Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters



Abstract
:1. Introduction
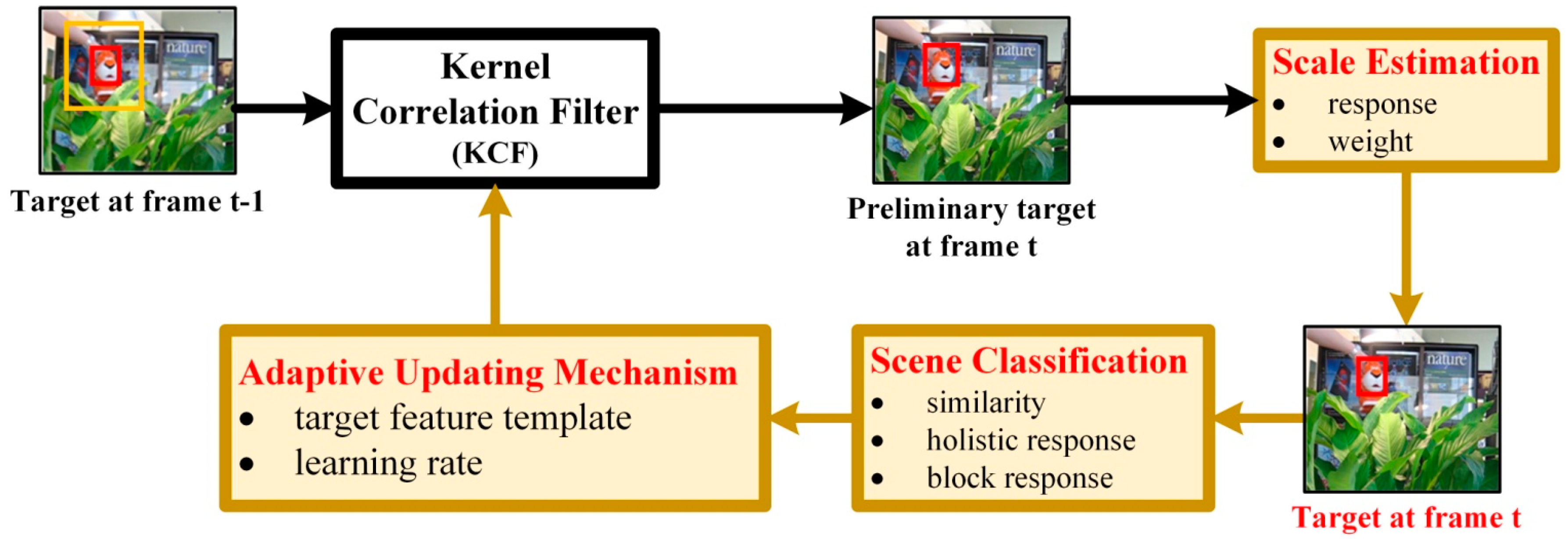
2. Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters
2.1. Kernel Correlation Filter
2.2. Low Complexity Scale Estimation Method
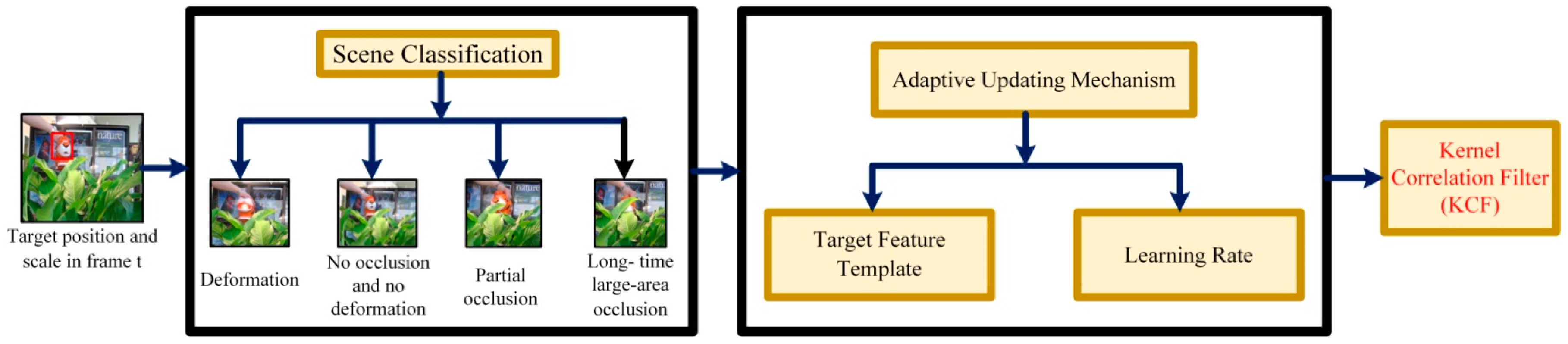
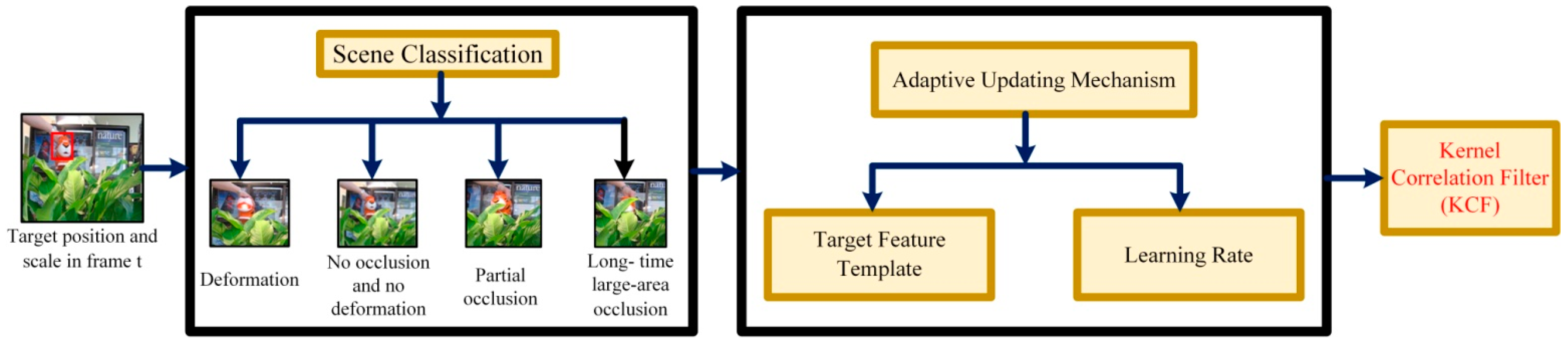
2.3. The Scene-Aware Adaptive Updating Mechanism
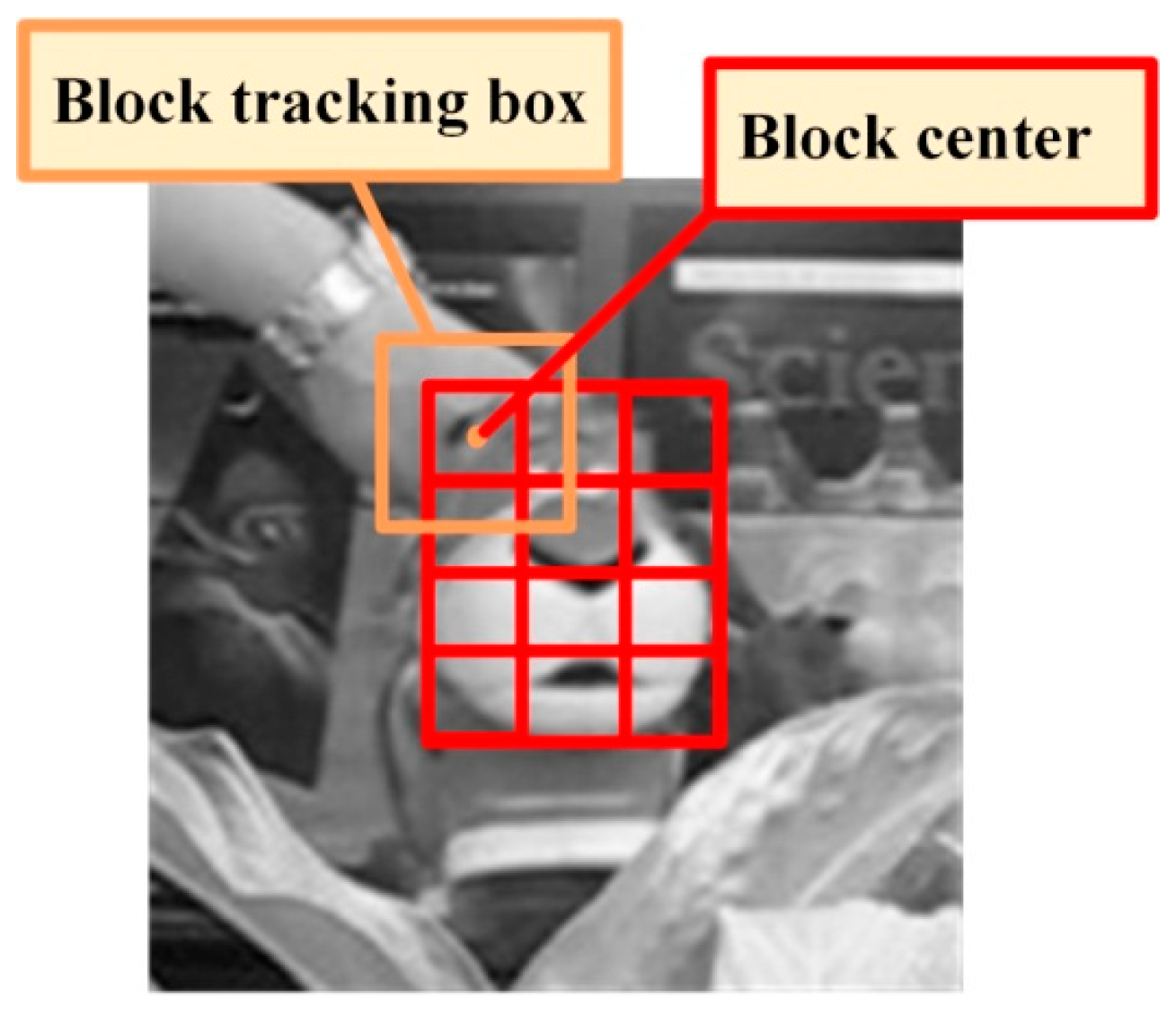
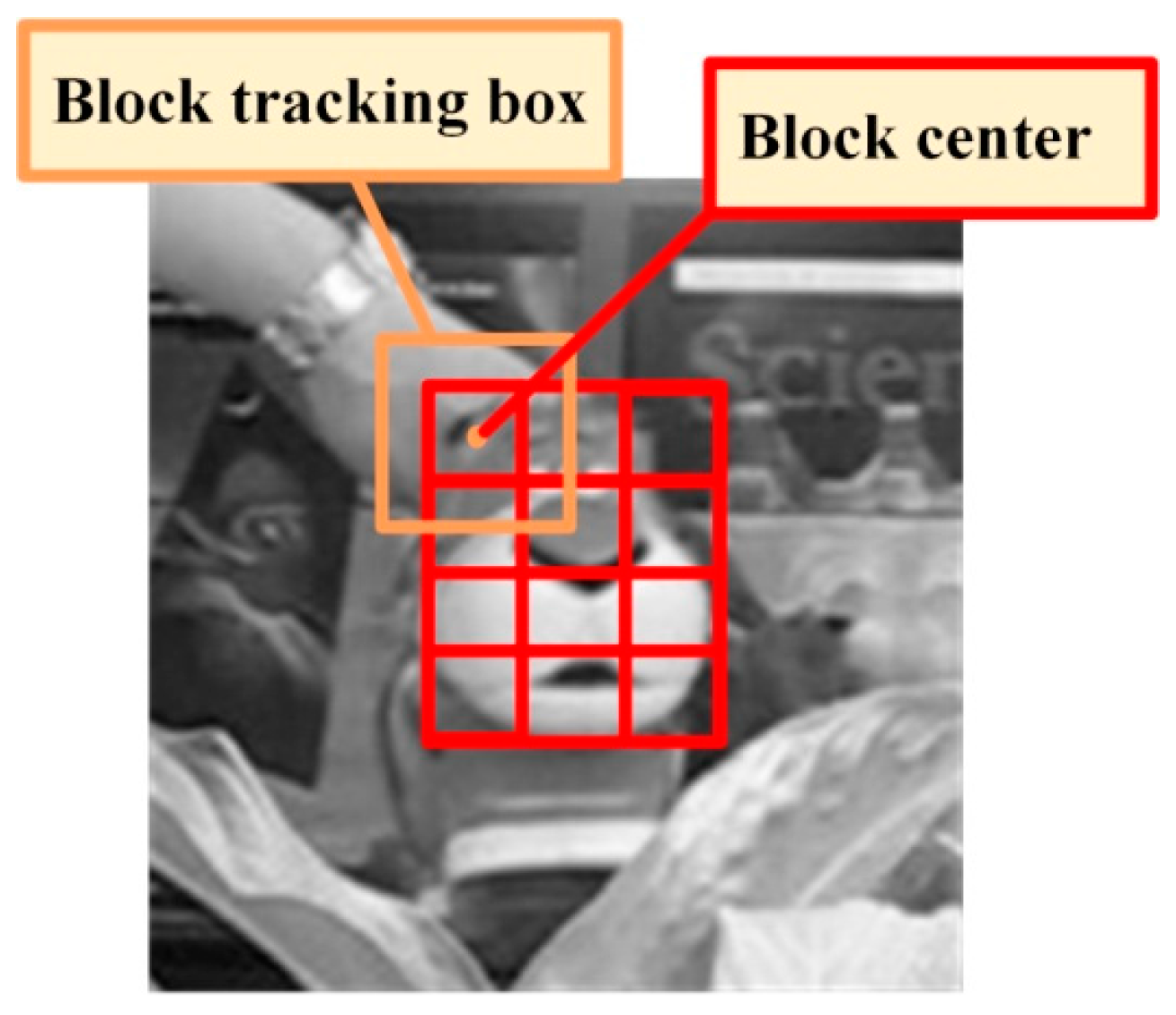
2.3.1. Target Scene Classification
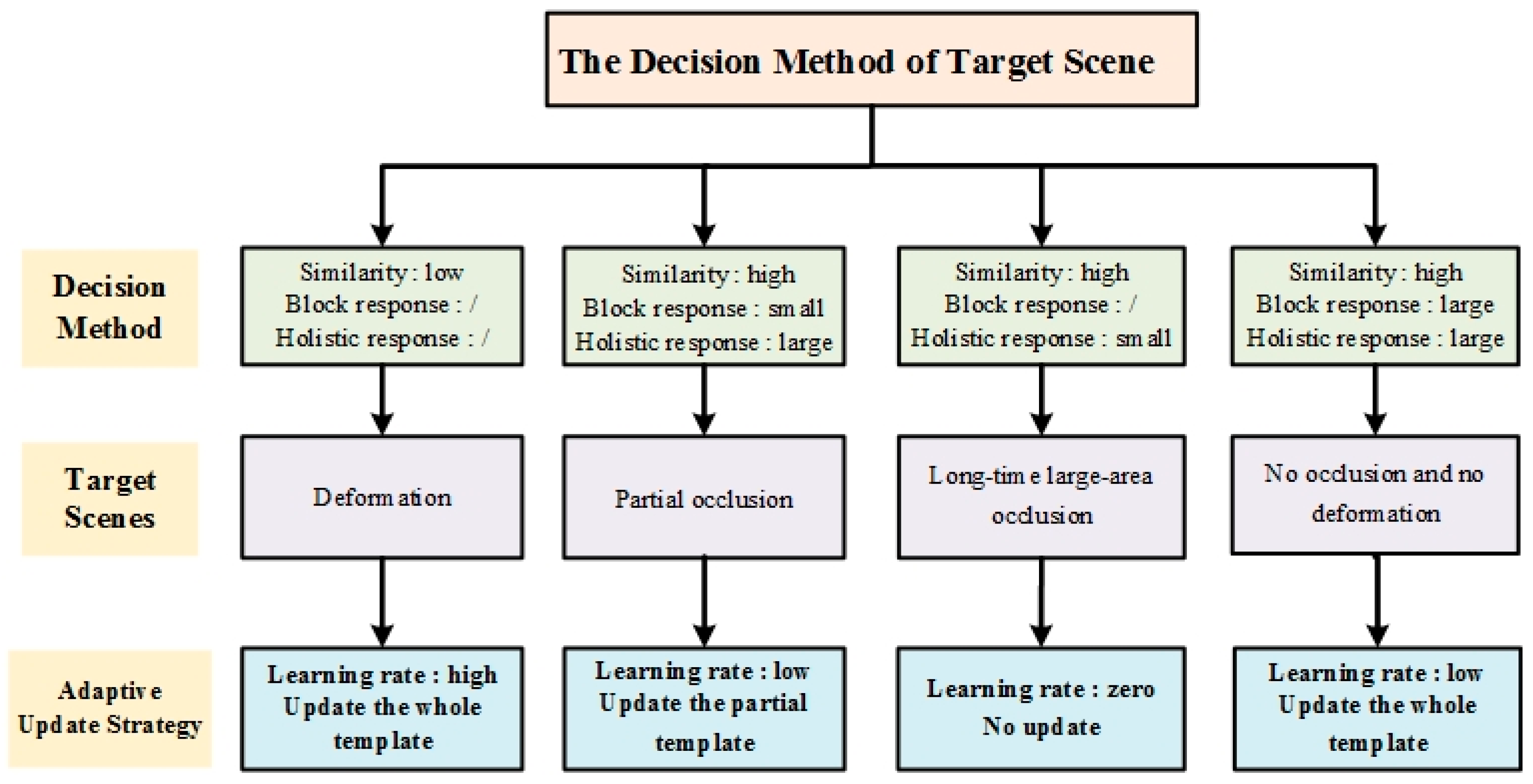
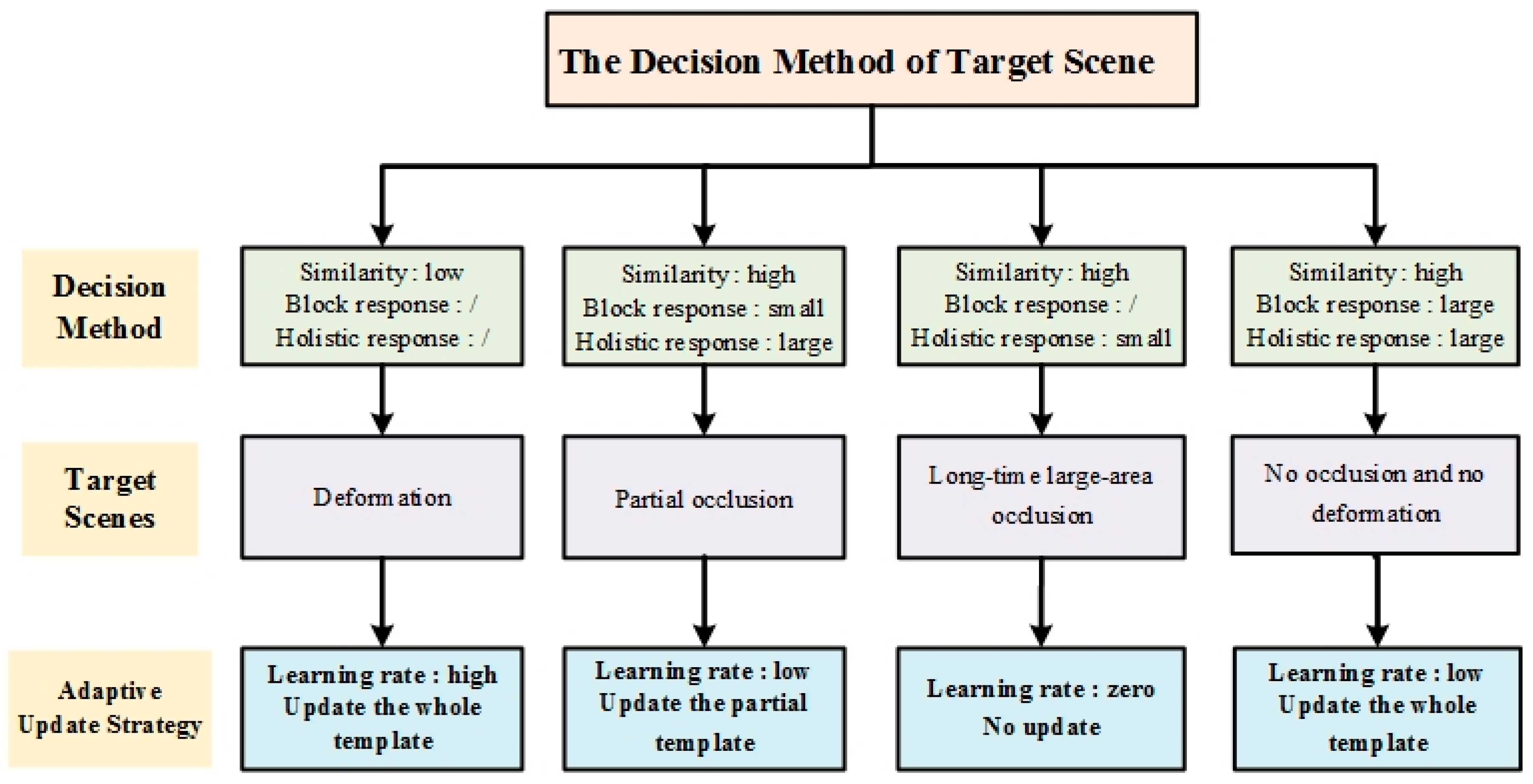
2.3.2. Decision Method of Target Scenes
2.3.3. Adaptive Updating Strategy
| Algorithm 1: The AKCF tracker |
| 1: Input: video and the target initial position; 2: Output: the target position and scale; 3: Based on the target position in the initial frame, the feature is extracted and the target initial kernel correlation filter is obtained by Equation (2); 4: For the sequent frames 5: For the new image frame, extract the new features at the target position of the previous frame and use Equation (3) to obtain the preliminary target position of the new frame; 6: Use Equation (2) to obtain the similarity filter of the first two frames; 7: Use the Equation (6) to estimate the target scale of the current frame at the new target position; 8: When the target meets the division condition, the target is divided into blocks and the corresponding parameters are obtained; 9: Use Equations (7)–(10) to determine the scene where the target is located; 10: Update the target feature template of the current frame with the adaptive updating strategies and obtain the learning rate by Equation (11) to update the kernel correlation filter based on the scene in which the target is located; 11: end |
