Classifier for Activities with Variations †


Abstract
1. Introduction
2. Background
2.1. Pose, Motion and Activity
- Pose—a pose is the position of the human body at one point in time. A unique body pose is defined by the unique angles of all body limbs with respect to each other, disregarding the location and orientation of the subject.
- Motion—a motion is a sequence of body poses throughout time. A motion is not bounded by a specific duration.
- Activity—an activity is a meaningful label that could be assigned to a motion.
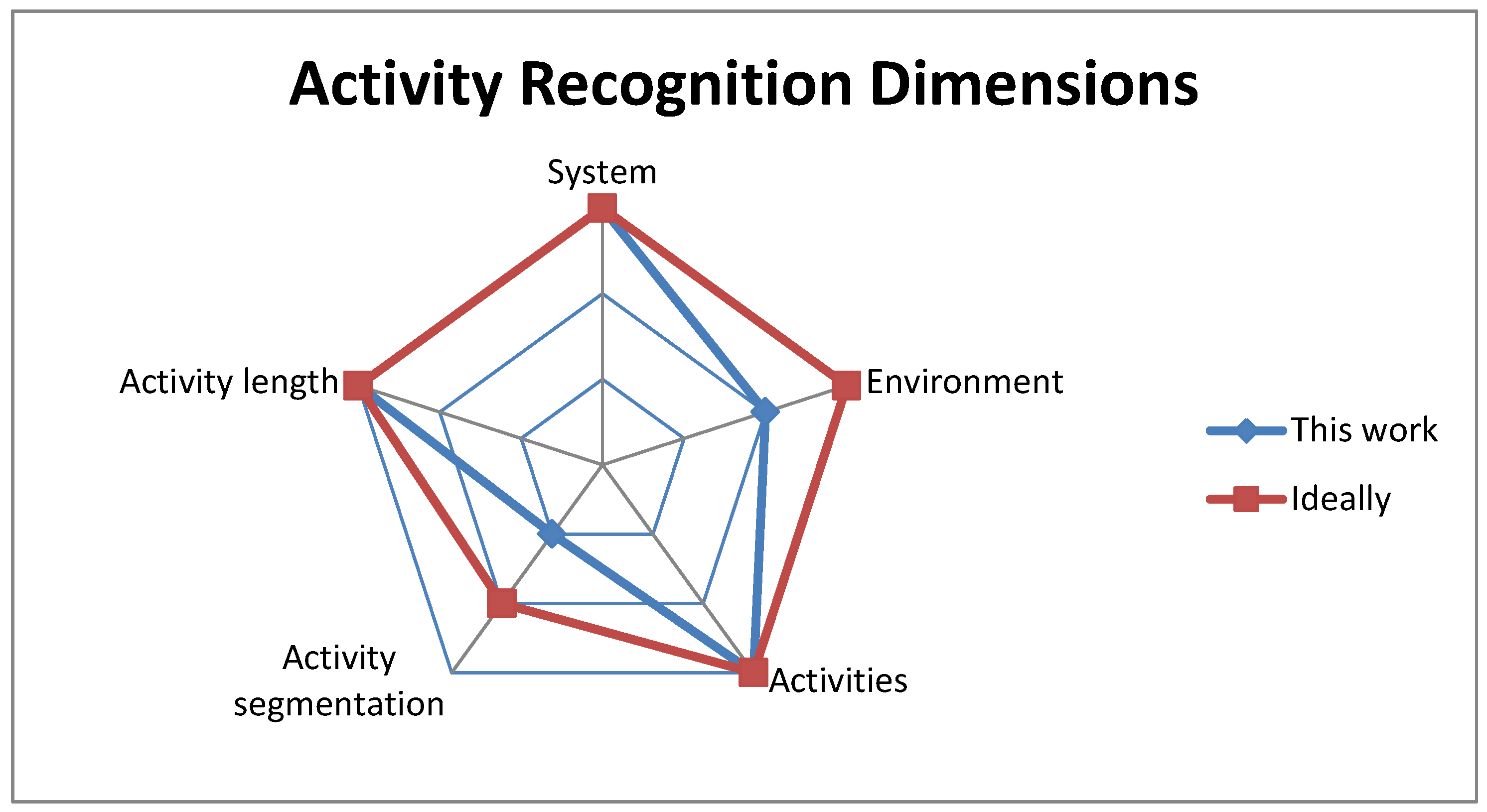
2.2. Activity Recognition Dimensions
- System: the recognition system, which could be:
- User-dependent and sensor-dependent
- User-independent and sensor-dependent (or the less frequent case of user-dependent and sensor-independent)
- User-independent and sensor-independent
- Environment: the data collection environment, which could be:
- Fixed with tracked objects
- Fixed with objects not tracked
- In the wild
- Activities: the recognized activities, which could be:
- Unlabeled
- Labeled and strictly scripted
- Labeled and high-level scripted
- Activity segmentation: the segmentation that occurs in the inference procedure, which could be:
- Manual
- Automated
- Activity length: the length of the recognized activities, which could be:
- Known
- Bounded
- Unknown
