A Survey of Data Semantization in Internet of Things


Abstract
1. Introduction
- It provides a detailed overview of data semantization such as the related concepts and existing architectures for adding semantics to IoT data and summarizes a general processing architecture for data semantization.
- It presents key techniques involved in data semantization including techniques in data collection, data preprocessing and semantic annotation.
- It analyzes challenges and open issues that are worth studying in future work such as standardization and generalization, complexity and dynamicity, and security and privacy.
2. Overview
2.1. The Definition of Data Semantization
2.2. The Significance of Data Semantization
- Data IntegrationData are sensed and gathered from a stakeholder, no matter it is a sensor, a device or triggered by a inhabitant. Therefore, it is vital to seamlessly integrate data and information to a consistent description format [9]. Adding semantics supports data integration by allowing data interoperability between different sources and prompts domain-across applications [10] largely.
- Data InteroperabilityData interoperability mainly refers to data from different sources being understood and interpreted unambiguously. Since it is demanding to explore implicit meanings of an independent area, information from different domains need to communicate and interact with each other. By adding unified data descriptions, it is possible for different domains [11] such as weather forecasting and healthcare to exchange and share information.
- Data UnderstandingData semantization means formatting data with fixed mark-ups, thus providing a unified description for sensor data. With semantic notifications, most information can be expressed with a formal specification language, therefore it improves the possibility of data understanding to a great degree. Data semantization facilitates the progress for machines to accept and understand information totally.
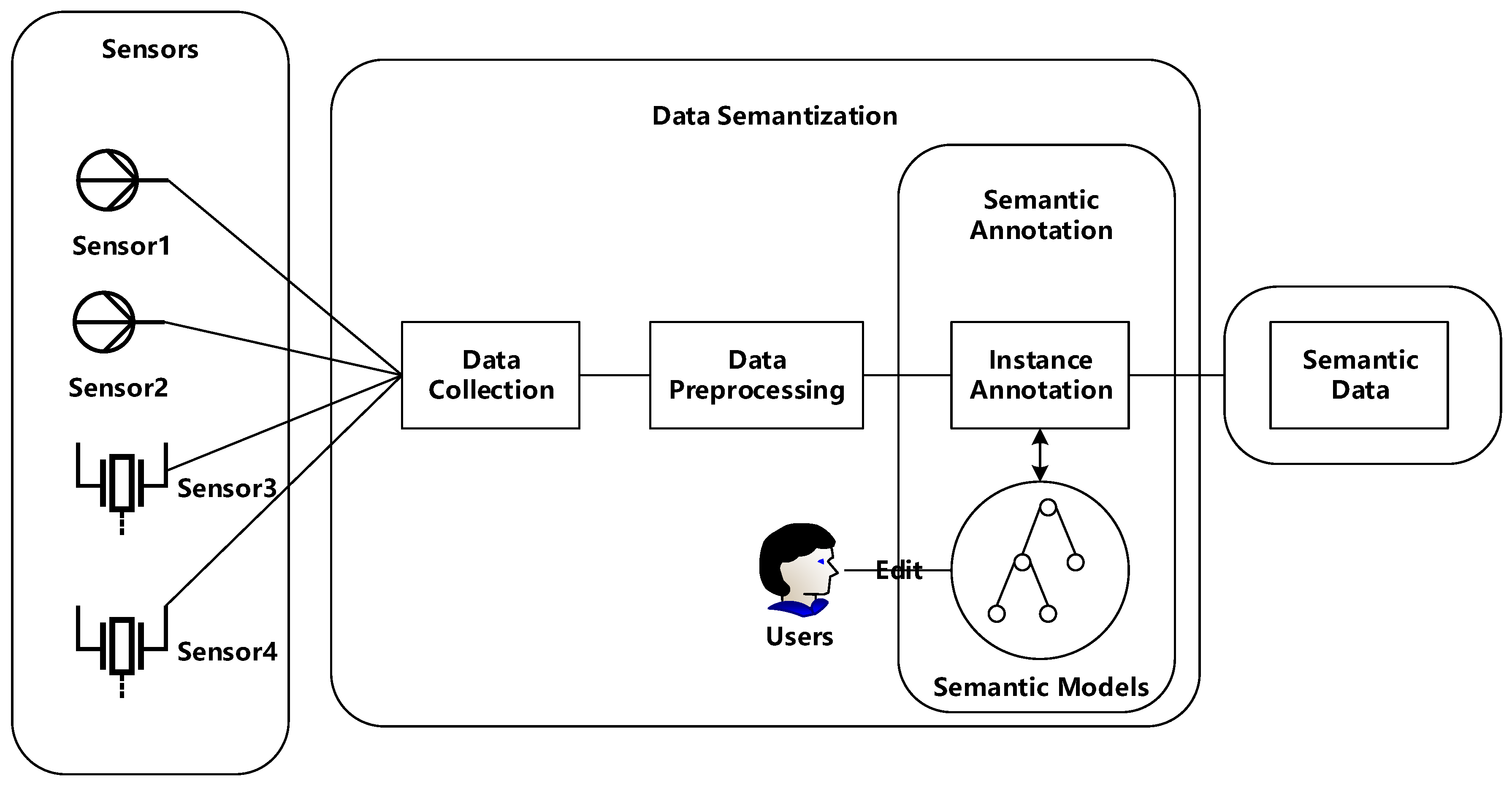
2.3. General Architecture for Data Semantization
- Data Collection. In this stage, the main work is to sense and gather heterogenous data from diverse sensors including sensor id, value, measurement and other information. For separate sensor nodes, there is no doubt to transfer data to a processer via wired/wireless communication technologies. However, for sensor networks, a main challenge is how to arrange the roles of all sensor nodes based on the requirements and limited resources constraints, as well as the protocols used for communications between networks.
