1. Introduction
Camera calibration is the first process for 3D computer vision which recovers metric information from 2D images. There are two types of approaches for calibration: photogrametric calibration uses both 2D information and knowledge of the scene such as coordinates of 3D points, shape of reference objects, direction of 3D lines, etc.; self-calibration does not require any knowledge but only 2D information. Generally speaking, the former approaches give more stable and accurate calibration results than the latter because using the knowledge reduces the number of parameters. The proposed method in this paper belongs to the photogrametric approaches.
The standard photogrametric calibration is Zhang’s method [
1] which uses a 3D plane called a chessboard or checkerboard, even though many methods have been proposed which use perpendicular planes [
2,
3], circles [
4,
5], spheres [
6,
7], and vanishing points [
8,
9]. The merits of Zhang’s method are the ease of use and its extensibility. The requirement is only a camera and a paper on which a pattern is printed. Pattern images are captured by moving either the camera or the plane manually. Then, camera parameters are estimated by decomposing the homography between 3D points on the plane and their 2D projections on the image. The basic idea of Zhang’s method is not only for a single camera calibration, but also applicable to multiple camera calibration [
10], projector-camera calibration [
11], and depth sensor-camera calibration [
12].
Most parts of Zhang’s conventional method, such as checkerboard detection, can be automatically processed by software [
13,
14]. However, a manual part remains at the capture step. This part makes a calibration result unstable although it takes a lot of time. For stable calibration, many images under varied motions, generally ≥20 images, are required so that all detected points are distributed uniformly.
Figure 1a shows an example in which all points from four images are scattered over the camera view. Otherwise, in a situation like
Figure 1b, the conventional method does not give an accurate result for any trials.
To get well distributed points, robust methods are proposed for detecting partial occluded patterns [
15,
16,
17]. By using those methods, if a part of the pattern is outside of the camera view, visible points including those near the image boundary are helpful for improving calibration accuracy. However, the manual part still exists.
This paper proposes a full-automatic calibration method to resolve the two problems caused by the manual operation: the time consuming problem and the point distribution problem. Instead of a physical pattern, the proposed method uses a virtual pattern which is transformed in the virtual world coordinates and projected on a fixed screen. The pattern on the screen is captured by a fixed camera, then, the proposed method performs calibration by using point correspondences between the virtual 3D points and their 2D projections. The virtual pattern can be actively displayed on the screen so that all points are uniformly distributed. Also, the camera and the screen are fixed during the whole process. Therefore, the proposed method can be stable and fully automatic.
This paper is organized as follows.
Section 2 describes Zhang’s conventional method from basic equations. Although the derivation of Zhang’s method is widely known, it is highly related to the proposed method in
Section 3. In
