A Novel Unsupervised Adaptive Learning Method for Long-Term Electromyography (EMG) Pattern Recognition



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Related Work
1.1.1. Adaptive Learning on Surface EMG Data
1.1.2. Adaptive Learning Based on SVM
1.1.3. Validation Method for Adaptive Learning
1.2. Significance of This Paper
2. Materials and Methods
2.1. Principles of Adaptive Learning
- (a)
- Since we don’t know when the concept drift happens, information from old data may on one hand be useful to the classification generalization, and on the other hand be harmful to the representability of the classifier [40]. Therefore, a good adaptive classifier should balance the benefit and the risk of using old data.
- (b)
- Drifting concepts are learnable only when the rate or the extent of the drift is limited in particular ways [41]. In many studies, the extent of concept drift is defined as the probability that two concepts disagree on randomly drawn samples [19], whereas the rate of concept drift is defined as the extent of the drift between two adjacent updating processes [42]. Considering that the sample distribution and the recognition accuracy are immeasurable for a single sample, we define the dataset of samples with the same distribution as a session. In this way, drift extent (DE) is defined as the difference of sample distribution between two sessions, and drift rate (DR) is defined as the drift extent between two adjacent sessions in a validating session sequence.
2.2. Incremental SVC
2.2.1. Nonadapting SVC
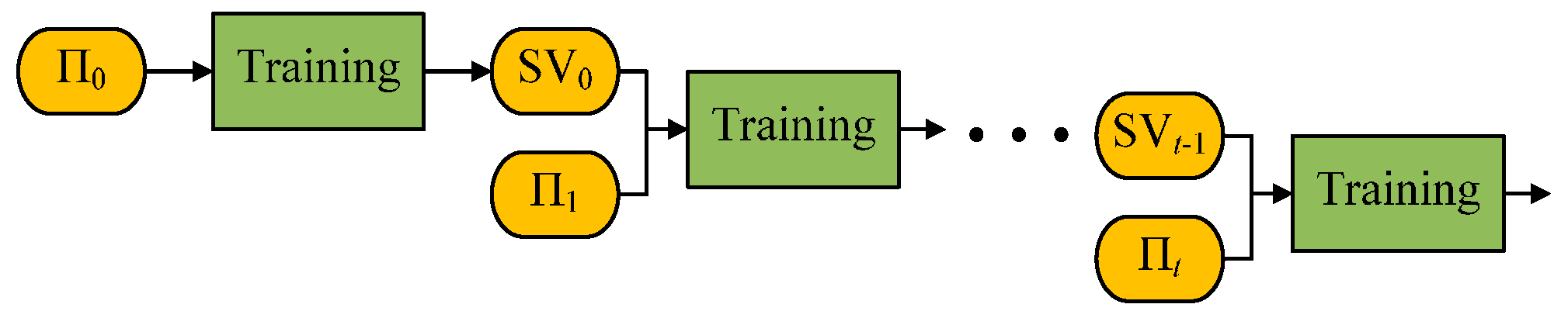
2.2.2. Incremental SVM
2.2.3. Program Codes and Parameters of NSVC and ISVC
2.3. The Parcticle Adaptive Classifier
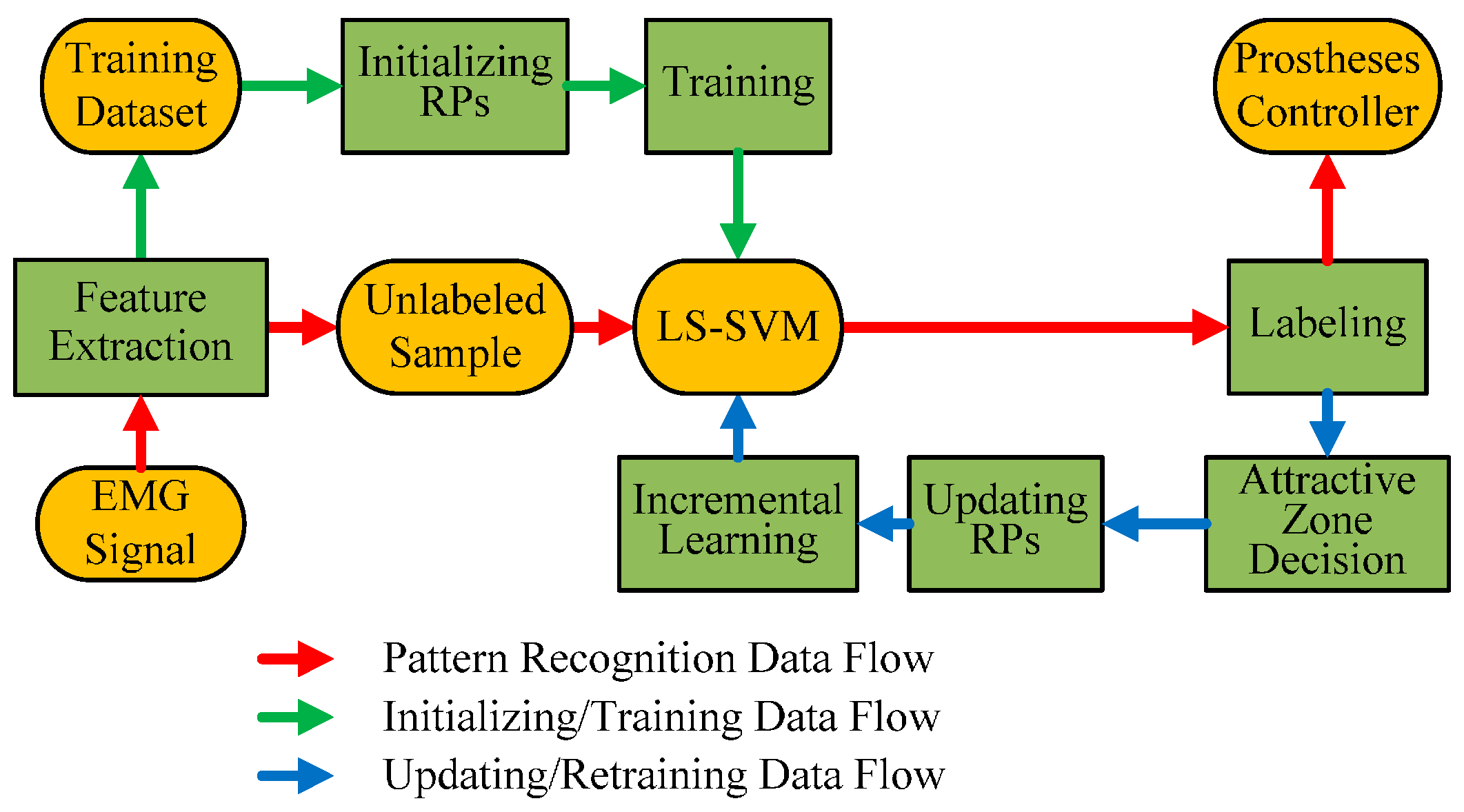
2.3.1. General Structure of PAC Classifier
- (1)
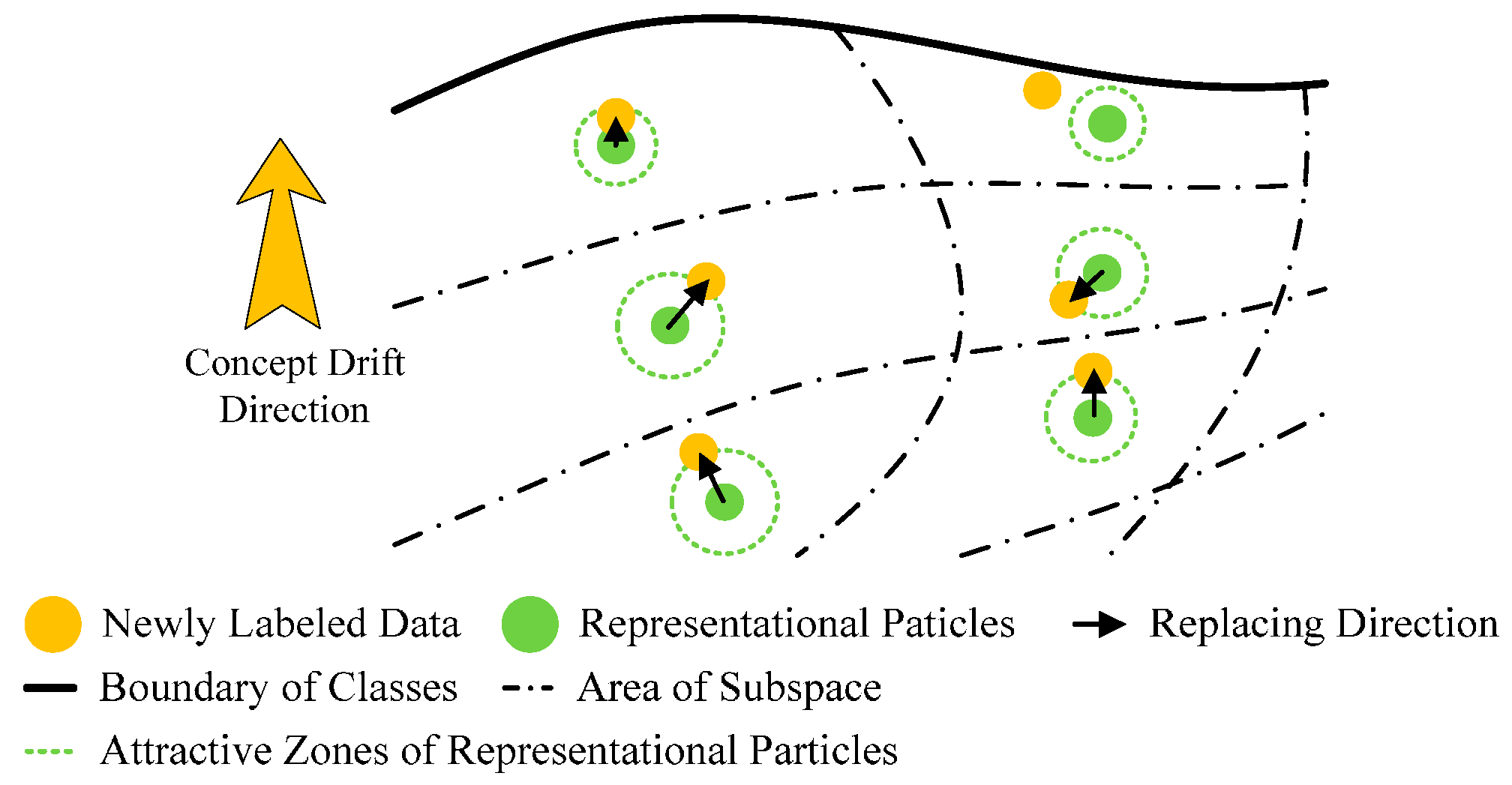
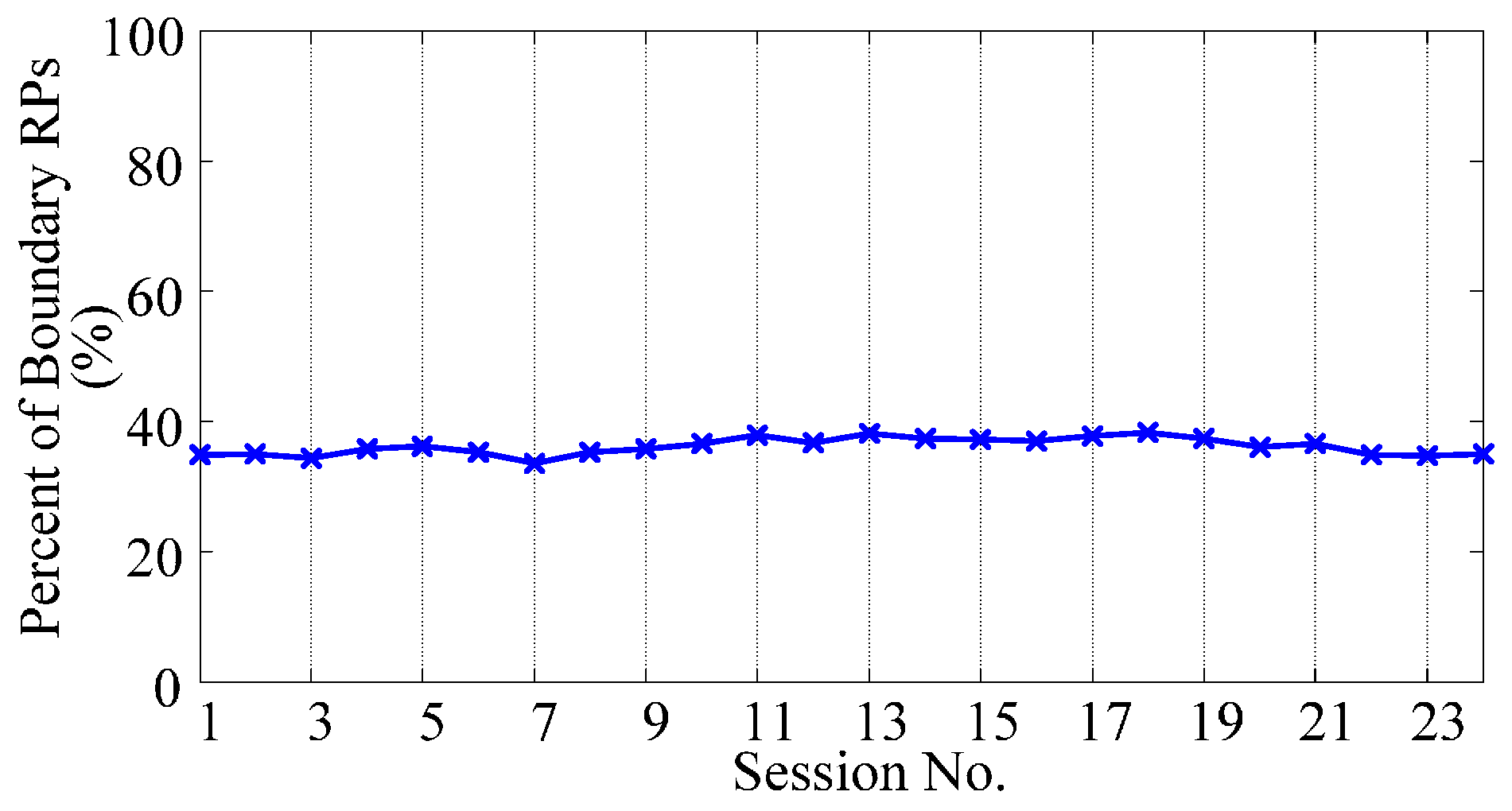
- The distribution of RPs is sparse. Different from traditional KKT-conditions-based pruning, the sparsity of RPs is originated from the down sampling of original training dataset. The down sampling process will keep the distribution characteristics of the whole feature space, rather than the distribution characteristics of the class boundary. Specifically, each RP can be regarded as a center point of a subspace in the feature space, and thus the distribution density of RPs largely approximates the probability density function (PDF) of the feature space. The predictive model trained by RPs will have the similar classification performance with the predictive model trained by original training dataset, but have higher computational efficiency.
- (2)