3. Experiments
3.1. Quantitative Evaluation
3.1.1. Evaluation Metric
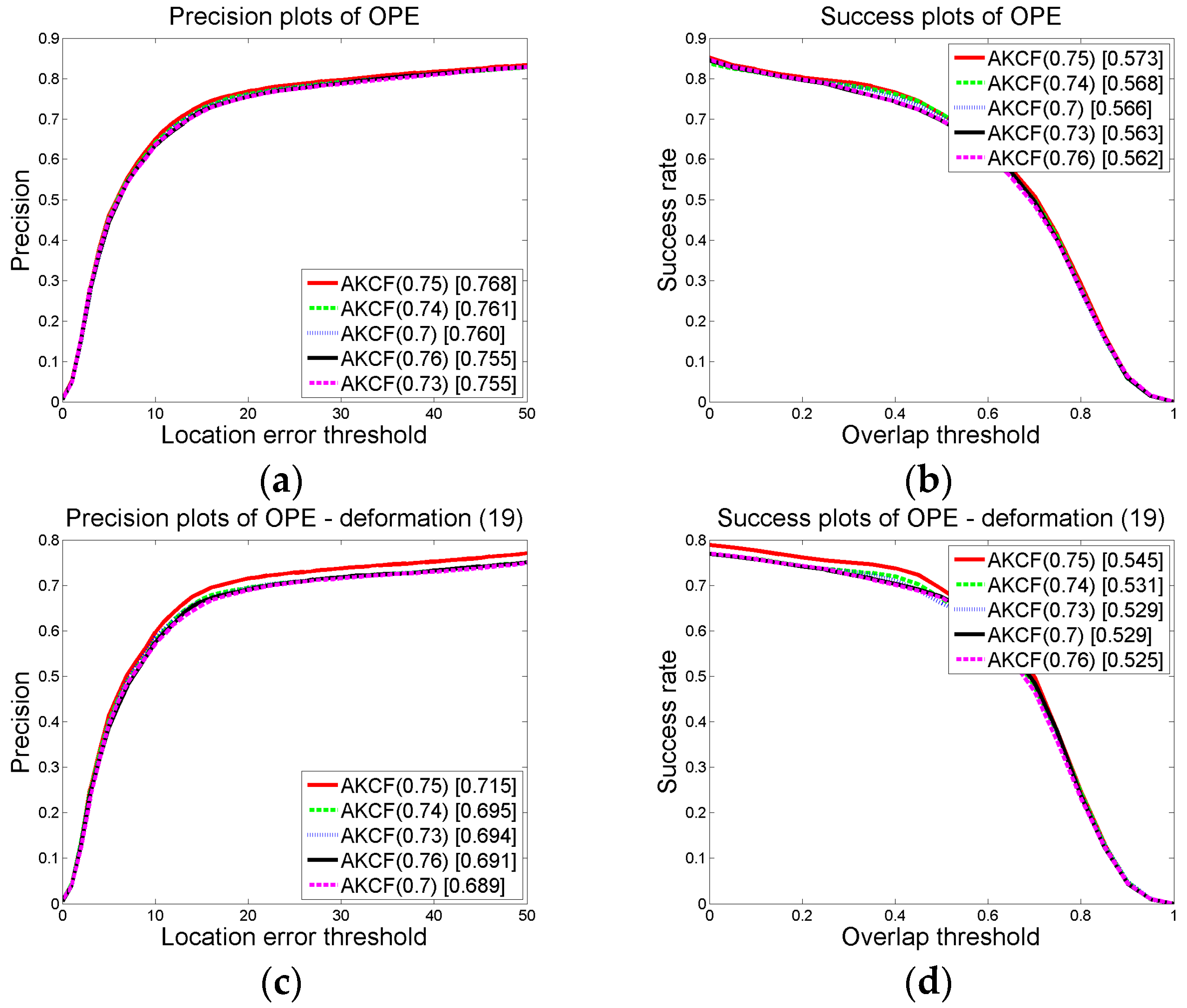
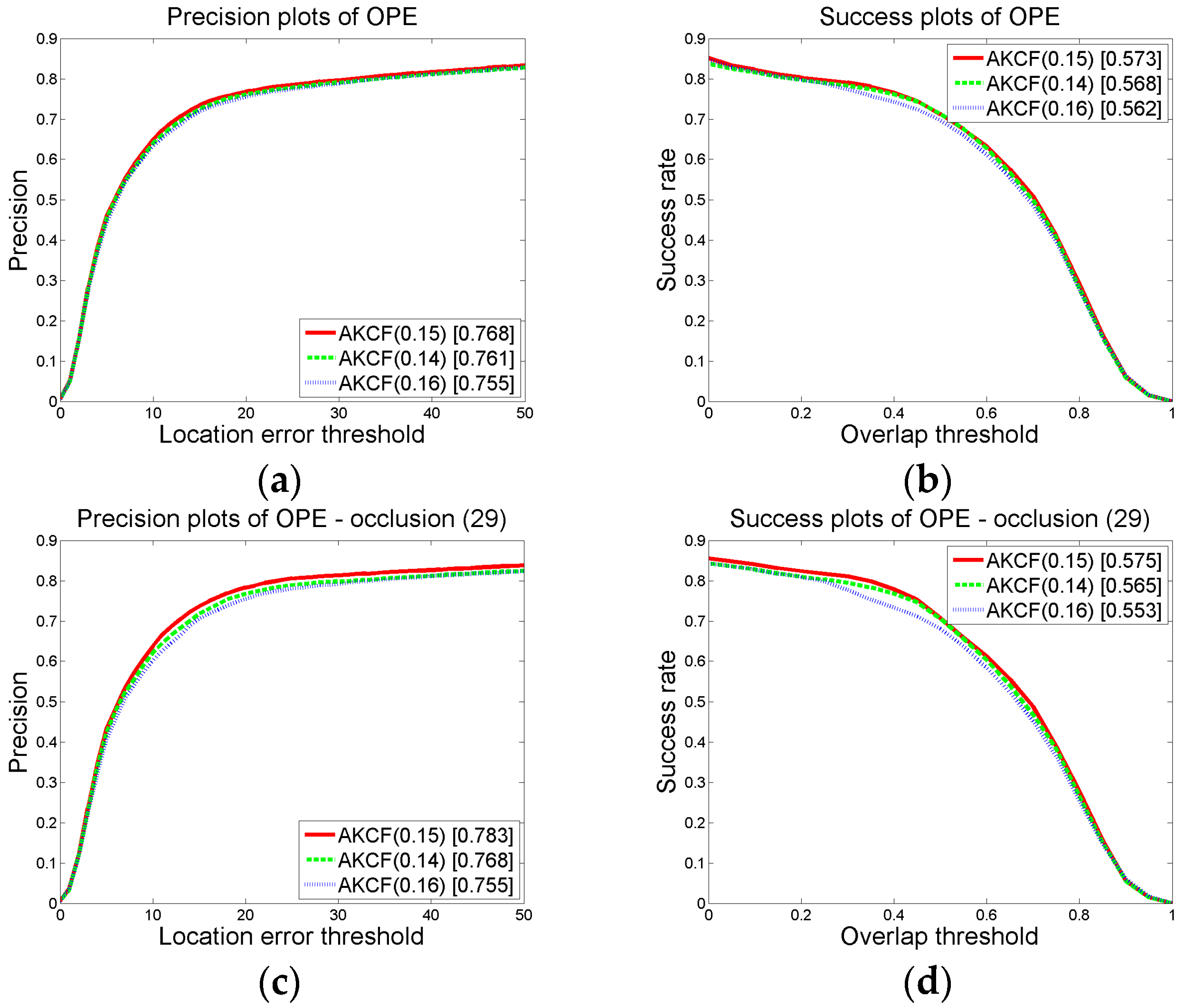
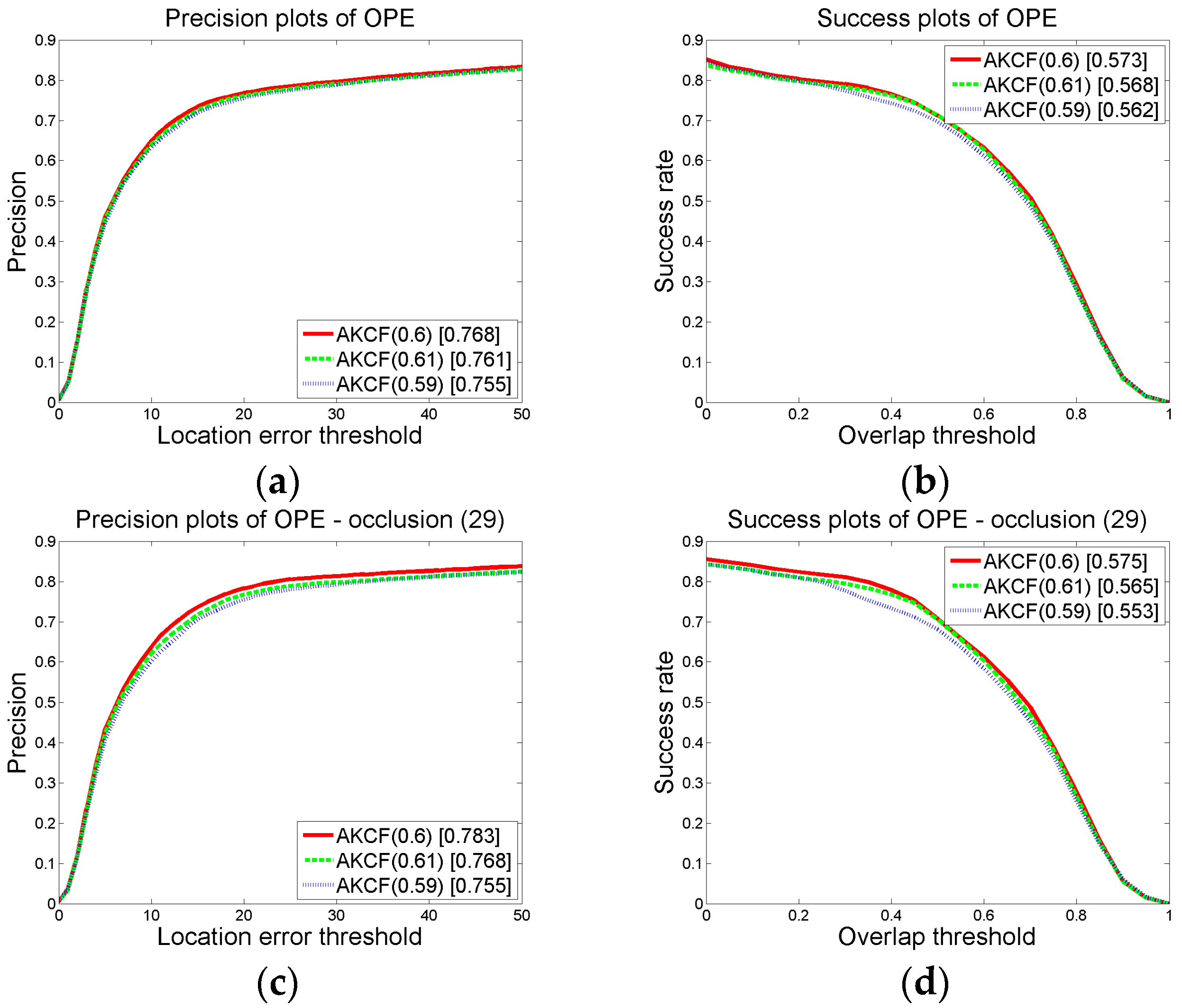
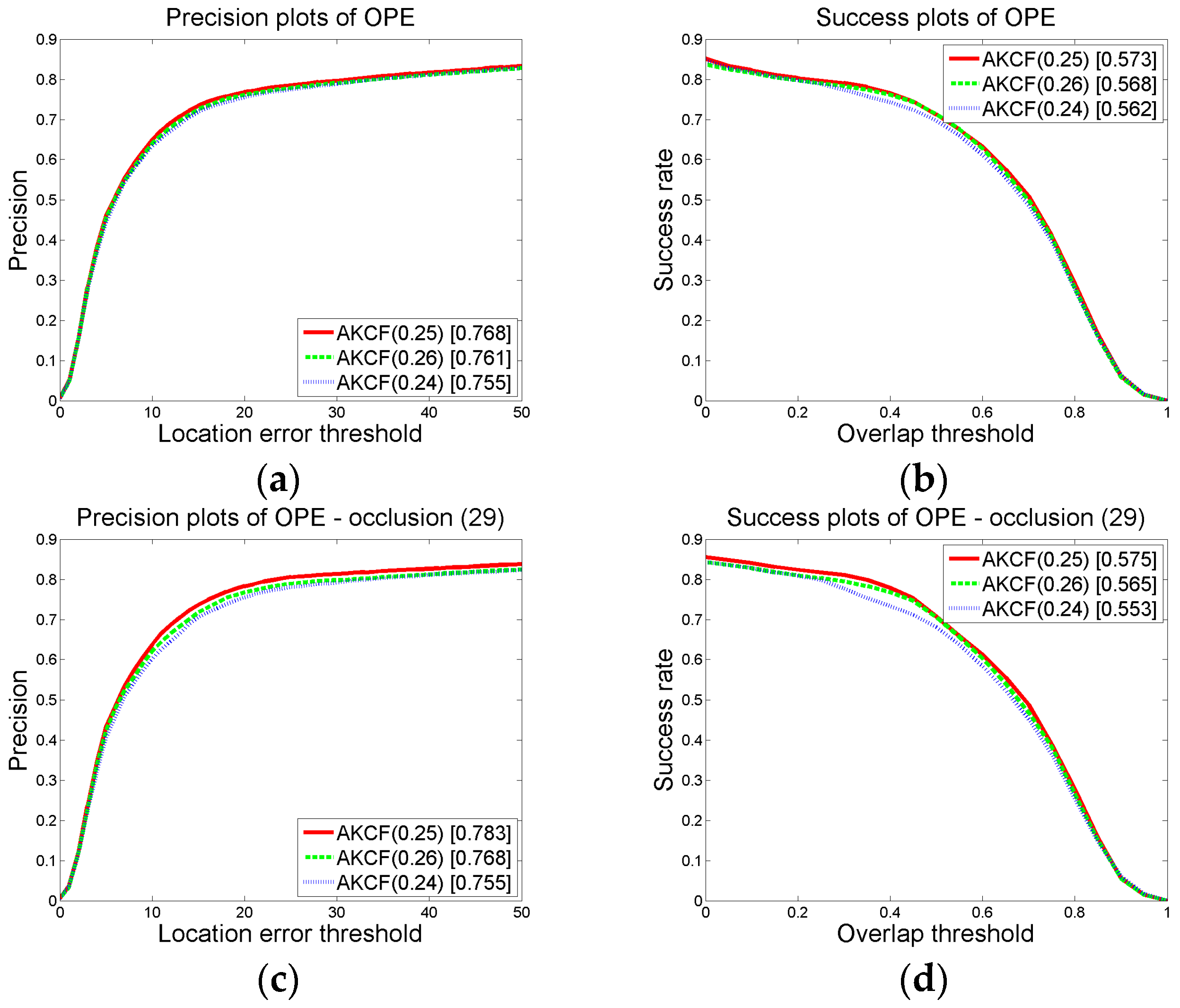
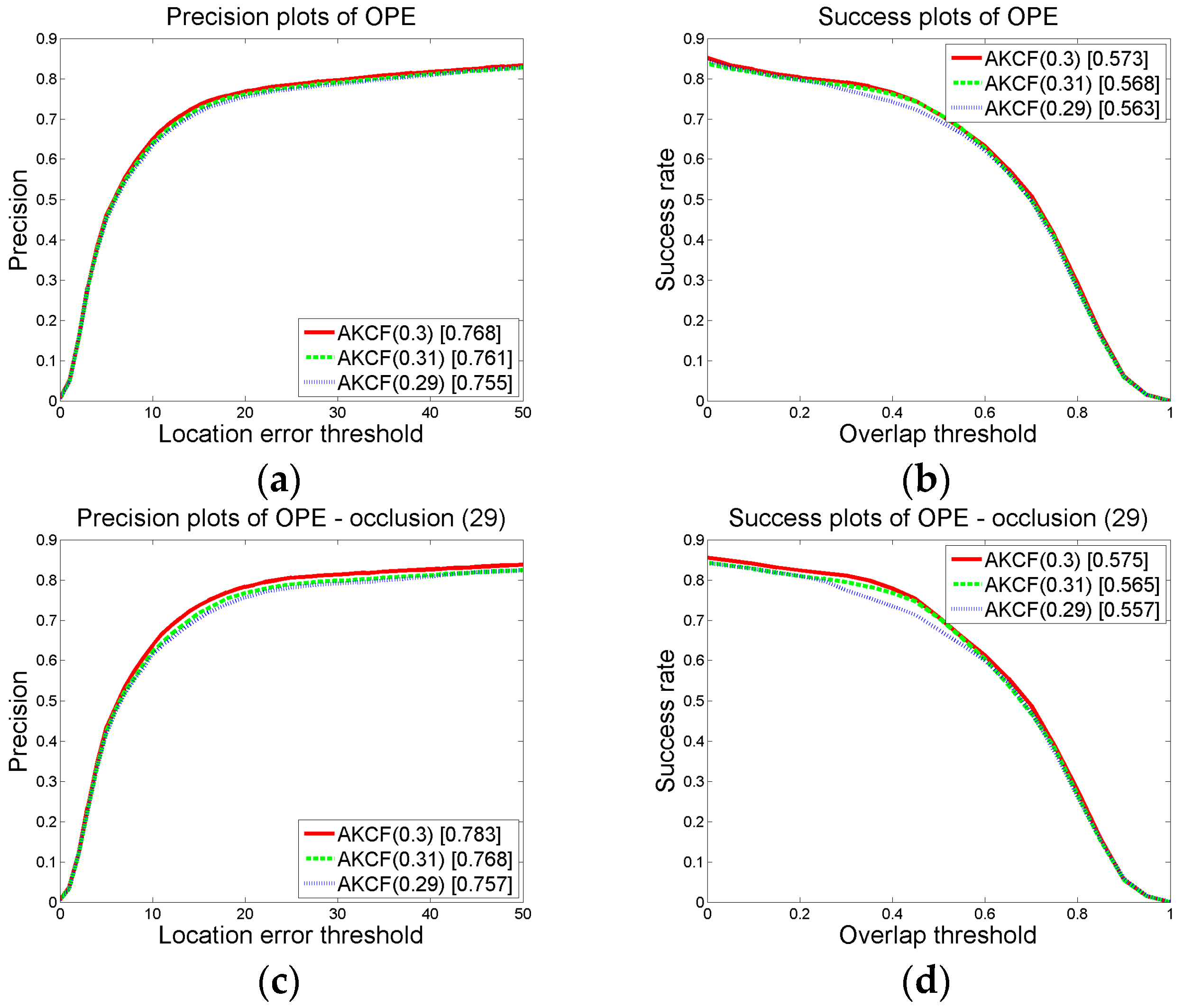
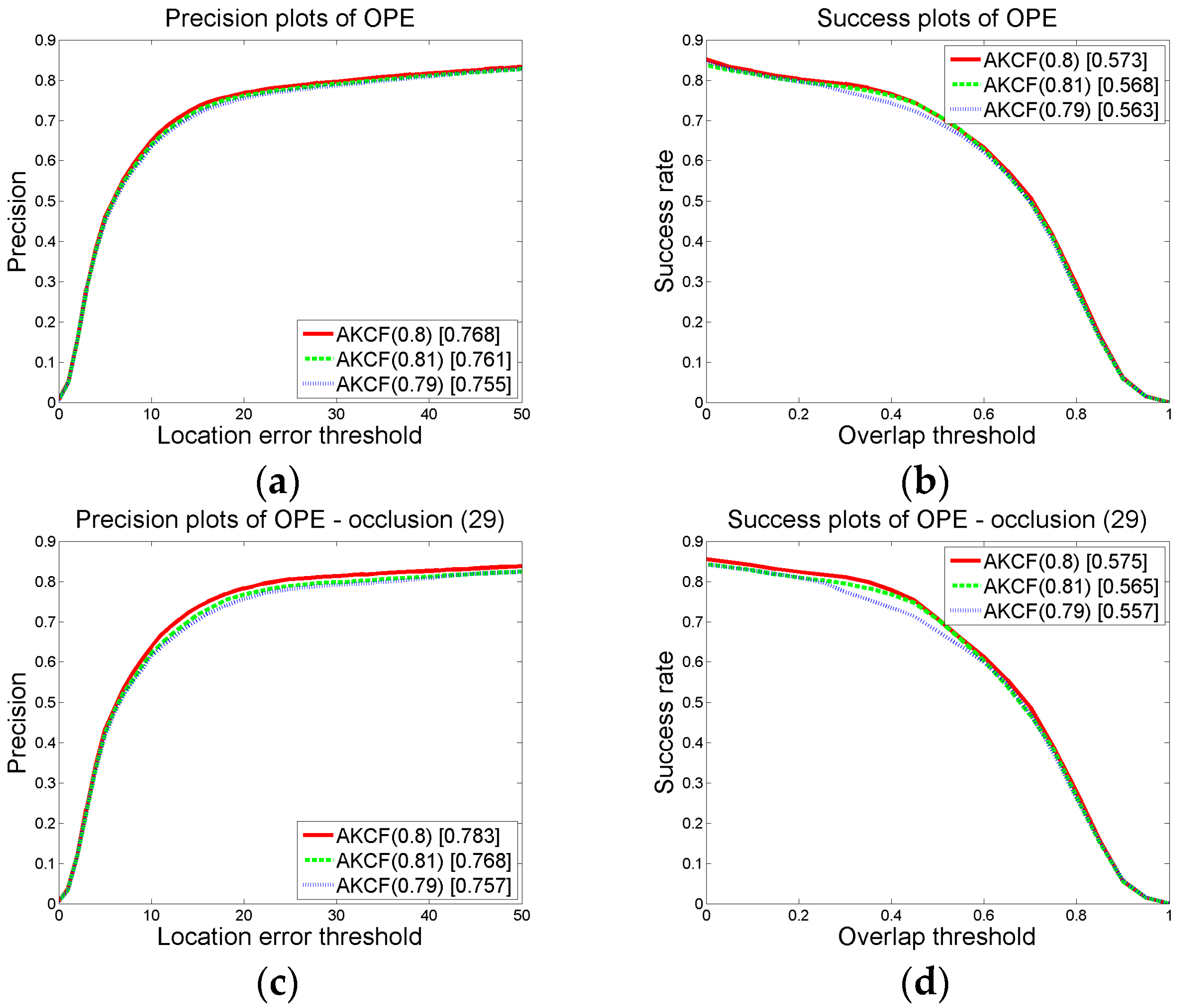
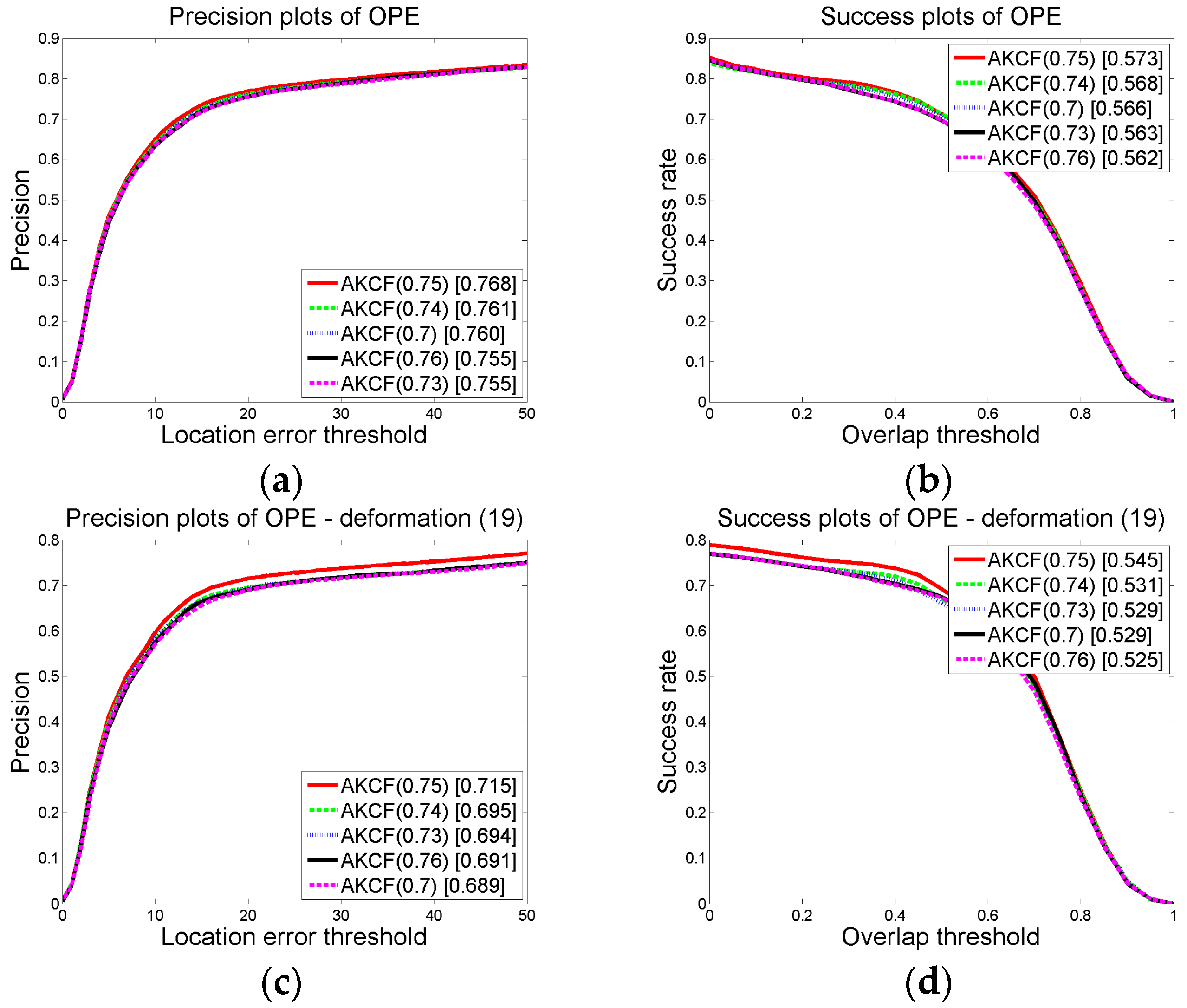
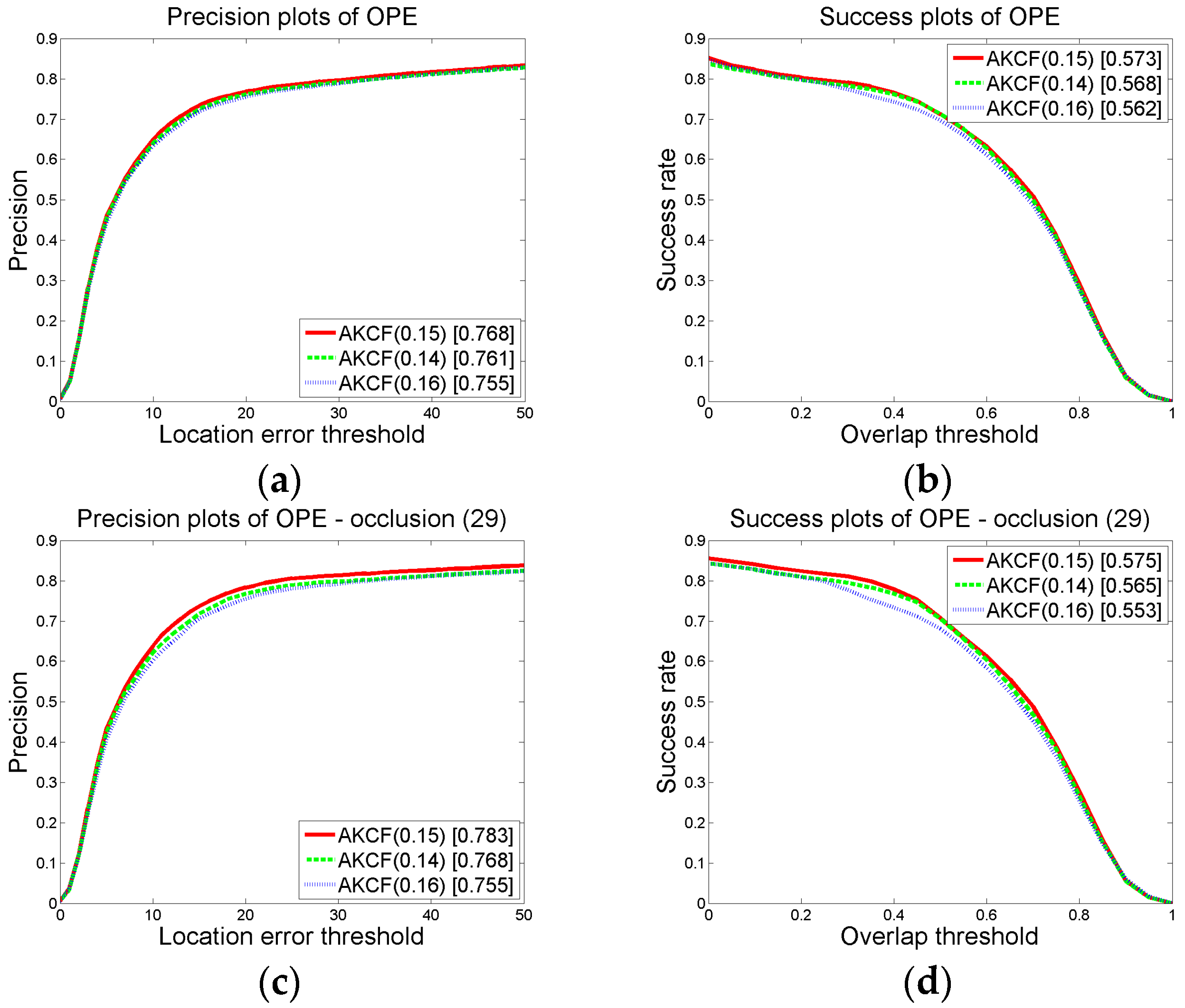
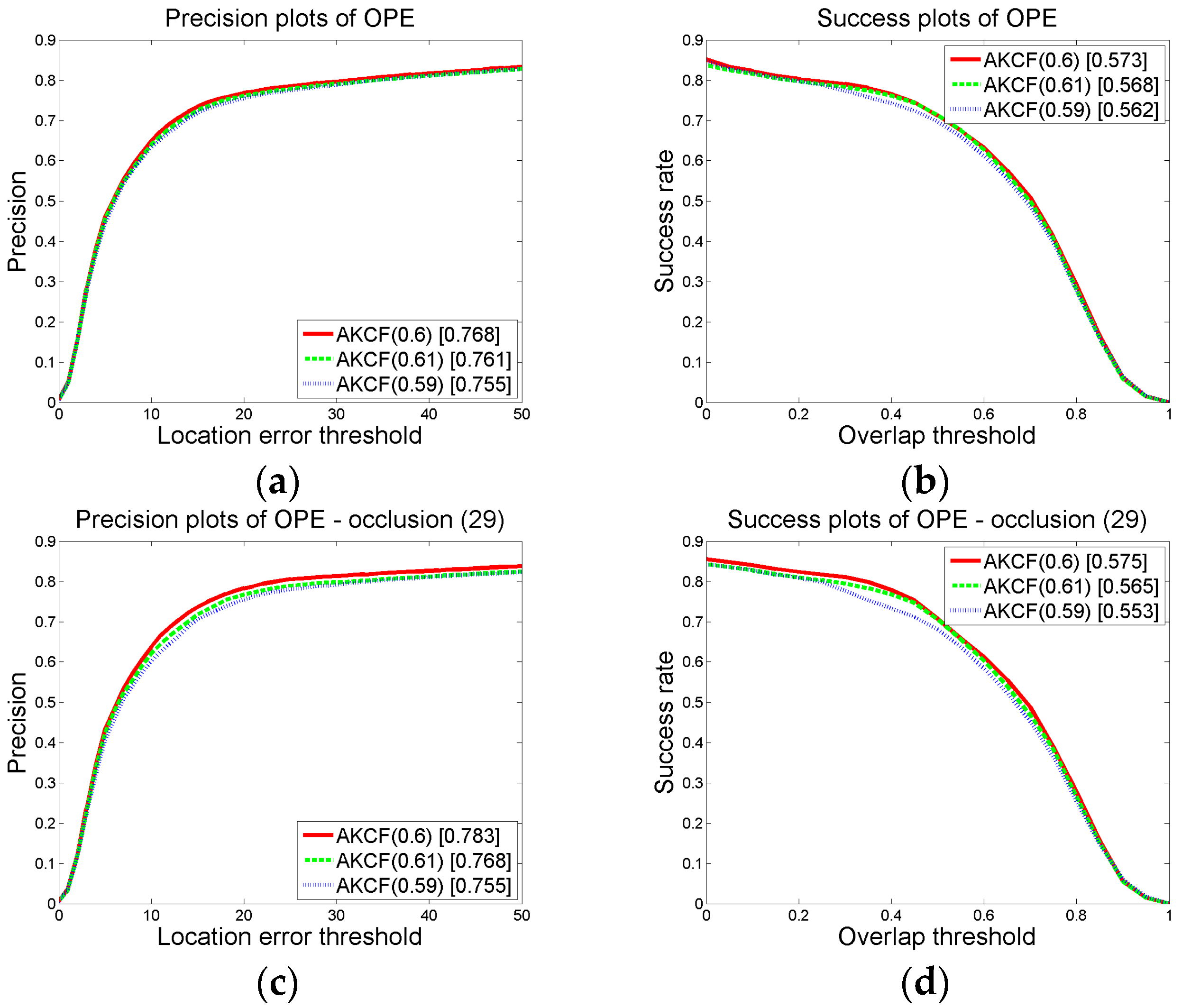
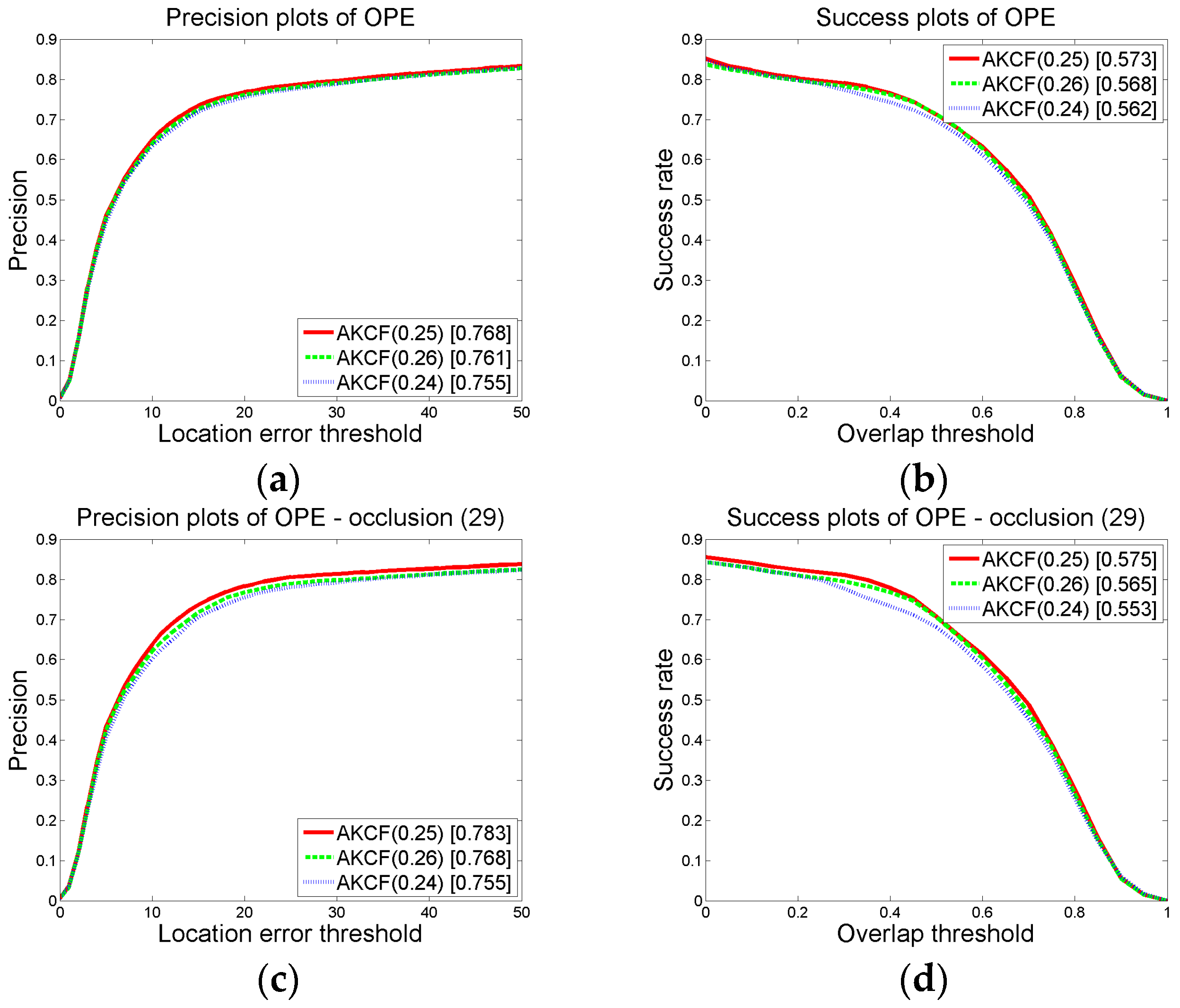
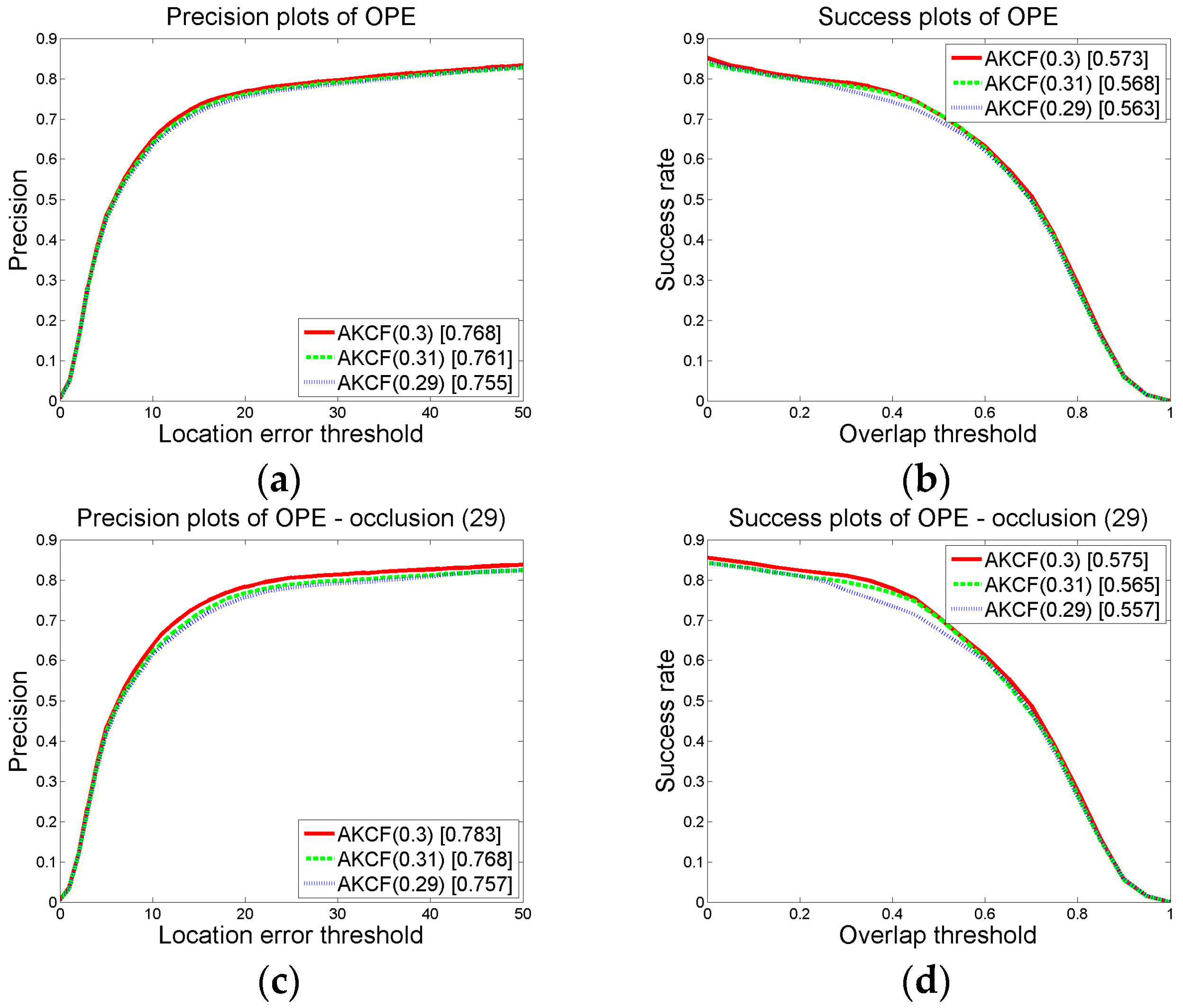
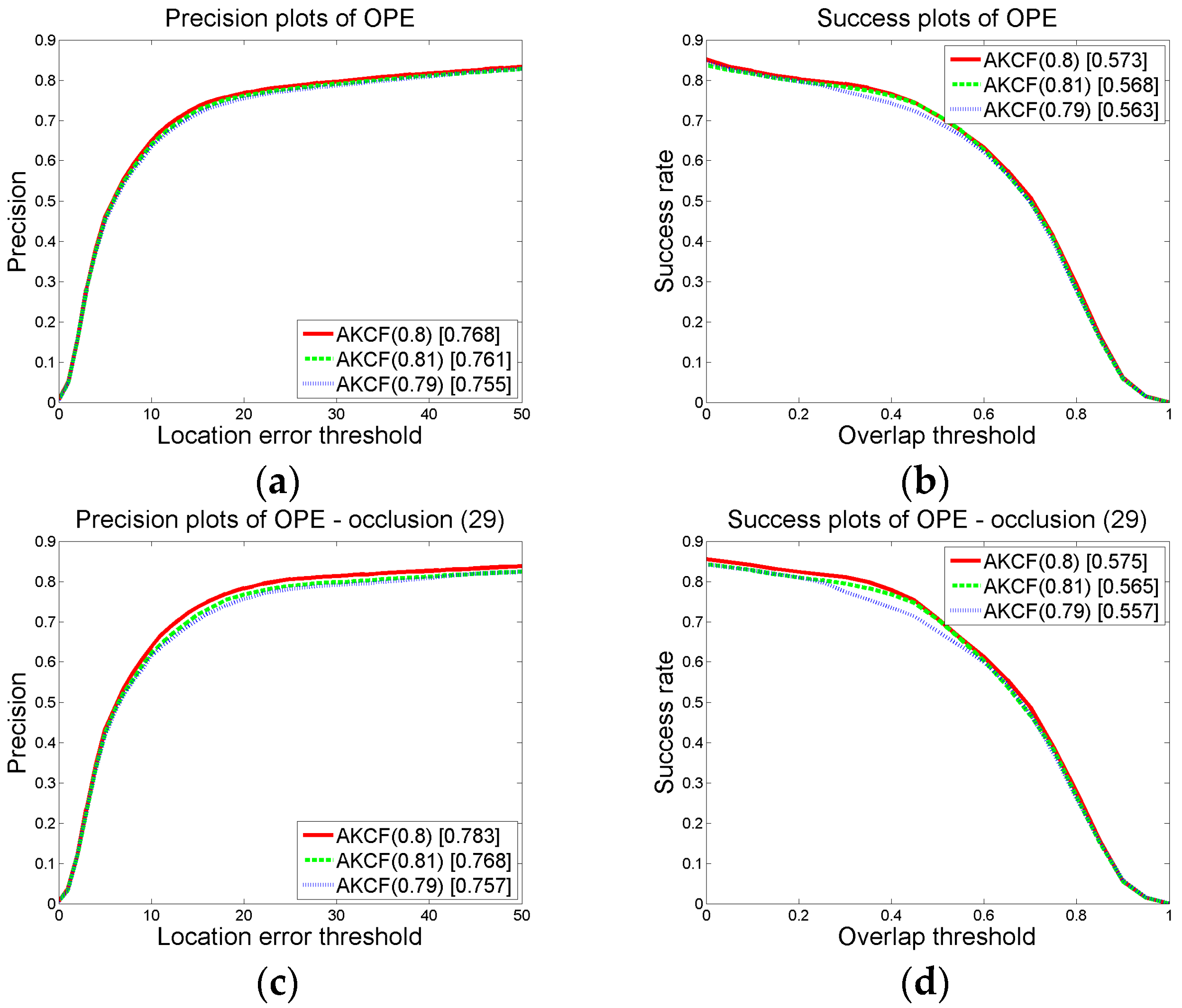
3.1.2. Parameter Settings and Discussion
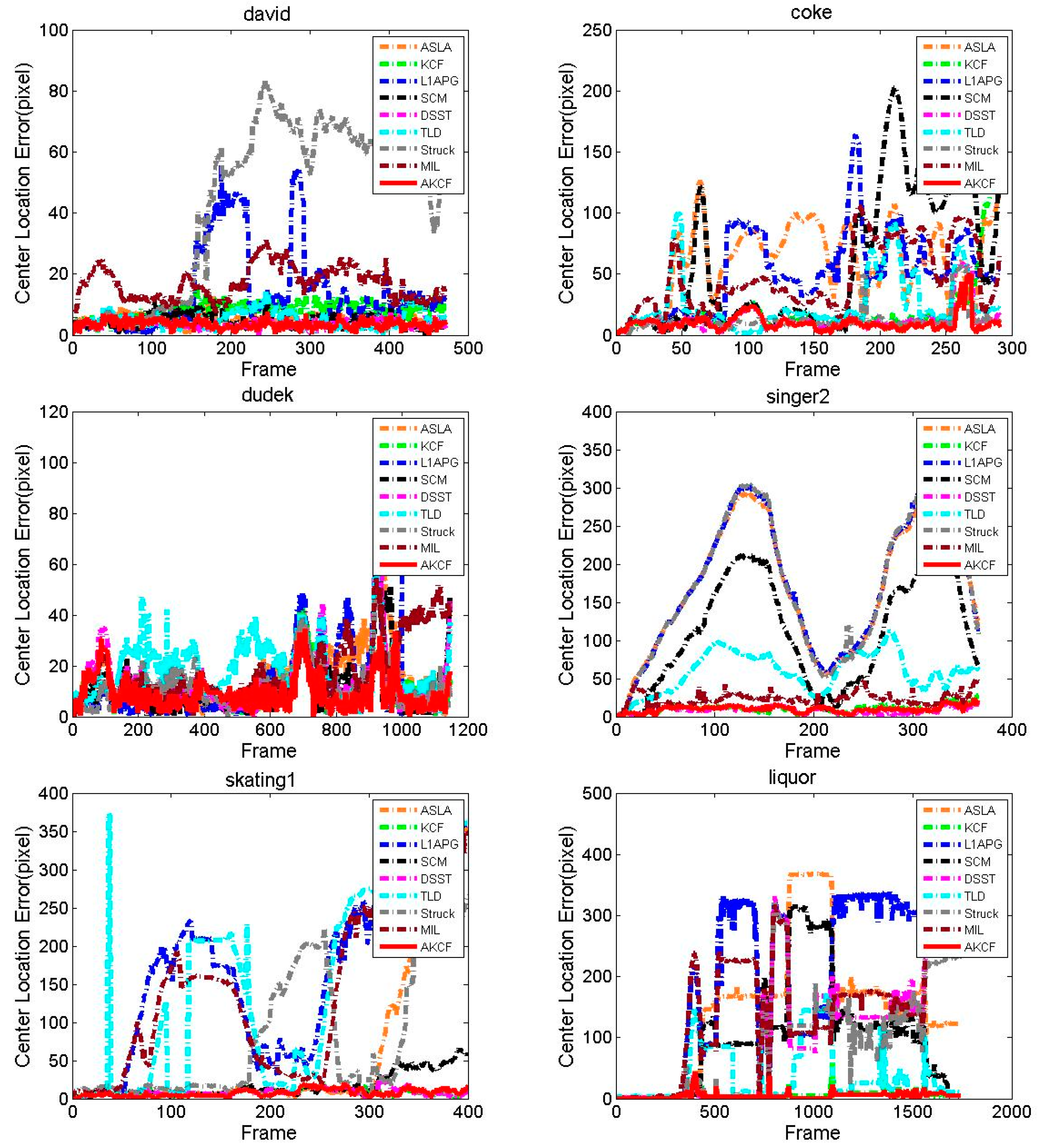
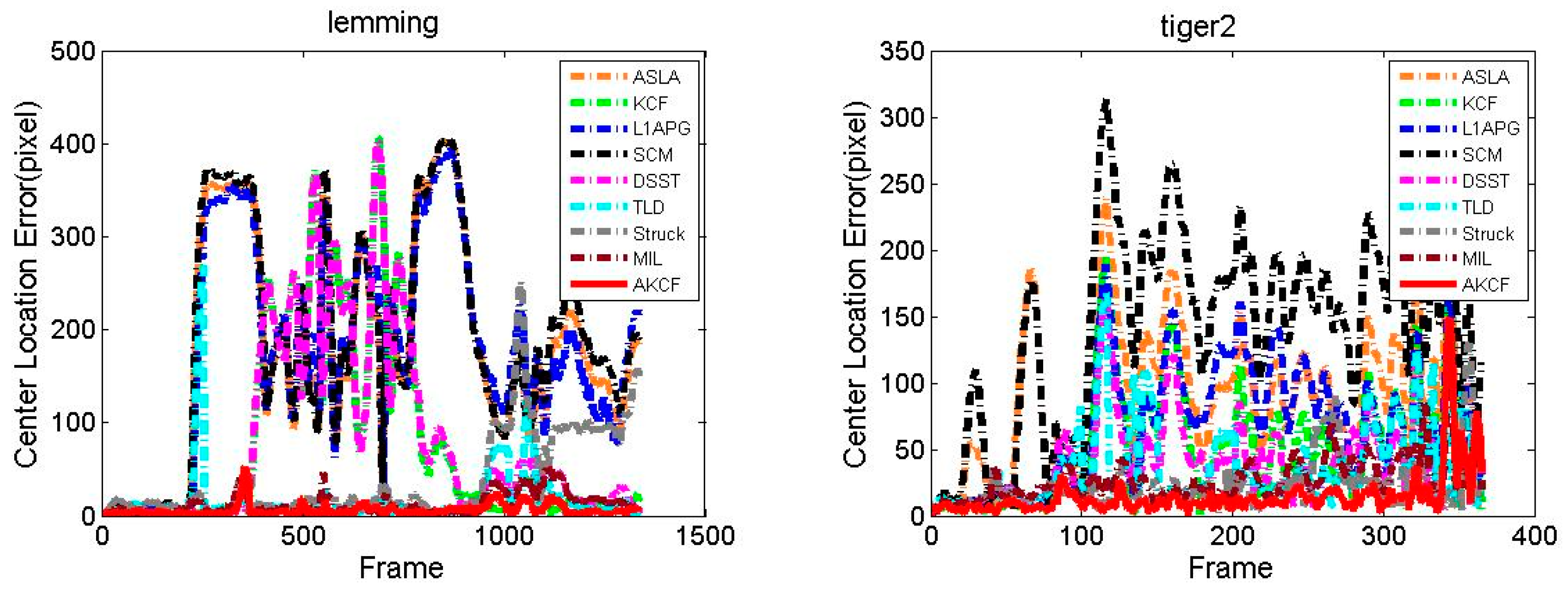
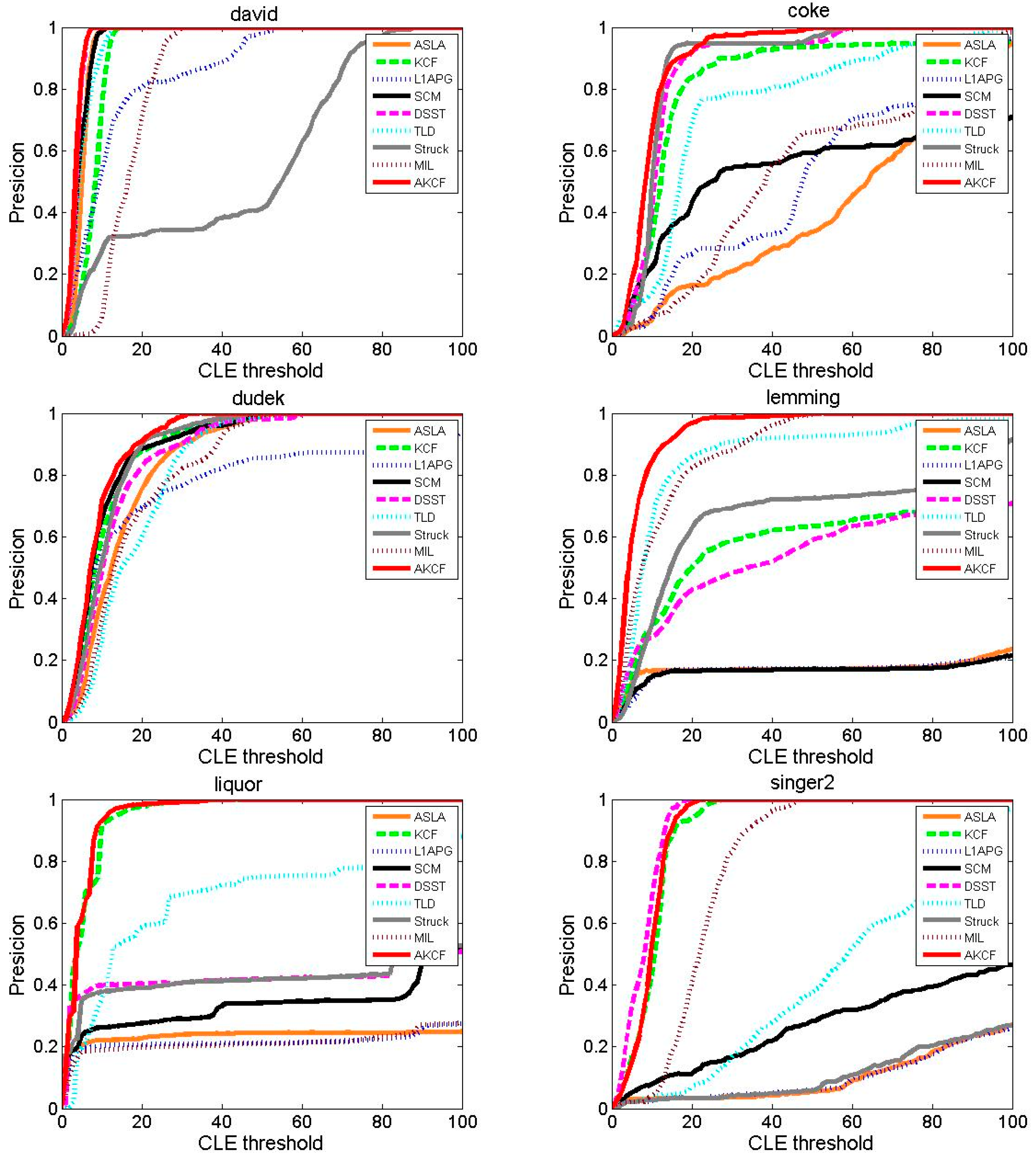
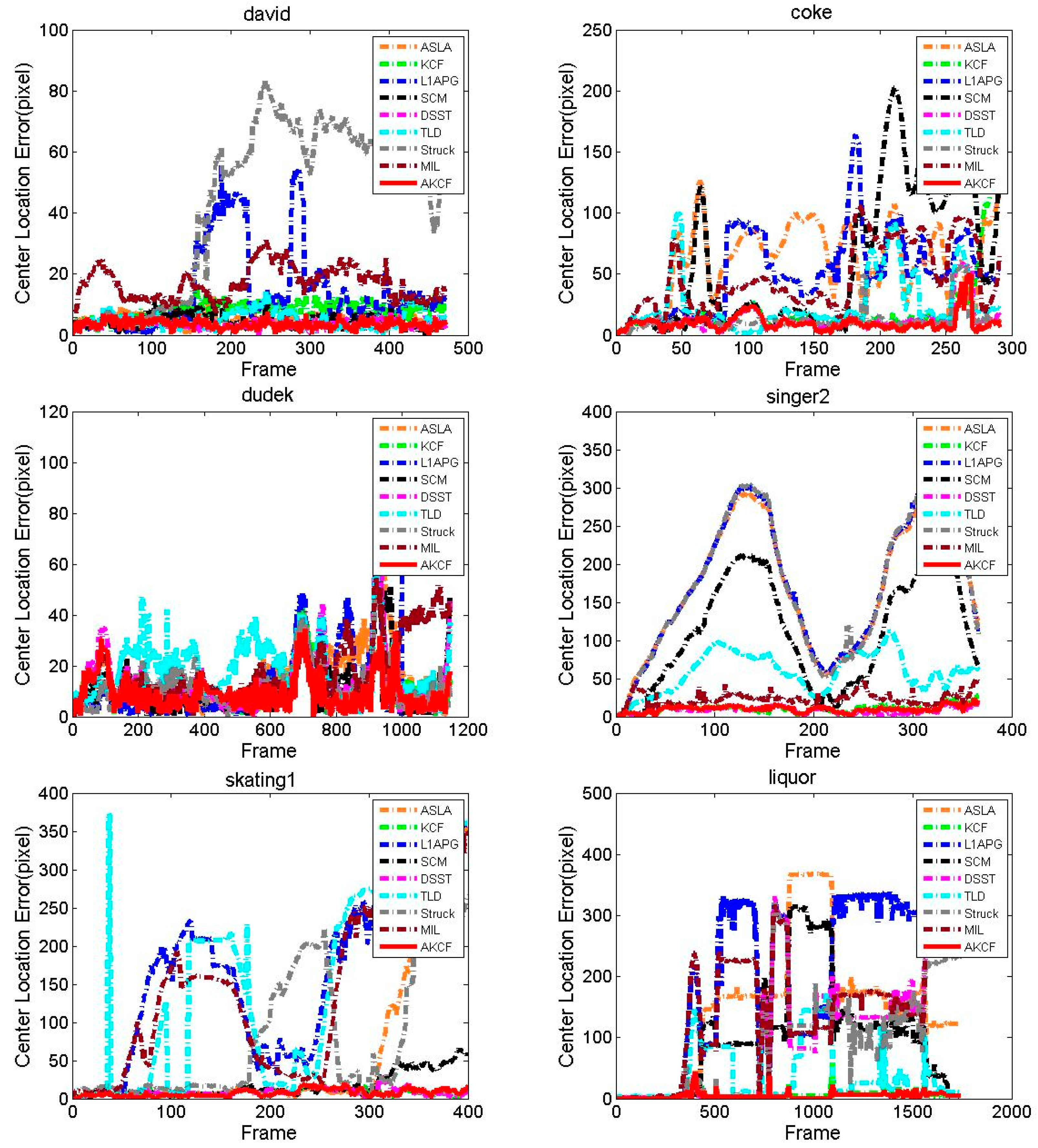
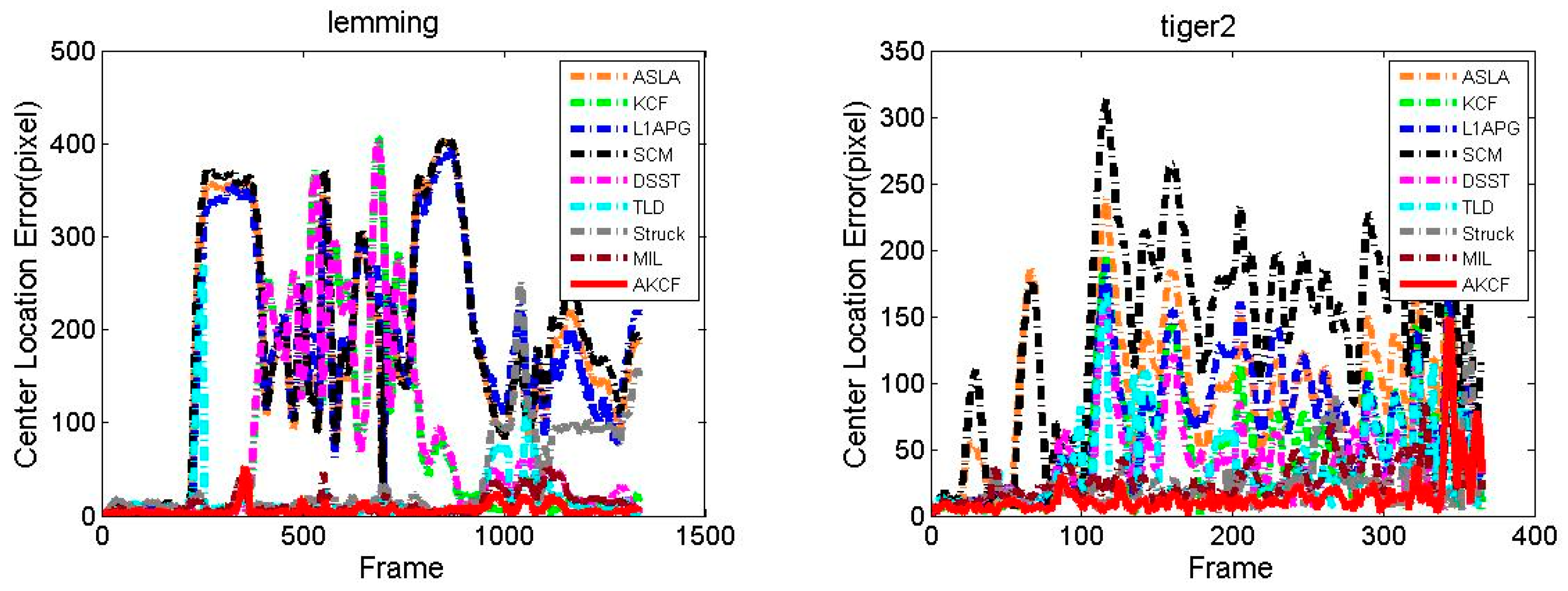
3.1.3. Experiment on Eight Typical Video Sequences
Center Location Error Comparison
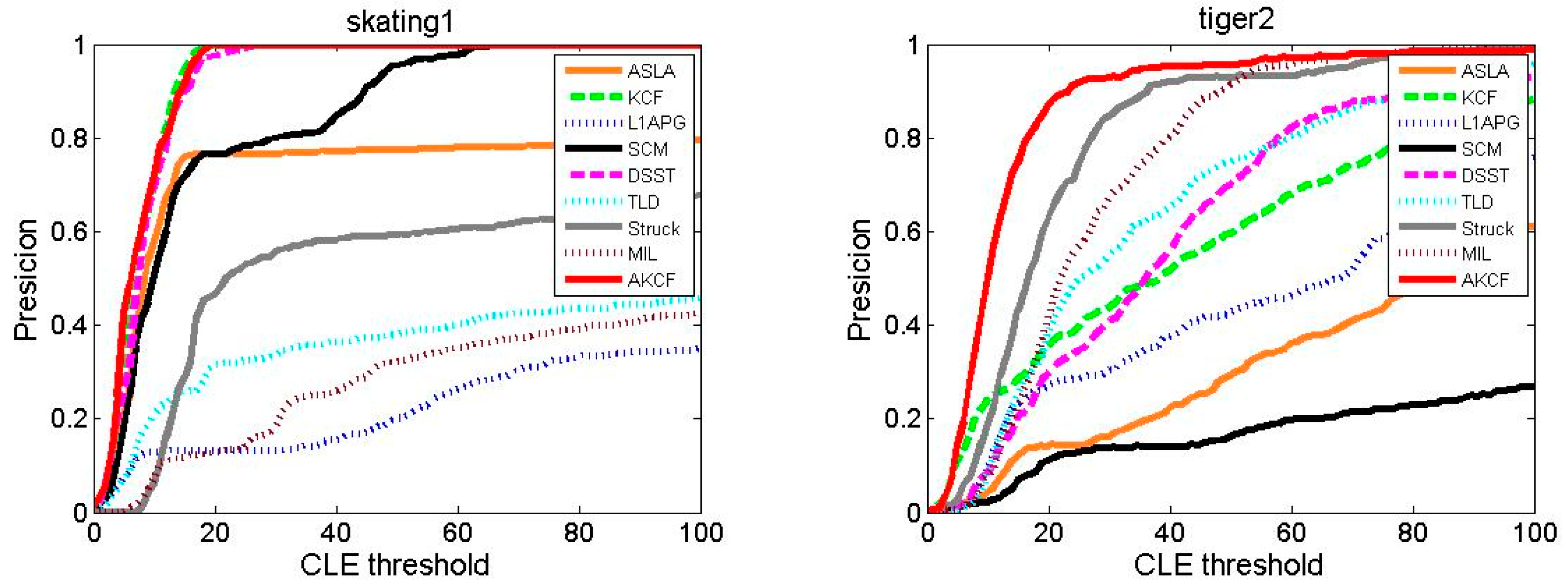
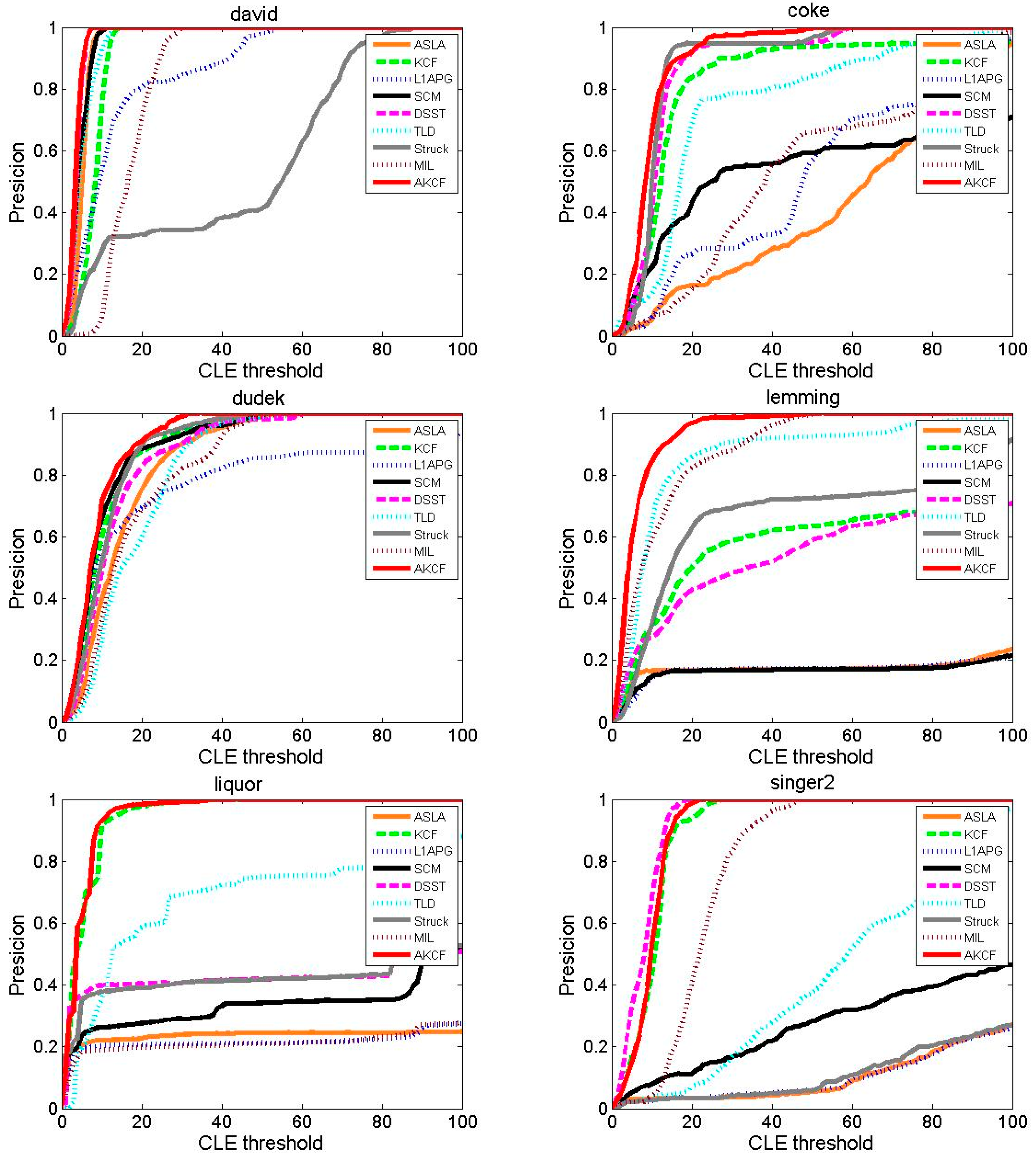
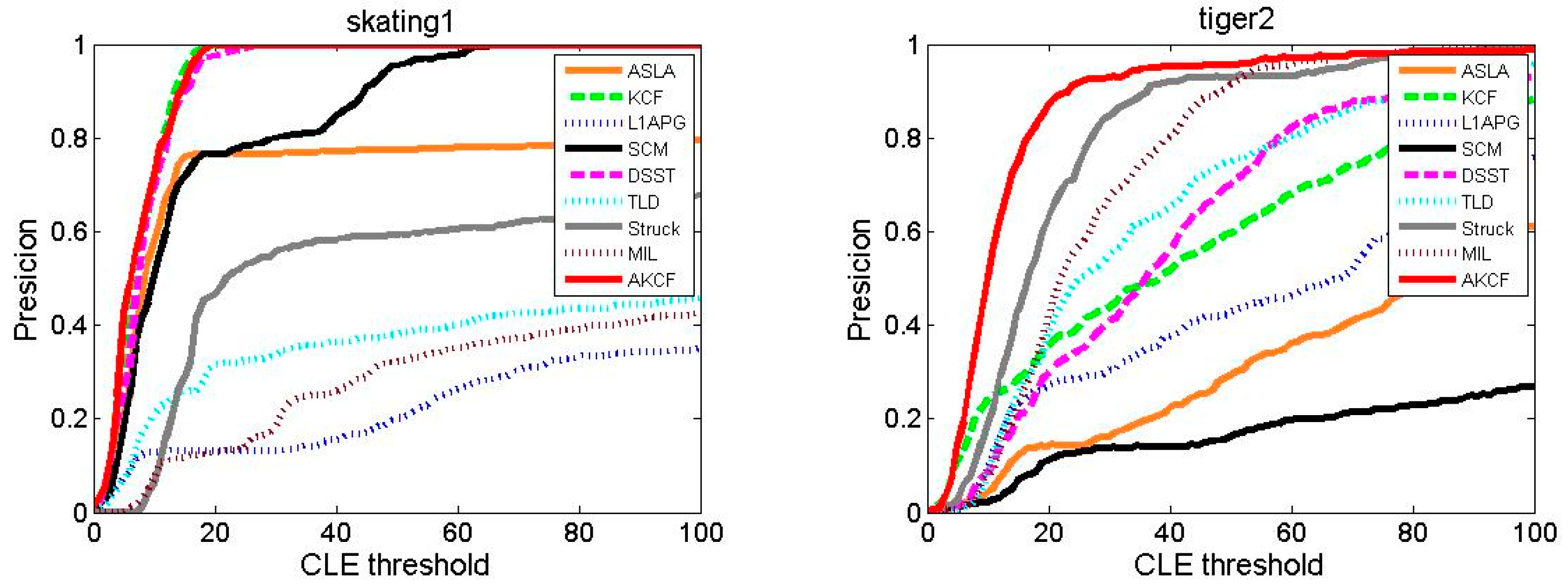
Tracking Precision Comparison
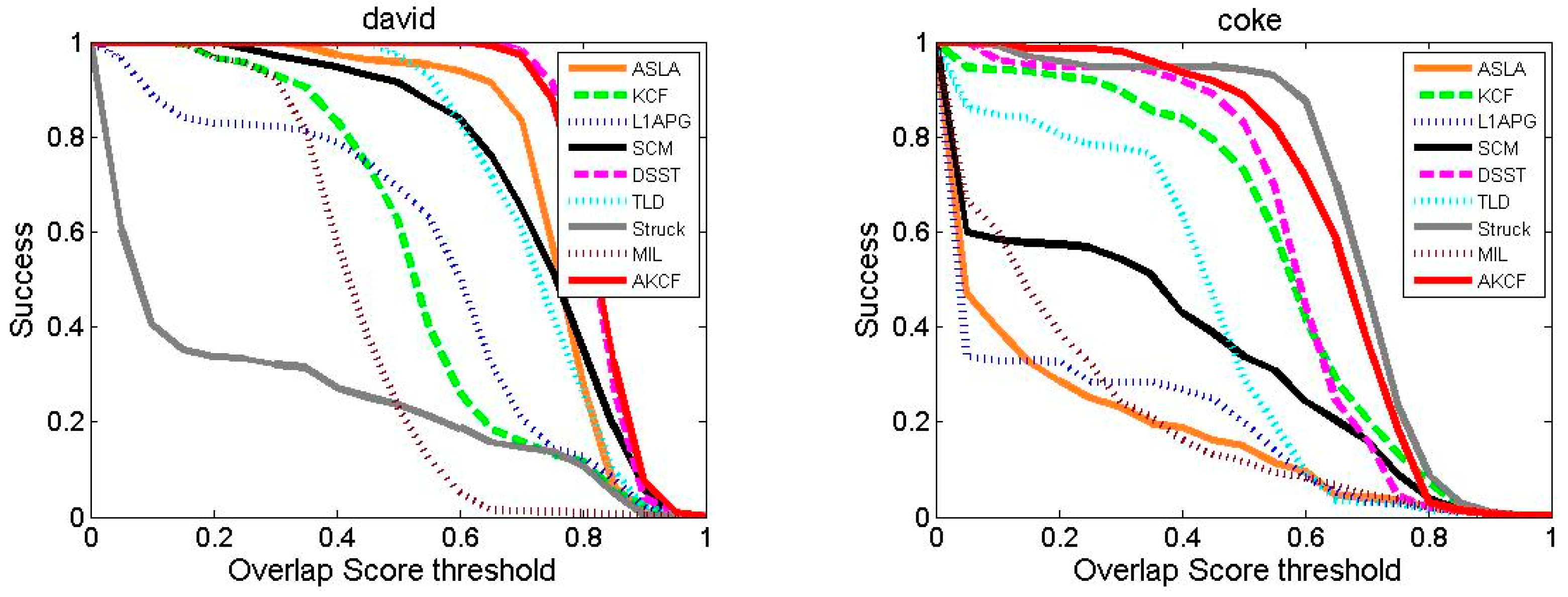
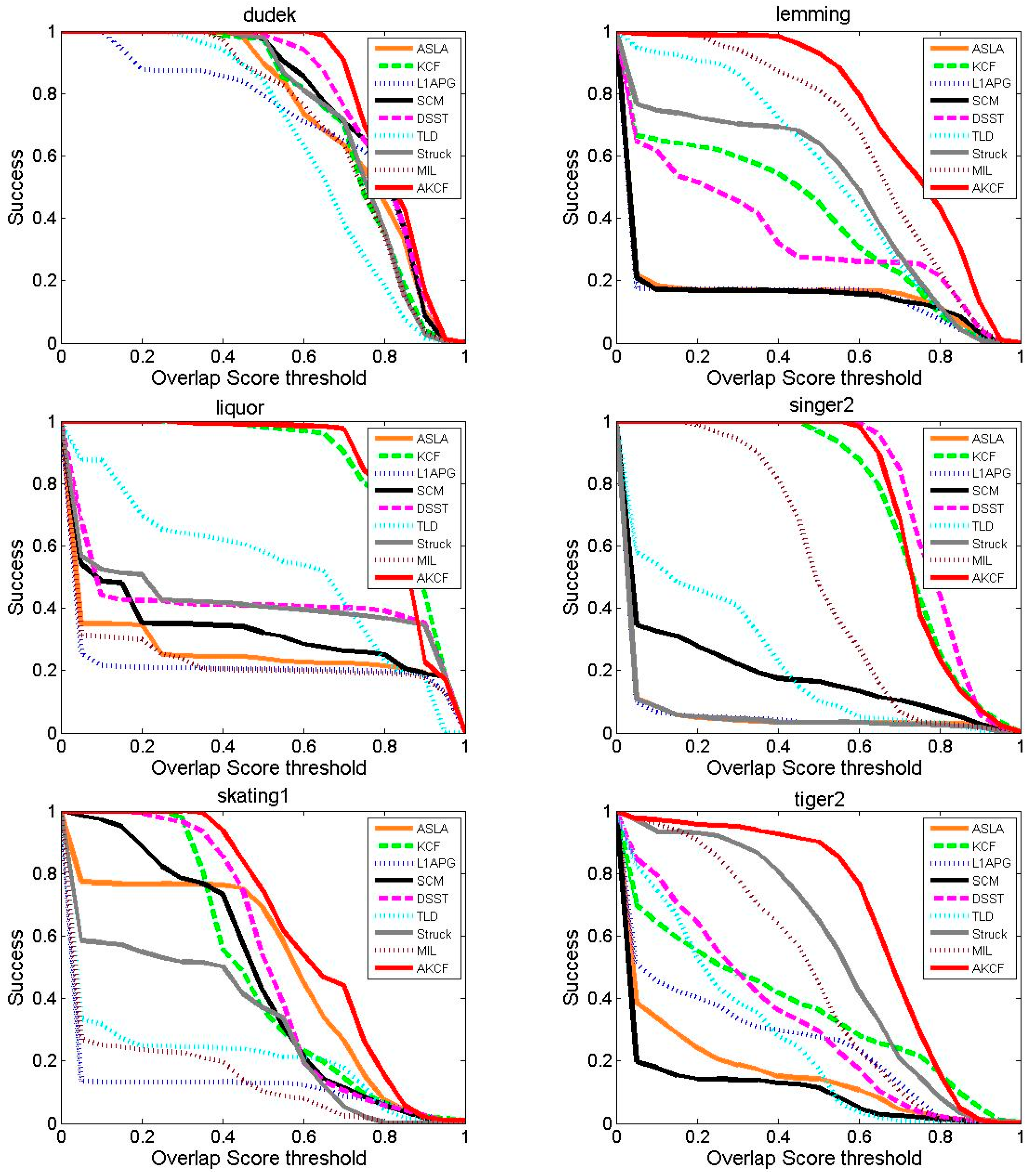
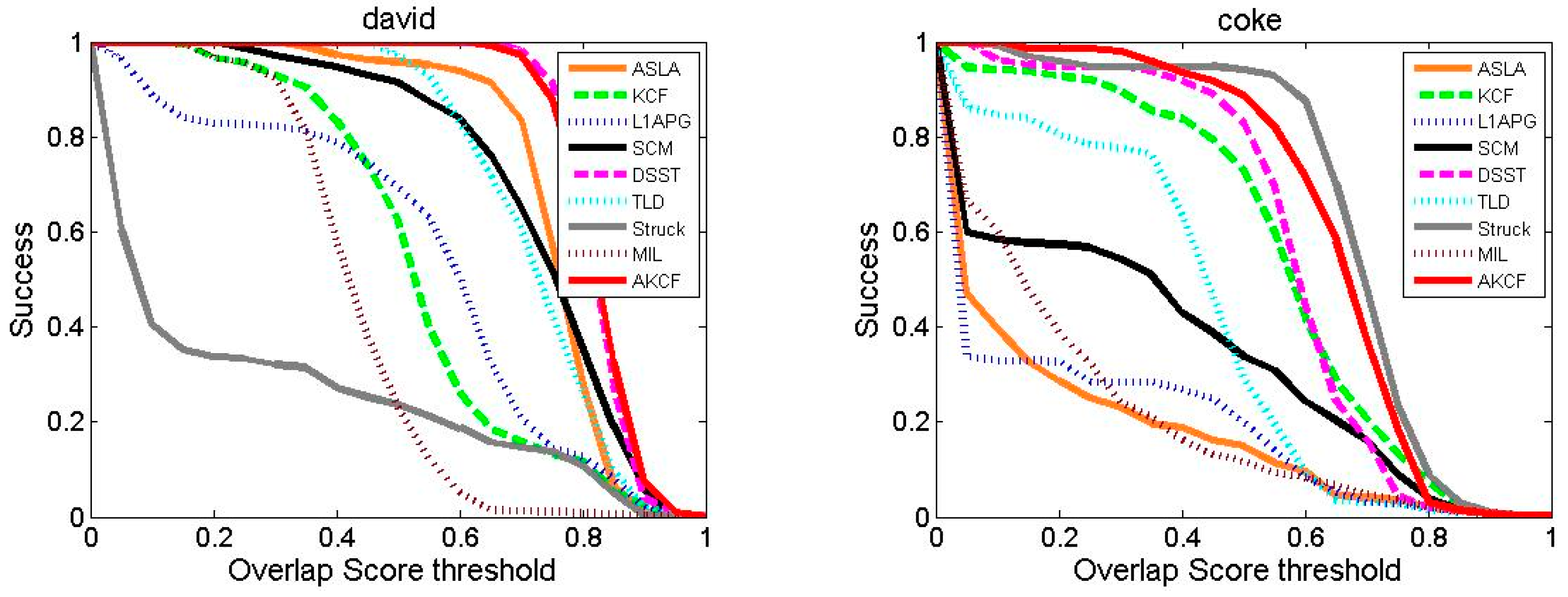
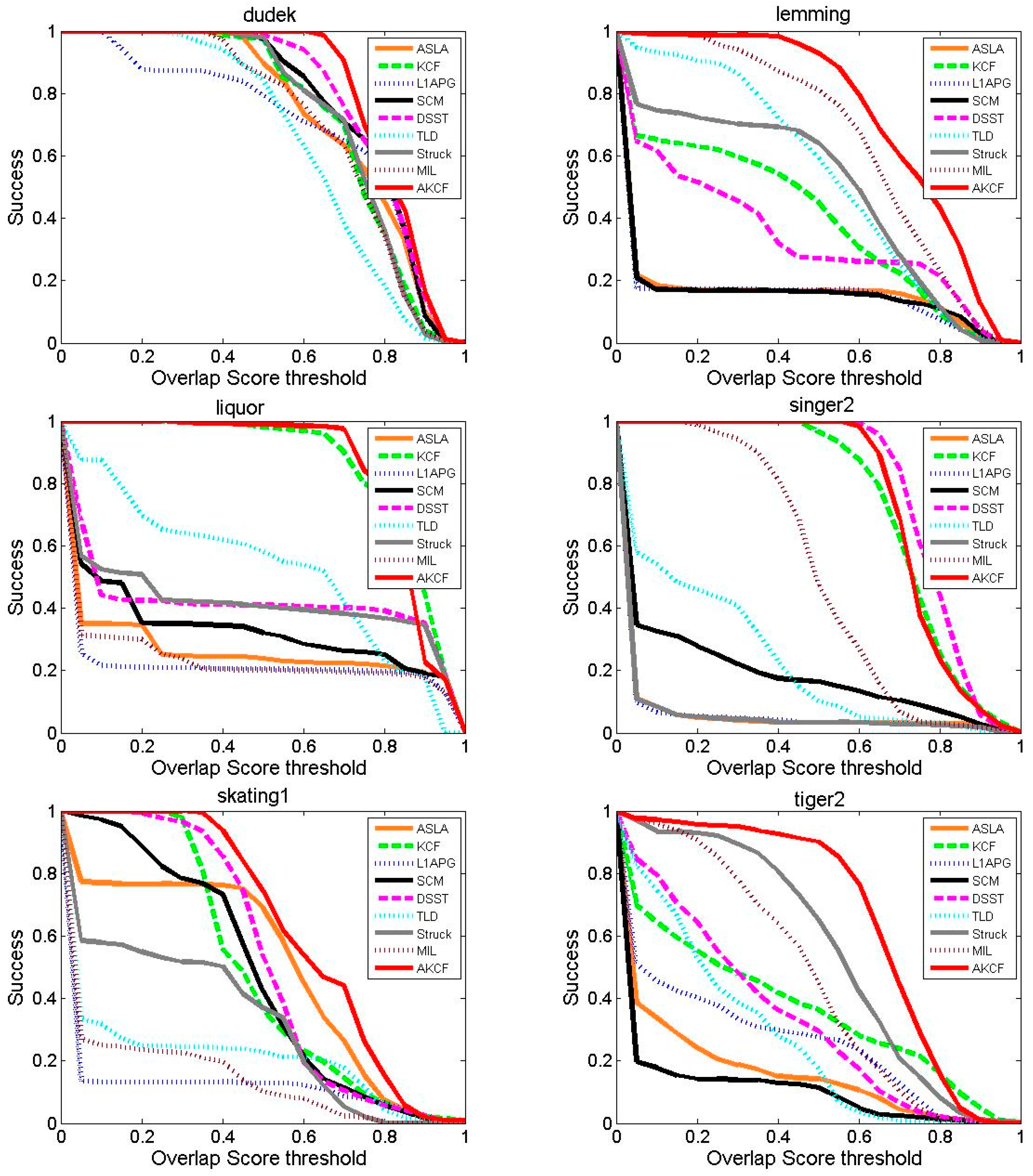
Tracking Success Rate Comparison
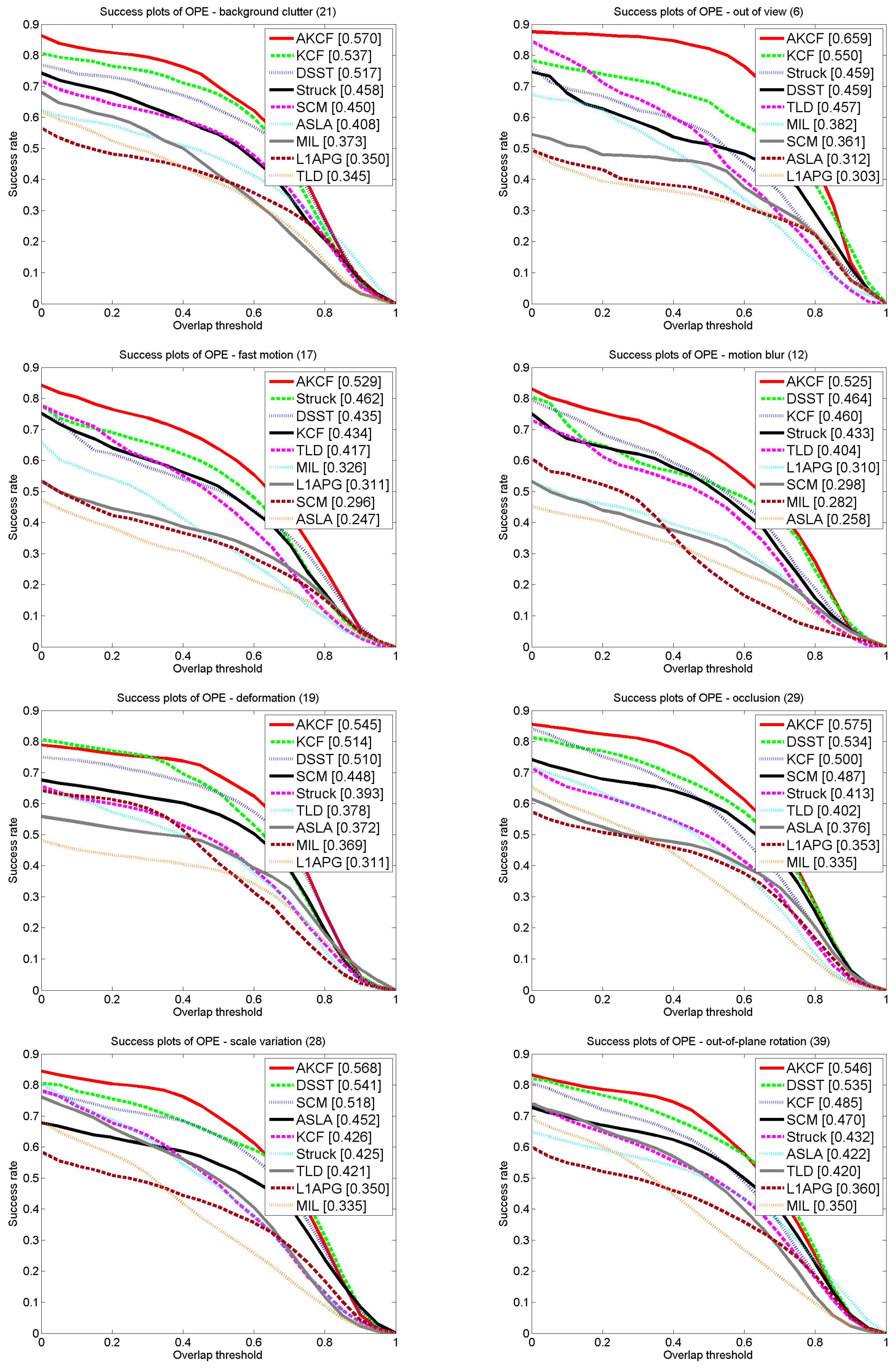
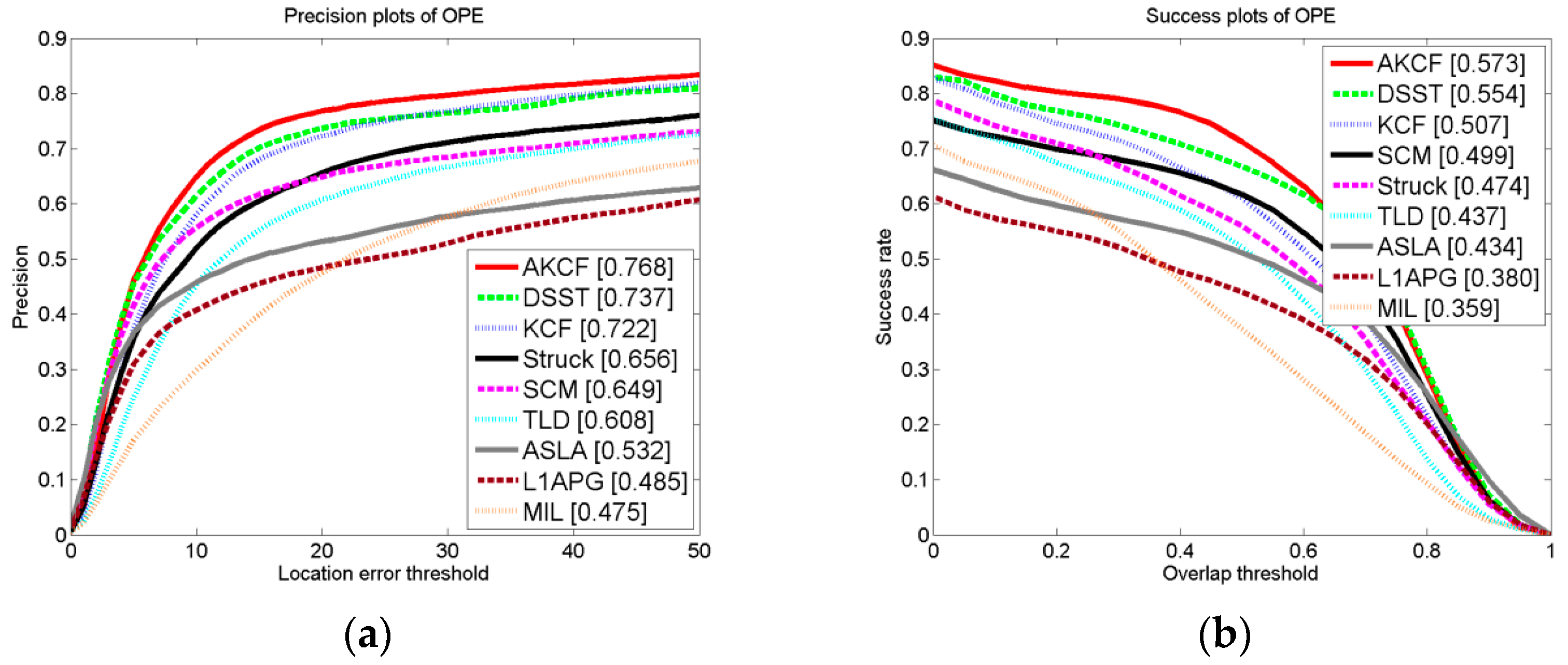
3.1.4. Experiment on CVPR2013 Benchmark
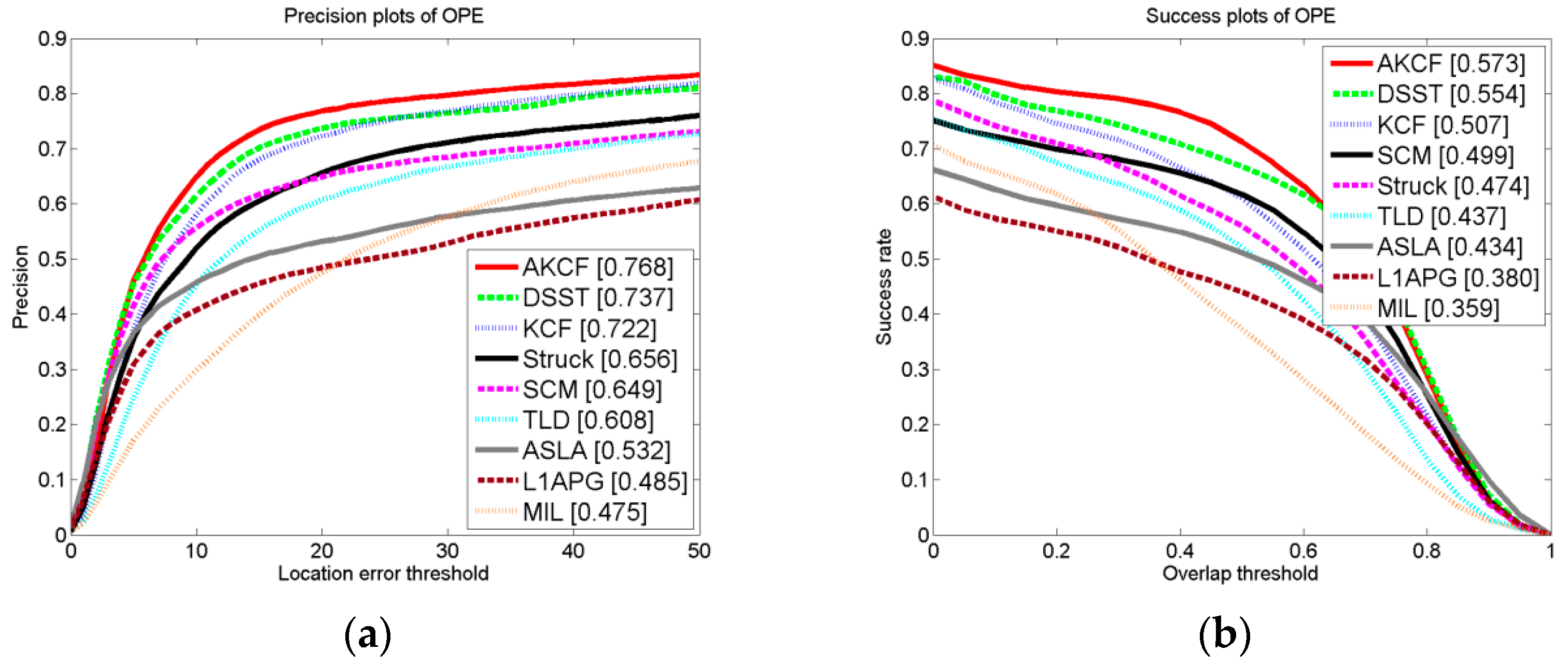
Overall Performance Comparison
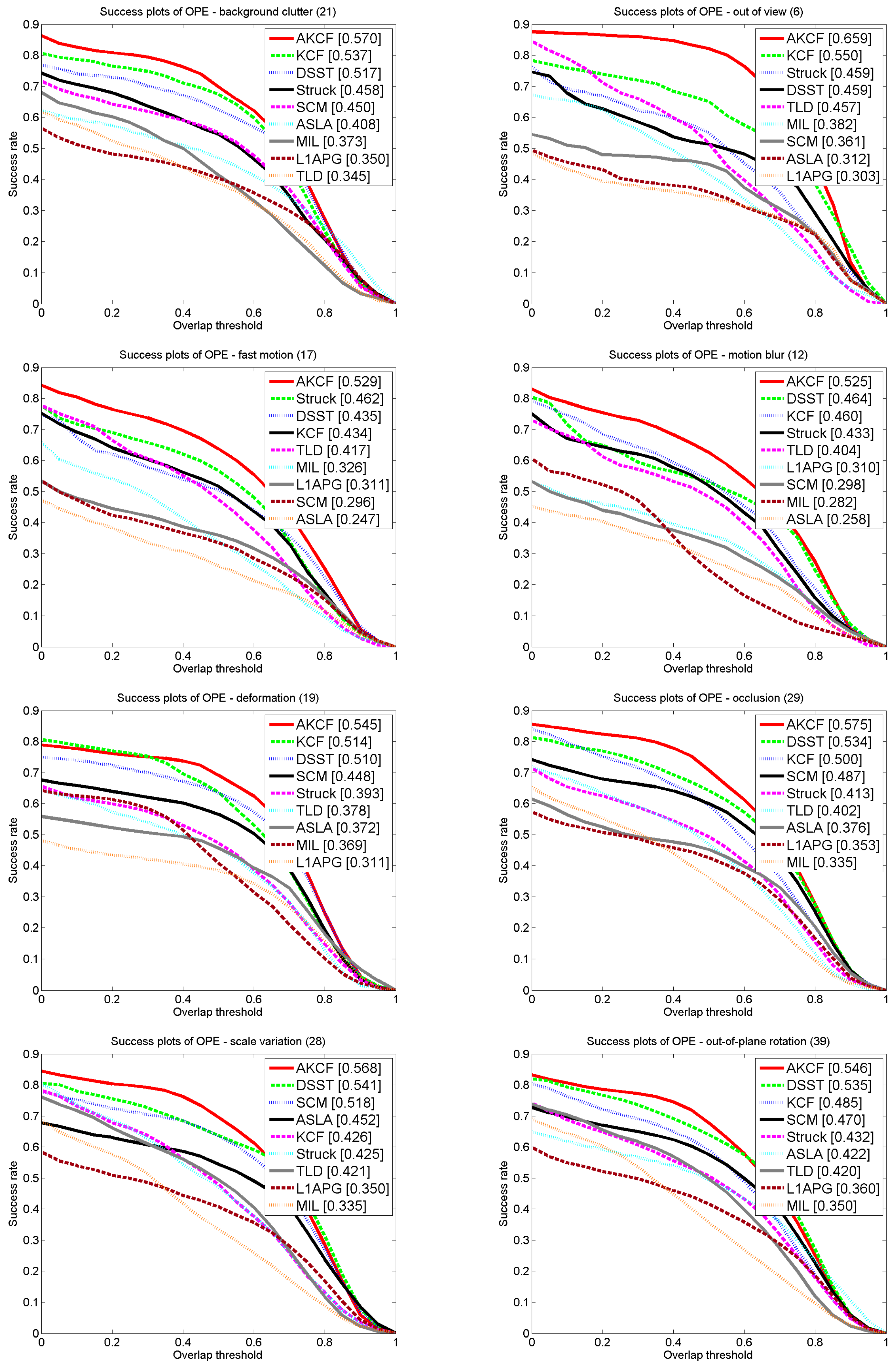
