1. Introduction
With the proliferation of cheap but reasonably accurate sensors, indoor air quality can be determined by measuring various factors (e.g., fine dust density) through the sensors installed in a given space. Such measurements can be used to detect changes in the atmospheric state. Air quality can change sharply based on variables such as the entrance of people, the use of air conditioners and radiators, and the rate at which the air quality returns to its base state when the variable is removed. As such, a model designed to predict changes in indoor air quality must be able to take into account the various impacts of many variables. It also means that the model must be able to calculate the volume of the space in which it is being applied, as well as the thermal conductivity of other objects within the space, among other things. Furthermore, the model needs to calculate these values for any unspecified number of objects, which makes the development of such a model very difficult.
Due to the above difficulties, until recently, many indoor air quality control systems have controlled the variables by establishing thresholds. This method applies a given operation when current conditions exceed preset values, regardless of the number of variables or obstacles in the space. For example, in the case of a refrigerator, the air within the refrigerator is regulated via a cooling system that turns on when the temperature rises above a set value, and turns off when the temperature drops below a set value. Air quality is controlled in the same way in precision machines. In the case of anaerobic incubators used for microbiological experiments, if the oxygen concentration exceeds a preset critical point, the concentration of nitrogen gas and carbon dioxide gas is increased to maintain the anaerobic organism culture environment.
