Reputation-Aware Recruitment and Credible Reporting for Platform Utility in Mobile Crowd Sensing with Smart Devices in IoT


Abstract
:1. Introduction
- (1)
- We designed a novel mechanism for mobile worker recruitment based on reputation level and expected quality of task. We present a recruitment mechanism to hire skilled MWs while mainly considering feasible budget, quality, platform utility, and individual rationality. In the similar vein, we propose a selection algorithm and reputation-updating system that considers the weight and score for both reporters and requesters.
- (2)
- Next, we present a credibility inspection and incentive mechanism to reward or penalize MWs. We also present a novel algorithm for ensuring credible sensing. Additionally, our approach verifies the outcomes of MWs by considering sensing data from smart devices in that region for the IoT scenario. This helps to guard against false reporting from MWs and in taking strict actions in terms of penalties. For quality reporting, MWs are awarded. We are the first to analyze truthful reporting for platform maximization. The proposed mechanism is expected to ensure platform profitability with other task completion constraints while paying necessary incentives to the MWs.
- (3)
- Finally, we developed a testbed using Windows Communication Foundation (WCF) services on Windows Azure cloud to evaluate and analyze the datasets containing MW reporting details. Moreover, we simulated the scenarios for collecting sensing data from smart devices and transmitting aggregated data at sink nodes via collectors. Sensing data are further saved in a database for analysis in combination with reporting data to identify false reporting by MWs. Results proved the dominance of our work as compared to its counterparts in the literature.
2. Related Work
2.1. Incentive Mechanisms in MCS
2.2. Quality-Centered Reputation-Based Approaches