Section 4, experimental results on synthetic and real images are provided and discussed. Finally,
Section 5 gives the conclusions.
2. Conventional Method
Zhang’s conventional calibration method estimates the intrinsic and the extrinsic parameters of a camera from images of a physical planar pattern.
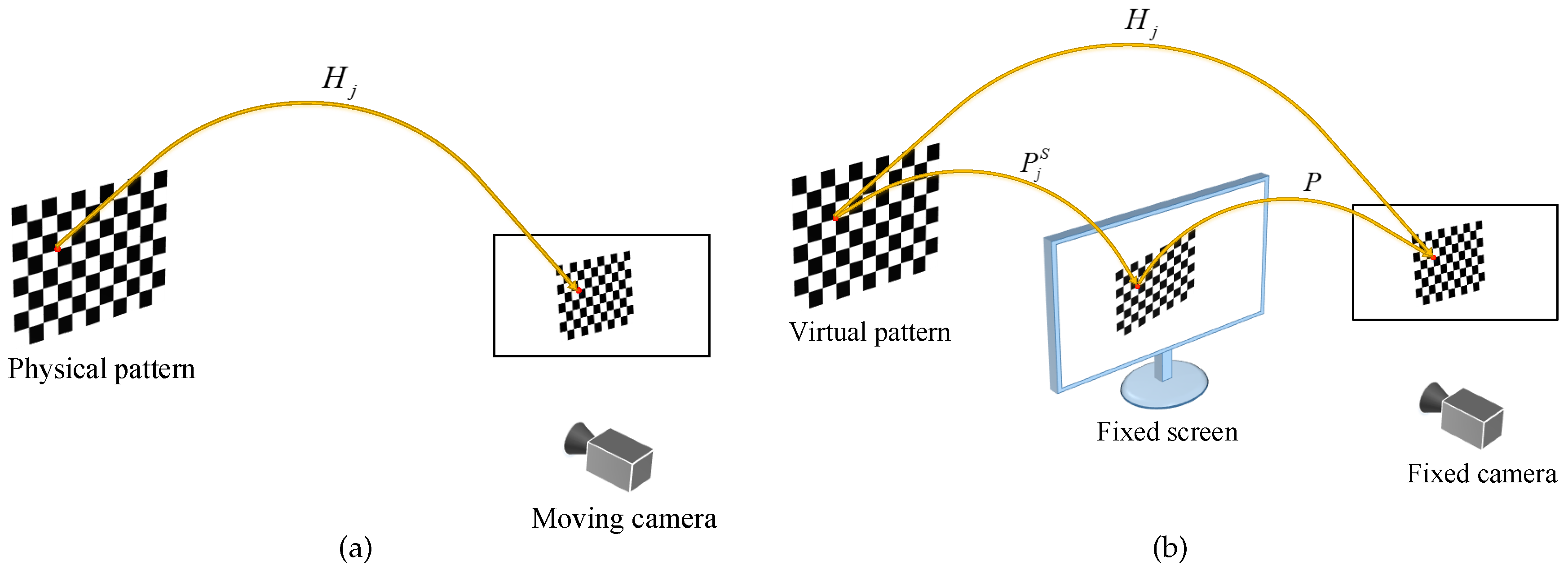
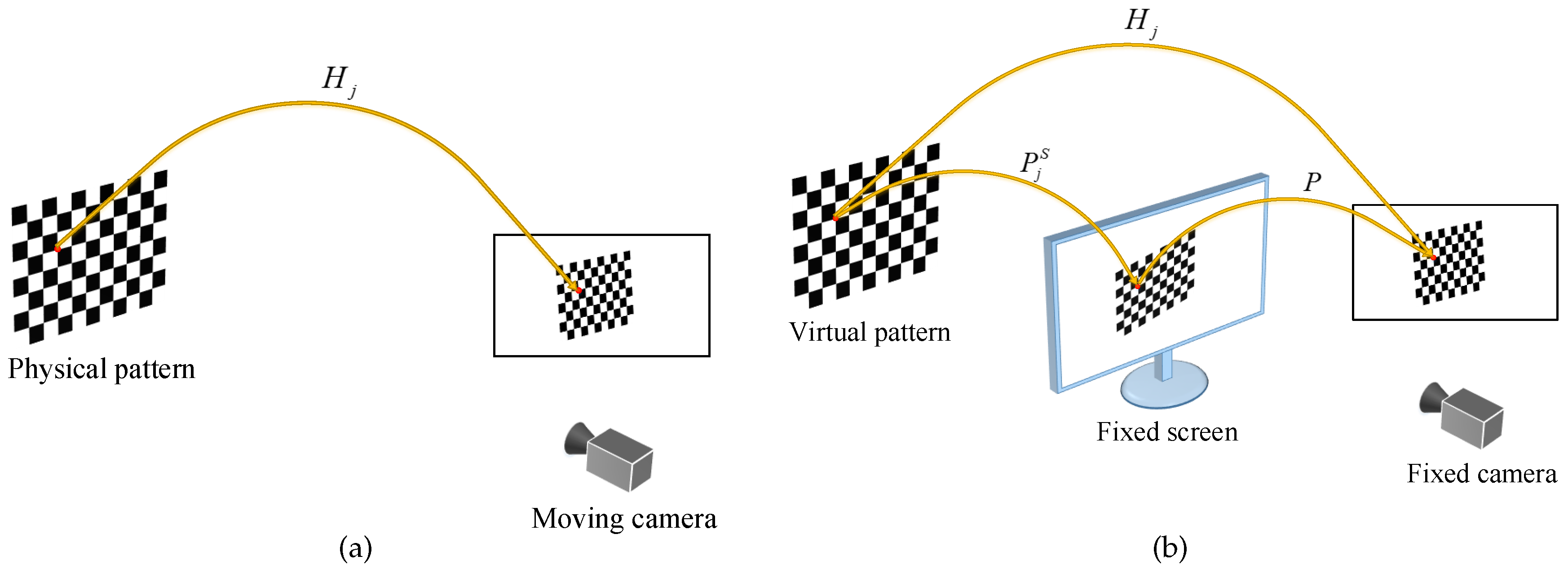
Figure 2a shows an overview where the camera is moved by hand to take the pattern images.
2.1. Basic Equations
Assume that
n 3D points are on a
plane and the plane is shot by a pinhole model camera with
m times. In a
j-th shot (
), the relation between a 3D point
(
) and its 2D projection
can be expressed by
where ∝ denotes equality up to scale,
is a
j-th
rotation matrix,
is a
j-th
translation vector, and
K is a
upper triangular matrix given by
with
the principal point,
s the skewness, and
the focal length for
x and
y axis.
The third column of
can be eliminated due to
. From Equation (
1), then we have
where
,
denotes the the
k-th column of
. Furthermore we can simplify this projection by using a
matrix
, called a homography matrix, is given by at least four point correspondences
and
[
1]. Multiplying
from the left side of Equation (
4) and using the orthogonality of
, we obtain two constraints for
K:
where
, and
denotes the
k-th column of
.
B is a
symmetric matrix and has a six components. However, the degrees of freedom is five due to the scale ambiguity.
2.2. Estimating Parameters
Equations (
5) and (
6) are linear to
B. Therefore, we can obtain
B by solving
where
V is a 2 m
matrix and
is a vectorization operator. Note that the dimension of
is six. In a general case, where all the intrinsic parameters are unknown,
observations are required for getting a unique solution of
. After getting
B,
K is extracted by decomposing
B. More details on estimating the intrinsic parameters are described in [
1] and [
18].
Once
K is known,
and
can be recovered as
with scale factor
. Because of noisy data,
derived from the above equation does not generally satisfy the properties of a rotation matrix. The best rotation matrix from a general
matrix can be estimated through singular value decomposition [
18].
2.3. Nonlinear Refinement
The estimated parameters above are not accurate because they are derived by linear methods based on the algebraic error without lens distortion. To refine the linear estimation, a nonlinear optimization is carried out by minimizing the re-projection error:
where
I is the
identity matrix, and
p is a projective function with lens distortion parameter
d.
3. Proposed Method
As shown in
Figure 2b, the proposed method uses a virtual calibration pattern instead of a physical one. The virtual pattern is transformed by some pre-generated parameters and projected onto a screen, then, the pattern on the screen is captured by a fixed camera. For stable calibrations, the virtual pattern is actively displayed on the screen and these pre-generated parameters ensure that all 2D projections of the corner points are uniformly distributed in the camera coordinates. The proposed method estimates the intrinsic and the extrinsic parameters from correspondences between the virtual world points and their 2D projections.
In contrast to the conventional method, the proposed method does not require moving either the camera or the pattern. Since the camera and the screen are fixed during the whole process, the proposed method can be implemented as a fully automatic calibration software.