- Data Preprocessing. Data collected from environments are full of uncertainty and noise, which may result in severe problems with regard to data utilization. For example, in applications where data are adopted for trend predictions, the more accurate the data are, the more reasonable the trend is predicted. It is undeniable that anomalies or outliers are essential in the case of discovering abnormal situations, for instance, when the patient’s heart beat is different from normal values, an alarm would inform the doctor. However, there do exist situations where noise, anomalies and outliers need to be tackled and cleaned. By adopting data preprocessing algorithms, accuracy of sensor data would be improved and it is beneficial for further processes.
- Semantic Annotation. Semantic annotation is regarded as the key step in the whole processing architecture, which means adding semantic notifications to preprocessed data. Generally, semantic annotation is composed of two steps, semantic modeling and instance annotation. Semantic modeling serves as an important role, and users may define new or reuse existing semantic models depending on situations. The preprocessed data would be instantiated based on predefined semantic models to finish the process of semantic annotation.
3. Key Techniques
3.1. Data Collection
3.1.1. Techniques in WSNs
3.1.2. Techniques between WSNs
3.2. Data Preprocessing
3.2.1. Noisy Data Cleaning
3.2.2. Missing Data Completing
3.2.3. Data Dimensionality Reduction
3.3. Semantic Annotation
3.3.1. Semantic Expression Formats
3.3.2. Semantic Models
- Ontologies for ActivitiesIn this part, user-centric ontologies are introduced which mainly focus on users. It is known that activities are triggered by users with different operation sequences and manners. To improve the activity ontologies, it is required to consider influencing factors, such as user profiles, user privacy and so forth. Nowadays, an increasing number of ontologies are designed to help recognize users’ activities in daily life.The Standard Ontology for Ubiquitous and Pervasive Applications (SOUPA) [62] represents intelligent agents with associated beliefs, desires, and intentions, as well as time, space, events, user profiles, actions, and policies for security and privacy. One advantage of SOUPA is that it supports combination with pervasive environments. CoBrA-Ont [63] is an extension of SOUPA which defines key categories like agent, action, device, time, space, and so forth. The distinct improvement of CoBrA-Ont is it integrates considerations of users’ privacy by restricting the sharing of information sensed by hidden sensors or devices. Preuveneers [64] also proposes an ontology named CoDAMoS targeted at the description of four components, user, environment, service and platform. The main advantage of this ontology model is it describes two levels of granularity, tasks and activities. Another ontology put forward by Lewis [65]-The Delivery Context Ontology-provides a definition of device characters, environment, hardware and so on. In 2011, Riboni [66] proposed an ontology for human activity recognition named PalSPOT ontology. It involves descriptions of individual and social activities such as comment, proposal or request for information. However, all ontologies mentioned above ignore the situation with incomplete knowledge, thus Rodríguez [67] establishes a fuzzy model that enables modeling uncertain and vague knowledge. In 2014, Natalia [68] made a comparison between important ontologies in terms of the components and items modeled in them.
