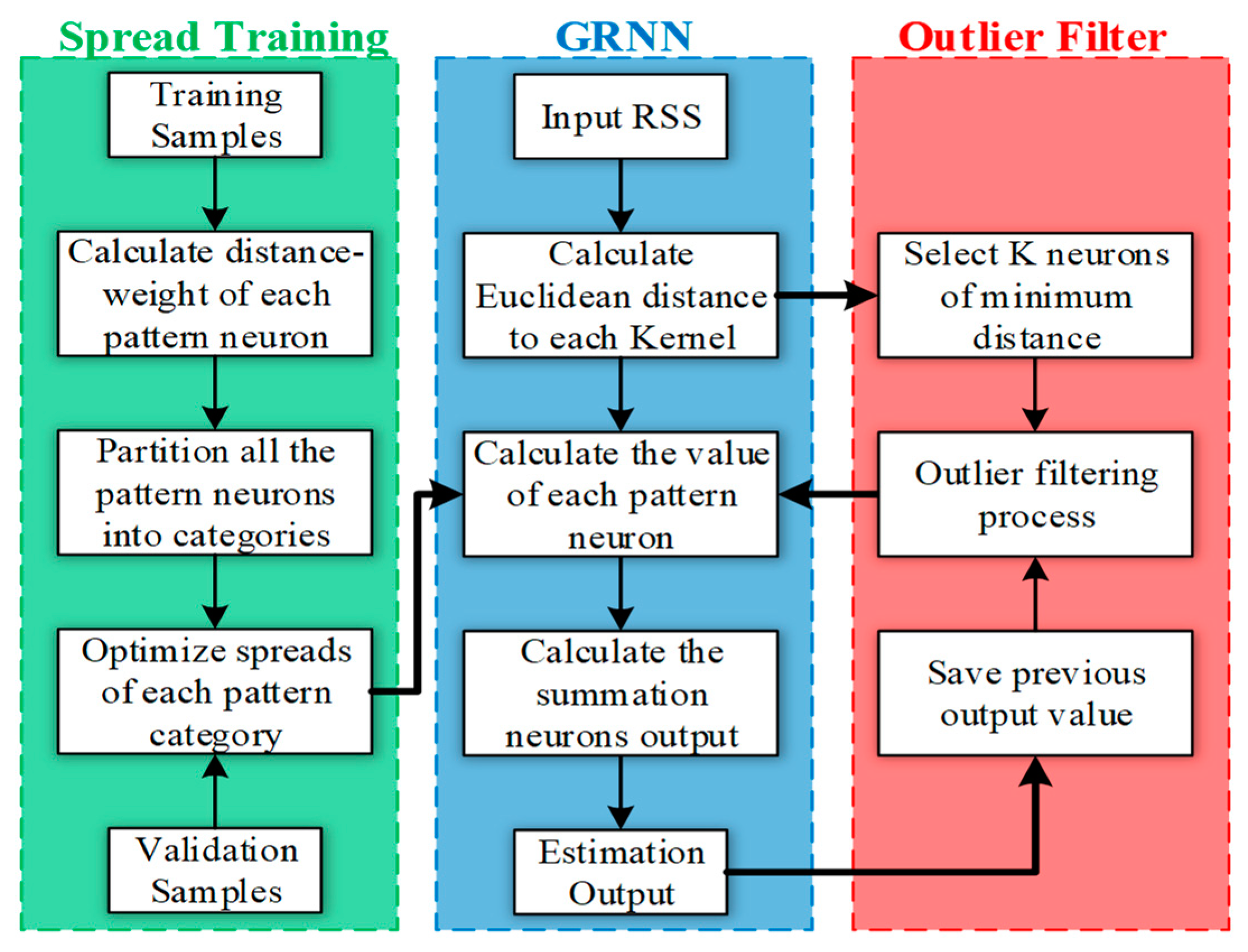
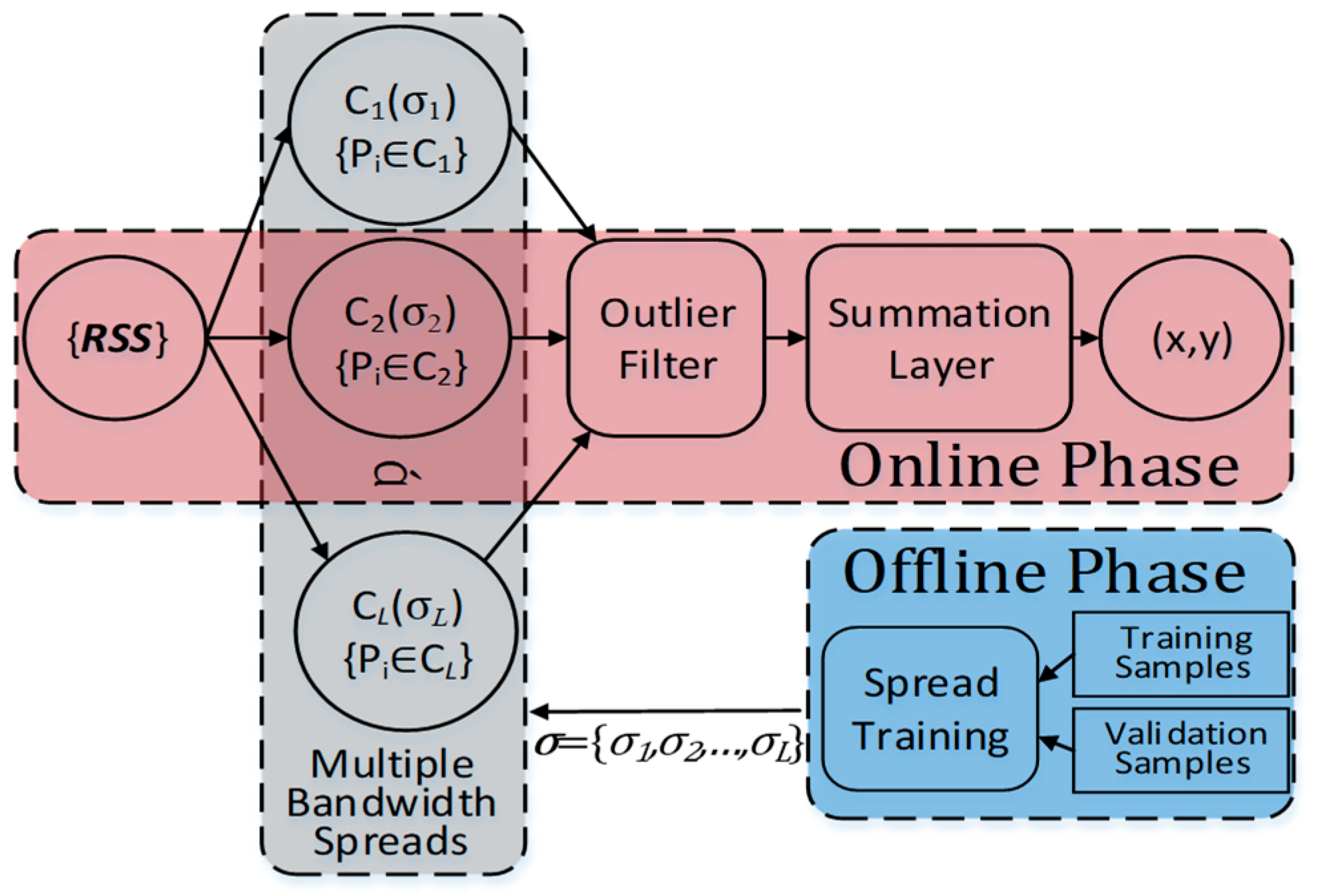
In this section, we present the rationale and methodology of the proposed approach. We first analyze the existing challenges of the standard GRNN algorithm in IPSs. Then, we will show the framework of the GROF method, introduce the multiple-bandwidth kernel spread training process, and discuss the outlier filter algorithm.
3.3. Multiple-Bandwidth Kernel Spread Training
In this section, we present a kind of heuristic method to train the spread values of the multiple-bandwidth kernel network.
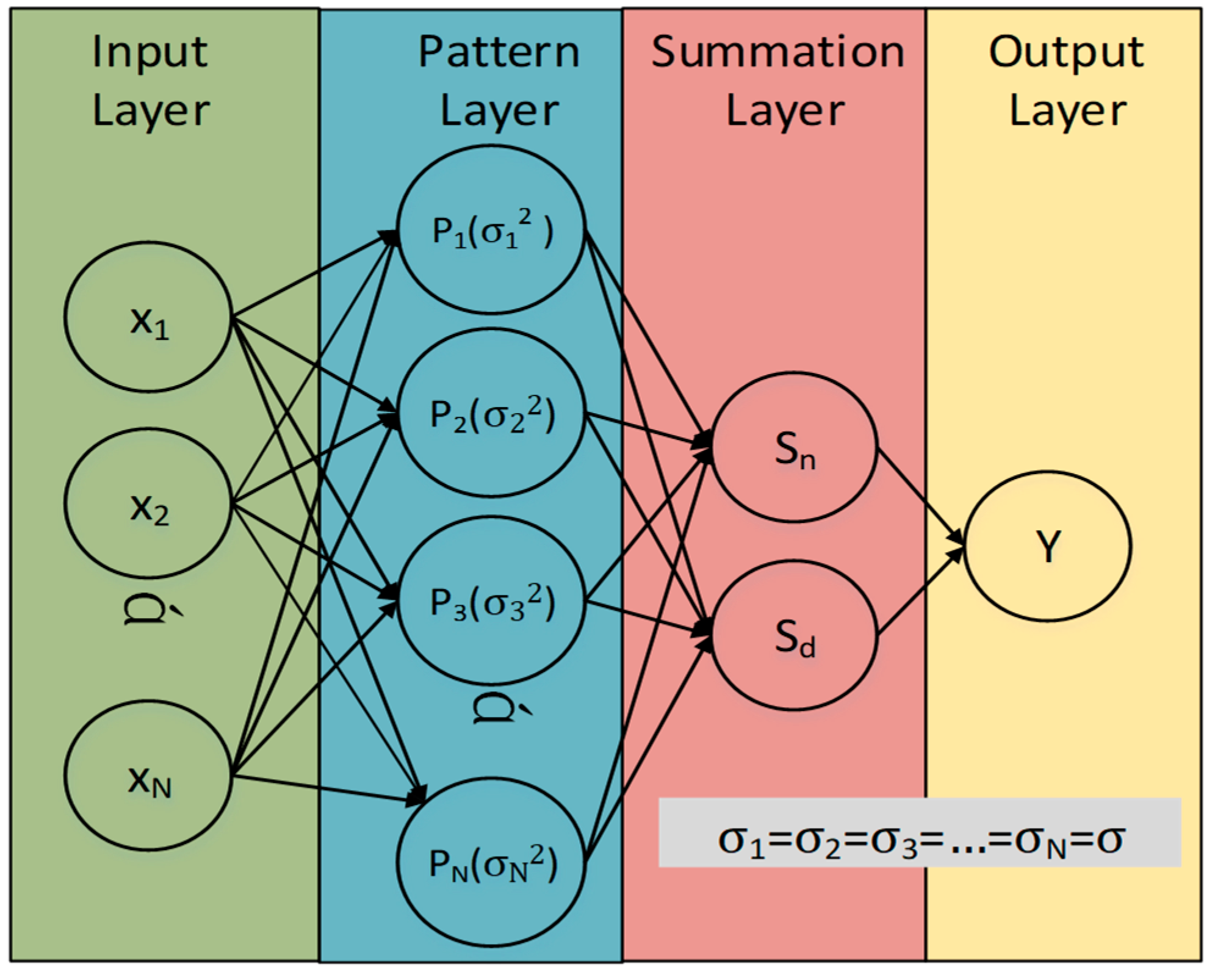
As the GRNN estimation is derived from the Parzen–Rosenblatt density estimation, we can formulate the multivariate Gaussian kernel using Equation (10).
