A Study on the Design of Fog Computing Architecture Using Sensor Networks


Abstract
1. Introduction
2. Related Research
2.1. Internet of Things
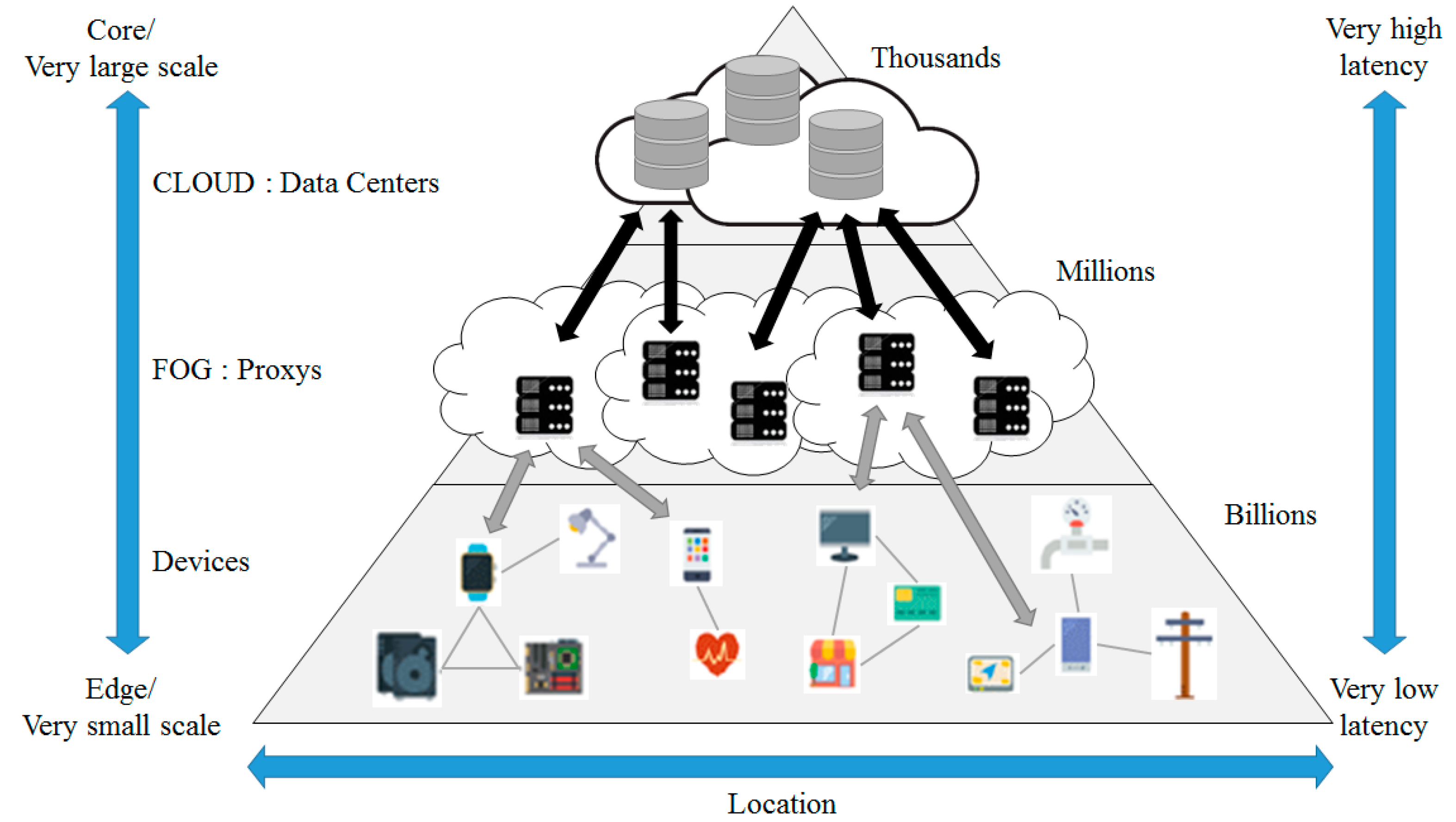
2.2. Fog Computing
- Reduced network load: In the fog computing structure, the amount of data flowing into a network is reduced because computation is conducted at a network edge near IoT devices.
- Mobility support as a default function: The Mobility according to reliability is a fundamental requirement to many IoT applications. The device resources like smart phones and laptops may provide physical or virtual mobility to support a mobile IoT application.
