Influence of the Distribution of Tag IDs on RFID Memoryless Anti-Collision Protocols



Abstract
:1. Introduction
2. Background
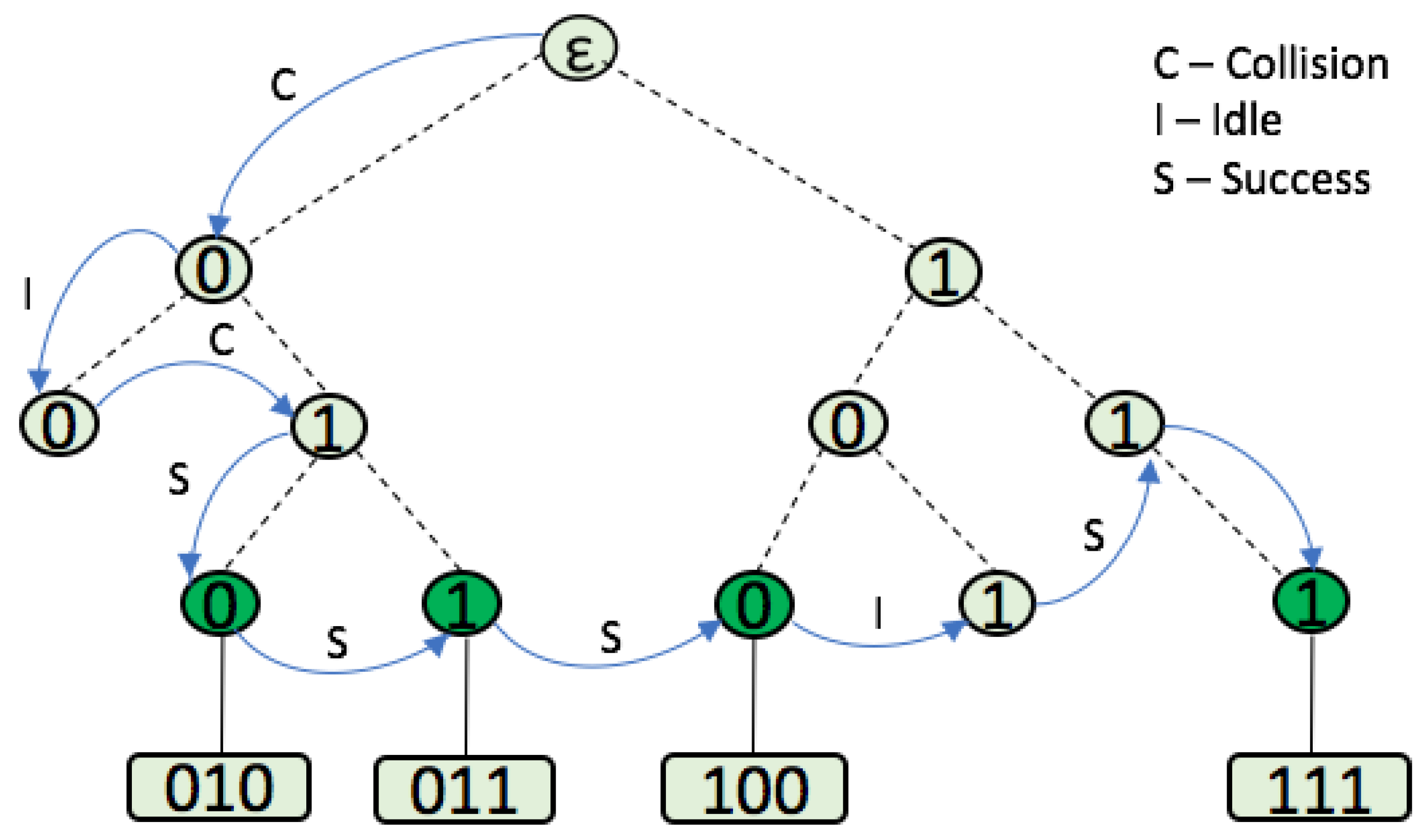
- Slot: The period of time that divides the tags’ responses is called a slot. It includes a reader command and a tag response. During the identification process, and depending on the number of tag responses received by the reader, three types of slot can occur: collision, idle, and success. A collision occurs when more than one tag answers the reader’s command in the same slot. When no tag responds to the reader’s command, then an idle slot happens. Finally, a success occurs when just one tag is correctly read by the reader and, therefore, identified.
- Query: A bit-string broadcast command transmitted by a reader. The query consists of a prefix-binary string that all tags in the interrogation area will compare with their ID. In case a tag’s ID does not match the query, the reader command will be rejected.
- Identification process: This is the time period that includes a certain number of time slots or rounds that the reader needs to identify all tags in the range of its antenna.
