3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network


Abstract
1. Introduction
- The point cloud is not in a regular format. Unlike an image, a point cloud is a set of points distributed in space. Hence, it is non-grid data. However, typical convolutional architectures can merely deal with highly regular data formats, and it is, therefore, hard to use convolutional neural networks to process raw point clouds.
- The point cloud is unordered. There are various orderings of points, indicating that there are many matrix representations of a particular point cloud. Therefore, how to adapt the changes of the waypoints are arranged is a problem in point cloud processing.
- Three-dimensional point clouds normally contain only the spatial coordinates of points, lacking rich textures, colors, and other information.
2. Related Work
3. Point Cloud Data
3.1. Point Cloud Data Representation
3.2. Multi-View 2.5D Point Cloud Data Generation
3.3. Multi-View 2.5D Point Cloud Data Characteristics
- Multi-view 2.5D point cloud data are unordered [19]. Multi-view 2.5D point cloud data are a set of points with no specific order.
- There exists a correlation among the points [19]. Each point does not exist in isolation but shares spatial information with nearby points.
- Multi-view 2.5D point cloud data are sensitive to some transformations such as translation, scaling, and rotation. The coordinates of the points change after transformations, but the recognition results should remain unchanged since the shapes of point clouds are invariant.
- Multi-view 2.5D point cloud data are composed of 2.5D point clouds from multiple views. Consequently, each view contains local features that make up global features.
4. Methods
4.1. Symmetry Module
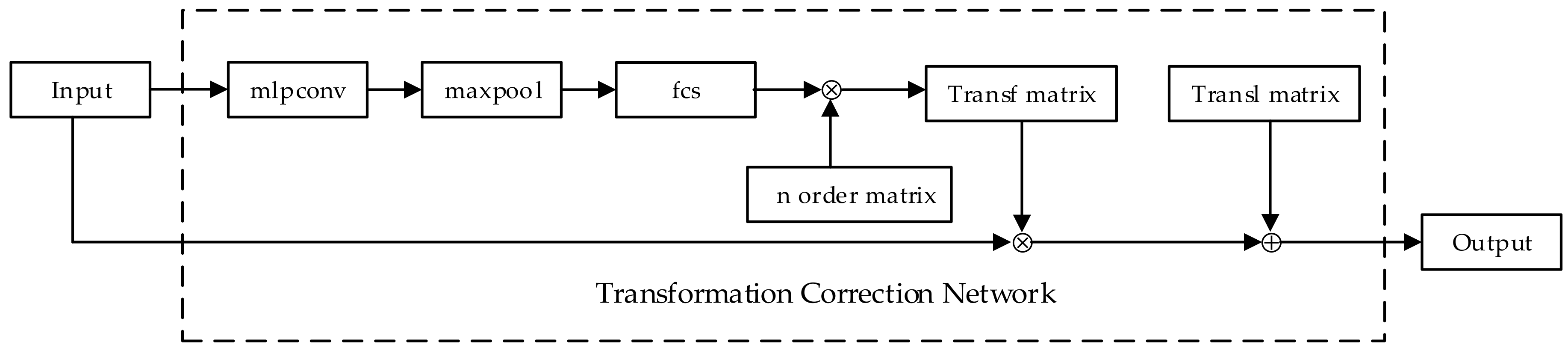
4.2. The Transformation Correction Network
= SMX + A
= TX+A
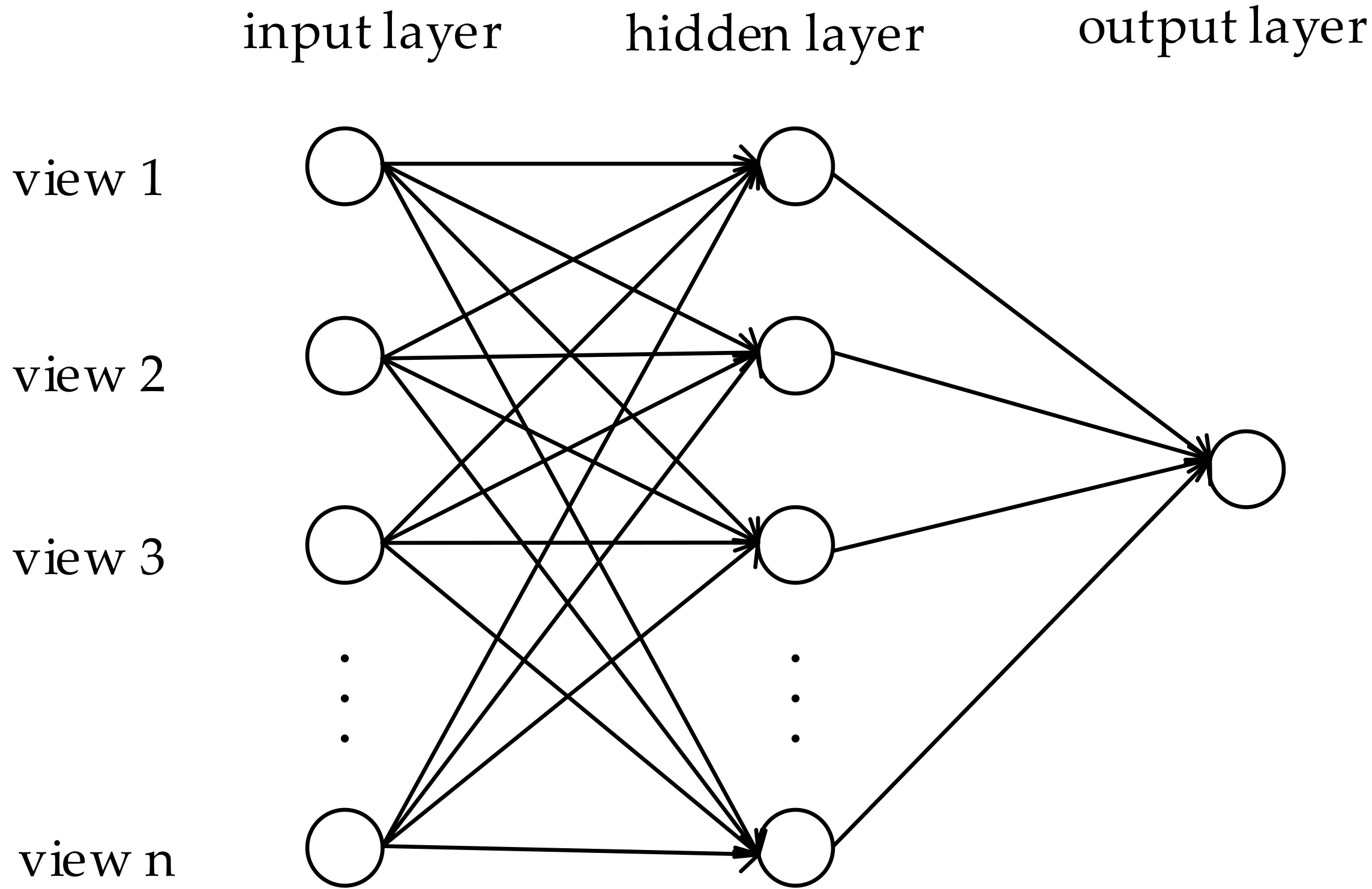
4.3. The View Fusion Network
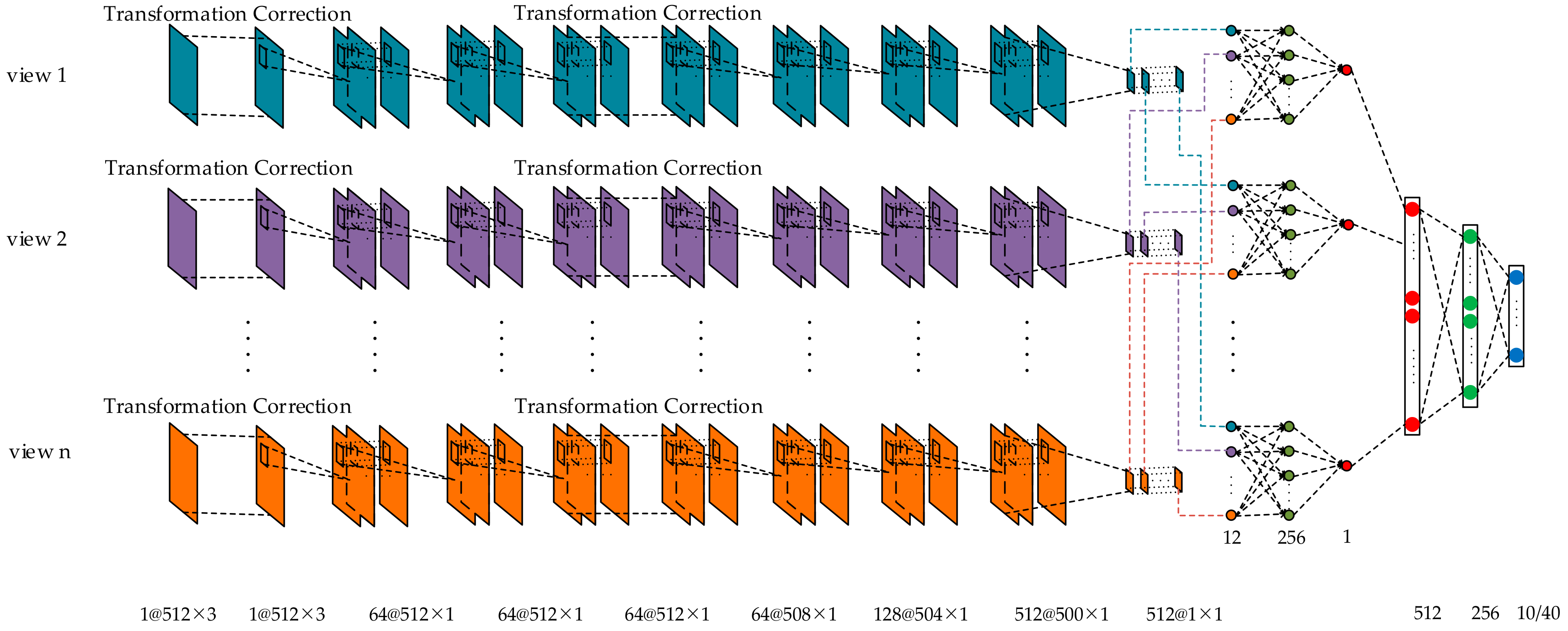
4.4. The Multi-View Convolutional Neural Network
5. Results
5.1. The Effect of the Number of Points on Recognition Results
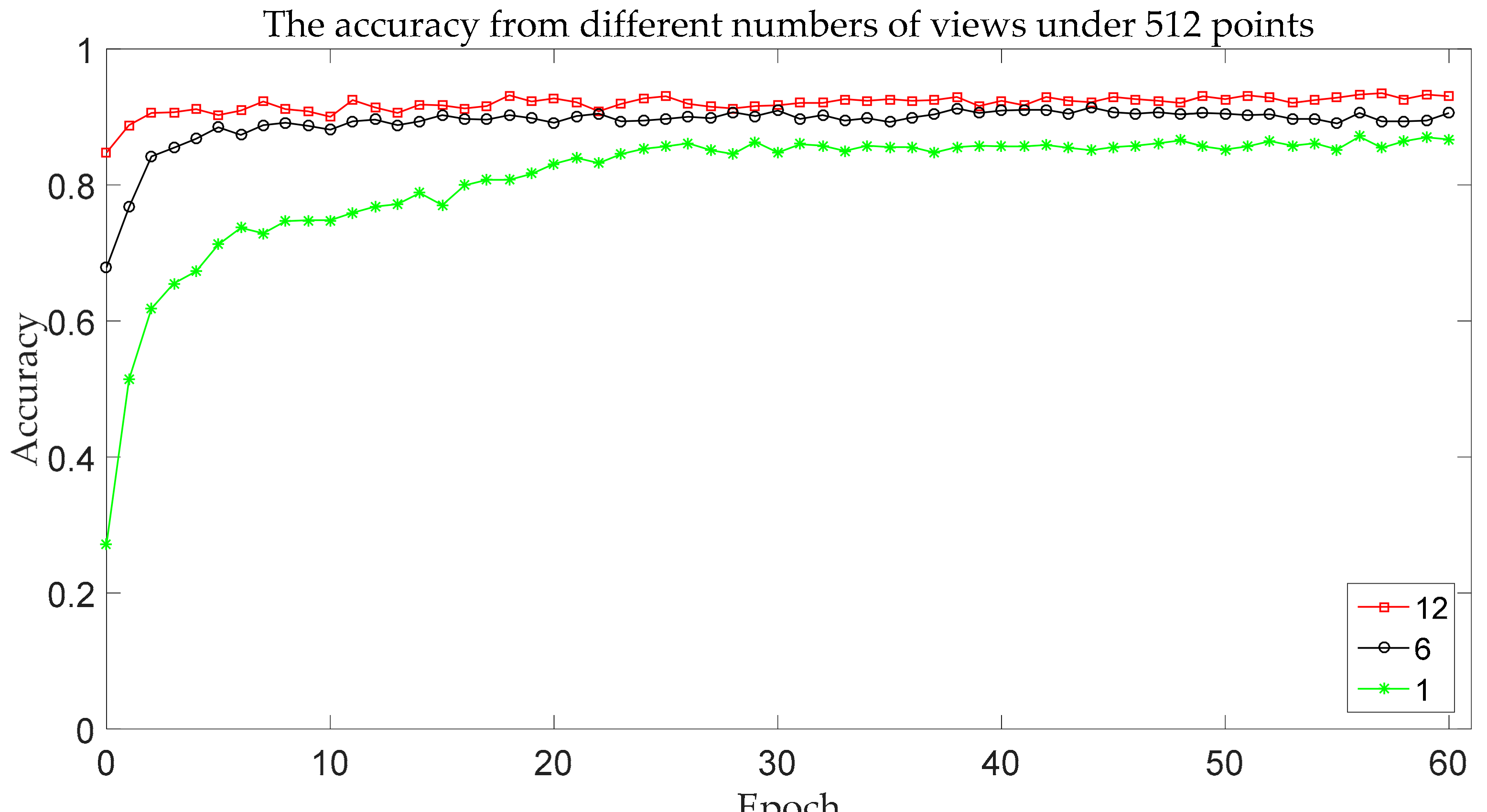
5.2. The Effect of the Number of Views on Recognition Results
5.3. The Effectiveness of Symmetry Module, Transformation Correction Network, and View Fusion Network
5.4. Comparison with Other Methods
6. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Bruch, M. Velodyne HDL-64E lidar for unmanned surface vehicle obstacle detection. Proc. SPIE Int. Soc. Opt. Eng. 2010, 7692, 76920D. [Google Scholar]
- Liu, J.; Liang, H.; Wang, Z.; Chen, X. A Framework for Applying Point Clouds Grabbed by Multi-Beam LIDAR in Perceiving the Driving Environment. Sensors 2015, 15, 21931–21956. [Google Scholar] [CrossRef] [PubMed]
- Hussein, M.W.; Tripp, J.W. 3D imaging lidar for lunar robotic exploration. Proc. SPIE Int. Soc. Opt. Eng. 2009, 7331, 73310H. [Google Scholar]
- Wang, X.; Lile, H.E.; Zhao, T. Mobile Robot for SLAM Research Based on Lidar and Binocular Vision Fusion. Chin. J. Sens. Actuators 2018, 31, 394–399. [Google Scholar]
