Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique



Abstract
1. Introduction
2. Methodology
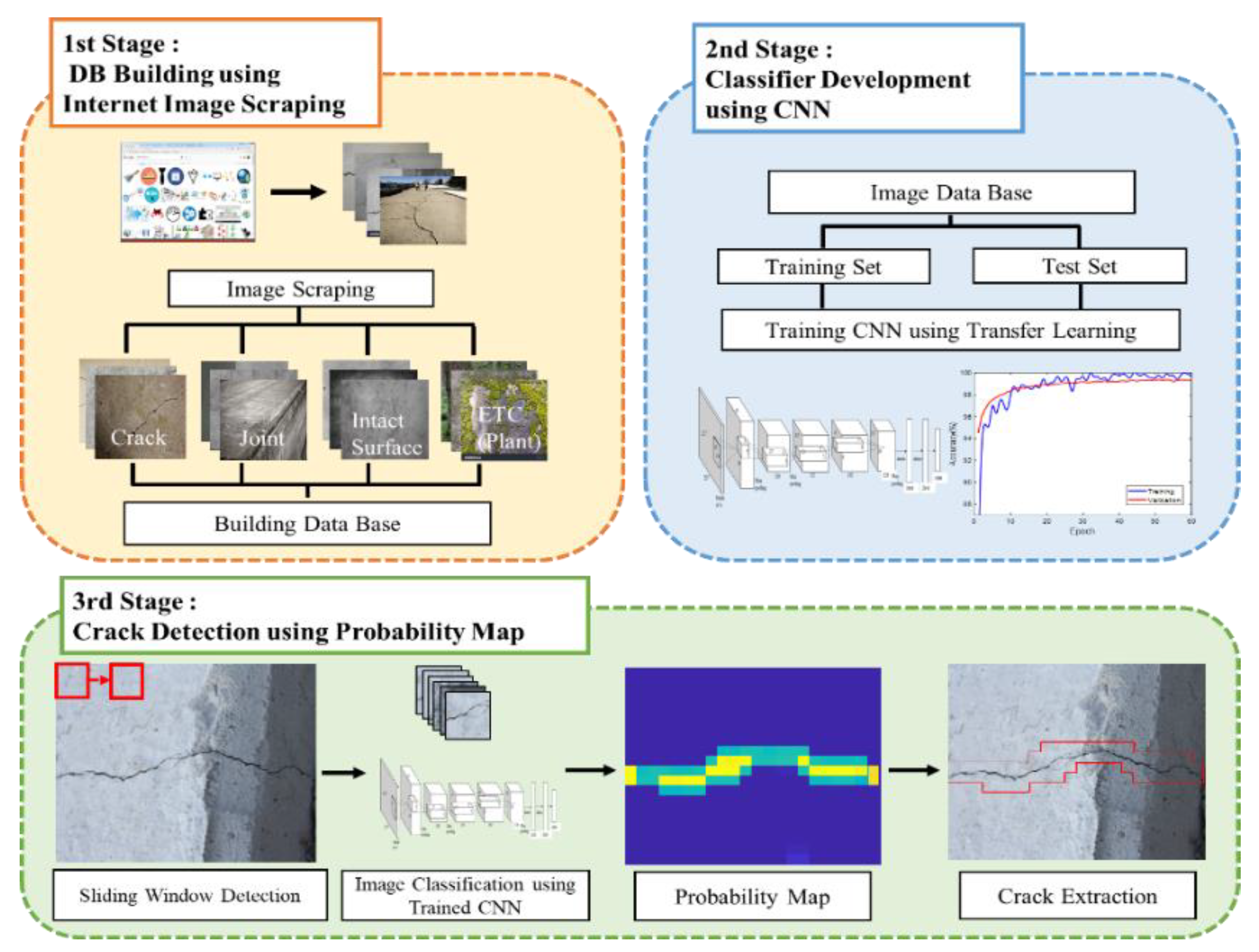
2.1. Overall Framework of the Proposed Method
2.2. First Stage: DB Building Using Internet Image Scraping
2.3. Second Stage: Classifier Development Using a CNN
2.4. Third Stage: Crack Detection Using a Probability Map
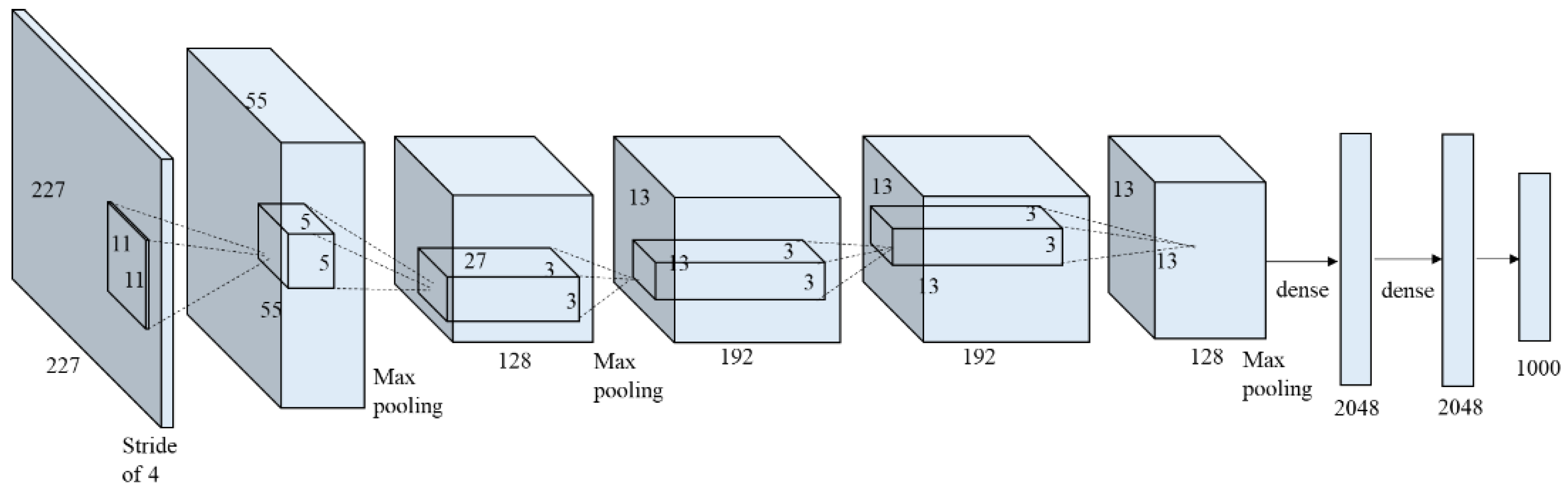
3. Development of a CNN Classifier
3.1. Data Augmentation
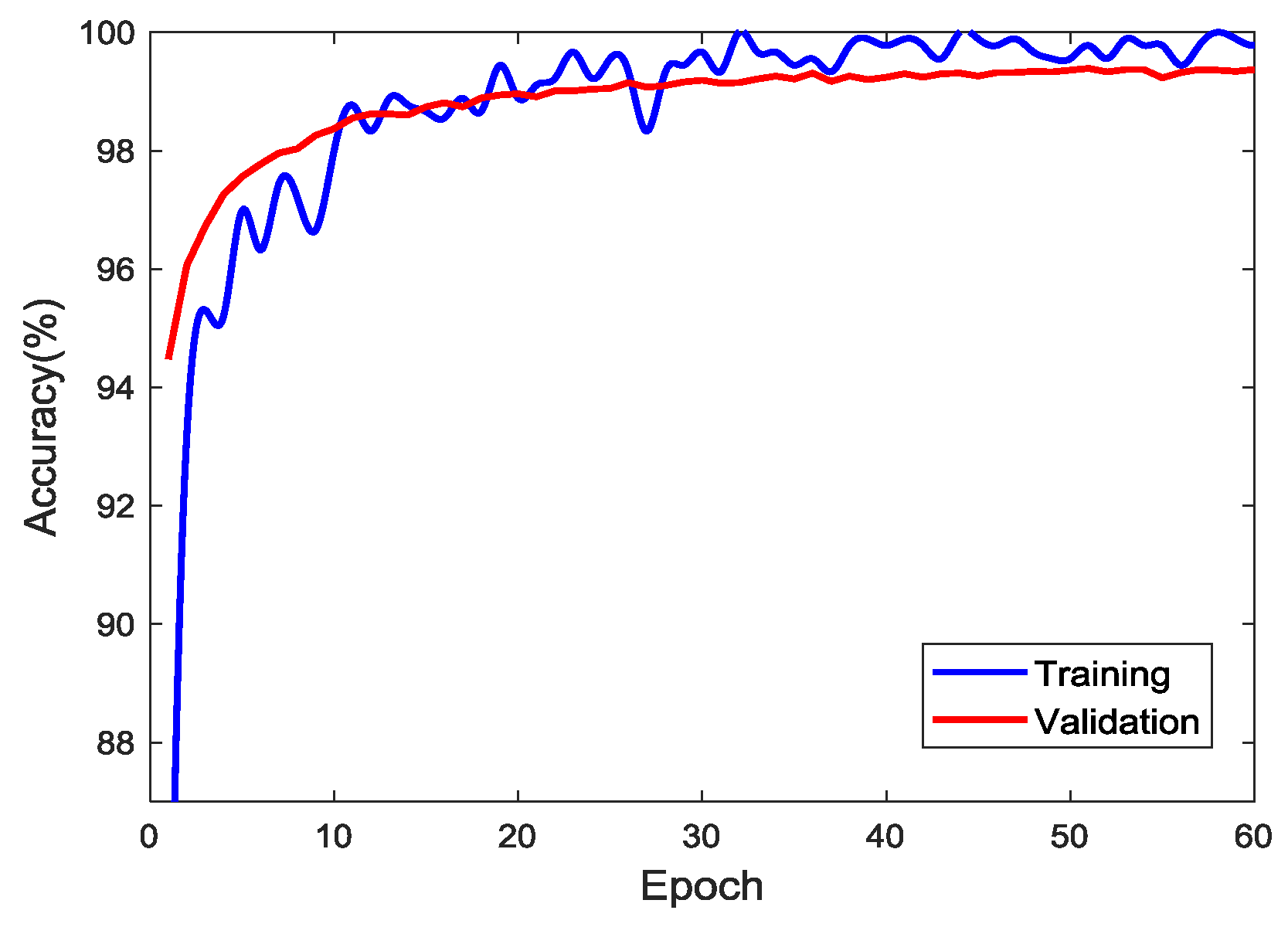
3.2. Training: Transfer Learning
4. Skills for Increased Detectability