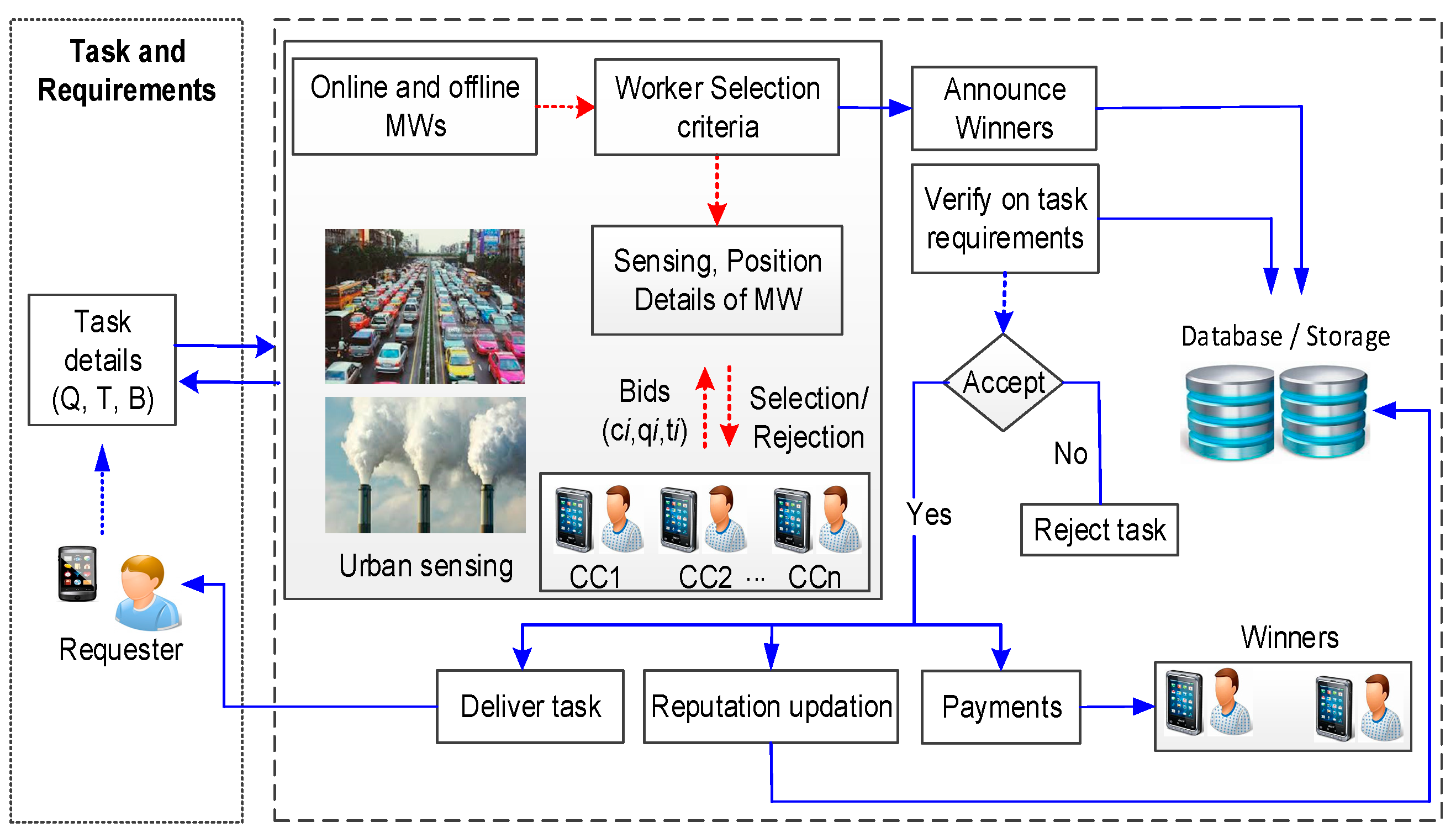
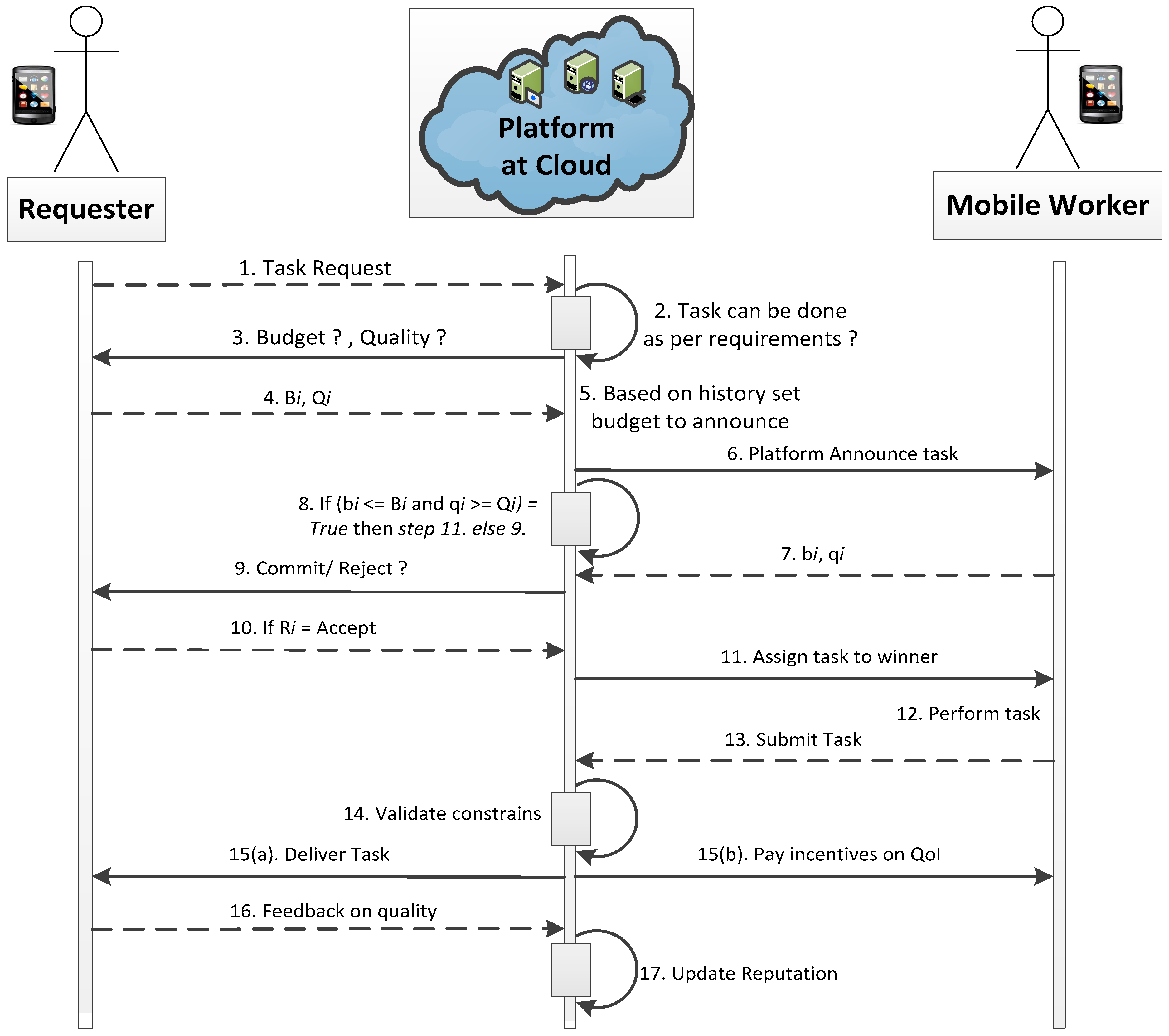
3. System Model and Problem Statement
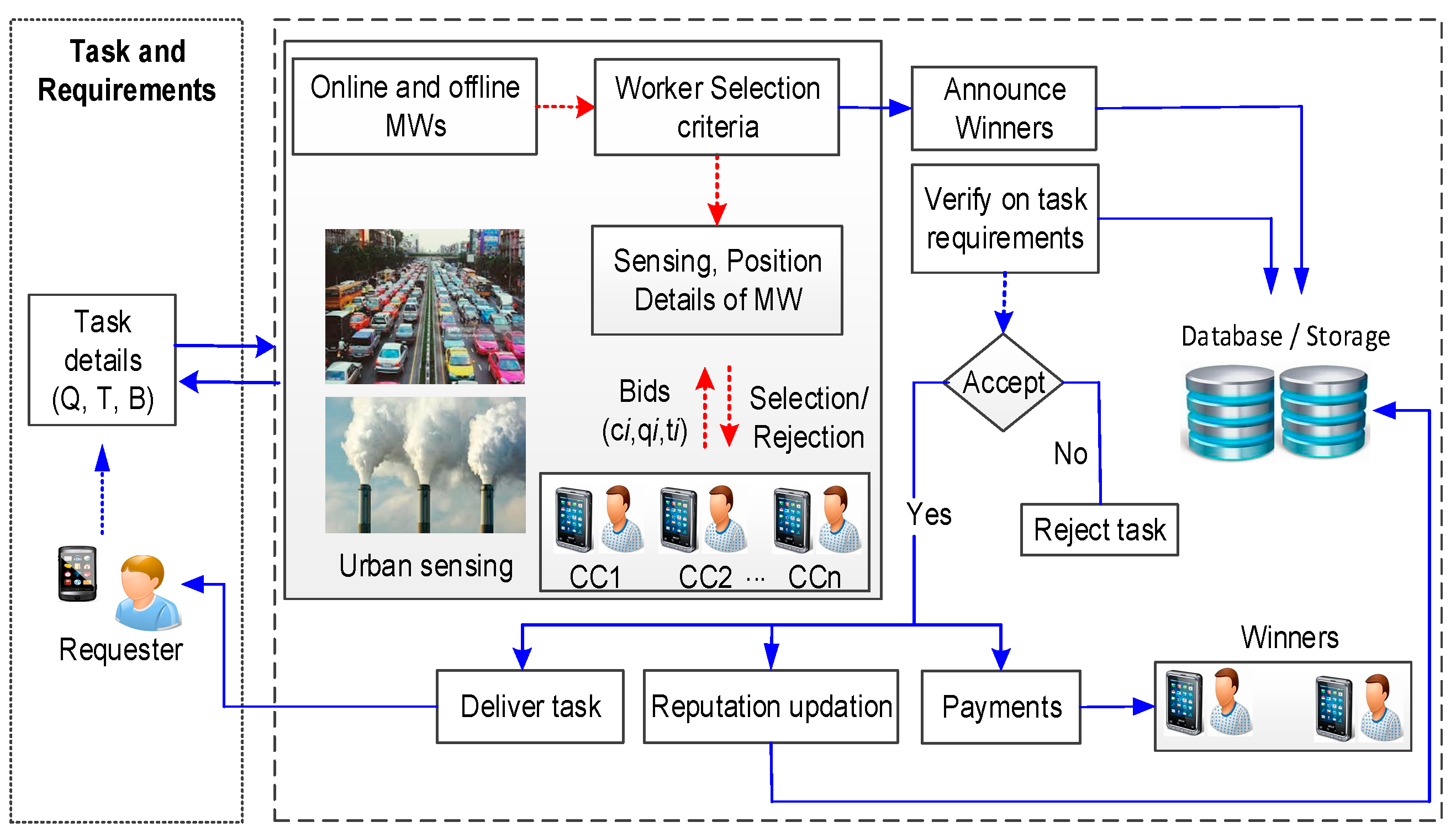
3.1. MCS Model
- (1)
- Imperfect information about true cost of task completion of MWs.
- (2)
- A variety of task completion requirements encourage dynamic budgets, as cost may vary from task to task with worker skill level, required quality, and with time sensitivity.
| Algorithm 1: Selection of Suitable Mobile worker. |
| INPUT: Attributes of task (, Assumption: Every MW has maximum task completion capacity |
| OUTPUT: |
| 1. Initialize: ; |
| 2. MWs(N) bids on their private value: ; |
| 3. For (i = 1; i ≤ () && ); i++) |
| 4. If then |
| 5. If then |
| 6. If then |
| 7. If ) then |
| 8. //considered as real candidate |
| 9. Else |
| 10. |
| 11. End If |
| 12. End For |
| 13. Sort list of in descending order w.r.t low bids and high |
| 14. For any task If are same then |
| 15. Select with higher or |
| 16. Select the from the set of w.r.t Max , |
| 17. End For |
| 18. Return |
3.2. Problem Definition
| Algorithm 2: Credible Sensing. |
| INPUT: |
| OUTPUT: |
| 1. |
| 2. For T; i++) |
| 3. If ] then |
| 4. If then |
| 5. If then |
| 6. Accept |
| 7. // increase in reputation |
| 8. Else |
| 9. // add the MW’s task in rejected array of |
| 10. // decrease in reputation as penalty |
| 11. End If |
| 12. End If |
| 13. End For |
| 14. For |
| 15. |
| 16. |
| 17. |
| 18. according to R_Score; |
| 19. If is reported by newly recruited MW then |
| 20. R_Score is initialized by 0.5; |
| 21. End If |
| 22. End For |
| 23. // winnersandtheir quality scores |
| 24. // is updated for upcoming task to set benchmark |
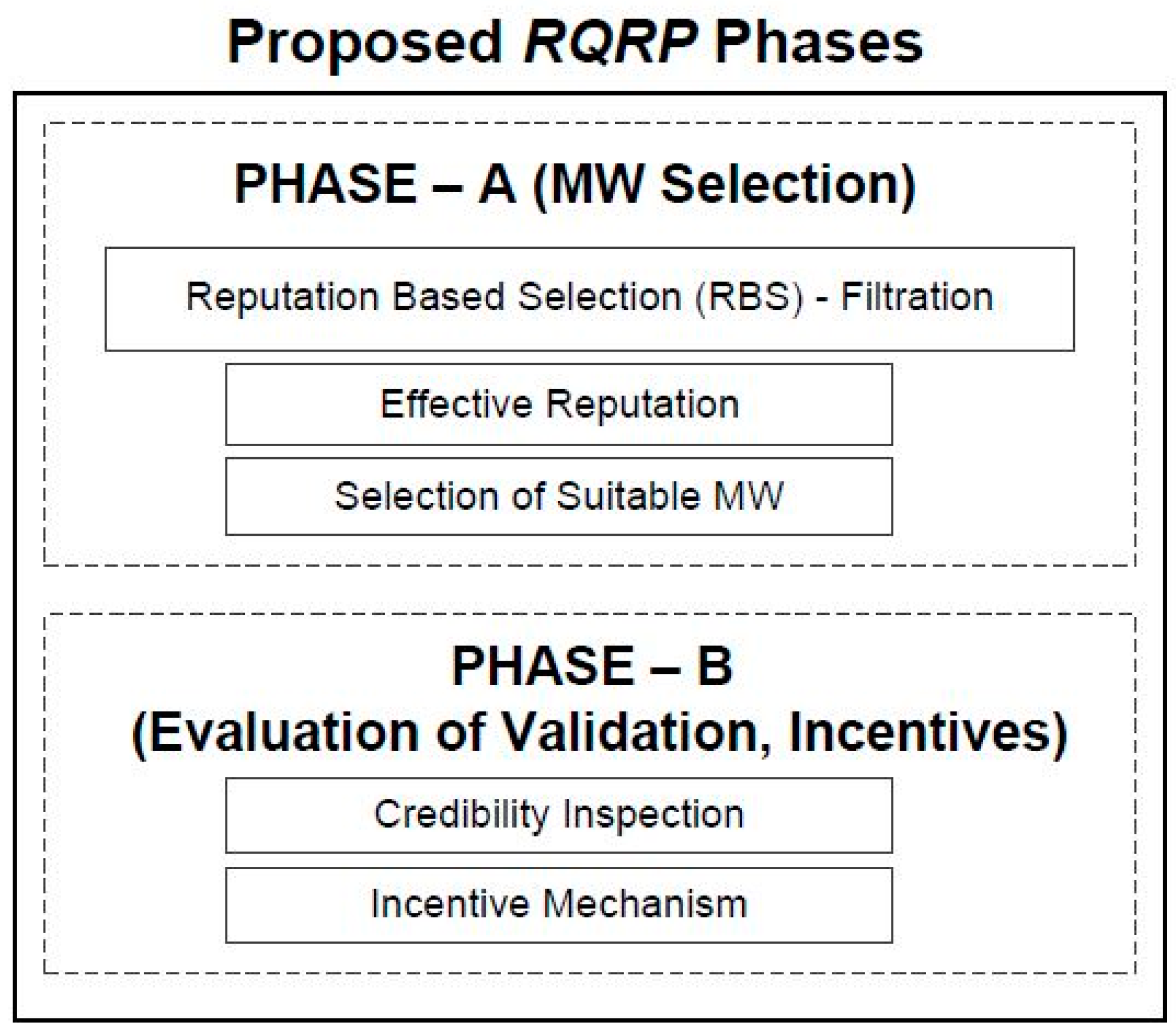
4. Proposed Reputation Quality Aware Recruitment for Platform (RQRP)
- (1)
- Selection of suitable MWs by fulfilling the task’s constraints.
