An Automatic Car Counting System Using OverFeat Framework



Abstract
:1. Introduction
2. Related Work
3. Methodology
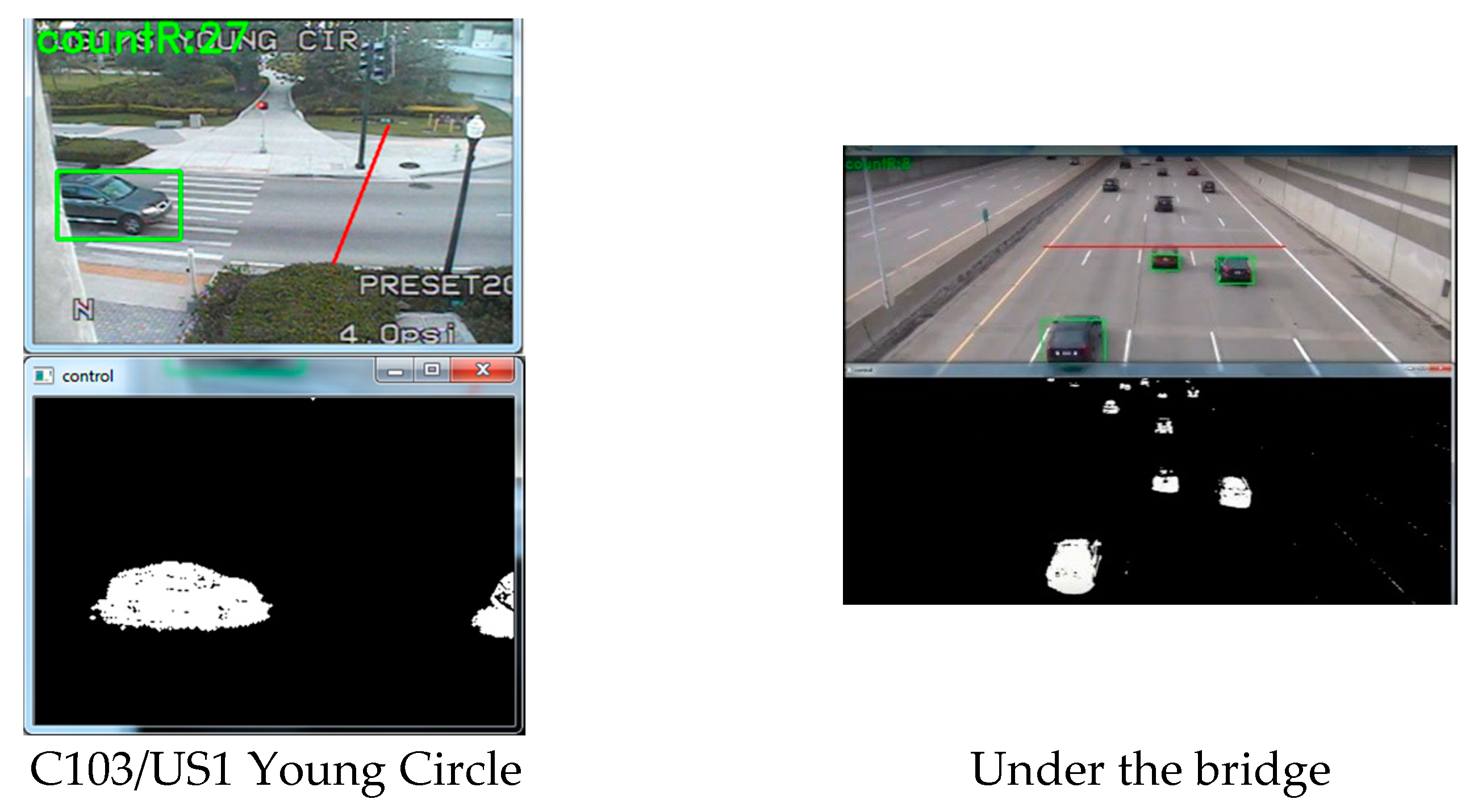
3.1. Background Subtraction Method
3.1.1. Gaussian Mixture Model (GMM)
- model the values of a particular pixel as a mixture of Gaussians;
- determine which Gaussians may correspond to background colors-based on the persistence and the variance of each of the Gaussians;
- pixel values that do not fit the background distributions are considered foreground until there is a Gaussian that includes them;
- update the Gaussians;
- pixel values that do not match one of the pixel’s “background” Gaussians are grouped using connected components.