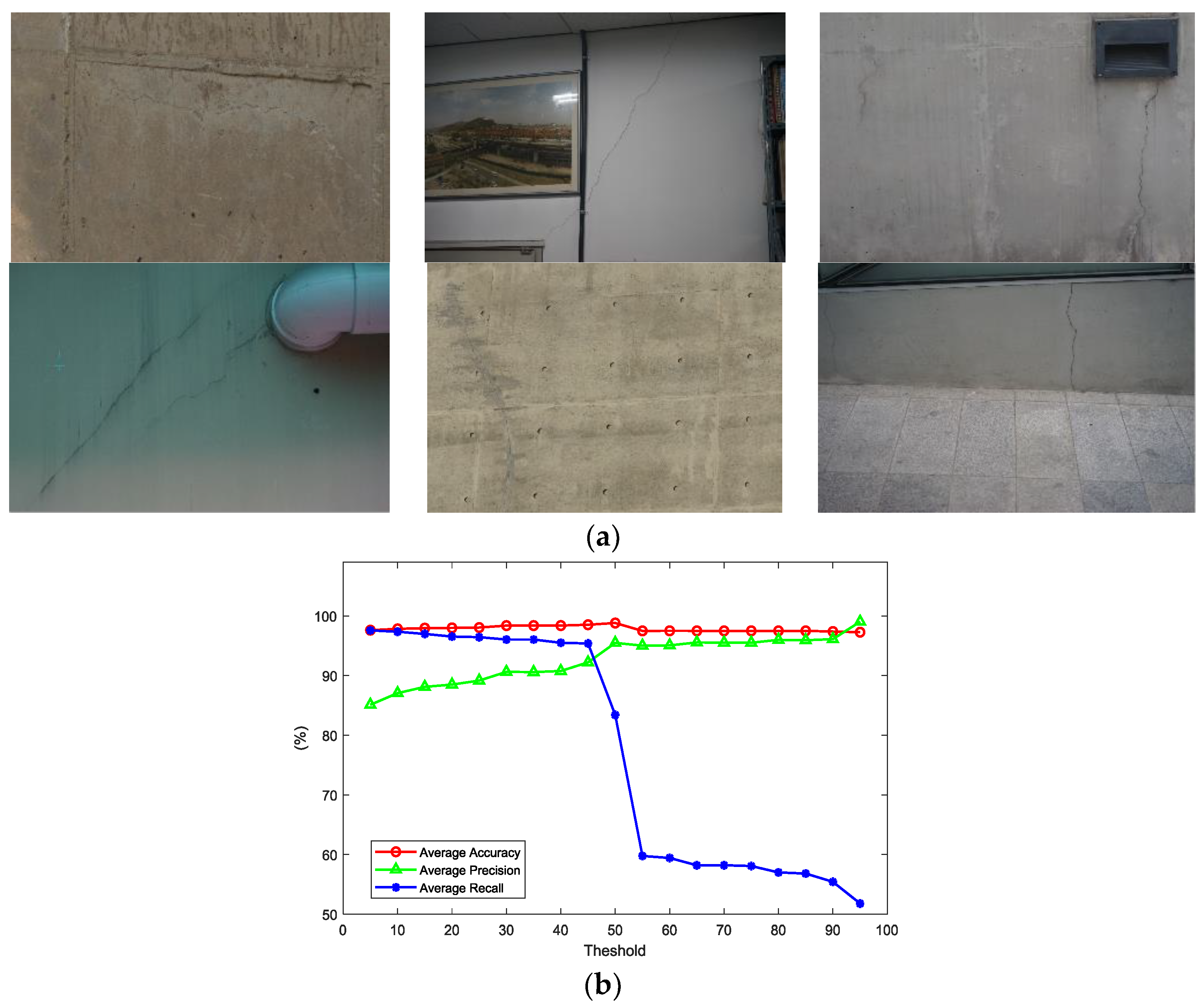
4.1. Detailed Categorization for Accurate Crack Detection
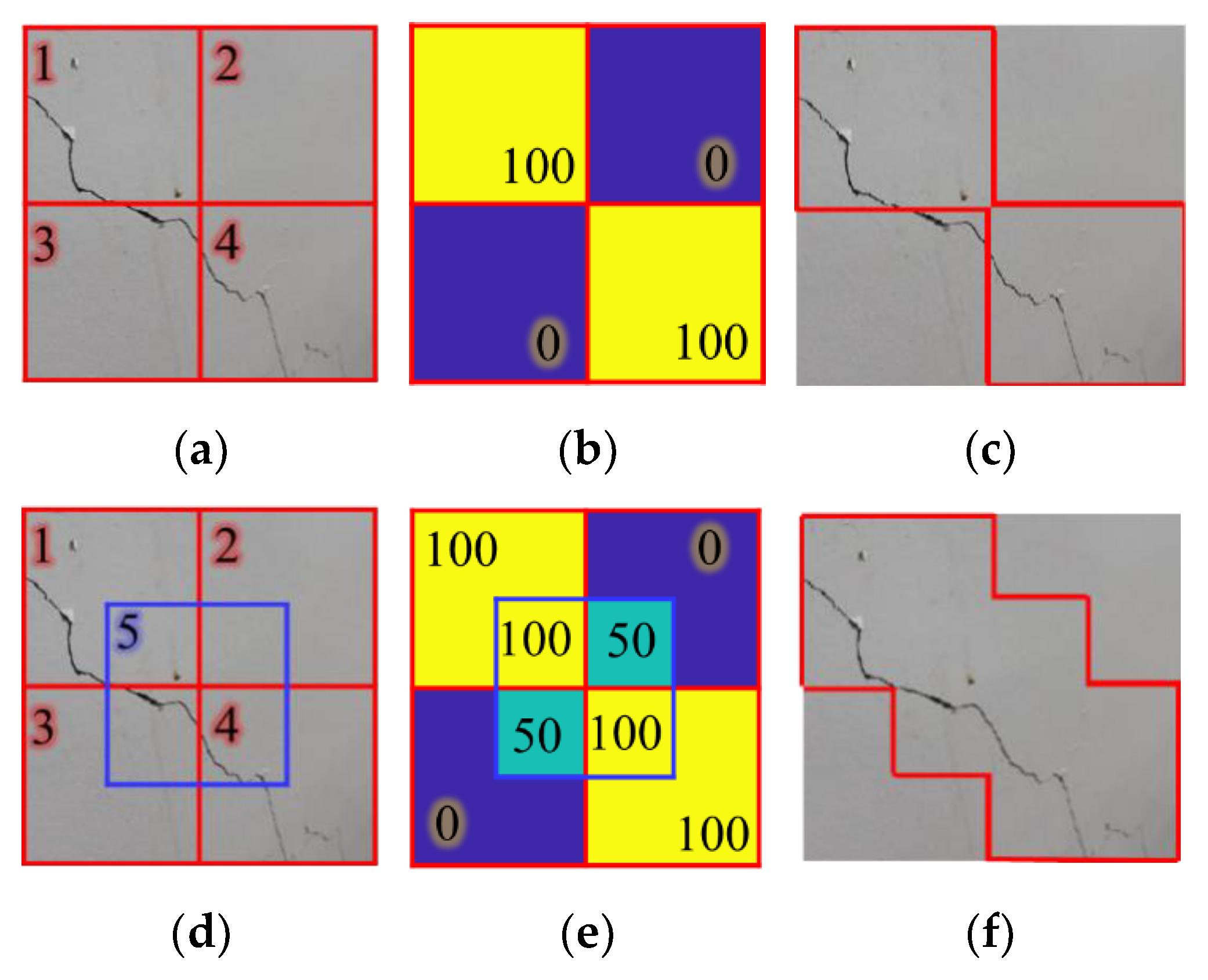
4.2. Parametric Study of the Probability Threshold
5. Automated Crack Detection on Real Concrete Structures
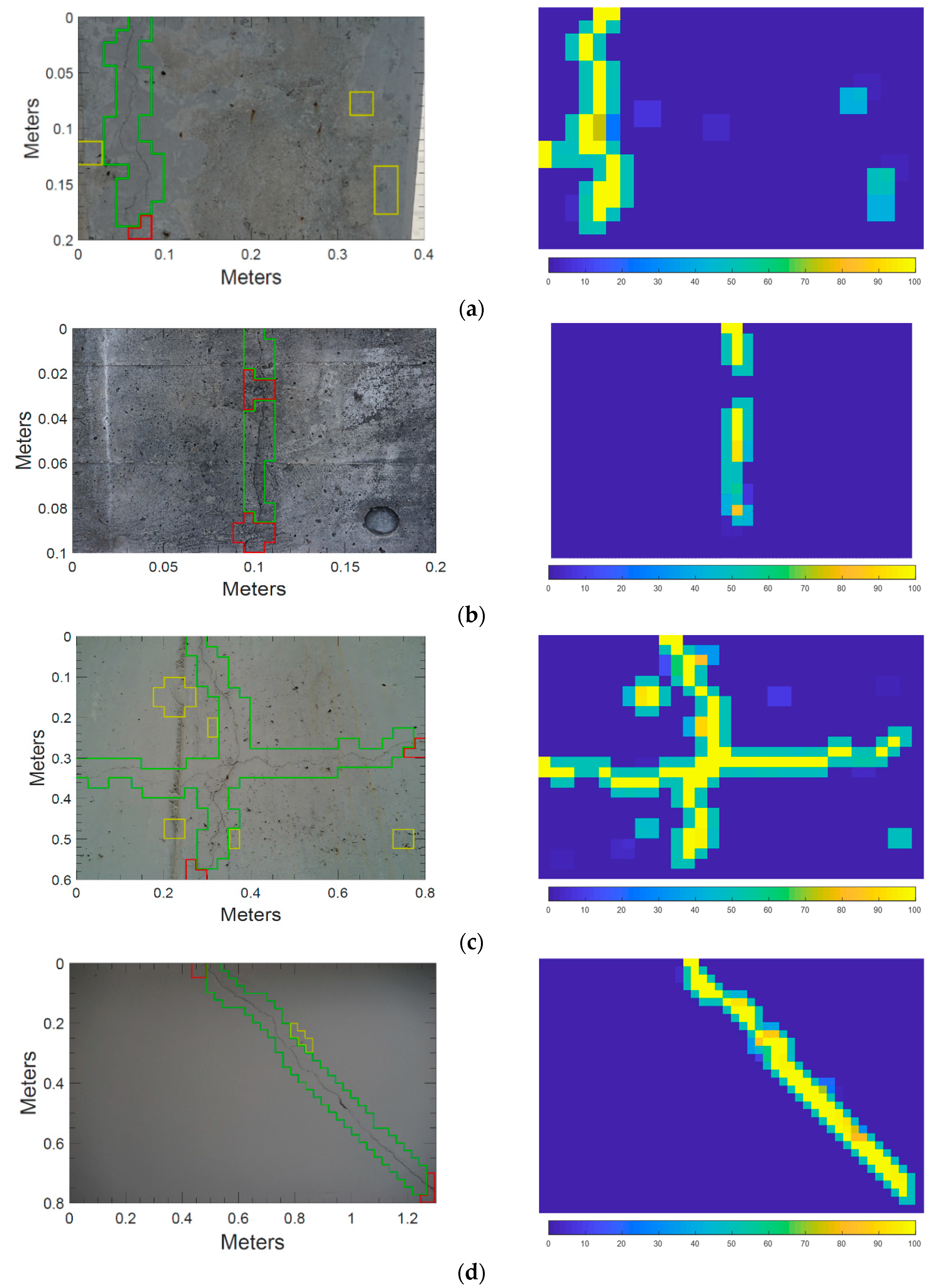
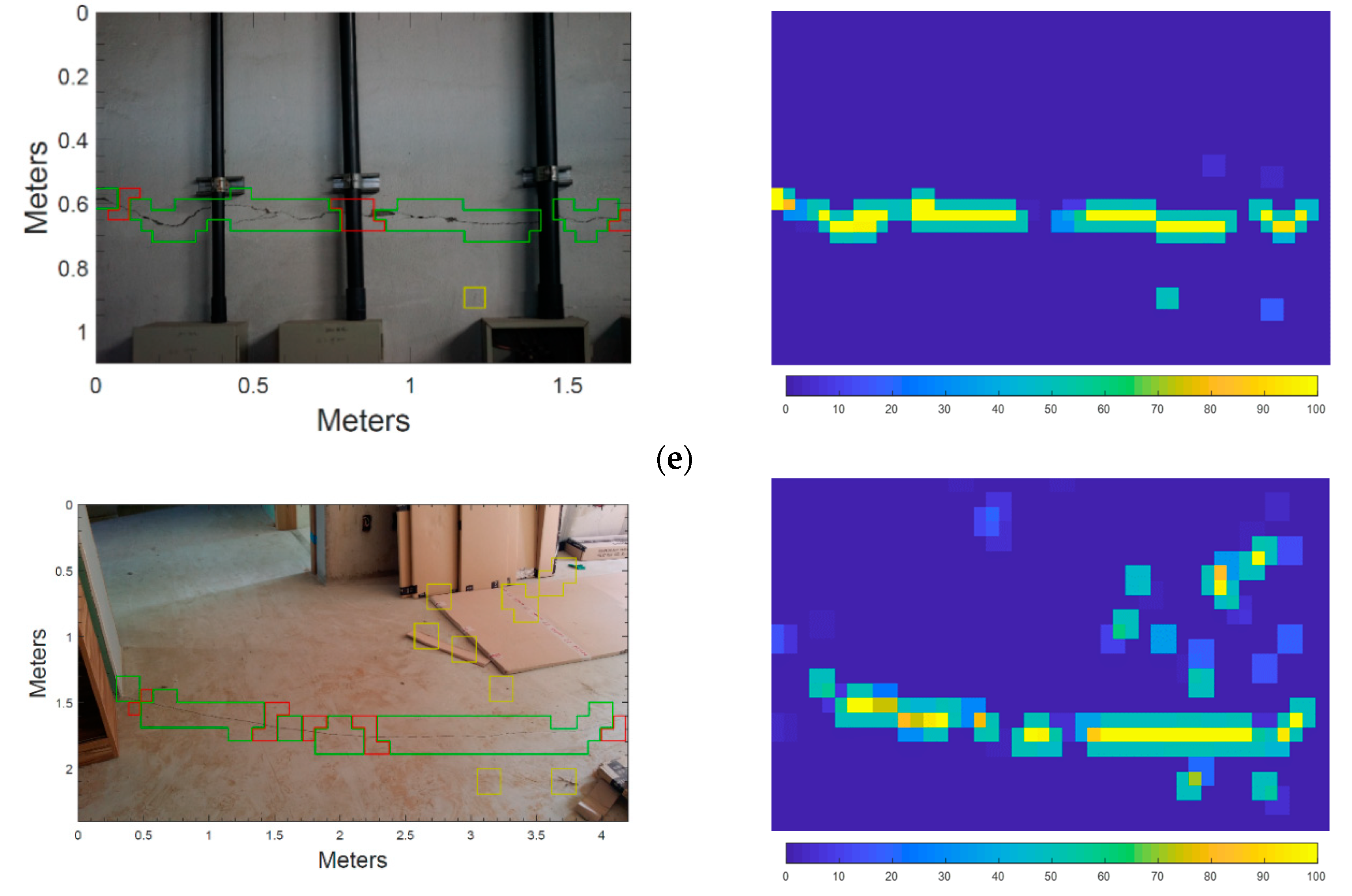
5.1. Automated Crack Detection on Still Images
5.2. Automated Crack Detection on Video Taken by Drone
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image No. | Resolution | Elapsed Time (s) | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| 1 | 3343 × 2191 | 1.63 | 96.25 | 93.67 | 94.22 |