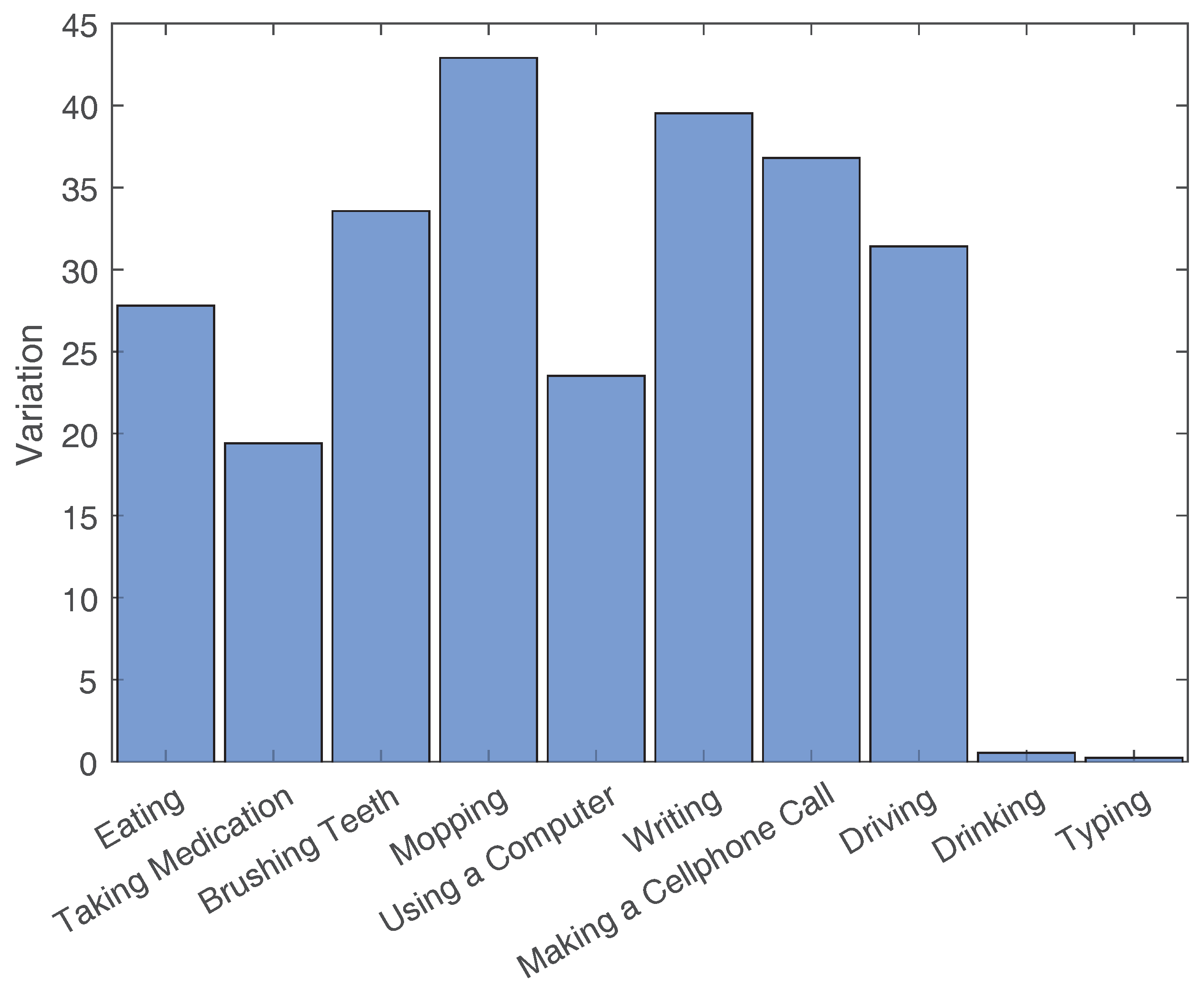
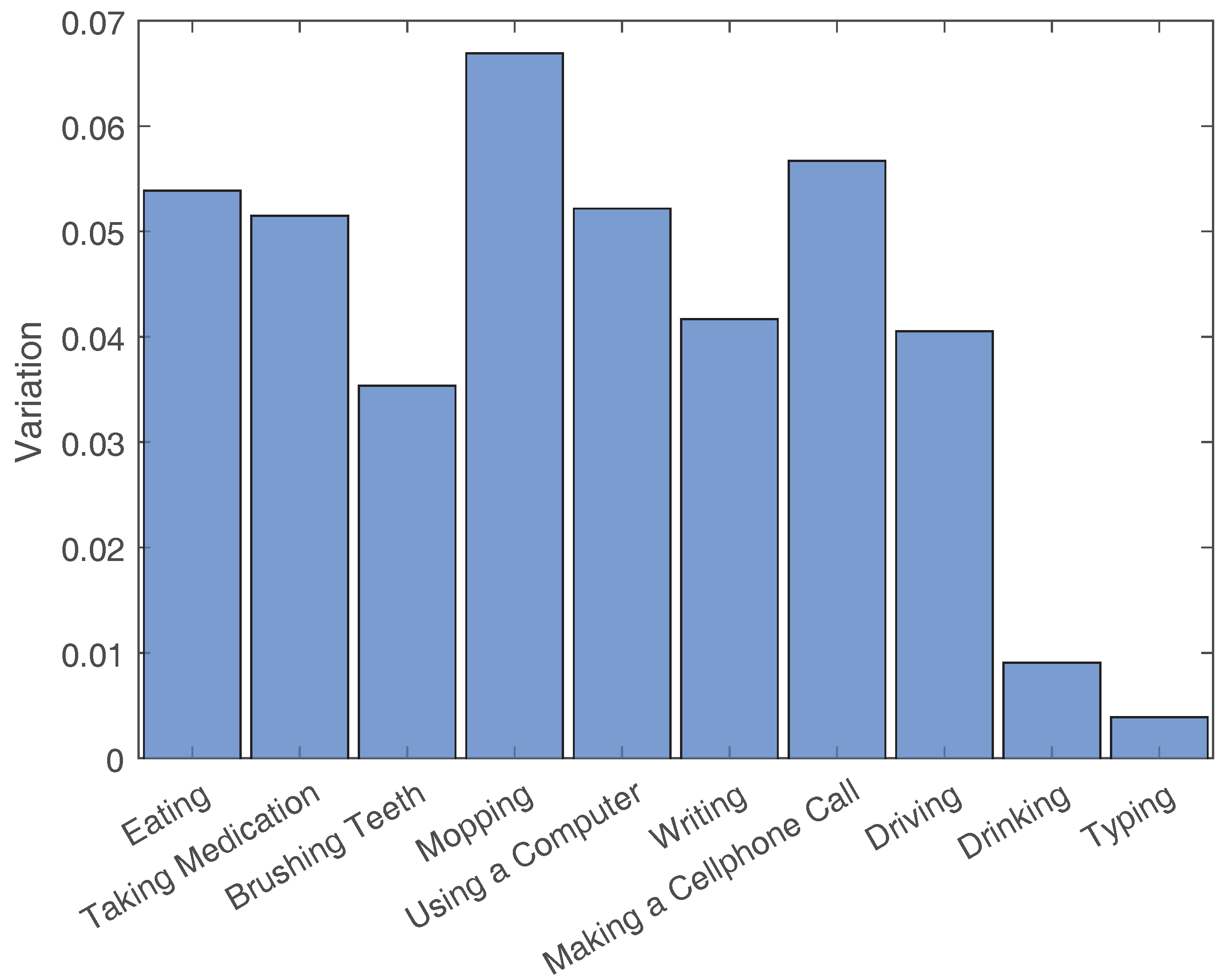
2.3. Activity Variations
3. Materials and Methods
3.1. Data Collection
- Eating:Before recording starts: The subject chooses what to eat and which utensils to use among an available variety of food and utensils. The subject then sits at a table with his/her food and utensils in front of them.While recording: The subject eats their food.
- Taking medication:Before recording starts: The subject stands in front of a table that has three types of medication containers—two types of pill bottles that open differently and a pill packet (actual pills are not used; candy is used instead)—and a cup of water.While recording: The subject chooses one medication and takes one “pill”.
- Brushing teeth:Before recording starts: The subject stands in front of a table that has a toothbrush, toothpaste and a cup of water.While recording: The subject brushes his/her teeth. He/she may clean his/her mouth using the cup of water, and he/she may also spit in it.
- Mopping:Before recording starts: The subject chooses a mop among two available types. The subject chooses an empty (no furniture) area to be mopped. The subject stands (holding the mop) at a chosen starting point in the designated mopping area.While recording: The subject mops the entire designated mopping area.