- Ontologies for Context and SituationApart from activity models, context and situation ontologies become more and more crucial in expressing semantics. With the awareness of context, it is possible to understand current situations and make instant reactions. In [64] environment concepts such as time, location and environmental conditions are described. Chen et al. [5] presents an ontology including modelings of physical environment, inhabitants, sensors, devices and middleware services. In 2015, a Smart Appliances REFerence (Appliances REFerence) ontology [69] was published with descriptions of smart devices such as meters, switches and other energy controllers.Sensors are also objects that need to be semantically described. To provide a standardized expression, the W3C Semantic Sensor Network Incubator Group puts forward the most foundational ontology for sensors named the Semantic Sensor Network (SSN) Ontology [70]. It provides descriptions of concepts such as deployment, device and data. The core pattern in SSN is called the Stimulus Sensor Observation (SSO). In 2017, W3C published a new version of SSN ontology based on Sensor, Observation, Sample, and Actuator (SOSA) ontology [71] and the latest SSN ontology represents actuation models. However, as pointed out in [72], the SSN ontology is lack of descriptions of other fileds of IoT. The IoT ontology [73] expands from SSN, with descriptions of concepts like Physical Entity and Smart Network in order to support semantic expressions for interconnected, aligned and clustered entities. IoT-Lite Ontology [74] is also regarded as an expansion of SSN ontology. In addition to the definition of “ssn:Device”, IoT-Lite Ontology defines new concepts such as “iot-lite:Object” and “iot-lite:Service” which have become the core concepts in this model. It focuses on key concepts which support interoperability among different IoT platforms [75] by adopting lightweight semantics. [76] presents a set of information models based on IoT-Lite ontologies in which sensors are regarded as abstract components. The experiments show that the proposed models provide better data aggregation in sensors networks. According to oneM2M standard [77], an IoT-O is proposed including the definition of sensors, services, units as well as nodes, things and actuators. In addition, Ahvar [78] proposes a FUSE-IT ontology funded by Facility Using Smart secured Energy and Information Technology project, in which it combines several existing models including SAREF and SSN in order to provide a unified overview of smart homes.
3.3.3. Semantic Annotators
3.3.4. Analysis and Conclusions
4. Applications
4.1. Smart Homes
4.2. E-Health
4.3. Smart Cities
5. Challenges and Open Issues
5.1. Standardization and Generalization
5.2. Complexity and Dynamicity
5.3. Security and Privacy
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Su, X.; Riekki, J.; Nurminen, J.K.; Nieminen, J.; Koskimies, M. Adding semantics to internet of things. Concurr. Comput. Pract. Exp. 2015, 27, 1844–1860. [Google Scholar] [CrossRef]
- Evans, D. The Internet of Things: How the Next Evolution of the Internet is Changing Everything; Cisco Internet Business Solutions Group: San Jose, CA, USA, 2011. [Google Scholar]
- Knaian, A.N.; Paradiso, J.; Smith, A.C. A Wireless Sensor Network for Smart Roadbeds and Intelligent Transportation Systems. Mass. Internet Technol. 2000. Available online: https://dspace.mit.edu/handle/1721.1/9072 (accessed on 17 January 2018).
- Eysenbach, G. What is e-health? J. Med. Internet Res. 2001, 3, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Nugent, C.; Mulvenna, M.; Finlay, D.; Hong, X. Semantic Smart Homes: Towards Knowledge Rich Assisted Living Environments. Intell. Patient Manag. Stud. Comput. Intell. 2009, 189, 279–296. [Google Scholar]
- Sheth, A.; Henson, C.; Sahoo, S.S. Semantic Sensor Web. IEEE Internet Comput. 2008, 12, 78–83. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 28–37. [Google Scholar] [CrossRef]
- Ning, Z. The research of knowledge organization based on linked data under information space. In Proceedings of the 2011 International Conference on Business Management and Electronic Information (BMEI), Guangzhou, China, 13–15 May 2011; Volume 2, pp. 358–360. [Google Scholar]
- Barnaghi, P.; Wang, W.; Henson, C.; Taylor, K. Semantics for the Internet of Things: Early progress and back to the future. Int. J. Semant. Web Inf. Syst. 2012, 8, 1–21. [Google Scholar] [CrossRef]
- Gyrard, A.; Datta, S.K.; Bonnet, C.; Boudaoud, K. Standardizing generic cross-domain applications in Internet of Things. In Proceedings of the 2014 IEEE Globecom Workshops (GC Wkshps), Austin, TX, USA, 8–12 December 2014; pp. 589–594. [Google Scholar]
- Gyrard, A.; Bonnet, C.; Boudaoud, K. Enrich machine-to-machine data with semantic web technologies for cross-domain applications. In Proceedings of the 2014 IEEE World Forum on Internet of Things (WF-IoT), Seoul, Korea, 6–8 March 2014; pp. 559–564. [Google Scholar]