3.1. Basic Equations
Let be the projection from the screen to the camera and be the projection from the virtual pattern to the screen where , , and are the screen’s intrinsic and j-th extrinsic parameters, respectively.
Then, the projection between a virtual world space 3D point
and a 2D image point
can be expressed by
where 0 is a
zero vector.
Let us consider the two projections separately. The first projection by
can be rewritten by
where
denotes the
k-th column of
, and
.
is the screen’s intrinsic parameters which are preset in the calibration, and
and
are the extrinsic parameters of the screen at the j-th capture in the calibration. Since the virtual pattern is transformed by pre-generated parameters,
and
are actually known. Also the second projection by
P can be rewritten by
Letting
be the
k-th column of
, and from Equations (14) and (16), we can write Equation (
11) by using a
homography:
where
Similarly to the conventional method, given virtual world space 3D points and their 2D image projections, homography
can be calculated using the same technique introduced in Zhang’s paper [
1]. However, we cannot extract constraints from Equation (
18) in the same way as Equations (
5) and (
6) since the form of
is not identical. The proposed method uses the ratio constraints of the vector dot product instead of the orthogonality.
Multiplying
from the left side of Equation (
18), we have three equations from the first and the second columns:
where
denotes the
k-th column of
. If we take a ratio from any two of the above equations, we can obtain one constraints. For example, picking Equations (
19) and (
20), we have
There are three possible combinations, but only two of them are linearly independent. Thus, we have two constraints by taking any two of them, e.g.,
with
. Note that
and
are known but only
B is unknown.
3.2. Estimating Parameters
As shown in Equations (
23) and (
24), we have two constraints from an
. Therefore, we can solve
B and extract
K in the same manner as the conventional method. On the other hand, a new approach is required for estimating the extrinsic parameters.
As soon as
K is computed, a linear method can be employed to solve the extrinsic parameters. Stacking
and
for
horizontally, we have
where
is a scaling factor.
Then, Equation (
25) can be linearly solved by
3.3. Nonlinear Refinement
Nonlinear refinement must be applied to the linear estimation for more accuracy. The nonlinear optimization for the proposed method can be written by
where
is the projection of point
onto the image,
denotes the lens distortion coefficients and all the screen parameters
,
, and
are known. In our implementation, this optimization is also solved by using the Levenberg- Marquardt algorithm [
19,
20].
Distortion coefficients are estimated based on Zhang’s method [
18] and included while minimizing Equation (
27). For simplicity, only the first two coefficients of radial distortion
and
are considered, since the distortion function is mainly dominated by the radial components, especially the first term [
2]. The relationship between the distortion-free pixel
and the distorted point
is presented by
where
. Readers can refer to [
3] for more details on lens distortion model and how to compensate lens distortion.
3.4. Summary
The procedure of the proposed method is very similar to the conventional one and includes the following steps:
Place the camera in front of the screen and adjust its position and orientation;
Fix the camera when the whole camera view is covered by the screen and it contains as much part of the screen as possible;
Take a few images of the screen while the virtual checkerboard is being transformed and displayed;
Detect the corner points in the images;
Estimate focal length
and
, principal point
, skewness
s, rotation matrix
R and translation vector
t using the closed-form solution as stated in
Section 3.2;
Refine intrinsic and extrinsic parameters, including lens distortion coefficients, by nonlinear optimization as described in
Section 3.3.
4. Experiments and Discussion
To demonstrate the validity and robustness of the proposed method, experiments on both synthetic data and real data have been conducted.
4.1. Experiment Setup
Before starting the calibration, the camera to be calibrated needs to be setup to ensure that the whole camera view is covered by a screen. To start with, the screen is placed within the working distance of the camera and the camera is looking straight to the screen. Ideally, using a screen with appropriate size and let the optical axis of a camera cross vertically with the screen at the center, the aforementioned condition should be satisfied. This setup may not work for a real camera, since its principal point is usually not at the center of the image. Also a real camera has lens distortion. Therefore, we still need to manually adjust the orientation and position of the camera, and fix the camera until its entire image is covered by the screen.
Then, a set of parameters about orientation and position are generated. They are used to transform the virtual pattern in the experiments. The orientation of the pattern is generated as follows: the pattern is parallel to the screen at first; a rotation axis is randomly chosen from a uniform sphere; the pattern is then rotated around that axis with an arbitrary angle
between
and
. The reason for choosing
in that range is because it achieves the best performance according to the experimental results in [
18]. The position of the pattern can be expressed by the 3D coordinate of its center point
in the screen’s coordinates. In order to generate appropriate position for the pattern, following scheme is adopted. The pattern and the screen are initially on the same plane, and the center of the pattern coincides with the center of the screen. The pattern is then moved along the positive direction of
Z axis. When the projection of the pattern on the screen is about 1/4 size of the screen, the value of
z is fixed. The value of
x and
y are determined by randomly choosing points on the plane
, within the screen’s field of view. If given enough number (≥20) of patterns, all the 2D projections of the corner points should scatter all over the image and the uniform distribution is achieved.
4.2. Experiment on Synthetic Images
In the computer simulation, a simulated camera is created with the following intrinsic parameters:
,
,
= 942,
= 547,
,
= −0.0806,
= −0.0393. The screen which has
resolution can be described using ideal pinhole model with 2500 (in pixels) focal length, and the principal point is located at the center of the screen. The virtual checkerboard contains
= 160 corner points, and each square has 100 units per side. To investigate the performance of the proposed method regarding the noise level and the number of images of the calibration pattern, the following two experiments are designed and conducted. The method used for corner detection in the experiments is the method developed by Vezhnevets Vladimir, which is also integrated in OpenCV [
21].