- is an estimate of the weight of ith Gaussian in the mixture at time t (the portion of data accounted for by this Gaussian). Initially, we considered that all the Gaussians have the same weights.
- is the mean value of the ith Gaussian in the mixture at time t.
- is the covariance matrix of the ith Gaussian in the mixture at time t.
- Every new pixel value, is checked against the existing k Gaussian distributions until a match is found.
- If none of the k distributions match the current pixel value, the least probable distribution is discarded.
- A new distribution with the current value as its mean value, and an initially high variance and low prior weight is entered.
- The prior weights of the k distribution at time t are adjusted as follows:
3.1.2. Implementation of the Background Subtraction Method
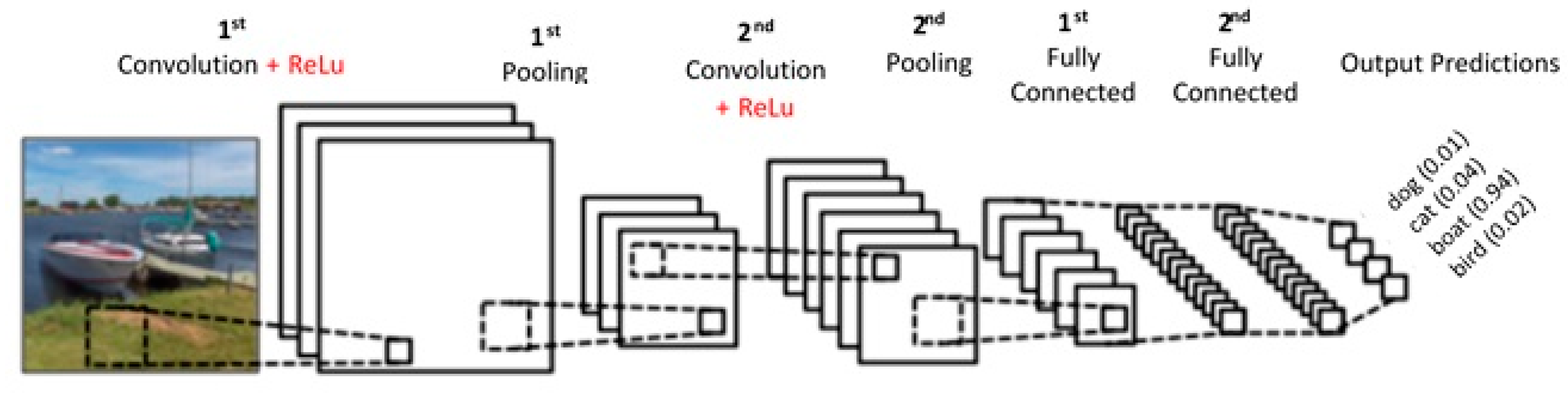
3.2. OverFeat Framework
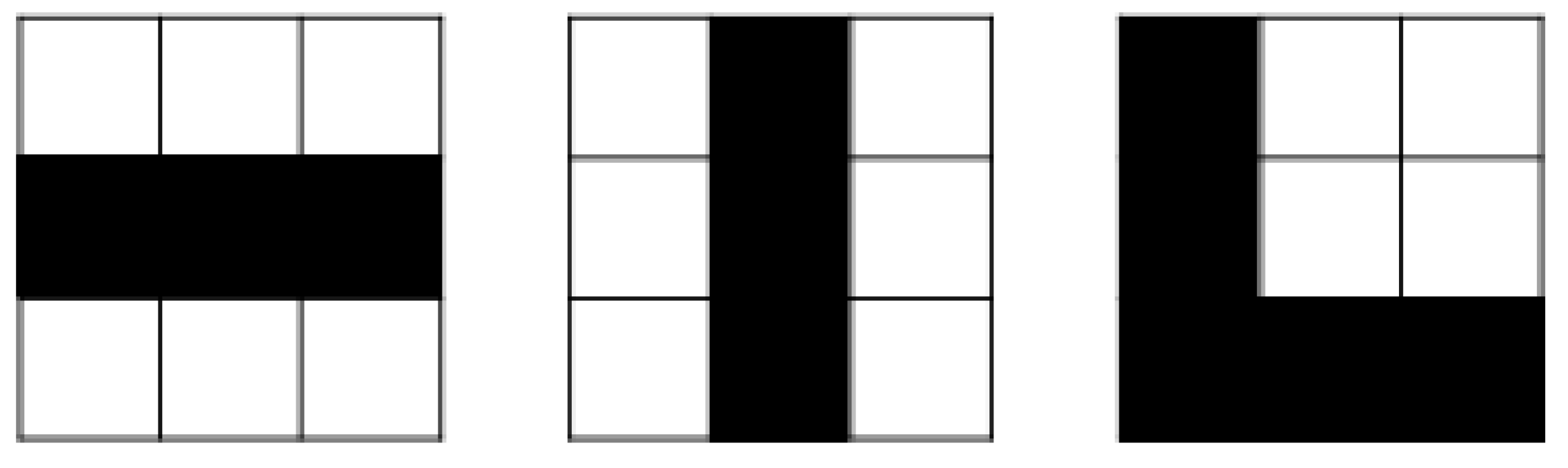
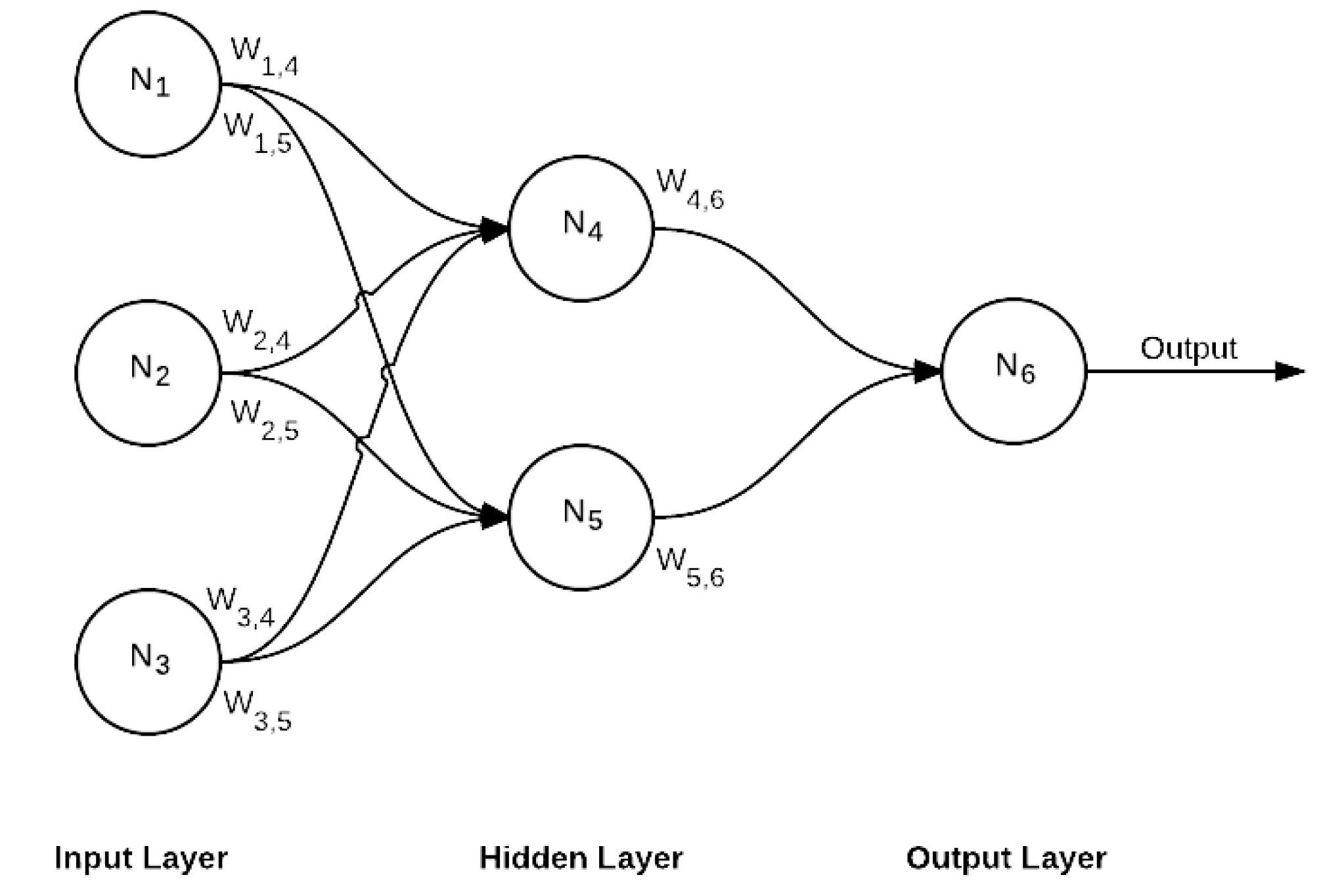
3.2.1. Convolution Neural Network (CNN)
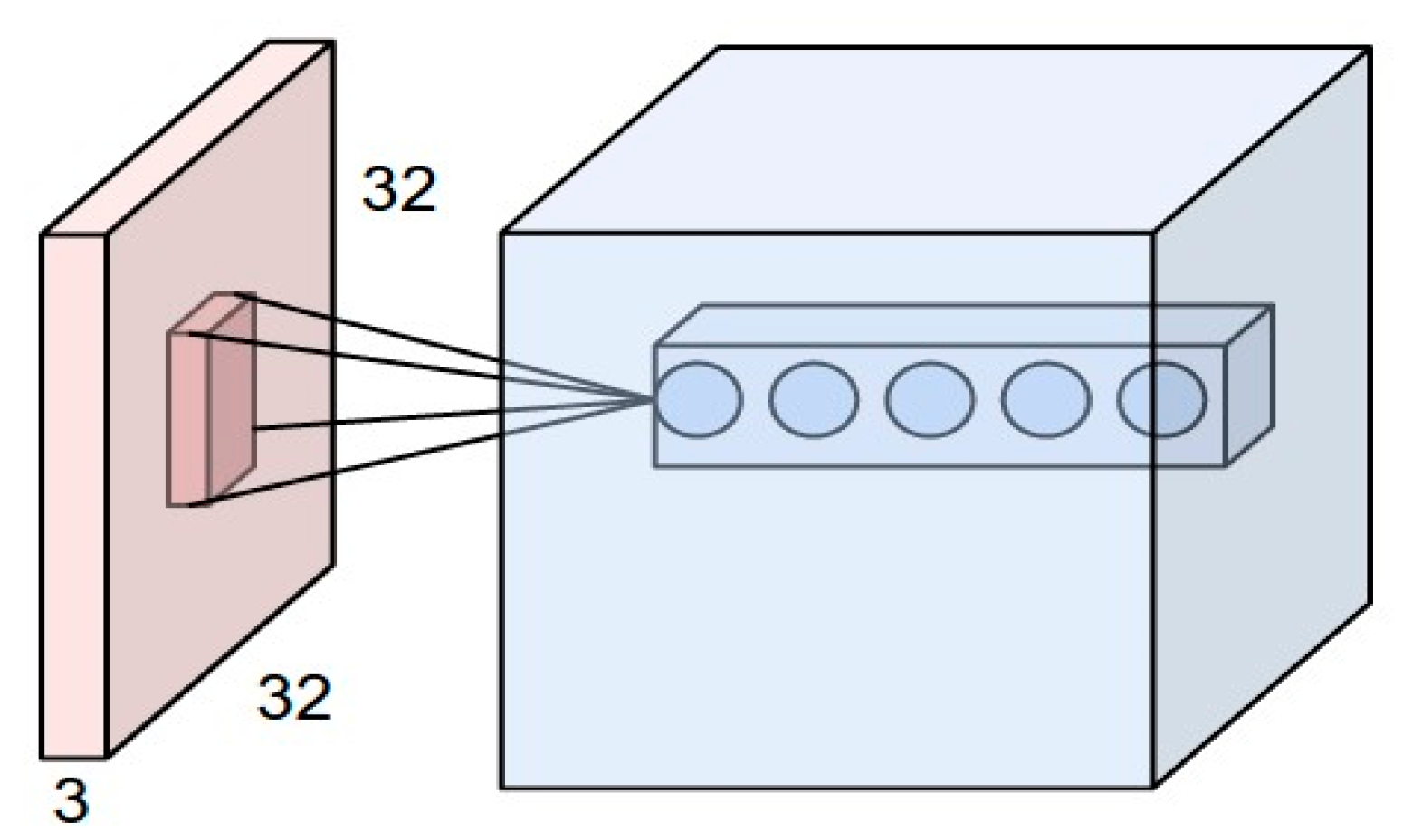
- Convolution
- Nonlinearity (ReLu)
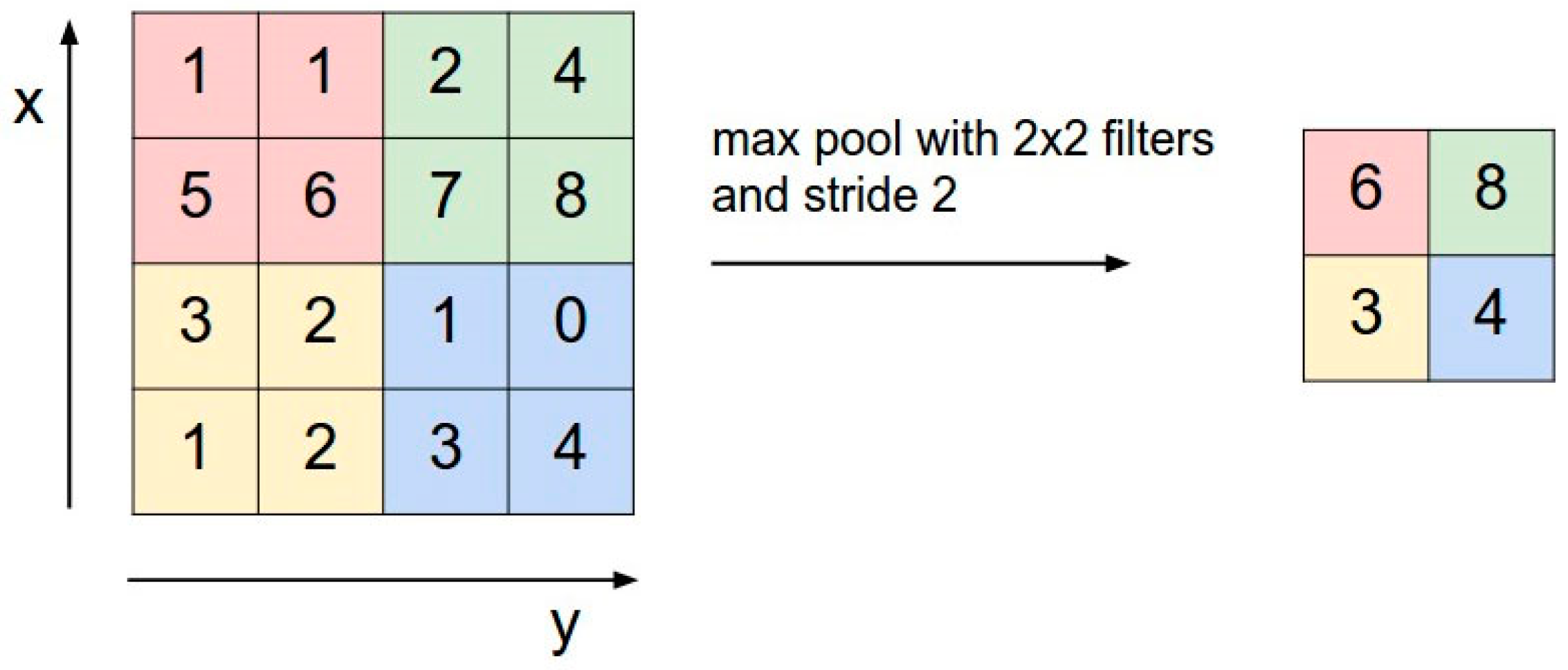
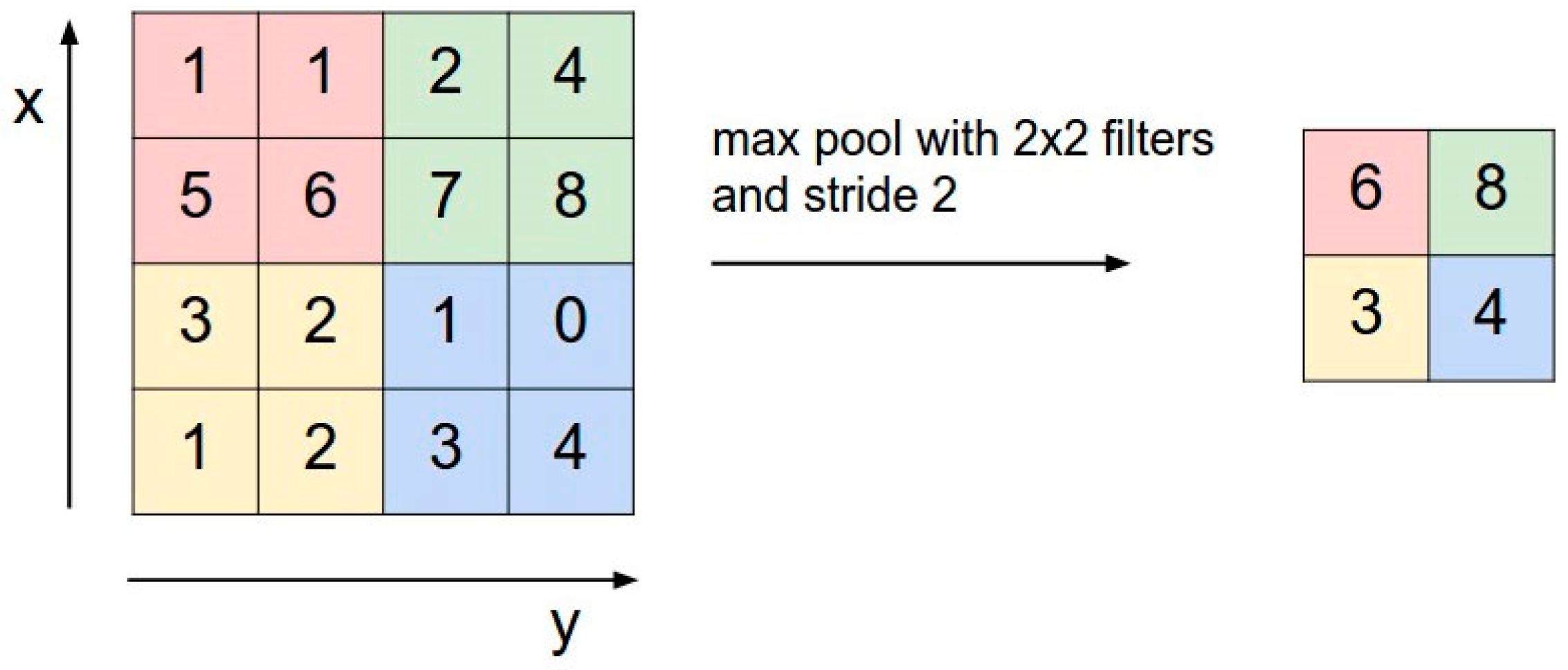
- Pooling
- Fully-connected layer (FC)
Convolution
Nonlinearity (ReLu)
Pooling
Fully-Connected Layer (FC)
3.2.2. OverFeat Architecture
3.2.3. Implementation of the OverFeat Framework
3.3. Commercial Software (Placemeter)
3.4. Manual Counting
4. Datasets
4.1. Training Data
4.2. Testing Data
5. Result and Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Traffic Scorecard. INRIX. Available online: http://inrix.com/ (accessed on 5 May 2017).
- Hsieh, J.-W.; Yu, S.-H.; Chen, Y.-S.; Hu, W.-F. Automatic traffic surveillance system for vehicle tracking and classification. IEEE Trans. Intell. Transp. Syst. 2006, 7, 175–187. [Google Scholar] [CrossRef]
- Buch, N.; Velastin, S.A.; Orwell, J. A review of computer vision techniques for the analysis of urban traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv. 2013. Available online: https://arxiv.org/abs/1312.6229 (accessed on 6 February 2017).