Given a collection of fingerprints, F = [f1, f2, …, fn] ∈ k×n, the corresponding kernel quantity is n and there are k variables in each kernel. The bandwidths of the kernels are controlled by the diagonal matrix, , which contains the spread values, h, of each individual variable in kernel i. During the spread design process, the major challenge is how to compromise the fine-grained spread design and the training workload alleviation.
The multiple-bandwidth spread training method is implemented in following steps:
Step 1: Calculate the distances of the RSS vectors between different pattern neurons, in order to find the adjacent kernels.
According to the traditional calculation approach, we have to calculate the RSS vector distances from every pattern neuron to the others, thus obtaining
n(
n − 1)/2 different distance values. The calculation complexity increases geometrically with the growth of the pattern number. To simplify this calculation procedure, we hold the assumption that the adjacent kernels are supposed to be the fingerprints that are neighbors in the ground truth. As in the line-of-sight (LOS) condition, it makes sense that the fingerprints are more similar when they are geographically closer. According to this assumption, the necessary calculation amount is significantly reduced and alleviates the computational overhead. As RPs are distributed in a rectangle area in most cases, the proposed algorithm can reduce the calculation amount by at least
, referring to
Appendix A.
Step 2: We partition the pattern neurons into categories by referring to the distance–weights distribution. The distance–weight of the
i-th pattern neuron is defined according to Equation (12).
where
k stands for the number of neighbors. Once the distance–weights set,
W = [
w1,
w2, …,
wn] ∈
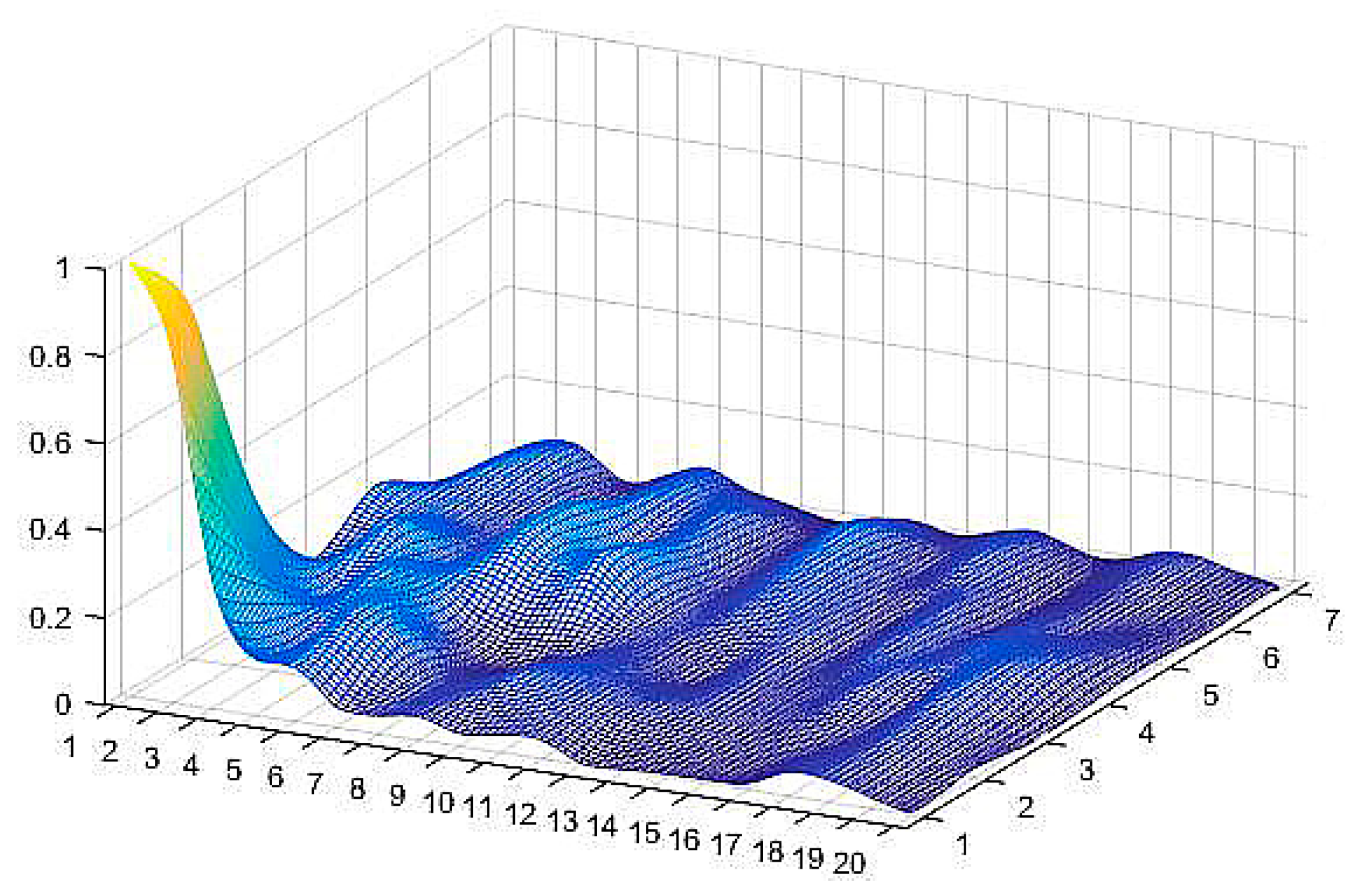
1×n, has been determined, the distributional diagram of all of the patterns’ distance–weights is available. There are 140 pattern neurons on the basis of fingerprints that are located in the
x–y plane. The distribution surface is generated by the set
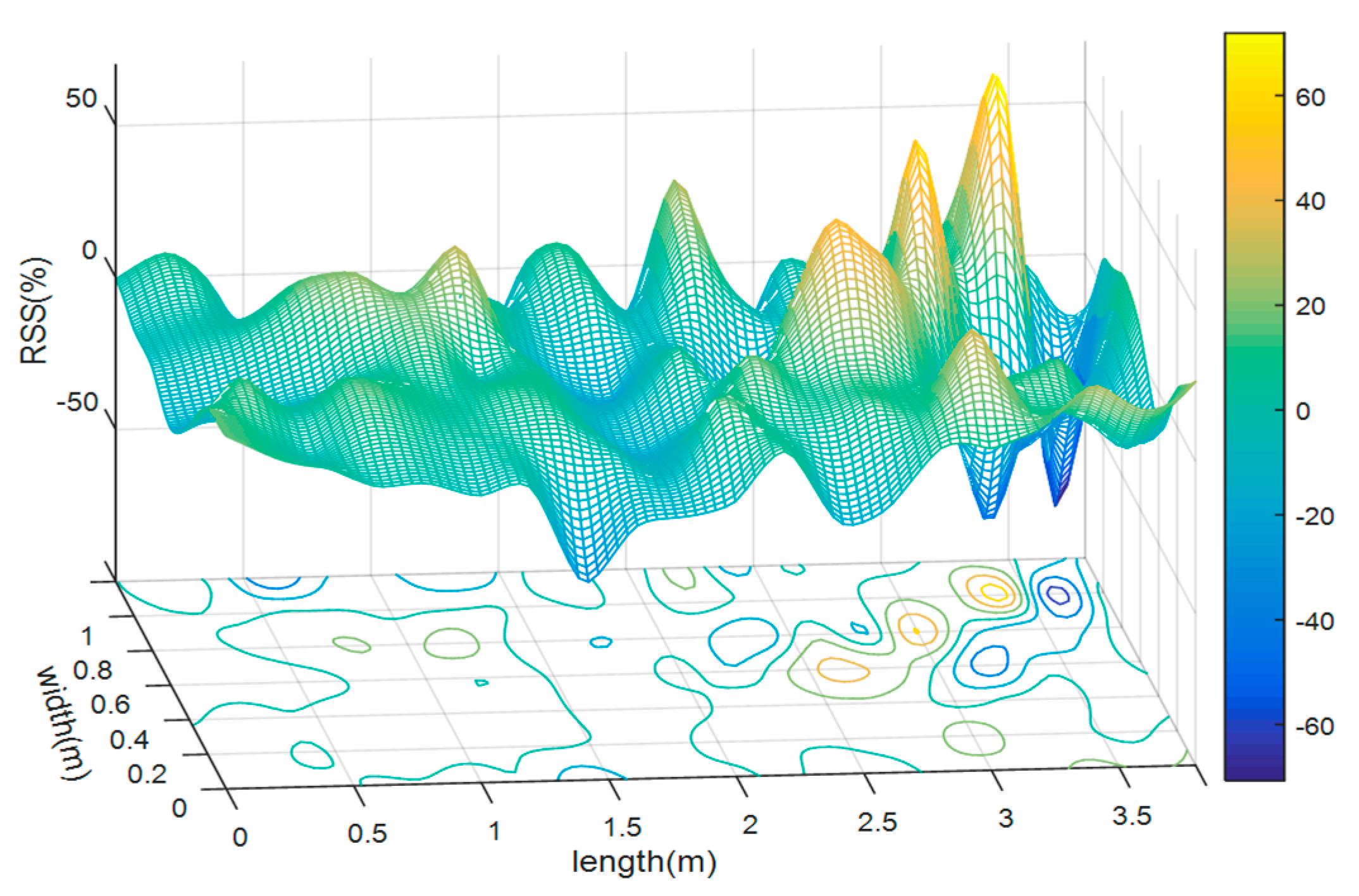
W with the triangulation-based natural neighbor interpolation method, as shown in
Figure 4. The data was from our training sample data set. The distance–weights are calculated by Equation (12), and are then regularized by the max–min method for convenience. It is very intuitional that the distance–weights of the training data are distributed on a rough surface with a steep crest in the bottom left corner of it. The peak indicates where the maximum distance–weight pattern neuron is.
