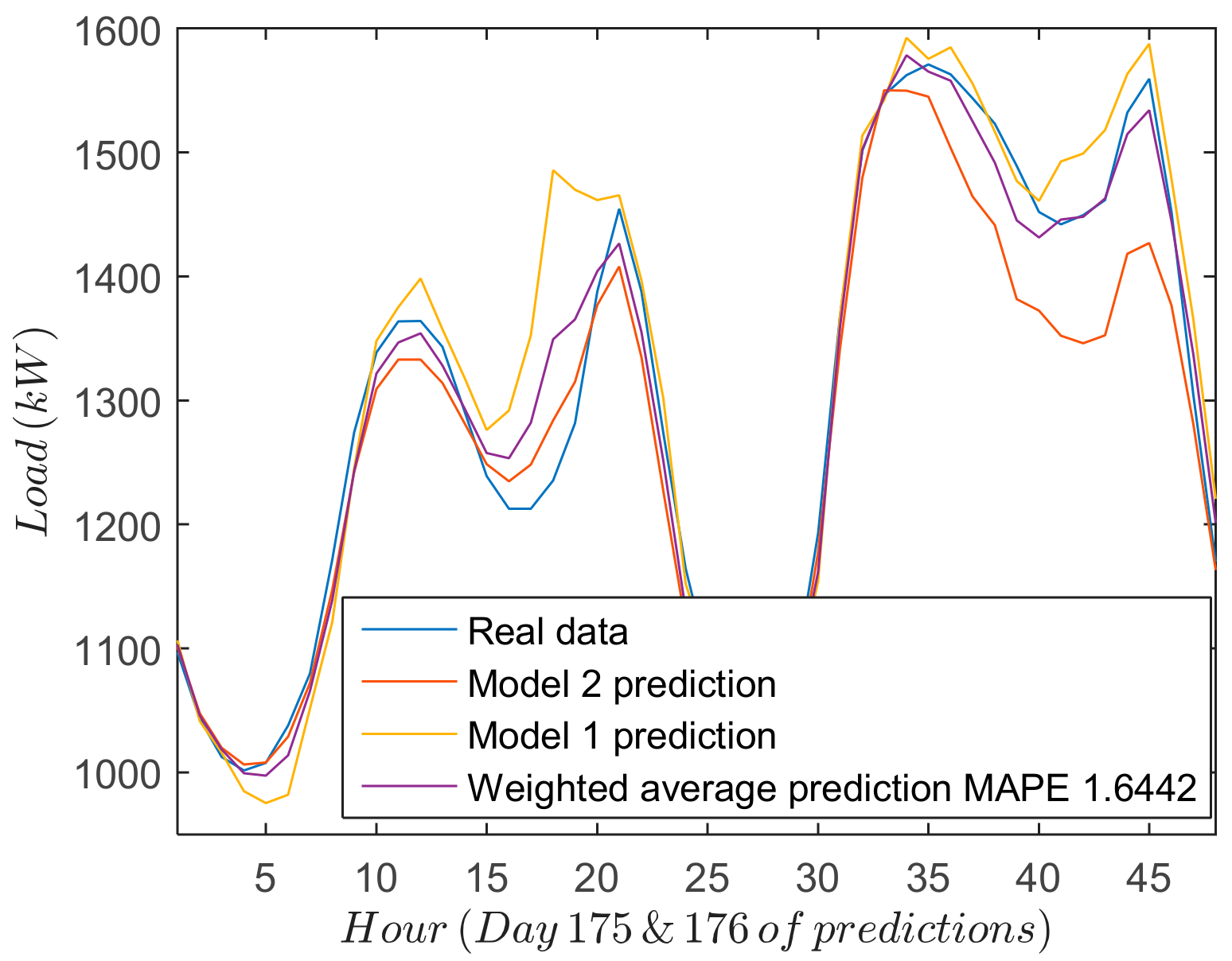
The performance of the different forecasting strategies is shown in
Figure 6, which includes for two days: (1) real measurements; (2) forecasted results for both models; and (3) final results when the weighted average is applied. From the results yielded by both SSA-ANN (Model 1) and ANN (Model 2) approaches, some conclusions can be drawn. Firstly, the most significant deviations of the forecasting values from the real measurements occur at the turning points of the forecast load curve. Secondly, in some cases Model 1 offers a good prediction (last 24 h of
Figure 6) whereas in others, Model 2 works better (first 24 h of
Figure 6). Consequently, a combination of both models can offer a good global prediction.