- Beck, S.M.; Gelbwachs, J.A.; Hinkley, D.A.; Warren, D.W. Aerospace applications of optical sensing with lidar. In Proceedings of the Aerospace Applications Conference, Aspen, CO, USA, 10 February 1998. [Google Scholar]
- Mcmanamon, P. Aerospace Applications Of Lidar For DOD. In Proceedings of the Spaceborne Photonics: Aerospace Applications of Lasers and Electro-Optics/Optical Millimeter-Wave Interactions: Measurements, Generation, Transmission and Control, Newport Beach, CA, USA, 22–24 July 1991. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hinton, G.; Deng, L.; Dong, Y.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.; Rao, K.; Beaufays, F. Fast and Accurate Recurrent Neural Network Acoustic Models for Speech Recognition. arXiv, 2015; arXiv:1507.06947. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Natural Language Processing. arXiv, 2016; arXiv:1606.01781. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Comput. Sci. 2014, 4, 3104–3112. [Google Scholar]
- Prokhorov, D. A convolutional learning system for object classification in 3-D Lidar data. IEEE Trans. Neural Netw. 2010, 21, 858. [Google Scholar] [CrossRef] [PubMed]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Charles, R.Q.; Hao, S.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learnedmiller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Sfikas, K.; Pratikakis, I.; Theoharis, T. Ensemble of PANORAMA-based convolutional neural networks for 3D model classification and retrieval. Comput. Graph. 2017, 71, 208–218. [Google Scholar] [CrossRef]
