
Training Classifiers with Shadow Features for Sensor-Based Human Activity Recognition



Abstract
:1. Introduction
2. Related Work
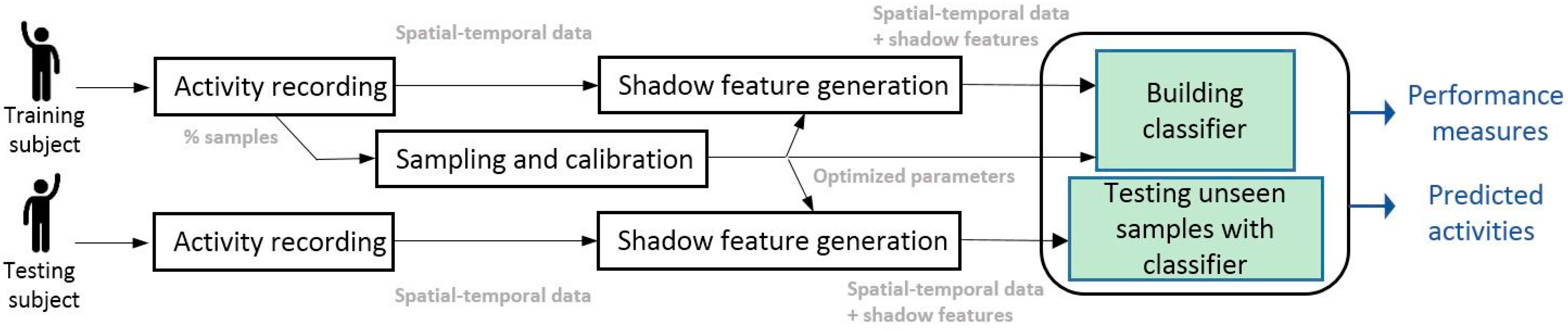
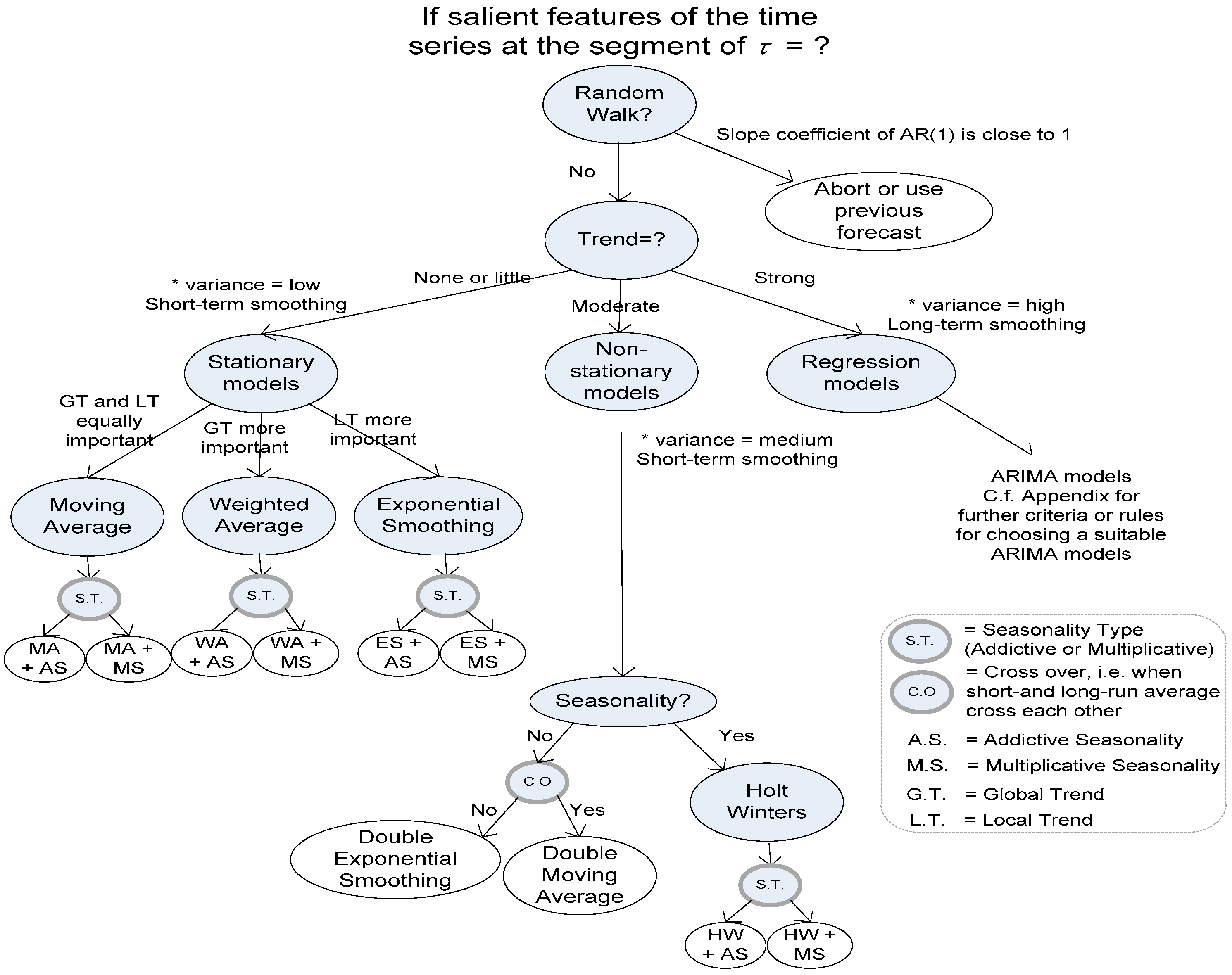
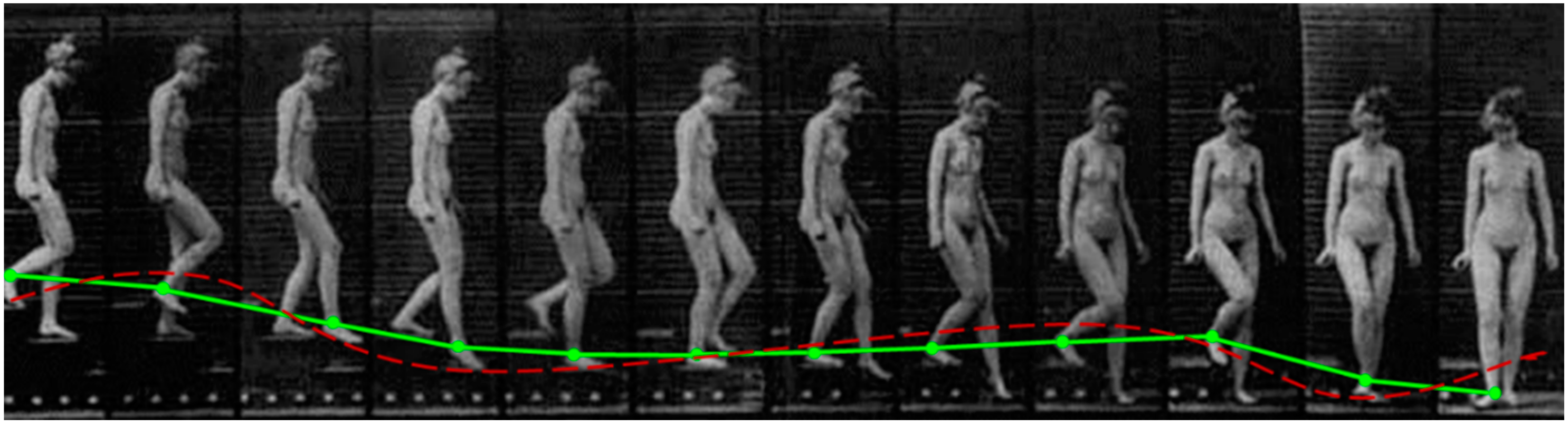
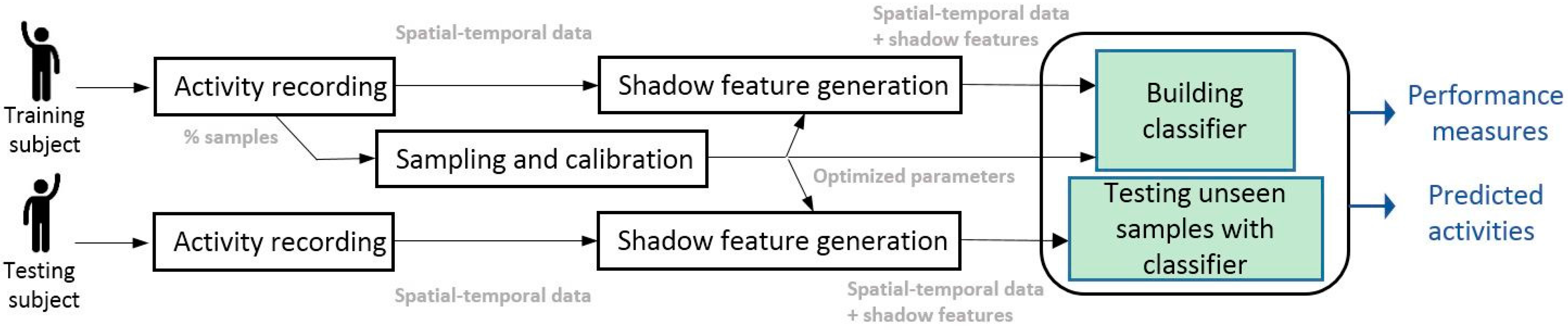
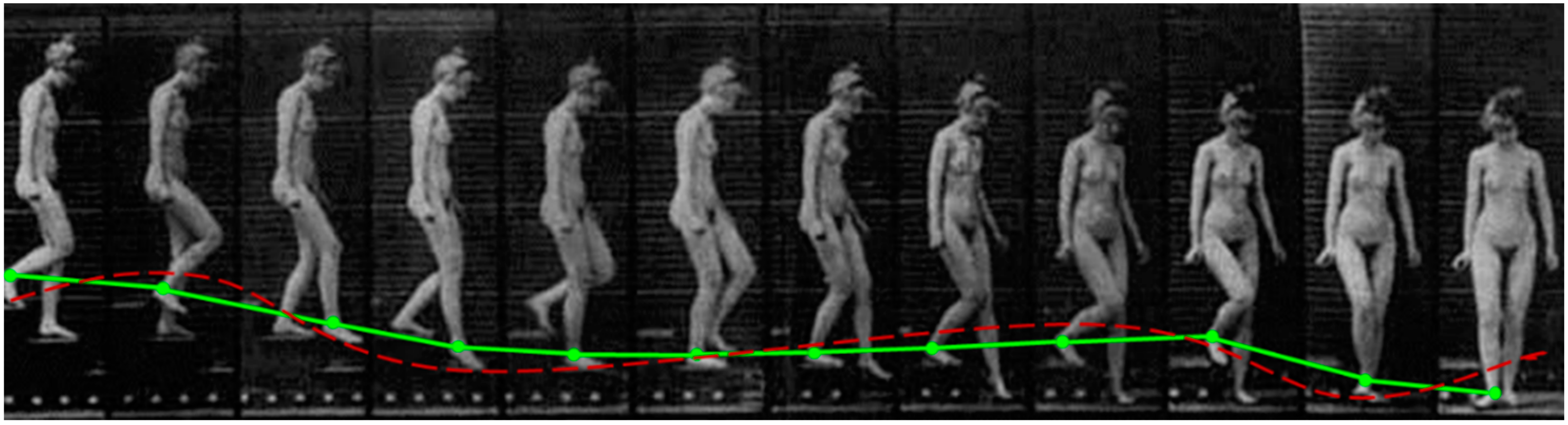
3. Proposed Shadow Feature Classification Model
New Classification Model
4. Experiments
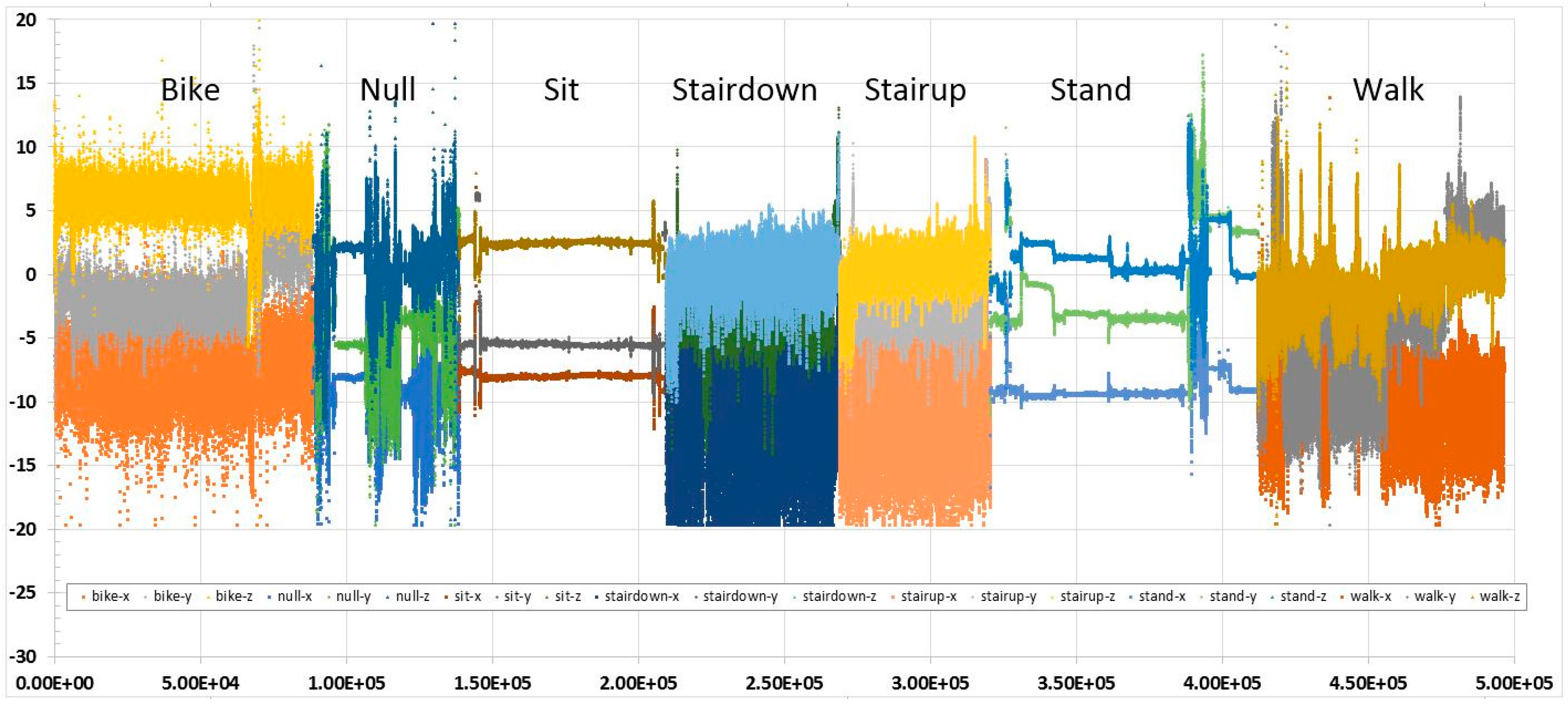
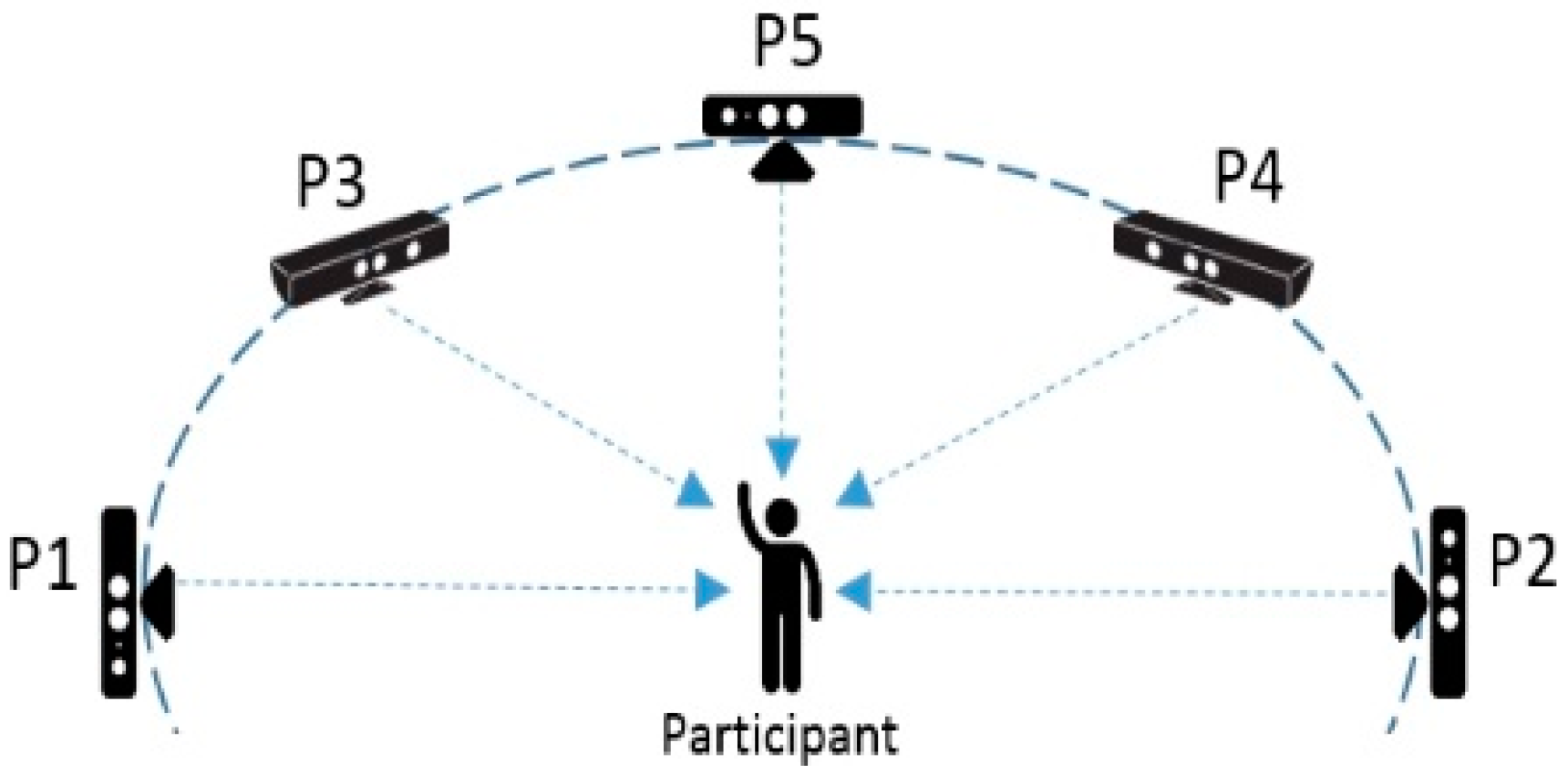
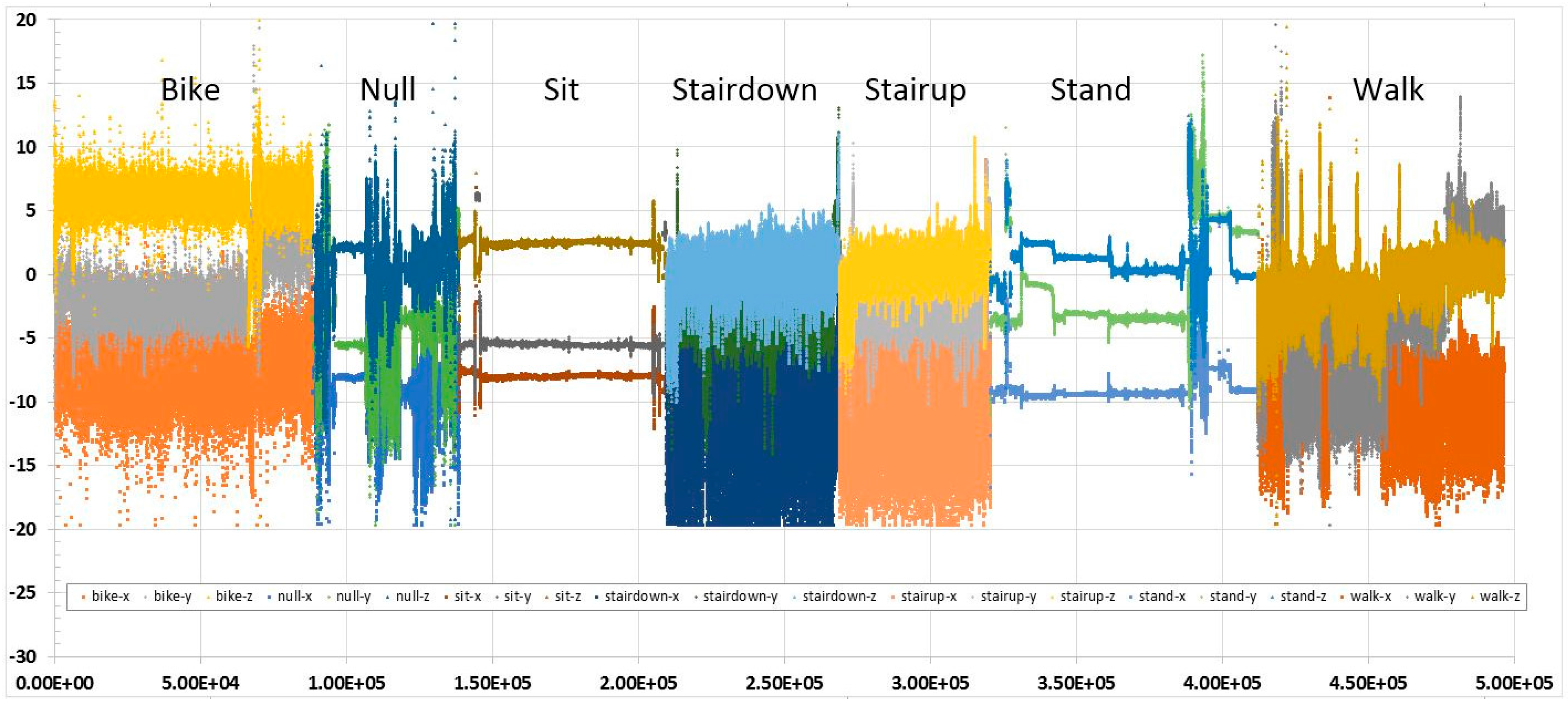
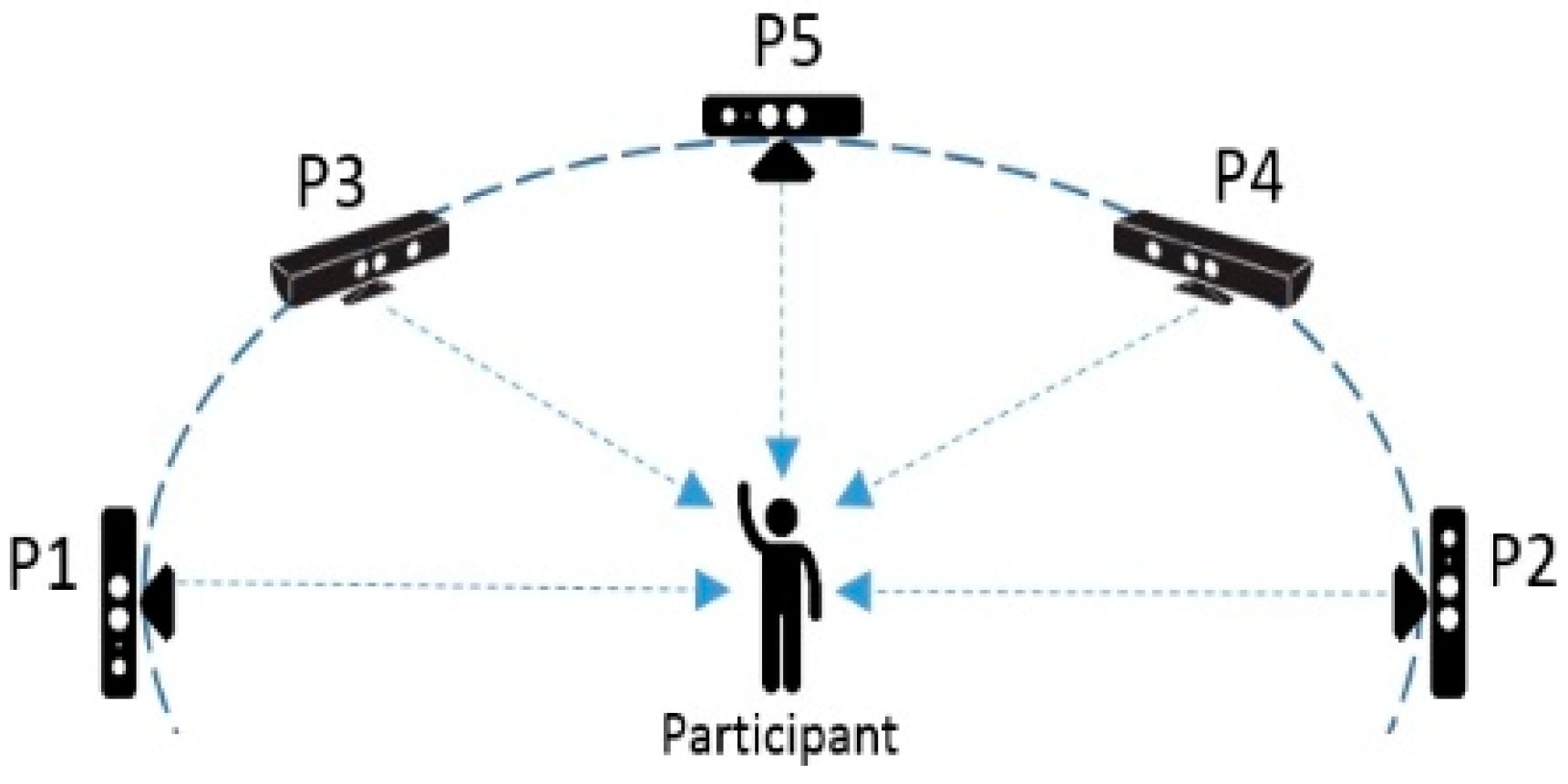
4.1. Data Sets and Experiment Setups
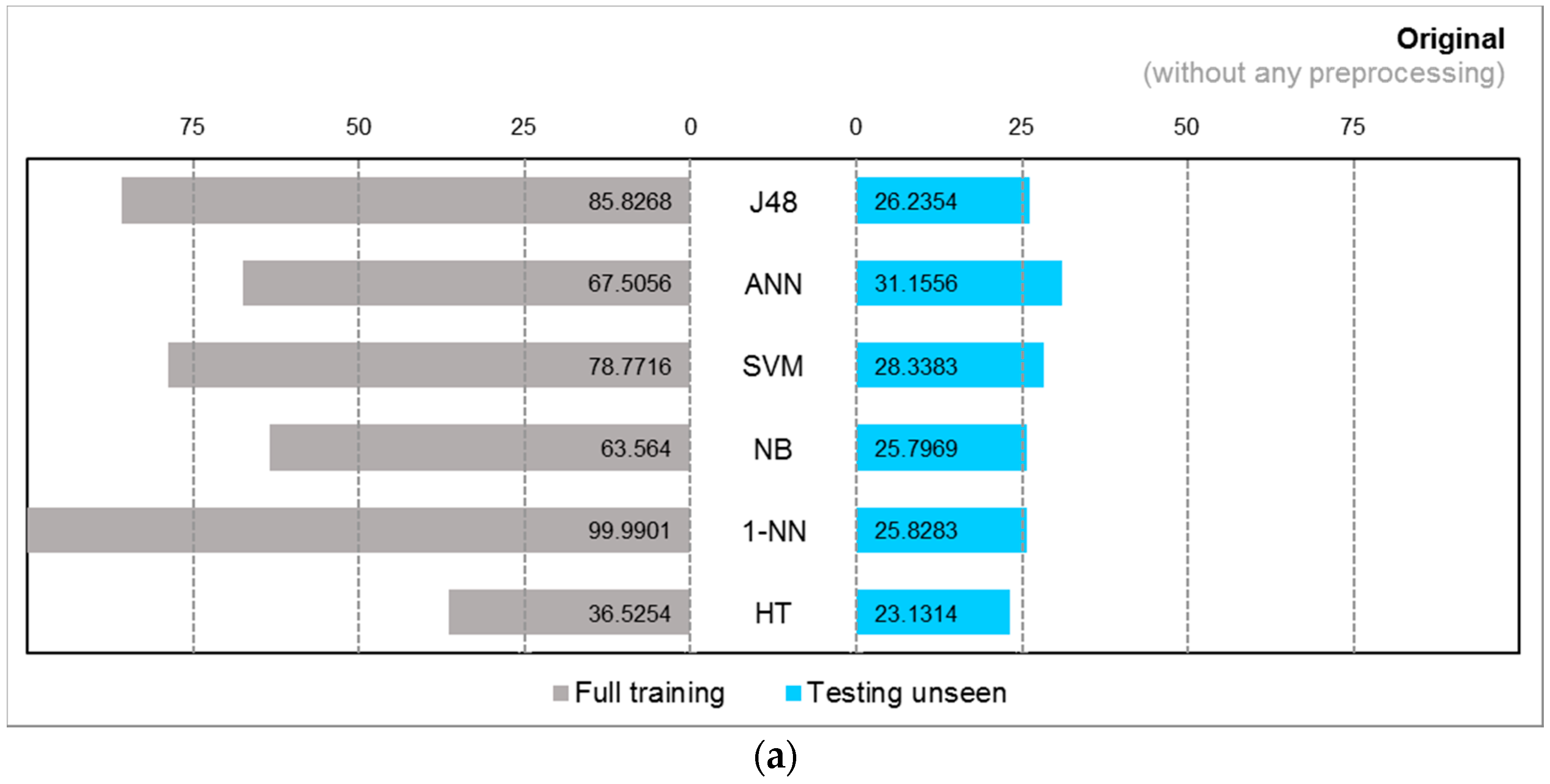
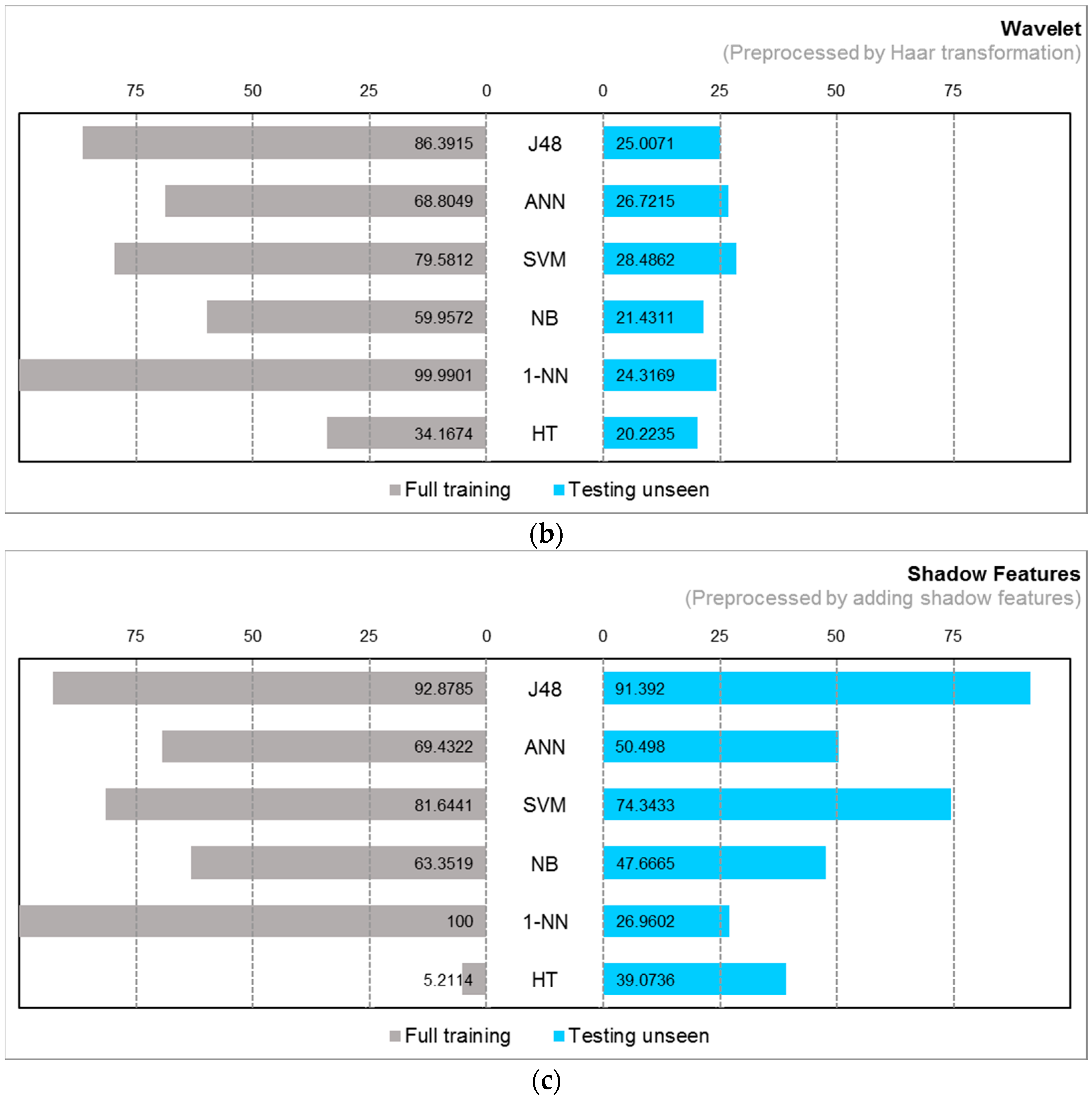
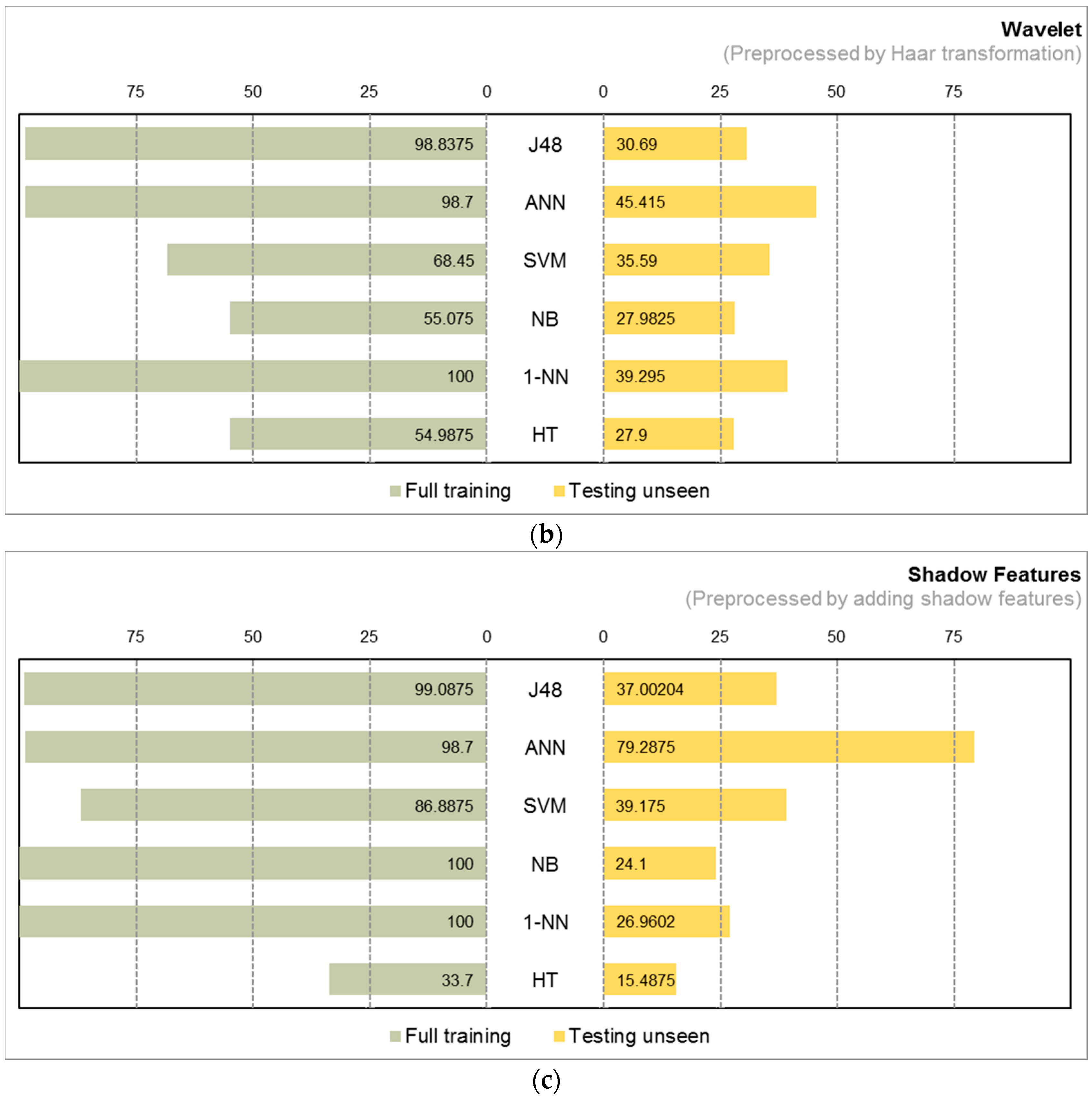
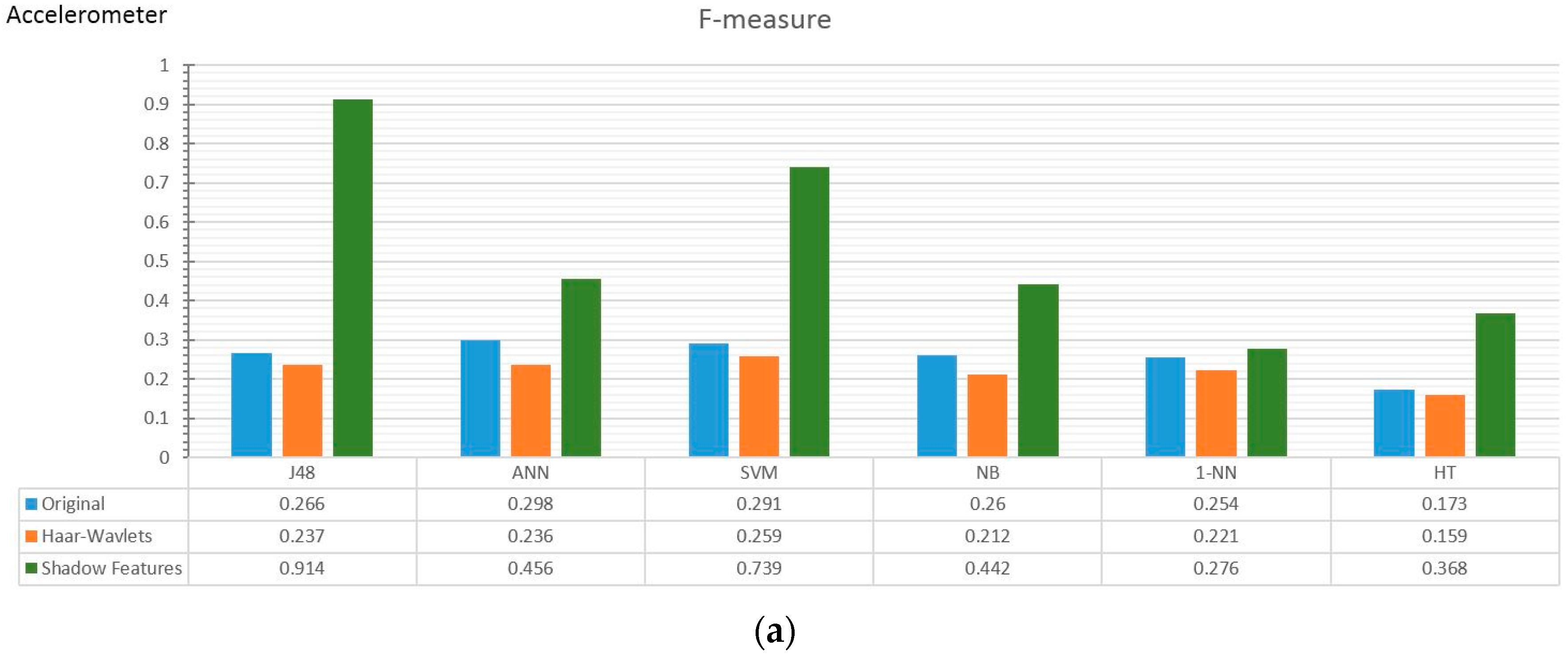
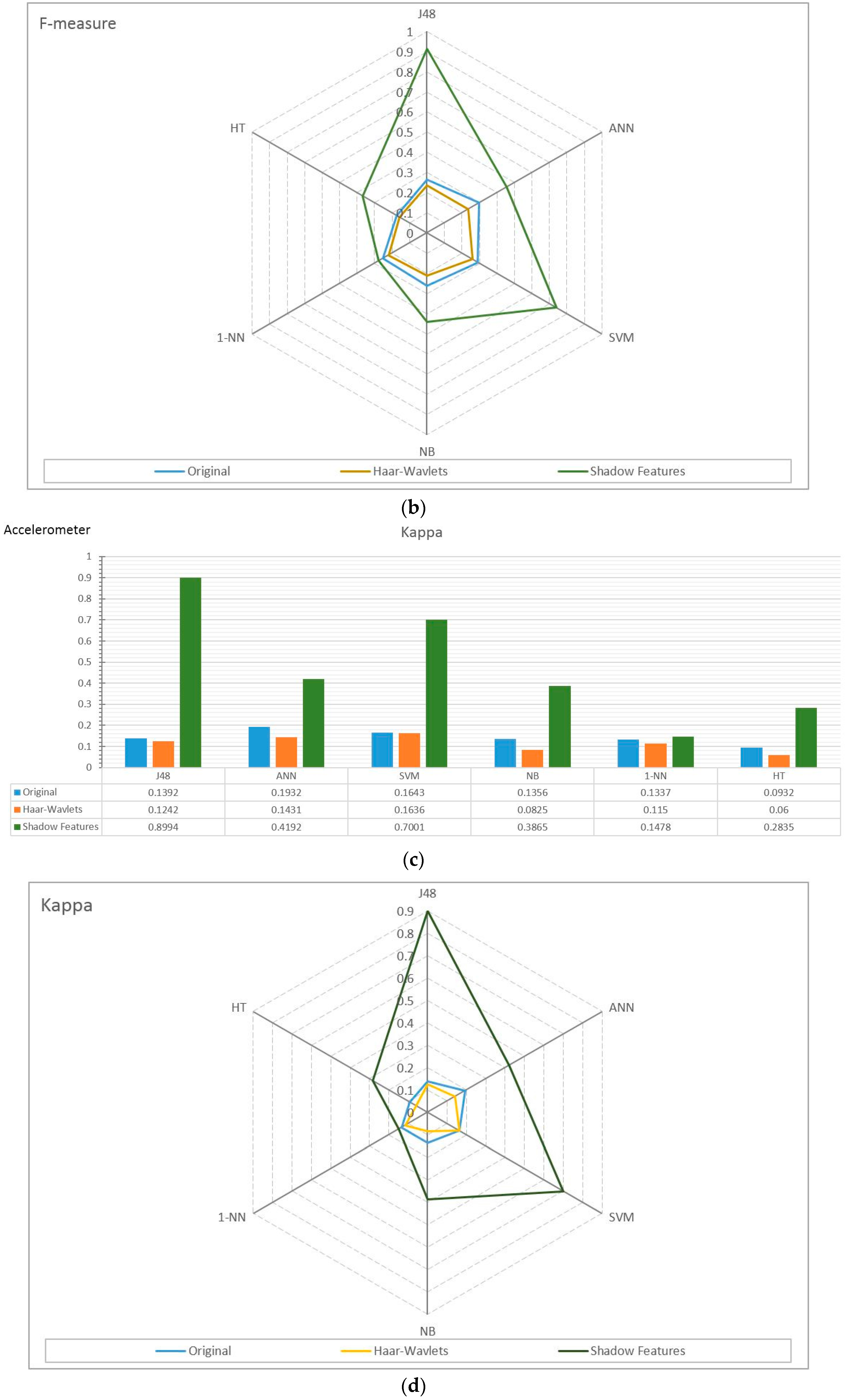
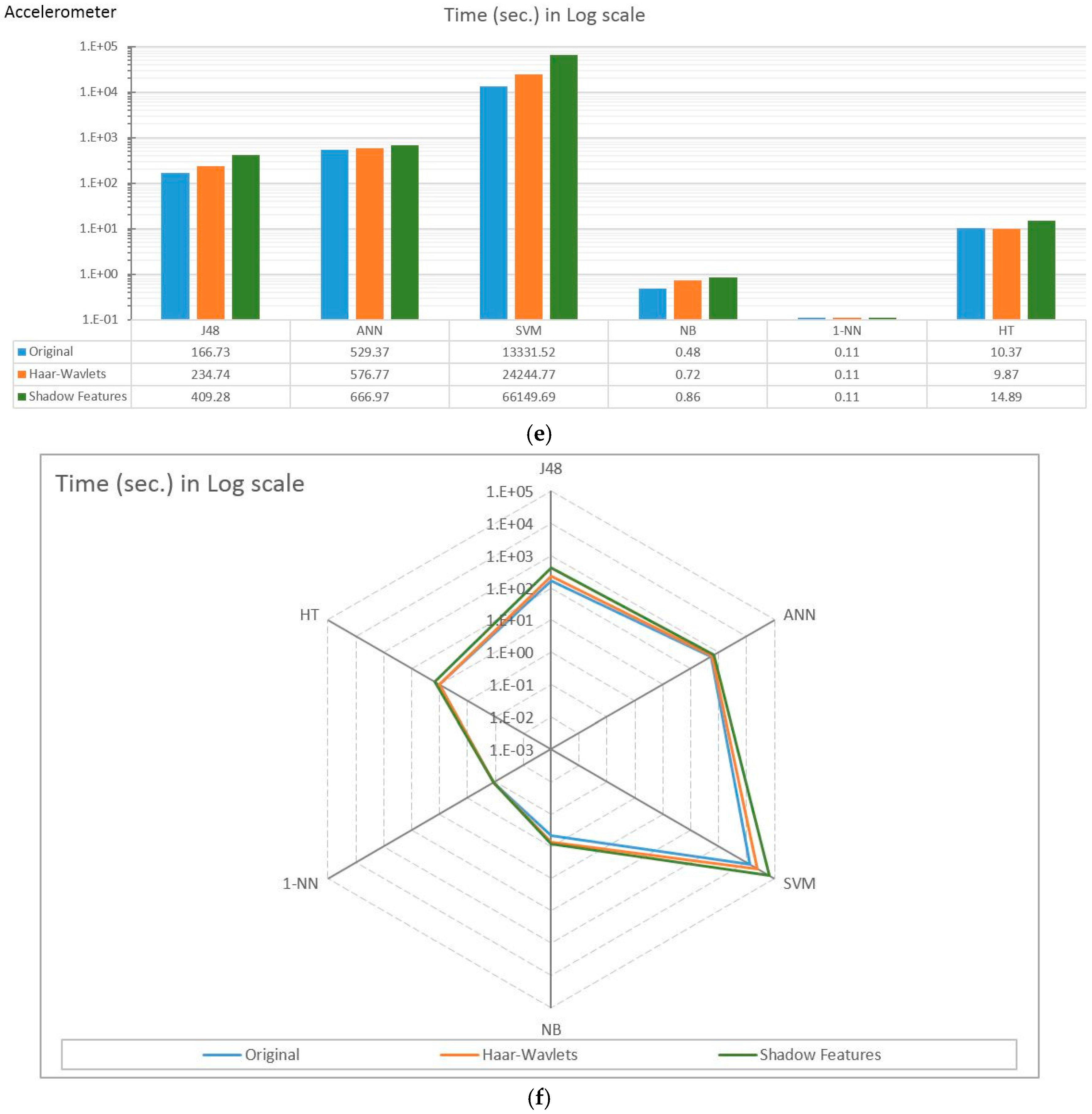
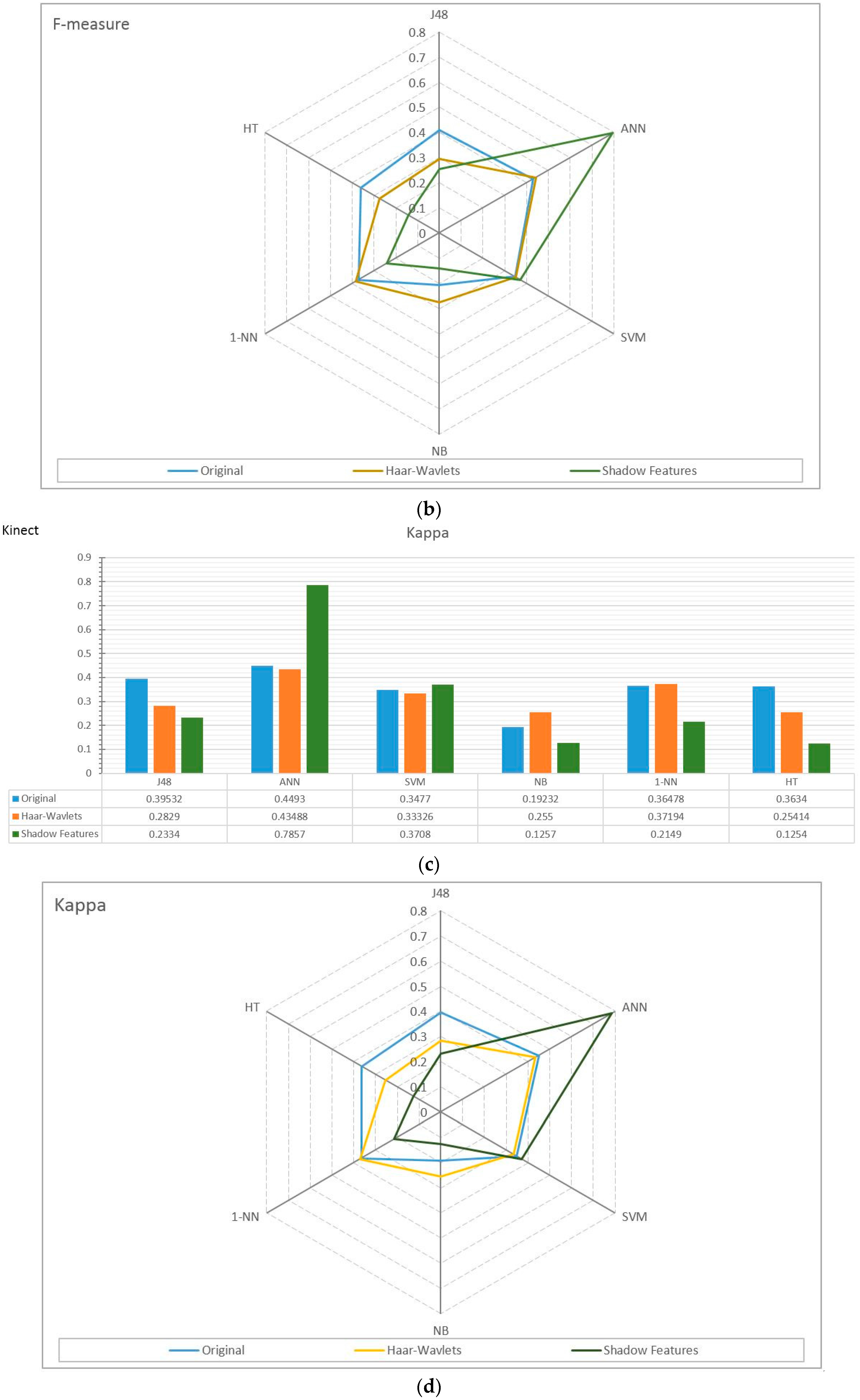
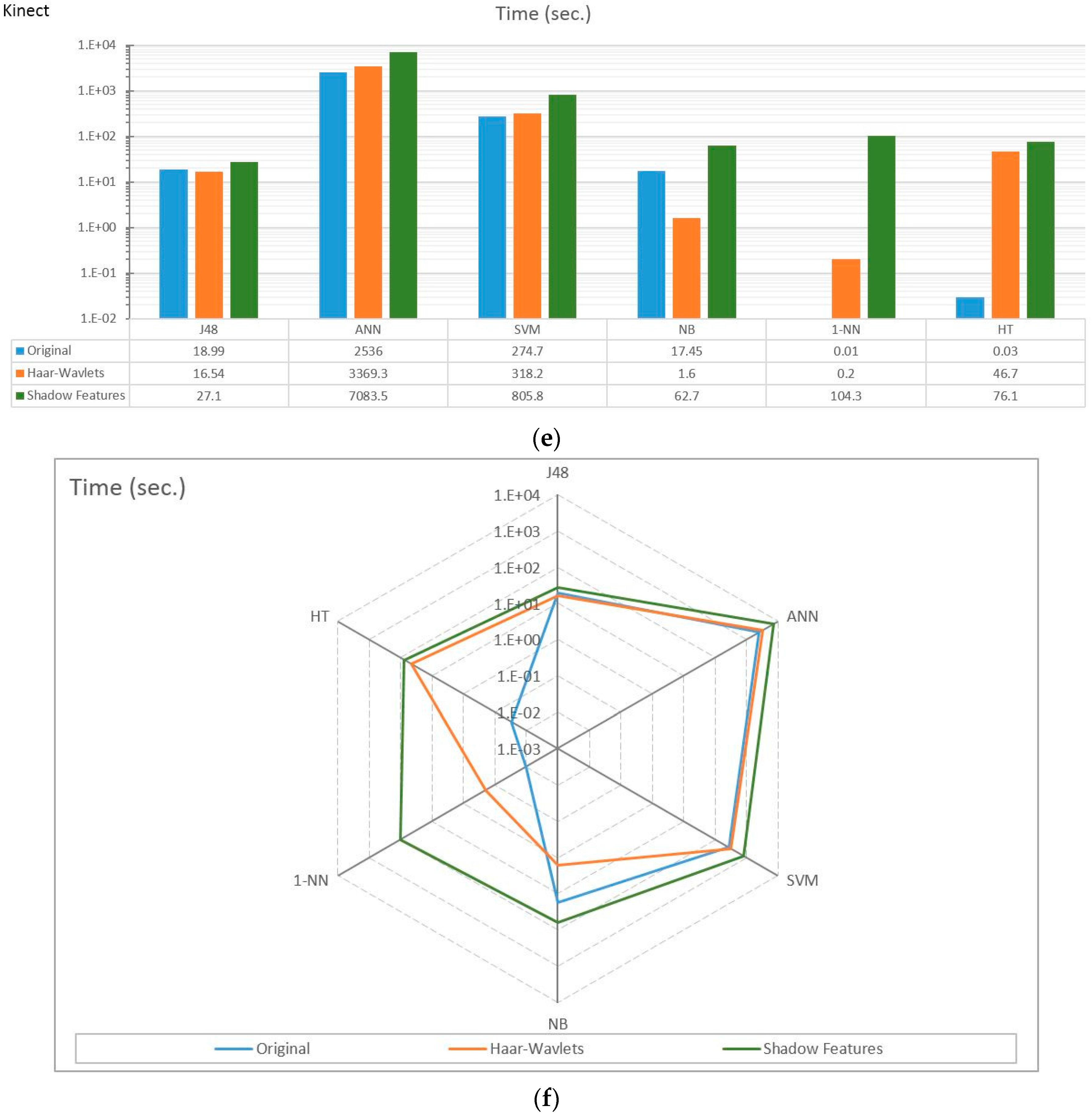
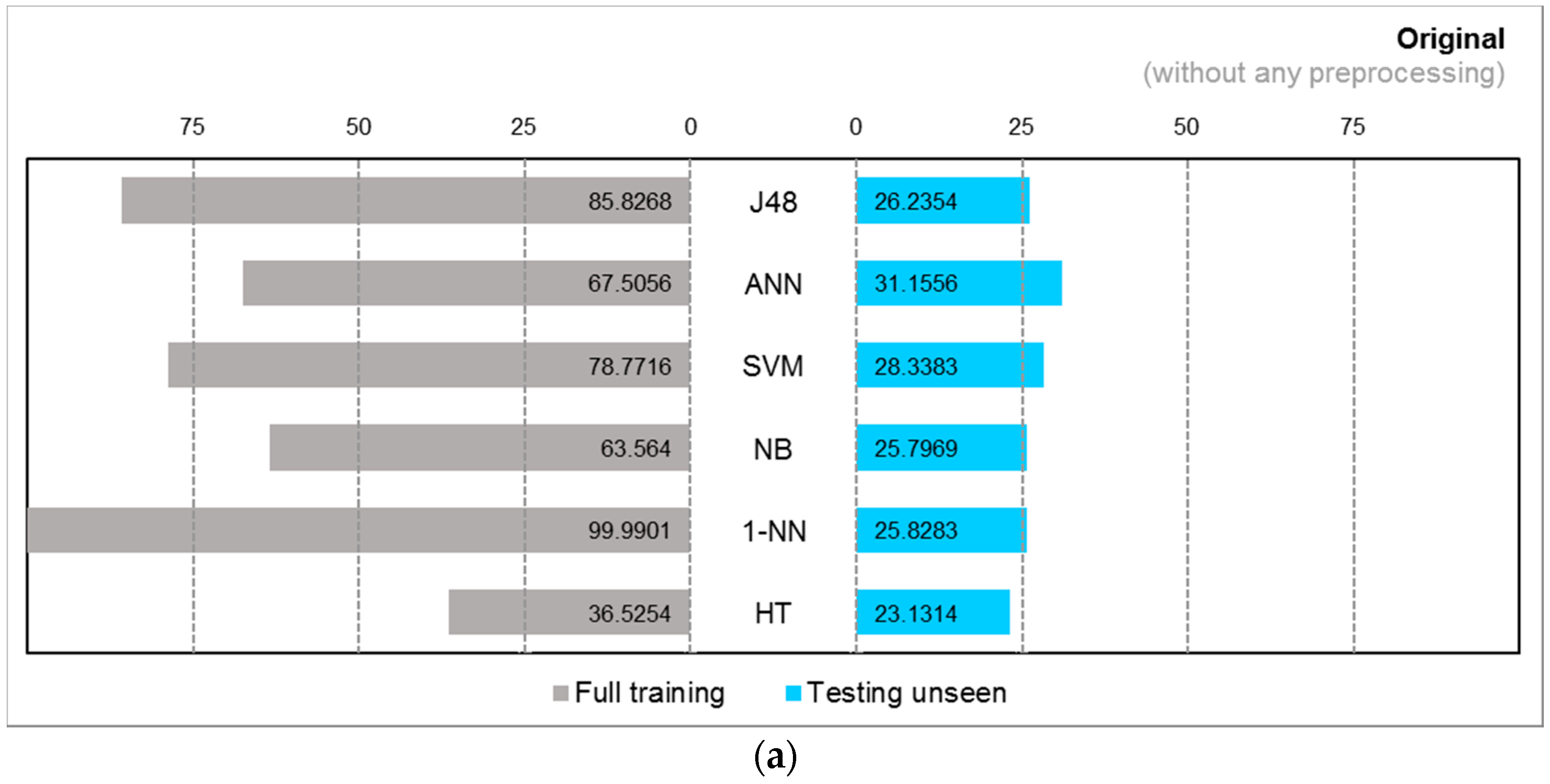
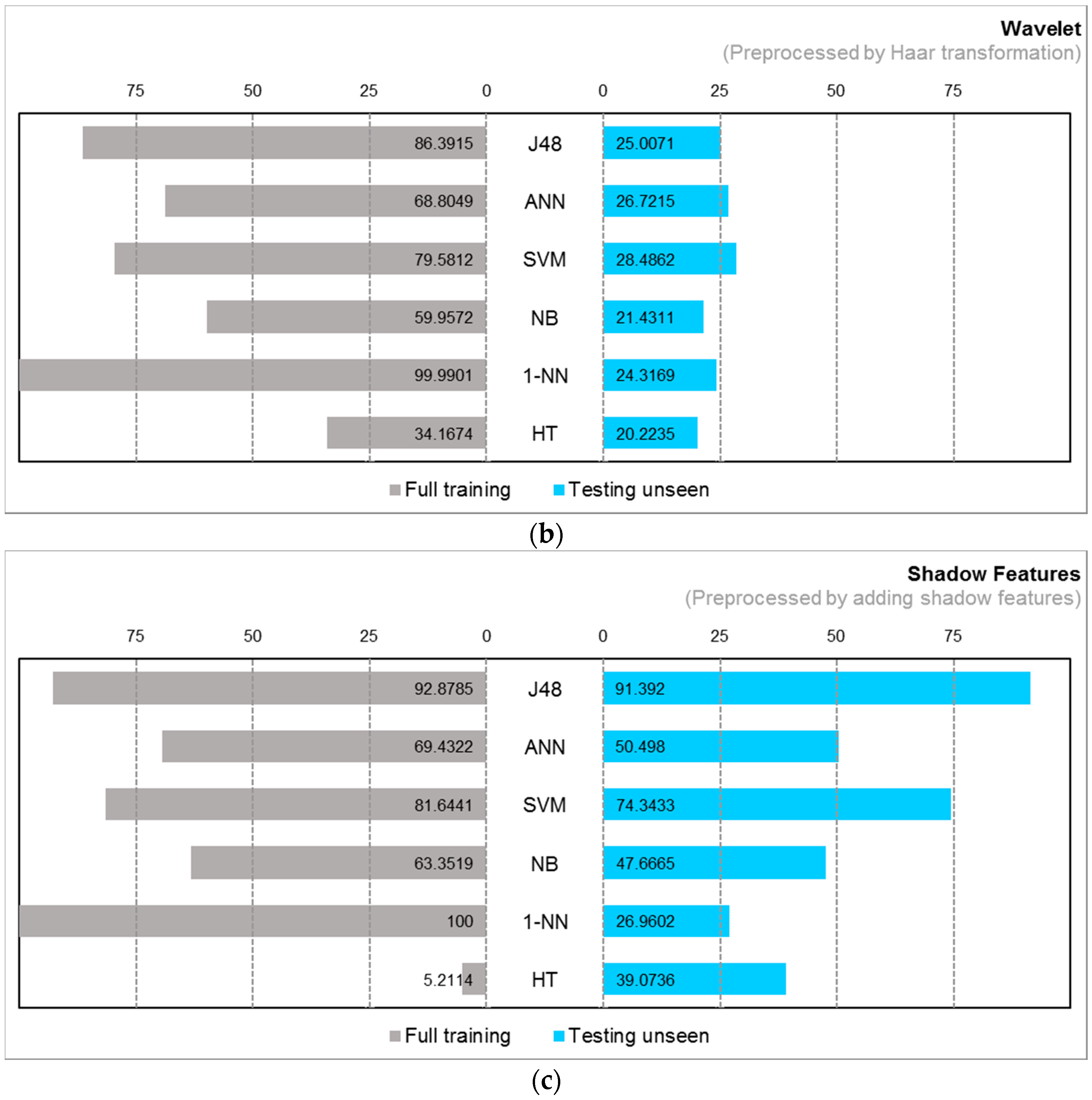
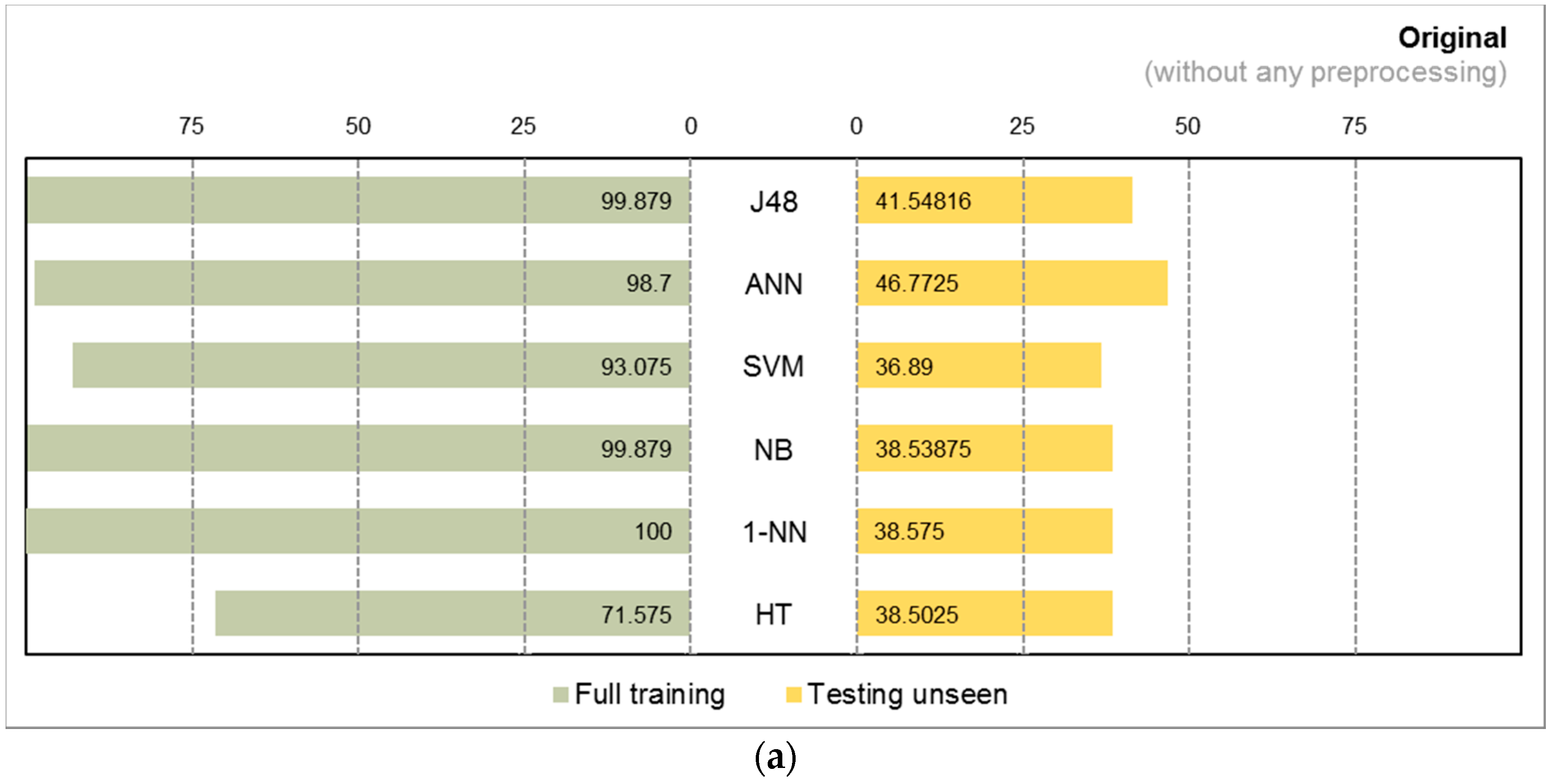
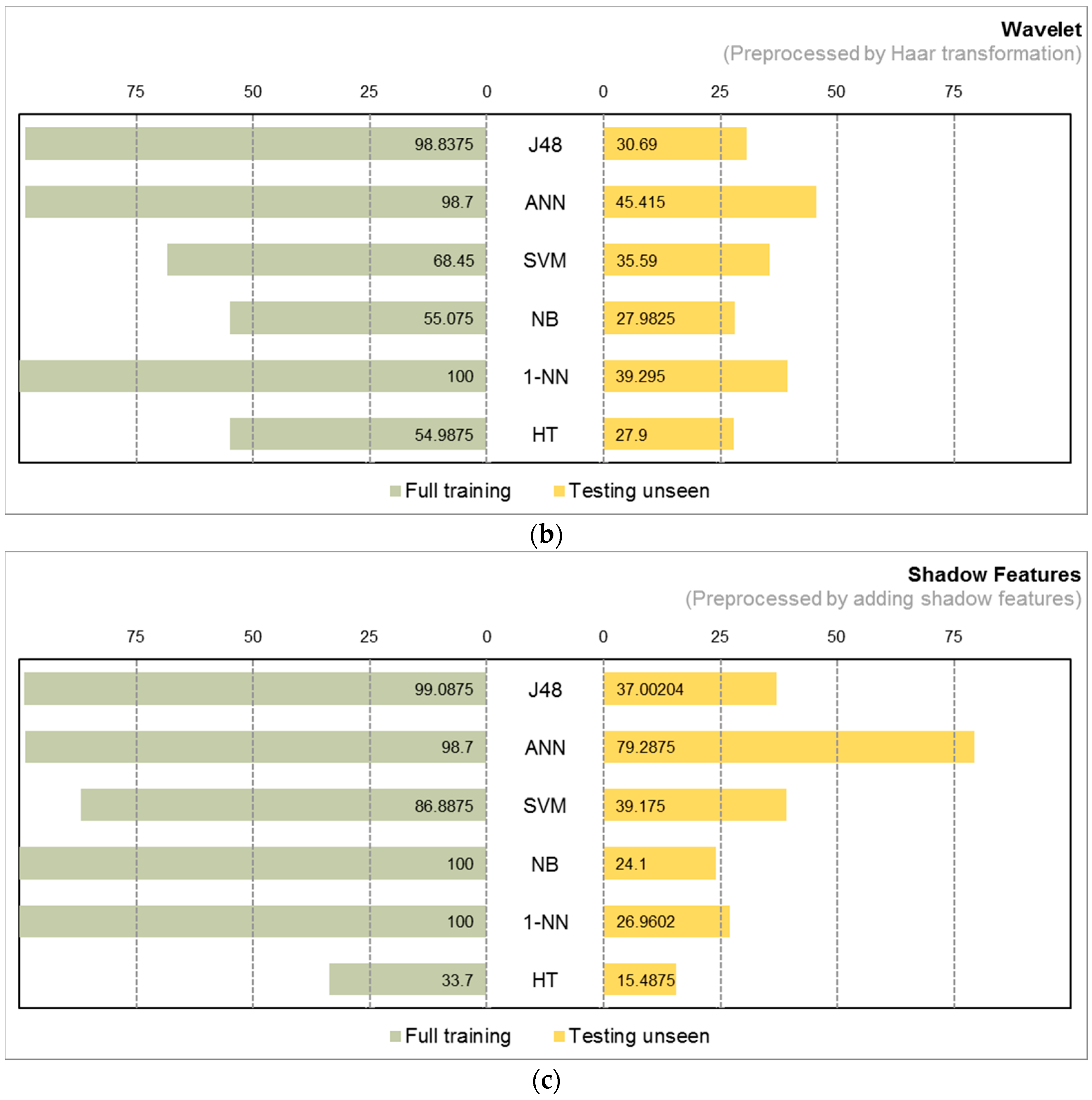