- Zhang, X.; Zhao, Y.; Liu, W. A method for mapping sensor data to SSN ontology. Int. J. Ser. Sci. Technol. 2015, 8, 303–316. [Google Scholar] [CrossRef]
- Corno, F.; Razzak, F. Publishing LO(D)D: Linked Open (Dynamic) Data for Smart Sensing and Measuring Environments. Proced. Comput. Sci. 2012, 10, 381–388. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef]
- Heinzelman, W.R.; Chandrakasan, A.; Balakrishnan, H. Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 7 January 2000; pp. 8020–8029. [Google Scholar]
- Manjeshwar, A.; Agrawal, D.P. TEEN: A routing protocol for enhanced efficiency in wireless sensor networks. In Proceedings of the 15th International Parallel and Distributed Processing Symposium, San Francisco, CA, USA, 23–27 April 2001; pp. 2009–2015. [Google Scholar]
- Lindsey, S.; Raghavendra, C.S. PEGASIS: Power-efficient gathering in sensor information systems. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 9–16 March 2002; pp. 1125–1130. [Google Scholar]
- Lu, G.; Krishnamachari, B.; Raghavendra, C.S. An adaptive energy-efficient and low-latency MAC for data gathering in wireless sensor networks. In Proceedings of the 18th International Parallel and Distributed Processing Symposium, Santa Fe, NM, USA, 26–30 April 2004; pp. 224–231. [Google Scholar]
- Ye, M.; Li, C.; Chen, G.; Wu, J. EECS: An energy efficient clustering scheme in wireless sensor networks. In Proceedings of the 24th IEEE International Performance, Computing, and Communications Conference, Phoenix, AZ, USA, 7–9 April 2005; pp. 535–540. [Google Scholar]
- Qing, L.; Zhu, Q.; Wang, M. Design of a distributed energy-efficient clustering algorithm for heterogeneous wireless sensor networks. Comput. Commun. 2006, 29, 2230–2237. [Google Scholar] [CrossRef]
- Bouldin, J.; Meghanathan, N. Rank-Based Data Gathering in Wireless Sensor Networks. Int. J. Res. Rev. Appl. Sci. 2010, 5, 159–163. [Google Scholar]
- Bajaber, F.; Awan, I. An efficient cluster-based communication protocol for wireless sensor networks. Telecommun. Syst. 2014, 55, 387–401. [Google Scholar] [CrossRef]
- Chhabra, G.S.; Sharma, D. Cluster-tree based data gathering in wireless sensor network. Int. J. Soft Comput. Eng. 2011, 1, 27–31. [Google Scholar]
- Rajeswari, A.; Manavalan, R. Data Collection Methods in Wireless Sensor Network: A Study. Int. J. Res. Appl. Sci. Eng. Technol. 2014, 2, 259–272. [Google Scholar]
- Prasanth, A. A Review on Data Collection Techniques in Wireless Sensor Networks. J. Comput. Technol. 2015, 5, 80–85. [Google Scholar]
- Eurotech. MQ Telemetry Transport (MQTT) V3.1 Protocol Specification. Available online: https://www.ibm.com/developerworks/library/ws-mqtt/ (accessed on 19 November 2017).
- Bormann, C.; Castellani, A.P.; Shelby, Z. CoAP: An Application Protocol for Billions of Tiny Internet Nodes. IEEE Internet Comput. 2012, 16, 62–67. [Google Scholar] [CrossRef]
- Caro, N.D.; Colitti, W.; Steenhaut, K.; Mangino, G.; Reali, G. Comparison of two lightweight protocols for smartphone-based sensing. In Proceedings of the 2013 IEEE 20th Symposium on Communications and Vehicular Technology in the Benelux (SCVT), Namur, Belgium, 21 November 2013; pp. 1–6. [Google Scholar]
- Videla, A.; Williams, J.J. RabbitMQ in Action; Manning Publications: New York, NY, USA, 2012. [Google Scholar]
- Kramer, J. Advanced Message Queuing Protocol (AMQP). Linux J. 2009. Available online: https://dl.acm.org/citation.cfm?id=1653250 (accessed on 17 January 2018).
- Ionescu, V.M. The analysis of the performance of RabbitMQ and ActiveMQ. In Proceedings of the 2015 14th RoEduNet International Conference-Networking in Education and Research (RoEduNet NER), Craiova, Romania, 24–26 September 2015; pp. 132–137. [Google Scholar]
- Ganz, F.; Puschmann, D.; Barnaghi, P.; Carrez, F. A Practical Evaluation of Information Processing and Abstraction Techniques for the Internet of Things. IEEE Internet Things J. 2015, 2, 340–354. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Managing and Mining Sensor Data; Springer Science and Business Media: Berlin, Germany, 2013. [Google Scholar]
- Zhuang, Y.; Chen, L.; Wang, X.S.; Lian, J. A Weighted Moving Average-based Approach for Cleaning Sensor Data. In Proceedings of the 27th International Conference on Distributed Computing Systems, Toronto, ON, Canada, 25–27 June 2007; pp. 38–45. [Google Scholar]
- Pumpichet, S.; Pissinou, N. Virtual Sensor for Mobile Sensor Data Cleaning. In Proceedings of the 2010 IEEE Global Telecommunications Conference GLOBECOM 2010, Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; Technical Report; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Tan, Y.L.; Sehgal, V.; Shahri, H.H. SensoClean: Handling Noisy and Incomplete Data in Sensor Networks using Modeling. 2005. Available online: https://www.sccs.swarthmore.edu/users/03/yeelin/docs/finalreport.pdf (accessed on 17 January 2018).