- (2)
- Validation of task quality is necessary, as MWs can submit low-quality reports and may want to enjoy a free ride. They can also be selfish, strategic, and may intentionally manipulate results to misguide the platform. To avoid all this, quite a strict check and balance should be maintained on submitted reports. The challenge lies in how to ensure the quality of reports.
- (3)
- Enforcement of work quality. The development of an efficient system which can hire trustworthy CCs is necessary. Furthermore, there should be a method to avoid the monopoly of MWs, which is also a necessary step to maintain quality by keeping their interest.
- (4)
- Ensuring that budget and time constraints are operated within.
- (5)
- Stimulation of MWs with a proper incentive mechanism, which can handle online mobile crowdsensing task distribution.
4.1. Phase-A: MW Selection
4.1.1. Reputation-Based Selection (RBS)—Filtration
4.1.2. Effective Reputation
(1) Reputation of Mobile Worker
(2) Weighting of Requester Rating
(3) Weight Updation
(4) Task Rating
- (1)
- For any , if her R_Score is highest among (crowd contributor), it ensures the task completion requirements will be met, and no other currently available online MW with a better offer than this MW is likely to be selected.
- (2)
- The DM computes the probability of expected quality based on R_Score of (real candidate). Any candidate with higher probability has a higher chance of selection.
4.1.3. Selection of Suitable MW
4.2. Phase-B: Evaluation of Validation and Incentives
4.2.1. Credibility Inspection
4.2.2. Incentive Mechanism
4.2.3. Utility of Platform
4.2.4. Utility of MW
5. Theoretical Analysis
5.1. Truthfulness
5.2. Platform Profitability
5.3. Individual Rationality
5.4. Time Computation
6. Results and Analysis
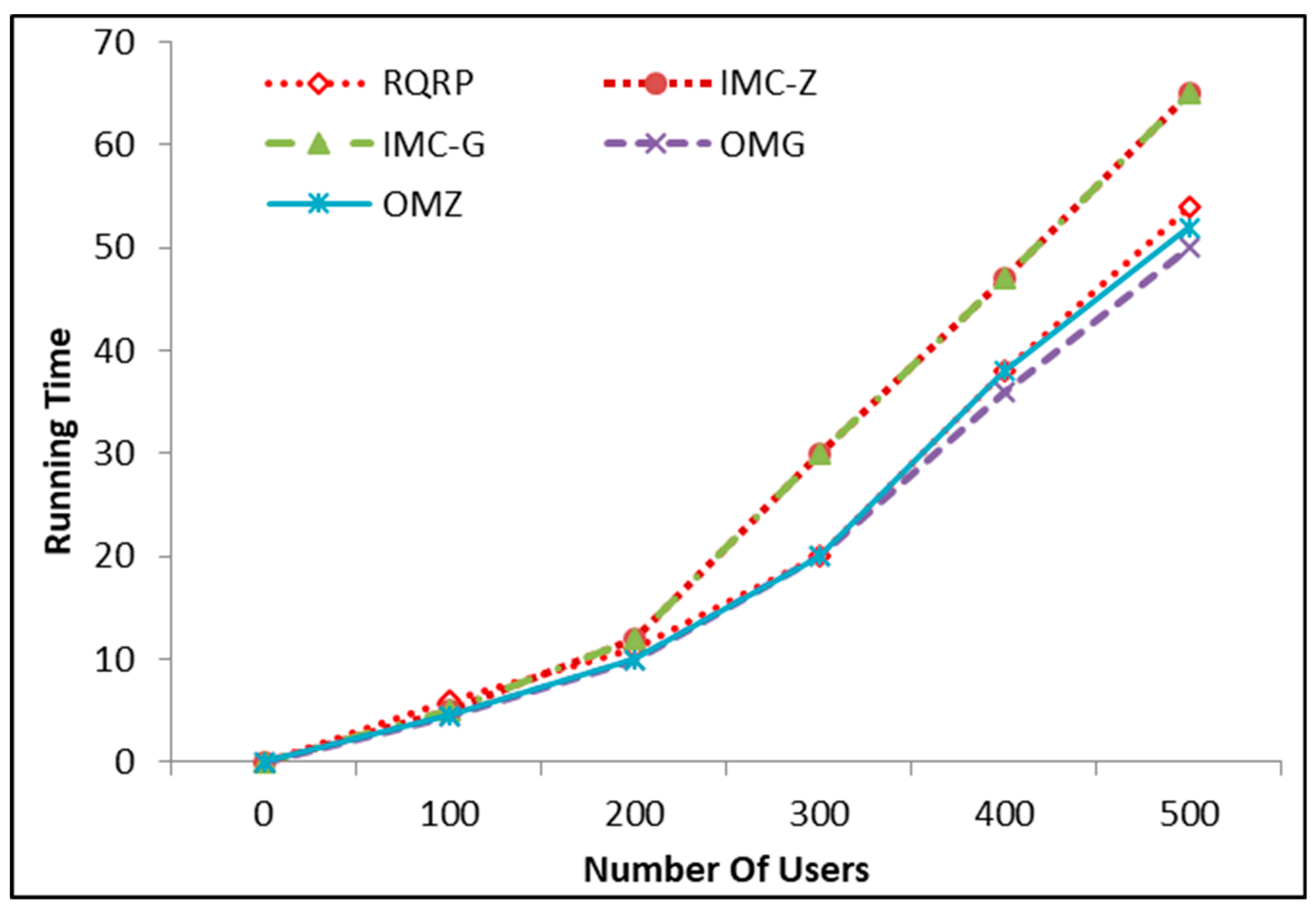
6.1. Running Time
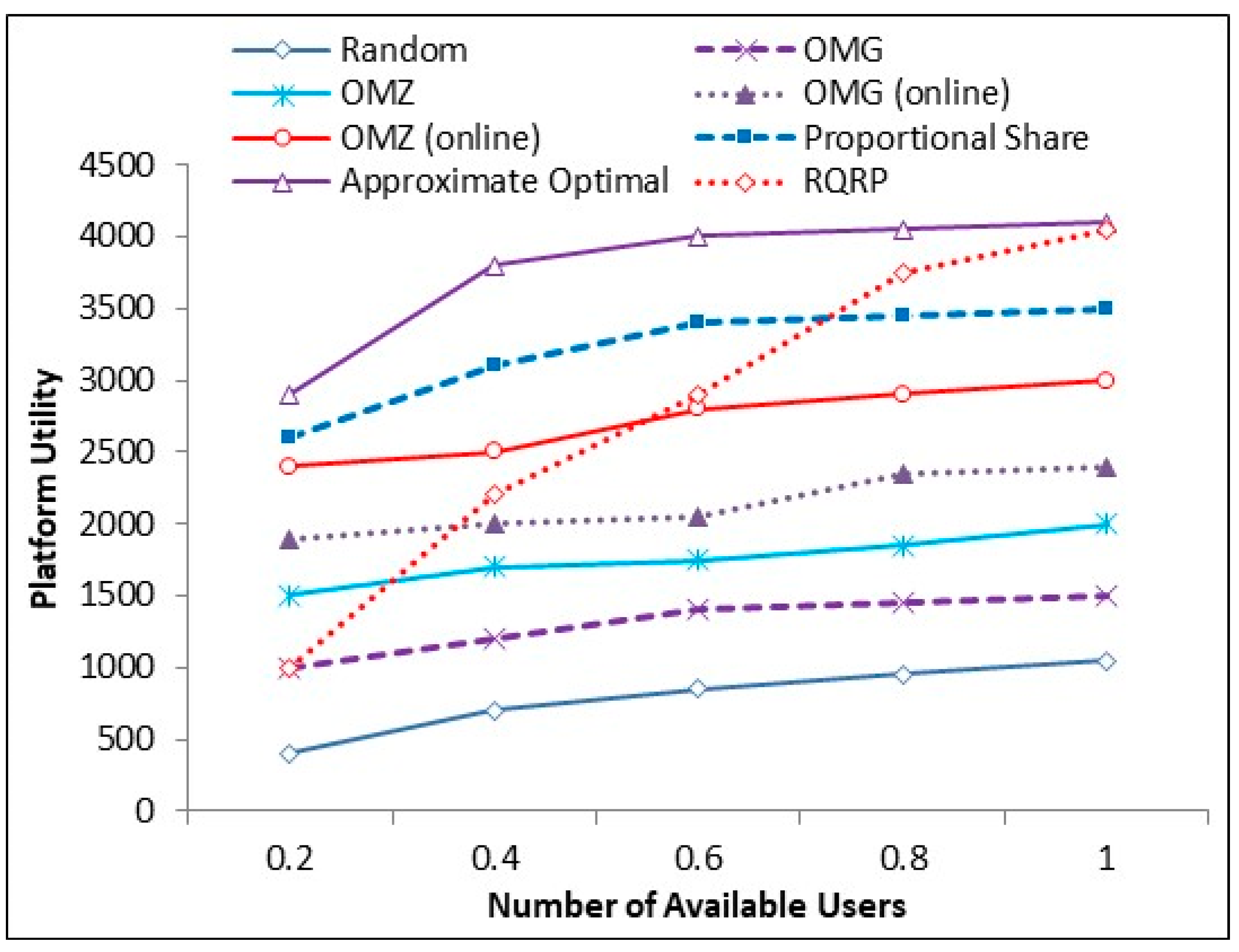
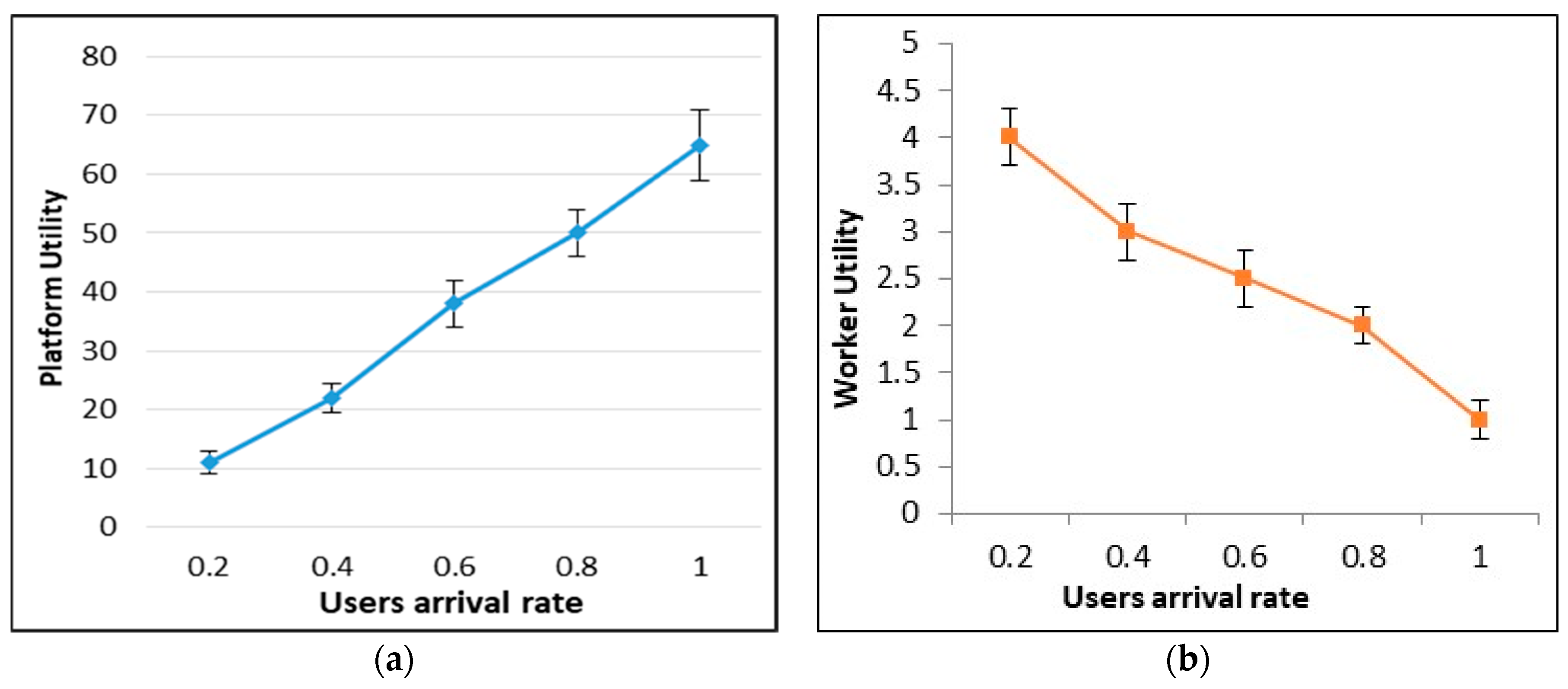
6.2. Platform Utility
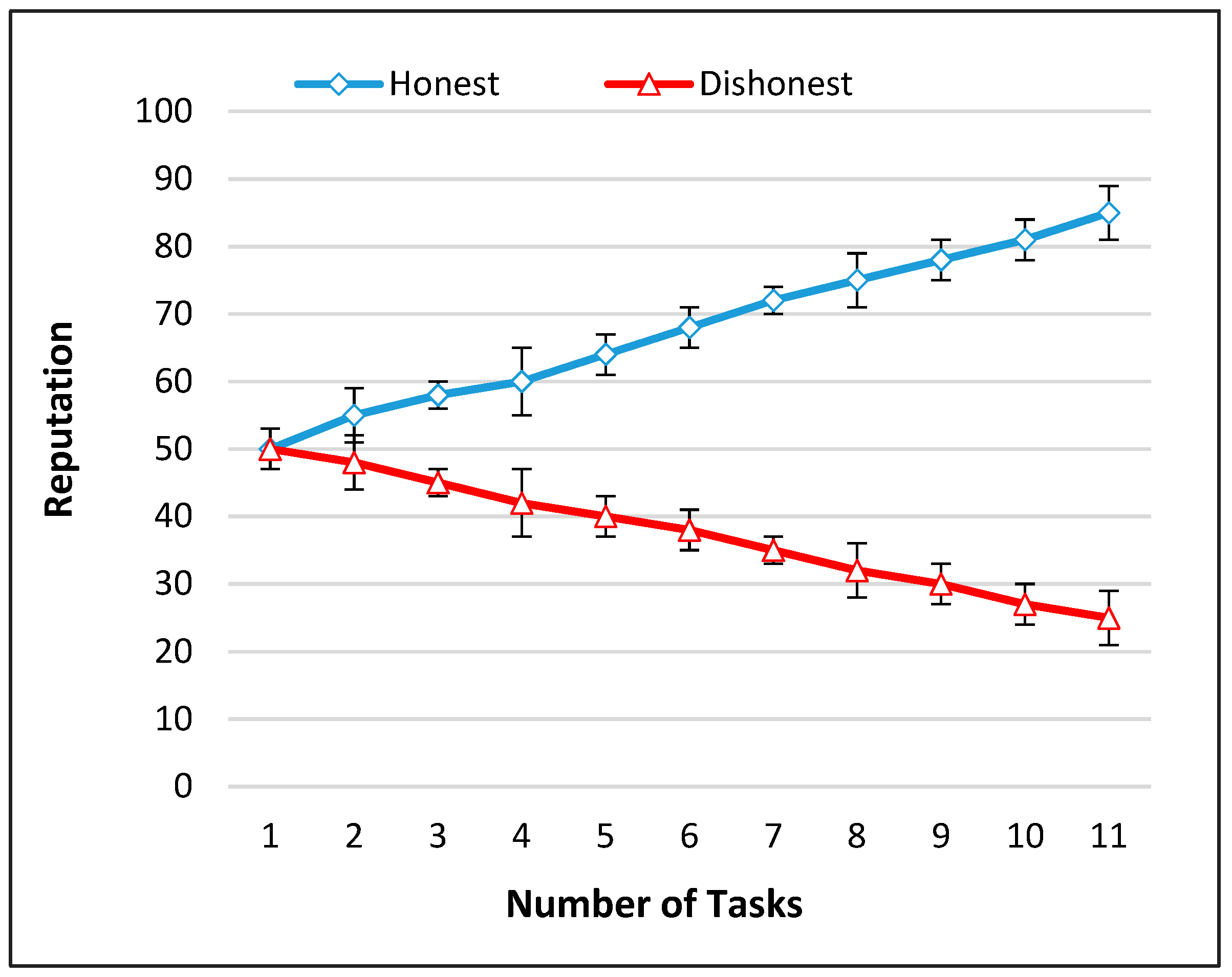
6.3. Truthfulness
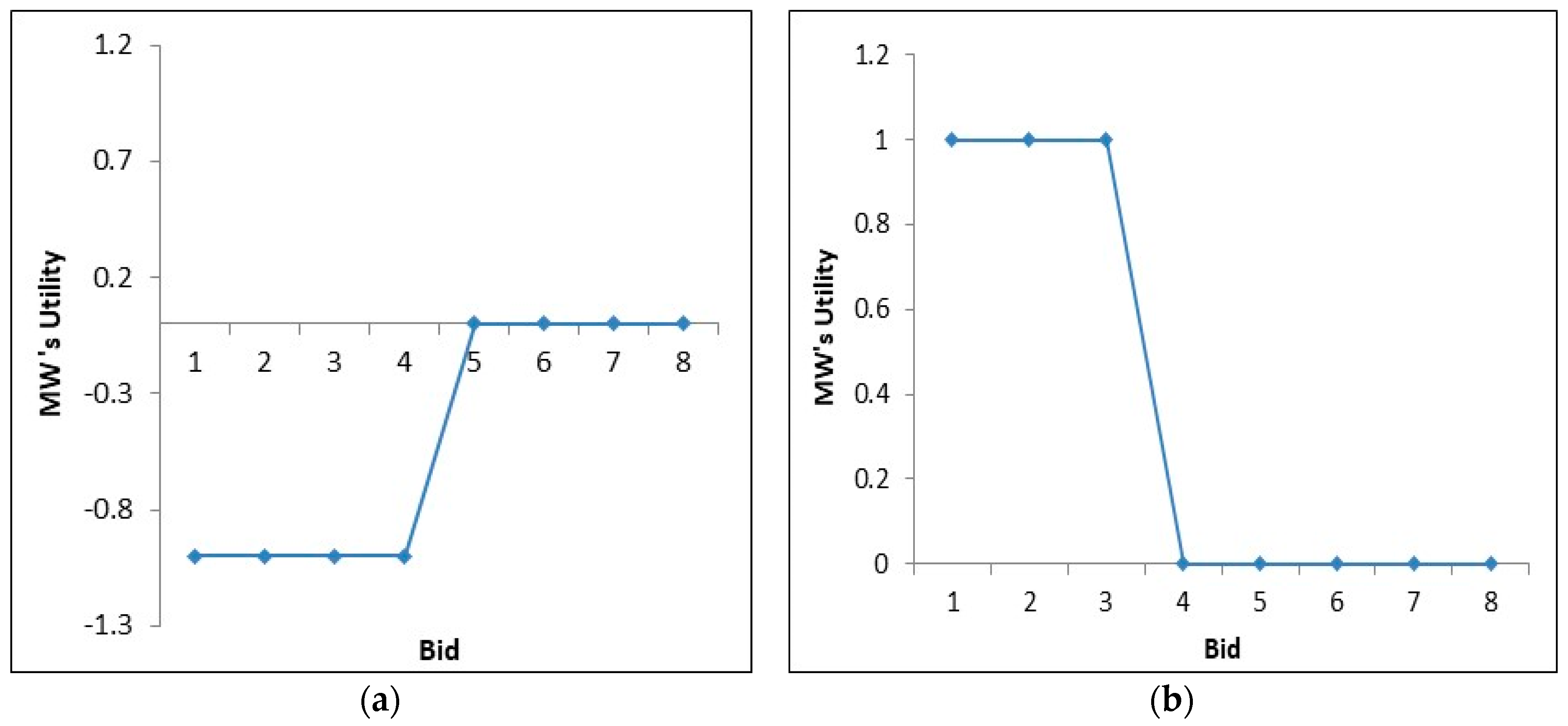
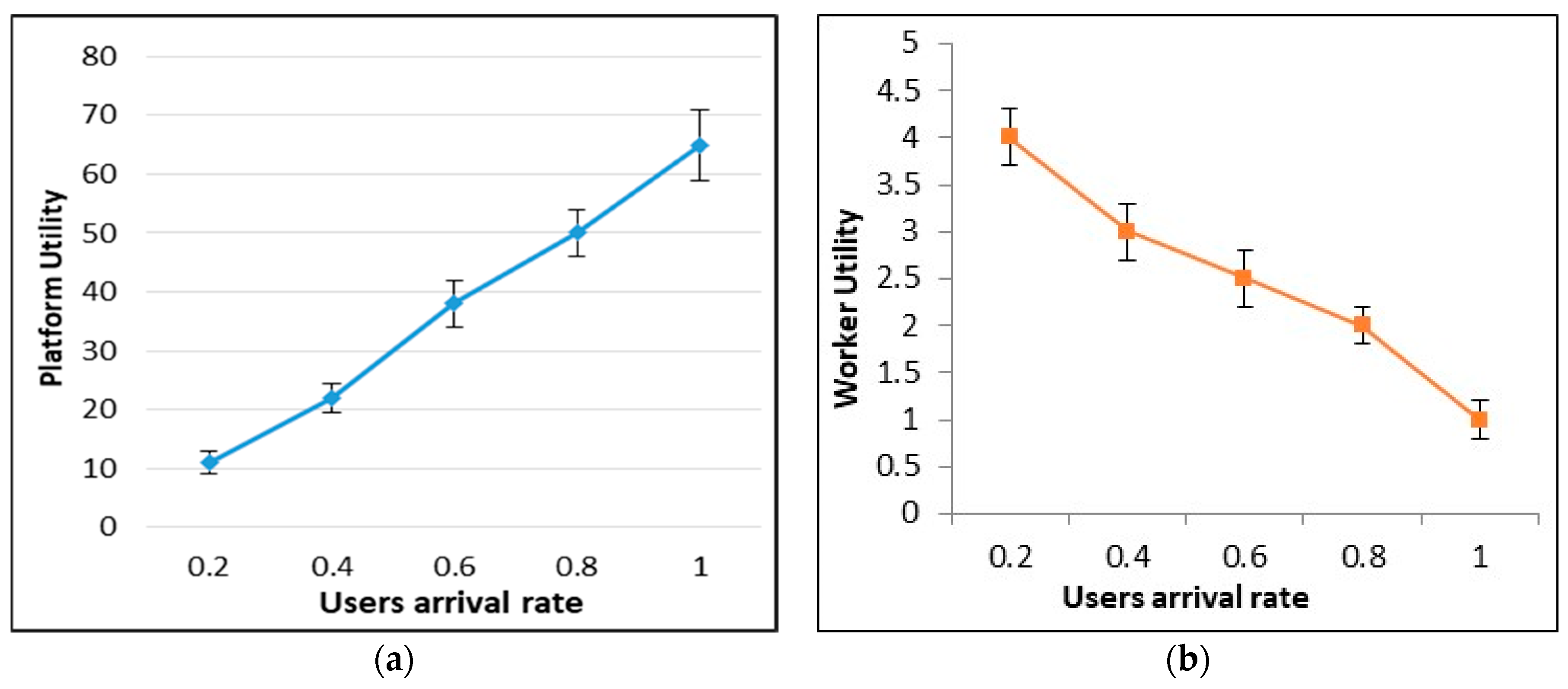
6.4. Platform vs. Mobile Worker Utility
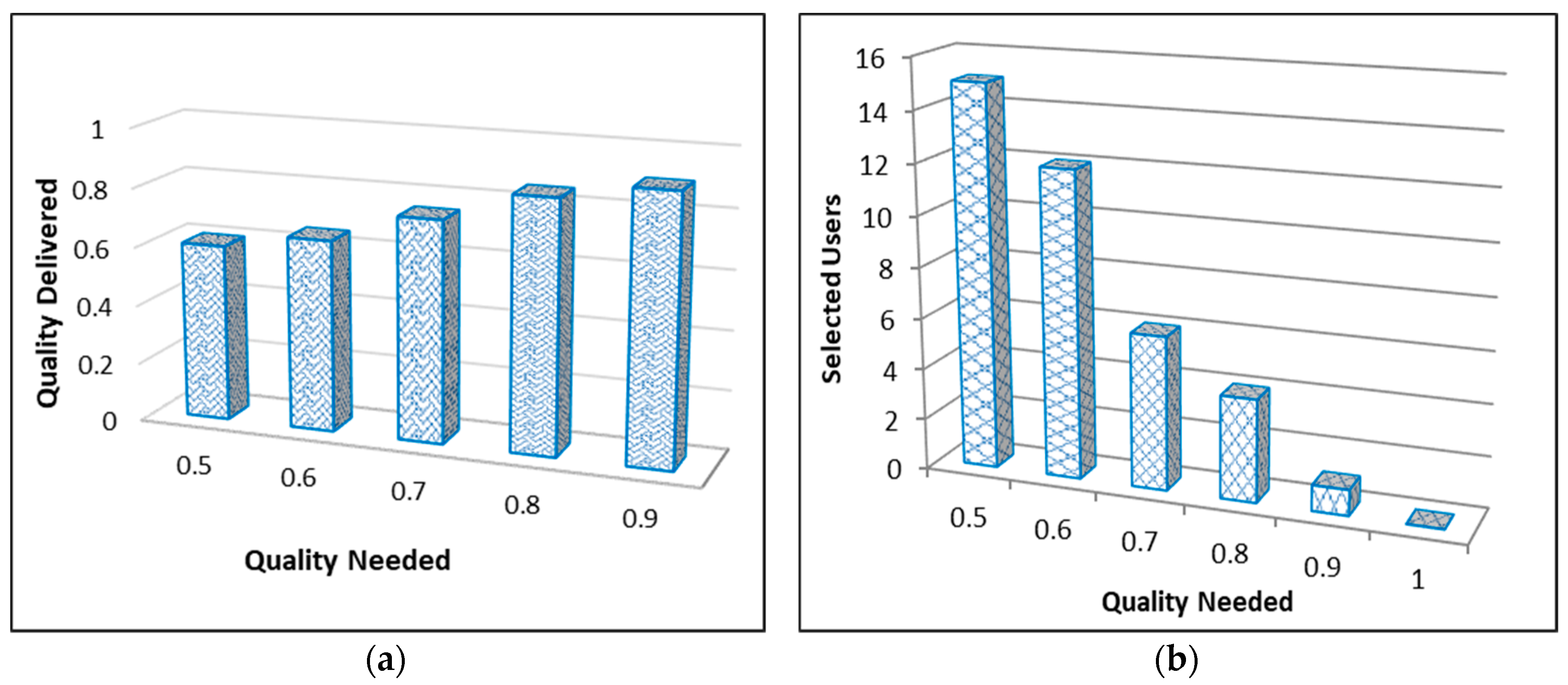
6.5. Required Quality vs. Quality Delivered
6.6. Required Quality vs. Selected MW
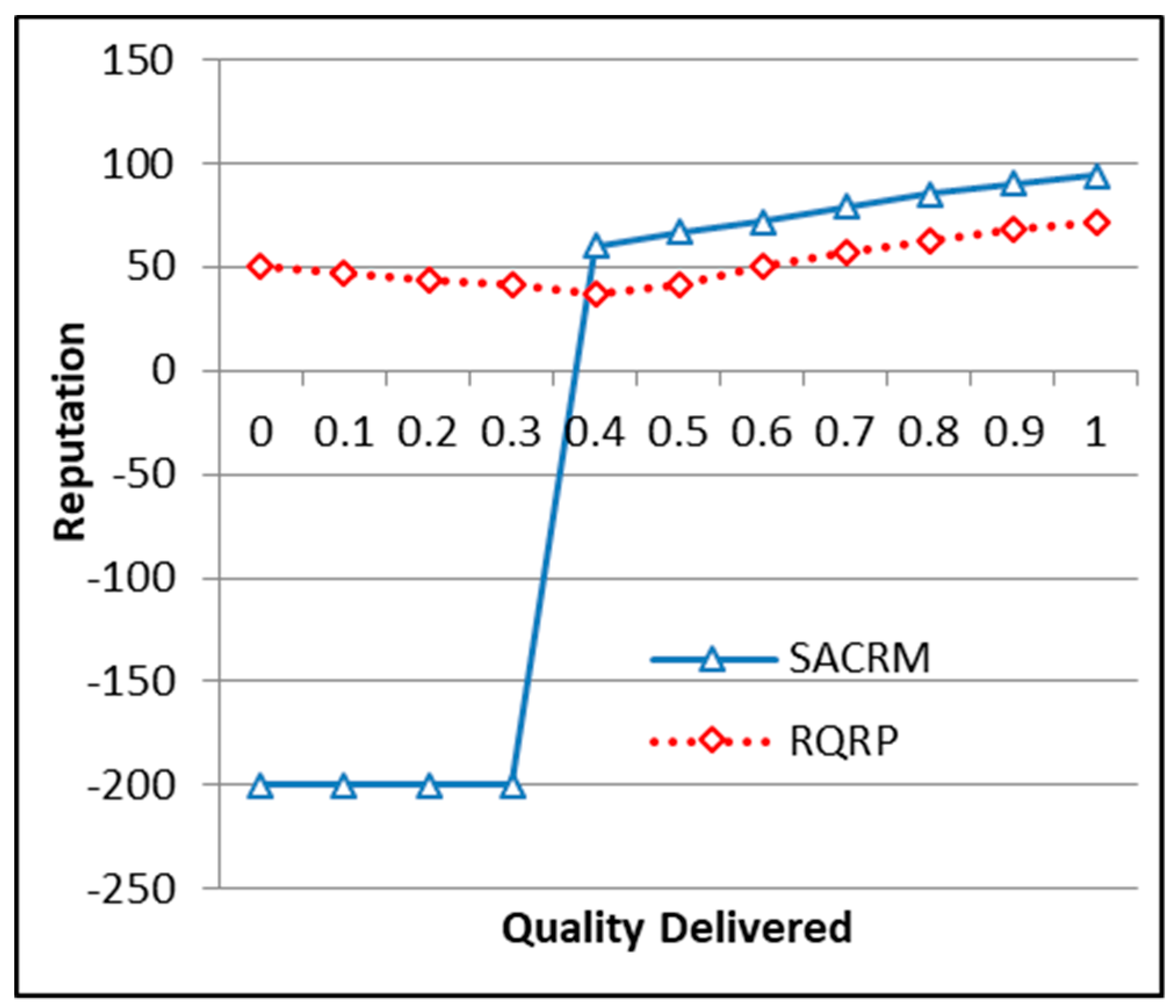
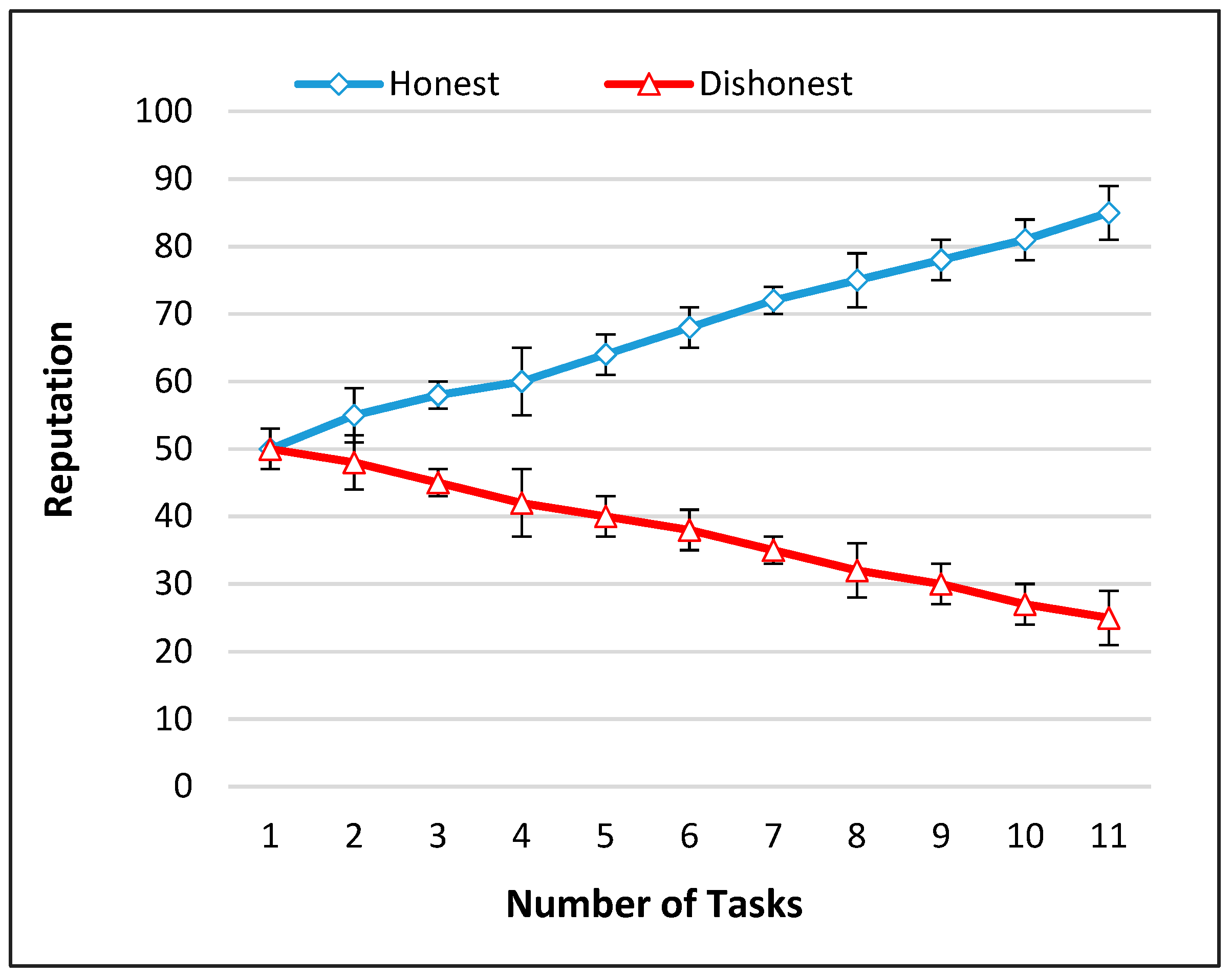
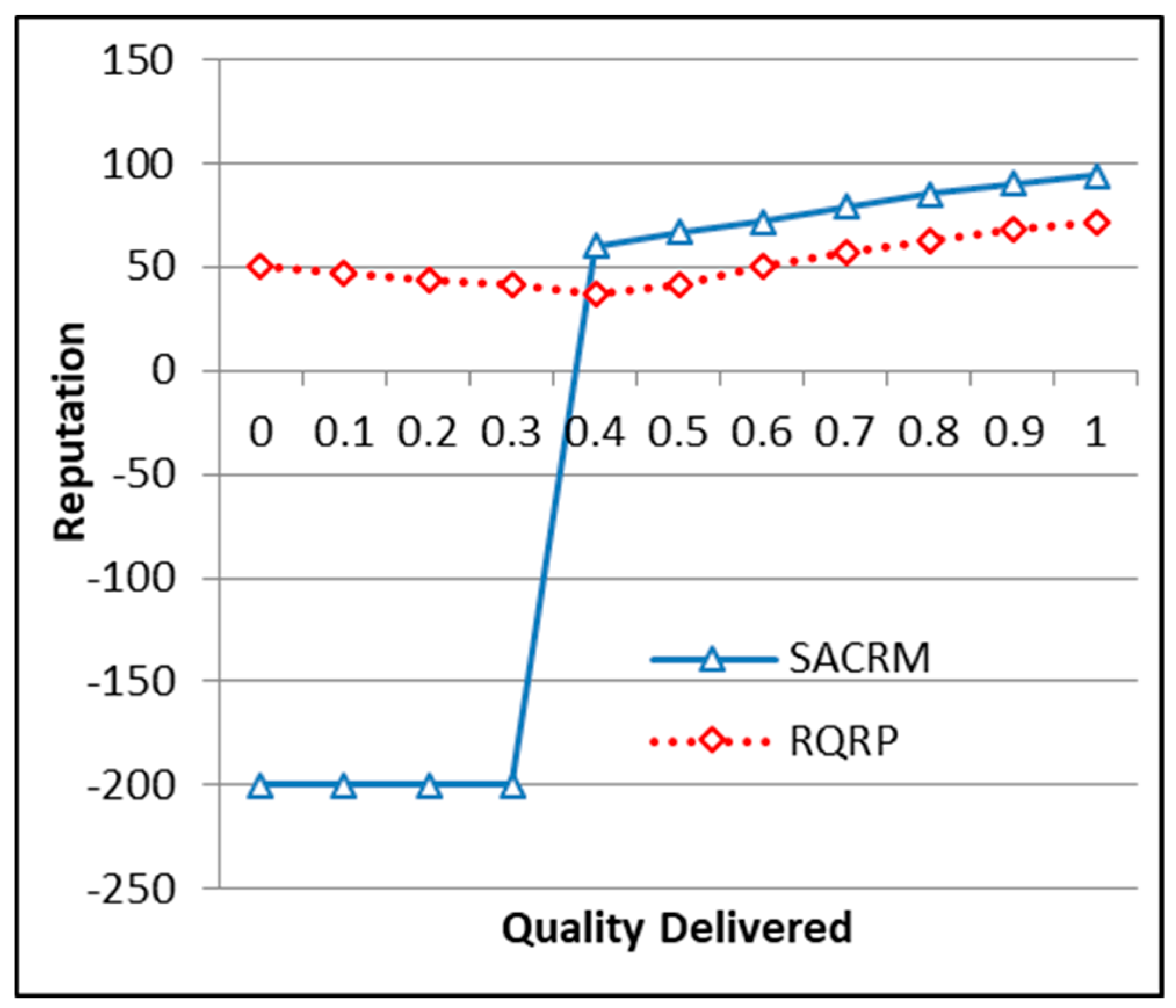
6.7. Impact of Quality on Reputation
6.8. User Reputation
6.9. Error Bars
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cuomo, S.; Michele, P.D.; Piccialli, F.; Galletti, A.; Jung, J.E. IoT-Based Collaborative Reputation System for Associating Visitors and Artworks in a Cultural Scenario. Expert Syst. Appl. 2017, 79, 101–111. [Google Scholar] [CrossRef]
- Ren, J.; Zhang, Y.; Zhang, K.; Shen, X. Exploiting Mobile Crowdsourcing for Pervasive Cloud Services: Challenges and Solutions. IEEE Commun. Mag. 2015, 53, 98–105. [Google Scholar] [CrossRef]