However, the use of critical points is not suitable for precision instruments which are highly affected by minute air quality changes. In many precision instruments, if the critical point is exceeded rapidly, the control is likely no longer meaningful. For example, in an incubator for biological experiments, microorganisms cannot survive after they have passed beyond the critical point of survival, even if the environment is restored to its prior state.
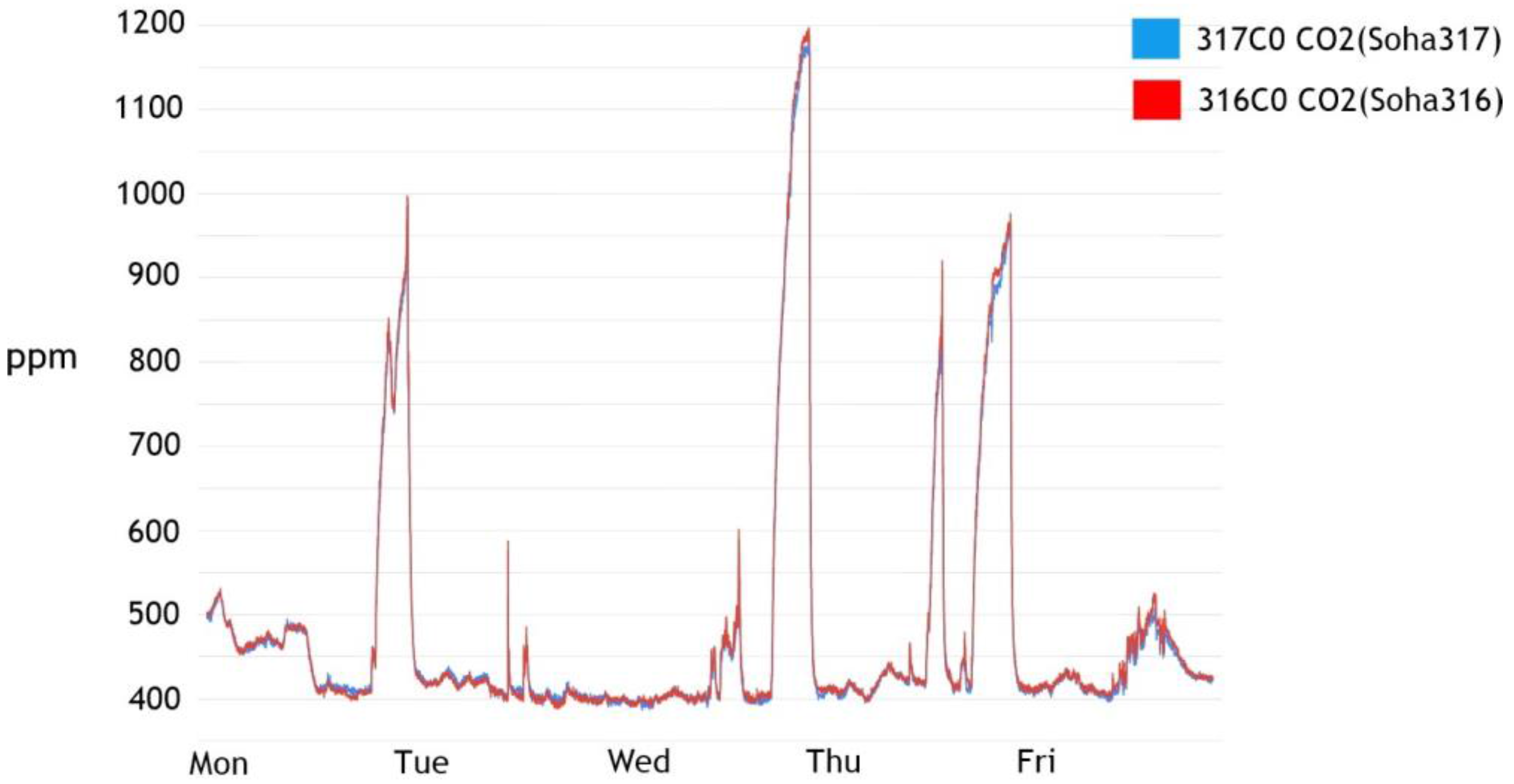
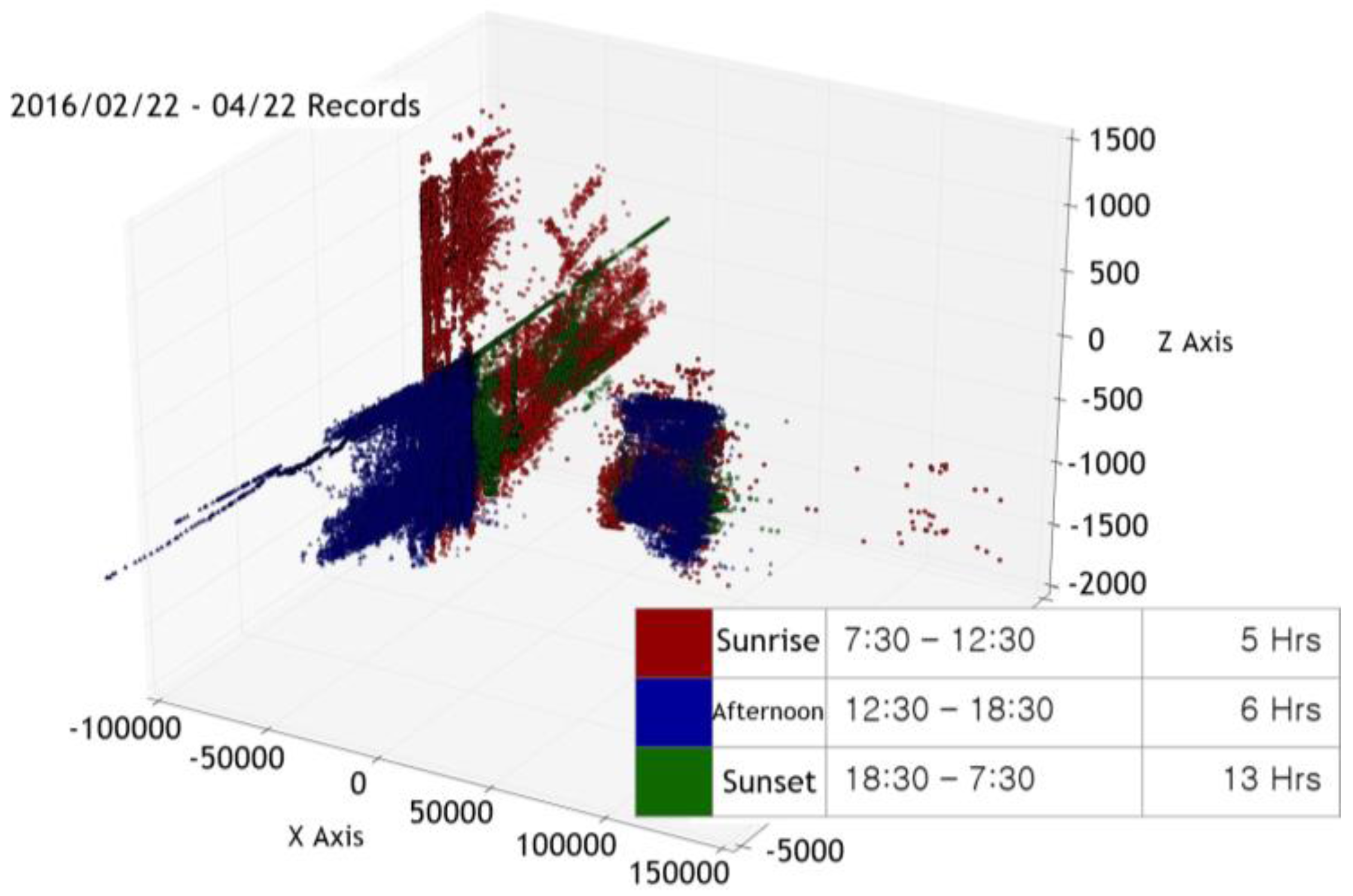
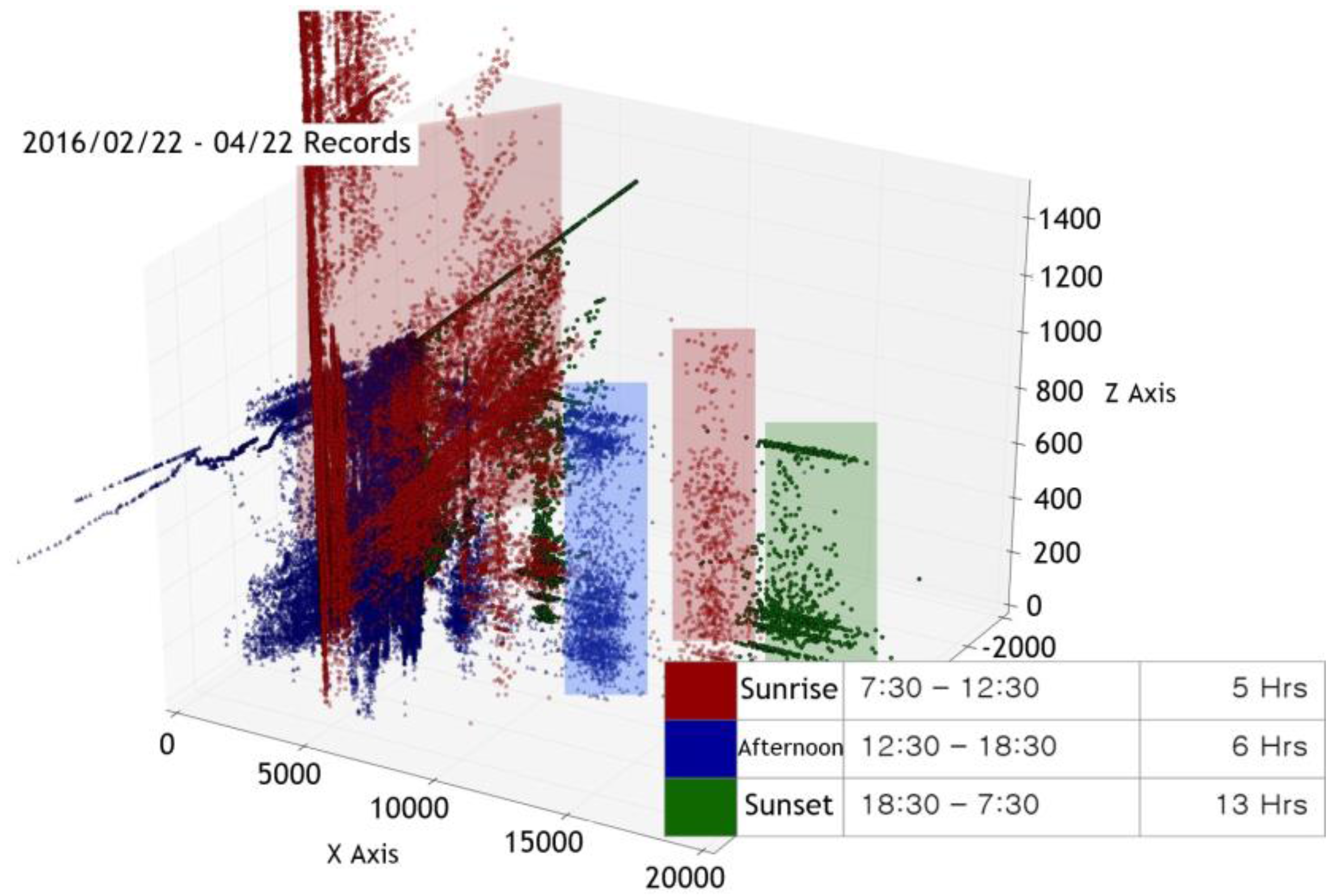
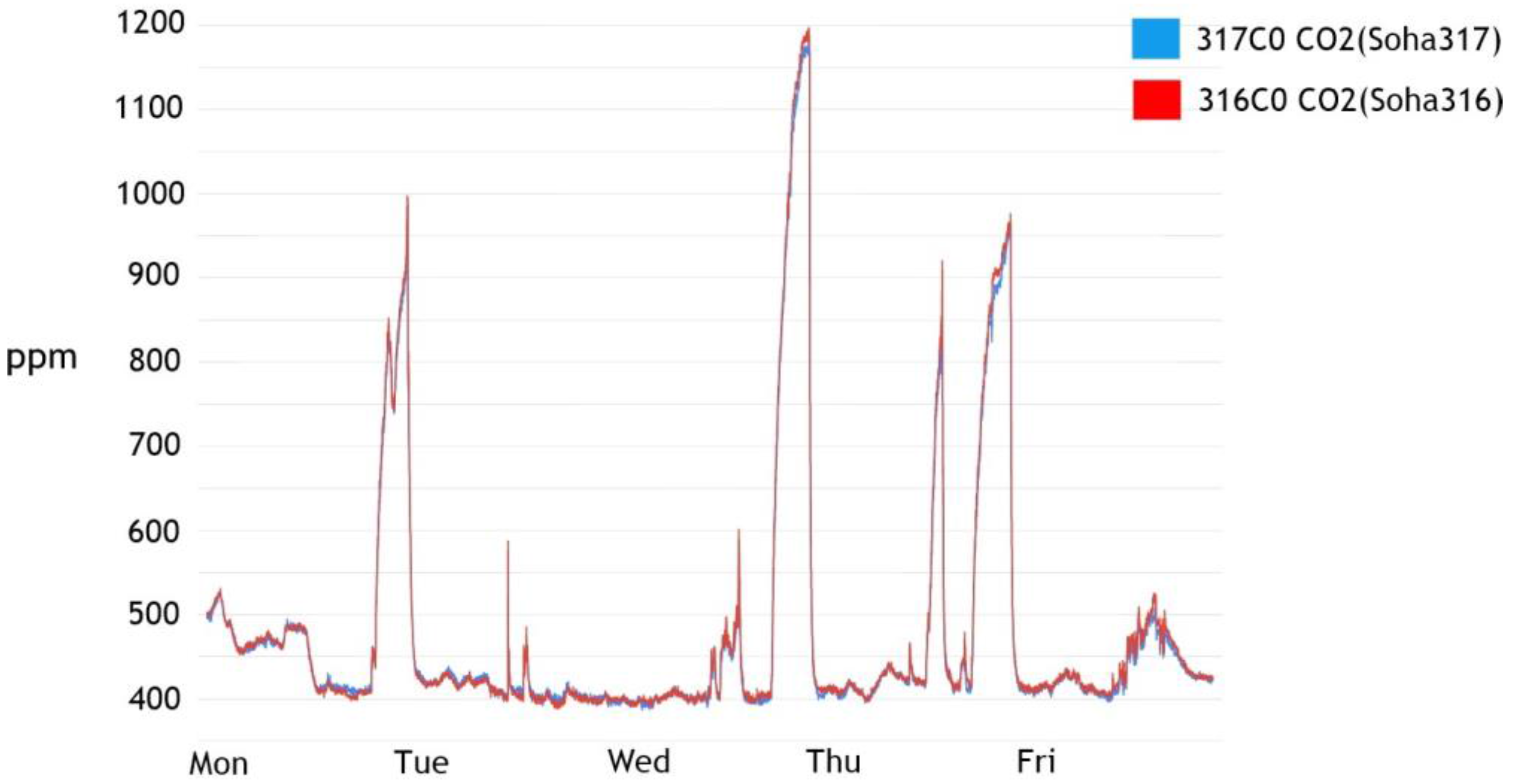
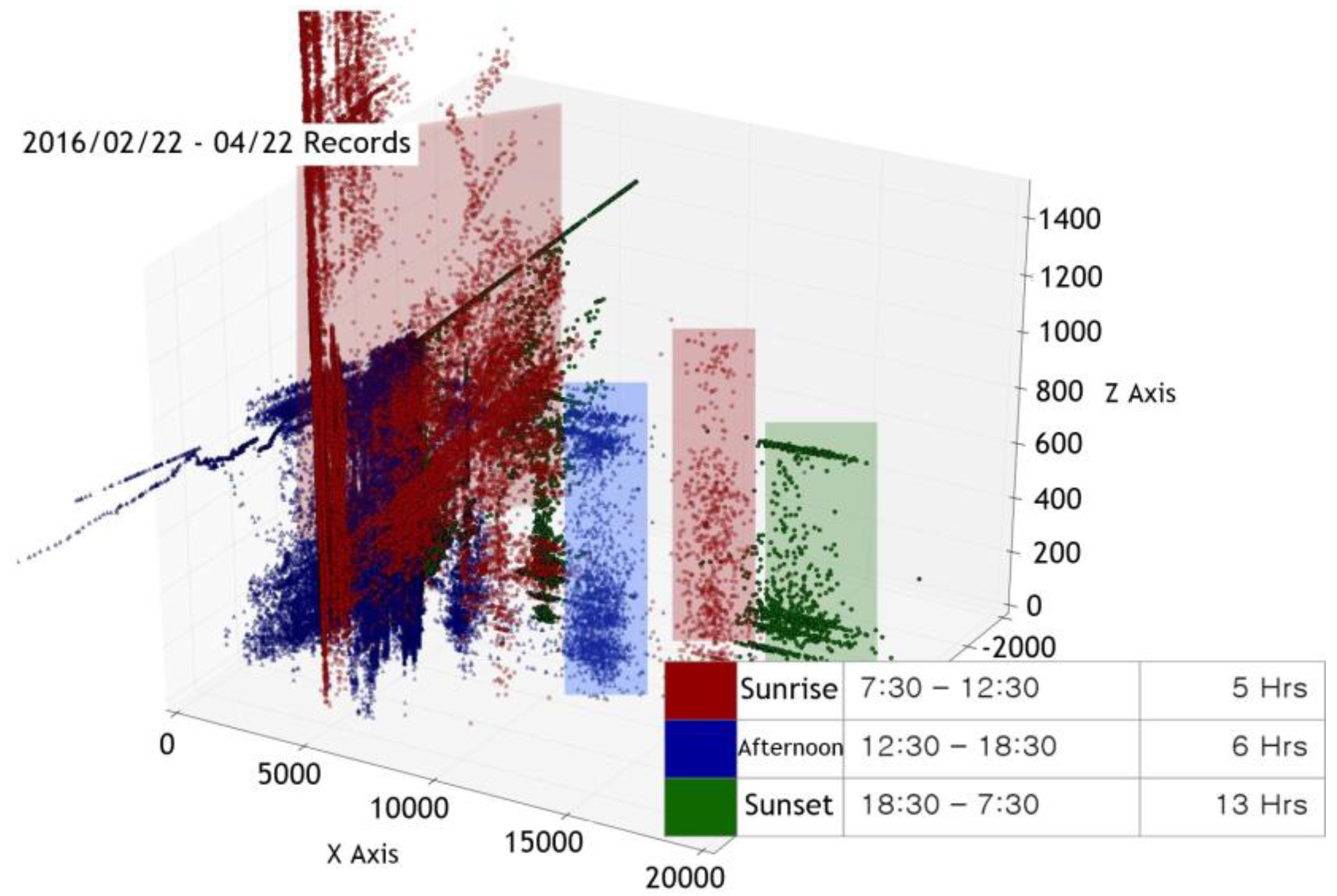
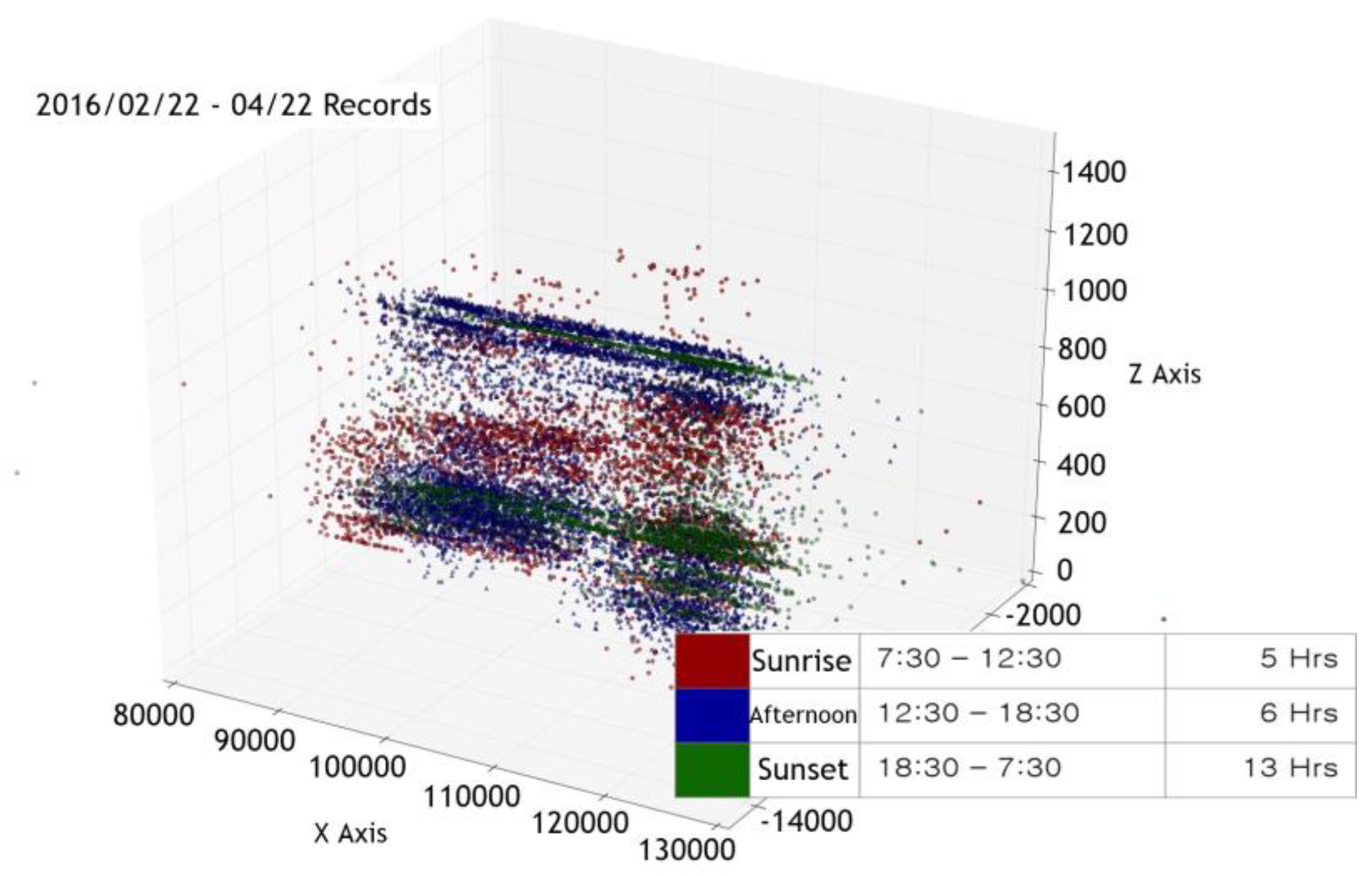
In addition, the critical point measurement method does not take into consideration the interaction between the surrounding environment and the given space. Generally, when the indoor measurement cycle is set at a given time interval, the variable with the greatest effect on the space is the sun. The phase changes of the sun affect the troposphere and as a result has a lasting impact on numerous measurable factors, including temperature, humidity, light quantity, and fine dust. This example implies that a single variable does not affect only one specific factor but instead creates a complex, powerful, and correlated variable. However, in the case of the critical point measurement method, it is difficult to grasp or distinguish the cause of the variable because it operates only for one specific factor. For example, when the amount of light exceeds a given critical point, the observer cannot distinguish whether this value is due to a person entering the space or the change in the sun’s positioning.
