Hyperspectral Remote Sensing Image Classification Based on Maximum Overlap Pooling Convolutional Neural Network

 ,
,  , ,
, ,
Abstract
1. Introduction
2. Convolutional Neural Network
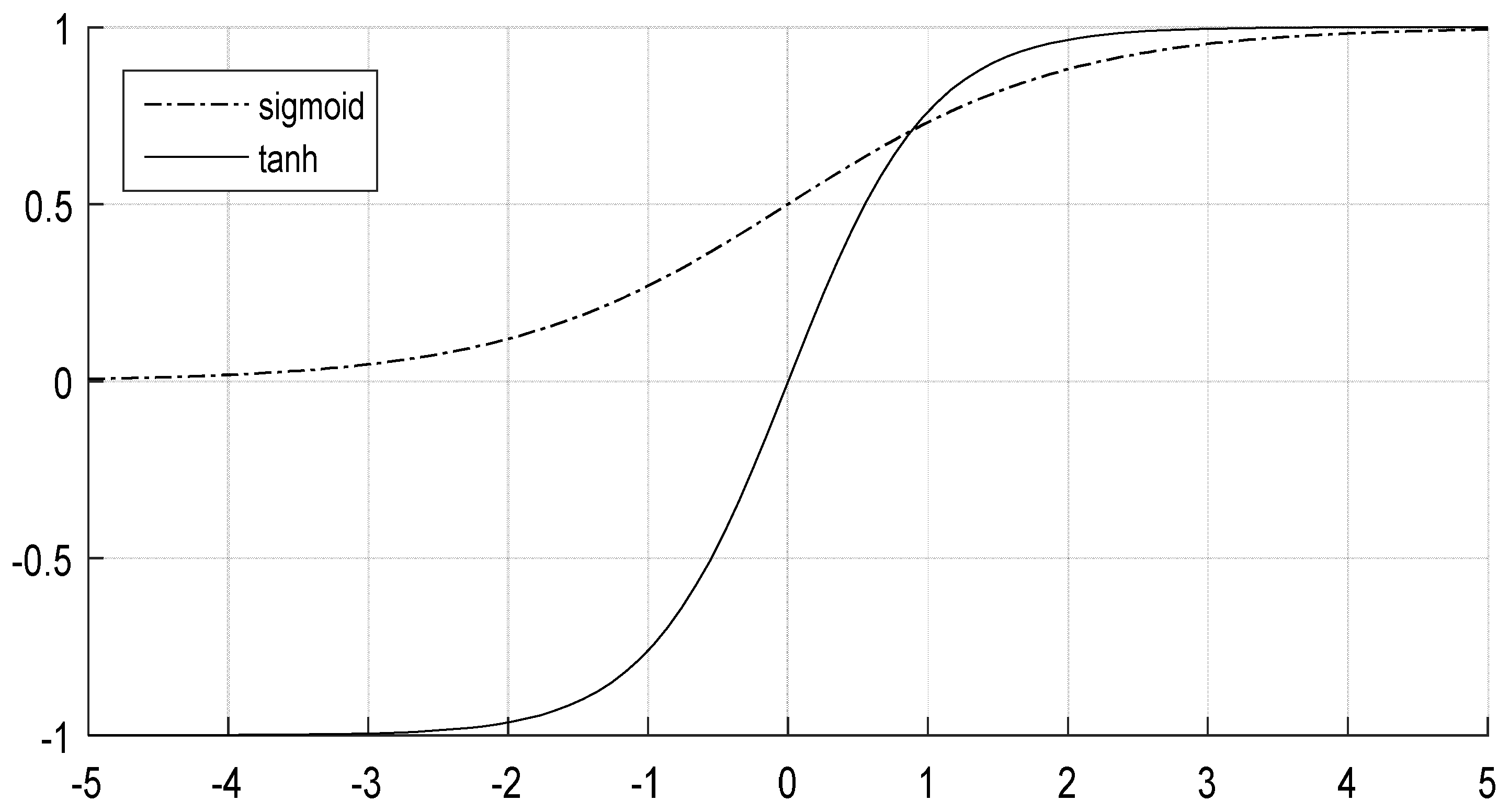
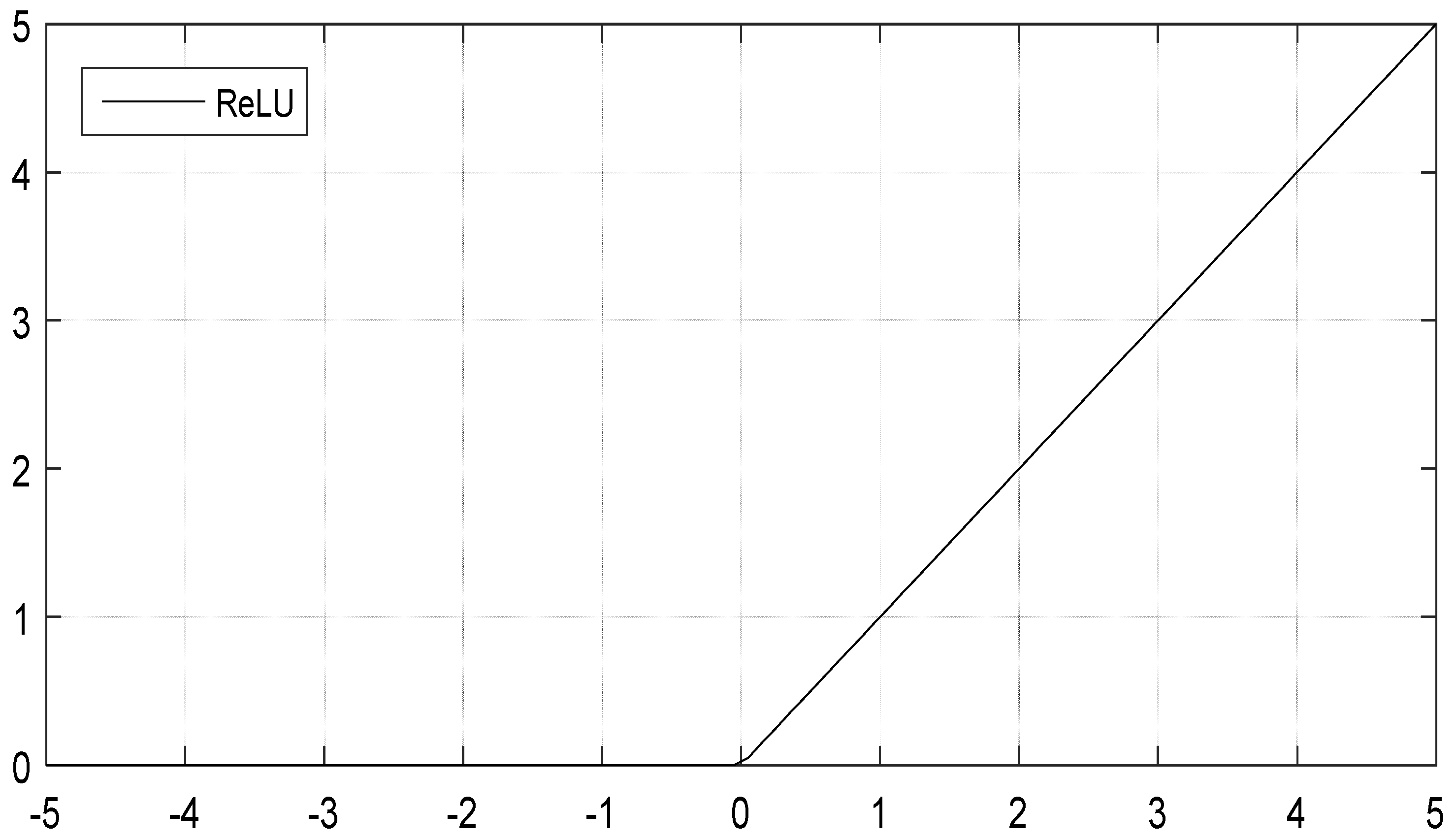
2.1. Convolutional Layer
2.2. Pooling Layer
2.3. Fully Connected Layer
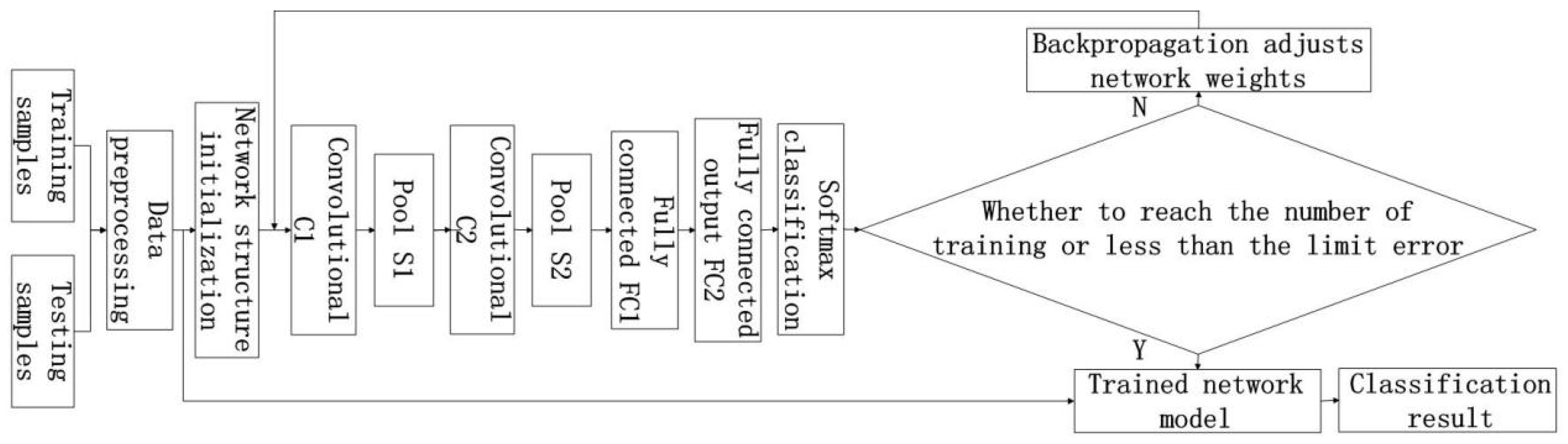
3. Hyperspectral Image Classification Based on Maximum Overlap Pooling CNN
3.1. Major Improvement Methods and Advantages
3.2. Training Model Design
3.3. Classification Steps
4. Experiments and Results Analysis
4.1. Experimental Environment
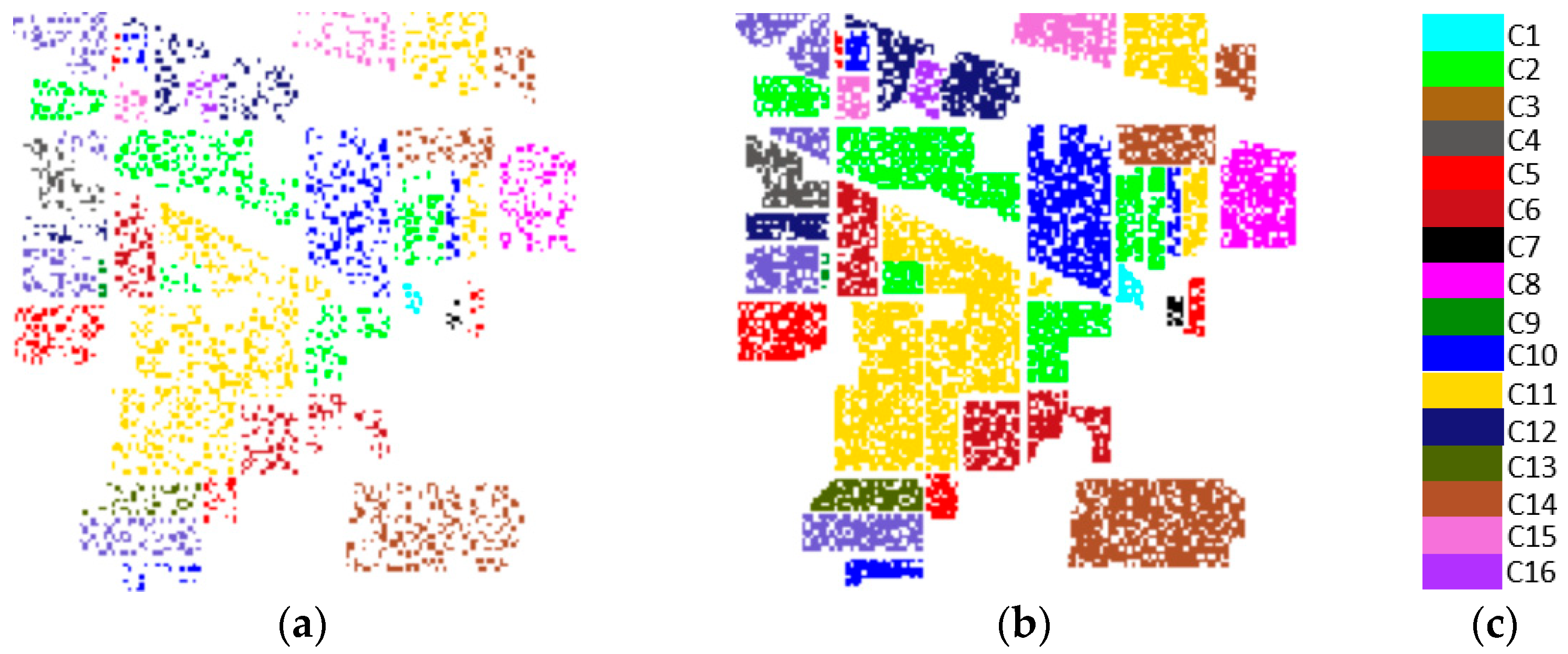
4.2. Experimental Data
4.3. Classification Results and Analysis
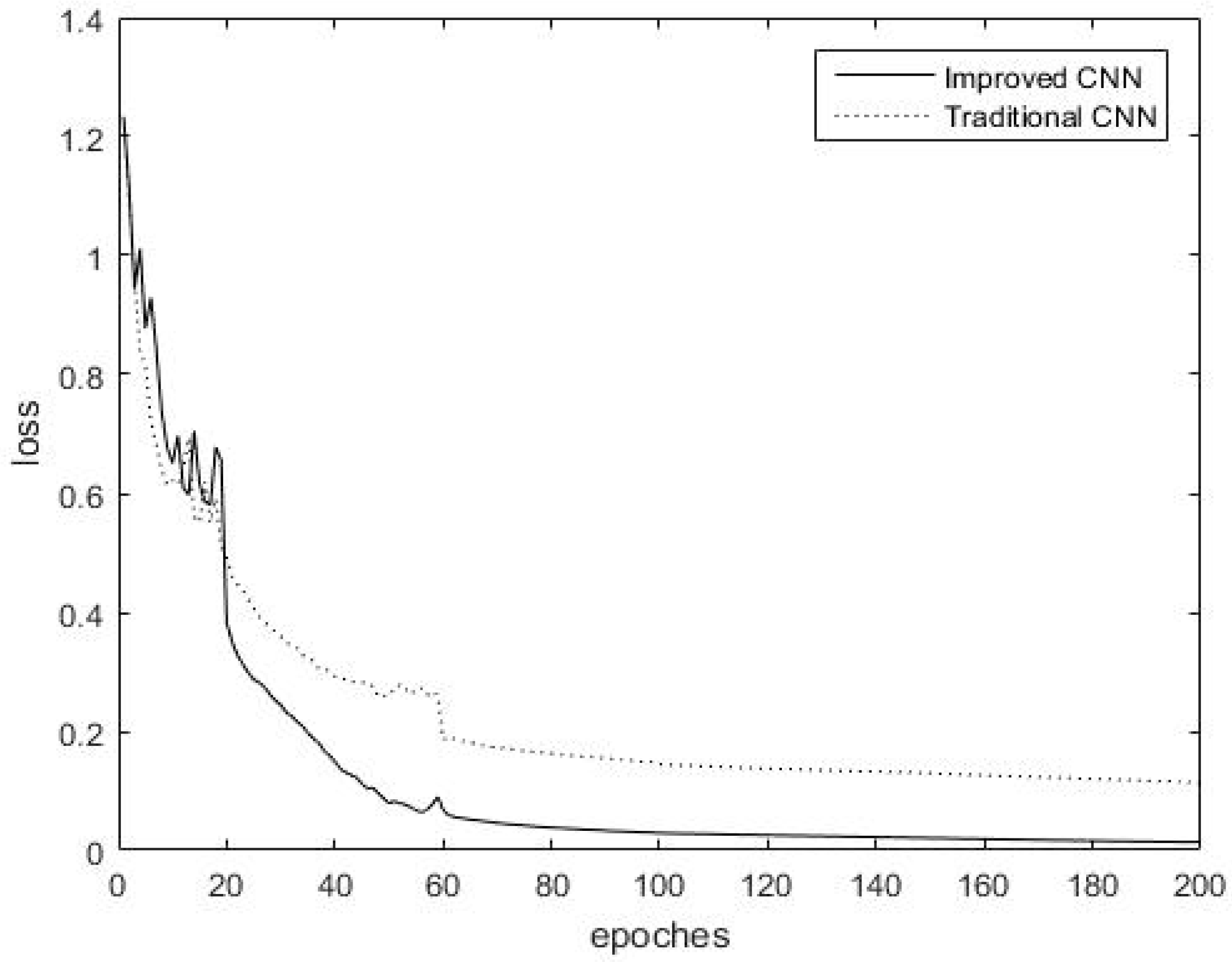
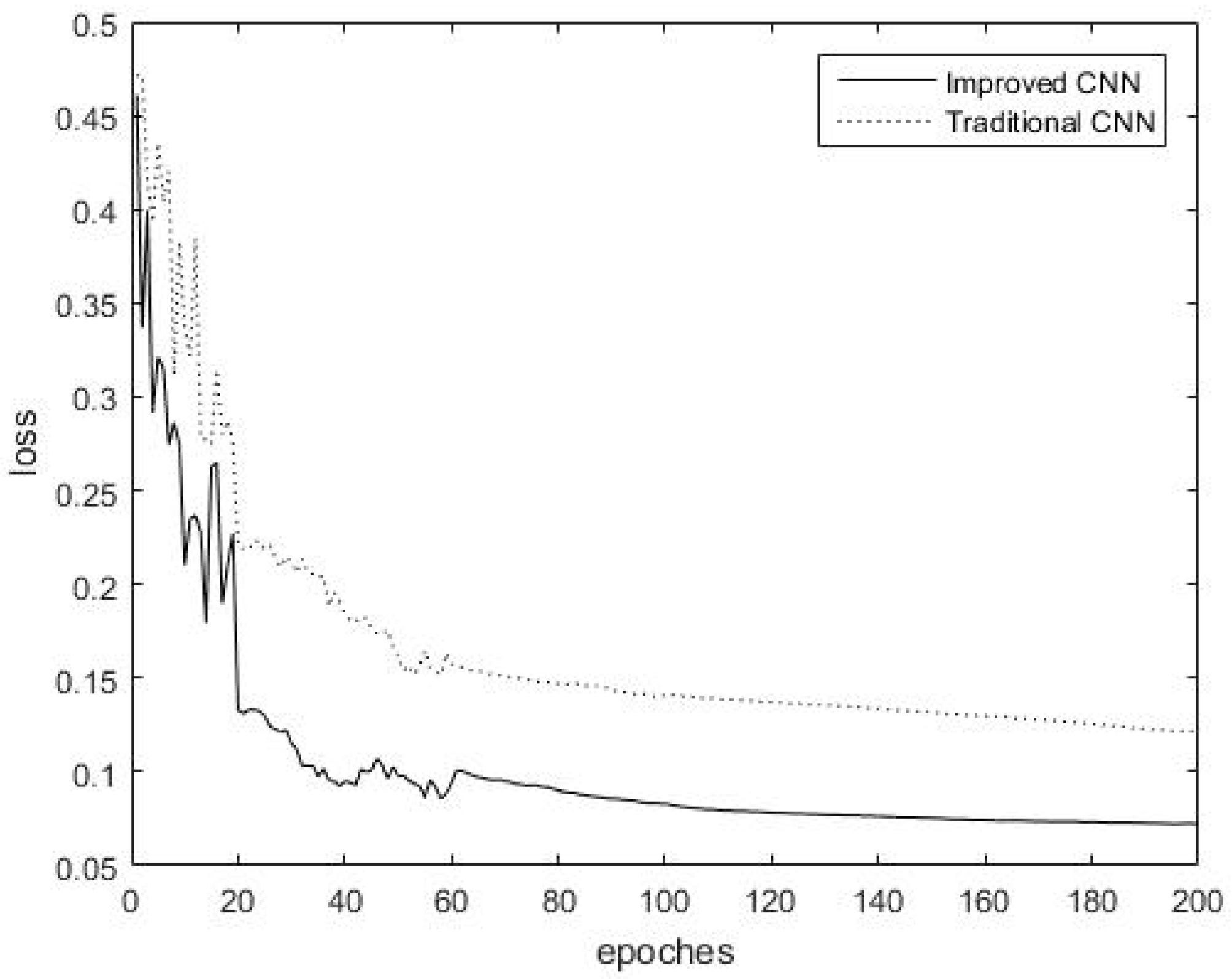
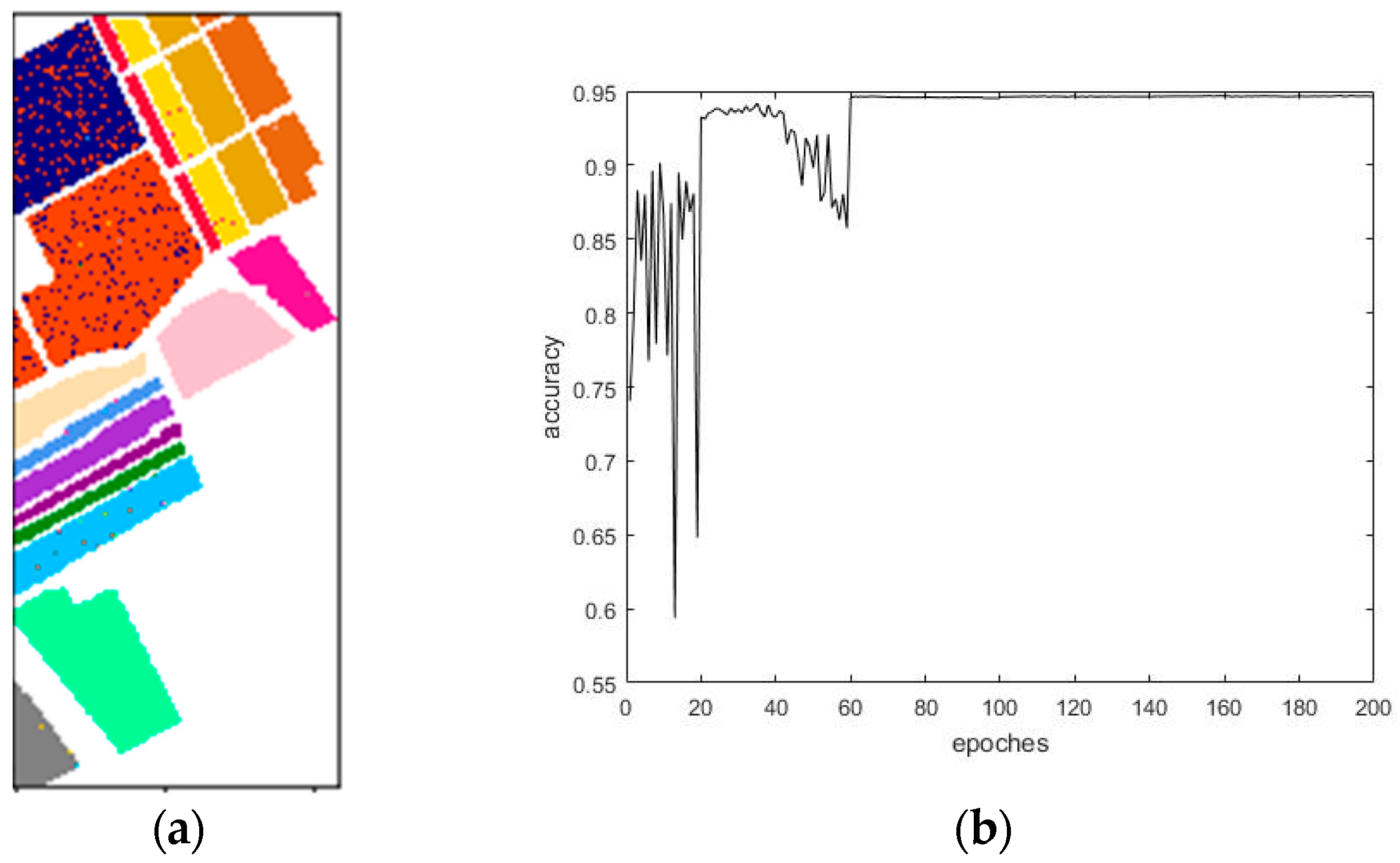
4.3.1. Comparison of Convergence Rates
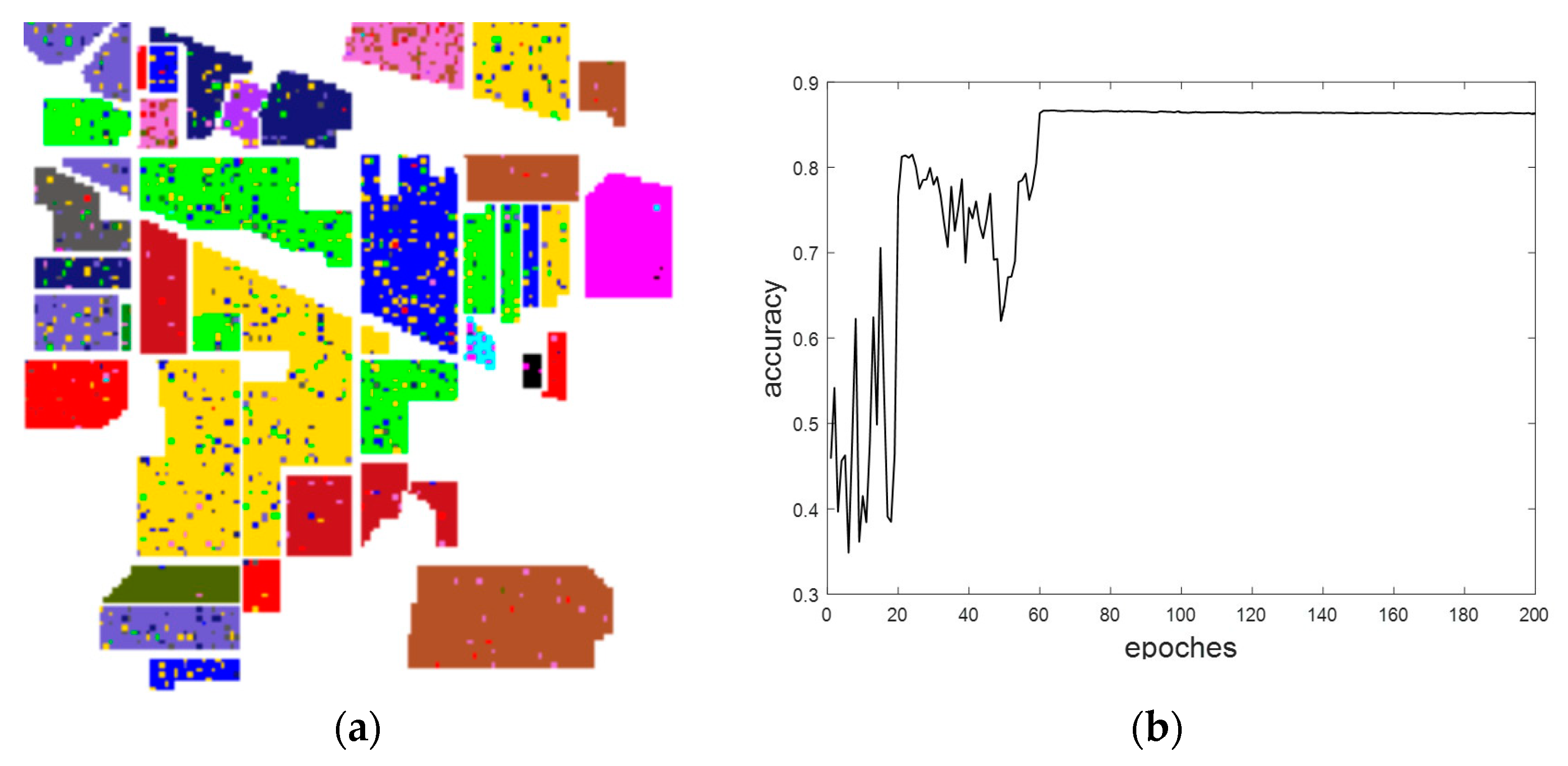
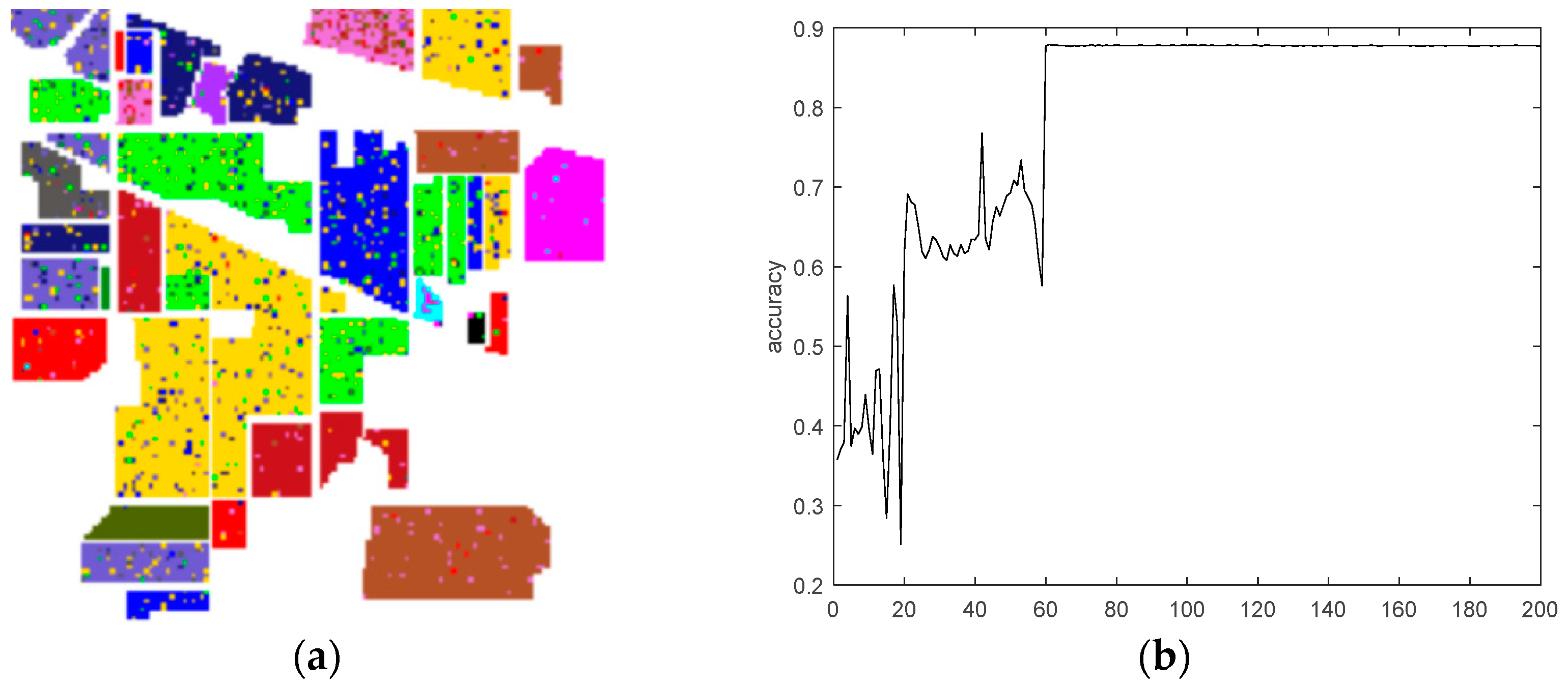
4.3.2. Comparison of Time and Classification Accuracies
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Qiu, Z.; Zhang, S.W. Application of remote sensing technology in hydrology and water resources. Jiangsu Water Resour. 2018, 2, 64–66. [Google Scholar]
- Du, P.J.; Xia, J.S.; Xue, Z.H.; Tan, K.; Su, H.J.; Bao, R. Review of hyperspectral remote sensing image classification. J. Remote Sens. 2016, 20, 236–256. [Google Scholar] [CrossRef]
- Li, H.; Zhang, S.; Ding, X.; Zhang, C.; Dale, P. Performance Evaluation of Cluster Validity Indices (CVIs) on Multi/Hyperspectral Remote Sensing Datasets. Remote Sens. 2016, 8, 295. [Google Scholar] [CrossRef]
- Yang, G.; Yu, X.C.; Zhou, X. Research on Relevance Vector Machine for Hyperspectral Imagery Classification. Acta Geod. Cartogr. Sin. 2010, 39, 572–578. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Amiri, F.; Kahaei, M.H. New Bayesian approach for semi-supervised hyperspectral unmixing in linear mixing models. In Proceedings of the Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 2–4 May 2017; pp. 1752–1756. [Google Scholar]
- Ma, N.; Peng, Y.; Wang, S.; Leong, P.H. An Unsupervised Deep Hyperspectral Anomaly Detector. Sensors 2018, 18, 693. [Google Scholar] [CrossRef] [PubMed]