2.1. Multi-Access Methods
2.2. Aloha-Based Protocols
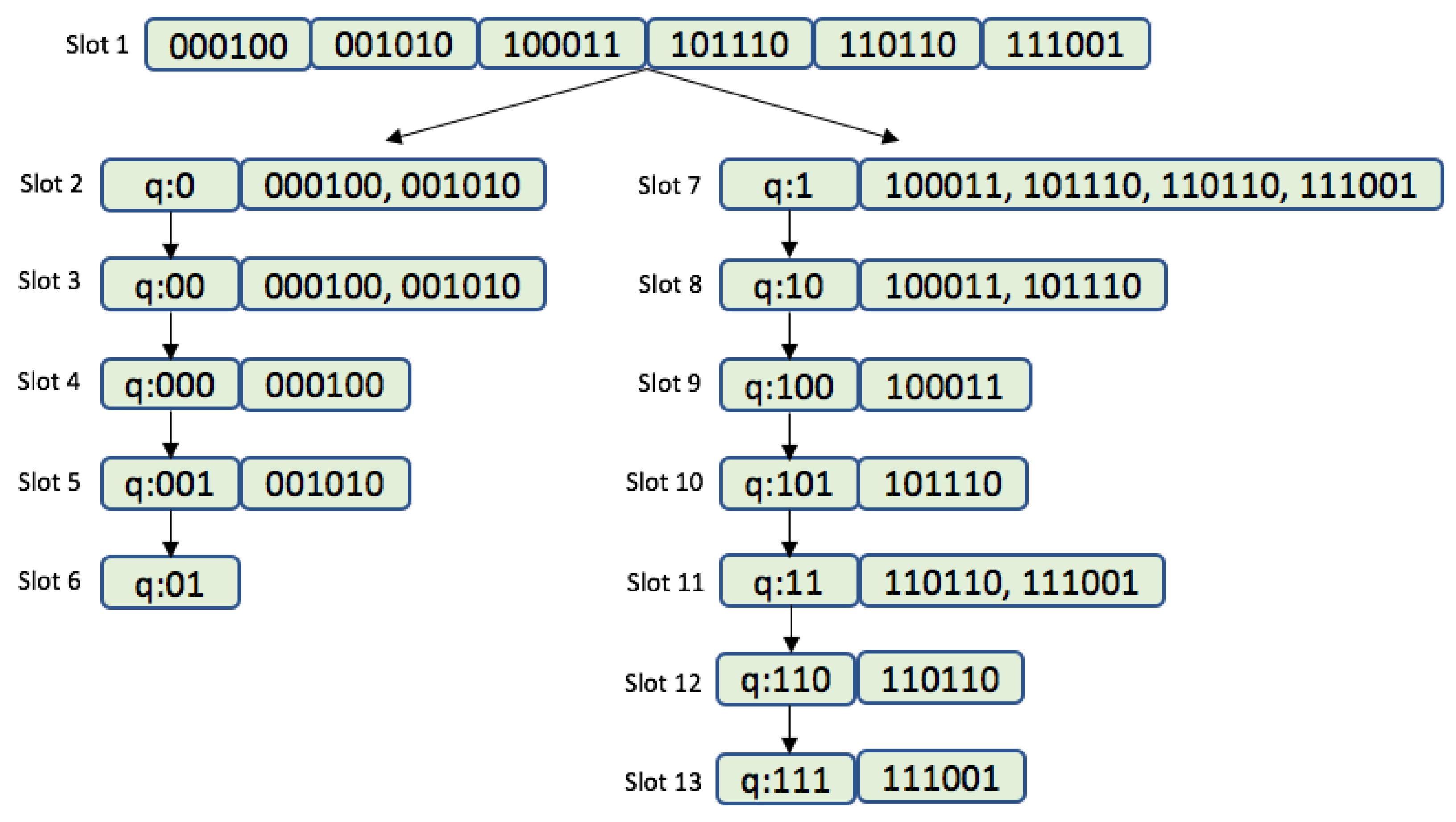
2.3. Tree-Based Protocols
2.4. Hybrid Protocols
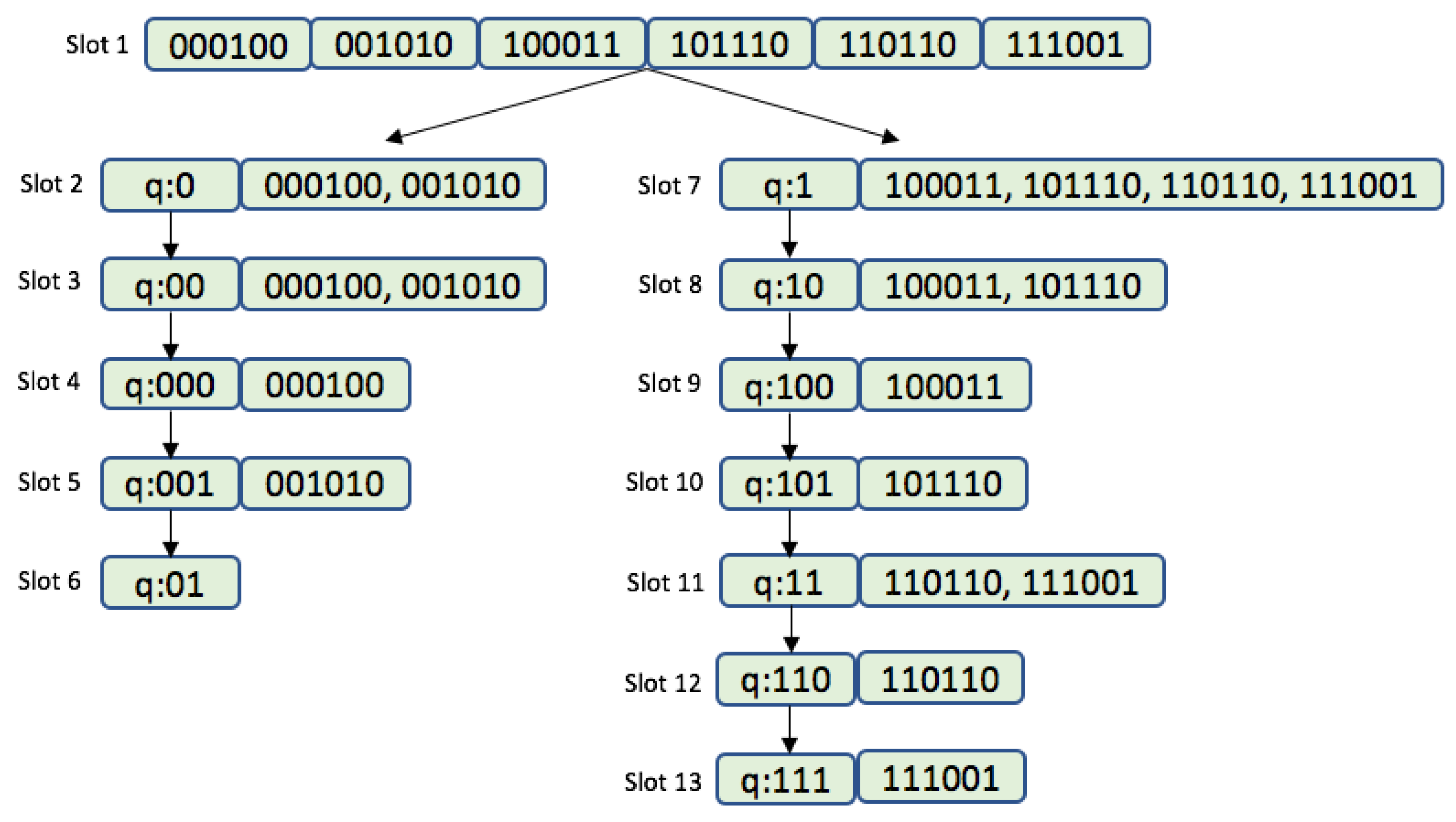
2.5. Query Tree Protocol
2.6. Smart Trend Traversal Protocol
- A collision occurs when QTP is at too high level and should move down by adding a longer prefix to the query. Consequently, the reader appends t bits of 0’s to the last query, where t = s + − 1. Let s denote the minimum increase, and be the number of consecutive colliding slots.
- An idle slot occurs when no tag responds to a reader query. QTP needs to traverse up just one level, which can lead to a new collision. This rule will be applied only to the right side. If the empty response comes from the left side of the tree, QTP must move horizontally to the right. The reader will decrease the query length by m bits, where m = s + − 1 and is the number of consecutive idle slots.
- Upon a successful response, a single node is visited, indicating that the tag has been identified successfully by the reader. Then QTP moves to the symmetric node if the query finishes with 0, but it returns one level if the query finishes with 1.
