Robust and Efficient CPU-Based RGB-D Scene Reconstruction


Abstract
1. Introduction
- A fast camera tracking method combining points and edges, by which the tracking stability in textureless scenes is improved;
- An efficient data fusion strategy based on a novel camera view selection algorithm, by which the performance of volumetric integration is enhanced.
- A novel RGB-D scene reconstruction system, which can be quickly implemented on a standard CPU.
2. Related Work
2.1. Camera Tracking
2.2. Volumetric Integration
3. System Overview
4. The Proposed Methods
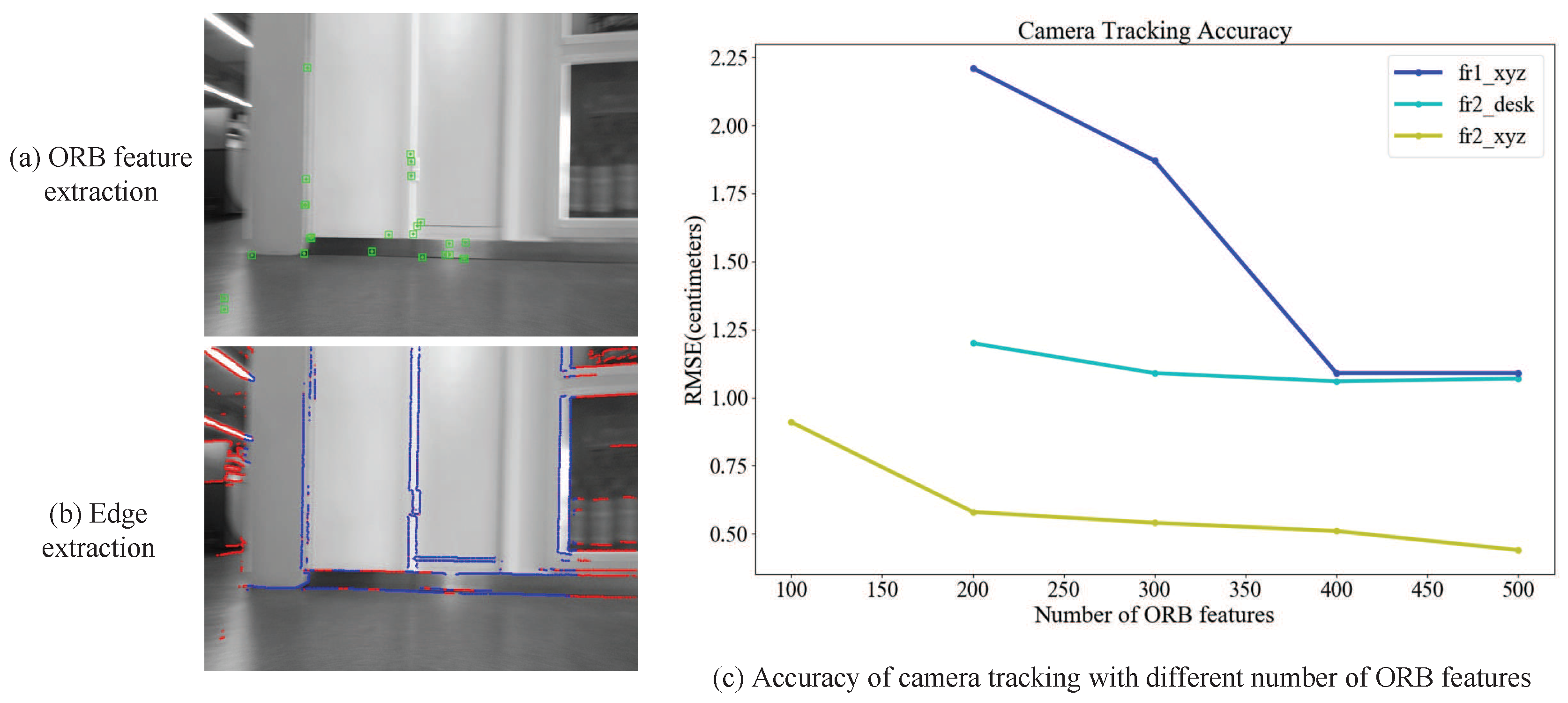
4.1. Tracking via Points and Edges
- First, 3D point corresponding to the pixel on the edge map is reconstructed using the inverse of the projection function as:where is the depth value of pixel in the first depth frame.
