1. Introduction
Determining the pedestrian location in indoor environments using consumer smart phones has been a fundamental requirement in many applications such as path finding, emergency planning and augmented reality. Since GPS signals cannot achieve satisfactory results in indoor environments, many alternatives have been proposed. The prominent methods for the most current indoor localization technologies are based on dedicated infrastructures, such as Wi-Fi access points [
1,
2], Bluetooth [
3,
4], ultrasonic networks [
5], ultra-wideband (UWB) [
6] and magnetic fields [
7]. However, these methods are expensive and label-extensive for large-scale deployment and suffer from discontinuous tracking during pedestrian movement [
8]. Google Tango has devised a depth camera equipped smartphone that can localize itself as well as simultaneously reconstructing the indoor model [
9]. However, this is more of a model reconstruction technology than a localization strategy, for the reason that keeping the camera on during walking does not conform to the common human waking mode and localizing the smartphone and simultaneously reconstructing the scene becomes computationally expensive and memory-infeasible for larger scenes. Fortunately, vision-based localization can provide visual gyroscope and visual odometer in GPS-challenging indoor spaces [
10] and serve as a low-cost and high-accuracy solution in ubiquitous indoor localization.
Vision-based localization has two main approaches, which are the simultaneous localization and mapping (SLAM) approaches such as Google Tango and image-based localization. Compared with SLAM [
11], reconstructing the scene model in advance and opening the camera for localization only when lost is a more appropriate approach in indoor pedestrian localization [
12]. The image-based localization result can be directly treated as the pedestrian location because people tend to carry their smartphone close to their body. Given the 2D image features and the 3D scene features, the camera pose can be estimated from the 2D-3D correspondences by applying an
n-point pose solver inside a random sample consensus (RANSAC) loop [
13]. Recent affordable or free structure-from-motion (SfM) software, such as Bundler [
14], VisualSfM [
15] and Photoscan [
16], have allowed us to reconstruct indoor scenes and thus make it possible to undertake image-based localization in indoor environments. When combined with pedestrian dead reckoning (PDR) that estimates the distance and heading measurements of every step from the accelerometer and gyroscope embedded in the smartphone [
17], discrete image-based localization can be interpolated to recover a continuous pedestrian trajectory. On the other hand, the relative positioning and the error accumulation of PDR can be remedied by the high-accuracy image localization result, by providing the initial position and regular correction when drifting. Therefore, with the 3D scene model provided, combining image-based localization and PDR can complement each other and achieve self-dependent and high-accuracy localization using only smart phones, without any extra equipment.
Image-based localization was initially formulated as an image retrieval problem focused on matching a query image to an image database with geolocations [
18]. When combined with the bag-of-visual-words model [
19], an image retrieval system is applicable to scalable scenes from the street-level [
20], to the city-level [
21] and to the worldwide-level [
22]. Since the image database may contain thousands of millions of images, to efficiently retrieve and localize the query images, Li et al. [
23] used an iconic scene graph to create a compact summary of the global images. Chen et al. [
24], on the other hand, improved the system’s robustness to perspective views and hence the recall rate, by fusing the orthogonal and perspective street images to build synthetic views. Other improvements have focused on avoiding mismatches by dealing with repetitive scenes [
25] and confusing scenes [
26]. Compared to our method, the image retrieval strategy can only yield coarse location estimation. Furthermore, the raw images in the database are stored independently, with ignoring the underlying geometry [
27].
In contrast to the pure image retrieval approach, SfM-based localization can obtain accurate pose estimation with exact orientation and position by correlating 2D features in a query image with 3D scene features in the model. Moreover, the SfM model presents a precise summary of the scene, with each 3D point triangulated from a trace of matched features and the noisy ones eliminated and not used for the matching. Consequently, it can accelerate the correspondence search by containing orders of magnitude fewer points than there are features in the images [
28]. The most popular correspondence search algorithm is 2D-to-3D matching that directly uses the 2D descriptors as the query features to search for the corresponding 3D scene features based on the approximate nearest neighbor. This is followed by the use of Lowe’s ratio test [
29] to eliminate the ambiguous matches. However, the Lowe’s ratio test tends to reject more and more correct matches as too ambiguous for larger scenes since the descriptor space defined by the 3D points becomes denser [
13]. Therefore, the 3D-to-2D approach, which inversely matches the 3D points in the model against the 2D features in the image, is adopted to register images. The ratio test of the 3D-to-2D algorithm is not sensitive to large scenes as the descriptor space remains relatively constant and is not negatively affected by the density of the 3D model. The efficiency is affected however, when the scenes become larger.