- Aggarwal, C.C. Probabilistic and Statistical Models for Outlier Detection; Springer International Publishing: Cham, Switzerland, 2017; pp. 41–74. [Google Scholar]
- García, S.; Ramírezgallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 9–30. [Google Scholar] [CrossRef]
- Wang, H.; Wang, S. Mining incomplete survey data through classification. Knowl. Inf. Syst. 2010, 24, 221–233. [Google Scholar] [CrossRef]
- SubirGhosh. Statistical Analysis with Missing Data. Technometrics 1988, 30, 455. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Stroud, J.R.; Stein, M.L.; Lysen, S. Bayesian and Maximum Likelihood Estimation for Gaussian Processes on an Incomplete Lattice. J. Comput. Gr. Stat. 2017, 26, 108–120. [Google Scholar] [CrossRef]
- Bellman, R. Adaptive Control Processes: A Guided Tour; Princeton University Press: Princeton, NJ, USA, 1961. [Google Scholar]
- Kuhn, M.; Johnson, K. An Introduction to Feature Selection; Springer: New York, NY, USA, 2013; pp. 487–519. [Google Scholar]
- Liu, H.; Zhao, Z. Manipulating Data and Dimension Reduction Methods: Feature Selection; Springer: New York, NY, USA, 2012; pp. 1790–1800. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Kim, J.O.; Mueller, C. Factor Analysis: Statistical Methods and Practical Issues (Quantitative Applications in the Social Sciences). Can. Med. Assoc. J. 1978, 161, 1414–1415. [Google Scholar]
- Jolliffe, I.T. Principal Components Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Miller, E. An Introduction to the Resource Description Framework. Bull. Am. Soc. Inf. Sci. Technol. 1998, 25, 15–19. [Google Scholar] [CrossRef]
- Harth, A.; Hose, K.; Schenkel, R. Linked Data Management; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Fabien, G.; Guus, S. RDF/XML Syntax Specification (Revised). Available online: https://www.w3.org/TR/rdf-syntax-grammar/ (accessed on 25 November 2017).
- Zhang, X.; Zhao, Y.; Liu, W. Transforming sensor data to RDF based on ssn ontology. Adv. Sci. Technol. Lett. 2015, 81, 95–98. [Google Scholar]
- Satterfield, S.; Reichherzer, T.; Coffey, J.; El-Sheikh, E. Application of Structural Case-Based Reasoning to Activity Recognition in Smart Home Environments. In Proceedings of the International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; pp. 1–6. [Google Scholar]
- Christophides, V. Resource Description Framework (RDF) Schema (RDFS); Springer: New York, NY, USA, 2009; pp. 2425–2428. [Google Scholar]
- Jennings, C.; Shelby, Z.; Arkko, J.; Keranen, A. Media Types for Sensor Markup Language (SenML) Draft-Jennings-Core-Senml-06. Available online: https://tools.ietf.org/html/draft-jennings-core-senml-06 (accessed on 25 November 2017).
- John, S.; Takuki, K.; Daniel, P.; Rumen, K. Efficient XML Interchange (EXI) Format 1.0 (Second Edition). Available online: https://www.w3.org/TR/exi/ (accessed on 25 November 2017).
- Su, X.; Riekki, J.; Haverinen, J. Entity Notation: enabling knowledge representations for resource-constrained sensors. Pers. Ubiquitous Comput. 2012, 16, 819–834. [Google Scholar] [CrossRef]
- Hitzler, P.; Krtzsch, M.; Rudolph, S. Foundations of Semantic Web Technologies; Chapman and Hall/CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Chen, H.; Perich, F.; Finin, T.; Joshi, A. SOUPA: Standard Ontology for Ubiquitous and Pervasive Applications. In Proceedings of the First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services, Boston, MA, USA, 26 August 2004; pp. 258–267. [Google Scholar]
- Chen, H.; Finin, T.; Joshi, A. An ontology for context-aware pervasive computing environments. knowl. Eng. Rev. 2003, 18, 197–207. [Google Scholar] [CrossRef]
- Preuveneers, D.; Bergh, J.V.D.; Wagelaar, D.; Georges, A.; Rigole, P.; Clerckx, T.; Berbers, Y.; Coninx, K.; Jonckers, V.; Bosschere, K.D. Towards an Extensible Context Ontology for Ambient Intelligence. In European Symposium on Ambient Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 148–159. [Google Scholar]
- Cantera, J.M.; Lewis, R. Delivery Context Ontology. Available online: https://www.w3.org/TR/dcontology/ (accessed on 28 November 2017).