- Pang, G.; Neumann, U. Fast and Robust Multi-view 3D Object Recognition in Point Clouds. In Proceedings of the International Conference on 3d Vision, Lyon, France, 19–22 October 2015; pp. 171–179. [Google Scholar]
- Pang, G.; Neumann, U. 3D point cloud object detection with multi-view convolutional neural network. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 585–590. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. arXiv, 1611; arXiv:1611.07759. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order Matters: Sequence to sequence for sets. arXiv, 1511; arXiv:1511.06391. [Google Scholar]
- Ravanbakhsh, S.; Schneider, J.; Poczos, B. Deep Learning with Sets and Point Clouds. arXiv, 2016; arXiv:1611.04500. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv, 2015; arXiv:1506.02025. [Google Scholar]
- Xie, R.; Wang, X.; Li, Y.; Zhao, K. Research and application on improved BP neural network algorithm. In Proceedings of the Industrial Electronics and Applications, Taichung, Taiwan, 15–17 June 2010. [Google Scholar]
- Kazhdan, M.; Funkhouser, T.; Rusinkiewicz, S. Rotation invariant spherical harmonic representation of 3D shape descriptors. In Proceedings of the 2003 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing, Aachen, Germany, 23–25 June 2003; pp. 156–164. [Google Scholar]
- Chen, D.Y. On Visual Similarity Based 3D Model Retrieval. Comput. Graph. Forum 2010, 22, 223–232. [Google Scholar] [CrossRef]
- Shi, B.; Bai, S.; Zhou, Z.; Bai, X. DeepPano: Deep Panoramic Representation for 3-D Shape Recognition. IEEE Signal Process. Lett. 2015, 22, 2339–2343. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of Points | Accuracy |