At the core of correct SfM-based localization is the robust estimation of accurate 2D-3D matches. Due to large viewpoint changes and repetitive textures, using the above-mentioned correspondence search algorithm alone may fail to register an image affected by a high outlier ratio. In order to improve the recall rate, Svarm et al. [
30] and Zeisl et al. [
27] exploited gravity direction and the height of the camera from inertial measurement unit (IMU) measurements as prior information to create a probabilistic model for the camera pose estimation, which is able to handle an inlier ratio of 1% or less. However, this method requires accurate estimation of the height and gravity direction. Li et al. [
31], on the other hand, combined 2D-to-3D matching and 3D-to-2D matching to increase the robustness to high outlier ratios. Mismatches are removed and the lost matches are detected by searching from both side. Sattler et al. [
13] adopted the same strategy and extended it to larger scenes by incorporating a bag-of-visual-words model to encode the features. The visibility information embedded in the SfM model was also explored to improve the correspondence search efficiency by getting rid of unrelated images. These methods however, only yield a discrete localization result and apply mainly to outdoor scenes.
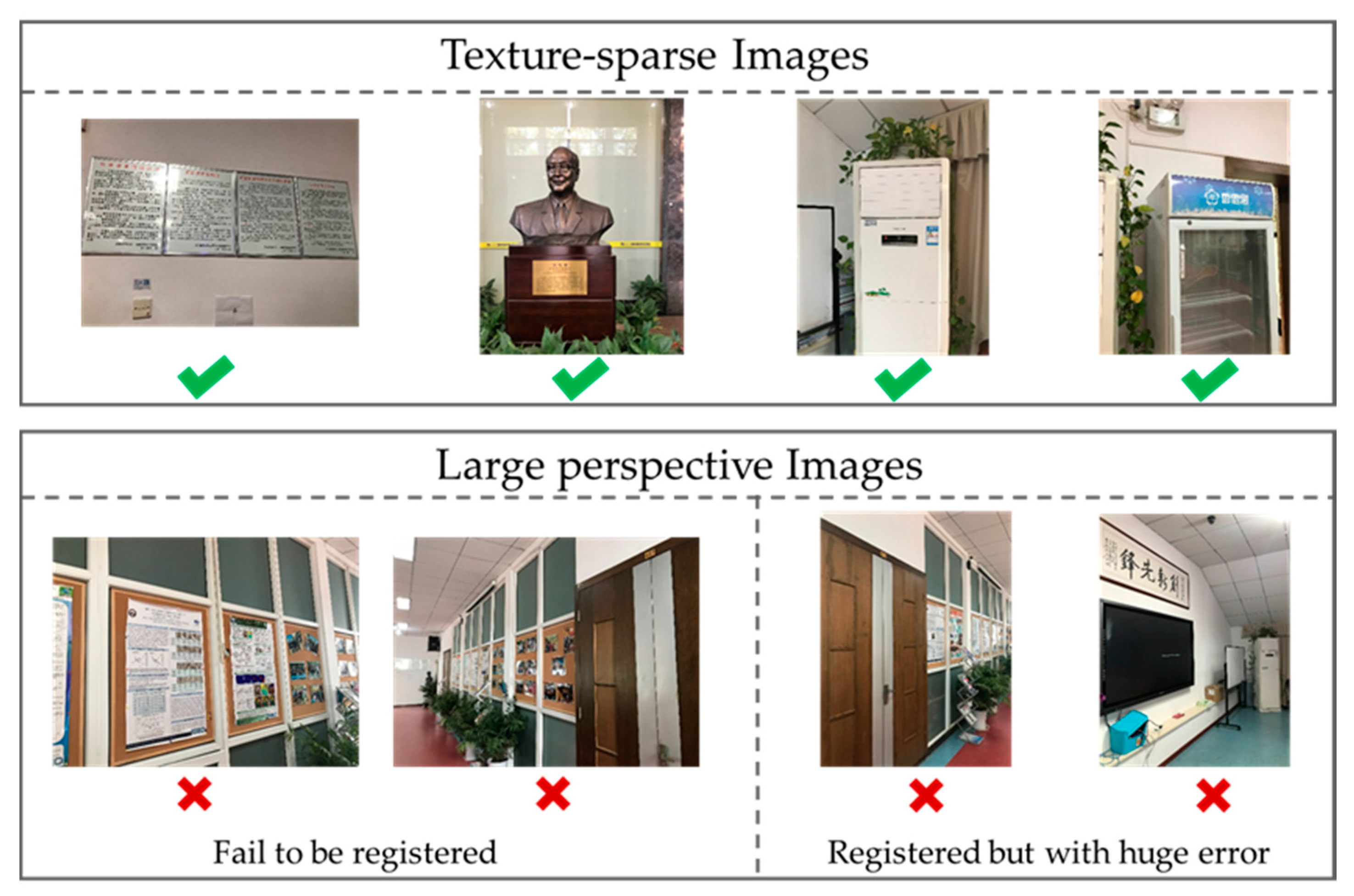
Image-based localization in indoor space applications for mobile devices faces challenges. The mobile device is memory and computationally limited, posing a challenge for its practical use in larger scenes, especially in the SLAM mode. Furthermore, changing environments, such as the appearance aliasing caused by illumination or structural change, demand a method that can robustly recognize the right place. Research has explored potential solutions to these problems; FAB-MAP [
32], fast appearance-based mapping, is a typical approach for obtaining a location from a single image, based on bag-of-words image retrieval. This solution is widely used in online loop closure detection in mobile robotics, as the algorithm is scalable and adapts in a linear fashion to changes in the number of points and the size of map. In contrast, rather than using a single image, SeqSLAM [
33] selected the best candidate location within an image sequence, improving the robustness to extreme environmental change such as moving from daytime to nighttime, from season to season, or from fair weather to rain. Similar to the SeqSLAM method, which uses the image sequence, ABLE-M [
34] deploys a binary description of images that reduces memory and computational costs, remaining stable despite environmental changes that affect image appearance. Nowicki et al. [
35] evaluated the application of single image and image sequence localization in indoor environments on mobile devices, validating the feasibility and real-time performance of both of these algorithms. Furthermore, Nowicki et al. also found that algorithms using single images are not susceptible to local self-similarity issues inside buildings, as texture changes in images are not as large as those images taken in outdoor space. Thus, we infer that an image sequence is more suitable in situations with a known trajectory but does not perform well at junctions or in open-spaces. Consequently, based on the existing research, we adopted the single image strategy, as it conforms the typical patterns of human movements through space and scalable to larger scenes in indoor localization. Although the single image strategy only obtains a user location for discrete set of positions and is not applicable to highly occluded spaces; nevertheless, this method can be combined with other indoor localization technologies, such as PDR to achieve continuous localization. Moreover, PRD results can constrain image-based localization to the proper locations, avoiding false recognition of places with an appearance similar to the target location.
