1. Introduction
For decades, underwater wireless sensor networks (UWSNs) have attracted significant interest. Many applications of UWSNs, including commercial exploitation, marine mammal studies and oceanography data collection [
1,
2] allow humans to sense the vast underwater domain and motivate research on UWSN design.
However, because of the harsh environment and limited spectrum source, communications in UWSNs are much more difficult than those in terrestrial sensor networks. One of the reasons is that the radiowaves employed in terrestrial sensor networks is not feasible in the underwater environment because of their rapid attenuation. For example, Berkeley Mica 2 motes have been reported to have only 120 cm communication range in an underwater environment at 433 MHz [
3]. Currently, the only appropriate method for long distance communications is acoustic communication. The speed of sound in water is about 1500 m/s, five-orders slower than the speed of radiowaves, thus there is a long propagation delay in UWSNs [
4]. Moreover, the sensor nodes are deployed under the sea, therefore, it is difficult to recharge their batteries [
5]. Since the sensors are powered by batteries, the limited energy restricts the network lifetime of UWSNs. Network lifetime is the time span from the deployment to the instant when the network is considered nonfunctional [
6]. In this paper, the network lifetime is defined as the time span from the deployment to the instant the energy of the first node is exhausted. All these different characteristics make the algorithms, especially the routing algorithms used in terrestrial networks, unfeasible for UWSNs [
7,
8].
Typical routing algorithms employ shortest path algorithms for routing decisions. Thus, nodes chosen frequently on the shortest paths drain more quickly than other nodes, leading to a shorter network lifetime. To prolong the network lifetime, many routing algorithms are proposed. The energy efficient algorithm in [
9] pays attention to coverage. It can preserve k-coverage and achieve maximal coverage for an area with the least energy consumption. However, low energy consumption does not necessarily lead to a long network lifetime. The distribution of residual energy also affects the network lifetime. In [
10], the prolong stable election protocol (P-SEP) exploits the heterogeneity of energy thresholds to avoid low-energy nodes to nominate cluster heads and avoid continuous selection of a node. P-SEP has features like aliveness, fairness, full distribution in cluster head selection and can prolong network lifetime remarkably. However, like P-SEP, many routing algorithms employ greedy approaches to determine the next hop or the cluster head on the path, without considering the long-term rewards. That is to say, greedy routing algorithms only choose the node with the highest direct reward, even if the packet transmission thereafter needs more hops. Thus, the optimal next hop for the current node determined by these algorithms may not be the global optimal one for the whole routing path.
Moreover, the algorithms mentioned above pay no attention to the end-to-end delay, which is an important indicator in UWSNs. The fog-supported learning automata adaptive probabilistic search (FLAPS) algorithm in [
11] is a delay-efficient distributed route-discovering algorithm. It can forward messages at the minimum bandwidth cost and latency. Although the synchronization functions in FLAPS are not suitable in UWSNs because of the long propagation delay in UWSNs, the application of Q-learning algorithm improves the performance remarkably. Nodes can process in an adaptive and distributed way using the reward-penalty mechanism of the Q-learning algorithm. With moderate improvement, the Q-learning algorithm can be implemented in UWSNs. The Min-delay routing in [
12] based on the Dijkstra algorithm can minimize delay, reduce link interruption and improve reliability. However, it is a multipath routing method, which means that there is more than one path from the source node to the sink node. Thus, Min-delay routing may increase the energy consumption. Above all, in order to prolong the network lifetime, nodes with more residual energy should be chosen as relay nodes even though they are far from the sink node, while in order to minimize the end-to-end delay, nodes near to the sink node should be chosen. Network life and end-to-end delay are both important in UWSNs. Therefore, it is necessary to introduce significant compromises at the routing design stage.