- Using a computer:Before recording starts: The subject sits at a table with his/her laptop in front of him/her. A mouse is provided in case he/she prefers using it instead of the laptop’s touchpad. The laptop is up and running.While recording: The subject opens his/her email and looks for an email from the researcher asking him/her how his/her day was. He/she reads the email and then replies to it.
- Writing:Before recording starts: The subject sits at a table with two types of notebooks and two types of pens in front of him/her. The subject chooses a notebook and a pen to use.While recording: The subject writes a few lines about his/her day in the chosen notebook.
- Making a cell phone call:Before recording starts: The subject stands while having his/her cell phone in one of his/her pockets.While recording: The subject picks up his/her phone, calls the researcher, waits for the phone to ring two or three times, hangs up and puts the phone back in his/her pocket.
- Driving:Before recording starts: The subject sits in front of a driving gaming system consisting of a computer, a steering wheel, a transmission and pedals. A driving game is loaded on the computer.While recording: The subject drives to a randomly chosen location in the game.
- For eating: Sitting at the table with different postures. Knee angles for each leg varying between 70 and 120 degrees. Using a spoon, fork or chopsticks. Using right or left hand. Having the other hand on the table or on the leg. Different leaning angles while approaching food.
- For taking medication: The choice of pill bottle or packet. Picking the pill bottle/packet using the right or left hand. Easily getting the pill out or struggling while extracting only one pill out of the bottle. Using right or left hand to take the pill. Using right or left hand to drink the water. Taking the pill before drinking the water, or vice versa.
- For brushing teeth: Picking up the toothbrush and toothpaste with the right or left hand. Using toothpaste or not using it. Different techniques of brushing teeth. Picking up the cup of water with the right or left hand. Cleaning mouth with water or not. Spitting once or multiple times.
- For mopping: The choice of mop type. Putting the right or left hand on top. Switching between hands or not. Different leaning angles, ranging between 10 and 60 degrees. Performing linear or circular mopping movements. Starting/ending at different locations and traveling different paths in between.
- For using a computer: Different knee angles for each leg. Different leaning angles. Using the mouse or not. Using the mouse only at the beginning or using it intermittently throughout the activity. Using the mouse with the right or left hand.
- For writing: Choice of notebook and pen types and consequently the way subjects open/close them. Opening the book and the pen with the right or left hand. Putting the notebook and writing at different angles. Writing with the right or left hand. Putting the other hand on the notebook, the table or the leg. Different leaning angles. Different knee angles for each leg.