- Hemissi, S.; Farah, I.R. Efficient multi-temporal hyperspectral signatures classification using a Gaussian-Bernoulli RBM based approach. Pattern Recognit. Image Anal. 2016, 26, 190–196. [Google Scholar] [CrossRef]
- Zhao, C.; Li, X.; Zhu, H. Hyperspectral anomaly detection based on stacked denoising Autoencoder. J. Appl. Remote Sens. 2017, 11, 042605. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Wang, P.; Meng, C.; Bai, X.; Gong, G.; Liu, M.; Qi, J. Region Based CNN for Foreign Object Debris Detection on Airfield Pavement. Sensors 2018, 18, 737. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Hong, H.G.; Park, K.R. Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors. Sensors 2017, 17, 1065. [Google Scholar]
- Gao, H.; Yang, Y.; Li, C.; Zhou, H.; Qu, X. Joint Alternate Small Convolution and Feature Reuse for Hyperspectral Image Classification. ISPRS Int. J. Geo-Inf. 2018, 7, 349. [Google Scholar] [CrossRef]
- Guo, Z. Researches on Data Compression and Classification of Hyperspectral Images. Master’s Thesis, Xidian University, Xi’an, China, 2015. [Google Scholar]
- Serre, T.; Riesenhuber, M.; Louie, J.; Poggio, T. On the Role of Object-Specific Features for Real World Object Recognition in Biological Vision. International Workshop on Biologically Motivated Computer Vision. In Proceedings of the International Workshop on Biologically Motivated Computer Vision, Tübingen, Germany, 22–24 November 2002; pp. 387–397. [Google Scholar]
- Fu, G.Y.; Gu, H.Y.; Wang, H.Q. Spectral and Spatial Classification of Hyperspectral Images Based on Convolutional Neural Networks. Sci. Technol. Eng. 2017, 17, 268–274. [Google Scholar]
- Qu, J.Y.; Sun, X.; Gao, X. Remote sensing image target recognition based on CNN. Foreign Electron. Meas. Technol. 2016, 8, 45–50. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the International conference on machine learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Li, S.; Kwok, J.T.; Zhu, H.; Wang, Y. Texture classification using the support vector machines. Pattern Recognit. 2003, 36, 2883–2893. [Google Scholar] [CrossRef]
- Bai, C.; Huang, L.; Pan, X.; Zheng, J.; Chen, S. Optimization of deep convolutional neural network for large scale image retrieval. Neurocomputing 2018, 303, 60–67. [Google Scholar] [CrossRef]
