Data Aggregation Based on Overlapping Rate of Sensing Area in Wireless Sensor Networks


Abstract
:1. Introduction
2. Related Work
3. Network Model and Aggregation Rules
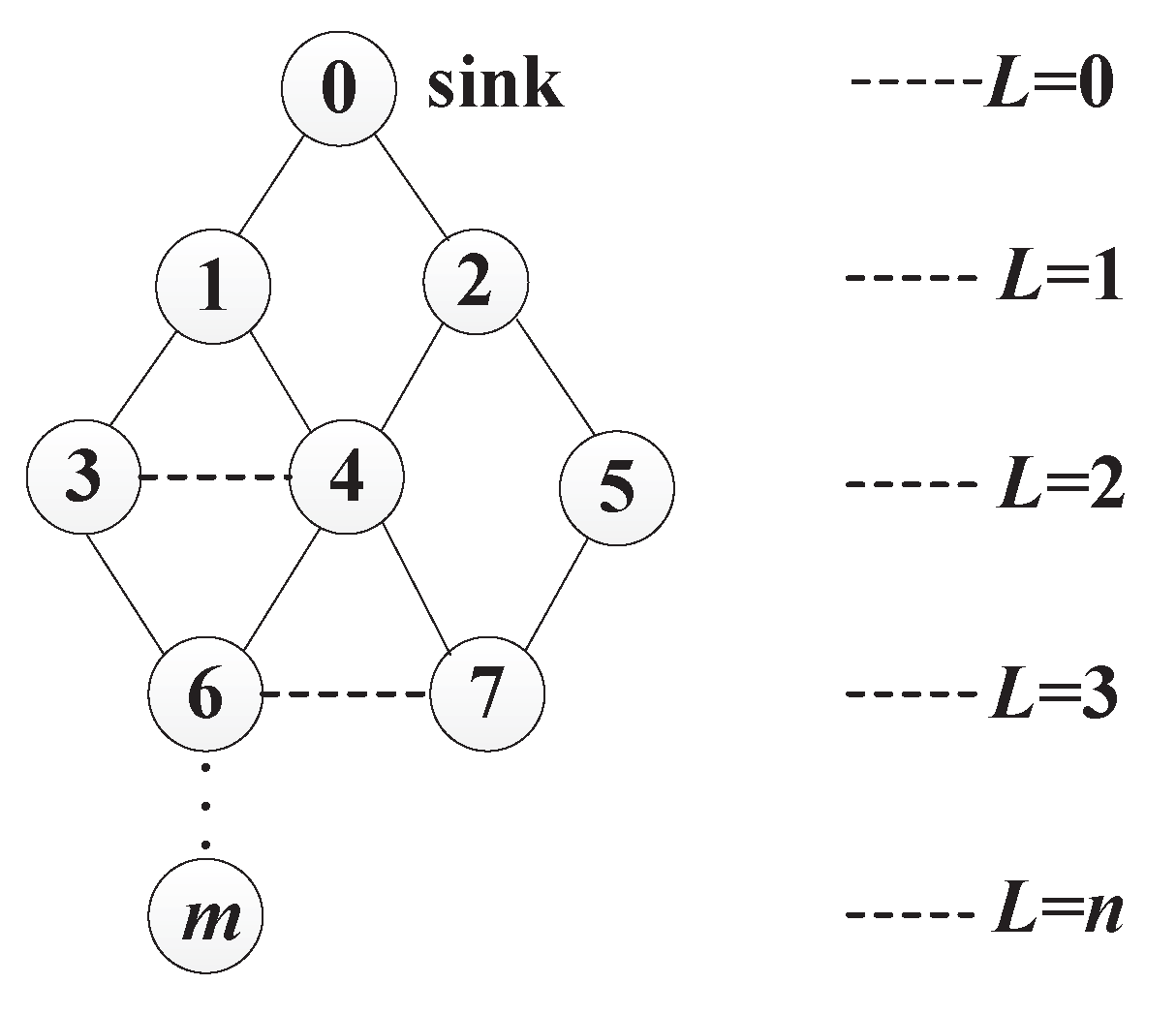
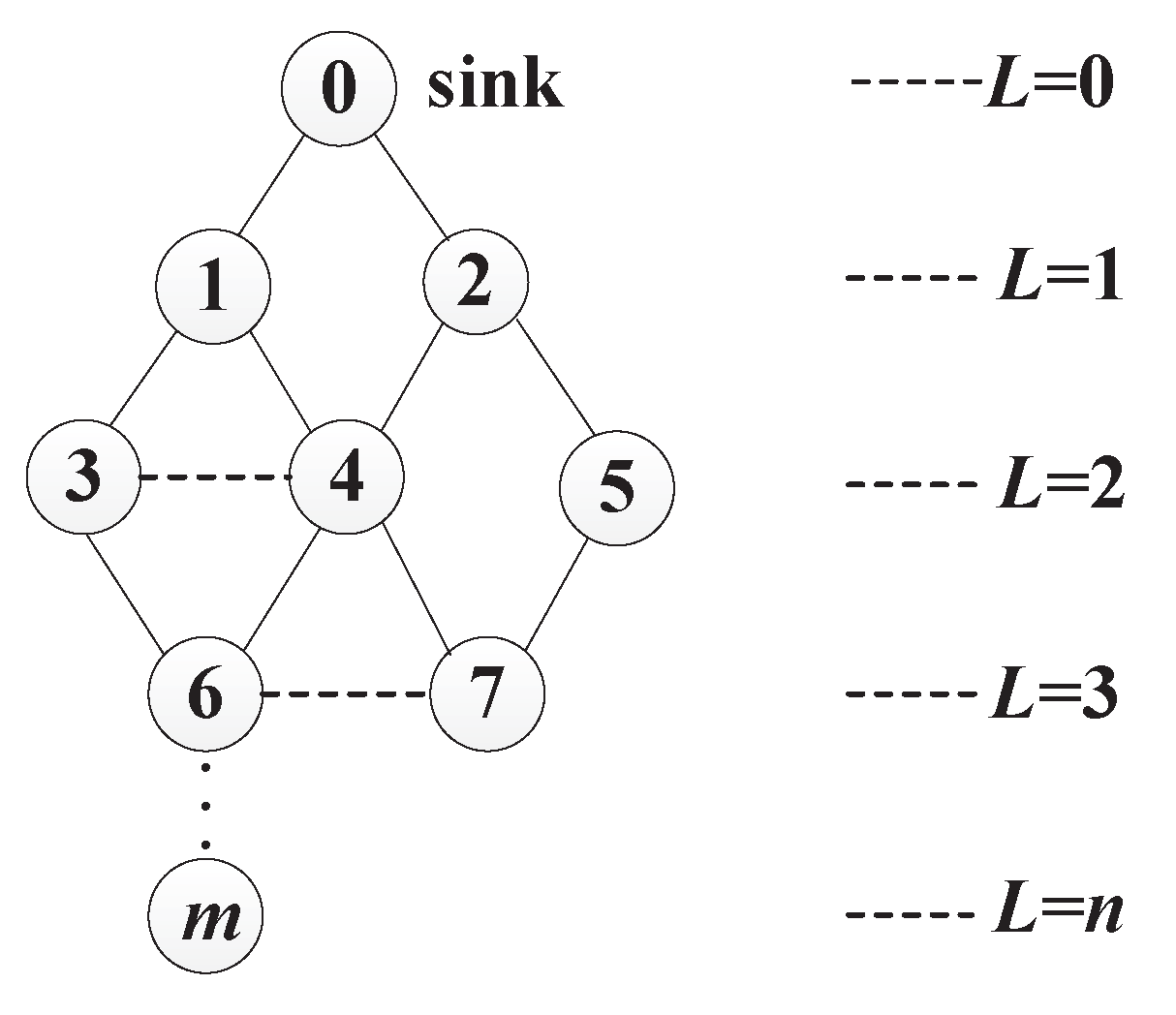
3.1. Network Model
3.2. Aggregation Rules
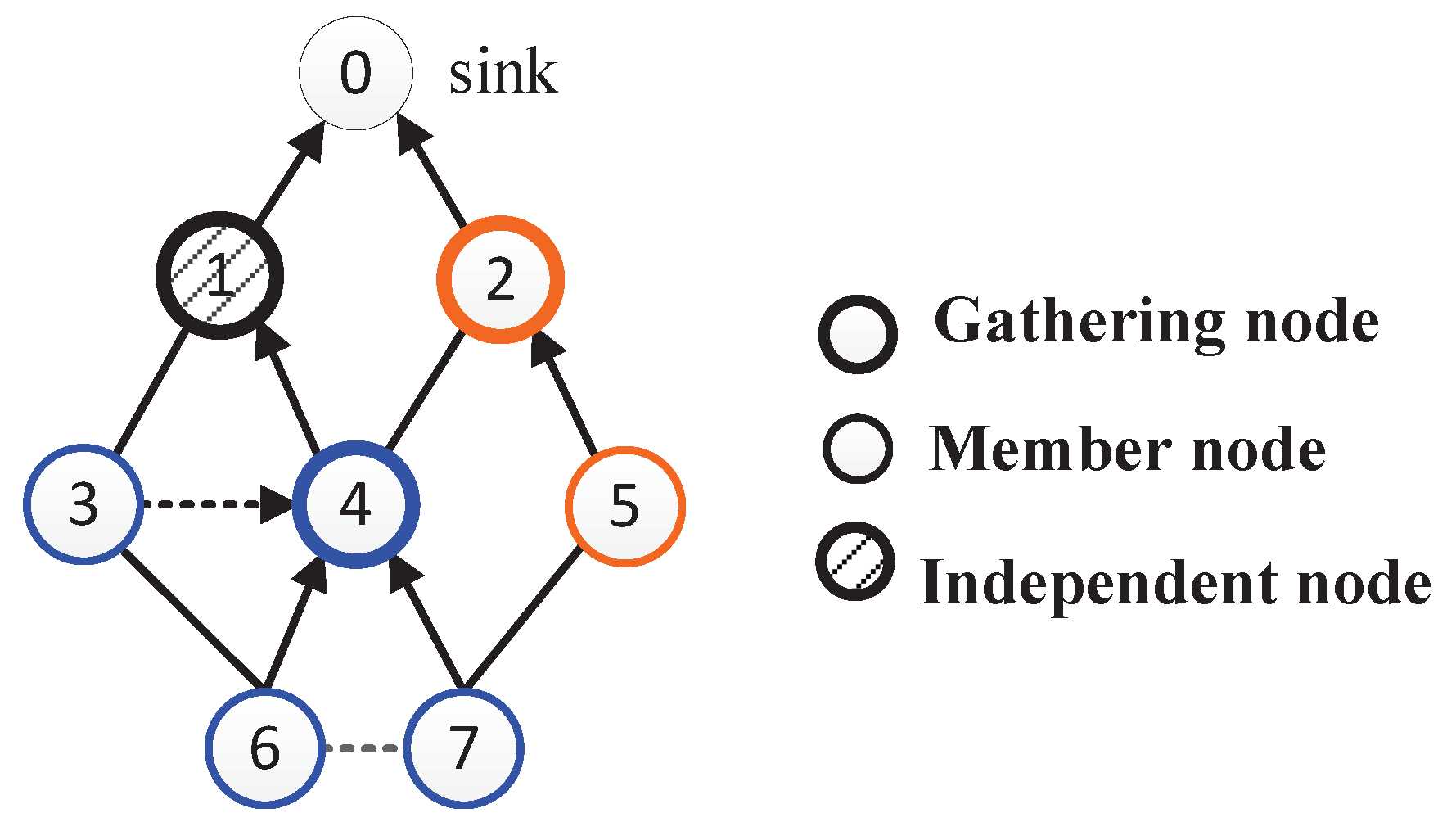
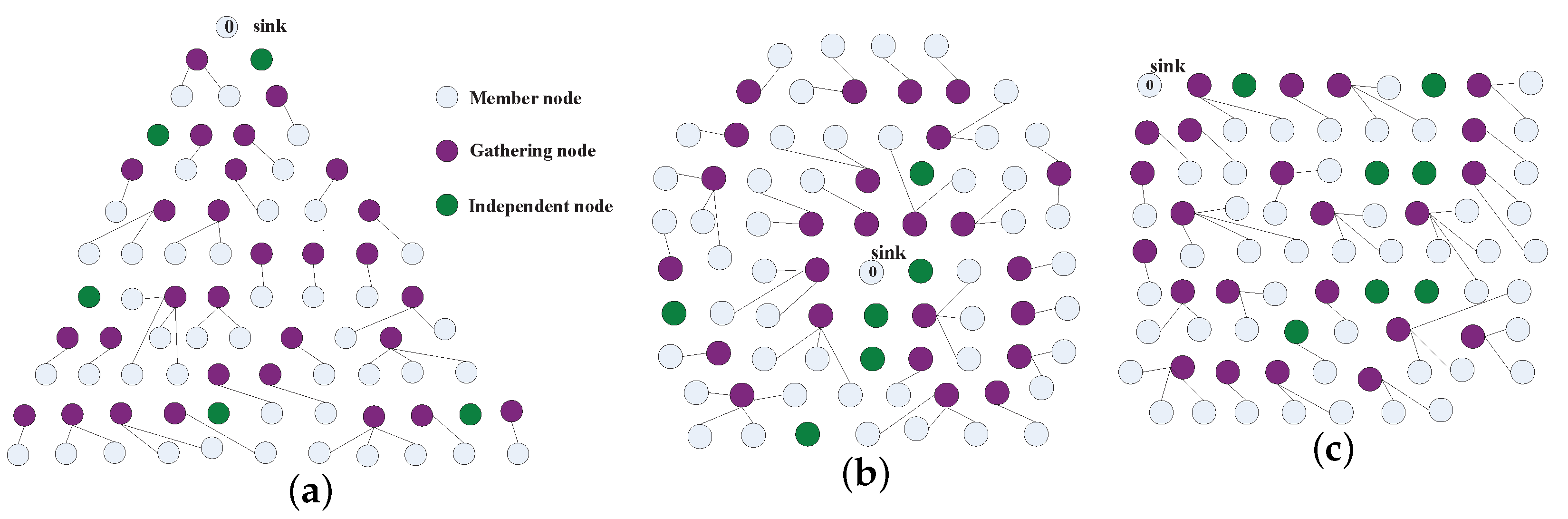
4. Implementation of AggOR Scheme