Based on the above observations, we propose a simple but efficient indoor localization approach that combines image-based localization and PDR for long-term indoor pedestrian trajectory estimation. Considering the memory and computational limitation of the currently available smart phones, we reconstruct the 3D scene model of the indoor environment with the SfM pipeline in advance. In the localization stage, we take an image with the smartphone and match it against the database through a fused 2D-to-3D and 3D-to-2D matching scheme. The image-based localization acts as the starting position for PDR and provides regular correction once the accumulative error is beyond the predefined threshold. We make three main contributions. Firstly, we perform the 3D-to-2D matching only when the 2D-to-3D matching cannot successfully register an image, to achieve a higher image recall rate while restraining the computation time. Secondly, we adopt the visibility and co-visibility information readily encoded in the SfM pipeline in searching for correspondences in both sides, by eliminating irrelevant images and facilitating robust matching. As for the third major contribution, we demonstrate that combining image-based localization and PDR can serve as a promising, low-cost, self-dependent and continuous indoor pedestrian localization strategy, especially in the situations where no map constraints can be exploited. From the experimental results, the proposed method offers an accurate and continuous trajectory estimation, with an error of only 0.56 m, based totally on the smartphone.
2. Materials and Methods
In this section, we describe our combined image-based localization and PDR framework, which allows for fast and accurate indoor pedestrian localization. The workflow of the proposed localization algorithm is illustrated in
Figure 1. We propose a simple but efficient 2D-to-3D and 3D-to-2D combination algorithm to estimate robustly the correspondences, with the 3D-to-2D matching triggered only when not enough valid matches are detected. In order to improve the search efficiency from both sides, the visibility and co-visibility information is adopted to remove the points that are less likely to generate potential matches. An early termination approach is also performed to stop the search once
matches are found. When combined with the PDR trajectory, we can obtain a bias-free estimation of the pedestrian locations.
2.1. Database Construction
Considering the memory and computational constraints of smartphones, in contrast to the SLAM algorithm, we adopt the strategy of reconstructing the 3D model of the indoor scene in advance and perform image-based localization only when lost. The constructed database consists of 3D points with descriptors, using image matching and the VisualSfM (VSFM) algorithm [
15]. Since each point of the SfM model is triangulated from the feature traces of multiple images, it is often associated with a cluster of related feature descriptors. Storing all the feature descriptors of each 3D point is straightforward and offers the most accurate description of the local appearance of a point. However, it also induces a high memory requirement and restrains the computational efficiency as some points may have hundreds of associated descriptors [
28]. A more concise alternative is to store a single descriptor for each point. We use the mean of the corresponding image feature descriptors to represent each point and a typical way of storing descriptors in a memory-limited environment. While this may not necessarily be representative for clusters of scale-invariant feature transform (SIFT) features that are large, Li et al. [
31] proved that this approach can achieve a comparable accuracy to the all-descriptors representation. Other concise descriptor representations such as the median of a related descriptor was also explored but these failed to achieve a performance comparable to the mean SIFT descriptors [
28].
