Selectivity Enhancement in Electronic Nose Based on an Optimized DQN


Abstract
1. Introduction
2. DQN-CNN
2.1. DQN
2.2. DQN-CNN
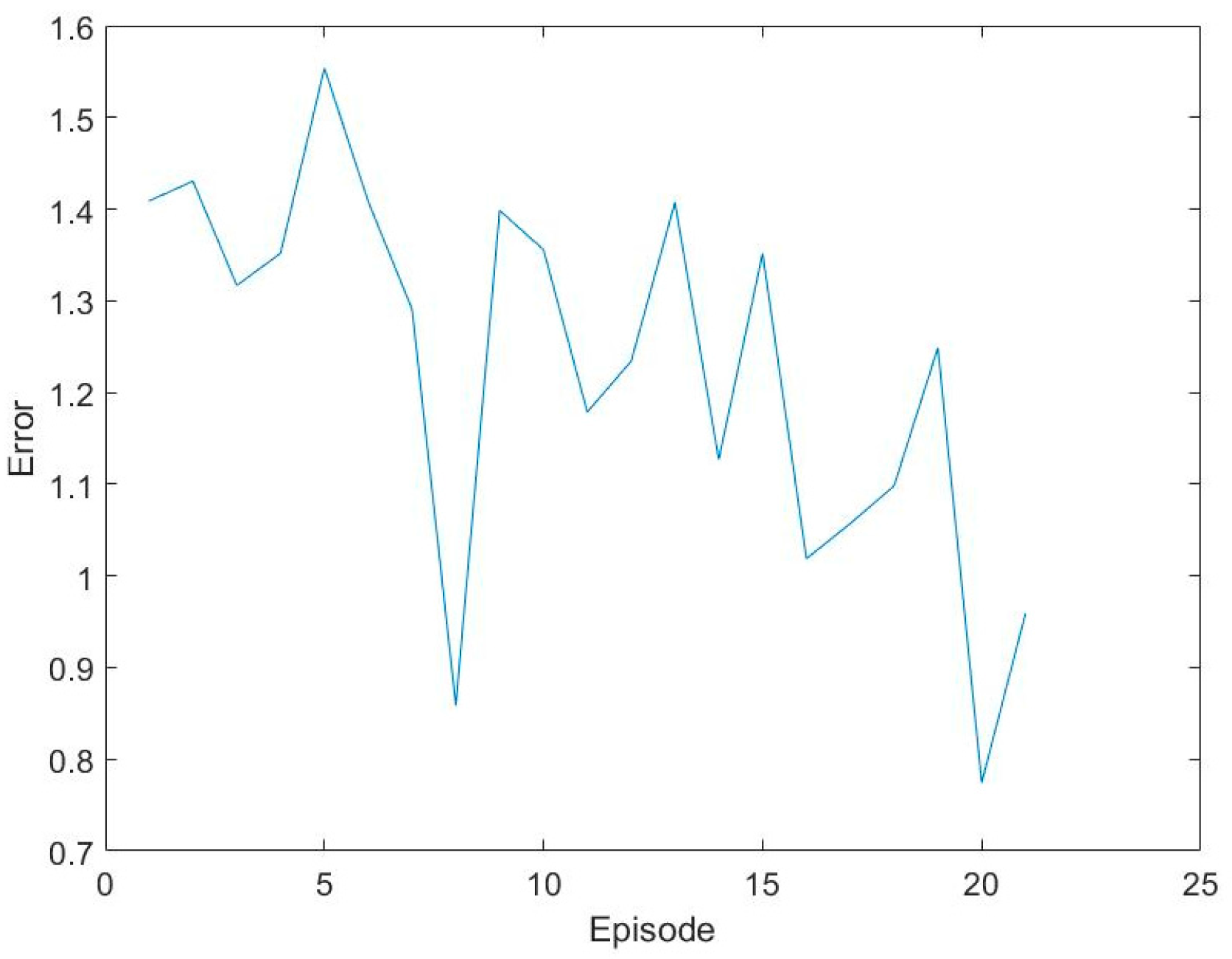
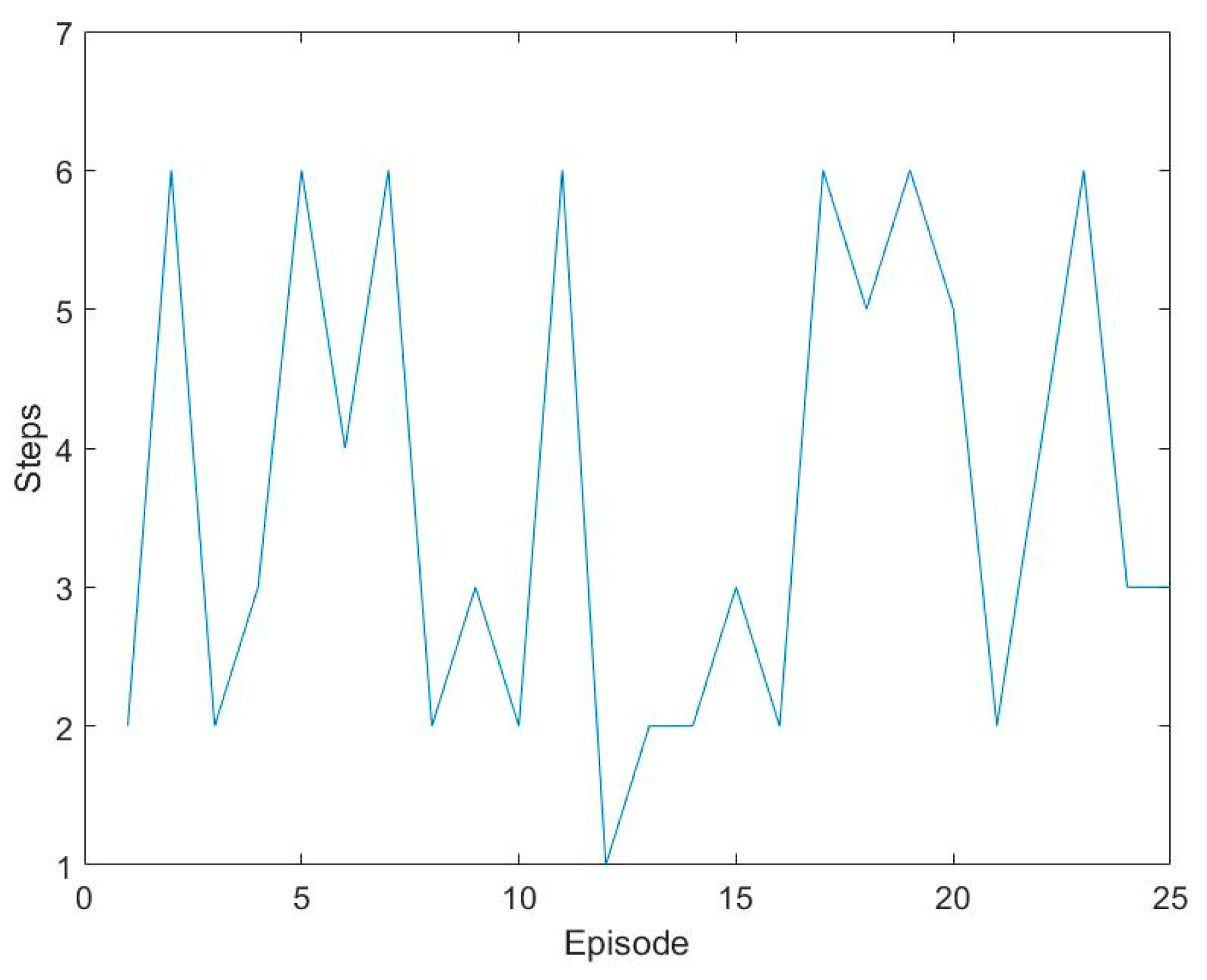
2.3. DQN-CNN Algorithm
| Algorithm 1 DQN-CNN with Experience Replay |
| Initialize the memory stored in the experience of replay D, the number of iterations M |
| Randomly initialize the Q-value function |
| for iteration number = 1, M do |
| randomly initialize the first action |
| initialize the first state |
| for = 1, T do |
| if the probability is ϵ, select a random action |
| otherwise select |
| input , into , get classification |
| if then |
| reward |
| if < T then |
| reward |
| else |
| execute , get and next state |
| stored () in D |
| using a gradient descending of random small batches to get sample ()
|
| Calculate the gradient of to update |
| end if |
| end for |
3. Experiment
3.1. Electronic Nose System
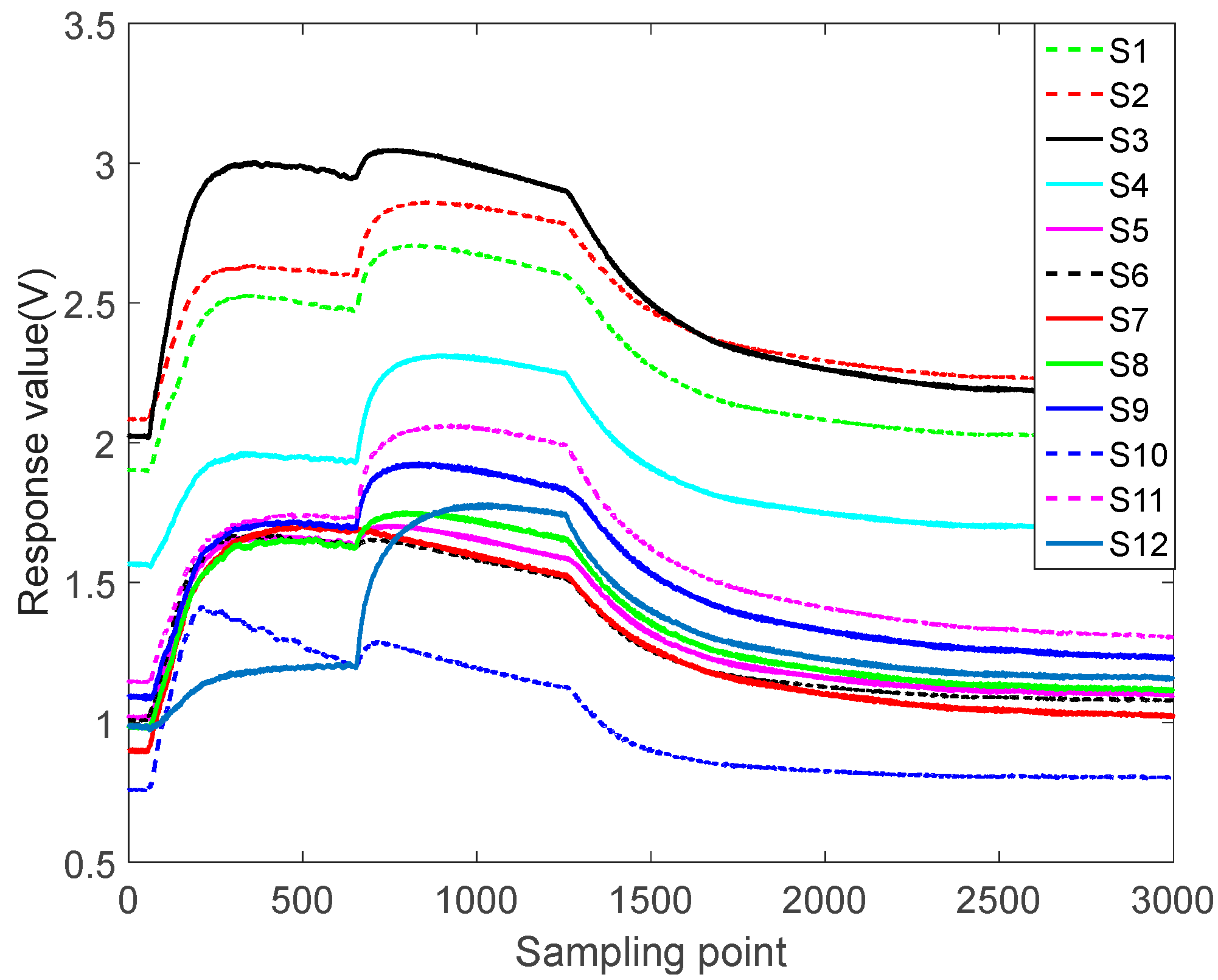
3.2. Experimental Analysis of 5 Kinds of Gases
3.3. Principal Component Analysis (PCA)
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bieganowski, A.; Jaromin-Gleń, K.; Guz, Ł.; Łagńd, G.; Jozefaciuk, G.; Franus, W.; Suchorab, Z.; Sobczuk, H. Evaluating Soil Moisture Status Using an e-Nose. Sensors 2016, 16, 886. [Google Scholar]
- Altomare, D.F.; Porcelli, F.; Picciariello, A.; Pinto, M.; Di Lena, M.; Caputi lambrenghi, O.; Ugenti, I.; Guglielmi, A.; Vincenti, L. The use of the PEN3 e-nose in the screening of colorectal cancer and polyps. Tech. Coloproctol. 2016, 20, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Gu, Y.; Jia, J. Classification of Multiple Chinese Liquors by Means of a QCM-based E-Nose and MDS-SVM Classifier. Sensors 2017, 17, 272. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Zhi, R.; Zhao, L.; Gao, H.; Shi, B.; Wang, H. Longjing tea quality classification by fusion of features collected from E-nose. Chemom. Intell. Lab. Syst. 2015, 144, 63–70. [Google Scholar] [CrossRef]