- Martínez-Estudillo, F.J.; Hervás-Martínez, C.; Peña, P.A.G.; Martínez, A.C.; Ventura, S. Evolutionary Product-Unit Neural Networks for Classification. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Burgos, Spain, 20–23 September 2006; pp. 1320–1328. [Google Scholar]
- Bouvrie, J. Notes on Convolutional Neural Networks. Available online: http://cogprints.org/5869/ (accessed on 12 December 2007).
- Guyon, I.; Albrecht, P.; Cun, Y.L.; Denker, J.; Hubbard, W. Design of a neural network character recognizer for a touch terminal. Pattern Recognit. 1991, 24, 105–119. [Google Scholar] [CrossRef]
- Zhou, S.; Chen, Q.; Wang, X. Convolutional Deep Networks for Visual Data Classification. Neural Process. Lett. 2013, 38, 17–27. [Google Scholar] [CrossRef]
- Li, H.F.; Li, C.G. Note on deep architecture and deep learning algorithms. J. Hebei Univ. (Nat. Sci. Ed.) 2012, 32, 538–544. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Xu, W.; Wu, Y.; Gong, Y. Human Tracking Using Convolutional Neural Networks. IEEE Trans. Neural Netw. 2010, 21, 1610–1623. [Google Scholar] [PubMed]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 7, 2094–2107. [Google Scholar] [CrossRef]
- Gao, F. Research on Lossless Predictive Compression Technique of Hyperspectral Images. Ph.D. Thesis, Jilin University, Changchun, China, 2016. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Name | Number of Samples |
|---|---|---|
| C1 | Alfalfa | 46 |
| C2 | Corn-notill | 1428 |
| C3 | Corn-mintill | 830 |
| C4 | Corn | 237 |
| C5 | Grass-pasture | 483 |
| C6 | Grass-trees | 730 |
| C7 | Grass-pasture-mowed | 28 |
| C8 | Hay-windrowed | 478 |
| C9 | Oats | 20 |
| C10 | Soybean-notill | 972 |
| C11 | Soybean-mintill | 2455 |
| C12 | Soybean-clean | 593 |
| C13 | Wheat | 205 |
| C14 | Woods | 1265 |
| C15 | Buildings-Grass-Trees-Drives | 386 |
| C16 | Stone-Steel-Towers | 93 |
| Total | 10,249 |
| Label | Name | Number of Samples |
|---|---|---|
| C1 | Brocoli_green_weeds_1 | 2009 |
| C2 | Brocoli_green_weeds_2 | 3726 |
| C3 | Fallow | 1976 |
| C4 | Fallow_rough_plow | 1394 |
| C5 | Fallow_smooth | 2678 |
| C6 | Stubble | 3959 |
| C7 | Celery | 3579 |
| C8 | Grapes_untrained | 11,271 |
| C9 | Soil_vinyard_develop | 6203 |
| C10 | Corn_senesced_green_weeds | 3278 |
| C11 | Lettuce_romaine_4wk | 1068 |
| C12 | Lettuce_romaine_5wk | 1927 |