The Comparison Results for Different Attributes
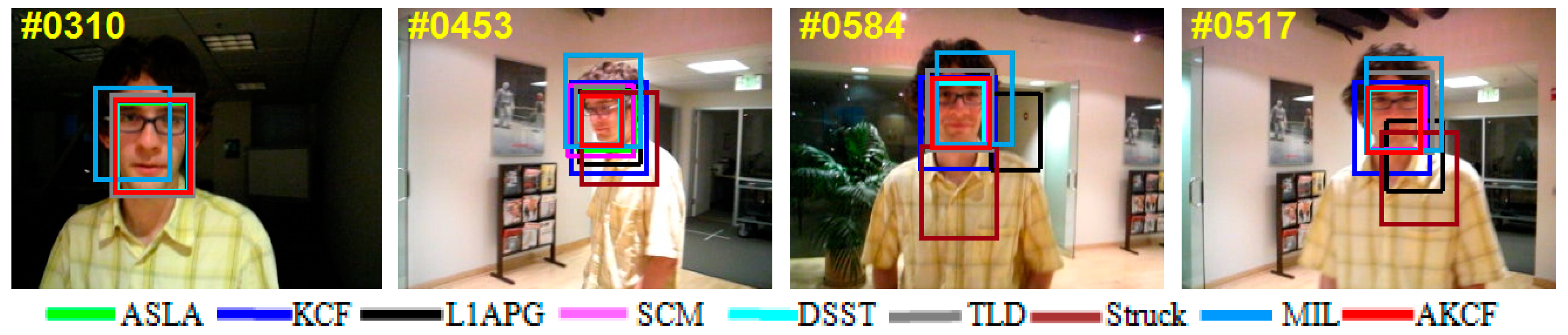
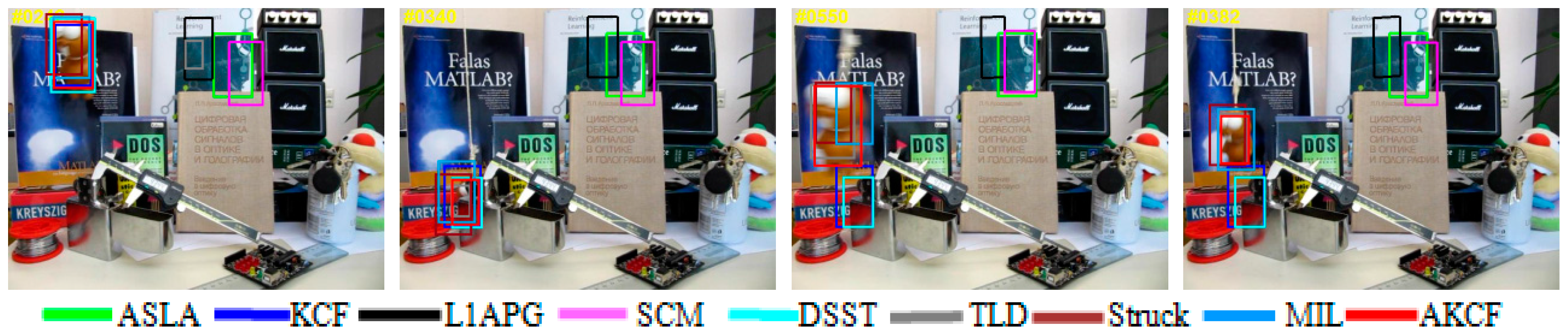
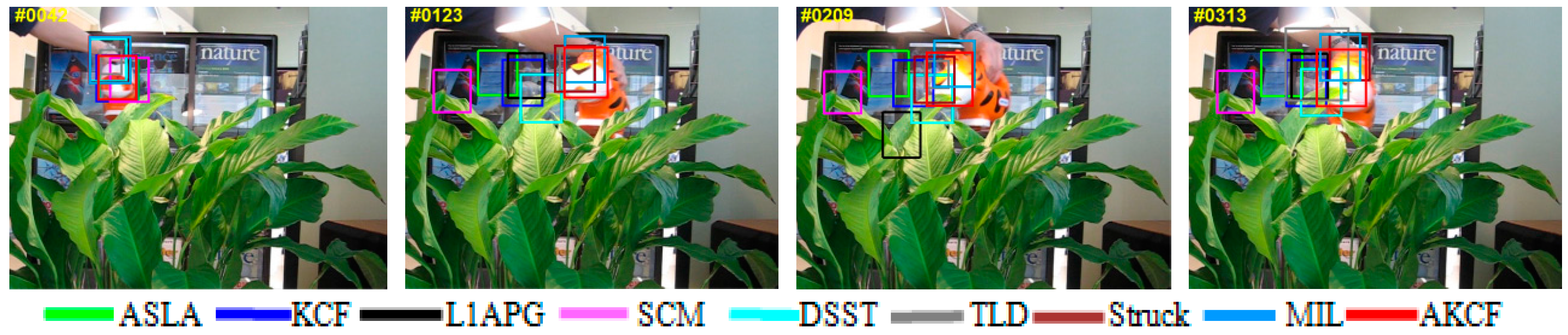
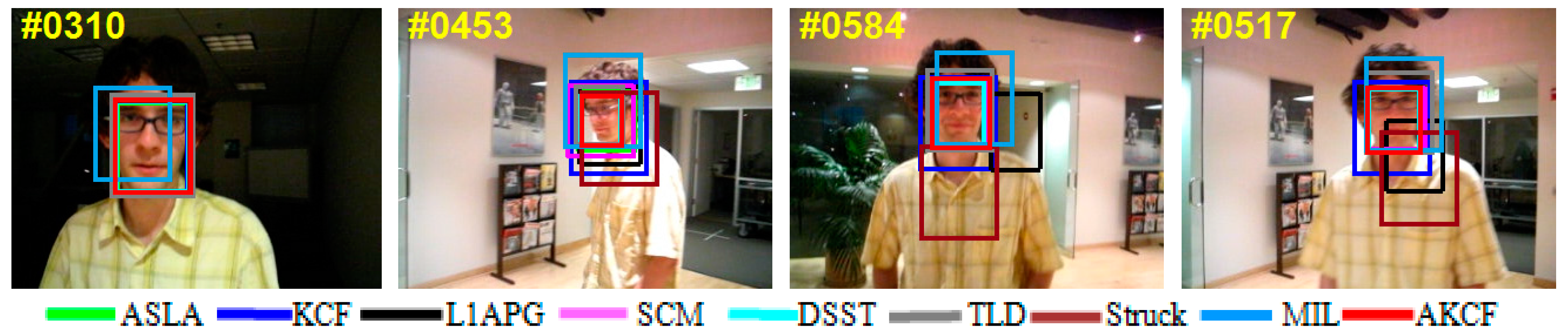
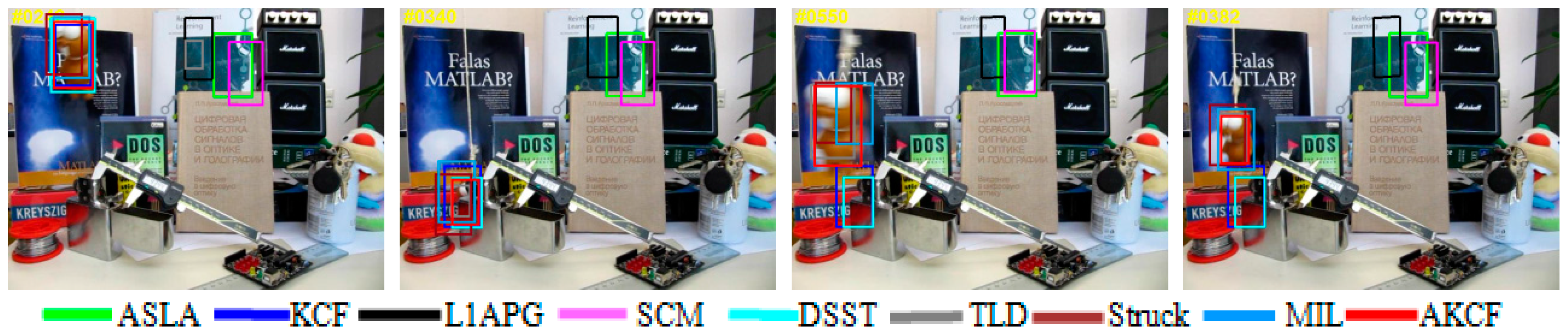
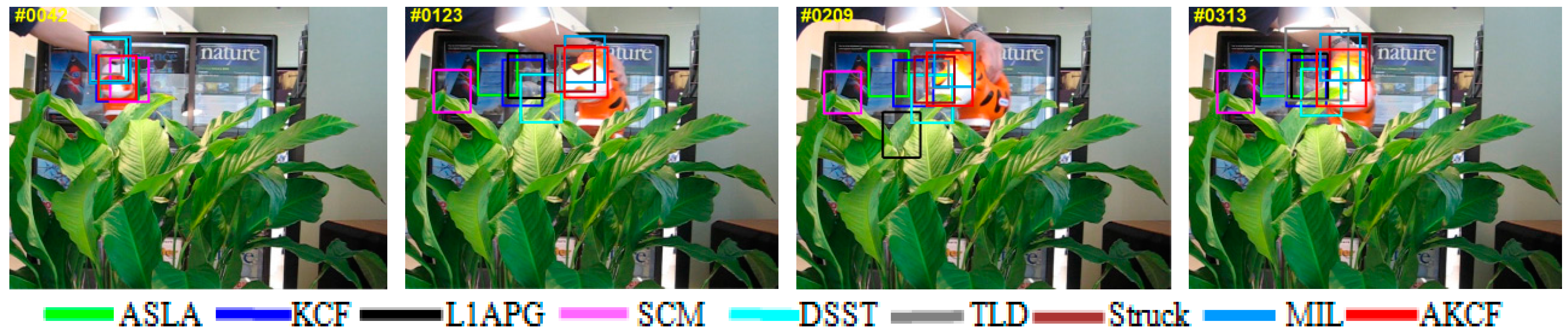
3.2. Qualitative Evaluation
3.3. Comparison of Tracking Speed
3.4. Discussion
3.4.1. Scale Variation
3.4.2. Partial or Long-Time Large-Area Occlusion
3.4.3. Out of View
3.4.4. Fast Motion
3.4.5. Deformation and Rotation
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38, 13. [Google Scholar] [CrossRef]
- Lee, D.Y.; Sim, J.Y.; Kim, C.S. Visual Tracking Using Pertinent Patch Selection and Masking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Jepson, A.D.; Fleet, D.J.; Elmaraghi, T.F. Robust Online Appearance Models for Visual Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1296–1311. [Google Scholar] [CrossRef]
- Grabner, H.; Grabner, M.; Bischof, H. Real-Time Tracking via On-line Boosting. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006. [Google Scholar]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.-H. Incremental Learning for Robust Visual Tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Zhong, W.; Lu, H.; Yang, M.H. Robust Object Tracking via Sparse Collaborative Appearance Model. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 23, 2356–2368. [Google Scholar] [CrossRef] [PubMed]
