
Distributed Fault Detection Based on Credibility and Cooperation for WSNs in Smart Grids



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Credibility Model of a Single Sensor
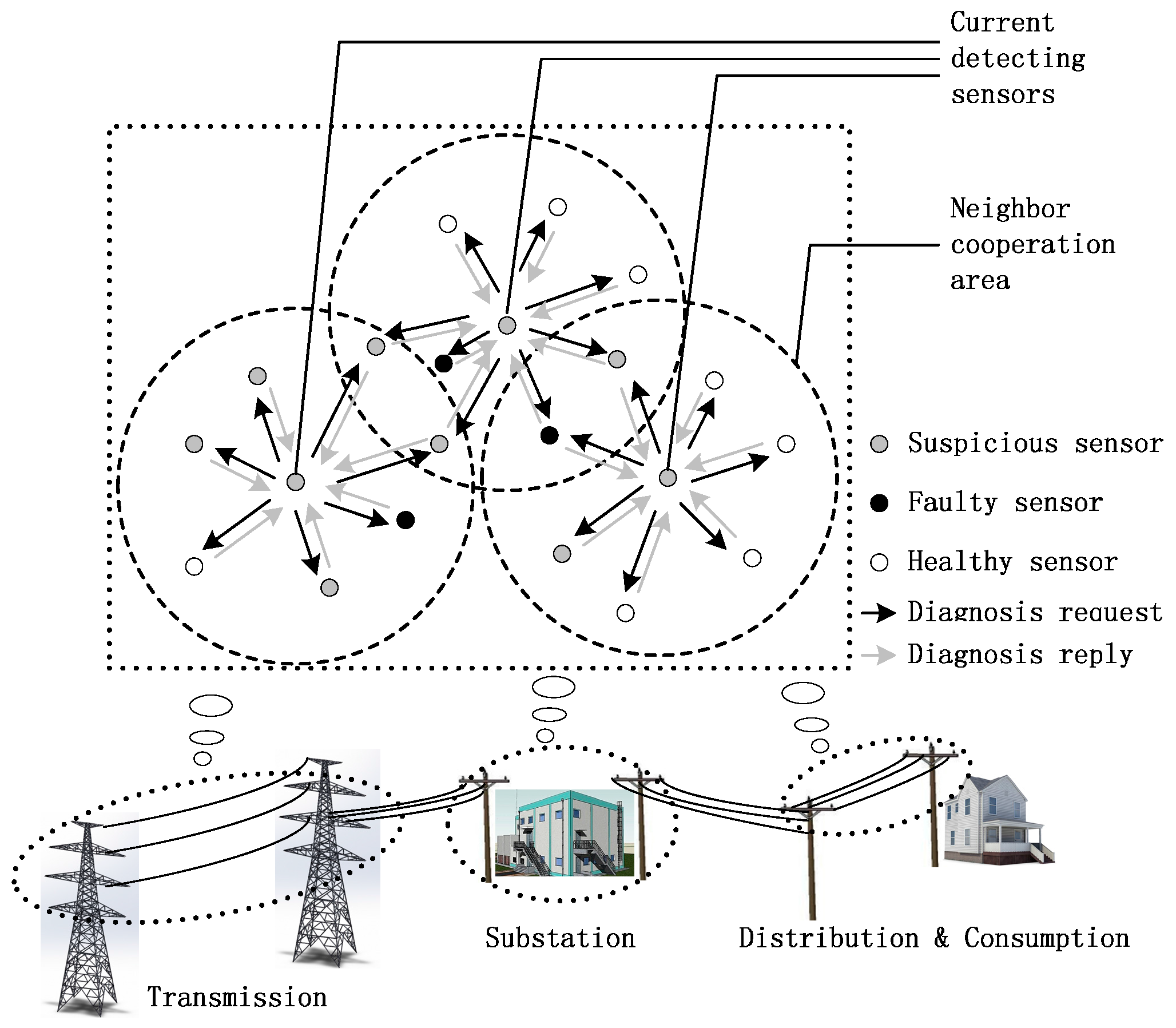
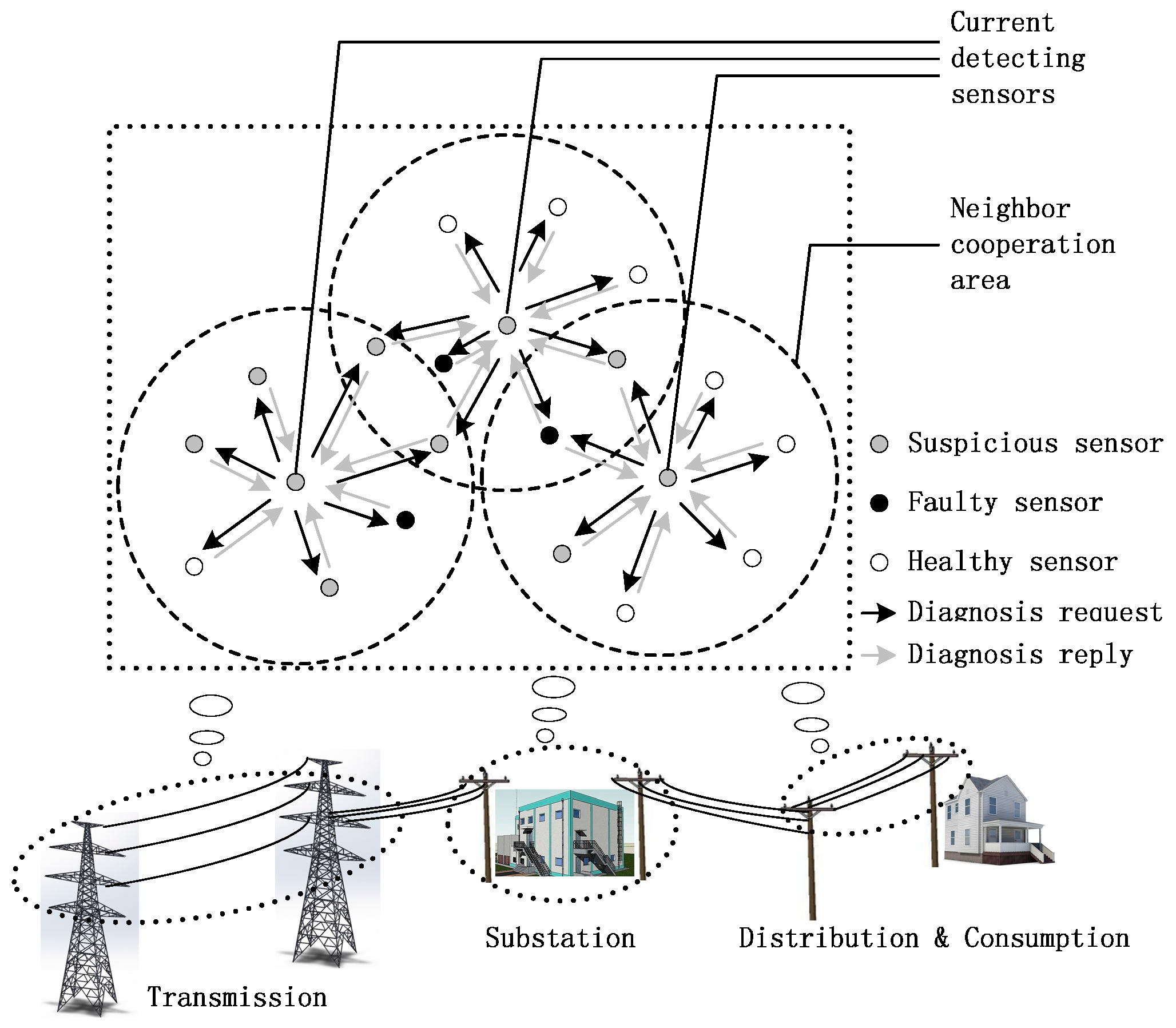
4. Fault Detection Mechanism Based on Credibility and Cooperation
4.1. Diagnosis Request
4.1.1. Diagnosis Request Parameter
4.1.2. Diagnosis Request Timing
4.2. Diagnosis Reply Based on Neighbor Cooperation
4.3. Fault Judgement Based on Modified Credibility
- (1)
- The healthy sensors are more than the faulty ones. For the similar reason of classification (a) in this section, another round of fault diagnosis process with 2T waiting time should be launched if , and should be directly judged as a faulty sensor if .
- (2)
- In this case, the faulty sensors are more than the healthy ones. For the similar reason given in classification (b), we directly judge as a faulty sensor if .