Performance regarding the noise level. To start with, virtual patterns with 20 different orientations and positions are synthesized. Then noisy images are created by adding Gaussian noise with a mean of
and a standard deviation of
to the projected image points. The noise level varies from
to
. For each noise level, our method is tested with 100 independent trials and assessed by comparing the results with the ground truth.
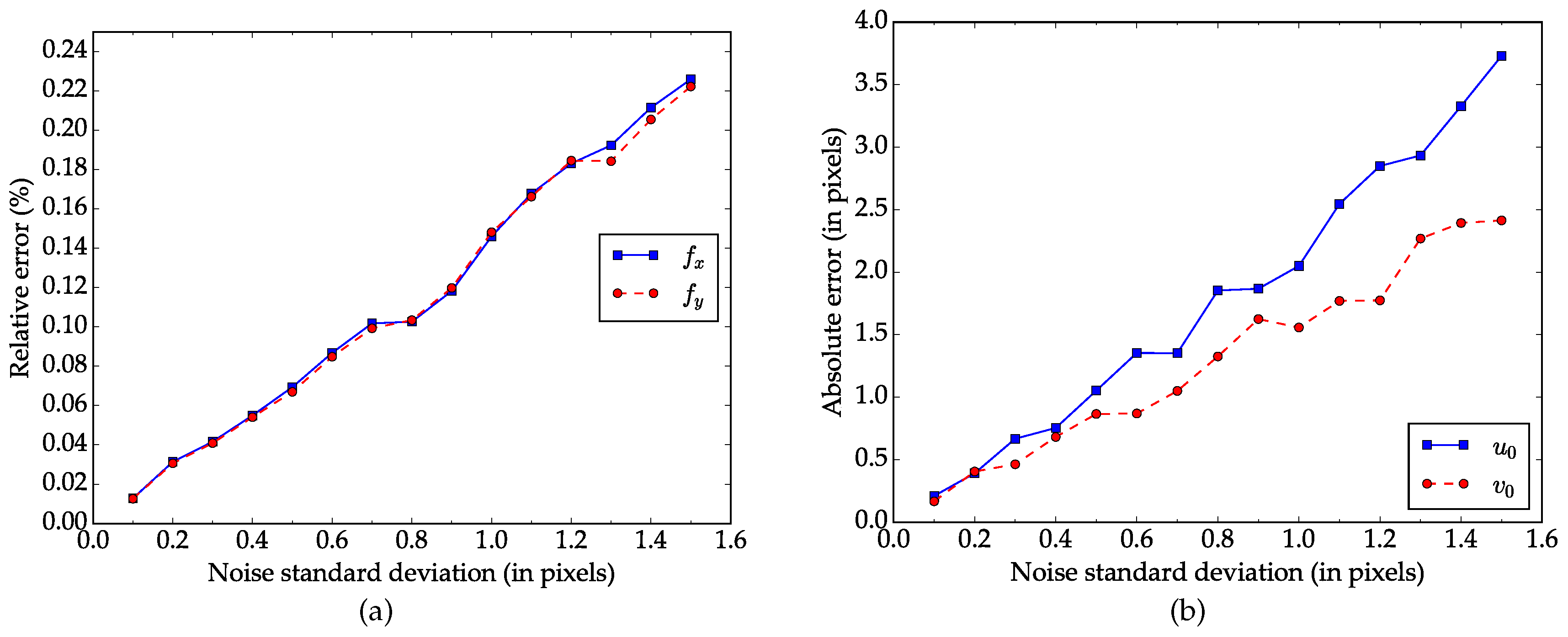
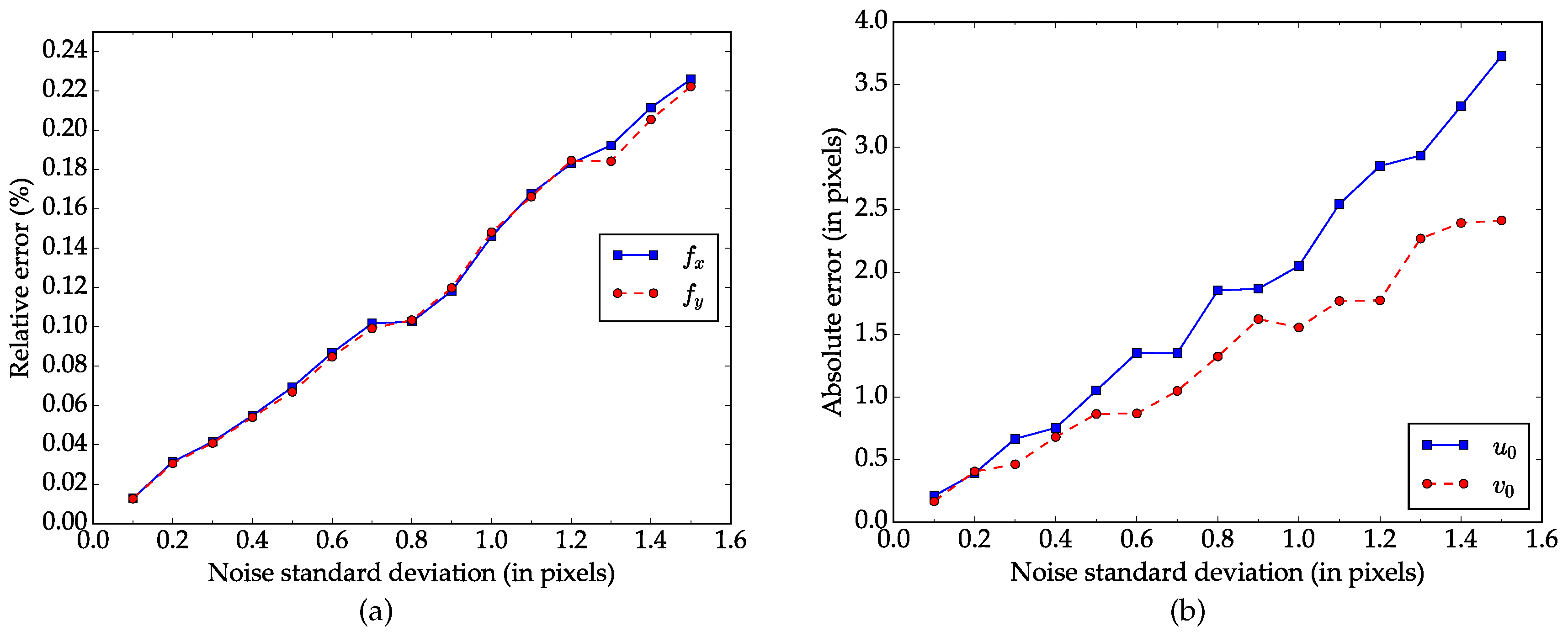
Figure 3a,b show the relative error for focal length and absolute error for principal point respectively. As we can see in
Figure 3, the average errors increases as the the noise level rises and the relationship between them is almost linear. When the noise level increases to
, which is larger than the normal noise in practical calibration [
18], the relative errors in focal length
and
are less than
, and the absolute errors in principal point
and
are around 1 pixel.