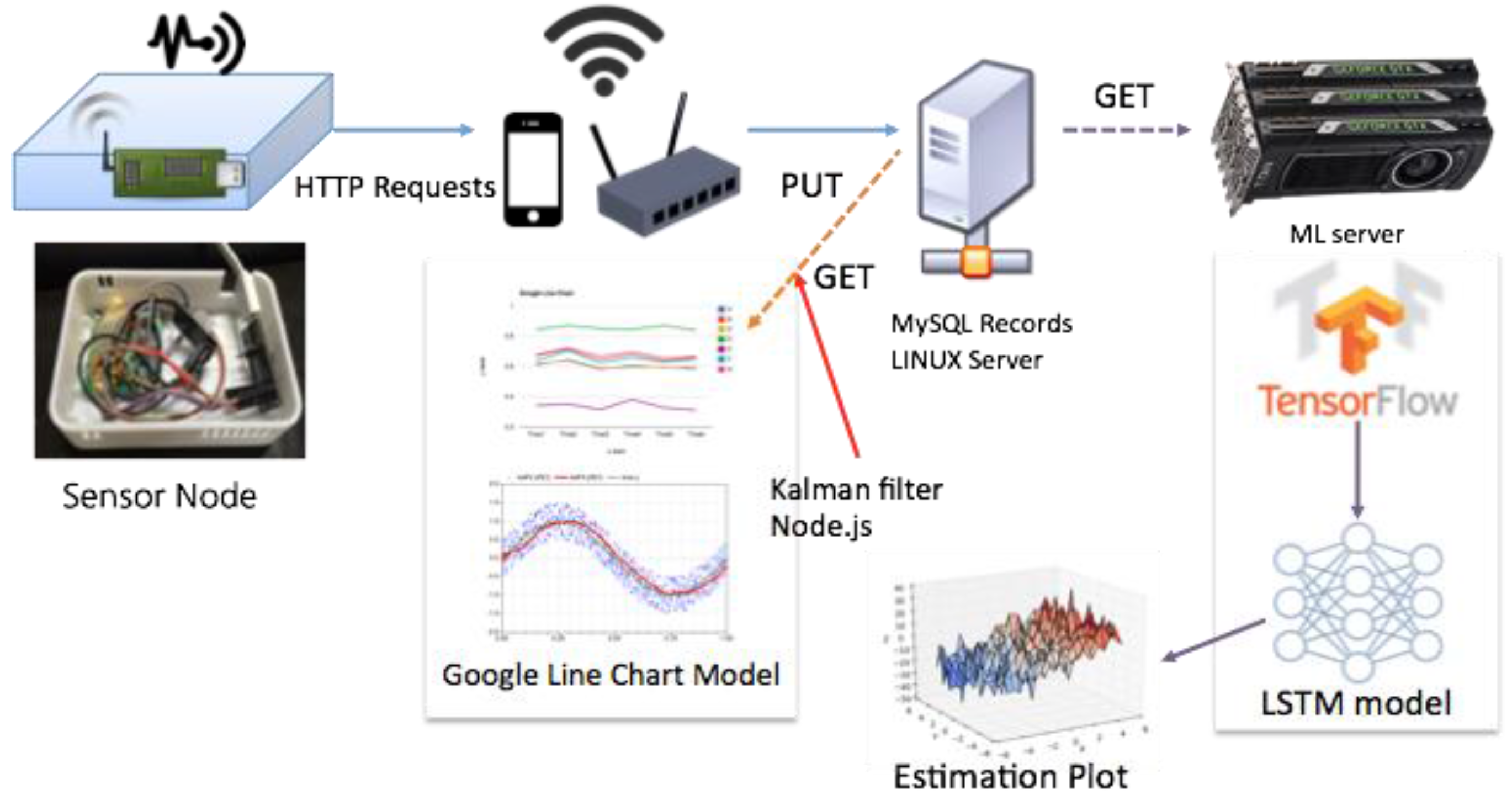
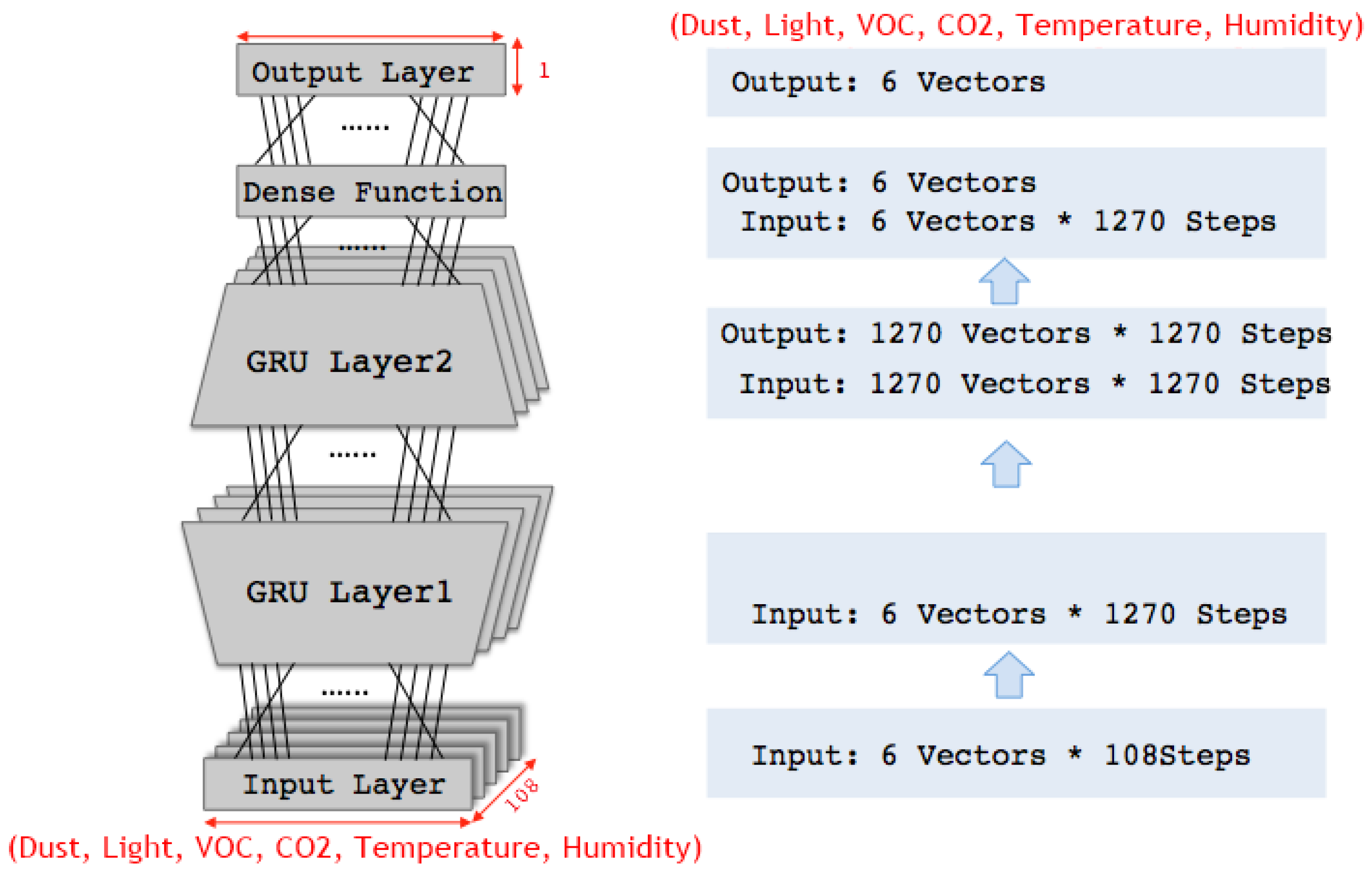
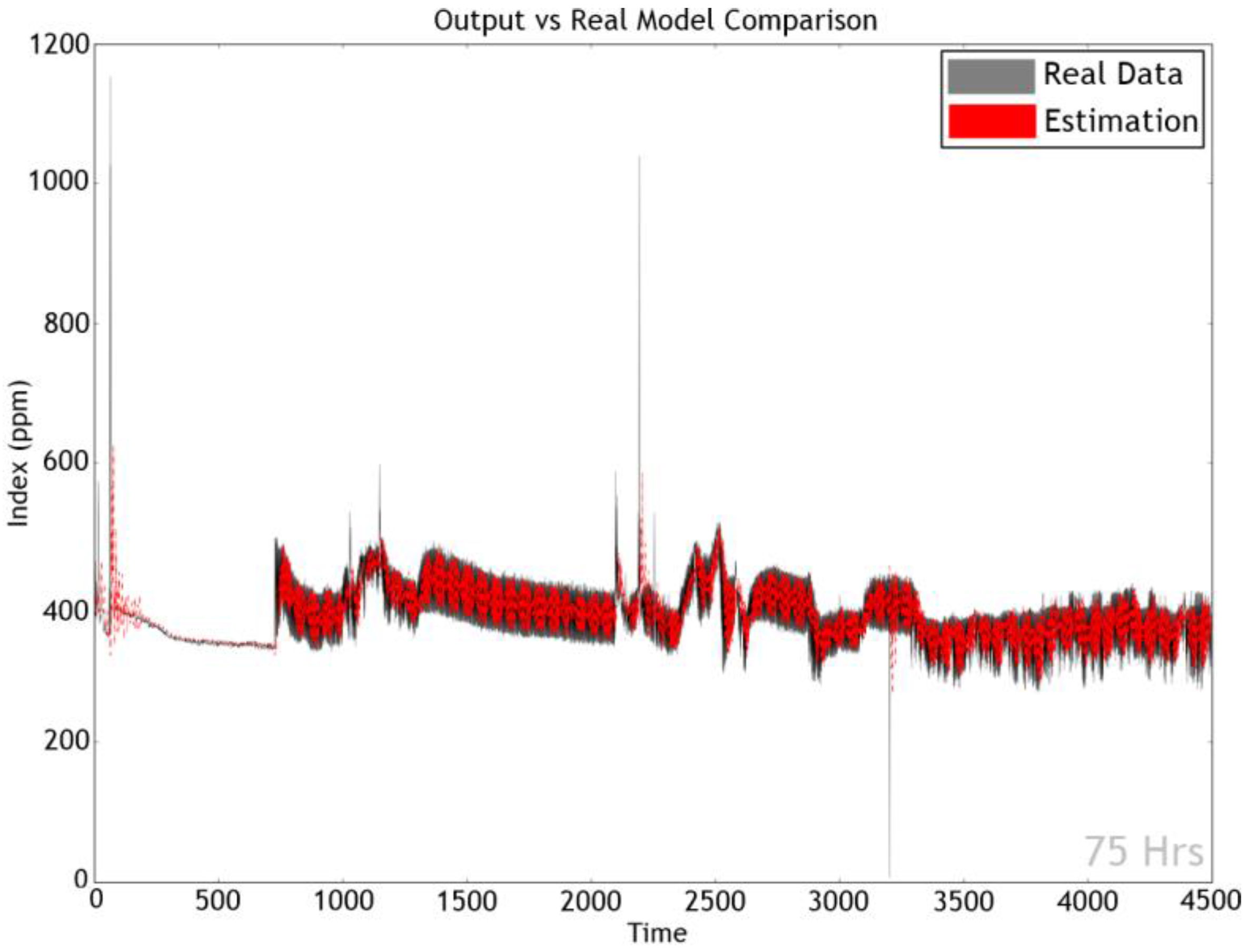
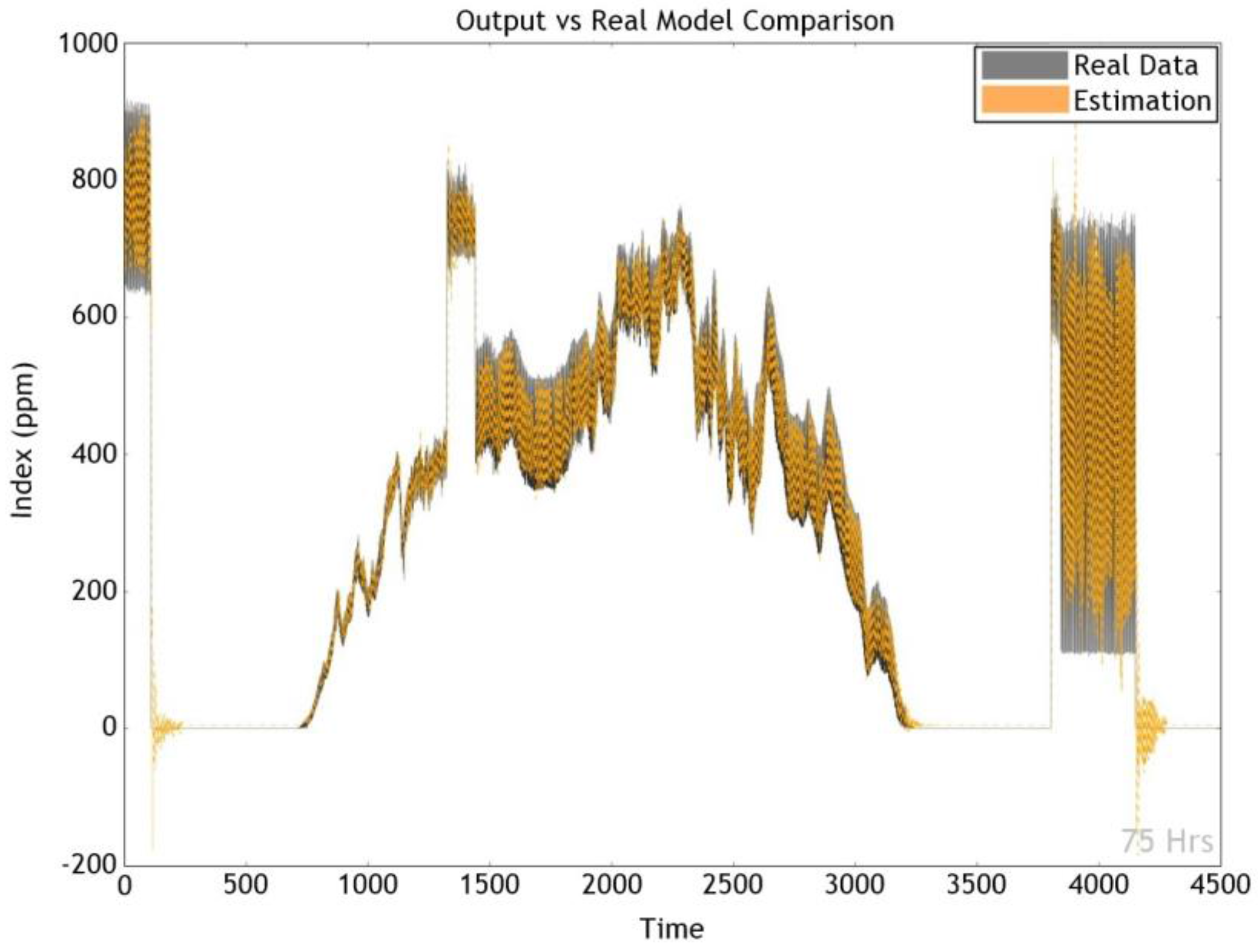
This paper recognizes the limitations in the conventional method described above and proposes a model for predicting the time series data using machine learning. In order to