- Ji, H. Real time robust L1 tracker using accelerated proximal gradient approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Kwon, J.; Lee, K.M. Visual tracking decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Fast Compressive Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Jia, X.; Yang, M.H. Visual tracking via adaptive structural local sparse appearance model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Jepson, A.D.; Fleet, D.J.; Elmaraghi, T.F. Robust Online Appearance Models for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Collins, R.T.; Liu, Y.; Leordeanu, M. Online selection of discriminative tracking features. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1631–1643. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Song, H. Real-time visual tracking via online weighted multiple instance learning. Pattern Recognit. 2013, 46, 397–411. [Google Scholar] [CrossRef]
- Henriques, J.F.; Rui, C.; Martins, P. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012. [Google Scholar]
- Matthews, I.; Ishikawa, T.; Baker, S. The template update problem. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 810–815. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Liu, Q.; He, Z. A multi-view model for visual tracking via correlation filters. Knowl.-Based Sys. 2016, 113, 88–99. [Google Scholar] [CrossRef]
- Ma, B.; Hu, H.; Shen, J. Generalized Pooling for Robust Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 25, 4199–4208. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.; Huang, L.; Shen, J. Visual Tracking under Motion Blur. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 25, 5867–5876. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Gustav, H.; Khan, F.S.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhang, L.; Suganthan, P.N. Robust Visual Tracking via Co-trained Kernelized Correlation Filters. Pattern Recognit. 2017, 69, 82–93. [Google Scholar] [CrossRef]
