Multivariate-Time-Series-Driven Real-time Anomaly Detection Based on Bayesian Network

Abstract
1. Introduction
- This paper proposes an anomaly detection framework based on multivariate-sensing time-series data to achieve real-time anomaly detection, and improve the performance of anomaly detection.
- This paper introduces the concept of health factor to describe the health of the system, and further more, greatly improve the detection efficiency of health systems.
- RADM combines HTM with naive Bayesian network to detect anomalies in multivariate-sensing time-series, and get better result compared with the algorithm just work in univariate-sensing time-series.
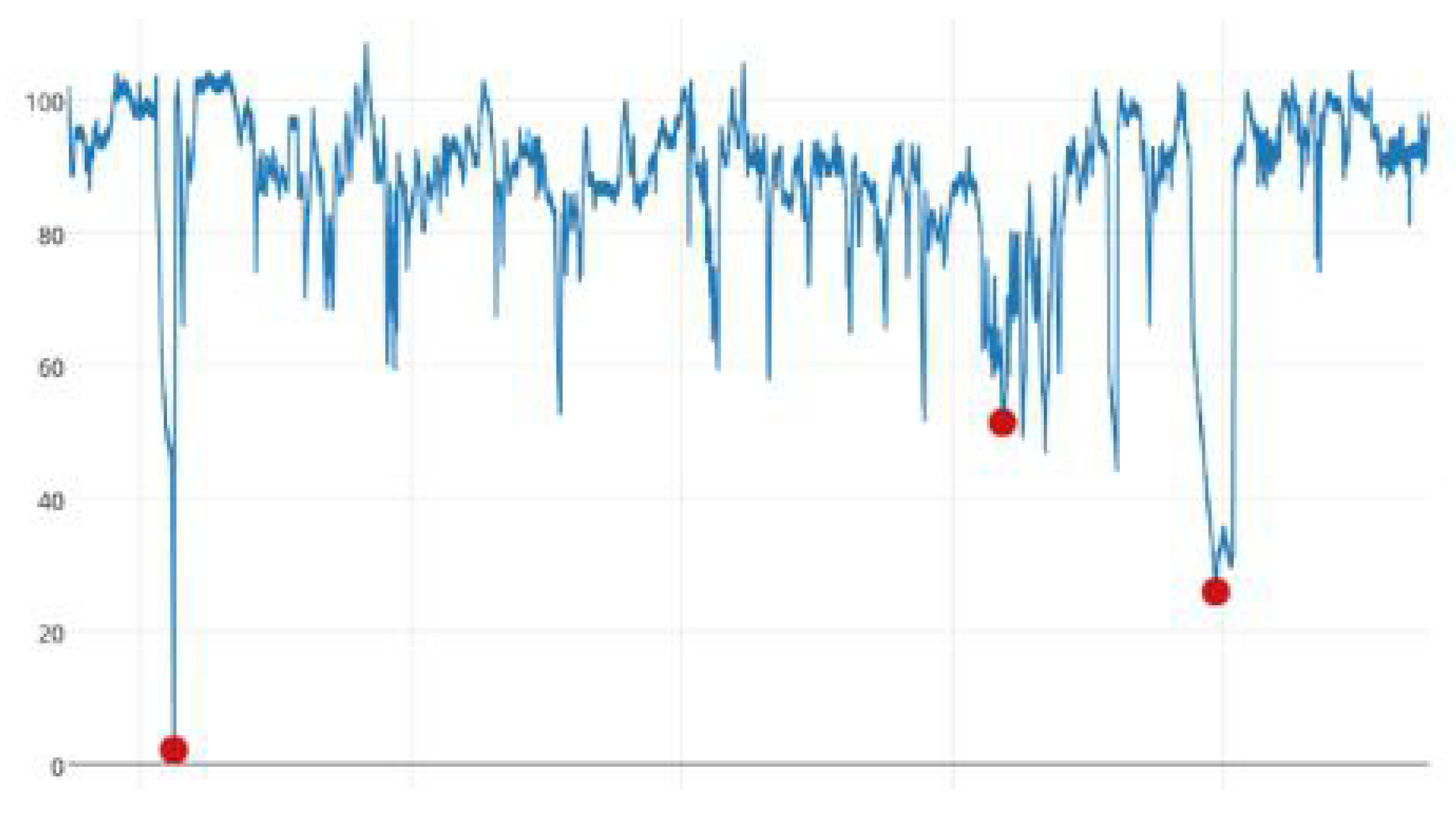
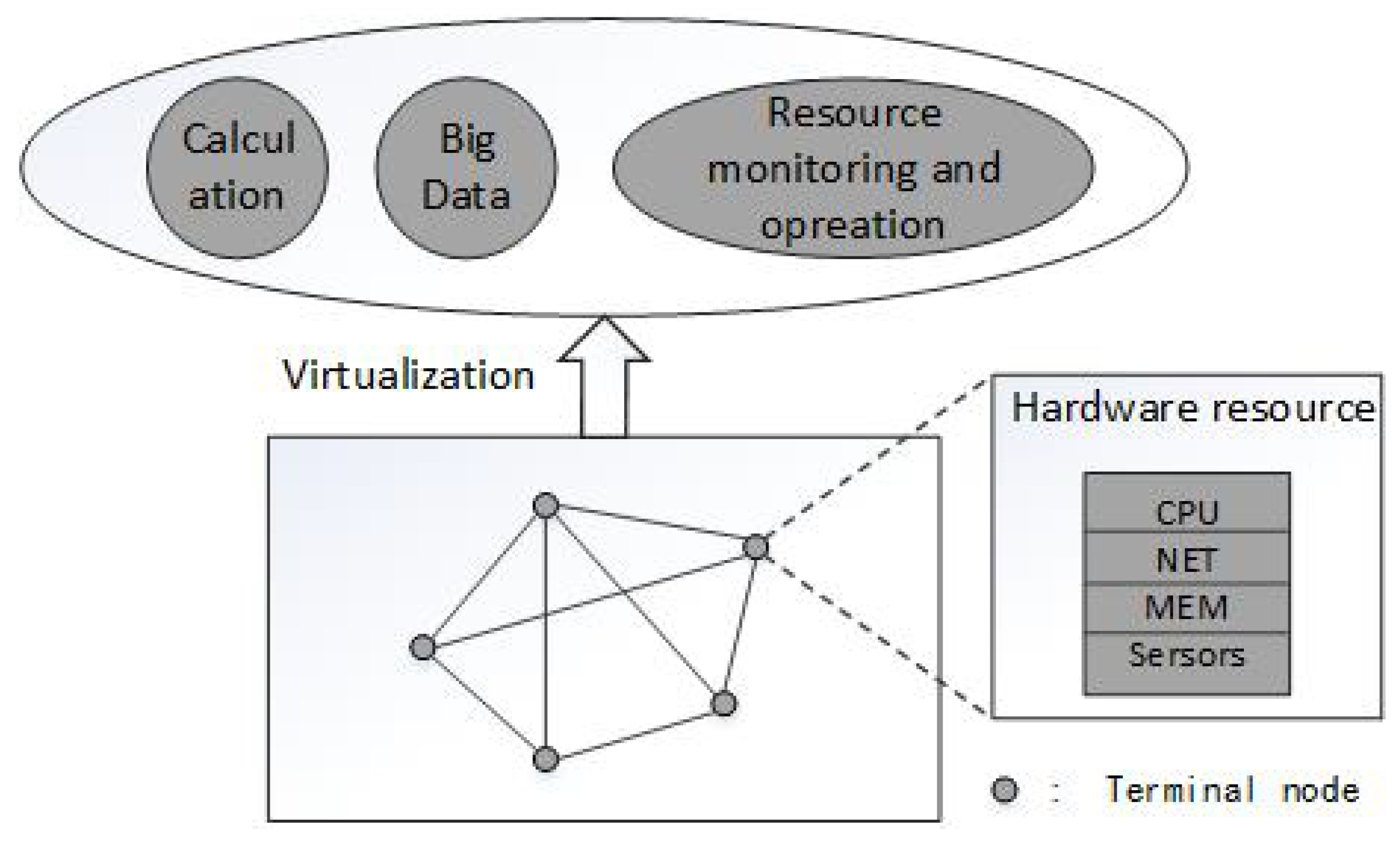
2. Performance Problems and Scenario
3. UTS and HTM
3.1. HTM Cortical Learning Algorithm
3.2. Anomaly Detection in UTS Based on HTM
3.2.1. Computing the Raw Anomaly Score
3.2.2. Computing the Anomaly Likelihood
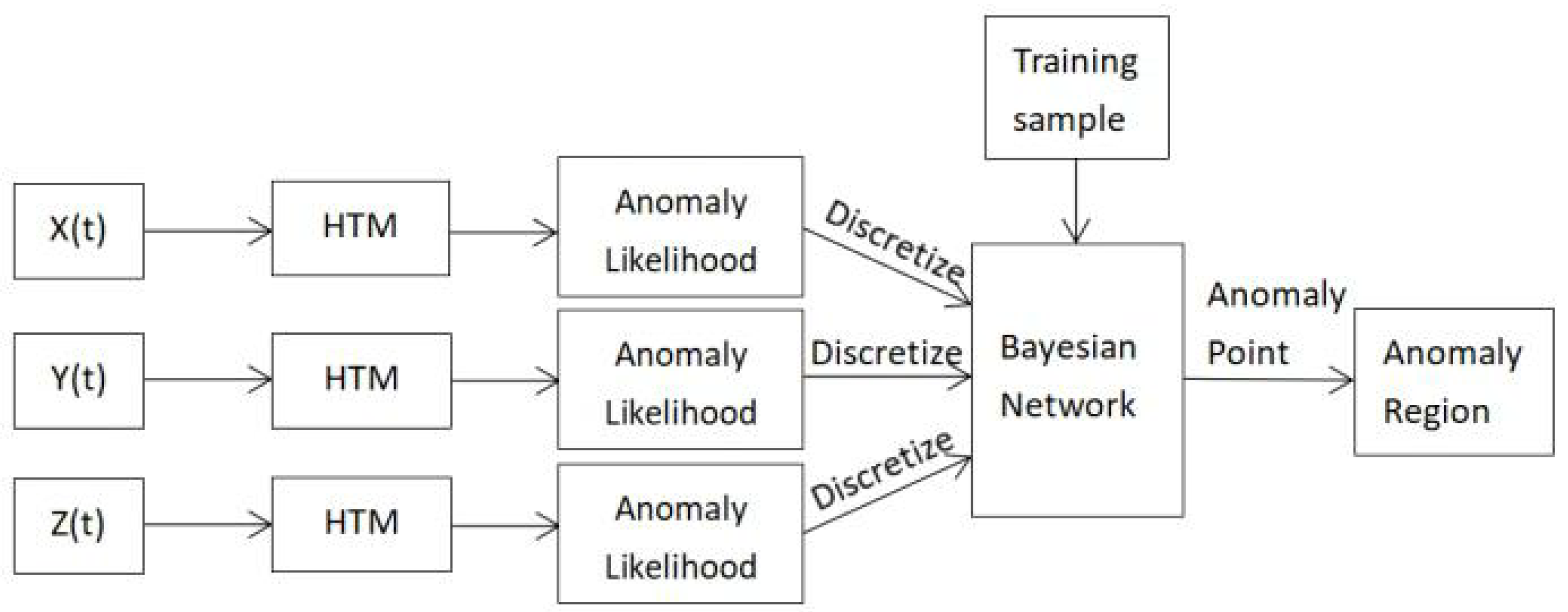
4. MTS and RADM