| C13 | Lettuce_romaine_6wk | 916 |
| C14 | Lettuce_romaine_7wk | 1070 |
| C15 | Vinyard_untrained | 7268 |
| C16 | Vinyard_vertical_trellis | 1807 |
| Total | 54,129 |
| Number of Layers | Species | Number of Output Features | Size of Output Features | Convolution Kernel Size |
|---|---|---|---|---|
| 0 | Input layer | 1 | 14 × 14 | / |
| 1 | Convolutional layer C1 | 6 | 7 × 7 | 5 × 5 |
| 2 | Maximum pooling layer S1 | 6 | 4 × 4 | 2 × 2 |
| 3 | Convolutional layer C2 | 16 | 4 × 4 | 5 × 5 |
| 4 | Maximum pooling layer S2 | 16 | 2 × 2 | 2 × 2 |
| 5 | Fully connected layer FC1 | 1 | 120 | / |
| 6 | Fully connected layer FC2 | 1 | 84 | / |
| Number of Layers | Species | Number of Output Features | Size of Output Features | Convolution Kernel Size |
|---|---|---|---|---|
| 0 | Input layer | 1 | 14 × 14 | / |
| 1 | Convolutional layer C1 | 6 | 7 × 7 | 5 × 5 |
| 2 | Maximum pooling layer S1 | 6 | 4 × 4 | 3 × 3 |
| 3 | Convolutional layer C2 | 16 | 4 × 4 | 5 × 5 |
| 4 | Maximum pooling layer S2 | 16 | 2 × 2 | 3 × 3 |
| 5 | Fully connected layer FC1 | 1 | 120 | / |
| 6 | Fully connected layer FC2 | 1 | 84 | / |
| Method | Time/s | Kappa Coefficient | Overall Accuracy | Average Accuracy |
|---|---|---|---|---|
| Traditional CNN | 114.60 | 0.8302 | 85.12% | 84.96% |
| Densenet | 124.20 | 0.8397 | 85.92% | 82.52% |
| Maximum overlap pooling CNN | 118.80 | 0.8714 | 88.73% | 87.62% |
| Method | Time/s | Kappa Coefficient | Overall Accuracy | Average Accuracy |
|---|---|---|---|---|
| Traditional CNN | 584.40 | 0.9303 | 93.75% | 97.22% |
| Densenet | 609.00 | 0.9372 | 94.35% | 97.18% |
| Maximum overlap pooling CNN | 615.00 | 0.9416 | 94.76% | 97.45% |
| Category | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 20 | 0 | 0 | 0 | 4 | 0 | 0 | 9 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 2 | 0 | 913 | 34 | 23 | 0 | 0 | 0 | 0 | 2 | 18 | 84 | 9 | 0 | 0 | 0 | 0 |
| 3 | 0 | 9 | 518 | 40 | 0 | 0 | 0 | 0 | 1 | 2 | 24 | 16 | 0 | 0 | 1 | 0 |
| 4 | 0 | 5 | 18 | 033 | 0 | 4 | 0 | 3 | 1 | 2 | 4 | 3 | 0 | 0 | 0 | 0 |
| 5 | 3 | 5 | 1 | 2 | 326 | 3 | 0 | 0 | 0 | 0 | 5 | 3 | 0 | 1 | 1 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 523 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 4 | 12 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 8 | 11 | 0 | 0 | 0 | 2 | 0 | 0 | 350 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 10 | 0 | 23 | 3 | 1 | 0 | 3 | 0 | 0 | 0 | 608 | 88 | 2 | 0 | 0 | 1 | 0 |