- Zuo, Z.; Wang, G.; Shuai, B; Zhao, L; Yang, Q. Exemplar based Deep Discriminative and Shareable Feature Learning for Scene Image Classification. Pattern Recognit. 2015, 48, 3004–3015. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Yang, X.; Zhang, C. Long-term correlation tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–12 June 2015. [Google Scholar]
- Yang, R.; Wei, Z. Discriminative descriptors for object tracking. Knowl.-Based Sys. 2016, 35, 146–154. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 21–23 September 2005. [Google Scholar]
- Danelljan, M.; Khan, F.S.; Felsberg, M. Adaptive Color Attributes for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Liu, T.; Wang, G.; Yang, Q. Real-time part-based visual tracking via adaptive correlation filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–12 June 2015. [Google Scholar]
- Jeong, S.; Kim, G.; Lee, S. Effective Visual Tracking Using Multi-Block and Scale Space Based on Kernelized Correlation Filters. Sensors 2017, 17, 433. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Zhang, L.; Xie, L. Kernel Cross-Correlator. Available online: https://arxiv.org/pdf/1709.05936.pdf (accessed on 14 November 2017).
- Ma, C.; Huang, J.B.; Yang, X. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Hare, S.; Torr, P.; Saffari, A. Struck: Structured Output Tracking with Kernels. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Kalal, Z.; Matas, J.; Mikolajczyk, K. P-N learning: Bootstrapping binary classifiers by structural constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | Image Size | Target Size | Main Confronted Scenes |