- Burke, J.A.; Estrin, D.; Hansen, M.; Parker, A.; Ramanathan, N.; Reddy, S.; Srivastava, M.B. Participatory Sensing; SenSys: Boulder, CO, USA, 2006. [Google Scholar]
- Ganti, R.K.; Ye, F.; Lei, H. Mobile crowdsensing: Current state and future challenges. IEEE Commun. Mag. 2011, 49, 32–39. [Google Scholar] [CrossRef]
- Guo, B.; Chen, C.; Zhang, D.; Yu, Z.; Chin, A. Mobile crowd sensing and computing: When participatory sensing meets participatory social media. IEEE Commun. Mag. 2016, 54, 131–137. [Google Scholar] [CrossRef]
- Guo, B.; Yu, Z.; Zhou, X.; Zhang, D. From participatory sensing to mobile crowd sensing. In Proceedings of the International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Budapest, Hungary, 24–28 March 2014; pp. 593–598. [Google Scholar]
- Liu, Y.; Li, X. Heterogeneous Participant Recruitment for Comprehensive Vehicle Sensing. PLoS ONE 2015, 10, e0138898. [Google Scholar] [CrossRef] [PubMed]
- Merlino, G.; Arkoulis, S.; Distefano, S.; Papagianni, C.; Puliafito, A.; Papavassiliou, S. Mobile crowdsensing as a service: A platform for applications on top of sensing clouds. Future Gener. Comput. Syst. 2016, 56, 623–639. [Google Scholar] [CrossRef]
- Mohan, P.; Padmanabhan, V.N.; Ramjee, R. Nericell: Rich monitoring of road and traffic conditions using mobile smartphones. In Proceedings of the 6th ACM Conference on Embedded Network Sensor Systems, Raleigh, NC, USA, 5–7 November 2008; pp. 323–336. [Google Scholar]
- Panichpapiboon, S.; Leakkaw, P. Traffic Density Estimation: A Mobile Sensing Approach. IEEE Commun. Mag. 2017, 55, 126–131. [Google Scholar] [CrossRef]
- Zappatore, M.; Longo, A.; Bochicchio, M.A. Using mobile crowd sensing for noise monitoring in smart cities. In Proceedings of the International Multidisciplinary Conference on Computer and Energy Science (SpliTech), Split, Croatia, 13–15 July 2016; pp. 1–6. [Google Scholar]
- Reddy, S.; Parker, A.; Hyman, J.; Burke, J.; Estrin, D.; Hansen, M. Image browsing, processing, and clustering for participatory sensing: Lessons from a DietSense prototype. In Proceedings of the 4th Workshop on Embedded Networked Sensors, Cork, Ireland, 25–26 June 2007; pp. 13–17. [Google Scholar]
- Longo, A.; Zappatore, M.; Bochicchio, M.; Navathe, S.B. Crowd-Sourced Data Collection for Urban Monitoring via Mobile Sensors. ACM Trans. Internet Technol. 2017, 18, 5. [Google Scholar] [CrossRef]
- Lane, N.D.; Eisenman, S.B.; Musolesi, M.; Miluzzo, E.; Campbell, A.T. Urban sensing systems: Opportunistic or participatory? In Proceedings of the 9th Workshop on Mobile Computing Systems and Applications, Napa Valley, CA, USA, 25–26 February 2008; pp. 11–16. [Google Scholar]
- Wang, L.; Zhang, D.; Wang, Y.; Chen, C.; Han, X.; M’hamed, A. Sparse mobile crowdsensing: Challenges and opportunities. IEEE Commun. Mag. 2016, 54, 161–167. [Google Scholar] [CrossRef]