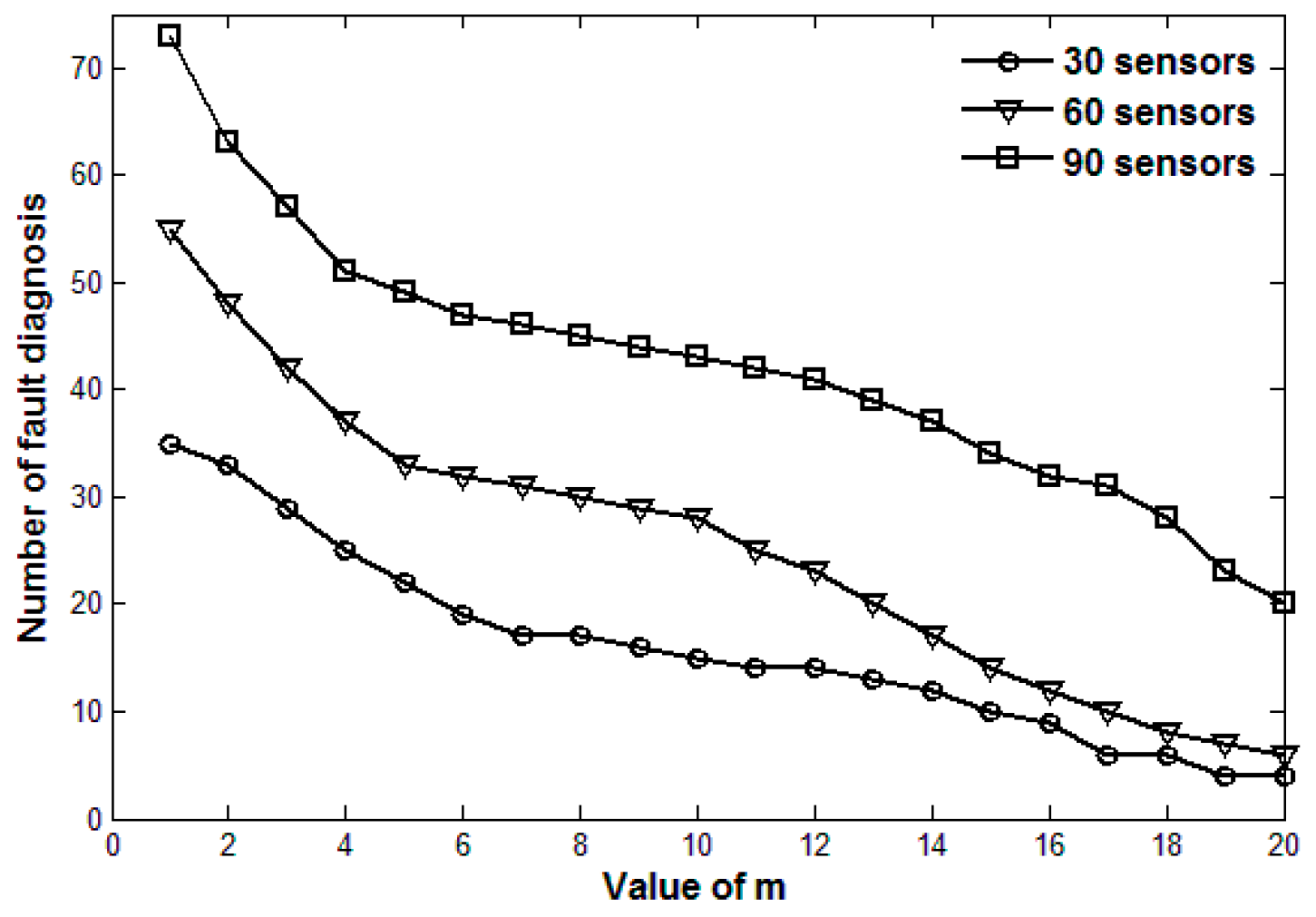
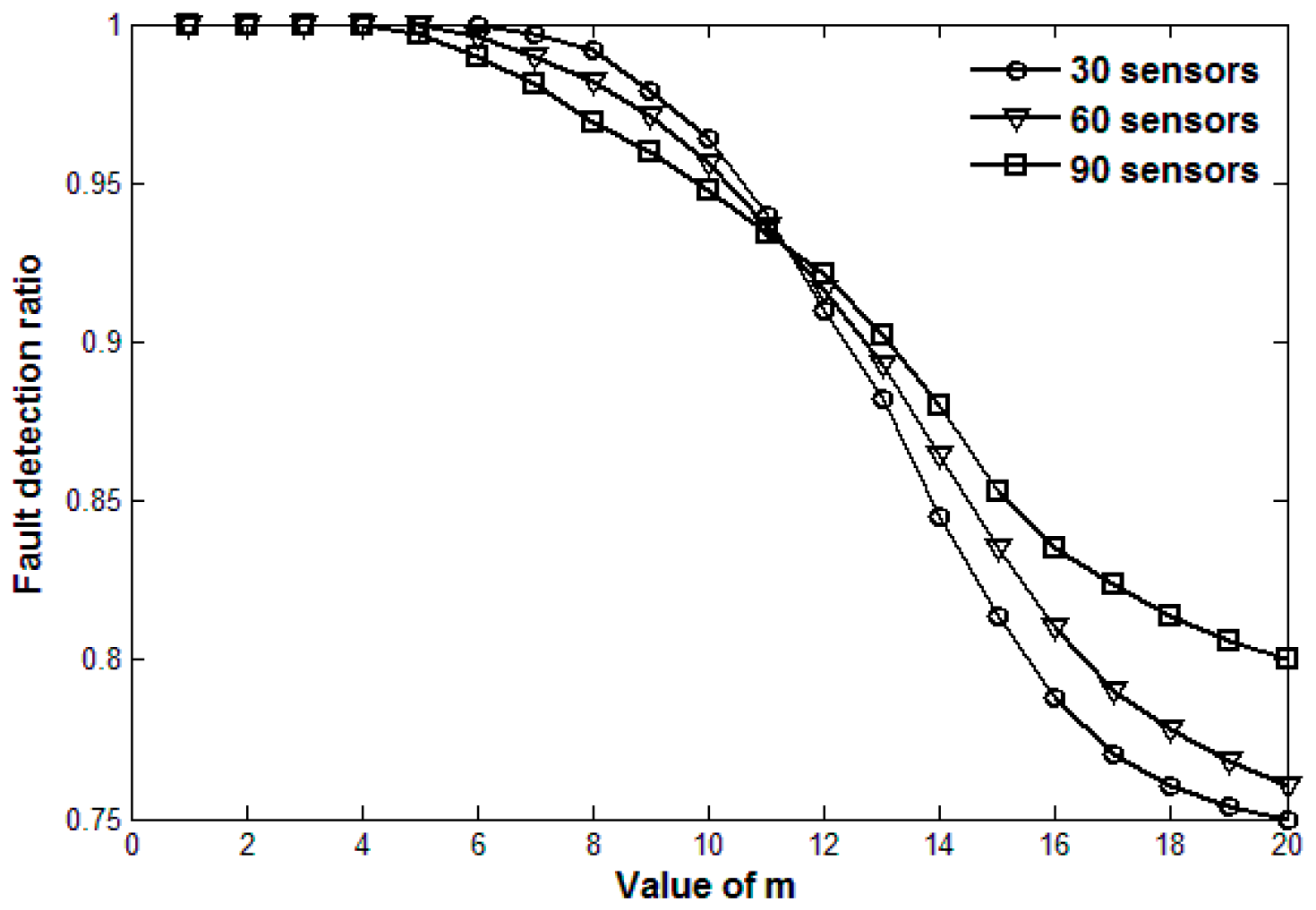
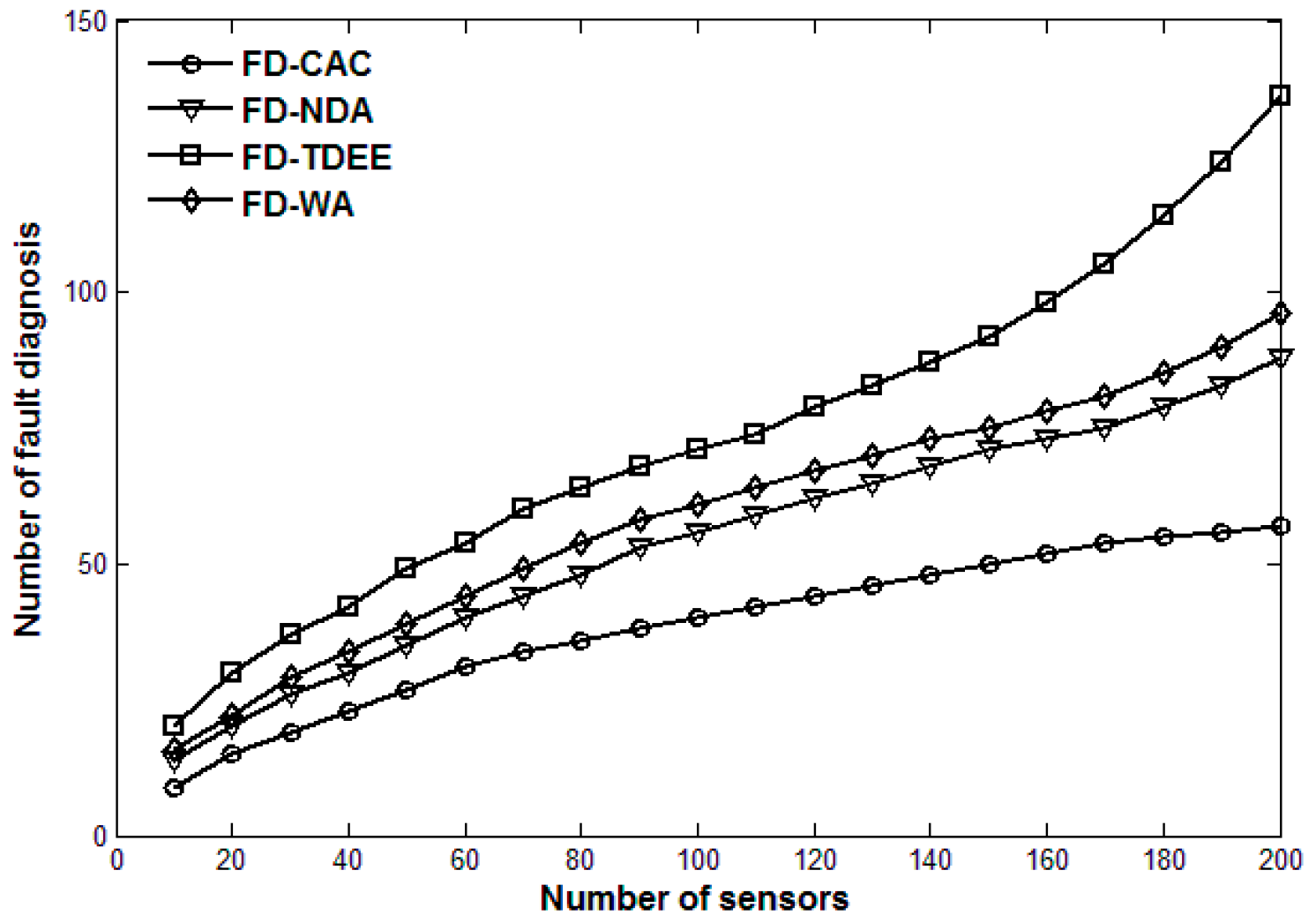
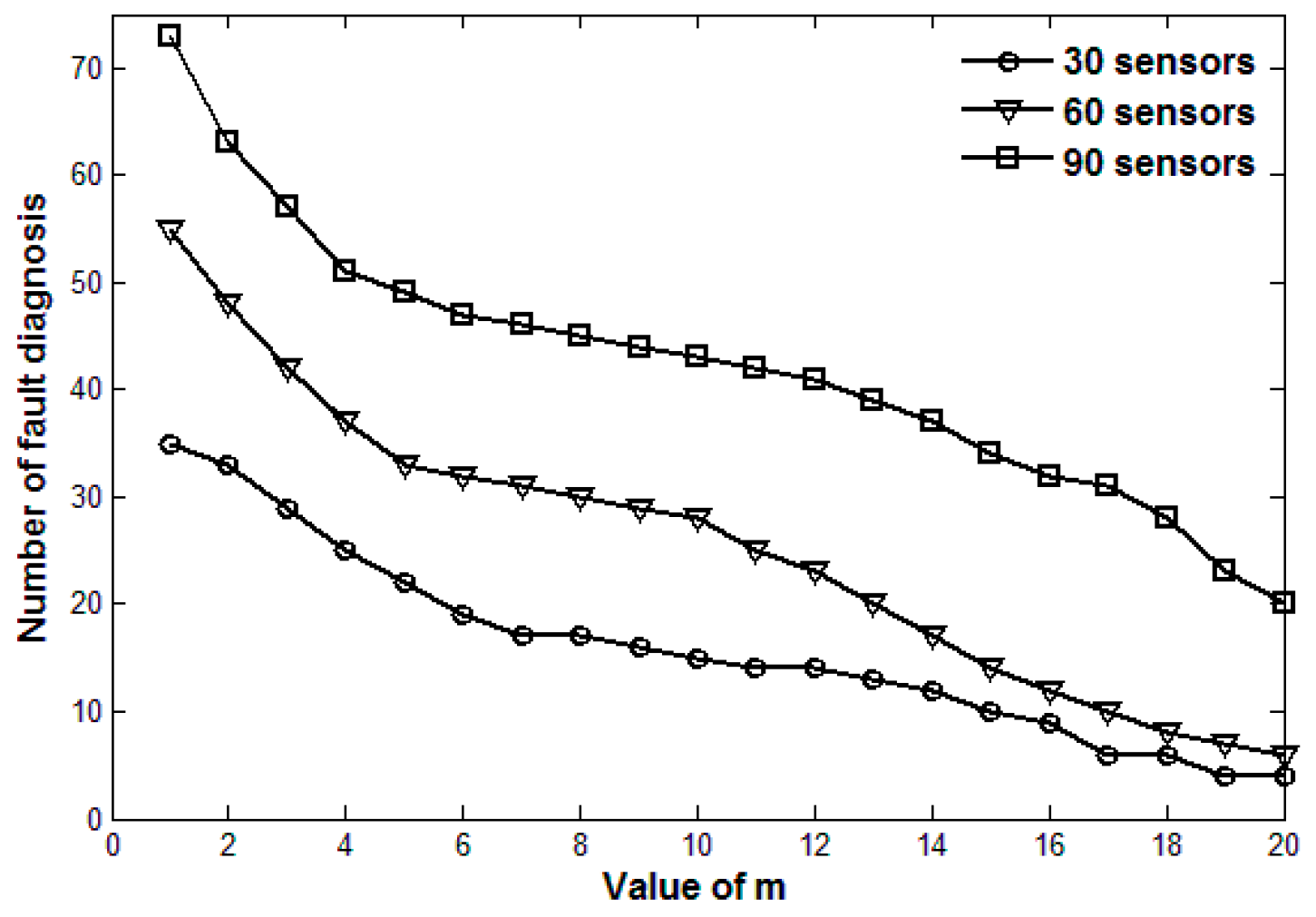
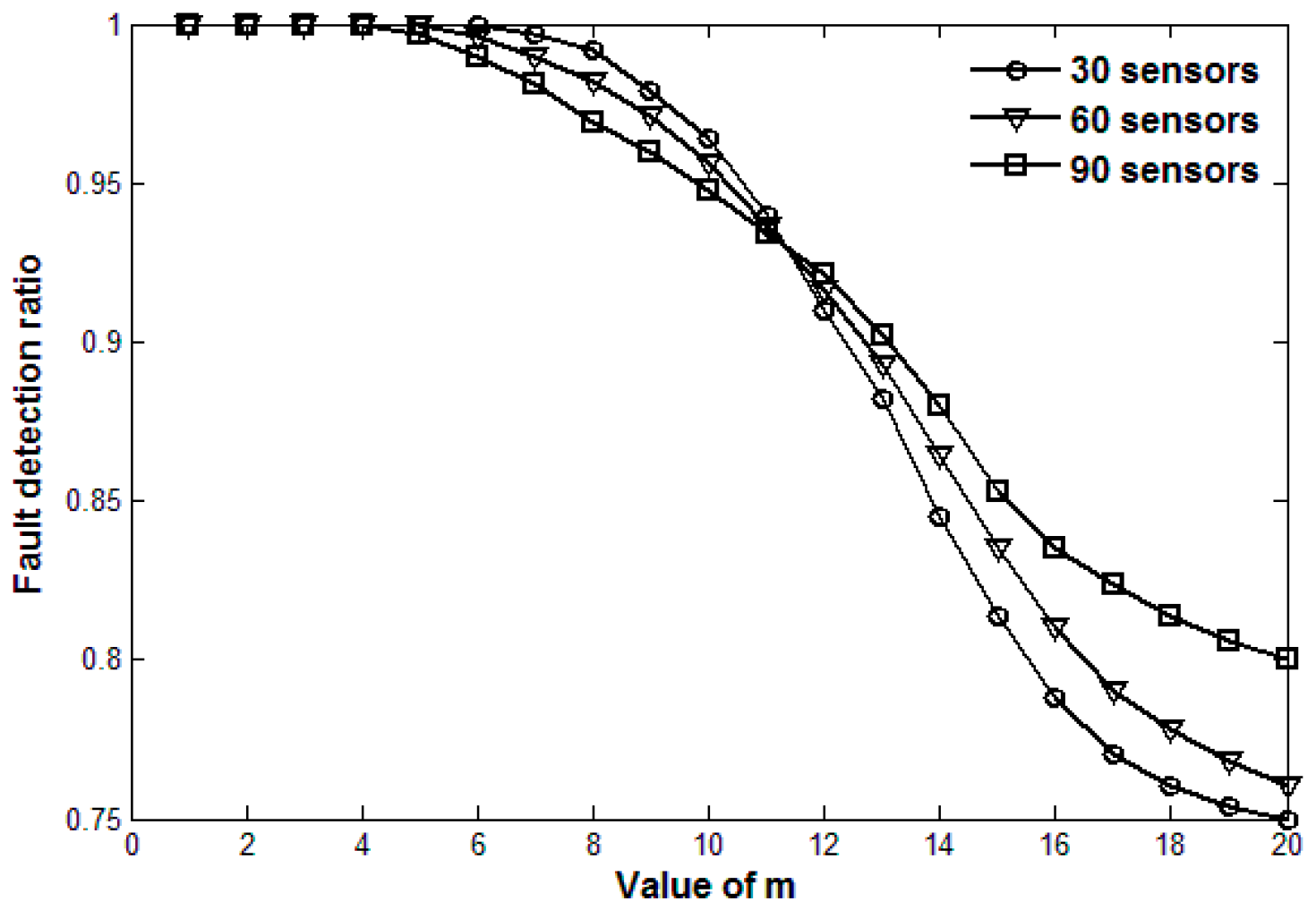
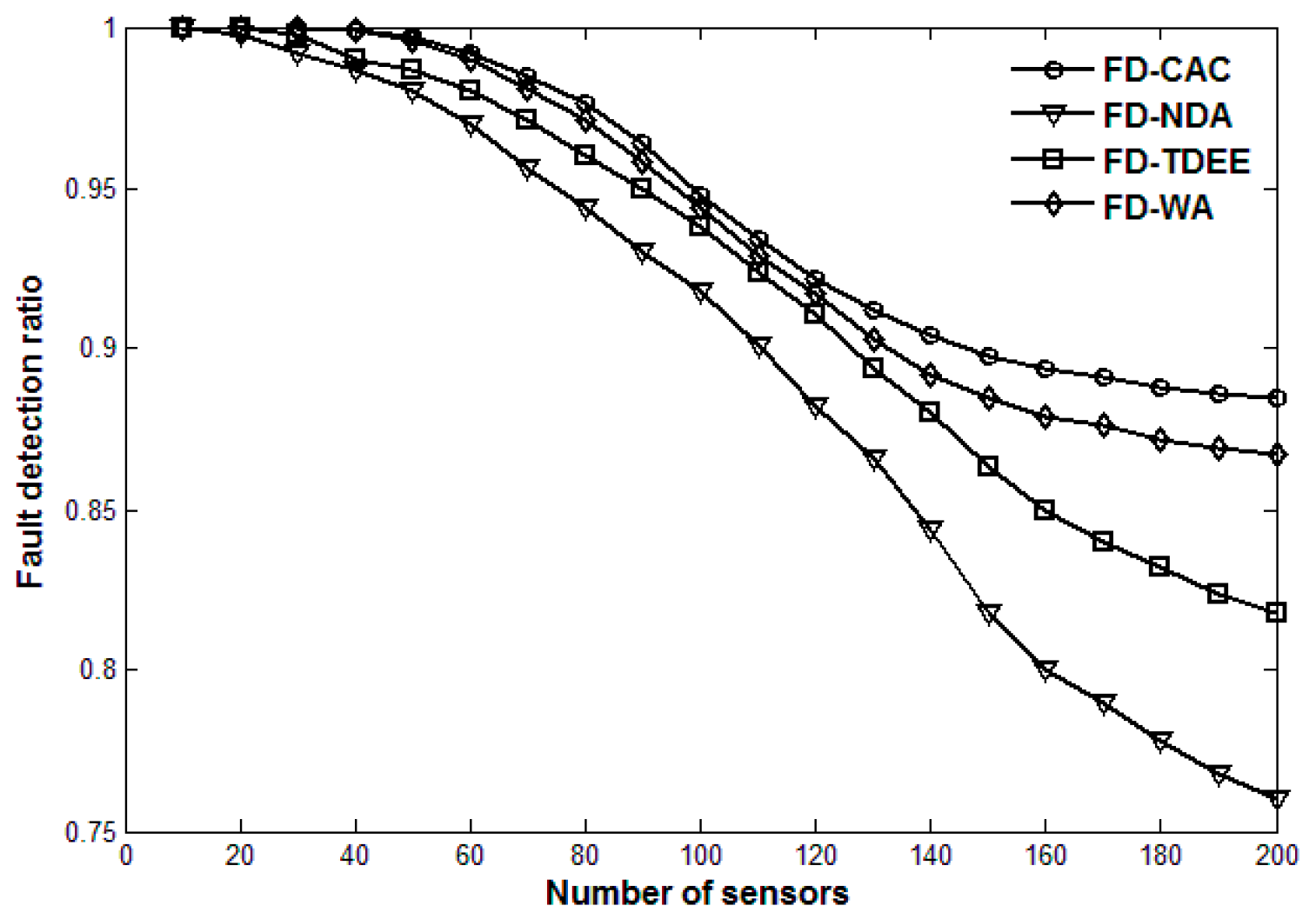
5. Simulation Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xu, X.H.; Song, M. Restricted coverage in wireless networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Toronto, ON, Canada, 27 April–2 May 2014; pp. 558–564. [Google Scholar]
- Habib, M.; Sajal, K. Centralized and clustered k-coverage protocols for wireless sensor networks. IEEE Trans. Comput. 2012, 61, 118–133. [Google Scholar]
- Lu, Z.Q.; Wen, Y.G. Distributed algorithm for tree-structured data aggregation service placement in smart grid. IEEE Syst. J. 2014, 8, 553–561. [Google Scholar]
- Paradis, L.; Han, Q. A survey of fault management in wireless sensor networks. J. Network Syst. Manag. 2007, 15, 171–190. [Google Scholar] [CrossRef]
- Chang, C.Y.; Lin, C.Y.; Kuo, C.H. EBDC: An energy-balanced data collection mechanism using a mobile data collector in WSNs. Sensors 2012, 12, 5850–5871. [Google Scholar] [CrossRef] [PubMed]