- For making a cell phone call: Having the cell phone in the right or left, front or back pocket. Using the right or left hand to pick the phone up, tap on the screen, putting it to the ear, hanging up and putting it back in the pocket. Using one or both hands when typing on the phone. Having to tap the numbers of the phone number or having the number already saved on the phone. Walking/moving while making the call or not.
- For driving: Different knee angles for both legs. Different ways of using the steering wheel. Using the transmission or not.
3.2. Classifier for Activities with Variations
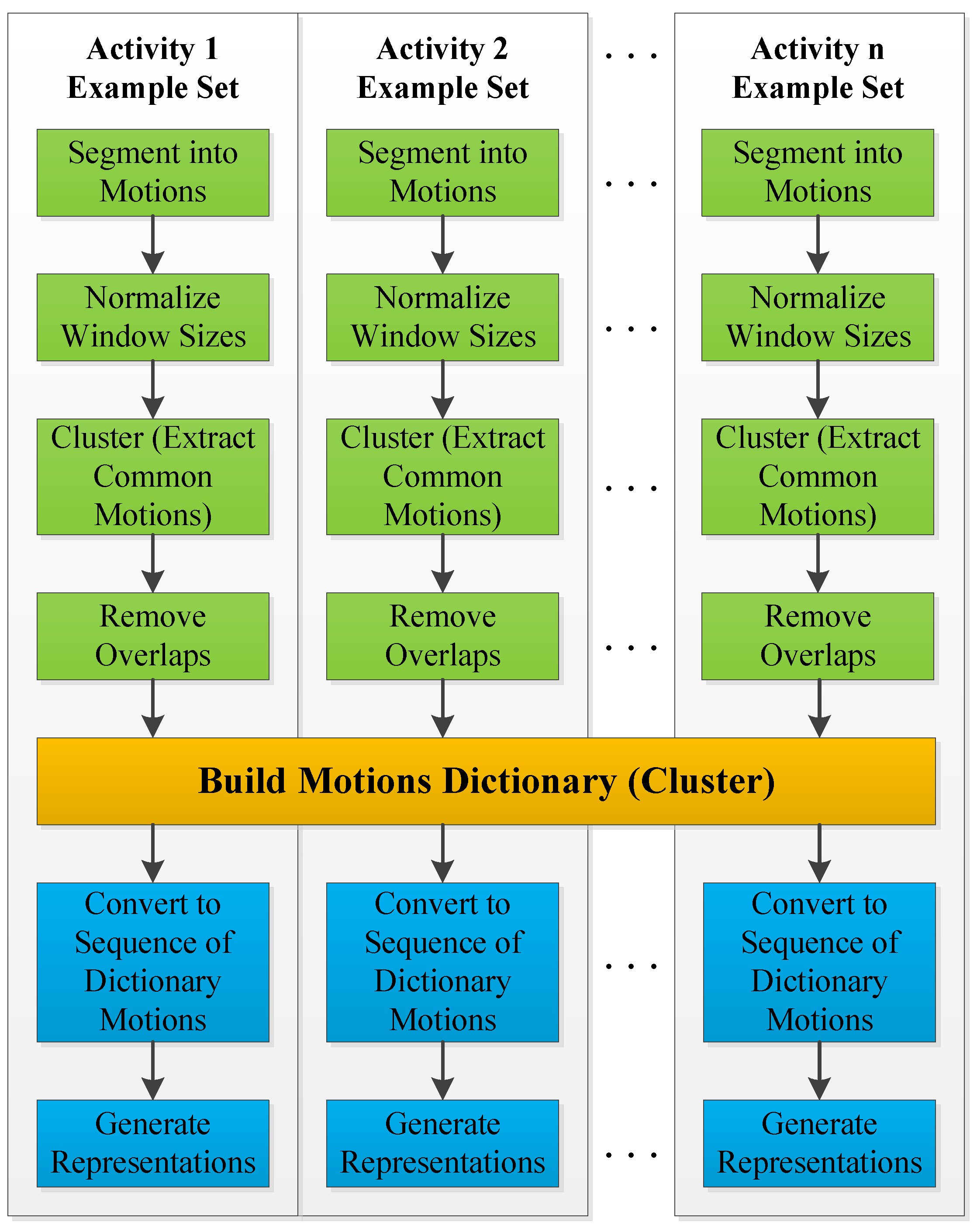
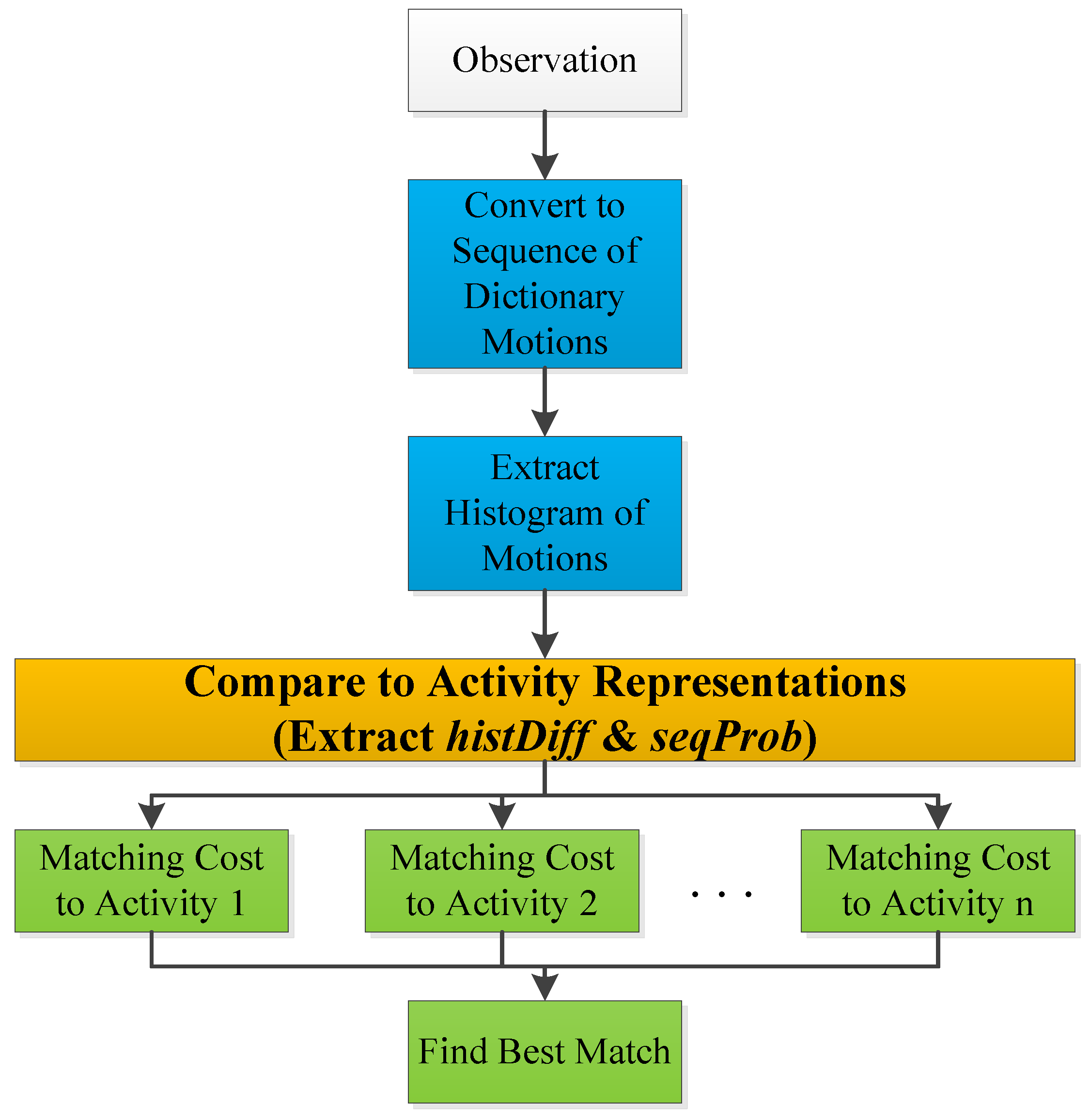
3.2.1. Training
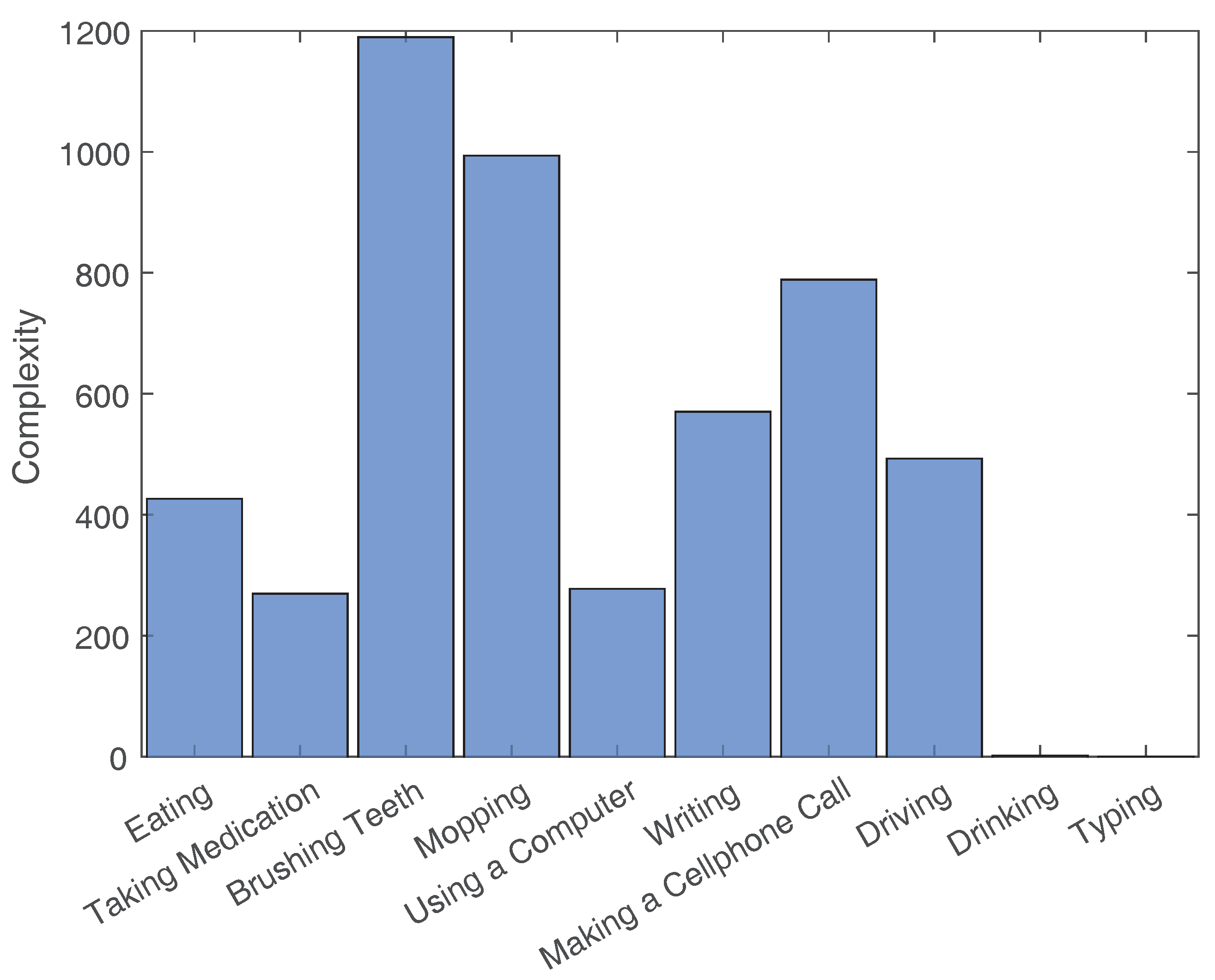
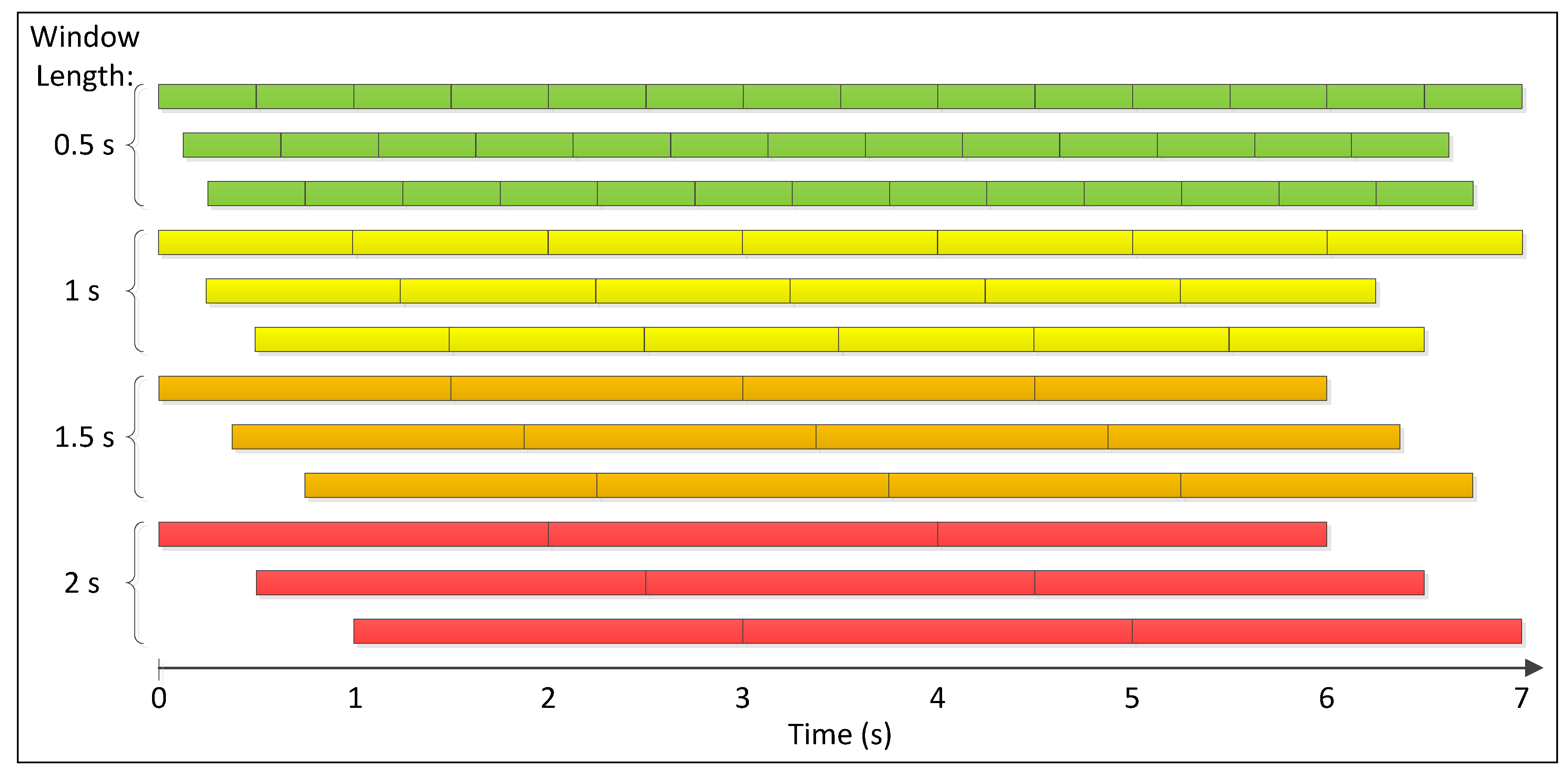
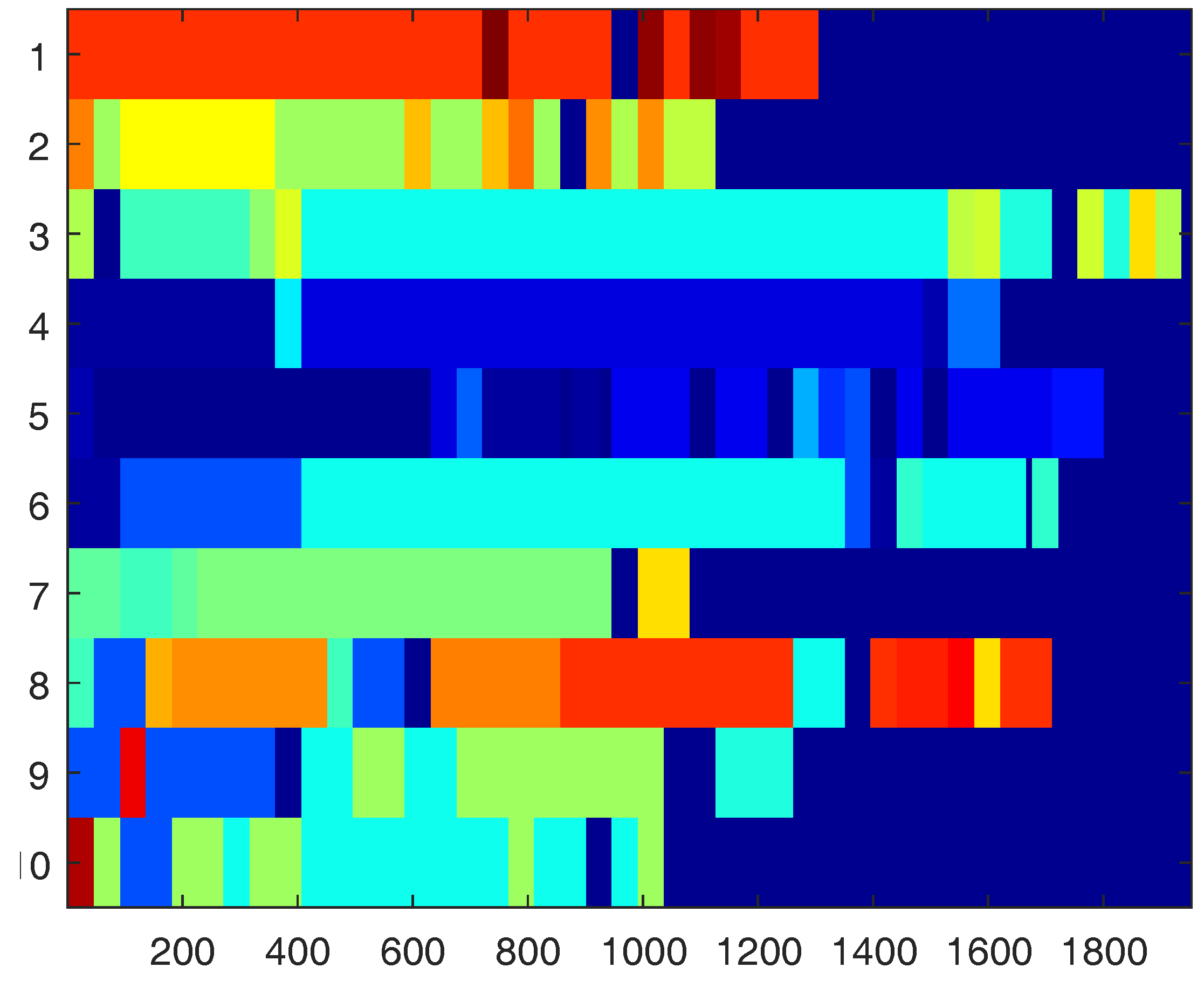
- Segment motions:Each example in the training set is first segmented into windows using four sizes that represent the lengths of 0.5, 1, 1.5 and 2 s. The four window lengths are chosen after studying the lengths of repeated motions and concluding that they usually vary within the chosen range. The segmentation process is repeated three times with segmentation increments of 0%, 25% and 50% of the window size; i.e., the starting points of all windows are shifted by 0%, 25% and 50% of the window size. An example of all resulting windows is shown in Figure 8. Windows longer than 0.5 s are sub-sampled, so that all extracted windows are normalized and have the same size.