- Jaimes, L.G.; Vergara-Laurens, I.J.; Raij, A. A survey of incentive techniques for mobile crowd sensing. IEEE Internet Things J. 2015, 2, 370–380. [Google Scholar] [CrossRef]
- Han, G.; Liu, L.; Chan, S.; Yu, R.; Yang, Y. HySense: A hybrid mobile crowdsensing framework for sensing opportunities compensation under dynamic coverage constraint. IEEE Commun. Mag. 2017, 55, 93–99. [Google Scholar] [CrossRef]
- Shu, L.; Chen, Y.; Huo, Z.; Bergmann, N.; Wang, L. When mobile crowd sensing meets traditional industry. IEEE Access 2017, 5, 15300–15307. [Google Scholar] [CrossRef]
- Xie, H.; Lui, J.C. Incentive mechanism and rating system design for crowdsourcing systems: Analysis, tradeoffs and inference. IEEE Trans. Serv. Comput. 2016, 1374, 1–14. [Google Scholar] [CrossRef]
- Jiang, L.Y.; He, F.; Wang, Y.; Sun, L.J.; Huang, H.P. Quality-Aware Incentive Mechanism for Mobile Crowd Sensing. J. Sens. 2017, 2017, 5757125. [Google Scholar] [CrossRef]
- Chiregi, M.; Navimipour, N.J. A new method for trust and reputation evaluation in the cloud environments using the recommendations of opinion leaders’ entities and removing the effect of troll entities. Comput. Hum. Behav. 2016, 60, 280–292. [Google Scholar] [CrossRef]
- Ahmad, W.; Wang, S.; Ullah, A.; Mahmood, Z. Reputation-Aware Trust and Privacy-Preservation for Mobile Cloud Computing. IEEE Access 2018, 6, 46363–46381. [Google Scholar] [CrossRef]
- Jin, H.; Su, L.; Xiao, H.; Nahrstedt, K. Inception: Incentivizing privacy-preserving data aggregation for mobile crowd sensing systems. In Proceedings of the 17th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Paderborn, Germany, 5–8 July 2016; pp. 341–350. [Google Scholar]
- Chen, X.; Liu, M.; Zhou, Y.; Li, Z.; Chen, S.; He, X. A Truthful Incentive Mechanism for Online Recruitment in Mobile Crowd Sensing System. Sensors 2017, 17, 79. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.N.; Huynh, M.Q.; Chi-wai, K.R.; Pi, S.M. The Evolution of Outsourcing Research: What Is the next Issue? In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000. [Google Scholar]
- Fan, J.; Wei, X.; Li, R.; Sun, Q. A Cooperative Incentive Structure for Mobile Cloud Computing. Parall. Cloud Comput. Res. 2015, 3, 5–10. [Google Scholar]
- Zhu, X.; An, J.; Yang, M.; Xiang, L.; Yang, Q.; Gui, X. A fair incentive mechanism for crowdsourcing in crowd sensing. IEEE Internet Things J. 2016, 3, 1364–1372. [Google Scholar] [CrossRef]
- Zhao, D.; Li, X.Y.; Ma, H. Budget-feasible online incentive mechanisms for crowdsourcing tasks truthfully. IEEE/ACM Trans. Netw. 2016, 24, 647–661. [Google Scholar] [CrossRef]
