Nighttime Foreground Pedestrian Detection Based on Three-Dimensional Voxel Surface Model


Abstract
:1. Introduction
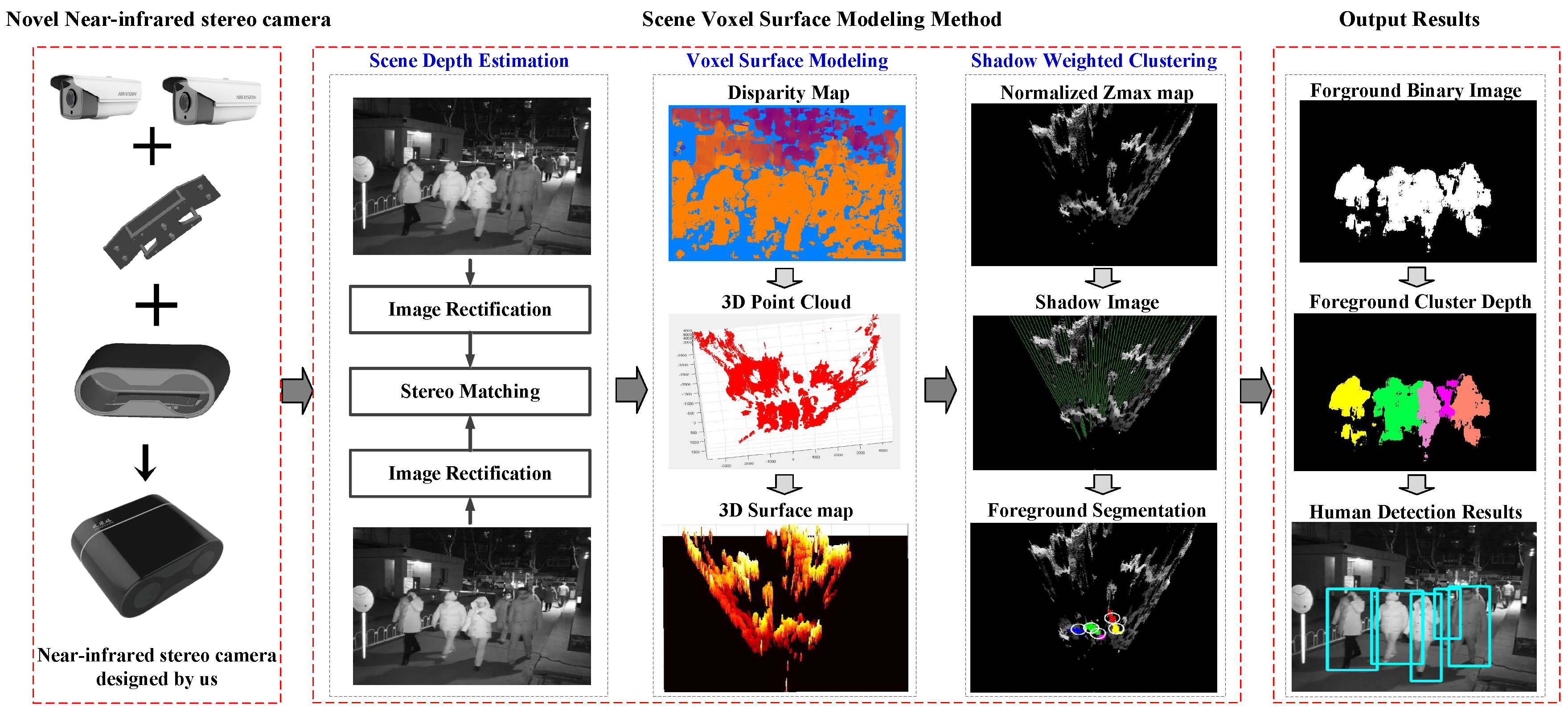
- First, in the system, we assemble a binocular camera to acquire stereo images at night. The characteristics of this camera mainly include two parts: (1) Our binocular camera is based on the network transmission, and it is convenient to be used in the far distance surveillance scenarios; (2) The binocular camera is built with two less expensive Near-Infrared cameras and LED lights, thus it can generate the stereo images in real nighttime monitoring scenes. The parameters of our binocular camera are shown in Table 1.