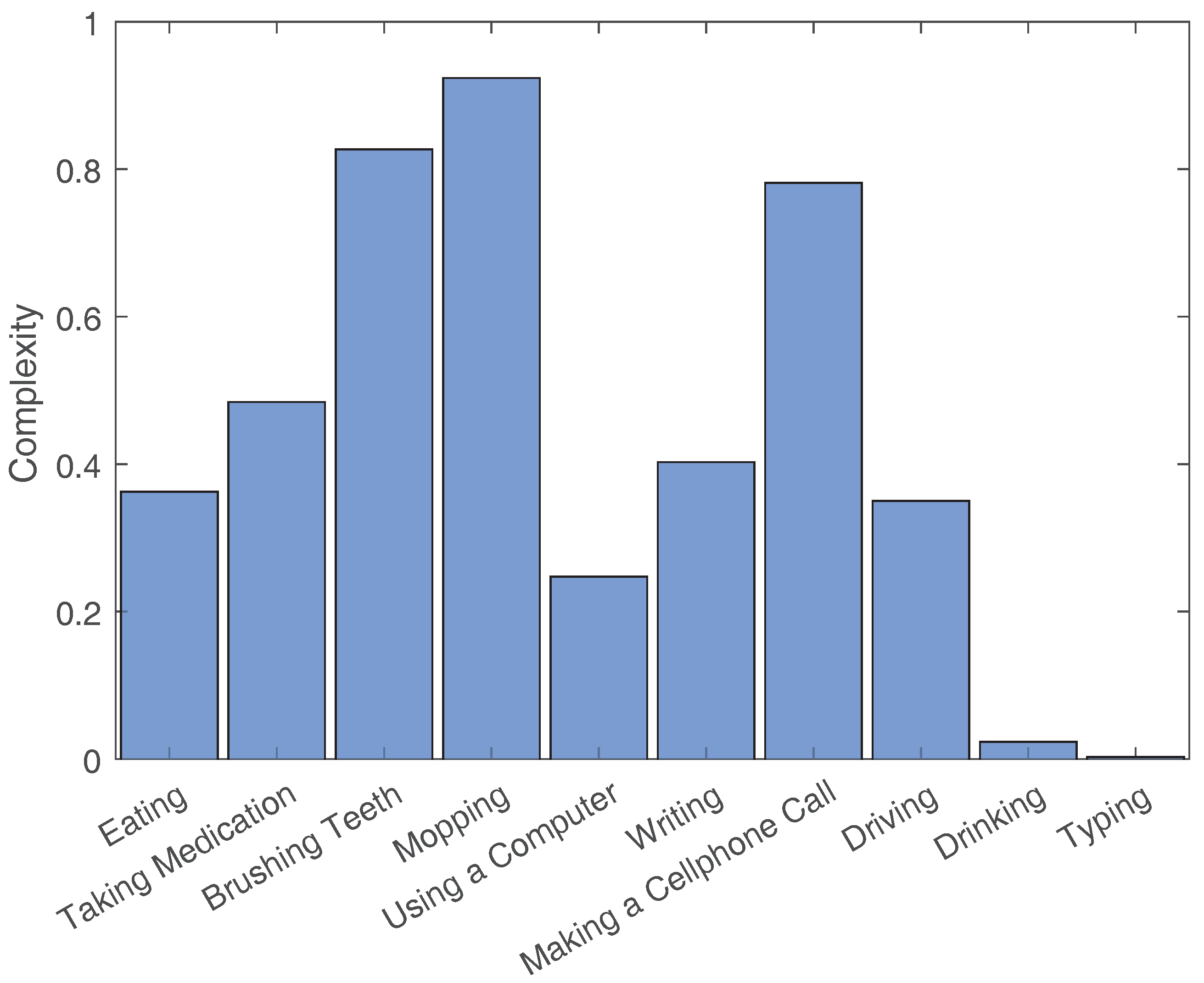
- Extract common motions:For each activity, all extracted windows are clustered using k-means clustering [25]. The distance metric used for k-means is Euclidean distance. Clusters containing a low number of windows (five windows or less) are dropped since only motions that often repeat are of interest. Afterward, overlapping windows are examined. Windows with larger sizes are kept, while their overlapping windows are removed. Figure 9 shows the results after these steps are performed on the brushing teeth activity.
- Build motions dictionary:This step consists of creating a dictionary of motions. First, cluster centers for all activities are clustered using k-means clustering. This second clustering is realized to make sure that motions in the dictionary are distinct since similar motions could exist between two or more activities. The motions dictionary is filled with the new cluster centers that form its vocabulary. Note that, at every step, the algorithm keeps track of where the cluster centers originated. This tracking enables it to get back to every motion in the original examples and label it with the correct dictionary motion ID. The dictionary motion ID is a unique number that identifies each motion in the dictionary.