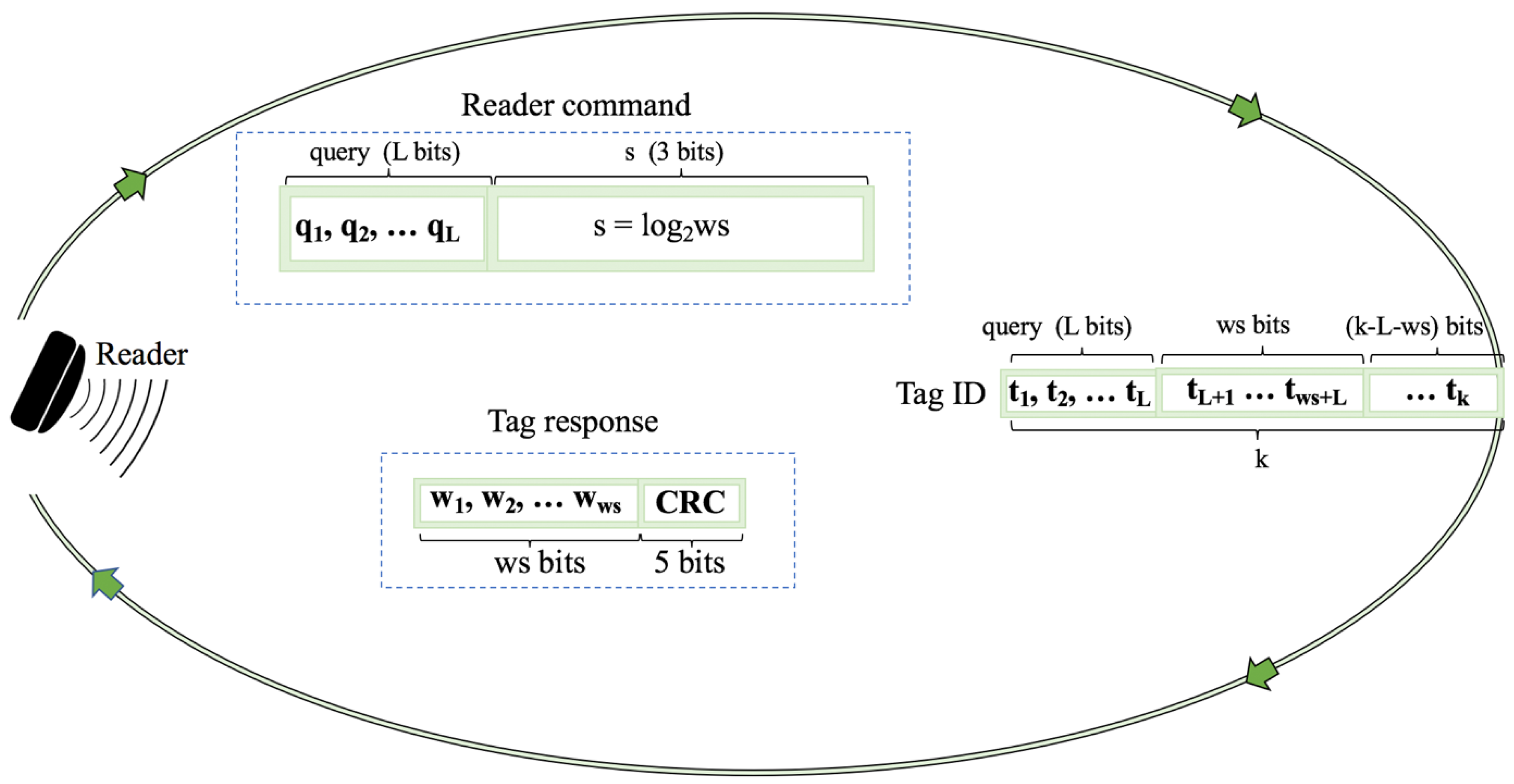
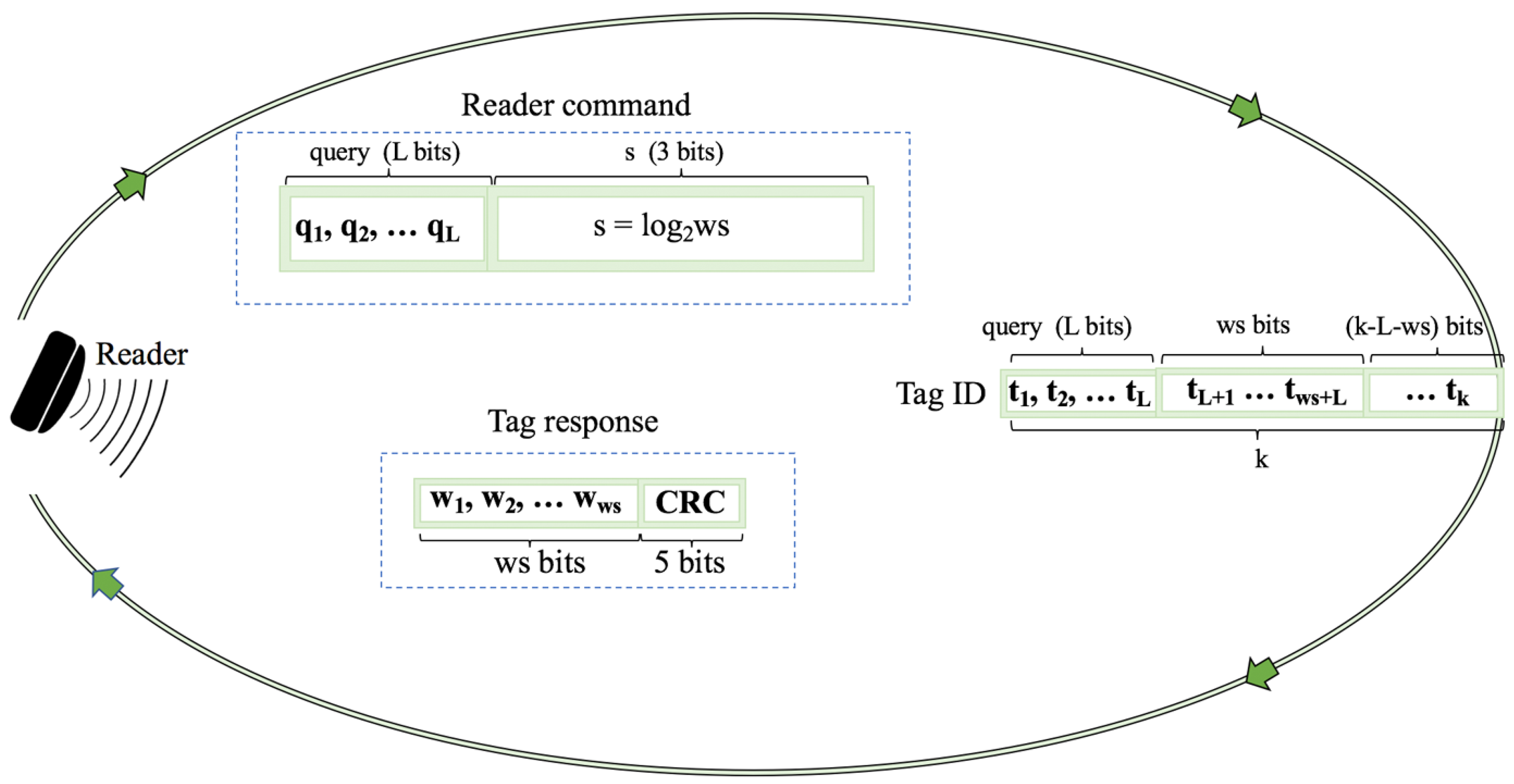
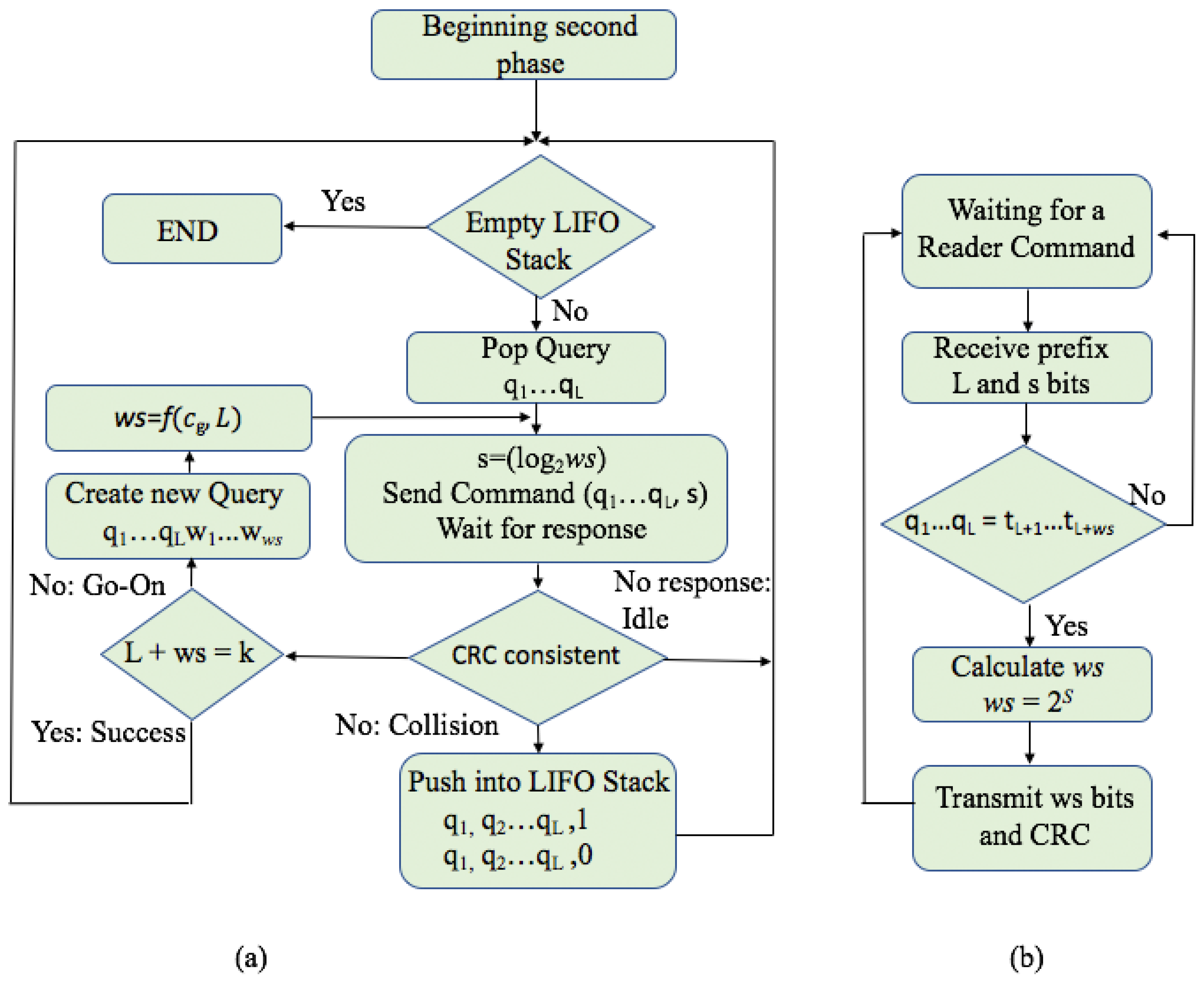
2.7. Window Method and Query Window Tree Protocol
- Collision slots: When the reader cannot differentiate the answer the reader will create two new queries by appending ‘0’ and ‘1’ on the former query [q, q, …, q]. The window size ws will remain unchanged from the previous query.
- Idle slots: When there is no response, the reader will discard the query and will retain the same ws from the last command.
- Go-on slots: When at least one tag responds with ws bits and the reader is able to understand it. If the equation ID L + ws < k is not true, the reader will transmit a new query created from the former query and received window. On this query, the reader will append an updated ws.
- Success slots: This is a type of go-on slot where the reader successfully receives the last part of the tag ID and L + ws = k. Then the reader saves the tag ID, calculates the new ws, and continues with the identification process.