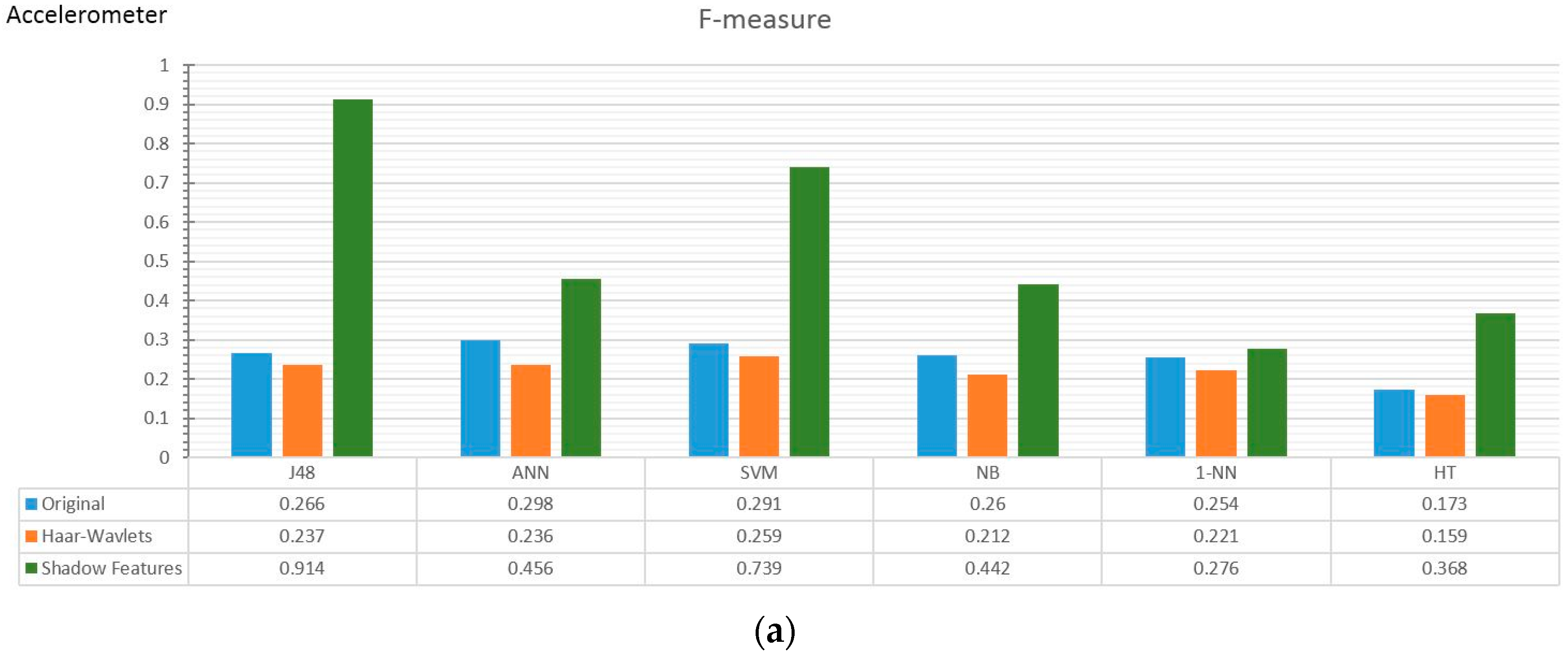
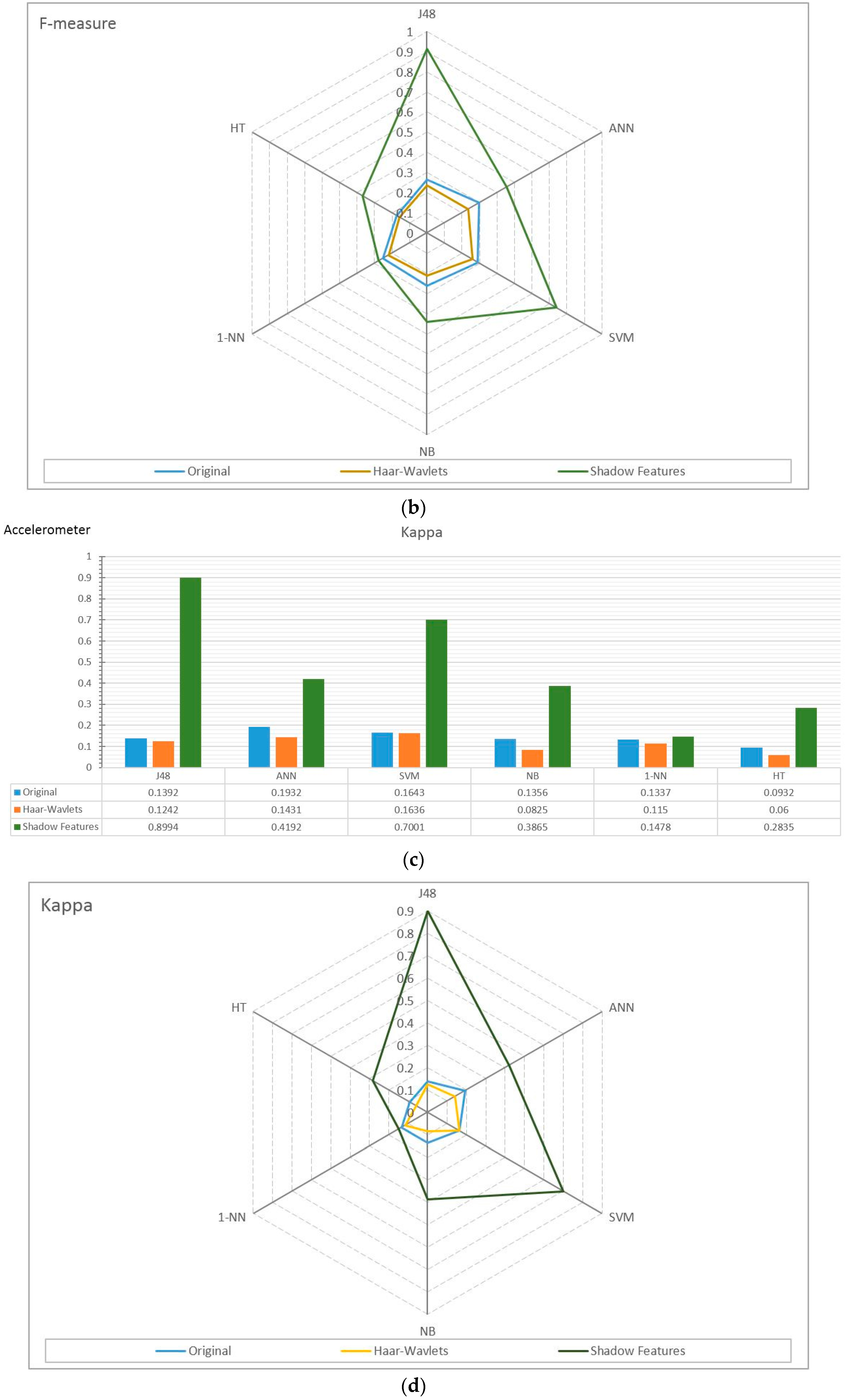
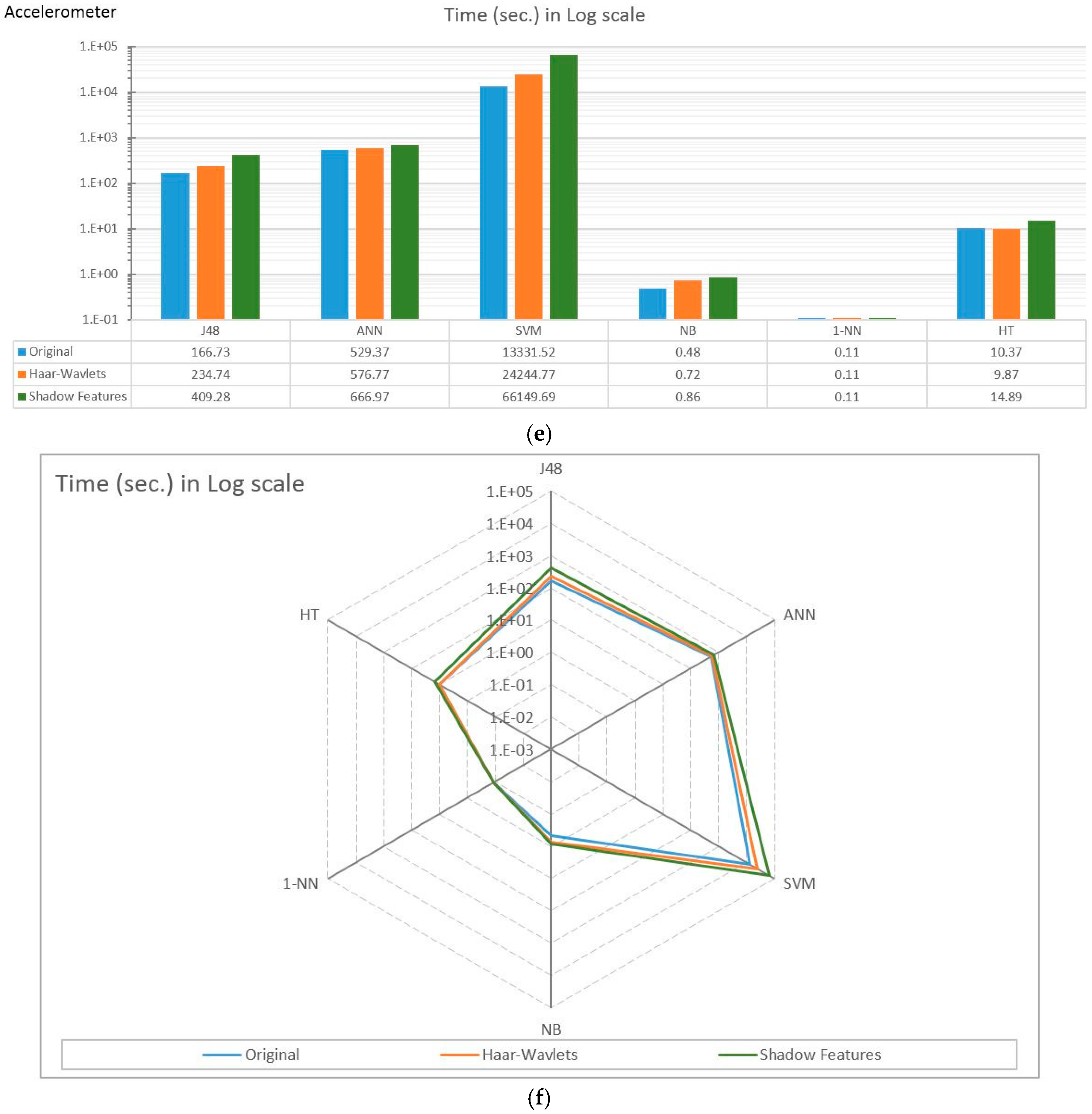
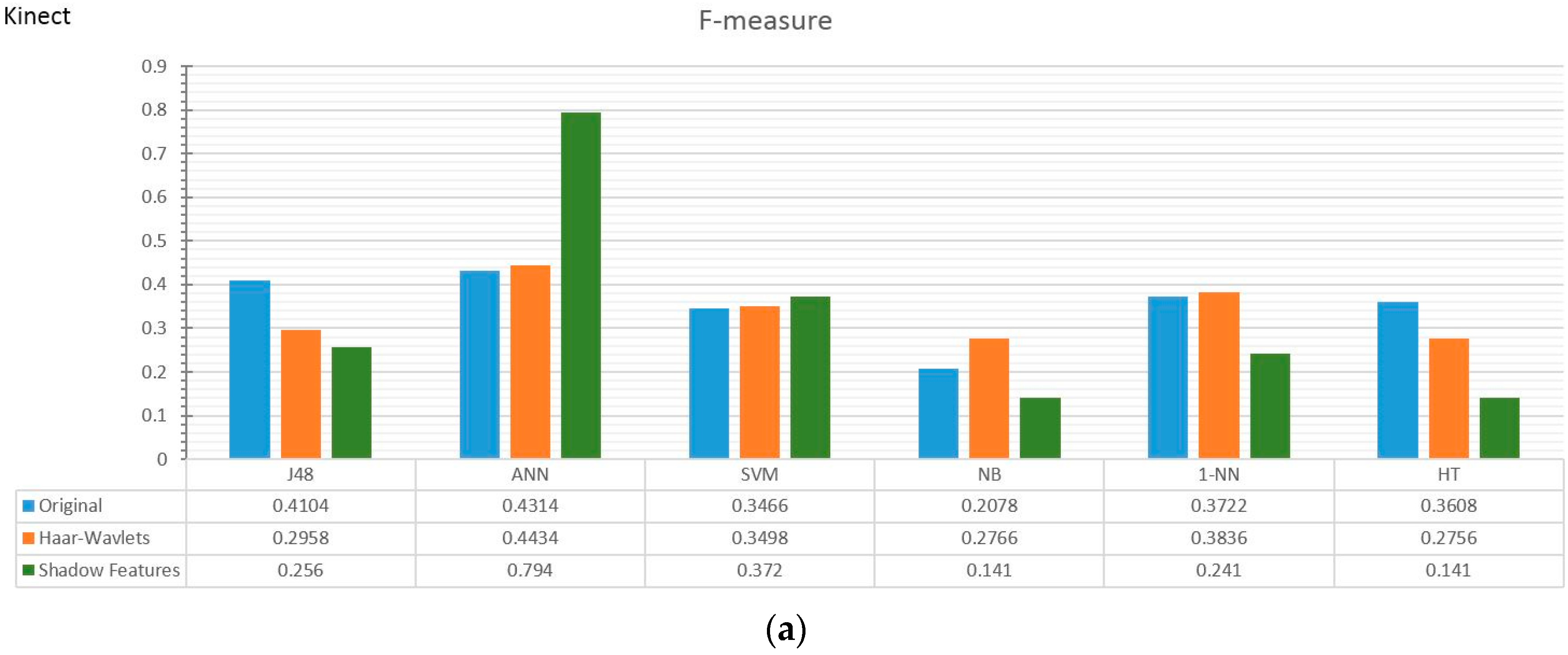
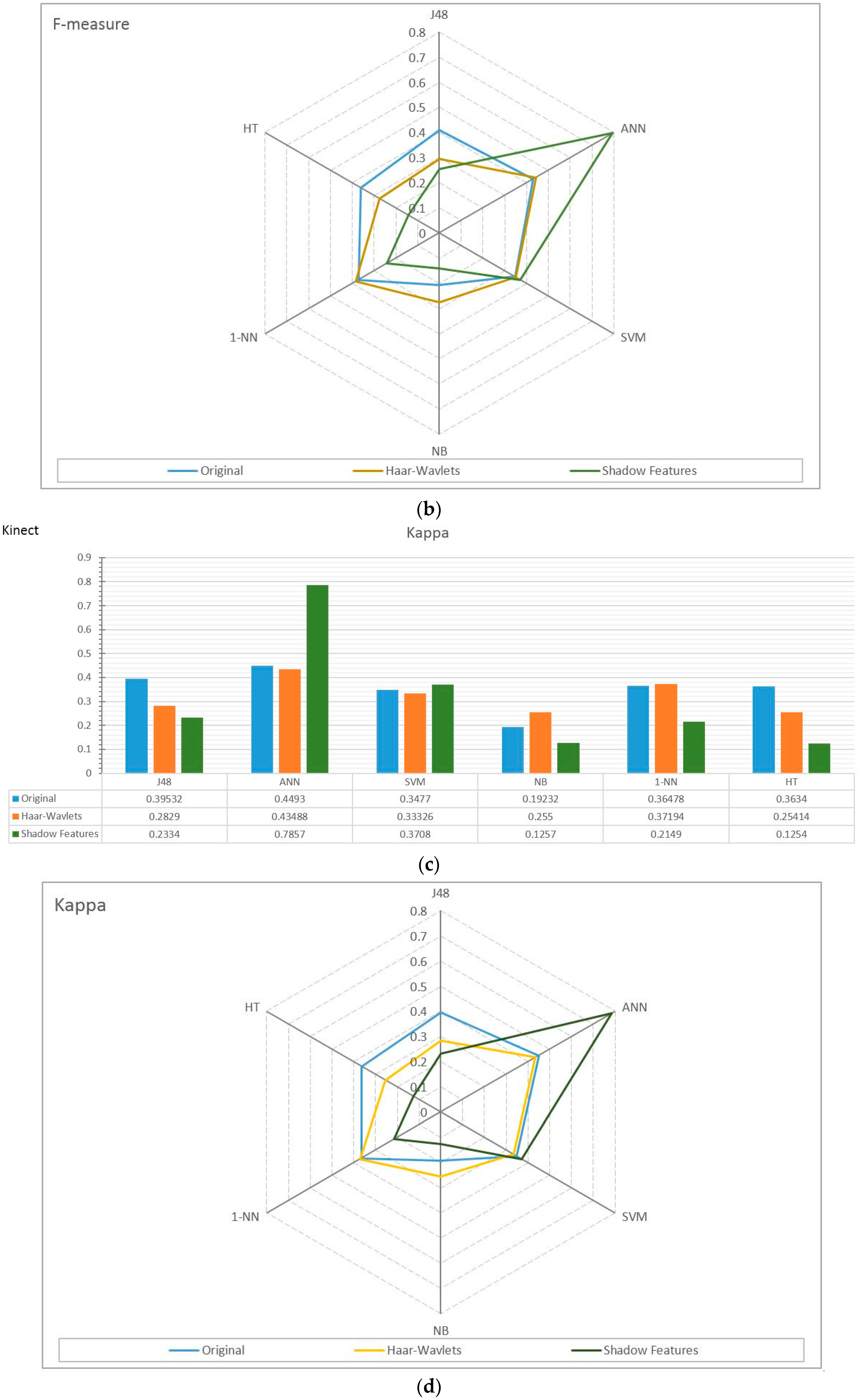
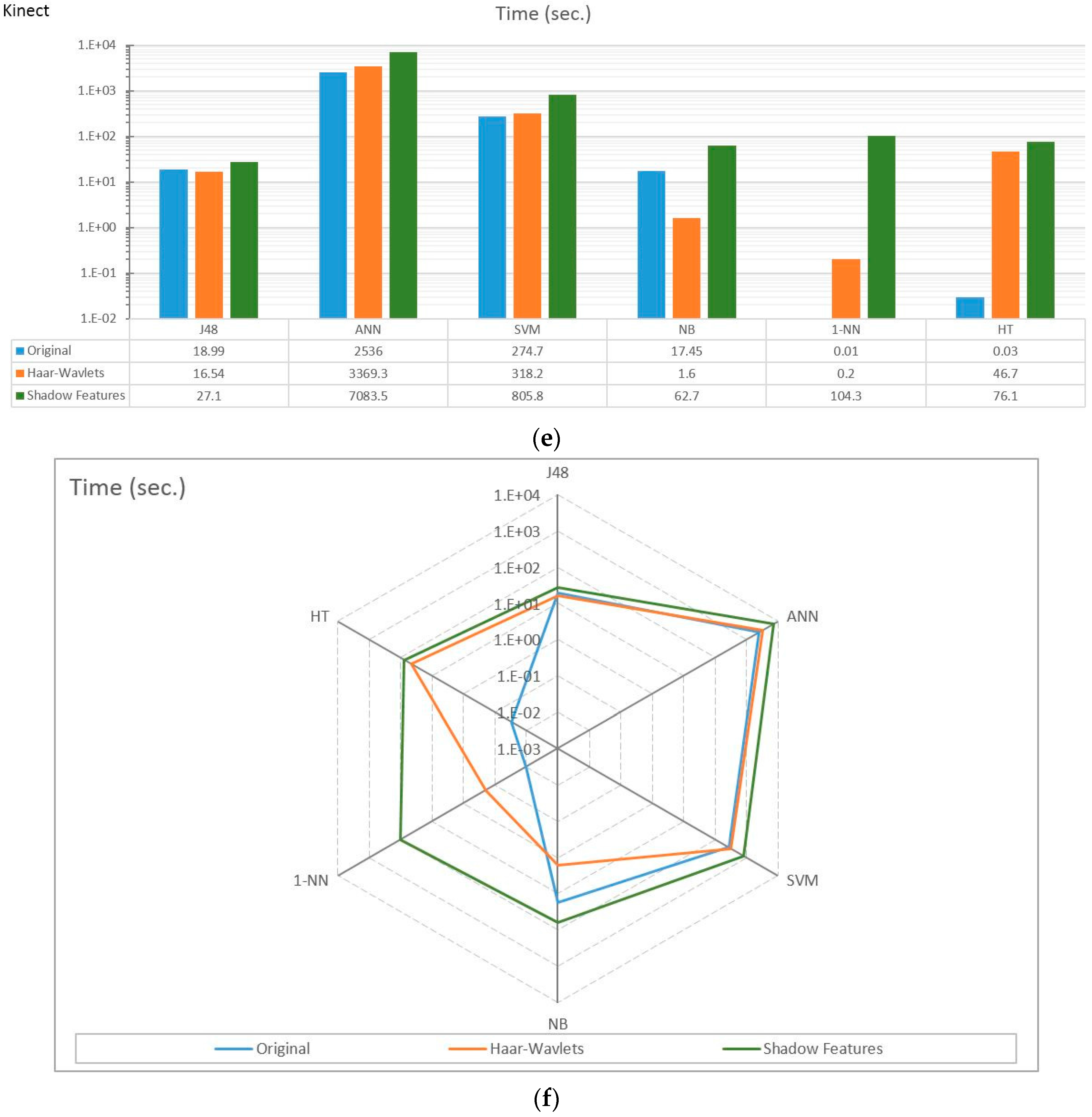
4.2. Experiment Results
4.3. Observations
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Braeken, A.; Porambage, P.; Gurtov, A.; Ylianttila, M. Secure and Efficient Reactive Video Surveillance for Patient Monitoring. Sensors 2016, 16, 32. [Google Scholar] [CrossRef] [PubMed]
- Chan, J.H.; Visutarrom, T.; Cho, S.-B.; Engchuan, W.; Mongolnam, P.; Fong, S. A Hybrid Approach to Human Posture Classification during TV Watching. J. Med. Imaging Health Inform. 2016, 6, 1119–1126. [Google Scholar] [CrossRef]
- Song, W.; Lu, Z.; Li, J.; Li, J.; Liao, J.; Cho, K.; Um, K. Hand Gesture Detection and Tracking Methods Based on Background Subtraction. In Future Information Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 485–490. [Google Scholar]
- Kim, Y.; Sim, S.; Cho, S.; Lee, W.-W.; Jeong, Y.-S.; Cho, K.; Um, K. Intuitive NUI for Controlling Virtual Objects Based on Hand Movements. In Future Information Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 457–461. [Google Scholar]