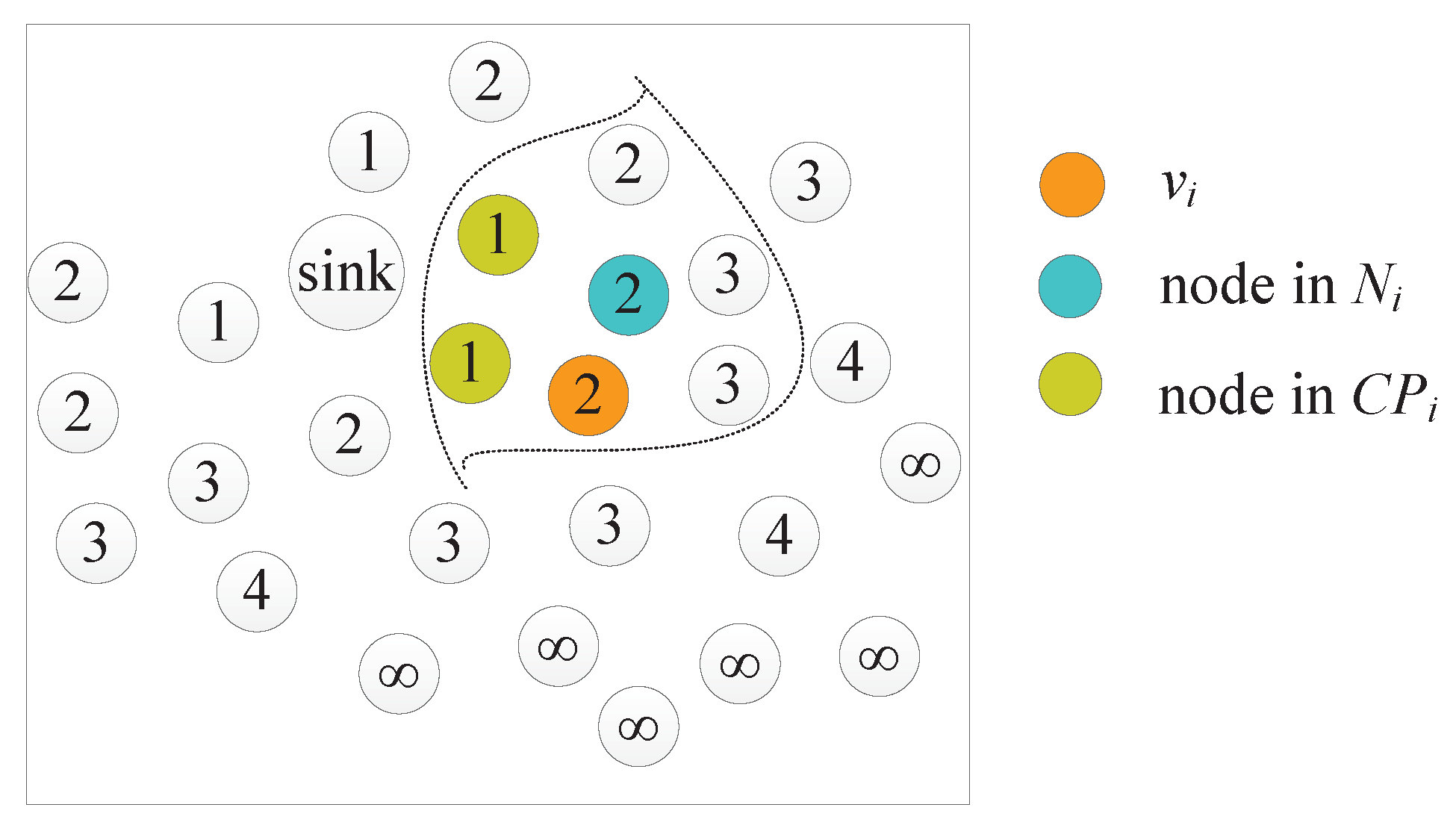
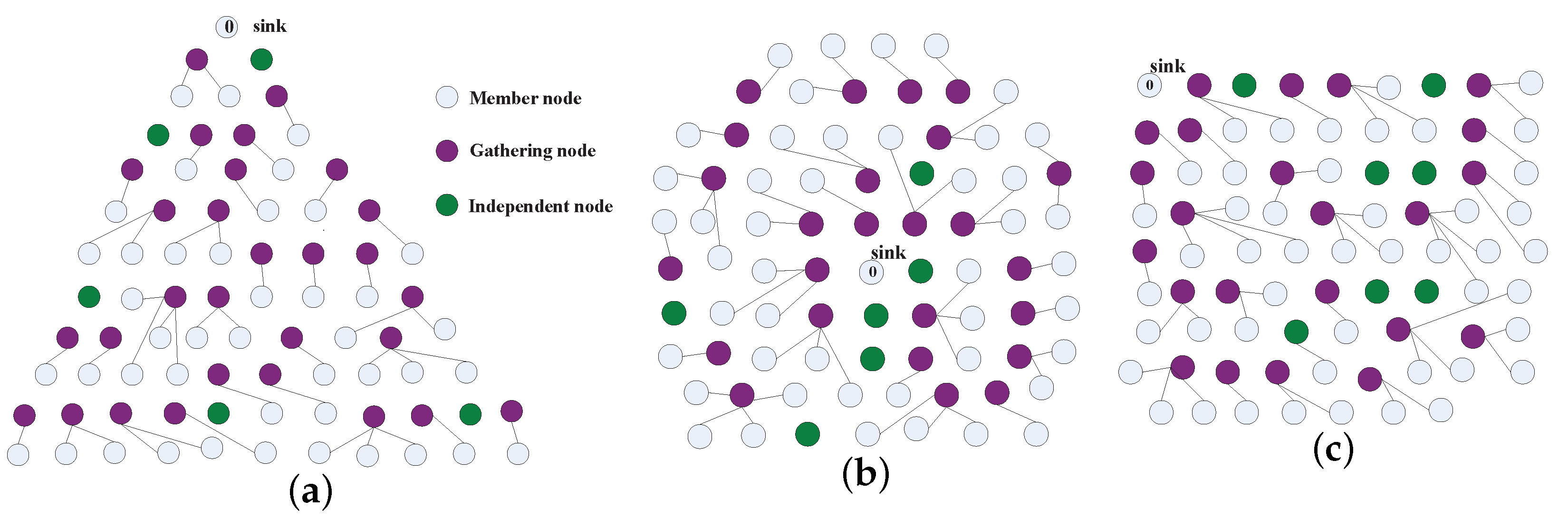
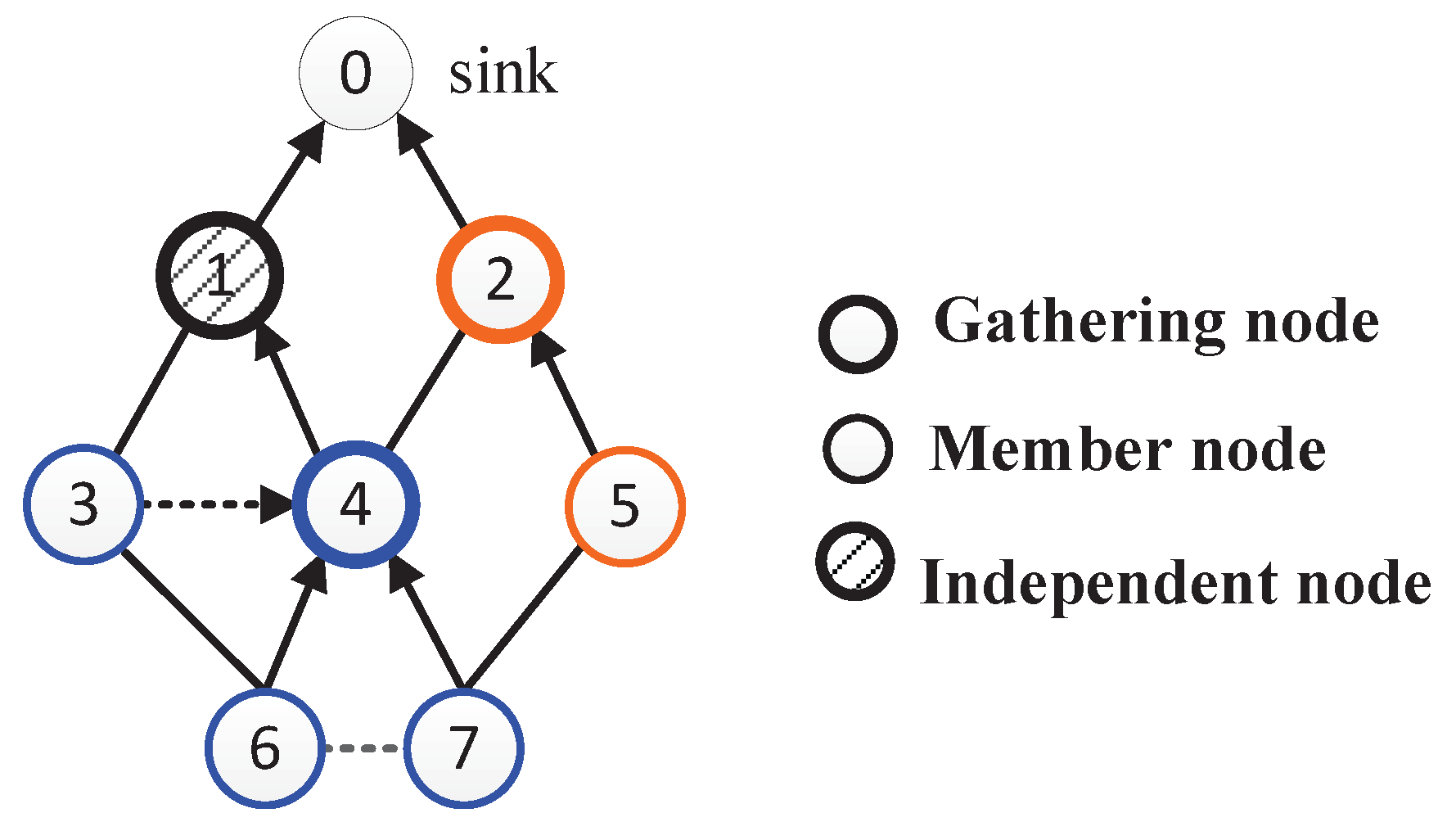
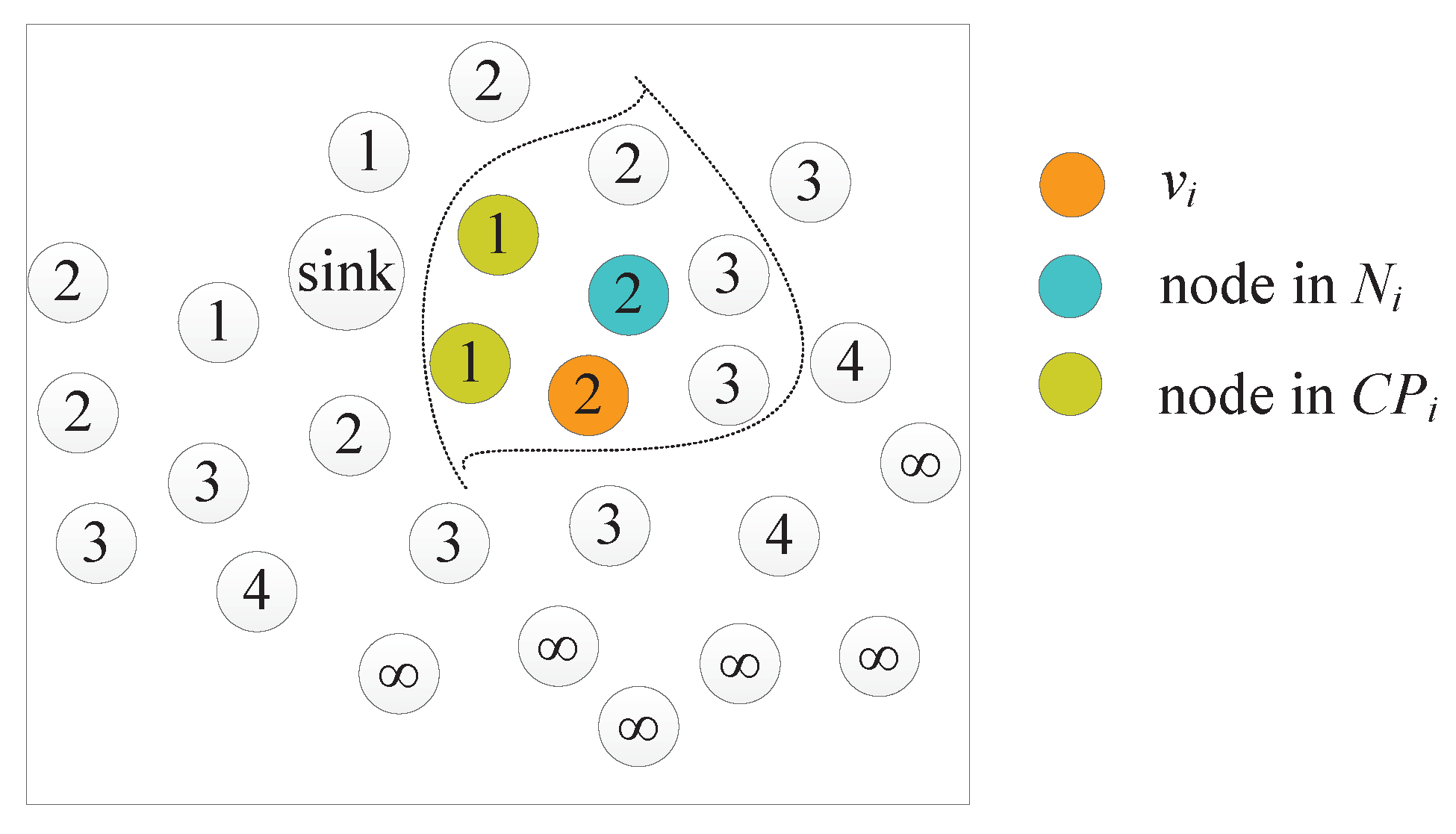
4.1. Gathering Area Construction
| Algorithm 1: Gathering Area Construction. |
 |
| Algorithm 2: Finding Candidate Gathering Node Set. |
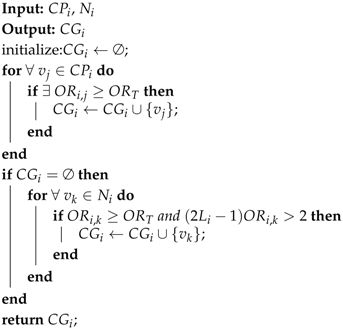 |
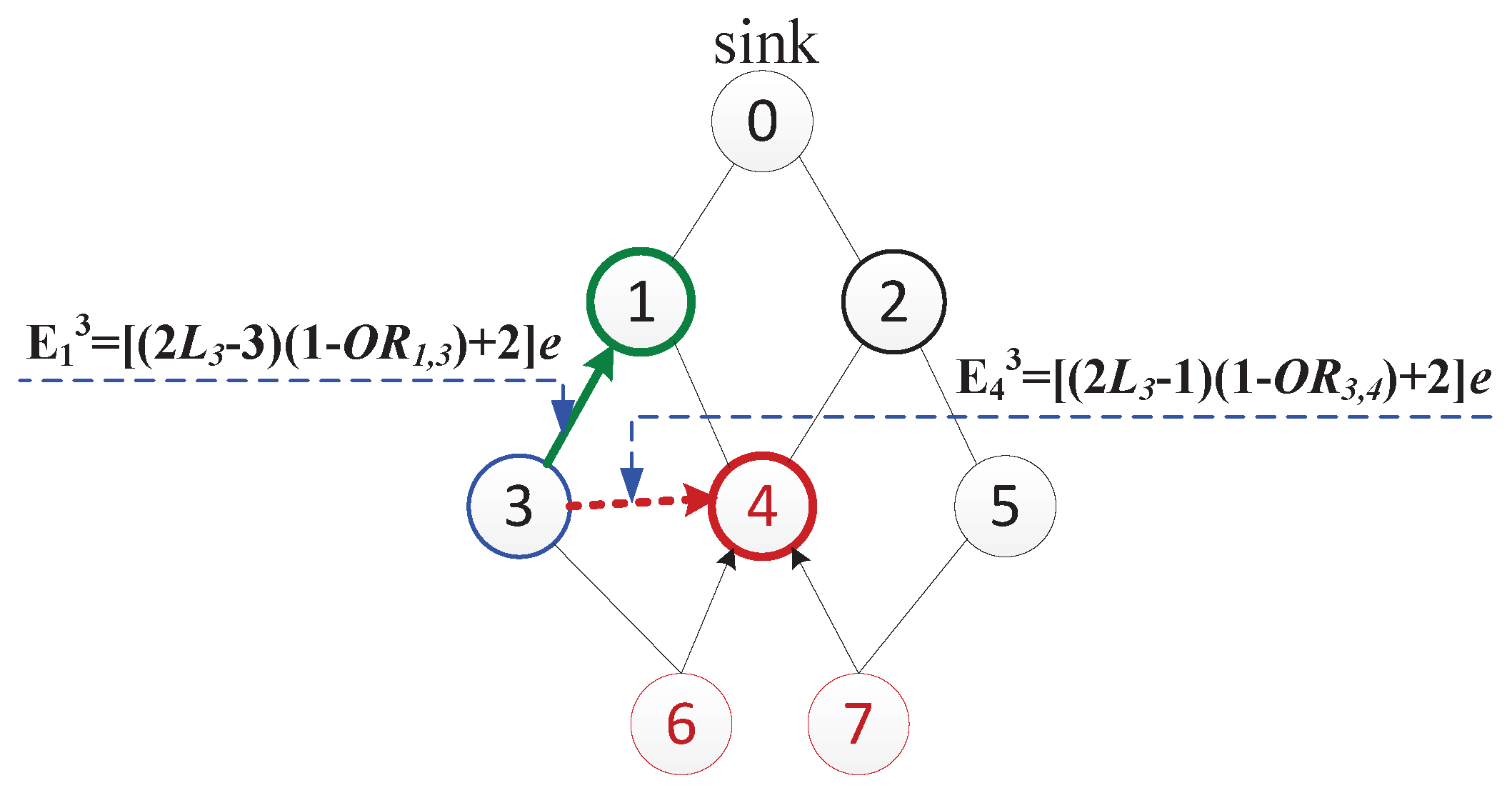
4.2. Data Routing
4.3. Complexity Analysis
5. Performance Evaluation