handle the time series data of measurements from diverse sensors, two deep learning methods are adopted long short-term memory (LSTM) [
1] and gated recurrent units (GRU) [
2]. (Detailed descriptions on the algorithms are given in the references.) All of the measurements are considered together in learning in a bid to exploit any relationships among them, and produce a model that correctly predicts the measurements (i.e., air quality) at the next time step.
The rest of the paper is organized as follows:
Section 2 describes previous work related to this research.
Section 3 gives detailed explanations on our method and the sensor data.
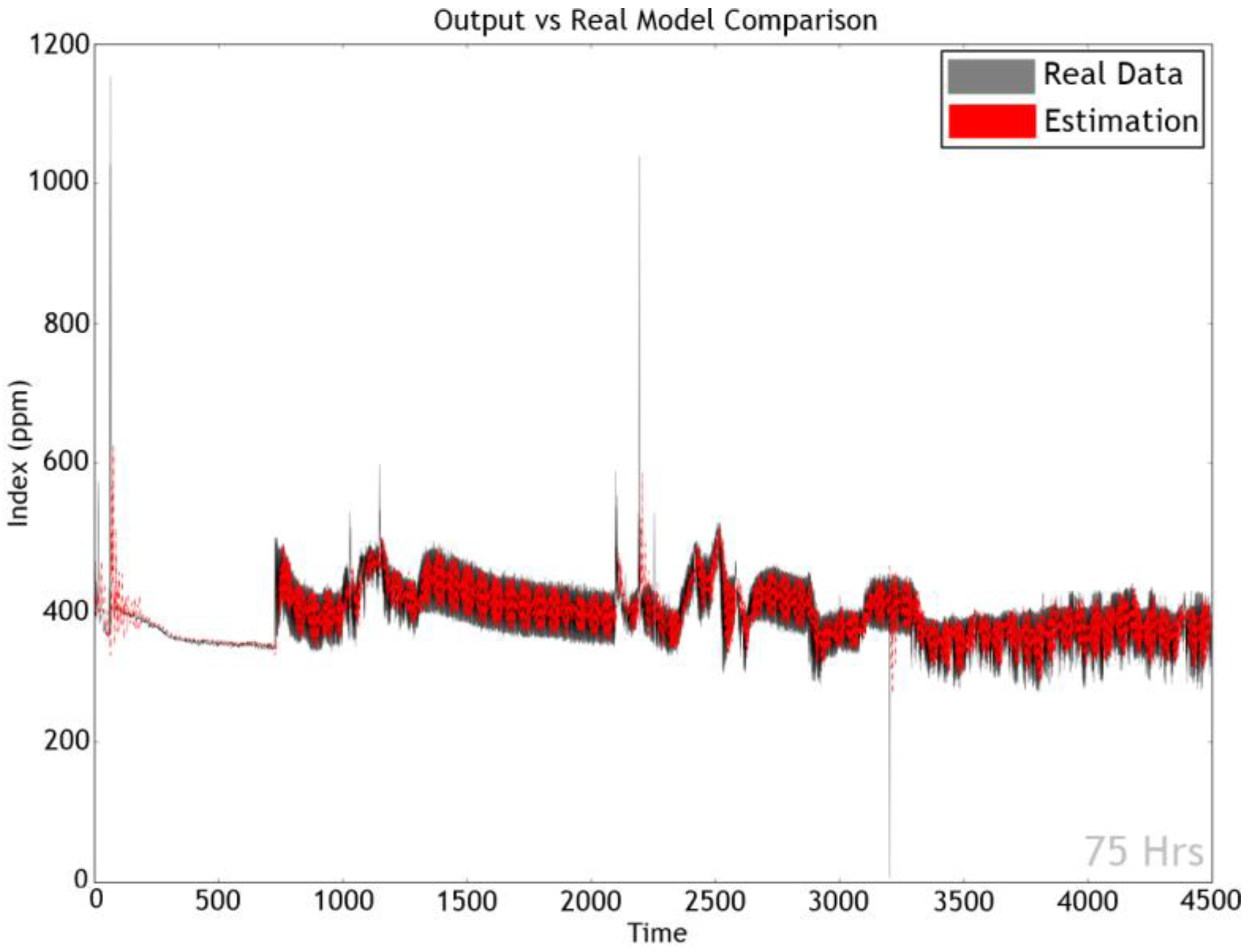