- With numerous replacements of RPs, the general predictive model is able to track the concept drift. Since the distribution density of RPs approximates the PDF of the feature space, the replacement for an RP with an appropriate new sample, is equivalent to update the PDF estimation of a subspace of the feature space. In this way, the classifier is able to track the concept drift.
- (3)
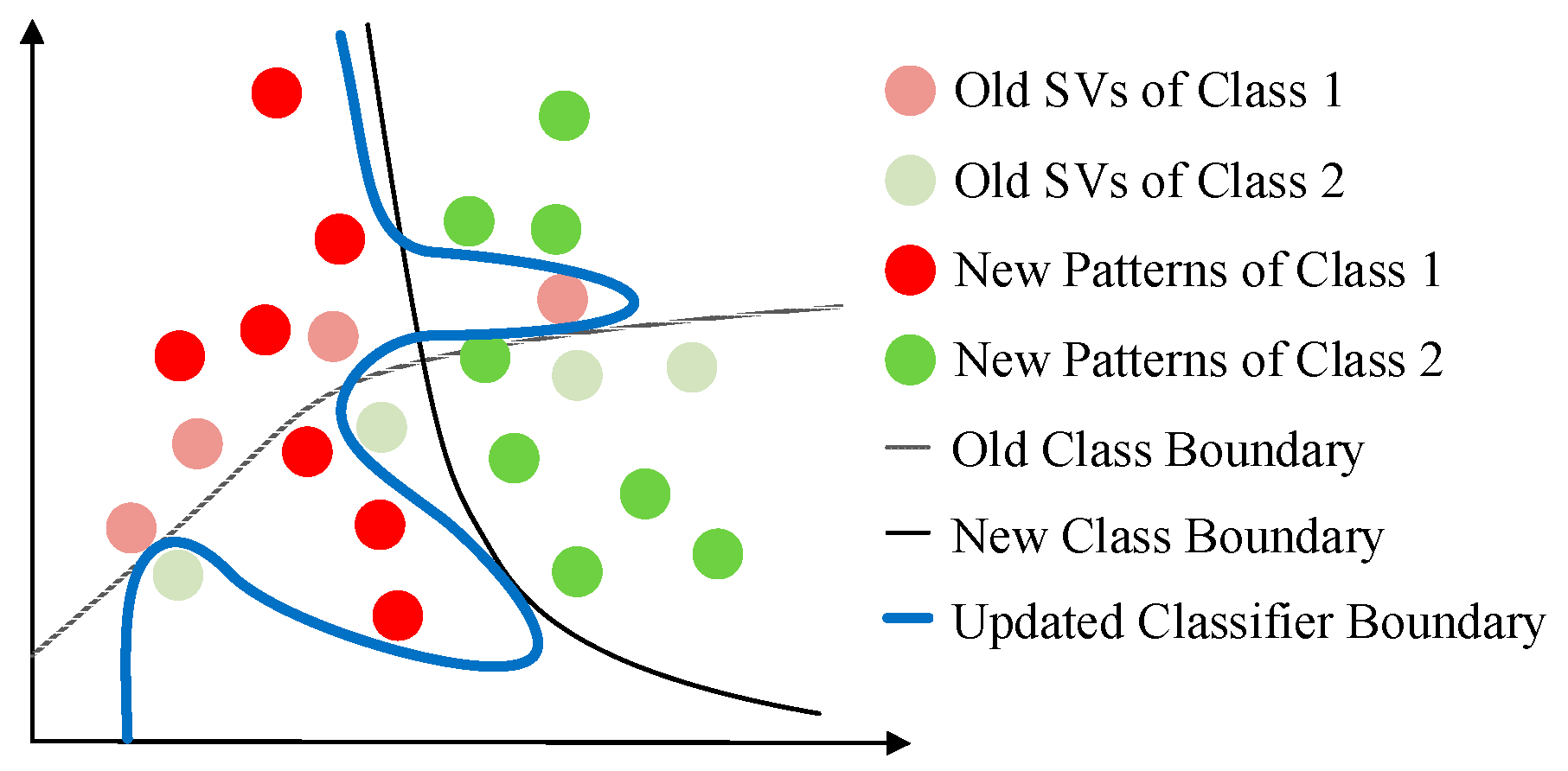
- Based on RPs, it is possible to evaluate the misclassification risk of a new sample. When we try to evaluate the misclassification risk of a new sample in unsupervised adaptive learning scenarios, we have to establish some basic assumptions. Considering the property of EMG signals [5], at least two widely used assumptions on the class boundary are valid for the classification problem of EMG signals: (a) cluster assumption [39], and (b) smoothness assumption [39]. The cluster assumption assumes that two samples near enough in the feature space are likely to share the same label. The smoothness assumption assumes that the class boundary is smooth, namely, the sample far away from the class boundary is more likely to maintain the label after concept drifting, than samples near the class boundary. If a sample is close enough to an RP, and has the same predicted label with the RP, it is likely to be rightly classified. When pruning newly coming samples with their distances to RPs, it is possible to suppress the accumulation of misclassification risk. The area in which the new sample is adopted to replace old RP is the attractive zone of the RP.
2.3.2. Universal Incremental LS-SVM
- Inserting: adding xp at the pth position into S(l − 1), is equivalent to training from S(l − 1) to S(l);
- Deleting: deleting xp at the pth position from S(l), is equivalent to training from S(l) to S(l − 1);
- Replacing: deleting xp at the pth position from S(l), adding xp* at the pth position into S(l − 1), is equivalent to the combination of training from S(l) to S(l − 1) and training from S(l − 1) to S*(l).
| Algorithm 1. Algorithm for inserting and deleting processes of universal incremental LS-SVM. | |||||
| Inserting | Deleting | ||||
| Input: , , , , C | Input: , , | ||||
| Output: , , | Output: , , | ||||
| 1 | 1 | ||||
| 2 | //divide at pth row and clomn | 2 | //divide at pth, p + 1st row and clomn | ||
| 3 | 3 | ||||
| 4 | 4 | //low-rank update | |||
| 5 | 5 | ||||
| 6 | 6 | ||||
| 7 | //forward substitution | 7 | |||
| 8 | 8 | ||||
| 9 | //low-rank downdate | ||||
| 10 | |||||
| 11 | //forward substitution | ||||
| 12 | //forward substitution | ||||
| 13 | |||||
2.3.3. Initialization and Updating of RPs
- (a)
- Dividing the training dataset into m clusters based on kernel space distance and k-medoids clustering method [49];
- (b)
- Randomly and proportionally picking samples from each cluster as RPs with a percentage p.