- Luo, T.T.; Kanhere, S.S.; Huang, J.; Das, S.K.; Wu, F. Sustainable Incentives for Mobile Crowdsensing: Auctions, Lotteries, and Trust and Reputation Systems. IEEE Commun. Mag. 2017, 55, 68–74. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, Z.; Liu, Y.; Li, J.; Ming, Z. Toward Efficient Mechanisms for Mobile Crowdsensing. IEEE Trans. Veh. Technol. 2017, 66, 1760–1771. [Google Scholar] [CrossRef]
- Wu, W.; Wang, W.; Li, M.; Member, S.; Wang, J. Incentive Mechanism Design to Meet Task Criteria in Crowdsourcing: How to Determine Your Budget. IEEE J. Sel. Areas Commun. 2017, 35, 502–516. [Google Scholar] [CrossRef]
- Luo, T.; Zeynalvand, L. Reshaping Mobile Crowd Sensing Using Cross Validation to Improve Data Credibility. In Proceedings of the 2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar]
- Yang, D.; Xue, G.; Fang, X.; Tang, J. Crowdsourcing to smartphones: Incentive mechanism design for mobile phone sensing. In Proceedings of the 18th Annual International Conference on Mobile Computing and Networking, Istanbul, Turkey, 22–26 August 2012; pp. 173–184. [Google Scholar]
- Jin, H.; Su, L.; Nahrstedt, K. CENTURION: Incentivizing Multi-Requester Mobile Crowd Sensing. arXiv, 2017; arXiv:1701.01533. [Google Scholar]
- Jin, H.; Su, L.; Nahrstedt, K. Theseus: Incentivizing truth discovery in mobile crowd sensing systems. In Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Chennai, India, 10–14 July 2017. [Google Scholar]
- Yang, D.; Xue, G.; Fang, X.; Tang, J. Incentive Mechanisms for Crowdsensing: Crowdsourcing with Smartphones. IEEE/ACM Trans. Netw. 2016, 24, 1732–1744. [Google Scholar] [CrossRef]
- Jin, H.; Su, L.; Chen, D.; Nahrstedt, K.; Xu, J. Quality of Information Aware Incentive Mechanisms for Mobile Crowd Sensing Systems. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hangzhou, China, 22–25 June 2015; pp. 167–176. [Google Scholar]
- Huang, K.; Kanhere, L.S.S.; Hu, W. On the Need for a Reputation System in Mobile Phone Based Sensing. Ad Hoc Netw. 2014, 12, 130–149. [Google Scholar] [CrossRef]
- Peng, D.; Wu, F.; Chen, G. Data Quality Guided Incentive Mechanism Design for Crowdsensing. IEEE Trans. Mob. Comput. 2018, 17, 307–319. [Google Scholar] [CrossRef]
- Gao, Y.; Li, X.; Li, J.; Gao, Y. DTRF: A Dynamic-Trust-Based Recruitment Framework for Mobile Crowd Sensing System. In Proceedings of the IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 632–635. [Google Scholar]
- Guo, B.; Chen, H.; Yu, Z.; Nan, W.; Xie, X.; Zhang, D.; Zhou, X. TaskMe: Toward a Dynamic and Quality-Enhanced Incentive Mechanism for Mobile Crowd Sensing. Int. J. Human-Comput. Stud. 2017, 102, 14–26. [Google Scholar] [CrossRef]
- Restuccia, F.; Das, S.K. FIDES: A Trust-Based Framework for Secure User Incentivization in Participatory Sensing. In Proceedings of the IEEE 15th International Symposium on World of Wireless, Mobile and Multimedia Networks (WoWMoM), Sydney, Australia, 19 June 2014; pp. 1–10. [Google Scholar]