2.2. Image Registration
In order to obtain immediate feedback after taking a photo of the indoor scene, the ultimate goal of our system is to produce an accurate and efficient pose estimation of a query image, given a relevant database of recovered 3D points. At the core of this is the accurate and efficient 2D-3D correspondence search, whose common pipeline can be described as: for each query feature
with descriptor
, we search the two nearest neighbor points
and
with descriptor
and
, by calculating the Euclidean distance between the descriptors and applying the kd-tree searching algorithm. In order to eliminate the ambiguity caused by repetitive textures, the matched correspondences are accepted as valid only when the Lowe’s ratio test is passed:
where
is a parameter that is experimentally ranged between [0.6, 0.8] [
12]. The generated set of 2D-3D matches are finally input to the RANSAC [
36]-based 6-point algorithm, which estimates the pose of the camera [
37] by iteratively calculating the transform matrix and choosing the best one with the most inliers. In our method, we consider a query image as successfully localized if the best pose found by RANSAC has at least 12 inliers. The algorithm can be summarized as Algorithm 1.
| Algorithm 1. 2D-to-3D matching |
| Input: Query image feature set , with descriptor , and 3D point database , with descriptor . |
| for i = 1 … n (n is the number of features in an image) |
Search two nearest neighbor points and in for each query feature , by calculating the nearest distance of the associated descriptor and descriptor using the FLANN algorithm.
Perform Lowe’s test, if , then is regarded as a valid match. |
| end |
| Calculate the camera pose by performing 6-point algorithm based on the 2D-3D matches . |
| Output: a 6-degree camera pose. |
However, following the typical workflow as described in this section, the query image may not be registered successfully all the time, especially in the case of large outlier matches being detected. The high outlier rate is caused by either the mismatches of the SIFT descriptors or the high true negative rate of Lowe’s ratio test in the 2D-to-3D matching, especially when the scene gets larger. This is because the descriptor space defined by the 3D points becomes denser for a larger scene, making the Lowe’s ratio test reject more and more correct matches as too ambiguous. As a compromise to the high outlier ratio, RANSAC requires more iteration to ensure the accuracy of the estimated pose, which negatively affects the efficiency of the algorithm. Therefore, other algorithms must be explored for robust estimation of 2D-3D matches.
3D-to-2D matching, which inversely matches 3D points against 2D features, is proposed to recover the lost matches rejected by the 2D-to-3D matching in Lowe’s ratio test, as described in Algorithm 2. The density of the descriptor space defined by the query image does not depend on the model and thus not affected by the scale of the scene. However, it tends to accept false matches because there is no global constraint on the 3D points. When considering the 3D points independently, the Lowe’s ratio test is likely to accept matches for all the 3D points in the set if one of the points passes the test, leading to a significantly higher false positive matching rate. On the other hand, if we suppose that
represents all the 3D points in the model and
represents all the features in the query image, then the time complexity for 2D-to-3D matching is
and the 3D-to-2D matching is
. It is easily observable that even in a compact scene, the number of points is much larger than that of detected query features in the image. In other words, 3D-to-2D matching is not as efficient as 2D-to-3D matching when a large scene with extensive 3D points is considered. As reported in [
13], when compared to other algorithms, 3D-to-2D matching does not perform well in considering the number of localized images. Therefore, in order to exploit the merits of both methods, a combination must be exploited and a more compact 3D scene must be constructed to accelerate the matching process.
| Algorithm 2. 3D-to-2D matching |
| Input: Query image feature set , with descriptor ,and database points , with descriptor |
| for i = 1 … m (m is the number of 3D points in the database) |
Search two nearest neighbor features and from feature set for the query point , by calculating the distance between associated descriptor with descriptor , using the FLANN algorithm;
Perform Lowe’s test, if , then is regarded as a valid match. |
| end |
| Calculate the camera pose by performing a 6-point algorithm based on the 3D-2D matches . |
| Output: a 6-degree camera pose. |
2.3. Visibility and Co-Visibility Information
Searching for correspondence from both sides inevitably increases the time needed to detect matches. In order to counteract the time consumption of the extra search process and improve the robustness of the search algorithm, we exploit the visibility and co-visibility information that encodes the underlying geometry in the SfM model, as well as an early termination strategy, to facilitate the correspondence search.
Visibility information is rooted in one of the major properties of SfM, in that each 3D point is recovered from several image features, which define the visibility significance of the point. The points with higher visibility have a larger possibility of being matched than the points with lower visibility, for the reason that a highly visible point is intuitively more likely to be visible in the query image [
31]. In the 2D-to-3D search, the image features search through the whole database and find a corresponding 3D point in a limited space, making large search work wasted. This implies that the correspondence search could be accelerated if we could generalize the 3D model with the points that are more likely to yield a match. We therefore apply a visibility filter to the SfM model and preserve a set of points that are visible in more than
images (
= 5 in our experiment) as a simplified model (as shown in
Figure 2a,b). The correspondence search is then performed between the query image and the simplified model until
matches are found.
controls the balance between run-time efficiency and localization effectiveness.