- (a)
- The new sample is close enough to its nearest RP;
- (b)
- Older RP is more likely to be replaced;
- (c)
- The new sample is in the same class with its nearest RP (for supervised adaption only).
| Algorithm 2. Initializing and updating algorithm for uPAC. | |
| Require: m > 0, p > 0, dTh > 0, > 0 | |
| 1 | Cluster training dataset into m clusters //k-medoids clustering |
| 2 | Extract representative particles with percentage p into dataset RP |
| 3 | Train LS-SVM predictive model PM with RP |
| 4 | while xN is valid do |
| 5 | //predict label |
| 6 | allti←ti + 1 //update unchanging time |
| 7 | |
| 8 | |
| 9 | if D > 0 |
| 10 | tI←0 //clear unchanging time |
| 11 | xI ←xN //update RP |
| 12 | Update PM //replcaing with universal incremental LS-SVM |
| 13 | end if |
| 14 | end while |
2.3.4. Program Codes and Parameters of PAC
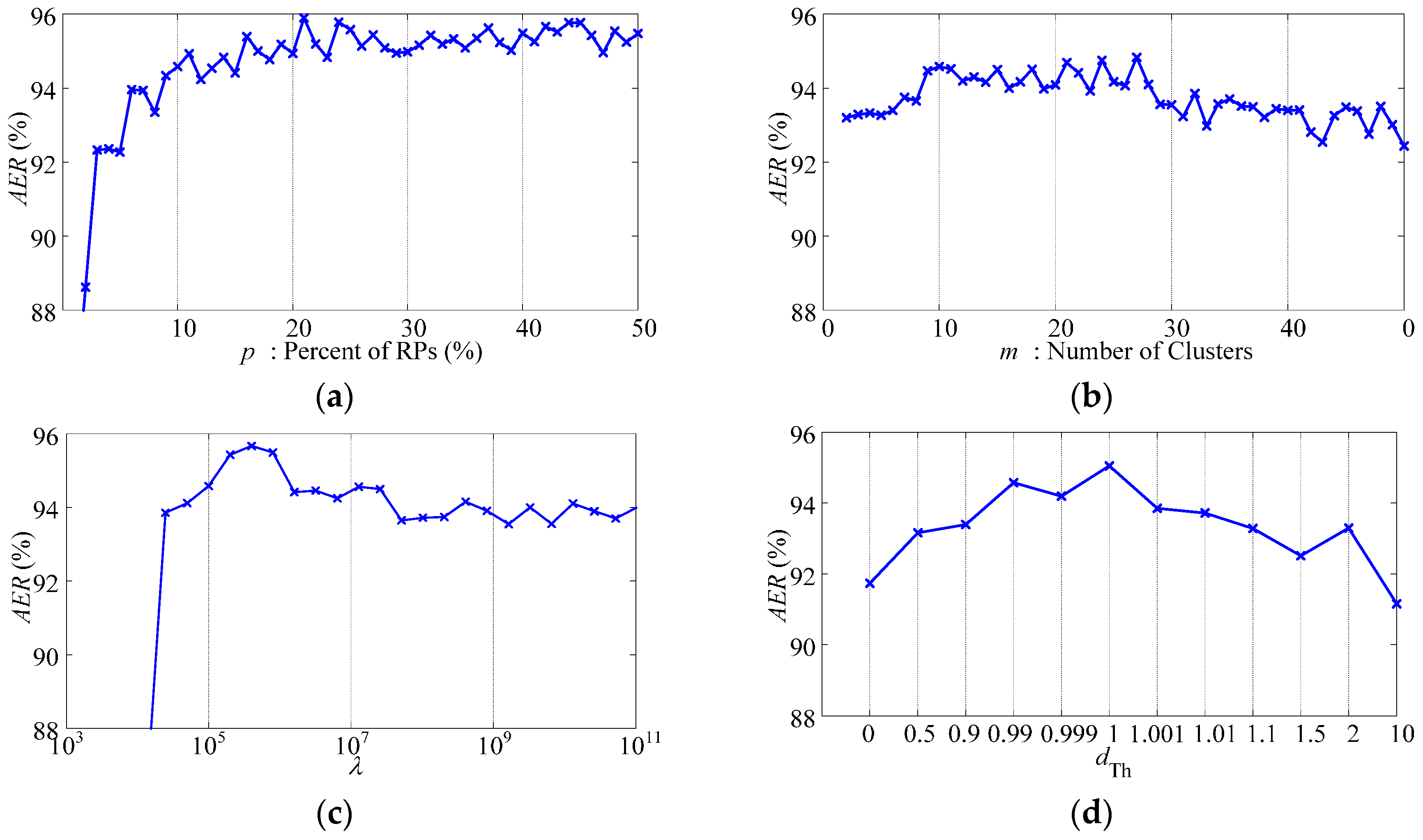
- Parameter p: With the increasing of p, the ending accuracy AER of the data sequence increases, while the slope of the increasing decreases. Such changing tendency indicates that PAC with redundant RPs is not only inefficient but also unnecessary. The recommended interval for p is between 10% and 20%.