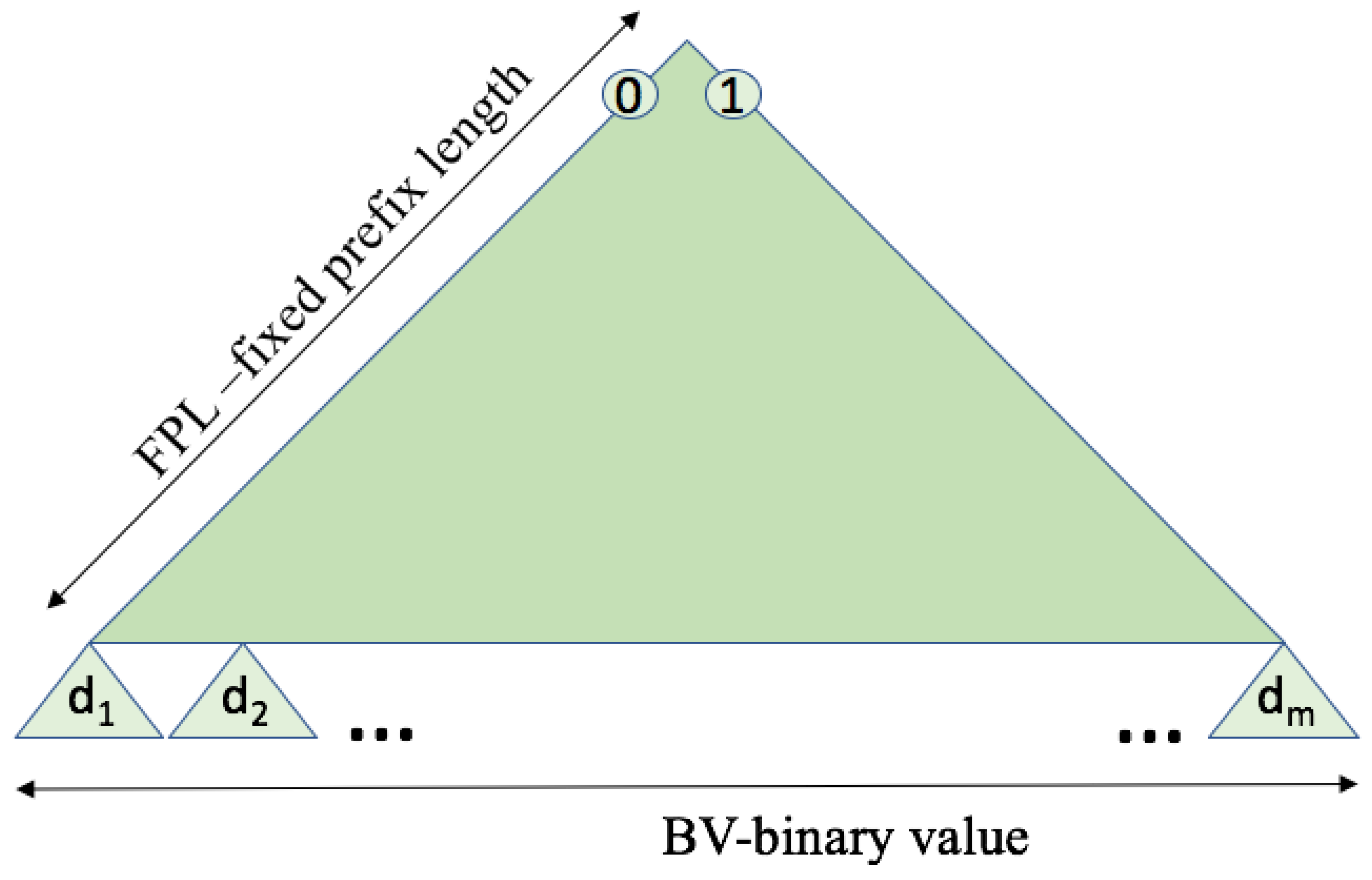
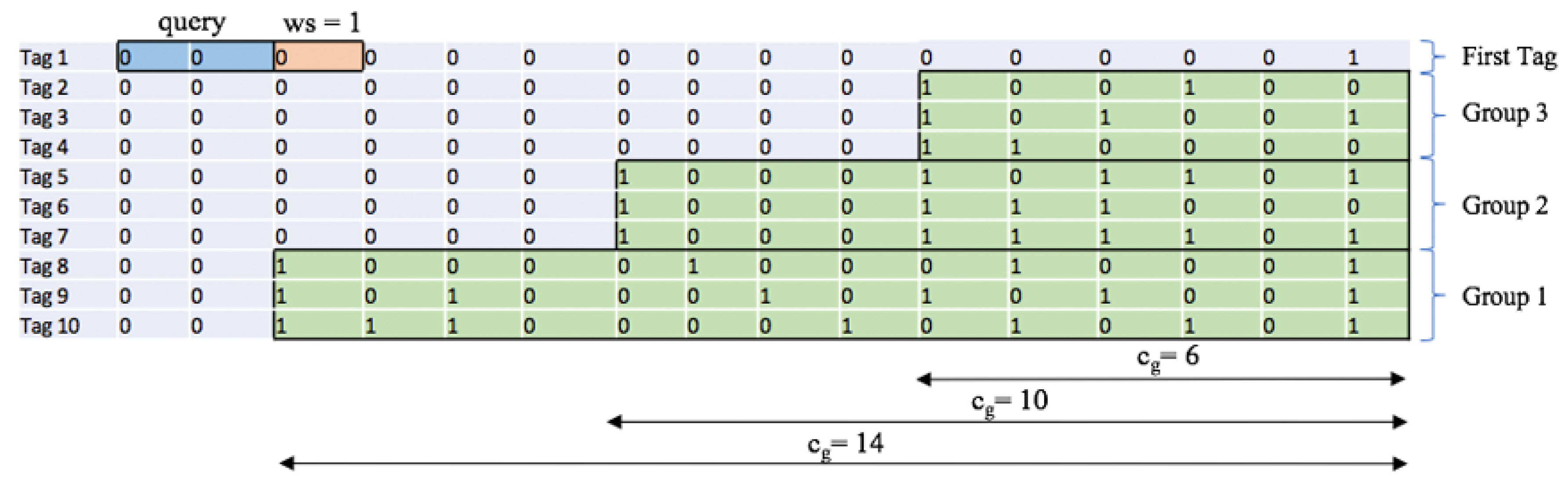
3. Representation of the ID Distribution
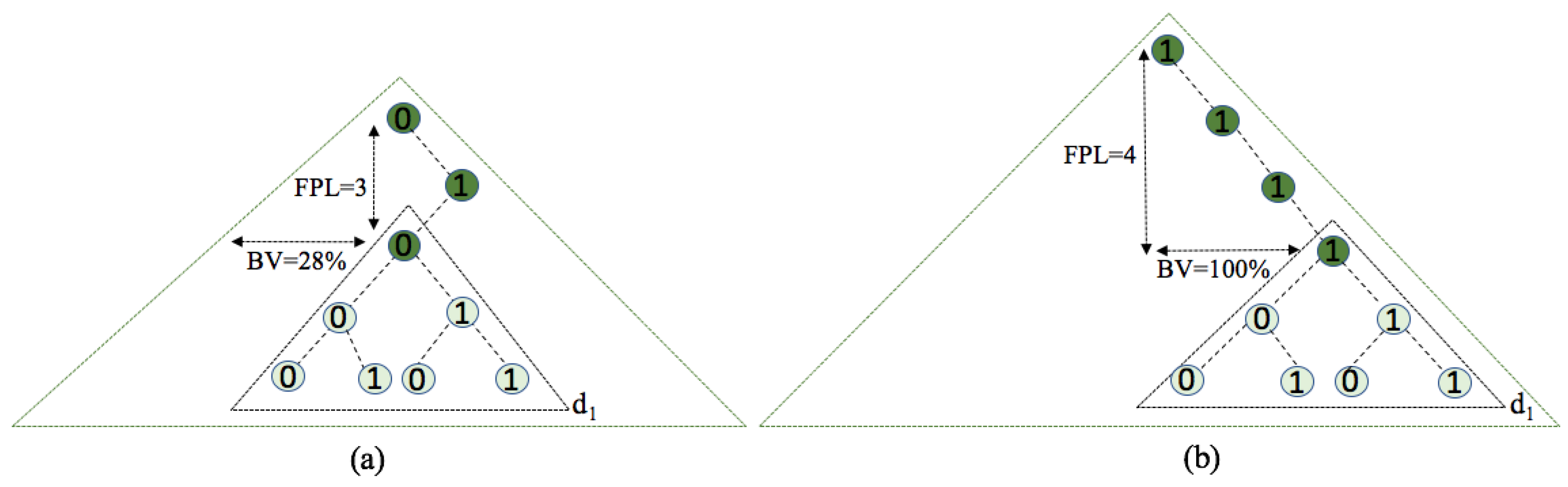
- Fixed prefix length (FPL) defines a specific organization of the distribution where all tags in the interrogation area share the initial part of the ID, of that length.
- Binary value (BV) denotes the horizontal position of the tag ID distribution at an FPL level. This horizontal position is given as a percentage of 2− 1.
- The number of the uniform subdistributions () asumes the organization of the tag ID distribution in several subdistributions m following UDs. The higher the number of subdistributions, the more similar the main distribution will be to a UD.