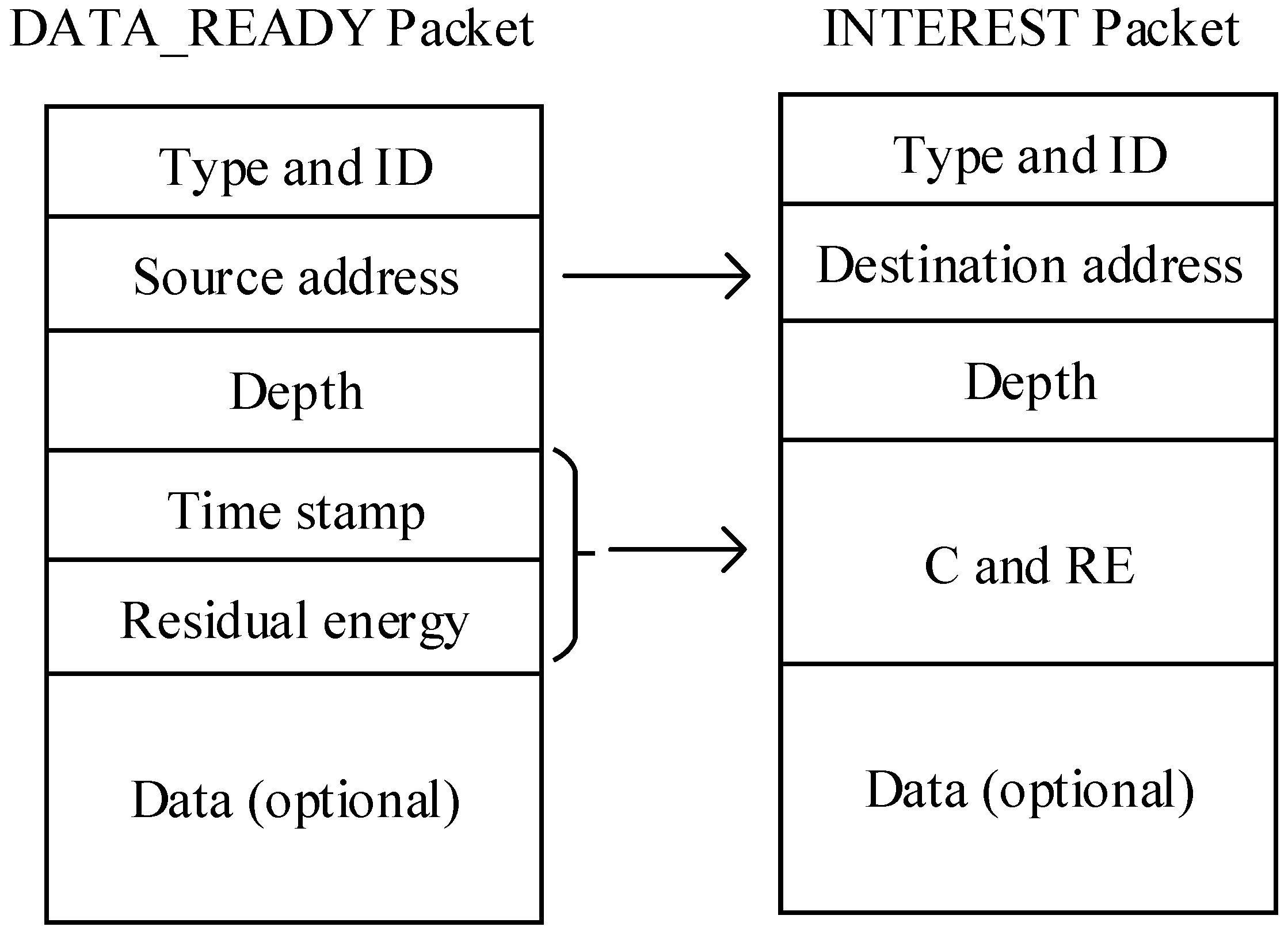
To cater for these issues, we propose a Q-learning-based delay-aware routing (QDAR) mechanism to extend the network lifetime for UWSNs. In QDAR, nodes only need to know about their residual energy and the delay from neighbors. As the action-utility function (Q-value) of Q-learning technique takes both direct reward and discounted long-term reward into account, Q-learning-based protocols can determine the global optimal next hop instead of a greedy one. The main contributions of QDAR can be summarized as follows: (1) it defines a data collection phase and designs the