- Generate activity representations:After converting each example in the training dataset to a sequence of dictionary motion IDs, two features that can be used to represent each example are extracted. The first feature is a histogram that contains the frequency of occurrence of each dictionary motion in the example. The second feature is a transition matrix containing normalized transition probabilities between motions for that example.
3.2.2. Inference
- : the difference between the observation’s motions histogram and the potential match’s motions histogram.
- : the observed motions sequence probability.
4. Results and Discussion
4.1. Cross-Validation
4.2. Narrowing the Training Set’s Variations
4.3. Comparing to Previous Methods
- Zinnen’s classifier [9]: This is the state-of-the-art work in wearable full-body activity recognition. It performs better than any other full-body user-independent activity classifier and is considered the state-of-the-art in multiple recent works [35,36,37,38]. It relies on an abstract body model that makes it user-independent and capable of being used with data from multiple sensor domains. This work was chosen because it had most of the characteristics that are needed in an ideal wearable activity classifier, as described in [39].
- Berlin’s classifier [40]: This work extracts “motifs” to be used in order to detect one simple fixed-length activity within a background of non-activity data. Motifs are reoccurring sequences of signal-oriented time series’ symbols that have fixed lengths. This work was chosen because it used a similar concept to CAV that relied on splitting the activities into smaller chunks.
- Peng’s classifier [41]: This is a more recent work that tried to classify complex activities by applying a method similar to what was used in Berlin’s classifier, but where smaller chunks—“actions”—were extracted and aggregated in a different way.
- Berlin’s classifier used only a bag-of-words approach for the motifs, while CAV used information about the transitions between the motions in addition to the bag-of-words approach.
- The motifs extracted in Berlin’s classifier were reoccurring sequences of symbols that had fixed lengths, while CAV’s motions can vary in length.
- Using smaller chunks of the activity: algorithms using features for smaller parts of the complex activity were shown to yield better results than others that used the whole activity as it was.
- Extracting the smaller chunks in a similar way to CAV, which allowed variation in length: taking into account the variations in the duration of a motion was shown to yield better results than other methods that used fixed-length motions/motifs/actions.
- Using temporal relationships between the small chunks: considering both the presence of the motions and their order within the activity was shown to yield better results than other methods that relied only on the presence of motions/motifs/actions within the activity.
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kinect for Xbox One. Available online: http://www.xbox.com/en-US/xbox-one/accessories/kinect (accessed on 10 April 2017).
- Fitbit. Available online: https://www.fitbit.com/home (accessed on 10 April 2017).
- Pawar, T.; Chaudhuri, S.; Duttagupta, S.P. Body Movement Activity Recognition for Ambulatory Cardiac Monitoring. IEEE Trans. Biomed. Eng. 2007, 54, 874–882. [Google Scholar] [CrossRef] [PubMed]
- Rahman, H.A.; Carrault, G.; Ge, D.; Amoud, H.; Prioux, J.; Faucheur, A.L.; Dumond, R. Ambulatory physical activity representation and classification using spectral distances approach. In Proceedings of the 2015 International Conference on Advances in Biomedical Engineering (ICABME), Beirut, Lebanon, 16–18 September 2015; pp. 69–72. [Google Scholar]
- Peng, Y.; Zhang, T.; Sun, L.; Chen, J. A Novel Data Mining Method on Falling Detection and Daily Activities Recognition. In Proceedings of the 2015 IEEE 27th International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015; pp. 675–681. [Google Scholar]
- Zhu, C.; Sheng, W.; Liu, M. Wearable Sensor-Based Behavioral Anomaly Detection in Smart Assisted Living Systems. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1225–1234. [Google Scholar] [CrossRef]
- Whitehouse, S.; Yordanova, K.; Paiement, A.; Mirmehdi, M. Recognition of unscripted kitchen activities and eating behaviour for health monitoring. In Proceedings of the 2nd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2016), London, UK, 24–25 October 2016; pp. 1–6. [Google Scholar]
- Oh, K.; Park, H.S.; Cho, S.B. A Mobile Context Sharing System Using Activity and Emotion Recognition with Bayesian Networks. In Proceedings of the 2010 7th International Conference on Ubiquitous Intelligence Computing and 7th International Conference on Autonomic Trusted Computing, Xi’an, China, 26–29 October 2010; pp. 244–249. [Google Scholar]
- Zinnen, A.; Wojek, C.; Schiele, B. Multi Activity Recognition Based on Bodymodel-Derived Primitives. In Proceedings of the LoCA 2009 4th International Symposium on Location and Context Awareness, Tokyo, Japan, 7–8 May 2009; Choudhury, T., Quigley, A., Strang, T., Suginuma, K., Eds.; Springer: Berlin/Heidelberg, German, 2009; pp. 1–18. [Google Scholar]
- Blake, M.; Younes, R.; Dennis, J.; Martin, T.L.; Jones, M. A User-Independent and Sensor-Tolerant Wearable Activity Classifier. Computer 2015, 48, 64–71. [Google Scholar] [CrossRef]
- Barshan, B.; Yurtman, A. Investigating Inter-Subject and Inter-Activity Variations in Activity Recognition Using Wearable Motion Sensors. Comput. J. 2016, 59, 1345. [Google Scholar] [CrossRef]
- Yurtman, A.; Barshan, B. Investigation of personal variations in activity recognition using miniature inertial sensors and magnetometers. In Proceedings of the 2012 20th Signal Processing and Communications Applications Conference (SIU), Mugla, Turkey, 18–20 Apirl 2012; pp. 1–4. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Oneto, L. Model selection and error estimation without the agonizing pain. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1252. [Google Scholar] [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A Review of Human Activity Recognition Methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef]
- Lester, J.; Choudhury, T.; Borriello, G. A Practical Approach to Recognizing Physical Activities. In Proceedings of the Pervasive Computing: 4th International Conference, PERVASIVE 2006, Dublin, Ireland, 7–10 May 2006; Fishkin, K.P., Schiele, B., Nixon, P., Quigley, A., Eds.; Springer: Berlin/Heidelberg, German, 2006; pp. 1–16. [Google Scholar]
- Amft, O. Self-Taught Learning for Activity Spotting in On-body Motion Sensor Data. In Proceedings of the 2011 15th Annual International Symposium on Wearable Computers, San Francisco, CA, USA, 12–15 June 2011; pp. 83–86. [Google Scholar]
- Vahdatpour, A.; Amini, N.; Sarrafzadeh, M. On-body device localization for health and medical monitoring applications. In Proceedings of the 2011 IEEE International Conference on Pervasive Computing and Communications (PerCom), Seattle, WA, USA, 21–25 March 2011; pp. 37–44. [Google Scholar]
- Sheikh, Y.; Sheikh, M.; Shah, M. Exploring the space of a human action. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV 2005), Beijing, China, 17–20 October 2005; Volume 1, pp. 144–149. [Google Scholar]
- Definition of Complex in US English by Oxford Dictionaries. Available online: https://en.oxforddictionaries.com/definition/us/complex (accessed on 10 January 2018).