- Daigavane, P.M.; Bajaj, P.R. Real Time Vehicle Detection and Counting Method for Unsupervised Traffic Video on Highways. Int. J. Comput. Sci. Netw. Secur. 2010, 10, 112–117. [Google Scholar]
- Chen, S.C.; Shyu, M.L.; Zhang, C. An Intelligent Framework for Spatio-Temporal Vehicle Tracking. In Proceedings of the 4th IEEE Intelligent Transportation Systems, Oakland, CA, USA, 25–29 August 2001. [Google Scholar]
- Gupte, S.; Masoud, O.; Martin, R.F.K.; Papanikolopoulos, N.P. Detection and Classification of Vehicles. IEEE Trans. Intell. Transp. Syst. 2002, 3, 37–47. [Google Scholar] [CrossRef]
- Cheung, S.; Kamath, C. Robust Techniques for Background Subtraction in Urban Traffic Video. In Proceedings of the Visual Communications and Image Processing, San Jose, CA, USA, 18 January 2004. [Google Scholar]
- Kanhere, N.; Pundlik, S.; Birchfield, S. Vehicle Segmentation and Tracking from a Low-Angle Off-Axis Camera. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Deva, R.; David, A.; Forsyth, D.A.; Andrew, Z. Tracking People by Learning their Appearance. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 65–81. [Google Scholar]
- Toufiq, P.; Ahmed, E.; Mittal, A. A Framework for Feature Selection for Background Subtraction. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Gao, T.; Liu, Z.; Gao, W.; Zhang, J. Moving vehicle tracking based on sift active particle choosing. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 1–5 December 2009. [Google Scholar]
- Jun, G.; Aggarwal, J.; Gokmen, M. Tracking and segmentation of highway vehicles in cluttered and crowded scenes. In Proceedings of the 2008 IEEE Workshop on Applications of Computer Vision, Copper Mountain, CO, USA, 7–9 January 2008; pp. 1–6. [Google Scholar]
- Leotta, M.J.; Mundy, J.L. Vehicle surveillance with a generic, adaptive, 3D vehicle model. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1457–1469. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Grimson, W.E.L. Edge-based rich representation for vehicle classification. In Proceedings of the 10th IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 1185–1192. [Google Scholar]
- Messelodi, S.; Modena, C.M.; Zanin, M. A computer vision system for the detection and classification of vehicles at urban road intersections. Pattern Anal. Appl. 2005, 8, 17–31. [Google Scholar] [CrossRef]
- Alonso, D.; Salgado, L.; Nieto, M. Robust vehicle detection through multidimensional classification for on board video based systems. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007. [Google Scholar]
- Lou, J.; Tan, T.; Hu, W.; Yang, H.; Maybank, S.J. 3-D modelbased vehicle tracking. IEEE Trans. Image Proc. 2005, 14, 1561–1569. [Google Scholar]
- Gentile, C.; Camps, O.; Sznaier, M. Segmentation for robust tracking in the presence of severe occlusion. IEEE Trans. Image Proc. 2004, 13, 166–178. [Google Scholar] [CrossRef]
- Song, X.; Nevatia, R. A model-based vehicle segmentation method for tracking. In Proceedings of the 10th IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 1124–1131. [Google Scholar]
- Liang, M.; Huang, X.; Chen, C.-H.; Chen, X.; Tokuta, A. Counting and Classification of Highway Vehicles by Regression Analysis. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2878–2888. [Google Scholar] [CrossRef]
- Salvi, G. An Automated Vehicle Counting System Based on Blob Analysis for Traffic Surveillance. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition, Las Vegas, NV, USA, 16–19 July 2012; pp. 397–402. [Google Scholar]
- Adi, N.; Wisnu, J.; Benny, H.; Ari, W.; Ibnu, S.; Petrus, M. Background Subtraction Using Gaussian Mixture Model Enhanced by Hole Filling Algorithm (GMMHF). In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 4006–4011. [Google Scholar]
- Yim, J.; Ju, J.; Jung, H.; Kim, J. Image Classification Using Convolutional Neural Networks with Multi-Stage Feature. In Robot Intelligence Technology and Applications 3; Kim, J.H., Yang, W., Jo, J., Sincak, P., Myung, H., Eds.; Springer: Cham, Switzerland, 2015; Volume 345. [Google Scholar]
- Logistic Regression. Available online: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html (accessed on 15 February 2017).