- J. Paul Getty Museum. Photography: Discovery and Invention; J. Paul Getty Museum: Malibu, CA, USA, 1990. [Google Scholar]
- Vishwakarma, D.K.; Rawat, P.; Kapoor, R. Human Activity Recognition Using Gabor Wavelet Transform and Ridgelet Transform. In Proceeding of the 3rd International Conference on Recent Trends in Computing 2015 (ICRTC-2015), Ghaziabad, India, 12–13 March 2015; Volume 57, pp. 630–636.
- Zhang, M.; Sawchuk, A.A. A feature selection-based framework for human activity recognition using wearable multimodal sensors. In Proceedings of the 6th International Conference on Body Area Networks, Beijing, China, 7–10 November 2011; pp. 92–98.
- Kumari, S.; Mitra, S.K. Human Action Recognition Using DFT. In Proceedings of the third IEEE National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Hubli, India, 15–17 December 2011; pp. 239–242.
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-time Shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV), Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402.
- Ke, Y.; Sukthankar, R.; Hebert, M. Spatio-temporal Shape and Flow Correlation for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.
- Shechtman, E.; Irani, M. Space-time Behavior Based Correlation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 405–412.
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior Recognition via Sparse Spatio-Temporal Features. In Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 65–72.
- Müller, M.; Röder, T.; Clausen, M. Efficient content-based retrieval of motion capture data. ACM Trans. Graph. 2005, 24, 677–685. [Google Scholar] [CrossRef]
- Campbell, L.W.; Becker, D.A.; Azarbayejani, A.; Bobick, A.F.; Pentland, A. Invariant Features for 3-D Gesture Recognition. In Proceedings of the Second International Conference on Automatic Face and Gesture Recognition, Killington, VT, USA, 14–16 October 1996; pp. 157–162.
- Hoang, L.U.T.; Tuan, P.V.; Hwang, J. An Effective 3D Geometric Relational Feature Descriptor for Human Action Recognition. In Proceedings of the IEEE RIVF International Conference on Computing and Communication Technologies, Research, Innovation, and Vision for the Future (RIVF), Ho Chi Minh City, Vietnam, 27 February–1 March 2012; pp. 1–6.