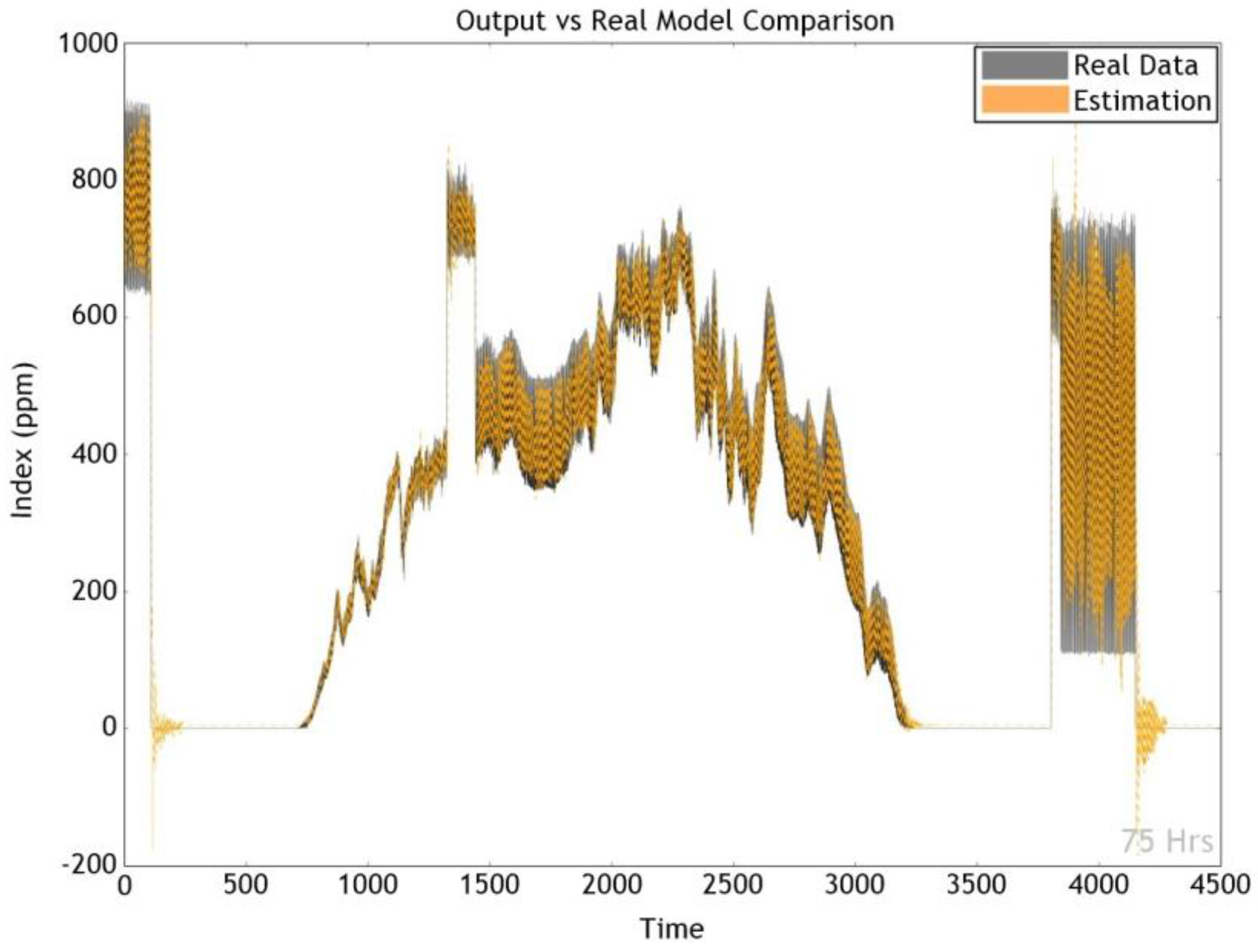
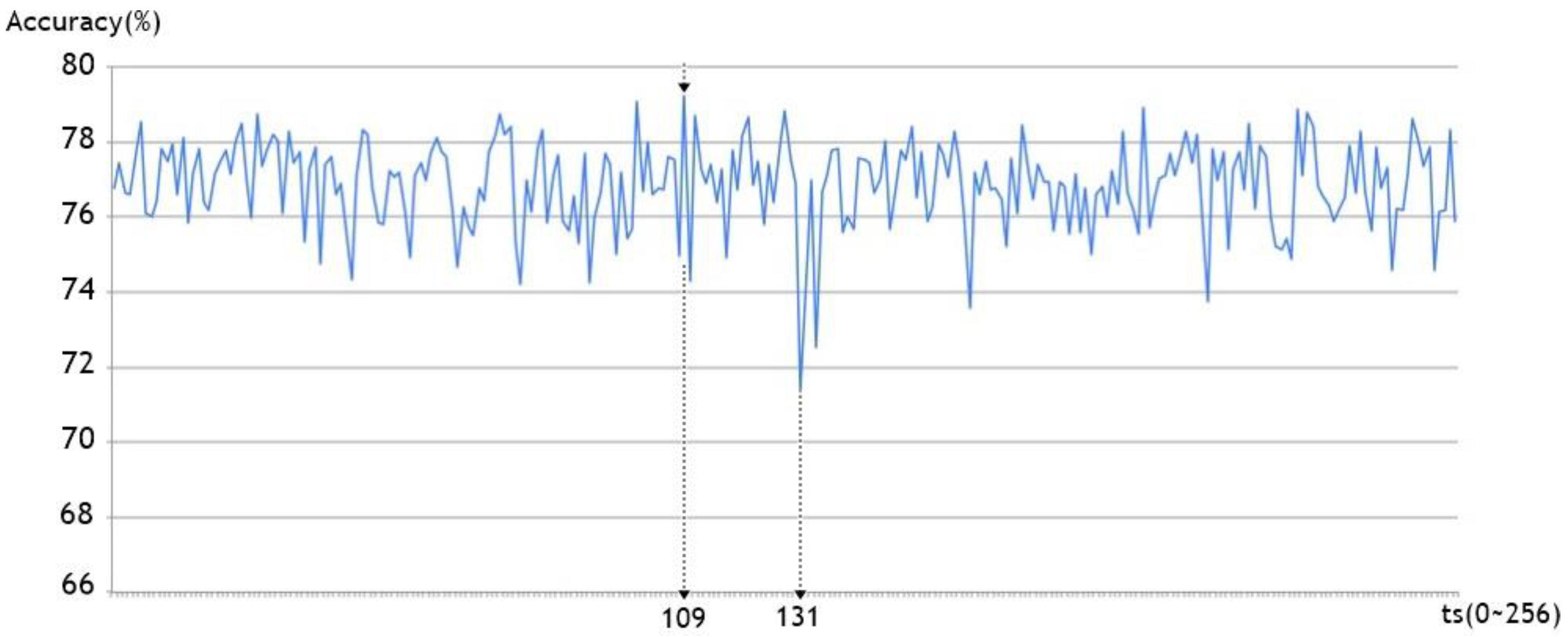
Section 4 presents the results of the experiments that were designed to evaluate the performance of our method.
Section 5 concludes with a summary and discussion of some directions for future research.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}