Instead of utilizing a complex algorithm such as clutering, we determined the category quantity
C according to Equation (13).
where
is the maximum distance–weight in set
W and
μw is the mean. As the distance–weights data are regularized by the max–min method, we can obtain
. The interval of one category is given as Δ =
β × μ. The parameter
β is an intermediate variable introduced to control the quantity of spreads. As
μ is the normalized mean value of distance–weight calculated by Equation (12),
β can be considered as a zoom factor to ensure that the value of Δ is within a reasonable range. The kernels in each interval form one category and share the same spread value. It is possible that some categories are null and no kernel falls into those intervals. Thus, the actual number of spread categories is likely to be less than
C.
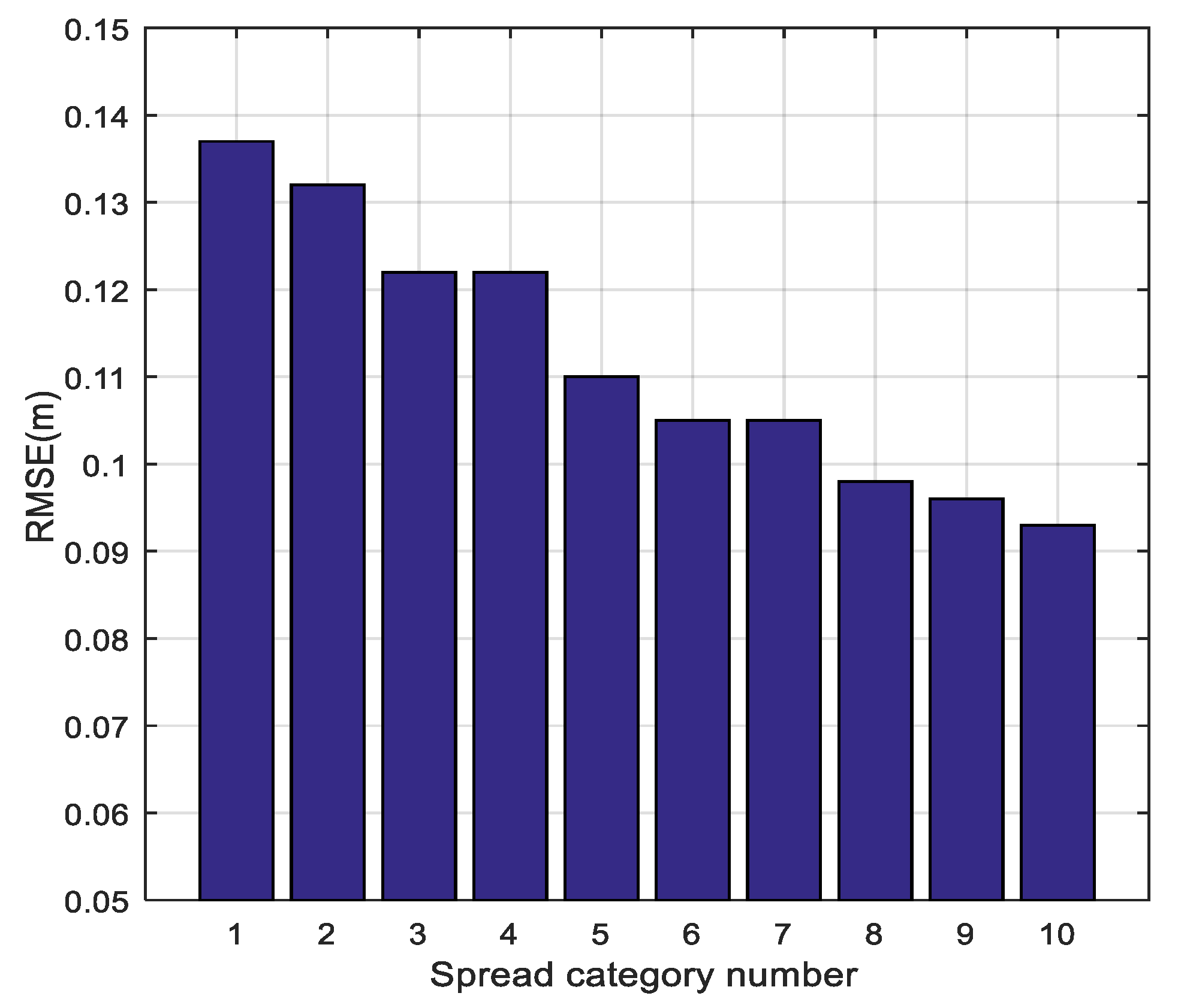
The spread quantity and the corresponding distribution are very flexible by tuning Δ, according to the requirement of the fitting performance.
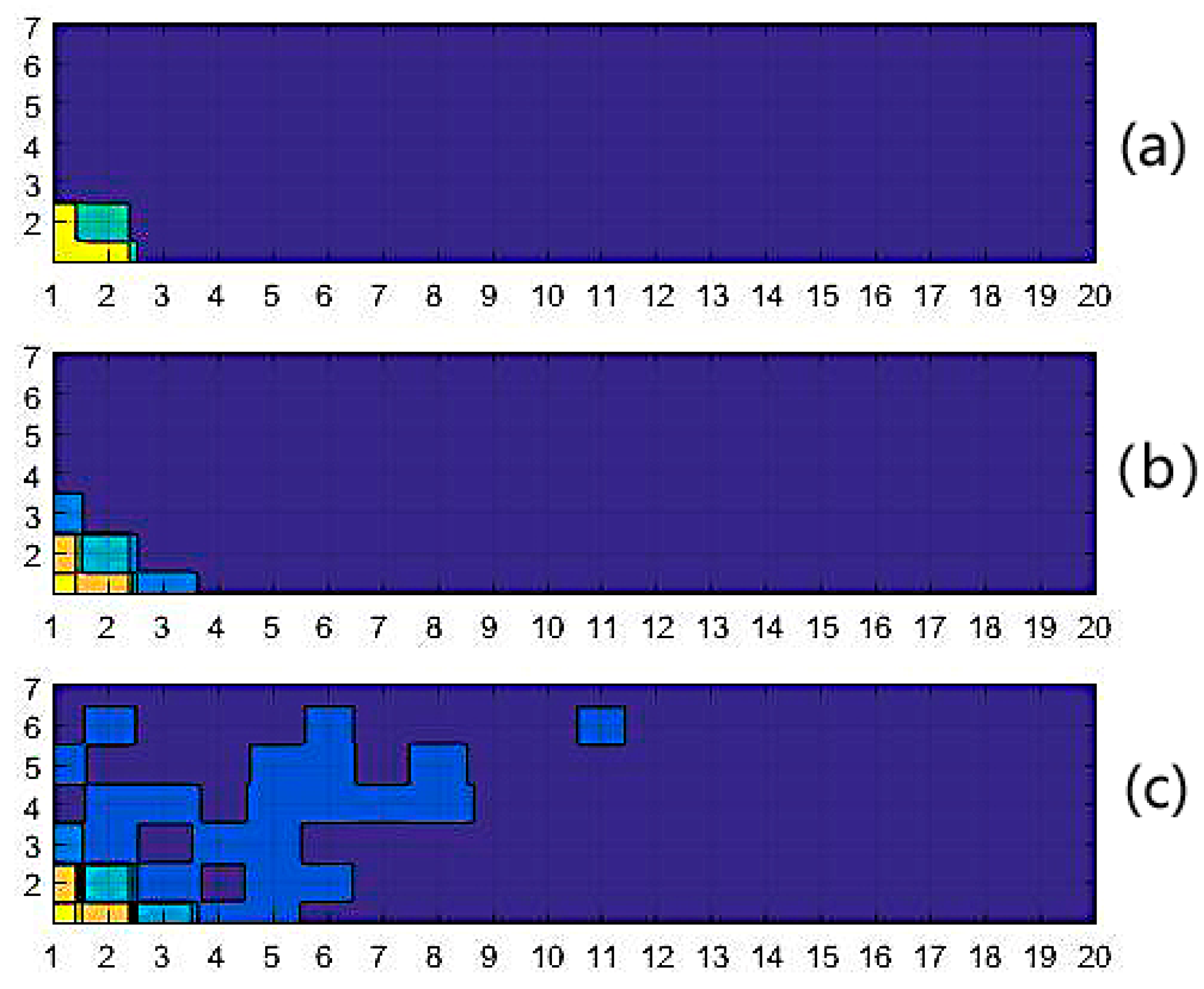
Figure 5 depicts the dynamic partition of the given fingerprint set under different Δ
s, where different categories are distinguished by colors. The distribution of the color blocks is in accordance with our hypothesis that adjacent fingerprints have similar distance–weights.
Step 3: Obtain the optimal spreads by applying a gradient-based optimization scheme.
Our iterative algorithm is based on the following assumptions:
- (1)
The spread value of kernel i should be proportional to the mean of {w}i.
- (2)
The categories with larger sizes are more significant to the GRNN performance.
- (3)
The spread diagonal matrix can be extended from the category spread, according to the distance–weights scaling relationship of each variable in the kernel.
Assuming that the kernels of the training samples are partitioned into l categories, the new sequence of categories is arranged according to the descending order of their distance–weights, which is denoted as {c1, …, cl| l ≤ C}.
The initial spread value of each category is defined as follows:
where
cl is the distance–weight set of the
i-th category,
ai is the distance–weight sum of the
i-th category,
bi is the member quantity of the
i-th category, and the initial value of
γi is set to 0.5. We can modify Equation (5) as follows:
where
X stands for the input vector data of the training sample set, and
Xi is the center value of the
i-th kernel. Σ
j is the diagonal matrix of kernel
i in category
j. The initial values of Σ
j are determined by referring to the average spread value of each variable in the kernel.