| 2 | 4099 × 2773 | 2.43 | 97.46 | 100.00 | 71.19 |
| 3 | 4160 × 3120 | 2.85 | 96.09 | 86.72 | 97.32 |
| 4 | 5941 × 3961 | 4.26 | 99.03 | 94.33 | 95.87 |
| 5 | 6000 × 4000 | 5.31 | 98.50 | 94.74 | 86.86 |
| 6 | 4128 × 2322 | 2.88 | 92.53 | 50.93 | 86.67 |
| 7 | 5875 × 3943 | 4.59 | 98.77 | 86.85 | 96.96 |
| 8 | 5101 × 3805 | 4.30 | 98.50 | 100.00 | 92.19 |
| 9 | 2515 × 2101 | 1.09 | 95.33 | 100.00 | 63.42 |
| 10 | 2431 × 2047 | 0.94 | 97.82 | 100.00 | 90.26 |
| 11 | 1107 × 925 | 0.39 | 98.44 | 100.00 | 93.66 |
| 12 | 5863 × 3877 | 4.74 | 97.51 | 90.22 | 79.05 |
| 13 | 3953 × 2593 | 2.20 | 94.85 | 87.19 | 80.14 |
| 14 | 1960 × 1540 | 1.11 | 96.94 | 94.86 | 100.00 |
| 15 | 3656 × 3082 | 2.14 | 98.48 | 97.20 | 96.27 |
| 16 | 5496 × 3670 | 4.50 | 100.00 | 100.00 | 100.00 |
| 17 | 2425 × 2095 | 1.06 | 96.27 | 100.00 | 86.68 |
| 18 | 6000 × 4000 | 4.84 | 97.92 | 80.11 | 95.02 |
| 19 | 3421 × 1987 | 2.59 | 95.99 | 94.60 | 95.92 |
| 20 | 1855 × 1153 | 0.98 | 98.09 | 90.78 | 98.84 |
| 21 | 1969 × 1369 | 0.93 | 93.76 | 90.40 | 67.17 |
| 22 | 1052 × 1000 | 0.60 | 98.96 | 100.00 | 95.37 |