- Second, the 3D point in the second frame is given as: , where represents the transformation by the Lie algebra associated with the group . When the second camera observes the transformed point , we obtain the warped pixel coordinates:
- Finally, the full warping function is given as:
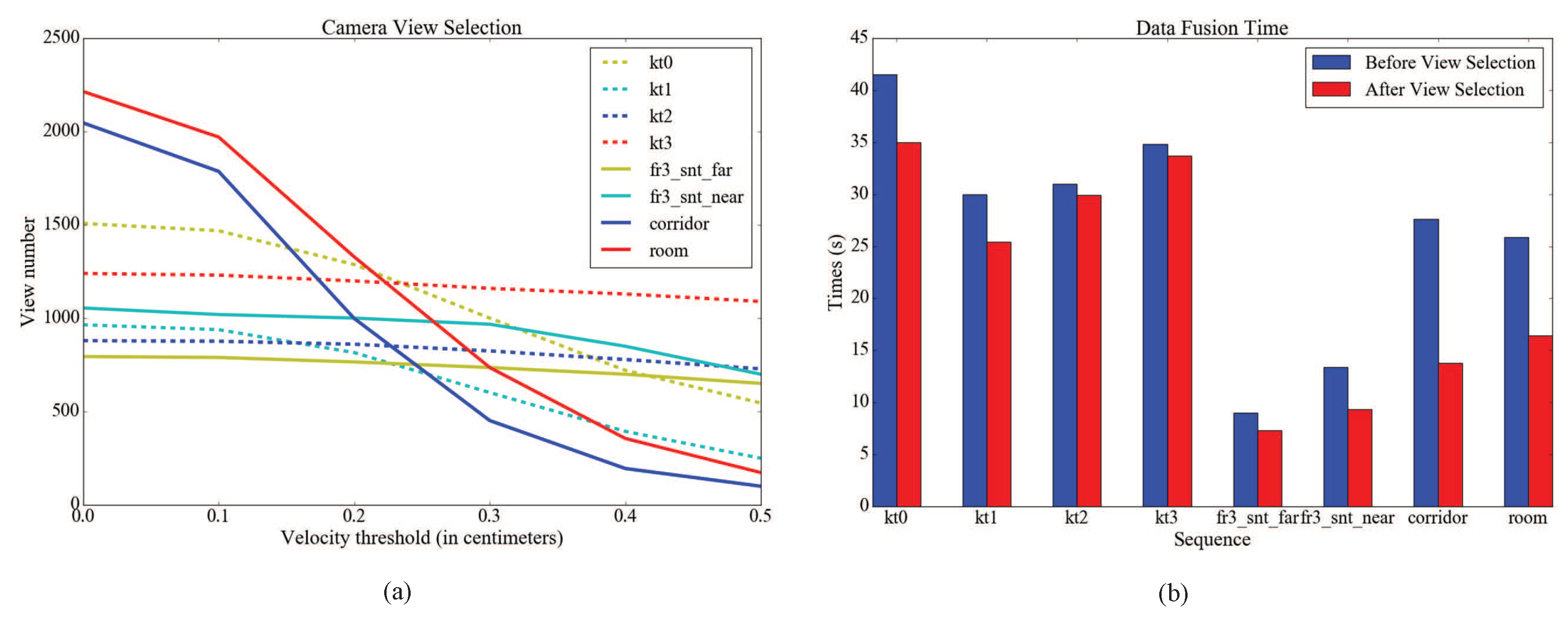
4.2. Efficient Data Fusion
- Three Euler angles , and are computed by relative rotation between consecutive frames:where , and represent the yaw, pitch and roll angles, respectively;
- Translational velocity is computed by:
- Loop closure key frames are detected in camera tracking;
- The similarity ratio between the ith and jth frame is measured by con-visibility content information [37] and defined as:where and are the number of available pixels in ith and jth depth images at the ith frame coordinate system.