- Hoang, L.U.T.; Ke, S.; Hwang, J.; Yoo, J.; Choi, K. Human Action Recognition based on 3D Body Modeling from Monocular Videos. In Proceedings of the Frontiers of Computer Vision Workshop, Tokyo, Japan, 2–4 February 2012; pp. 6–13.
- Veeraraghavan, A.; Roy-Chowdhury, A.K.; Chellappa, R. Matching shape sequences in video with applications in human movement analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1896–1909. [Google Scholar] [CrossRef] [PubMed]
- Danafar, S.; Gheissari, N. Action recognition for surveillance applications using optic flow and SVM. In Action Recognition for Surveillance Applications Using Optic Flow and SVM; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4844, pp. 457–466. [Google Scholar]
- Agarwal, A.; Triggs, B. Recovering 3D human pose from monocular images. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 44–58. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893.
- Lu, W.; Little, J.J. Simultaneous tracking and action recognition using the PCA-HOG descriptor. In Proceedings of the 3rd Canadian Conference on Computer and Robot Vision, Quebec City, QC, Canada, 7–9 June 2006.
- Bao, L.; Intille, S. Activity Recognition from User-Annotated Acceleration Data. In Activity Recognition from User-Annotated Acceleration Data; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar]
- Fong, S. Adaptive Forecasting of Earthquake Time Series by Incremental Decision Tree Algorithm. Inf. J. 2013, 16, 8387–8395. [Google Scholar]
- Witt, A.; Malamud, B.D. Quantification of Long-Range Persistence in Geophysical Time Series: Conventional and Benchmark-Based Improvement Techniques. Surv. Geophys. 2013, 34, 541–651. [Google Scholar] [CrossRef]
- Zhou, N. Earthquake Forecasting Using Dynamic Hurst Coefficiency. Master’s Thesis, University of Macau, Macau, China, 2013. [Google Scholar]
- Rodríguez, J.; Barrera-Animas, A.Y.; Trejo, L.A.; Medina-Pérez, M.A.; Monroy, R. Ensemble of One-Class Classifiers for Personal Risk Detection Based on Wearable Sensor Data. Sensors 2016, 16, 1619. [Google Scholar] [CrossRef] [PubMed]