- Second, we showcase a voxel surface model to detect pedestrians at night. This method is based on the three-dimensional spatial structure information and needs a new background surface model updating strategy, which is a free update policy for unknown points, which is essentially different from the traditional background subtraction method based on the gray value space.
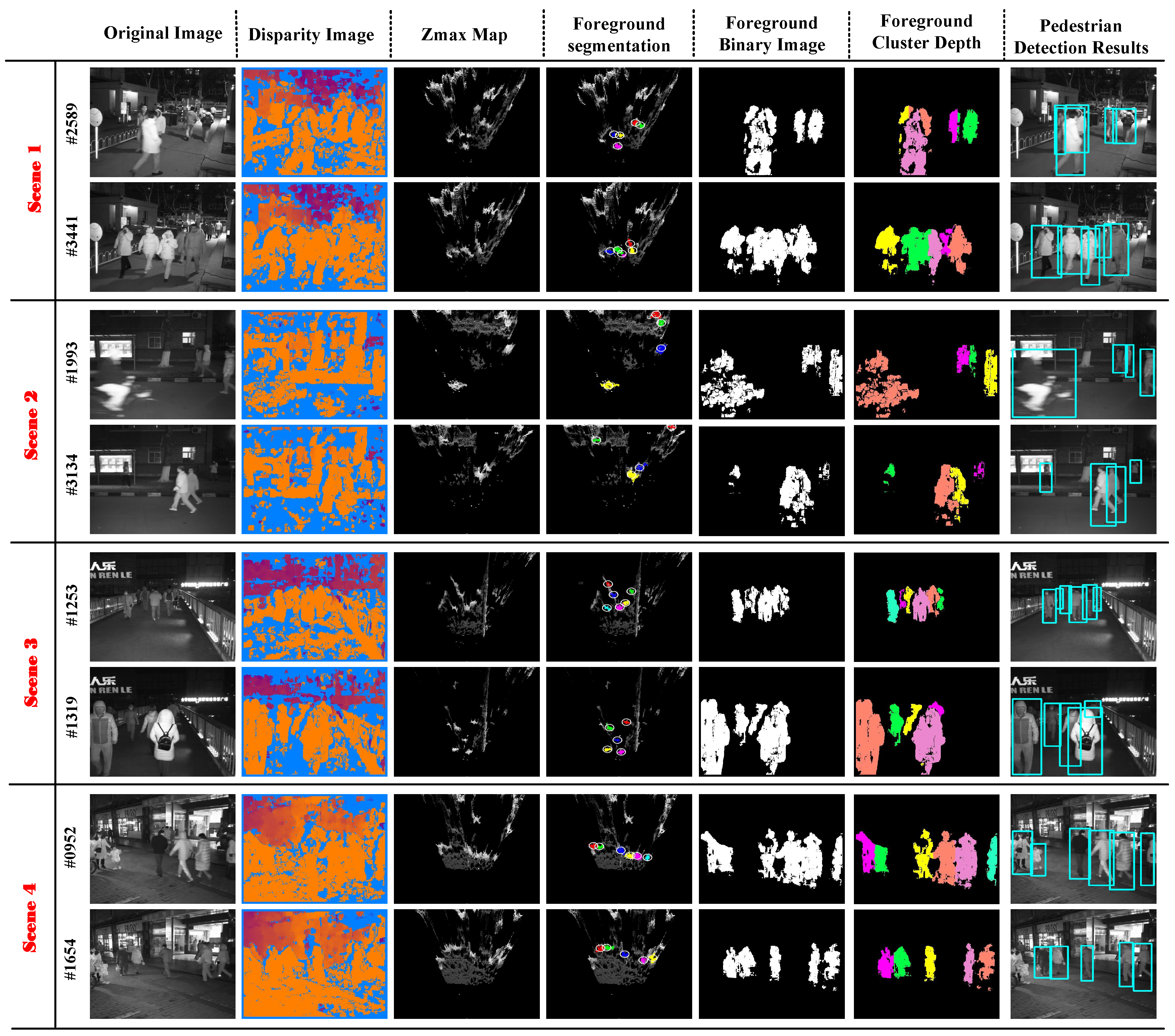
- Third, we built a new stereo night dataset; to the best of our knowledge, this is the first night stereo video surveillance dataset to address and analyze the performance of state-of-the-art pedestrian detection algorithms. There is a large number of experimental results that show that this system can solve the problem of partial occlusion and is not very sensitive to light intensity in night scenes. What is more, this method is fast and can meet the real-time requirements of our monitoring system and our output results are accurate. In addition to the detection of the bounding box, the foreground binary image and foreground cluster depth are also detected.