5.1. Network Configurations
- (1)
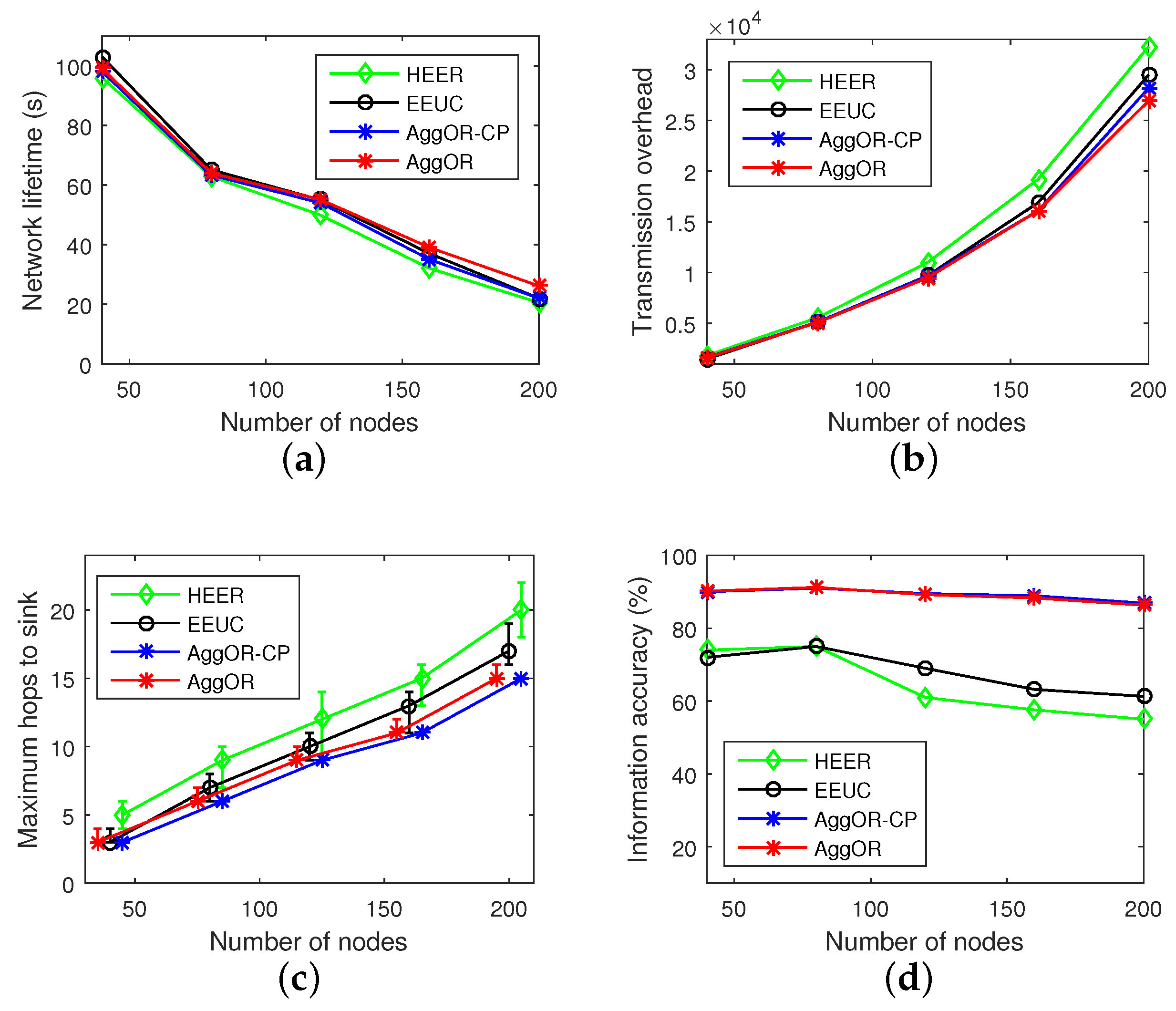
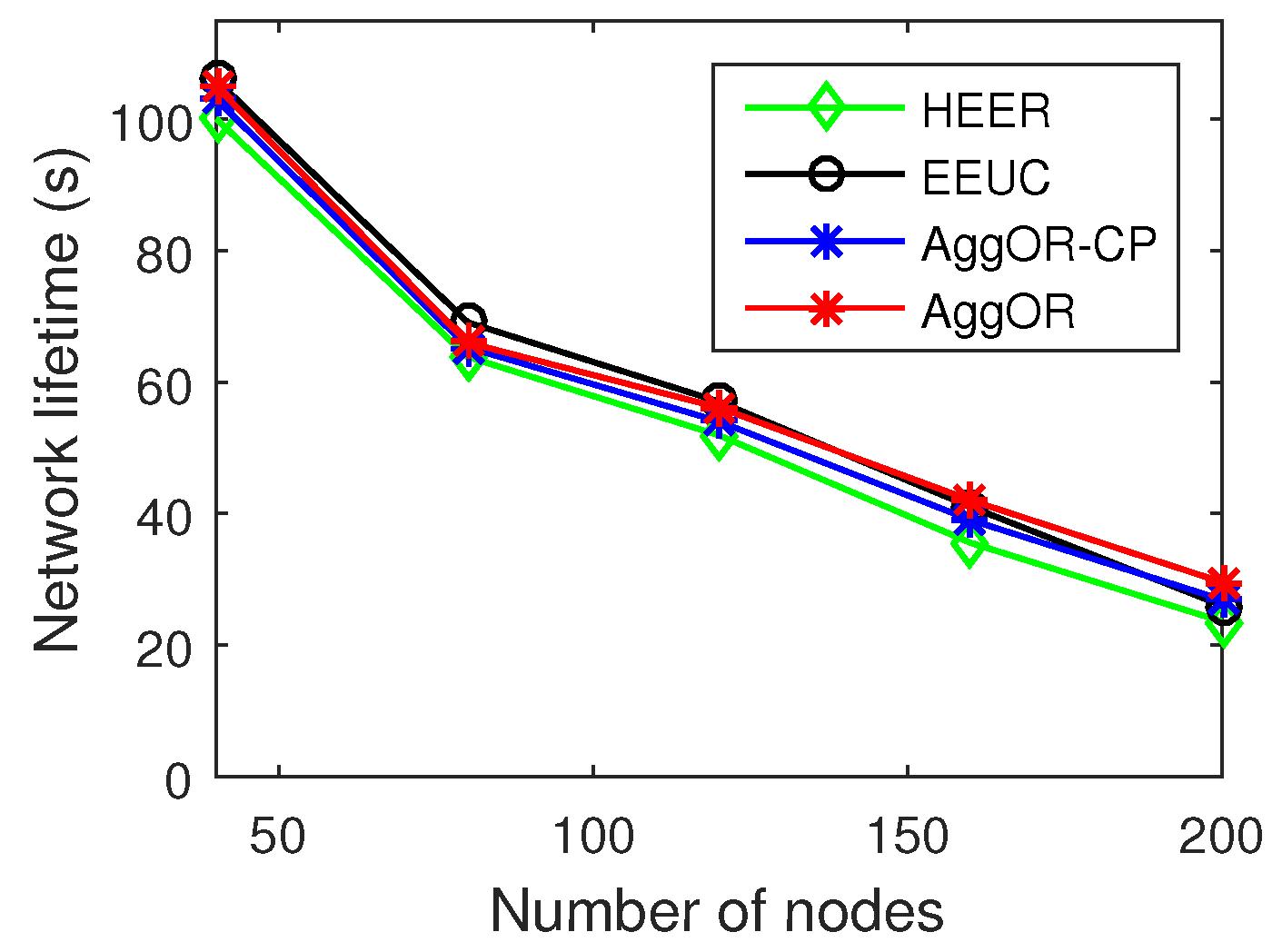
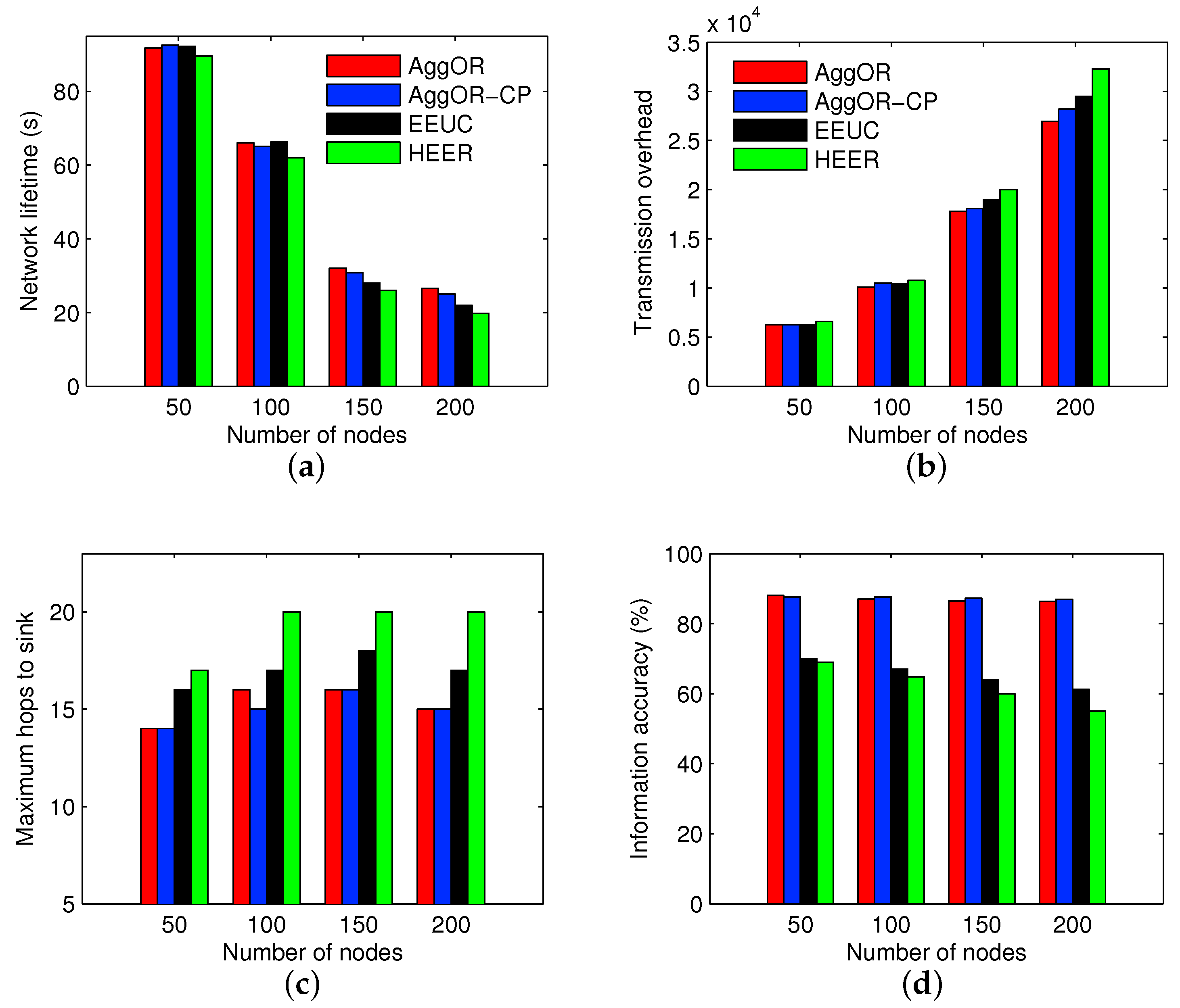
- Network lifetime: the time interval from the beginning of the network to the death of the first node.
- (2)
- Transmission overhead: the total amount of data transmitted in one data transmission round. It indicates the energy consumption of data sending and receiving in the whole network.
- (3)
- Maximum number of hops to the sink: the maximum number of hops from sensor nodes to the sink in the network. More hops mean a longer time for which the sink has to wait to collect all the data in the scenario. Hence it implies the data delivery delay.
- (4)
- Information accuracy: the ratio of the amount of information collected by the sink to the amount of information in all raw data.