| 11 | 0 | 70 | 106 | 6 | 0 | 0 | 0 | 0 | 0 | 30 | 1587 | 18 | 1 | 0 | 11 | 0 |
| 12 | 0 | 7 | 33 | 15 | 0 | 0 | 0 | 1 | 0 | 4 | 28 | 366 | 0 | 0 | 2 | 1 |
| 13 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 157 | 0 | 0 | 0 |
| 14 | 0 | 0 | 0 | 1 | 7 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 930 | 14 | 0 |
| 15 | 0 | 0 | 2 | 0 | 9 | 18 | 0 | 0 | 3 | 1 | 3 | 0 | 1 | 87 | 176 | 1 |
| 16 | 0 | 3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 1 | 0 | 0 | 1 | 58 |
| No. | Ground Category | Total Number of Pixels | Correct Classification | Classification Accuracy |
|---|---|---|---|---|
| 1 | Alfalfa | 36 | 20 | 55.56% |
| 2 | Corn-notill | 1083 | 913 | 84.30% |
| 3 | Corn-min | 611 | 518 | 84.78% |
| 4 | Corn | 73 | 33 | 45.21% |
| 5 | Grass/Pasture | 350 | 326 | 93.14% |
| 6 | Grass/Trees | 542 | 523 | 96.49% |
| 7 | Pasture-mowed | 21 | 19 | 90.48% |
| 8 | Hay-windrowed | 363 | 350 | 96.42% |
| 9 | Oats | 12 | 11 | 91.67% |
| 10 | Soybeans-notill | 729 | 608 | 83.40% |
| 11 | Soybeans-min | 1829 | 1587 | 86.77% |
| 12 | Soybeans-clean | 457 | 366 | 80.09% |
| 13 | Wheat | 159 | 157 | 98.74% |
| 14 | Woods | 954 | 930 | 97.48% |
| 15 | Building-trees- | 301 | 176 | 58.47% |
| 16 | Stone-steel | 67 | 58 | 86.57% |
| / | Overall classification accuracy | / | / | 86.93% |
| Category | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 22 | 0 | 0 | 0 | 1 | 0 | 0 | 11 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 844 | 21 | 7 | 1 | 0 | 0 | 0 | 3 | 54 | 103 | 9 | 0 | 0 | 1 | 0 |
| 3 | 0 | 14 | 475 | 36 | 0 | 0 | 0 | 0 | 1 | 6 | 63 | 15 | 0 | 0 | 1 | 0 |
| 4 | 0 | 4 | 11 | 136 | 0 | 1 | 0 | 0 | 2 | 0 | 13 | 5 | 0 | 0 | 1 | 0 |
| 5 | 1 | 0 | 0 | 1 | 321 | 8 | 0 | 0 | 0 | 0 | 10 | 2 | 0 | 3 | 4 | 0 |
| 6 | 0 | 0 | 0 | 2 | 0 | 521 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 3 | 14 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 21 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 1 | 0 | 0 | 0 | 00 | 0 | 0 | 360 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 9 | 0 | 0 | 0 | 0 | 00 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 24 | 3 | 3 | 3 | 2 | 0 | 0 | 0 | 619 | 70 | 4 | 0 | 0 | 1 | 0 |