|---|---|---|---|
| David | 240 × 20 | 64 × 78 | SV,OCC,DEF,OPR |
| Coke | 640 × 480 | 48 × 80 | IV,OCC,FM,IPR |
| Dudek | 480 × 720 | 132 × 176 | SV,IPR,OPR,FM |
| Lemming | 640 × 480 | 70 × 122 | SV,OCC,FM,OOV |
| Liquor | 480 × 640 | 73 × 210 | OPR,SV,OCC,BC |
| Singer2 | 352 × 624 | 67 × 122 | IV,OPR,DEF,IPR |
| Skating | 640 × 360 | 34 × 84 | IV,SV,OCC,DEF |
| Tiger2 | 480 × 640 | 68 × 78 | OPR,OCC,FM,IPR |
| Algorithm | Scale Estimation | The Model Update Method |
|---|---|---|
| ASLA | Y | Incremental subspace learning and sparse representation combined template updating strategies |
| SCM | Y | The tracking results and the original template overall considered template updating strategies |
| L1APG | Y | The updating strategies of exploiting the similarity of the tracking results and template |
| Struck | N | Updating the prediction function using the update function (sample,0) |
| TLD | N | Exploiting the training samples generated by the evaluation results to update the object model |
| MIL | N | Exploiting the tracking results to update the object model online |
| KCF | N | Updating the object model with a fixed learning rate |
| DSST | Y | Updating the object model with a fixed learning rate |
| Video | ASLA | KCF | L1APG | SCM | DSST | TLD | Struck | MIL | AKCF |
|---|---|---|---|---|---|---|---|---|---|
| David | 5.07 | 8.06 | 13.95 | 4.34 | 3.65 | 5.12 | 42.80 | 16.86 | 3.49 |
| Coke | 60.17 | 18.65 | 50.45 | 56.81 | 12.79 | 25.08 | 12.08 | 46.72 | 9.90 |