| Algorithm 1 Camera view selection. |
| Input: The complete trajectory ; the list of loop closure key frames . |
Output: The reduced trajectory .
|
5. Experiments
5.1. Camera Tracking
5.2. Volumetric Integration
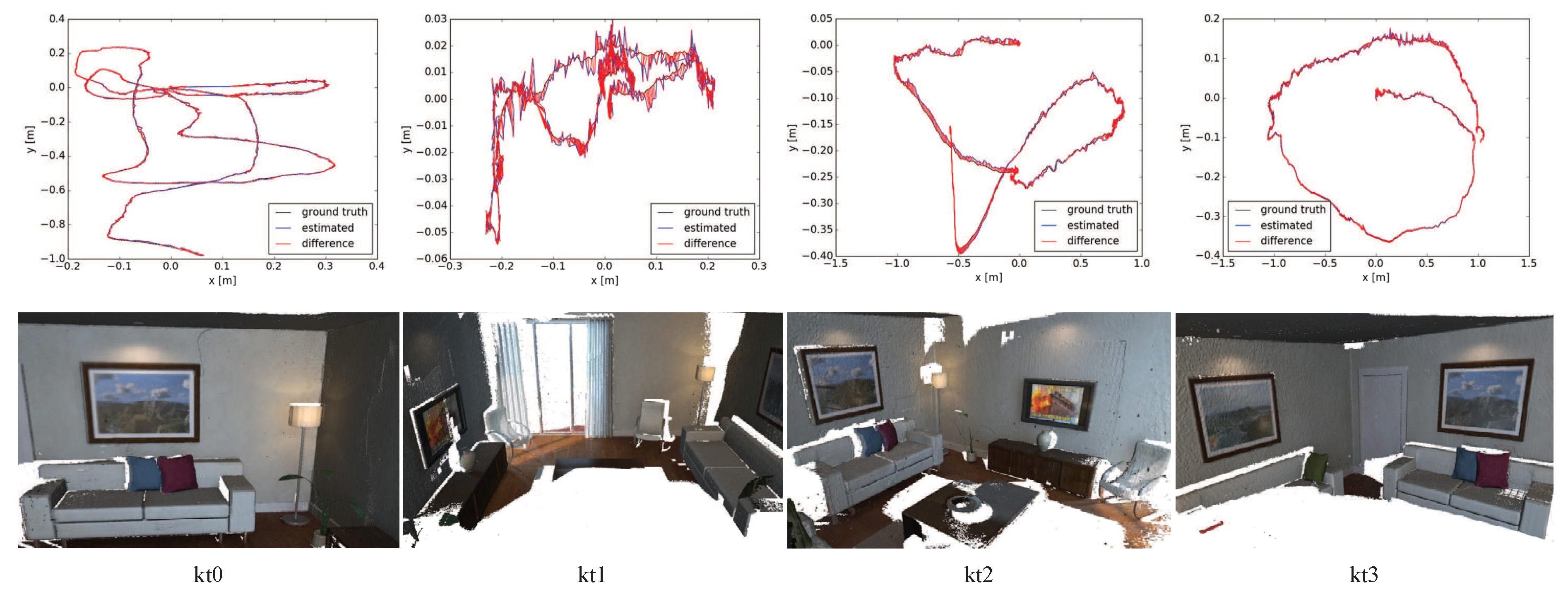
5.3. 3D Reconstruction
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; p. 145. [Google Scholar]
- Whelan, T.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.; Mcdonald, J. Kintinuous: Spatially extended KinectFusion. In Proceedings of the RSS Workshop on RGB-D: Advanced Reasoning with Depth Cameras, Berkeley, CA, USA, 12 July 2012. [Google Scholar]
- Whelan, T.; Kaess, M.; Leonard, J.J.; McDonald, J. Deformation-based loop closure for large scale dense RGB-D SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 548–555. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Robust odometry estimation for RGB-D cameras. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3748–3754. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the International Conference on Intelligent Robots and Systems, Daejeon, South Korea, 9–14 October 2014; pp. 2100–2106. [Google Scholar]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-time dense SLAM and light source estimation. Int. J. of Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Prisacariu, V.A.; Kahler, O.; Golodetz, S.; Sapienza, M.; Cavallari, T.; Torr, P.H.S.; Murray, D.W. Infinitam v3: A framework for large-scale 3D reconstruction with loop closure. arXiv. 2017. Available online: https://arxiv.org/abs/1708.00783 (accessed on 25 October 2018).