| 11 | 0 | 40 | 46 | 4 | 2 | 2 | 1 | 0 | 0 | 56 | 1661 | 8 | 0 | 0 | 9 | 0 |
| 12 | 0 | 9 | 19 | 4 | 4 | 1 | 0 | 0 | 0 | 2 | 27 | 387 | 0 | 0 | 3 | 1 |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 156 | 0 | 1 | 0 |
| 14 | 0 | 0 | 0 | 0 | 6 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 918 | 28 | 0 |
| 15 | 0 | 0 | 0 | 0 | 8 | 21 | 0 | 0 | 4 | 0 | 2 | 0 | 4 | 63 | 198 | 1 |
| 16 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 1 | 61 |
| No. | Ground Category | Total Number of Pixels | Correct Classification | Classification Accuracy |
|---|---|---|---|---|
| 1 | Alfalfa | 36 | 22 | 61.11% |
| 2 | Corn-notill | 1043 | 844 | 80.92% |
| 3 | Corn-min | 611 | 475 | 77.74% |
| 4 | Corn | 173 | 136 | 78.61% |
| 5 | Grass/Pasture | 350 | 321 | 91.71% |
| 6 | Grass/Trees | 542 | 521 | 96.13% |
| 7 | Pasture-mowed | 21 | 21 | 100.00% |
| 8 | Hay-windrowed | 363 | 360 | 99.17% |
| 9 | Oats | 12 | 12 | 100.00% |
| 10 | Soybeans-notill | 729 | 619 | 84.91% |
| 11 | Soybeans-min | 1829 | 1661 | 90.81% |
| 12 | Soybeans-clean | 457 | 387 | 84.68% |
| 13 | Wheat | 159 | 156 | 98.11% |
| 14 | Woods | 954 | 918 | 96.23% |
| 15 | Building-trees | 301 | 198 | 65.78% |
| 16 | Stone-steel | 67 | 61 | 91.04% |
| / | Overall classification accuracy | / | / | 87.78% |
| Category | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1470 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 2789 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 3 | 0 | 0 | 1458 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 1048 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 99 | 10 | 1896 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 1 | 2981 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 1 | 0 | 0 | 0 | 0 | 2641 | 1 | 0 | 0 | 0 | 0 | 1 | 4 | 0 | 1 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7540 | 1 | 25 | 0 | 0 | 0 | 5 | 873 | 1 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4666 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 3 | 1 | 3 | 0 | 0 | 16 | 27 | 2389 | 2 | 4 | 1 | 13 | 0 | 6 |
| 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 805 | 0 | 0 | 0 | 0 | 0 |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1430 | 0 | 2 | 0 | 0 |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 703 | 2 | 0 | 0 |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 13 | 815 | 0 | 0 |