- Xue, L.; Kim, D.; Zhu, Y. Multiple heterogeneous data ferry trajectory planning in wireless sensor networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Toronto, ON, Canada, 27 April–2 May 2014; pp. 2274–2282. [Google Scholar]
- Liu, X.F.; Cao, J.N.; Tang, S.J.; Guo, P. Fault tolerant complex event detection in WSNs: A case study in structural health monitoring. IEEE Trans. Mob. Comput. 2015, 12, 2502–2515. [Google Scholar] [CrossRef]
- Chen, J.; Kher, S.; Somani, A. Distributed Fault Detection of Wireless Sensor Networks. In Proceedings of the 2006 Workshop on Dependability Issues in Wireless Ah Hoc Networks and Sensor Networks, Los Angeles, CA, USA, 26 September 2006; pp. 65–71. [Google Scholar]
- Ji, S.; Yuan, S.F.; Ma, T.H.; Tan, C. Distributed Fault Detection for Wireless Sensor Based on Weighted Average. In Proceedings of the 2nd International Conference on Networks Security Wireless Communications and Trusted Computing (NSWCTC), Wuhan, China, 24–25 April 2010; pp. 57–60. [Google Scholar]
- Luo, X.; Dong, M.; Huang, Y. On distributed fault-tolerant detection in wireless sensor networks. IEEE Trans. Comput. 2006, 55, 58–70. [Google Scholar] [CrossRef]
- Ding, M.; Chen, D.C.; Xing, X.; Cheng, X.Z. Localized fault-torelant event boundary detection in sensor networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Miami, FL, USA, 13–17 March 2005; pp. 902–913. [Google Scholar]
- Huang, R.M.; Qiu, X.S.; Gao, Z.P. A neighbor-data analysis method for fault detection in wireless sensor networks. Beijing Youdian Daxue Xuebao 2011, 34, 31–34. (In Chinese) [Google Scholar]
- Amna, Z.; Bilal, W.; Beenish, A.A. A hybrid fault diagnosis architecture for wireless sensor networks. In Proceedings of the International Conference on Open Source Systems and Technologies (ICOSST), Lahore, Pakistan, 17–19 December 2015; pp. 7–15. [Google Scholar]
- Zhao, M.; Chow, T.W. Wireless sensor network fault detection via semi-supervised local kernel density estimation. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 1495–1500. [Google Scholar]