Assuming that the initial spread of set {
cv} is
σv, kernel
i belongs to set {
cv}. The distance–weight of every variable in kernel
i can be decomposed from Equation (11). The average distance–weight of each dimension in set {
cv} is normalized. The diagonal matrix is obtained based on the weighted average method following Equations (16)–(19).
The total estimation error of the m-length training samples is defined as follows:
where
is the estimation value and
is the corresponding target value. We calculated the gradient of the estimation error by differentiating with respect to the current spread
σi, as in Equation (17).
The traditional gradient descent algorithm is not the emphasis of this paper, and some details have been described in a similar scheme [
42].
Unlike other methods, the optimal spread of each category in our method is attained one by one, similar to completing a jigsaw puzzle. The highlight appears in the training and validation phase. Conventionally, the optimal spreads are supposed to minimize the target function, Equation (20), with the whole validation data set. In our approach, the target function is dynamic for different spreads, as their validation data sets are selected specially. We also partition the validation data by referring to the principle expounded in step 1.
Firstly, we selected the spread value of {
c1} as the benchmark. When the iteration begins, the spread of
σ1 is updated with the gradient descent algorithm, as in Equation (23), while the other spread values are varying in proportion to
σ1, according to Equation (24).
where
ε is the step coefficient that controls the fitting accuracy and convergence speed of the iterative algorithm. In particular, the validation data set that is injected into the target function has a similar distance–weight to set {
c1}. The optimal spread value
is calculated according to Equation (25).
Once the iteration is done, σ1 will be treated as a constant, and the validation data that is similar to {c2} would be supplemented to the target function. Repeat the above process until all of the spreads are acquired.
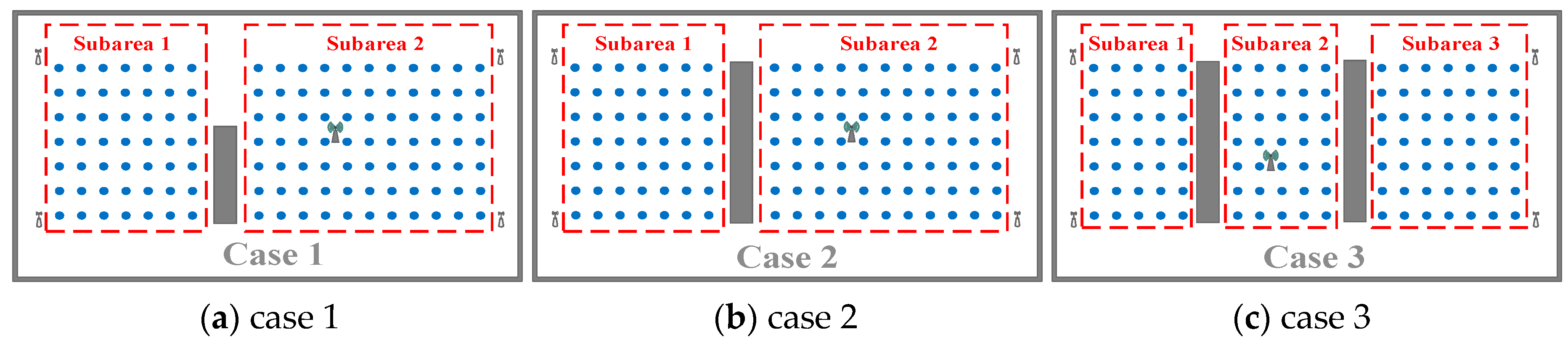
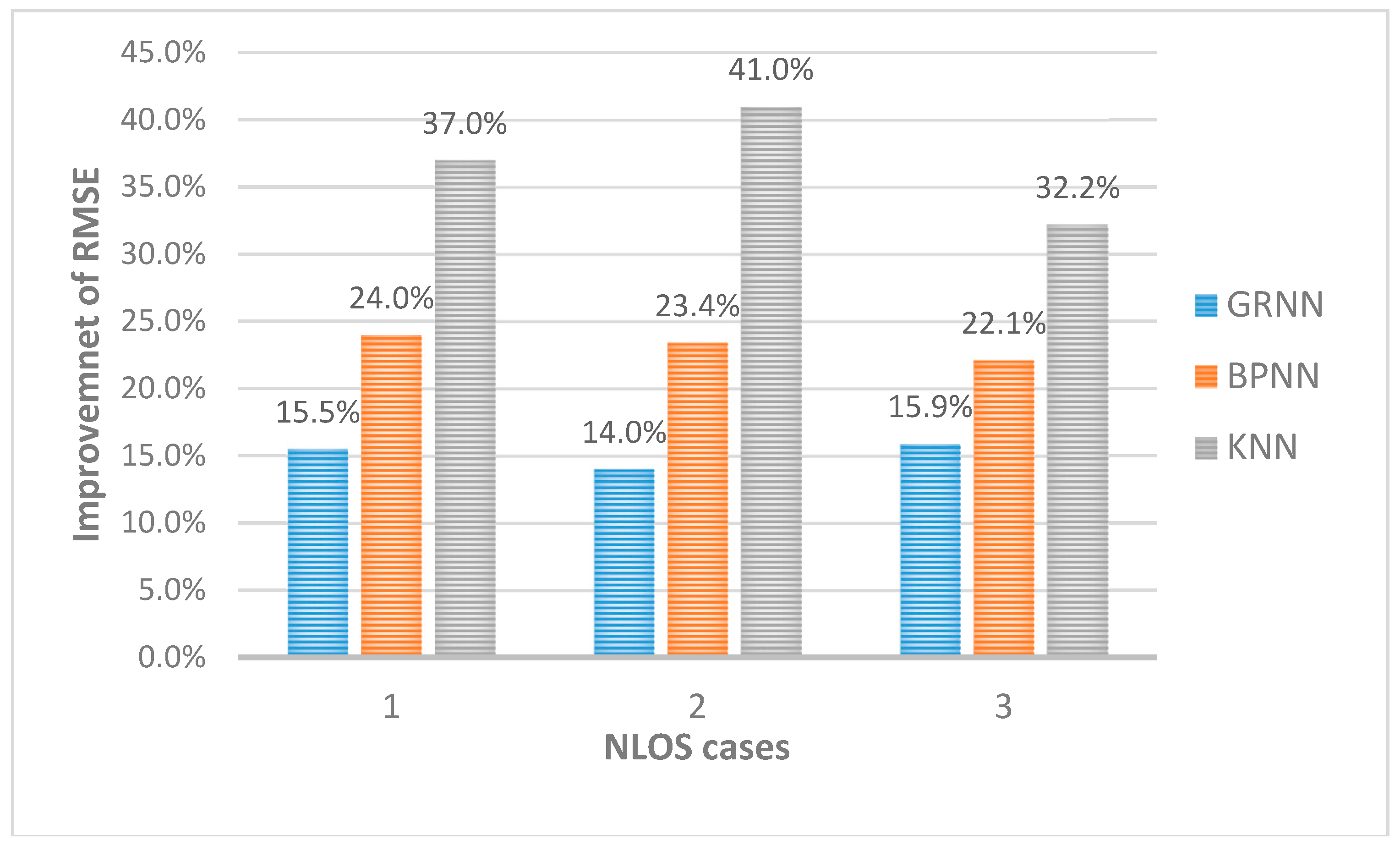
In the NLOS cases, as some adjacent fingerprints may be separated by walls, doors, pillars, or some other obstacles, their RSS vectors may be significantly different from each other. Thus, the assumption that the fingerprints are more similar when they are geographically closer is no longer valid.
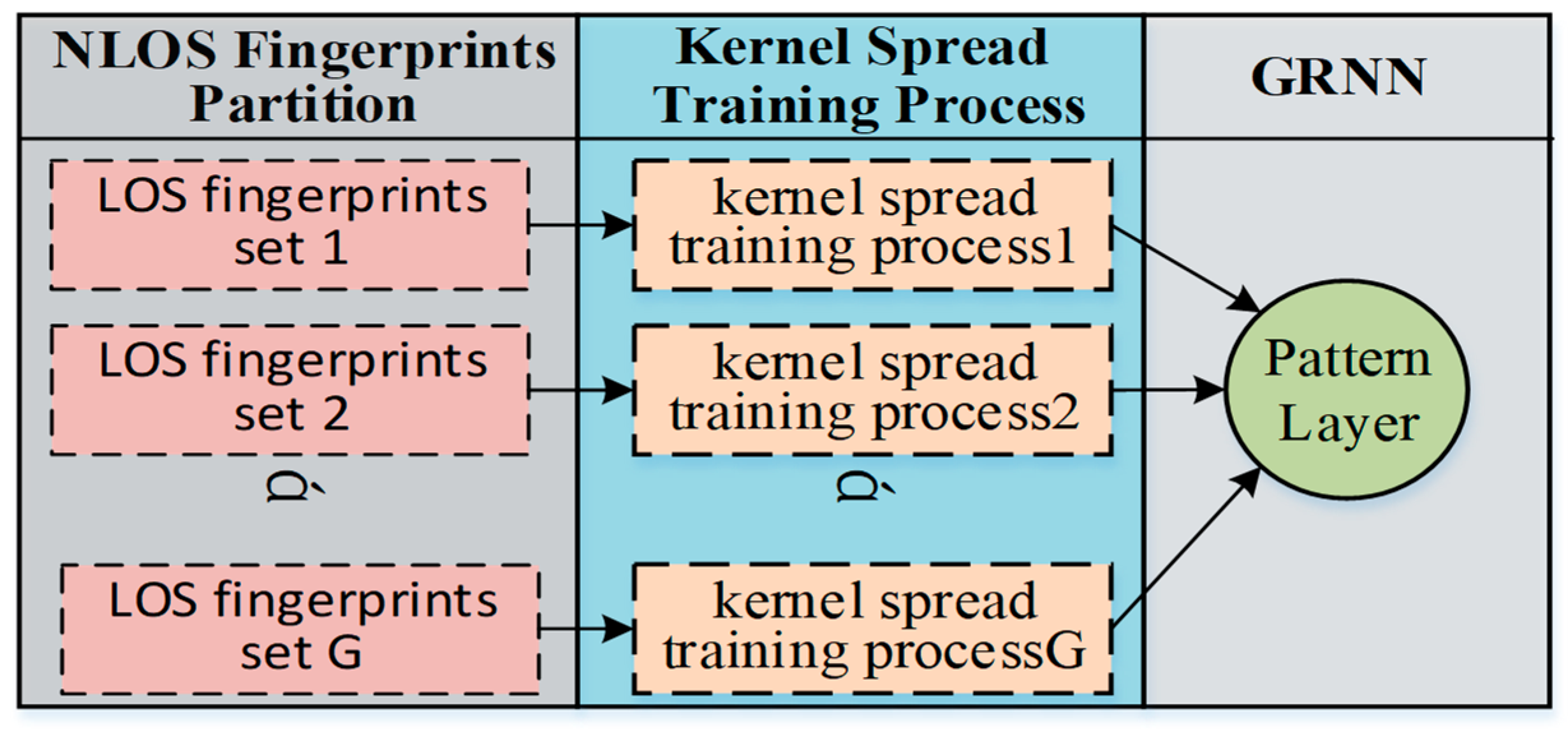
Fortunately, the pattern neuron of the GRNN is independent from the others, and the spread value of each pattern neuron can be calculated individually. Therefore, we can partition the NLOS object area into several subareas. The partition principle is to guarantee that each subarea is convex so that each RP in it is in LOS to each other, as shown in
Figure 6. To avoid confusion, here, the mentioned LOS actually means that there is no obstacle between each RP and its neighbor RPs rather than APs. The convex contour of the subarea guarantees that most of the RPs have sufficient LOS neighbors. In this way, the geographical correlation of the fingerprints, that the adjacent kernels are supposed to be neighbors in the ground truth still works in each subarea. Hence, the multiple-bandwidth kernel spread training process can be carried out in the subareas, as in the LOS case.