- Moschetti, A.; Fiorini, L.; Esposito, D.; Dario, P.; Cavallo, F. Recognition of Daily Gestures with Wearable Inertial Rings and Bracelets. Sensors 2016, 16, 134. [Google Scholar] [CrossRef] [PubMed]
- Özdemir, A.T. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors 2016, 16, 1161. [Google Scholar] [CrossRef] [PubMed]
- Procházka, A.; Schätz, M.; Vyšata, O.; Vališ, M. Microsoft Kinect Visual and Depth Sensors for Breathing and Heart Rate Analysis. Sensors 2016, 16, 996. [Google Scholar] [CrossRef] [PubMed]
- Saenz-de-Urturi, Z.; Garcia-Zapirain Soto, B. Kinect-Based Virtual Game for the Elderly that Detects Incorrect Body Postures in Real Time. Sensors 2016, 16, 704. [Google Scholar] [CrossRef]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic Recognition of Aggressive Behavior in Pigs Using a Kinect Depth Sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale of Hurst (H) Exponent Classifications | |||||
|---|---|---|---|---|---|
| Grade | Range of H Exponent | Continuity Intensity | Grade | Range of H Exponent | Continuity Intensity |
| 1 | 0.5 < H ≤ 0.55 | Very weak | −1 | 0.45 < H ≤ 0.50 | Very weak |
| 2 | 0.55 < H ≤ 0.65 | Weak | −2 | 0.35 < H ≤ 0.45 | Weak |