The mean absolute percentage error (MAPE) is chosen to assess the forecast accuracy is defined as follows:
where
and
denote the measured and forecast power at instant t, respectively, and T is the length of the horizon considered in the prediction, i.e., 24 h in this work.
The forecast time series for the power consumption can be written as:
where
and
denote the forecast consumption for the Model 1 and Model 2 respectively and
and
are the corresponding weights that define the relative influence of the forecast power in the final prediction.
The weights are calculated by means of the individual MAPEs, as follows:
where
and
represent the forecasting error for the Model 1 and Model 2, respectively.
Mean errors may differ as a function of the day of the week, especially between working days and weekends. With the aim of averaging out these differences and updating the weights on a daily basis, the average MAPE for
forecast values and
days is considered, which can be formulated as:
for
,
and
.
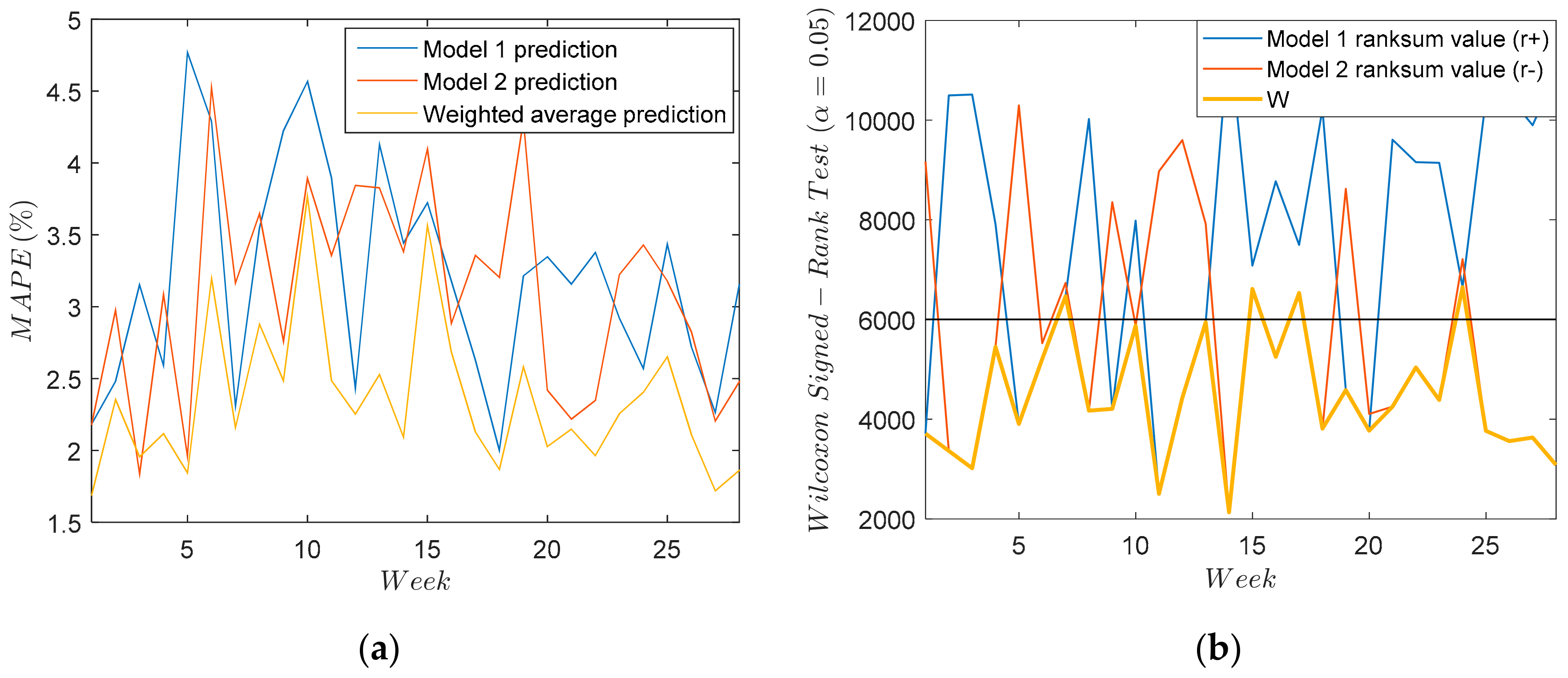
In
Figure 7a weekly MAPE is shown for every model. It can be observed that sometimes the first model shows better performance than the second and vice versa. However, the weighted average prediction always shows the best performance. As a result, the weighted average prediction will be used to detect gain and offset errors. In order to demonstrate the difference in forecasting accuracy between both models, the weekly Wilcoxon signed-rank test is carried out and its results are shown in
Figure 7b. The Wilcoxon signed-rank test [
22] is used to compare the significant differences in terms of central tendency between two equal-length data sets: the errors of the forecast strategies being compared. The statistic W of the Wilcoxon signed-rank test is shown as Equation (15):
where
represents the sum of ranks in which the first model is larger than the second one and
represents the sum of ranks when the opposite occurs. If
meets the criterion of the Wilcoxon distribution under
degrees of freedom, then, the null hypothesis of equal performance of these two compared models cannot be accepted [
23,
24].