The proposed NLOS area division method is simple and straightforward. The object area can be partitioned into several subareas according to the actual layout. As long as it is gathering all of the trained pattern neurons from all of the subareas, the spread training procedure in NLOS case is successfully achieved.
In conclusion, the proposed multiple-bandwidth kernel spread training method leverages the geographical correlation of the fingerprints, that the adjacent kernels are supposed to be neighbors in the ground truth. It is flexible and significant that the tunable spread scale is beneficial to achieve a good tradeoff between the performance and complexity for the positioning task. Furthermore, when the object area is very large or in the NLOS condition, the proposed method is still working, by dividing the area into several small and fingerprints-convex areas. Then, the spread training process runs in each subarea separately, and generates a part of the neurons in the pattern layer of the GRNN. The proposed algorithm does not need the information of the APs’ precise positions, it just needs the layout of the target area, which is usually a prerequisite for fingerprint-based IPSs.
3.4. Outlier Filter Algorithm
In this section, we present the detailed procedure of the outlier filter algorithm.
The first step is to find the nearest RPs to the target. No matter whether the GRNN or KNN algorithm is used, the pattern whose value is similar to the input has more effect on the result estimation, and they are usually considered to be the nearest neighbors. Therefore, it is very important to recognize the nearest fingerprints for the indoor localization scenario.
Theoretically, the reference point whose fingerprint has the shortest distance to the input RSS value is supposed to be the nearest neighbor. However, it is not exactly in the temporal dynamic indoor environment, where human presence and mobility interfere with the RSS measurement dramatically. According to experience and the experimental results, the positioning accuracy would deteriorate when the calculated nearest neighbor is false. To address this problem, we propose an outlier filtering scheme to identify whether these candidate patterns are real neighbors of the target location.
The Euclidean distance between the RSS vector of the input data,
rssin, and the RSS vector of all of the fingerprint data can be calculated by using Equation (11). Select
k fingerprints from the set {
fi}, and ∀
I ∈ [1,
n] as the neighbor candidates corresponding to the
k minimum distance. The candidate quantity
k is predefined as similar to in the KNN algorithm, and the main principle is to guarantee that the nearest neighbor to the target location is among the reference nodes corresponding to these
k minimum
pi. Although there is no analytical solution for the optimal value of
k, it can be determined experimentally for a given condition. In order to obtain a convincing result, we evaluated the distance rank of the real nearest neighbor in set {
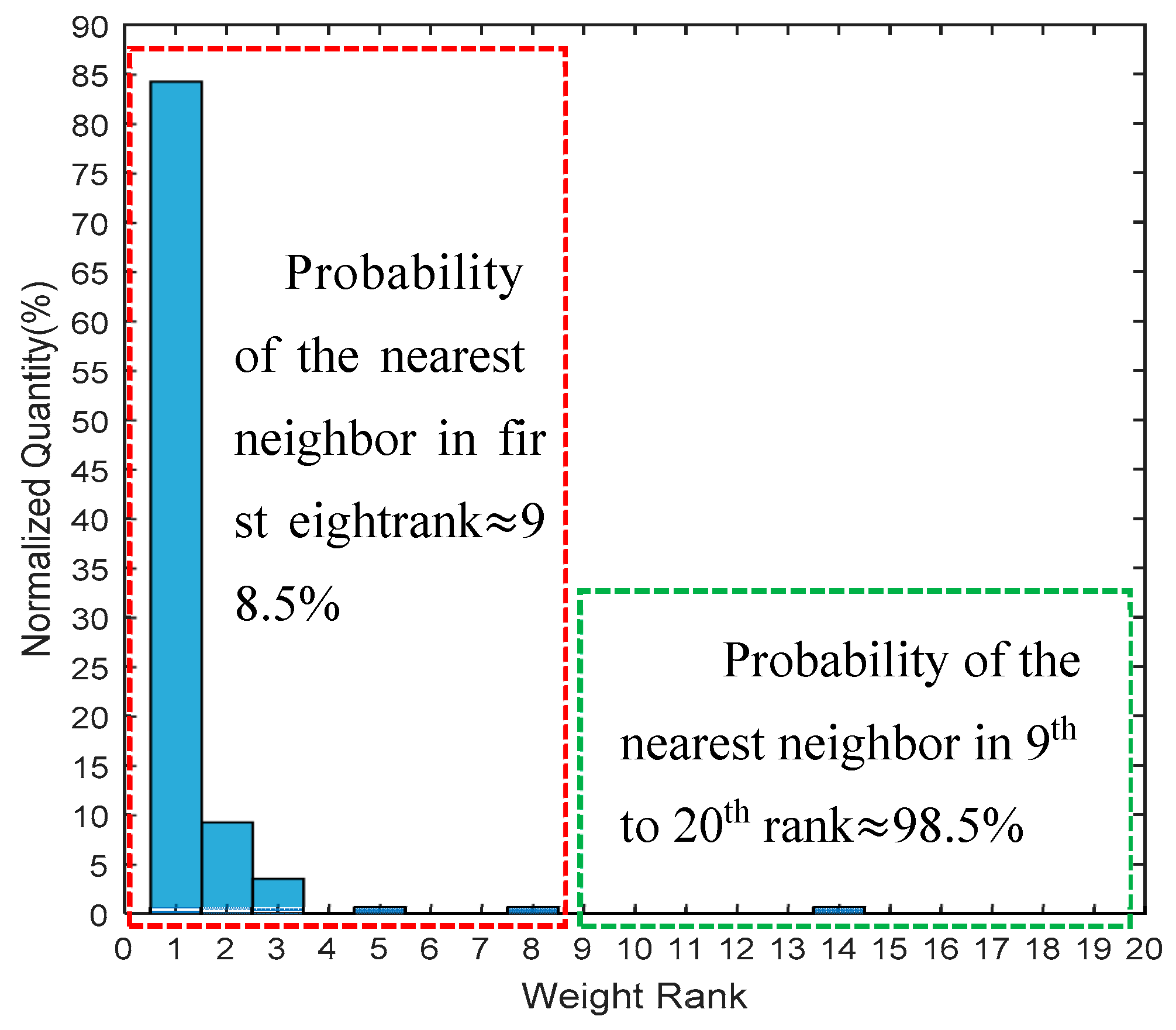
fi} with the given data set, which is composed of 9100 individual sample data collected under multi-conditions. The result is shown in
Figure 7, which depicts that the distance rank of the real nearest neighbor fingerprint was within 8 in 98.5% of the occasions, while being in first place 83% of the time. Referring to this analysis result, we define
k as 8 in the following discussion.