- Context awareness: In the fog computing structure, resources provide context awareness relating to data created by a sensor. The device resources play roles in combining data at a sensor, using position or application context.
- No single defective point: As calculation is completed in a distributed way in fog computing, the model does not have a single defective point. Several snapshots of an application can be allocated at a cloud to improve reliability.
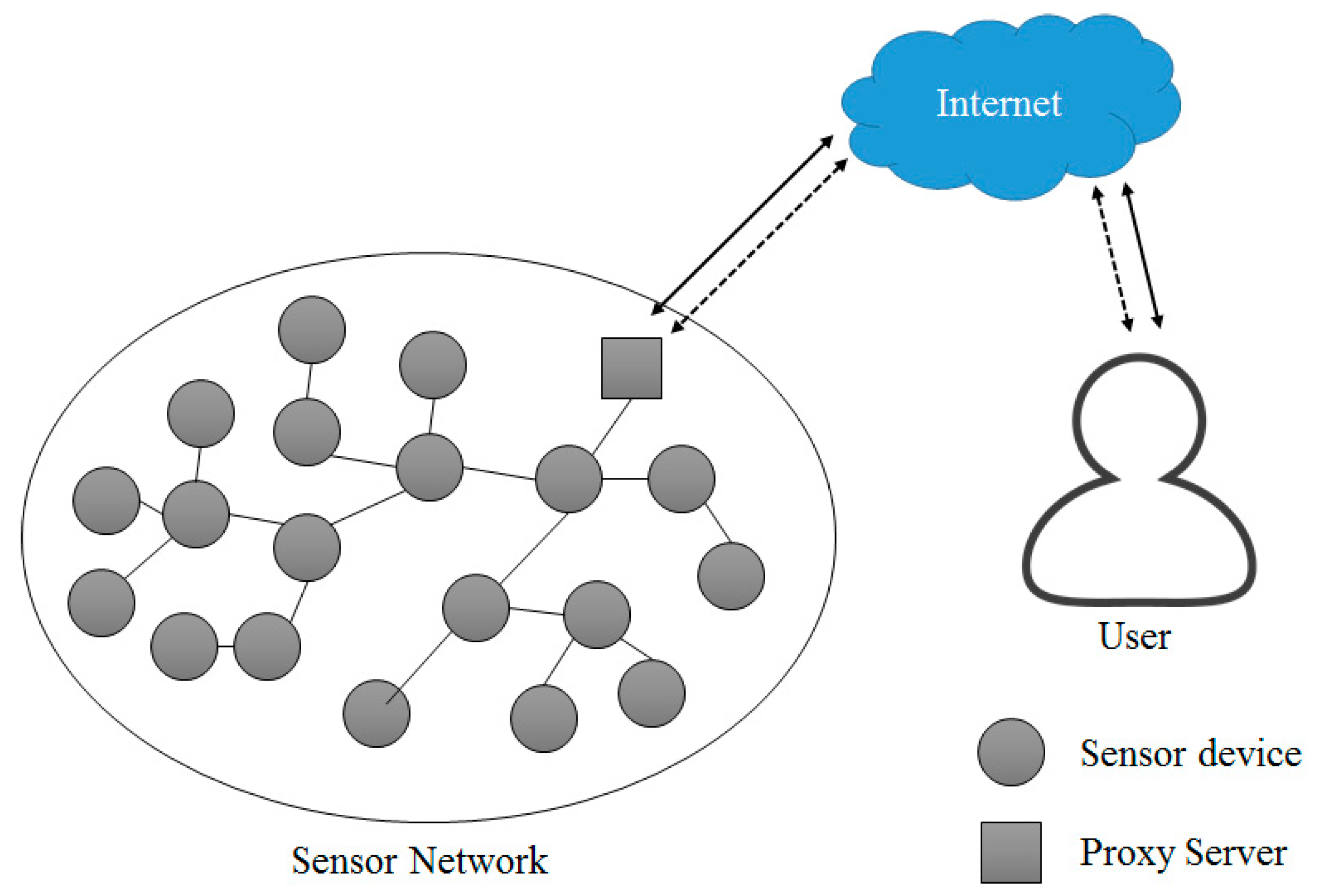
2.3. Sensor Network
2.4. Attribute-Based Encryption
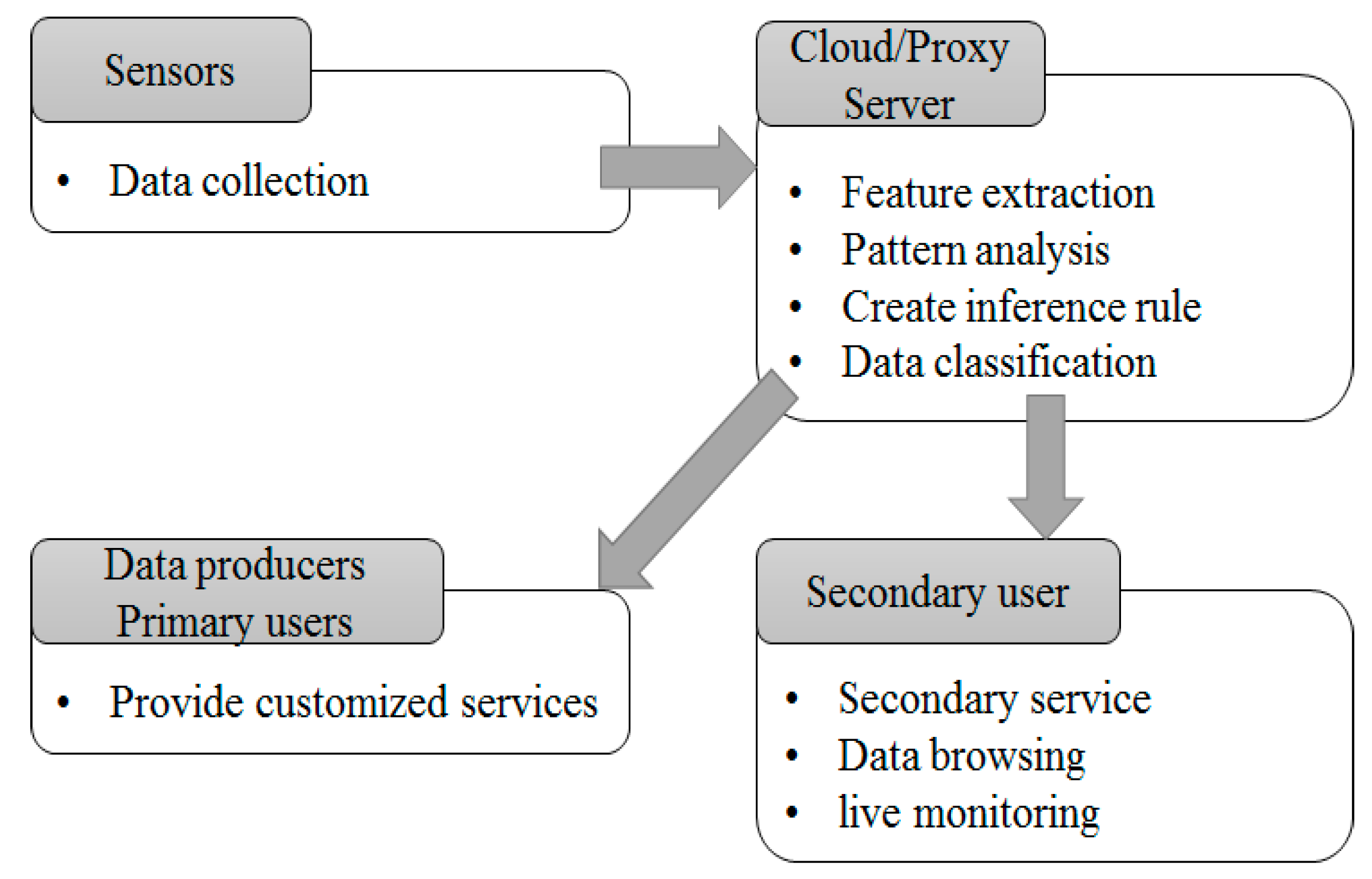
3. Proposed System
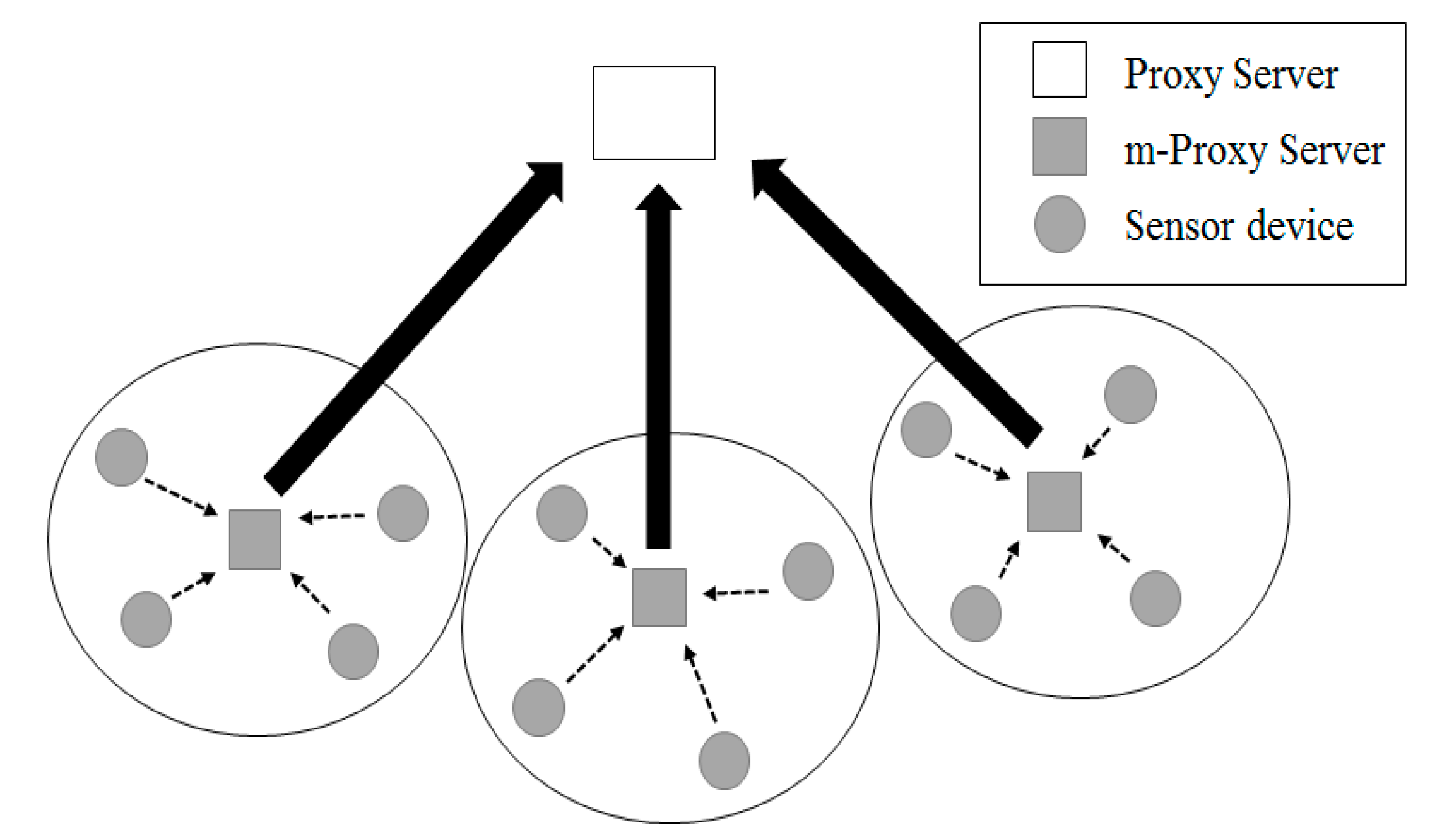
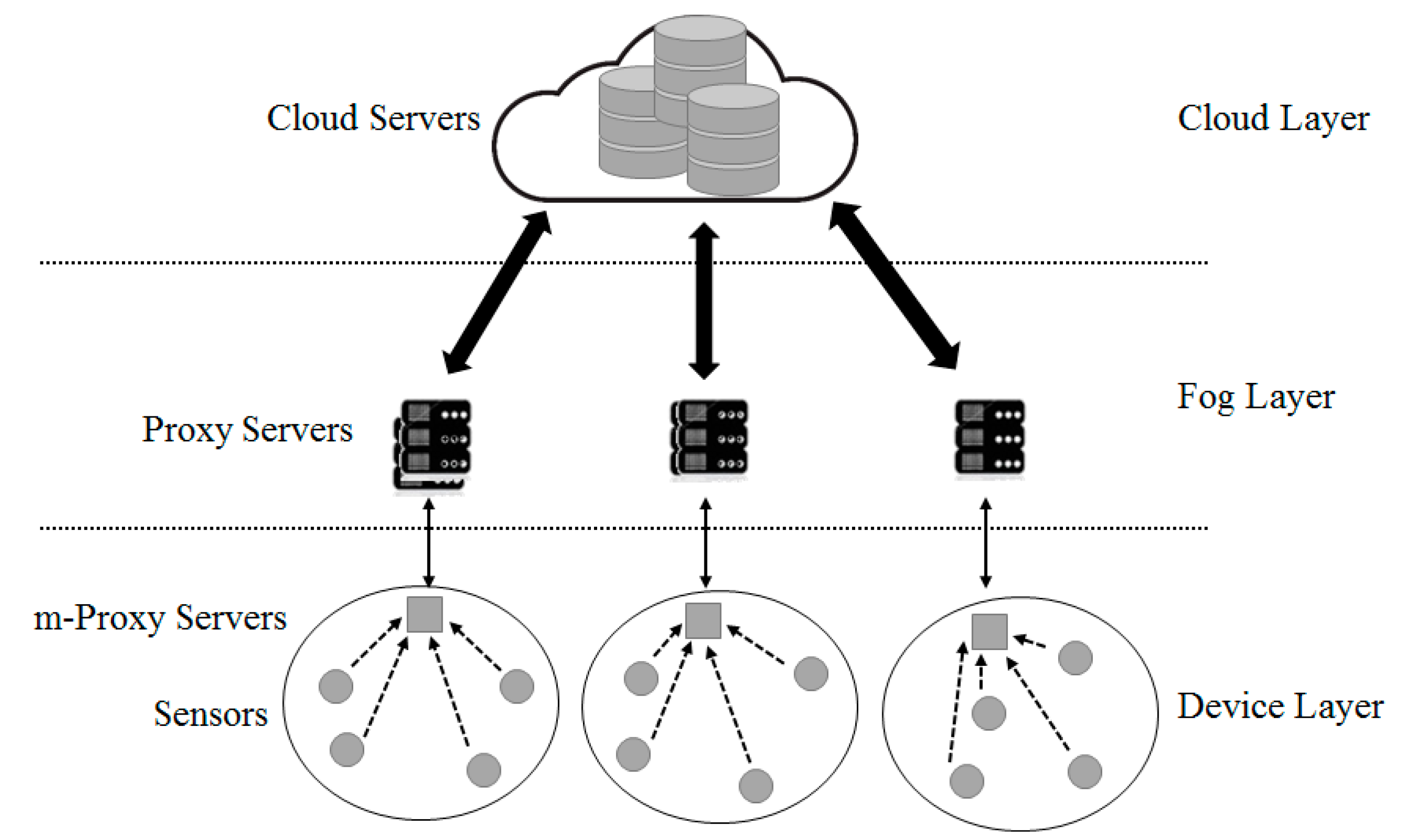
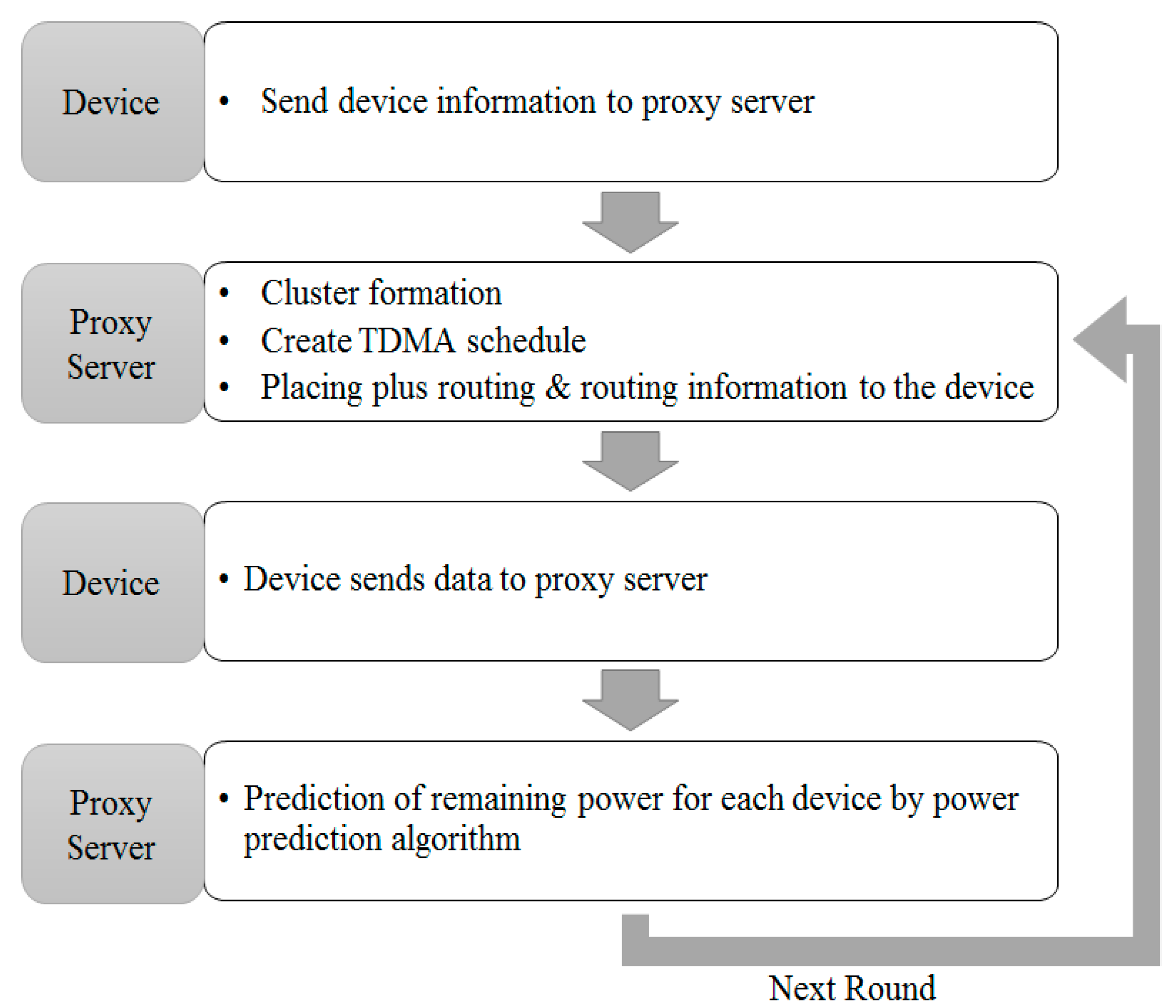
3.1. Platform Design
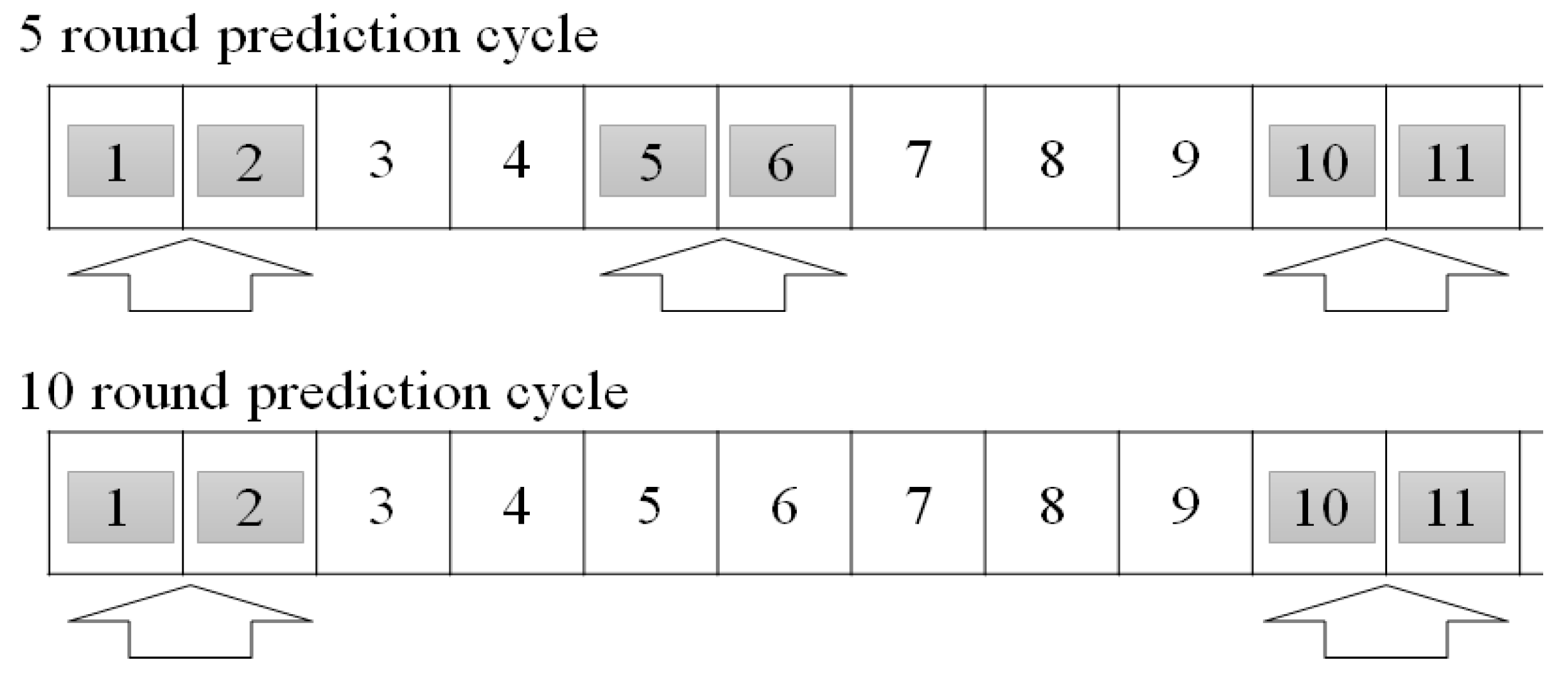