packet structure before routing decisions to quickly adapt to the dynamic underwater environment; (2) it takes both delay and residual energy into consideration by defining two kinds of cost functions: delay-related cost and energy-related cost; (3) it uses an adaptive mechanism to ensure a longer network lifetime and a relatively shorter delays: when the residual energy is enough, the end-to-end delay is restricted, while the residual energy of some nodes is lower than the threshold, an adequate path consisting of nodes with longer delays but more remaining energy is determined; (4) QDAR is easily extendible: energy consumption, channel capacity, communication reliability and many other metrics can be integrated into the action-utility functions in future research for different targets.
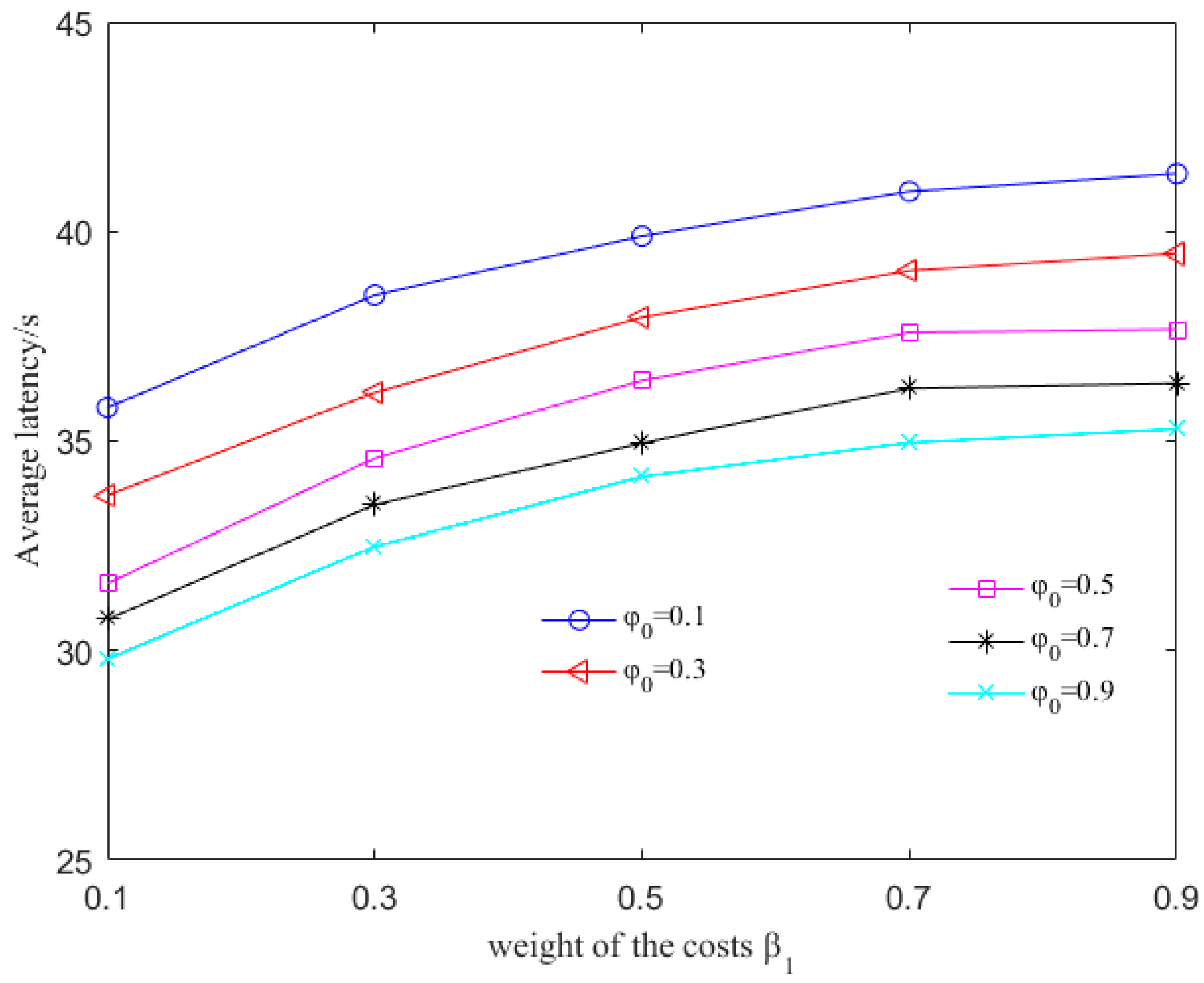
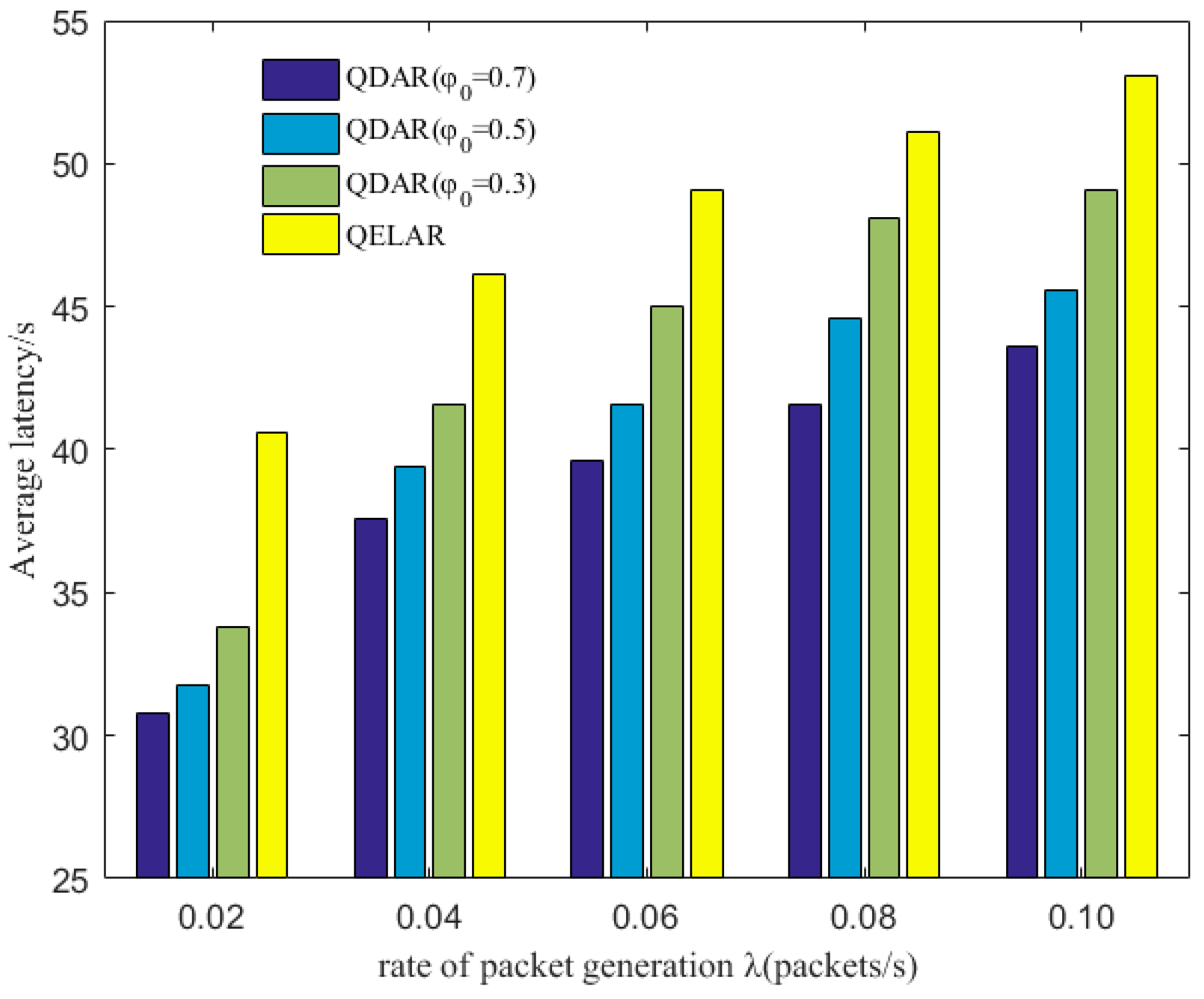
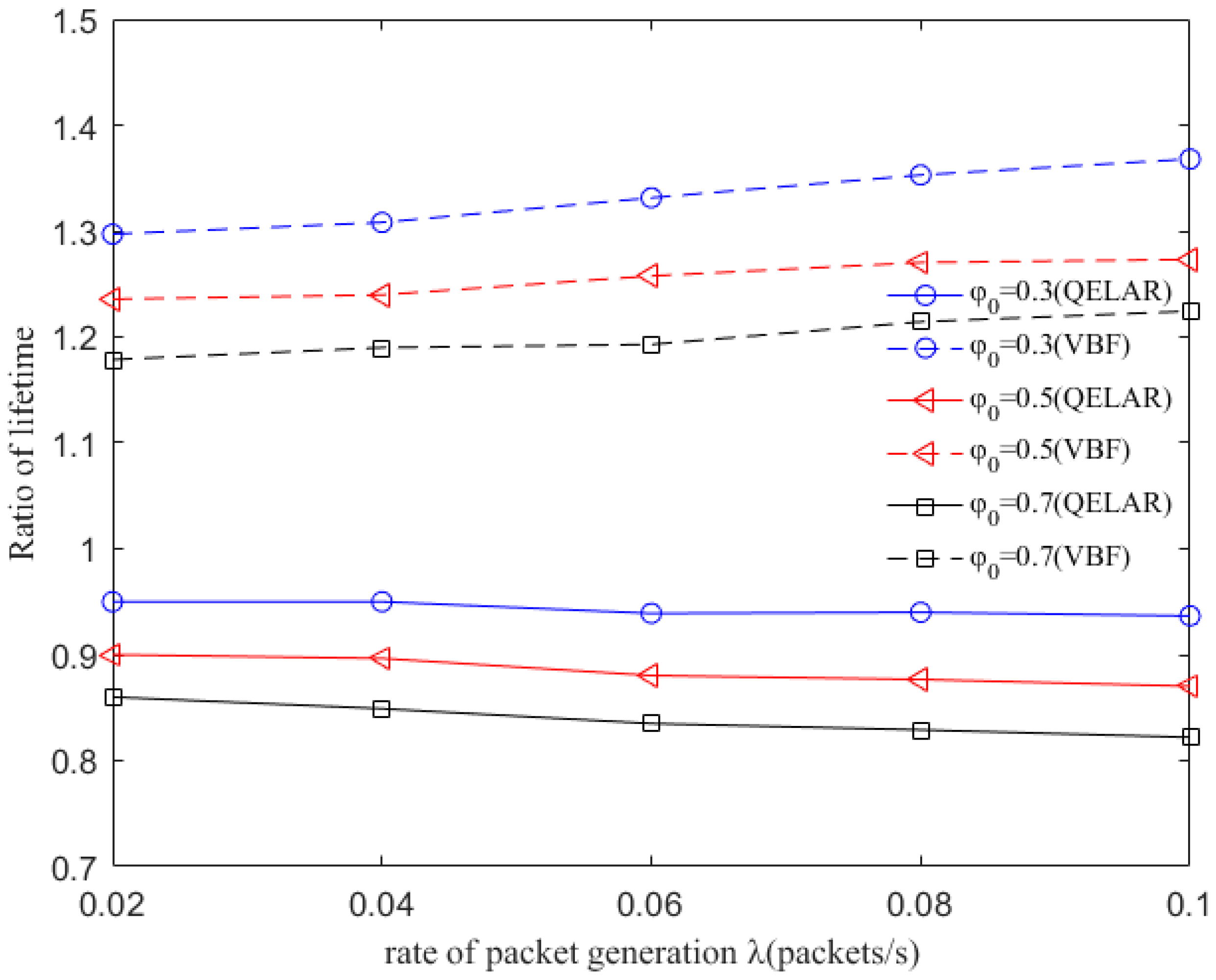
The QDAR algorithm can work adaptively and distributively through trade-offs between the network lifetime and end-to-end delays. The simulation results show that our algorithm achieves nearly the same network lifetime extension as the existing lifetime-extended protocol, and reduces end-to-end delay by 20–25%.