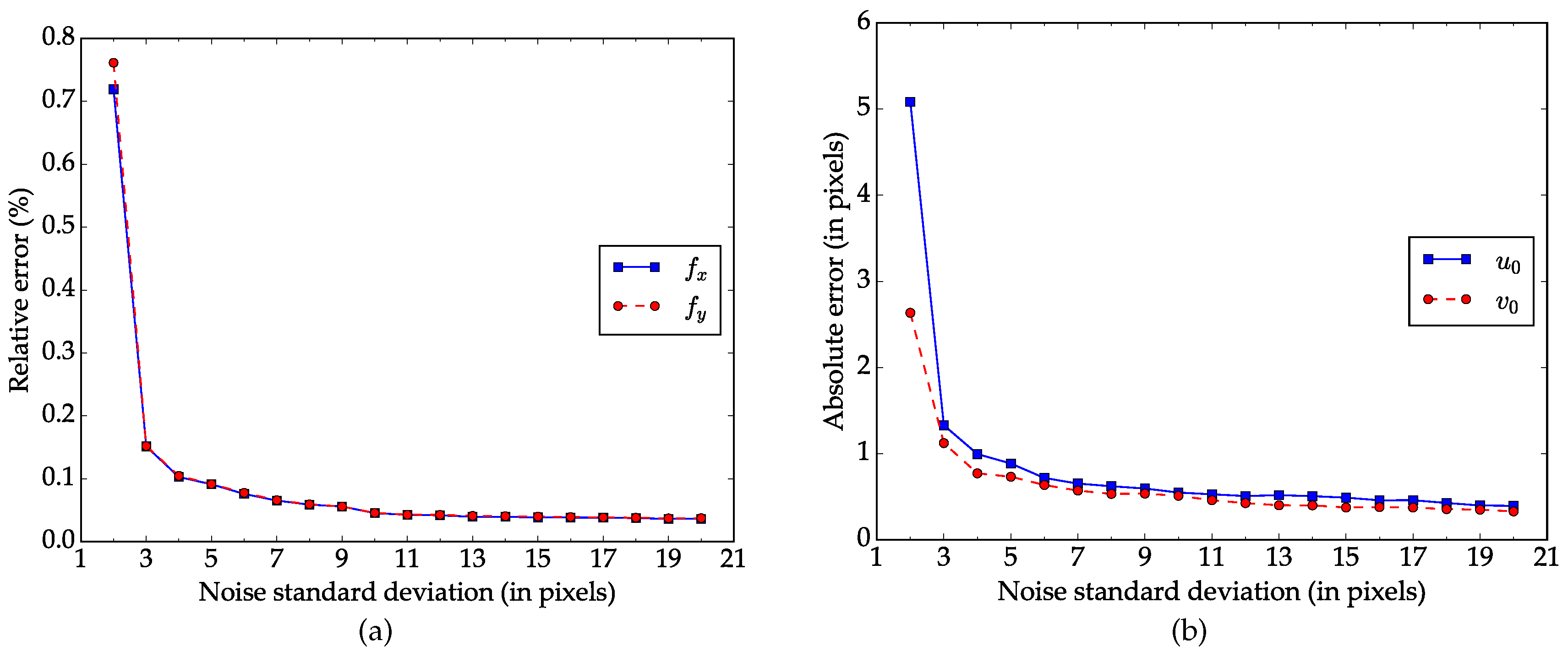
Performance regarding the number of images. This experiment is designed to explore how the number of images of the calibration pattern impacts the performance of our method. Starting from two, we increase the number of images by one each time until it reaches twenty. For each number, Gaussian noise(
,
) is first added to the images, calibration is then conducted with these independent images for 100 times. The errors are calculated based on the calibration results and ground truth data as in the previous experiment. The mean values of the errors are shown in
Figure 4. The errors decrease and tend to be stable as the number of image increases. Note that the errors decrease significantly when the number increases from 2 to 3.
4.3. Experiments on Real Images
To test our method on real images, we use a 24 inch LCD monitor to display the virtual pattern. Parameters of the screen and the virtual pattern are the same as in the computer simulation. The camera to be calibrated is the color camera of a Microsoft Kinect for Windows V2 sensor. As shown in
Figure 5, the camera is fixed approximately 40 cm away from the screen using a tripod, looking straight to the screen, so that the whole camera view is covered by the screen. Ten independent trials are performed with images of
resolution. In each trial, virtual pattern is transformed using parameters randomly chosen from the synthetic data and shown on the monitor. Meanwhile, the screen is captured by a real camera and 20 different images are used in each calibration.