3.2. Communication Control by Power Consumption
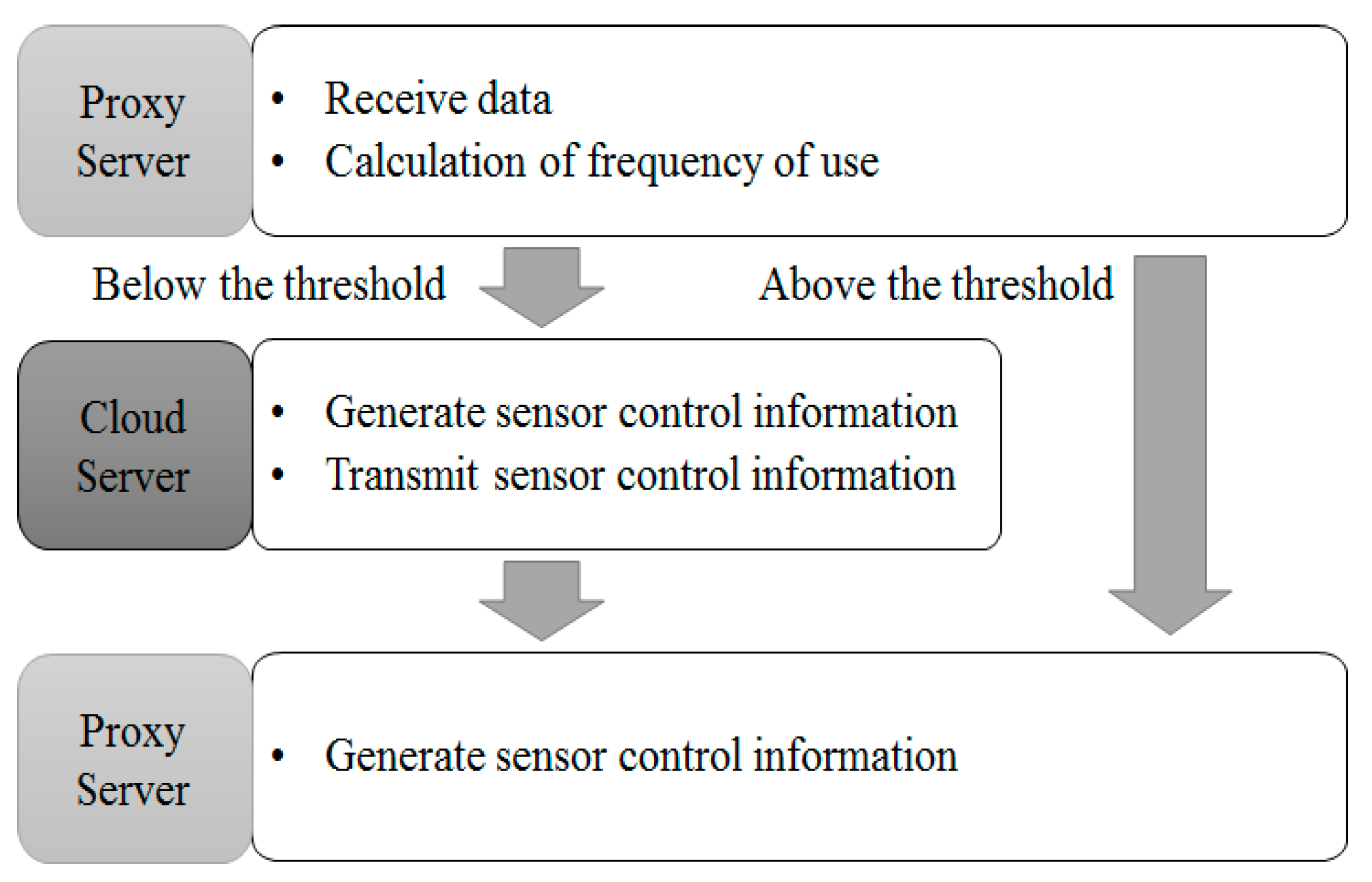
3.3. Communication Control by Frequency of Use
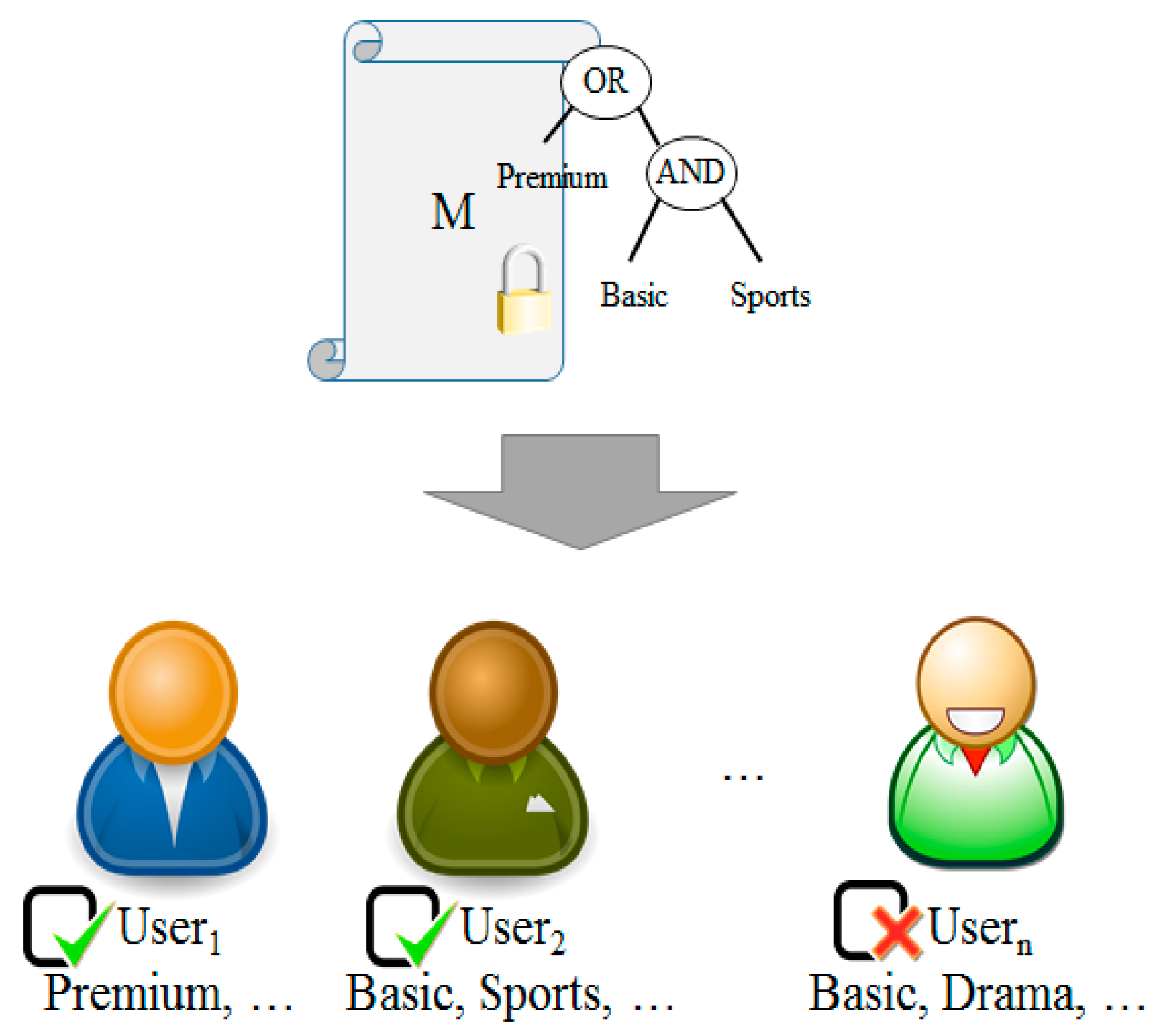
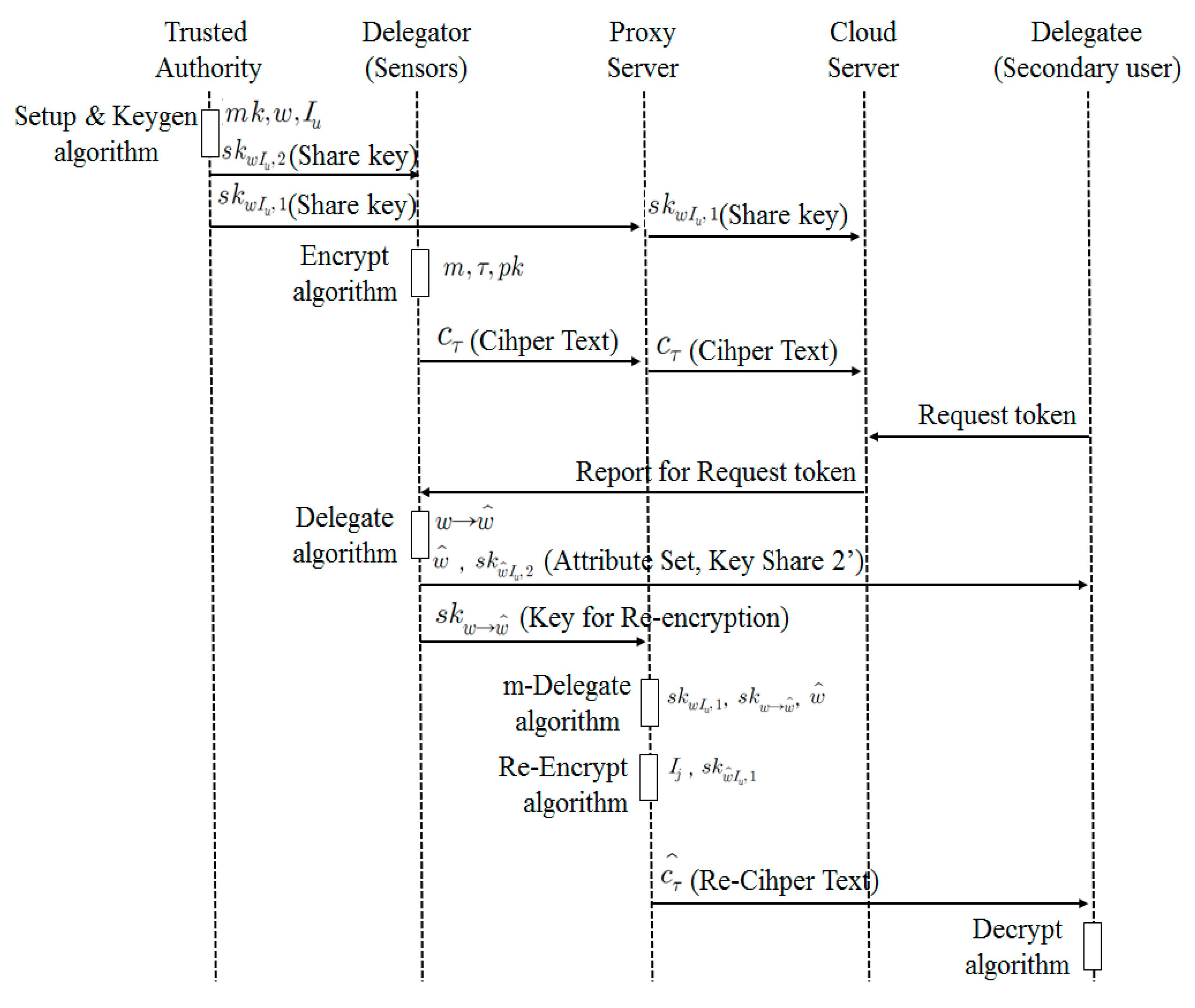
3.4. Communication Control by Access Authority
- A Trusted Authority (TA) defines system parameters using Setup (k) algorithm and creates the public key (pk) and the master key(mk). In addition, it creates two private key shares skwIu,1 and skwIu,2 relating to Attribute w and Public Key Iu and sends skwIu,1 to a proxy server and skwIu,2 to a sensor or a data owner, using KeyGen (mk, w, Iu) algorithm.
- A user transmits Ciphertext cτ that encrypts Data m using Encrypt (m, τ, pk) algorithm. In this context, data refers to sensing data.