| 15 | 0 | 0 | 2 | 0 | 1 | 0 | 1 | 1416 | 0 | 20 | 0 | 0 | 0 | 0 | 4021 | 1 |
| 16 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1349 |
| No. | Ground Category | Total Number of Pixels | Correct Classification | Classification Accuracy |
|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 1485 | 1470 | 98.99% |
| 2 | Brocoli_green_weeds_2 | 2793 | 2789 | 99.86% |
| 3 | Fallow | 1462 | 1458 | 99.73% |
| 4 | Fallow_rough_plow | 1051 | 1048 | 99.71% |
| 5 | Fallow_smooth | 2007 | 1896 | 94.47% |
| 6 | Stubble | 2982 | 2981 | 99.97% |
| 7 | Celery | 2649 | 2641 | 99.70% |
| 8 | Grapes_untrained | 8445 | 7540 | 89.28% |
| 9 | Soil_vinyard_develop | 4667 | 4666 | 99.98% |
| 10 | Corn_sensced_green_weeds | 2465 | 2389 | 96.92% |
| 11 | Lettuce_romaine_4wk | 805 | 805 | 100% |
| 12 | Lettuce_romaine_5wk | 1434 | 1430 | 99.72% |
| 13 | Lettuce_romaine_6wk | 705 | 703 | 99.72% |
| 14 | Lettuce_romaine_7wk | 832 | 815 | 97.96% |
| 15 | Vinyard_untrained | 5462 | 4021 | 73.62% |
| 16 | Vinyard_vertical_trellis | 1354 | 1349 | 99.63% |
| / | Overall classification accuracy | / | / | 93.60% |
| Category | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1479 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| 2 | 0 | 2792 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 1546 | 0 | 2 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1046 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 8 | 1997 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 1 | 0 | 0 | 1 | 2980 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 1 | 0 | 0 | 0 | 1 | 2642 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 1 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7576 | 1 | 7 | 0 | 0 | 0 | 0 | 861 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4666 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 0 | 1 | 1 | 2 | 0 | 19 | 24 | 2399 | 1 | 2 | 0 | 8 | 3 | 5 |
| 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 802 | 2 | 0 | 0 | 0 | 0 |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1432 | 2 | 0 | 0 | 0 |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 703 | 2 | 0 | 0 |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 5 | 0 | 0 | 12 | 814 | 0 | 0 |