The rest of this paper is organized as follows: in
Section 2, related works on underwater routing protocols are discussed briefly. In
Section 3, the basic Q-learning technique is introduced and adopted into our system model. In
Section 4 and
Section 5, the QDAR algorithm is described in detail. The simulation results are shown and discussed in
Section 6. Finally, we conclude this paper in
Section 7.
2. Related Work
Underwater routing techniques are a hot research topic for UWSNs nowadays. There are several kinds of routing protocols that aim to improve energy efficiency, reduce end-to-end delay and prolong network lifetime [
13,
14]. In this section, we provide a review on research works that have been done on this topic.
Most energy-efficient routing protocols aim to reduce energy consumption and prolong network lifetime. A hierarchical routing algorithm called queen-bee evolution algorithm (QEGA) [
15] works better in terms of energy consumption. QEGA has a high rate which results in premature convergence. Thus, the algorithm can find the optimal solution more quickly. However, QEGA does not consider the residual energy, which is important to extend network lifetime. The energy-saving vector-based forwarding (ES-VBF) protocol [
16] defines a desirableness factor based on residual energy and location information. In the routing pipe, nodes with more residual energy are more possible to forward packets. Although the algorithm prolongs the network lifetime, it needs the location information of all the nodes, which is still a challenge to be solved.
The adaptive power controlled routing (APCR) [
17] is an energy efficient routing schema that does not require any location information. In APCR, nodes are assigned to concentric layers according to the signal power of a received INTEREST packet broadcasted by sink nodes. Then, routing paths are decided based on layer numbers and residual energy. To improve the energy efficiency, nodes are able to adjust their transmission power to a set of values according to the information received during packet transmission. If forwarding nodes are found at multiple layers, the power is decreased. If no neighbor is found, the power is increased. Thus, APCR can achieve a high delivery ratio, but the number of forwarding nodes at each layer is not limited properly. If multiple nodes forward the same packet, the total energy consumption is increased.
The Q-learning-based adaptive routing (QELAR) protocol is proposed [
18] and Q-learning is proved to perform well in UWSNs in several aspects. QELAR defines the reward function based on the residual energy of the sensor nodes. In this protocol, sensor nodes choose the node with more residual energy as the next hop, so that the network lifetime of the network can be extended. However, in QELAR protocol, each node takes the responsibility to learn the environment by metadata exchanging and decide the next hop, leading to a higher energy consumption for each node. Moreover, the protocol does not restrict end-to-end delay. When the number of the sensor nodes increases, the routing will detour with more and more nodes, then the end-to-end delay is prolonged. Thus, QELAR works inefficiently in some situations because of the long delay.
Many research works point out that the problems of latency in UWSNs are serious, especially for time-critical applications. In [
19] the authors employ a probability model to describe the propagation delay of a link and select the next hop with lower delay. In [
20], an underwater opportunistic routing (UWOR) is proposed. The forwarding set in which nodes can hear each other and prevent packet duplication is established. Each node in the forwarding set is assigned a relay priority which is related to the probability of successful transmission. The node with the highest priority and limited end-to-end delay can be chosen as the relay node. The simulation results show that UWOR can maximize good put while satisfying end-to-end latency requirements. However, it disables retransmission mechanisms, leading to a lower delivery ratio.
Moreover, there are protocols that can jointly reduce energy consumption and end-to-end delay. Modified energy weight routing (MEWR) protocol [
3] is energy efficiency guaranteed using a minimum algorithm. In order to determine an optimal path with a low end-to-end delay as well as low energy consumption, the cost of a link is formulated as a mixture of energy weight and delay weight. In the path discovery phase, a node employs a greedy approach to find all its neighbors and determine an optimal one with the lowest cost. However, low energy consumption does not lead to long network lifetime effectively. Since MEWR does not take the residual energy of sensor nodes into account, it cannot optimize the energy distribution, which is crucial for network lifetime extension.
5. QDAR Algorithm
In this section, we describe the proposed QDAR algorithm in details. The important notations are listed in
Table 1.
In order to design a Q-learning-based delay-aware routing protocol to extend the network lifetime of UWSNs, we define an action-utility function whose value is . The sink node has a matrix in which values of all the nodes are stored. These values are future rewards of packet forwarding and are used in the routing decisions. In our protocol, node i and packet forwarding from node i to node j are seen as state i and action j of Q-learning technique, respectively.
Firstly, we define a reward function
for action
j, which is related to both propagation delay and residual energy. If this transmission is successful, the reward of the action for node
i is:
where
is action
j. Because forwarding packet occupies channel bandwidth and disturbs other nodes, a constant cost
is added into the function.
is the weight of the sum of delay-related cost and energy-related cost.
is the delay sensitivity. A higher
means the delay is more repellent.
If the transmission fails, node
i will resend the packet, which means the node should pay double energy-related cost and more delay-related cost. Thus, the reward function becomes:
where
is the time that node
i spends in the failed transmission.
is the weight of the sum of delay-related cost and energy-related cost, in the same position as
.