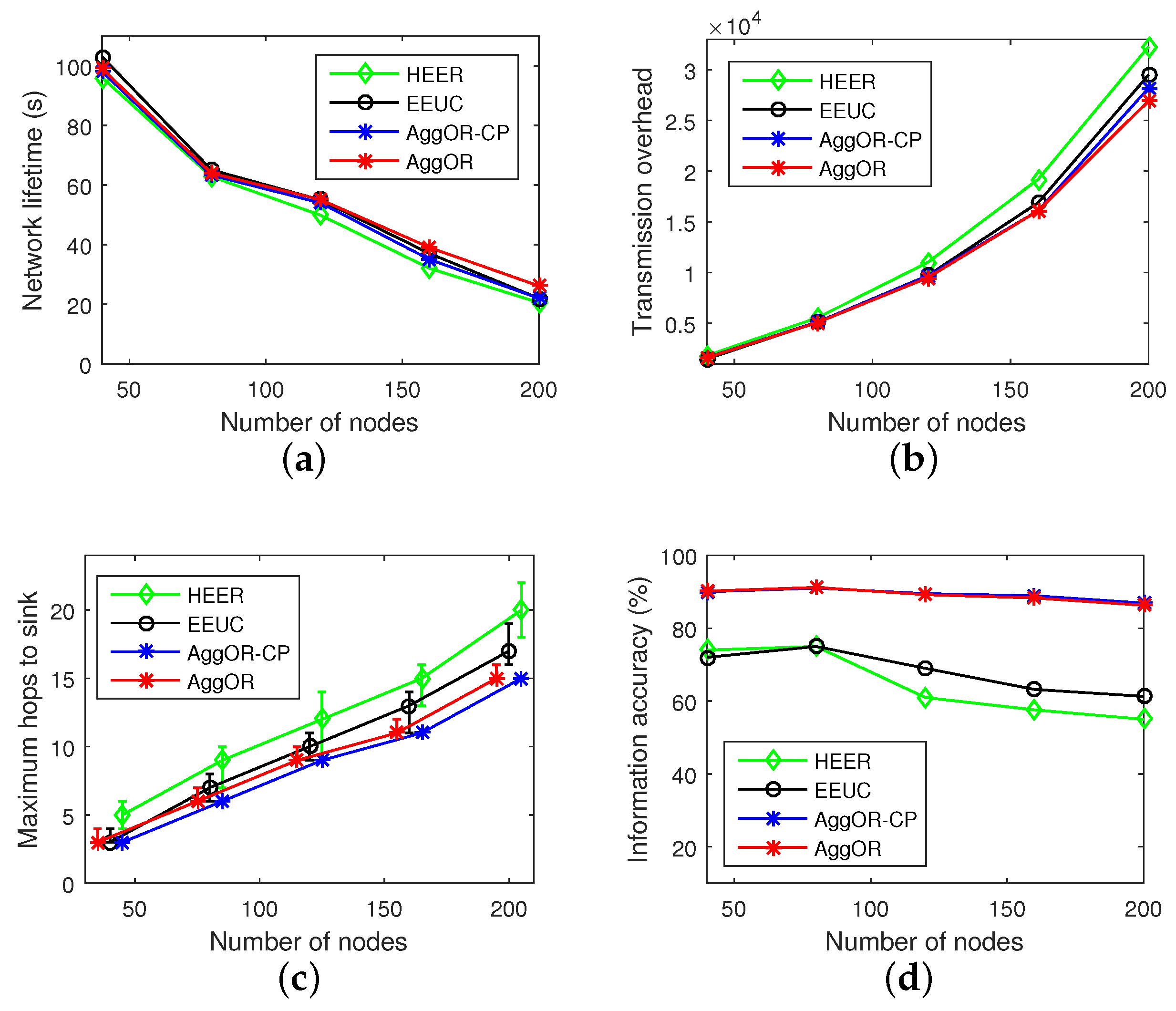
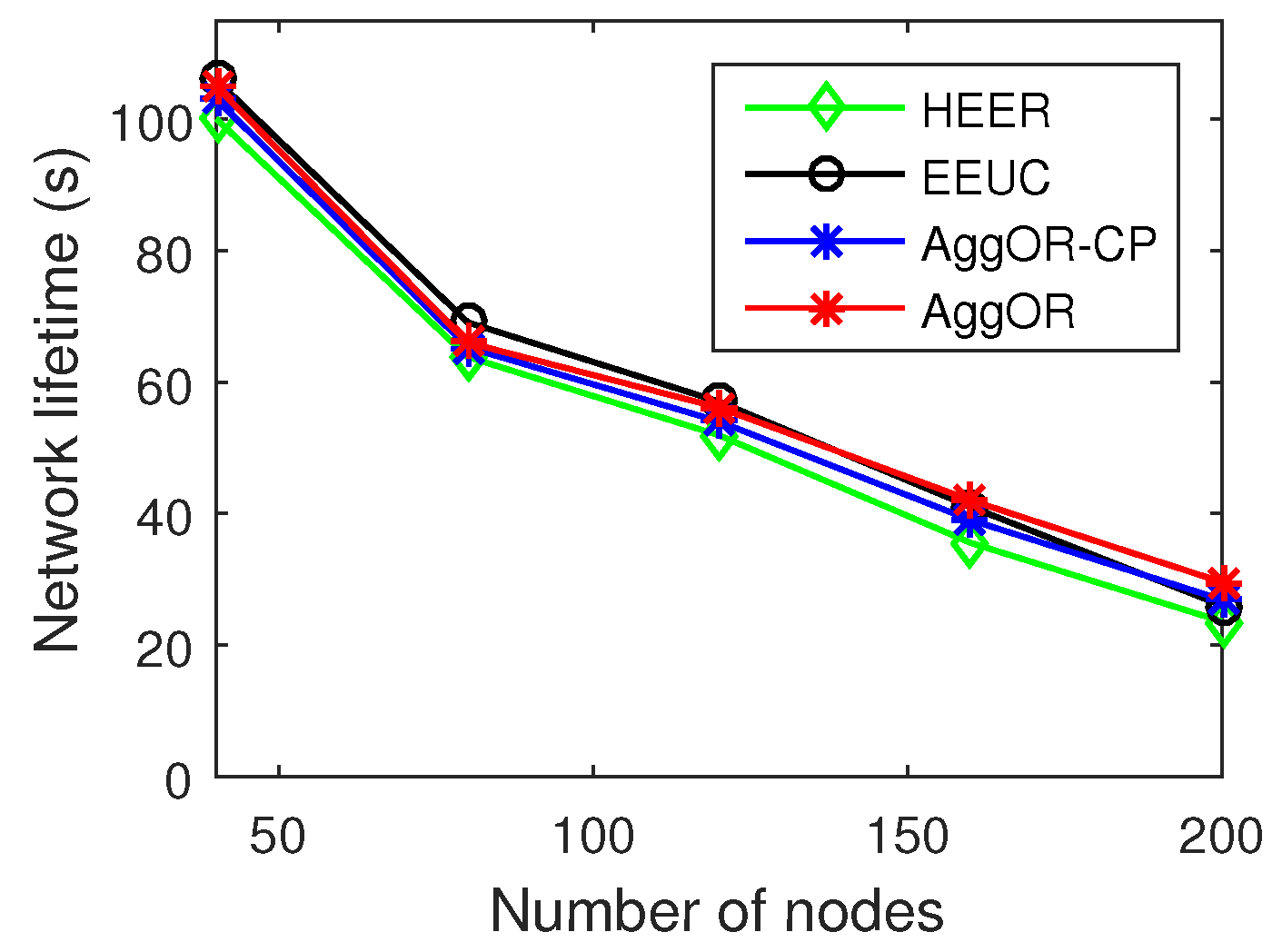
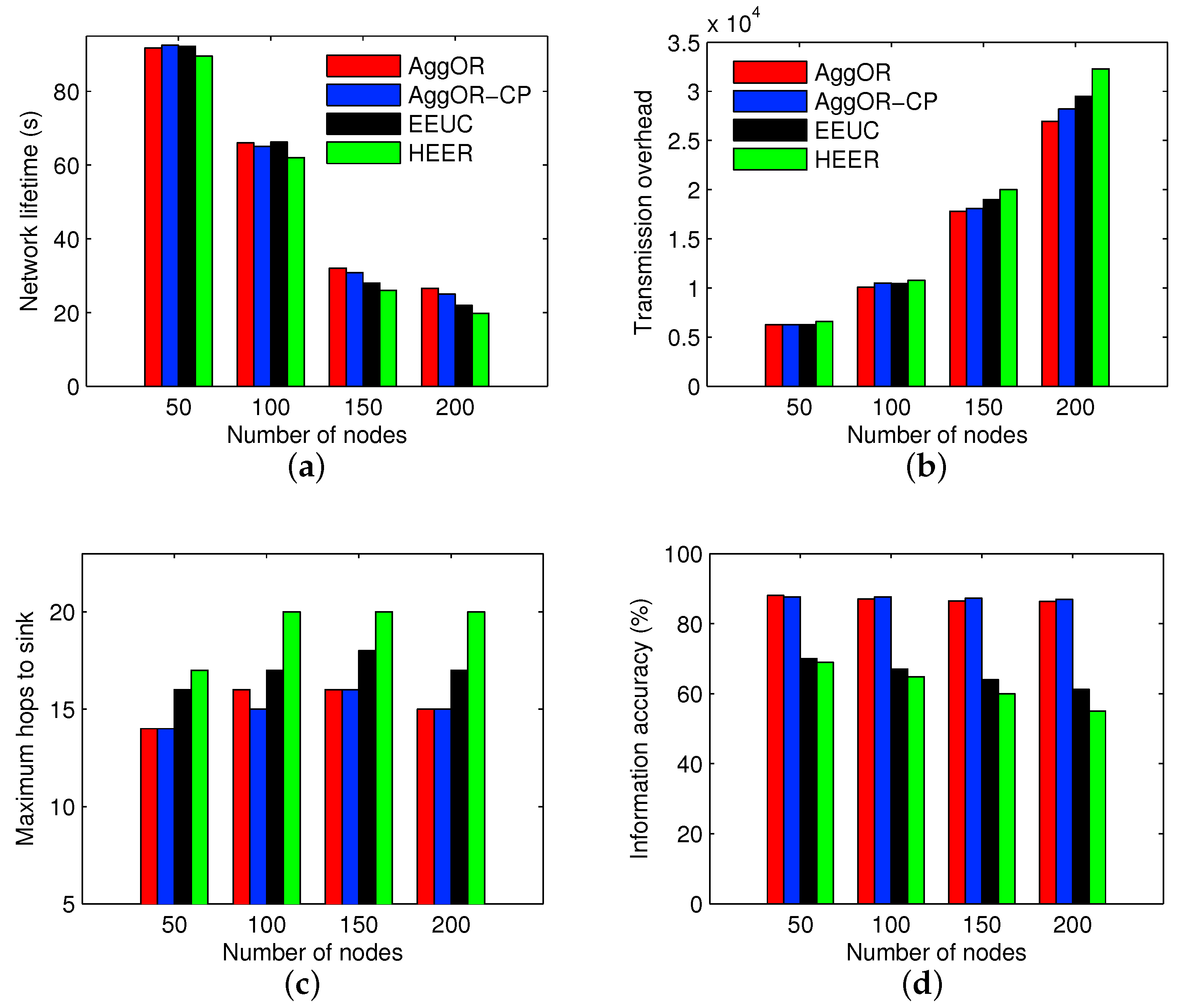
5.2. Experiment Results
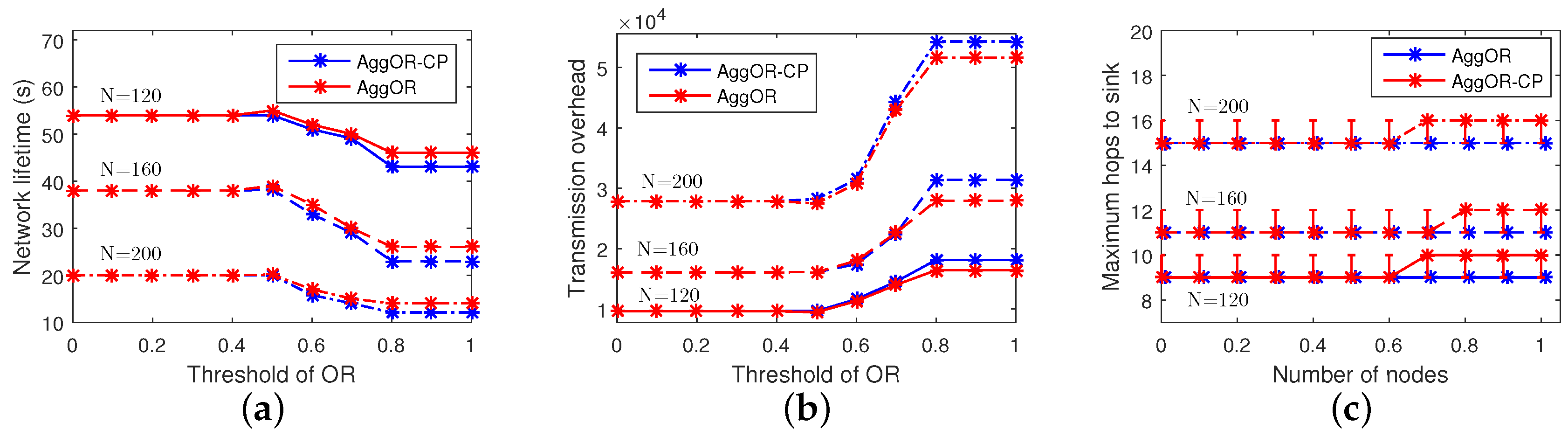
5.3. Parameter Analysis
5.3.1. Sensor Density Analysis
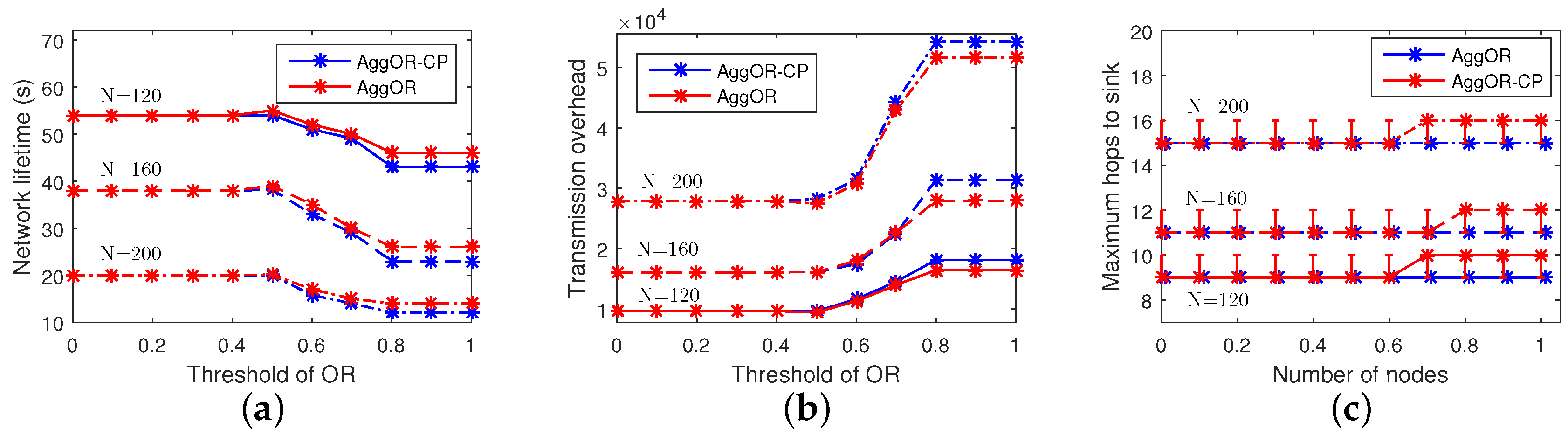
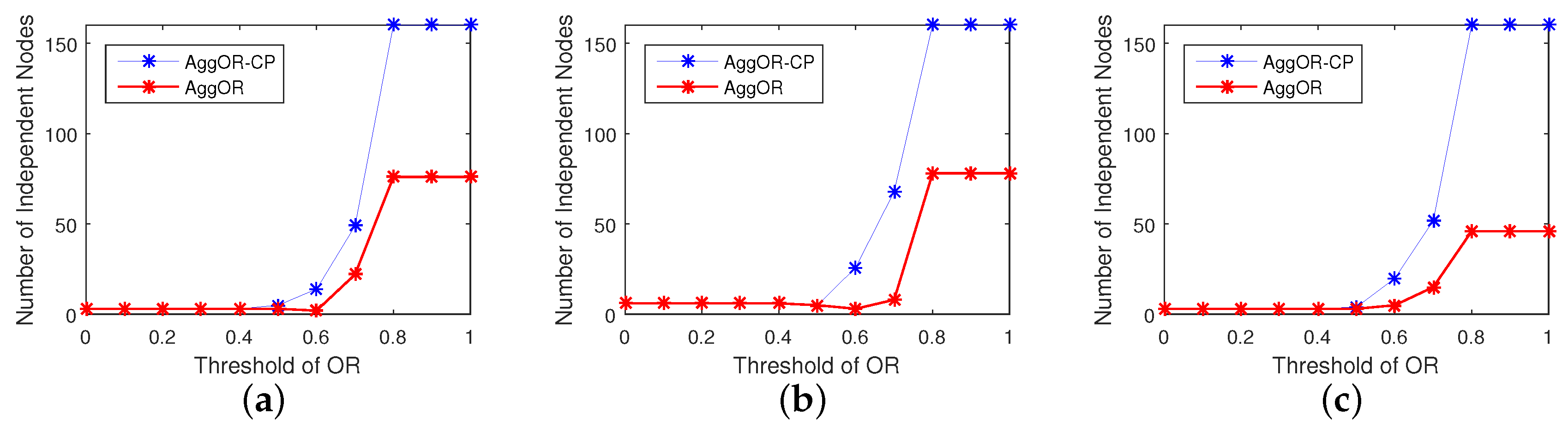
5.3.2. Analysis of the Threshold of Overlapping Rate of Sensing Area
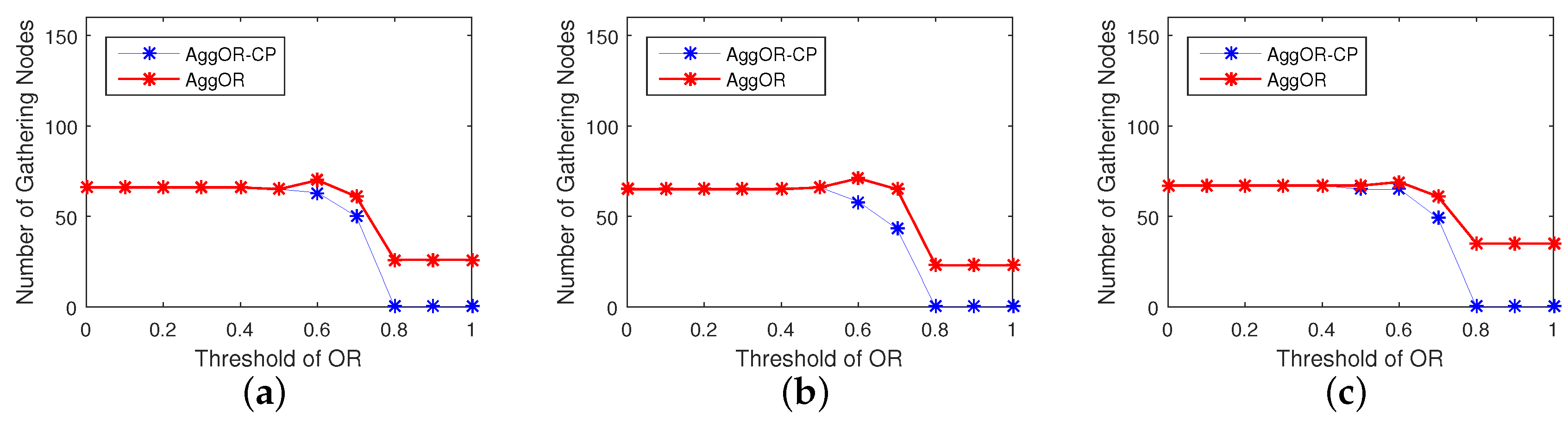
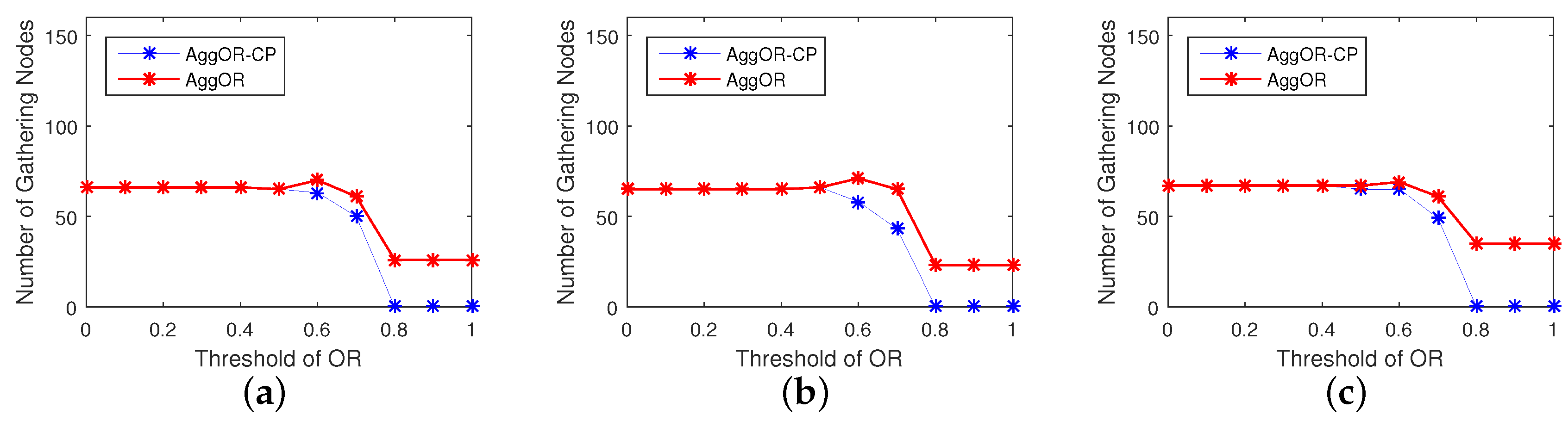
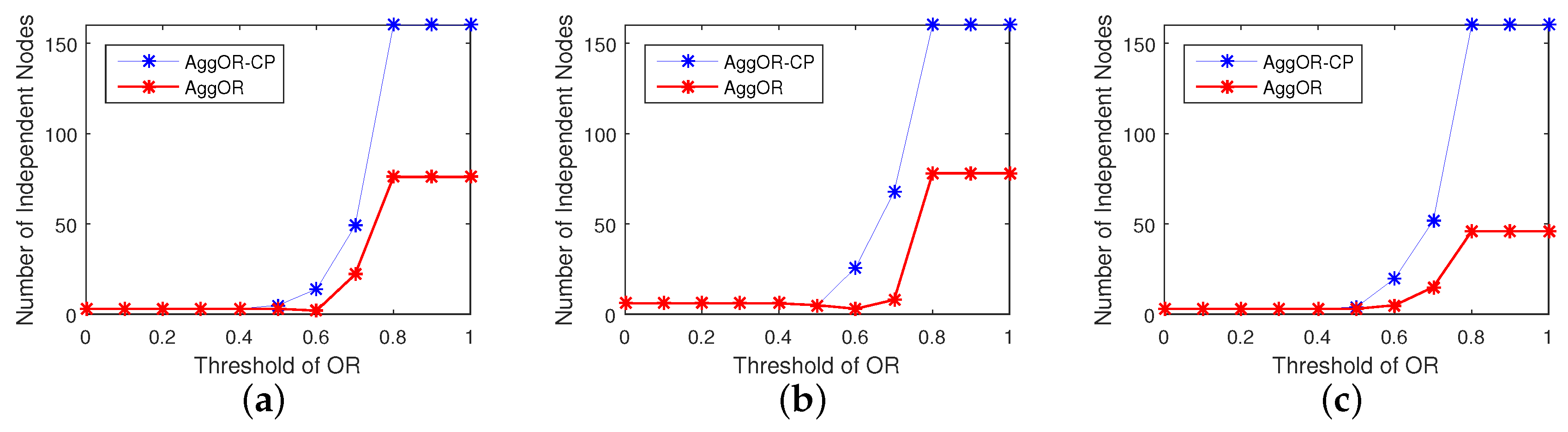
5.3.3. Gathering Node Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, J.; Zhou, J.; Lv, Z.; Wei, W.; Song, H. A real-time monitoring system of industry carbon monoxide based on wireless sensor networks. Sensors 2015, 15, 29535–29546. [Google Scholar] [CrossRef] [PubMed]
- Tang, X.; Pu, J.; Gao, Y.; Xiong, Z.; Weng, Y. Energy-efficient multicast routing scheme for wireless sensor networks. Trans. Emerg. Telecommun. Technol. 2014, 25, 965–980. [Google Scholar] [CrossRef]
- Jeschke, S.; Brecher, C.; Song, H.; Rawat, D. Industrial Internet of Things: Cyber Manufacturing Systems; Springer: Berlin, Germany, 2017. [Google Scholar]
- Shu, L.; Mukherjee, M.; Hu, L.; Bergmann, N.; Zhu, C. Geographic Routing in Duty-cycled Industrial Wireless Sensor Networks with Radio Irregularity. IEEE Access 2016, 4, 9043–9052. [Google Scholar] [CrossRef]
- Shu, L.; Wang, L.; Niu, J.; Zhu, C.; Mukherjee, M. Releasing network isolation problem in group-based industrial wireless sensor networks. IEEE Syst. J. 2015, 1, 1–11. [Google Scholar] [CrossRef]
- Kumar, A.; Baksh, R.; Thakur, R.K.; Singh, A.P. Data aggregation in wireless sensor networks. Int. J. Sci. Res. 2014, 3, 249–251. [Google Scholar]
- Singh, S.P.; Sharma, S.C. A survey on cluster based routing protocols in wireless sensor networks. Comput. Sci. 2015, 45, 687–695. [Google Scholar] [CrossRef]
- Zeb, A.; Islam, A.K.M.M.; Zareei, M.; Mamoon, I.A.; Mansoor, N.; Baharun, S.; Katayama, Y.; Komaki, S. Cluster analysis in wireless sensor networks: The ambit of performance metrics and schemes taxonomy. Int. J. Distrib. Sens. Netw. 2016, 12, 4979142. [Google Scholar] [CrossRef]