- Fu, J.; Li, G.; Qin, Y.; Freeman, W.J. A pattern recognition method for electronic noses based on an olfactory neural network. Sens. Actuators B Chem. 2007, 125, 489–497. [Google Scholar] [CrossRef]
- Jelen, H.H.; Wlazly, K.; Wasowicz, E.; Kaminski, E. Solid-phase microextraction for the analysis of some alcohols and esters in beer: Comparison with static headspace method. J. Agric. Food Chem. 1998, 46, 1469–1473. [Google Scholar] [CrossRef]
- Hong, X.; Wang, J.; Qi, G. E-nose combined with chemometrics to trace tomato-juice quality. J. Food Eng. 2015, 149, 38–43. [Google Scholar] [CrossRef]
- Ozmen, A.; Dogan, E. Design of a Portable E-Nose Instrument for Gas Classifications. IEEE Trans. Instrum. Meas. 2009, 58, 3609–3618. [Google Scholar] [CrossRef]
- Salvato, M.; Vito, S.D.; Esposito, E.; Massera, E.; Miglietta, M.; Fattoruso, G.; Francia, G.D. An Holistic Approach to e-Nose Response Patterns Analysis—An Application to Nondestructive Tests. IEEE Sens. J. 2016, 16, 2617–2626. [Google Scholar] [CrossRef]
- Di Natale, C.; Macagnano, A.; Martinelli, E.; Paolesse, R.; D’Arcangelo, G.; Roscioni, C. Lung cancer identification by the analysis of breath by means of an array of non-selective gas sensors. Biosens. Bioelectron. 2003, 18, 1209–1218. [Google Scholar] [CrossRef]
- Ortega, A.; Marco, S.; Perera, A.; Šundic, T.; Pardo, A.; Samitier, J. An intelligent detector based on temperature modulation of a gas sensor with a digital signal processor. Sens. Actuators B Chem. 2001, 78, 32–39. [Google Scholar] [CrossRef]
- Peng, N.; Zhang, Q.; Yi, C.L.; Tan, O.K.; Marzari, N. Gate modulation in carbon nanotube field effect transistors-based NH3 gas sensors. Sens. Actuators B Chem. 2008, 132, 191–195. [Google Scholar] [CrossRef]