- A secondary user requests a decryption token (attribute set and ciphertext) to a proxy server to access Data m of the data owner.
- The data owner defines w′ based on his/her own attribute set w to delegate decryption authority for Ciphertext cτ to a secondary user. The data owner creates the private key share for a secondary user skwIu,2 and the proxy server key to delegate an attribute skw→w′ using his/her own private key share skwIu,2 and the public key for a secondary user Ij, and send them a secondary user (w’, skw’Iu,2) and the proxy server (skw→w′).
- A proxy server creates its own private key share skwIu,1, proxy key skw→w′ and the private key share for a secondary user skw’Iu,1 using the attribute set w′ defined by a patient. It re-encrypts the ciphertext cτ with the public key for a secondary user Ij, skw’Iu,1 and sends the re-encrypted ciphertext cτ′ to a secondary user.
- A secondary user obtains the data m by decoding the ciphertext cτ′ using the key received from the proxy server and the data owner skw’Iu,2.
4. Experiment and Analysis
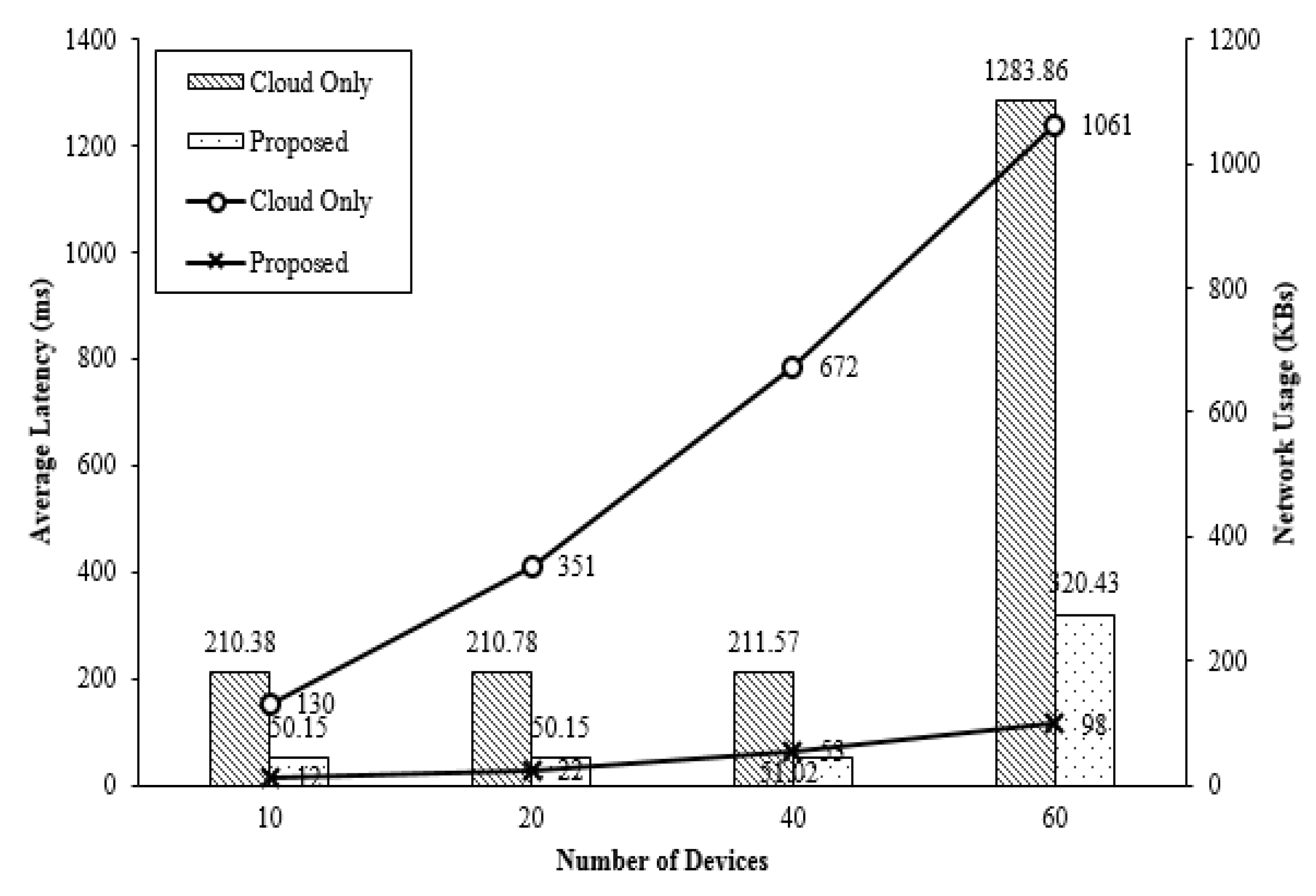
4.1. Performance of Proposed Fog Computing
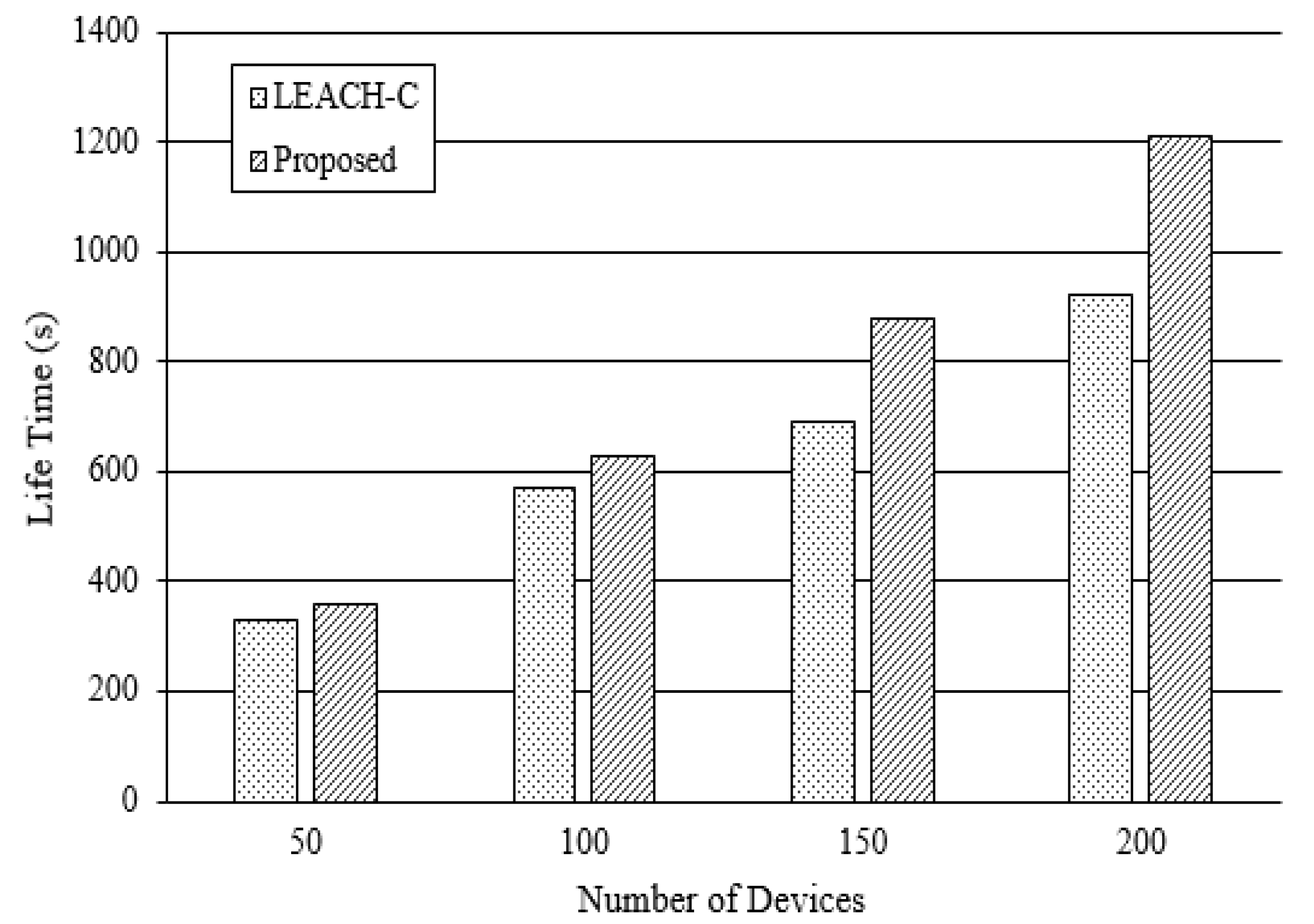
4.2. Sensor Network Performance by Communication Control
4.3. Security Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Doukas, C.; Maglogiannis, I. Bringing IoT and cloud computing