- Riboni, D.; Bettini, C. COSAR: Hybrid reasoning for context-aware activity recognition. Pers. Ubiquitous Comput. 2011, 15, 271–289. [Google Scholar] [CrossRef]
- Rodríguez, N.D.; Cuéllar, M.P.; Lilius, J.; Calvo-Flores, M.D. A fuzzy ontology for semantic modelling and recognition of human behaviour. Knowl. Based Syst. 2014, 66, 46–60. [Google Scholar] [CrossRef]
- Rodríguez, N.D.; Cuéllar, M.P.; Lilius, J.; Calvo-Flores, M.D. A survey on ontologies for human behavior recognition. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Laura, D. Smart Appliances REFerence Ontology. Available online: http://ontology.tno.nl/saref/ (accessed on 11 December 2017).
- Compton, M.; Barnaghi, P.; Bermudez, L.; GarcíA-Castro, R.; Corcho, O.; Cox, S.; Graybeal, J.; Hauswirth, M.; Henson, C.; Herzog, A. The SSN ontology of the W3C semantic sensor network incubator group. Web Semant. Sci. Ser. Agents World Wide Web 2012, 17, 25–32. [Google Scholar] [CrossRef]
- Armin, H.; Krzysztof, J.; Simon, C.; Danh, L.P.; Kerry, T.; Maxime, L. Semantic Sensor Network Ontology. Available online: https://www.w3.org/TR/vocab-ssn/ (accessed on 14 January 2018).
- Lanza, J.; Sanchez, L.; Gomez, D.; Elsaleh, T.; Steinke, R.; Cirillo, F. A Proof-of-Concept for Semantically Interoperable Federation of IoT Experimentation Facilities. Sensors 2016, 16, 1006. [Google Scholar] [CrossRef] [PubMed]
- Kotis, K.; Katasonov, A. An Iot-Ontology for the Representation of Interconnected, Clustered and Aligned Smart Entities; Technical Report; Finland VTT Technical Research Center: Espoo, Finland, 2012. [Google Scholar]
- Bermudez-Edo, M.; Elsaleh, T.; Barnaghi, P.; Taylor, K. IoT-Lite Ontology. 2015. Available online: http://www.w3.org/Submission/2015/SUBM-iot-lite-20151126/ (accessed on 19 November 2017).
- Bermudez-Edo, M.; Elsaleh, T.; Barnaghi, P.; Taylor, K. IoT-Lite: A lightweight semantic model for the internet of things and its use with dynamic semantics. Pers. Ubiquitous Comput. 2017, 21, 1–13. [Google Scholar] [CrossRef]
- Kikuchi, S.; Nakamura, A.; Yoshino, D. Evaluation on Information Model about Sensors Featured by Relationships to Measured Structural Objects. Adv. Internet Things 2016, 6, 31–53. [Google Scholar] [CrossRef]
- Alaya, M.B.; Medjiah, S.; Monteil, T.; Drira, K. Toward semantic interoperability in oneM2M architecture. IEEE Commun. Mag. 2015, 53, 35–41. [Google Scholar] [CrossRef]
- Ahvar, S.; Santos, G.; Tamani, N.; Istasse, B.; Praça, I.; Brun, P.E.; Ghamri, Y.; Crespi, N. Ontology-based model for trusted critical site supervision in FUSE-IT. In Proceedings of the 2017 20th Conference on Innovations in Clouds, Internet and Networks (ICIN), Paris, France, 7–9 March 2017; pp. 313–315. [Google Scholar]
- Horridge, M. A Practical Guide To Building OWL Ontologies Using Protégé 4 and CO-ODE Tools Edition 1.3; The University of Manchester: Manchester, UK, 2011; Volume 107. [Google Scholar]
- Surhone, L.M.; Tennoe, M.T.; Henssonow, S.F. Open Knowledge Base Connectivity. 2010. Available online: http://www.ai.sri.com/~okbc/spec/okbc2/okbc2.html (accessed on 17 January 2018).
- Protégé Axiom Language. Available online: https://protegewiki.stanford.edu/wiki/Protege_Axiom_Language_(PAL)_Tabs (accessed on 29 December 2017).
- Domingue, J. Tadzebao And Webonto: Discussing, Browsing, Editing Ontologies On The Web. 1998. Available online: http://oro.open.ac.uk/23013/1/domingue.pdf (accessed on 17 January 2018).
- Sure, Y.; Erdmann, M.; Angele, J.; Staab, S.; Studer, R.; Wenke, D. OntoEdit: Collaborative Ontology Development for the Semantic Web. Lect. Notes Comput. Sci. 2002, 2342, 221–235. [Google Scholar]
- Swartout, B.; Patil, R.; Knight, K.; Russ, T. Ontosaurus: A Tool for Browsing and Editing Ontologies. Available online: http://ksi.cpsc.ucalgary.ca/KAW/KAW96/swartout/ontosaurus_demo.html (accessed on 29 November 2017).