Figure 7b shows the values of
and
for both models, and the value of W. If the value of
is above the black line depicted in the figure, the test indicates that the null hypothesis under
should be accepted, showing that both models are similar enough. As can be seen from the figure, the value of
is usually under the black line, this value corresponding indistinctly with Model 1 and in other cases with Model 2, so it can be assumed that the performance of both models are complementary and the weighted average prediction provides better results.
In the field of STLF many works have been published and many types of strategies have been used showing the good performance of the techniques proposed in the papers. In this regard, for comparison purposes, it is complicated to reproduce the experiments presented in other works because either, the data set is not available or the explanatory variables are different or simply because the experimental setup has not been described in detail. This clearly does not facilitate comparison. Another challenging issue is the lack of standardized benchmarks: there is no a widely accepted model and dataset for benchmarking in STLF. Finally, although many papers use MAPE for quality assessment, there is no uniformity and it can be used for different time scales and horizons. Nevertheless, in the case study presented in this paper, two benchmark models can be used in order to assess the quality of the predictions, namely: (i) Seasonal ARIMA model and (ii) SSA-based model. Both models can be used for benchmarking purposes since they are accurate enough to capture the prominent features of the predictor variables.
The MAPE, the normalized root mean square error (NRMSE) and their non-normalized expressions are used to compare results, and are defined by the following Equations (16)–(19):
where and
denote the measured and forecast power at instant t, respectively, and
is the number of forecast days, i.e.,
days in this work, considering a
-h horizon.
The error indicators are shown in
Table 1. It can be seen that the weighted average model gives the best performance.
4. Experimental Results: Error Detection.
The system described in this paper has been tested against real data sets obtained from different SSs located in the Community of Madrid. This data contains hourly recorded information from several SSs in the period ranging from 1 June 2013 to 31 December 2016.
The data set is split into three groups: (1) the training subset (), which is used to train the ANNs; (2) the validation subset () used to ensure that the ANN is generalizing and to prevent overfitting; and (3) the test subset employed for a completely independent test of network generalization. Different values of offset and gain are inserted in the data set and are successfully detected.
Regarding gain and offset error detection, an approach to error analysis, similar to that introduced in [
25], has been implemented. The equipment involved in the data acquisition, mainly current transformers and measurement equipment, introduces an inherent measurement error, the value of which has been quantified. The transformers account for an error not higher than
[
26,
27] and the measurement equipment can introduce an error that ranges from
to
depending on the manufacturer [
28]. Therefore, under normal operating conditions, an average value
can be considered a conservative estimate for the maximum inherent error introduced by the measurement equipment. With this in mind and to avoid detection of false gain and offset errors, a minimum threshold of
has been considered.
In order to obtain an average error value, the measured error estimation is filtered by using a recursive least square algorithm (RLS). A prediction time (), which, in this context corresponds with the period of time considered to estimate the current gain and offset errors, must be defined. Needless to say, the longer the prediction time, the more precise the estimate. However, a which is too long can undermine the algorithm’s effectiveness, since an early error detection is to be desired. A of 7 days has therefore been defined considering that in measurement equipment, gain and offset errors evolve slowly in time.