The search algorithm can be formulated as follows. Firstly, we determine the subset that contains all the potential points that survive in the visibility filter. We then search for the 2D features against the 3D point subsets, such that the number of expected matches is at least . If the algorithm finds matches successfully, then the set of matches links the 2D features in the query image directly to the 3D points in the model. These matches are fed directly into the pose estimation routine. We use the 6-point direct linear transformation (DLT) approach to solve the projection matrix of the query camera, followed by local bundle adjustment to refine the pose.
However, there may exist situations where not enough valid matches can be found, due to the uneven distribution caused by preserving only the highly visible points. We therefore perform the 3D-to-2D matching to recover the lost matches. This begins with the 3D point set
obtained by performing the 2D-to-3D matching. We then apply k-nearest neighbor search to generate the set
, resulting in a set of potential valid 3D-to-2D correspondences. However, the spatial proximity does not necessarily imply the matching correspondence. For example, in
Figure 2c, the spatially close red and green points can never be observable in the same query image. Therefore, we exploit the co-visibility filter to remove such confusing neighbor points.
As illustrated in
Figure 2, co-visibility can be defined using a bipartite visibility graph. Each point refers to a 3D point in the model and each node refers to a camera. The edge
connects the 3D points and camera. The camera sets that observe the same points are thus defined as:
where
represents the 3D points and
represents the cameras. Consequently, the co-visible point sets
contain the largest component that is observed by camera sets
(as shown in
Figure 2d). The points that are spatially continuous but do not imply co-visibility may be confusing and contaminate the generation of correct correspondences. Therefore, through the co-visibility filter, we remove the points that are not contained in the bipartite graph, which means that the whole search set is a subgraph consisting of only the matching points and their cameras. Instead of applying RANSAC-based pose estimation on all the matches, our co-visibility filter thus first identifies all the connected components and then filters out all the matches not contained in
. By eliminating the wrong matches, the RANSAC-based pose estimation is accelerated and has a larger possibility of obtaining correct answers. The proposed algorithm is presented as Algorithm 3.
| Algorithm 3. The proposed 2D-to-3D/3D-to-2D matching |
| Input: Query image feature set , with descriptor , and database points , with descriptor |
Preserve the points that are visible in more than five images:
, . |
| for i = 1 … |
| Perform 2D-to-3D algorithm with early termination: . |
| end |
| If inlier > threshold |
| end |
| else |
Eliminate non-covisible points: , .
for j = 1 … y
Perform 3D-to-2D algorithm: .
end |
| end |
| Calculate the camera pose: . |
| Output: a 6-degree camera pose. |
2.4. PDR Combination
The image-based localization can obtain accurate pose estimation in discrete places. However, in most cases, we need continuous tracking of the pedestrian in applications such as indoor navigation and augmented reality. The PDR algorithm, which estimates the distance and heading measurements of every step, given an initial location from the accelerometer and gyroscope embedded in the smartphone, has become a promising low-cost and continuous localization technology in indoor environments. Four core components are considered in PDR: step detection, step length estimation, heading estimation and initial position determination.
The step detection algorithm relies on the fact that the accelerometer reveals a repetitive pattern when the user walks. We use a two-threshold based peak detection algorithm to identify the peaks. The first threshold is the minimum acceleration magnitude that determines a peak and the second threshold is the minimum time duration between two steps. Peaks that satisfy both the magnitude and frequency threshold are identified as true steps. The orientation is estimated from the gyroscope by exploiting the quaternion calculation. Our system assumes that the smartphone is held in hand, with it pointing in a forward direction. The angular rate reading from the gyroscope is then integrally calculated to determine the orientation quaternion at each step. The orientation quaternion (or the Euler rotation vector roll-pitch-yaw (
) between two successive epochs and a scalar component) from the gyroscope is then utilized to approximate the orientation update. The step length is calculated from the Weinberg model [
17]:
where
and
are the maximum and minimum values of the yaw acceleration samples, respectively. K is a constant determined by training. Our approach takes
as the initial value. Since step length exhibits variation, even with the same individual in the same walk, we add a random error
(uniformly distributed in the range of
) to the stride length.