The next step is to sort the
k candidate fingerprints in ascending order, based on the distance rank, which is denoted as
Fc = [
c1,
c2, …,
ck]
T, and list the corresponding location coordinates {(
xi,
yi)}(
i ∈ [1,
k]). The spatial distances between these patterns are easily obtained and expressed in matrix
V. Thus,
where
We can learn from
Figure 7 that the first candidate,
c1, is most likely to be the real nearest fingerprint, while
c2 has a one-in-ten chance. Different processing strategies are conducted according to the spatial relationship between
c1 and
c2. Given parameter
vth, which is defined as the adjacency threshold, it represents the maximum distance of the credible candidates to
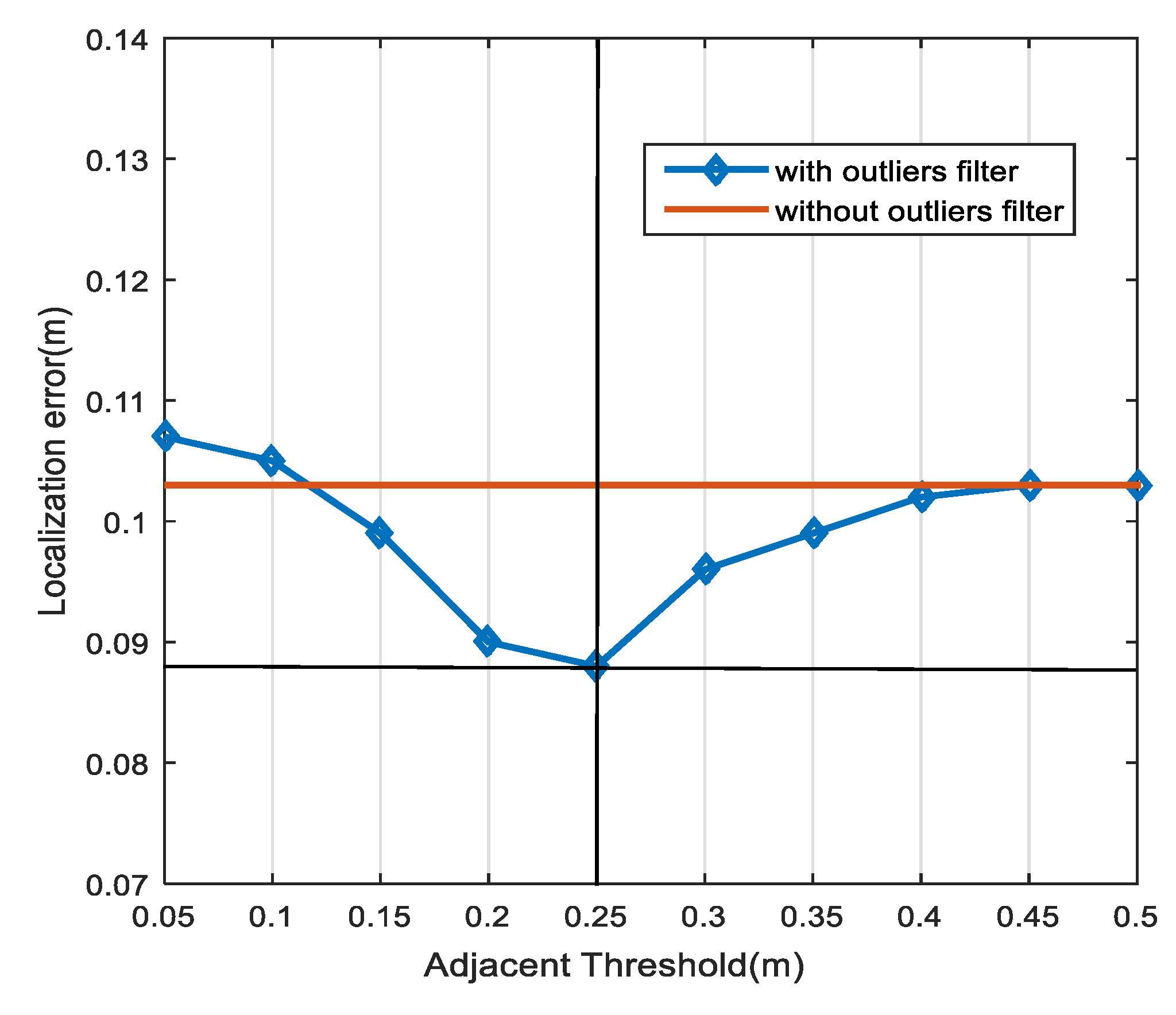
c1. The optimal threshold value,
vth, can be determined by using a cross-validation method, such as the leave-one-out (LOO) method.
If
v12 ≤
vth, then
c2 is supposed to be adjacent to
c1. In this situation, even though
c2 was the nearest one, the resulting error is tolerable. Otherwise,
c1 and
c2 are far apart in the ground truth, which would result in an unacceptable positioning error. We adopted a more cautious approach to identify the nearest neighbor between