| 3 | 0.65 < H ≤ 0.75 | Normal strong | −3 | 0.25 < H ≤ 0.35 | Normal strong |
| 4 | 0.75 < H ≤ 0.80 | Strong | −4 | 0.20 < H ≤ 0.25 | Strong |
| 5 | 0.80 < H ≤ 1.00 | Very strong | −5 | 0.00 < H ≤ 0.20 | Very strong |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fong, S.; Song, W.; Cho, K.; Wong, R.; Wong, K.K.L. Training Classifiers with Shadow Features for Sensor-Based Human Activity Recognition. Sensors 2017, 17, 476. https://doi.org/10.3390/s17030476
Fong S, Song W, Cho K, Wong R, Wong KKL. Training Classifiers with Shadow Features for Sensor-Based Human Activity Recognition. Sensors. 2017; 17(3):476. https://doi.org/10.3390/s17030476
Chicago/Turabian StyleFong, Simon, Wei Song, Kyungeun Cho, Raymond Wong, and Kelvin K. L. Wong. 2017. "Training Classifiers with Shadow Features for Sensor-Based Human Activity Recognition" Sensors 17, no. 3: 476. https://doi.org/10.3390/s17030476
APA StyleFong, S., Song, W., Cho, K., Wong, R., & Wong, K. K. L. (2017). Training Classifiers with Shadow Features for Sensor-Based Human Activity Recognition. Sensors, 17(3), 476. https://doi.org/10.3390/s17030476