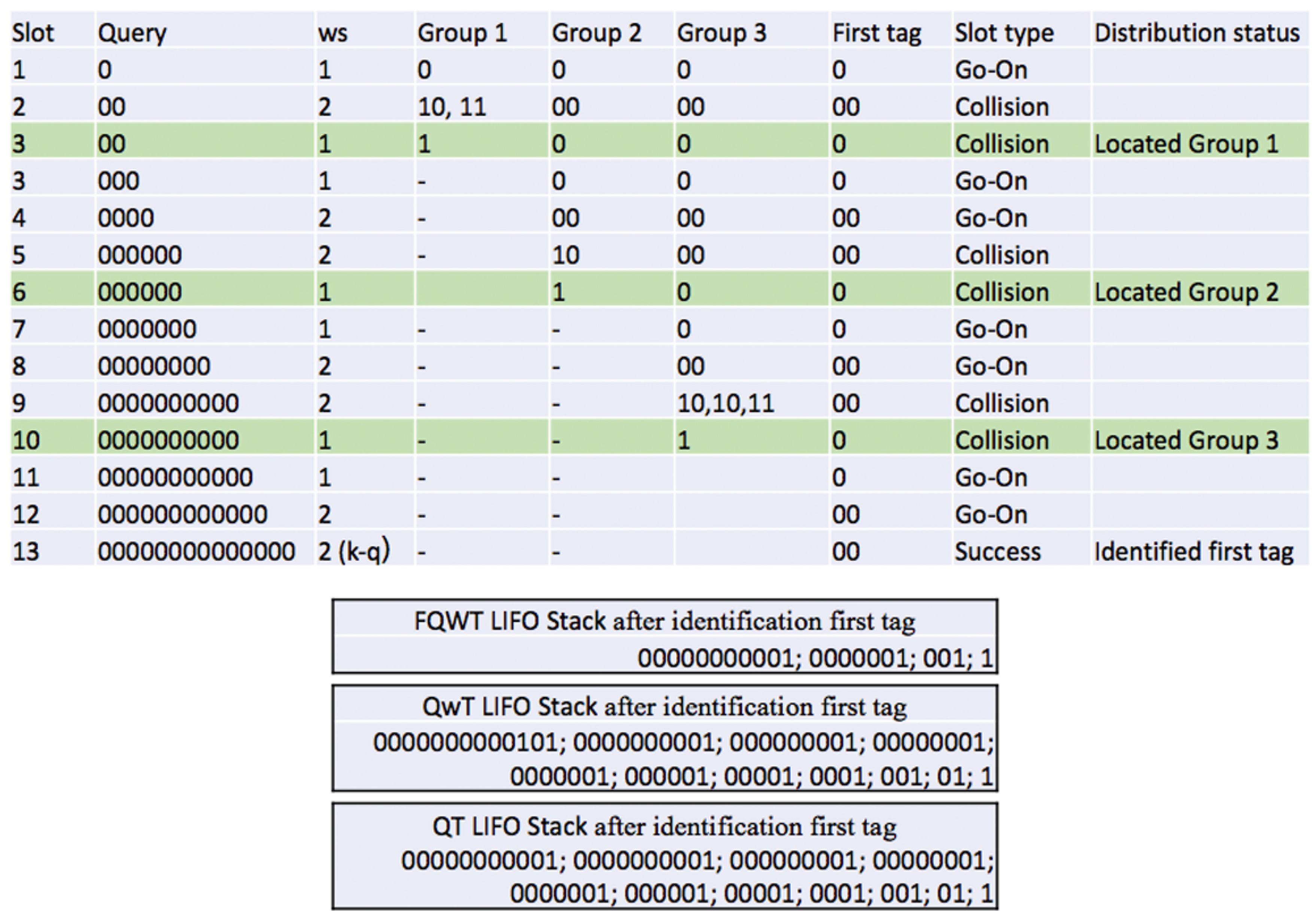
4. Flexible Query Window Tree Protocol
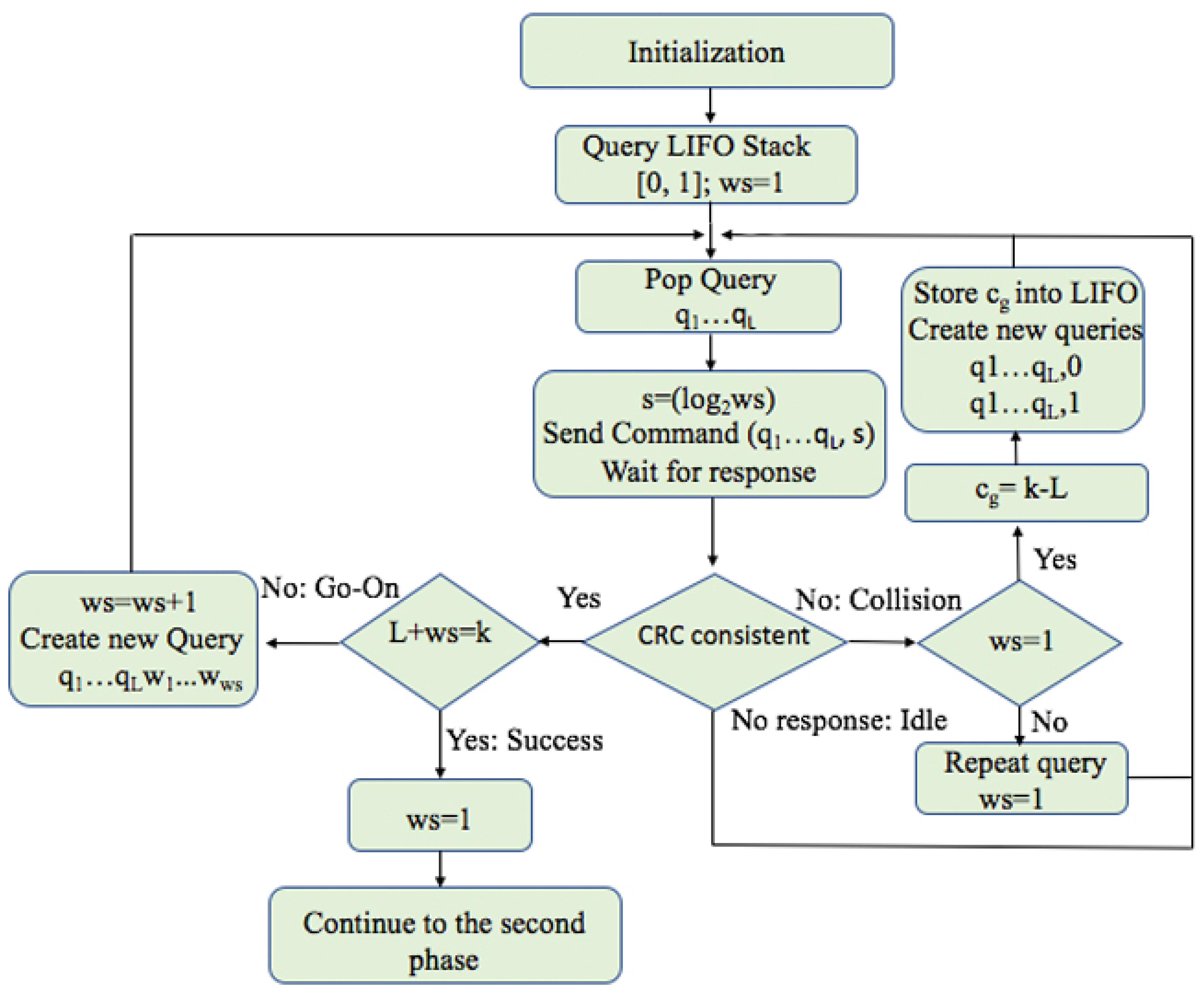
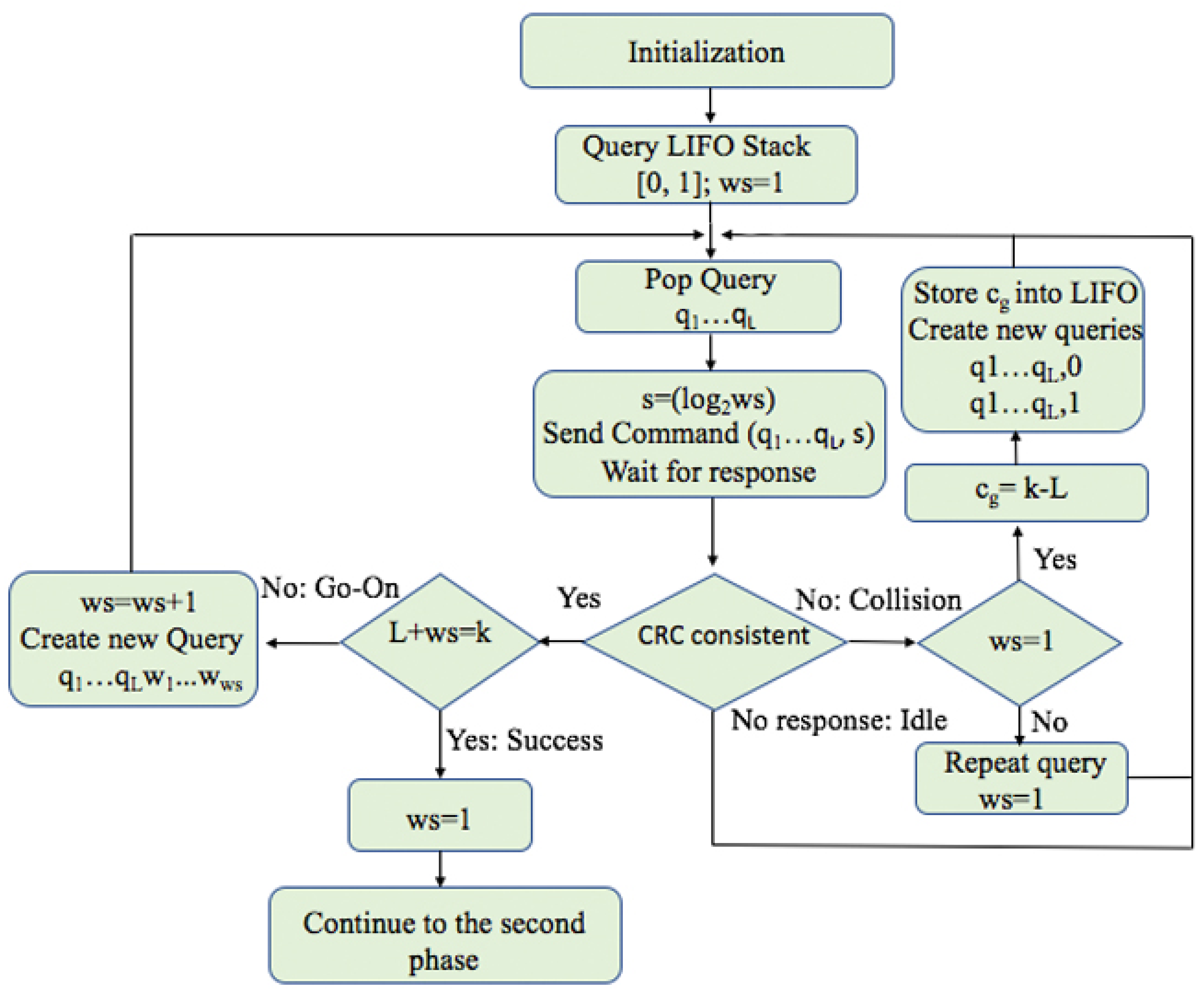
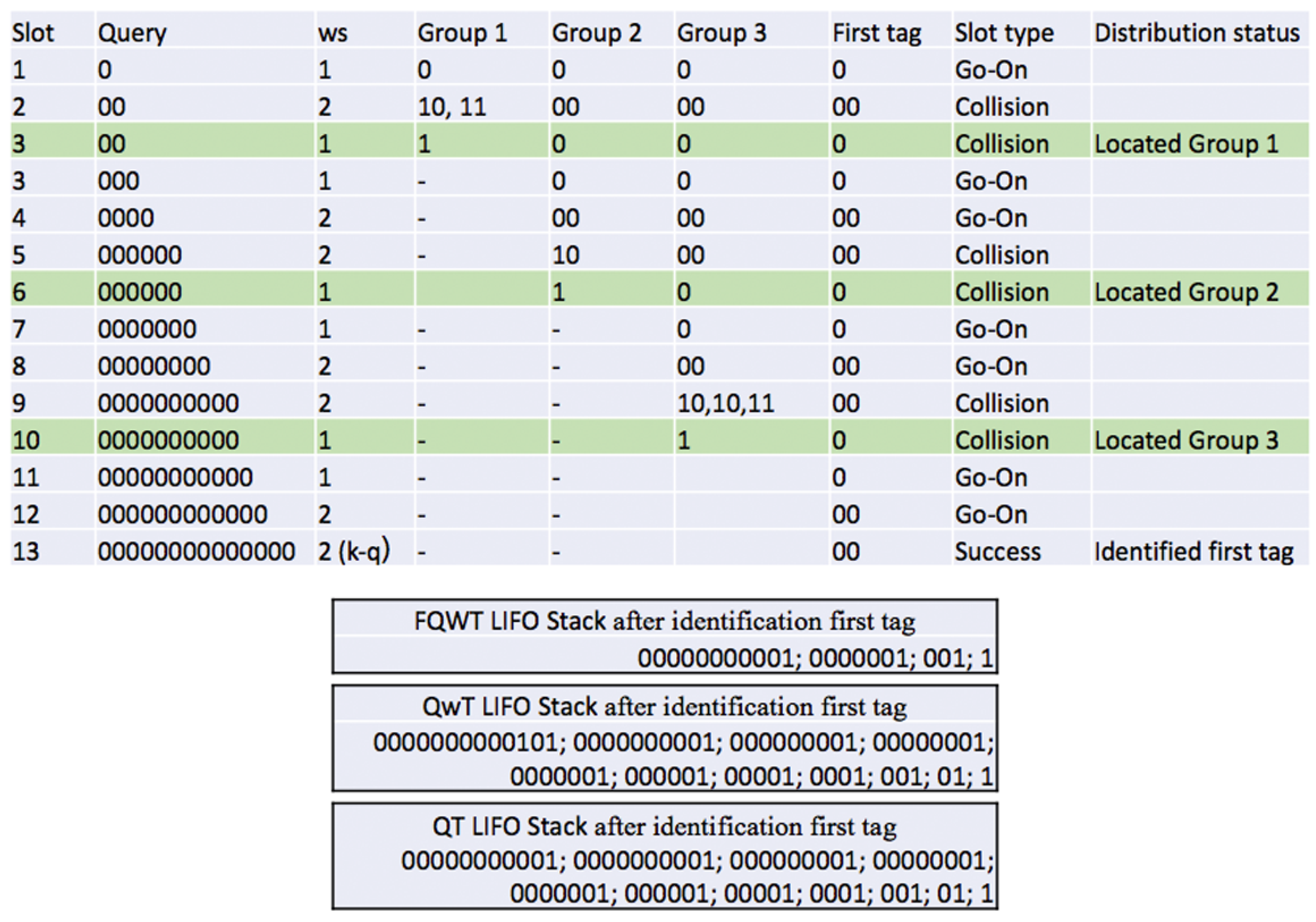
4.1. Phase 1: Estimation of the ID Distribution of the Tags
- Upon a collision, the reader will check the value of ws. If ws is bigger than 1, it will restart at the beginning value (ws = 1). When ws = 1, the reader will calculate , the difference between the ID length k and the current query length L, and locate the first group in a new type of ID subdistribution. The reader stores the first value of into LIFO and continues with the interrogation. All values are stored into the LIFO stack together with the the corresponding query, and used when a specific group is identified. Later, when the reader pops a query from the LIFO, it will use the same value for the whole identified group to calculate ws.
- In case of an empty response, the reader will continue the process with a new query from the stack and will be held unchanged.
- A go-on slot is received if the reader understands the response but the ID is not complete (q + ws < k). The reader will increase ws by 1 and store the received window in the stack and use it in the next query.
- Finally, when the reader receives last window bits and completes the whole ID, a successful slot occurs. The reader saves this tag and completes the first phase. The following procedure will follow a new phase with addition calculation.