- Zhou, T.; Cai, Z.; Wu, K.; Chen, Y.; Xu, M. FIDC: A framework for improving data credibility in mobile crowdsensing. Comput. Netw. 2017, 120, 157–169. [Google Scholar] [CrossRef]
- Habibzadeh, H.; Qin, Z.; Soyata, T.; Kantarci, B. Large-Scale Distributed Dedicated- and Non-Dedicated Smart City Sensing Systems. IEEE Sens. J. 2017, 17, 7649–7658. [Google Scholar] [CrossRef]
- Hou, W.; Ning, Z.; Guo, L. Green Survivable Collaborative Edge Computing in Smart Cities. IEEE Trans. Ind. Inform. 2018, 14, 1594–1605. [Google Scholar] [CrossRef]
- Marjanovic, M.; Antonic, A.; Podnar Zarko, I. Edge Computing Architecture for Mobile Crowdsensing. IEEE Access Spec. Sect. Mob. Edge Comput. 2018, 6, 10662–10674. [Google Scholar] [CrossRef]
- Guo, J.; Chen, R.; Tsai, J.J. A survey of trust computation models for service management in internet of things systems. Comput. Commun. 2017, 97, 1–14. [Google Scholar] [CrossRef]
- Restuccia, F.; Ghosh, N.; Bhattacharjee, S.; Das, S.K.; Melodia, T. Quality of Information in Mobile Crowdsensing: Survey and Research Challenges. ACM Trans. Sens. Netw. 2017, 13, 34. [Google Scholar] [CrossRef]
- Li, M.; Lin, J.; Yang, D.; Xue, G.; Tang, J. QUAC: Quality-Aware Contract-Based Incentive Mechanisms for Crowdsensing. In Proceedings of the 14th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Orlando, FL, USA, 22–25 October 2017; pp. 72–80. [Google Scholar]
- Pouryazdan, M.; Kantarci, B.; Soyata, T.; Foschini, L.; Song, H. Quantifying User Reputation Scores, Data Trustworthiness, and User Incentives in Mobile Crowd-Sensing. IEEE Access 2017, 5, 1382–1397. [Google Scholar] [CrossRef]
- Pu, L.; Chen, X.; Xu, J.; Fu, X. Crowd Foraging: A QoS-Oriented Self-Organized Mobile Crowdsourcing Framework Over Opportunistic Networks. IEEE J. Sel. Areas Commun. 2017, 35, 848–862. [Google Scholar] [CrossRef]
- Ozdemir, S. Functional Reputation Based Reliable Data Aggregation and Transmission for Wireless Sensor Networks. Comput. Commun. 2008, 31, 3941–3953. [Google Scholar] [CrossRef]
- Ismail, R.; Josang, A. The Beta Reputation System. In Proceedings of the 15th Bled Electronic Commerce Conference (Bled EConference), Bled, Slovenia, 17–19 June 2002; Volume 5, pp. 2502–2511. [Google Scholar]
- Pouryazdan, M.; Kantarci, B.; Soyata, T.; Song, H. Anchor-Assisted and Vote-Based Trustworthiness Assurance in Smart City Crowdsensing. IEEE Access 2016, 4, 529–541. [Google Scholar] [CrossRef]
- Ren, J.; Zhang, Y.; Zhang, K.; Shen, X.S. SACRM: Social aware crowdsourcing with reputation management in mobile sensing. Comput. Commun. 2015, 65, 55–65. [Google Scholar] [CrossRef]
- Hu, T.; Xiao, M.; Hu, C.; Gao, G.; Wang, B. A QoS-Sensitive Task Assignment Algorithm for Mobile Crowdsensing. Pervasive Mob. Comput. 2017, 41, 333–342. [Google Scholar] [CrossRef]