towards pervasivehealthcare. In Proceedings of the 2012 Sixth International Conference Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Palermo, Italy, 4–6 July 2012; pp. 922–926. [Google Scholar]
- Verma, J.K.; Katti, C.P. Study of Cloud Computing and its Issues: A Review. Smart Comput. Rev. 2014, 4, 389–411. [Google Scholar] [CrossRef]
- Stojmenovic, I.; Wen, S. The Fog computing paradigm: Scenarios and security issues. In Proceedings of the 2014 Federated Conference Computer Scienceand Information Systems (FedCSIS), Warsaw, Poland, 7–10 September 2014; pp. 1–8. [Google Scholar]
- Krishnamachari, L.; Estrin, D.; Wicker, S. The impact of data aggregation in wireless sensor networks. In Proceedings of the 22nd International Conference on Distributed Computing Systems Workshops, Vienna, Austria, 2–5 July 2002; pp. 575–578. [Google Scholar]
- Lindsay, S.; Raghavendra, C.S.; Sivalingam, K.M. Data gathering in sensor networks using the energy delay metric. In Proceedings of the 15th International Parallel & Distributed Processing, 23–27 April 2001; IEEE Computer Society: Washington, DC, USA, 2001; p. 188. [Google Scholar]
- Tan, H.O.; Korpeoglu, I. Power efficient data gathering and aggregation in wireless sensor networks. ACM Sigmod Record 2003, 32, 66–71. [Google Scholar] [CrossRef]
- Gartner. Gartner Hype Cycle Special Report for 2014. Available online: http://www.gartner.com/ (accessed on 6 August 2014).