- Zeng, A.; Song, S.; Niessner, M.; Fisher, M.; Xiao, J. 3Dmatch: Learning the matching of local 3D geometry in range scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Choi, S.; Zhou, Q.Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5556–5565. [Google Scholar]
- Zhou, Q.Y.; Miller, S.; Koltun, V. Elastic fragments for dense scene reconstruction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013; pp. 473–480. [Google Scholar]
- Dai, A.; Izadi, S.; Theobalt, C. BundleFusion: Real-time globally consistent 3D reconstruction using on-the-fly surface re-integration. ACM Trans. Graph. 2017, 36, 76. [Google Scholar] [CrossRef]
- Meng, X.R.; Gao, W.; Hu, Z.Y. Dense RGB-D SLAM with Multiple Cameras. Sensors 2018, 18, 2118. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Hu, Y. CuFusion: Accurate Real-Time Camera Tracking and Volumetric Scene Reconstruction with a Cuboid. Sensors 2017, 17, 2260. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM: Tracking and mapping recognizable features. In Proceedings of the Workshop on Multi View Geometry in Robotics, Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source slam system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2016, 33, 1255–1262. [Google Scholar] [CrossRef]
- Zhou, H.; Zou, D.; Pei, L.; Ying, R.; Liu, P.; Yu, W. Structslam: Visual SLAM with building structure lines. IEEE Trans. Veh. Technol. 2015, 64, 1364–1375. [Google Scholar] [CrossRef]
- Lu, Y.; Song, D. Robust RGB-D odometry using point and line features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 3934–3942. [Google Scholar]
- Zhang, G.; Jin, H.L.; Lim, J.; Suh, I.H. Building a 3-D line-based map using stereo SLAM. IEEE Trans. Robot. 2017, 31, 1364–1377. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.A.; Scaramuzza, D.; Gonzalez-Jimenez, J. Pl-SLAM: A stereo SLAM system through the combination of points and line segments. arXiv. 2018. Available online: https://arxiv.org/abs/1705.09479 (accessed on 25 October 2018).
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. Pl-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Tarrio, J.J.; Pedre, S. Realtime edge-based visual odometry for a monocular camera. In Proceedings of the IEEE International Conference on Computer (ICCV), Santiago, Chile, 11–18 December 2015; pp. 702–710. [Google Scholar]
- Maity, S.; Saha, A.; Bhowmick, B. Edge SLAM: Edge points based monocular visual SLAM. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 22–29 October 2017; pp. 2408–2417. [Google Scholar]
- Steinbrücker, F.; Sturm, J.; Cremers, D. Volumetric 3D mapping in real-time on a CPU. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 2021–2028. [Google Scholar]
- Zeng, M.; Zhao, F.; Zheng, J.; Liu, X. A memory-efficient KinectFusion using octree. In Proceedings of the International Conference on Computational Visual Media, Beijing, China, 8–10 November 2012; pp. 234–241. [Google Scholar]