- Dai, W.; Wang, Y.; Jin, Q.; Ma, J. Geo-QTI: A quality aware truthful incentive mechanism for cyber–physical enabled Geographic crowdsensing. Future Gener. Comput. Syst. 2018, 79, 447–459. [Google Scholar] [CrossRef]
- Zhan, Y.; Xia, Y.; Zhang, J. Quality-Aware Incentive Mechanism Based on Payoff Maximization for Mobile Crowdsensing. Ad Hoc Netw. 2018, 72, 44–55. [Google Scholar] [CrossRef]
- Tian, F.; Liu, B.; Sun, X.; Zhang, X.; Cao, G.; Gui, L. Movement-Based Incentive for Crowdsourcing. IEEE Trans. Veh. Technol. 2017, 66, 7223–7233. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| Reputation score | |
| Utility of platform and mobile worker | |
| is expected quality from bidding mobile worker and is the expected platform utility | |
| Task, Subtasks | |
| , | Deadline of task completion, and ground truth |
| Desired quality of task, is the real reported quality of any task according to (), and is quality score after task completion | |
| are threshold parameters, is the bid of any mobile worker and is the bid of any for task j | |
| Expected skill level | |
| is the total number of mobile workers, is the set of candidates who have submitted bids, is set of candidates who are considered as real candidates, is the number of winning MWs, is the total task assigned, is total task completion capacity of MW | |
| is sensing report, is ground truth, is a sensing location from a set of locations | |
| , | Upper and lower upper limits budget |
| , | is the unit cost paid to the MW whereas is the total cost paid to one |
| Parameter | Value |
|---|---|
| Target area | 1000 m × 1000 m |
| Number of MWs | 100–500 |
| Tasks announced | 100, 200, 300 |
| 1, 5, 10 | |
| Least task quality factor () | 0.3 |
| Effective mobility region | 30 m |
| Reputation score | [0–1] |
| Default reputation value | 0.5 |
| Ageing factor | 0.3–0.5 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, W.; Wang, S.; Ullah, A.; Sheharyar; Yasir Shabir, M. Reputation-Aware Recruitment and Credible Reporting for Platform Utility in Mobile Crowd Sensing with Smart Devices in IoT. Sensors 2018, 18, 3305. https://doi.org/10.3390/s18103305
Ahmad W, Wang S, Ullah A, Sheharyar, Yasir Shabir M. Reputation-Aware Recruitment and Credible Reporting for Platform Utility in Mobile Crowd Sensing with Smart Devices in IoT. Sensors. 2018; 18(10):3305. https://doi.org/10.3390/s18103305
Chicago/Turabian StyleAhmad, Waqas, Shengling Wang, Ata Ullah, Sheharyar, and Muhammad Yasir Shabir. 2018. "Reputation-Aware Recruitment and Credible Reporting for Platform Utility in Mobile Crowd Sensing with Smart Devices in IoT" Sensors 18, no. 10: 3305. https://doi.org/10.3390/s18103305
APA StyleAhmad, W., Wang, S., Ullah, A., Sheharyar, & Yasir Shabir, M. (2018). Reputation-Aware Recruitment and Credible Reporting for Platform Utility in Mobile Crowd Sensing with Smart Devices in IoT. Sensors, 18(10), 3305. https://doi.org/10.3390/s18103305