- Parameter m: The adjustment of m changes the performance slightly. With the increasing of m, the performance experiences slight improvement at first and then slight deterioration. It has an optimal interval as between 9 and 28.
- Parameter λ: The choices of dTh and λ are highly related. There is an optimal interval for λ as between 104 and 106, when dTh is chosen as 0.99. On one hand, the choices of λ below the lower boundary of the optimal interval will result in indiscriminate replacement of RPs and complete failure of the classifier. On the other hand, the choices of λ higher than the upper boundary of the optimal interval will weaken the influence of time and result in slight deterioration.
- Parameter dTh: Similar to λ, there is an optimal interval for dTh as between 0.9 and 1.1, when λ is chosen as 105. It is remarkable that, because we choose the nearest RP of the new sample to be replaced, the classifier does not complete fail even when dTh is set as 0.
2.4. Performance Validation for Adaptive Learning
2.4.1. Supervised and Unsupervised Adaptive Learning Scenarios
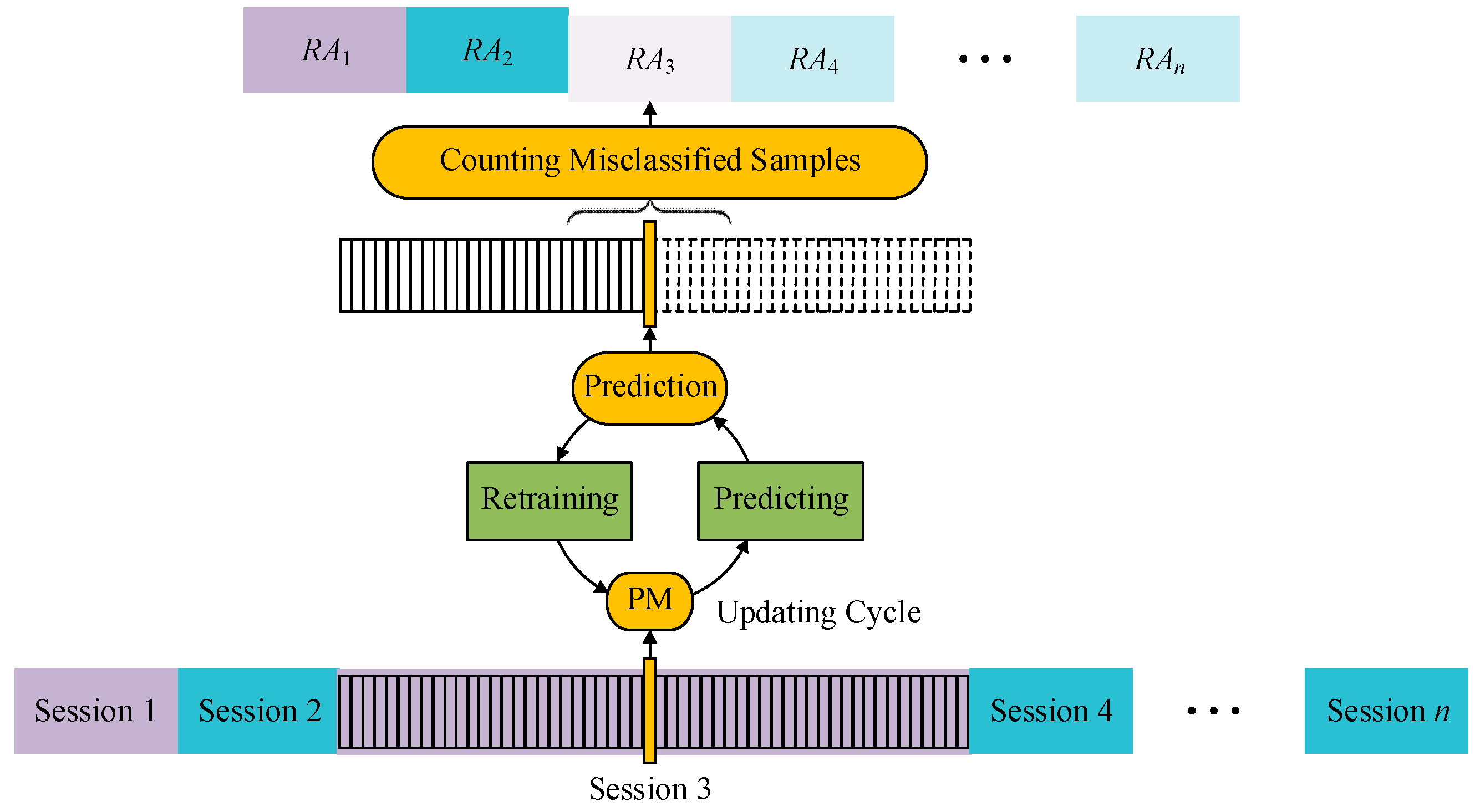
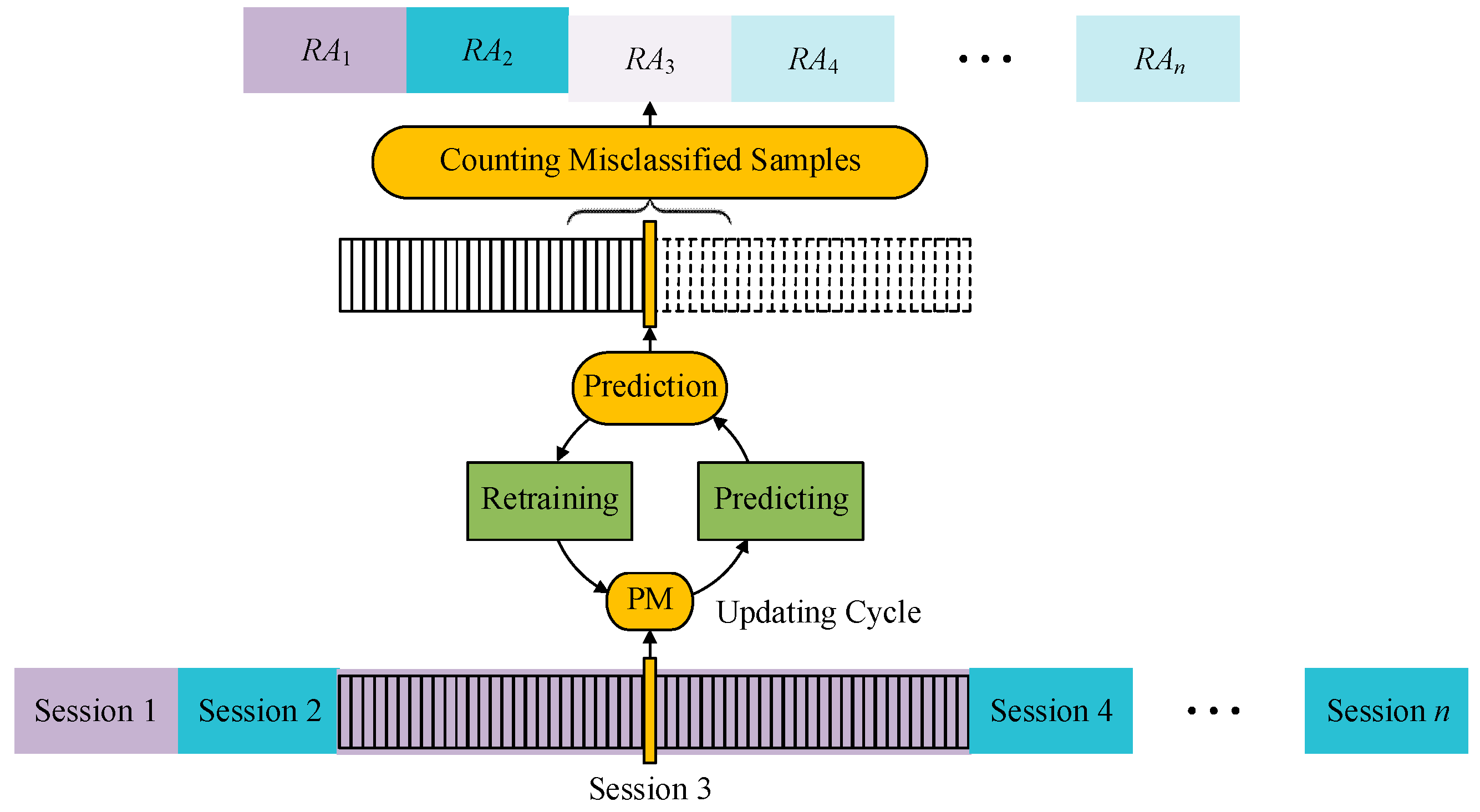
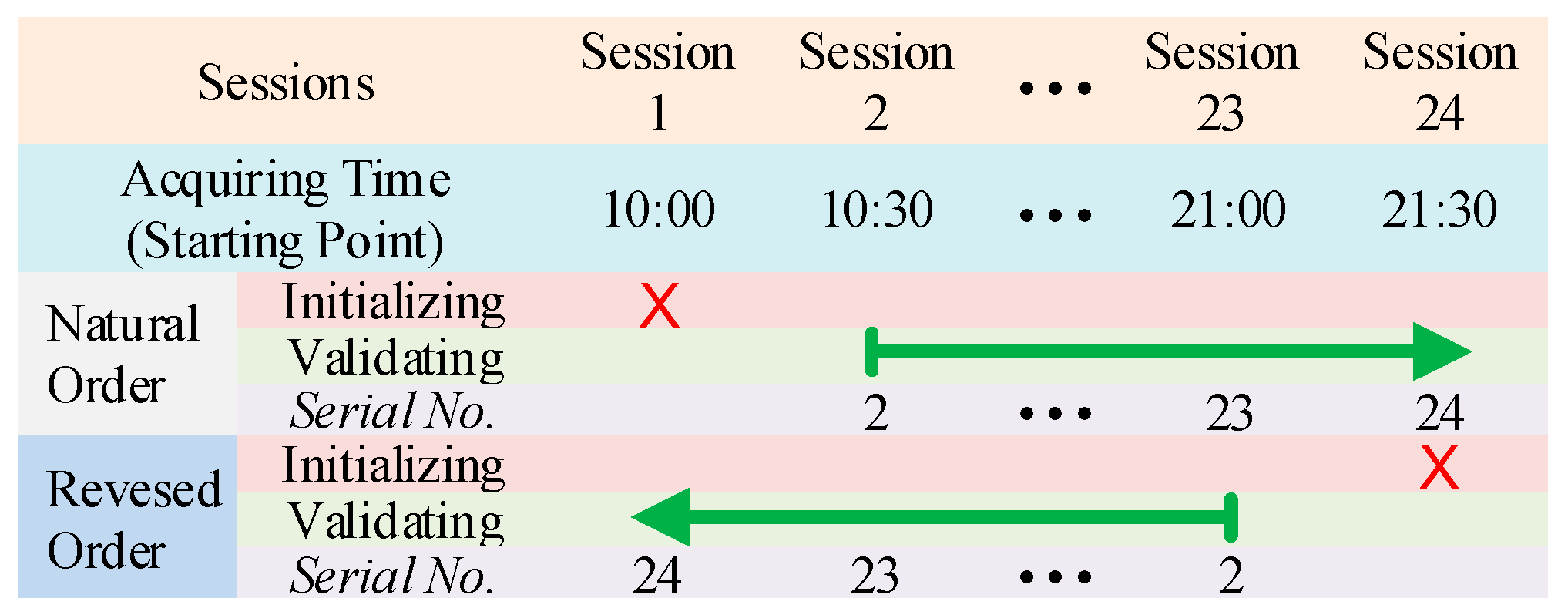
2.4.2. Data Organization for Validation
2.5. Experimental Setup
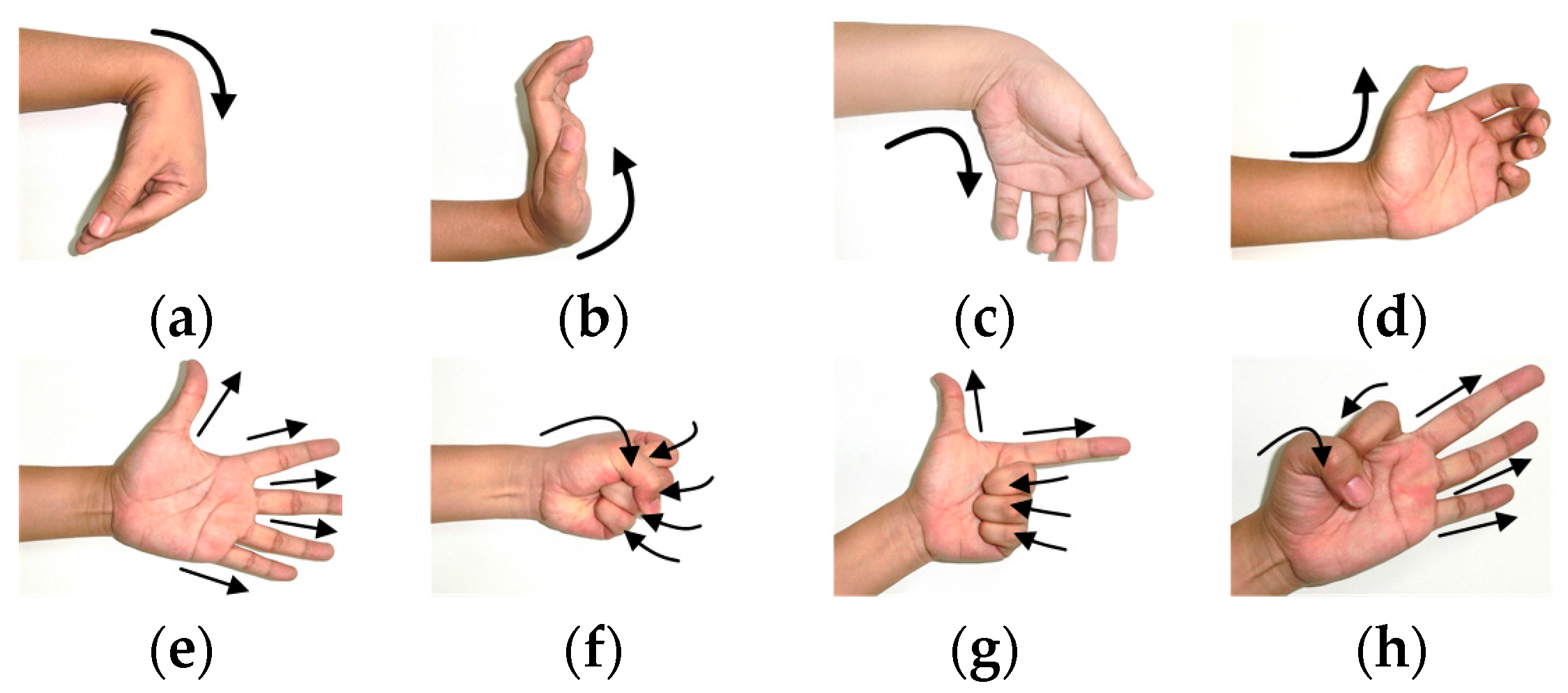
2.5.1. EMG Data Recording and Processing
2.5.2. Subjects
2.5.3. Experiment I: Simulated Data Validation
2.5.4. Experiment II: One-Day-Long Data Validation
3. Results
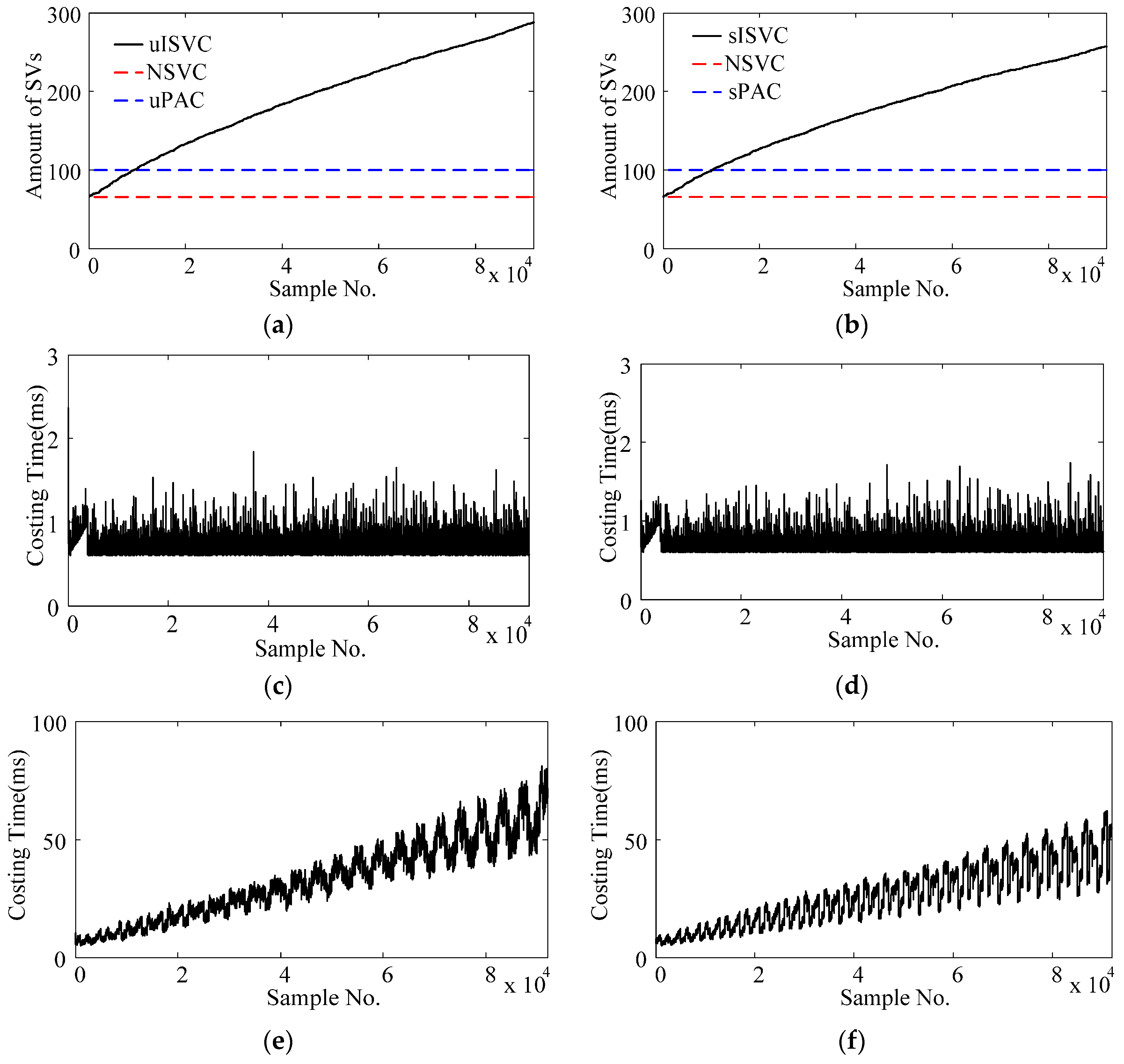
3.1. Support Vectors and Time Cost
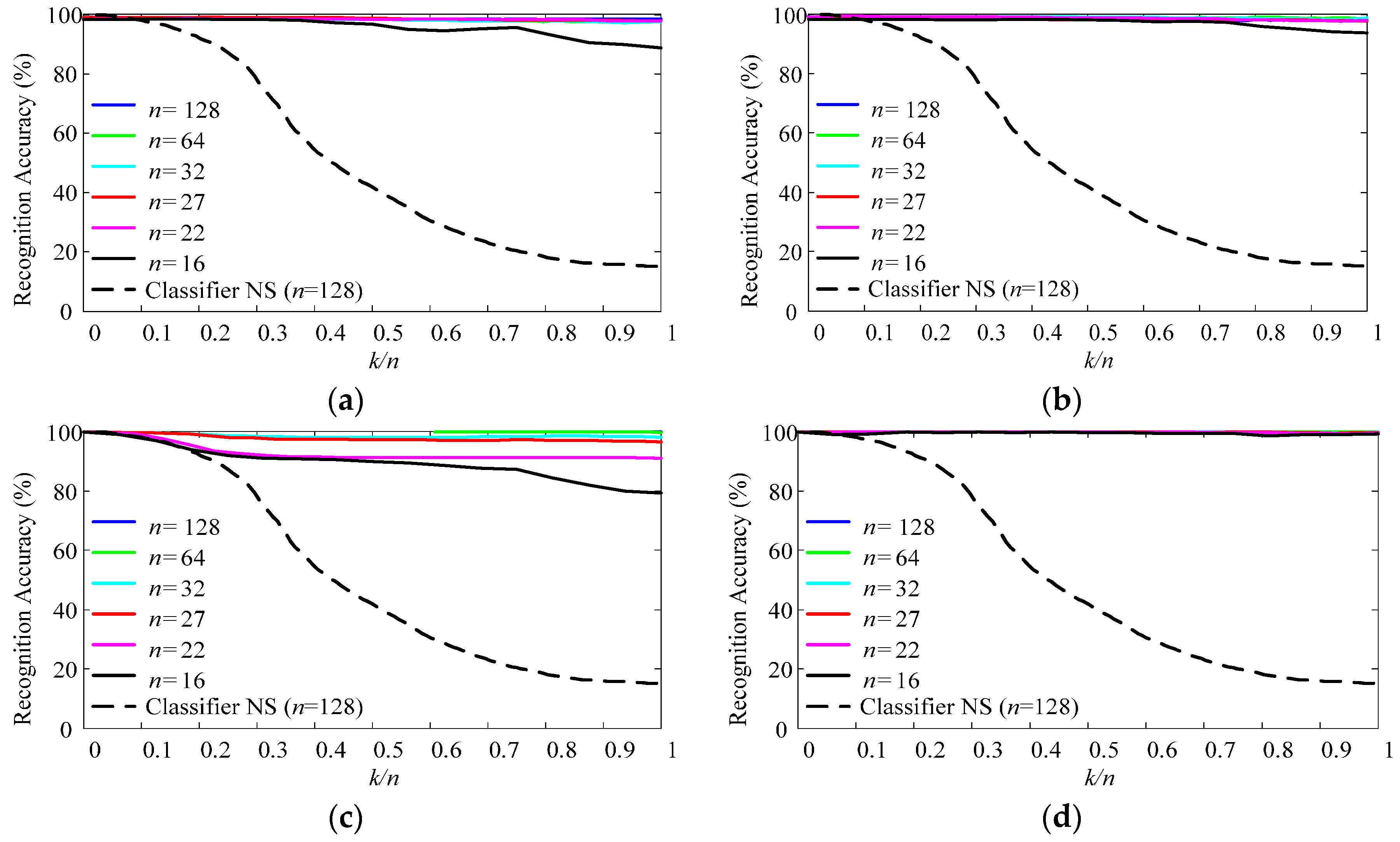
3.2. Classification Performance for Simulated Data
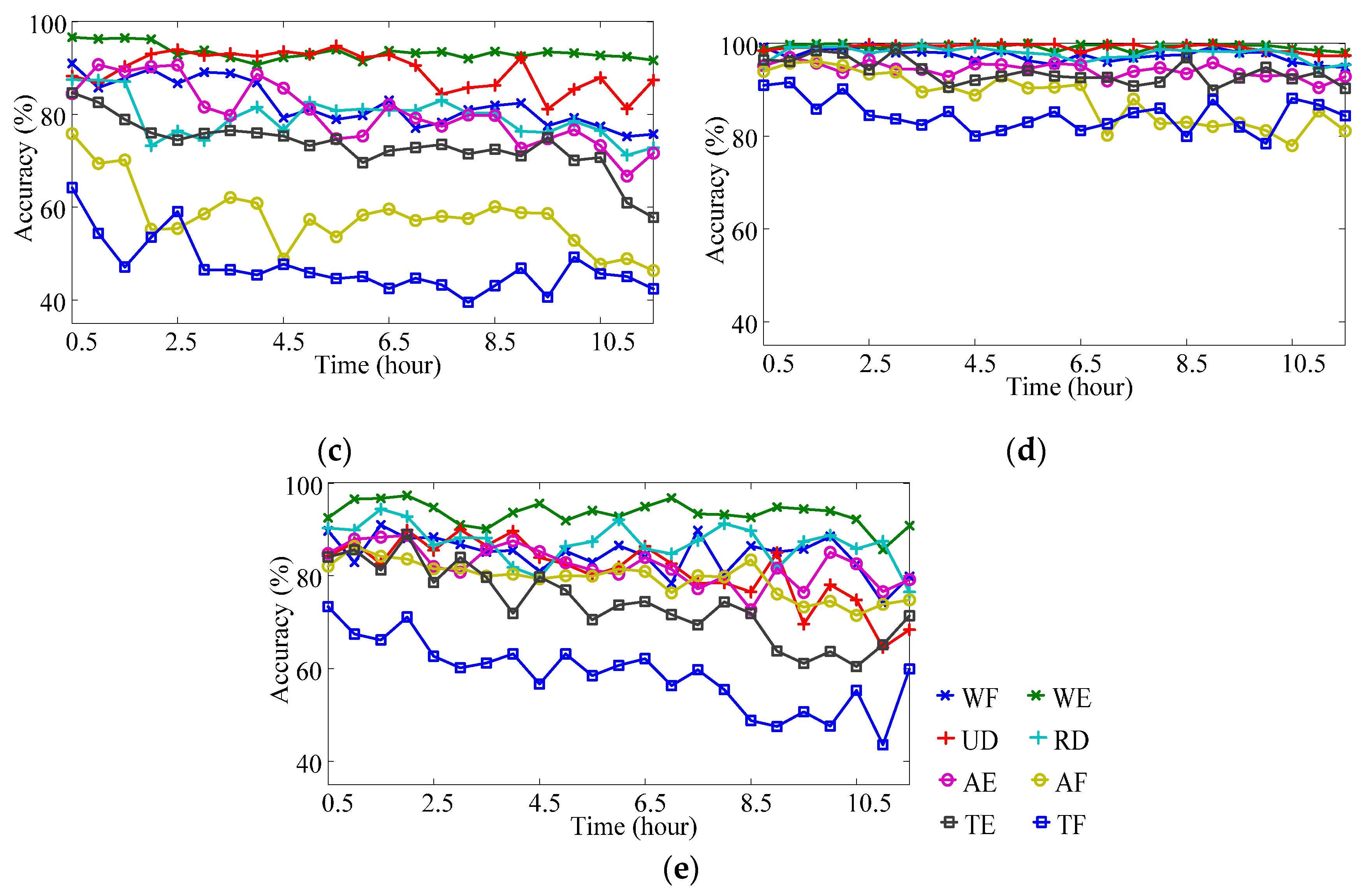
3.3. Classification Performance for One-Day-Long Data
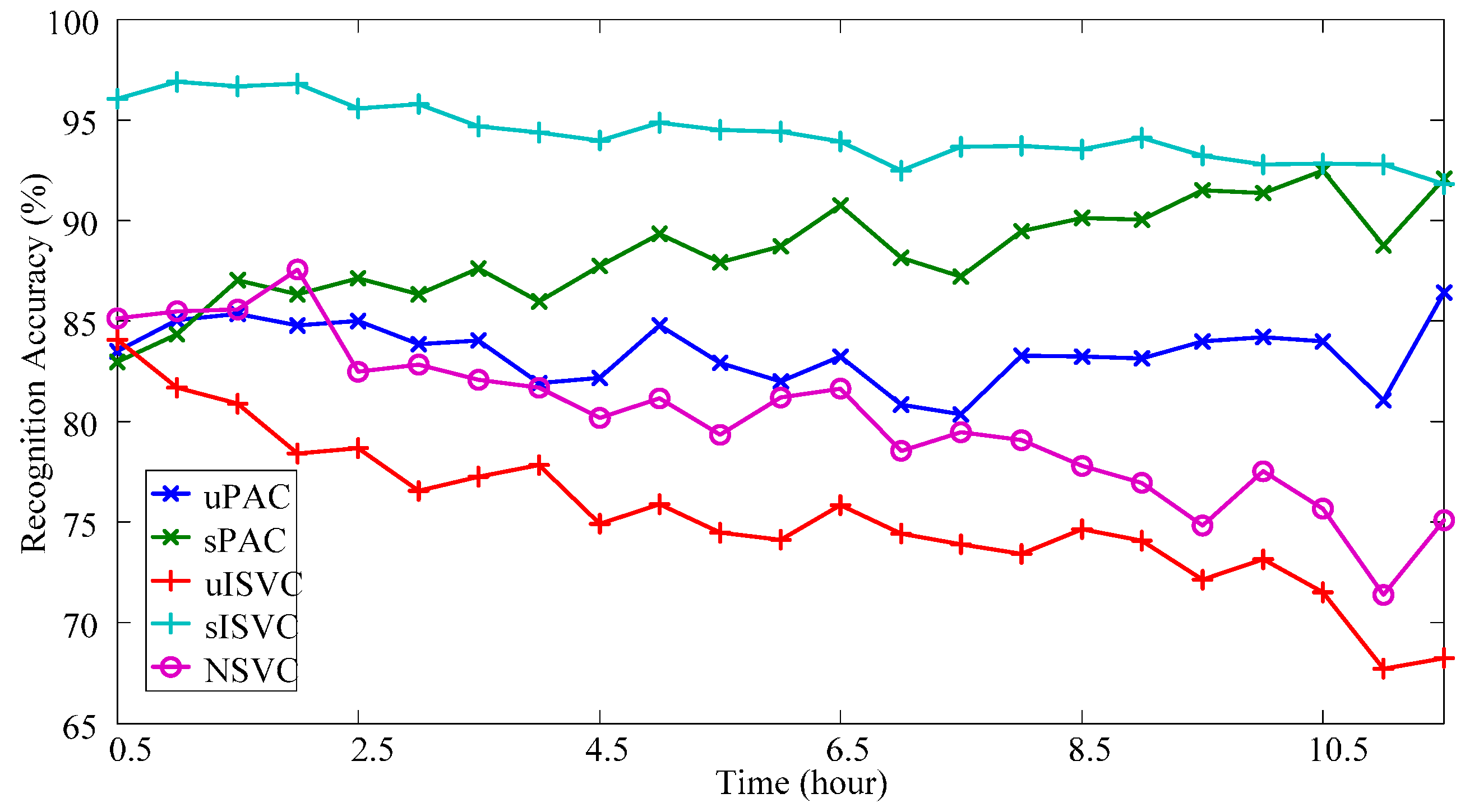
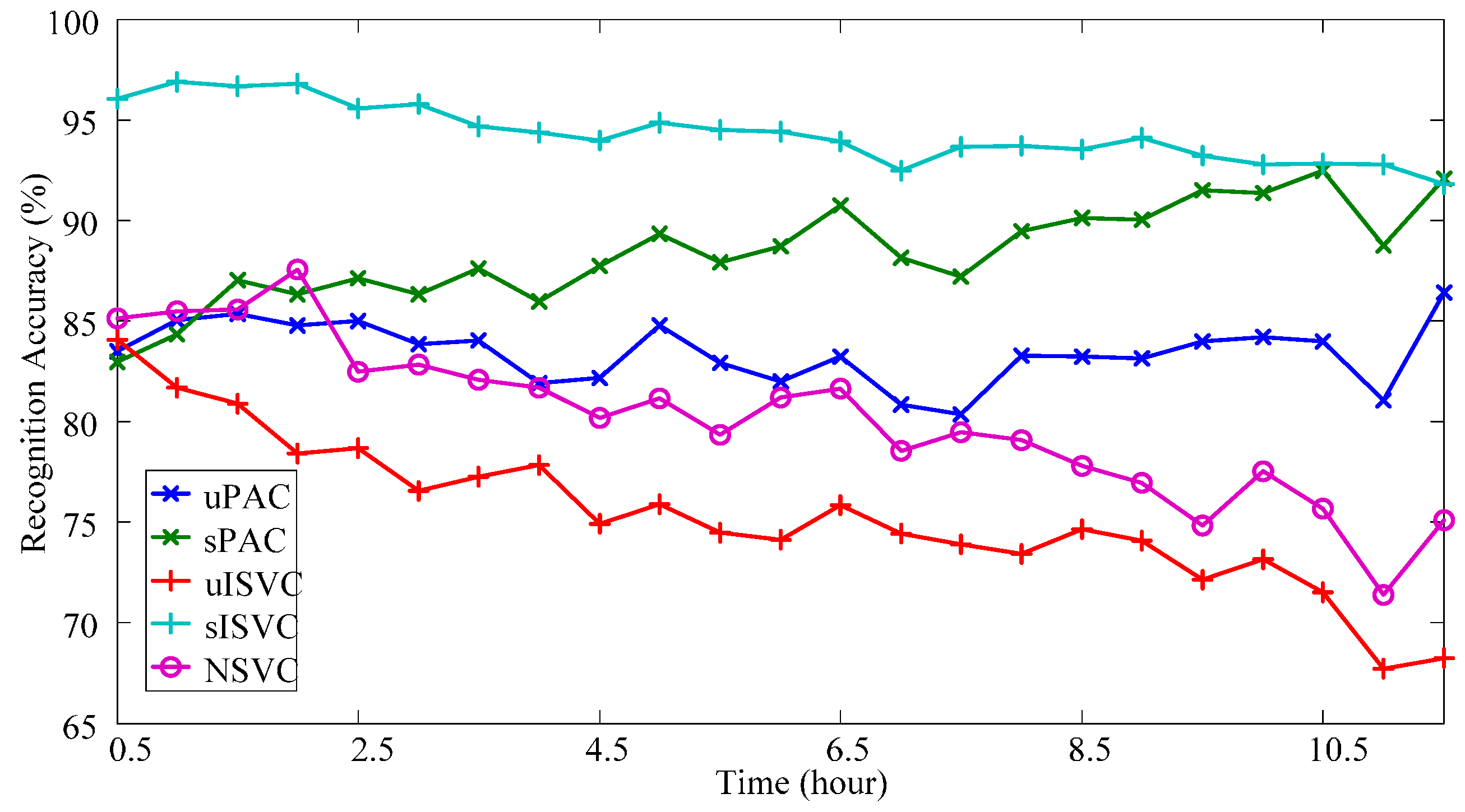
3.3.1. Overall Performance
- (1)
- Classifiers uPAC, sPAC and sISVC significantly improved the performance at the end of the day from NSVC by 9.03% ± 2.23% (p = 0.011, after Bonferroni correction of 10 comparison pairs, hereinafter), 16.32% ± 2.26% (p < 0.001), 17.77% ± 2.52% (p < 0.001) respectively, whereas uISVC showed no significant difference with NSVC (p = 0.857).