- Definition of Heterogeneous in US English by Oxford Dictionaries. Available online: https://en.oxforddictionaries.com/definition/us/heterogeneous (accessed on 10 January 2018).
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 567–572. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. RGBD-HuDaAct: A Color-Depth Video Database for Human Daily Activity Recognition. In Consumer Depth Cameras for Computer Vision: Research Topics and Applications; Fossati, A., Gall, J., Grabner, H., Ren, X., Konolige, K., Eds.; Springer: London, UK, 2013; pp. 193–208. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Younes, R.; Jones, M.; Martin, T.L. Toward Practical Activity Recognition: Recognizing Complex Activities with Wide Variations. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; pp. 9–14. [Google Scholar]
- Luhn, H.P. A Statistical Approach to Mechanized Encoding and Searching of Literary Information. IBM J. Res. Dev. 1957, 1, 309–317. [Google Scholar] [CrossRef]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Ling, Y.; Wang, H. Unsupervised Human Activity Segmentation Applying Smartphone Sensor for Healthcare. In Proceedings of the 2015 IEEE 12th Intl Conf on Ubiquitous Intelligence and Computing and 2015 IEEE 12th Intl Conf on Autonomic and Trusted Computing and 2015 IEEE 15th Intl Conf on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom), Beijing, China, 10–14 August 2015; pp. 1730–1734. [Google Scholar]
- Blanke, U.; Schiele, B.; Kreil, M.; Lukowicz, P.; Sick, B.; Gruber, T. All for one or one for all? Combining heterogeneous features for activity spotting. In Proceedings of the 2010 8th IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Mannheim, Germany, 29 March–2 April 2010; pp. 18–24. [Google Scholar]
- Ogris, G.; Stiefmeier, T.; Lukowicz, P.; Troster, G. Using a complex multi-modal on-body sensor system for activity spotting. In Proceedings of the 2008 12th IEEE International Symposium on Wearable Computers, Pittsburgh, PA, USA, 28 September–1 October 2008; pp. 55–62. [Google Scholar]
- Stone, M. Cross-Validatory Choice and Assessment of Statistical Predictions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 111–147. [Google Scholar]
- Kohavi, R. A Study of Cross-validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; Volume 2, pp. 1137–1143. [Google Scholar]
- Efron, B. Estimating the Error Rate of a Prediction Rule: Improvement on Cross-Validation. J. Am. Stat. Assoc. 1983, 78, 316–331. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial Sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Xu, Y.; Shen, Z.; Zhang, X.; Gao, Y.; Deng, S.; Wang, Y.; Fan, Y.; Chang, E.C. Learning multi-level features for sensor-based human action recognition. Pervasive Mob. Comput. 2017, 40, 324–338. [Google Scholar] [CrossRef]
- Hammerla, N.Y. Activity Recognition in Naturalistic Environments Using Body-Worn Sensors. Ph.D. Thesis, Newcastle University, Tyne, UK, 2015. [Google Scholar]
- Velloso, E. From Head to Toe: Body Movement for Human-Computer Interaction. Ph.D. Thesis, Lancaster University, Lancaster, UK, 2015. [Google Scholar]
- Younes, R. Toward Practical, In-The-Wild, and Reusable Wearable Activity Classification. Ph.D. Dissertation, Virginia Tech, Blacksburg, VA, USA, 2018. [Google Scholar]
- Berlin, E.; Van Laerhoven, K. Detecting Leisure Activities with Dense Motif Discovery. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; ACM: New York, NY, USA; pp. 250–259. [Google Scholar]
- Peng, L.; Chen, L.; Wu, X.; Guo, H.; Chen, G. Hierarchical Complex Activity Representation and Recognition Using Topic Model and Classifier Level Fusion. IEEE Trans. Biomed. Eng. 2017, 64, 1369–1379. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mopping | CellphoneCall | TakingMeds | BrushingTeeth | Driving | UsingComputer | Eating | Writing | |
|---|---|---|---|---|---|---|---|---|
| mopping | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| cellphoneCall | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 |
| takingMeds | 0 | 13.33 | 86.67 | 0 | 0 | 0 | 0 | 0 |
| brushingTeeth | 0 | 20 | 0 | 80 | 0 | 0 | 0 | 0 |
| driving | 0 | 0 | 0 | 0 | 86.67 | 13.33 | 0 | 0 |
| usingComputer | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 |
| eating | 0 | 0 | 0 | 0 | 0 | 6.67 | 93.33 | 0 |
| writing | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Mopping | CellphoneCall | TakingMeds | BrushingTeeth | Driving | UsingComputer | Eating | Writing | |
|---|---|---|---|---|---|---|---|---|
| mopping | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| cellphoneCall | 0 | 80 | 0 | 20 | 0 | 0 | 0 | 0 |
| takingMeds | 20 | 20 | 40 | 20 | 0 | 0 | 0 | 0 |
| brushingTeeth | 0 | 40 | 0 | 60 | 0 | 0 | 0 | 0 |
| driving | 0 | 0 | 0 | 0 | 60 | 40 | 0 | 0 |
| usingComputer | 0 | 0 | 0 | 0 | 0 | 40 | 60 | 0 |
| eating | 0 | 0 | 0 | 0 | 0 | 20 | 40 | 40 |
| writing | 0 | 0 | 0 | 0 | 0 | 40 | 0 | 60 |
| Mopping | CellphoneCall | TakingMeds | BrushingTeeth | Driving | UsingComputer | Eating | Writing | |
|---|---|---|---|---|---|---|---|---|
| mopping | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| cellphoneCall | 0 | 97 | 0 | 3 | 0 | 0 | 0 | 0 |
| takingMeds | 0 | 14 | 82 | 4 | 0 | 0 | 0 | 0 |
| brushingTeeth | 0 | 23 | 0 | 77 | 0 | 0 | 0 | 0 |
| driving | 0 | 0 | 0 | 0 | 78 | 22 | 0 | 0 |
| usingComputer | 0 | 0 | 0 | 0 | 0 | 83 | 17 | 0 |
| eating | 0 | 0 | 0 | 0 | 0 | 13 | 76 | 11 |
| writing | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 96 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Younes, R.; Jones, M.; Martin, T.L. Classifier for Activities with Variations. Sensors 2018, 18, 3529. https://doi.org/10.3390/s18103529
Younes R, Jones M, Martin TL. Classifier for Activities with Variations. Sensors. 2018; 18(10):3529. https://doi.org/10.3390/s18103529
Chicago/Turabian StyleYounes, Rabih, Mark Jones, and Thomas L. Martin. 2018. "Classifier for Activities with Variations" Sensors 18, no. 10: 3529. https://doi.org/10.3390/s18103529
APA StyleYounes, R., Jones, M., & Martin, T. L. (2018). Classifier for Activities with Variations. Sensors, 18(10), 3529. https://doi.org/10.3390/s18103529