2. Voxel Surface Model for Foreground Pedestrian Detection
2.1. The Binocular NIR Camera
2.2. Voxel Surface Model Generation
2.3. Voxel Surface Background Model Establishment and Updating
- (1)
- Conservative update policy: Foreground points will never be used to update the voxel surface background model.
- (2)
- Time subsampling: For a point that is classified as background in time t, it has a probability of to update its own model , and is a time subsampling factor.
- (3)
- Spatial consistency through background sample propagation: the point has a probability of to update its neighboring points’ background model.
- (4)
- Memoryless update policy: Every time the voxel surface background model is updated, the new point value will replace one sample randomly chosen from .
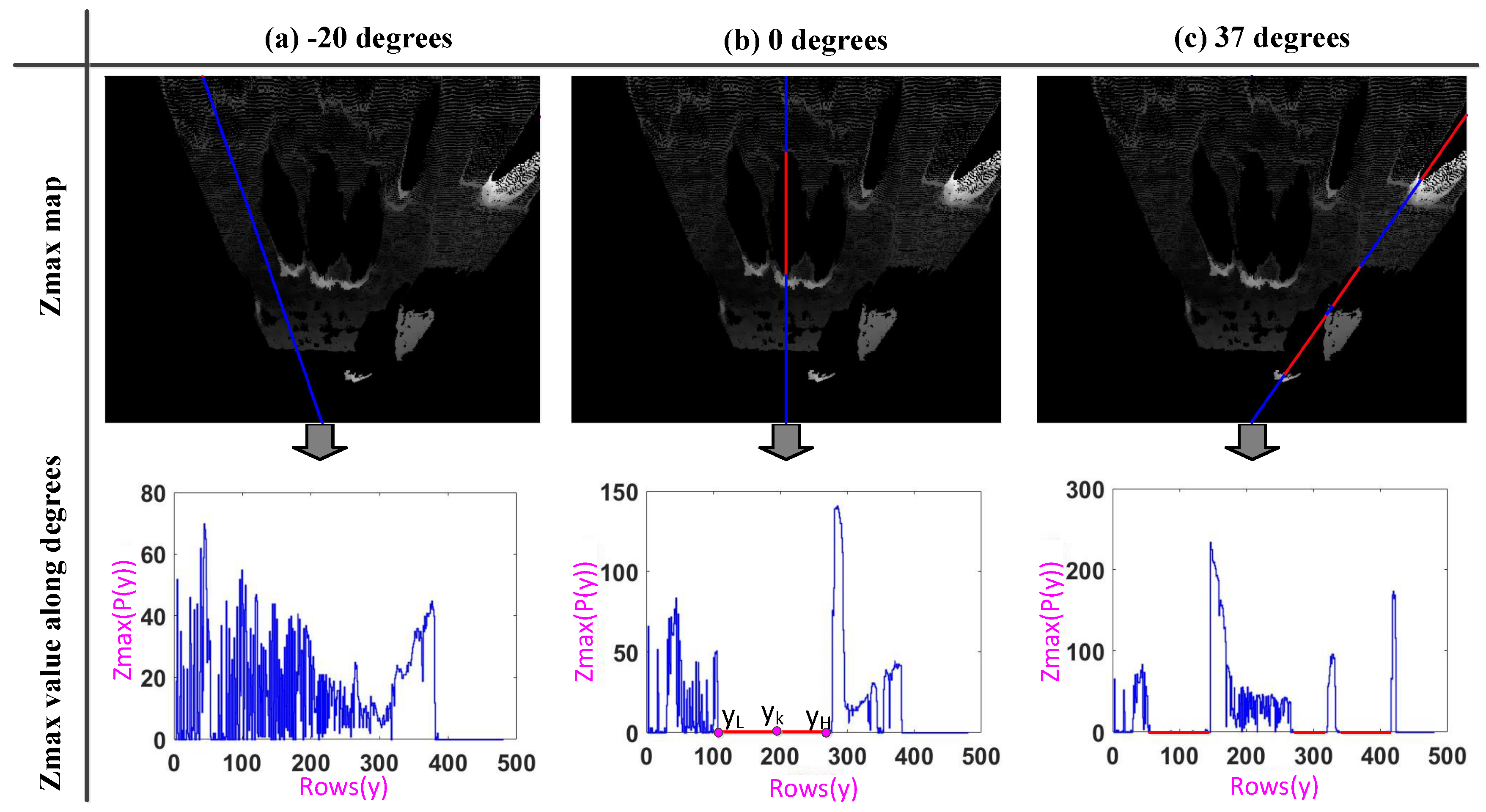
2.4. Shadow Extraction
- (1)
- The point where the gray value is zero on the Zmax map, which means .
- (2)