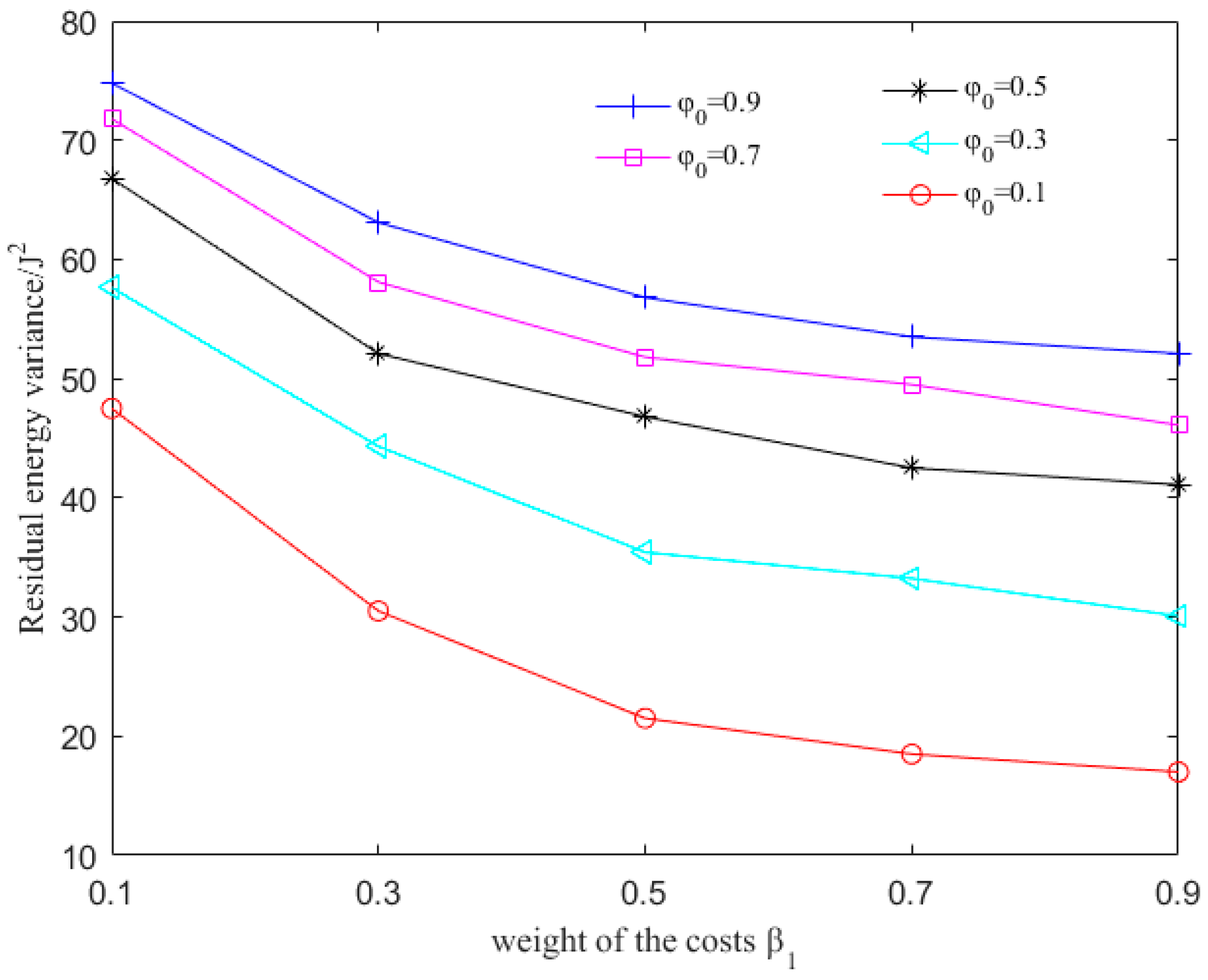
To further prolong the network lifetime, we design an adaptive detouring path strategy. We define a set for node i and an energy warning threshold . The elements of are neighbor nodes of node i. When the residual energy of the next hop of node i, for example, node j, is lower than , or the energy-related cost , the sink node modifies the values to , where , . In this way, the weight of delay-related cost of communication with node j is higher than those of the other nodes. With , the sink node can determine a detouring path by choosing nodes with more residual energy as the next hop of node i.
To calculate the direct reward, sink node keeps the communication record so as to estimate the state transition probabilities:
and
of each node.
and
are the probabilities of successful and failed packet forwarding respectively:
Suppose there have been
instances of communication up to time t and
is the frequency of successful packet forwarding, we can define the direct reward function as:
The highest
value among all the actions is described as:
If the next hop is the sink node, the
of this node is much higher than the others. According to Equations (5) and (14), we can define the action-utility function for each neighbor node of node
i as:
Then, we choose the neighbor node with the highest
as the next hop and update the previous
storied with newly chosen
. Initially, if the next hop is not the destination node,
Q values in the matrix are set to 0. Otherwise,
values are set to 1. Algorithm 1 for the routing mechanism is conducted as below.