- Placemeter. Available online: https://www.placemeter.com/ (accessed on 7 April 2017).
- Image Net Library. Available online: http://imagenet.stanford.edu/ (accessed on 15 April 2017).
- Under a Bridge Camera. Available online: https://www.youtube.com/watch?v=SF_xhxvSOLA (accessed on 10 April 2017).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | 1 | 2 | 3 | 4 | 5 | 6 | 7 | Output 8 |
|---|---|---|---|---|---|---|---|---|
| Stage | conv + max | conv + max | conv | conv | conv + max | full | full | full |
| #channels | 96 | 256 | 512 | 1024 | 1024 | 3072 | 4096 | 1000 |
| Filter size | 11 × 11 | 5 × 5 | 3 × 3 | 3 × 3 | 3 × 3 | - | - | - |
| Conv. stride | 4 × 4 | 1 × 1 | 1 × 1 | 1 × 1 | 1 × 1 | - | - | - |
| Pooling size | 2 × 2 | 2 × 2 | - | - | 2 × 2 | |||
| Pooling stride | 2 × 2 | 2 × 2 | - | - | 2 × 2 | - | - | - |
| Zero-Padding size | - | - | 1 × 1 × 1 × 1 | 1 × 1 × 1 × 1 | 1 × 1 × 1 × 1 | - | - | - |
| Spatial input size | 231 × 231 | 24 × 24 | 12 × 12 | 12 × 12 | 12 × 12 | 6 × 6 | 1 × 1 | 1 × 1 |
| Camera | Time Duration (Local Time) | Manual Counts | Placemeter | BSM | OverFeat |
|---|---|---|---|---|---|
| C34 | 10:00–11:00 | 879 | 582 (66.21%) | 597 (67.91%) | 910 (96.47%) |
| 18:00–19:00 | 2075 | 1467 (70.96%) | 1335 (64.33%) | 2120 (99.97%) | |
| C35 | 07:00–08:00 | 1862 | 1332 (71.53%) | 2236 (79.91%) | 1902 (97.85%) |
| C66 | 11:00–12:00 | 1978 | 1393 (70.42%) | 1674 (84.63%) | 1942 (98.17%) |
| 23:00–00:00 | 549 | 335 (61.02%) | 108 (19.67%) | 566 (99.96%) | |
| C73 | 11:00–11:10 (for 10 min) | 270 | 156 (57.77%) | 151 (52.92%) | 255 (94.44%) |
| C103 | 07:00–08:00 | 210 | 145 (69.04%) | 372 (22.85%) | 225 (92.85%) |
| 11:00–12:00 | 579 | 432 (74.61%) | 463 (79.96%) | 619 (93.09%) | |
| Under the bridge | 09:00-09:01 (1 min) | 52 | - | 50 (96.15%) | 54 (96.15%) |
| Average | - | - | 67.69% | 63.14% | 96.55% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biswas, D.; Su, H.; Wang, C.; Blankenship, J.; Stevanovic, A. An Automatic Car Counting System Using OverFeat Framework. Sensors 2017, 17, 1535. https://doi.org/10.3390/s17071535
Biswas D, Su H, Wang C, Blankenship J, Stevanovic A. An Automatic Car Counting System Using OverFeat Framework. Sensors. 2017; 17(7):1535. https://doi.org/10.3390/s17071535
Chicago/Turabian StyleBiswas, Debojit, Hongbo Su, Chengyi Wang, Jason Blankenship, and Aleksandar Stevanovic. 2017. "An Automatic Car Counting System Using OverFeat Framework" Sensors 17, no. 7: 1535. https://doi.org/10.3390/s17071535
APA StyleBiswas, D., Su, H., Wang, C., Blankenship, J., & Stevanovic, A. (2017). An Automatic Car Counting System Using OverFeat Framework. Sensors, 17(7), 1535. https://doi.org/10.3390/s17071535