- Fasolo, E.; Rossi, M.; Widmer, J.; Zorzi, M. In-network aggregation techniques for wireless sensor networks: A survey. IEEE Wirel. Commun. 2007, 14, 70–87. [Google Scholar] [CrossRef]
- Madden, S.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TAG: A tiny aggregation service for ad-hoc sensor networks. ACM SIGOPS Oper. Syst. Rev. 2002, 36, 131–146. [Google Scholar] [CrossRef]
- Deligiannakis, A.; Kotidis, Y.; Stoumpos, V.; Delis, A. Building efficient aggregation trees for sensor network event-monitoring queries. Int. Conf. GeoSens. Netw. 2009, 5659, 63–76. [Google Scholar]
- Zhang, Y.; Pu, J.; Liu, X.; Chen, Z. An adaptive spanning tree-based data collection scheme in wireless sensor networks. Int. J. Distrib. Sens. Netw. 2015, 2015, 637387. [Google Scholar] [CrossRef]
- Manjhi, A.; Nath, S.; Gibbons, P.B. Tributaries and deltas: Efficient and robust aggregation in sensor network stream. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 287–298. [Google Scholar]
- Shukla, K.V. Research on energy efficient routing protocol LEACH for wireless sensor networks. Int. J. Eng. 2013, 2, 1–5. [Google Scholar]
- Younis, O.; Fahmy, S. HEED: A hybrid, energy-efficient, distributed clustering approach for Ad hoc sensor networks. IEEE Trans. Mob. Comput. 2004, 3, 660–669. [Google Scholar] [CrossRef]
- Li, C.; Ye, M.; Chen, G.; Wu, J. An energy-efficient unequal clustering mechanism for wireless sensor networks. In Proceedings of the 2005 IEEE International Conference on Mobile Adhoc and Sensor Systems Conference (MASS), Washington, DC, USA, 7 November 2005; pp. 597–604. [Google Scholar]
- Sabet, M.; Naji, H.R. A decentralized energy efficient hierarchical cluster-based routing algorithm for wireless sensor networks. AEU Int. J. Electron. Commun. 2015, 69, 790–799. [Google Scholar] [CrossRef]
- Leu, J.S.; Chiang, T.H.; Yu, M.C.; Su, K.W. Energy efficient clustering scheme for prolonging the lifetime of wireless sensor network with isolated nodes. IEEE Commun. Lett. 2015, 19, 259–262. [Google Scholar] [CrossRef]