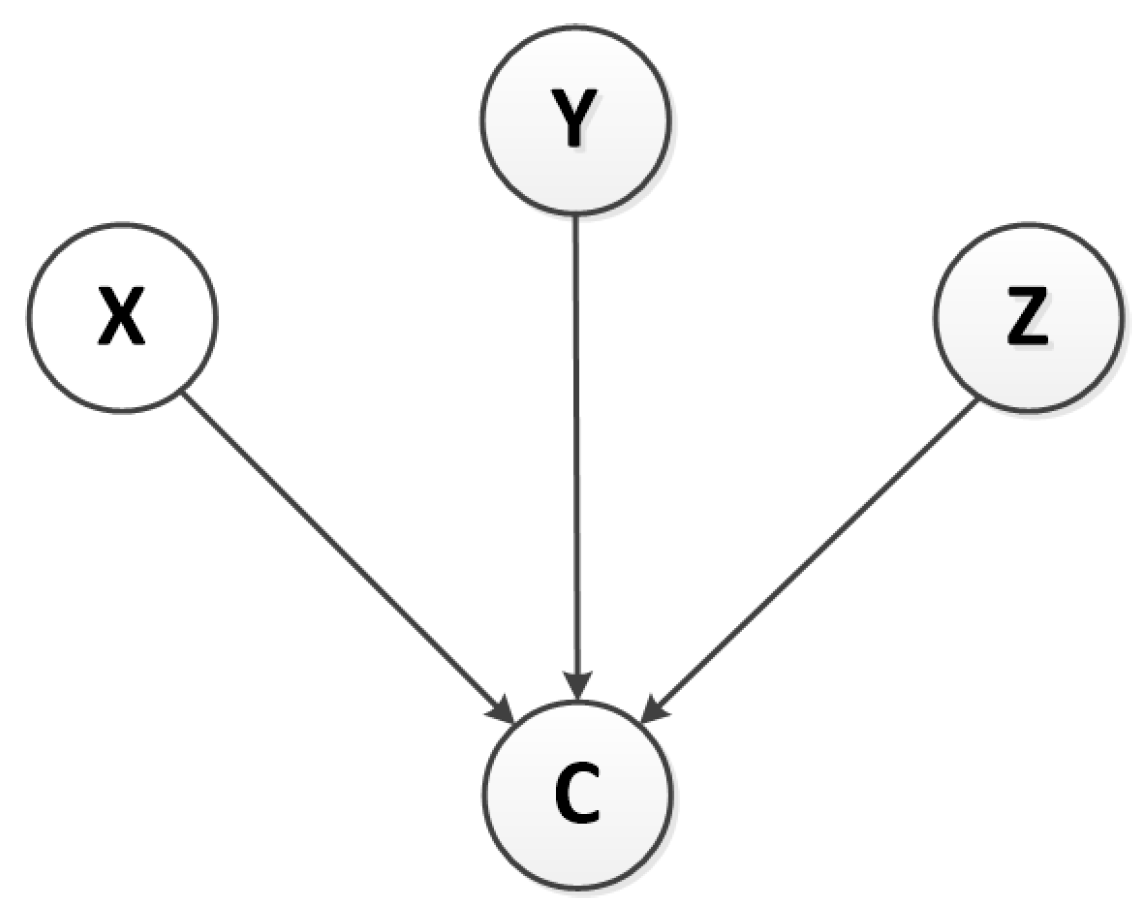
4.1. Bayesian Network Analysis
4.1.1. Bayesian Network
4.1.2. Naive Bayesian Network in MTS
4.2. RADM
| Algorithm 1: RADM. |
| 1: Input: ; 2: Output: ; Anomaly regions in MTS 3: while 1 do 4: = ; The list of anomaly likelihood in X (t) through HTM 5: = ; 6: = ; 7: = ; Discretization 8: = ; BN inference 9: end while |
5. Experimental Simulation and Performance Analysis
5.1. Simulation Environment and Parameter Settings
5.2. Data Sample Description
5.3. Performance Analysis and Comparison
5.3.1. Relevance Analysis
5.3.2. Accuracy Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ahmad, S.; Purdy, S. Real-Time Anomaly Detection for Streaming Analytics. arXiv 2016, arXiv:1607.02480. [Google Scholar]
- Szmit, M.; Szmit, A. Usage of modified holtwinters method in the anomaly detection of network traffic: Case studies. J. Comput. Netw. Commun. 2012, 2012, 192913. [Google Scholar]
- A Stanway. Etsy Skyline. Available online: https://github.com/etsy/skyline (accessed on 9 October 2018).