In order to verify the accuracy of the detection of the normalized error, defined as the combination of the offset and gain errors, Equation (20) is used:
where
and
represent the detected errors and
and
are the injected errors for the gain and offset, respectively. Likewise, Equation (21) defines a threshold above which an alarm warning is generated. Taking into account the previously mentioned inherent error introduced by the measurement equipment, the threshold is set to
:
By using Equation (21) and setting different values for
and
, ranging from
to
, several scenarios are considered (
Table 2): (1) when both
and
are greater than 4
, this is regarded as a true positive (TP), which means that the combined error has been successfully detected, otherwise, i.e., when
, it is a false negative (FN); and (2) when both
and
are less than or equal to
, this is regarded as a true negative (TN), otherwise, i.e., when
, it is a false positive (FP).
Table 3 depicts several values of
, which have been calculated for a random week.
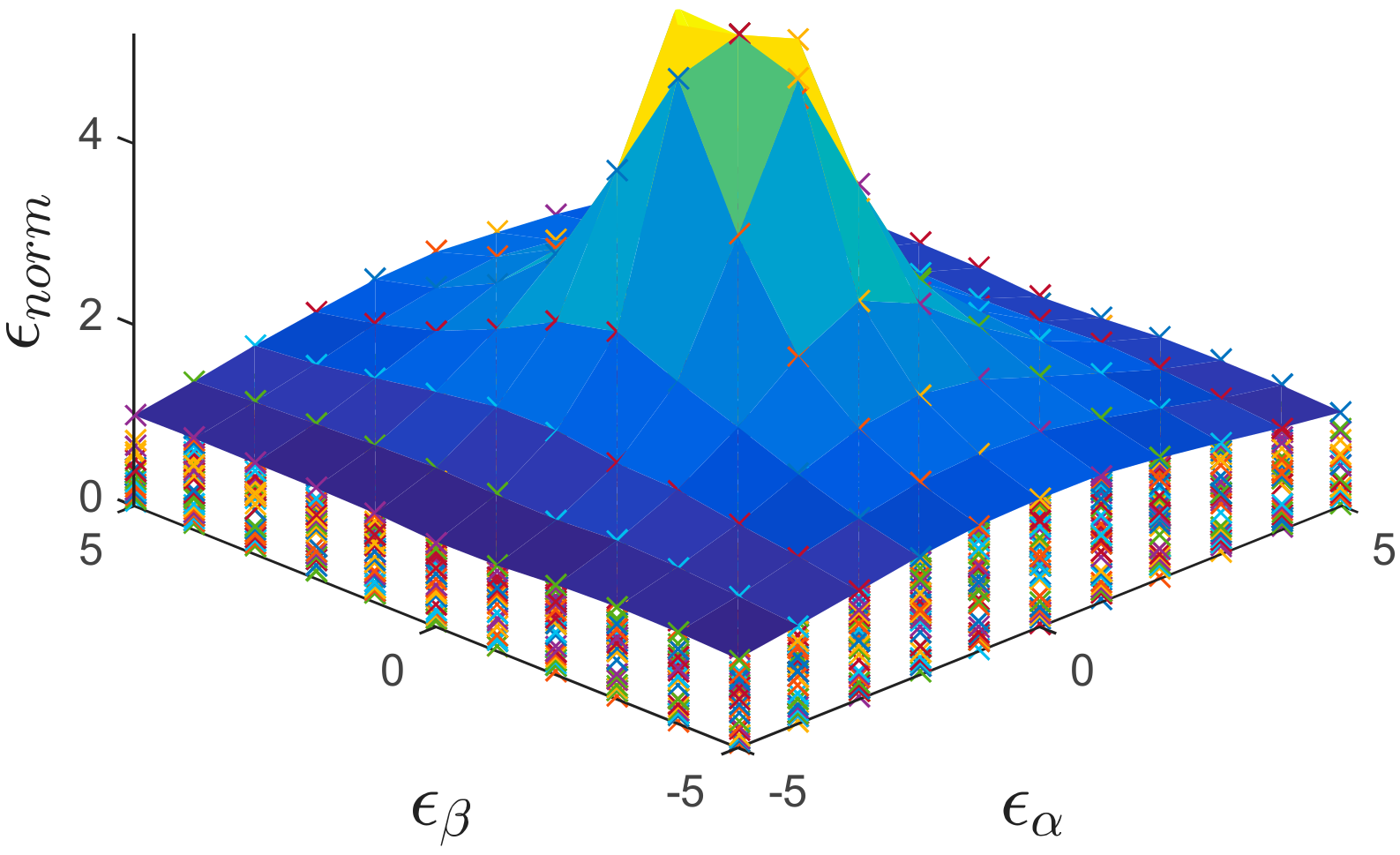
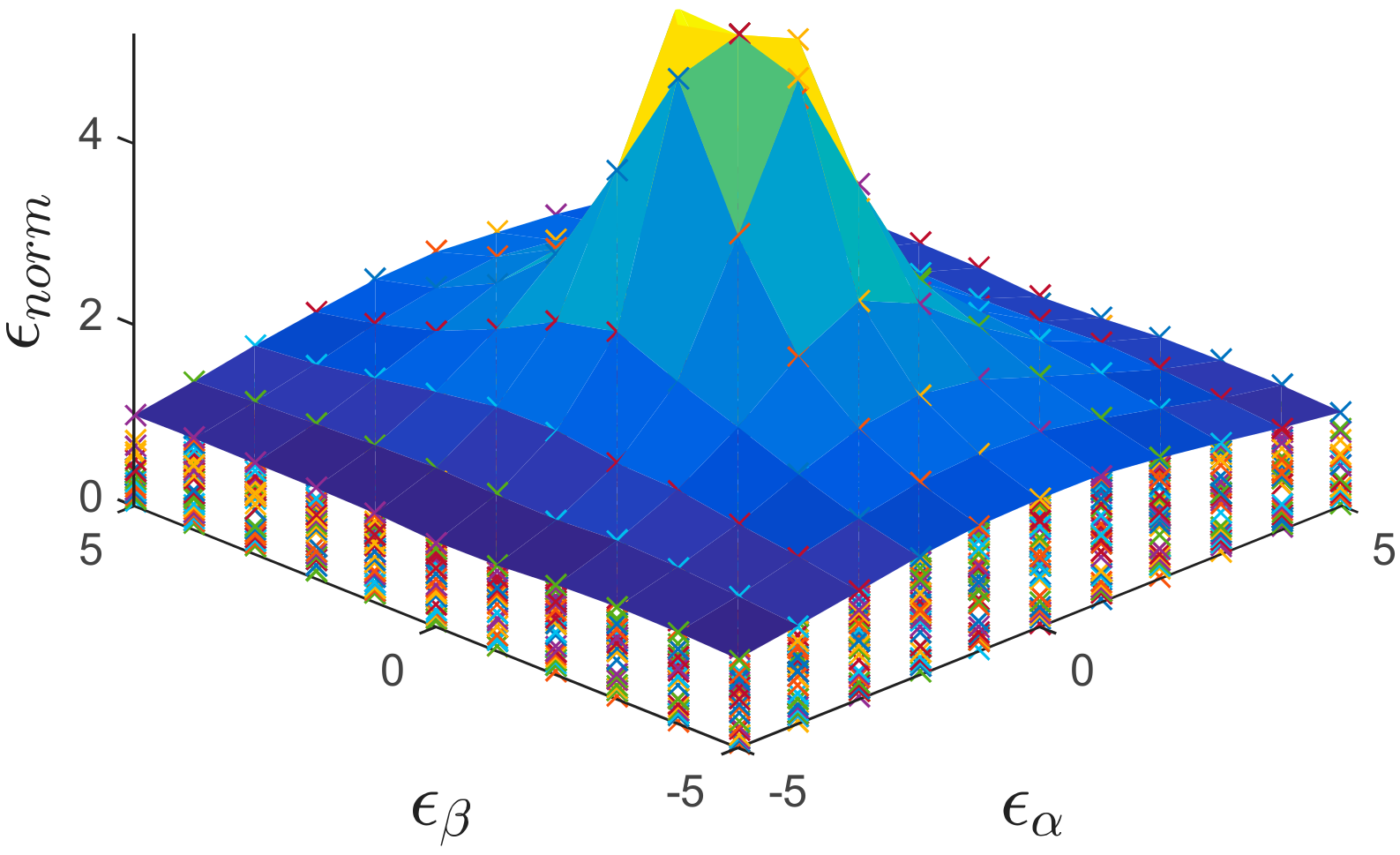
Figure 8, on the other hand, shows a more general case in which all the weeks for the error detection are considered. In this figure the envelope represents the worst-case scenario, i.e., the worst week regarding the detection errors for the offset and gain. It can be noticed from
Figure 8, that the normalized error follows a zero-centered bi-dimensional normal distribution.