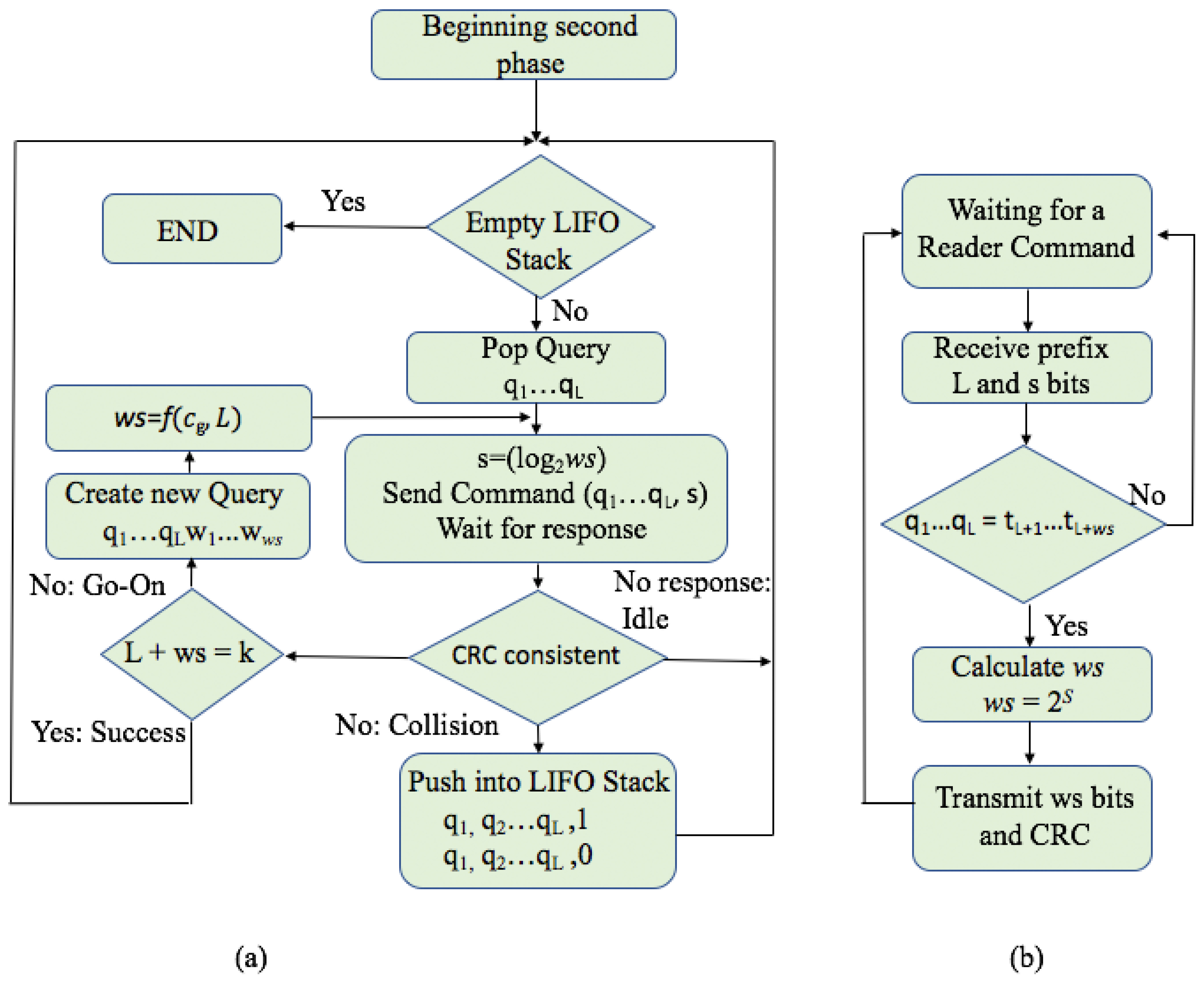
4.2. Phase 2: Identification Phase
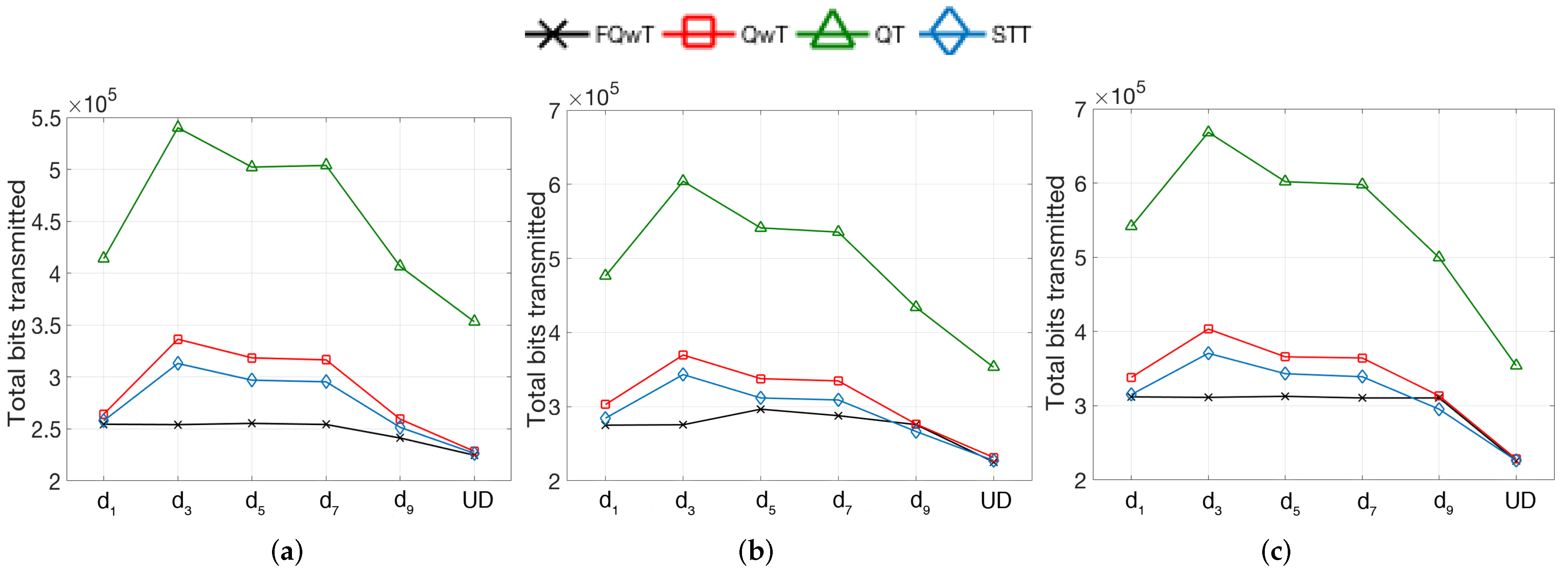
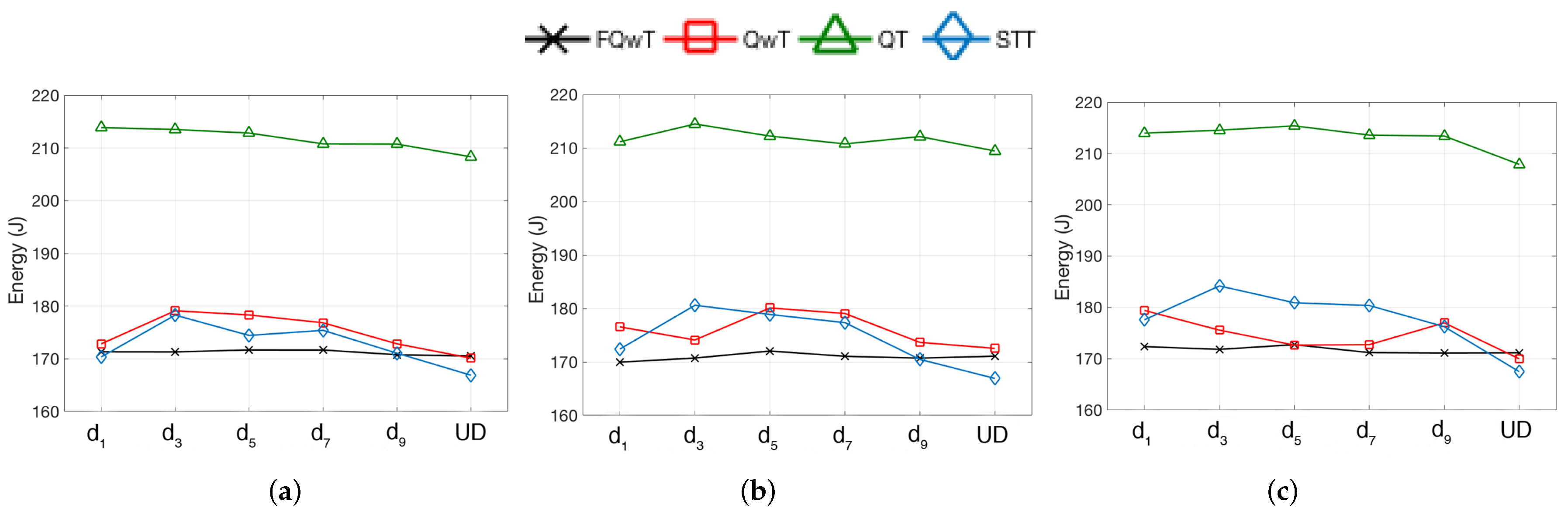
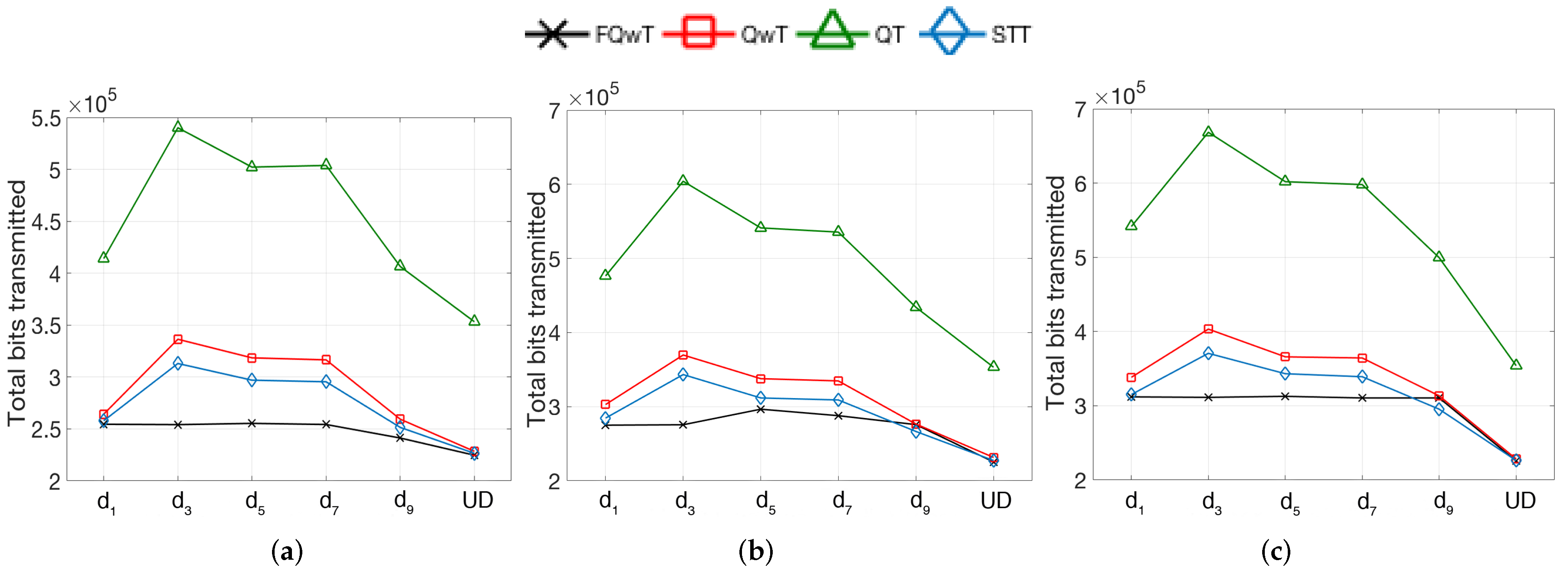
5. Simulations
5.1. Distribution Organization by Modification of the BV Value
5.2. Distribution Organization by Modification of FPL
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- IDTechEx. RFID Forecasts, Players and Opportunities 2016–2026. 2015. Available online: http://www.idtechex.com/research/reports/rfid-forecasts-players-and-opportunities-2016-2026-000451.asp (accessed on 16 March 2017).