- (2)
- Supervised adaptive learning scenarios had great superiorities on the performance over unsupervised adaptive learning scenarios. Specifically, sPAC had superiority over uPAC by 7.30% ± 1.10% (p < 0.001), and sISVC had superiority over uISVC by 22.12% ± 2.67% (p < 0.001). The conclusion is consistent with previous researches. But we can also found that the difference between sISVC and uISVC was much larger than the difference between sPAC and uPAC.
- (3)
- In unsupervised adaptive learning scenarios, PAC was superior to ISVC, and in supervised adaptive learning scenarios, PAC was competitive with ISVC. Specifically, for sessions at the end of the day, the recognition accuracy of uPAC was higher than that of uISVC by 13.38% ± 2.62% (p = 0.001), whereas the recognition accuracy of sPAC had no significant difference with that of sISVC (p = 1).
3.3.2. Performance Diversity of Different Motion Types
- (1)
- Classifiers uPAC, sPAC and sISVC significantly improved WMP from NSVC by 14.45% ± 4.06% (p = 0.028), 35.93% ± 3.79% (p < 0.001), 35.53% ± 4.94% (p < 0.001) respectively, whereas uISVC significantly deteriorated WMP by 14.26% ± 3.86% (p = 0.022).
- (2)
- According to WMP, sPAC had superiority over uPAC by 21.48% ± 3.27% (p < 0.001), and sISVC had superiority over uISVC by 49.79% ± 5.48% (p < 0.001).
- (3)
- According to WMP, uPAC had superiority over uISVC by 28.71% ± 5.66% (p = 0.001), whereas the recognition accuracy of sPAC had no significant difference with that of sISVC (p = 1).
4. Discussion
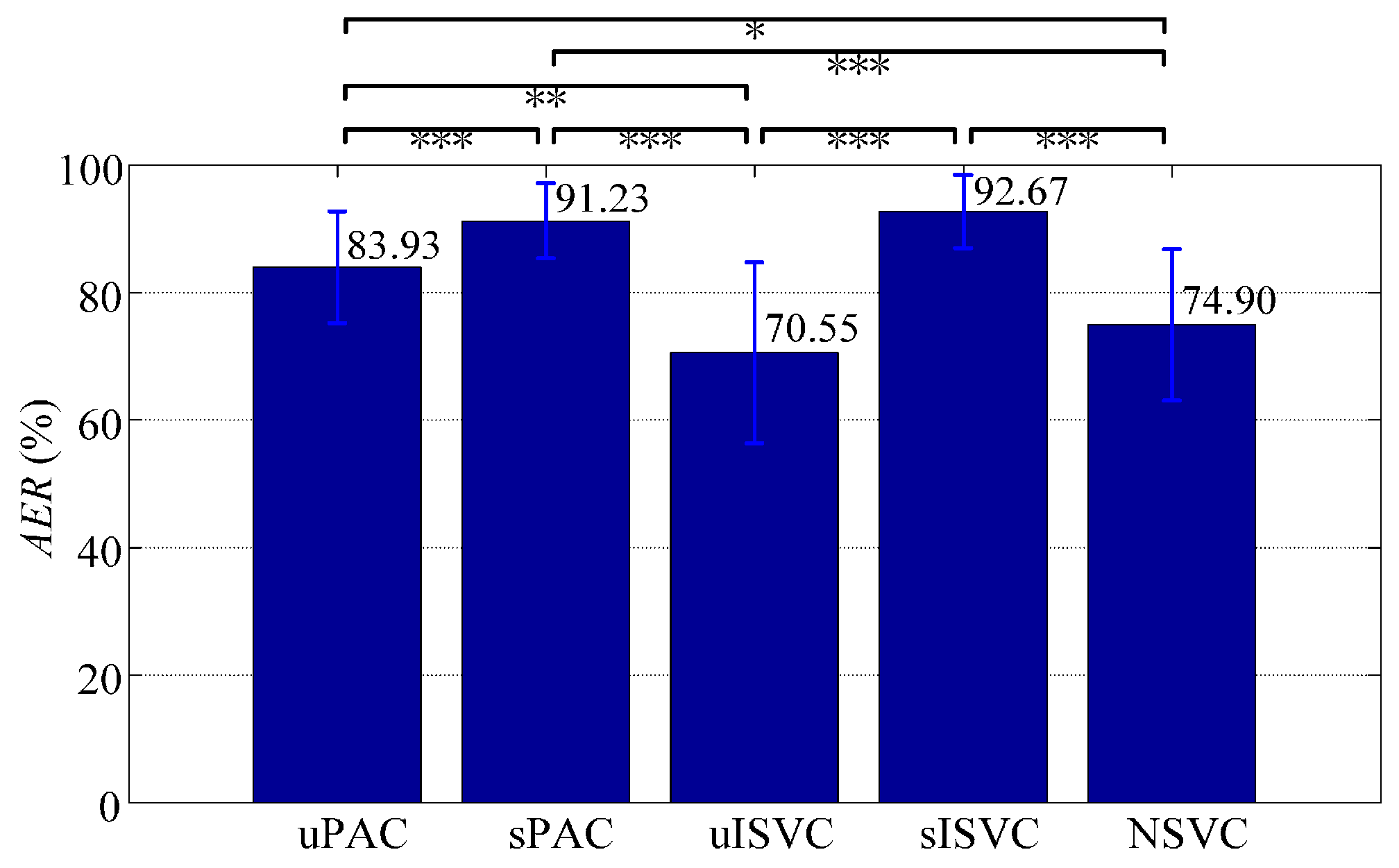
- (1)
- At the beginning of the day, sISVC was with highest overall recognition accuracy at more than 96.02%. The other classifiers shared the similar overall recognition accuracy at around 85%. With time moving forward, sISVC and uPAC almost maintained the overall recognition accuracy at 92.67% and 83.93% respectively; sPAC improved the overall recognition accuracy to 91.23%; uISVC and NSVC deteriorated the overall recognition accuracy to 70.55% and 74.90% respectively. The overall recognition accuracy at the end of the day was measured by AER.
- (2)
- According to the changing tendency within the day, supervised adaptive learning scenarios had superiorities on the performance over unsupervised adaptive learning scenarios (sISVC, sPAC, vs. uISVC, uPAC), while PAC had superiorities over ISVC (sPAC, uPAC, vs. sISVC, uISVC). It was remarkable that, in unsupervised adaptive learning scenarios, uPAC significantly improved the performance from NSVC, no matter for overall recognition accuracy AER (9.03% ± 2.23%, p = 0.011) or lowest motion recognition accuracy WMP (14.45% ± 4.06%, p = 0.028), whereas uISVC did not significantly improved the performance.