| 23 | 4160 × 3120 | 2.60 | 97.92 | 93.75 | 83.82 |
| 24 | 2119 × 1411 | 0.94 | 96.40 | 95.12 | 94.62 |
| 25 | 1481 × 947 | 0.71 | 92.13 | 100.00 | 83.24 |
| 26 | 1442 × 926 | 0.57 | 90.04 | 100.00 | 48.15 |
| 27 | 1742 × 930 | 0.71 | 100.00 | 100.00 | 100.00 |
| 28 | 1506 × 931 | 0.55 | 94.61 | 55.81 | 100.00 |
| 29 | 1064 × 732 | 0.42 | 98.61 | 100.00 | 93.81 |
| 30 | 4096 × 2160 | 1.70 | 99.38 | 100.00 | 97.27 |
| 31 | 819 × 614 | 0.49 | 98.15 | 100.00 | 92.23 |
| 32 | 4160 × 3120 | 3.36 | 98.44 | 94.48 | 94.21 |
| 33 | 4597 × 3175 | 3.55 | 95.67 | 61.91 | 89.77 |
| 34 | 1456 × 937 | 0.58 | 98.34 | 90.48 | 100.00 |
| 35 | 3120 × 4160 | 3.0 | 98.98 | 91.13 | 96.86 |
| 36 | 3094 × 2174 | 1.91 | 95.73 | 100.00 | 57.25 |
| 37 | 1891 × 925 | 0.88 | 100.00 | 100.00 | 100.00 |
| 38 | 1723 × 914 | 0.65 | 96.54 | 95.76 | 86.65 |
| 39 | 1480 × 935 | 0.68 | 97.10 | 97.06 | 90.32 |
| 40 | 1828 × 939 | 1.39 | 95.17 | 86.12 | 100.00 |
| Average | 97.02 | 92.36 | 89.28 | ||
References
- ASCE’s 2017 Infrastructure Report Card | GPA: D+. Available online: https://www.infrastructurereportcard.org/ (accessed on 17 September 2018).