- Yi, D.; Yang, H. HEER-A delay-aware and energy efficient routing protocol for wireless sensor networks. Comput. Netw. 2016, 104, 155–173. [Google Scholar] [CrossRef]
- Villas, L.A.; Boukerche, A.; de Oliveira, H.A.B.F.; de Araujo, R.B.; Loureiro, A.A.F. A special correlation aware algorithm to perform efficient data collection in wireless sensor networks. Ad Hoc Netw. 2011, 12, 10–30. [Google Scholar]
- Villas, L.A.; Boukerche, A.; Ramos, H.S. DRINA: A lightweight and reliable routing approach for in-network aggregation in wireless sensor networks. IEEE Trans. Comput. 2013, 64, 676–689. [Google Scholar] [CrossRef]
- Gherbi, C.; Aliouat, Z.; Benmohammed, M. An adaptive cluster approach to dynamic load balancing and energy efficiency in wireless sensor networks. Energy 2016, 114, 647–662. [Google Scholar] [CrossRef]
- Pu, J.; Gu, Y.; Zhang, Y.; Chen, J.; Xiong, Z. A Hole-Tolerant Redundancy Scheme for Wireless Sensor Networks. Int. J. Distrib. Sens. Netw. 2012, 2012, 184–195. [Google Scholar] [CrossRef]
- Imon, S.K.A.; Khan, A.; Francesco, M.D.; Das, S.K. Energy-efficient randomized switching for maximizing lifetime in tree-based wireless sensor networks. IEEE ACM Trans. Netw. 2015, 23, 1401–1415. [Google Scholar] [CrossRef]
- Xiang, M.; Wang, P.; Luo, Z. Node classification method based on integrative support degree in WSN. Comput. Eng. 2010, 36, 97–99. [Google Scholar]
- George, T.; Trevor, C. Simulation tools for multilayer fault restoration. IEEE Commun. Mag. 2009, 47, 128–134. [Google Scholar]
- Dong, M.; Ota, K.; Liu, A. RMER: Reliable and Energy-Efficient Data Collection for Large-Scale Wireless Sensor Networks. IEEE Internet Things J. 2016, 3, 511–519. [Google Scholar] [CrossRef]
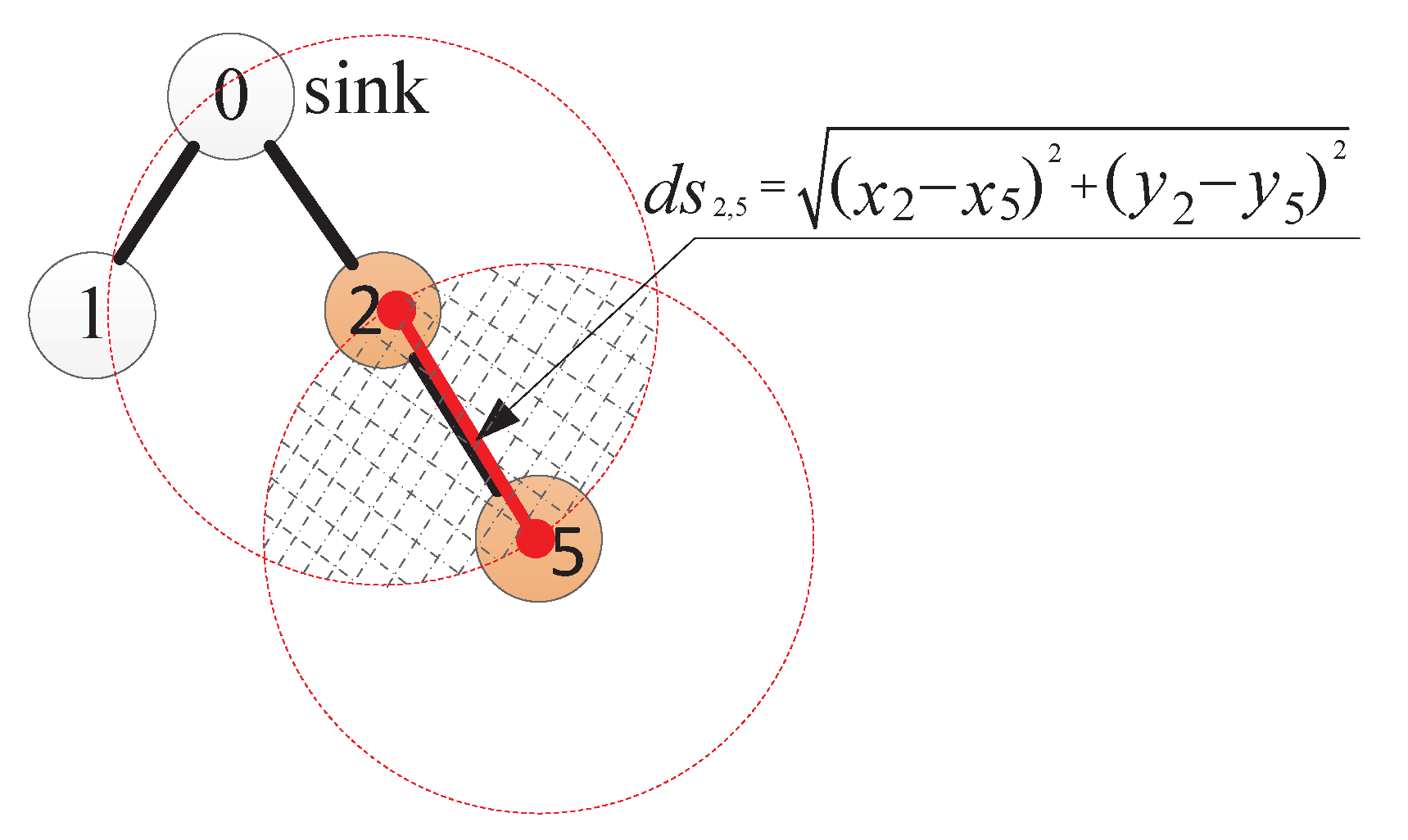
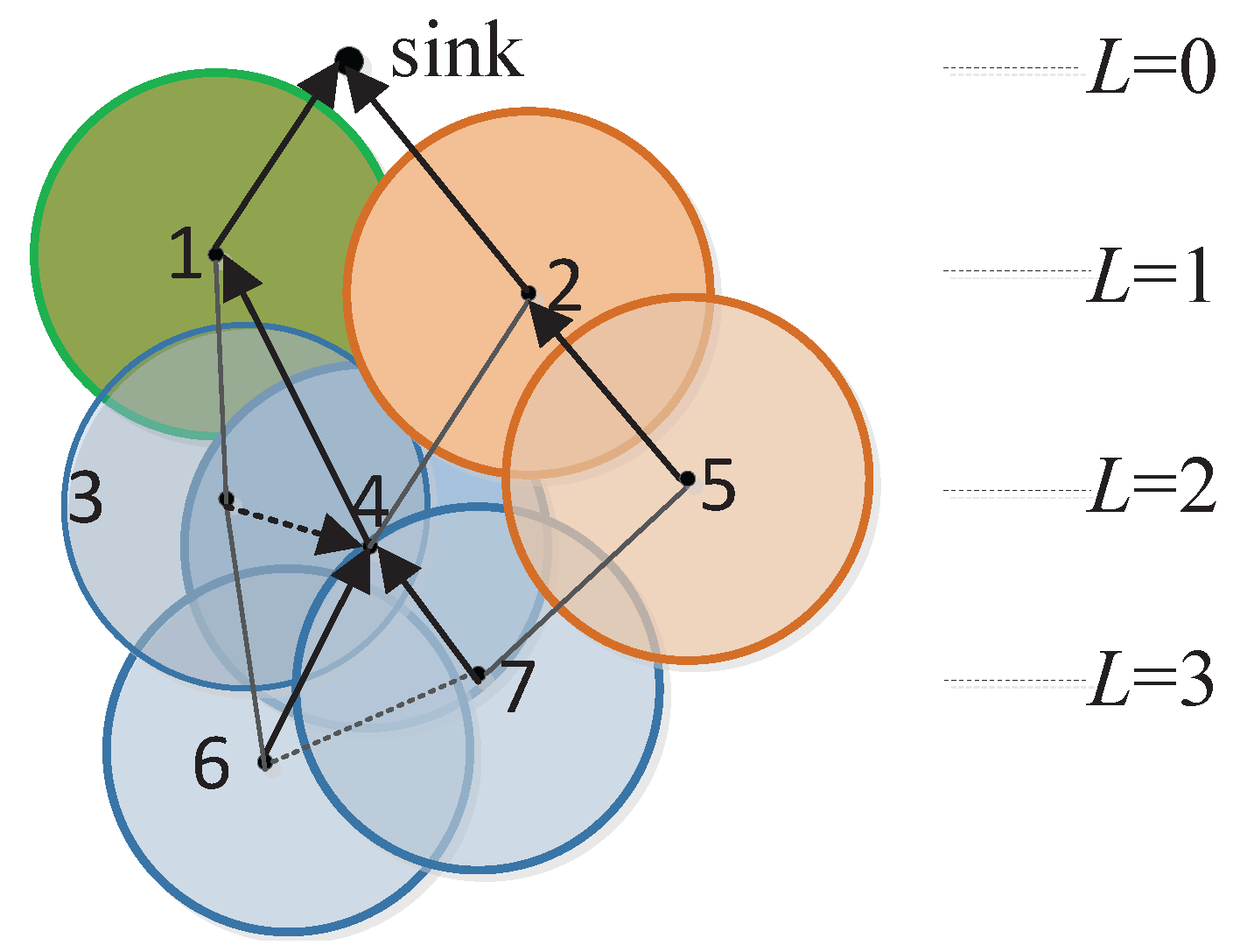

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
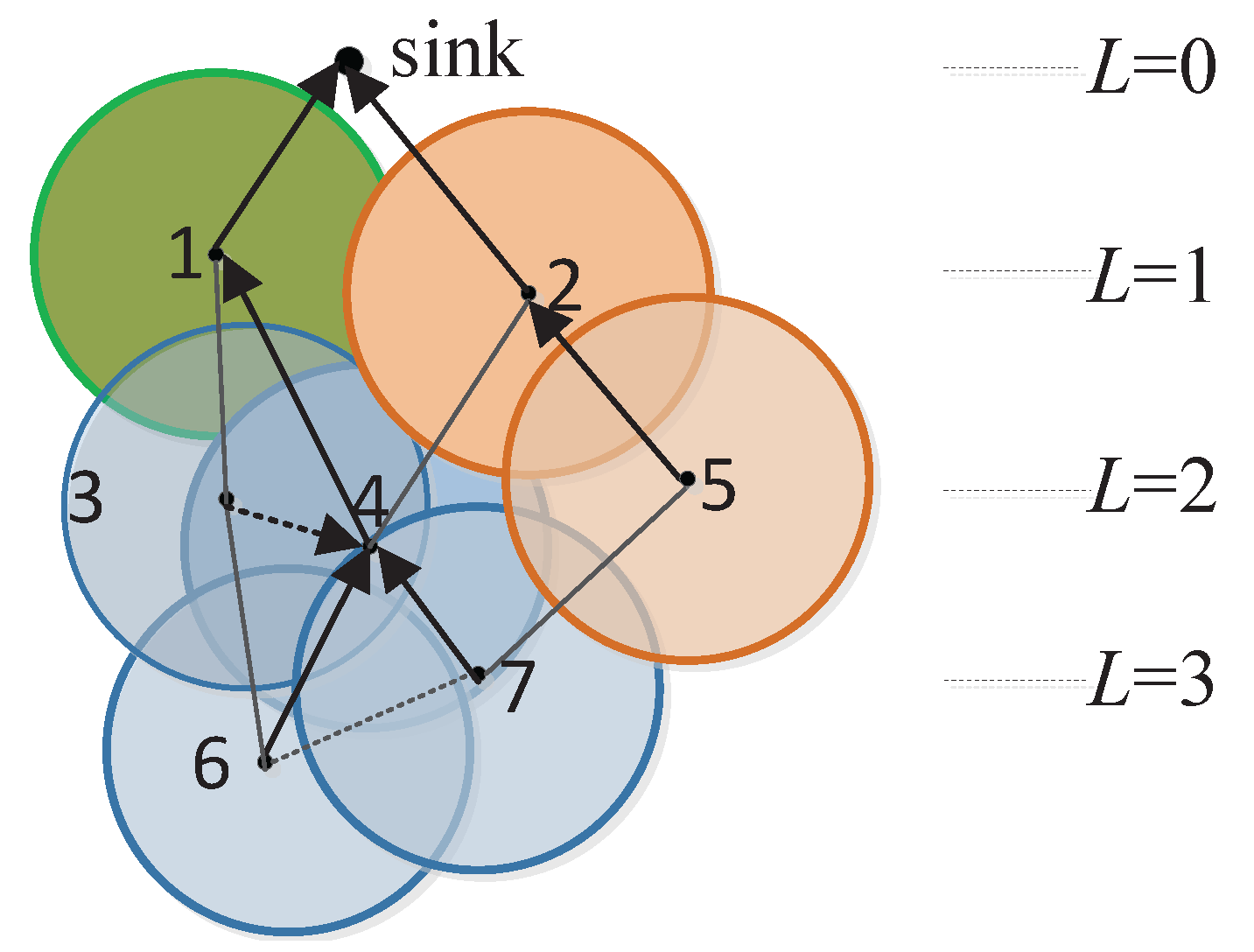{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Sensing radius of a sensor node. | |
| Communication radius of a sensor node. | |
| Consumed energy of sending per unit data. | |