- Bastuck, M.; Bur, C.; Spetz, A.L.; Andersson, M.; Schütze, A. Gas identification based on bias induced hysteresis of a gas-sensitive SiC field effect transistor. J. Sens. Sens. Syst. 2014, 3, 9–19. [Google Scholar] [CrossRef]
- Auerbach, F. Pattern Recognition Using Gasmodulation. In Proceedings of the 8th International Conference on Solid-State Sensors and Actuators 1995 and Eurosensors IX Transducers ’95, Stockholm, Sweden, 25–29 June 1995; pp. 791–794. [Google Scholar]
- Harun, F.K.C.; Covington, A.; Gardner, J.W. Portable e-Mucosa System: Mimicking the biological olfactory. Proced. Chem. 2009, 1, 991–994. [Google Scholar] [CrossRef]
- Vergara, A.; Llobet, E.; Brezmes, J.; Ivanov, P.; Vilanova, X.; Gracia, I.; Cané, C.; Correig, X. Optimised temperature modulation of metal oxide micro-hotplate gas sensors through multilevel pseudo random sequences. Sens. Actuators B Chem. 2005, 111, 271–280. [Google Scholar] [CrossRef]
- Huang, X.; Meng, F.; Pi, Z.; Xu, W.; Liu, J. Gas sensing behavior of a single tin dioxide sensor under dynamic temperature modulation. Sens. Actuators B Chem. 2004, 99, 444–450. [Google Scholar] [CrossRef]
- Gosangi, R.; Gutierrez-Osuna, R. Active Temperature Programming for Metal-Oxide Chemoresistors. IEEE Sens. J. 2010, 10, 1075–1082. [Google Scholar] [CrossRef]
- Staszek, K.; Rydosz, A.; Maciak, E.; Wincza, K.; Gruszczynski, S. Six-port microwave system for volatile organic compounds detection. Sens. Actuators B Chem. 2017, 245, 882–894. [Google Scholar] [CrossRef]
- Zarifi, M.H.; Farsinezhad, S.; Abdolrazzaghi, M.; Daneshmand, M.; Shankar, K. Selective microwave sensors exploiting the interaction of analytes with trap states in TiO2 nanotube arrays. Nanoscale 2016, 8, 7466–7473. [Google Scholar] [CrossRef] [PubMed]