| Dudek | 15.26 | 11.38 | 23.46 | 10.77 | 13.46 | 18.05 | 11.45 | 17.70 | 9.03 |
| Lemming | 178.82 | 77.80 | 177.59 | 185.72 | 81.91 | 15.99 | 37.75 | 12.06 | 6.13 |
| Liquor | 146.74 | 5.34 | 212.87 | 99.23 | 98.70 | 37.58 | 90.99 | 141.88 | 4.94 |
| Singer2 | 175.28 | 10.33 | 180.87 | 113.63 | 7.77 | 58.32 | 174.32 | 22.53 | 9.69 |
| Skating1 | 59.86 | 7.67 | 158.70 | 16.38 | 8.33 | 145.45 | 82.94 | 139.38 | 7.39 |
| Tiger2 | 85.83 | 47.44 | 65.16 | 141.17 | 41.44 | 37.10 | 21.64 | 27.17 | 14.27 |
| Average | 90.88 | 23.33 | 110.38 | 78.51 | 33.51 | 42.84 | 59.25 | 53.04 | 8.11 |
| Video | ASLA | KCF | L1APG | SCM | DSST | TLD | Struck | MIL | AKCF |
|---|---|---|---|---|---|---|---|---|---|
| David | 0.944 | 0.915 | 0.857 | 0.952 | 0.959 | 0.944 | 0.571 | 0.828 | 0.961 |
| Coke | 0.404 | 0.818 | 0.510 | 0.528 | 0.868 | 0.746 | 0.875 | 0.532 | 0.897 |
| Dudek | 0.844 | 0.882 | 0.764 | 0.888 | 0.862 | 0.816 | 0.881 | 0.820 | 0.905 |
| Lemming | 0.171 | 0.571 | 0.167 | 0.164 | 0.532 | 0.853 | 0.654 | 0.876 | 0.934 |
| Liquor | 0.235 | 0.941 | 0.215 | 0.331 | 0.420 | 0.671 | 0.417 | 0.212 | 0.946 |
| Singer2 | 0.097 | 0.892 | 0.097 | 0.263 | 0.918 | 0.420 | 0.106 | 0.772 | 0.899 |
| Skating1 | 0.717 | 0.919 | 0.217 | 0.833 | 0.913 | 0.351 | 0.512 | 0.271 | 0.922 |
| Tiger2 | 0.295 | 0.565 | 0.418 | 0.159 | 0.602 | 0.639 | 0.783 | 0.727 | 0.857 |
| Average | 0.463 | 0.813 | 0.406 | 0.515 | 0.759 | 0.680 | 0.600 | 0.630 | 0.915 |
| Video | ASLA | KCF | L1APG | SCM | DSST | TLD | Struck | MIL | AKCF |
|---|---|---|---|---|---|---|---|---|---|