- Park, C.-H.; Lee, H.-I. Future Trend of Capital Investment for Korean Transportation Infrastructure; Construction and Economy Research Institute of Korea: Seoul, Korea, 2016. [Google Scholar]
- Choi, H.-S.; Cheung, J.-H.; Kim, S.-H.; Ahn, J.-H. Structural dynamic displacement vision system using digital image processing. NDT E Int. 2011, 44, 597–608. [Google Scholar] [CrossRef]
- Park, S.W.; Park, H.S.; Kim, J.H.; Adeli, H. 3D displacement measurement model for health monitoring of structures using a motion capture system. Measurement 2015, 59, 352–362. [Google Scholar] [CrossRef]
- Feng, D.; Feng, M.Q. Vision-based multipoint displacement measurement for structural health monitoring. Struct. Control Heal. Monit. 2016, 23, 876–890. [Google Scholar] [CrossRef]
- Leung, C.; Wan, K.; Chen, L.; Leung, C.K.Y.; Wan, K.T.; Chen, L. A Novel Optical Fiber Sensor for Steel Corrosion in Concrete Structures. Sensors 2008, 8, 1960–1976. [Google Scholar] [CrossRef] [PubMed]
- Jahanshahi, M.R.; Masri, S.F. Parametric Performance Evaluation of Wavelet-Based Corrosion Detection Algorithms for Condition Assessment of Civil Infrastructure Systems. J. Comput. Civ. Eng. 2013, 27, 345–357. [Google Scholar] [CrossRef]
- Valeti, B.; Pakzad, S. Automated Detection of Corrosion Damage in Power Transmission Lattice Towers Using Image Processing. In Structures Congress 2017; American Society of Civil Engineers: Reston, VA, USA, 2017; pp. 474–482. [Google Scholar]
- German, S.; Brilakis, I.; DesRoches, R. Rapid entropy-based detection and properties measurement of concrete spalling with machine vision for post-earthquake safety assessments. Adv. Eng. Inform. 2012, 26, 846–858. [Google Scholar] [CrossRef]
- Dawood, T.; Zhu, Z.; Zayed, T. Machine vision-based model for spalling detection and quantification in subway networks. Autom. Constr. 2017, 81, 149–160. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.H. Comparative analysis of image binarization methods for crack identification in concrete structures. Cem. Concr. Res. 2017, 99, 53–61. [Google Scholar] [CrossRef]
- Lecompte, D.; Vantomme, J.; Sol, H. Crack Detection in a Concrete Beam using Two Different Camera Techniques. Struct. Heal. Monit. Int. J. 2006, 5, 59–68. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Shingo, N.; Ryo, S.; Shuji, H. Image-Based Crack Detection for Real Concrete Surfaces. IEEJ Trans. Electr. Electron. Eng. 2008, 3, 128–135. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Rabah, M.; Elhattab, A.; Fayad, A. Automatic concrete cracks detection and mapping of terrestrial laser scan data. NRIAG J. Astron. Geophys. 2013, 2, 250–255. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Quoc, V.L. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar] [CrossRef]
- Gillick, D.; Brunk, C.; Vinyals, O.; Subramanya, A. Multilingual Language Processing From Bytes. arXiv 2015, arXiv:1512.00103. [Google Scholar]
- Jozefowicz, R.; Vinyals, O.; Schuster, M.; Shazeer, N.; Wu, Y. Exploring the Limits of Language Modeling. arXiv 2016, arXiv:1602.02410. [Google Scholar]
- Badhe, A. Using Deep Learning Neural Networks to Find Best Performing Audience Segments. Int. J. Sci. Technol. Res. 2016, 5, 30–31. [Google Scholar]
- Alipanahi, B.; Delong, A.; Weirauch, M.T.; Frey, B.J. Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nat. Biotechnol. 2015, 33, 831–838. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Dawson, D.; Sarasua, W.A.; Birchfield, S.T. Automated Traffic Surveillance System with Aerial Camera Arrays Imagery: Macroscopic Data Collection with Vehicle Tracking. J. Comput. Civ. Eng. 2017, 31, 04016072. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Tong, Z.; Gao, J.; Han, Z.; Wang, Z. Recognition of asphalt pavement crack length using deep convolutional neural networks. Road Mater. Pavement Des. 2018, 19, 1334–1349. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- ScrapeBox—The Swiss Army Knife of SEO! Available online: http://www.scrapebox.com/ (accessed on 17 September 2018).