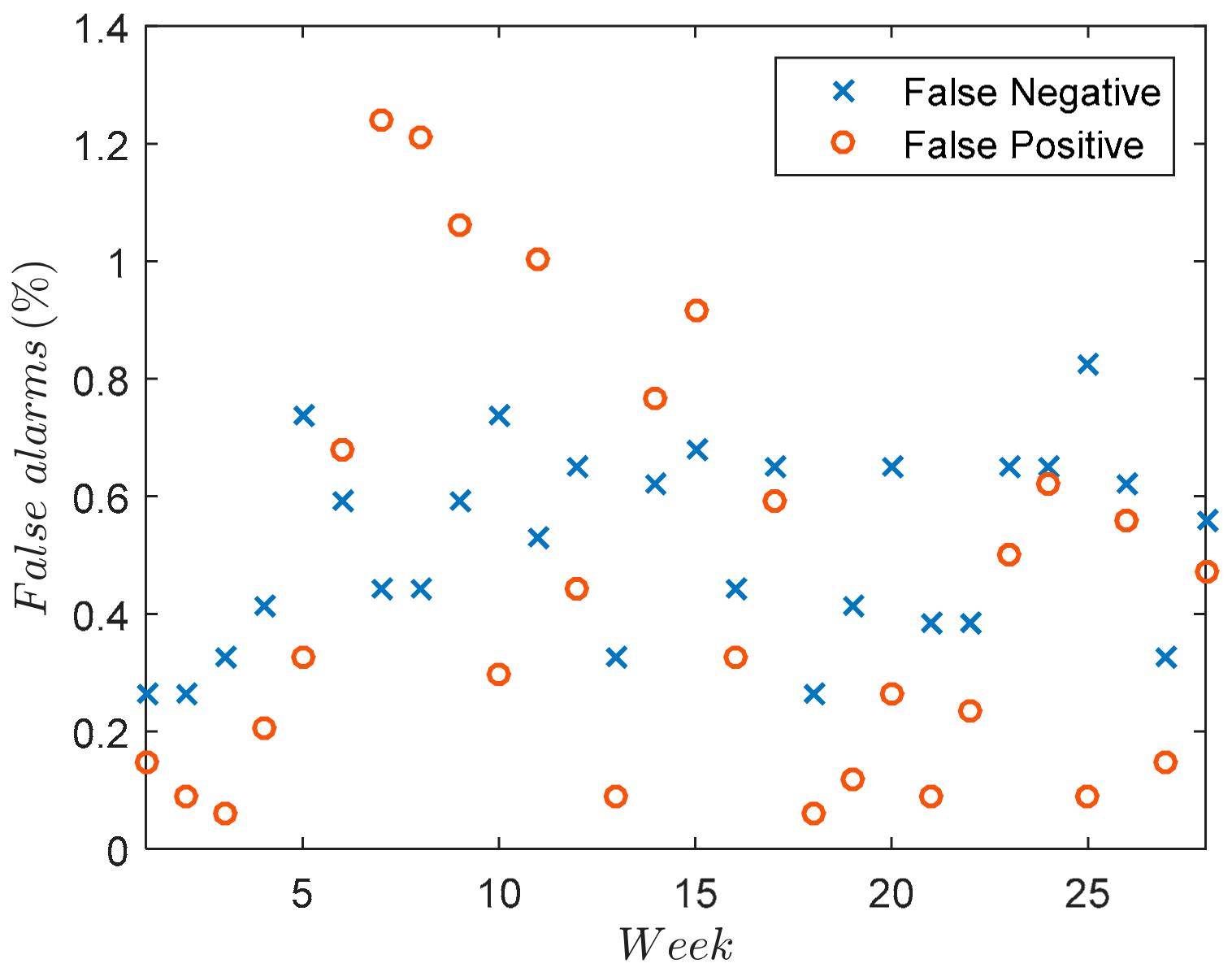
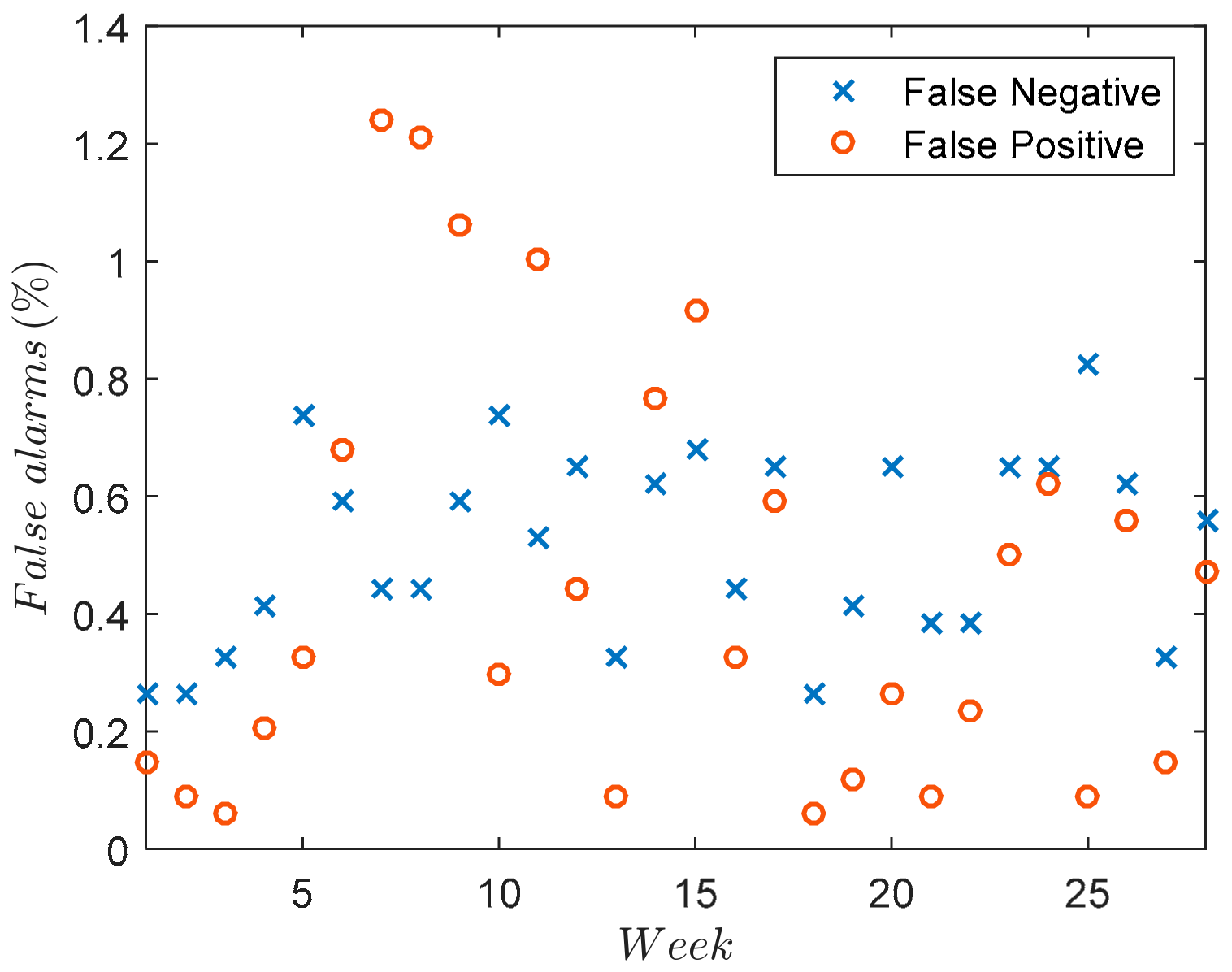
Figure 9 shows, represented as a percentage, the false positives (FP) and false negatives (FN) for each week, taking into account the criterion explained in
Table 2 and the values used in
Table 3.
It can be concluded, therefore, that the algorithm accuracy does not greatly depend upon the existing offset and gain. However, this accuracy does depend upon the performance of the load forecasting algorithm.
5. Conclusions
Power system state estimation is a crucial functionality which ensures reliability and security of power grid operation. Measurements provided by secondary substations are important since LV networks are no longer passive on account of the growing presence of DG connected to the LV grid.
However, bad data in the shape of incorrect measurements and/or outliers can have a significant impact on the state estimation. Early detection of bad data in monitoring devices in secondary substations, i.e., at a decentralized level, is, therefore of enormous importance. This paper has proposed a novel approach to detect bad data in the electronic instrumental transducers (EITs) with the aim of enhancing PSSE. The strength of the contribution made in this work lies in using a highly accurate STLF strategy based on SSA and ANNs.
Finally, the strategy can be extended to other exogenous variables provided that there is data available, such as electricity price, consumer types and other weather factors, e.g cloud cover. Further research could also be done on applying this strategy to solar power forecasting with different forecasting granularity.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}