- Kaehler, O.; Prisacariu, V.A.; Murray, D.W. Real-time large-scale dense 3D reconstruction with loop closure. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 500–516. [Google Scholar]
- Kahler, O.; Prisacariu, V.A.; Ren, C.Y.; Sun, X.; Torr, P.H.S.; Murray, D.W. Very High Frame Rate Volumetric Integration of Depth Images on Mobile Device. IEEE Trans. Vis. Comput. Graph. 2015, 21, 1241–1250. [Google Scholar] [CrossRef] [PubMed]
- Niessner, M.; Izadi, S.; Stamminger, M. Real-time 3D reconstruction at scale using voxel hashing. ACM Trans. Graph. 2013, 32, 1–11. [Google Scholar] [CrossRef]
- Lorensen, W.E. Marching cubes: A high resolution 3D surface construction algorithm. In Proceedings of the Acm Siggraph Computer Graphics, Anaheim, CA, USA, 27–31 July 1987; Volume 21, pp. 163–169. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to sift or surf. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Marr, D.; Hildreth, E. Theory of edge detection. Proc. R. Soc. Lond. 1980, 207, 187–217. [Google Scholar] [CrossRef] [PubMed]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Nguyen, C.V.; Izadi, S.; Lovell, D. Modeling kinect sensor noise for improved 3D reconstruction and tracking. In Proceedings of the International Conference on 3D Imaging, Zurich, Switzerland, 13–15 October 2012; pp. 524–530. [Google Scholar]
- Li, J.W.; Gao, W.; Wu, Y.H. Elaborate scene reconstruction with a consumer depth camera. Int. J. Autom. Comput. 2018, 15, 1–11. [Google Scholar] [CrossRef]
- Handa, A.; Whelan, T.; Mcdonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Point | Edge | Point and Line | Point and Edge | ||
|---|---|---|---|---|---|---|
| ORB-SLAM | Edge VO | Edge SLAM | PL-SLAM | Our Method | ||
| Monocular | RGB-D | Monocular | Monocular | Monocular | RGB-D | |
| fr1_xyz | 0.90 | 1.07 | 16.51 | 1.31 | 1.21 | 0.91 |
| fr2_desk | 0.88 | 0.90 | 33.67 | 1.75 | - | 0.92 |
| fr2_xyz | 0.30 | 0.40 | 21.41 | 0.49 | 0.43 | 0.37 |
| fr3_st_near | 1.58 | 1.10 | 47.63 | 1.12 | 1.25 | 0.91 |
| fr3_st_far | 0.77 | 1.06 | 121.00 | 0.65 | 0.89 | 1.02 |
| fr3_snt_near | X | X | 101.03 | 8.29 | - | 2.11 |
| fr3_snt_far | X | 6.71 | 41.76 | 6.71 | - | 1.91 |
| Operation | Point | Point and Line | Point and Edge |
|---|---|---|---|
| ORB-SLAM | PL-SLAM | Our Method | |
| Features Extraction (ms) | 10.76 | 31.32 | Point: 10.76 |
| Edge: 21.08 | |||
| Initial Pose Estimation (ms) | 7.16 | 7.16 | 2.76 |
| Track Local Map (ms) | 3.18 | 12.58 | 3.18 |
| Total (fps) | 50 Hz | 20 Hz | 31–58 Hz |
| Methods | Point | Edge | Point and Edge | |
|---|---|---|---|---|
| ORB-SLAM [19] | Edge VO [25] | Our Method | ||
| RGB-D | RGB-D | RGB-D | ||
| ICL-NUIM Living room | kt0 | X | 39.6 | 0.55 |
| kt1 | 0.77 | 27.7 | 0.69 | |
| kt2 | 1.29 | 64.8 | 1.22 | |
| kt3 | 0.89 | 114 | 0.94 | |
| ICL-NUIM Office | kt0 | 3.26 | X | 3.48 |
| kt1 | X | 92.9 | 2.49 | |