- Arpírez, J.C.; Corcho, O.; Fernández-López, M.; Gómez-Pérez, A. WebODE: A scalable workbench for ontological engineering. In Proceedings of the 1st International Conference on Knowledge Capture, Victoria, BC, Canada, 21–23 October 2001; pp. 6–13. [Google Scholar]
- Farquhar, A.; Fikes, R.; Rice, J. The Ontolingua Server. Int. J. Hum. Comput. Stud. 1997, 46, 707–727. [Google Scholar] [CrossRef]
- Su, X.; Ilebrekke, L. A comparative study of ontology languages and tools. In Proceedings of the International Conference on Advanced Information Systems Engineering, Toronto, ON, Canada, 27–31 May 2002; pp. 761–765. [Google Scholar]
- Kapoor, B.; Sharma, S. A comparative study ontology building tools for semantic web applications. Int. J. Web Semant. Technol. 2010, 1, 1–13. [Google Scholar] [CrossRef]
- Reeve, L.; Han, H. Survey of semantic annotation platforms. In Proceedings of the ACM Symposium on Applied Computing, Santa Fe, NM, USA, 13–17 March 2005; pp. 1634–1638. [Google Scholar]
- Kogut, P.; Holmes, W. AeroDAML: Applying Information Extraction to Generate DAML Annotations from Web Pages. In Proceedings of the First International Conference on Knowledge Capture (K-CAP 2001), Victoria, BC, Canada, 21–23 October 2001. [Google Scholar]
- Popov, B.; Kiryakov, A.; Kirilov, A.; Manov, D.; Ognyanoff, D.; Goranov, M. KIM–Semantic Annotation Platform. In Proceedings of the International Semantic Web Conference, Sanibel, FL, USA, 20–23 October 2003; pp. 834–849. [Google Scholar]
- Vargas-Vera, M.; Motta, E.; Domingue, J.; Lanzoni, M.; Stutt, A.; Ciravegna, F. MnM: Ontology Driven Semi-automatic and Automatic Support for Semantic Markup. In Proceedings of the International Conference on Knowledge Engineering and Knowledge Management: Ontologies and the Semantic Web, Sigüenza, Spain, 1–4 October 2002; pp. 379–391. [Google Scholar]
- Dill, S.; Eiron, N.; Gibson, D.; Gruhl, D.; Guha, R.; Jhingran, A.; Kanungo, T.; Rajagopalan, S.; Tomkins, A.; Tomlin, J.; et al. SemTag and Seeker: Bootstrapping the semantic web via automated semantic annotation. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2004; pp. 178–186. [Google Scholar]
- Vlachostergiou, A.; Stratogiannis, G.; Caridakis, G.; Siolas, G.; Mylonas, P. User Adaptive and Context-Aware Smart Home Using Pervasive and Semantic Technologies. J. Electr. Comput. Eng. 2016, 2016, 8–27. [Google Scholar] [CrossRef]
- Horrocks, I.; Patel-Schneider, P.F.; Boley, H.; Tabet, S.; Grosof, B.; Dean, M. SWRL: A Semantic Web Rule Language Combining OWL and RuleML. Available online: https://www.w3.org/Submission/SWRL/ (accessed on 25 November 2017).
- Huang, X.; Yi, J.; Zhu, X.; Chen, S. A Semantic Approach with Decision Support for Safety Service in Smart Home Management. Sensors 2016, 16, 1224. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Ciuciu, I.G. Semantic Decision Support Models for Energy Efficiency in Smart-Metered Homes. In Proceedings of the IEEE International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 1777–1784. [Google Scholar]
- Fensel, A.; Tomic, S.; Kumar, V.; Stefanovic, M.; Aleshin, S.V.; Novikov, D.O. SESAME-S: Semantic Smart Home System for Energy Efficiency. Inform. Spektrum 2013, 36, 46–57. [Google Scholar] [CrossRef]
- Jin, K.; Sang, O.P. U-Health Smart system architecture and ontology model. J. Supercomput. 2015, 71, 1–17. [Google Scholar]
- Krummenacher, R.; Simperl, E.; Nixon, L.J.B.; Cerizza, D.; Valle, E.D. Enabling the European Patient Summary through Triplespaces. In Proceedings of the Twentieth IEEE International Symposium on Computer-Based Medical Systems, Maribor, Slovenia, 20–22 June 2007; pp. 319–324. [Google Scholar]
- Mirhaji, P.; Allemang, D.; Coyne, R.; Casscells, S.W. Improving the Public Health Information Network through Semantic Modeling. IEEE Intell. Syst. 2007, 22, 13–17. [Google Scholar] [CrossRef]
- Lee, H.J.; Kim, H.S. eHealth Recommendation Service System Using Ontology and Case-Based Reasoning. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 1108–1113. [Google Scholar]