- Abdolrazzaghi, M.; Zarifi, M.H.; Pedrycz, W.; Daneshmand, M. Robust Ultra-High Resolution Microwave Planar Sensor Using Fuzzy Neural Network Approach. IEEE Sens. J. 2016, 17, 323–332. [Google Scholar] [CrossRef]
- Rydosz, A.; Maciak, E.; Wincza, K.; Gruszczynski, S. Microwave-based sensors with phthalocyanine films for acetone, ethanol and methanol detection. Sens. Actuators B Chem. 2016, 237, 876–886. [Google Scholar] [CrossRef]
- Mirsky, V.M. Affinity sensors in non-equilibrium conditions: Highly selective chemosensing by means of low selective chemosensors. Sensors 2001, 1, 13–17. [Google Scholar] [CrossRef]
- Joel, M.; Noam, S. The Sniff is Part of the Olfactory Percept. Chem. Sens. 2006, 31, 181–196. [Google Scholar] [CrossRef]
- Mozell, M.M.; Jagodowicz, M. Chromatographic separation of odorants by the nose: Retention times measured across in vivo olfactory mucosa. Science 1973, 181, 1247–1249. [Google Scholar] [CrossRef] [PubMed]
- Youngentob, S.L.; Markert, L.M.; Hill, T.W.; Matyas, E.P.; Mozell, M.M. Odorant identification in rats: An update. Physiol. Behav. 1991, 49, 1293–1296. [Google Scholar] [CrossRef]
- Barbri, N.E.; Duran, C.; Brezmes, J.; Cañellas, N.; Ramírez, J.L.; Bouchikhi, B.; Llobet, E. Selectivity Enhancement in Multisensor Systems Using Flow Modulation Techniques. Sensors 2008, 8, 7369–7379. [Google Scholar] [CrossRef] [PubMed]
- Ziyatdinov, A.; Fonollosa, J.; Fernández, L.; Gutierrez-Gálvez, A.; Marco, S.; Perera, A. Bioinspired early detection through gas flow modulation in chemo-sensory systems. Sens. Actuators B Chem. 2015, 206, 538–547. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv, 2013; arXiv:1312.5602. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. arXiv, 2015; arXiv:1511.06581. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards; King’s College: Cambridge, UK, 1989. [Google Scholar]