| kt2 | 1.88 | 44.5 | 1.96 | |
| kt3 | 1.36 | 27.3 | 1.25 | |
| Augmented ICL-NUIM | Living Room 1 | 3.71 | X | 3.67 |
| Living Room 2 | 1.09 | 112 | 1.01 | |
| Office 1 | X | 176 | 6.77 | |
| Office 2 | 3.08 | 178 | 3.13 | |
| Methods | Camera Trajectories (RMSE) | Surface Reconstruction (Median Distance) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| kt0 | kt1 | kt2 | kt3 | Average | kt0 | kt1 | kt2 | kt3 | Average | ||
| GPU | Kintinuous [6] | 7.2 | 0.5 | 1.0 | 35.5 | 11.05 | 1.1 | 0.8 | 0.9 | 15.0 | 4.45 |
| Choi et al. [12] | 1.4 | 7.0 | 1.0 | 3.0 | 1.53 | 1.0 | 1.4 | 1.0 | 1.9 | 1.33 | |
| ElasticFusion [9] | 0.9 | 0.9 | 1.4 | 10.6 | 3.45 | 0.7 | 0.7 | 0.8 | 2.8 | 1.25 | |
| InfiniTAMv3 [10] | 0.9 | 2.9 | 0.9 | 4.1 | 2.20 | 1.3 | 1.1 | 0.1 | 1.4 | 0.98 | |
| BundleFusion [14] | 0.6 | 0.4 | 0.6 | 1.1 | 0.68 | 0.5 | 0.6 | 0.7 | 0.8 | 0.65 | |
| CPU | DVOSLAM [8] | 10.4 | 2.9 | 19.1 | 15.2 | 11.90 | 3.2 | 6.1 | 11.9 | 5.3 | 6.63 |
| Our method | 0.5 | 0.7 | 1.2 | 0.9 | 0.80 | 0.5 | 0.7 | 1.0 | 0.7 | 0.73 | |
| Methods | Living Room 1 | Living Room 2 | Office 1 | Office 2 | Average | |
|---|---|---|---|---|---|---|
| GPU | Kintinuous [6] | 0.27 | 0.28 | 0.19 | 0.26 | 0.250 |
| Choi et al. [12] | 0.10 | 0.13 | 0.13 | 0.09 | 0.113 | |
| ElasticFusion [9] | 0.62 | 0.37 | 0.13 | 0.13 | 0.313 | |
| InfiniTAM v3 [10] | X | X | X | X | X | |
| BundleFusion [14] | 0.01 | 0.01 | 0.15 | 0.01 | 0.045 | |
| CPU | DVO SLAM [8] | 1.02 | 0.14 | 0.11 | 0.11 | 0.345 |
| Our method | 0.04 | 0.01 | 0.07 | 0.03 | 0.038 | |
| Methods | Camera Trajectories (RMSE) | Mean Speed (fps) | |||||
|---|---|---|---|---|---|---|---|
| fr1_desk | fr2_xyz | fr3_office | fr3_nst | Average | GPU | CPU | |
| Kintinuous [6] | 3.7 | 2.9 | 3.0 | 3.1 | 3.18 | 15 Hz | - |
| Choi et al. [12] | 39.6 | 29.4 | 8.1 | - | 25.7 | offline | - |
| ElasticFusion [9] | 2.0 | 1.1 | 1.7 | 1.6 | 1.60 | 32 Hz | - |
| InfiniTAM v3 [29] | 1.8 | 2.1 | 2.2 | 2.0 | 2.03 | 910 Hz | - |
| BundleFusion [14] | 1.6 | 1.1 | 2.2 | 1.2 | 1.53 | 36 Hz | - |
| DVO SLAM [8] | 2.1 | 1.8 | 3.5 | 1.8 | 2.30 | - | 30 Hz |
| Our method | 1.6 | 0.4 | 1.0 | 1.9 | 0.98 | - | 81 Hz |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Gao, W.; Li, H.; Tang, F.; Wu, Y. Robust and Efficient CPU-Based RGB-D Scene Reconstruction. Sensors 2018, 18, 3652. https://doi.org/10.3390/s18113652
Li J, Gao W, Li H, Tang F, Wu Y. Robust and Efficient CPU-Based RGB-D Scene Reconstruction. Sensors. 2018; 18(11):3652. https://doi.org/10.3390/s18113652
Chicago/Turabian StyleLi, Jianwei, Wei Gao, Heping Li, Fulin Tang, and Yihong Wu. 2018. "Robust and Efficient CPU-Based RGB-D Scene Reconstruction" Sensors 18, no. 11: 3652. https://doi.org/10.3390/s18113652
APA StyleLi, J., Gao, W., Li, H., Tang, F., & Wu, Y. (2018). Robust and Efficient CPU-Based RGB-D Scene Reconstruction. Sensors, 18(11), 3652. https://doi.org/10.3390/s18113652