- Vannieuwenborg, F.; Ongenae, F.; Demyttenaere, P.; Poucke, L.V.; Ooteghem, J.V.; Verstichel, S.; Verbrugge, S.; Colle, D.; Turck, F.D.; Pickavet, M. Techno-economic evaluation of an ontology-based nurse call system via discrete event simulations. In Proceedings of the 2014 IEEE 16th International Conference on e-Health Networking, Applications and Services (Healthcom), Natal, Brazil, 15–18 October 2014; pp. 82–87. [Google Scholar]
- Ongenae, F.; Bleumers, L.; Sulmon, N.; Verstraete, M.; Gils, M.V.; Jacobs, A.; Zutter, S.D.; Verhoeve, P.; Ackaert, A.; Turck, F.D. Participatory design of a continuous care ontology: Towards a user-driven ontology engineering methodology. In Proceedings of the International conference on Knowledge Engineering and Ontology Development (KEOD 2011), Paris, France, 26–29 October 2011; pp. 81–90. [Google Scholar]
- Soldatos, J.; Kefalakis, N.; Hauswirth, M.; Serrano, M.; Calbimonte, J.P.; Riahi, M.; Aberer, K.; Jayaraman, P.P.; Zaslavsky, A.; Žarko, I.P.; et al. OpenIoT: Open Source Internet-of-Things in the Cloud; Springer International Publishing: Cham, Switzerland, 2015; pp. 13–25. [Google Scholar]
- Barnaghi, P.; TOnjes, R.; HOller, J.; Hauswirth, M.; Amit, S.; Anantharam, P. CityPulse: Real-Time IoT Stream Processing and Large-scale Data Analytics for Smart City Applications. Available online: http://www.ict-citypulse.eu/page/ (accessed on 19 November 2017).
- Petrolo, R.; Loscri, V.; Mitton, N. Towards a Cloud of Things Smart City. IEEE COMSOC MMTC E-Lett. 2014, 9, 44–48. [Google Scholar]
- Gyrard, A.; Serrano, M. A Unified Semantic Engine for Internet of Things and Smart Cities: From Sensor Data to End-Users Applications. In Proceedings of the 2015 IEEE International Conference on Data Science and Data Intensive Systems, Sydney, Australia, 11–13 December 2015; pp. 718–725. [Google Scholar]
- Kolozali, Ş.; Puschmann, D.; Bermudez-Edo, M.; Barnaghi, P. On the Effect of Adaptive and Nonadaptive Analysis of Time-Series Sensory Data. IEEE Internet Things J. 2016, 3, 1084–1098. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Name | Inference | Type Separation | Items Restricted for Usage |
|---|---|---|---|
| OWL FULL | Undecidable | Non-mandatory | None |
| OWL DL | Decidable | Mandatory | RDF(s) language constructor, Role |
| OWL Lite | Decidable | Mandatory | RDF(s) language constructor, Role, Class constructor, Cardinality Restriction |
| Type | Cooperation Work | Ontology Library | Expressivity | Consistency Check |
|---|---|---|---|---|
| Protégé | N | Y | Y | Y |
| WebOnto | Y | Y | Y | Y |
| OntoEdit | Y | Y | Y | Y |
| Ontolingua Server | Y | Y | N | N |
| Ontosaurus | Y | Y | Y | Y |
| WebODE | Y | N | N | Y |
| Semantic Annotators | Semantic Models |
|---|---|
| AeroDAML [90] | DAML |
| KIM [91] | KIMO |
| M3 Semantic Annotator [11] | M3 |
| MnM [92] | Kmi |
| SemTag [93] | TAP |
| Name | Activity Granularity | Social Interoperability | Fuzzy Inference |
|---|---|---|---|
| SOUPA | Action | N | N |
| CoBrA-Ont | Action | N | N |
| CoDAMoS | (Task, Acitivty) | N | N |
| PalSPOT | Activity | Y | N |
| The Delivery Context Ontology | N | N | N |
| Fuzzy-Onto | (Actions, Activities, Behaviours) | Y | Y |
| Name | Service Modeling | Actuation Modeling | Electronic Labels Modeling |
|---|---|---|---|
| SSN | N | Y | N |
| IoT-ontology | Y | Y | Y |
| IoT-Lite | Y | Y | Y |
| IoT-O | Y | Y | N |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, F.; Li, Q.; Zhu, T.; Ning, H. A Survey of Data Semantization in Internet of Things. Sensors 2018, 18, 313. https://doi.org/10.3390/s18010313
Shi F, Li Q, Zhu T, Ning H. A Survey of Data Semantization in Internet of Things. Sensors. 2018; 18(1):313. https://doi.org/10.3390/s18010313
Chicago/Turabian StyleShi, Feifei, Qingjuan Li, Tao Zhu, and Huansheng Ning. 2018. "A Survey of Data Semantization in Internet of Things" Sensors 18, no. 1: 313. https://doi.org/10.3390/s18010313
APA StyleShi, F., Li, Q., Zhu, T., & Ning, H. (2018). A Survey of Data Semantization in Internet of Things. Sensors, 18(1), 313. https://doi.org/10.3390/s18010313