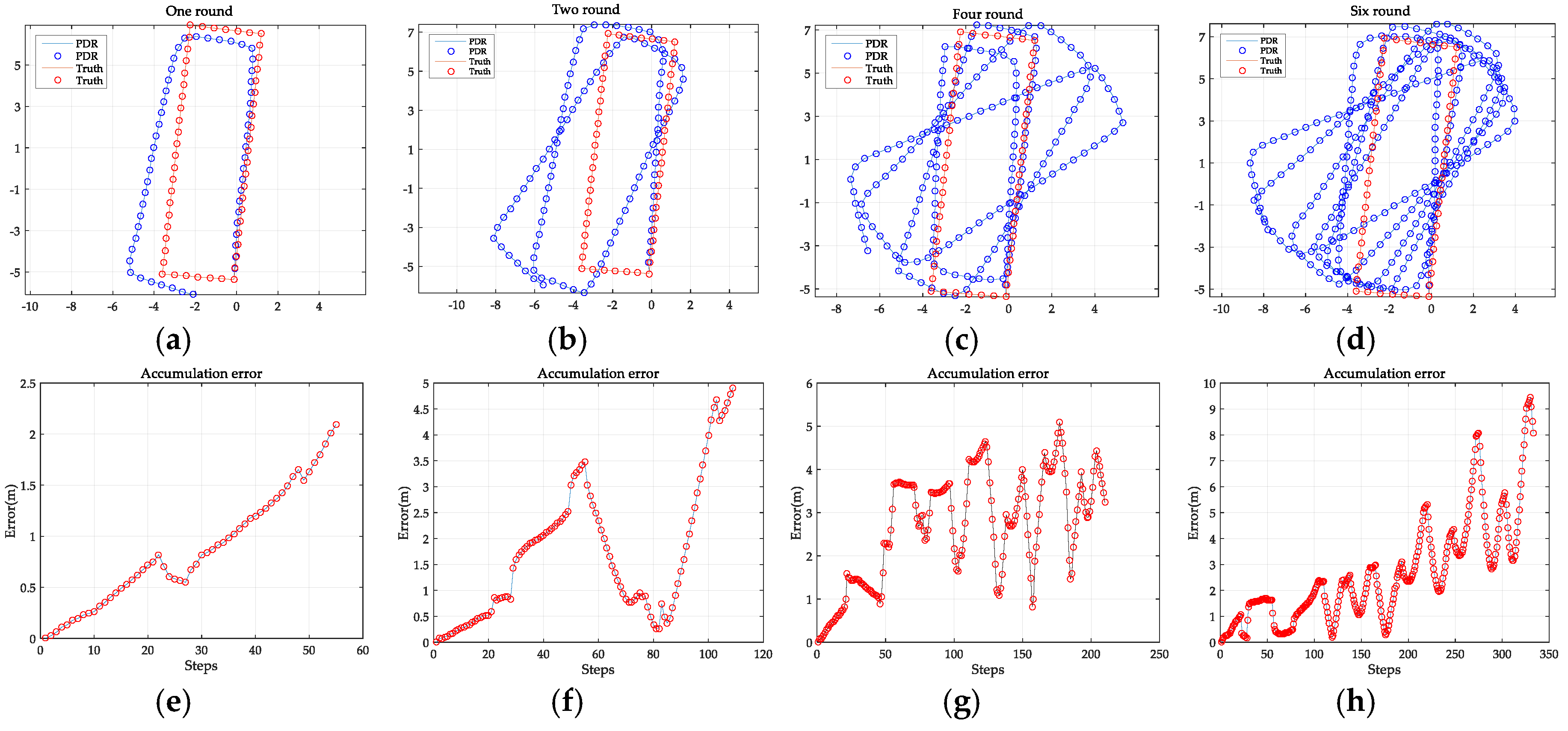
However, due to the low-cost nature of the micro-electromechanical system (MEMS) sensors, the long-term tracking of PDR may locate the user several meters away from the true location. Moreover, the initial location must be provided by other absolute positioning technologies, which means that the PDR method alone is unable to achieve acceptable results. To solve this problem, we combine image-based localization with PDR to correct the biased trajectory and provide reliable long-term indoor localization.
The image-based localization provides the initial location and regular correction for the PDR when lost. After obtaining the image-based localization result and the PDR trajectory, we now combine them. The key problem is identifying the action of taking a photograph and discriminating it from the PDR step counting procedure. Therefore, we analyzed the pattern of the accelerometer and gyroscope when taking a photo with the smartphone. The user was asked to walk a distance as usual, with the smartphone held in hand. After a while, the user was asked to stop to take a photo of the environment and then continue to walk. The readings of the accelerometer and gyroscope are shown in
Figure 3.