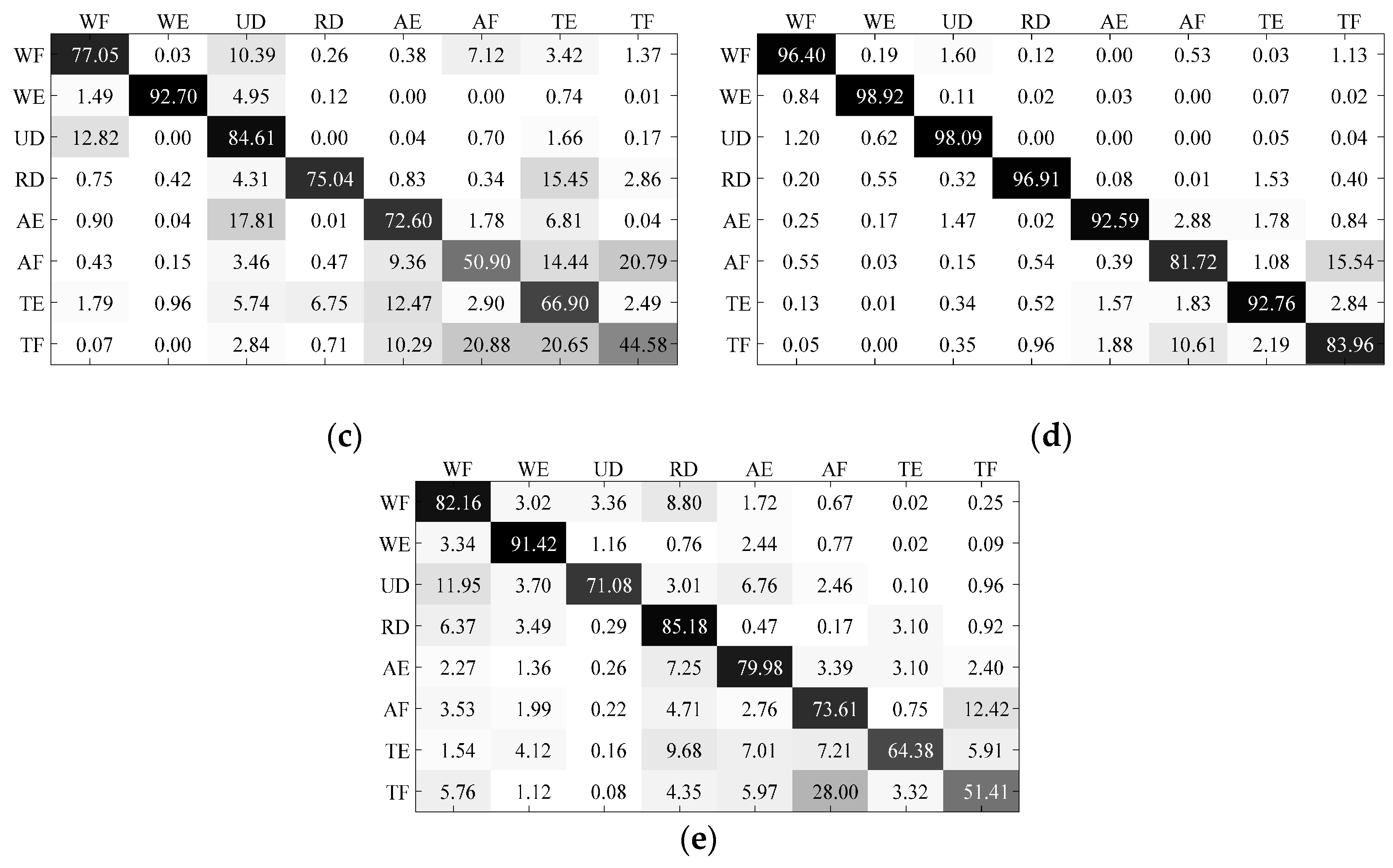
- (3)
- The accuracy variations within one day for different motion types were different. Compared with wrist motion classifications, finger motion classifications had lower recognition accuracy. Among all motion types, Motion TF (thumb-index flexion) had the lowest classification recognition accuracy compared with other motion types. According to the confusion matrices of different motions, the confusion between Motion AF (all finger flexion) and Motion TF was the largest component of misclassification. Therefore, in future research, it is necessary to strengthen or compensate the classification of finger flexion movements.
- (4)
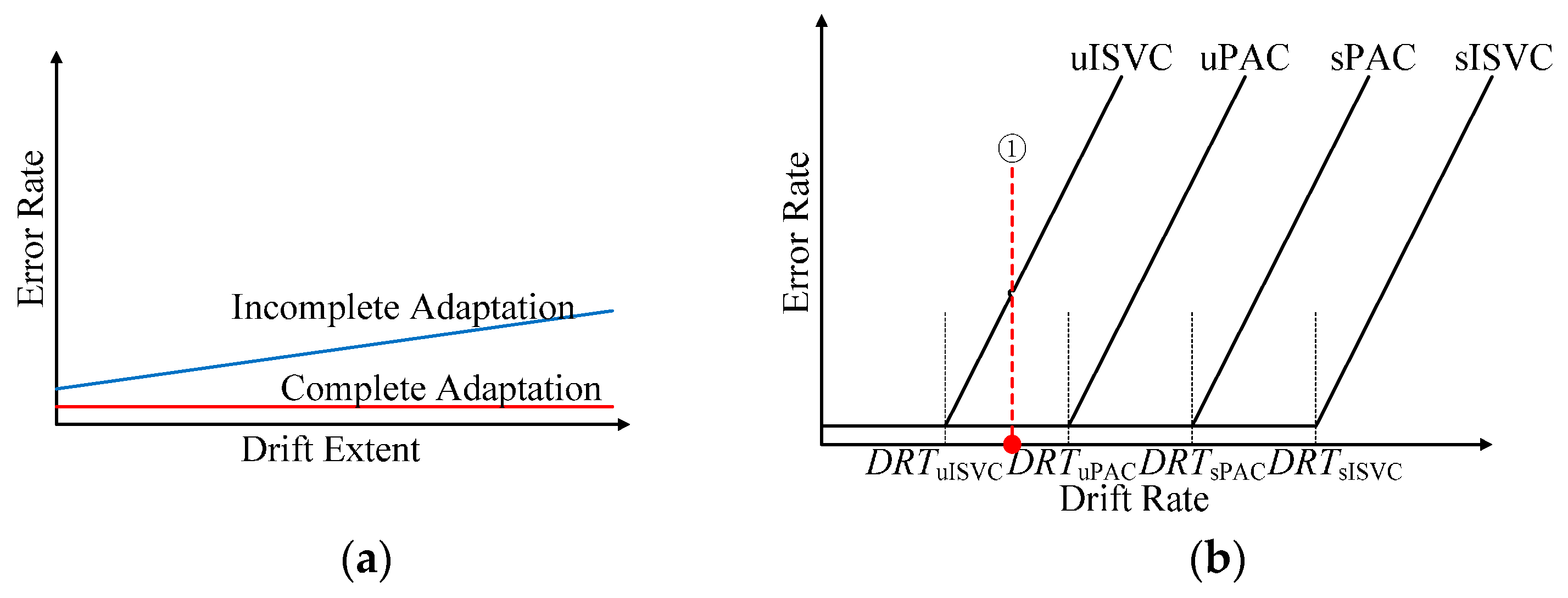
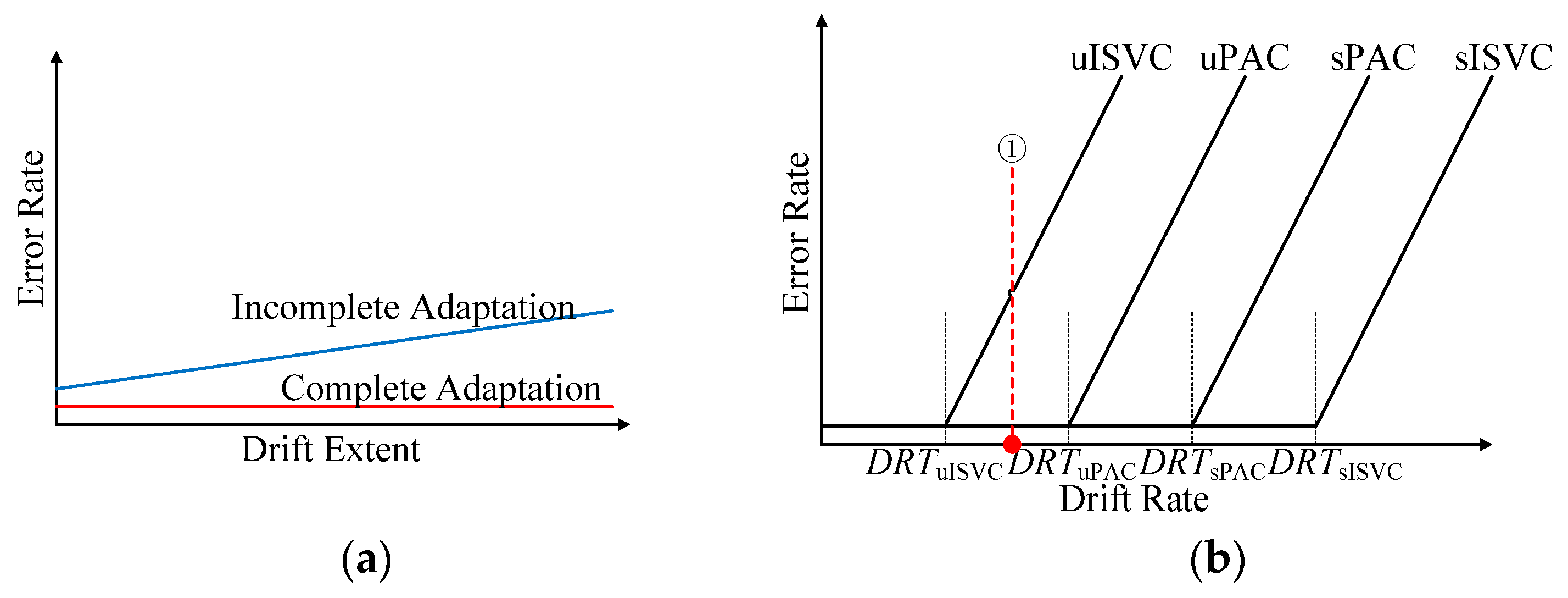
- (a)
- No matter in supervised or unsupervised adaptive learning scenarios, the performance could be divided into two categories: complete adaption, the accuracy not falling down with drift extent increasing, and incomplete adaption, the accuracy falling down with drift extent increasing.
- (b)
- There was a threshold of the drift rate for a particular adaptive strategy, noting as DRT. When and only when the drift rate of the dataset was less than DRT, the adaptive strategy achieved complete adaption. Therefore, DRT could be seen as the inherent property of an adaptive classifier. According to Figure 13, DRTuISVC < DRTuPAC < DRTsPAC < DRTsISVC.