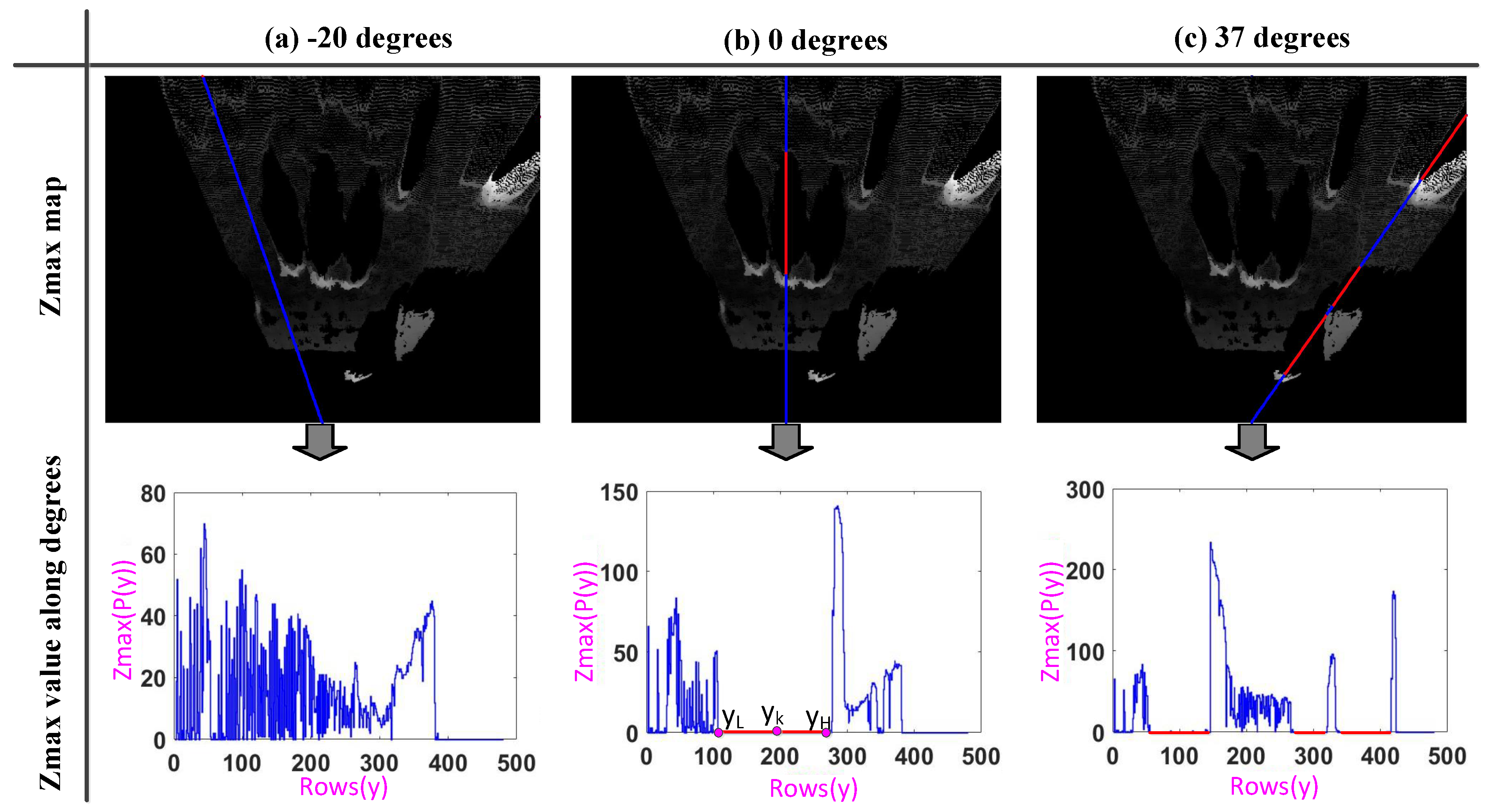
- The front of the shadow area must have a relatively high target. This means that there are some points with a larger gray value in front of the shadow area on the Zmax map, so the point must satisfy the following condition: , making and and marking as , as (b) in Figure 3.
- (3)
- The shadow area cannot be too small. We know there must , making and , and marking y as , like (b) in Figure 3. Then, we can set a threshold to determine whether the size of the shadow area is acceptable. That is to say, the must satisfy the following condition: .
2.5. Foreground Extraction and Pedestrian Segmentation
- (1)
- The first one is , which means point belongs to the unknown region.
- (2)
- The second is when:represents one background point sample value that is randomly extracted from the voxel surface background model at location , so . We think that could represent the height of its