- Bianco, A.M.; Garcia Ben, M.; Martinez, E.J.; Yohai, V.J. Outlier detection in regression models with ARIMA errors using robust estimates. J. Forecast. 2010, 20, 565–579. [Google Scholar]
- Adams, R.P.; MacKay, D.J. Bayesian Online Changepoint Detection. arXiv 2007, arXiv:0710.3742v1. [Google Scholar]
- Tartakovsky, A.G.; Polunchenko, A.S.; Sokolov, G. Efficient Computer Network Anomaly Detection by Changepoint Detection Methods. IEEE J. Sel. Top. Sign. Process. 2013, 7, 4–11. [Google Scholar] [CrossRef]
- Lavin, A.; Ahmad, S. Evaluating Real-time Anomaly Detection Algorithms–the Numenta Anomaly Benchmark. In Proceedings of the IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 38–44. [Google Scholar]
- Kejariwal, A. Twitter Engineering: Introducing practical and robust anomaly detection in a time series. Available online: http://bit.ly/1xBbX0Z (accessed on 6 January 2015).
- Lee, E.K.; Viswanathan, H.; Pompili, D. Model-based thermal anomaly detection in cloud datacenters. In Proceedings of the International Conference on Distributed Computing in Sensor SystemsModel-based thermal anomaly detection in cloud datacenters, Cambridge, MA, USA, 20–23 May 2013. [Google Scholar]
- Klerx, T.; Anderka, M.; Büning, H.K.; Priesterjahn, S. Model-Based Anomaly Detection for Discrete Event Systems. In Proceedings of the IEEE 26th International Conference on Tools with Artificial Intelligence, Limassol, Cyprus, 10–12 November 2014. [Google Scholar]
- Simon, D.L.; Rinehart, A.W. A Model-Based Anomaly Detection Approach for Analyzing Streaming Aircraft Engine Measurement Data; GT2014-27172; American Society of Mechanical Engineers: New York, NY, USA, 2015. [Google Scholar]
- Candelieri, A. Clustering and support vector regression for water demand forecasting and anomaly detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Candelieri, A.; Soldi, D.; Archetti, F. Short-term forecasting of hourly water consumption by using automatic metering readers data. Procedia Eng. 2015, 119, 844–853. [Google Scholar] [CrossRef]
- Li, Z.X.; Zhang, F.M.; Zhang, X.F.; Yang, S.M. Research on Feature Dimension Reduction Method for Multivariate Time Series. J Chin. Comput. Syst. 2001, 20, 565–579. (In Chinese) [Google Scholar]
- Xu, Y.; Hou, X.; Li, S.; Cui, J. Anomaly detection of multivariate time series based on Riemannian manifolds.Computer Science. Int. J. Biomed. Eng. 2015, 32, 542–547. [Google Scholar]
- Qiu, T.; Zhao, A.; Xia, F.; Si, W.; Wu, D.O.; Qiu, T.; Zhao, A.; Xia, F.; Si, W.; Wu, D.O. ROSE: Robustness Strategy for Scale-Free Wireless Sensor Networks. IEEE/ACM Trans. Netw. 2017, 24, 2944–2959. [Google Scholar] [CrossRef]
- Majhi, S.K.; Dhal, S.K. A Study on Security Vulnerability on Cloud Platforms. Procedia Comput. Sci. 2016, 78, 55–60. [Google Scholar] [CrossRef]
- Qiu, T.; Zheng, K.; Han, M.; Chen, C.P.; Xu, M. A Data-Emergency-Aware Scheduling Scheme for Internet of Things in Smart Cities. IEEE Trans. Ind. Inf. 2018, 14, 2042–2051. [Google Scholar] [CrossRef]
- Hawkins, J.; Ahmad, S.; Dubinsky, D. HTM Cortical Learning Algorithms. Available online: https://numenta.org/resources/HTM_CorticalLearningAlgorithms.pdf (accessed on 12 September 2011).