- (c)
- When comparing the performances of NSVC in Figure 12 and Figure 14, we could find out that the average error rate of the realistic data sequence changed linearly within the day, showing the similarity to a simulated data sequence with a fixed drift rate between DRTuPAC and DRTuISVC. The similarity could explain why uPAC, uISVC and sPAC maintained and even improved the recognition accuracy whereas uISVC deteriorated the recognition accuracy with time moving forward. Therefore, in the future, we could employ the drift rate threshold to describe the essential adaptability of an adaptive learning strategy.In this paper, we compared the performance of proposed PAC with incremental SVC and nonadapting SVC in both supervised and unsupervised adaptive learning scenarios. Compared with other classifiers, proposed PAC had two advantages: (a) the stable and small time cost per updating cycle, and (b) the capability to maintain or improve the classification performance no matter in supervised or unsupervised adaptive learning scenarios. The two advantages will contribute to performance improvement from conventional PR-based myoelectric control method in clinical use.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Biddiss, E.; Chau, T. Upper-limb prosthetics: critical factors in device abandonment. Am. J. Phys. Med. Rehabil. 2007, 86, 977–987. [Google Scholar] [CrossRef] [PubMed]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848–854. [Google Scholar] [CrossRef] [PubMed]
- Nurhazimah, N.; Azizi, A.R.M.; Shin-Ichiroh, Y.; Anom, A.S.; Hairi, Z.; Amri, M.S. A review of classification techniques of EMG signals during isotonic and isometric contractions. Sensors 2016, 16, 1304. [Google Scholar] [CrossRef]
- Chowdhury, R.H.; Reaz, M.B.I.; Ali, M.A.M. Surface Electromyography Signal Processing and Classification Techniques. Sensors 2013, 13, 12431–12466. [Google Scholar] [CrossRef] [PubMed]
- Scheme, E.; Englehart, K. Electromyogram pattern recognition for control of powered upper-limb prostheses: State of the art and challenges for clinical use. J. Rehabil. Res. Dev. 2011, 48, 643–659. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Yang, W.; Huang, Q.; Liu, H. Classification of Multiple Finger Motions during Dynamic Upper Limb Movements. IEEE J. Biomed. Health Inform. 2017, 21, 134–141. [Google Scholar] [CrossRef] [PubMed]
- Farina, D.; Jiang, N.; Rehbaum, H.; Holobar, A.; Graimann, B.; Dietl, H.; Aszmann, O.C. The extraction of neural information from the surface EMG for the control of upper-limb prostheses: Emerging avenues and challenges. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Young, A.J.; Hargrove, L.J.; Kuiken, T.A. The effects of electrode size and orientation on the sensitivity of myoelectric pattern recognition systems to electrode shift. IEEE Trans. Biomed. Eng. 2011, 58, 2537–2544. [Google Scholar] [CrossRef] [PubMed]
- Young, A.J.; Hargrove, L.J.; Kuiken, T.A. Improving myoelectric pattern recognition robustness to electrode shift by changing interelectrode distance and electrode configuration. IEEE Trans. Biomed. Eng. 2012, 59, 645–652. [Google Scholar] [CrossRef] [PubMed]
- Ison, M.; Vujaklija, I.; Whitsell, B.; Farina, D.; Artemiadis, P. High-density electromyography and motor skill learning for robust long-term control of a 7-DoF robot arm. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 424–433. [Google Scholar] [CrossRef] [PubMed]
- Muceli, S.; Jiang, N.; Farina, D. Extracting signals robust to electrode number and shift for online simultaneous and proportional myoelectric control by factorization algorithms. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 623–633. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Sheng, X.; Zhang, D.; Jiang, N.; Zhu, X. Towards zero retraining for myoelectric control based on common model component analysis. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 444–454. [Google Scholar] [CrossRef] [PubMed]
- Sensinger, J.W.; Lock, B.A.; Kuiken, T.A. Adaptive pattern recognition of myoelectric signals: exploration of conceptual framework and practical algorithms. IEEE Trans. Neural Syst. Rehabil. Eng. 2009, 17, 270–278. [Google Scholar] [CrossRef] [PubMed]
- Amsuss, S.; Goebel, P.M.; Jiang, N.; Graimann, B.; Paredes, L.; Farina, D. Self-correcting pattern recognition system of surface EMG signals for upper limb prosthesis control. IEEE Trans. Biomed. Eng. 2014, 61, 1167–1176. [Google Scholar] [CrossRef] [PubMed]
- Pilarski, P.M.; Dawson, M.R.; Degris, T.; Carey, J.P.; Chan, K.M.; Hebert, J.S.; Sutton, R.S. Adaptive artificial limbs a real-time approach to prediction and anticipation. IEEE Robot. Autom. Mag. 2013, 20, 53–64. [Google Scholar] [CrossRef]
- Vidaurre, C.; Kawanabe, M.; Bunau, P.; Blankertz, B.; Muller, K.R. Toward unsupervised adaptation of LDA for brain–computer interfaces. IEEE Trans. Biomed. Eng. 2011, 58, 587–597. [Google Scholar] [CrossRef] [PubMed]
- Hahne, J.M.; Dahne, S.; Hwang, H.J.; Muller, K.R.; Parra, L.C. Concurrent adaptation of human and machine improves simultaneous and proportional myoelectric control. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 618–627. [Google Scholar] [CrossRef] [PubMed]
- Schlimmer, J.C.; Granger, R.H. Incremental learning from noisy data. Mach. Learn. 1986, 1, 317–354. [Google Scholar] [CrossRef]
- Gama, J.; Zliobaite, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. 2014, 46, 44. [Google Scholar] [CrossRef]
- Liu, J.; Sheng, X.; Zhang, D.; He, J.; Zhu, X. Reduced daily recalibration of myoelectric prosthesis classifiers based on domain adaptation. IEEE J. Biomed. Health Inform. 2016, 20, 166–176. [Google Scholar] [CrossRef] [PubMed]
- Vidovic, M.M.C.; Hwang, H.J.; Amsuess, S.; Hahne, J.M.; Farina, D.; Muller, K.R. Improving the robustness of myoelectric pattern recognition for upper limb prostheses by covariate shift adaptation. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 961–970. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhang, D.; Zhu, X. Application of a self-enhancing classification method to electromyography pattern recognition for multifunctional prosthesis control. J. Neuroeng. Rehabil. 2013, 10, 44. [Google Scholar] [CrossRef] [PubMed]
- Fukuda, O.; Tsuji, T.; Kaneko, M.; Otsuka, A. A human-assisting manipulator teleoperated by EMG signals and arm motions. IEEE Trans. Robot. Autom. 2003, 19, 210–222. [Google Scholar] [CrossRef]
- Kasuya, M.; Kato, R.; Yokoi, H. Development of a Novel Post-Processing Algorithm for Myoelectric Pattern Classification (in Japanese). Trans. Jpn. Soc. Med. Biomed. Eng. 2015, 53, 217–224. [Google Scholar]
- Scheme, E.J.; Englehart, K.B.; Hudgins, B.S. Selective classification for improved robustness of myoelectric control under non-ideal conditions. IEEE Trans. Biomed. Eng. 2011, 58, 1698–1705. [Google Scholar] [CrossRef] [PubMed]
- Hargrove, L.J.; Englehart, K.B.; Hudgins, B.S. A comparison of surface and intramuscular myoelectric signal classification. IEEE Trans. Biomed. Eng. 2007, 54, 847–853. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Jiang, L.; Liu, R.; Liu, H. Adaptive learning of multi-finger motion recognition based on support vector machine. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, China, 12–14 December 2013; pp. 2231–2238. [Google Scholar]
- Liu, J. Adaptive myoelectric pattern recognition toward improved multifunctional prosthesis control. Med. Eng. Phys. 2015, 37, 424–430. [Google Scholar] [CrossRef] [PubMed]
- Vapnik, V.N. Constructing Learning Algorithms. In The Nature of Statistical Learning Theory, 1st ed.; Springer: New York, NY, USA, 1995; pp. 119–161. [Google Scholar]
- Li, Z.; Wang, B.; Yang, C.; Xie, Q.; Su, C.-Y. Boosting-based EMG patterns classification scheme for robustness enhancement. IEEE J. Biomed. Health Infor. 2013, 17, 545–552. [Google Scholar] [CrossRef]
- Al-Timemy, A.; Bugmann, G.; Escudero, J.; Outram, N. Classification of finger movements for the dexterous hand prosthesis control with surface electromyography. IEEE J. Biomed. Health Inform. 2013, 17, 608–618. [Google Scholar] [CrossRef]
- Benatti, S.; Milosevic, B.; Farella, E.; Gruppioni, E.; Benini, L. A Prosthetic Hand Body Area Controller Based on Efficient Pattern Recognition Control Strategies. Sensors 2017, 17, 869. [Google Scholar] [CrossRef] [PubMed]
- Syed, N.A.; Liu, H.; Sung, K.K. Handling concept drifts in incremental learning with support vector machines. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’99), San Diego, CA, USA, 15–18 August 1999; pp. 317–321. [Google Scholar]
- Gestel, T.; Suykens, J.A.K.; Baesens, B.; Viaene, S.; Vanthienen, J.; Dedene, G.; Moor, B.; Vandewalle, J. Benchmarking least squares support vector machine classifiers. Mach. Learn. 2004, 54, 5–32. [Google Scholar] [CrossRef]
- Yang, X.; Lu, J.; Zhang, G. Adaptive pruning algorithm for least squares support vector machine classifier. Soft Comput. 2010, 14, 667–680. [Google Scholar] [CrossRef]
- Wong, P.; Wong, H.; Vong, C. Online time-sequence incremental and decremental least squares support vector machines for engine air-ratio prediction. Int. J. Engine Res. 2012, 13, 28–40. [Google Scholar] [CrossRef]
- Tommasi, T.; Orabona, F.; Castellini, C.; Caputo, B. Improving control of dexterous hand prostheses using adaptive learning. IEEE Trans. Robot. 2013, 29, 207–219. [Google Scholar] [CrossRef]
- Vapnik, V. Transductive inference and semi-supervised learning. In Semi-Supervised Learning, 1st ed.; MIT Press: Cambridge, MA, USA, 2006; pp. 454–472. [Google Scholar]
- Chapelle, O.; Schölkopf, B.; Zien, A. Introduction to semi-supervised learning. In Semi-Supervised Learning, 1st ed.; MIT Press: Cambridge, MA, USA, 2006; pp. 1–12. [Google Scholar]
- Kuncheva, L.I.; Zliobaite, I. On the window size for classification in changing environments. Intell. Data Anal. 2009, 13, 861–872. [Google Scholar] [CrossRef]
- Klinkenberg, R. Learning drifting concepts: Example selection vs. example weighting. Intell. Data Anal. 2004, 8, 281–300. [Google Scholar]
- Kuh, A.; Petsche, T.; Rivest, R.L. Learning time-varying concepts. In Proceedings of the Advances in Neural Information Processing Systems 1990 (NIPS-3), Denver, CO, USA, 26–29 November 1990; pp. 183–189. [Google Scholar]
- Keerthi, S.S.; Lin, C.J. Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Yang, S.; Zhang, R.; Jin, H. Sparse least square support vector machine via coupled compressive pruning. Neurocomputing 2014, 131, 77–86. [Google Scholar] [CrossRef]
- Cawley, G.C.; Talbot, N.L. Fast exact leave-one-out cross-validation of sparse least-squares support vector machines. Neural Netw. 2004, 17, 1467–1475. [Google Scholar] [CrossRef] [PubMed]
- Golub, G.H.; Loan, C.F. Cholesky updating and downdating. In Matrix Computations, 4th ed.; The John Hopkins University Press: Baltimore, MA, USA, 2013; pp. 338–341. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- 13E200 Myobock Electrode; Otto Bock Healthcare Products GmbH: Vienna, Austria, 2010; pp. 8–12.
- Atzori, M.; Gijsberts, A.; Heynen, S.; Hager, A.G.M. Building the Ninapro database: A resource for the biorobotics community. In Proceedings of the IEEE RAS & EMBS International Conference on Biomedical Robotics and Biomechatronics, Roma, Italy, 24–27 June 2012; pp. 1258–1265. [Google Scholar]
- Castellini, C.; Gruppioni, E.; Davalli, A.; Sandini, G. Fine detection of grasp force and posture by amputees via surface electromyography. J. Physiol. Paris 2009, 103, 255–262. [Google Scholar] [CrossRef] [PubMed]
- Cutkosky, M.R. On grasp choice, grasp models, and the design of hands for manufacturing tasks. IEEE Trans. Robot. Autom. 1989, 5, 269–279. [Google Scholar] [CrossRef]
- Yang, D.; Zhao, J.; Jiang, L.; Liu, H. Dynamic hand motion recognition based on transient and steady-state EMG signals. Int. J. Humanoid Robot. 2012, 9, 1250007. [Google Scholar] [CrossRef]






© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Yang, D.; Jiang, L.; Zhang, H.; Liu, H.; Kotani, K. A Novel Unsupervised Adaptive Learning Method for Long-Term Electromyography (EMG) Pattern Recognition. Sensors 2017, 17, 1370. https://doi.org/10.3390/s17061370
Huang Q, Yang D, Jiang L, Zhang H, Liu H, Kotani K. A Novel Unsupervised Adaptive Learning Method for Long-Term Electromyography (EMG) Pattern Recognition. Sensors. 2017; 17(6):1370. https://doi.org/10.3390/s17061370
Chicago/Turabian StyleHuang, Qi, Dapeng Yang, Li Jiang, Huajie Zhang, Hong Liu, and Kiyoshi Kotani. 2017. "A Novel Unsupervised Adaptive Learning Method for Long-Term Electromyography (EMG) Pattern Recognition" Sensors 17, no. 6: 1370. https://doi.org/10.3390/s17061370
APA StyleHuang, Q., Yang, D., Jiang, L., Zhang, H., Liu, H., & Kotani, K. (2017). A Novel Unsupervised Adaptive Learning Method for Long-Term Electromyography (EMG) Pattern Recognition. Sensors, 17(6), 1370. https://doi.org/10.3390/s17061370