Figure 6a shows sample images captured in this experiment. The images are collected automatically by computer program, and the screen and the camera are fixed during the whole process. We use the same method as in the synthetic experiments for corner detection.
In comparison, we also calibrated the real camera using a physical checkerboard. The pattern is printed by a high-quality printer and attached to a glass board with guaranteed flatness. It contains the same number of squares as the virtual pattern, and each square is 15 mm × 15 mm. The camera is fixed by a tripod, and images are collected while the checkerboard is being manually moved. A sample images used in this experiment is shown in
Figure 6b. Ten independent trials are performed, with 20 images each time.
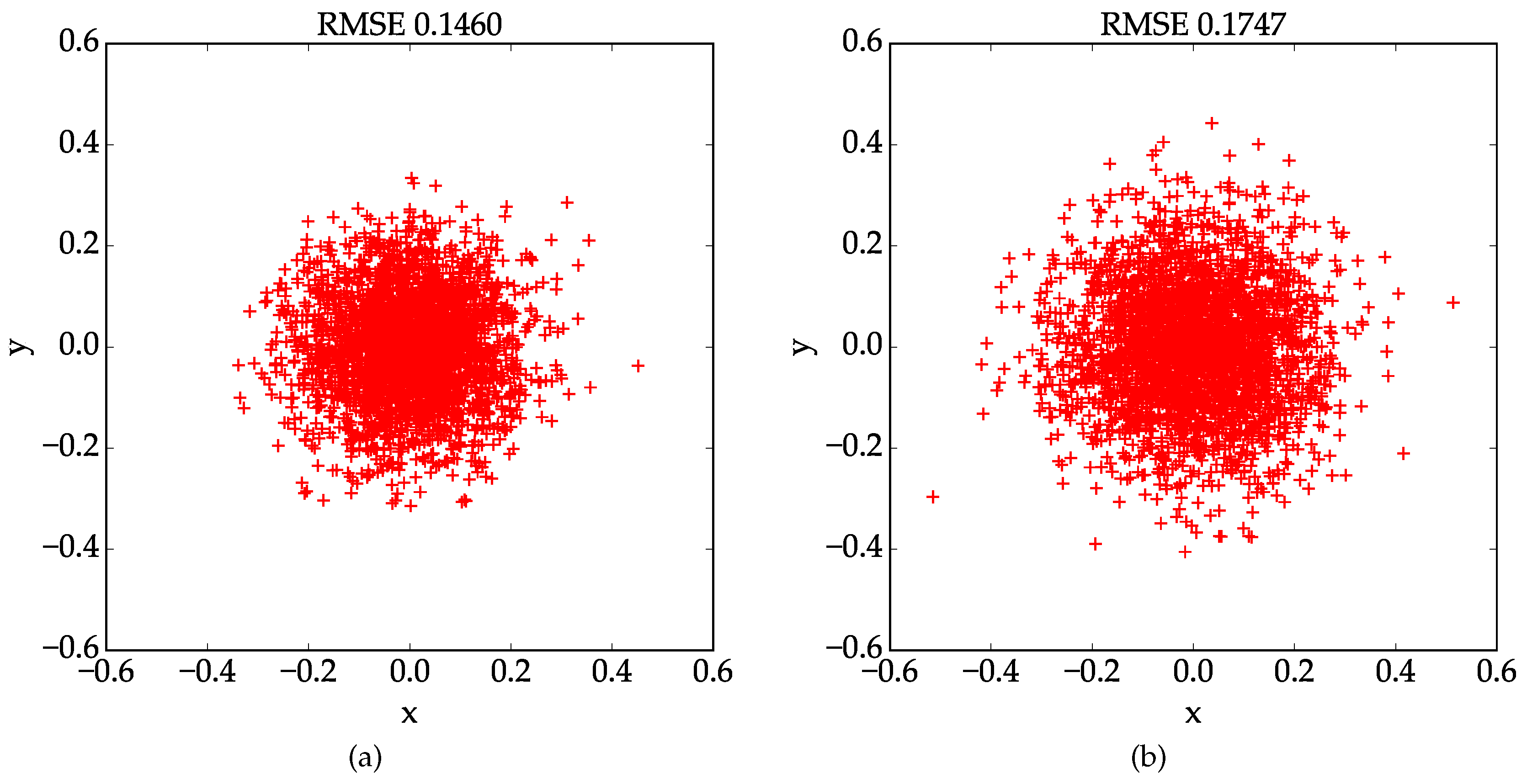
Explicit calibration experiments results are reported in
Table 1 and
Table 2. For the first 10 lines in the tables, each line shows the result obtained in an independent trial, which are the 6 camera parameters and the root mean square error( RMSE). Here, the RMSE is defined as the root mean square distance between every detected corner point and the re-projected one using the estimated parameters. The mean and standard deviation values of the estimated parameters are listed in the last two lines. As we can see in
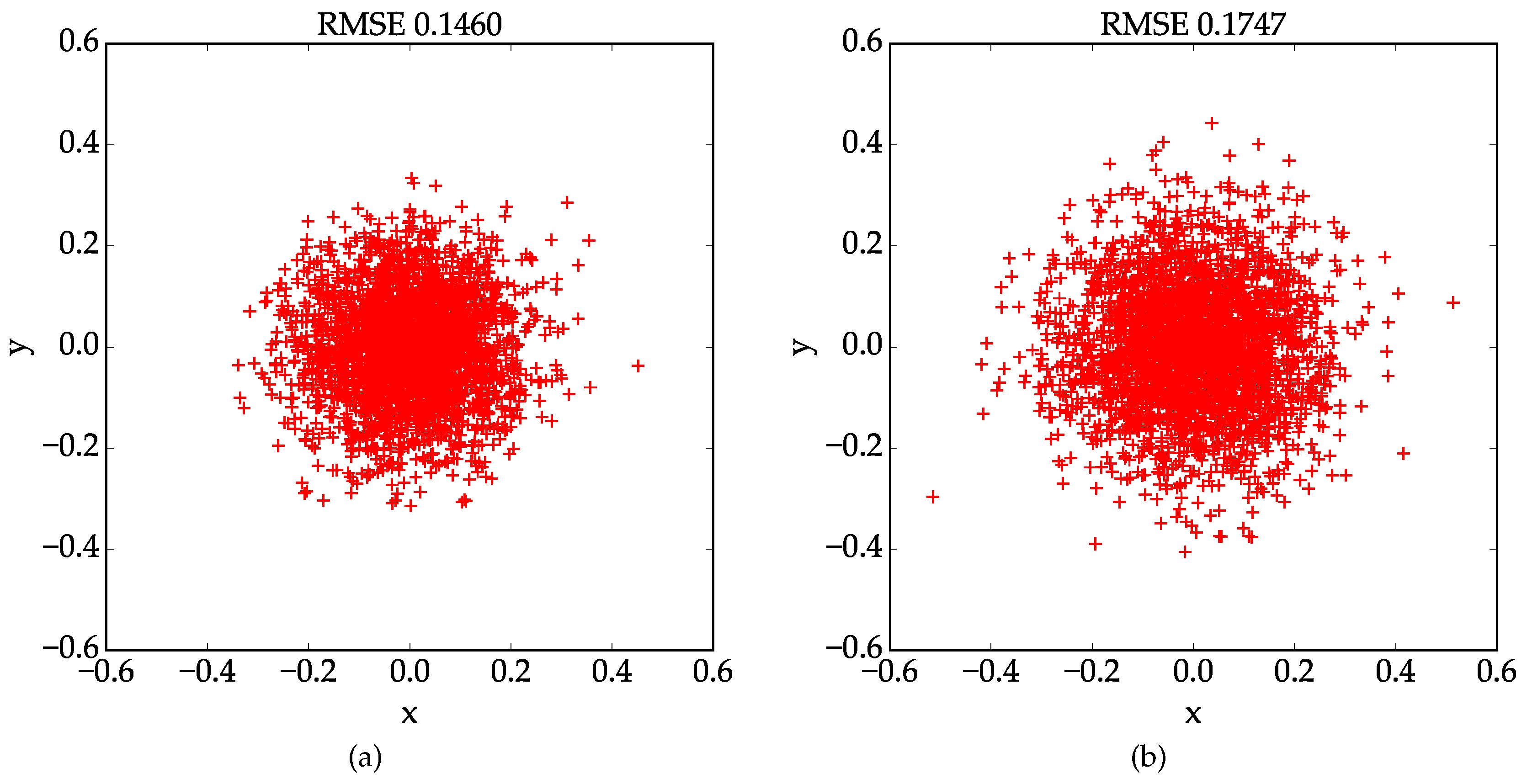
Table 1, results obtained using the proposed method are very consistent with each other and the standard deviations for all parameters are pretty small, which suggests that our method is very robust. Contrarily speaking, performance of the conventional results are not as stable as the proposed one. Since we don’t have ground truth data of the real world experiment, the camera parameters estimation result is evaluated based on re-projection error. With the proposed method and the conventional one, the mean value of the RMSE are 0.1855 and 0.2337 pixels, respectively. And the lowest RMSE, which is 0.1460, is achieved by the proposed method. We choose the best calibration results obtained by our method and the conventional method, and plot the localization errors of the control points in
Figure 7. The results indicate that the proposed method outperforms the conventional one in terms of stability and accuracy in real world experiments.
4.4. Discussion