| Consumed energy of receiving per unit data. | |
| d | The size of data collected by a sensor node. |
| Overlapping rate of sensing area of two nodes and . | |
| Threshold of overlapping rate of sensing area. | |
| Gathering area with as the gathering node. | |
| Gathering node, which aggregates the data collected in a gathering area. | |
| Candidate gathering node set of . | |
| Candidate parent node set of , including all the upper-level nodes that couldcommunicate with directly. | |
| Neighbor node set of , which consists of the nodes at the same level that couldcommunicate with directly. | |
| Level of , and . | |
| The total amount of data transferred from . | |
| The total amount of data received by . | |
| The energy consumed for delivering aggregated data from the gathering node . | |
| The total energy cost of the nodes in the gathering area . | |
| The total energy cost of transmitting data of node to the sink via another node . | |
| Free nodes at the level n. |
| Parameter | Value |
|---|---|
| Scenario (m) | |
| Number of sink node | 1 |
| Number of sensor nodes, N | 40, 80, 120, 160 and 200 |
| Sensing radius (m) | 25 |
| Communication radius (m) | 52 |
| Data collection cycle (s) | 60 |
| 0.5 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Xie, H.; Chen, W.; Niu, J.; Wang, S. Data Aggregation Based on Overlapping Rate of Sensing Area in Wireless Sensor Networks. Sensors 2017, 17, 1527. https://doi.org/10.3390/s17071527
Tang X, Xie H, Chen W, Niu J, Wang S. Data Aggregation Based on Overlapping Rate of Sensing Area in Wireless Sensor Networks. Sensors. 2017; 17(7):1527. https://doi.org/10.3390/s17071527
Chicago/Turabian StyleTang, Xiaolan, Hua Xie, Wenlong Chen, Jianwei Niu, and Shuhang Wang. 2017. "Data Aggregation Based on Overlapping Rate of Sensing Area in Wireless Sensor Networks" Sensors 17, no. 7: 1527. https://doi.org/10.3390/s17071527
APA StyleTang, X., Xie, H., Chen, W., Niu, J., & Wang, S. (2017). Data Aggregation Based on Overlapping Rate of Sensing Area in Wireless Sensor Networks. Sensors, 17(7), 1527. https://doi.org/10.3390/s17071527