- Finkenzeller, K. RFID Handbook; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Li, Y.; Ding, X. Protecting RFID communications in supply chains. In Proceedings of the 2nd ACM Symposium on Information, Computer and Communications Security, 2007, Singapore, 20–22 March 2007; ACM: New York, NY, USA, 2007; pp. 234–241. [Google Scholar]
- Shirehjini, A.; Yassine, A.; Shirmohammadi, S. Equipment location in hospitals using RFID-based positioning system. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1058–1069. [Google Scholar] [CrossRef] [PubMed]
- Dardari, D.; Decarli, N.; Guerra, A.; Guidi, F. The future of ultra-wideband localization in RFID. In Proceedings of the 2016 IEEE International Conference on RFID (RFID), Orlando, FL, USA, 3–5 May 2016; pp. 1–7. [Google Scholar]
- Qiu, L.; Huang, Z.; Wirström, N.; Voigt, T. 3DinSAR: Object 3D localization for indoor RFID applications. In Proceedings of the 2016 IEEE International Conference on RFID (RFID), Orlando, FL, USA, 3–5 May 2016; pp. 1–8. [Google Scholar]
- Naderiparizi, S.; Parks, A.N.; Kapetanovic, Z.; Ransford, B.; Smith, J.R. WISPCam: A battery-free RFID camera. In Proceedings of the 2015 IEEE International Conference on RFID (RFID), San Diego, CA, USA, 15–17 April 2015; pp. 166–173. [Google Scholar]
- Philipose, M.; Smith, J.R.; Jiang, B.; Mamishev, A.; Roy, S.; Sundara-Rajan, K. Battery-free wireless identification and sensing. IEEE Pervasive Comput. 2005, 4, 37–45. [Google Scholar] [CrossRef]
- Want, R. The magic of RFID: Threat of promise? RFID 2004, 2, 40–48. [Google Scholar] [CrossRef]
- Abraham, C.; Ahuja, V.; Ghosh, A.K.; Pakanati, P. Inventory Management Using Passive RFID Tags: A Survey; Department of Computer Science, The University of Texas at Dallas: Richardson, TX, USA, 2002. [Google Scholar]
- Klair, D.; Chin, K.; Raad, R. A survey and tutorial of RFID anti-collision protocols. IEEE Commun. Surv. Tutor. 2010, 12, 400–421. [Google Scholar] [CrossRef]
- Schoute, F. Dynamic frame length ALOHA. IEEE Trans. Commun. 2010, 31, 565–568. [Google Scholar] [CrossRef]
- Vogt, H. Efficient object identification with passive RFID tags. In Proceedings of the International Conference on Pervasive Computing, Zurich, Switzerland, 26–28 August 2002. [Google Scholar]
- Wang, C.; Daneshmand, M.; Sohraby, K.; Li, B. Performance analysis of RFID Generation-2 protocol. IEEE Trans. Wirel. Commun. 2009, 8, 2592–2601. [Google Scholar] [CrossRef]
- Feng, B.; Li, J.-T.; Guo, J.-B.; Ding, Z.-H. ID-Binary tree stack anticollision algorithm for RFID. In Proceedings of the 11th IEEE Symposium on Computers and Communications, Cagliari, Italy, 26–29 June 2006; pp. 207–212. [Google Scholar]
- Kim, S.H.; Park, P.G. An efficient tree-based tag anti-collision protocol for RFID systems. IEEE Commun. Lett. 2007, 11, 449–451. [Google Scholar] [CrossRef]
- Bang, O.; Choi, J.H.; Lee, D.; Lee, H. Efficient Novel Anti-Collision Protocols for Passive RFID Tags: Three Methods for Fast Tag Identification: Bi-Slotted Tree Based RFID Tag Anti-Collision Protocols, Query Tree Based Reservation, and the Combining Method of Them; Auto-ID Labs White Paper, WP-HARDWARE-050; The MIT Auto-ID Labs: Zurich, Switzerland, 2009. [Google Scholar]
- Chen, Y.H.; Horng, S.J.; Run, R.S.; Lai, J.L.; Chen, R.J.; Chen, W.C.; Pan, Y.; Takao, T. A novel anti-collision algorithm in RFID systems for identifying passive tags. IEEE Trans. Ind. Inform. 2010, 6, 105–121. [Google Scholar] [CrossRef]
- GS1 and EPCglobal. GS1 EPC Tag Data Standard 1.6; GS1 AISBL: Brussels, Belgium, 2011. [Google Scholar]
- Shahzad, M.; Liu, A.X. Probabilistic optimal tree hopping for RFID identification. IEEE/ACM Trans. Netw. 2015, 23, 796–809. [Google Scholar] [CrossRef]
- Pan, L.; Wu, H. Smart trend-traversal protocol for RFID tag arbitration. IEEE Trans. Wirel. Commun. 2011, 10, 3565–3569. [Google Scholar] [CrossRef]
- Rohatgi, A.; Durgin, G.D. RFID Anti-Collision System Using the Spread Spectrum Technique; Technical Report; Georgia Institute of Technology: Atlanta, GA, USA, 2005. [Google Scholar]
- Law, C.; Lee, K.; Siu, K. Efficient memoryless protocol for tag identification. In Proceedings of the 4th International Workshop on Discrete Algorithms and Methods for Mobile Computing and Communications, Boston, MA, USA, 11 August 2000. [Google Scholar]
- Zhang, L.; Zhang, J.; Tang, X. Assigned tree slotted Aloha RFID tag anti-collision protocols. IEEE Trans. Wirel. Commun. 2013, 12, 5493–5505. [Google Scholar] [CrossRef]
- Wu, H.; Zeng, Y.; Feng, J.; Gu, Y. Binary tree slotted ALOHA for passive RFID tag anticollision. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 19–31. [Google Scholar] [CrossRef]
- Landaluce, H.; Perallos, A.; Onieva, E.; Arjona, L.; Bengtsson, L. An energy and identification time decreasing procedure for memoryless RFID tag anticollision protocols. IEEE Trans. Wirel. Commun. 2016, 15, 4234–4247. [Google Scholar] [CrossRef]
- Choi, J.; Lee, I.; Du, D.Z.; Lee, W. FTTP: A fast tree traversal protocol for efficient tag identification in RFID networks. IEEE Commun. Lett. 2010, 14, 713–715. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| k | 128 bits |
| CRC | 5 bits |
| Tari | 6.25 s |
| Data rate | 160 kbps |
| RTCal | 18.75 s |
| TRCal | 24.38 s |
| T1 | 26.75 s |
| T2 | 27.5 s |
| T3 | 72 s |
| Ptx | 825 mW |
| Prx | 125 mW |
| Protocol | Reader Command | Tag Response | Tag Response in ID Distribution Estimation |
|---|---|---|---|
| FQwT | CRC | ws | |
| QT | L | k | / |
| STT | L | / | |
| QwT | CRC | / |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cmiljanic, N.; Landaluce, H.; Perallos, A.; Arjona, L. Influence of the Distribution of Tag IDs on RFID Memoryless Anti-Collision Protocols. Sensors 2017, 17, 1891. https://doi.org/10.3390/s17081891
Cmiljanic N, Landaluce H, Perallos A, Arjona L. Influence of the Distribution of Tag IDs on RFID Memoryless Anti-Collision Protocols. Sensors. 2017; 17(8):1891. https://doi.org/10.3390/s17081891
Chicago/Turabian StyleCmiljanic, Nikola, Hugo Landaluce, Asier Perallos, and Laura Arjona. 2017. "Influence of the Distribution of Tag IDs on RFID Memoryless Anti-Collision Protocols" Sensors 17, no. 8: 1891. https://doi.org/10.3390/s17081891
APA StyleCmiljanic, N., Landaluce, H., Perallos, A., & Arjona, L. (2017). Influence of the Distribution of Tag IDs on RFID Memoryless Anti-Collision Protocols. Sensors, 17(8), 1891. https://doi.org/10.3390/s17081891