The above experiments show not only the practicality but also the advantage of the proposed method. In conventional calibration method, a key step is to capture images while manually moving a physical calibration pattern. Usually, this step takes as long as several minutes. In contrast, our method takes much less time to prepare calibration pattern and collect high quality data, and the whole procedure is done fully automatically within one minute.
The use of virtual pattern affects the calibration result in the following aspects. First, virtual pattern is transformed by computer program so that all the control points are uniformly distributed in the image. Well distributed points usually lead to more stable and accurate calibration result. Second, since the screen is fixed in the calibration, image blur caused by motion can be eliminated, therefore, control points can be more precisely localized. Otherwise, in a blurry image which is taken by a moving camera like
Figure 8, the observed feature location in the image may deviate from the actual feature location. Even though the checkerboard patten can be detected by some algorithms (e.g., OpenCV’s checkerboard detection algorithm [
21]), uncertainty in the localizations of the control points yields incorrect correspondences which lead to performance degradation of the calibration.
However, the proposed method also shows some limitations. An essential requirement of this method is that the entire camera view has to be covered by a screen. In some cases, it is difficult to satisfy the above requirement. For a camera with large working distance or wide field of view, it is necessary to use a large size screen, e.g., flat screen TV, to cover the entire image of the camera. However, screen size cannot be increased without limitation, our method may not be applicable if the camera has very large working distance or very wide field of view. The proposed method also does not work in some certain applications, such as high precision visual measurement, where the camera to be calibrated has very short working distance or very high resolution. In this case, the resolution of the camera is usually higher than that of the screen. Hence the image of a screen is discretized, and corner point detection and localization can be a problem. Although the effect of discretization can be reduced by using high resolution screen, it still affects the accuracy of calibration unless it is completely eliminated.