The action of taking a photograph reflects on the accelerometer as a slight wave between two steps and on the gyroscope as a sharp increase and then back to normal (as shown in
Figure 3). The pattern reflected by the accelerometer may be confused with the action of standing still. In addition, the two starting and ending peaks detected by the accelerometer are not real steps and may contaminate the step count because the sensor reading of the user raising the phone and then moving it back to its original position is similar to that of regular walking. This can be discriminated from a standing still action by detecting the sharp orientation change on the gyroscope reading. Any of the single readings in the xyz coordinates of the orientation may result in a different pattern due to the jitter of the smartphone. Therefore, we use the mean-square-root of the three axes for detection, which show a large, sharp change in orientation. The combinational detection of the accelerometer and gyroscope can discriminate the action of taking a photograph from both staying still and walking.
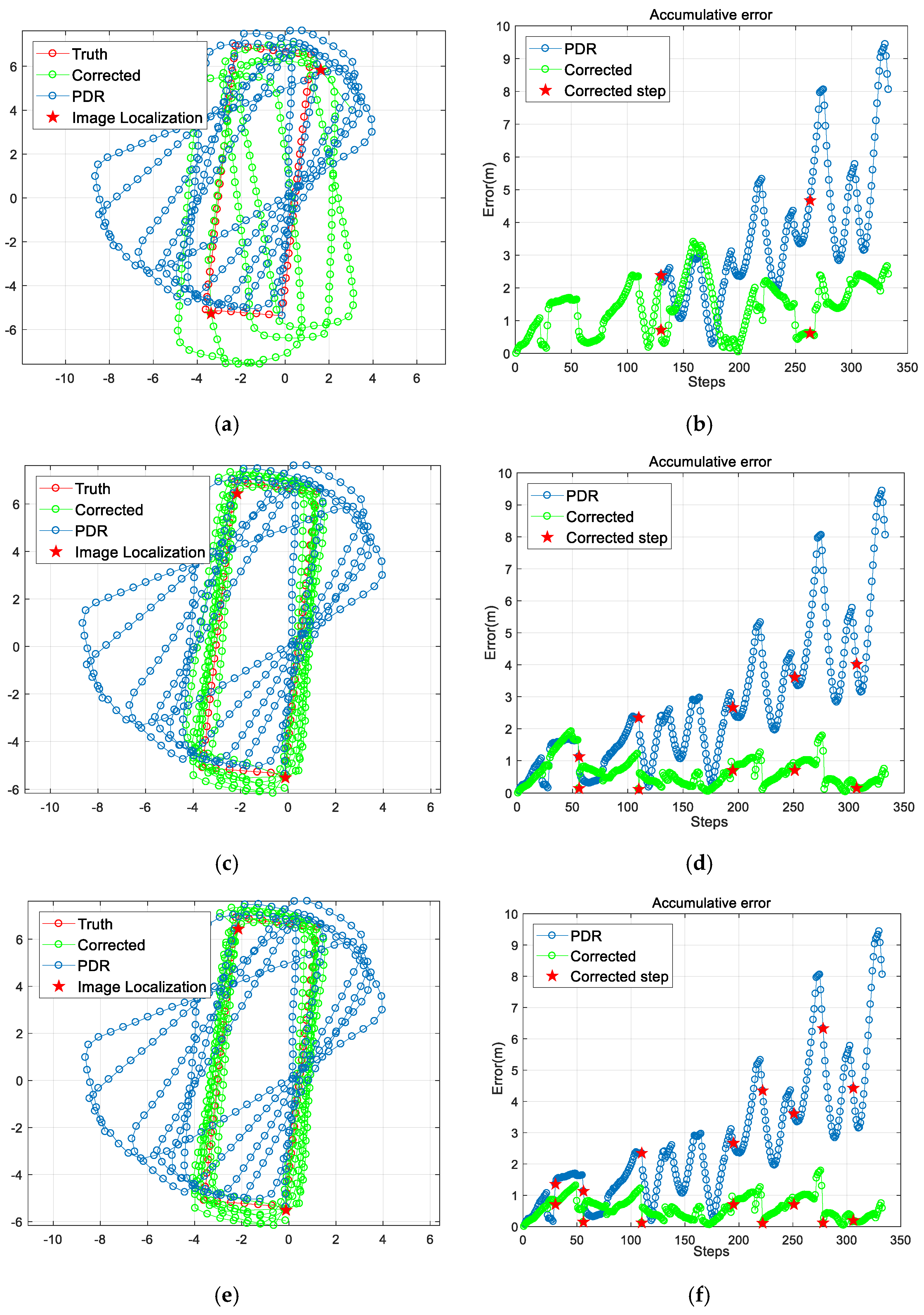
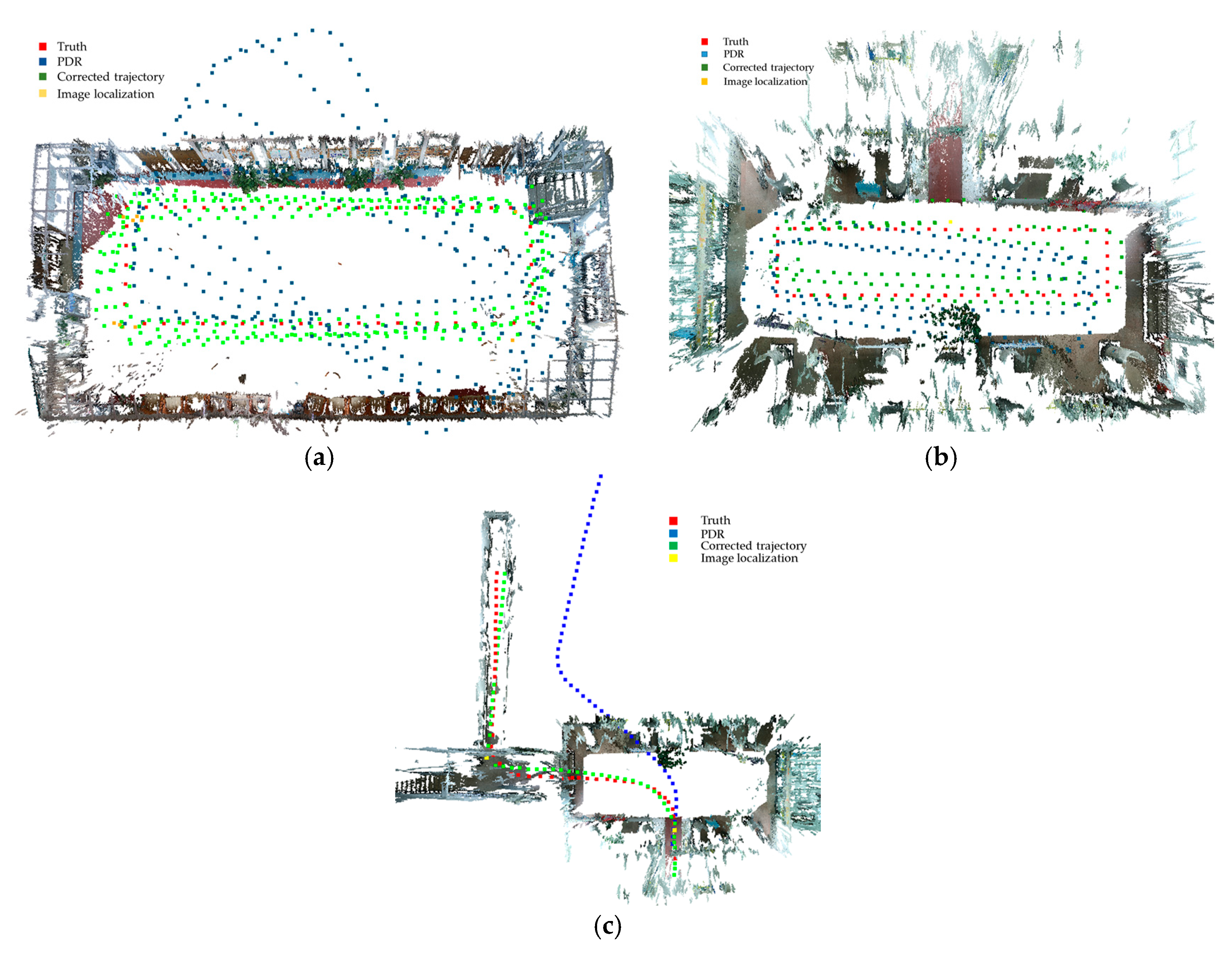
The PDR stops step counting when detecting the action of taking a photograph and resumes working after receiving the image-based localization result and treating it as the initial location of the current position estimation. Because of the trajectory drift caused by accumulative error, there may be a discrepancy between the newly relocated result and the last location estimated by PDR, indicating that large errors exist in the PDR-estimated trajectory. In order to reduce this discrepancy, we inversely recalibrate the PDR result based on the image-based localization. Since the errors of the PDR are accumulated step-by-step, we backward counteract the error linearly as the number of steps. If the past trajectory is a straight line, the linear transformation is performed directly. If the past trajectory consists of several lines with corners, we first perform rotation transformation according to the corner of two lines connecting the start point and the two endpoints and then segment the trajectory into several parts with corners. Finally, we apply a linear transformation to each segment as in line transformation. The process is illustrated in
Figure 4. However, even the estimated trajectory may not perfectly reflect the trajectory of the pedestrian. For example, the user is supposed to have made an orthogonal turn but the estimated orientation is larger than 90°, as shown in
Figure 4. However, this minor error has no significant negative impact on the estimated localization. It is within the tolerance error of indoor pedestrian localization and does not require absolute accuracy. It is an image-based localization, which avoids large location mistakes and PDR continuously tracks the pedestrian trajectory that jointly determines the effectiveness of the localization result. In this way, we achieve continuous and accurate pedestrian trajectory estimation in an indoor environment.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}