- Lin, L. Reinforcement Learning for Robots Using Neural Networks. Ph.D. Thesis, School of Computer Science, Carnegie-Mellon University, Pittsburgh, PA, USA, 1993. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Model | Nominal Test Target Gas |
|---|---|---|
| S1 | MQ-8 | hydrogen, coal, gas, etc. |
| S2 | MQ-9B | carbon monoxide, etc. |
| S3 | MQ-2 | flammable gas, smoke, etc |
| S4 | MQ-5 | liquefied petroleum gas, methane, coal gas, etc |
| S5 | MQ-135 | ammonia, sulfides, etc. |
| S6 | MQ-3B | alcohol, etc |
| S7 | MQ-7B | carbon monoxide, etc. |
| S8 | MQ-4 | natural gas, methane, etc. |
| S9 | MQ-2 | flammable gas, smoke, etc. |
| S10 | MQ-6 | liquefied petroleum gas, isobutane, propane, etc. |
| S11 | MQ-5 | liquefied petroleum gas, methane, coal gas ,etc |
| S12 | MQ-7 | carbon monoxide, etc. |
| Steps | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Sesame oil | 0 | 2 | 1 | 0 | 0 | 2 |
| Lactic acid | 0 | 2 | 1 | 1 | 0 | 1 |
| Acetaldehyde | 1 | 2 | 0 | 0 | 0 | 2 |
| Acetic acid | 0 | 1 | 0 | 0 | 2 | 2 |
| Ethyl acetate | 0 | 1 | 2 | 1 | 0 | 1 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Xing, J.; Qian, S. Selectivity Enhancement in Electronic Nose Based on an Optimized DQN. Sensors 2017, 17, 2356. https://doi.org/10.3390/s17102356
Wang Y, Xing J, Qian S. Selectivity Enhancement in Electronic Nose Based on an Optimized DQN. Sensors. 2017; 17(10):2356. https://doi.org/10.3390/s17102356
Chicago/Turabian StyleWang, Yu, Jianguo Xing, and Shu Qian. 2017. "Selectivity Enhancement in Electronic Nose Based on an Optimized DQN" Sensors 17, no. 10: 2356. https://doi.org/10.3390/s17102356
APA StyleWang, Y., Xing, J., & Qian, S. (2017). Selectivity Enhancement in Electronic Nose Based on an Optimized DQN. Sensors, 17(10), 2356. https://doi.org/10.3390/s17102356