|---|---|
| 64 | 89.9% |
| 128 | 90.7% |
| 256 | 92.2% |
| 512 | 93.5% |
| The Number of Views | Accuracy |
|---|---|
| 1 | 86.6% |
| 6 | 90.5% |
| 12 | 93.5% |
| Method | Accuracy of ModelNet10 | Accuracy of ModelNet40 |
|---|---|---|
| all | 93.5% | 90.5% |
| no symmetry module | 86.7% | 76.1% |
| no TCN 1 | 88.9% | 82.0% |
| no view fusion network | 84.3% | 73.3% |
| Method | Views | ModelNet10 | ModelNet40 |
|---|---|---|---|
| SPH [29] | -- | 79.79% | 68.23% |
| LFD [30] | -- | 79.87% | 75.47% |
| 3D ShapeNets [18] | -- | 83.54% | 77.32% |
| DeepPano [31] | -- | 88.66% | 82.54% |
| VoxNet [17] | -- | 92.0% | 83.0% |
| PointNet [19] | -- | -- | 89.2% |
| MVCNN [20] | 12 | -- | 89.9% |
| MVCNN [20] | 80 | -- | 90.1% |
| Our Methods 1 | 12 | 90.5% | 89.4% |
| Our Methods 2 | 12 | 93.5% | 90.5% |
| Our Methods 2 | 20 | 94.1% | 90.8% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Sun, J.; Zheng, Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors 2018, 18, 3681. https://doi.org/10.3390/s18113681
Zhang L, Sun J, Zheng Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors. 2018; 18(11):3681. https://doi.org/10.3390/s18113681
Chicago/Turabian StyleZhang, Le, Jian Sun, and Qiang Zheng. 2018. "3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network" Sensors 18, no. 11: 3681. https://doi.org/10.3390/s18113681
APA StyleZhang, L., Sun, J., & Zheng, Q. (2018). 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors, 18(11), 3681. https://doi.org/10.3390/s18113681