- Ravindra, V.K.; Ashish, B.J. A fault tolerant approach to extend network life time of wireless sensor network. In Proceedings of the IEEE International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; pp. 993–998. [Google Scholar]
- Sharma, K.P.; Sharma, T.P. A Throughput Descent and Energy Efficient Mechanism for Fault Detection in WSNs. In Proceedings of the International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; pp. 28–30. [Google Scholar]
- Qiu, X.S.; Chen, X.Y.; Yang, Y. Neighbor-coordination in wireless sensor network. Beijing Youdian Daxue Xuebao 2015, 38, 1–5. (In Chinese) [Google Scholar]
- Paola, A.D.; Gaglio, S.; Giuseppe, L.G. Adaptive distributed outlier detection for WSNs. IEEE Trans. Cybern. 2015, 45, 888–899. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Zhao, X.X.; Yu, L.Y. A Distributed Bayesian Algorithm for data fault detection in wireless sensor networks. In Proceedings of the International Conference on Information Networking (ICOIN), Siem Reap, Cambodia, 12–14 January 2015; pp. 63–68. [Google Scholar]
- Senthil, M.; Sugashini, K.; Abirami, M. Identification and recovery of repaired nodes based on distributed hash table in WSN. In Proceedings of the IEEE Sponsored 2nd International Conference on Innovations in Information Embedded and Communication Systems (ICIIECS), Coimbatore, India, 19–20 March 2015; pp. 1–4. [Google Scholar]
- Yang, Y.; Liu, Q.; Gao, Z.P. Data clustering-based fault detection in WSNs. In Proceedings of the 7th International Conference on Advanced Computational Intelligence (ICACI), Wuyi, China, 27–29 March 2015; pp. 334–339. [Google Scholar]
- Saihi, M.; Boussaid, B.; Zouinkhi, A.; abdelkrim, N. Distributed fault detection based on HMM for wireless sensor networks. In Proceedings of the 4th International Conference on Systems and Control (ICSC), Sousse, Tunisia, 28–30 April 2015; pp. 189–193. [Google Scholar]
- Melike, Y.; Eyup, A.Y.; Cagri, V.G. Performance of MAC Protocols for Wireless Sensor Networks in Harsh Smart Grid Environment. In Proceedings of the 1st International Black Sea Conference on Communications and Networking (BlackSeaCom), Batumi, Georgia, 3–5 July 2013; pp. 50–53. [Google Scholar]
- Irfan, A.A.; Melike, E.K.; Hussein, T.M. Delay-Aware Medium Access Schemes for WSN-Based Partial Discharge Measurement. IEEE Trans. Instrum. Meas. 2014, 63, 3045–3057. [Google Scholar]
- Irfan, A.A.; Melike, E.K.; Hussein, T.M. An Adaptive QoS Scheme for WSN-based Smart Grid Monitoring. In Proceedings of the IEEE International Conference on Communications Workshops (ICC), Budapest, Hungary, 9–13 June 2013; pp. 1046–1051. [Google Scholar]

© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, S.; Guo, S.; Qiu, X. Distributed Fault Detection Based on Credibility and Cooperation for WSNs in Smart Grids. Sensors 2017, 17, 983. https://doi.org/10.3390/s17050983
Shao S, Guo S, Qiu X. Distributed Fault Detection Based on Credibility and Cooperation for WSNs in Smart Grids. Sensors. 2017; 17(5):983. https://doi.org/10.3390/s17050983
Chicago/Turabian StyleShao, Sujie, Shaoyong Guo, and Xuesong Qiu. 2017. "Distributed Fault Detection Based on Credibility and Cooperation for WSNs in Smart Grids" Sensors 17, no. 5: 983. https://doi.org/10.3390/s17050983
APA StyleShao, S., Guo, S., & Qiu, X. (2017). Distributed Fault Detection Based on Credibility and Cooperation for WSNs in Smart Grids. Sensors, 17(5), 983. https://doi.org/10.3390/s17050983