- Padilla, D.E.; Brinkworth, R.; McDonnell, M.D. Performance of a hierarchical temporal memory network in noisy sequence learning. In Proceedings of the IEEE International Conference on Computational Intelligence and Cybernetics, Yogyakarta, Indonesia, 3–4 December 2013; pp. 45–51. [Google Scholar]
- Karagiannidis, G.K.; Lioumpas, A.S. An improved approximation for the Gaussian Q-function. IEEE Commun. Lett. 2007, 11, 644–646. [Google Scholar] [CrossRef]
- Cocu, A.; Craciun, M.V.; Cocu, B. Learning the Structure of Bayesian Network from Small Amount of Data. Ann. Dunarea de Jos Univ. Galati Fascicle III Electrotechn. Electron. Autom. Control Inform. 2009, 32, 12–16. [Google Scholar]
- Taheri, S.; Mammadov, M. Learning the naive Bayes classifier with optimization models. Int. J. Appl. Math. Comput. Sci. 2013, 23, 787–795. [Google Scholar] [CrossRef]
- Htm.java. Available online: https://github.com/numenta/htm.java (accessed on 9 October 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tail Probability Elements | Values |
|---|---|
| Q[0] | 0.500000000 |
| Q[1] | 0.460172163 |
| Q[2] | 0.420740291 |
| ⋯ | ⋯ |
| Q[68] | 0.000000000005340 |
| Q[69] | 0.000000000002653 |
| Q[70] | 0.000000000001305 |
| Time Series | Threshold Intervals | Discrete Values |
|---|---|---|
| Input | 0-0.890401416 | 1 |
| 0.890401416-0.997300202 | 2 | |
| 0.997300202-0.99998220767 | 3 | |
| 0.99998220767-1 | 4 | |
| Output | Normal | 1 |
| Anormal | 2 |
| Group | Sequence Length | Algorithm | Number of Anomaly Regions | Precision |
|---|---|---|---|---|
| 1 | 4806 | HTM | 18 | 0.613 |
| RADM | 27 | 0.675 | ||
| 2 | 4688 | HTM | 22 | 0.667 |
| RADM | 22 | 0.724 | ||
| 3 | 4317 | HTM | 27 | 0.603 |
| RADM | 27 | 0.632 | ||
| 4 | 4216 | HTM | 21 | 0.659 |
| RADM | 22 | 0.757 | ||
| 5 | 4813 | HTM | 32 | 0.724 |
| RADM | 26 | 0.775 | ||
| 6 | 4127 | HTM | 17 | 0.655 |
| RADM | 15 | 0.710 | ||
| 7 | 4342 | HTM | 14 | 0.584 |
| RADM | 14 | 0.656 | ||
| 8 | 4334 | HTM | 20 | 0.653 |
| RADM | 22 | 0.749 | ||
| 9 | 4656 | HTM | 21 | 0.622 |
| RADM | 25 | 0.695 | ||
| 10 | 4357 | HTM | 28 | 0.707 |
| RADM | 27 | 0.778 | ||
| 11 | 4442 | HTM | 16 | 0.575 |
| RADM | 20 | 0.644 | ||
| 12 | 4553 | HTM | 22 | 0.643 |
| RADM | 22 | 0.686 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, N.; Gao, H.; Bu, H.; Ma, H.; Si, H. Multivariate-Time-Series-Driven Real-time Anomaly Detection Based on Bayesian Network. Sensors 2018, 18, 3367. https://doi.org/10.3390/s18103367
Ding N, Gao H, Bu H, Ma H, Si H. Multivariate-Time-Series-Driven Real-time Anomaly Detection Based on Bayesian Network. Sensors. 2018; 18(10):3367. https://doi.org/10.3390/s18103367
Chicago/Turabian StyleDing, Nan, Huanbo Gao, Hongyu Bu, Haoxuan Ma, and Huaiwei Si. 2018. "Multivariate-Time-Series-Driven Real-time Anomaly Detection Based on Bayesian Network" Sensors 18, no. 10: 3367. https://doi.org/10.3390/s18103367
APA StyleDing, N., Gao, H., Bu, H., Ma, H., & Si, H. (2018). Multivariate-Time-Series-Driven Real-time Anomaly Detection Based on Bayesian Network. Sensors, 18(10), 3367. https://doi.org/10.3390/s18103367