- CISCO. IoT Reference Model White Paper; CISCO: San Jose, CA, USA, 2014. [Google Scholar]
- Arkin, H.R.; Diyanat, A.; Pourkhalili, A. MIST: Fog-based data analytics scheme with cost-efficient resource provisioning for IoT crowdsensing applications. J. Netw. Comput. Appl. 2017, 82, 152–165. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog Computing and Its Role in the Internet of Things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012; ACM: New York, NY, USA; pp. 13–16. [Google Scholar]
- Stojmenovic, I. Fog computing: A cloud to the ground support for smart things and machine-to-machine networks. In Proceedings of the Telecommunication Networks and Applications Conference (ATNAC), Southbank, VIC, Australia, 26–28 November 2014; pp. 117–122. [Google Scholar]
- Mohan, N.; Kangashaju, J. Edge-Fog Cloud: A Distributed Cloud for Internet of Things Computation. In Proceedings of the International Conference Cloudification of the Internet of Things (CIoT), Paris, France, 23–25 November 2016; pp. 1–6. [Google Scholar]
- Varchola, M.; Drutarovský, M. Zigbee based home automation wireless sensor network. Acta Electrotech. Inf. 2007, 7, 1–8. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Cipher Text-Policy Attribute-Based Encryption. In Proceedings of the IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Ibraimi, L.; Petkovic, M.; Nikova, S.; Hartel, P.; Jonker, W. Ciphertext-Policy Attribute-Based Threshold Decryption with Flexible Delegation and Revocation of User Attributes; Centre for Telematics and Information Technology, Internal Report; University of Twente: Enschede, The Netherlands, 2009. [Google Scholar]
- Ostrovsky, R.; Shai, A.; Waters, B. Attrobute-Based Encryption with Non-Monotonic Access Structures. In Proceedings of the 14th ACM conference on Computer and communications security, Alexandria, VA, USA, 28 October 2007; ACM: New York, NY, USA; pp. 195–203. [Google Scholar]
- Attrapadung, N.; Imai, H. Conjunctive Broadcast and Attribute-Based Encryption. In Proceedings of the International Conference on Pairing-Based Cryptography, Palo Alto, CA, USA, 12–14 August 2009; Springer: Berlin/Heidelberg, Germany; pp. 248–265. [Google Scholar]
- Attrapadung, N.; Imai, H. Attribute-Based Encryption Supporting Direct/Indirect Revocation Modes. In Proceedings of the IMA International Conferrence on Cryptography and Coding, Cirencester, UK, 15–17 December 2009; Springer: Berlin/Heidelberg, Germany; pp. 278–300. [Google Scholar]
- Boldyreva, A.; Goyal, V.; Kumar, V. Identity-based encryption with efficient revocation. In Proceedings of the 15th ACM Conference on Computer and Communications Security (CCS’08), Alexandria, VA, USA, 27–31 October 2008; ACM: New York, NY, USA; pp. 417–426. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
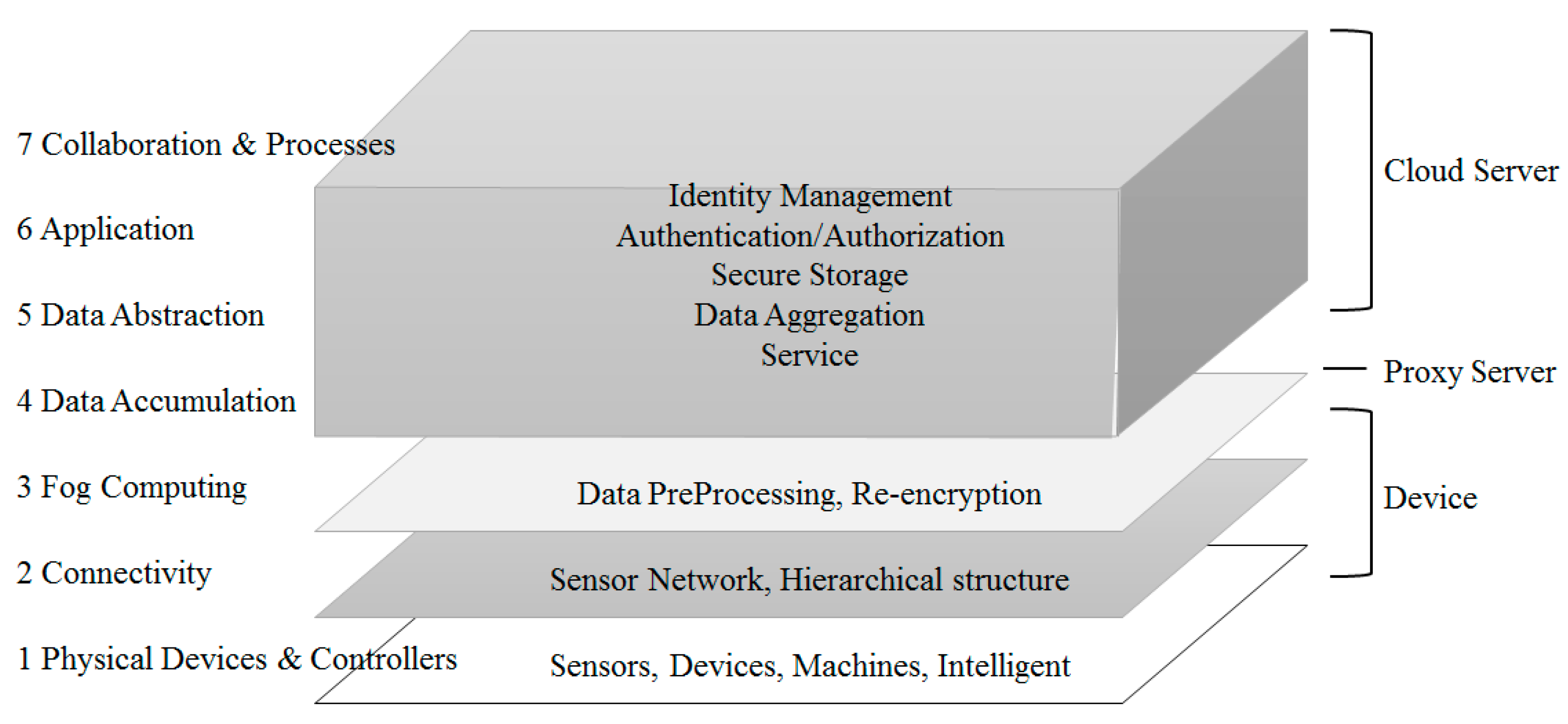
| Layer | Name | Detailed Role |
|---|---|---|
| 1 | Physical Devices & Controllers | The “Things” in IoT |
| 2 | Connectivity | Communication, Processing Units |
| 3 | Fog Computing | Data Element Analysis, Transformation |
| 4 | Data Accumulation | Storage |
| 5 | Data Abstraction | Aggregation, access |
| 6 | Application | Reporting, Analytics, Control |
| 7 | Collaboration & Processes | Involving People, Business Processes |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, H.-J.; Yang, H.-K.; Song, Y.-J. A Study on the Design of Fog Computing Architecture Using Sensor Networks. Sensors 2018, 18, 3633. https://doi.org/10.3390/s18113633
Cha H-J, Yang H-K, Song Y-J. A Study on the Design of Fog Computing Architecture Using Sensor Networks. Sensors. 2018; 18(11):3633. https://doi.org/10.3390/s18113633
Chicago/Turabian StyleCha, Hyun-Jong, Ho-Kyung Yang, and You-Jin Song. 2018. "A Study on the Design of Fog Computing Architecture Using Sensor Networks" Sensors 18, no. 11: 3633. https://doi.org/10.3390/s18113633
APA StyleCha, H.-J., Yang, H.-K., & Song, Y.-J. (2018). A Study on the Design of Fog Computing Architecture Using Sensor Networks. Sensors, 18(11), 3633. https://doi.org/10.3390/s18113633