| Algorithm 1: The routing mechanism. |
| Initialize (); |
| While xi. next_hop ! = source node |
| for xj in Ni do |
| calculate ce, ct, P; |
| nodes satisfy are saved in set ; |
| end for |
| if then |
| set to , ; |
| calculate the direct reward r; |
| select the node xj with maximum value in set Ni; |
| calculate (xi, ah),; |
| aj = argmax((xi, ah)); |
| else aj = argmax((xi, ah)) |
| end if |
| xi = xj |
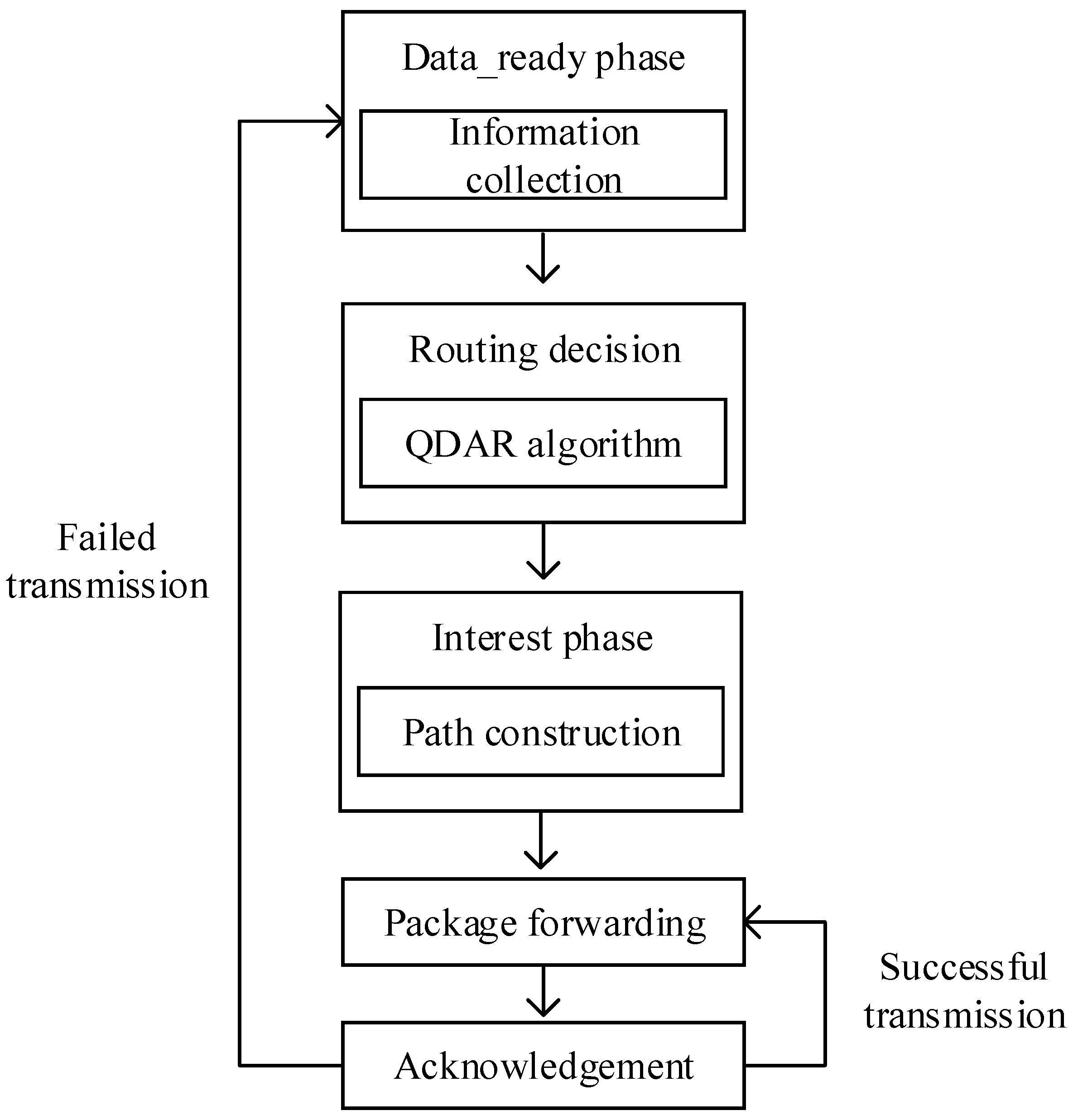
The QDAR mechanism can adapt to the dynamic underwater environment quickly. An energy-related cost function and a delay-related cost function are defined in the data_ready phase. After that, the sink node has the collected information and performs QDAR algorithm. Firstly, it defines two reward functions with the cost functions for both successful and failed transmission. In the reward functions, there is an alterable parameter. Based on this parameter, an adaptive detouring path strategy is designed. Thus, QDAR algorithm can work adaptively with different residual energy. Then, with the reward functions and the corresponding probability functions, the action-utility function (Q-value) is determined.
Finally, the sink node chooses the global optimal next hop and then determines the routing path. In the next section, the simulation results prove that the adaptive solution in QDAR ensures a longer network lifetime and a relatively shorter delay.