corresponding voxel surface background model at time . Therefore, this situation means the height of the new point below the voxel surface background model at the location .
- (3)
- The final case is a point belonging to the background model if the following condition is satisfied:denotes a sphere region centered at with a radius R; the operator ♯ denotes the cardinality of a set; and C is a predefined constant and is used as a threshold for comparison. This formula involves the computation of N distances between and model samples and of N comparisons with a thresholded Euclidean distance R. This formula indicates that the cardinality of the set intersection of this sphere and the background model sample set is larger than or equal to a given threshold C.
| Algorithm 1: voxel surface modeling |
 |
3. Experimental Results
3.1. System Setup and Nighttime Stereo Dataset
3.2. System Performance Evaluation
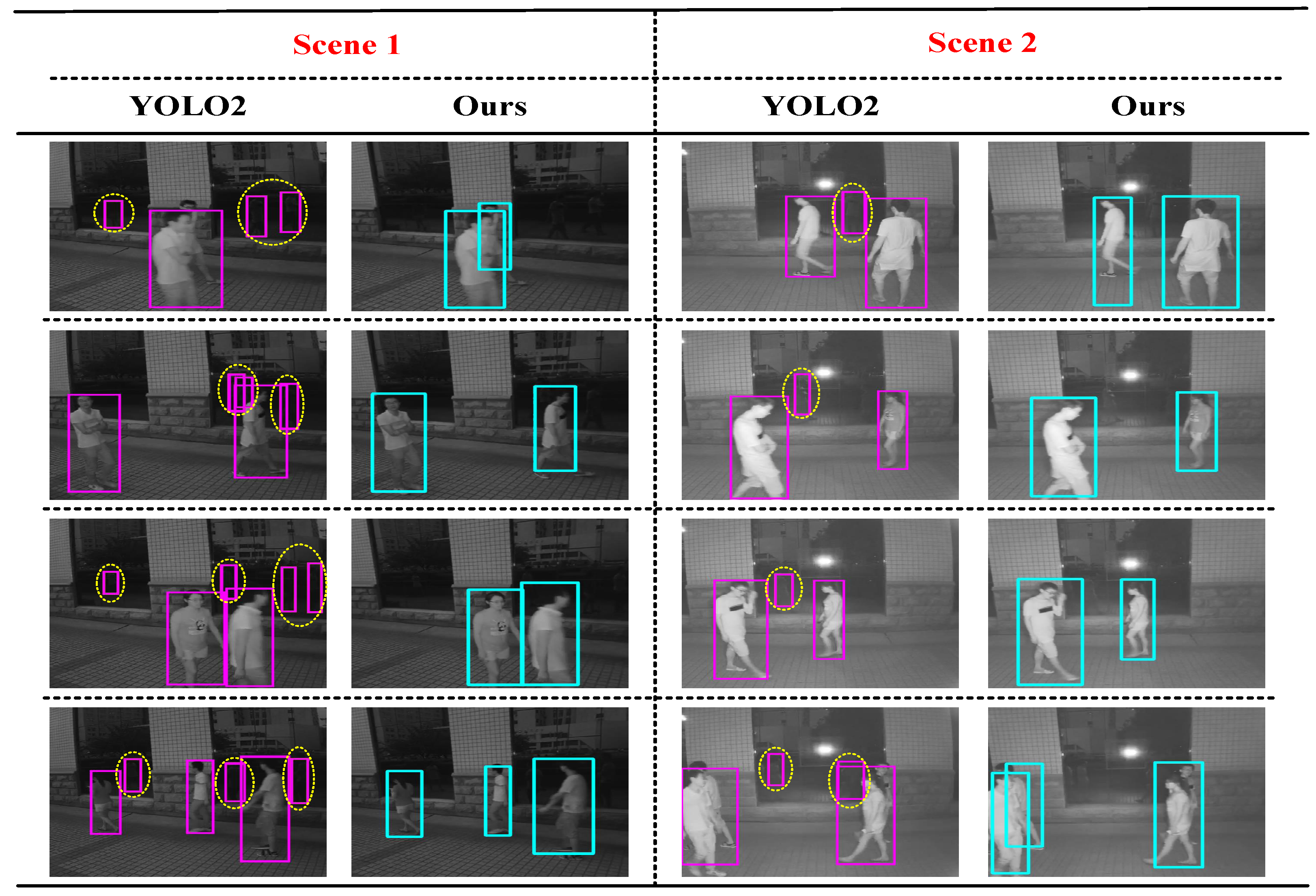
3.3. Comparing with State-Of-The-Art Methods
- (1)
- Background subtraction methods: the widely-used background subtraction algorithms, such as ViBe [17] and fast MCD [18]. ViBe [17] has the advantages of a small amount of calculation, a small memory footprint, high processing speed and the detection of good features. Fast MCD [18] models the background through the dual-mode Single Gaussian Model (SGM) with age for foreground object detection on non-stationary cameras.
- (2)
- (3)
- Learning-based detection methods such as the classic algorithm DPM [21] and the current popular deep learning algorithm YOLO2 [26]: DPM [21] is a successful target detection algorithm and has become an important part of many classifiers, segmentation, human gesture and behavior classification. YOLO2 [26] is a state-of-the-art, real-time object detection algorithm that can detect over 9000 object categories.
4. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Enzweiler, M.; Eigenstetter, A.; Schiele, B.; Gavrila, D.M. Multi-cue pedestrian classification with partial occlusion handling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 990–997. [Google Scholar]
- Tang, S.; Andriluka, M.; Schiele, B. Detection and tracking of occluded people. Int. J. Comput. Vis. 2014, 110, 58–69. [Google Scholar] [CrossRef]
- Hurney, P.; Waldron, P.; Morgan, F.; Jones, E.; Glavin, M. Night-time pedestrian classification with histograms of oriented gradients-local binary patterns vectors. IET Intell. Transp. Syst. 2015, 9, 75–85. [Google Scholar] [CrossRef]
- Tsuji, T.; Hattori, H.; Watanabe, M.; Nagaoka, N. Development of night vision system. IEEE Trans. Intell. Transp. Syst. 2002, 3, 203–209. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, Z.; Wang, H.; Sun, X. Saliency-based pedestrian detection in far infrared images. IEEE Access 2017, 5, 5013–5019. [Google Scholar] [CrossRef]
- Shashua, A.; Gdalyahu, Y.; Hayun, G. Pedestrian detection for driving assistance systems: Single-frame classification and system level performance. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 1–6. [Google Scholar]
- Lin, C.F.; Lin, S.F.; Hwang, C.H.; Chen, Y.C. Real-time pedestrian detection system with novel thermal features at night. In Proceedings of the 2014 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Montevideo, Uruguay, 12–15 May 2014; pp. 1329–1333. [Google Scholar]
- Liu, X.; Fujimura, K. Pedestrian detection using stereo night vision. IEEE Trans. Veh. Technol. 2004, 53, 1657–1665. [Google Scholar] [CrossRef]
- Olmeda, D.; De, I.E.A.; Armingol, J.M. Contrast invariant features for human detection in far infrared images. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 117–122. [Google Scholar]
- Piniarski, K.; Pawlowski, P.; Dabrowski, A. Pedestrian detection by video processing in automotive night vision system. In Proceedings of the 2014 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 22–24 September 2014; pp. 104–109. [Google Scholar]
- Govardhan, P.; Pati, U.C. Nir image based pedestrian detection in night vision with cascade classification and validation. In Proceedings of the International Conference on Advanced Communication Control and Computing Technologies, Ramanathapuram, India, 8–10 May 2014; pp. 1435–1438. [Google Scholar]
- Yasuno, M.; Ryousuke, S.; Yasuda, N.; Aoki, M. Pedestrian detection and tracking in far infrared images. In Proceedings of the Intelligent Transportation Systems, Vienna, Austria, 13–15 September 2005; pp. 182–187. [Google Scholar]
- Lee, Y.S.; Chan, Y.M.; Fu, L.C.; Hsiao, P.Y. Near-infrared-based nighttime pedestrian detection using grouped part models. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1–12. [Google Scholar] [CrossRef]
- Dong, J.; Ge, J.; Luo, Y. Nighttime pedestrian detection with near infrared using cascaded classifiers. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 19 January 2007; pp. VI185–VI188. [Google Scholar]
- Li, J.; Zhang, F.; Wei, L.; Yang, T.; Li, Z. Cube surface modeling for human detection in crowd. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1027–1032. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, p. 252. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. Vibe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Yi, K.M.; Yun, K.; Kim, S.W.; Chang, H.J.; Jin, Y.C. Detection of moving objects with non-stationary cameras in 5.8ms: Bringing motion detection to your mobile device. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 27–34. [Google Scholar]
- Jiang, Y.S.; Ma, J.W. Combination features and models for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 240–248. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; Mcallester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.L.; Luo, P.; Wang, X.G.; Tang, X.O. Deep learning strong parts for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Hosang, J.; Omran, M.; Benenson, R.; Schiele, B. Taking a deeper look at pedestrians. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4073–4082. [Google Scholar]
- Kang, J.K.; Hong, H.G.; Park, K.R. Pedestrian detection based on adaptive selection of visible light or far-infrared light camera image by fuzzy inference system and convolutional neural network-based verification. Sensors 2017, 17, 1598. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 20–27 July 2017. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Tian, L.C.; Zhang, G.Y.; Li, M.C.; Liu, J.; Chen, Y.Q. Reliably detecting humans in crowded and dynamic environments using RGB-D camera. In Proceedings of the International Conference on Multimedia and Expo, Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Ubukata, T.; Shibata, M.; Terabayashi, K.; Mora, A.; Kawashita, T.; Masuyama, G.; Umeda, K. Fast human detection combining range image segmentation and local feature based detection. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 4281–4286. [Google Scholar]
- Shen, Y.J.; Hao, Z.H.; Wang, P.F.; Ma, S.W. A novel human detection approach based on depth map via kinect. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 535–541. [Google Scholar]
- Jafari, O.H.; Mitzel, D.; Leibe, B. Real-time RGB-D based people detection and tracking for mobile robots and head-worn cameras. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5636–5643. [Google Scholar]
- Po, L.M.; Ma, W.C. A novel four-step search algorithm for fast block motion estimation. IEEE Trans. Circuits Syst. Video Technol. 1996, 6, 313–317. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Roser, M.; Urtasun, R. Efficient large-scale stereo matching. In Proceedings of the Asian Conference on Computer Vision (ACCV), Queenstown, New Zealand, 8–12 November 2010; pp. 25–38. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Transa. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- ViBe—A Powerful Technique for Background Detection and Subtraction in Video Sequences. Available online: http://www.telecom.ulg.ac.be/research/vibe/ (accessed on 14 March 2017).