| David | 0.736 | 0.538 | 0.536 | 0.712 | 0.804 | 0.707 | 0.259 | 0.432 | 0.806 |
| Coke | 0.192 | 0.550 | 0.203 | 0.342 | 0.570 | 0.404 | 0.665 | 0.224 | 0.637 |
| Dudek | 0.725 | 0.720 | 0.682 | 0.756 | 0.774 | 0.640 | 0.723 | 0.698 | 0.798 |
| Lemming | 0.180 | 0.398 | 0.172 | 0.176 | 0.344 | 0.530 | 0.485 | 0.642 | 0.722 |
| Liquor | 0.276 | 0.836 | 0.231 | 0.340 | 0.418 | 0.520 | 0.420 | 0.248 | 0.834 |
| Singer2 | 0.086 | 0.721 | 0.084 | 0.200 | 0.769 | 0.239 | 0.084 | 0.512 | 0.734 |
| Skating1 | 0.501 | 0.491 | 0.143 | 0.471 | 0.526 | 0.221 | 0.328 | 0.161 | 0.624 |
| Tiger2 | 0.176 | 0.368 | 0.266 | 0.128 | 0.337 | 0.276 | 0.544 | 0.461 | 0.650 |
| Average | 0.359 | 0.578 | 0.290 | 0.391 | 0.568 | 0.442 | 0.439 | 0.422 | 0.725 |
| KCF | CSK | TLD | Struck | L1APG | SCM | ASLA | AKCF | |
|---|---|---|---|---|---|---|---|---|
| Scale estimation | × | × | × | × | √ | √ | √ | √ |
| Tracking speed (FPS) | 157.1 | 221.7 | 28.1 | 20.0 | 2.0 | 0.51 | 8.5 | 26.17 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Zhang, S.; Qiao, X. Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters. Sensors 2017, 17, 2626. https://doi.org/10.3390/s17112626
Li F, Zhang S, Qiao X. Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters. Sensors. 2017; 17(11):2626. https://doi.org/10.3390/s17112626
Chicago/Turabian StyleLi, Fan, Sirou Zhang, and Xiaoya Qiao. 2017. "Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters" Sensors 17, no. 11: 2626. https://doi.org/10.3390/s17112626
APA StyleLi, F., Zhang, S., & Qiao, X. (2017). Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters. Sensors, 17(11), 2626. https://doi.org/10.3390/s17112626