7. Conclusions
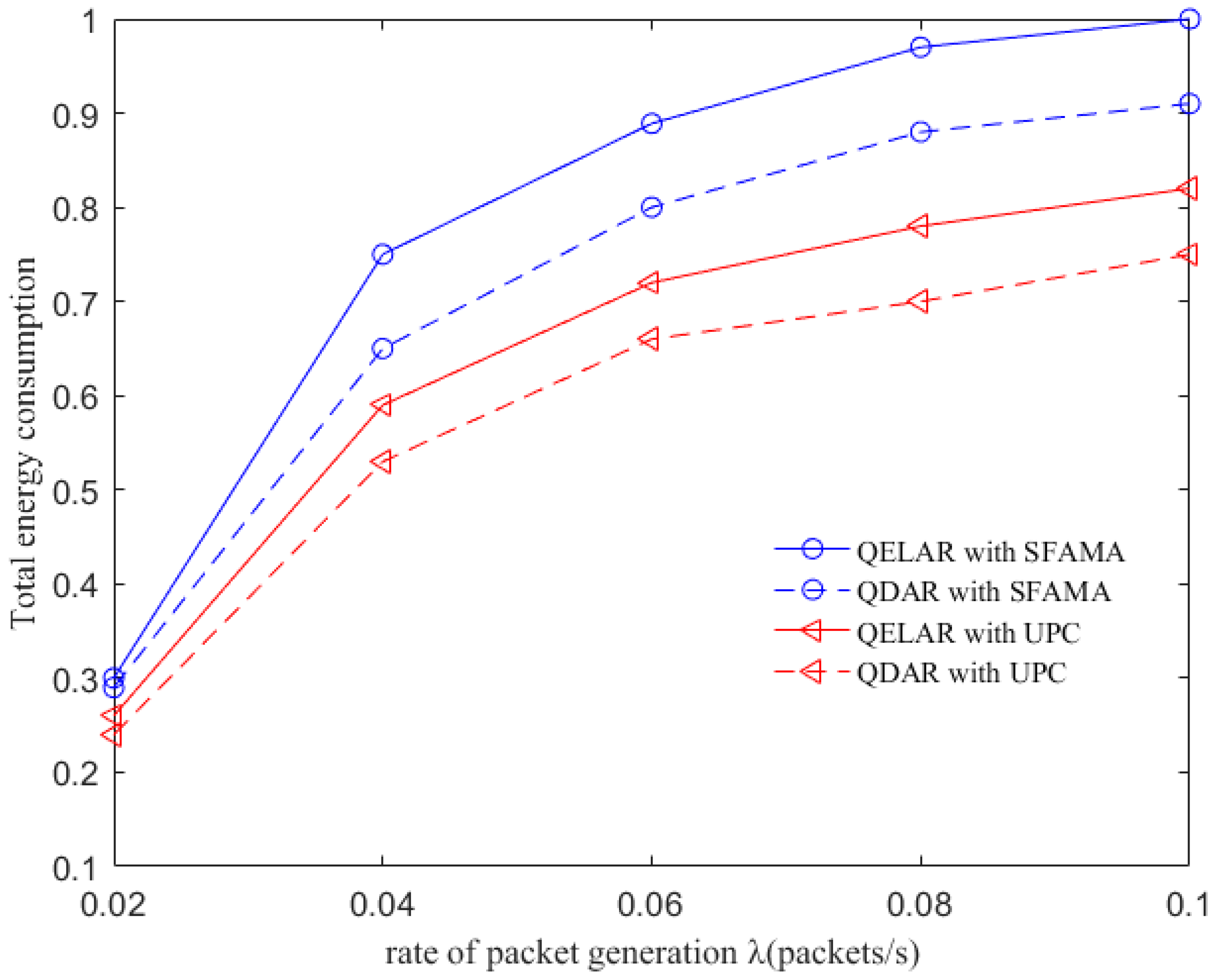
In this paper, we have designed a novel delay-aware routing (QDAR) mechanism based on the Q-learning technique to extend the network lifetime of underwater sensor networks. The QDAR mechanism can reduce average latency as well as extend the network lifetime. The data_ready phase and the packet structures are designed for data collection. Then, the sink node applies the QDAR algorithm to determine the routing path. In QDAR, we extend the action-utility function with both residual energy-related cost and delay-related cost. In order to have a better tradeoff between residual energy of nodes and delay, an adaptive detouring path strategy is designed. When the residual energy is sufficient, a path with shorter delay is chosen. When the residual energy of a node is lower than a threshold, the weight of the delay-related cost is decreased so as to construct an adequate path avoiding nodes with relatively less energy, even though these nodes may be nearer to the sink node. Thus, QDAR can distribute the residual energy more evenly, which is crucial to extend the network lifetime. Moreover, as QDAR takes both direct rewards and future rewards into account, it can choose a global optimal next hop, whereas greedy algorithms only pay attention to the direct reward. After a routing decision, the path is constructed during the interest phase. Then, packets are forwarded and the communication ends with an acknowledgement. The QDAR mechanism can work adaptively and distributively in the dynamic underwater environment. We evaluate the performance of QDAR with different parameters and compare it with QELAR and VBF. The simulation results show that QDAR reduces the total energy consumption effectively and decreases the average latency significantly by 20–25% at the cost of only a little reduction in network lifetime. Therefore, QDAR is more adequate for time-critical applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}