- Detection of Moving Objects with Non-Stationary Cameras in 5.8ms: Bringing Motion Detection to Your Mobile Device (Fast MCD). Available online: https://github.com/kmyid/fastMCD (accessed on 10 June 2017).
- Deformable Part-Based Models(DPM). Available online: http://docs.opencv.org/trunk/d9/d12/group__dpm.html (accessed on 13 April 2017).
- YOLO9000: Better, Faster, Stronger. Available online: https://pjreddie.com/darknet/yolo/ (accessed on 18 May 2017).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Binocular Camera | Specification | Parameter |
|---|---|---|
 | sensors | 1/3 Progressive Scan CMOS |
| day and night conversion mode | Infrared Cutfilter Removal(ICR) infrared filter | |
| infrared irradiation distance | 25 m | |
| baseline distance | 190 mm | |
| maximum resolution | at 25 fps | |
| working voltage | DC 12 V ± 10% | |
| maximum power consumption | 7.5 W | |
| operating temperature | C∼60 C |
| Algorithm | Total Targets | TP | FP | FN | Precision | Recall | F1-Measure | Speed (fps) |
|---|---|---|---|---|---|---|---|---|
| ViBe [17] | 1476 | 714 | 2839 | 762 | 20.10% | 48.37% | 0.28 | 33.3 |
| DPM [21] | 1476 | 694 | 35 | 782 | 95.20% | 47.02% | 0.63 | 1.7 |
| fast MCD [18] | 1476 | 804 | 1677 | 672 | 32.41% | 54.48% | 0.41 | 18.2 |
| YOLO2 [26] | 1476 | 1269 | 435 | 207 | 74.47% | 85.97% | 0.80 | 25 (GPU) |
| RGB-D [30] | 1476 | 953 | 126 | 523 | 88.32% | 64.56% | 0.75 | 20.0 |
| Ours | 1476 | 1057 | 51 | 419 | 95.40% | 71.61% | 0.82 | 25.3 |
| Algorithm | Computing Platform | Speed | Sample Training | Foreground Binary Image | Foreground Depth Information | Bounding Box |
|---|---|---|---|---|---|---|
| YOLO2 | Navida Geforce gtx1060 | 25 fps | √ | × | × | √ |
| Ours | Normal CPU | 25.3 fps | × | √ | √ | √ |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, F.; Wei, L.; Yang, T.; Lu, Z. Nighttime Foreground Pedestrian Detection Based on Three-Dimensional Voxel Surface Model. Sensors 2017, 17, 2354. https://doi.org/10.3390/s17102354
Li J, Zhang F, Wei L, Yang T, Lu Z. Nighttime Foreground Pedestrian Detection Based on Three-Dimensional Voxel Surface Model. Sensors. 2017; 17(10):2354. https://doi.org/10.3390/s17102354
Chicago/Turabian StyleLi, Jing, Fangbing Zhang, Lisong Wei, Tao Yang, and Zhaoyang Lu. 2017. "Nighttime Foreground Pedestrian Detection Based on Three-Dimensional Voxel Surface Model" Sensors 17, no. 10: 2354. https://doi.org/10.3390/s17102354
APA StyleLi, J., Zhang, F., Wei, L., Yang, T., & Lu, Z. (2017). Nighttime Foreground Pedestrian Detection Based on Three-Dimensional Voxel Surface Model. Sensors, 17(10), 2354. https://doi.org/10.3390/s17102354