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput. Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Shan, B.; Zheng, S.; Ou, J. A stereovision-based crack width detection approach for concrete surface assessment. KSCE J. Civ. Eng. 2016, 20, 803–812. [Google Scholar] [CrossRef]
- Eschmann, C.; Kuo, C.-M.; Boller, C. Unmanned Aircraft Systems for Remote Building Inspection and Monitoring. In Proceedings of the 6th European Workshop on Structural Health Monitoring, Dresden, Germany, 3–6 July 2012; Volume 2, pp. 1–8. [Google Scholar]
- Morgenthal, G.; Hallermann, N. Quality Assessment of Unmanned Aerial Vehicle (UAV) Based Visual Inspection of Structures. Adv. Struct. Eng. 2014, 17, 289–302. [Google Scholar] [CrossRef]
- Yang, L.; Li, B.; Li, W.; Liu, Z.; Yang, G.; Xiao, J. Deep Concrete Inspection Using Unmanned Aerial Vehicle Towards CSSC Database. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems 2017, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Kim, H.; Lee, J.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.-H.; Kim, H.; Lee, J.; Ahn, E.; Cho, S.; et al. Concrete Crack Identification Using a UAV Incorporating Hybrid Image Processing. Sensors 2017, 17, 2052. [Google Scholar] [CrossRef] [PubMed]













| Class | Keywords | Valid Images/Total Images |
|---|---|---|
| Crack | concrete crack | 497/723 |
| concrete wall crack | 573/703 | |
| crack on concrete | 537/683 | |
| crack on concrete brick | 429/905 | |
| cement crack | 485/681 | |
| After Deleting Duplicates | 2073 | |
| Joint/Edge | concrete corner | 456/697 |
| concrete joint | 225/794 | |
| concrete tile | 396/701 | |
| grey concrete tile | 446/705 | |
| After Deleting Duplicates | 1400 | |
| Plant | moss on concrete | 654/757 |
| moss on concrete wall | 773/929 | |
| plant on concrete | 452/890 | |
| After Deleting Duplicates | 1511 | |
| Intact Surface | cement texture | 547/606 |
| concrete surface | 518/853 | |
| concrete texture | 476/489 | |
| concrete wall | 489/644 | |
| smooth concrete wall | 493/619 | |
| After Deleting Duplicates | 2211 |
| Image. | Resolution | Elapsed Time (s) | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| (a) | 3343 × 2191 | 1.63 | 96.25 | 93.67 | 94.22 |
| (b) | 4099 × 2773 | 2.43 | 97.46 | 100.00 | 71.19 |
| (c) | 4160 × 3120 | 2.85 | 96.09 | 86.72 | 97.32 |
| (d) | 5941 × 3961 | 4.26 | 99.03 | 94.33 | 95.87 |
| (e) | 6000 × 4000 | 5.31 | 98.5 | 94.74 | 86.86 |
| (f) | 4128 × 2322 | 2.88 | 92.53 | 50.93 | 86.67 |
| Average | 3.22 | 96.64 | 86.73 | 88.68 | |
| False-Positive (FP) | False-Negative (FN) | ||
|---|---|---|---|
| Groups | Solutions | Groups | Solutions |
| crack-shaped contaminants | 1, 3 | crack hidden behind object | 4 |
| overlaid cement paste | 3 | crack having straight line | 2 |
| continuously-distributed concrete pores | 2 | crack obscured by dark surface | 1 |
| edge of linear-shaped construction material | 2 | crack on the corner of detecting window | 4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. https://doi.org/10.3390/s18103452
Kim B, Cho S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors. 2018; 18(10):3452. https://doi.org/10.3390/s18103452
Chicago/Turabian StyleKim, Byunghyun, and Soojin Cho. 2018. "Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique" Sensors 18, no. 10: 3452. https://doi.org/10.3390/s18103452
APA StyleKim, B., & Cho, S. (2018). Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors, 18(10), 3452. https://doi.org/10.3390/s18103452