| 15 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 1069 | 0 | 4 | 0 | 0 | 0 | 0 | 4387 | 0 |
| 16 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1350 |
| No. | Ground Category | Total Number of Pixels | Correct Classification | Classification Accuracy |
|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 1485 | 1479 | 99.60% |
| 2 | Brocoli_green_weeds_2 | 2793 | 2792 | 99.96% |
| 3 | Fallow | 1552 | 1546 | 99.61% |
| 4 | Fallow_rough_plow | 1051 | 1046 | 99.52% |
| 5 | Fallow_smooth | 2007 | 1997 | 99.50% |
| 6 | Stubble | 2982 | 2980 | 99.93% |
| 7 | Celery | 2648 | 2642 | 99.77% |
| 8 | Grapes_untrained | 8445 | 7576 | 89.71% |
| 9 | Soil_vinyard_develop | 4667 | 4666 | 99.98% |
| 10 | Corn_sensced_green_weeds | 2465 | 2399 | 97.32% |
| 11 | Lettuce_romaine_4wk | 805 | 802 | 99.63% |
| 12 | Lettuce_romaine_5wk | 1434 | 1432 | 99.86% |
| 13 | Lettuce_romaine_6wk | 705 | 703 | 99.72% |
| 14 | Lettuce_romaine_7wk | 832 | 814 | 97.84% |
| 15 | Vinyard_untrained | 5462 | 4387 | 80.32% |
| 16 | Vinyard_vertical_trellis | 1354 | 1350 | 99.70% |
| / | Overall classification accuracy | / | / | 94.90% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Yang, S.X.; Yang, Y.; Gao, H.; Zhao, J.; Qu, X.; Wang, Y.; Yao, D.; Gao, J. Hyperspectral Remote Sensing Image Classification Based on Maximum Overlap Pooling Convolutional Neural Network. Sensors 2018, 18, 3587. https://doi.org/10.3390/s18103587
Li C, Yang SX, Yang Y, Gao H, Zhao J, Qu X, Wang Y, Yao D, Gao J. Hyperspectral Remote Sensing Image Classification Based on Maximum Overlap Pooling Convolutional Neural Network. Sensors. 2018; 18(10):3587. https://doi.org/10.3390/s18103587
Chicago/Turabian StyleLi, Chenming, Simon X. Yang, Yao Yang, Hongmin Gao, Jia Zhao, Xiaoyu Qu, Yongchang Wang, Dan Yao, and Jianbing Gao. 2018. "Hyperspectral Remote Sensing Image Classification Based on Maximum Overlap Pooling Convolutional Neural Network" Sensors 18, no. 10: 3587. https://doi.org/10.3390/s18103587
APA StyleLi, C., Yang, S. X., Yang, Y., Gao, H., Zhao, J., Qu, X., Wang, Y., Yao, D., & Gao, J. (2018). Hyperspectral Remote Sensing Image Classification Based on Maximum Overlap Pooling Convolutional Neural Network. Sensors, 18(10), 3587. https://doi.org/10.3390/s18103587