c1 and
c2. First, we calculated the square of the Euclidean distance between the RSS vector of the input data
rssin and the RSS vector of
c1 and
c2, such that
A score scheme is addressed by comparing each dimension of the RSS value according to
When the
q-th distance component of
c1 is not greater than that of
c2, score one, and the total score ranges from 1 to
p. Furthermore, we consider the output location of the last estimation as another constraint. As the target’s movement velocity is limited, the upper limit of the distance between two successive estimation outputs is denoted as the vigilance parameter,
ρ. We define the constraint function
ξ as follows:
where
v20 denotes the distance between estimation of
c2 and the estimated result at the previous time.
The final score is as follows:
If
S = 0, we assume that
c2 is more likely to be closer to the target, and we exclude
c1 from the candidate set. Otherwise,
c1 defends its nearest neighbor rank. The determined nearest neighbor fingerprint is set as the benchmark in order to identify the outliers in
Fc, by referring to the updated matrix,
V, and the adjacency threshold,
vth, such that
We listed the “fake” candidate fingerprint index in the outlier set Z, which is sent to the GRNN block, and the corresponding neuron is excluded from the summation layer.
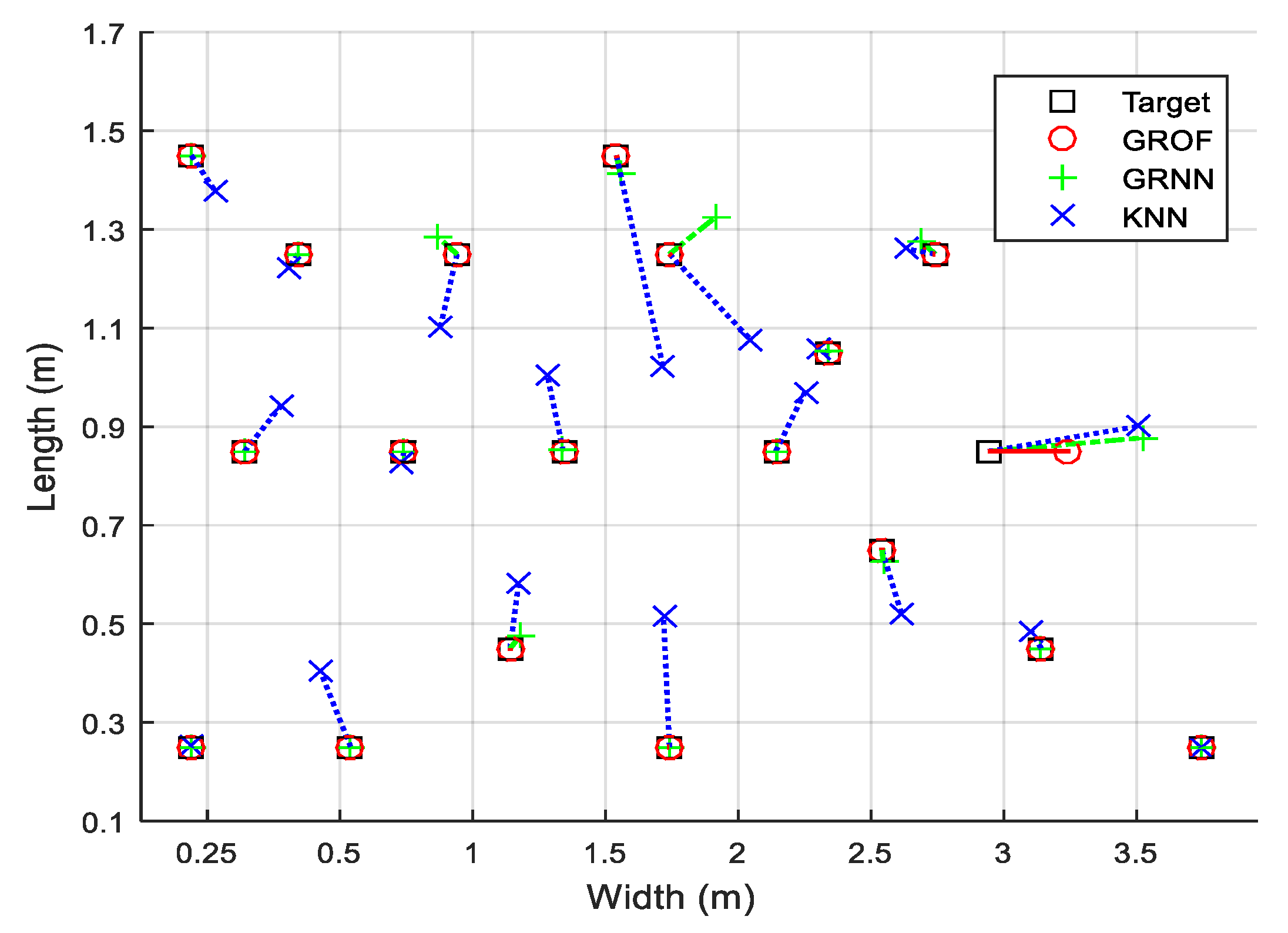
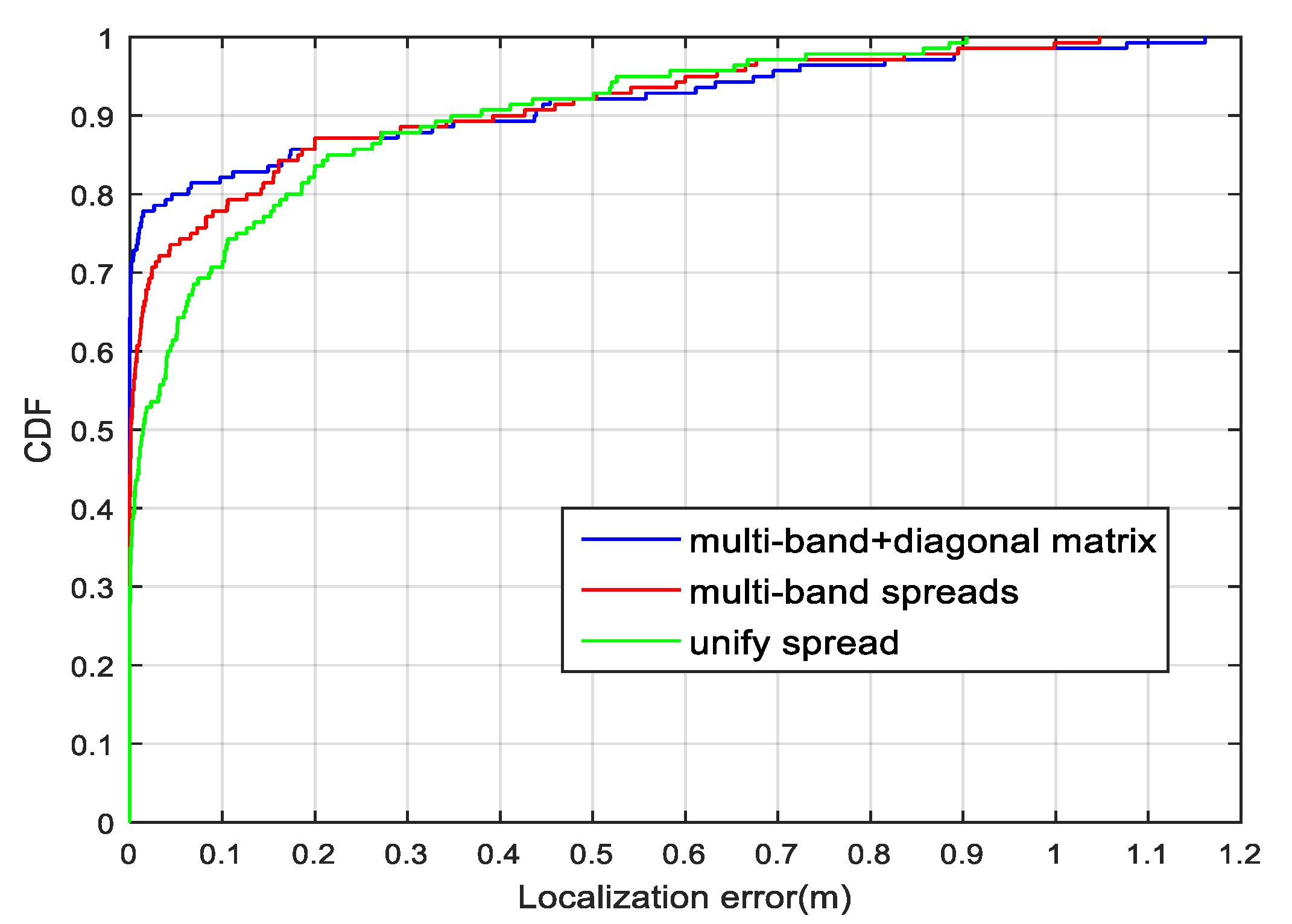
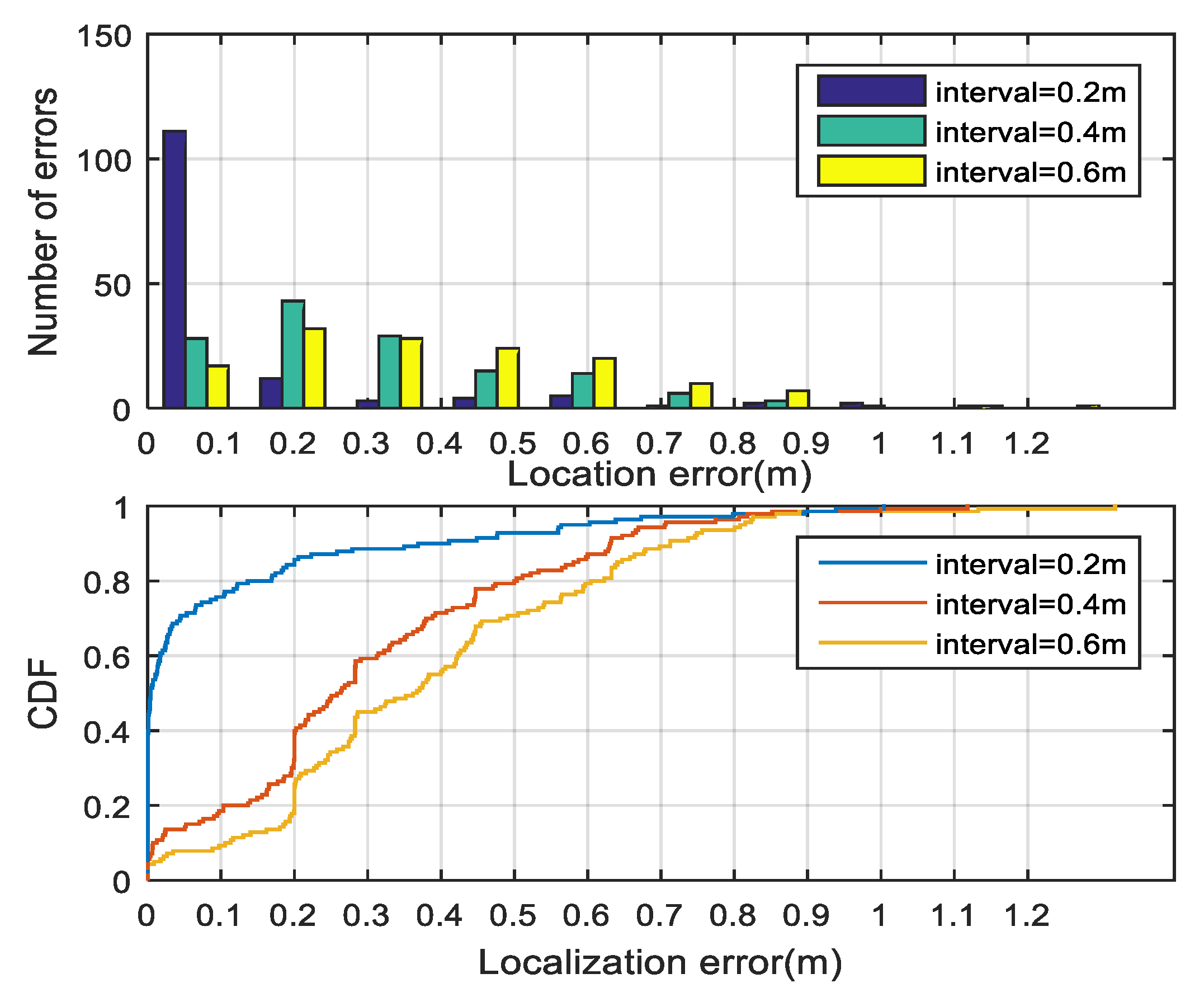
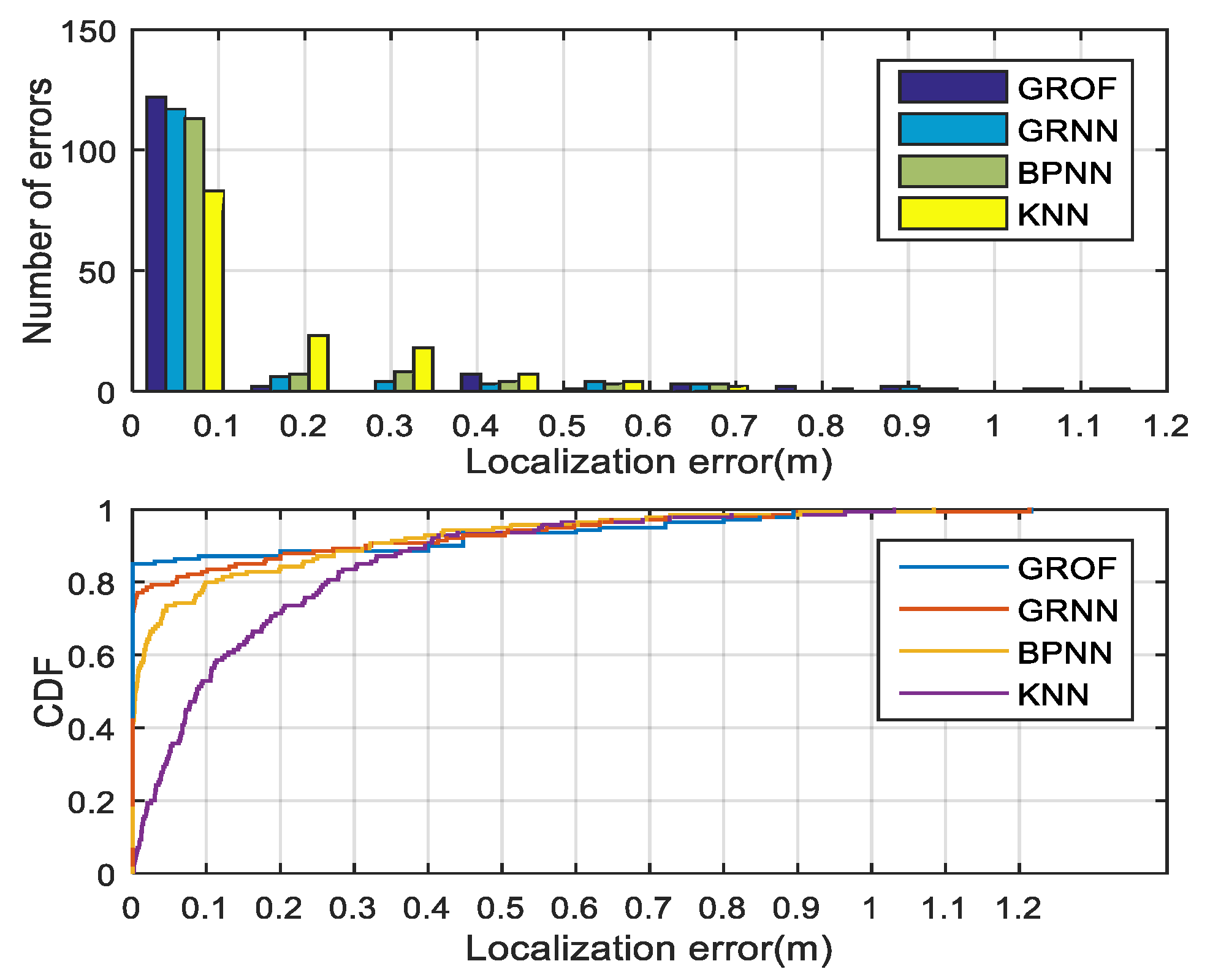
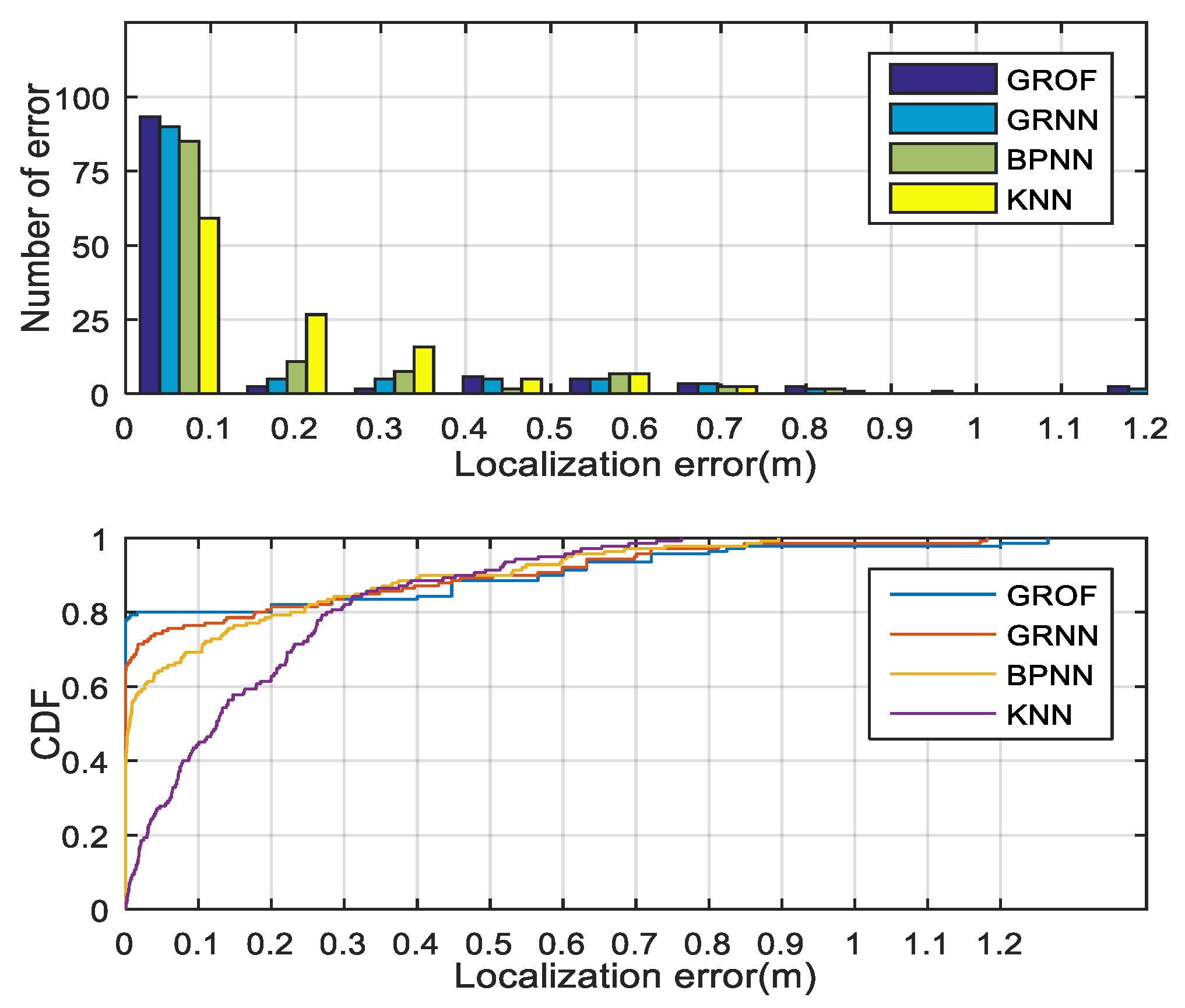
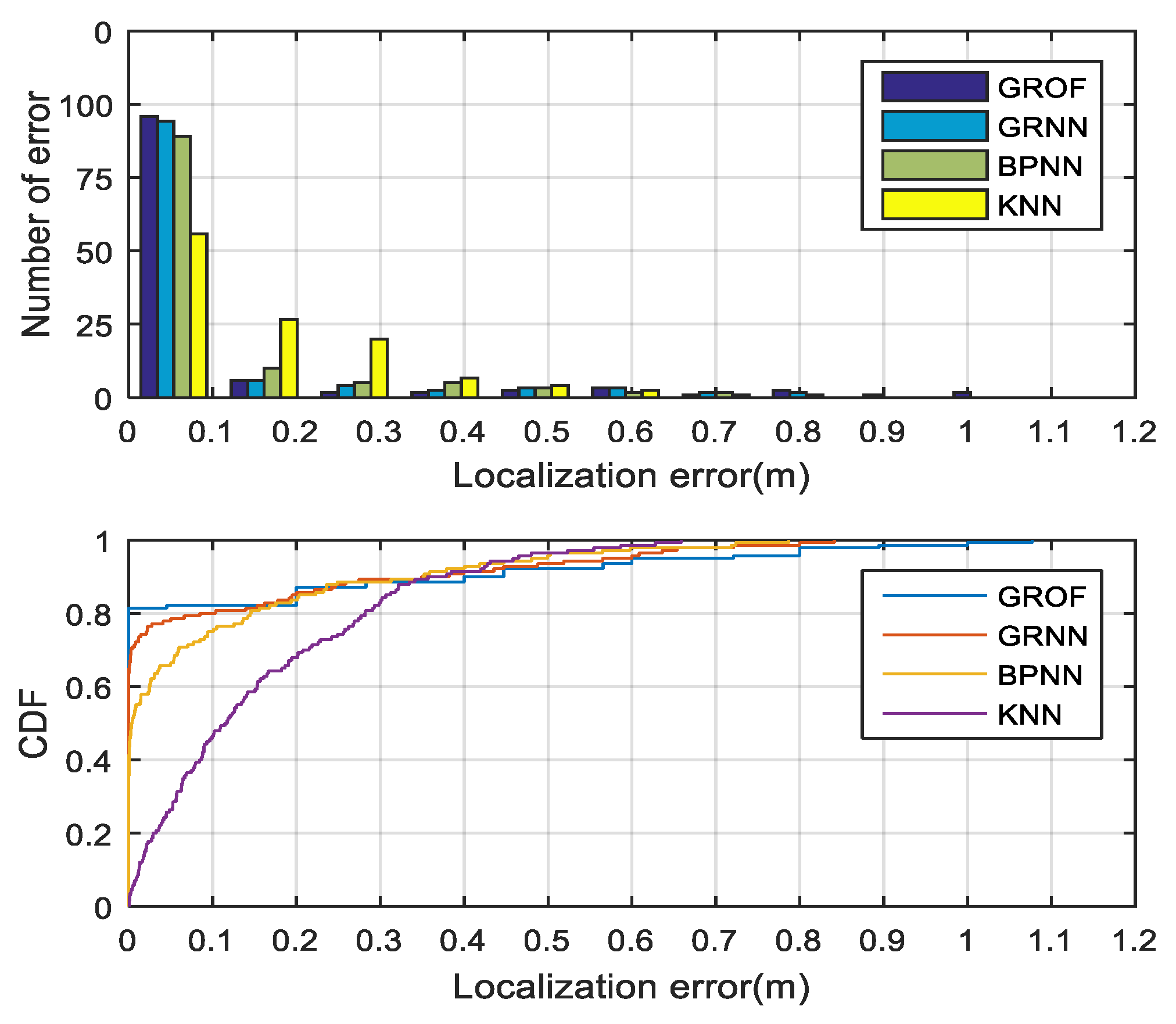
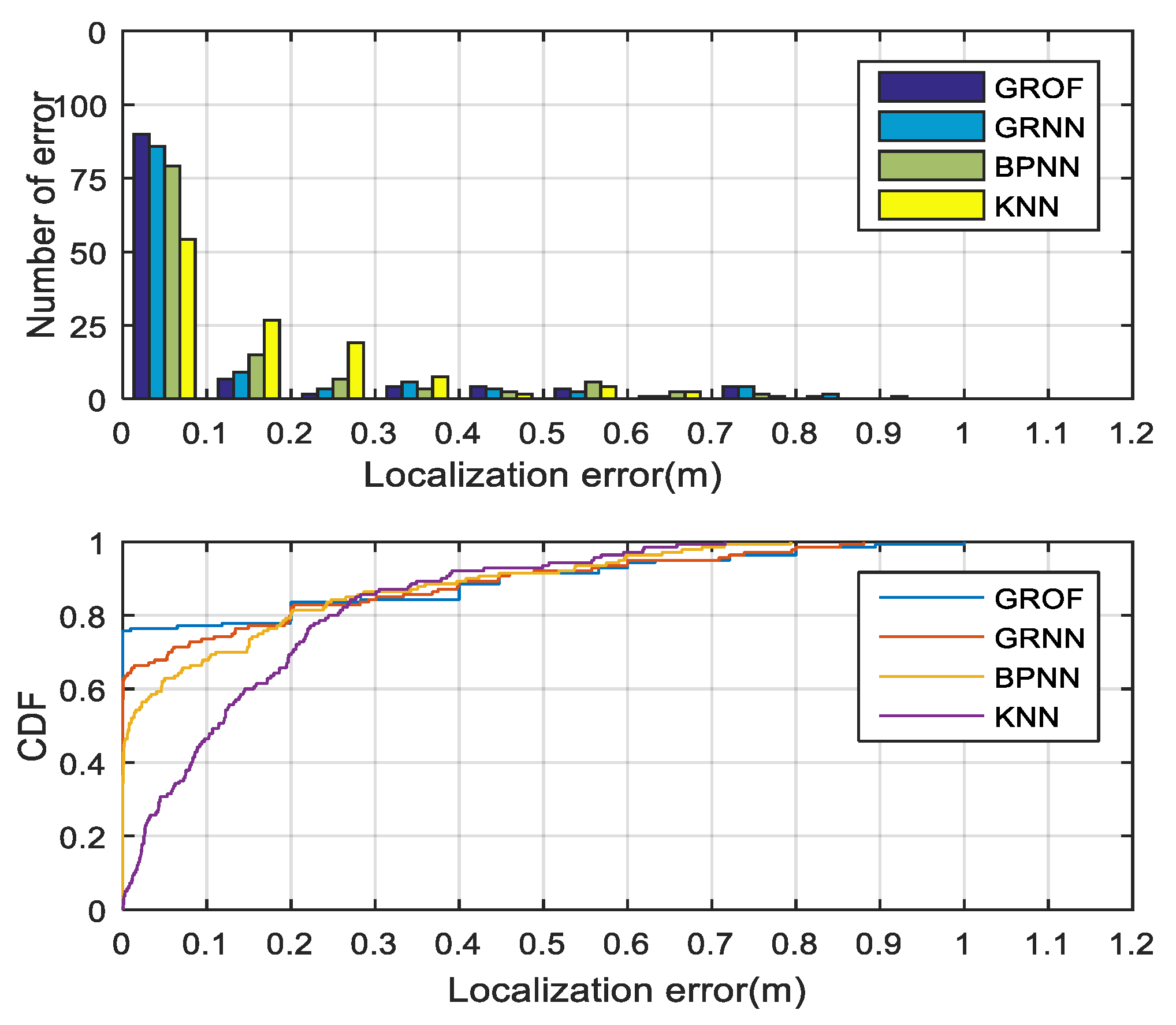
As shown in
Figure 8, we randomly select 20 RPs to compare the localization performances. The combination of the GRNN and the outlier filtering mechanism is named GROF, while the combination of the KNN and the outlier filtering mechanism is named KOF. With the help of the outlier filter algorithm, both the GRNN and the KNN method achieve better localization accuracy and enhance the system’s robustness against RSS fluctuations. The localization results indicate that the GROF method significantly alleviates the deviation of the estimation results compared with the KOF, GRNN, and KNN methods.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}