5. Conclusions
The conventional calibration technique using a 2D planar object is widely used due to its ease of use. Although many efforts have been focused on making the whole calibration procedure as automatic as possible, there is still a manual part at the capture step which takes a lot of time and makes the result unstable. In this paper, we proposed a full-automatic method for camera calibration to resolve the issues brought about by manual operations. Different from the conventional method, we use a virtual pattern which is transformed in the virtual world coordinates and projected on a fixed screen. The pattern shown on the screen is then captured by a fixed camera. Calibration is performed by using point correspondences between the virtual 3D points and their 2D projections, and the solution to camera parameters estimation is very similar to the conventional method.
Owing to the use of virtual pattern, there is no need to manually adjust the position and orientation of the checkerboard during calibration. Moreover, the virtual pattern can be actively displayed on the screen so that all corner points are uniformly distributed. Once the camera and the screen are set up, they are fixed during the whole calibration process. Thus, the proposed method can be fully automatic and the problems caused by manual operation are resolved without loss of usability. Experimental results show that our method is more robust and accurate than the conventional method.
Acknowledgments
This work has been supported by National Natural Science Foundation of China (Grant No. 61573134, 61573135), National Key Technology Support Program (Grant No. 2015BAF11B01), National Key Scientific Instrument and Equipment Development Project of China (Grant No. 2013YQ140517), Key Research and Development Project of Science and Technology Plan of Hunan Province(Grant No. 2015GK3008), Key Project of Science and Technology Plan of Guangdong Province(Grant No. 2013B011301014).
Author Contributions
The paper was a collaborative effort between the authors. Lei Tan, Yaonan Wang and Hongshan Yu proposed the idea of the paper. Lei Tan and Jiang Zhu implemented the algorithm, designed and performed the experiments. Lei Tan and Hongshan Yu analyzed the experimental results and prepared the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Tsai, R.Y. A Versatile Camera Calibration Technique for High-Accuracy 3D Machine Vision Metrology Using Off-the-Shelf TV Cameras and Lenses. IEEE J. Robot. Autom. 1987, 3, 323–344. [Google Scholar] [CrossRef]
- Heikkila, J.; Silven, O. A four-step camera calibration procedure with implicit image correction. In Proceedings of the 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PuertoRico, 17–19 June 1997; pp. 1106–1112. [Google Scholar]
- Chen, Q.; Wu, H.; Wada, T. Camera calibration with two arbitrary coplanar circles. In Computer Vision-ECCV 2004; Springer: New York, NY, USA, 2004; pp. 521–532. [Google Scholar]
- Bergamasco, F.; Cosmo, L.; Albarelli, A.; Torsello, A. Camera calibration from coplanar circles. In Proceedings of the 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 2137–2142. [Google Scholar]
- Agrawal, M.; Davis, L.S. Camera calibration using spheres: A semi-definite programming approach. In Proceedings of the 2003 Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1–8. [Google Scholar]
- Wong, K.Y.K.; Zhang, G.; Member, S.; Chen, Z. Calibration Using Spheres. Image 2011, 20, 305–316. [Google Scholar]
- Caprile, B.; Torre, V. Using vanishing points for camera calibration. Int. J. Comput. Vis. 1990, 4, 127–139. [Google Scholar] [CrossRef]
- Radu, O.; Joaquim, S.; Mihaela, G.; Bogdan, O. Camera calibration using two or three vanishing points. In Proceedings of the 2012 Federated Conference on Computer Science and Information Systems (FedCSIS), Wroclaw, Poland, 9–12 September 2012; pp. 123–130. [Google Scholar]
- Li, B.; Heng, L.; Koser, K.; Pollefeys, M. A multiple-camera system calibration toolbox using a feature descriptor-based calibration pattern. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1301–1307. [Google Scholar]
- Moreno, D.; Taubin, G. Simple, accurate, and robust projector-camera calibration. In Proceedings of the 2012 2nd International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 464–471. [Google Scholar]
- Raposo, C.; Barreto, J.P.; Nunes, U. Fast and accurate calibration of a kinect sensor. In Proceedings of the 2013 International Conference on 3DTV-Conference, Seattle, WA, USA, 29 June–1 July 2013; pp. 342–349. [Google Scholar]
- Rufli, M.; Scaramuzza, D.; Siegwart, R. Automatic detection of checkerboards on blurred and distorted images. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3121–3126. [Google Scholar]
- Donné, S.; De Vylder, J.; Goossens, B.; Philips, W. MATE: Machine Learning for Adaptive Calibration Template Detection. Sensors 2016, 16, 1858. [Google Scholar] [CrossRef] [PubMed]
- Pilett, J.; Geiger, A.; Lagger, P.; Lepetit, V.; Fua, P. An all-in-one solution to geometric and photometric calibration. In Proceedings of the 2006 Fifth IEEE/ACM International Symposium on Mixed and Augmented Reality, Santa Barbar, CA, USA, 22–25 October 2006; pp. 69–78. [Google Scholar]
- Atcheson, B.; Heide, F.; Heidrich, W. CALTag: High Precision Fiducial Markers for Camera Calibration. Vis. Model. Vis. 2010, 10, 41–48. [Google Scholar]
- Oyamada, Y. Single Camera Calibration using partially visible calibration objects based on Random Dots Marker Tracking Algorithm. In Proceedings of the IEEE ISMAR 2012 Workshop on Tracking Methods and Applications (TMA), Atlanta, GA, USA, 5–8 November 2012. [Google Scholar]
- Zhang, Z. A Flexible New Technique for Camera Calibration; Technical Report MSR-TR-98-71; Microsoft Research: Redmond, WA, USA, 1998. [Google Scholar]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef]
- Vezhnevets, V. OpenCV Calibration Object Detection, Part of the Free Open-Source OpenCV Image Processing Library. Available online: http://graphicon.ru/oldgr/en/research/calibration/opencv.html (accessed on 20 December 2016).
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}